
Posted by Nikita Namjoshi, Machine Learning Solutions Engineer
When a single machine is not enough, it’s time to train and iterate faster with TensorFlow’s MultiWorkerMirroredStrategy. In this tutorial-style article you’ll learn how to launch a multi-worker training job on Google Cloud Platform (GCP) using AI Platform Training. You’ll also learn the basics of how TensorFlow distributes data and implements synchronous data parallelism across multiple machines. While this article focuses on a managed solution on GCP, you can also do all of this entirely in open-source on your own hardware.
Overview of Distributed Training
If you have a single GPU, TensorFlow will use this accelerator to speed up model training with no extra work on your part. However, if you want to get an additional boost from using multiple GPUs on a single machine or multiple machines (each with potentially multiple GPUs), then you’ll need to use tf.distribute, which is TensorFlow’s library for running a computation across multiple devices.
The simplest way to get started with distributed training is a single machine with multiple GPU devices. A TensorFlow distribution strategy from the tf.distribute module will manage the coordination of data distribution and gradient updates across all of the GPUs. If you want to learn more about training in this scenario, check out the previous post on distributed training basics.
If you’ve mastered single host training and are looking to scale even further, then adding multiple machines to your cluster can help you get an even greater performance boost. You can make use of a cluster of machines that are CPU only, or that each have one or more GPUs.
There are many ways to do multi-worker training on GCP. In this article we’ll use AI Platform Training, as it’s the quickest way to launch a distributed training job and has additional features that make it very easy to include as part of your production pipeline. To use this managed service, you’ll need to add a bit of extra code to your program and set up a config file that is specific to AI Platform. However; you will not have to endure the pains of GPU driver installation or cluster management, which can be very challenging in a distributed scenario.
Multi-Worker Cluster Configuration
The tf.distribute module currently provides two strategies for multi-worker training. In TensorFlow 2.5, ParameterServerStrategy is experimental, and MultiWorkerMirroredStrategy is a stable API.
Like its single-worker counterpart, MirroredStrategy, MultiWorkerMirroredStrategy is a synchronous data parallelism strategy that you can use with only a few code changes.
However, unlike MirroredStrategy, for a multi-worker setup TensorFlow needs to know which machines are part of your cluster. This is generally specified with the environment variable TF_CONFIG.
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief": ["host1:port"],
"worker": ["host2:port", "host3:port"],
},
"task": {"type": "worker", "index": 1}
})
In this simple TF_CONFIG example, the “cluster” key contains a dictionary with the internal IPs and ports of all the machines. In MultiWorkerMirroredStrategy, all machines are designated as workers, which are the physical machines on which the replicated computation is executed. In addition to each machine being a worker, there needs to be one worker that takes on some extra work such as saving checkpoints and writing summary files to TensorBoard. This machine is known as the chief (or by its deprecated name master).
After you’ve added your machines to the cluster key, the next step is to set the “task”. This specifies the task type and task index of the current machine, which is an index into the cluster dictionary. The cluster key should be the same on each machine, but the task keys will be different.
Conveniently, when using AI Platform Training, the TF_CONFIG environment variable is set for you on each machine in your cluster so you don’t need to worry about this set up!
However, if you were trying to run a multi-worker job with, for example, 3 instances on Google Compute Engine, you would need to set this environment variable on each machine as shown below. For the machines that are not the chief, the TF_CONFIG looks the same except the task index increments by 1.
Machine 1 (Chief)
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief": ["host1:port"],
"worker": ["host2:port", "host3:port"],
},
"task": {"type": "chief", "index": 0}
})
Machine 2
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief": ["host1:port"],
"worker": ["host2:port", "host3:port"],
},
"task": {"type": "worker", "index": 0}
})
Machine 3
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief": ["host1:port"],
"worker": ["host2:port", "host3:port"],
},
"task": {"type": "worker", "index": 1}
})
Setting this environment variable is fairly easy to do when you have only a few machines in your cluster; however, once you start scaling up, you don’t want to be assigning this variable to each machine manually. As mentioned earlier, one of the many benefits of using AI Platform is that this coordination happens automatically. The only configuration you have to provide is the number of machines in your cluster, and the number and type of GPUs per machine. We’ll do this step in a later section.
Set up the Distribution Strategy
In this Colab notebook, you’ll find the code to train a ResNet50 architecture on the Cassava dataset. In the following sections, we’ll review the new code that needs to be added to our program in order to do distributed training on multiple machines.
As with any strategy in the tf.distribute module, step one is to instantiate the strategy.
strategy = tf.distribute.MultiWorkerMirroredStrategy()
Note that there is a limitation where the instance of MultiWorkerMirroredStrategy needs to be created at the beginning of the program. Code that may create ops should be placed after the strategy is instantiated.
Next, you wrap the creation of your model variables within the strategy’s scope. This crucial step tells TensorFlow which variables should be mirrored across the replicas.
with strategy.scope():
model = create_model()
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
Lastly, you’ll need to scale your batch size by the number of replicas in your cluster. This ensures that each replica processes the same number of examples on each step.
per_replica_batch_size = 64
global_batch_size = per_replica_batch_size * strategy.num_replicas_in_sync
If you’ve used MirroredStrategy before, then the previous steps should be familiar. The main difference when moving from synchronous data parallelism on one machine to many is that the gradients at the end of each step now need to be synchronized across all GPUs in a machine and across all machines in the cluster. This additional step of synchronizing across the machines increases the overhead of distribution.
In TensorFlow, the multi-worker all-reduce communication is achieved via CollectiveOps. You don’t need to know much detail to execute a successful and performant training job, but at a high level, a collective op is a single op in the TensorFlow graph that can automatically choose an all-reduce algorithm according to factors such as hardware, network topology, and tensor sizes.
Dataset Sharding
In the single worker case, at each step your dataset is divided up across the replicas on your machine. This data splitting process becomes slightly more complicated in the multi-worker case. The data now also needs to be sharded, meaning that each worker is assigned a subset of the entire dataset. Therefore, at each step a global batch size of non overlapping dataset elements will be processed by each worker. This sharding happens automatically with tf.data.experimental.AutoShardPolicy.
By default, TensorFlow will first attempt to shard your data by FILE. This means that if your data exists across multiple files, each worker will process different file(s) and split the corresponding data amongst the replicas. FILE is the default autoshard policy because MultiWorkerMirroredStrategy works best for use cases with very large datasets, which are likely to not be in a single file. However, this option can lead to idle workers if the number of files is not divisible by the number of workers, or if some files are substantially longer than others.
If your data is not stored in multiple files, then the AutoShardPolicy will fall back to DATA, meaning that TensorFlow will autoshard the elements across all the workers. This guards against the potential idle worker scenario, but the downside is that the entire dataset will be read on each worker. You can read more about the different policies and see examples in the Distributed Input guide.
If you don’t want to use the default AUTO policy, you can set the desired AutoShardPolicy with the following code:
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
Save Your Model
Saving your model is slightly more complicated in the multi-worker case because the destination needs to be different for each of the workers. The chief worker will save to the desired model directory, while the other workers will save the model to temporary directories. It’s important that these temporary directories are unique in order to prevent multiple workers from writing to the same location. Saving can contain collective ops, so all workers must save and not just the chief.
The following is boilerplate code that implements the intended saving logic, as well as some cleanup to delete the temporary directories once the training has completed. Note that the model_path is the name of the Google Cloud Storage (GCS) bucket where your model will be saved at the end of training.
model_path = {gs://path_to_your_gcs_bucket}
# Note that with MultiWorkerMirroredStrategy,
# the program is run on every worker.
def _is_chief(task_type, task_id):
# Note: there are two possible `TF_CONFIG` configurations.
# 1) In addition to `worker` tasks, a `chief` task type is used.
# The implementation demonstrated here is for this case.
# 2) Only `worker` task type is used; in this case, worker 0 is
# regarded as the chief. In this case, this function
# should be modified to
# return (task_type == 'worker' and task_id == 0) or task_type is None
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(model_path, task_type, task_id)
model.save(write_model_path)
Everything we’ve covered about setting up the distribution strategy, sharding data, and saving models applies whether you’re training on GCP, your own hardware, or another cloud platform.
Prepare code for AI Platform
The basic prerequisites for using AI Platform are that you need to have a GCP project with billing enabled, the AI Platform APIs enabled, and sufficient AI Platform quota. If any of these steps are a mystery to you, refer to the previous post to get up to speed on GCP basics.
If you’re already familiar with training on AI Platform with a single node, then you’ll likely breeze through this section. We’ll take the pieces we walked through in the previous section, and do a bit of rearranging to match AI Platform Training convention. All of the code can be found in this Github repo, but we’ll walk through it in detail in this section.
By AI Platform convention, training code is arranged according to the diagram below. The task.py file contains the code that executes your training job. The example in this tutorial also includes a model.py file, which has the Keras functional API code for the model. For more complex production applications you’ll likely have additional util.py or setup.py files, and you can see where those fit in the hierarchy below.
Model code
The model.py file can be found in Github here. You can see that this file just has the code for building the ResNet50 model architecture.
Task code
The task.py file can be found in Github here. This file contains the main function, which will execute the training job and save the model.
def main():
args = get_args()
strategy = tf.distribute.MultiWorkerMirroredStrategy()
global_batch_size = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
train_data, number_of_classes = create_dataset(global_batch_size)
with strategy.scope():
model = create_model(number_of_classes)
model.fit(train_data, epochs=args.epochs)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(args.job_dir, task_type, task_id)
model.save(write_model_path)
In this simple example, the data preprocessing happens directly in the task.py file, but in reality for more complicated data processing you would probably want to split out this code into a separate data.py file that you can import into task.py (for example if your preprocessing includes parsing TFRecord files).
We explicitly set the AutoShardPolicy to DATA in this case because the Cassava dataset is not downloaded as multiple files. However, if we did not set the policy to DATA, the default AUTO policy would kick in and the end result would be the same.
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
The task.py file also parses any command line arguments we need. In this simple example, the epochs are passed in via the command line. Additionally, we need to parse the argument job-dir, which is the GCS bucket where our model will be stored.
def get_args():
'''Parses args.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--epochs',
required=True,
type=int,
help='number training epochs')
parser.add_argument(
'--job-dir',
required=True,
type=str,
help='bucket to save model')
args = parser.parse_args()
return args
Lastly, the task.py file contains our boilerplate code for saving the model. For a production example, you probably would want to add this boilerplate to a util.py file, but again for this simple example we’ll keep everything in one file.
Custom Container Set up
AI Platform provides standard runtimes for you to execute your training job. While these runtimes might work for your use case, more specialized needs require a custom container. In this section, we’ll walk through how to set up your container image and push it to Google Container Registry (GCR).
Write Your Dockerfile
The following Dockerfile specifies the base image, using the TensorFlow 2.5 Enterprise GPU Deep Learning Container. Using the TensorFlow Enterprise image as our base image provides a useful design pattern for developing on GCP. TensorFlow Enterprise is a distribution of TensorFlow that is optimized for GCP. You can use TensorFlow Enterprise with AI Platform Notebooks, the Deep Learning VMs, and AI Platform Training, providing a seamless transition between different environments.
The code in our trainer directory is copied to the Docker image, and our entry point is the task.py script, which we will run as a module.
# Specifies base image and tag
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-5
WORKDIR /root
# Copies the trainer code to the docker image.
COPY trainer/ /root/trainer/
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Push Your Dockerfile to GCR
Next, we’ll set up some useful environment variables. You can select any name of your choosing for IMAGE_REPO_NAME and IMAGE_TAG. If you have not already set up the Google Cloud SDK, you can follow the steps here, as you’ll need to use the gcloud tool to push your container and kick off the training job.
export PROJECT_ID=$(gcloud config list project --format "value(core.project)")
export IMAGE_REPO_NAME={your_repo_name}
export IMAGE_TAG={your_image_tag}
export IMAGE_URI=gcr.io/$PROJECT_ID/$IMAGE_REPO_NAME:$IMAGE_TAG
Next, you’ll build your Dockerfile.
docker build -f Dockerfile -t $IMAGE_URI ./
Lastly, you can push your image to GCR.
gcloud auth configure-docker
docker push $IMAGE_URI
If you navigate to the GCR page in the GCP console UI, you should see your newly pushed image.
Configure Your Cluster
The final step before we can kick off our training job is to set up the cluster. AI Platform offers a set of predefined cluster specifications called scale tiers, but we’ll need to provide our own cluster setup for distributed training.
In the following config.yaml file, we’ve designated one master (equivalent to chief) and one worker. Each machine has one NVIDIA T4 Tensor Core GPU. For both machines, you’ll also need to specify the imageUri as the image you pushed to GCR in the previous step.
trainingInput:
scaleTier: CUSTOM
masterType: n1-standard-8
masterConfig:
acceleratorConfig:
count: 1
type: NVIDIA_TESLA_T4
imageUri: gcr.io/{path/to/image}:{tag}
useChiefInTfConfig: true
workerType: n1-standard-8
workerCount: 1
workerConfig:
acceleratorConfig:
count: 1
type: NVIDIA_TESLA_T4
imageUri: gcr.io/{path/to/image}:{tag}
In case you’re wondering what the useChiefInTfConfig flag does, TensorFlow uses the terminology “Chief” and AI Platform uses the terminology “Master”, so this flag will manage that discrepancy. You don’t need to worry about the details (although you will see an error message if you forget to set this flag!).
Feel free to experiment with this configuration by adding machines, adding GPUs, or removing all GPUs and training with CPUs only. You can see the supported regions and GPU types here for AI Platform, so just make sure your project has sufficient quota for whatever configuration you choose.
Launch Your Training Job
You can launch your training job easily with the following command:
gcloud ai-platform jobs submit training {job_name}
--region europe-west2
--config config.yaml
--job-dir gs://{gcs_bucket/model_dir} --
--epochs 5
In the command above, you’ll need to give your job a name. In addition to passing in the region, you’ll need to define job-dir, which is the directory in your GCS bucket where you want your saved model file to be stored after training completes.
The empty — flag marks the end of the gcloud specific flags and the start of the args that you want to pass to your application (in this case, this is just the epochs).
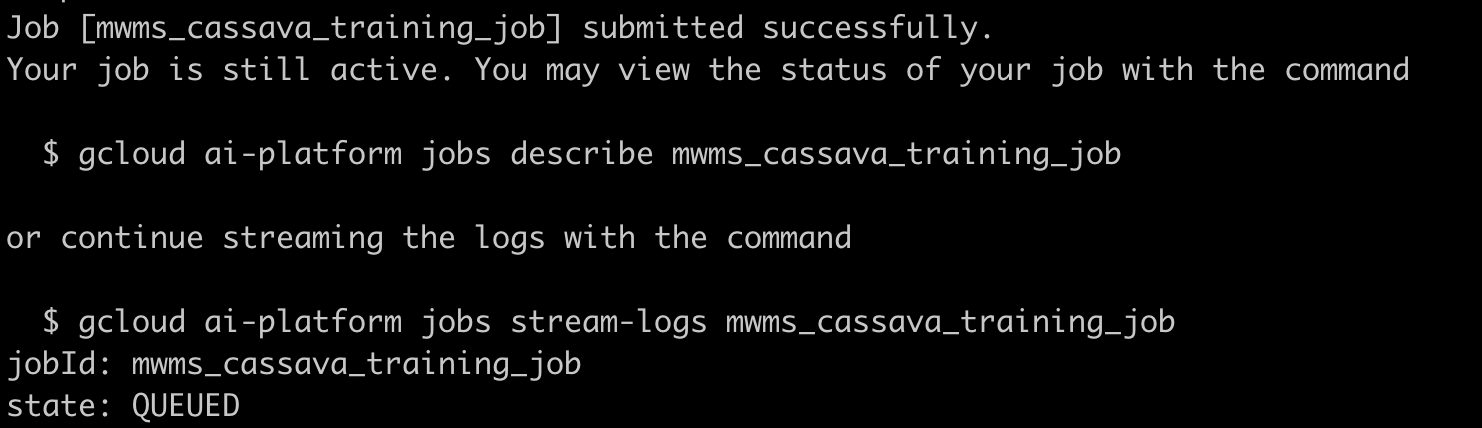
After executing the training command, you should see the following message.
You can navigate to the AI Platform UI in the GCP console and track the status of your job.
You’ll notice that your job will take around ten minutes to launch. This overhead might seem huge in our simple example where it doesn’t even take ten minutes to train on a single GPU. However, this overhead will be amortized for large jobs.
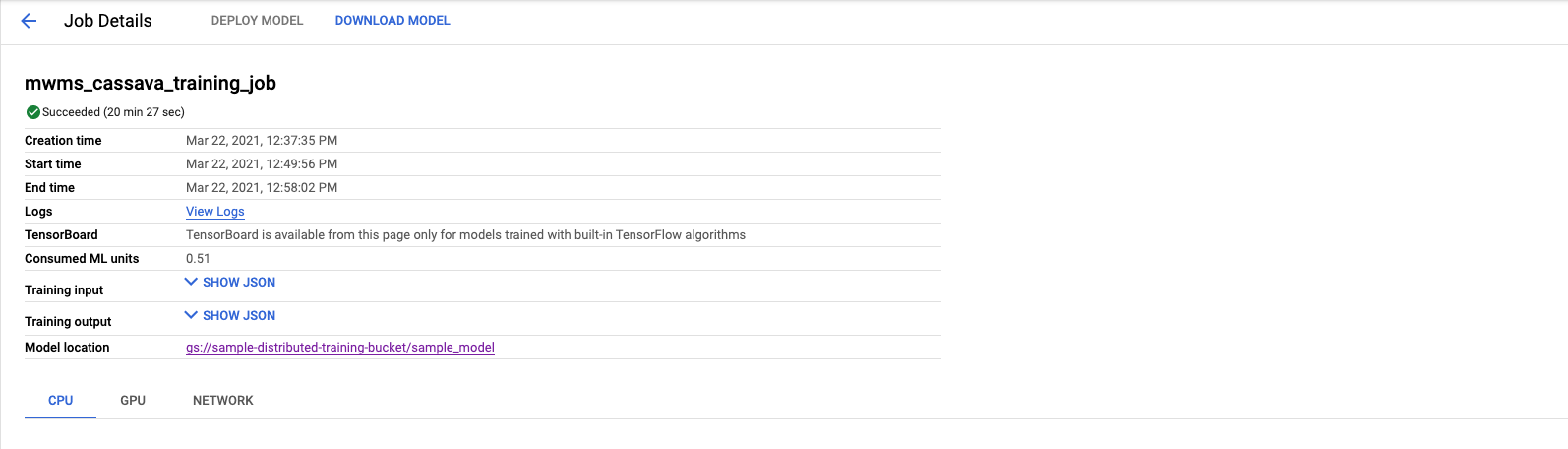
When the job completes training, you’ll see a green check mark next to the job. You can then click the Model location URI and you’ll find your saved_model.pb file.
What’s Next
You now know the basics of launching a multi-worker training job on GCP. You also know the core concepts of MultiWorkerMirroredStrategy. To take your skills to the next level, try leveraging AI Platform’s hyperparameter tuning feature for your next training job (in open-source, you can use Keras Tuner), or using TFRecord files as your input data. You can also try out Parameter Server Strategy if you’d like to explore asynchronous training in TensorFlow. Happy distributed training!
Read More










 Cameron Peron is Senior Marketing Manager for AWS AI/ML Education and the AWS AI/ML community. He evangelizes how AI/ML innovation solves complex challenges facing community, enterprise, and startups alike. Out of the office, he enjoys staying active with kettlebell-sport, spending time with his family and friends, and is an avid fan of Euro-league basketball.
Cameron Peron is Senior Marketing Manager for AWS AI/ML Education and the AWS AI/ML community. He evangelizes how AI/ML innovation solves complex challenges facing community, enterprise, and startups alike. Out of the office, he enjoys staying active with kettlebell-sport, spending time with his family and friends, and is an avid fan of Euro-league basketball.




 Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in Lyon, France. Olivier helps French customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in Lyon, France. Olivier helps French customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.



 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music. Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.