Watch the replay of the Interspeech 2020 industry forum session.Read More
Alexa scientists discuss relevant work in the field of conversational AI
Watch the replay of the Interspeech 2020 industry forum session.Read More
Amazon Consumer Science Summit goes virtual
COVID-19-induced trend toward virtual conferences may change how science is conducted.Read More
Building a real-time conversational analytics platform for Amazon Lex bots
Conversational interfaces like chatbots have become an important channel for brands to communicate with their customers, partners, and employees. They offer faster service, 24/7 availability, and lower service costs. By analyzing your bot’s customer conversations, you can discover challenges in user experience, trending topics, and missed utterances. These additional insights can help you identify how to improve your bot and user engagement continuously. Whether you’re a product owner looking for user engagement insights or a conversation designer wanting to review missed utterances, a conversational analytics dashboard plays a vital role in serving these needs.
In this post, we build a real-time conversational analytics solution using the conversational logs from Amazon Lex. Amazon Lex is a service for building conversational interfaces into any application using voice and text. We use Amazon QuickSight to create a dashboard to visualize business KPIs, identify trends, and provide training data for bots to learn from their past failures. Some of the metrics we cover in this post include:
- Daily summary statistics
- User adoption
- Intent and utterance metrics
- Conversation review
- Sentiment analysis
Solution architecture
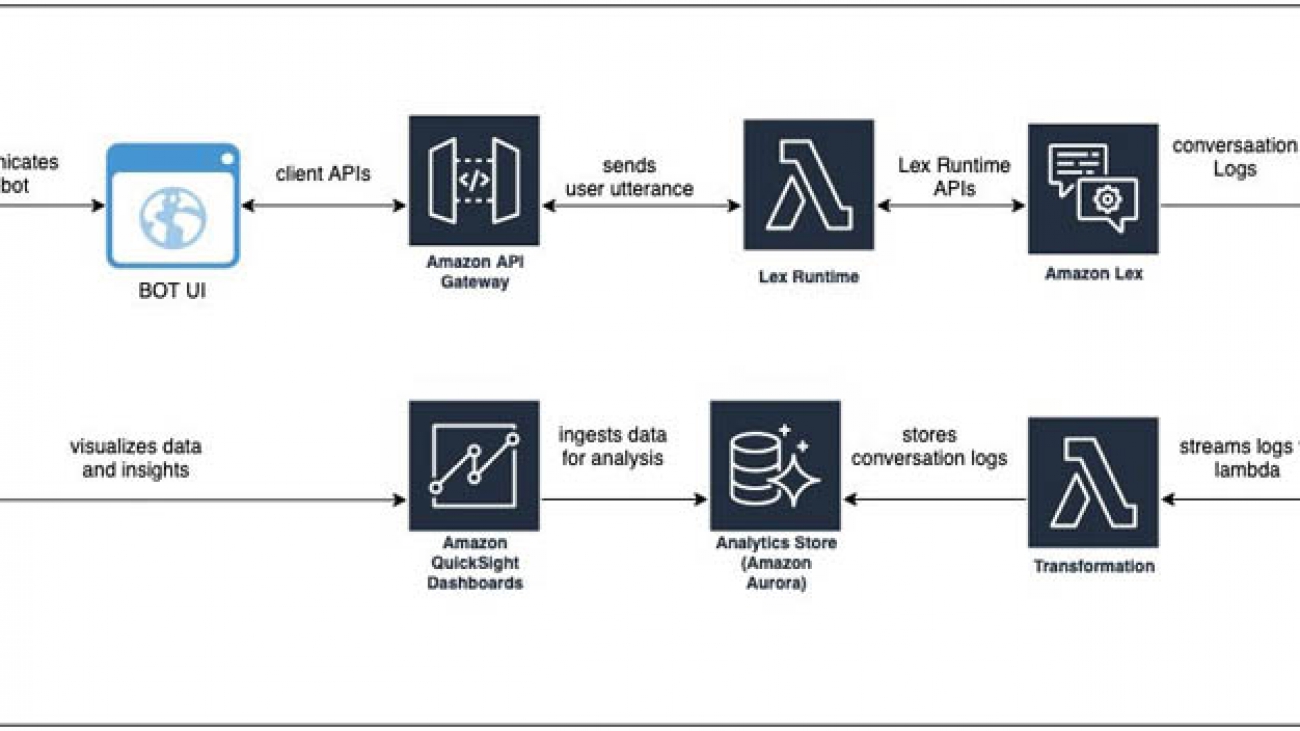
The following diagram illustrates the architecture of our solution.

The architecture comprises streaming the conversation logs from Amazon CloudWatch to Amazon Kinesis Data Streams and having a stream consumer (an AWS Lambda function) transforming the data to be written into an Amazon Aurora database that serves as the analytics store.
Depending on your project’s scale and your organizational needs and preferences, you may want to look into a data warehousing solution like Amazon Redshift or use Amazon Athena and Amazon Simple Storage Service (Amazon S3). For more information, see Building a business intelligence dashboard for your Amazon Lex bots.
We use the Aurora connector in QuickSight to pull in the data, create datasets and analysis, and publish a conversation analytics dashboard. QuickSight lets you easily create and publish interactive dashboards. You can choose from an extensive library of visualizations, charts, and tables, and add interactive features such as drill-downs and filters.
Solution overview
For this post, we created an Amazon Lex bot using the sample OrderFlowers blueprint. The default sample only comes with one intent: OrderFlowers. To make the analytics more interesting, we added custom intents like BusinessHoursIntent, OffersIntent, and MyFallbackIntent. For the export of this bot, download OrderFlowers.zip. You can import this file into your Amazon Lex console or use your own Amazon Lex bot.
To implement the solution, we need to complete the following tasks:
- Enable the conversation logs feature for your Amazon Lex bot.
- Create a Kinesis data stream and make it a subscriber to the CloudWatch log group created on the AWS CloudFormation
- Create an Aurora database to store the conversation log data.
- Create a Lambda function and subscribe it to listen to the data stream. The Lambda function extracts the data from the stream and writes it to the Aurora database.
- Set up QuickSight to consume data from the Aurora database.
- Create datasets and analysis, and publish the dashboard in QuickSight.
Deploying the CloudFormation template
The CloudFormation template deploys the following resources:
- An AWS Identity and Access Management (IAM) role to allow Amazon Lex to stream to CloudWatch Logs
- A CloudWatch log group
- A CloudWatch subscription filter
- A Kinesis data stream and its associated IAM role
- A Kinesis data stream consumer
- A Lambda function for object construction and its associated IAM role
- A serverless Aurora RDS cluster and its associated security group
- A security group for QuickSight access to Amazon Relational Database Service (Amazon RDS)
- An AWS Secrets Manager secret with Amazon RDS information
- A fresh VPC for the Aurora cluster
- Two subnets in the generated VPC
- A DB Subnet Group comprised of the two subnets
Complete the following steps:
- Deploy the template by choosing Launch Stack:
![]()
- Give your stack a unique name.
- Customize AWS CloudFormation deployment as needed.
- Deploy the template. This deployment should take approximately 5 minutes to complete
- Navigate to the Outputs tab of the CloudFormation stack and take note of the following values to use later:
SecretARNQuickSightSecurityGroupIDRDSEndpointRDSPort
Enabling the conversation logs option in your Amazon Lex bot
Conversation logs are generated when communicating with a Lex bot on an associated alias. Make sure that the AWS CloudFormation deployment is complete before attempting this step.
- On the Amazon Lex console, open your bot page and make sure the bot has been built and published.
- On the Settings tab, choose Conversation Logs.
- Publish an alias if you haven’t done so already by choosing the one you want and choosing the Settings
You’re prompted to select the log type, the CloudWatch log group, and IAM role on the next page.
- For Log Type, select Text logs.
- For Log Group, choose [STACK-NAME]
-LexAnalyticsLogGroup-[RANDOM-STRING]. - For IAM Role, choose [STACK-NAME]
-LexAnalyticsToCWLRole-[RANDOM-STRING].
You now create the FlowersLogs table in Amazon RDS.
- On the Amazon RDS console, navigate to the cluster created by the CloudFormation stack ([STACK-NAME]
-orderflowersrds-[RANDOM-STRING]). - Choose Query Editor.
- Select your RDS cluster.
- Choose Connect with a Secrets Manager ARN.
- Enter the
SecretARNfrom the Outputs tab of the CloudFormation stack. - Connect to the database and run the following query to create the table:
CREATE TABLE LexAnalyticsDB.FlowersLogs ( `id` mediumint(9) NOT NULL AUTO_INCREMENT, `botName` varchar(50) DEFAULT NULL, `botAlias` varchar(50) DEFAULT NULL, `botVersion` int(11) DEFAULT NULL, `inputTranscript` varchar(255) DEFAULT NULL, `botResponse` varchar(255) DEFAULT NULL, `intent` varchar(100) DEFAULT NULL, `slots` varchar(255) DEFAULT NULL, `missedUtterance` BOOLEAN DEFAULT NULL, `inputDialog` varchar(50) DEFAULT NULL, `requestId` varchar(255) DEFAULT NULL, `userId` varchar(100) DEFAULT NULL, `sessionId` varchar(255) DEFAULT NULL, `tmstmp` timestamp(2) NULL DEFAULT NULL, `sentiment` varchar(50) DEFAULT NULL, `topic` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2865933 DEFAULT CHARSET=latin1If you don’t have a client generating data on the Amazon Lex alias, you can generate test data using the aws-lex-web-ui deployment.
- Navigate to the aws-lex-web-ui GitHub repo.
- In the Getting Started section, choose Launch Stack for the Region you want to build in.
- For BotName, enter the name of your bot.
- For BotAlias, enter the alias of your bot.
- Keep the other settings at their default; they should be sufficient in generating sample data.
- Choose Create stack.
- When the stack is built, on the Outputs page, choose the link for WebAppUrl.
You can now use this page to generate traffic for your bot.
Configuring QuickSight access
For this post, we assume that you’re starting from scratch and haven’t signed up for QuickSight.
Create a VPC Connection in Amazon QuickSight
- On the QuickSight console, choose Sign up for QuickSight.

- Keep the default settings, and make sure that you deploy in the same region where you deployed your CloudFormation stack.
- On the Settings page, on the Manage VPC connections tab, choose Add VPC connection.

- Enter a connection name.
- Choose the same VPC you deployed your RDS instance into.
- Choose any subnet in the VPC.
- For Security Group ID, enter the
QuickSightSecurityGroupIDvalue from the Outputs tab of the CloudFormation stack. - Choose Create.
Create a Dataset in QuickSight
- Go to the Resources tab of your CloudFormation stack.
- Navigate to the LexAnalyticsSecret resource and choose the blue link to the resource.
- Choose Retrieve secret value.
- Copy the username and password.
- On the QuickSight console, choose Manage Data.
- Choose New Data Set.
- For Data source, choose Aurora.
- Enter a name for your data source.
- For Connection type, select the connection you created in the previous section.
- For Database connector, choose MySQL.
- For the server and port, use the
RDSEndpointandRDSPortfields from the CloudFormation stack Outputs. - For Database name, enter
LexAnalyticsDB. - Enter the username and password for the RDS instance earlier.
- Choose Create data source.
- Select the FlowersLogs
- Import to SPICE.
Configuring QuickSight visuals
You have an assortment of pivots to base the analytical dashboard on, depending on the use case you’re targeting: summary view, trend analysis, user level, intent level, utterance level, conversation review, and sentiment analysis.
A summary view can help you compare and contrast the number of users, sessions, and utterances between the current day and the previous day, or the current hour and the previous hour.

A trend analysis of sessions, users, and utterances can help you spot anomalies and cyclical patterns.

User-level metrics measure which users are adopting the chatbots more regularly versus users who are not. You can use this data in conjunction with persona data to segment users to create personalized experiences.

Intent-level metrics help identify the top N intents, which improves staffing decisions at the contact centers serving phone and chat channels. When deciding to prune a bot’s intent structure, you can use these metrics to remove the bottom N intents that don’t serve significant traffic.

Utterance-level metrics help you identify missed utterances and group them by phrases. You can either add the utterances with high counts to the existing intents or create new intents if those utterances don’t already fit into the existing intents.

Conversation review helps you look at the entire conversation between the user and the bot.

Sentiment analysis helps you learn your users’ overall sentiment concerning their experience with the bot. Reviewing conversations that received negative sentiment helps you identify the root cause.


Conclusion
Whether you’re a product owner, conversation designer, developer, or data scientist, conversational analytics are pivotal to understanding user adoption and teaching your bot to learn from its past mistakes. This post covered how to use conversation logs and QuickSight to capture useful insights from user conversations and visualize them. Get started with Amazon Lex and start building your a customized analytics dashboard for your conversation logs.
About the Authors
 Shanthan Kesharaju is a Senior Architect who helps our customers with AI/ML strategy and architecture. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
Shanthan Kesharaju is a Senior Architect who helps our customers with AI/ML strategy and architecture. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
 Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
Amazon’s new research on automatic speech recognition
Interspeech papers include novel approaches to speaker identification and the training of end-to-end speech recognition models.Read More

SoftBank Group, NVIDIA CEOs on What’s Next for AI
Good news: AI will soon be everywhere. Better news: it will be put to work by everyone.
Sharing a vision of AI enabling humankind, NVIDIA CEO Jensen Huang Wednesday joined Masayoshi Son, Chairman and CEO of SoftBank Group Corp. as a guest for his keynote at the annual SoftBank World conference.
“For the first time, we’re going to democratize software programming,” Huang said. “You don’t have to program the computer; you just have to teach the computer.”
Son is a legendary entrepreneur, investor and philanthropist who pioneered the development of the PC industry, the internet and mobile computing in Japan.
A Technological Jewel
The online conversation comes six weeks after NVIDIA agreed to acquire Arm from SoftBank in a transaction valued at $40 billion. Huang described Arm as “one of the technology world’s great jewels” in his conversation with Son.
“The reason why combining Arm and NVIDIA makes so much sense is because we can then bring NVIDIA’s AI to the most popular edge CPU in the world,” Huang said while seated beside the fireplace of his Silicon Valley home.
Arm has long provided its intellectual property to many chipset vendors, who deploy it on many different applications, in many different systems-on-a-chip, or SoCs, Son explained.
Huang said the combined company would “absolutely” continue this.
An Ecosystem Like No Other
“Of course the CPU is fantastic, energy-efficient and it’s improving all the time, thanks to incredible computer scientists building the best CPU in the world,” Huang said. “But the true value of Arm is in the ecosystem of Arm — the 500 companies that use Arm today.”
That ecosystem is growing fast. Son said it won’t be long until a trillion Arm-based SoCs have been shipped. Making NVIDIA AI available to those trillion chipsets “will be an amazing combination,” Son said.
“Our dream is to bring NVIDIA’s AI to Arm’s ecosystem, and the only way to bring it to the Arm ecosystem is through all of the existing customers, licensees and partners,” Huang said. “We would like to offer the licensees more, even more.”
Arm, Son said, provides toolsets to enable companies to create SoCs for very different applications, from game machines and home appliances to robots that fly or run or swim. These devices will, in turn, communicate with cloud AI “so each of them become smarter.”
“That’s the reason why combining Arm and NVIDIA makes so much sense because we can then bring NVIDIA AI to the most popular edge CPU in the world,” Huang said.
‘Intelligence at Scale’
That will allow even more companies to participate in the AI boom.
“AI is a new kind of computer science; the software is different, the chips are different, the methodology is different,” Huang said.
It’s a huge shift, Son agreed.
First, Son said, computers enabled advancements in calculation; next, came the ability to store massive amounts of data; and “now, finally, computers are the ears and the eyes, so they can recognize voice and speech.”
“It’s intelligence at scale,” Huang responded. “That’s the reason why this age of AI is such an important time.”
Extending Human Capabilities
Son and Huang spoke about how enterprises worldwide — from AstraZeneca and GlaxoSmithKline in drug discovery, to American Express in banking, to Walmart in retail, to Microsoft in software, to Kubota in agriculture — are now adopting NVIDIA AI tools.
Huang cited a new generation of systems, called recommender systems, that are already helping humans sort through vast array choices available online in everything from what clothes they wear to what music they listen to.
Huang and Son describe such systems — and AI more broadly — as a way to extend human capabilities.
“Humans will always be in the loop,” Huang said.
“We have a heart, a desire to be nice to other humans,” Son said. “We will utilize AI as a tool, for our happiness, for our joy — humans will choose which recommendations to take.”
‘Perpetually Learning Machines’
Such intelligent systems are being woven into the world around us, through smart, connected systems, or “edge AI,” Son said, which will work hand in hand with powerful cloud AI systems able to aggregate input from devices in the real world.
The result will be a “learning loop,” or “perpetually learning machines,” Huang said.
“The cloud side will aggregate information from edge AI, it will become smarter and smarter,” Son said.
Democratizing AI
One result: computing will finally be democratized, Huang said. Only a small number of people want to pursue a career as a computer programmer, but “everyone can teach,” Huang said.
“You [will] just ask the computer, ‘This is what I want to do, can you give me a solution?,’” Son responded. “Then the computer will give us the solution and the tools to make it happen.”
Such tools will amplify Japan’s strengths in precision engineering and manufacturing.
“This is the time of AI for Japan,” Huang said.
Huang described how, in tools such as NVIDIA Omniverse, a digital factory can be continually optimized.
“This robotic factory will be filled with robots that will build robots in virtual reality,” Huang said. “The whole thing will be simulated … and when you come in in the morning the whole thing will be optimized more than it was when you went to bed.”
Once it’s ready, a physical twin of the digital factory can be built and continually optimized with lessons learned in the virtual one.
“It’s the concept of the metaverse” Son said, referring to the shared, online world of imagined in Neal Stephensen’s 1992 cyberpunk classic, “Snow Crash.”
“… and it’s right in front of us now,” Huang added.
Connecting Humans with One Another
In addition to extending human capabilities with AI, it will help humans better connect with one another.
Video conferencing will soon be the vast majority of the world’s internet traffic, Huang said. Using AI to reconstruct a speaker’s facial expressions can “reduce bandwidth” by a factor of 10.
It can also unleash new capabilities, such as the ability for a speaker to make direct eye contact with 20 different people watching simultaneously, or real-time language translation.
“So you can speak to me in the future in Japanese and I can speak to you in English, and you will hear Japanese and I will hear English,” Huang said.
Enabling Big Dreams
Melding human judgment and AI, adaptive, autonomous machines and tightly connected teams of people will give entrepreneurs, philanthropists and others with “big wishes and big dreams” the ability to tackle ever more ambitious challenges, Huang said.
Son said AI is playing a role in the development of technologies that can detect heart attacks before they happen, speed the discovery of new treatments for cancer, and eliminate car accidents, among others.
“It is a big help,” Son said. “So we should be having a big smile, and big excitement, welcoming this revolution in AI.”
The post SoftBank Group, NVIDIA CEOs on What’s Next for AI appeared first on The Official NVIDIA Blog.
Configuring your Amazon Kendra Confluence Server connector
Many builders and teams on AWS use Confluence as a way of collaborating and sharing information within their teams and across their organizations. These types of workspaces are rich with data and contain sets of knowledge and information that can be a great source of truth to answer organizational questions.
Unfortunately, it isn’t always easy to tap into these data sources to extract the information you need. For example, the data source might not be connected to an enterprise search service within the organization, or the service is outdated and lacks natural language search capabilities, leading to poorer search experiences.
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization.
Amazon Kendra lets you easily add data sources using a wide range of connector types, so you can use its intelligent search capabilities to search your content repositories. Amazon Kendra maintains document access rights and automatically syncs with your index to make sure you’re always searching the most up-to-date content.
In this post, we walk through the process of setting up your Amazon Kendra connector for Confluence Server.
Prerequisites
The post assumes that you have Confluence set up and an index created in Amazon Kendra. For instructions on setting up your index, see Creating an index.
Creating the Confluence connector
To set up your Confluence connector, complete the following steps:
- On the Amazon Kendra console, navigate to your index and choose Add data sources.

- From the list of available connectors, choose Confluence Server.
- Choose Add connector.

Next, we need to specify the data source details.
- For Data source name, enter a name.
- For Description, enter an optional description.

The next step is data access and security.
- For Confluence URL, enter the URL to your Confluence site.
If your site is running in a private VPC, you must configure Amazon Kendra to access your VPC resources.

- In the Set authentication section, for Type of authentication, you can choose to create new authentication credentials or use an existing one. (For this post, we choose New.)
- For Secret name, enter a name.
- For User name¸ enter your Confluence account user name.
- For Password, enter a password.
This information is stored in AWS Secrets Manager.

- In the Set IAM role section, choose the AWS Identity and Access Management (IAM) role that Amazon Kendra uses to crawl your Confluence data and update the index.
At minimum, the role should have permission to create and update indexes in Amazon Kendra and read your Confluence credentials from Secrets Manager.

In the Configure sync settings section, you set up your index sync options.
- For Set sync scope, choose to include or exclude specific Confluence workspaces.
- For Set sync run schedule, choose the schedule you want for your sync jobs. Each data source can have its own update schedule.

Custom attributes allow you to add additional metadata to your documents in the index. For example, you can create a custom attribute called Department with values HR, Sales, and Manufacturing. You can apply these attributes to your documents so that you can limit the response to documents in the HR department, for example.
- In the field mapping section, you can choose the mappings of Confluence fields to Amazon Kendra fields in the index. You can update required fields, recommended fields, and additional suggested field mappings.

- Review your settings summary to check if everything looks okay and choose Add data source.

Starting the Confluence connector manually
After you create your data source, you can start the sync process manually by choosing Sync now.


When the sync job is complete, the status shows as Succeeded.

Testing the results
After the sync job is complete, you can search many different ways. For this post, we walk through using the Amazon Kendra console to test the results. For more information, see Querying an index (console).
In the navigation pane, choose Search console.

Now you can search the index.

Conclusion
In this post, we walked through the process of creating and running the Confluence Server data source connector. This connector enables you to connect to a Confluence data source, specify which areas to crawl, and how to process field metadata elements and other key functions.
By doing this, you can use the intelligent search capabilities of Amazon Kendra, powered by ML, on your Confluence Server content. To see a full list of data sources currently supported by Amazon Kendra, see Data sources.
About the Authors
 Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
 Sam Palani is an AI/ML Specialist Solutions Architect at AWS. He works with public sector customers to help them architect and implement machine learning solutions at scale. When not helping customers, he enjoys long hikes, unwinding with a good book, listening to his classical vinyl collection and hacking projects with Raspberry Pi.
Sam Palani is an AI/ML Specialist Solutions Architect at AWS. He works with public sector customers to help them architect and implement machine learning solutions at scale. When not helping customers, he enjoys long hikes, unwinding with a good book, listening to his classical vinyl collection and hacking projects with Raspberry Pi.

Estimating the Impact of Training Data with Reinforcement Learning
Posted by Jinsung Yoon and Sercan O. Arik, Research Scientists, Cloud AI Team, Google Research
Recent work suggests that not all data samples are equally useful for training, particularly for deep neural networks (DNNs). Indeed, if a dataset contains low-quality or incorrectly labeled data, one can often improve performance by removing a significant portion of training samples. Moreover, in cases where there is a mismatch between the train and test datasets (e.g., due to difference in train and test location or time), one can also achieve higher performance by carefully restricting samples in the training set to those most relevant for the test scenario. Because of the ubiquity of these scenarios, accurately quantifying the values of training samples has great potential for improving model performance on real-world datasets.
 |
 |
| Top: Examples of low-quality samples (noisy/crowd-sourced); Bottom: Examples of a train and test mismatch. |
In addition to improving model performance, assigning a quality value to individual data can also enable new use cases. It can be used to suggest better practices for data collection, e.g., what kinds of additional data would benefit the most, and can be used to construct large-scale training datasets more efficiently, e.g., by web searching using the labels as keywords and filtering out less valuable data.
In “Data Valuation Using Deep Reinforcement Learning”, accepted at ICML 2020, we address the challenge of quantifying the value of training data using a novel approach based on meta-learning. Our method integrates data valuation into the training procedure of a predictor model that learns to recognize samples that are more valuable for the given task, improving both predictor and data valuation performance. We have also launched four AI Hub Notebooks that exemplify the use cases of DVRL and are designed to be conveniently adapted to other tasks and datasets, such as domain adaptation, corrupted sample discovery and robust learning, transfer learning on image data and data valuation.
Quantifying the Value of Data
Not all data are equal for a given ML model — some have greater relevance for the task at hand or are more rich in informative content than others. So how does one evaluate the value of a single datum? At the granularity of a full dataset, it is straightforward; one can simply train a model on the entire dataset and use its performance on a test set as its value. However, estimating the value of a single datum is far more difficult, especially for complex models that rely on large-scale datasets, because it is computationally infeasible to re-train and re-evaluate a model on all possible subsets.
To tackle this, researchers have explored permutation-based methods (e.g., influence functions), and game theory-based methods (e.g., data Shapley). However, even the best current methods are far from being computationally feasible for large datasets and complex models, and their data valuation performance is limited. Concurrently, meta learning-based adaptive weight assignment approaches have been developed to estimate the weight values using a meta-objective. But rather than prioritizing learning from high value data samples, their data value mapping is typically based on gradient descent learning or other heuristic approaches that alter the conventional predictor model training dynamics, which can result in performance changes that are unrelated to the value of individual data points.
Data Valuation Using Reinforcement Learning (DVRL)
To infer the data values, we propose a data value estimator (DVE) that estimates data values and selects the most valuable samples to train the predictor model. This selection operation is fundamentally non-differentiable and thus conventional gradient descent-based methods cannot be used. Instead, we propose to use reinforcement learning (RL) such that the supervision of the DVE is based on a reward that quantifies the predictor performance on a small (but clean) validation set. The reward guides the optimization of the policy towards the action of optimal data valuation, given the state and input samples. Here, we treat the predictor model learning and evaluation framework as the environment, a novel application scenario of RL-assisted machine learning.
 |
| Training with Data Value Estimation using Reinforcement Learning (DVRL). When training the data value estimator with an accuracy reward, the most valuable samples (denoted with green dots) are used more and more, whereas the least valuable samples (red dots) are used less frequently. |
Results
We evaluate the data value estimation quality of DVRL on multiple types of datasets and use cases.
<!–
- –>
- Model performance after removing high/low value samples
Removing low value samples from the training dataset can improve the predictor model performance, especially in the cases where the training dataset contains corrupted samples. On the other hand, removing high value samples, especially if the dataset is small, decreases the performance significantly. Overall, the performance after removing high/low value samples is a strong indicator for the quality of data valuation.

Accuracy with the removal of most and least valuable samples, where 20% of the labels are noisy by design. By removing such noisy labels as the least valuable samples, a high-quality data valuation method achieves better accuracy. We demonstrate that DVRL outperforms other methods significantly from this perspective. DVRL shows the fastest performance degradation after removing the most important samples and the slowest performance degradation after removing the least important samples in most cases, underlining the superiority of DVRL in identifying noisy labels compared to competing methods (Leave-One-Out and Data Shapley).
- Robust learning with noisy labels
We consider how reliably DVRL can learn with noisy data in an end-to-end way, without removing the low-value samples. Ideally, noisy samples should get low data values as DVRL converges and a high performance model would be returned.

Robust learning with noisy labels. Test accuracy for ResNet-32 and WideResNet-28-10 on CIFAR-10 and CIFAR-100 datasets with 40% of uniform random noise on labels. DVRL outperforms other popular methods that are based on meta-learning. We show state-of-the-art results with DVRL in minimizing the impact of noisy labels. These also demonstrate that DVRL can scale to complex models and large-scale datasets.
- Domain adaptation
We consider the scenario where the training dataset comes from a substantially different distribution from the validation and testing datasets. Data valuation is expected to be beneficial for this task by selecting the samples from the training dataset that best match the distribution of the validation dataset. We focus on the three cases: (1) a training set based on image search results (low-quality web-scraped) applied to the task of predicting skin lesion classification using HAM 10000 data (high-quality medical); (2) an MNIST training set for a digit recognition task on USPS data (different visual domain); (3) e-mail spam data to detect spam applied to an SMS dataset (different task). DVRL yields significant improvements for domain adaptation, by jointly optimizing the data valuator and corresponding predictor model.



<!–
–>
Conclusions
We propose a novel meta learning framework for data valuation which determines how likely each training sample will be used in training of the predictor model. Unlike previous works, our method integrates data valuation into the training procedure of the predictor model, allowing the predictor and DVE to improve each other’s performance. We model this data value estimation task using a DNN trained through RL with a reward obtained from a small validation set that represents the target task performance. In a computationally-efficient way, DVRL can provide high quality ranking of training data that is useful for domain adaptation, corrupted sample discovery and robust learning. We show that DVRL significantly outperforms alternative methods on diverse types of tasks and datasets.
Acknowledgements
We gratefully acknowledge the contributions of Tomas Pfister.

How Alexa scientists are advancing speech science
Watch as four Amazon Alexa scientists talk about current state, new developments, and recent announcements surrounding advancements in Alexa speech technologies.Read More
Exploring AI for radiotherapy planning with Mayo Clinic
More than 18 million new cancer cases are diagnosed globally each year, and radiotherapy is one of the most common cancer treatments—used to treat over halfof cancers in the United States. But planning for a course of radiotherapy treatment is often a time-consuming and manual process for clinicians. The most labor-intensive step in planning is a technique called “contouring” which involves segmenting both the areas of cancer and nearby healthy tissues that are susceptible to radiation damage during treatment. Clinicians have to painstakingly draw lines around sensitive organs on scans—a time-intensive process that can take up to seven hours for a single patient.
Technology has the potential to augment the work of doctors and other care providers, like the specialists who plan radiotherapy treatment. We’re collaborating with Mayo Clinic on research to develop an AI system that can support physicians, help reduce treatment planning time and improve the efficiency of radiotherapy. In this research partnership, Mayo Clinic and Google Health will work to develop an algorithm to assist clinicians in contouring healthy tissue and organs from tumors, and conduct research to better understand how this technology could be deployed effectively in clinical practice.
Mayo Clinic is an international center of excellence for cancer treatment with world-renowned radiation oncologists. Google researchers have studied how AI can potentially be used to augment other areas of healthcare—from mammographies to the early deployment of an AI system that detects diabetic retinopathy using eye scans.
In a previous collaboration with University College London Hospitals, Google researchers demonstrated how an AI system could analyze and segment medical scans of patients with head and neck cancer— similar to how expert clinicians would. Our research with Mayo Clinic will also focus on head and neck cancers, which are particularly challenging areas to contour, given the many delicate structures that sit close together.
In this first phase of research with Mayo Clinic, we hope to develop and validate a model as well as study how an AI system could be deployed in practice. The technology will not be used in a clinical setting and algorithms will be developed using only de-identified data.
While cancer rates continue to rise, the shortage of radiotherapy experts continues to grow as well. Waiting for a radiotherapy treatment plan can be an agonizing experience for cancer patients, and we hope this research will eventually support a faster planning process and potentially help patients to access treatment sooner.