 Artists in Residence at the Google Arts & Culture Lab are developing playful tools to inspire creativity with gen AI – discover how their latest experiments can be a sou…Read More
Artists in Residence at the Google Arts & Culture Lab are developing playful tools to inspire creativity with gen AI – discover how their latest experiments can be a sou…Read More

Artists in Residence at the Google Arts & Culture Lab are developing playful tools to inspire creativity with gen AI – discover how their latest experiments can be a sou…Read More
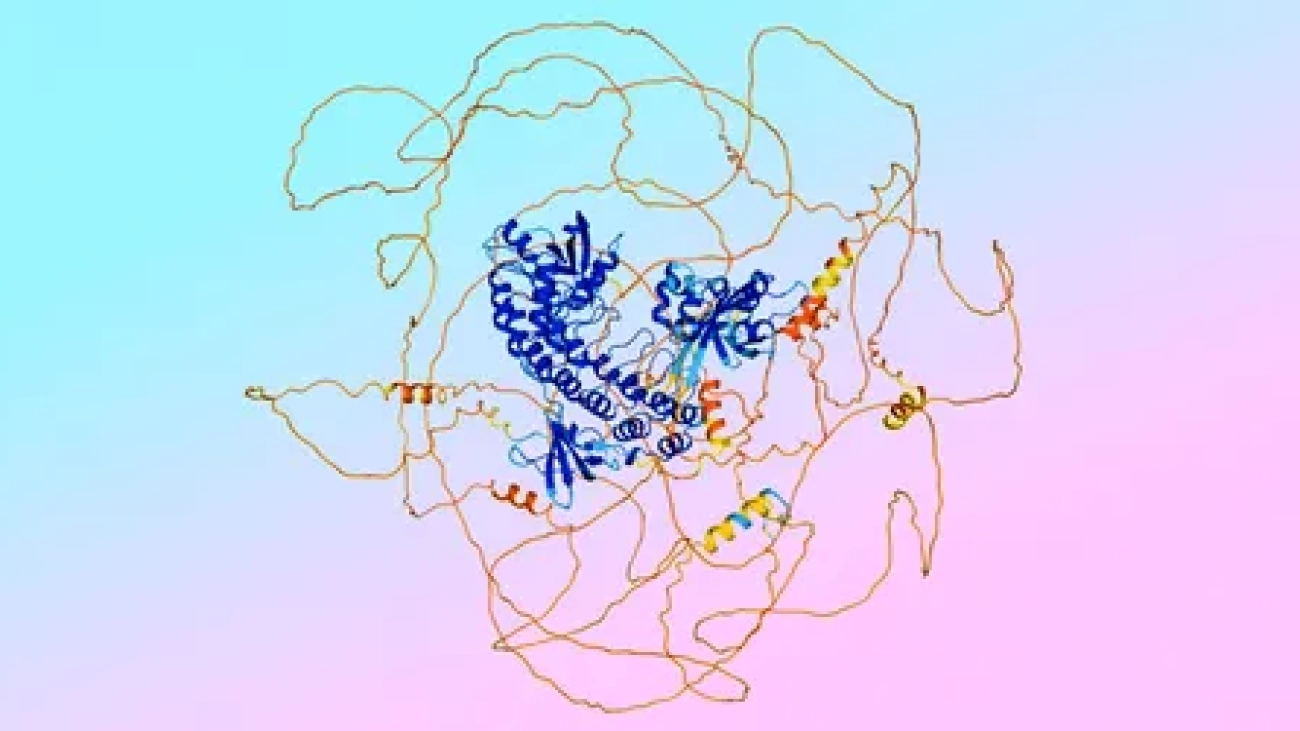
 Here’s how this model came to be.Read More
Here’s how this model came to be.Read More
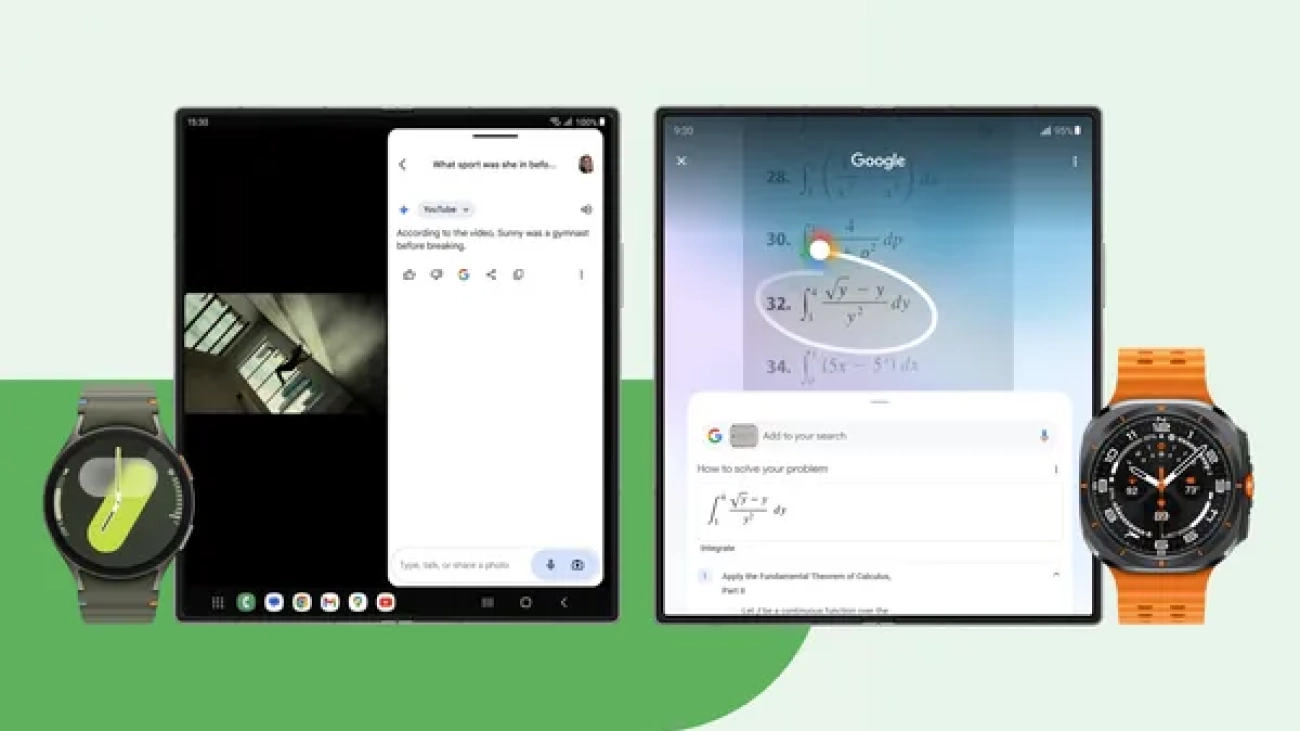
 New Circle to Search capabilities, Wear OS 5 and more are coming to Samsung’s latest devices.Read More
New Circle to Search capabilities, Wear OS 5 and more are coming to Samsung’s latest devices.Read More

 Researchers on our Connectomics team have completed the largest ever AI-assisted digital reconstruction of human brain tissue. Here’s why they’re taking on the mouse bra…Read More
Researchers on our Connectomics team have completed the largest ever AI-assisted digital reconstruction of human brain tissue. Here’s why they’re taking on the mouse bra…Read More
![]() Try these AI features to get the most out of your Pixel.Read More
Try these AI features to get the most out of your Pixel.Read More

 Our 2024 Environmental Report looks at our use of technology to drive environmental change and operate our business sustainably.Read More
Our 2024 Environmental Report looks at our use of technology to drive environmental change and operate our business sustainably.Read More

 Gemma 2, our next generation of open models, is now available globally for researchers and developers.Read More
Gemma 2, our next generation of open models, is now available globally for researchers and developers.Read More

![]() Google Translate adds 110 new languages using AI, breaking down communication barriers for millions around the world.Read More
Google Translate adds 110 new languages using AI, breaking down communication barriers for millions around the world.Read More

![]() Google Translate adds 110 new languages using AI, breaking down communication barriers for millions around the world.Read More
Google Translate adds 110 new languages using AI, breaking down communication barriers for millions around the world.Read More

 How Googlers used Gemini to build the Crossword puzzle, showing developers what’s possible with generative AI.Read More
How Googlers used Gemini to build the Crossword puzzle, showing developers what’s possible with generative AI.Read More