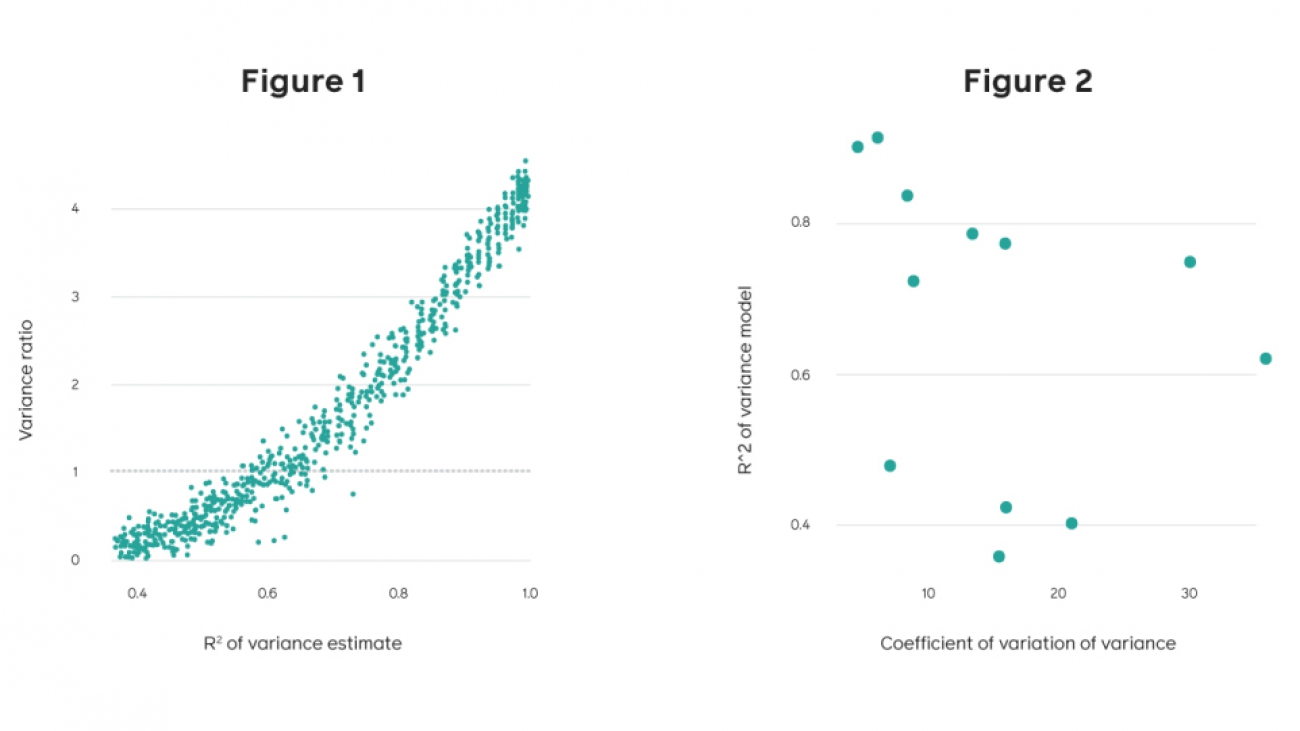
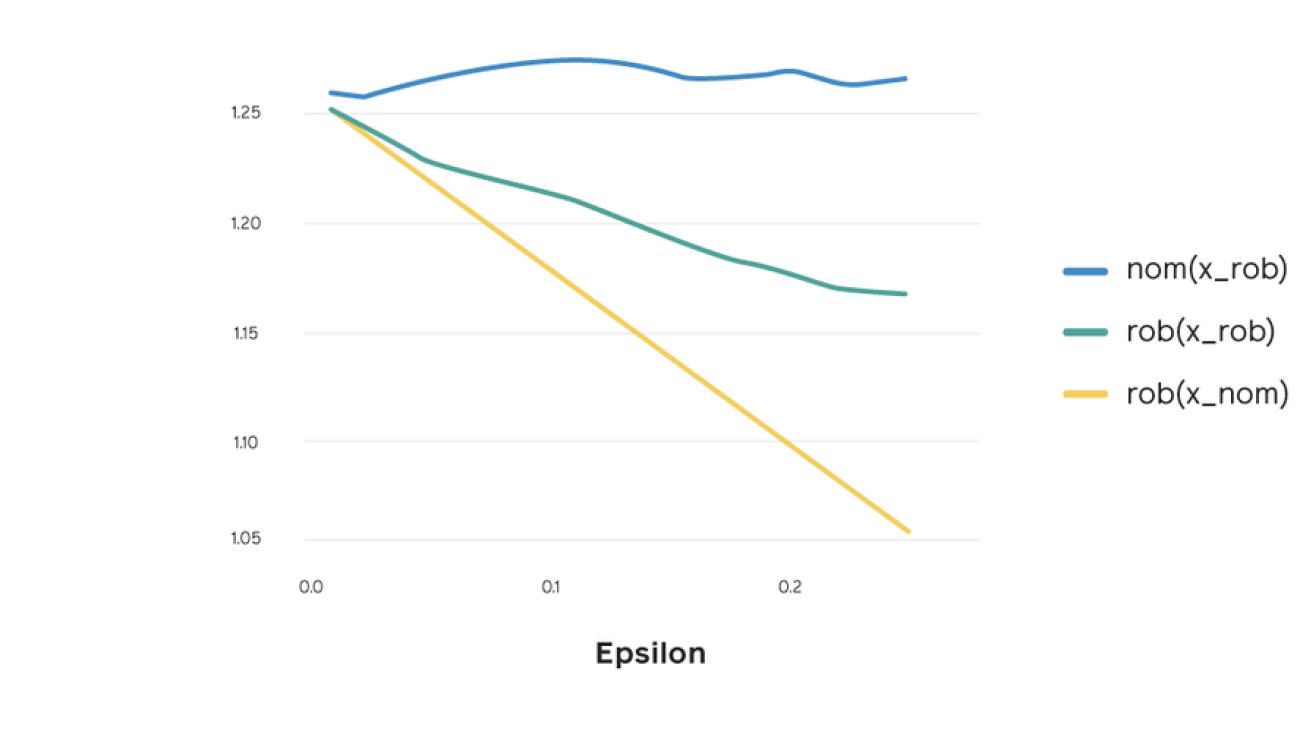
The ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW) is an important venue where Facebook researchers can share their work and engage with others in the community. Previous Facebook submissions to the conference have explored diverse topics such as how social ties can relate to disaster response and how automatic photo tagging can affect the visually impaired. This year, our contribution includes a paper that explores how social comparison on social media differs between countries, published by Facebook’s Justin Cheng, Moira Burke, and Bethany de Gant.
Earlier this year, the team published a paper on social comparison at the Conference on Human Factors in Computing Systems. In that paper, Cheng, Burke, and de Gant conducted a large, rigorous international study to learn how using social media relates to social comparison. Through a survey conducted with over 37,000 participants in 18 countries, they discovered that country was the strongest predictor of how often a person experienced social comparison, making it a stronger predictor than age, gender, or what they saw on Facebook. Their present work at CSCW delves deeper into this topic.
About the study
In order to build better and more inclusive products, we need to understand how people use them all around the world. When it comes to digital well-being, social comparison on social media is a common concern. “Social comparison, or the act of comparing yourself to others, is something that everyone does,” says Cheng. “To better understand global variation in social comparison, we conducted a survey in 18 countries and interviewed people in three countries: India, Mexico, and the U.S. Our goal is to use this knowledge to influence product design that better supports people’s well-being.”
These in-person interviews confirmed that social comparison varied substantially by country. “Overall, we do find country differences in the frequency, causes, and outcomes of social comparison, suggesting that it’s important to take these differences into account when we do research or are identifying ways to better support people’s well-being,” Cheng explains.
Insights
According to Cheng, there are substantial differences in how often people feel social comparison in different countries. “Many previous studies compare the U.S. to Korea or Japan, but this actually only captures a small amount of the global variation in social comparison,” he says. “Social comparison is actually most frequent in countries such as Vietnam and India and least frequent in countries such as Germany and Mexico.”
The study also shows gender differences between countries when it comes to social comparison. “We often hear that women experience social comparison more than men — that this is something that only affects women,” says Burke. “But our study shows that this is a mindset based in globally western countries.
“The story is very different in India: Men feel more social comparison than women there. Our interviews suggest that it has to do with men feeling pressure both at work and at home, and our data suggest that in countries like India, where men comprise a much greater fraction of the labor force, social comparison is higher among men. In countries such as the U.S. and U.K., where women make up a more equal proportion of the labor force, women experience more social comparison than men.”
“If you remember only one thing from this research, it would be that country differences matter,” says Cheng. “And because they matter, designs that are effective in one country may not work as well in a different country.”
Opportunities
Cheng and Burke are Research Scientists on Core Data Science, a research and development team that works to improve Facebook’s products, infrastructure, and processes. De Gant is a UX Researcher within Social Impact. Together, their work on social comparison provides design opportunities for the Facebook and Instagram platforms within the realm of digital well-being.
“One design opportunity could be to encourage people [on our platforms] to share a broader range of experiences in their life, including the negative ones,” says Cheng. “This could reduce the feeling of social media being a ‘highlight reel.’ However, when asked, people in different countries had different reactions to this idea. In Mexico, for example, people said that they visited Facebook to be motivated, not to be brought down, suggesting that more of these posts might make people in Mexico feel worse. In the U.S., people were more receptive to sharing these broader experiences but also did not want to feel compelled to open up.”
Cheng says another opportunity is making changes to how Like counts are shown: “Our research suggests that people around the world may experience less social comparison if Like counts were made less salient. This may be more effective in countries such as the U.S. and India, and less effective in countries such as the Philippines. Still, feelings about hiding Like counts were mixed. Several people we interviewed talked about how they were valuable as a signal for what to pay attention to.”
“Technology developments may impact digital well-being differently in different parts of the world,” says de Gant. “As such, we hope this paper serves as motivation for both researchers and technologists to deeply understand how new developments impact digital well-being in different places before implementing large-scale changes.”
What’s next
Through their work, Cheng, Burke, and de Gant plan to pursue similar research topics to inform Facebook’s apps, infrastructure, and services. “There are many open questions around digital well-being and social media’s impact on people, and there’s continuing interest in it,” says Cheng. “We’re always conducting and planning additional research to understand the different ways that platforms such as Facebook and Instagram affect well-being, both positively and negatively, and we hope to share more findings in the future as well.”
To learn more about Facebook’s presence at CSCW 2020, visit our event page.
The post Facebook at CSCW 2020: Understanding social comparison by country appeared first on Facebook Research.