Computer vision uses machine learning (ML) to build applications that process images or videos. With Amazon Rekognition, you can use pre-trained computer vision models to identify objects, people, text, activities, or inappropriate content. Our customers have use cases that span every industry, including media, finance, manufacturing, sports, and technology. Some of these use cases require training custom computer vision models to detect business-specific objects. When building custom computer vision models, customers tell us they face two main challenges: availability of labeled training data, and accessibility to resources with ML expertise.
In this post, I show you how to mitigate these challenges by using Amazon SageMaker Ground Truth to easily build a training dataset from unlabeled data, followed by Amazon Rekognition Custom Labels to train a custom computer vision model without requiring ML expertise.
For this use case, we want to build a claims processing application for motor vehicle insurance that allows customers to submit an image of their vehicle with their insurance claim. Customers might accidentally submit a wrong picture, and some may try to commit fraud by submitting false pictures. Various ML models can fully or partially automate the processing of these images and the rest of the claim contents. This post walks through the steps required to train a simple computer vision model that detects if images are relevant to vehicle insurance claims or not.
Services overview
Amazon Rekognition Custom Labels is an automated machine learning (AutoML) feature that enables you to train custom ML models for image analysis without requiring ML expertise. Upload a small dataset of labeled images specific to your business use case, and Amazon Rekognition Custom Labels takes care of the heavy lifting of inspecting the data, selecting an ML algorithm, training a model, and calculating performance metrics.
Amazon Rekognition Custom Labels provides a UI for viewing and labeling a dataset on the Amazon Rekognition console, suitable for small datasets. It also supports auto-labeling based on the folder structure of an Amazon Simple Storage Service (Amazon S3) bucket, and importing labels from a Ground Truth output file. Ground Truth is the recommended labeling tool when you have a distributed labeling workforce, need to implement a complex labeling pipeline, or have a large dataset.
Ground Truth is a fully managed data labeling service used to easily and efficiently build accurate datasets for ML. It provides built-in workflows to label image, text, and 3D point cloud data, and supports custom workflows for other types of data. You can set up a public or private workforce, and take advantage of automatic data labeling to reduce the time required to label the dataset.
Solution overview
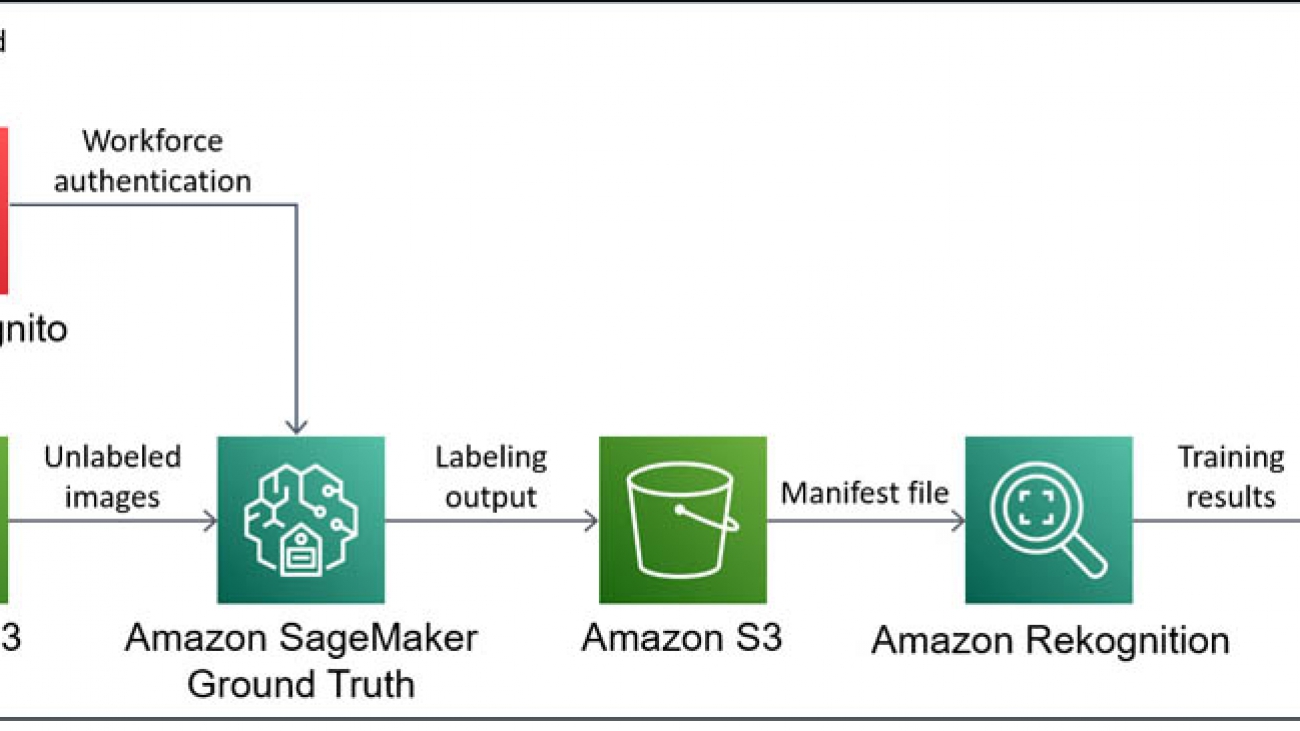
The core of the solution is Ground Truth and Amazon Rekognition Custom Labels, but you also use S3 buckets to store data between each step. You first need an S3 bucket to store unlabeled images. Then, you set up a labeling job in Ground Truth for the image data in the bucket, using Amazon Cognito to authenticate users for your private workforce. Ground Truth saves the labeling results in another S3 bucket as a manifest file, which is used to build training and test datasets in Amazon Rekognition Custom Labels. Finally, you can train a custom model using your new dataset in Amazon Rekognition Custom Labels, the results of which are saved in another S3 bucket.
The following diagram illustrates the architecture of this solution.

Detailed walkthrough
In this post, I show you how to train a custom computer vision model to detect if images are relevant to vehicle insurance claims. These steps are as follows:
- Collect data
- Label the data
- Train the computer vision model
- Evaluate the computer vision model
Before you start collecting data, you need decide which type of computer vision model to use. At the time of writing, Amazon Rekognition Custom Labels supports two computer vision models:
- Image classification – Assigns labels to an image as a whole
- Object detection – Draws bounding boxes around objects of interest in an image
Object detection is more specific than image classification, but labeling images for object detection also requires more time and effort, so it’s important to consider the requirements of the use case.
For this use case, I start by building a model to detect the difference between images with a vehicle and images without a vehicle. At this point, I’m not interested in knowing exactly where the vehicle is located on the image, so I can start with image classification.
Prerequisites
To successfully follow the steps in this walkthrough, you need to complete the following prerequisites:
In this post, I demonstrate how to build the full solution using the AWS CLI, which allows you to programmatically create, manage, and monitor AWS resources from a terminal. The AWS CLI supports all AWS services and can be used to automate your cloud infrastructure. If you prefer to use the console, I provide links to console instructions in each section.
Collecting data
First, you need to collect relevant images. Ideally, I would source these images from actual images submitted by insurance customers, which are representative of what the model sees in production. However, for this post, I use images from the COCO (Common Objects in Context) dataset. This is a large dataset of everyday images where common objects have been labeled with semantic segmentation, captions, and keypoints.
The original COCO dataset from 2017 is up to 26 GB in size and can take a long time to download. This walkthrough only relies on a small subset of images from the dataset, so you can download the COCO subset (3 GB) provided by the fast.ai research group instead. You can complete the data collection steps on your local machine, an Amazon Elastic Compute Cloud (Amazon EC2) instance, an Amazon SageMaker Jupyter notebook, or any other compute resource.
- Enter the following code to download the dataset:
wget https://s3.amazonaws.com/fast-ai-coco/coco_sample.tgz
- When the download is complete, extract the .tgz file:
tar -xvzf coco_sample.tgz
You now have a directory called coco_sample, with two sub-directories: annotations and train_sample. The COCO dataset already provides labels for various vehicles and other objects in the images, but you can ignore these for this use case, because you want to use Ground Truth for labeling.
- Navigate to the directory that contains only the images:
cd ./coco_sample/train_sample
Even though this is only a subset of the COCO dataset, this directory still contains 21,837 images. For this use case, I spent some time looking through the images in this dataset to collect the file names of images that contain vehicles. I then took a random sample of file names from the remaining images to create a dataset of images without vehicles.
- To use the same images, copy the file names into a text file using the following code:
echo "000000000723.jpg 000000057387.jpg 000000121555.jpg 000000175523.jpg 000000280926.jpg 000000482049.jpg 000000000985.jpg 000000060548.jpg 000000128015.jpg 000000179251.jpg 000000296696.jpg 000000498570.jpg 000000004764.jpg 000000067222.jpg 000000131465.jpg 000000184543.jpg 000000302415.jpg 000000509657.jpg 000000005965.jpg 000000068668.jpg 000000135438.jpg 000000185262.jpg 000000303590.jpg 000000515020.jpg 000000007713.jpg 000000068801.jpg 000000136185.jpg 000000188440.jpg 000000306415.jpg 000000517921.jpg 000000016593.jpg 000000069577.jpg 000000137475.jpg 000000190026.jpg 000000318496.jpg 000000540547.jpg 000000020289.jpg 000000077837.jpg 000000140332.jpg 000000190447.jpg 000000318672.jpg 000000543058.jpg 000000024396.jpg 000000078407.jpg 000000142847.jpg 000000195538.jpg 000000337265.jpg 000000547345.jpg 000000025453.jpg 000000079481.jpg 000000144992.jpg 000000197792.jpg 000000337638.jpg 000000553862.jpg 000000026992.jpg 000000079873.jpg 000000146907.jpg 000000206539.jpg 000000341429.jpg 000000557155.jpg 000000028333.jpg 000000081315.jpg 000000148165.jpg 000000213342.jpg 000000341902.jpg 000000557819.jpg 000000030001.jpg 000000084171.jpg 000000158130.jpg 000000217043.jpg 000000361140.jpg 000000560123.jpg 000000033505.jpg 000000093070.jpg 000000159280.jpg 000000219762.jpg 000000361255.jpg 000000561126.jpg 000000035382.jpg 000000099453.jpg 000000164178.jpg 000000237031.jpg 000000375500.jpg 000000566364.jpg 000000039100.jpg 000000104844.jpg 000000168817.jpg 000000241279.jpg 000000375654.jpg 000000571584.jpg 000000043270.jpg 000000109738.jpg 000000170784.jpg 000000247473.jpg 000000457725.jpg 000000573286.jpg 000000047425.jpg 000000111889.jpg 000000171970.jpg 000000250955.jpg 000000466451.jpg 000000576449.jpg 000000049006.jpg 000000120021.jpg 000000173001.jpg 000000261479.jpg 000000468652.jpg 000000053580.jpg 000000121162.jpg 000000174911.jpg 000000264016.jpg 000000479219.jpg" > vehicle-images.txt
The dataset contains many more images featuring vehicles, but this subset of 56 images (plus 56 non-vehicle images) should be sufficient to demonstrate the full pipeline for training a custom computer vision model.
- To store this subset of images, create a new directory:
- Using the text file containing the image file names, copy the relevant images into the new directory:
xargs -a ./vehicle-images.txt cp -t ./vehicle_dataset
You now have an unlabeled dataset on your local computer that you can use to build your model.
You can now create a new S3 bucket in your AWS account and upload your images into this bucket. At this point, it’s important to choose the Region where you want to deploy the resources. Use the Region Table to choose a Region that supports Amazon Rekognition Custom Labels and Ground Truth. I use us-west-2, but if you want to use a different Region, adjust the --region flag in the following CLI commands. You can also create a bucket and upload the dataset on the console.
- First, create an S3 bucket with a unique name. Replace <BUCKET_NAME> with a bucket name of your choice:
aws s3 mb s3://<BUCKET_NAME> --region us-west-2
- Copy the data from your local computer into your new S3 bucket:
aws s3 cp ./vehicle_dataset s3://<BUCKET_NAME>/imgs/ --recursive
Labeling the data
After you successfully upload the unlabeled images to your S3 bucket, you use Ground Truth to label the data. This service is designed to help you build highly accurate training datasets for ML. For more information, see Use Amazon SageMaker Ground Truth to Label Data or the AWS Blog.
To create your dataset of labeled vehicle images, you complete three steps:
- Create a workforce
- Set up a labeling job
- Complete the labeling task
Creating a workforce
There are several options for setting up a workforce of annotators in Ground Truth:
- A crowdsourced workforce using Amazon Mechanical Turk
- A private workforce of your own internal resources
- A workforce provided by one of the curated third-party vendors on AWS Marketplace
Because this use case is small (only 112 images), you can complete the task yourself by setting up a private workforce. In this post, I show you how to set up a private workforce using the AWS CLI. For instructions on setting up your workforce on the console, see the section Creating a labeling workforce in the post Amazon SageMaker Ground Truth – Build Highly Accurate Datasets and Reduce Labeling Costs by up to 70%. Alternatively, see Create a Private Workforce (Amazon SageMaker Console).
For more information about using the AWS CLI and the commands in this section, see the following:
- First, create an Amazon Cognito user pool:
aws cognito-idp create-user-pool
--pool-name vehicle-experts-user-pool
--region us-west-2
- Record the Id value in the output. This should have a format similar to
us-west-2_XXXXXXXXX.
- Create a user group in the user pool. Replace the value for <USER_POOL_ID> with the ID value you recorded in the previous step:
aws cognito-idp create-group
--group-name vehicle-experts-user-group
--user-pool-id <USER_POOL_ID>
--region us-west-2
- Create a user pool client:
aws cognito-idp create-user-pool-client
--user-pool-id <USER_POOL_ID>
--client-name vehicle-experts-user-pool-client
--generate-secret
--explicit-auth-flows ALLOW_CUSTOM_AUTH ALLOW_USER_PASSWORD_AUTH ALLOW_USER_SRP_AUTH ALLOW_REFRESH_TOKEN_AUTH
--supported-identity-providers COGNITO
--region us-west-2
- Record the ClientId value in the output.
- Create a user pool domain:
aws cognito-idp create-user-pool-domain
--domain vehicle-experts-user-pool-domain
--user-pool-id <USER_POOL_ID>
--region us-west-2
- Create a work team for Ground Truth. Replace the values for <USER_POOL_ID> and <USER_POOL_CLIENT_ID> with the user pool ID and the user pool client ID, respectively. If you used a different name for your user group than
vehicle-experts-user-group, replace this value as well.
aws sagemaker create-workteam
--workteam-name vehicle-experts-workteam
--member-definitions '{"CognitoMemberDefinition": {"UserPool": "<USER_POOL_ID>", "UserGroup": "vehicle-experts-user-group", "ClientId": "<USER_POOL_CLIENT_ID>"}}'
--description "A team of vehicle experts"
--region us-west-2
- Record the WorkteamARN value in the output.
After you create a work team in Amazon SageMaker, update the user pool client to allow for OAuth flows and scopes. To complete this step, you need to find the callback URL and the logout URL generated during the creation of the work team.
- Find the URLs with the following code:
aws cognito-idp describe-user-pool-client
--user-pool-id <USER_POOL_ID>
--client-id <USER_POOL_CLIENT_ID>
--region us-west-2
- Make a note of the URL in the CallbackURLs list, which should look similar to
https://XXXXXXXXXX.labeling.us-west-2.sagemaker.aws/oauth2/idpresponse.
- Also make a note of the URL in the LogoutURLs list, which should look similar to
https://XXXXXXXXXX.labeling.us-west-2.sagemaker.aws/logout.
- Use these URLs to update the user pool client:
aws cognito-idp update-user-pool-client
--user-pool-id <USER_POOL_ID>
--client-id <USER_POOL_CLIENT_ID>
--allowed-o-auth-flows-user-pool-client
--allowed-o-auth-scopes email openid profile
--allowed-o-auth-flows code implicit
--callback-urls '["<CALLBACK_URL>"]'
--logout-urls '["<LOGOUT_URL>"]'
--supported-identity-providers COGNITO
--region us-west-2
You should now be able to access the labeling portal sign-in screen by navigating to the root of the callback and logout URLs (http://XXXXXXXXXX.labeling.us-west-2.sagemaker.aws). If you want to create any more Amazon SageMaker work teams in this Region in the future, you only need to create a new user pool group and a new work team.
You now have a work team without any workers, and need to add some.
- Add yourself as a worker using the following code:
aws cognito-idp admin-create-user
--user-pool-id <USER_POOL_ID>
--username the_vehicle_expert
--user-attributes '[{"Name": "email", "Value": "<EMAIL_ADDRESS>"}]'
--region us-west-2
It’s important to provide a valid email address because Amazon Cognito sends an email with your username and temporary password. You use these credentials to log in to the labeling portal, and you must change your password when you log in for the first time.
- Add your user to the user group created within the user pool, because labeling jobs in Ground Truth are assigned to user pool groups. Replace the value of <USER_POOL_ID> with the ID of your user pool. If you used a different name for your user group than
vehicle-experts-user-group, replace this value as well.
aws cognito-idp admin-add-user-to-group
--user-pool-id <USER_POOL_ID>
--username the_vehicle_expert
--group-name vehicle-experts-user-group
--region us-west-2
If you forget this step, you can log in to the labeling portal, but you aren’t assigned any labeling tasks.
Setting up a labeling job
You can now set up the labeling job in Ground Truth. In this post, I demonstrate how to set up a labeling job using the AWS CLI. For instructions on setting up your workforce on the console, see the section Creating a labeling job in the post Amazon SageMaker Ground Truth – Build Highly Accurate Datasets and Reduce Labeling Costs by up to 70%. Be careful to choose the image classification task type instead of the bounding box task type. Alternatively, see Create a Labeling Job.
For more information about using the AWS CLI and the commands in this section, see the following:
To create a labeling job in Ground Truth, you need to create a manifest file that points to the location of your unlabeled images. After labeling is complete, Ground Truth generates a new version of this manifest file with the labeling results added. A manifest file is a JSON lines file with a well-defined structure. For the input manifest file for Ground Truth, each JSON object only requires the source-ref key. The console has an option to have Ground Truth generate the manifest file for you. However, you can generate the manifest file with one piece of code, using the images.txt file created earlier.
- Generate the manifest file with the following code:
cat vehicle-images.txt | tr ' ' 'n' | awk '{print "{"source-ref":"s3://<BUCKET_NAME>/imgs/" $0 ""}"}' > vehicle-dataset.manifest
- Upload this manifest file to a new directory in your S3 bucket:
aws s3 cp ./vehicle-dataset.manifest s3://<BUCKET_NAME>/groundtruth-input/
You need to create a template for the labeling UI that the annotators (for this use case, you) use to label the data. To create this UI template, I use the image classification UI sample from the Amazon SageMaker Ground Truth Sample Task UIs GitHub repo, and edit the text to represent this use case. You can save the following template in a file called template.liquid on your local machine.
- Create and save the template with the following code:
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
<crowd-form>
<crowd-image-classifier
name="crowd-image-classifier"
src="{{ task.input.taskObject | grant_read_access }}"
header="If the image contains a vehicle in plain sight, assign the 'vehicle' label. Otherwise, assign the 'other' label."
categories="{{ task.input.labels | to_json | escape }}"
>
<full-instructions header="Classification Instructions">
<p>Read the task carefully and inspect the image.</p>
<p>Choose the appropriate label that best suits the image.</p>
</full-instructions>
<short-instructions>
<p>Read the task carefully and inspect the image.</p>
<p>Choose the appropriate label that best suits the image.</p>
</short-instructions>
</crowd-image-classifier>
</crowd-form>
- Upload this UI template to your S3 bucket:
aws s3 cp ./template.liquid s3://<BUCKET_NAME>/groundtruth-input/
Ground Truth expects a file that specifies the labels the annotators can assign to objects in the images. For this use case, you define two labels: vehicle and other. This label category configuration file is a JSON file with a simple structure as shown in the following code. You can save the template in a file called data.json on your local machine.
- Define the labels with the following code:
{"document-version":"2018-11-28","labels":[{"label":"vehicle"},{"label":"other"}]}
- As with the manifest file before, upload the label category configuration to the S3 bucket:
aws s3 cp ./data.json s3://<BUCKET_NAME>/groundtruth-input/
For certain image tasks, the S3 bucket where the data is stored must have CORS settings enabled. You can do this with the following CLI command:
aws s3api put-bucket-cors
--bucket <BUCKET_NAME>
--cors-configuration '{"CORSRules": [{"AllowedMethods": ["GET"], "AllowedOrigins": ["*"]}]}'
Ground Truth needs to be assigned an IAM role that allows it to perform necessary actions and access the S3 bucket containing the data. Create a new IAM service role for Amazon SageMaker with a maximum session duration longer than the default value. You set a task time limit for the labeling job later, and the maximum session duration for the IAM role needs to be larger than or equal to this task time limit.
- Create the role with the following code:
aws iam create-role
--role-name SageMakerGroundTruthRole
--assume-role-policy-document '{"Version": "2012-10-17", "Statement": {"Effect": "Allow", "Principal": {"Service": "sagemaker.amazonaws.com"}, "Action": "sts:AssumeRole"}}'
--max-session-duration 36000
- Make a note of the
Arn value in the output.
- Attach the
AmazonSageMakerFullAccess managed policy to this role:
aws iam attach-role-policy
--role-name SageMakerGroundTruthRole
--policy-arn arn:aws:iam::aws:policy/AmazonSageMakerFullAccess
- Create a new IAM policy that allows read and write access to the S3 bucket containing the data input for Ground Truth:
aws iam create-policy
--policy-name AccessVehicleDatasetBucket
--policy-document '{"Version": "2012-10-17", "Statement": [{"Effect": "Allow", "Action": ["s3:GetObject", "s3:PutObject", "s3:GetBucketLocation", "s3:ListBucket"], "Resource": ["arn:aws:s3:::<BUCKET_NAME>/*"]}]}'
- Make a note of the
Arn value in the output.
- Attach your new policy to the IAM role. Replace <POLICY_ARN> with the ARN value copied from the output of the previous command:
aws iam attach-role-policy
--role-name SageMakerGroundTruthRole
--policy-arn <POLICY_ARN>
You can now create the labeling job. This is a large CLI command compared to the earlier ones. You need to provide the Amazon S3 URIs for the manifest file, the output directory, the label category configuration file, and the UI template. Replace <BUCKET_NAME> with your chosen bucket name in each URI. Replace <ROLE_ARN> with the ARN value copied from the output of the create-role command, and replace <WORKTEAM_ARN> with the ARN value copied from the output of the create-workteam command.
- Create the labeling job with the following code:
aws sagemaker create-labeling-job
--labeling-job-name vehicle-labeling-job
--label-attribute-name vehicle
--input-config '{"DataSource": {"S3DataSource": {"ManifestS3Uri": "s3://<BUCKET_NAME>/groundtruth-input/vehicle-dataset.manifest"}}}'
--output-config '{"S3OutputPath": "s3://<BUCKET_NAME>/groundtruth-output/"}'
--role-arn <ROLE_ARN>
--label-category-config-s3-uri s3://<BUCKET_NAME>/groundtruth-input/data.json
--human-task-config '{"WorkteamArn": "<WORKTEAM_ARN>", "UiConfig": {"UiTemplateS3Uri": "s3://<BUCKET_NAME>/groundtruth-input/template.liquid"}, "PreHumanTaskLambdaArn": "arn:aws:lambda:us-west-2:081040173940:function:PRE-ImageMultiClass", "TaskTitle": "Vehicle labeling task", "TaskDescription": "Assign a label to each image based on the presence of vehicles in the image.", "NumberOfHumanWorkersPerDataObject": 1, "TaskTimeLimitInSeconds": 600, "AnnotationConsolidationConfig": {"AnnotationConsolidationLambdaArn": "arn:aws:lambda:us-west-2:081040173940:function:ACS-ImageMultiClass"}}'
--region us-west-2
For this use case, because you’re the only annotator in the work team, each image is labeled by only one worker, which is specified through NumberOfHumanWorkersPerDataObject. PreHumanTaskLambdaArn and AnnotationConsolidationLambdaArn determine how Ground Truth processes the data and labels. There are default ARNs available for each type of labeling task and each Region, both for the pre-human tasks and the annotation consolidation.
Completing the labeling task
In a browser, navigate to the labeling sign-in portal that you created when you set up the work team. It should have a format similar to http://XXXXXXXXXX.labeling.us-west-2.sagemaker.aws. Log in with the credentials for your user and start the labeling task that appears in the UI.
Follow the instructions in the UI to label each of the 112 images with a vehicle or other label. The following screenshot shows an image labeled vehicle.

I label buses, motorcycles, cars, trucks, and bicycles as vehicles. I also assume that for the insurance use case, the image should show an external view of the vehicle, meaning images of vehicle interiors are labeled as other.
The following screenshot shows an image labeled other.

After you label all the images, Ground Truth processes your labeling work and generates a manifest file with the output. This process can take a few minutes. To check on the status of your labeling job, use the following code and check the LabelingJobStatus in the output:
aws sagemaker describe-labeling-job
--labeling-job-name vehicle-labeling-job
--region us-west-2
When the LabelingJobStatus is Completed, make a note of the OutputDatasetS3Uri value under LabelingJobOutput in the output.
Training the computer vision model
If you have followed all the steps in the post so far, well done! It’s finally time to train the custom computer vision model using Amazon Rekognition Custom Labels. Again, I show you how to use the AWS CLI to complete these steps. For instructions on completing these steps on the console, see Getting Started with Amazon Recognition Custom Labels and Training a custom single class object detection model with Amazon Rekognition Custom Labels.
Before continuing with the CLI, I recommend navigating to Amazon Rekognition Custom Labels on the console to set up a default S3 bucket. This request appears the first time you access Amazon Rekognition Custom Labels in a Region, and ensures that future datasets are visible on the console. If you want to take advantage of the Rekognition interface to view and edit your dataset before training a model, I recommend using the console to upload your dataset, with the manifest file generated by Ground Truth. If you choose to follow the steps in this post, you see your dataset on the Amazon Rekognition console only after a model has been trained.
For more information about using the AWS CLI and the commands in this section, see the following:
Before you can train a computer vision model with Amazon Rekognition, you need to allow Amazon Rekognition Custom Labels to access the data from the S3 bucket by changing the bucket policy.
- Grant permissions with the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSRekognitionS3AclBucketRead20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": ["s3:GetBucketAcl",
"s3:GetBucketLocation"],
"Resource": "arn:aws:s3:::<BUCKET_NAME>"
},
{
"Sid": "AWSRekognitionS3GetBucket20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": ["s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectVersion",
"s3:GetObjectTagging"],
"Resource": "arn:aws:s3:::<BUCKET_NAME>/*"
},
{
"Sid": "AWSRekognitionS3ACLBucketWrite20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::<BUCKET_NAME>"
},
{
"Sid": "AWSRekognitionS3PutObject20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::<BUCKET_NAME>/rekognition-output/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
- Save the bucket policy in a new file called
bucket-policy.json.
- Enter the following code to set this policy for your S3 bucket:
aws s3api put-bucket-policy --bucket <BUCKET_NAME> --policy file://bucket-policy.json
Amazon Rekognition Custom Labels uses the concept of projects to differentiate between different computer vision models you may want to build.
- Create a new project within Amazon Rekognition Custom Labels:
aws rekognition create-project
--project-name vehicle-detector
--region us-west-2
- Make a note of the value for
ProjectArn in the output to use in the next step.
An Amazon Rekognition Custom Labels project can contain multiple models; each trained model is called a project version. To train a new model, you must give it a name and provide training data, test data, and an output directory. Instead of splitting the dataset into a training and test set yourself, you can tell Amazon Rekognition Custom Labels to automatically split off 20% of the data and use this as a test set.
- Enter the following code. Replace <BUCKET_NAME> with your chosen bucket name, and replace <PROJECT_ARN> with the ARN from the output of the
create-project command.
aws rekognition create-project-version
--project-arn <PROJECT_ARN>
--version-name vehicle-detector-v1
--output-config '{"S3Bucket": "<BUCKET_NAME>", "S3KeyPrefix": "rekognition-output"}'
--training-data '{"Assets": [{"GroundTruthManifest": {"S3Object": {"Bucket": "<BUCKET_NAME>", "Name": " groundtruth-output/vehicle-labeling-job/manifests/output/output.manifest"}}}]}'
--testing-data '{"AutoCreate": true}'
--region us-west-2
Amazon Rekognition Custom Labels spends some time training a computer vision model based on your data. In my case, this process took up to 2 hours. To check the status of your training, enter the following code:
aws rekognition describe-project-versions
--project-arn <PROJECT_ARN>
--region us-west-2
When the training process is complete, you see the status TRAINING_COMPLETED in the output. You should also navigate to Amazon Rekognition Custom Labels on the console to check on the training status of your project version.
Evaluating the computer vision model
When Amazon Rekognition Custom Labels is finished training the model, you can view various evaluation metrics to determine how well the model is performing on the test set. The easiest way to view these metrics is to look on the console. The following screenshot shows the macro average metrics.

The following screenshot shows results for individual test images.

If you prefer to fetch these results programmatically, you first need to identify the output files that Amazon Rekognition Custom Labels has saved in the S3 bucket, so you can fetch the results stored in these files:
aws rekognition describe-project-versions
--project-arn <PROJECT_ARN>
--region us-west-2
Assuming the training process is complete, the output of this command provides the location of the output files. Amazon Rekognition Custom Labels saves the detailed results for each test image in a JSON file stored in Amazon S3. You can find the file details under TestingDataResult -> Output -> Assets -> GroundTruthManifest. The file name has the format TestingGroundTruth-<PROJECT_NAME>-<PROJECT_VERSION_NAME>.json. I recommend downloading this file to view it in an IDE, but you can also view the contents of the file without downloading it by using the following code (replace <S3_URI> with the URI of the file you want to view):
aws s3 cp <S3_URI> - | head
Similarly, Amazon Rekognition Custom Labels stores the macro average precision, recall, and F1 score in a JSON file, which you can find under EvaluationResults -> Summary. Again, you can view the contents of this file without downloading it by using the preceding command.
For this use case, the test set results in a precision and recall of 1, which means the model identified all the vehicle and non-vehicle images correctly. The assumed threshold used to generate the F1 score, precision, and recall metrics for vehicles is 0.99. By default, the model returns predictions above this assumed threshold. Examining the individual test images confirms that the model identifies vehicles with a consistently high confidence score. In addition to analyzing the test set results on the console, you can set up Custom Labels Demonstration UI to apply the model to images from your local computer.
Cleaning up
To avoid incurring future charges, clean up the following resources:
- Amazon Rekognition Custom Labels project
- Amazon SageMaker work team
- Amazon Cognito user pool
- S3 bucket
Conclusion
In this post, you learned how to create a labeled dataset and use it to train a custom computer vision model without any prior ML expertise. In addition, you learned how to accomplish all of this programmatically using the AWS CLI.
After gathering a collection of unlabeled images and storing these images in an S3 bucket, you set up a labeling job in Ground Truth and used the output of the labeling job to train a model in Amazon Rekognition Custom Labels. I hope you can apply this combination of AWS services to quickly create computer vision models for use cases in your own industry and domain.
To learn more, see the following resources:
About the Author
 Sara van de Moosdijk, simply known as Moose, is a Machine Learning Partner Solutions Architect at AWS Australia. She helps AWS partners build and scale AI/ML solutions through technical enablement, support, and architectural guidance. Moose spends her free time figuring out how to fit more books in her overflowing bookcase.
Sara van de Moosdijk, simply known as Moose, is a Machine Learning Partner Solutions Architect at AWS Australia. She helps AWS partners build and scale AI/ML solutions through technical enablement, support, and architectural guidance. Moose spends her free time figuring out how to fit more books in her overflowing bookcase.
Read More










 Tushar Agrawal leads Outbound Product Management for Amazon Rekognition. In this role, he focuses on making customers successful by solving their business challenges with the right solution and go-to-market capabilities. In his spare time, he loves listening to music and re-living his childhood with his kindergartener.
Tushar Agrawal leads Outbound Product Management for Amazon Rekognition. In this role, he focuses on making customers successful by solving their business challenges with the right solution and go-to-market capabilities. In his spare time, he loves listening to music and re-living his childhood with his kindergartener. Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning. Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano.
Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano. Connor Kirkpatrick is an AWS Solution Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations and quickstarts. He is an enthusiastic squash player, wobbly cyclist, and occasional baker.
Connor Kirkpatrick is an AWS Solution Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations and quickstarts. He is an enthusiastic squash player, wobbly cyclist, and occasional baker.













 Hidenori Koizumi is a Solutions Architect in Japan’s Healthcare and Life Sciences team. He is good at developing solutions in the research field based on his scientific background (biology, chemistry, and more). His specialty is machine learning, and he has recently been developing applications using React and TypeScript. His hobbies are traveling and photography.
Hidenori Koizumi is a Solutions Architect in Japan’s Healthcare and Life Sciences team. He is good at developing solutions in the research field based on his scientific background (biology, chemistry, and more). His specialty is machine learning, and he has recently been developing applications using React and TypeScript. His hobbies are traveling and photography. Mari Ohbuchi is a Machine Learning Solutions Architect at Amazon Web Services Japan. She worked on developing image processing algorithms for about 10 years at a manufacturing company before joining AWS. In her current role, she supports the implementation of machine learning solutions and creating prototypes for manufacturing and ISV/SaaS customers. She is a cat lover and has published blog posts, hands-on content, and other content that involves both AWS AI/ML services and cats.
Mari Ohbuchi is a Machine Learning Solutions Architect at Amazon Web Services Japan. She worked on developing image processing algorithms for about 10 years at a manufacturing company before joining AWS. In her current role, she supports the implementation of machine learning solutions and creating prototypes for manufacturing and ISV/SaaS customers. She is a cat lover and has published blog posts, hands-on content, and other content that involves both AWS AI/ML services and cats.