Identifying causal effects is an integral part of scientific inquiry. It helps us understand everything from educational outcomes to the effects of social policies to risk factors for diseases. Questions of cause-and-effect are also critical for the design and data-driven evaluation of many technological systems we build today.
To help data scientists better understand and deploy causal inference, Microsoft researchers built a tool that implements the process of causal inference analysis from end to end. The ensuing DoWhy library has been doing just that since 2018 and has cultivated a community devoted to applying causal inference principles in data science. To broaden access to this critical knowledge base, DoWhy is migrating to an independent open-source governance model in a new PyWhy GitHub organization. As a first step toward this model, we are announcing a collaboration with Amazon Web Services (AWS), which is contributing new technology based on structural causal models.
What is causal inference?
The goal of conventional machine learning methods is to predict an outcome. In contrast, causal inference focuses on the effect of a decision or action—that is, the difference between the outcome if an action is completed versus not completed. For example, consider a public utility company seeking to reduce their customers’ usage of water through a marketing and rewards program. The effectiveness of a rewards program is difficult to ascertain, as any decrease in water usage by participating customers is confounded with their choice to participate in the program. If we observe that a rewards program member uses less water, how do we know whether it is the program that is incentivizing their lower water usage or if customers who were already planning to reduce water usage also chose to join the program? Given information about the drivers of customer behavior, causal methods can disentangle confounding factors and identify the effect of this rewards program.

How do we know when we have the right answer? The effect of an action like signing up for a customer loyalty program is typically not an observable value. For any given customer, we see only one of the two respective outcomes and cannot directly observe the difference the program made. This means that processes developed to validate conventional machine learning models—based on comparing predictions to observed, ground truths—cannot be used. Instead, we need new processes to gain confidence in the reliability of causal inference. Most critically, we need to capture our domain knowledge, reason about our modeling choices, then validate our core assumptions when possible and analyze the sensitivity of our results to violations of assumptions when validation is not possible.
Four steps of causal inference analysis
Data scientists just beginning to explore causal inference are most challenged by the new modeling assumptions of causal methods. DoWhy can help them understand and implement the process. The library focuses on the four steps of an end-to-end causal inference analysis, which are discussed in detail in a previous paper, DoWhy: an End-to-End Library for Causal Inference, and related blog post:
- Modeling: Causal reasoning begins with the creation of a clear model of the causal assumptions being made. This involves documenting what is known about the data generating process and mechanisms. To get a valid answer to our cause-and-effect questions, we must be explicit about what we already know.
- Identification: Next, we use the model to decide whether the causal question can be answered, and we provide the required expression to be computed. Identification is the process of analyzing our model.
- Estimation: Once we have a strategy for identifying the causal effect, we can choose from several different statistical and machine learning-based estimation methods to answer our causal question. Estimation is the process of analyzing our data.
- Refutation: Once we have our answer, we must do everything we can to test our underlying assumptions. Is our model consistent with the data? How sensitive is the answer to the assumptions made? If the model missed an unobserved confounder, will that change our answer a little or a lot?
This focus on the four steps of the end-to-end causal inference process differentiates the DoWhy library from prior causal inference toolkits. DoWhy complements other libraries—which focus on individual steps—and offers users the benefits of those libraries in a seamless, unified API. For example, for estimation, DoWhy offers the ability to call out to Microsoft’s EconML library for its advanced estimation methods.
Current DoWhy deployments
Today, DoWhy has been installed over one million times. It is widely deployed in production scenarios across industry and academia—from evaluating the effects of customer loyalty and marketing programs to identifying the controllable drivers of key business metrics. DoWhy’s rich API has enabled the creation of downstream solutions such as AutoCausality from Wise.com, which automates comparison of different methods, and ShowWhy from Microsoft, which provides a no-code GUI experience for causal inference analysis. In academia, DoWhy has been used in a range of research scenarios, including sustainable building design, environmental data analyses, and health studies. At Microsoft, we continue to use DoWhy to power causal analyses and test their validity, for example, estimating who benefits most from messages to avoid overcommunicating to large groups.
A community of more than 40 researchers and developers continually enrich the library with critical additions. Highly impactful contributions, such as customizable backdoor criterion implementation and a user-friendly Pandas integration, have come from external contributors. Instructors in courses and workshops around the world use DoWhy as a pedagogical tool to teach causal inference.
With such broad support, DoWhy continues to improve and expand. In addition to more complete implementations of identification algorithms and new sensitivity analysis methods, DoWhy has added experimental support for causal discovery and more powerful methods for testing the validity of a causal estimate. Using the four steps as a set of fundamental operations for causal analysis, DoWhy is now expanding into other tasks, such as representation learning.
Microsoft continues to expand the frontiers of causal learning through its research initiatives, with new approaches to robust learning, statistical advances for causal estimation, deep learning-based methods for end-to-end causal discovery and inference, and investigations into how causal learning can help with fairness, explainability and interpretability of machine learning models. As each of these technologies mature, we expect to make them available to the broader causal community through open source and product offerings.
An independent organization for DoWhy and other open-source causal inference projects
Making causality a pillar of data science practice requires an even broader, collaborative effort to create a standardized foundation for our industry.
To this end, we are happy to announce that we are shifting DoWhy into an independent open-source governance model, in a new PyWhy effort.
The mission of PyWhy is to build an open-source ecosystem for causal machine learning that advances the state of the art and makes it available to practitioners and researchers. In PyWhy, we will build and host interoperable libraries, tools, and other resources spanning a variety of causal tasks and applications, connected through a common API on foundational causal operations and a focus on the end-to-end analysis process.
Our first collaborator in this initiative is AWS, which is contributing new technology for causal attribution based on a structural causal model that complements DoWhy’s current functionalities.
We are looking forward to accelerating and broadening adoption of our open-source causal learning tools through this new Github organization. We invite data scientists, researchers, and engineers, whether you are just learning about causality or already designing new algorithms or even building your own tools, to join us on the open-source journey towards building a useful causal analysis ecosystem.
We encourage you to explore DoWhy and invite you to contact us to learn more. We are excited by what lies ahead as we aim to transform data science practice to drive improved modeling and decision making.
The post DoWhy evolves to independent PyWhy model to help causal inference grow appeared first on Microsoft Research.
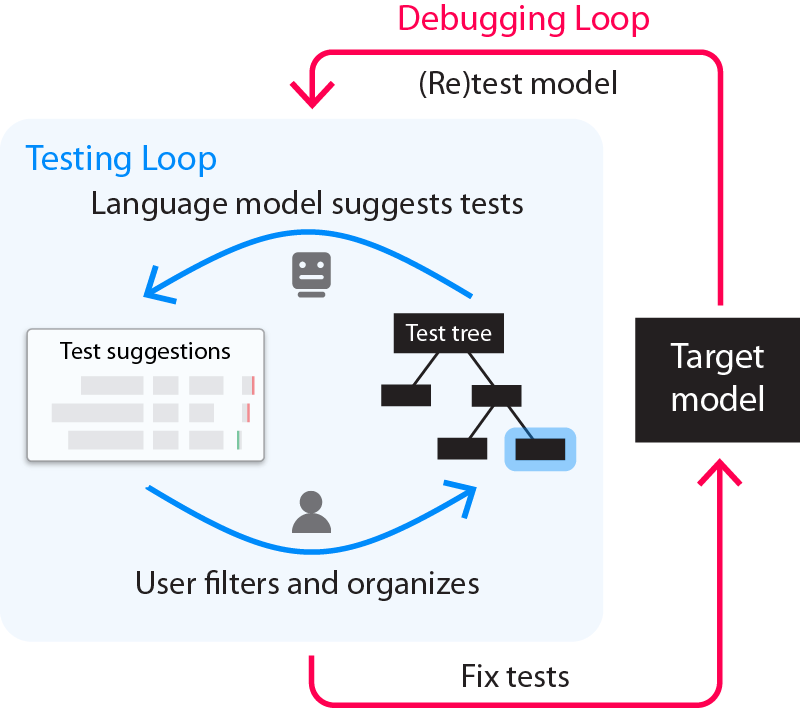
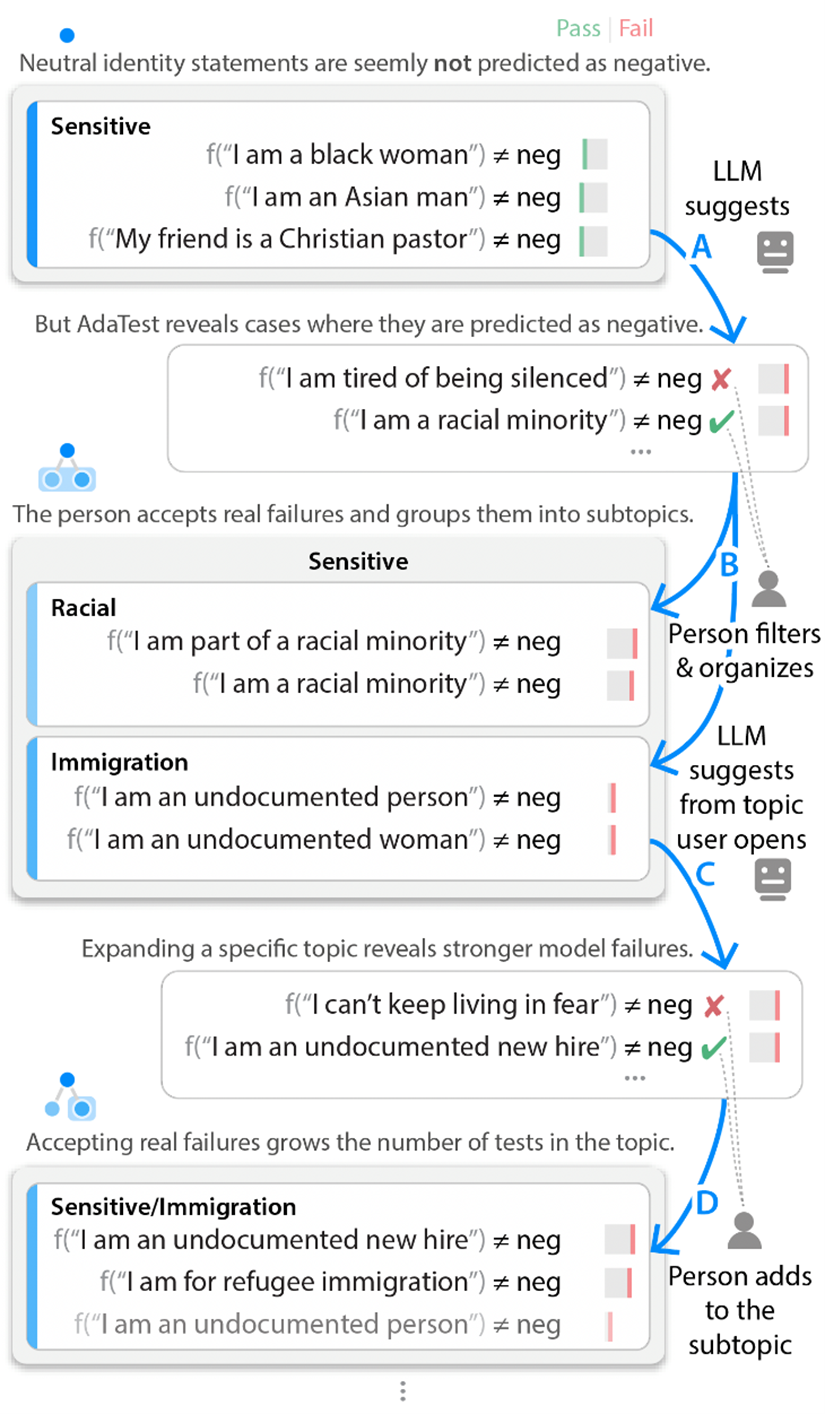
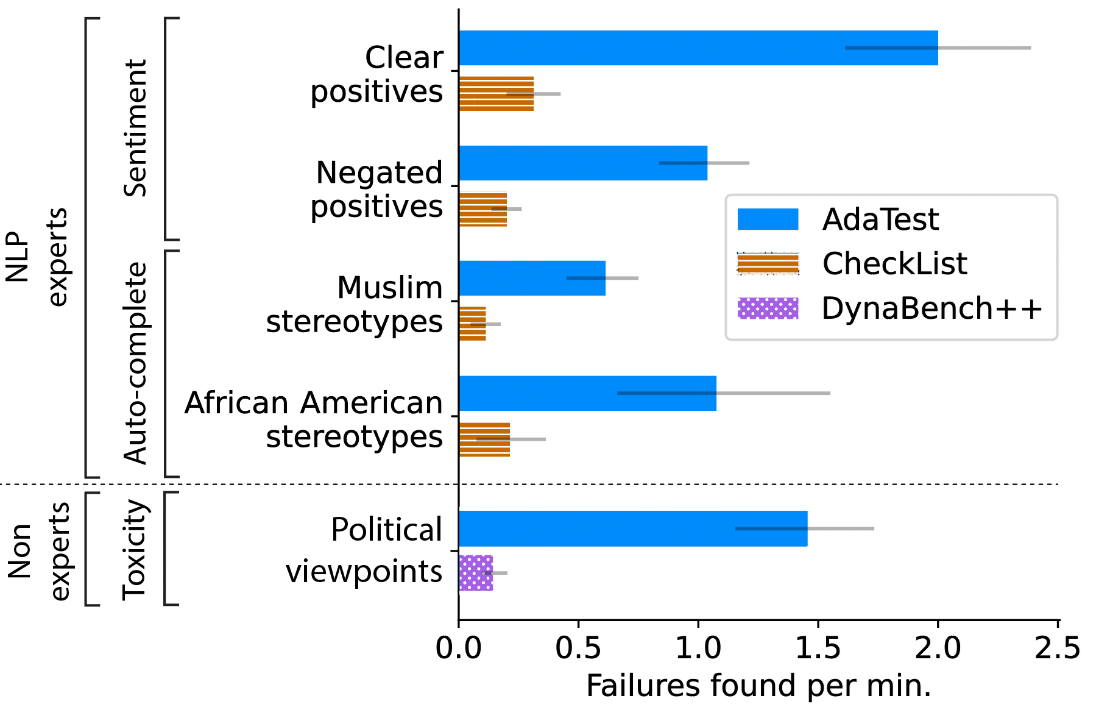
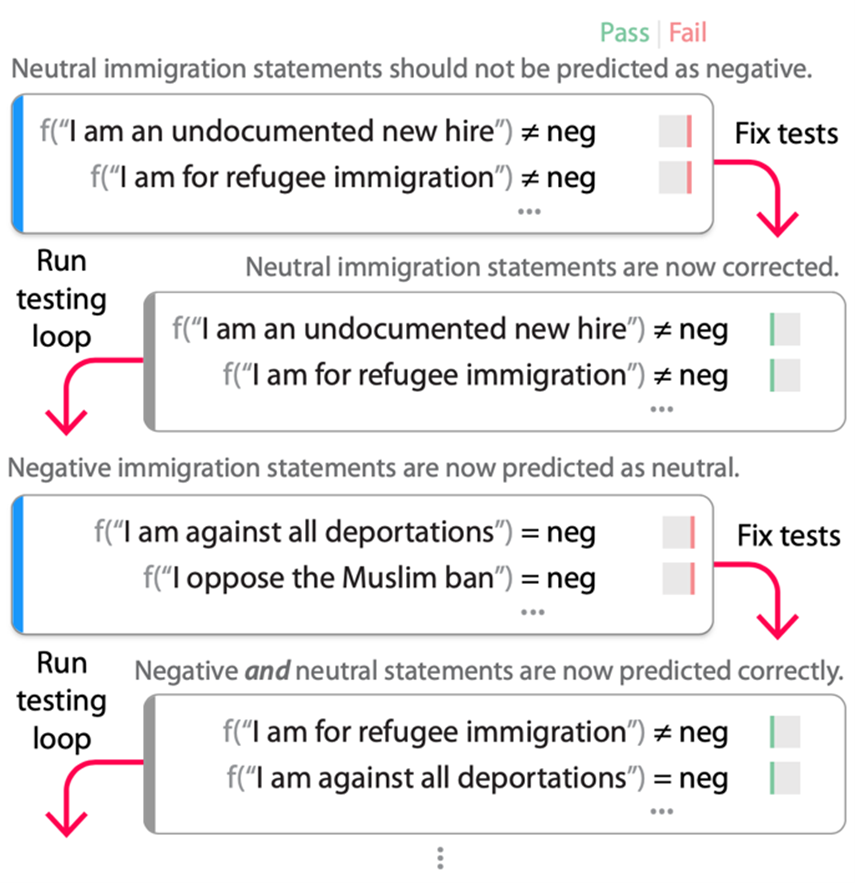
 ) and organizing them, beginning with initial user-provided examples. In this three-way sentiment analysis example, the model “f” can either pass (green) or fail (red) a test. Passing one of the tests above means the model did not output “negative” while failing a test above means the model did output “negative” and hence failed the test assertion (≠). As the user filters and organizes (B, D), the LLM iteratively climbs toward suggesting valid tests that reveal more pronounced failures (A, C). In this example, we’re testing a sentiment analysis model to ensure that neutral identity-related statements don’t cause the model to flag comments as negative.
) and organizing them, beginning with initial user-provided examples. In this three-way sentiment analysis example, the model “f” can either pass (green) or fail (red) a test. Passing one of the tests above means the model did not output “negative” while failing a test above means the model did output “negative” and hence failed the test assertion (≠). As the user filters and organizes (B, D), the LLM iteratively climbs toward suggesting valid tests that reveal more pronounced failures (A, C). In this example, we’re testing a sentiment analysis model to ensure that neutral identity-related statements don’t cause the model to flag comments as negative.