Dataset contains more than 11,000 newly collected dialogues to aid research in open-domain conversation.Read More
Break-It-Fix-It: Unsupervised Learning for Fixing Source Code Errors
Machine Learning for Code Repair
Across the board, programming has increased in popularity, ranging from developing with general-purpose programming languages like Python, C, Java to using simpler languages like HTML, SQL, LaTeX, and Excel formulas. When writing code we often make syntax errors such as typos, unbalanced parentheses, invalid indentations, etc., and need to fix them. In fact, several studies 1 show that both beginner and professional programmers spend 50% of time fixing code errors during programming. Automating code repair can dramatically enhance the programming productivity 2.
Recent works 3 use machine learning models to fix code errors by training the models on human-labeled (broken code, fixed code) pairs. However, collecting this data for even a single programming language is costly, much less the dozens of languages commonly used in practice.
On the other hand, unlabeled (unaligned) data—not aligned as (broken, fixed) pairs—is readily available: for example, raw code snippets on the web like GitHub. An unsupervised approach for training code repair models would make them much more scalable and widely deployable. In our recent work 4 published at ICML 2021, we study how to leverage unlabeled data to learn code fixers effectively.
Problem Setup
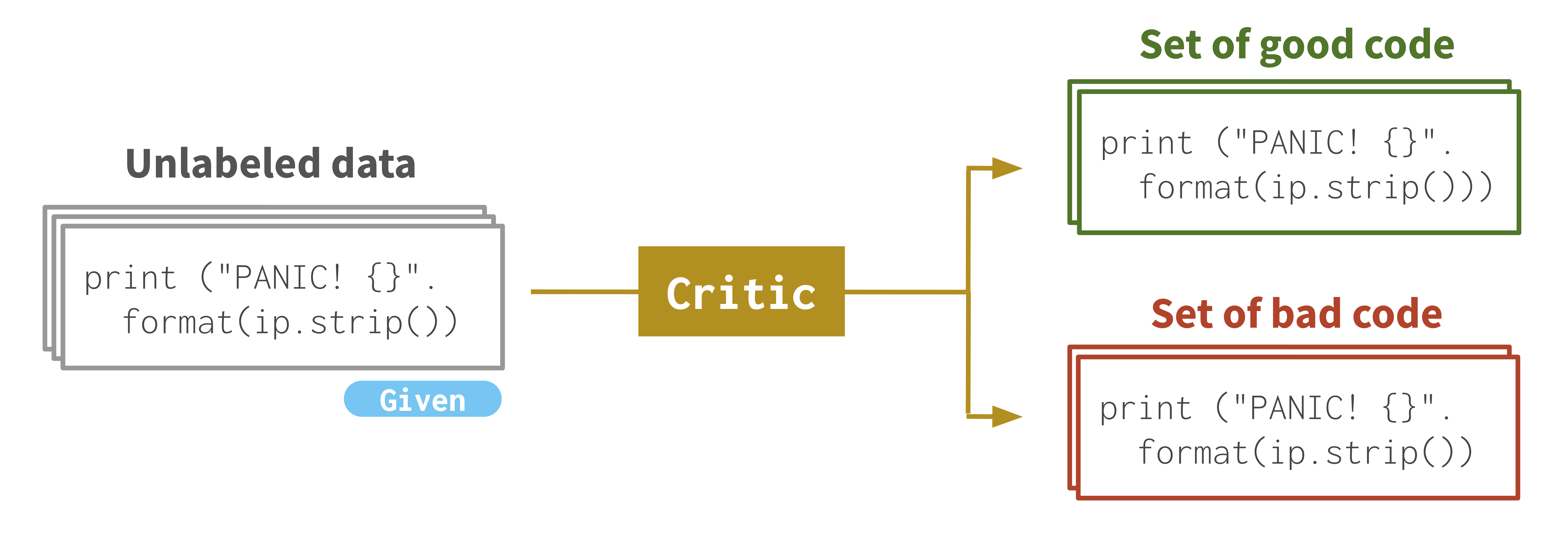
In code repair, we are given a critic that assesses the quality of an input: for instance, a compiler or code analyzer that tells us if input code has any syntax errors. The code is bad if there is at least one error and it is good if there are no errors. What we want is a fixer that repairs bad code into good code that satisfies the critic, e.g. repairing missing parenthesis as in the figure below. Our goal is to use unlabeled data and critic to learn a fixer.
Challenges
While unlabeled data can be split into a set of good code and a set of bad code using the critic, they are unaligned; in other words, they do not form (broken, fixed) pairs ready to be used for training a fixer.
A straightforward technique 5 is to apply random or heuristic perturbations to good code, such as dropping tokens, and prepare synthetic paired data (perturbed code, good code) to train a fixer. However, such synthetically-generated bad code does not match the distribution of real bad code written by humans. For instance, as the figure below shows, synthetic perturbations (purple box) may drop parentheses arbitrarily from code, generating errors that are rare in real code. In contrast, human-written code (red box) rarely misses parentheses when only a single pair appears, but misses parentheses often in a nested context (e.g., 10x more than non-nested in our Python code dataset collected from GitHub). This distributional mismatch between synthetic data and real data can result in low code repair performance when used in practice. To tackle this challenge, we introduce a new training approach, Break-It-Fix-It (BIFI), that adapts the fixer towards real distributions of bad code.

Approach: Break-It-Fix-It
The basic idea of BIFI is to introduce a machine learning-based breaker that learns to corrupt good code into realistic bad code, and iteratively train both the fixer and the breaker while using them in conjunction to generate more realistic paired data. Concretely, BIFI takes as inputs:
- Critic
- Unaligned set of good and bad code
- Initial fixer, which potentially is trained on synthetic data
BIFI then improves the fixer by performing the following cycle of data generation and training procedure:
- Apply the fixer to the set of bad code, which consists of real code errors made by humans, and use the critic to assess if the fixer’s output is good. If good, keep the pair
- Train the breaker on the resulting paired data from Step 1. Consequently, the breaker can generate more realistic errors than the initial synthetic data
- Apply the breaker to the set of good code, and keep outputs that the critic judges as bad
- Train the fixer on the newly-generated paired data in Step 1 and Step 3
These steps are also illustrated in the left panel of the figure below. We iterate over this cycle to improve the fixer and the breaker simultaneously until they have both converged. The intuition is that a better fixer and breaker will be able to generate more realistic paired data, which in turn helps to train a better fixer and breaker.
BIFI is related to the backtranslation (cycle-consistency) method in unsupervised translation 6. If we apply backtranslation directly to the code repair task, we would do the following:
- Apply the fixer to the set of bad code and generate (noisy) good code
- Train the breaker to reconstruct the bad code
- Apply the breaker to the set of good code and generate (noisy) bad code
- Train the fixer to reconstruct the good code
as illustrated in the right panel of the figure. BIFI improves on backtranslation in two aspects. First, while backtranslation may include non-fixed code as good or non-broken code as bad in Step 1 or 3, BIFI uses the critic to verify if the generated code is actually fixed or broken in Step 1 and 3, as highlighted with pink in the left panel of the figure. This ensures the correctness of training data generated by the breaker and fixer. Second, while backtranslation only uses paired data generated in Step 3 to train the fixer in Step 4, BIFI uses paired data generated in both Step 3 and Step 1, as paired data from Step 1 contains real code errors made by humans. This improves the distributional match of generated training data.
Let’s use our code repair model!
We apply and evaluate our method, BIFI, on two code repair benchmarks:
- GitHub-Python 7: Fix syntax errors in Python code. Critic is Python AST parser.
- DeepFix 8: Fix compiler errors in C code. Critic is C compiler.
BIFI improves on existing unsupervised methods for code repair
Using the GitHub-Python dataset, we first compare BIFI with existing unsupervised methods for code repair: a synthetic baseline that uses synthetic paired data generated by randomly dropping, inserting or replacing tokens from good code, and a backtranslation baseline that directly applies backtracklation to code repair. The synthetic baseline serves as the initial fixer for our BIFI algorithm. We find that BIFI improves the repair accuracy by 28% (62%→90%) over the synthetic baseline and by 10% (80%→90%) over the backtranslation baseline, as shown in the left panel of the figure. This result suggests that while we started from a simple initial fixer trained with random perturbations, BIFI can automatically turn it into a usable fixer with high repair accuracy.
For the other dataset, DeepFix, there are several prior works that use heuristic ways to generate synthetic paired data for the task: Gupta+17 9, Hajipour+19 10, DrRepair 11. We take the existing best model, DrRepair, as our initial fixer and apply BIFI. We find that it improves the repair accuracy by 5% (66%→71%), as shown in the right panel of the figure. This result suggests that while the initial fixer DrRepair was already trained with manually designed heuristics, there is still room for improving the adaptation to a more realistic distribution of code errors. BIFI helps to achieve this without additional manual effort.
Examples of breaker outputs
Let’s look at several examples of code generated by the trained breaker. Given the good Python code shown on the left below, we show on the right outputs that the breaker places high probability on. In output 1, the breaker converts raise ValueError(...) into raise ValueError, ..., which is an obsolete usage of raise in Python. In output 2, the breaker drops a closing parenthesis in a nested context. These are both errors commonly seen in human written bad code.
Examples of fixer outputs
Let’s look at how our fixer performs through examples too. The left side of the figure shows human-written Python code with an indentation error—one needs to add indent to the err = 0 line and remove indent in the next line. The initial fixer, shown in the center, only inserts one indent token and fails to fix the error. This is most likely due to the mismatch between real errors and synthetic errors used in training: synthetic errors generated by random perturbations do not frequently contain this kind of indentation error where multiple tokens need to be inserted/removed accordingly. The fixer trained by BIFI, shown on the right, fixes the indentation error by inserting and removing the correct pair of indent tokens. We find that this is one of the representative examples of when BIFI successfully fixes code errors but the initial fixer fails.

Finally, one limitation of this work is that we focus on fixing syntactic errors (we use critics such as AST parser and compiler), and we are not evaluating the semantic correctness of our outputs. Extending BIFI to fixing semantic errors is an exciting future research avenue.
Conclusion
Machine learning of source code repair is an important direction to enhance programming productivity, but collecting human-labeled data is costly. In this work, we studied how to learn source code repair in an unsupervised way, and developed a new training method, BIFI. The key innovation of BIFI is that it creates realistic paired data for training fixers from a critic (e.g. compiler) and unlabeled data (e.g. code snippets on the web) only, which are cheaply available.
More broadly, the idea of learning fixers from critics + unlabeled data is applicable to various repair tasks beyond code repair, such as grammatical error correction 12 and molecule design, using domain-specific critics. Additionally, the idea of using a critic to improve the quality of paired data is applicable to various translation tasks by introducing a learned critic. We hope that BIFI can be an effective solution to unsupervised repair tasks and translation tasks.
You can check out our full paper here and our source code/data on GitHub.
Acknowledgments
This blog post is based on the paper:
- Break-It-Fix-It: Unsupervised Learning for Program Repair. Michihiro Yasunaga and Percy Liang. ICML 2021.
Many thanks to Percy Liang, as well as members of the Stanford P-Lambda group, SNAP group and NLP group for their valuable feedback. Many thanks to Jacob Schreiber and Sidd Karamcheti for edits on this blog post.
-
Reversible Debugging Software. Tom Britton, Lisa Jeng, Graham Carver, Paul Cheak, Tomer Katzenellenbogen. 2013. Programmers’ Build Errors: A Case Study (at Google). Hyunmin Seo, Caitlin Sadowski, Sebastian Elbaum, Edward Aftandilian, Robert Bowdidge. 2014. ↩
-
Improving programming productivity with machine learning is an extremely active area of research. A prominent example is the Copilot / Codex service recently released by OpenAI and GitHub, which translates natural language (e.g. English) descriptions into code. Automated code repair is another complementary technology to improve programming productivity. ↩
-
SEQUENCER: Sequence-to-Sequence Learning for End-to-End Program Repair. Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noël Pouchet, Denys Poshyvanyk, Martin Monperrus. 2019. DeepDelta: Learning to Repair Compilation Errors. Ali Mesbah Andrew Rice Emily Johnston Nick Glorioso Eddie Aftandilian. 2019. Patching as Translation: the Data and the Metaphor. Yangruibo Ding, Baishakhi Ray, Premkumar Devanbu, Vincent J. Hellendoorn. 2020 ↩
-
Break-It-Fix-It: Unsupervised Learning for Program Repair. Michihiro Yasunaga, Percy Liang. 2021. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. DeepBugs: A Learning Approach to Name-based Bug Detection. Michael Pradel, Koushik Sen. 2018. Neural program repair by jointly learning to localize and repair. Marko Vasic, Aditya Kanade, Petros Maniatis, David Bieber, Rishabh Singh. 2019. Global relational models of source code. Vincent J. Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, David Bieber. 2020. ↩
-
Improving Neural Machine Translation Models with Monolingual Data. Rico Sennrich, Barry Haddow, Alexandra Birch. 2016. Phrase-Based & Neural Unsupervised Machine Translation. Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato. 2018. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. ↩
-
SampleFix: Learning to Correct Programs by Sampling Diverse Fixes. Hossein Hajipour, Apratim Bhattacharya, Mario Fritz. 2019. ↩
-
Graph-based, Self-Supervised Program Repair from Diagnostic Feedback. Michihiro Yasunaga, Percy Liang. 2020. ↩
-
LM-Critic: Language Models for Unsupervised Grammatical Error Correction. Michihiro Yasunaga, Jure Leskovec, Percy Liang. 2021. ↩
TensorFlow Hub’s Experience with Google Summer of Code 2021

Posted by Sayak Paul (MLE at Carted, and GDE) and Morgan Roff (Google)
We’re happy to share the work completed by Google Summer of Code students working with TensorFlow Hub this year. If you’re a student who is interested in writing open source code, then you’ll likely be interested in Google’s Summer of Code program.
Through this program, students propose project ideas to open source organizations, and if selected, receive a stipend to work with them to complete their projects over the summer. Students have the opportunity to learn directly from mentors within their selected organization, and organizations benefit from the students’ contributions. This year, 17 successful students completed their projects with the TensorFlow organization on many projects. In this article, we’ll focus on some of the work completed on TensorFlow Hub.
We’re Sayak and Morgan, two mentors for projects on TensorFlow Hub (TF Hub). Here we share what the students learned about building and publishing state-of-the-art models, training them on large-scale benchmark datasets, what we learned as mentors, and how rewarding summer of code was for each of us, and for the community.
We had the opportunity to mentor two students – Aditya Kane and Vasudev Gupta. Aditya successfully implemented several variants of RegNets including one based on this paper, and trained them on the ImageNet-1k dataset. Vasudev ported the pre-trained wav2vec2 weights from this paper to TensorFlow, which required him to implement the model architecture from scratch. He then demonstrated fine-tuning these pre-trained checkpoints on the LibriSpeech dataset, making his work more customizable and relevant for the community.
With model training happening at such a large scale, it becomes especially important to follow good engineering practices during the implementation. These include code modularization, unit tests, good design patterns, optimizations, and so on. Models were trained on Cloud TPUs to accelerate training time, and as such, substantial effort was put into the data input pipelines to ensure maximum accelerator utilization.
All of these factors collectively contributed to the complexity of the projects. Thanks to the Summer of Code program, students have the opportunity to tackle these challenges with the help of experienced mentors. This also enables students to gain insight into their organizations, and interact with people with many skillsets who cooperate to make large projects possible. A big thank you here to our students, who gracefully handled this engineering work and listened to our feedback.
Vasudev and Aditya contributed significant pre-trained models to TensorFlow Hub, along with tutorials (Wav2Vec, RegNetY) on their use, and TensorFlow implementations for folks who want to dig deeper. In their own words:
The last 2-3 months were full of lots of learning and coding. GSoC helped me get into the speech domain and motivated me to explore more about the TensorFlow ecosystem. I am thankful to my mentors for their continuous & timely feedback. I am looking forward to contributing more to the TensorFlow community and other awesome open source projects out there. – Vasudev Gupta
More about RegNets and Wav2Vec2
Almost 6 years after they were first published, ResNets are still widely used as benchmark architectures across image understanding tasks. Many recent self-supervised and semi-supervised learning frameworks still leverage ResNet50 as their backbone architectures. However, ResNets often do not scale well under larger data regimes and suffer from large training and inference time latencies as they grow. In contrast, RegNets were developed specifically to be a scalable architecture framework that maintains low latency while demonstrating high performance on standard image recognition tasks. Aditya’s models are published on TF Hub, with code and tutorials on GitHub.
Self-supervised learning is an important area of machine learning research. Many recent success stories have been focused on NLP and Computer Vision, and for Vasudev’s project, we wanted to explore speech. Last year, a group of researchers released the wav2vec2 framework for learning representations from audio in a self-supervised manner, benefiting downstream tasks like speech-to-text.
Using wav2vec2, you can now pre-train speech models without labeled data, and fine-tune those models on downstream tasks like speaker recognition. Vasudev’s models are available on TF Hub, along with a new tutorial on fine-tuning, and code on GitHub.
Wrapping up
We’d like to say a heartfelt thank you to all the students, mentors, and organizers who made Summer of Code a success despite this year’s many challenges. We encourage you to check out these models and share what you have built with us by tagging #TFHub on your social media posts, or share your work for the community spotlight program. If you have questions or want to learn more about these new models, you can ask them on discuss.tensorflow.org.
How Erica Aduh learned to love robots
Today she’s a research scientist working on significant challenges for Amazon Robotics, but it was a college class that proved fateful.Read More
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent’s repertoire to solve related tasks.Read More
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent’s repertoire to solve related tasks.Read More
How Waze Uses TFX to Scale Production-Ready ML
Posted by Gal Moran, Iris Shmuel, and Daniel Marcous (Data Scientists at Waze)
Waze
Waze is the world’s largest community-based traffic and navigation app. It uses real-time data to help users circumvent literal and figurative bumps in the road. On top of mobile navigation, Waze offers a web platform, a carpool app, partnership services, an advertisement platform and more. Such a broad portfolio brings along diverse technological challenges and many different use cases.

ML @Waze
Waze relies on many ML solutions, including:
- Predicting ETA
- Matching Riders & Drivers (Carpool)
- Serving The Right Ads
But it’s not that easy to get something like these right and “production grade”. It is very common for these kinds of projects to have requirements for complex surrounding infrastructure for getting them to production and hence require multiple engineers (data scientist, software engineer and software reliability engineers) and a lot of time. Even more so when you mix in the Waze-y requirements like large scale data, low (real-time, actually) latency inference, diverse use cases, and a whole lot of geospatial data.
The above is a good reason why opportunistically starting to do ML created a chaotic state at Waze. For us it manifested as:
- Multiple ML frameworks – you name it (sklearn, xgboost, TensorFlow, fbprophet, Java PMML, hand made etc.)
- ML & Ops disconnect – models & feature engineering embedded in (Java) backend servers by engineers with limited monitoring and validation capabilities
- Semi-manual operations for training, validation and deployment
- A hideously long development cycle from idea to production
Overall, data scientists ended up spending a lot of their time on ops and monitoring instead of focusing on the actual modelling and data processing. At a certain level of growth we’ve decided to organize the chaos and invest in automation and processes so we can scale faster. We’ve decided to heavily invest in a way to dramatically increase velocity and quality by adopting a full cycle data science philosophy. This means that in this new world we wanted to build, a single data scientist is able to close the product cycle from research to a production grade service.
Data scientists now directly contribute to production to maximize impact. They focus on modelling and data processing and get many infrastructures and ops work out-of-the-box. While we are not yet at the end of this journey fully realizing the above vision, we feel like the effort layed out here was crucial in putting us on the right track.
Waze’s ML Stack
Translating the above philosophy to a tech spec, we were set on creating an easy, stable, automated and uniform way of building ML pipelines at Waze.
Deep diving into tech requirements we came up with the below criteria:
- Simple — to understand, use, operate
- Managed — no servers, no hardware, just code
- Customizable — get the simple stuff for free, yet flexible enough to go crazy for the 5% that would require going outside the lines
- Scalable — auto scalable data processing, training, inference
- Pythonic — we need something production-ready, that works with most tools and code today and fits the standard data scientist. There are practically no other options than Python these days.
For the above reasons we’ve landed on TFX and the power of its built-in components to deliver these capabilities mostly out of the box.
It’s worth saying – Waze runs its tech stack on Google Cloud Platform (GCP).
It happens to be that GCP offers a suite of tools called Vertex AI. It is the ML infrastructure platform Waze is building on top of. While we use many components of Vertex AI’s managed services, we will focus here on – Vertex Pipelines – a framework for ML pipelines that helps us encapsulate TFX (or any pipeline) complexity and setup.
Together with our data tech stack, the overall ML architecture at Waze (all managed, scaled, pythonic etc.) is as follows:

Careful readers will notice the alleged caveat here – we go all in on TensorFlow.
TFX means TensorFlow (even though that’s not exactly true anymore, let’s assume it is).
It might be a little scary at first when you have many different use cases.
Fortunately, the TF ecosystem is rich and Waze has the merit of having large enough data that neural nets converge.
Since starting this we’ve yet to find a use case that TF magic does not solve better or adequately as other frameworks (and not talking about micro % points, not trying to do a Kaggle competition here but get something to production).
Waze TFX
You might think that landing on TFX and Vertex Pipelines solved all our problems, but that’s not exactly true.
In order to make things truly simple we’ve had to write some “glue code” (integrating the various products in the above architecture diagram) and abstracting enough details so the common data scientist could use this stuff effectively and fast.
That resulted in:
- Eliminated boilerplate
- Hiding all common TFX components so data scientists only focus on feature engineering and modelling and get the entire pipeline for free
- Generating BigQuery based train / eval split
- Providing pre-implemented optional common features transform (e.g. scaling, normalization, imputations)
- Providing pre-implemented Keras models (e.g. DNN/RNN model. TF Estimator like but in Keras that speaks TFX)
- Utility functions (e.g. TF columns preparation)
- Unit testing framework for tf.transform feature engineering code
- Orchestrated and scheduled pipeline runs from Airflow using a Cloud run instance with all TFX packages installed (without installing it on the Airflow composer)
We’ve put it all in an easy to use Python package called “waze-data-tfx”

On top, we provided a super detailed walkthrough, usage guides and code templates, to our data scientists, so the common DS workflow is: fork, change config, tweak the code a little, deploy.
For reference this is how a simple waze-data-tfx pipeline looks like:
- Configuration
_DATASET_NAME = 'tfx_examples'
_TABLE_NAME = 'simple_template_data'
_LABEL_KEY = 'label'
_CATEGORICAL_INT_FEATURES = {
"categorical_calculated": 2,
}
_DENSE_FLOAT_FEATURE_KEYS = ["numeric_feature1", "numeric_feature2"]
_BUCKET_FEATURES = {
"numeric_feature1": 5,
}
_VOCAB_FEATURES = {
"categorical_feature": {
'top_k': 5,
'num_oov_buckets': 3
}
}
_TRAIN_BATCH_SIZE = 128
_EVAL_BATCH_SIZE = 128
_NUM_EPOCHS = 250
_TRAINING_ARGS = {
'dnn_hidden_units': [6, 3],
'optimizer': tf.keras.optimizers.Adam,
'optimizer_kwargs': {
'learning_rate': 0.01
},
'layer_activation': None,
'metrics': ["Accuracy"]
}
_EVAL_METRIC_SPEC = create_metric_spec([
mse_metric(upper_bound=25, absolute_change=1),
accuracy_metric()
]) - Feature Engineering
def preprocessing_fn(inputs):
"""tf.transform's callback function for preprocessing inputs.
Args:
inputs: map from feature keys to raw not-yet-transformedfeatures.
Returns:
Map from string feature key to transformed feature operations.
"""
outputs = features_transform(
inputs=inputs,
label_key=_LABEL_KEY,
dense_features=_DENSE_FLOAT_FEATURE_KEYS,
vocab_features=_VOCAB_FEATURES,
bucket_features=_BUCKET_FEATURES,
)
return outputs - Modelling
def _build_keras_model(**training_args):
"""Build a keras model.
Args:
hidden_units: [int], the layer sizes of the DNN (input layer first).
learning_rate: [float], learning rate of the Adam optimizer.
Returns:
A keras model
"""
feature_columns =
prepare_feature_columns(
dense_features=_DENSE_FLOAT_FEATURE_KEYS,
vocab_features=_VOCAB_FEATURES,
bucket_features=_BUCKET_FEATURES,
)
return _dnn_regressor(deep_columns=list(feature_columns.values()),
dnn_hidden_units=training_args.get(
"dnn_hidden_units"),
dense_features=_DENSE_FLOAT_FEATURE_KEYS,
vocab_features=_VOCAB_FEATURES,
bucket_features=_BUCKET_FEATURES,
) - Orchestration
pipeline_run = WazeTFXPipelineOperator(
dag=dag,
task_id='pipeline_run',
model_name='basic_pipeline_template',
package=tfx_pipeline_basic,
pipeline_project_id=EnvConfig.get_value('gcp-project-infra'),
table_project_id=EnvConfig.get_value('gcp-project-infra'),
project_utils_filename='utils.py',
gcp_conn_id=gcp_conn_id,
enable_pusher=True,
)
Simple, right?
When you commit a configuration file to the code base it gets deployed and sets up continuous training, and a full blown pipeline including all TFX and Vertex AI magics like data validation, transforms deployed to Dataflow, monitoring etc.
Summary
We knew we were up to something good when one of our data scientists came back from a long leave and had to use this new framework for a use case. She said that she was able to spin up a full production-ready pipeline in hours, something that before her leave would have taken her weeks to do.
Going forward we have much planned that we want to bake into `waze-data-tfx`. A key advantage that we see in having this common infrastructure is that once a feature is added, then everyone can enjoy it “for free”. For example, we plan on adding additional components to the pipeline, such as Infra Validator and Fairness Indicators. Once these are supported, every new or existing ML pipeline will add these components out-of-the-box, no extra code needed.
Additional improvements we are planning are around deployment. We wish to provide deployment quality assurance while automating as much as possible.
One way we are currently exploring doing so is using canary deployments. A data scientist will simply need to configure an evaluation metric and the framework (using Vertex Prediction traffic splitting capabilities and other continuous evaluation magic) would test the new model in production and gradually deploy or rollback according to the evaluated metrics.
Using learning-to-rank to precisely locate where to deliver packages
Models adapted from information retrieval deal well with noisy GPS input and can leverage map information.Read More
Our Journey towards Data-Centric AI: A Retrospective
This article provides a brief, biased retrospective of our road to data-centric AI. Our hope is to provide an entry point for people interested in this area, which has been scattered to the nooks and crannies of AI—even as it drives some of our favorite products, advancements, and benchmark improvements.
We’re collecting pointers to these resources on GitHub, and plan to write a few more articles about exciting new directions. We hope to engage with folks who are excited about data-centric AI in an upcoming HAI workshop in November — folks like you!
Starting in about 2016, researchers from our lab — the Hazy Research lab — circled through academia and industry giving talks about an intentionally provocative idea: machine learning (ML) models—long the darlings of researchers and practitioners—were no longer the center of AI. In fact, models were becoming commodities. Instead, we claimed that it was the training data that would drive progress towards more performant ML models and systems.
To underscore this, we had taglines like “AI is driven by data—not code” or worse ”Training data is the new new oil”. We started building systems championed by little octopuses wearing snorkels. Eventually, we turned to others and called this “Software 2.0” (inspired by Karpathy’s post. Others have since termed it data-centric AI, and recently Andrew Ng gave a great talk about his perspective on this direction.
Our view that models were becoming a commodity was heretical for a few reasons.
First, people often think of data as a static thing. After all, data literally means “that which is given”. For most ML people, they download an off-the-shelf dataset, drop it into a PyTorch dataloader, and plug-and-play: losses go down, accuracy goes up, and the data is a mere accessory.
But to an engineer in the wild, the training data is never “that which is given”. It is the result of a process — usually a dirty, messy process that is critical and underappreciated.

Still, we had hope. In applications, we took time to clean and merge data. We engineered it. We began to talk about how AI and ML systems were driven by this data, how they were programmed by this data. This led to understandably (obtuse) names like “data programming”.
Unfortunately, we were telling people to put on galoshes, jump into the sewer that is your data, and splash around. Not an easy sales pitch for researchers used to life in beautiful PyTorch land.
We started to recognize that model-itis is a real problem. With some friends at Apple, we realized that teams would often spend time writing new models instead of understanding their problem—and its expression in data—more deeply. We weren’t the only ones thinking this way, lots of no-code AI folks like Ludwig, H2O, DataRobot were too. We began to argue that this aversion to data didn’t really lead to a great use of time. To make matters worse, 2016-2017 was a thrilling time to be in ML. Each week a new model came out, and each week, it felt like we were producing demos that we couldn’t dream of a decade earlier.
Despite this excitement, it was clear to us that success or failure to a level usable in applications we cared about—in medicine, at large technology companies or even pushing the limits on benchmarks—wasn’t really tied to models per se. That is, the advances were impressive, but they were hitting diminishing returns. You can see this in benchmarks, where most of the progress after 2017 is fueled by new advances in augmentations, weak supervision, and other issues of how you feed machines data. In round numbers, ten points of accuracy were due to those—while (by and large) model improvements were squeaking out a few tenths in accuracy points.
At the time, many of the folks who are now converts have shared with us that they were skeptical of our view of the future. We get it, our stupid jokes and general demeanor didn’t inspire confidence. But we weren’t totally insane. This idea has become mainstream and widespread. Our friends at Google in Ads, Gmail, YouTube and Apple extended to us a level of technical trust that we hope we’ve repaid. You’ve probably used some of the products that have incorporated these crazy ideas in the last few minutes. The Octopus is now widely used in the enterprise, and we’re just at the beginning!
This blog post is an incomplete, biased retrospective of this road. We’ll close with two thoughts:
- There is a data-centric research agenda inside AI. It’s intellectually deep, and it has been lurking at the core of AI progress for a while. Perhaps by calling it out we can make even more progress on an important viewpoint.
- We’d love to provide entry points for folks interested in this area. Our results are scattered in a number of different research papers, and we’d enjoy writing a survey (if anyone is interested – we have a form!). We’ve opted to be biased about what influenced us the most to try to present a coherent story here. Necessarily, this means we’re leaving out amazing work. Apologies, please send us notes and corrections.
On our end, we’ll do our best to build this data-centric community up on GitHub, with a collage of exciting related papers and lines of work. If you’re new to the area, use it as a pedagogical resource, and if you’re a veteran, please go ahead and send us PRs and contributions so we can expand the discussion! We’re gathering real-world case studies, so if you work on real applications that have benefited from a data-centric viewpoint (in academia, industry or anywhere), please don’t hesitate to reach out at kgoel@cs.stanford.edu or create an Issue on the Github so we can bring your experiences into the fold.
A more informal version of this blog can be found here.
Challenges in Detoxifying Language Models
In our paper, we focus on LMs and their propensity to generate toxic language. We study the effectiveness of different methods to mitigate LM toxicity, and their side-effects, and we investigate the reliability and limits of classifier-based automatic toxicity evaluation.Read More