Other paper topics include natural-language processing, dataset optimization, and the limits of existing machine learning techniques.Read More
Part 4: How NatWest Group migrated ML models to Amazon SageMaker architectures
The adoption of AWS cloud technology at NatWest Group means moving our machine learning (ML) workloads to a more robust and scalable solution, while reducing our time-to-live to deliver the best products and services for our customers.
In this cloud adoption journey, we selected the Customer Lifetime Value (CLV) model to migrate to AWS. The model enables us to understand our customers better and deliver personalized solutions. The CLV model consists of a series of separate ML models that are brought together into a single pipeline. This requires a scalable solution, given the amount of data it processes.
This is the final post in a four-part series detailing how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform. This post is intended for ML engineers, data scientists, and C-suites executives who want to understand how to build complex solutions using Amazon SageMaker. It proves the platform’s flexibility by demonstrating how, given some starter code templates, you can deliver a complex, scalable use case quickly and repeatably.
Read the entire series:
|
Challenges
NatWest Group, on its mission to delight its customers while remaining in line with regulatory obligations, has been working with AWS to build a standardized and secure solution to implement and productionize ML workloads. Previous implementations in the organization led to data silos and long lead times for environments spin up and spin down. This has also led to underutilized compute resources. To help improve this, AWS and NatWest collaborated to develop a series of ML project and environment templates using AWS services.
NatWest Group is using ML to derive new insights so we can predict and adapt to our customers’ future banking needs across the bank’s retail, wealth, and commercial operations. When developing a model and deploying it to production, many considerations need to be addressed to ensure compliance with the bank’s standards. These include requirements on model explainability, bias, data quality, and drift monitoring. The templates developed through this collaboration incorporate features to assess these points, and are now used by NatWest teams to onboard and productionize their use cases in a secure multi-account setup using SageMaker.
The templates embed standards for production-ready ML workflows by incorporating AWS best practices using MLOps capabilities in SageMaker. They also include a set of self-service, secure, multi-account infrastructure deployments for AWS ML services and data services via Amazon Simple Storage Service (Amazon S3).
The templates help use case teams within NatWest to do the following:
- Building capabilities in line with the NatWest MLOps maturity model
- Implement AWS best practices for MLOps capabilities in SageMaker services
- Create and use templated standards to develop production-ready ML workflows
- Provide self-service, secure infrastructure deployment for AWS ML services
- Reduce time to spin up and spin down environments for projects using a managed approach
- Reduce the cost of maintenance due to standardization of processes, automation, and on-demand compute
- Productionize code, which allows for the migration of existing models where code is functionally decomposed to take advantage of on-demand cloud architectures while improving code readability and remove technical debt
- Use continuous integration, deployment, and training for proof of concept (PoC) and use case development, as well as enable additional MLOps features (model monitoring, explainability, and condition steps)
The following sections discuss how NatWest uses these templates to migrate existing projects or create new ones.
Custom SageMaker templates and architecture
NatWest and AWS built custom project templates with the capabilities of existing SageMaker project templates, and integrated these with infrastructure templates to deploy to production environments. This setup already contains example pipelines for training and inference, and allows NatWest users to immediately use multi-account deployment.
The multi-account setup keeps development environments secure while allowing testing in a production-like environment. This enables project teams to focus on the ML workloads. The project templates take care of infrastructure, resource provisioning, security, auditability, reproducibility, and explainability. They also allow for flexibility so that users can extend the template based on their specific use case requirements.
Solution overview
To get started as a use case team at NatWest, the following steps are required based on the templates built by NatWest and provided via AWS Service Catalog:
- The project owner provisions new AWS accounts, and the operations team sets up the MLOps prerequisite infrastructure to these new accounts.
- The project owner creates an Amazon SageMaker Studio data science environment using AWS Service Catalog.
- The data scientist lead starts a new project and creates SageMaker Studio users via the templates provided in AWS Service Catalog.
- The project team works on the project, updating the template’s folder structure to aid their use case.
The following figure shows how we adapted the template architecture to fit our CLV use case needs. It showcases how multiple training pipelines are developed and run within a development environment. The deployed models can then be tested and productionized within pre-production and production environments.
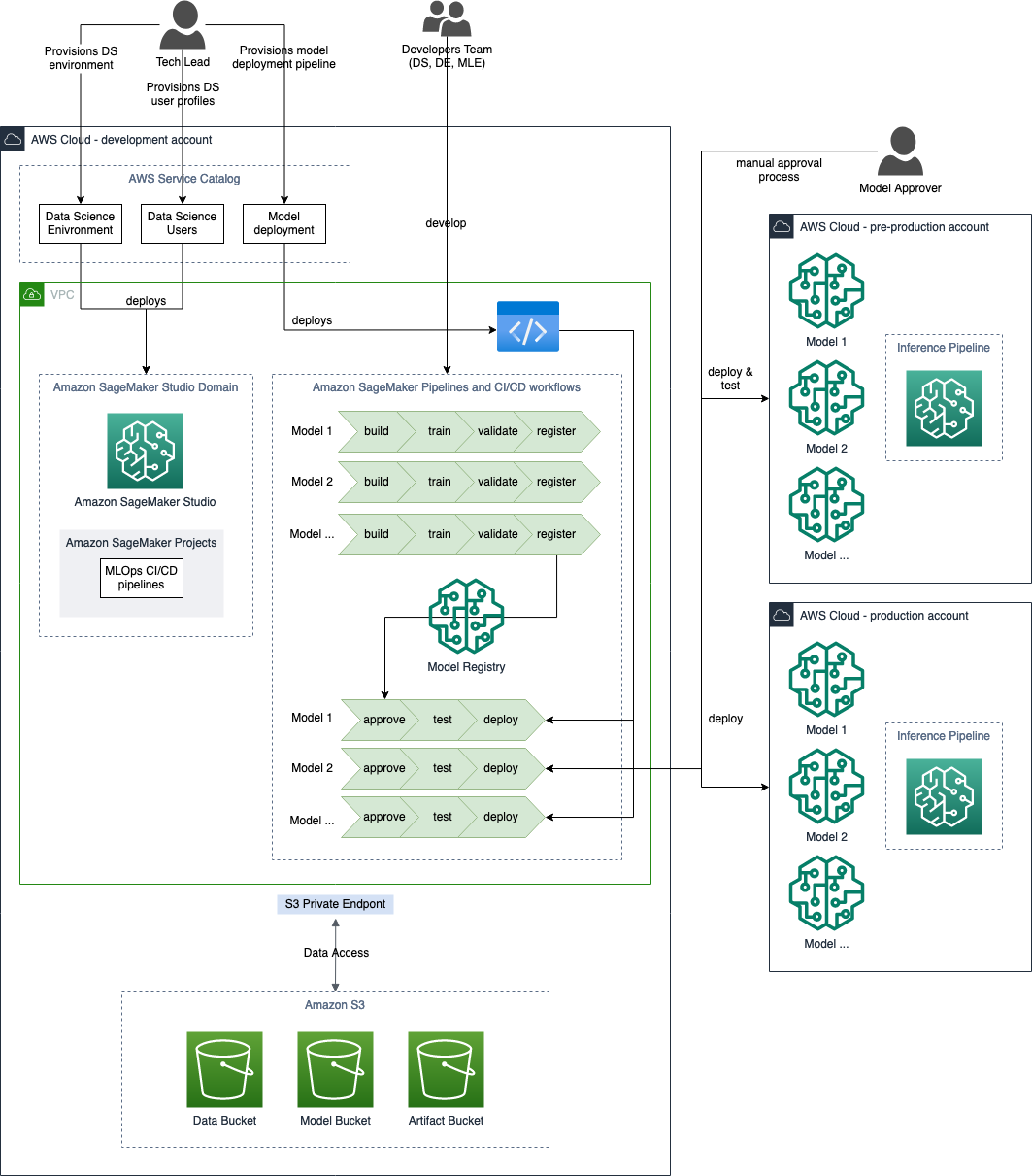
The CLV model is a sequence of different models, which includes different tree-based models and an inference setup that combines all the outputs from these. The data used in this ML workload is collected from various sources and amounts to more than half a billion rows and nearly 1,900 features. All processing, feature engineering, model training, and inference tasks on premises were done using PySpark or Python.
SageMaker pipeline templates
CLV is composed of multiple models that are built in a sequence. Each model feeds into another, so we require a dedicated training pipeline for each one. Amazon SageMaker Pipelines allows us to train and register multiple models using the SageMaker model registry. For each pipeline, existing NatWest code was refactored to fit into SageMaker Pipelines, while ensuring the logical components of processing, feature engineering, and model training stayed the same.
In addition, the code for applying the models to perform inference consecutively was refactored into one pipeline dedicated for inference. Therefore, the use case required multiple training pipelines but only one inference pipeline.
Each training pipeline results in the creation of an ML model. To deploy this model, approval from the model approver (a role defined for ML use cases in NatWest) is required. After deployment, the model is available to the SageMaker inference pipeline. The inference pipeline applies the trained models in sequence to the new data. This inference is performed in batches, and the predictions are combined to deliver the final customer lifetime value for each customer.
The template contains a standard MLOps example with the following steps:
- PySpark Processing
- Data Quality Check and Data Bias Check
- Model Training
- Condition
- Create Model
- Model Registry
- Transform
- Model Bias Check, Explainability Check, and Quality Check
This pipeline is described in more detail in Part 3: How NatWest Group built audible, reproducible, and explainable ML models with Amazon SageMaker.
The following figure shows the design of the example pipeline provided by the template.
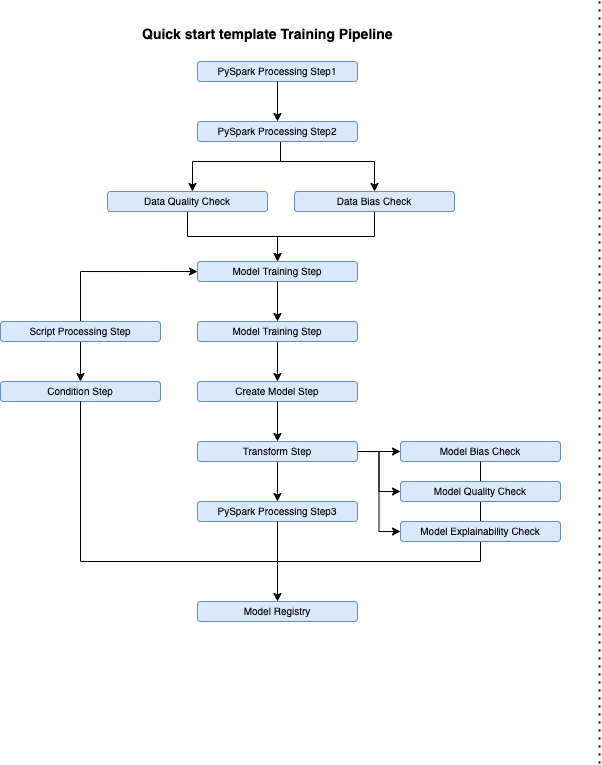
Data is preprocessed and split into train, test, and validation sets (Processing step) before training the model (Training). After the model is deployed (Create Model), it is used to create batch predictions (Transform). The predictions are then postprocessed and stored in Amazon S3 (Processing).
Data quality and data bias checks provide baseline information on the data used for training. Model bias, explainability, and quality checks use predictions on the test data to investigate the model behavior further. This information as well as model metrics from the model evaluation (Processing) are later displayed within the model registry. The model is only registered when a certain condition with regards to previous best models is met (Condition step).
Any artifacts and datasets created when a pipeline is run are saved in Amazon S3 using the buckets that are automatically created when provisioning the template.
Customizing the pipelines
We needed to customize the template to ensure the logical components of the existing codebase were migrated.
We used the LightGBM framework in building our models. The first of the models built in this use case is a simple decision tree to enforce certain feature splits during model training. Furthermore, we split the data based on a given feature. This procedure effectively resulted in training two separate decision tree models.
We can use trees to apply two kinds of predictions: value and leaf. In our case, we use value predictions on the test set to calculate custom metrics for model evaluation, and we use leaf prediction for inference.
Therefore, we needed to add specifications to the training and inference pipeline provided by the template. To account for the complexity provided by the use case model as well as to showcase the flexibility of the template, we added additional steps to the pipeline and customized the steps to apply the required code.
The following figure shows our updated template. It also demonstrates how you can have as many deployed models as you need, which you can pass to the inference pipeline.
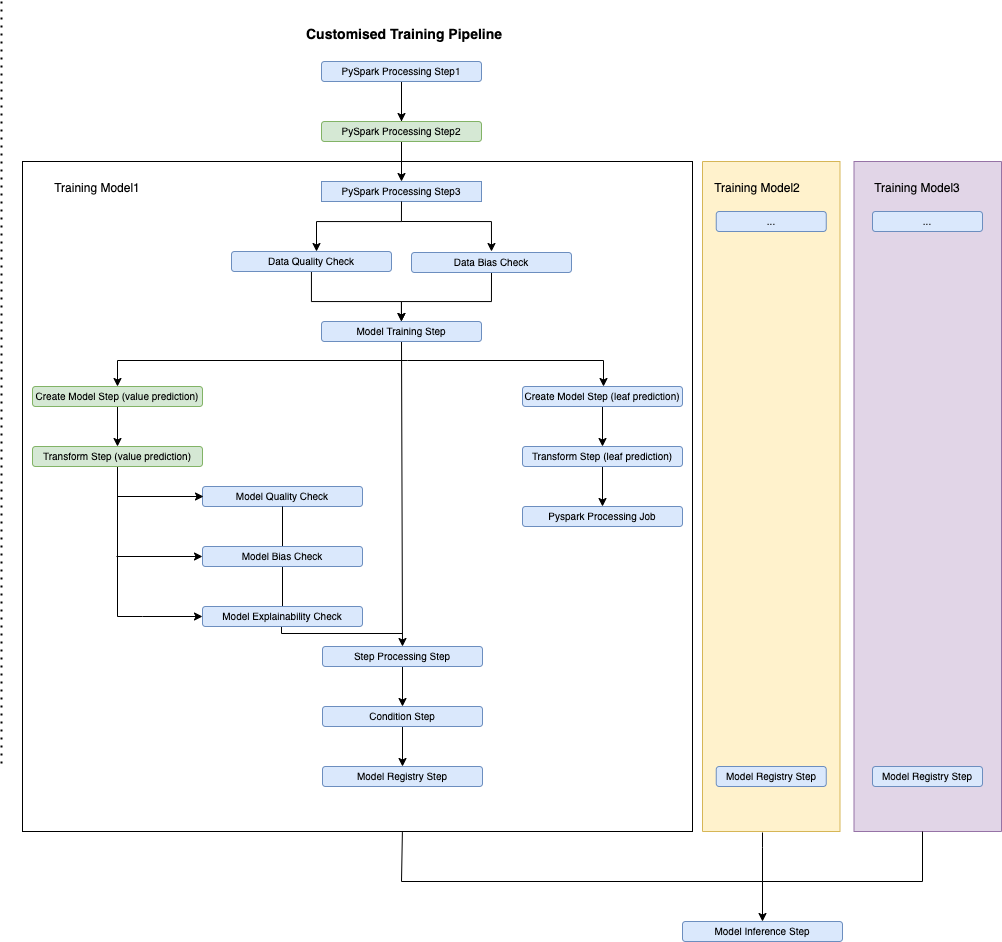
Our first model enforces business knowledge and splits the data on a given feature. For this training pipeline, we had to register two different LightGBM models for each dataset.
The steps involved in training them were almost identical. Therefore, all steps were carried out twice for each data split compared to the standard template—except the first processing steps. A second processing step is applied to cater to different models with unique datasets.
In the following sections, we discuss the customized steps in more detail.
Processing
Each processing step is provided with a processor instance, which handles the SageMaker processing tasks. This use case uses two kinds of processors to run Python code:
- PySpark processor – Each processing job with a PySpark processor uses its own set of Spark configurations to optimize the job.
- Script processor – We use the existing Python code from the use case to generate custom metrics based on the predictions and actual data provided, and format the output to be viewed later in the model registry (JSON). We use a custom image created by the template.
In each case, we can modify the instance type, instance count, and size in GB of the Amazon Elastic Block Store (Amazon EBS) volume to adjust to the training pipeline needs. In addition, we apply custom container images created by the template, and we can extend the default libraries if needed.
Model training
SageMaker training steps support managed training and inference for a variety of ML frameworks. In our case, we use the custom Scikit-learn image provided using Amazon ECR in combination with the Scikit-learn estimator to train our two LightGBM models.
The previous design for the decision tree model involved a custom class, which was complicated and had to be simplified by fitting separate decision trees to filtered slices of the data. We accomplished this by implementing two training steps with different parameter and data inputs required for each model.
Condition
Conditional steps in SageMaker Pipelines support conditional branching in the running of steps. If all the conditions in the condition list evaluate to True, the “if” steps are marked as ready to run. Otherwise, the “else” steps are marked as ready to run. For our use case, we use two condition steps (ConditionLessThan) to determine if the current custom metrics for each model (for example the mean absolute error calculated on a test set) are below a performance threshold. This way, we only register models when the model quality is acceptable.
Create model
The create model step helps make models available for inference tasks and also inherits the code to be used to create predictions. Because our use case needs value and leaf predictions for two different models, the training pipelines have four different create model steps.
Each step is given an entry point file depending whether the consecutive transform step is to predict a leaf or value on given data.
Transform
Each transform step uses a model (created by the create model step) to return predictions. In our case, we have one for each created model, resulting in a total of four transform steps. Each of these steps returns either leaf or value predictions for each of the models. The output is customized depending on the next step in the pipeline. For example, a transform step for value predictions has different output filters to create a specific input required for the following model check steps in the pipeline.
Model registry
Finally, both model branches within the training pipeline have a unique model registry step. Like the standard setup, each model registry step takes the model-specific information from all the check steps (quality, explainability, and bias) as well as custom metrics and model artefacts. Each model is registered with a unique model package group.
While applying the use case-specific changes to the example code base, pipelines ran using the cache configurations for each pipeline step to enhance the debugging experience. Caching steps are useful when developing SageMaker pipelines because it reduces cost and saves time when testing pipelines.
We can optimize the settings of each step that requires an instance type and count (and if applicable EBS volume) for on-demand instances according to the use case needs.
Benefits
The AWS-NatWest collaboration has brought innovation to the implementation of ML models via SageMaker pipelines and MLOps best practices. NatWest Group now uses a standardized and secure solution to implement and productionize ML workloads on AWS, via flexible custom templates. Additionally, the model migration detailed in this post created multiple immediate and ongoing business benefits.
Firstly, we reduced complexity via standardization:
- We can integrate custom third-party models to SageMaker in a highly modular way to build a reusable solution
- We can create non-standard pipelines using templates, and these templates are supported in a standardized MLOps production environment
We saw the following benefits in software and infrastructure engineering:
- We can customize templates based on individual use cases
- Functionally decomposing and refactoring the original model code allows us to rearchitect, remove a significant technical debt caused by legacy code, and move our pipelines to a managed on-demand execution environment
- We can use the added capabilities available via the standardized templates to upgrade and standardize model explainability, as well as check data and model quality and bias
- The NatWest project team is empowered to provision environments, implement models, and productionize models in an almost completely self-service environment
Finally, we achieved improved productivity and lower cost of maintenance:
- Reduced time-to-live for ML projects – We can now start projects with generic templates that implement code standards, unit tests, and CI/CD pipelines for production-ready use case development from the beginning of a project. The new standardization means that we can expect reduced time to onboard future use cases.
- Reduced cost for running ML workflows in the cloud – Now we can run data processing and ML workflows with a managed architecture and adapt the underlying infrastructure to use case requirements using standardized templates.
- Increased collaboration between project teams – The standardized development of models means that we’ve increased the reusability of model functions developed by individual teams. This creates an opportunity to implement continuous improvement strategies in both development and operations.
- Boundaryless delivery – This solution allows us to make our elastic on-demand infrastructure available 24/7.
-
Continuous integration, delivery, and testing – Reduced deployment times between development completion and production availability lead to the following benefits:
- We can optimize the configuration of our infrastructure and software for model training and inference runtime.
- The ongoing cost of maintenance is reduced due to standardization of processes, automation, and on-demand compute. Therefore, in production, we only incur runtime costs once a month during retraining and inference.
Conclusion
With SageMaker and the assistance of AWS innovation leadership, NatWest has created an ML productivity virtuous circle. The templates, modular and reusable code, and standardization freed up the project team from existing delivery constraints. Furthermore, the MLOps automation freed up support effort to enable the team to work on other use cases and projects, or to improve existing models and processes.
This is the fourth post of a four-part series on the strategic collaboration between NatWest Group and AWS Professional Services. Check out the rest of the series for the following topics:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their compliant and self-service MLOps platform
- Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models
About the Authors
 Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in the financial and sports & media industries in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in the financial and sports & media industries in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
 Maren Suilmann is a data scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. In her spare time, she enjoys kickboxing, hiking to great views and board game nights.
Maren Suilmann is a data scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. In her spare time, she enjoys kickboxing, hiking to great views and board game nights.
 Craig Sim is a Senior Data Scientist at NatWest Group with a passion for data science research, particularly within graph machine learning domain, and model development process optimisation using MLOps best practices. Craig additionally has extensive experience in software engineering and technical program management within financial services. Craig has an MSc in Data Science, PGDip in Software Engineering and a BEng(Hons) in Mechanical and Electrical Engineering. Outside of work Craig is a keen golfer, having played at junior and senior county level. Craig was fortunate to be able to incorporate his golf interest, with data science, by collaborating with the PGA European Tour and World Golf Rankings for his MSc Data Science thesis. Craig also enjoys tennis and skiing and is a married father of three, now adult, children.
Craig Sim is a Senior Data Scientist at NatWest Group with a passion for data science research, particularly within graph machine learning domain, and model development process optimisation using MLOps best practices. Craig additionally has extensive experience in software engineering and technical program management within financial services. Craig has an MSc in Data Science, PGDip in Software Engineering and a BEng(Hons) in Mechanical and Electrical Engineering. Outside of work Craig is a keen golfer, having played at junior and senior county level. Craig was fortunate to be able to incorporate his golf interest, with data science, by collaborating with the PGA European Tour and World Golf Rankings for his MSc Data Science thesis. Craig also enjoys tennis and skiing and is a married father of three, now adult, children.
 Shoaib Khan is a Data Scientist at NatWest Group. He is passionate for solving business problems particularly in the domain of customer lifetime value and pricing using MLOps best practices. He is well equipped with managing a large machine learning codebase and is always excited to test new tools and packages. Loves to educate others around him as he runs a YouTube channel called convergeML. In his spare time, enjoys taking long walks and travel.
Shoaib Khan is a Data Scientist at NatWest Group. He is passionate for solving business problems particularly in the domain of customer lifetime value and pricing using MLOps best practices. He is well equipped with managing a large machine learning codebase and is always excited to test new tools and packages. Loves to educate others around him as he runs a YouTube channel called convergeML. In his spare time, enjoys taking long walks and travel.
Part 3: How NatWest Group built auditable, reproducible, and explainable ML models with Amazon SageMaker
This is the third post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. This post is intended for data scientists, MLOps engineers, and data engineers who are interested in building ML pipeline templates with Amazon SageMaker. We explain how NatWest Group used SageMaker to create standardized end-to-end MLOps processes. This solution reduced the time-to-value for ML solutions from 12 months to less than 3 months, and reduced costs while maintaining NatWest Group’s high security and auditability requirements.
NatWest Group chose to collaborate with AWS Professional Services given their expertise in building secure and scalable technology platforms. The joint team worked to produce a sustainable long-term solution that supports NatWest’s purpose of helping families, people, and businesses thrive by offering the best financial products and services. We aim to do this while using AWS managed architectures to minimize compute and reduce carbon emissions.
Read the entire series:
|
SageMaker project templates
One of the exciting aspects of using ML to answer business challenges is that there are many ways to build a solution that include not only the ML code itself, but also connecting to data, preprocessing, postprocessing, performing data quality checks, and monitoring, to name a few. However, this flexibility can create its own challenges for enterprises aiming to scale the deployment of ML-based solutions. It can lead to a lack of consistency, standardization, and reusability that limits the time to create new business propositions. This is where the concept of a template for your ML code comes in. It allows you to define a standard way to develop an ML pipeline that you can reuse across multiple projects, teams, and use cases, while still allowing the flexibility needed for key components. This makes the solutions we build more consistent, robust, and easier to test. This also makes development go much faster.
Through a recent collaboration between NatWest Group and AWS, we developed a set of SageMaker project templates that embody all the standard processes and steps that form part of a robust ML pipeline. These are used within the data science platform built on infrastructure templates that were described in Part 2 of this series.
The following figure shows the architecture of our training pipeline template.
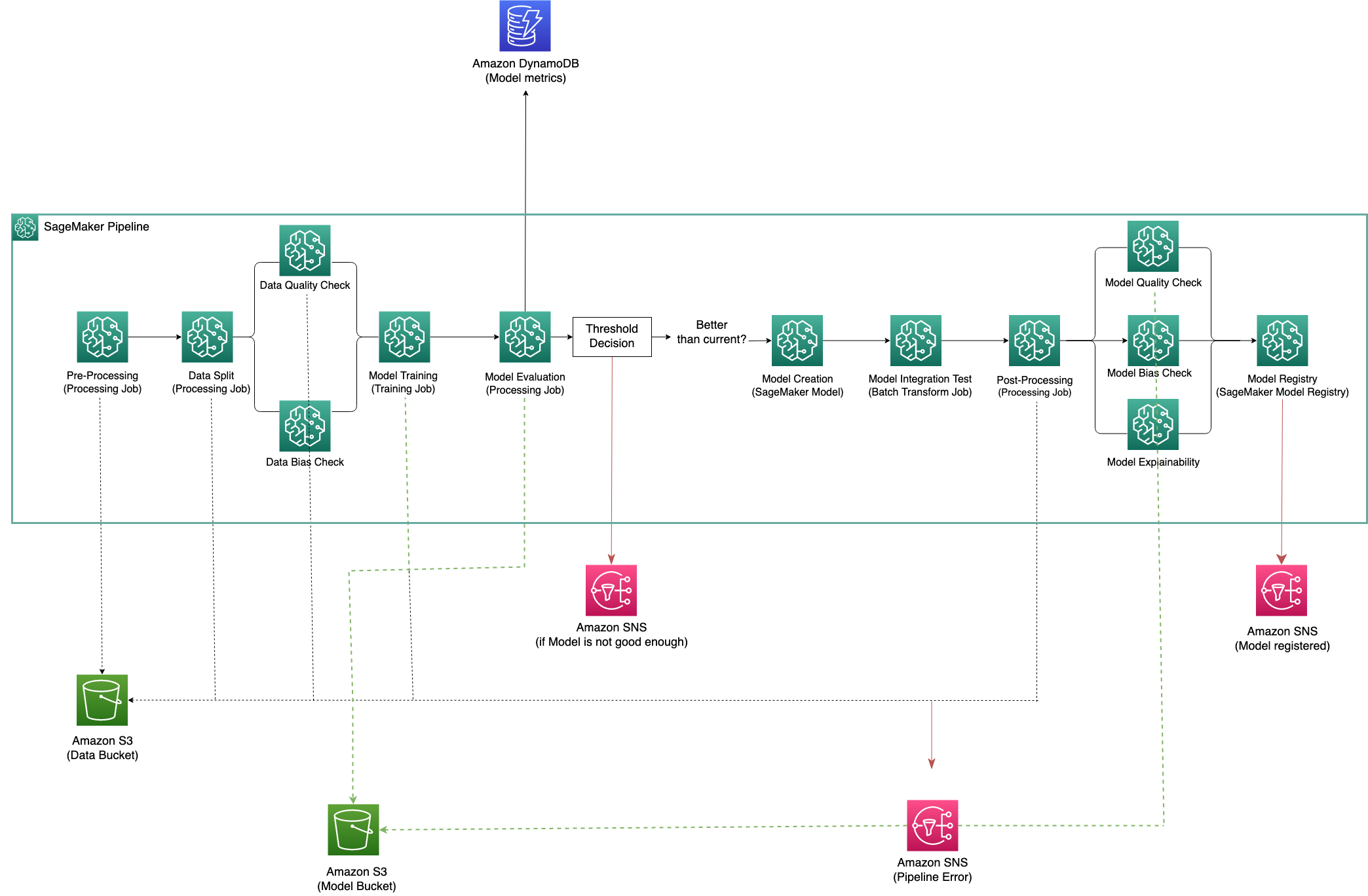
The following screenshot shows what is displayed in Amazon SageMaker Studio when this pipeline is successfully run.

All of this helps improve our ML development practices in multiple ways, which we discuss in the following sections.
Reusable
ML projects at NatWest often require cross-disciplinary teams of data scientists and engineers to collaborate on the same project. This means that shareability and reproducibility of code, models, and pipelines are two important features teams should be able to rely on.
To meet this requirement, the team set up Amazon SageMaker Pipelines templates for training and inference as dual starting points for new ML projects. The templates are deployed by the data science team via a single click into new development accounts via AWS Service Catalog as SageMaker projects. These AWS Service Catalog products are managed and developed by a central platform team so that best practice updates are propagated across all business units, but consuming teams can contribute their own developments to the common codebase.
To achieve easy replication of templates, NatWest utilized AWS Systems Manager Parameter Store. The parameters were referenced in the generic templates, where we followed a naming convention in which each project’s set of parameters uses the same prefix. This means templates can be started up quickly and still access all necessary platform resources, without users needing to spend time configuring them. This works because AWS Service Catalog replaces any parameters in the use case accounts with the correct value.
Not only do these templates enable a much quicker startup of new projects, but they also provide more standardized model development practices in teams aligned to different business areas. This means that model developers across the organization can more easily understand code written by other teams, facilitating collaboration, knowledge sharing, and easier auditing.
Efficient
The template approach encouraged model developers to write modular and decoupled pipelines, allowing them to take advantage of the flexibility of SageMaker managed instances. Decoupled steps in an ML pipeline mean that smaller instances can be used where possible to save costs, so larger instances are only used when needed (for example, for larger data preprocessing workloads).
SageMaker Pipelines also offers a step-caching capability. Caching means that steps that were already successfully run aren’t rerun in case of a failed pipeline—the pipeline skips those, reuses their cached outputs, and starts only from the failed step. This approach means that the organization is only charged for the higher-cost instances for a minimal amount of time, which also aligns ML workloads with NatWest’s climate goal to reduce carbon emissions.
Finally, we used SageMaker integration with Amazon EventBridge and Amazon Simple Notification Service (Amazon SNS) for custom email notifications on key pipeline updates to ensure that data scientists and engineers are kept up to date with the status of their development.
Auditable
The template ML pipelines contain steps that generate artifacts, including source code, serialized model objects, scalers used to transform data during preprocessing, and transformed data. We use the Amazon Simple Storage service (Amazon S3) versioning feature to securely keep multiple variants of objects like these in the same bucket. This means objects that are deleted or overwritten can be restored. All versions are available, so we can keep track of all the objects generated in each run of the pipeline. When an object is deleted, instead of removing it permanently, Amazon S3 inserts a delete marker, which becomes the current object version. If an object is overwritten, it results in a new object version in the bucket. If necessary, it can be restored to the previous version. The versioning feature provides a transparent view for any governance process, so the artifacts generated are always auditable.
To properly audit and trust our ML models, we need to keep a record of the experiments we ran during development. SageMaker allows for metrics to be automatically collected by a training job and displayed in SageMaker experiments and the model registry. This service is also integrated with the SageMaker Studio UI, providing a visual interface to browse active and past experiments, visually compare trials on key performance metrics, and identify the best performing models.
Secure
Due to the unique requirements of NatWest Group and the financial services industry, with an emphasis on security in a banking context, the ML templates we created required additional features compared to standard SageMaker pipeline templates. For example, container images used for processing and training jobs need to download approved packages from AWS CodeArtifact because they can’t do so from the internet directly. The templates need to work with a multi-account deployment model, which allows secure testing in a production-like environment.
SageMaker Model Monitor and SageMaker Clarify
A core part of NatWest’s vision is to help our customers thrive, which we can only do if we’re making decisions in a fair, equitable, and transparent manner. For ML models, this leads directly to the requirement for model explainability, bias reporting, and performance monitoring. This means that the business can track and understand how and why models make specific decisions.
Given the lack of standardization across teams, no consistent model monitoring capabilities were in place, leading to teams creating a lot of bespoke solutions. Two vital components of the new SageMaker project templates were bias detection on the training data and monitoring the trained model. Amazon SageMaker Model Monitor and Amazon SageMaker Clarify suit these purposes, and both operate in a scalable and repeatable manner.
Model Monitor continuously monitors the quality of SageMaker ML models in production against predefined baseline metrics. Clarify offers bias checks on training data based on the Deequ open-source library. After the model is trained, Clarify offers model bias and explainability checks using various metrics, such as Shapley values. The following screenshot shows an explainability report viewed in SageMaker Studio and produced by Clarify.
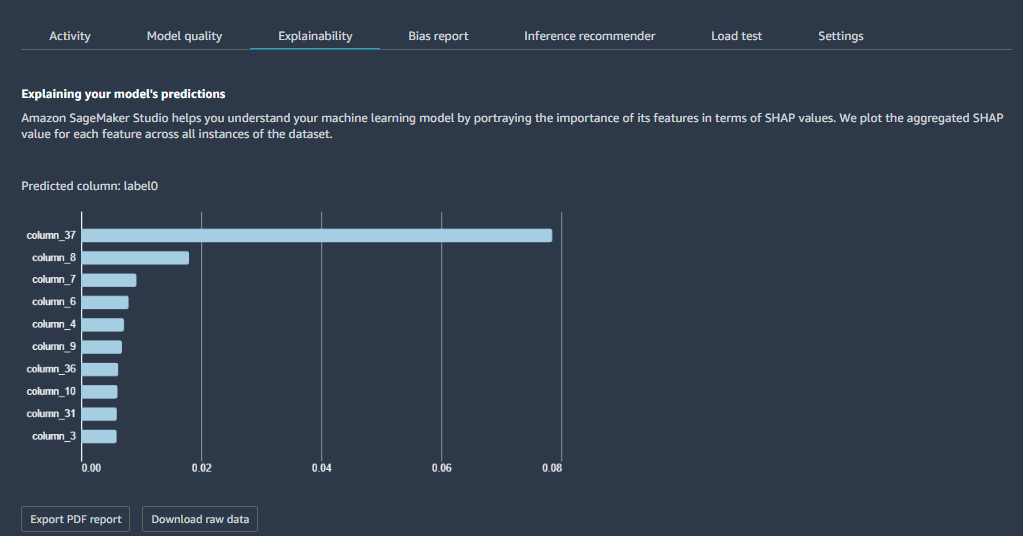
The following screenshot shows a similarly produced example model bias report.
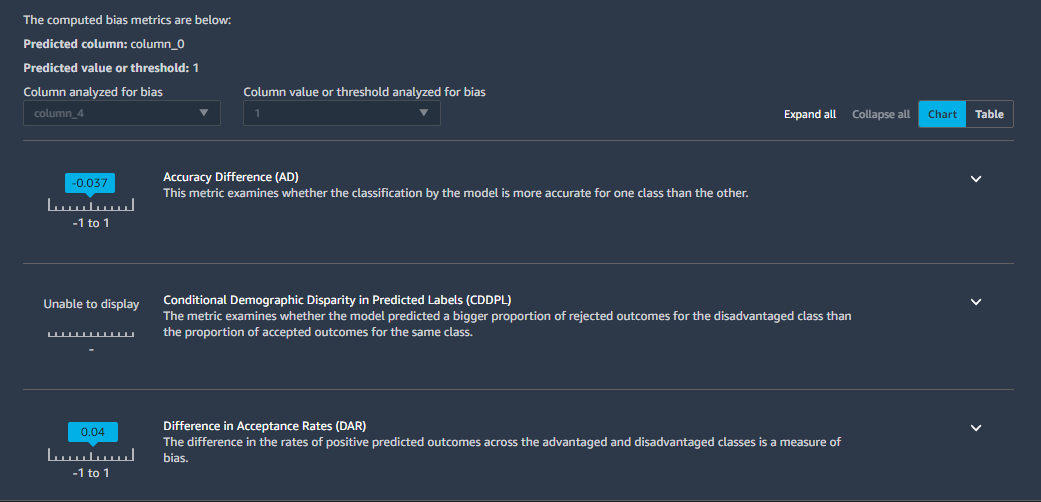
Conclusion
NatWest’s ML templates align our MLOps solution to our need for auditable, reusable, and explainable MLOps assets across the organization. With this blueprint for instantiating ML pipelines in a standardized manner using SageMaker features, data science and engineering teams at NatWest feel empowered to operate and collaborate with best practices, with the control and visibility needed to manage their ML workloads effectively.
In addition to the quick-start ML templates and account infrastructure, several existing NatWest ML use cases were developed using these capabilities. The development of these use cases informed the requirements and direction of the overall collaboration. This meant that the project templates we set up are highly relevant for the organization’s business needs.
This is the third post of a four-part series on the strategic collaboration between NatWest Group and AWS Professional Services. Check out the rest of the series for the following topics:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their compliant and self-service MLOps platform
- Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures
About the Authors
 Ariadna Blanca Romero is a Data Scientist/ML Engineer at NatWest with a background in computational material science. She is passionate about creating tools for automation that take advantage of the reproducibility of results from models and optimize the process to ensure prompt decision-making to deliver the best customer experience. Ariadna volunteers as a STEM virtual mentor for a non-profit organization helping the professional development of Latin-American students and young professionals, particularly for empowering women. She has a passion for practicing yoga, cooking, and playing her electric guitar.
Ariadna Blanca Romero is a Data Scientist/ML Engineer at NatWest with a background in computational material science. She is passionate about creating tools for automation that take advantage of the reproducibility of results from models and optimize the process to ensure prompt decision-making to deliver the best customer experience. Ariadna volunteers as a STEM virtual mentor for a non-profit organization helping the professional development of Latin-American students and young professionals, particularly for empowering women. She has a passion for practicing yoga, cooking, and playing her electric guitar.
 Lucy Thomas is a data engineer at NatWest Group, working in the Data Science and Innovation team on ML solutions used by data science teams across NatWest. Her background is in physics, with a master’s degree from Lancaster University. In her spare time, Lucy enjoys bouldering, board games, and spending time with family and friends.
Lucy Thomas is a data engineer at NatWest Group, working in the Data Science and Innovation team on ML solutions used by data science teams across NatWest. Her background is in physics, with a master’s degree from Lancaster University. In her spare time, Lucy enjoys bouldering, board games, and spending time with family and friends.
 Sarah Bourial is a Data Scientist at AWS Professional Services. She is passionate about MLOps and supports global customers in the financial services industry in building optimized AI/ML solutions to accelerate their cloud journey. Prior to AWS, Sarah worked as a Data Science consultant for various customers, always looking to achieve impactful business outcomes. Outside work, you will find her wandering around art galleries in exotic destinations.
Sarah Bourial is a Data Scientist at AWS Professional Services. She is passionate about MLOps and supports global customers in the financial services industry in building optimized AI/ML solutions to accelerate their cloud journey. Prior to AWS, Sarah worked as a Data Science consultant for various customers, always looking to achieve impactful business outcomes. Outside work, you will find her wandering around art galleries in exotic destinations.
Pauline Ting is Data Scientist in the AWS Professional Services team. She supports financial, sports and media customers in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
Part 2: How NatWest Group built a secure, compliant, self-service MLOps platform using AWS Service Catalog and Amazon SageMaker
This is the second post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. In this post, we share how the NatWest Group utilized AWS to enable the self-service deployment of their standardized, secure, and compliant MLOps platform using AWS Service Catalog and Amazon SageMaker. This has led to a reduction in the amount of time it takes to provision new environments from days to just a few hours.
We believe that decision-makers can benefit from this content. CTOs, CDAOs, senior data scientists, and senior cloud engineers can follow this pattern to provide innovative solutions for their data science and engineering teams.
Read the entire series:
|
Technology at NatWest Group
NatWest Group is a relationship bank for a digital world that provides financial services to more than 19 million customers across the UK. The Group has a diverse technology portfolio, where solutions to business challenges are often delivered using bespoke designs and with lengthy timelines.
Recently, NatWest Group adopted a cloud-first strategy, which has enabled the company to use managed services to provision on-demand compute and storage resources. This move has led to an improvement in overall stability, scalability, and performance of business solutions, while reducing cost and accelerating delivery cadence. Additionally, moving to the cloud allows NatWest Group to simplify its technology stack by enforcing a set of consistent, repeatable, and preapproved solution designs to meet regulatory requirements and operate in a controlled manner.
Challenges
The pilot stages of adopting a cloud-first approach involved several experimentation and evaluation phases utilizing a wide variety of analytics services on AWS. The first iterations of NatWest Group’s cloud platform for data science workloads confronted challenges with provisioning consistent, secure, and compliant cloud environments. The process of creating new environments took from a few days to weeks or even months. A reliance on central platform teams to build, provision, secure, deploy, and manage infrastructure and data sources made it difficult to onboard new teams to work in the cloud.
Due to the disparity in infrastructure configuration across AWS accounts, teams who decided to migrate their workloads to the cloud had to go through an elaborate compliance process. Each infrastructure component had to be analyzed separately, which increased security audit timelines.
Getting started with development in AWS involved reading a set of documentation guides written by platform teams. Initial environment setup steps included managing public and private keys for authentication, configuring connections to remote services using the AWS Command Line Interface (AWS CLI) or SDK from local development environments, and running custom scripts for linking local IDEs to cloud services. Technical challenges often made it difficult to onboard new team members. After the development environments were configured, the route to release software in production was similarly complex and lengthy.
As described in Part 1 of this series, the joint project team collected large amounts of feedback on user experience and requirements from teams across NatWest Group prior to building the new data science and MLOps platform. A common theme in this feedback was the need for automation and standardization as a precursor to quick and efficient project delivery on AWS. The new platform uses AWS managed services to optimize cost, cut down on platform configuration efforts, and reduce the carbon footprint from running unnecessarily large compute jobs. Standardization is embedded in the heart of the platform, with preapproved, fully configured, secure, compliant, and reusable infrastructure components that are sharable among data and analytics teams.
Why SageMaker Studio?
The team chose Amazon SageMaker Studio as the main tool for building and deploying ML pipelines. Studio provides a single web-based interface that gives users complete access, control, and visibility into each step required to build, train, and deploy models. The maturity of the Studio IDE (integrated development environment) for model development, metadata tracking, artifact management, and deployment were among the features that appealed strongly to the NatWest Group team.
Data scientists at NatWest Group work with SageMaker notebooks inside Studio during the initial stages of model development to perform data analysis, data wrangling, and feature engineering. After users are happy with the results of this initial work, the code is easily converted into composable functions for data transformation, model training, inference, logging, and unit tests so that it’s in a production-ready state.
Later stages of the model development lifecycle involve the use of Amazon SageMaker Pipelines, which can be visually inspected and monitored in Studio. Pipelines are visualized in a DAG (Directed Acyclic Graph) that color-codes steps based on their state while the pipeline runs. In addition, a summary of Amazon CloudWatch Logs is displayed next to the DAG to facilitate the debugging of failed steps. Data scientists are provided with a code template consisting of all the foundational steps in a SageMaker pipeline. This provides a standardized framework (consistent across all users of the platform to ease collaboration and knowledge sharing) into which developers can add the bespoke logic and application code that is particular to the business challenge they’re solving.
Developers run the pipelines within the Studio IDE to ensure their code changes integrate correctly with other pipeline steps. After code changes have been reviewed and approved, these pipelines are built and run automatically based on a main Git repository branch trigger. During model training, model evaluation metrics are stored and tracked in SageMaker Experiments, which can be used for hyperparameter tuning. After a model is trained, the model artifact is stored in the SageMaker model registry, along with metadata related to model containers, data used during training, model features, and model code. The model registry plays a key role in the model deployment process because it packages all model information and enables the automation of model promotion to production environments.
MLOps engineers deploy managed SageMaker batch transform jobs, which scale to meet workload demands. Both offline batch inference jobs and online models served via an endpoint use SageMaker’s managed inference functionality. This benefits both platform and business application teams because platform engineers no longer spend time configuring infrastructure components for model inference, and business application teams don’t write additional boilerplate code to set up and interact with compute instances.
Why AWS Service Catalog?
The team chose AWS Service Catalog to build a catalog of secure, compliant, and preapproved infrastructure templates. The infrastructure components in an AWS Service Catalog product are preconfigured to meet NatWest Group’s security requirements. Role access management, resource policies, networking configuration, and central control policies are configured for each resource packaged in an AWS Service Catalog product. The products are versioned and shared with application teams by following a standard process that enables data science and engineering teams to self-serve and deploy infrastructure immediately after obtaining access to their AWS accounts.
Platform development teams can easily evolve AWS Service Catalog products over time to enable the implementation of new features based on business requirements. Iterative changes to products are made with the help of AWS Service Catalog product versioning. When a new product version is released, the platform team merges code changes to the main Git branch and increments the version of the AWS Service Catalog product. There is a degree of autonomy and flexibility in updating the infrastructure because business application accounts can use earlier versions of products before they migrate to the latest version.
Solution overview
The following high-level architecture diagram shows how a typical business application use case is deployed on AWS. The following sections go into more detail regarding the account architecture, how infrastructure is deployed, user access management, and how different AWS services are used to build ML solutions.
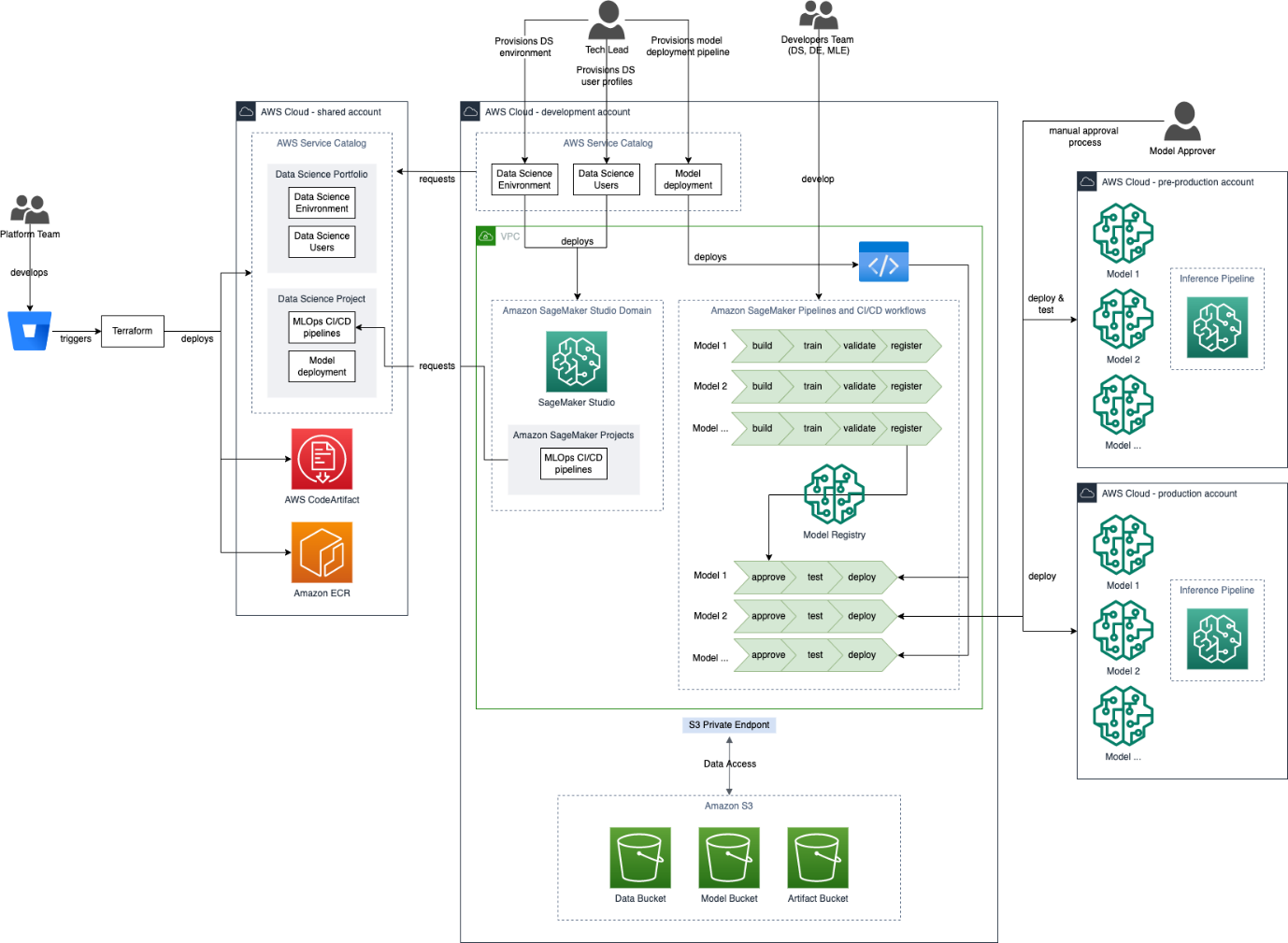
As shown in the architecture diagram, accounts follow a hub and spoke model. A shared platform account serves as a hub account, where resources required by business application team (spoke) accounts are hosted by the platform team. These resources include the following:
- A library of secure, standardized infrastructure products used for self-service infrastructure deployments, hosted by AWS Service Catalog
- Docker images, stored in Amazon Elastic Container Registry (Amazon ECR), which are used during the run of SageMaker pipeline steps and model inference
- AWS CodeArtifact repositories, which host preapproved Python packages
These resources are automatically shared with spoke accounts via the AWS Service Catalog portfolio sharing and import feature, and AWS Identity and Access Management (IAM) trust policies in the case of both Amazon ECR and CodeArtifact.
Each business application team is provisioned three AWS accounts in the NatWest Group infrastructure environment: development, pre-production, and production. The environment names refer to the account’s intended role in the data science development lifecycle. The development account is used to perform data analysis and wrangling, write model and model pipeline code, train models, and trigger model deployments to pre-production and production environments via SageMaker Studio. The pre-production account mirrors the setup of the production account and is used to test model deployments and batch transform jobs before they are released into production. The production account hosts models and runs production inferencing workloads.
User management
NatWest Group has strict governance processes to enforce user role separation. Five separate IAM roles have been created for each user persona.
The platform team uses the following roles:
- Platform support engineer – This role contains permissions for business-as-usual tasks and a read-only view of the rest of the environment for monitoring and debugging the platform.
- Platform fix engineer – This role has been created with elevated permissions. It’s used if there are issues with the platform that require manual intervention. This role is only assumed in an approved, time-limited manner.
The business application development teams have three distinct roles:
- Technical lead – This role is assigned to the application team lead, often a senior data scientist. This user has permission to deploy and manage AWS Service Catalog products, trigger releases into production, and review the status of the environment, such as AWS CodePipeline statuses and logs. This role doesn’t have permission to approve a model in the SageMaker model registry.
- Developer – This role is assigned to all team members that work with SageMaker Studio, which includes engineers, data scientists, and often the team lead. This role has permissions to open Studio, write code, and run and deploy SageMaker pipelines. Like the technical lead, this role doesn’t have permission to approve a model in the model registry.
- Model approver – This role has limited permissions relating to viewing, approving, and rejecting models in the model registry. The reason for this separation is to prevent any users that can build and train models from approving and releasing their own models into escalated environments.
Separate Studio user profiles are created for developers and model approvers. The solution uses a combination of IAM policy statements and SageMaker user profile tags so that users are only permitted to open a user profile that matches their user type. This makes sure that the user is assigned the correct SageMaker execution IAM role (and therefore permissions) when they open the Studio IDE.
Self-service deployments with AWS Service Catalog
End-users utilize AWS Service Catalog to deploy data science infrastructure products, such as the following:
- A Studio environment
- Studio user profiles
- Model deployment pipelines
- Training pipelines
- Inference pipelines
- A system for monitoring and alerting
End-users deploy these products directly through the AWS Service Catalog UI, meaning there is less reliance on central platform teams to provision environments. This has vastly reduced the time it takes for users to gain access to new cloud environments, from multiple days down to just a few hours, which ultimately has led to a significant improvement in time-to-value. The use of a common set of AWS Service Catalog products supports consistency within projects across the enterprise and lowers the barrier for collaboration and reuse.
Because all data science infrastructure is now deployed via a centrally developed catalog of infrastructure products, care has been taken to build each of these products with security in mind. Services have been configured to communicate within Amazon Virtual Private Cloud (Amazon VPC) so traffic doesn’t traverse the public internet. Data is encrypted in transit and at rest using AWS Key Management Service (AWS KMS) keys. IAM roles have also been set up to follow the principle of least privilege.
Finally, with AWS Service Catalog, it’s easy for the platform team to continually release new products and services as they become available or required by business application teams. These can take the form of new infrastructure products, for example providing the ability for end-users to deploy their own Amazon EMR clusters, or updates to existing infrastructure products. Because AWS Service Catalog supports product versioning and utilizes AWS CloudFormation behind the scenes, in-place upgrades can be used when new versions of existing products are released. This allows the platform teams to focus on building and improving products, rather than developing complex upgrade processes.
Integration with NatWest’s existing IaC software
AWS Service Catalog is used for self-service data science infrastructure deployments. Additionally, NatWest’s standard infrastructure as code (IaC) tool, Terraform, is used to build infrastructure in the AWS accounts. Terraform is used by platform teams during the initial account setup process to deploy prerequisite infrastructure resources such as VPCs, security groups, AWS Systems Manager parameters, KMS keys, and standard security controls. Infrastructure in the hub account, such as the AWS Service Catalog portfolios and the resources used to build Docker images, are also defined using Terraform. However, the AWS Service Catalog products themselves are built using standard CloudFormation templates.
Improving developer productivity and code quality with SageMaker projects
SageMaker projects provide developers and data scientists access to quick-start projects without leaving SageMaker Studio. These quick-start projects allow you to deploy multiple infrastructure resources at the same time in just a few clicks. These include a Git repository containing a standardized project template for the selected model type, Amazon Simple Storage Service (Amazon S3) buckets for storing data, serialized models and artifacts, and model training and inference CodePipeline pipelines.
The introduction of standardized code base architectures and tooling now make it easy for data scientists and engineers to move between projects and ensure code quality remains high. For example, software engineering best practices such as linting and formatting checks (run both as automated checks and pre-commit hooks), unit tests, and coverage reports are now automated as part of training pipelines, providing standardization across all projects. This has improved the maintainability of ML projects and will make it easier to move these projects into production.
Automating model deployments
The model training process is orchestrated using SageMaker Pipelines. After models have been trained, they’re stored in the SageMaker model registry. Users assigned the model approver role can open the model registry and find information relating to the training process, such when the model was trained, hyperparameter values, and evaluation metrics. This information helps the user decide whether to approve or reject a model. Rejecting a model prevents the model from being deployed into an escalated environment, whereas approving a model triggers a model promotion pipeline via CodePipeline that automatically copies the model to the pre-production AWS account, ready for inference workload testing. After the team has confirmed that the model works correctly in pre-production, a manual step in the same pipeline is approved and the model is automatically copied over to the production account, ready for production inferencing workloads.
Outcomes
One of the main aims of this collaborative project between NatWest and AWS was to reduce the time it takes to provision and deploy data science cloud environments and ML models into production. This has been achieved—NatWest can now provision new, scalable, and secure AWS environments in a matter of hours, compared to days or even weeks. Data scientists and engineers are now empowered to deploy and manage data science infrastructure by themselves using AWS Service Catalog, reducing reliance on centralized platform teams. Additionally, the use of SageMaker projects enables users to begin coding and training models within minutes, while also providing standardized project structures and tooling.
Because AWS Service Catalog serves as the central method to deploy data science infrastructure, the platform can easily be expanded and upgraded in the future. New AWS services can be offered to end-users quickly when the need arises, and existing AWS Service Catalog products can be upgraded in place to take advantage of new features.
Finally, the move towards managed services on AWS means compute resources are provisioned and shut down on demand. This has provided cost savings and flexibility, while also aligning with NatWest’s ambition to be net-zero by 2050 due to an estimated 75% reduction in CO2 emissions.
Conclusion
The adoption of a cloud-first strategy at NatWest Group led to the creation of a robust AWS solution that can support a large number of business application teams across the organization. Managing infrastructure with AWS Service Catalog has improved the cloud onboarding process significantly by using secure, compliant, and preapproved building blocks of infrastructure that can be easily expanded. Managed SageMaker infrastructure components have improved the model development process and accelerated the delivery of ML projects.
To learn more about the process of building production-ready ML models at NatWest Group, take a look at the rest of this four-part series on the strategic collaboration between NatWest Group and AWS Professional Services:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models
- Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures
About the Authors
 Junaid Baba is DevOps Consultant at AWS Professional Services He leverages his experience in Kubernetes, distributed computing, AI/MLOps to accelerated cloud adoption of UK financial services industry customers. Junaid has been with AWS since June 2018. Prior to that, Junaid worked with number of financial start-ups driving DevOps practices. Outside of work he has interests in trekking, modern art, and still photography.
Junaid Baba is DevOps Consultant at AWS Professional Services He leverages his experience in Kubernetes, distributed computing, AI/MLOps to accelerated cloud adoption of UK financial services industry customers. Junaid has been with AWS since June 2018. Prior to that, Junaid worked with number of financial start-ups driving DevOps practices. Outside of work he has interests in trekking, modern art, and still photography.
 Yordanka Ivanova is a Data Engineer at NatWest Group. She has experience in building and delivering data solutions for companies in the financial services industry. Prior to joining NatWest, Yordanka worked as a technical consultant where she gained experience in leveraging a wide variety of cloud services and open-source technologies to deliver business outcomes across multiple cloud platforms. In her spare time, Yordanka enjoys working out, traveling and playing guitar.
Yordanka Ivanova is a Data Engineer at NatWest Group. She has experience in building and delivering data solutions for companies in the financial services industry. Prior to joining NatWest, Yordanka worked as a technical consultant where she gained experience in leveraging a wide variety of cloud services and open-source technologies to deliver business outcomes across multiple cloud platforms. In her spare time, Yordanka enjoys working out, traveling and playing guitar.
 Michael England is a software engineer in the Data Science and Innovation team at NatWest Group. He is passionate about developing solutions for running large-scale Machine Learning workloads in the cloud. Prior to joining NatWest Group, Michael worked in and led software engineering teams developing critical applications in the financial services and travel industries. In his spare time, he enjoys playing guitar, travelling and exploring the countryside on his bike.
Michael England is a software engineer in the Data Science and Innovation team at NatWest Group. He is passionate about developing solutions for running large-scale Machine Learning workloads in the cloud. Prior to joining NatWest Group, Michael worked in and led software engineering teams developing critical applications in the financial services and travel industries. In his spare time, he enjoys playing guitar, travelling and exploring the countryside on his bike.
Part 1: How NatWest Group built a scalable, secure, and sustainable MLOps platform
This is the first post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS to build a scalable, secure, and sustainable machine learning operations (MLOps) platform.
This initial post provides an overview of the AWS and NatWest Group joint team implemented Amazon SageMaker Studio as the standard for the majority of their data science environment in just 9 months. The intended audience includes decision-makers that would like to standardize their ML workflows, such as CDAO, CDO, CTO, Head of Innovation, and lead data scientists. Subsequent posts will detail the technical implementation of this solution.
Read the entire series:
|
MLOps
For NatWest Group, MLOps focuses on realizing the value from any data science activity through the adoption of DevOps and engineering best practices to build solutions and products that have an ML component at their core. It provides the standards, tools, and framework that supports the work of data science teams to take their ideas from the whiteboard to production in a timely, secure, traceable, and repeatable manner.
Strategic collaboration between NatWest Group and AWS
NatWest Group is the largest business and commercial bank in the UK, with a leading retail business. The Group champions potential by supporting 19 million people, families, and businesses in communities throughout the UK and Ireland to thrive by acting as a relationship bank in a digital world.
As the Group attempted to scale their use of advanced analytics in the enterprise, they discovered that the time taken to develop and release ML models and solutions into production was too long. They partnered with AWS to design, build, and launch a modern, secure, scalable, and sustainable self-service platform for developing and productionizing ML-based services to support their business and customers. AWS Professional Services worked with them to accelerate the implementation of AWS best practices for Amazon SageMaker services.
The aims of the collaboration between NatWest Group and AWS were to provide the following:
- A federated, self-service, and DevOps-driven approach for infrastructure and application code, with a clear route-to-live that will lead to deployment times being measured in minutes (the current average is 60 minutes) and not weeks.
- A secure, controlled, and templated environment to accelerate innovation with ML models and insights using industry best practices and bank-wide shared artifacts.
- The ability to access and share data more easily and consistently across the enterprise.
- A modern toolset based upon a managed architecture running on demand that would minimize compute requirements, drive down costs, and drive sustainable ML development and operations. This should have the flexibility to accommodate new AWS products and services to meet ongoing use case and compliance requirements.
- Adoption, engagement, and training support for data science and engineering teams across the enterprise.
To meet the security requirements of the bank, public internet access is disabled and all data is encrypted with custom keys. As described in Part 2 of this series, a secure instance of SageMaker Studio is deployed to the development account in 60 minutes. When the account setup is complete, a new use case template is requested by the data scientists via SageMaker projects in SageMaker Studio. This process deploys the necessary infrastructure that ensures MLOps capabilities in the development account (with minimal support required from operational teams) such as CI/CD pipelines, unit testing, model testing, and monitoring.
This was to be provided in a common layer of capability, displayed in the following figure.

The process
The joint AWS-NatWest Group team used an agile five-step process to discover, design, build, test, and deploy the new platform over 9 months:
- Discovery – Several information-gathering sessions were conducted to identify the current pain points within their ML lifecycle. These included challenges around data discovery, infrastructure setup and configuration, model building, governance, route-to-live, and the operating model. Working backward, AWS and NatWest Group understood the core requirements, priorities, and dependencies that helped create a common vision, success criteria, and delivery plan for the MLOps platform.
- Design – Based on the output from the Discovery phase, the team iterated towards the final design for the MLOps platform by combining best practices and advice from AWS and existing experience of using cloud services within NatWest Group. This was done with a particular focus on ensuring compliance with the security and governance requirements typical within the financial services domain.
- Build – The team collaboratively built the Terraform and AWS CloudFormation templates for the platform infrastructure. Feedback was continually gathered from end-users (data scientists, ML and data engineers, platform support team, security and governance, and senior stakeholders) to ensure deliverables matched original goals.
- Test – A crucial aspect of the delivery was to demonstrate the platform’s viability on real business analytics and ML use cases. NatWest identified three projects that covered a range of business challenges and data science complexity that would allow the new platform to be tested across dimensions including scalability, flexibility, and accessibility. AWS and NatWest Group data scientists and engineers co-created the baseline environment templates and SageMaker pipelines based upon these use cases.
- Launch – Once the capability was proven, the team launched the new platform into the organization, providing bespoke training plans and careful adoption and engagement support to the federated business teams to onboard their own use cases and users.
The scalable ML framework
In a business with millions of customers sitting across multiple lines of business, ML workflows require the integration of data owned and managed by siloed teams using different tools to unlock business value. Because NatWest Group is committed to the protection of its customers’ data, the infrastructure used for ML model development is also subject to high security standards, which adds further complexity and impacts the time-to-value for new ML models. In a scalable ML framework, toolset modernization and standardization are necessary to reduce the efforts required for combining different tools and to simplify the route-to-live process for new ML models.
Prior to engaging with AWS, support for data science activity was controlled by a central platform team that collected requirements, and provisioned and maintained infrastructure for data teams across the organization. NatWest has ambitions to rapidly scale the use of ML in federated teams across the organization, and needed a scalable ML framework that enables developers of new models and pipelines to self-serve the deployment of a modern, pre-approved, standardized, and secure infrastructure. This reduces the dependency on the centralized platform teams and allows for a faster time-to-value for ML model development.
The framework in its simplest terms allows a data consumer (data scientist or ML engineer) to browse and discover the pre-approved data they require to train their model, gain access to that data in a quick and simple manner, use that data to prove their model viability, and release that proven model to production for others to utilize, thereby unlocking business value.
The following figure denotes this flow and the benefits that the framework provides. These include reduced compute costs (due to the managed and on-demand infrastructure), reduced operational overhead (due to the self-service templates), reduced time to spin up and spin down secure compliant ML environments (with AWS Service Catalog products), and a simplified route-to-live.
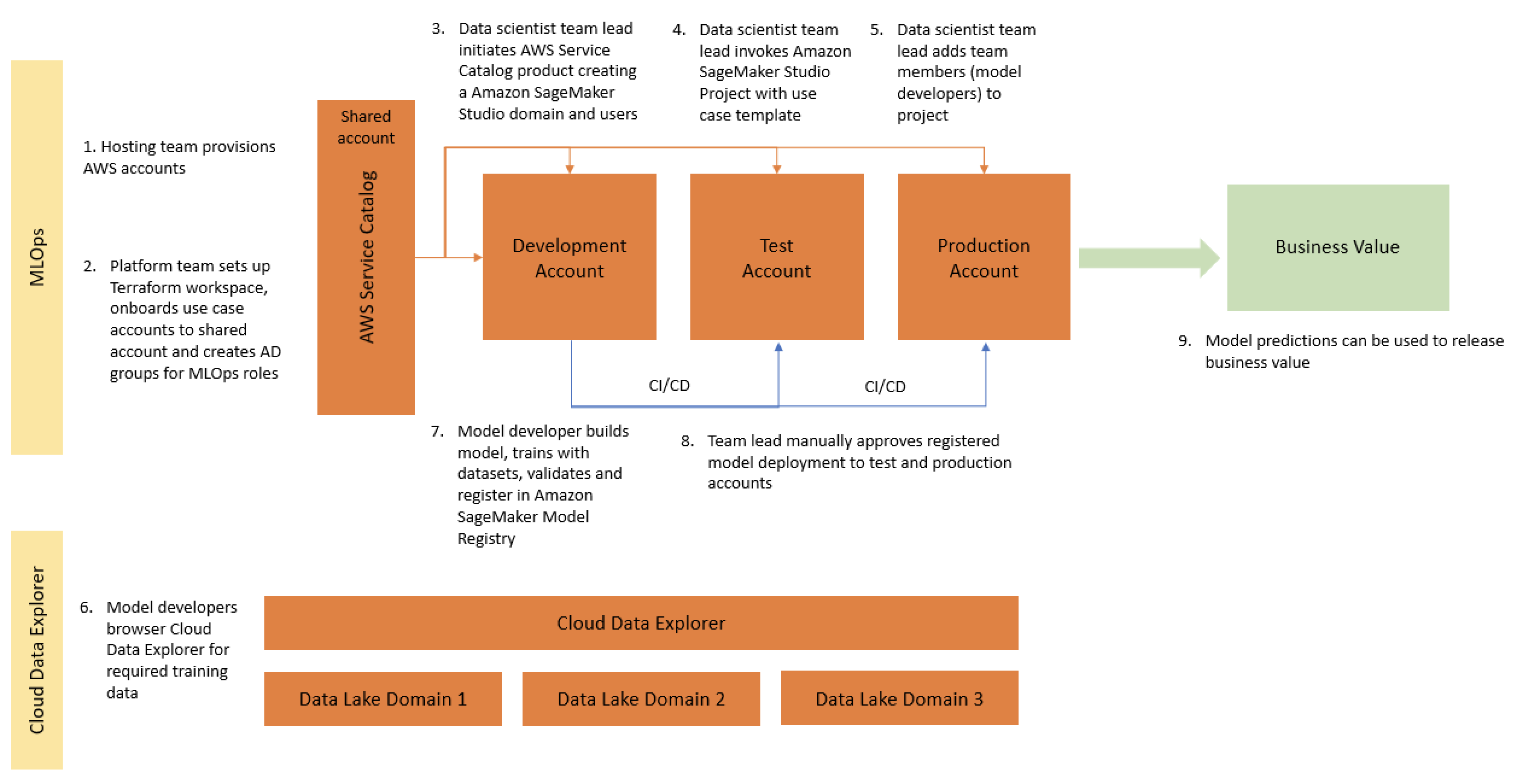
At a lower level, the scalable ML framework comprises the following:
- Self-service infrastructure deployment – Reduces dependency on centralized teams.
- A central Python package management system – Makes pre-approved Python packages available for model development.
- CI/CD pipelines for model development and promotion – Decreases time-to-live by including CI/CD pipelines as part of infrastructure as code (IaC) templates.
- Model testing capabilities – Unit testing, model testing, integration testing, and end-to-end testing functionalities are automatically available for new models.
- Model decoupling and orchestration – Decouples model steps according to computational resource requirements and orchestration of the different steps via Amazon SageMaker Pipelines. This avoids unnecessary compute and makes deployments more robust.
- Code standardization – Code quality standardization with Python Enhancement Proposal (PEP8) standards validation via CI/CD pipelines integration.
- Quick-start generic ML templates – AWS Service Catalog templates that instantiate your ML modelling environments (development, pre-production, production) and associated pipelines with the click of a button. This is done via Amazon SageMaker Projects deployment.
- Data and model quality monitoring – Automatically monitors drift in your data and model quality via Amazon SageMaker Model Monitor. This helps ensure your models perform to operational requirements and within risk appetite.
- Bias monitoring – Automatically checks for data imbalances and if changes in the world have introduced bias to your model. This helps the model owners ensure that they make fair and equitable decisions.
To prove SageMaker’s capabilities across a range of data processing and ML architectures, three use cases were selected from different divisions within the banking group. Use case data was obfuscated and made available in a local Amazon Simple Storage Service (Amazon S3) data bucket in the use case development account for the capabilities proving phase. When the model migration was complete, the data was made available via the NatWest cloud-hosted data lake, where it’s read by the production models. The predictions generated by the production models are then written back to the data lake. Future use cases will incorporate Cloud Data Explorer, an accelerator that allows data engineers and scientists to easily search and browse NatWest’s pre-approved data catalog, which accelerates the data discovery process.
As defined by AWS best practices, three accounts (dev, test, prod) are provisioned for each use case. To meet security requirements, public internet access is disabled and all data is encrypted with custom keys. As described in this blog post, a secure instance of SageMaker Studio is then deployed to the development account in a matter of minutes. When the account setup is complete, a new use case template is requested by the data scientists via SageMaker Projects in Studio. This process deploys the necessary infrastructure that ensures MLOps capabilities in the development account (with minimal support required from operational teams) such as CI/CD pipelines, unit testing, model testing, and monitoring.
Each use case was then developed (or refactored in the case of an existing application codebase) to run in a SageMaker architecture as illustrated in this blog post, utilizing SageMaker capabilities such as experiment tracking, model explainability, bias detection, and data quality monitoring. These capabilities were added to each use case pipeline as described in this blog post.
Cloud-first: The solution for sustainable ML model development and deployment
Training ML models using large datasets requires a lot of computational resources. However, you can optimize the amount of energy used by running training workflows in AWS. Studies suggest that AWS typically produces a nearly 80% lower carbon footprint and is five times more energy efficient than the median-surveyed European enterprise data centers. In addition, adopting an on-demand managed architecture for ML workflows, such as what they developed during the partnership, allows NatWest Group to only provision the necessary resources for the work to be done.
For example, in a use case with a big dataset where 10% of the data columns contain actual useful information and are used for the model training, the on-demand architecture orchestrated by SageMaker Pipelines allows for the split of the data preprocessing step into two phases: first, read and filter, and second, feature engineering. That way, a larger compute instance is used for reading and filtering the data, because that requires more computational resources, whereas a smaller instance is used for the feature engineering, which only needs to process 10% of the useful columns. Finally, the inclusion of SageMaker services such as Model Monitor and Pipelines allows for the continuous monitoring of the data quality, avoiding inference on models that have drifted in data and model quality. This further saves energy and computer resources with compute jobs that don’t bring business value.
During the partnership, multiple sustainability optimization techniques were introduced to NatWest’s ML model development and deployment strategy, from the selection of efficient on-demand managed architectures to the compression of data in efficient file formats. Initial calculations suggest considerable carbon emissions reductions when compared to other cloud architectures, supporting NatWest Group’s ambition to be net zero by 2050.
Outcomes
During the 9 months of delivery, NatWest and AWS worked as a team to build and scale the MLOps capabilities across the bank. The overall achievements of the partnership include:
- Scaling MLOps capability across NatWest, with over 300 data scientists and data engineers being trained to work in the developed platform
- Implementation of a scalable, secure, cost-efficient, and sustainable infrastructure deployment using AWS Service Catalog to create a SageMaker on-demand managed infrastructure
- Standardization of the ML model development and deployment process across multiple teams
- Reduction of technical debt of existing models and the creation of reusable artifacts to speed up future model development
- Reduction of idea-to-value time for data and analytics use cases from 40 to 16 weeks
- Reduction for ML use case environment creation time from 35–40 days to 1–2 days, including multiple validations of the use case required by the bank
Conclusion
This post provided an overview of the AWS and NatWest Group partnership that resulted in the implementation of a scalable ML framework and successfully reduced the time-to-live of ML models at NatWest Group.
In a joint effort, AWS and NatWest implemented standards to ensure scalability, security, and sustainability of ML workflows across the organization. Subsequent posts in this series will provide more details on the implemented solution:
- Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their secure, compliant, and self-service MLOps platform. It is intended to provide details for platform developers such as DevOps, platform engineers, security, and IT teams.
- Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models. It is intended to provide details for model developers, such as data scientists and ML or data engineers.
- Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures. It is intended to provide details of how to successfully migrate existent models to model developers, such as data scientists and ML or data engineers.
AWS Professional Services is ready to help your team develop scalable and production-ready ML in AWS. For more information, see AWS Professional Services or reach out through your account manager to get in touch.
About the Authors
 Maira Ladeira Tanke is a Data Scientist at AWS Professional Services. As a technical lead, she helps customers accelerate their achievement of business value through emerging technology and innovative solutions. Maira has been with AWS since January 2020. Prior to that, she worked as a data scientist in multiple industries focusing on achieving business value from data. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
Maira Ladeira Tanke is a Data Scientist at AWS Professional Services. As a technical lead, she helps customers accelerate their achievement of business value through emerging technology and innovative solutions. Maira has been with AWS since January 2020. Prior to that, she worked as a data scientist in multiple industries focusing on achieving business value from data. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
 Andy McMahon is a ML Engineering Lead in the Data Science and Innovation team in NatWest Group. He helps develop and implement best practices and capabilities for taking machine learning products to production across the bank. Andy has several years’ experience leading data science and ML teams and speaks and writes extensively on MLOps (this includes the book “Machine Learning Engineering with Python”, 2021, Packt). In his spare time, he loves running around after his young son, reading, playing badminton and golf, and planning the next family adventure with his wife.
Andy McMahon is a ML Engineering Lead in the Data Science and Innovation team in NatWest Group. He helps develop and implement best practices and capabilities for taking machine learning products to production across the bank. Andy has several years’ experience leading data science and ML teams and speaks and writes extensively on MLOps (this includes the book “Machine Learning Engineering with Python”, 2021, Packt). In his spare time, he loves running around after his young son, reading, playing badminton and golf, and planning the next family adventure with his wife.
 Greig Cowan is a data science and engineering leader in the financial services domain who is passionate about building data-driven solutions and transforming the enterprise through MLOps best practices. Over the past four years, his team have delivered data and machine learning-led products across NatWest Group and have defined how people, process, data, and technology should work together to optimize time-to-business-value. He leads the NatWest Group data science community, builds links with academic and commercial partners, and provides leadership and guidance to the technical teams building the bank’s data and analytics infrastructure. Prior to joining NatWest Group, he spent many years as a scientific researcher in high-energy particle physics as a leading member of the LHCb collaboration at the CERN Large Hadron. In his spare time, Greig enjoys long-distance running, playing chess, and looking after his two amazing children.
Greig Cowan is a data science and engineering leader in the financial services domain who is passionate about building data-driven solutions and transforming the enterprise through MLOps best practices. Over the past four years, his team have delivered data and machine learning-led products across NatWest Group and have defined how people, process, data, and technology should work together to optimize time-to-business-value. He leads the NatWest Group data science community, builds links with academic and commercial partners, and provides leadership and guidance to the technical teams building the bank’s data and analytics infrastructure. Prior to joining NatWest Group, he spent many years as a scientific researcher in high-energy particle physics as a leading member of the LHCb collaboration at the CERN Large Hadron. In his spare time, Greig enjoys long-distance running, playing chess, and looking after his two amazing children.
 Brian Cavanagh is a Senior Global Engagement Manager at AWS Professional Services with a passion for implementing emerging technology solutions (AI, ML, and data) to accelerate the release of value for our customers. Brian has been with AWS since December 2019. Prior to working at AWS, Brian delivered innovative solutions for major investment banks to drive efficiency gains and optimize their resources. Outside of work, Brian is a keen cyclist and you will usually find him competing on Zwift.
Brian Cavanagh is a Senior Global Engagement Manager at AWS Professional Services with a passion for implementing emerging technology solutions (AI, ML, and data) to accelerate the release of value for our customers. Brian has been with AWS since December 2019. Prior to working at AWS, Brian delivered innovative solutions for major investment banks to drive efficiency gains and optimize their resources. Outside of work, Brian is a keen cyclist and you will usually find him competing on Zwift.
 Sokratis Kartakis is a Senior Customer Delivery Architect on AI/ML at AWS Professional Services. Sokratis’s focus is to guide enterprise and global customers on their AI cloud transformation and MLOps journey targeting business outcomes and leading the delivery across EMEA. Prior to AWS, Sokratis spent over 15 years inventing, designing, leading, and implementing innovative solutions and strategies in AI/ML and IoT, helping companies save billions of dollars in energy, retail, health, finance and banking, supply chain, motorsports, and more. Outside of work, Sokratis enjoys spending time with his family and riding motorbikes.
Sokratis Kartakis is a Senior Customer Delivery Architect on AI/ML at AWS Professional Services. Sokratis’s focus is to guide enterprise and global customers on their AI cloud transformation and MLOps journey targeting business outcomes and leading the delivery across EMEA. Prior to AWS, Sokratis spent over 15 years inventing, designing, leading, and implementing innovative solutions and strategies in AI/ML and IoT, helping companies save billions of dollars in energy, retail, health, finance and banking, supply chain, motorsports, and more. Outside of work, Sokratis enjoys spending time with his family and riding motorbikes.
Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler is a new capability of Amazon SageMaker that helps data scientists and data engineers quickly and easily prepare data for machine learning (ML) applications using a visual interface. It contains over 300 built-in data transformations so you can quickly normalize, transform, and combine features without having to write any code.
Today, we’re excited to announce the new Data Quality and Insights Report feature within Data Wrangler. This report automatically verifies data quality and detects abnormalities in your data. Data scientists and data engineers can use this tool to efficiently and quickly apply domain knowledge to process datasets for ML model training.
The report includes the following sections:
- Summary statistics – This section provides insights into the number of rows, features, % missing, % valid, duplicate rows, and a breakdown of the type of feature (e.g. numeric vs. text).
- Data Quality Warnings – This section provides insights into warnings that the insights report has detected including items such as presence of small minority class, high target cardinality, rare target label, imbalanced class distribution, skewed target, heavy tailed target, outliers in target, regression frequent label, and invalid values.
- Target Column Insights – This section provides statistics on the target column including % valid, % missing, % outliers, univariate statistics such as min/median/max, and also presents examples of observations with outlier or invalid target values.
- Quick Model – The data insights report automatically trains a model on a small sample of your data set to provide a directional check on feature engineering progress and provides associated model statistics in the report.
- Feature Importance – This section provides a ranking of features by feature importance which are automatically calculated when preparing the data insights and data quality report.
- Anomalous and duplicate rows – The data quality and insights report detects anomalous samples using the Isolation forest algorithm and also surfaces duplicate rows that may be present in the data set.
- Feature details – This section provides summary statistics for each feature in the data set as well as the corresponding distribution of the target variable.
In this post, we use the insights and recommendations of the Data Quality and Insights Report to process data by applying the suggested transformation steps without writing any code.
Get insights with the Data Quality and Insights Report
Our goal is to predict the rent cost of houses using the Brazilian houses to rent dataset. This dataset has features describing the living unit size, number of rooms, floor number, and more. To import the data set, first upload it to an Amazon Simple Storage Service (S3) bucket, and follow the steps here. After we load the dataset into Data Wrangler, we start by producing the report.
- Choose the plus sign and choose Get data insights.

- To predict rental cost, we first choose Create analysis within the Data Wrangler data flow UI.
- For Target column, choose the column
rent amount (R$). - For Problem type, select Regression.
- Choose Start to generate the report.
If you don’t have a target column, you can still produce the report without it.

The Summary section from the generated report provides an overview of the data and displays general statistics such as the number of features, feature types, number of rows in the data, and missing and valid values.

The High Priority Warnings section lists warnings for you to see. These are abnormalities in the data that could affect the quality of our ML model and should be addressed.

For your convenience, high-priority warnings are displayed at the top of the report, while other relevant warnings appear later. In our case, we found two major issues:
- The data contains many (5.65%) duplicate samples
- A feature is suspected of target leakage
You can find further information about these issues in the text that accompanies the warnings as well as suggestions on how to resolve them using Data Wrangler.
Investigate the Data Quality and Insights Report warnings
To investigate the first warning, we go to the Duplicate Rows section, where the report lists the most common duplicates. The first row in the following table shows that the data contains 22 samples of the same house in Porto Alegre.

From our domain knowledge, we know that there aren’t 22 identical apartments, so we conclude that this is an artifact caused by faulty data collection. Therefore, we follow the recommendation and remove the duplicate samples using the suggested transform.
We also note the duplicate rows in the dataset because they can affect the ability to detect target leakage. The report warns us of the following:
“Duplicate samples resulting from faulty data collection, could derail machine learning processes that rely on splitting to independent training and validation folds. For example quick model scores, prediction power estimation….”
So we recheck for target leakage after resolving the duplicate rows issue.
Next, we observe a medium-priority warning regarding outlier values in the Target Column section (to avoid clutter, medium-priority warnings aren’t highlighted at the top of the report).

Data Wrangler detected that 0.1% of the target column values are outliers. The outlier values are gathered into a separate bin in the histogram, and the most distant outliers are listed in a table.

While for most houses, rent is below 15,000, a few houses have much higher rent. In our case, we’re not interested in predicting these extreme values, so we follow the recommendation to remove these outliers using the Handle outliers transform. We can get there by choosing the plus sign for the data show, then choosing Add transform. Then we add the Handle outliers transform and provide the necessary configuration.

We follow the recommendations to drop duplicate rows using the Manage rows transform and drop outliers in the target column using the Handle outliers transform.

Address additional warnings on transformed data
After we address the initial issues found in the data, we run the Data Quality and Insights Report on the transformed data.

We can verify that the problems of duplicate rows and outliers in the target column were resolved.


However, the feature fire insurance (R$) is still suspected for target leakage. Furthermore, we see that the feature Total (R$) has very high prediction power. From our domain expertise, we know that is tightly coupled with rent cost, and isn’t available when making the prediction.

Similarly, Total (R$) is the sum of a few columns, which includes our target rent column. Therefore, Total (R$) isn’t available in prediction time. We follow the recommendation to drop these columns using the Manage columns transform.
To provide an estimate of the expected prediction quality of a model trained on the data, Data Wrangler trains an XGBoost model on a training fold and calculates prediction quality scores on a validation fold. You can find the results in the Quick Model section of the report. The resulting R2 score is almost perfect—0.997. This is another indication of target leakage—we know that rent prices can’t be predicted that well.

In the Feature Details section, the report raises a Disguised missing value warning for the hoa (R$) column (HOA stands for Home Owners Association):
“The frequency of the value 0 in the feature hoa (R$) is 22.2% which is uncommon for numeric features. This could point to bugs in data collection or processing. In some cases the frequent value is a default value or a placeholder to indicate a missing value….”

We know that HOA stands for home owner association tax, and that zeros represents missing values. It’s better to indicate that we don’t know if these homes belong to an association. Therefore, we follow the recommendation to replace the zeros with NaNs using the Convert regex to missing transform under Search and edit.

We follow the recommendation to drop the fire insurance (R$) and Total (R$) columns using the Manage columns transform and replacing zeros with NaNs for hoa (R$).

Create the final report
To verify that all issues are resolved, we generate the report again. First, we note that there are no high-priority warnings.

Looking again at Quick model, we see that due to removing the columns with target leakage, the validation R2 score dropped from the “too good to be true” value of 0.997 to 0.653, which is more reasonable.

Additionally, fixing hoa (R$) by replacing zeros with NaNs improved the prediction power of that column from 0.35 to 0.52.

Finally, because ML algorithms usually require numeric inputs, we encode the categorical and binary columns (see the Summary section) as ordinal integers using the Ordinal encode transform under Encode Categorical. In general, categorical variables can be encoded as one-hot or ordinal variables.
Now the data is ready for model training. We can export the processed data to an Amazon Simple Storage Service (Amazon S3) bucket or create a processing job.
Additionally, you can download the reports you generate by choosing the download icon.

Conclusion
In this post, we saw how the Data Quality and Insights Report can help you employ domain expertise and business logic to process data for ML training. Data scientists of all skillsets can find value in this report. Experienced users can also find value in these reports to speed up their work because it automatically produces various statistics and performs many checks that would otherwise be done manually.
We encourage you to replicate the example in this post in your Data Wrangler data flow to see how you can apply this to your domain and datasets. For more information on using Data Wrangler, refer to Get Started with Data Wrangler.
About the Authors
 Stephanie Yuan is an SDE in the SageMaker Data Wrangler team based out of Seattle, WA. Outside of work, she enjoys going out to nature that PNW has to offer.
Stephanie Yuan is an SDE in the SageMaker Data Wrangler team based out of Seattle, WA. Outside of work, she enjoys going out to nature that PNW has to offer.
 Joseph Cho is an engineer who’s built a number of web applications from bottom up using modern programming techniques. He’s driven key features into production and has a history of practical problem solving. In his spare time Joseph enjoys playing chess and going to concerts.
Joseph Cho is an engineer who’s built a number of web applications from bottom up using modern programming techniques. He’s driven key features into production and has a history of practical problem solving. In his spare time Joseph enjoys playing chess and going to concerts.
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications.
 Yotam Elor is a Senior Applied Scientist at Amazon SageMaker. His research interests are in machine learning, particularly for tabular data.
Yotam Elor is a Senior Applied Scientist at Amazon SageMaker. His research interests are in machine learning, particularly for tabular data.
In the NVIDIA Studio: April Driver Launches Alongside New NVIDIA Studio Laptops and Featured 3D Artist
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology accelerates creative workflows.
This week In the NVIDIA Studio, we’re launching the April NVIDIA Studio Driver with optimizations for the most popular 3D apps, including Unreal Engine 5, Cinema4D and Chaos Vantage. The driver also supports new NVIDIA Omniverse Connectors from Blender and Redshift.
Digital da Vincis looking to upgrade their canvases can learn more about the newly announced Lenovo ThinkPad P1 NVIDIA Studio laptop, or pick up the Asus ProArt Studiobook 16, MSI Creator Pro Z16 and Z17 — all available now.
These updates are part of the NVIDIA Studio advantage: dramatically accelerated 3D creative workflows that are essential to this week’s featured In the NVIDIA Studio creator, Andrew Averkin, lead 3D environment artist at NVIDIA.
April Showers Bring Studio Driver Powers
The April NVIDIA Studio Driver supports many of the latest creative app updates, starting with the highly anticipated launch of Unreal Engine 5.
NVIDIA RTX GPUs support Lumen — UE5’s new, fully dynamic global illumination system — for both software and hardware ray tracing. Along with Nanite, developers are empowered to create games and apps that contain massive amounts of geometric detail with fully dynamic global illumination. At GTC last month, NVIDIA introduced an updated Omniverse Connector that includes the ability to export the source geometry of Nanite meshes from Unreal Engine 5.
NVIDIA has collaborated with Epic Games to integrate a host of key RTX technologies with Unreal Engine 5. These plugins are also available on the Unreal Engine Marketplace. RTX-accelerated ray tracing and NVIDIA DLSS in the viewport make iterating on and refining new ideas simpler and faster. For the finished product, those same technologies power beautifully ray-traced graphics while AI enables higher frame rates.
With NVIDIA Reflex — a standard feature in UE5 that does not require a separate plugin or download — PC games running on RTX GPUs experience unimaginably low latency.
NVIDIA real-time denoisers offer real-time performance, increasing the efficiency of art pipelines. RTX global illumination produces realistic bounce lighting in real time, giving artists instant feedback in the Unreal Editor viewport. With the processing power of RTX GPUs, suite of high-quality RTX UE plugins, and the next-generation UE5, there’s no limit to creation.
Maxon’s Cinema 4D version S26 includes all-new cloth and rope dynamics, accelerated by NVIDIA RTX GPUs, allowing artists to model digital subjects with increased realism, faster.
In the time it took to render “The City” scene with an NVIDIA GeForce RTX 3090 GPU, the CPU alone took an hour longer!
Additional features include OpenColorIO adoption, a new camera and enhanced modeling tools.
Chaos Vantage, aided by real-time ray tracing exclusive to NVIDIA RTX GPUs, adds normal map support, a new feature for converting texture models to clay to focus on lighting, and ambient occlusion for shadows.
NVIDIA Omniverse Connector updates are giving real-time workflows new features and options. Blender adds new blend shape I/O support to ensure detailed, multifaceted subjects automate and animate correctly. Plus, new USD scale maps unlock large-scale cinematic visualization.

Blender and Redshift have added hydra-based rendering. Artists can now use their renderer of choice within the viewport of all Omniverse apps.
New Studio Driver, Meet New Studio Laptops
April also brings a new Lenovo mobile workstation to the NVIDIA Studio lineup, plus the availability of three more.
The Lenovo ThinkPad P1 features a thin and light design, 16-inch panel and impressive performance powered by GeForce RTX and NVIDIA RTX professional graphics, equipped with up to the new NVIDIA RTX A5500 Laptop GPU.
Studio laptops from other partners include the recently announced Asus ProArt Studiobook 16, MSI Creator Pro Z16 and Z17, all now available for purchase.
Walk Down Memory Lane With Andrew Averkin
Andrew Averkin is a Ukraine-based lead 3D environment artist at NVIDIA. He specializes in creating photorealistic 3D scenes, focused on realism that intentionally invokes warm feelings of nostalgia.

Averkin leads with empathy, a critical component of his flow state, saying he aims to create “artwork that combines warm feelings that fuel my passion and artistic determination.”
He created the piece below, called When We Were Kids, using the NVIDIA Omniverse Create app and Autodesk 3ds Max, accelerated by an NVIDIA RTX A6000 GPU.

Here, Averkin harkens back to the pre-digital days of playing with toys and letting one’s imagination do the work.
Averkin first modeled When We Were Kids in Autodesk 3ds Max.

The RTX GPU-accelerated viewport and RTX-accelerated AI denoising in Autodesk 3ds Max enable fluid interactivity despite the massive file size.

Averkin then brought When We Were Kids into Omniverse Create to light, simulate and render his 3D scene in real time.
Omniverse allows 3D artists, like Averkin, to connect their favorite design tools to a single scene and simultaneously create and edit between the apps. The “Getting Started in NVIDIA Omniverse” series on the NVIDIA Studio YouTube channel is a great place to learn more.
“Most of the assets were taken from the Epic marketplace,” Averkin said. “My main goal was in playing with lighting scenarios, composition and moods.”

In Omniverse Create, Averkin used specialized lighting tools for his artwork, updating the original Autodesk 3ds Max file automatically with no need for messy and time-consuming file conversions and uploads, concluding with final files rendered at lightspeed with his RTX GPU.
Previously, Averkin worked at Axis Animation, Blur Studio and elsewhere. View his portfolio and favorite projects on ArtStation.
Dive Deeper In the NVIDIA Studio
Tons of resources are available to creators who want to learn more about the apps used by this week’s featured artist, and how RTX and GeForce RTX GPUs help accelerate creative workflows.
Take a behind-the-scenes look at The Storyteller, built in Omniverse and showcasing a stunning, photorealistic retro-style writer’s room.
Check out this tutorial from 3D artist Sir Wade Neistadt, who shows how to bring multi-app workflows into Omniverse using USD files, setting up Nucleus for live-linking tools.
View curated playlists on the Studio YouTube channel, plus hundreds more on the Omniverse YouTube channel. Follow NVIDIA Studio on Facebook, Twitter and Instagram, and get updates directly in your inbox by joining the NVIDIA Studio newsletter.
The post In the NVIDIA Studio: April Driver Launches Alongside New NVIDIA Studio Laptops and Featured 3D Artist appeared first on NVIDIA Blog.
A smarter way to develop new drugs
Pharmaceutical companies are using artificial intelligence to streamline the process of discovering new medicines. Machine-learning models can propose new molecules that have specific properties which could fight certain diseases, doing in minutes what might take humans months to achieve manually.
But there’s a major hurdle that holds these systems back: The models often suggest new molecular structures that are difficult or impossible to produce in a laboratory. If a chemist can’t actually make the molecule, its disease-fighting properties can’t be tested.
A new approach from MIT researchers constrains a machine-learning model so it only suggests molecular structures that can be synthesized. The method guarantees that molecules are composed of materials that can be purchased and that the chemical reactions that occur between those materials follow the laws of chemistry.
When compared to other methods, their model proposed molecular structures that scored as high and sometimes better using popular evaluations, but were guaranteed to be synthesizable. Their system also takes less than one second to propose a synthetic pathway, while other methods that separately propose molecules and then evaluate their synthesizability can take several minutes. In a search space that can include billions of potential molecules, those time savings add up.
“This process reformulates how we ask these models to generate new molecular structures. Many of these models think about building new molecular structures atom by atom or bond by bond. Instead, we are building new molecules building block by building block and reaction by reaction,” says Connor Coley, the Henri Slezynger Career Development Assistant Professor in the MIT departments of Chemical Engineering and Electrical Engineering and Computer Science, and senior author of the paper.
Joining Coley on the paper are first author Wenhao Gao, a graduate student, and Rocío Mercado, a postdoc. The research is being presented this week at the International Conference on Learning Representations.
Building blocks
To create a molecular structure, the model simulates the process of synthesizing a molecule to ensure it can be produced.
The model is given a set of viable building blocks, which are chemicals that can be purchased, and a list of valid chemical reactions to work with. These chemical reaction templates are hand-made by experts. Controlling these inputs by only allowing certain chemicals or specific reactions enables the researchers to limit how large the search space can be for a new molecule.
The model uses these inputs to build a tree by selecting building blocks and linking them through chemical reactions, one at a time, to build the final molecule. At each step, the molecule becomes more complex as additional chemicals and reactions are added.
It outputs both the final molecular structure and the tree of chemicals and reactions that would synthesize it.
“Instead of directly designing the product molecule itself, we design an action sequence to obtain that molecule. This allows us to guarantee the quality of the structure,” Gao says.
To train their model, the researchers input a complete molecular structure and a set of building blocks and chemical reactions, and the model learns to create a tree that synthesizes the molecule. After seeing hundreds of thousands of examples, the model learns to come up with these synthetic pathways on its own.
Molecule optimization
The trained model can be used for optimization. Researchers define certain properties they want to achieve in a final molecule, given certain building blocks and chemical reaction templates, and the model proposes a synthesizable molecular structure.
“What was surprising is what a large fraction of molecules you can actually reproduce with such a small template set. You don’t need that many building blocks to generate a large amount of available chemical space for the model to search,” says Mercado.
They tested the model by evaluating how well it could reconstruct synthesizable molecules. It was able to reproduce 51 percent of these molecules, and took less than a second to recreate each one.
Their technique is faster than some other methods because the model isn’t searching through all the options for each step in the tree. It has a defined set of chemicals and reactions to work with, Gao explains.
When they used their model to propose molecules with specific properties, their method suggested higher quality molecular structures that had stronger binding affinities than those from other methods. This means the molecules would be better able to attach to a protein and block a certain activity, like stopping a virus from replicating.
For instance, when proposing a molecule that could dock with SARS-Cov-2, their model suggested several molecular structures that may be better able to bind with viral proteins than existing inhibitors. As the authors acknowledge, however, these are only computational predictions.
“There are so many diseases to tackle,” Gao says. “I hope that our method can accelerate this process so we don’t have to screen billions of molecules each time for a disease target. Instead, we can just specify the properties we want and it can accelerate the process of finding that drug candidate.”
Their model could also improve existing drug discovery pipelines. If a company has identified a particular molecule that has desired properties, but can’t be produced, they could use this model to propose synthesizable molecules that closely resemble it, Mercado says.
Now that they have validated their approach, the team plans to continue improving the chemical reaction templates to further enhance the model’s performance. With additional templates, they can run more tests on certain disease targets and, eventually, apply the model to the drug discovery process.
“Ideally, we want algorithms that automatically design molecules and give us the synthesis tree at the same time, quickly,” says Marwin Segler, who leads a team working on machine learning for drug discovery at Microsoft Research Cambridge (UK), and was not involved with this work. “This elegant approach by Prof. Coley and team is a major step forward to tackle this problem. While there are earlier proof-of-concept works for molecule design via synthesis tree generation, this team really made it work. For the first time, they demonstrated excellent performance on a meaningful scale, so it can have practical impact in computer-aided molecular discovery.
The work is also very exciting because it could eventually enable a new paradigm for computer-aided synthesis planning. It will likely be a huge inspiration for future research in the field.”
This research was supported, in part, by the U.S. Office of Naval Research and the Machine Learning for Pharmaceutical Discovery and Synthesis Consortium.
Host Hugging Face transformer models using Amazon SageMaker Serverless Inference
The last few years have seen rapid growth in the field of natural language processing (NLP) using transformer deep learning architectures. With its Transformers open-source library and machine learning (ML) platform, Hugging Face makes transfer learning and the latest transformer models accessible to the global AI community. This can reduce the time needed for data scientists and ML engineers in companies around the world to take advantage of every new scientific advancement. Amazon SageMaker and Hugging Face have been collaborating to simplify and accelerate adoption of transformer models with Hugging Face DLCs, integration with SageMaker Training Compiler, and SageMaker distributed libraries.
SageMaker provides different options for ML practitioners to deploy trained transformer models for generating inferences:
- Real-time inference endpoints, which are suitable for workloads that need to be processed with low latency requirements in the order of milliseconds.
- Batch transform, which is ideal for offline predictions on large batches of data.
- Asynchronous inference, which is ideal for workloads requiring large payload size (up to 1 GB) and long inference processing times (up to 15 minutes). Asynchronous inference enables you to save on costs by auto scaling the instance count to zero when there are no requests to process.
- Serverless Inference, which is a new purpose-built inference option that makes it easy for you to deploy and scale ML models.
In this post, we explore how to use SageMaker Serverless Inference to deploy Hugging Face transformer models and discuss the inference performance and cost-effectiveness in different scenarios.
Overview of solution
AWS recently announced the General Availability of SageMaker Serverless Inference, a purpose-built serverless inference option that makes it easy for you to deploy and scale ML models. With Serverless Inference, you don’t need to provision capacity and forecast usage patterns upfront. As a result, it saves you time and eliminates the need to choose instance types and manage scaling policies. Serverless Inference endpoints automatically start, scale, and shut down capacity, and you only pay for the duration of running the inference code and the amount of data processed, not for idle time. Serverless inference is ideal for applications with less predictable or intermittent traffic patterns. Visit Serverless Inference to learn more.
Since its preview launch at AWS re:Invent 2021, we have made the following improvements:
- General Availability across all commercial Regions where SageMaker is generally available (except AWS China Regions).
- Increased maximum concurrent invocations per endpoint limit to 200 (from 50 during preview), allowing you to onboard high traffic workloads.
- Added support for the SageMaker Python SDK, abstracting the complexity from ML model deployment process.
- Added model registry support. You can register your models in the model registry and deploy directly to serverless endpoints. This allows you to integrate your SageMaker Serverless Inference endpoints with your MLOps workflows.
Let’s walk through how to deploy Hugging Face models on SageMaker Serverless Inference.
Deploy a Hugging Face model using SageMaker Serverless Inference
The Hugging Face framework is supported by SageMaker, and you can directly use the SageMaker Python SDK to deploy the model into the Serverless Inference endpoint by simply adding a few lines in the configuration. We use the SageMaker Python SDK in our example scripts. If you have models from different frameworks that need more customization, you can use the AWS SDK for Python (Boto3) to deploy models on a Serverless Inference endpoint. For more details, refer to Deploying ML models using SageMaker Serverless Inference (Preview).
First, you need to create HuggingFaceModel. You can select the model you want to deploy on the Hugging Face Hub; for example, distilbert-base-uncased-finetuned-sst-2-english. This model is a fine-tuned checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2. See the following code:
After you add the HuggingFaceModel class, you need to define the ServerlessInferenceConfig, which contains the configuration of the Serverless Inference endpoint, namely the memory size and the maximum number of concurrent invocations for the endpoint. After that, you can deploy the Serverless Inference endpoint with the deploy method:
This post covers the sample code snippet for deploying the Hugging Face model on a Serverless Inference endpoint. For a step-by-step Python code sample with detailed instructions, refer to the following notebook.
Inference performance
SageMaker Serverless Inference greatly simplifies hosting for serverless transformer or deep learning models. However, its runtime can vary depending on the configuration setup. You can choose a Serverless Inference endpoint memory size from 1024 MB (1 GB) up to 6144 MB (6 GB). In general, memory size should be at least as large as the model size. However, it’s a good practice to refer to memory utilization when deciding the endpoint memory size, in addition to the model size itself.
Serverless Inference integrates with AWS Lambda to offer high availability, built-in fault tolerance, and automatic scaling. Although Serverless Inference auto-assigns compute resources proportional to the model size, a larger memory size implies the container would have access to more vCPUs and have more compute power. However, as of this writing, Serverless Inference only supports CPUs and does not support GPUs.
On the other hand, with Serverless Inference, you can expect cold starts when the endpoint has no traffic for a while and suddenly receives inference requests, because it would take some time to spin up the compute resources. Cold starts may also happen during scaling, such as if new concurrent requests exceed the previous concurrent requests. The duration for a cold start varies from under 100 milliseconds to a few seconds, depending on the model size, how long it takes to download the model, as well as the startup time of the container. For more information about monitoring, refer to Monitor Amazon SageMaker with Amazon CloudWatch.
In the following table, we summarize the results of experiments performed to collect latency information of Serverless Inference endpoints over various Hugging Face models and different endpoint memory sizes. As input, a 128 sequence length payload was used. The model latency increased when the model size became large; the latency number is related to the model specifically. The overall model latency could be improved in various ways, including reducing model size, a better inference script, loading the model more efficiently, and quantization.
| Model-Id | Task | Model Size | Memory Size | Model Latency Average |
Model Latency p99 |
Overhead Latency Average |
Overhead Latency p99 |
| distilbert-base-uncased-finetuned-sst-2-english | Text classification | 255 MB | 4096 MB | 220 ms | 243 ms | 17 ms | 43 ms |
| xlm-roberta-large-finetuned-conll03-english | Token classification | 2.09 GB | 5120 MB | 1494 ms | 1608 ms | 18 ms | 46 ms |
| deepset/roberta-base-squad2 | Question answering | 473 MB | 5120 MB | 451 ms | 468 ms | 18 ms | 31 ms |
| google/pegasus-xsum | Summarization | 2.12 GB | 6144 MB | 22501 ms | 32516 ms | 27 ms | 97 ms |
| sshleifer/distilbart-cnn-12-6 | Summarization | 1.14 GB | 6144 MB | 12683 ms | 18669 ms | 25 ms | 53 ms |
Regarding price performance, we can use the DistilBERT model as an example and compare the serverless inference option to an ml.t2.medium instance (2 vCPUs, 4 GB Memory, $42 per month) on a real-time endpoint. With the real-time endpoint, DistilBERT has a p99 latency of 240 milliseconds and total request latency of 251 milliseconds. Whereas in the preceding table, Serverless Inference has a model latency p99 of 243 milliseconds and an overhead latency p99 of 43 milliseconds. With Serverless Inference, you only pay for the compute capacity used to process inference requests, billed by the millisecond, and the amount of data processed. Therefore, we can estimate the cost of running a DistilBERT model (distilbert-base-uncased-finetuned-sst-2-english, with price estimates for the us-east-1 Region) as follows:
- Total request time – 243ms + 43ms = 286ms
- Compute cost (4096 MB) – $0.000080 USD per second
- 1 request cost – 1 * 0.286 * $0.000080 = $0.00002288
- 1 thousand requests cost – 1,000 * 0.286 * $0.000080 = $0.02288
- 1 million requests cost – 1,000,000 * 0.286 * $0.000080 = $22.88
The following figure is the cost comparison for different Hugging Face models on SageMaker Serverless Inference vs. real-time inference (using a ml.t2.medium instance).

Figure 1: Cost comparison for different Hugging Face models on SageMaker Serverless Inference vs. real-time inference
As you can see, Serverless Inference is a cost-effective option when the traffic is intermittent or low. If you have a strict inference latency requirement, consider using real-time inference with higher compute power.
Conclusion
Hugging Face and AWS announced a partnership earlier in 2022 that makes it even easier to train Hugging Face models on SageMaker. This functionality is available through the development of Hugging Face AWS DLCs. These containers include the Hugging Face Transformers, Tokenizers, and Datasets libraries, which allow us to use these resources for training and inference jobs. For a list of the available DLC images, see Available Deep Learning Containers Images. They are maintained and regularly updated with security patches. We can find many examples of how to train Hugging Face models with these DLCs in the following GitHub repo.
In this post, we introduced how you can use the newly announced SageMaker Serverless Inference to deploy Hugging Face models. We provided a detailed code snippet using the SageMaker Python SDK to deploy Hugging Face models with SageMaker Serverless Inference. We then dived deep into inference latency over various Hugging Face models as well as price performance. You are welcome to try this new service and we’re excited to receive more feedback!
About the Authors
 James Yi is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
 Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
 Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
 Yanyan Zhang is a Data Scientist in the Energy Delivery team with AWS Professional Services. She is passionate about helping customers solve real problems with AI/ML knowledge. Outside of work, she loves traveling, working out and exploring new things.
Yanyan Zhang is a Data Scientist in the Energy Delivery team with AWS Professional Services. She is passionate about helping customers solve real problems with AI/ML knowledge. Outside of work, she loves traveling, working out and exploring new things.
Estimating the informativeness of data
Not all data are created equal. But how much information is any piece of data likely to contain? This question is central to medical testing, designing scientific experiments, and even to everyday human learning and thinking. MIT researchers have developed a new way to solve this problem, opening up new applications in medicine, scientific discovery, cognitive science, and artificial intelligence.
In theory, the 1948 paper, “A Mathematical Theory of Communication,” by the late MIT Professor Emeritus Claude Shannon answered this question definitively. One of Shannon’s breakthrough results is the idea of entropy, which lets us quantify the amount of information inherent in any random object, including random variables that model observed data. Shannon’s results created the foundations of information theory and modern telecommunications. The concept of entropy has also proven central to computer science and machine learning.
The challenge of estimating entropy
Unfortunately, the use of Shannon’s formula can quickly become computationally intractable. It requires precisely calculating the probability of the data, which in turn requires calculating every possible way the data could have arisen under a probabilistic model. If the data-generating process is very simple — for example, a single toss of a coin or roll of a loaded die — then calculating entropies is straightforward. But consider the problem of medical testing, where a positive test result is the result of hundreds of interacting variables, all unknown. With just 10 unknowns, there are already 1,000 possible explanations for the data. With a few hundred, there are more possible explanations than atoms in the known universe, which makes calculating the entropy exactly an unmanageable problem.
MIT researchers have developed a new method to estimate good approximations to many information quantities such as Shannon entropy by using probabilistic inference. The work appears in a paper presented at AISTATS 2022 by authors Feras Saad ’16, MEng ’16, a PhD candidate in electrical engineering and computer science; Marco-Cusumano Towner PhD ’21; and Vikash Mansinghka ’05, MEng ’09, PhD ’09, a principal research scientist in the Department of Brain and Cognitive Sciences. The key insight is, rather than enumerate all explanations, to instead use probabilistic inference algorithms to first infer which explanations are probable and then use these probable explanations to construct high-quality entropy estimates. The paper shows that this inference-based approach can be much faster and more accurate than previous approaches.
Estimating entropy and information in a probabilistic model is fundamentally hard because it often requires solving a high-dimensional integration problem. Many previous works have developed estimators of these quantities for certain special cases, but the new estimators of entropy via inference (EEVI) offer the first approach that can deliver sharp upper and lower bounds on a broad set of information-theoretic quantities. An upper and lower bound means that although we don’t know the true entropy, we can get a number that is smaller than it and a number that is higher than it.
“The upper and lower bounds on entropy delivered by our method are particularly useful for three reasons,” says Saad. “First, the difference between the upper and lower bounds gives a quantitative sense of how confident we should be about the estimates. Second, by using more computational effort we can drive the difference between the two bounds to zero, which ‘squeezes’ the true value with a high degree of accuracy. Third, we can compose these bounds to form estimates of many other quantities that tell us how informative different variables in a model are of one another.”
Solving fundamental problems with data-driven expert systems
Saad says he is most excited about the possibility that this method gives for querying probabilistic models in areas like machine-assisted medical diagnoses. He says one goal of the EEVI method is to be able to solve new queries using rich generative models for things like liver disease and diabetes that have already been developed by experts in the medical domain. For example, suppose we have a patient with a set of observed attributes (height, weight, age, etc.) and observed symptoms (nausea, blood pressure, etc.). Given these attributes and symptoms, EEVI can be used to help determine which medical tests for symptoms the physician should conduct to maximize information about the absence or presence of a given liver disease (like cirrhosis or primary biliary cholangitis).
For insulin diagnosis, the authors showed how to use the method for computing optimal times to take blood glucose measurements that maximize information about a patient’s insulin sensitivity, given an expert-built probabilistic model of insulin metabolism and the patient’s personalized meal and medication schedule. As routine medical tracking like glucose monitoring moves away from doctor’s offices and toward wearable devices, there are even more opportunities to improve data acquisition, if the value of the data can be estimated accurately in advance.
Vikash Mansinghka, senior author on the paper, adds, “We’ve shown that probabilistic inference algorithms can be used to estimate rigorous bounds on information measures that AI engineers often think of as intractable to calculate. This opens up many new applications. It also shows that inference may be more computationally fundamental than we thought. It also helps to explain how human minds might be able to estimate the value of information so pervasively, as a central building block of everyday cognition, and help us engineer AI expert systems that have these capabilities.”
The paper, “Estimators of Entropy and Information via Inference in Probabilistic Models,” was presented at AISTATS 2022.