Facebook researchers and engineers in data science, data mining, knowledge discovery, large-scale data analytics, and more will be presenting their research at the Conference on Knowledge Discovery and Data Mining (KDD). Researchers will also be giving talks and participating in workshops and tutorials throughout the conference.
The Facebook Core Data Science team is presenting two research papers: “CLARA: Confidence of labels and raters” and “TIES: Temporal interaction embeddings for enhancing social media integrity at facebook.” CLARA, which is described more in this blog post, is a system built and deployed at Facebook to estimate the uncertainty in human-generated decisions in our content review process. TIES is a deep learning, application-agnostic, scalable framework that leverages interactions between accounts to improve the safety and security of our online community.
For more information on Facebook’s presence at KDD this year, from August 23 to 28, check out the Facebook at KDD page.
Facebook research being presented at KDD 2020
AutoCTR: Towards automated neural architecture discovering for click-through rate prediction
Qingquan Song, Dehua Cheng, Eric Zhou, Jiyan Yang, Yuandong Tian, Xia Hu
Click-through rate (CTR) prediction is one of the most important machine learning tasks in recommender systems, driving personalized experience for billions of consumers. Neural architecture search (NAS), as an emerging field, has demonstrated its capabilities in discovering powerful neural network architectures, which motivates us to explore its potential for CTR predictions. Due to (1) diverse unstructured feature interactions, (2) heterogeneous feature space, and (3) high data volume and intrinsic data randomness, it is challenging to construct, search, and compare different architectures effectively for recommendation models. To address these challenges, we propose an automated interaction architecture discovering framework for CTR prediction named AutoCTR. Via modularizing simple yet representative interactions as virtual building blocks and wiring them into a space of direct acyclic graphs, AutoCTR performs evolutionary architecture exploration with learning-to-rank guidance at the architecture level and achieves acceleration using low-fidelity model. Empirical analysis demonstrates the effectiveness of AutoCTR on different data sets comparing to human-crafted architectures. The discovered architecture also enjoys generalizability and transferability among different data sets.
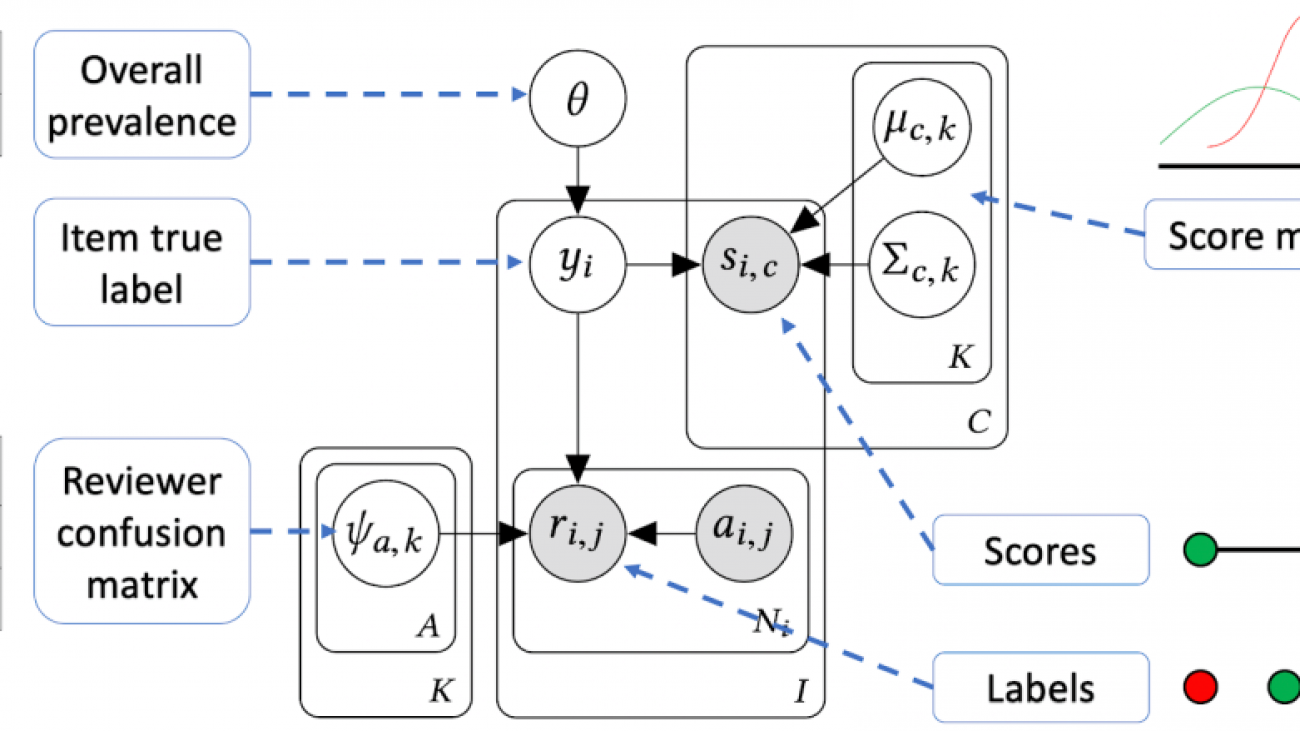
CLARA: Confidence of labels and raters
Viet-An Nguyen, Peibei Shi, Jagdish Ramakrishnan, Udi Weinsberg, Henry C. Lin, Steve Metz, Neil Chandra, Jane Jing, Dimitris Kalimeris
Large online services employ thousands of people to label content for applications such as video understanding, natural language processing, and content policy enforcement. While labelers typically reach their decisions by following a well-defined protocol, humans may still make mistakes. A common countermeasure is to have multiple people review the same content; however, this process is often time-intensive and requires accurate aggregation of potentially noisy decisions.
In this paper, we present CLARA (confidence of labels and raters), a system developed and deployed at Facebook for aggregating reviewer decisions and estimating their uncertainty. We perform extensive validations and describe the deployment of CLARA for measuring the base rate of policy violations, quantifying reviewers’ performance, and improving their efficiency. In our experiments, we found that CLARA (a) provides an unbiased estimator of violation rates that is robust to changes in reviewer quality, with accurate confidence intervals, (b) provides an accurate assessment of reviewers’ performance, and (c) improves efficiency by reducing the number of reviews based on the review certainty, and enables the operational selection of a threshold on the cost/accuracy efficiency frontier.
Compositional embeddings using complementary partitions for memory-efficient recommendation models
Hao-Jun Michael Shi, Dheevatsa Mudigere, Maxim Naumov, Jiyan Yang
Modern deep learning-based recommendation systems exploit hundreds to thousands of different categorical features, each with millions of different categories ranging from clicks to posts. To respect the natural diversity within the categorical data, embeddings map each category to a unique dense representation within an embedded space. Since each categorical feature could take on as many as tens of millions of different possible categories, the embedding tables form the primary memory bottleneck during both training and inference. We propose a novel approach for reducing the embedding size in an end-to-end fashion by exploiting complementary partitions of the category set to produce a unique embedding vector for each category without explicit definition. By storing multiple smaller embedding tables based on each complementary partition and combining embeddings from each table, we define a unique embedding for each category at smaller cost. This approach may be interpreted as using a specific fixed codebook to ensure uniqueness of each category’s representation. Our experimental results demonstrate the effectiveness of our approach over the hashing trick for reducing the size of the embedding tables in terms of model loss and accuracy, while retaining a similar reduction in the number of parameters.
Embedding-based retrieval in Facebook search
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, Linjun Yang
Search in social networks such as Facebook poses different challenges than in classical web search: Besides the query text, it is important to take into account the searcher’s context to provide relevant results. Their social graph is an integral part of this context and is a unique aspect of Facebook search. While embedding-based retrieval (EBR) has been applied in web search engines for years, Facebook search was still mainly based on a Boolean matching model. In this paper, we discuss the techniques for applying EBR to a Facebook Search system. We introduce the unified embedding framework developed to model semantic embeddings for personalized search, and the system to serve embedding-based retrieval in a typical search system based on an inverted index. We discuss various tricks and experiences on end-to-end optimization of the whole system, including ANN parameter tuning and full-stack optimization. Finally, we present our progress on two selected advanced topics about modeling. We evaluated EBR on verticals for Facebook Search with significant metrics gains observed in online A/B experiments. We believe this paper will provide useful insights and experiences to help people on developing embedding-based retrieval systems in search engines.
ShopNet: Unified computer vision model trunk and embeddings for commerce
Sean Bell, Yiqun Liu, Sami Alsheikh, Yina Tang, Ed Pizzi, Michael Henning, Karun Singh, Fedor Borisyuk
In this paper, we present ShopNet, a deployed image recognition system for commerce applications. ShopNet leverages a multi-task learning approach to train a single computer vision trunk. We achieve a 2.1x improvement in exact product match accuracy when compared to the previous state-of-the-art Facebook product recognition system. We share our experience of combining different data sources with wide-ranging label semantics and image statistics, including learning from human annotations, user-generated tags, and noisy search engine interaction data. We experiment with a diverse set of loss functions, optimizing jointly for exact product recognition accuracy and various classification tasks. We provide insights on what worked best in practice. ShopNet is deployed in production applications with gains and operates at Facebook scale.
TIES: Temporal interaction embeddings for enhancing social media integrity at Facebook
Nima Noorshams, Saurabh Verma, Aude Hofleitner
Since its inception, Facebook has become an integral part of the online social community. People rely on Facebook to make connections with others and build communities. As a result, it is paramount to protect the integrity of such a rapidly growing network in a fast and scalable manner. In this paper, we present our efforts to protect various social media entities at Facebook from people who try to abuse our platform. We present a novel temporal interaction embeddings (TIES) model that is designed to capture rogue social interactions and flag them for further suitable actions. TIES is a supervised, deep learning, production-ready model at Facebook-scale networks. Prior works on integrity problems are mostly focused on capturing either only static or certain dynamic features of social entities. In contrast, TIES can capture both of these variant behaviors in a unified model owing to the recent strides made in the domains of graph embedding and deep sequential pattern learning. To show the real-world impact of TIES, we present a few applications especially for preventing spread of misinformation, fake account detection, and reducing ads payment risks in order to enhance the Facebook platform’s integrity.
Training deep learning recommendation model with quantized collective communications
Jie (Amy) Yang, Jongsoo Park, Srinivas Sridharan, Ping Tak Peter Tang
Deep learning recommendation model (DLRM) captures our representative model architectures developed for click-through rate (CTR) prediction based on high-dimensional sparse categorical data. Collective communications can account for a significant fraction of time in synchronous training of DLRM at scale. In this work, we explore using fine-grain integer quantization to reduce the communication volume of alltoall and allreduce collectives. We emulate quantized alltoall and allreduce, the latter using ring or recursive-doubling and each with optional carried-forward error compensation. We benchmark accuracy loss of quantized alltoall and allreduce with a representative DLRM model and Kaggle 7D data set. We show that alltoall forward and backward passes and dense allreduce can be quantized to 4 bits without accuracy loss, compared to full-precision training.
Other activities at KDD 2020
Applied data science invited talks
Data paucity and low resource scenarios: Challenges and opportunities
Mona Diab, invited speaker
Preserving integrity in online social media
Alon Halevy, invited speaker
Hands-on tutorials
Building recommender systems with PyTorch
Dheevatsa Mudigere, Maxim Naumov, Joe Spisak, and Geeta Chauhan, presenters
Special days
Deep learning day
Joelle Pineau
Workshops
Humanitarian mapping workshop
Shankar Iyer, initiative lead/chair
Kristen Altenburger, Eugenia Giraudy, Alex Dow, Paige Maas, Alex Pompe, Eric Sodomka, program committee
Workshop on applied data science for Healthcare
Paper: Information extraction of clinical trial eligibility criteria
Yitong Tseo, M. I. Salkola, Ahmed Mohamed, Anuj Kumar, Freddy Abnousi
Workshop on deep learning practice for high-dimensional spare data
Liang Xiong, workshop chair
Workshop on mining and learning with graphs
Aude Hofleitner, organizer
Jin Kyu Kim, program committee
The post Facebook research at KDD 2020 appeared first on Facebook Research.
Read More