
Posted by the TensorFlow team
Thanks to everyone who joined our virtual I/O 2021 livestream! While we couldn’t meet in person, we hope we were able to make the event more accessible than ever. In this article, we’re recapping a few of the updates we shared during the keynote. You can watch the keynote below, and you can find recordings of every talk on the TensorFlow YouTube channel. Here’s a summary of a few announcements by product area (and there’s more in the videos, so be sure to check them out, too).
TensorFlow for Mobile and Web
The TensorFlow Lite runtime will be bundled with Google Play services
Let’s start with the announcement that the TensorFlow Lite runtime is going to be bundled with Google Play services, meaning you don’t need to distribute it with your app. This can greatly reduce your app’s bundle size. Now you can distribute your model without needing to worry about the runtime. You can sign up for an early access program today, and we expect a full rollout later this year.
You can now run TensorFlow Lite models on the web
All your TensorFlow Lite models can now directly be run on the web in the browser with the new TFLite Web APIs that are unified with TensorFlow.js. This task-based API supports running all TFLite Task Library models for image classification, objection detection, image segmentation, and many NLP problems. It also supports running arbitrary, custom TFLite models with easy, intuitive TensorFlow.js compatible APIs. With this option, you can unify your mobile and web ML development with a single stack.
A new On-Device Machine Learning site
We understand that the most effective developer path to reach Android, the Web and iOS isn’t always the most obvious. That’s why we created a new On-Device Machine Learning site to help you navigate your options, from turnkey to custom models, from cross platform mobile, to in-browser. It includes pathways to take you from an idea to a deployed app, with all the steps in between.
Performance profiling
When it comes to performance, we’re also working on additional tooling for Android developers. TensorFlow Lite includes built-in support for Systrace, integrating seamlessly with perfetto for Android 10.
And perf improvements aren’t limited to Android – for iOS developers TensorFlow Lite comes with built-in support for signpost-based profiling. When you build your app with the trace option enabled, you can run the Xcode profiler to see the signpost events, letting you dive deeper, and seeing all the way down to individual ops during execution.

TFX
TFX 1.0: Production ML at Enterprise-scale
Moving your ML models from prototype to production requires lots of infrastructure. Google created TFX because we needed a strong framework for our ML products and services, and then we open-sourced it so that others can use it too. It includes support for training models for mobile and web applications, as well as server-based applications.
After a successful beta with many partners, today we’re announcing TFX 1.0 — ready today for production ML at enterprise-scale. TFX includes all of the things an enterprise-ready framework needs, including enterprise-grade support, security patches, bug fixes, and guaranteed backward compatibility for the entire 1.X release cycle. It also includes strong support for running on Google Cloud and support for mobile, web, and NLP applications.
If you’re ready for production ML, TFX is ready for you. Visit the TFX site to learn more.
Responsible AI
We’re also sharing a number of new tools to help you keep Responsible AI top of mind in everything that you do when developing with ML.
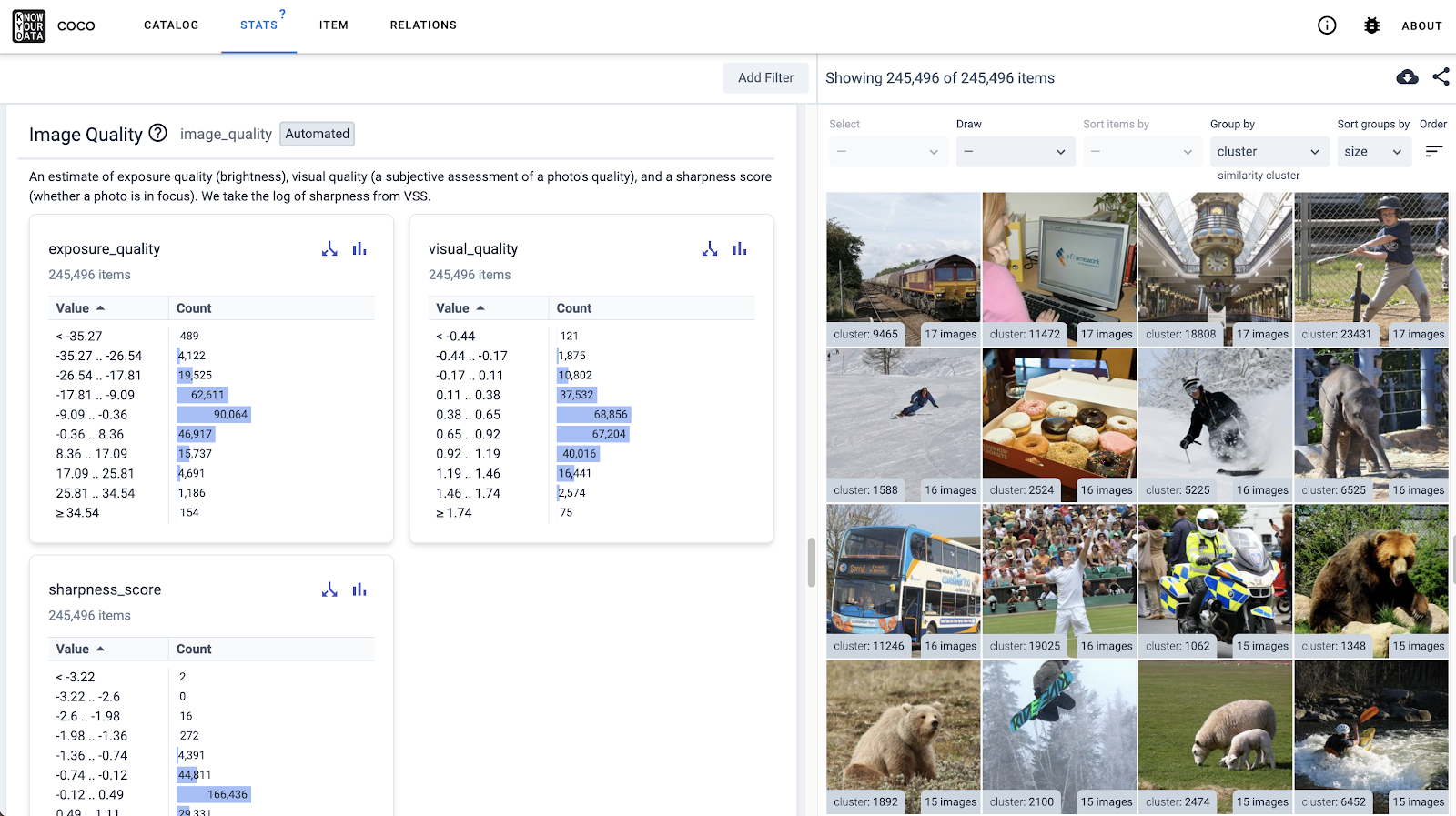
Know Your Data
Know Your Data (KYD) is a new tool to help ML researchers and product teams understand rich datasets (images and text) with the goal of improving data and model quality, as well as surfacing and mitigating fairness and bias issues. Try the interactive demo at the link above to learn more.
People + AI Guidebook 2.0
As you create AI solutions, building with a people centric approach is a key to doing it responsibly, and we’re delighted to announce the People + AI Guidebook 2.0. This update is designed to help you put best practices and guidance for people-centric AI into practice with a lot of new resources including code, design patterns and much more!
Also check out our Responsible AI Toolkit to help you integrate Responsible AI practices into your ML workflow using TensorFlow.
Decision forests in Keras
New support for random forests and gradient boosted trees
There’s more to ML than neural networks. Starting with TensorFlow 2.5, you can easily train powerful decision forest models (including favorites like random forests and gradient boosted trees) using familiar Keras APIs. There’s support for many state-of-the-art algorithms for training, serving and interpreting models for classification, regression and ranking tasks. And you can serve your decision forests using TF Serving, just like any other model trained with TensorFlow. Check out the tutorials here, and the video from this session.
TensorFlow Lite for Microcontrollers
A new pre-flashed board, experiments, and a challenge
TensorFlow Lite for Microcontrollers is designed to help you run ML models on microcontrollers and other devices with only a few kilobytes of memory. You can now purchase pre-flashed Arduino boards that will connect via Bluetooth and your browser. And you can use these to try out new Experiments With Google that let you make gestures and even create your own classifiers and run custom TensorFlow models. If you’re interested in challenges, we’re also running a new TensorFlow Lite for Microcontrollers challenge, you can check it out here. And also be sure to check out the TinyML workshop video in the next steps below.

Google Cloud
Vertex AI: A new managed ML platform on Google Cloud
An ML model is only valuable if you can actually put it into production. And as you know, it can be challenging to productionize efficiently and at scale. That’s why Google Cloud is releasing Vertex AI, a new managed machine learning platform to help you accelerate experimentation and deployment of AI models. Vertex AI has tools that span every stage of the developer workflow, from data labeling, to working with notebooks and models, to prediction tools and continuous monitoring – all unified into one UI. While many of these offerings may be familiar to you, what really distinguishes Vertex AI is the introduction of new MLOps features. You can now manage your models with confidence using our MLOps tools such as Vertex Pipelines and Vertex Feature Store, to remove the complexity of robust self-service model maintenance and repeatability.
TensorFlow Cloud: Transition from local model building to distributed training on the Cloud
TensorFlow Cloud provides APIs that ease the transition from local model building and debugging to distributed training and hyperparameter tuning on Google Cloud. From inside a Colab or Kaggle Notebook or a local script file, you can send your model for tuning or training on Cloud directly, without needing to use the Cloud Console. We recently added a new site and new features, check it out if you’re interested in learning more.
Community
A new TensorFlow Forum
We created a new TensorFlow Forum for you to ask questions and connect with the community. It’s a place for developers, contributors, and users to engage with each other and the TensorFlow team. Create your account and join the conversation at discuss.tensorflow.org.

Find all the talks here
This is just a small part of what was shared at Google I/O 2021. You can find all of the TensorFlow sessions in this playlist, and for your convenience here are direct links to each of the sessions also:
- ML Recap Video
- What’s new in Machine Learning (Keynote)
- Machine learning for next gen web apps with TensorFlow.js
- Does your app use machine learning? Make it a product with TFX
- Optimize your TensorFlow Lite models
- ML Kit: turnkey APIs to use on-device ML in mobile apps
- TensorFlow Hub for real world impact
- Modern Keras design patterns
- Building with the Responsible AI Toolkit
- Decision forests in TensorFlow
- Cross platform computer vision made easy with Model Maker
- Coral: Expanding the edge AI landscape
- Spotting and solving everyday problems with machine learning
- Easily deploy TF Lite models to the web (Demo)
- Train TensorFlow models at cloud scale with TensorFlow Cloud (Demo)
- Beyond evaluation: Improving fairness with Model Remediation (Demo)
To learn more about TensorFlow, you check out tensorflow.org, read other articles on the blog, follow us on social media, and subscribe to our YouTube Channel, or join a TensorFlow User Group near you.

 Arte Merritt leads partnerships for Contact Center Intelligence and Conversational AI. He is a frequent author and speaker in the conversational AI space. He was the co-founder and CEO of the leading analytics platform for conversational interfaces, leading the company to 20,000 customers, 90B messages, and multiple acquisition offers. Previously he founded Motally, a mobile analytics platform he sold to Nokia. Arte has more than 20 years experience in big data analytics. Arte is an MIT alum.
Arte Merritt leads partnerships for Contact Center Intelligence and Conversational AI. He is a frequent author and speaker in the conversational AI space. He was the co-founder and CEO of the leading analytics platform for conversational interfaces, leading the company to 20,000 customers, 90B messages, and multiple acquisition offers. Previously he founded Motally, a mobile analytics platform he sold to Nokia. Arte has more than 20 years experience in big data analytics. Arte is an MIT alum.
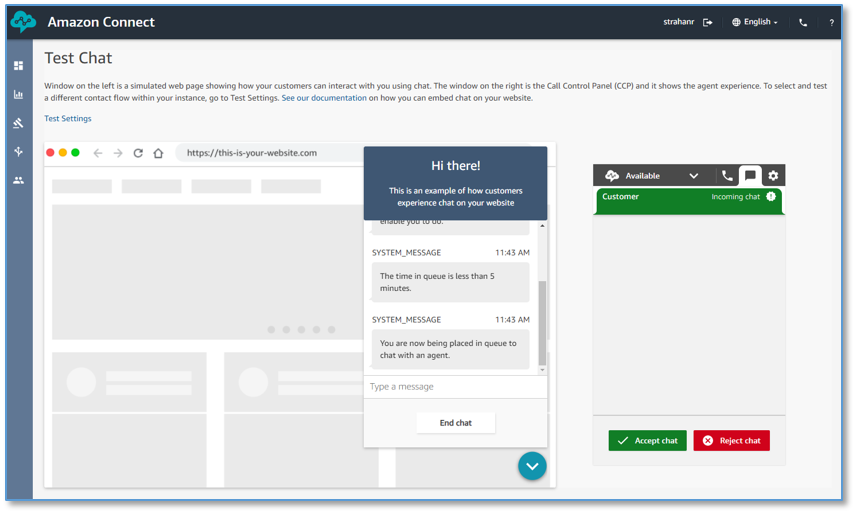
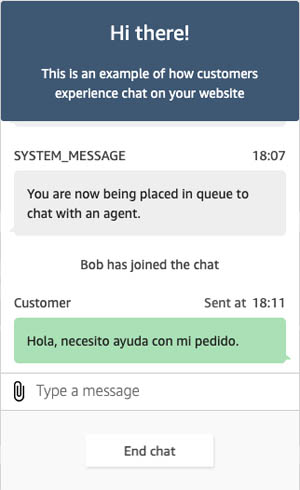
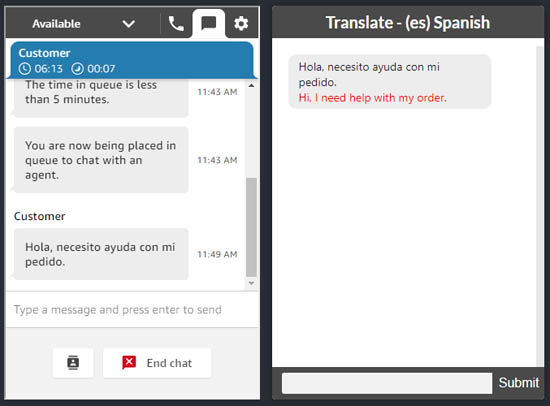
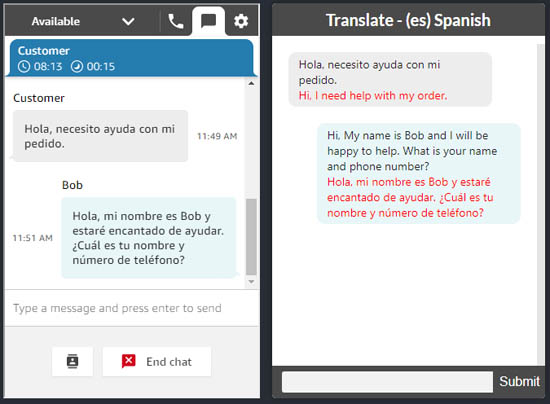
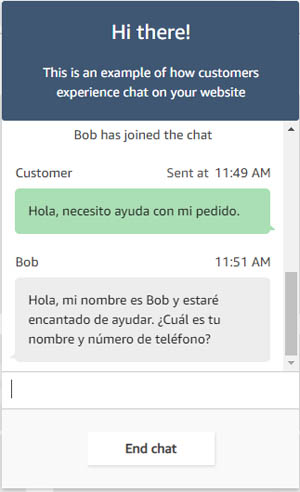
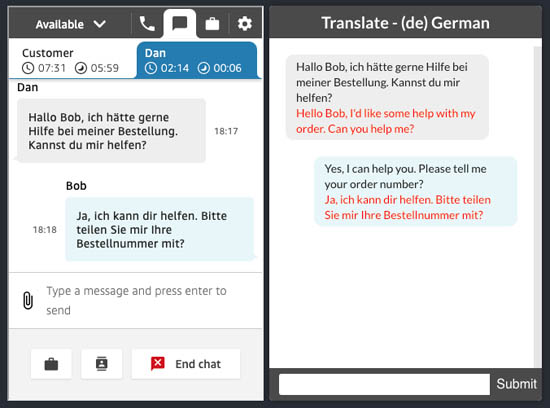
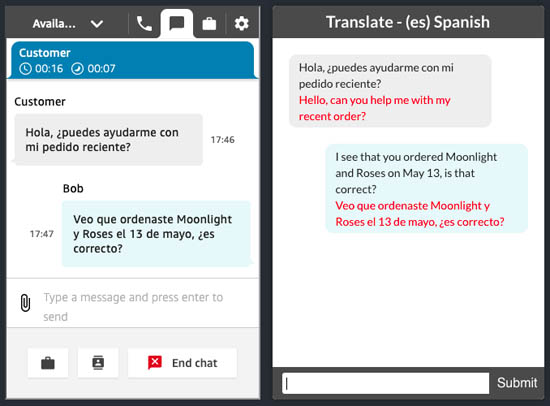
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team. Daniel Bloy is a practice leader for VoiceFoundry, an Amazon Connect specialty partner.
Daniel Bloy is a practice leader for VoiceFoundry, an Amazon Connect specialty partner. Researchers and scientists from Apple, Amazon Web Services and the University of Utah shared their experiences working in AI, and the value that the perspectives of underrepresented groups can provide in the field.
Researchers and scientists from Apple, Amazon Web Services and the University of Utah shared their experiences working in AI, and the value that the perspectives of underrepresented groups can provide in the field.
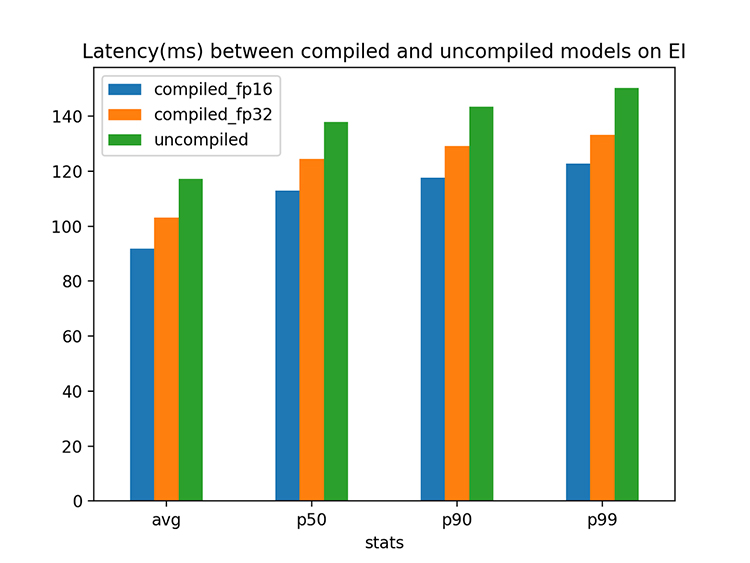
 Jiacheng Guo is a Software Engineer with AWS AI. He is passionate about building high performance deep learning systems with state-of-art techniques. In his spare time, he enjoys drifting on dirt track and playing with his Ragdoll cat.
Jiacheng Guo is a Software Engineer with AWS AI. He is passionate about building high performance deep learning systems with state-of-art techniques. In his spare time, he enjoys drifting on dirt track and playing with his Ragdoll cat. Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.