AI-related products and technologies are constructed and deployed in a societal context: that is, a dynamic and complex collection of social, cultural, historical, political and economic circumstances. Because societal contexts by nature are dynamic, complex, non-linear, contested, subjective, and highly qualitative, they are challenging to translate into the quantitative representations, methods, and practices that dominate standard machine learning (ML) approaches and responsible AI product development practices.
The first phase of AI product development is problem understanding, and this phase has tremendous influence over how problems (e.g., increasing cancer screening availability and accuracy) are formulated for ML systems to solve as well many other downstream decisions, such as dataset and ML architecture choice. When the societal context in which a product will operate is not articulated well enough to result in robust problem understanding, the resulting ML solutions can be fragile and even propagate unfair biases.
When AI product developers lack access to the knowledge and tools necessary to effectively understand and consider societal context during development, they tend to abstract it away. This abstraction leaves them with a shallow, quantitative understanding of the problems they seek to solve, while product users and society stakeholders — who are proximate to these problems and embedded in related societal contexts — tend to have a deep qualitative understanding of those same problems. This qualitative–quantitative divergence in ways of understanding complex problems that separates product users and society from developers is what we call the problem understanding chasm.
This chasm has repercussions in the real world: for example, it was the root cause of racial bias discovered by a widely used healthcare algorithm intended to solve the problem of choosing patients with the most complex healthcare needs for special programs. Incomplete understanding of the societal context in which the algorithm would operate led system designers to form incorrect and oversimplified causal theories about what the key problem factors were. Critical socio-structural factors, including lack of access to healthcare, lack of trust in the health care system, and underdiagnosis due to human bias, were left out while spending on healthcare was highlighted as a predictor of complex health need.
To bridge the problem understanding chasm responsibly, AI product developers need tools that put community-validated and structured knowledge of societal context about complex societal problems at their fingertips — starting with problem understanding, but also throughout the product development lifecycle. To that end, Societal Context Understanding Tools and Solutions (SCOUTS) — part of the Responsible AI and Human-Centered Technology (RAI-HCT) team within Google Research — is a dedicated research team focused on the mission to “empower people with the scalable, trustworthy societal context knowledge required to realize responsible, robust AI and solve the world’s most complex societal problems.” SCOUTS is motivated by the significant challenge of articulating societal context, and it conducts innovative foundational and applied research to produce structured societal context knowledge and to integrate it into all phases of the AI-related product development lifecycle. Last year we announced that Jigsaw, Google’s incubator for building technology that explores solutions to threats to open societies, leveraged our structured societal context knowledge approach during the data preparation and evaluation phases of model development to scale bias mitigation for their widely used Perspective API toxicity classifier. Going forward SCOUTS’ research agenda focuses on the problem understanding phase of AI-related product development with the goal of bridging the problem understanding chasm.
Bridging the AI problem understanding chasm
Bridging the AI problem understanding chasm requires two key ingredients: 1) a reference frame for organizing structured societal context knowledge and 2) participatory, non-extractive methods to elicit community expertise about complex problems and represent it as structured knowledge. SCOUTS has published innovative research in both areas.
| An illustration of the problem understanding chasm. |
A societal context reference frame
An essential ingredient for producing structured knowledge is a taxonomy for creating the structure to organize it. SCOUTS collaborated with other RAI-HCT teams (TasC, Impact Lab), Google DeepMind, and external system dynamics experts to develop a taxonomic reference frame for societal context. To contend with the complex, dynamic, and adaptive nature of societal context, we leverage complex adaptive systems (CAS) theory to propose a high-level taxonomic model for organizing societal context knowledge. The model pinpoints three key elements of societal context and the dynamic feedback loops that bind them together: agents, precepts, and artifacts.
- Agents: These can be individuals or institutions.
- Precepts: The preconceptions — including beliefs, values, stereotypes and biases — that constrain and drive the behavior of agents. An example of a basic precept is that “all basketball players are over 6 feet tall.” That limiting assumption can lead to failures in identifying basketball players of smaller stature.
- Artifacts: Agent behaviors produce many kinds of artifacts, including language, data, technologies, societal problems and products.
The relationships between these entities are dynamic and complex. Our work hypothesizes that precepts are the most critical element of societal context and we highlight the problems people perceive and the causal theories they hold about why those problems exist as particularly influential precepts that are core to understanding societal context. For example, in the case of racial bias in a medical algorithm described earlier, the causal theory precept held by designers was that complex health problems would cause healthcare expenditures to go up for all populations. That incorrect precept directly led to the choice of healthcare spending as the proxy variable for the model to predict complex healthcare need, which in turn led to the model being biased against Black patients who, due to societal factors such as lack of access to healthcare and underdiagnosis due to bias on average, do not always spend more on healthcare when they have complex healthcare needs. A key open question is how can we ethically and equitably elicit causal theories from the people and communities who are most proximate to problems of inequity and transform them into useful structured knowledge?
 |
| Illustrative version of societal context reference frame. |
 |
| Taxonomic version of societal context reference frame. |
Working with communities to foster the responsible application of AI to healthcare
Since its inception, SCOUTS has worked to build capacity in historically marginalized communities to articulate the broader societal context of the complex problems that matter to them using a practice called community based system dynamics (CBSD). System dynamics (SD) is a methodology for articulating causal theories about complex problems, both qualitatively as causal loop and stock and flow diagrams (CLDs and SFDs, respectively) and quantitatively as simulation models. The inherent support of visual qualitative tools, quantitative methods, and collaborative model building makes it an ideal ingredient for bridging the problem understanding chasm. CBSD is a community-based, participatory variant of SD specifically focused on building capacity within communities to collaboratively describe and model the problems they face as causal theories, directly without intermediaries. With CBSD we’ve witnessed community groups learn the basics and begin drawing CLDs within 2 hours.
 |
| Data 4 Black Lives community members learning system dynamics. |
There is a huge potential for AI to improve medical diagnosis. But the safety, equity, and reliability of AI-related health diagnostic algorithms depends on diverse and balanced training datasets. An open challenge in the health diagnostic space is the dearth of training sample data from historically marginalized groups. SCOUTS collaborated with the Data 4 Black Lives community and CBSD experts to produce qualitative and quantitative causal theories for the data gap problem. The theories include critical factors that make up the broader societal context surrounding health diagnostics, including cultural memory of death and trust in medical care.
The figure below depicts the causal theory generated during the collaboration described above as a CLD. It hypothesizes that trust in medical care influences all parts of this complex system and is the key lever for increasing screening, which in turn generates data to overcome the data diversity gap.
 |
 |
| Causal loop diagram of the health diagnostics data gap |
These community-sourced causal theories are a first step to bridge the problem understanding chasm with trustworthy societal context knowledge.
Conclusion
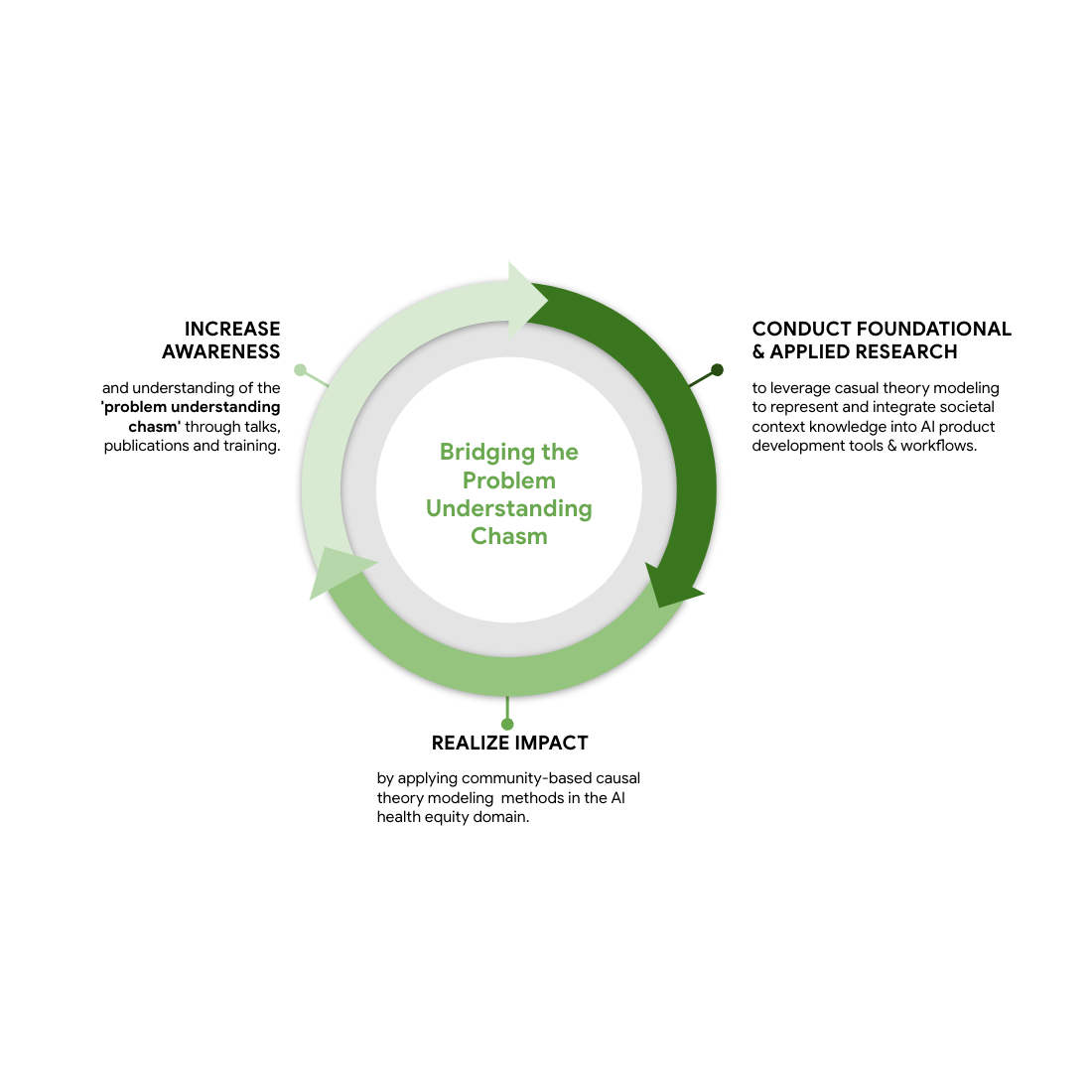
As discussed in this blog, the problem understanding chasm is a critical open challenge in responsible AI. SCOUTS conducts exploratory and applied research in collaboration with other teams within Google Research, external community, and academic partners across multiple disciplines to make meaningful progress solving it. Going forward our work will focus on three key elements, guided by our AI Principles:
- Increase awareness and understanding of the problem understanding chasm and its implications through talks, publications, and training.
- Conduct foundational and applied research for representing and integrating societal context knowledge into AI product development tools and workflows, from conception to monitoring, evaluation and adaptation.
- Apply community-based causal modeling methods to the AI health equity domain to realize impact and build society’s and Google’s capability to produce and leverage global-scale societal context knowledge to realize responsible AI.
 |
| SCOUTS flywheel for bridging the problem understanding chasm. |
Acknowledgments
Thank you to John Guilyard for graphics development, everyone in SCOUTS, and all of our collaborators and sponsors.

 Today we’re publishing information on Google’s AI Red Team for the first time
Today we’re publishing information on Google’s AI Red Team for the first time





 We worked with TONL, a stock image company, to create more representative datasets to help teams build more inclusive products.
We worked with TONL, a stock image company, to create more representative datasets to help teams build more inclusive products.
 A new $5 million grant aims to help Woodwell Climate Research Center track Arctic permafrost thaw in near real-time.
A new $5 million grant aims to help Woodwell Climate Research Center track Arctic permafrost thaw in near real-time.
 Homenajeamos a Eunice Newton Foot, científica pionera de la ciencia climática, y a 6 organizaciones beneficiarias de Google.org dirigidas por mujeres que construyen un f…
Homenajeamos a Eunice Newton Foot, científica pionera de la ciencia climática, y a 6 organizaciones beneficiarias de Google.org dirigidas por mujeres que construyen un f…