The qubits that make up Google quantum devices are delicate and noisy, so it’s necessary to incorporate error correction procedures that identify and account for qubit errors on the way to building a useful quantum computer. Two of the most prevalent error mechanisms are bit-flip errors (where the energy state of the qubit changes) and phase-flip errors (where the phase of the encoded quantum information changes). Quantum error correction (QEC) promises to address and mitigate these two prominent errors. However, there is an assortment of other error mechanisms that challenges the effectiveness of QEC.
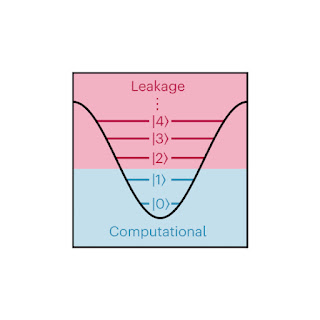
While we want qubits to behave as ideal two-level systems with no loss mechanisms, this is not the case in reality. We use the lowest two energy levels of our qubit (which form the computational basis) to carry out computations. These two levels correspond to the absence (computational ground state) or presence (computational excited state) of an excitation in the qubit, and are labeled |0⟩ (“ket zero”) and |1⟩ (“ket one”), respectively. However, our qubits also host many higher levels called leakage states, which can become occupied. Following the convention of labeling the level by indicating how many excitations are in the qubit, we specify them as |2⟩, |3⟩, |4⟩, and so on.
In “Overcoming leakage in quantum error correction”, published in Nature Physics, we identify when and how our qubits leak energy to higher states, and show that the leaked states can corrupt nearby qubits through our two-qubit gates. We then identify and implement a strategy that can remove leakage and convert it to an error that QEC can efficiently fix. Finally, we show that these operations lead to notably improved performance and stability of the QEC process. This last result is particularly critical, since additional operations take time, usually leading to more errors.
Working with imperfect qubits
Our quantum processors are built from superconducting qubits called transmons. Unlike an ideal qubit, which only has two computational levels — a computational ground state and a computational excited state — transmon qubits have many additional states with higher energy than the computational excited state. These higher leakage states are useful for particular operations that generate entanglement, a necessary resource in quantum algorithms, and also keep transmons from becoming too non-linear and difficult to operate. However, the transmon can also be inadvertently excited into these leakage states through a variety of processes, including imperfections in the control pulses we apply to perform operations or from the small amount of stray heat leftover in our cryogenic refrigerator. These processes are collectively referred to as leakage, which describes the transition of the qubit from computational states to leakage states.
Consider a particular two-qubit operation that is used extensively in our QEC experiments: the CZ gate. This gate operates on two qubits, and when both qubits are in their |1⟩ level, an interaction causes the two individual excitations to briefly “bunch” together in one of the qubits to form |2⟩, while the other qubit becomes |0⟩, before returning to the original configuration where each qubit is in |1⟩. This bunching underlies the entangling power of the CZ gate. However, with a small probability, the gate can encounter an error and the excitations do not return to their original configuration, causing the operation to leave a qubit in |2⟩, a leakage state. When we execute hundreds or more of these CZ gates, this small leakage error probability accumulates.
 |
| Transmon qubits support many leakage states (|2⟩, |3⟩, |4⟩, …) beyond the computational basis (|0⟩ and |1⟩). While we typically only use the computational basis to represent quantum information, sometimes the qubit enters these leakage states, and disrupts the normal operation of our qubits. |
A single leakage event is especially damaging to normal qubit operation because it induces many individual errors. When one qubit starts in a leaked state, the CZ gate no longer correctly entangles the qubits, preventing the algorithm from executing correctly. Not only that, but CZ gates applied to one qubit in leaked states can cause the other qubit to leak as well, spreading leakage through the device. Our work includes extensive characterization of how leakage is caused and how it interacts with the various operations we use in our quantum processor.
Once the qubit enters a leakage state, it can remain in that state for many operations before relaxing back to the computational states. This means that a single leakage event interferes with many operations on that qubit, creating operational errors that are bunched together in time (time-correlated errors). The ability for leakage to spread between the different qubits in our device through the CZ gates means we also concurrently see bunches of errors on neighboring qubits (space-correlated errors). The fact that leakage induces patterns of space- and time-correlated errors makes it especially hard to diagnose and correct from the perspective of QEC algorithms.
The effect of leakage in QEC
We aim to mitigate qubit errors by implementing surface code QEC, a set of operations applied to a collection of imperfect physical qubits to form a logical qubit, which has properties much closer to an ideal qubit. In a nutshell, we use a set of qubits called data qubits to hold the quantum information, while another set of measure qubits check up on the data qubits, reporting on whether they have suffered any errors, without destroying the delicate quantum state of the data qubits. One of the key underlying assumptions of QEC is that errors occur independently for each operation, but leakage can persist over many operations and cause a correlated pattern of multiple errors. The performance of our QEC strategies is significantly limited when leakage causes this assumption to be violated.
 |
| Once leakage manifests in our surface code transmon grid, it persists for a long time relative to a single surface code QEC cycle. To make matters worse, leakage on one qubit can cause its neighbors to leak as well. |
Our previous work has shown that we can remove leakage from measure qubits using an operation called multi-level reset (MLR). This is possible because once we perform a measurement on measure qubits, they no longer hold any important quantum information. At this point, we can interact the qubit with a very lossy frequency band, causing whichever state the qubit was in (including leakage states) to decay to the computational ground state |0⟩. If we picture a Jenga tower representing the excitations in the qubit, we tumble the entire stack over. Removing just one brick, however, is much more challenging. Likewise, MLR doesn’t work with data qubits because they always hold important quantum information, so we need a new leakage removal approach that minimally disturbs the computational basis states.
Gently removing leakage
We introduce a new quantum operation called data qubit leakage removal (DQLR), which targets leakage states in a data qubit and converts them into computational states in the data qubit and a neighboring measure qubit. DQLR consists of a two-qubit gate (dubbed Leakage iSWAP — an iSWAP operation with leakage states) inspired by and similar to our CZ gate, followed by a rapid reset of the measure qubit to further remove errors. The Leakage iSWAP gate is very efficient and greatly benefits from our extensive characterization and calibration of CZ gates within the surface code experiment.
Recall that a CZ gate takes two single excitations on two different qubits and briefly brings them to one qubit, before returning them to their respective qubits. A Leakage iSWAP gate operates similarly, but almost in reverse, so that it takes a single qubit with two excitations (otherwise known as |2⟩) and splits them into |1⟩ on two qubits. The Leakage iSWAP gate (and for that matter, the CZ gate) is particularly effective because it does not operate on the qubits if there are fewer than two excitations present. We are precisely removing the |2⟩ Jenga brick without toppling the entire tower.
By carefully measuring the population of leakage states on our transmon grid, we find that DQLR can reduce average leakage state populations over all qubits to about 0.1%, compared to nearly 1% without it. Importantly, we no longer observe a gradual rise in the amount of leakage on the data qubits, which was always present to some extent prior to using DQLR.
This outcome, however, is only half of the puzzle. As mentioned earlier, an operation such as MLR could be used to effectively remove leakage on the data qubits, but it would also completely erase the stored quantum state. We also need to demonstrate that DQLR is compatible with the preservation of a logical quantum state.
The second half of the puzzle comes from executing the QEC experiment with this operation interleaved at the end of each QEC cycle, and observing the logical performance. Here, we use a metric called detection probability to gauge how well we are executing QEC. In the presence of leakage, time- and space-correlated errors will cause a gradual rise in detection probabilities as more and more qubits enter and stay in leakage states. This is most evident when we perform no reset at all, which rapidly leads to a transmon grid plagued by leakage, and it becomes inoperable for the purposes of QEC.
 |
| The prior state-of-the-art in our QEC experiments was to use MLR on the measure qubits to remove leakage. While this kept leakage population on the measure qubits (green circles) sufficiently low, data qubit leakage population (green squares) would grow and saturate to a few percent. With DQLR, leakage population on both the measure (blue circles) and data qubits (blue squares) remain acceptably low and stable. |
With MLR, the large reduction in leakage population on the measure qubits drastically decreases detection probabilities and mitigates a considerable degree of the gradual rise. This reduction in detection probability happens even though we spend more time dedicated to the MLR gate, when other errors can potentially occur. Put another way, the correlated errors that leakage causes on the grid can be much more damaging than the uncorrelated errors from the qubits waiting idle, and it is well worth it for us to trade the former for the latter.
When only using MLR, we observed a small but persistent residual rise in detection probabilities. We ascribed this residual increase in detection probability to leakage accumulating on the data qubits, and found that it disappeared when we implemented DQLR. And again, the observation that the detection probabilities end up lower compared to only using MLR indicates that our added operation has removed a damaging error mechanism while minimally introducing uncorrelated errors.
 |
| Leakage manifests during surface code operation as increased errors (shown as error detection probabilities) over the number of cycles. With DQLR, we no longer see a notable rise in detection probability over more surface code cycles. |
Prospects for QEC scale-up
Given these promising results, we are eager to implement DQLR in future QEC experiments, where we expect error mechanisms outside of leakage to be greatly improved, and sensitivity to leakage to be enhanced as we work with larger and larger transmon grids. In particular, our simulations indicate that scale-up of our surface code will almost certainly require a large reduction in leakage generation rates, or an active leakage removal technique over all qubits, such as DQLR.
Having laid the groundwork by understanding where leakage is generated, capturing the dynamics of leakage after it presents itself in a transmon grid, and showing that we have an effective mitigation strategy in DQLR, we believe that leakage and its associated errors no longer pose an existential threat to the prospects of executing a surface code QEC protocol on a large grid of transmon qubits. With one fewer challenge standing in the way of demonstrating working QEC, the pathway to a useful quantum computer has never been more promising.
Acknowledgements
This work would not have been possible without the contributions of the entire Google Quantum AI Team.

 Generative AI in Search, or Search Generative Experience (SGE), is expanding around the world, and adding four new languages.
Generative AI in Search, or Search Generative Experience (SGE), is expanding around the world, and adding four new languages.
 Today, we’re announcing the Swedish recipients of Google.org Impact Challenge: Tech for Social Good – receiving technical support and 3 million Euros in funding for char…
Today, we’re announcing the Swedish recipients of Google.org Impact Challenge: Tech for Social Good – receiving technical support and 3 million Euros in funding for char…