 How Googlers used Gemini to build the Crossword puzzle, showing developers what’s possible with generative AI.Read More
How Googlers used Gemini to build the Crossword puzzle, showing developers what’s possible with generative AI.Read More

How Googlers used Gemini to build the Crossword puzzle, showing developers what’s possible with generative AI.Read More
 Today we’re sharing 7 principles for responsible AI regulation, and endorsing 5 bills in Congress.Read More
Today we’re sharing 7 principles for responsible AI regulation, and endorsing 5 bills in Congress.Read More

 Learn more about how (and why) we created our Google AI Essentials course.Read More
Learn more about how (and why) we created our Google AI Essentials course.Read More

 Test your knowledge of Google updates with our May news quiz.Read More
Test your knowledge of Google updates with our May news quiz.Read More

 Google launches GARA program to fund and support groundbreaking research in computing and technology, addressing global challenges.Read More
Google launches GARA program to fund and support groundbreaking research in computing and technology, addressing global challenges.Read More

 Applications are open for two new Google for Startups Accelerator programs in Europe and Israel.Read More
Applications are open for two new Google for Startups Accelerator programs in Europe and Israel.Read More
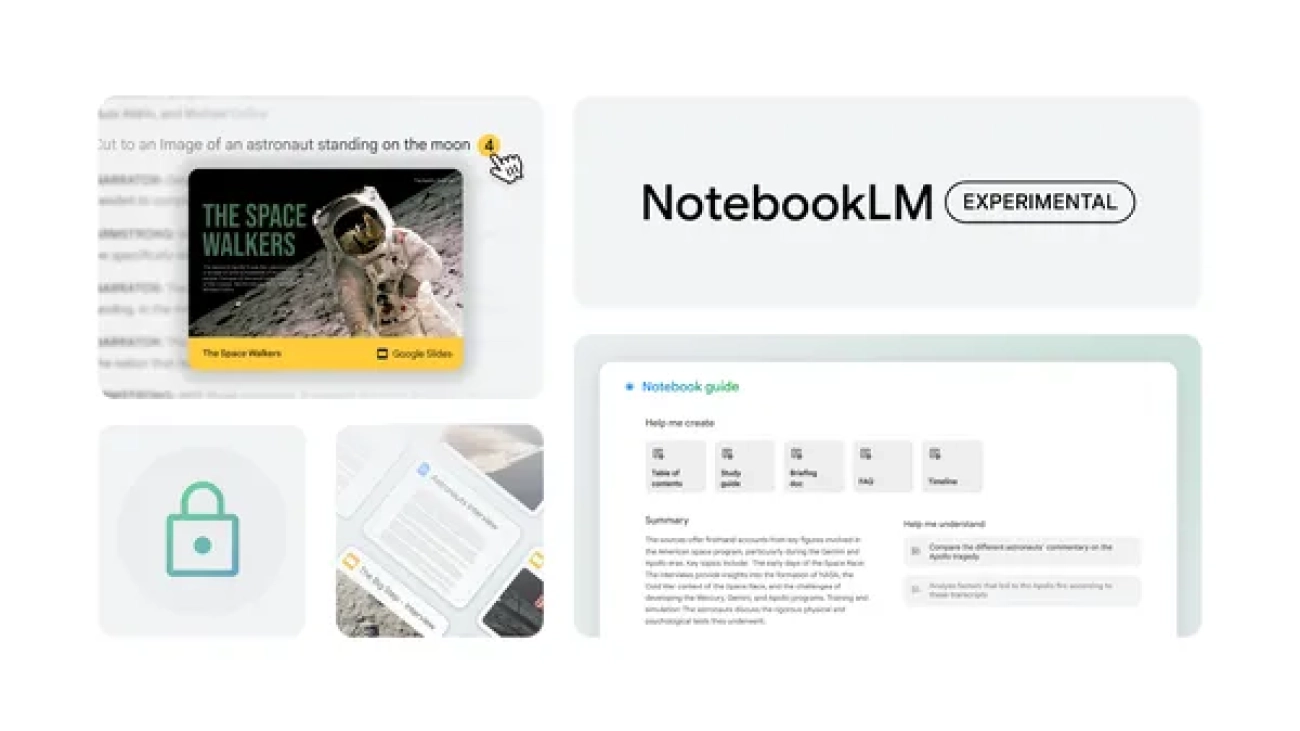
 NotebookLM, our AI-powered research and writing assistant, is getting new features and expanding to over 200 countries and territories.Read More
NotebookLM, our AI-powered research and writing assistant, is getting new features and expanding to over 200 countries and territories.Read More

 Here’s one Googler’s experience of experimenting our newest AI products and updates at Google I/O 2024.Read More
Here’s one Googler’s experience of experimenting our newest AI products and updates at Google I/O 2024.Read More

 Technology companies based in the U.S. can now apply for the new Google for Startups AI Academy: American Infrastructure program.Read More
Technology companies based in the U.S. can now apply for the new Google for Startups AI Academy: American Infrastructure program.Read More

 Artificial intelligence can help take on tasks that range from the everyday to the extraordinary, whether it’s crunching numbers or curing diseases. But the only way to …Read More
Artificial intelligence can help take on tasks that range from the everyday to the extraordinary, whether it’s crunching numbers or curing diseases. But the only way to …Read More