 Gemini 2.5 Flash and Pro are now generally available, and we’re introducing 2.5 Flash-Lite, our most cost-efficient and fastest 2.5 model yet.Read More
Gemini 2.5 Flash and Pro are now generally available, and we’re introducing 2.5 Flash-Lite, our most cost-efficient and fastest 2.5 model yet.Read More

Gemini 2.5 Flash and Pro are now generally available, and we’re introducing 2.5 Flash-Lite, our most cost-efficient and fastest 2.5 model yet.Read More
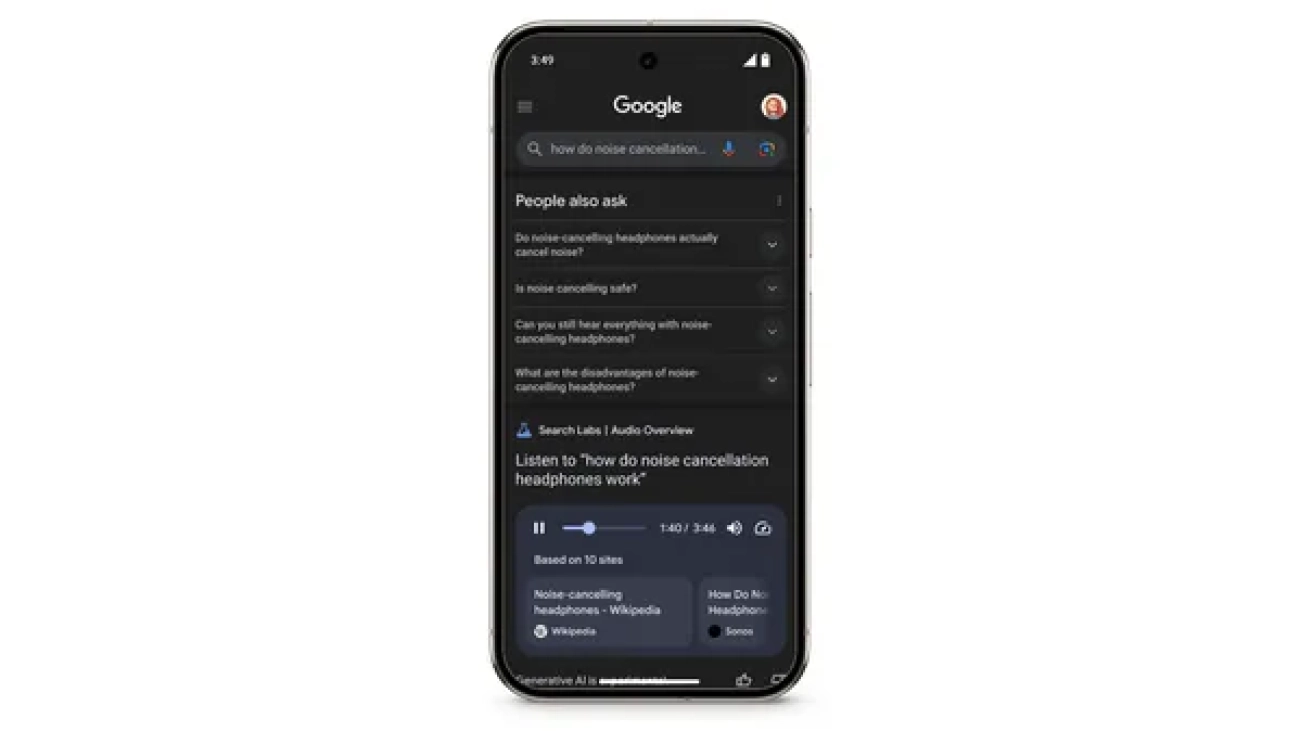
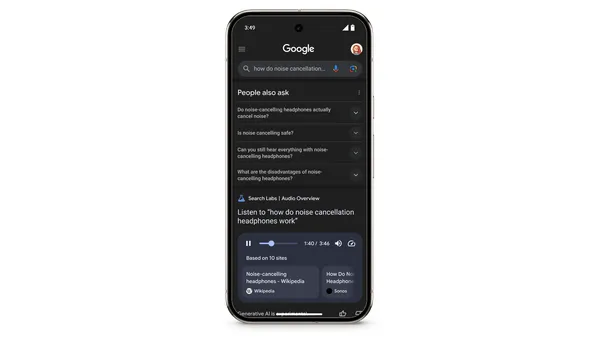 Today, we’re launching a new Search experiment in Labs – Audio Overviews, which uses our latest Gemini models to generate quick, conversational audio overviews for certa…Read More
Today, we’re launching a new Search experiment in Labs – Audio Overviews, which uses our latest Gemini models to generate quick, conversational audio overviews for certa…Read More

 We partnered with Darren Aronofsky, Eliza McNitt and a team of more than 200 to make ANCESTRA.Read More
We partnered with Darren Aronofsky, Eliza McNitt and a team of more than 200 to make ANCESTRA.Read More
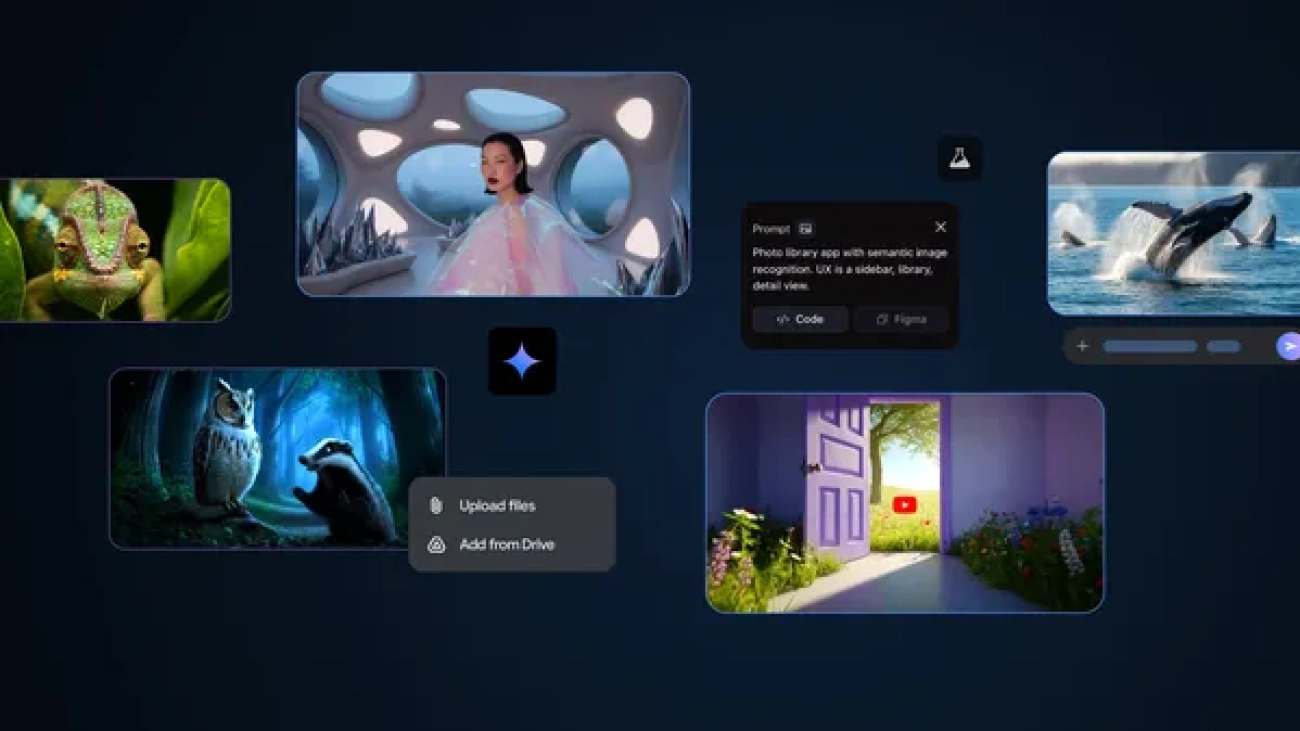
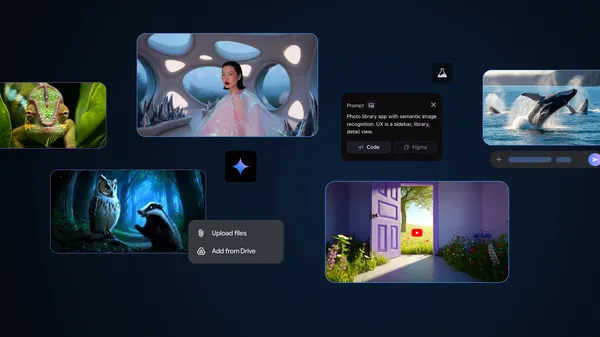 These AI tools from Google I/O 2025 are available globally for your experimentation.Read More
These AI tools from Google I/O 2025 are available globally for your experimentation.Read More

 Google for Nonprofits is expanding to 100 more countries, and introducing new Workspace for Nonprofits and Ad Grants AI features.Read More
Google for Nonprofits is expanding to 100 more countries, and introducing new Workspace for Nonprofits and Ad Grants AI features.Read More

 From the keynote countdown to speaker title cards and beyond, generative AI took the stage at I/O 2025.Read More
From the keynote countdown to speaker title cards and beyond, generative AI took the stage at I/O 2025.Read More

 Learn how Google Research’s team worked with collaborators at HHMI Janelia and Harvard University to build a dataset that tracks both the neural activity and nanoscale s…Read More
Learn how Google Research’s team worked with collaborators at HHMI Janelia and Harvard University to build a dataset that tracks both the neural activity and nanoscale s…Read More

 Meet the 20 organizations using generative AI to address tough societal issues.Read More
Meet the 20 organizations using generative AI to address tough societal issues.Read More
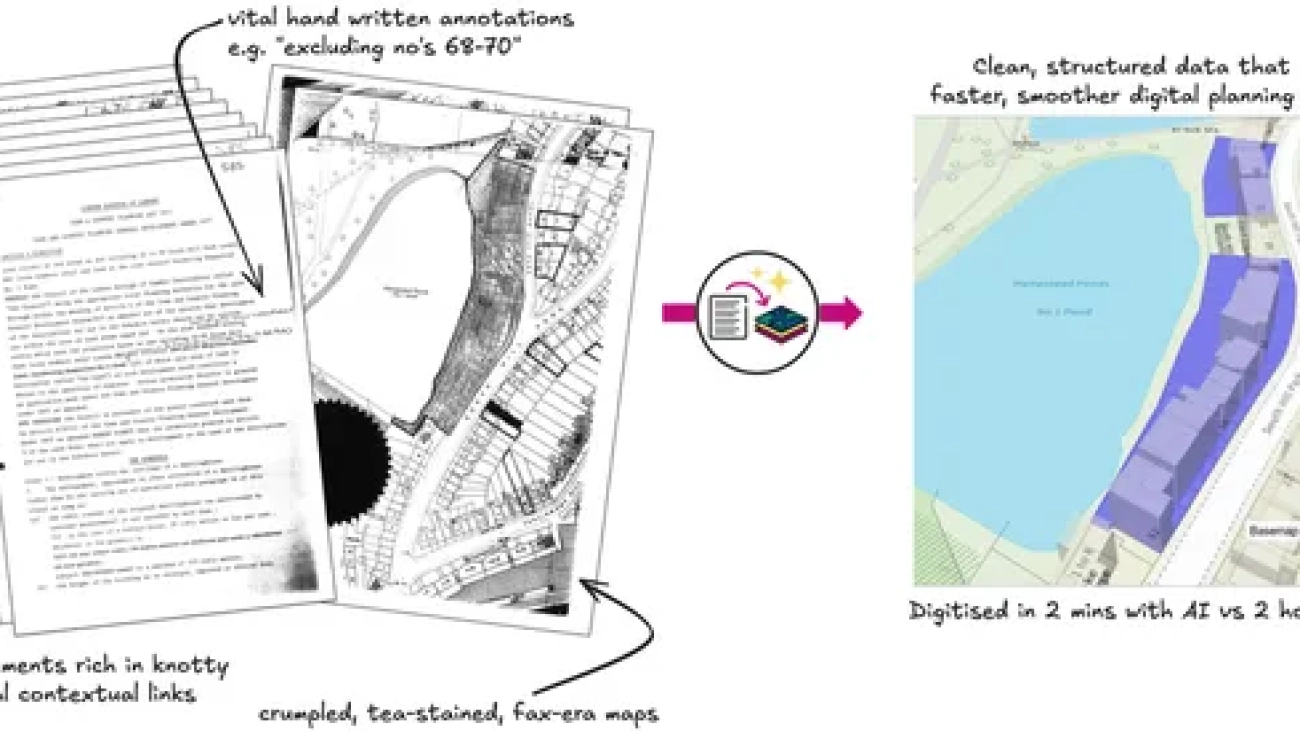
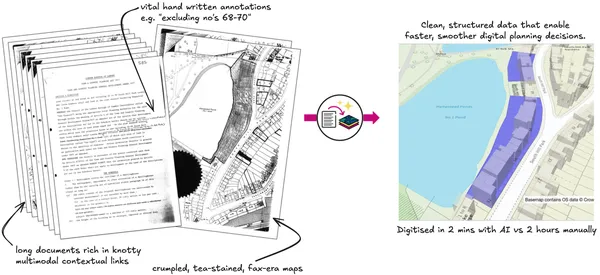 Extract, built with Gemini, uses the model’s advanced visual reasoning and multi-modal capabilities to help councils turn old planning documents—including blurry maps an…Read More
Extract, built with Gemini, uses the model’s advanced visual reasoning and multi-modal capabilities to help councils turn old planning documents—including blurry maps an…Read More
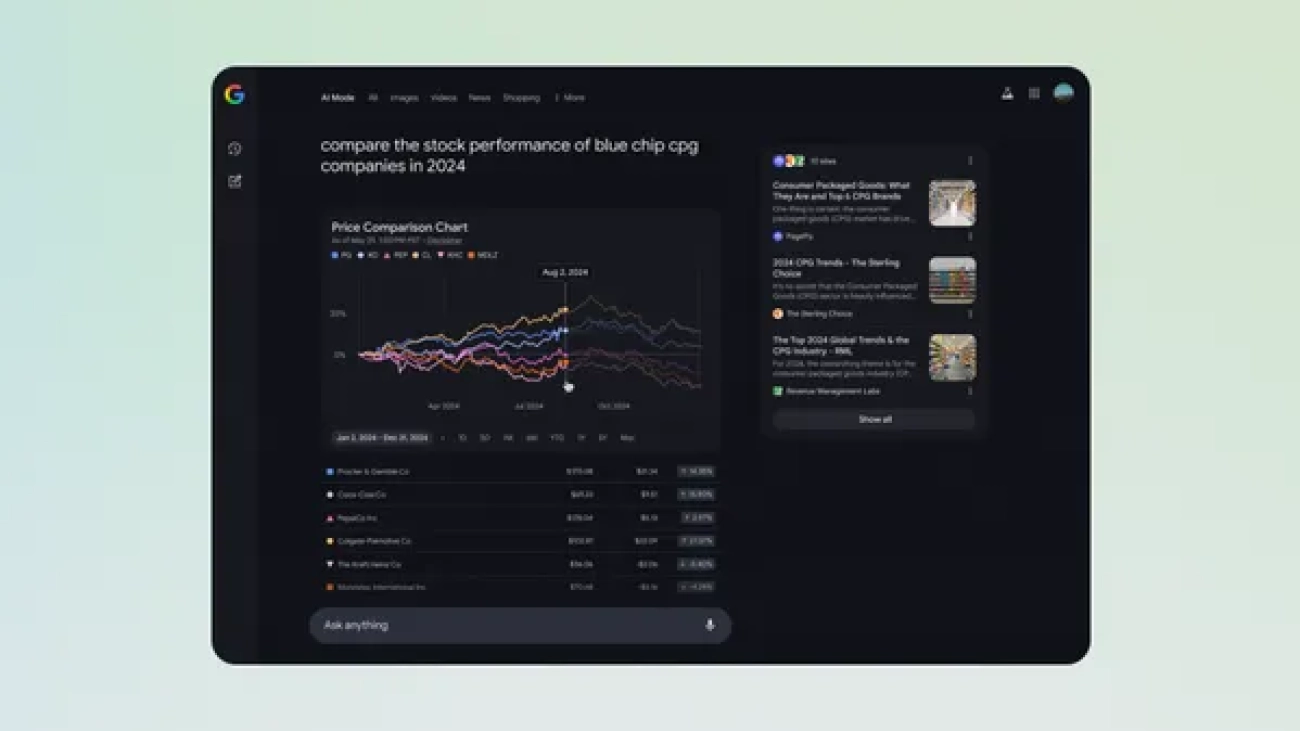
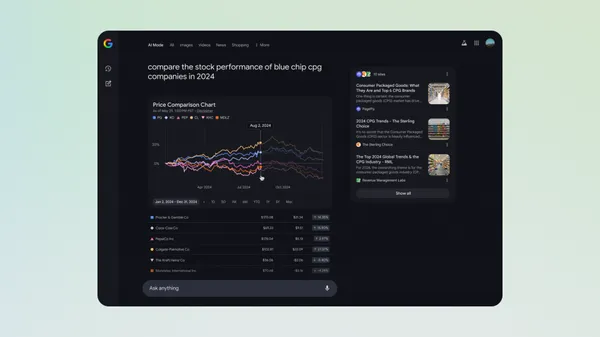 Today, we’re starting to roll out interactive chart visualizations in AI Mode in Labs to help bring financial data to life for questions on stocks and mutual funds.Now, …Read More
Today, we’re starting to roll out interactive chart visualizations in AI Mode in Labs to help bring financial data to life for questions on stocks and mutual funds.Now, …Read More