You may have applications that generate streaming data that is full of records containing customer case notes, product reviews, and social media messages, in many languages. Your task is to identify the products that people are talking about, determine if they’re expressing positive or negative sentiment, translate their comments into a common language, and create enriched copies of the data for your business analysts. Additionally, you need to remove any personally identifiable information (PII), such as names, addresses, and credit card numbers.
You already know how to ingest streaming data into Amazon Kinesis Data Streams for sustained high-throughput workloads. Now you can also use Amazon Kinesis Data Analytics Studio powered by Apache Zeppelin and Apache Flink to interactively analyze, translate, and redact text fields, thanks to Amazon Translate and Amazon Comprehend via user-defined functions (UDFs). Amazon Comprehend is a natural language processing (NLP) service that makes it easy to uncover insights from text. Amazon Translate is a neural machine translation service that delivers fast, high-quality, affordable, and customizable language translation.
In this post, we show you how to use these services to perform the following actions:
- Detect the prevailing sentiment (positive, negative, neither, or both)
- Detect the dominant language
- Translate into your preferred language
- Detect and redact entities (such as items, places, or quantities)
- Detect and redact PII entities
We discuss how to set up UDFs in Kinesis Data Analytics Studio, the available functions, and how they work. We also provide a tutorial in which we perform text analytics on the Amazon Customer Reviews dataset.
The appendix at the end of this post provides a quick walkthrough of the solution capabilities.
Solution overview
We set up an end-to-end streaming analytics environment, where a Kinesis data stream is ingested with a trimmed-down version of the Amazon Customer Reviews dataset and consumed by a Kinesis Data Analytics Studio notebook powered by Apache Zeppelin. A UDF is attached to the entire notebook instance, which allows the notebook to trigger Amazon Comprehend and Amazon Translate APIs using the payload from the Kinesis data stream. The following diagram illustrates the solution architecture.
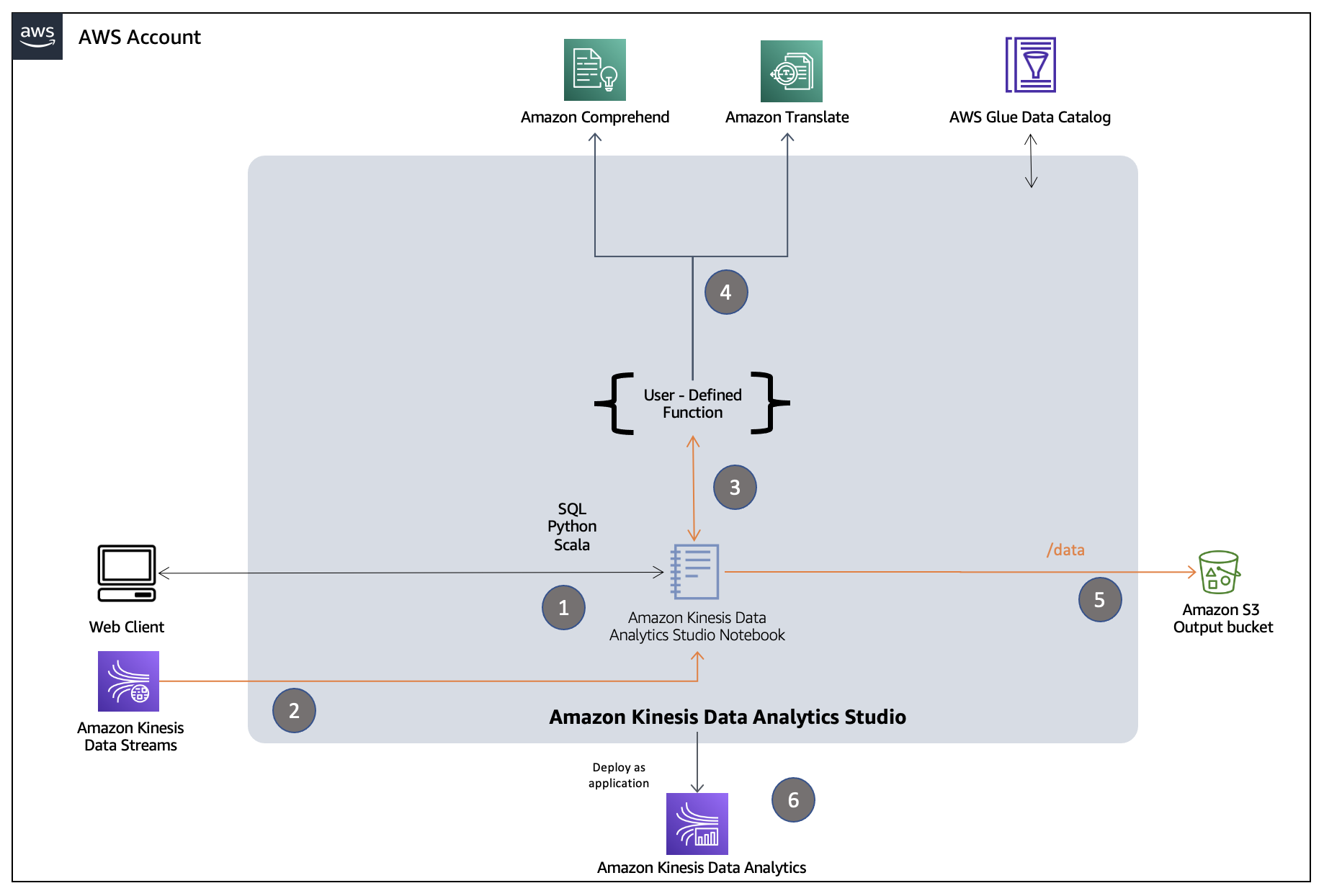
The response from the UDF is used to enrich the payloads from the data stream, which are then stored in an Amazon Simple Storage Service (Amazon S3) bucket. Schema and related metadata are stored in a dedicated AWS Glue Data Catalog. After the results in S3 bucket meet your expectations, the Studio notebook instance is deployed as a Kinesis Data Analytics application for continuous streaming analytics.
How the UDF works
The Java class TextAnalyticsUDF implements the core logic for each of our UDFs. This class extends ScalarFunction to allow invocation from Kinesis Data Analytics for Flink on a per-record basis. The required eval method is then overloaded to receive input records, the identifier for the use case to perform, and other supporting metadata for the use case. A switch case within the eval methods then maps the input record to a corresponding public method. Within these public methods, use case-specific API calls of Amazon Comprehend and Amazon Translate are triggered, for example DetectSentiment, DetectDominantLanguage, and TranslateText.
Amazon Comprehend API service quotas provide guardrails to limit your cost exposure from unintentional high usage (we discuss this more in the following section). By default, the single-document APIs process up to 20 records per second. Our UDFs use exponential backoff and retry to throttle the request rate to stay within these limits. You can request increases to the transactions per-second quota for APIs using the Quota Request Template on the AWS Management Console.
Amazon Comprehend and Amazon Translate each enforce a maximum input string length of 5,000 utf-8 bytes. Text fields that are longer than 5,000 utf-8 bytes are truncated to 5,000 bytes for language and sentiment detection, and split on sentence boundaries into multiple text blocks of under 5,000 bytes for translation and entity or PII detection and redaction. The results are then combined.
Cost involved
In addition to Kinesis Data Analytics costs, the text analytics UDFs incur usage costs from Amazon Comprehend and Amazon Translate. The amount you pay is a factor of the total number of records and characters that you process with the UDFs. For more information, see Amazon Kinesis Data Analytics pricing, Amazon Comprehend pricing, and Amazon Translate pricing.
Example 1: Analyze the language and sentiment of tweets
Let’s assume you have 10,000 tweet records, with an average length of 100 characters per tweet. Your SQL query detects the dominant language and sentiment for each tweet. You’re in your second year of service (the Free Tier no longer applies). The cost details are as follows:
- Size of each tweet = 100 characters
- Number of units (100 character) per record (minimum is 3 units) = 3
- Total units = 10,000 (records) x 3 (units per record) x 2 (Amazon Comprehend requests per record) = 60,000
- Price per unit = $0.0001
- Total cost for Amazon Comprehend = [number of units] x [cost per unit] = 60,000 x $0.0001 = $6.00
Example 2: Translate tweets
Let’s assume that 2,000 of your tweets aren’t in your local language, so you run a second SQL query to translate them. The cost details are as follows:
- Size of each tweet = 100 characters
- Total characters = 2,000 (records) * 100 (characters per record) x 1 (Amazon Translate requests per record) = 200,000
- Price per character = $0.000015
- Total cost for Amazon Translate = [number of characters] x [cost per character] = 200,000 x $0.000015 = $3.00
Deploy solution resources
For this post, we provide an AWS CloudFormation template to create the following resources:
- An S3 bucket named
amazon-reviews-bucket-<your-stack-id> that contains artifacts copied from another public S3 bucket outside of your account. These artifacts include:
- A trimmed-down version of the Amazon Product Review dataset with 2,000 tab-separated reviews of personal care and grocery items. The number of reviews has been reduced to minimize costs of implementing this example.
- A JAR file to support UDF logic.
- A Kinesis data stream named
amazon-kinesis-raw-stream-<your-stack-id> along with a Kinesis Analytics Studio notebook instance named amazon-reviews-studio-application-<your-stack-id> with a dedicated AWS Glue Data Catalog, pre-attached UDF JAR, and a pre-configured S3 path for the deployed application.
-
AWS Identity and Access Management (IAM) roles and policies with appropriate permissions.
-
AWS Lambda functions for supporting the following operations :
- Customize Zeppelin notebooks as per the existing stack environment and copy them to the S3 bucket
- Start the Kinesis Data Analytics Studio instance
- Modify the CORS policy of the S3 bucket to allow notebook imports via S3 pre-signed URLs
- Empty the S3 bucket upon stack deletion
To deploy these resources, complete the following steps:
- Launch the CloudFormation stack:

- Enter a stack name, and leave other parameters at their default.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
- When the stack is complete, choose the Outputs tab to review the primary resources created for this solution.

- Copy the S3 bucket name from the Outputs
- Navigate to the Amazon S3 console in a new browser tab and enter the bucket name in the search bar to filter.
- Choose the bucket name and list all objects created under the
/artifacts/ prefix.
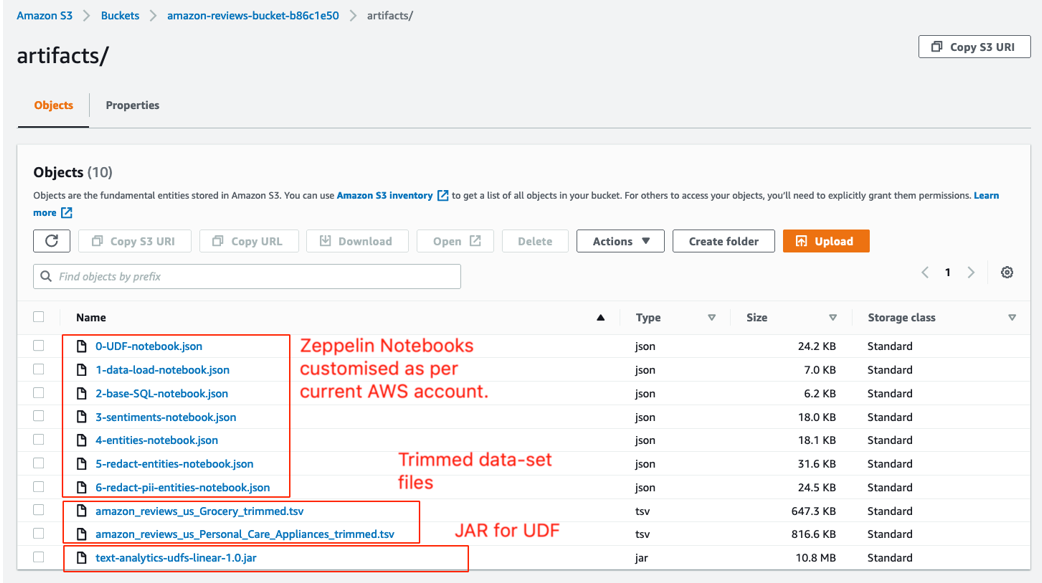
In upcoming steps, we upload these customized Zeppelin notebooks from this S3 bucket to the Kinesis Data Analytics Studio instance via Amazon S3 pre-signed URLs. The import is made possible because the CloudFormation stack attaches a CORS policy on the S3 bucket, which allows the Kinesis Data Analytics Studio instance to perform GET operations. To confirm, navigate to the root prefix of the S3 bucket, choose the Permissions tab, and navigate to the Cross-origin resource sharing (CORS) section.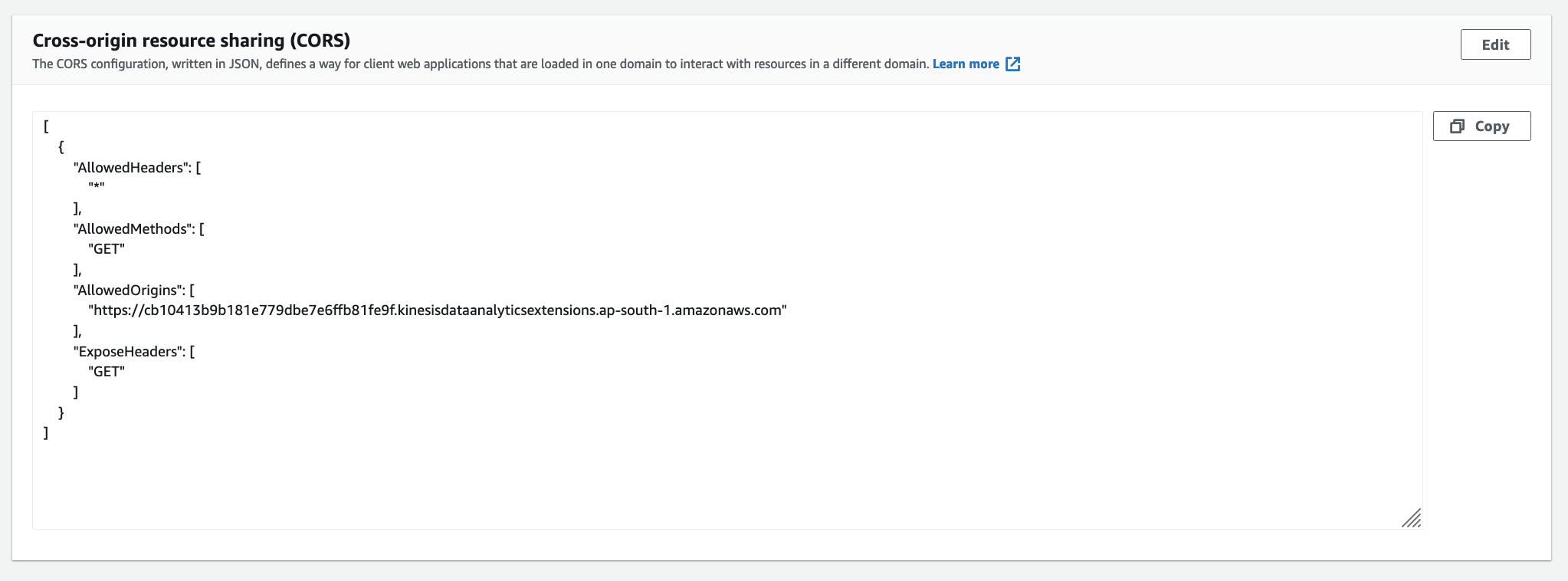
Set up the Studio notebooks
To set up your notebooks, complete the following steps:
- On the Kinesis Data Analytics console, choose the Studio tab.
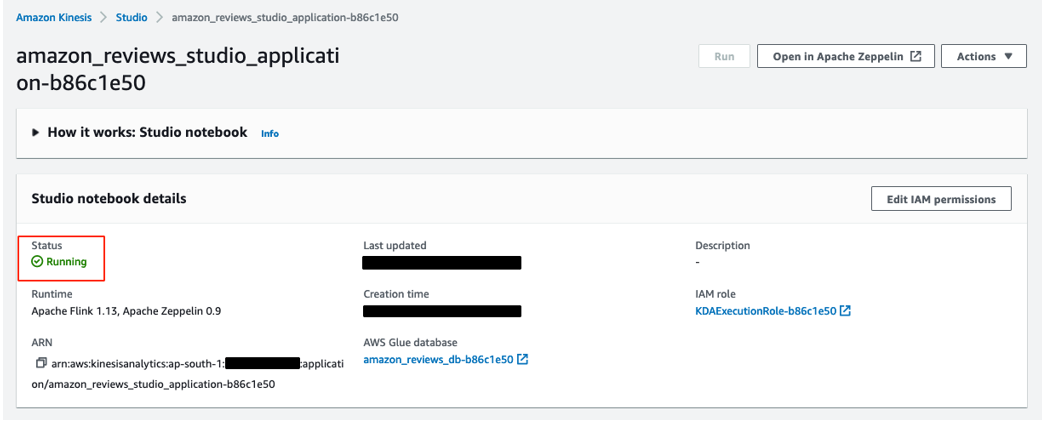
- Filter for the notebook instance you created and choose the notebook name.

- Confirm that the status shows as
Running.
- Choose the Configuration tab and confirm that the application is attached with an S3 path similar to
s3://amazon-reviews-bucket-<stack-id>/zeppelin-code/ under Deploy as application configuration.
This path is used during the export of a notebook to a Kinesis Data Analytics application.
- Also confirm that an S3 path similar to
s3://amazon-reviews-bucket-<stack-id>/artifacts/text-analytics-udfs-linear-1.0.jar exists under User-defined functions.
This path points the notebook instance towards the UDF JAR.
- Choose Open in Apache Zeppelin to be redirected to the Zeppelin console.

Now you’re ready to import the notebooks to the Studio instance.
- Open a new browser tab and navigate to your bucket on the Amazon S3 console.
- Choose the hyperlink for the
0-data-load-notebook.json

- Choose Open.

- Copy the pre-signed URL of the S3 file.
 If your browser doesn’t parse the JSON file in a new tab but downloads the file upon choosing Open, then you can also generate the presigned URL by choosing the Object actions drop-down menu and then Share with a presigned URL.
If your browser doesn’t parse the JSON file in a new tab but downloads the file upon choosing Open, then you can also generate the presigned URL by choosing the Object actions drop-down menu and then Share with a presigned URL.
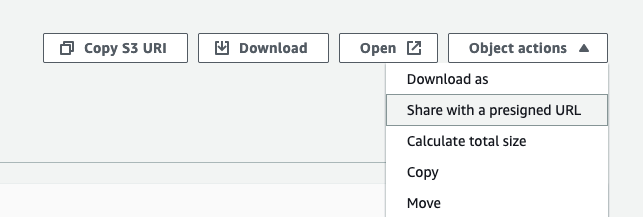
- On the Zeppelin console, choose Import Note.
- Choose Add from URL.
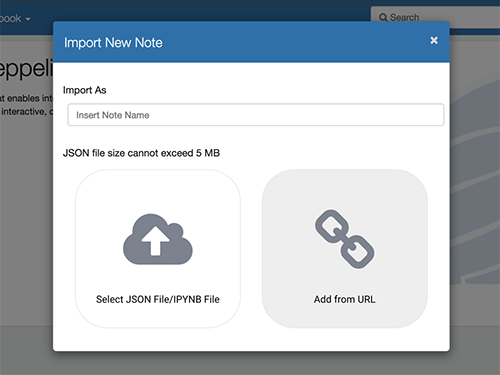
- Enter the pre-signed URL that you copied.
- Choose Import Note.

- Repeat these steps for the remaining notebook files:
1-UDF-notebook.json2-base-SQL-notebook.json3-sentiments-notebook.json
The following screenshot shows your view on the Zeppelin console after importing all four files.
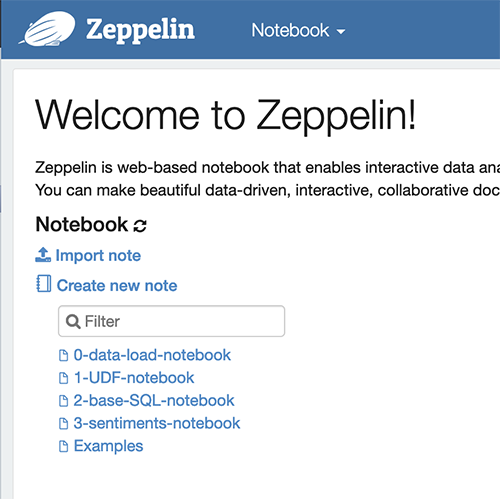
For the sake of brevity, this post illustrates a step-by-step walkthrough of the import and run process for the sentiment analysis and language translation use case only. We don’t illustrate the similar processes for 4-entities-notebook, 5-redact-entities-notebook, or 6-redact-pii-entities-notebook in the amazon-reviews-bucket-<your-stack-id> S3 bucket.
That being said, 0-UDF-notebook, 1-data-load-notebook, and 2-base-SQL-notebook are prerequisite resources for all use cases. If you already have the prerequisites set up, these distinct use case notebooks can operate similar to 3-sentiments-notebook. In a later section, we showcase the expected results for these use cases.
Studio notebook structure
To visualize the flow better, we have segregated the separate use cases into individual Studio notebooks. You can download all seven notebooks from the GitHub repo. The following diagram helps illustrate the logical flow for our sentiment detection use case.
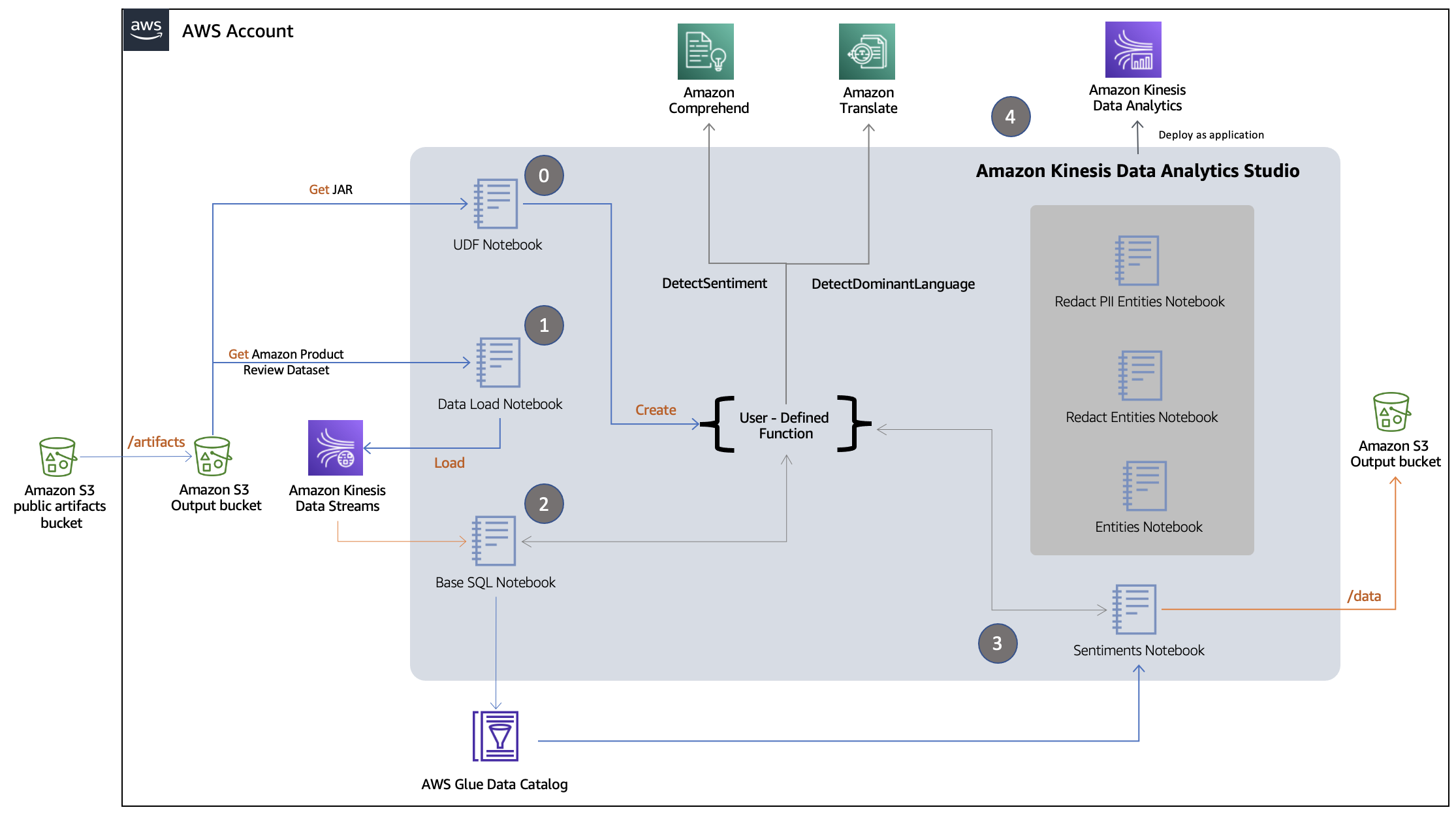
The workflow is as follows:
-
Step 0 – The notebook
0-data-load-notebook reads the Amazon Product Review dataset from the local S3 bucket and ingests the tab-separated reviews into a Kinesis data stream.
-
Step 1 – The notebook
1-UDF-notebook uses the attached JAR file to create a UDF within StreamTableEnvironment. It also consists of other cells (#4–14) that illustrate UDF usage examples on non-streaming static data.
-
Step 2 – The notebook
2-base-SQL-notebook creates a table for the Kinesis data stream in the AWS Glue Data Catalog and uses the language detection and translation capabilities of UDF to enrich the schema with extra columns: review_body_detected_language and review_body_in_french.
-
Step 3 – The notebook 3-sentiments-notebook performs the following actions:
-
Step 3.1 – Reads from the table created in Step 2.
-
Step 3.2 – Interacts with the UDF to create views with use case-specific columns (for example,
detected_sentiment and sentiment_mixed_score).
-
Step 3.3 – Dumps the streaming data into a local S3 bucket.
-
Step 4 – The studio instance saves the notebook as zip export into Amazon S3 bucket which is then used to create a standalone Amazon Kinesis Data Analytics application .
Steps 0–2 are mandatory for the remaining steps to run. Step 3 remains the same for use cases with the other notebooks (4-entities-notebook, 5-redact-entities-notebook, and 6-redact-pii-entities-notebook).
Run Studio notebooks
In this section, we walk through the cells of the following notebooks:
0-UDF-notebook1-data-load-notebook2-base-SQL-notebook3-sentiments-notebook
0-data-load-notebook
Cell #1 registers a Flink UDF with StreamTableEnvironment. Choose the play icon at the top of cell to run this cell.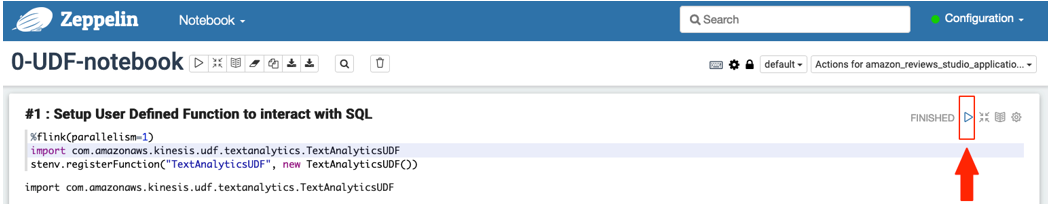 Cell #2 enables checkpointing, which is important for allowing S3Sink (used in 3-sentiments-notebook later) to run as expected.
Cell #2 enables checkpointing, which is important for allowing S3Sink (used in 3-sentiments-notebook later) to run as expected.

Cells #3–13 are optional for understanding the functionality of UDFs on static non-streaming text. Additionally, the appendix at the end of this post provides a quick walkthrough of the solution capabilities.
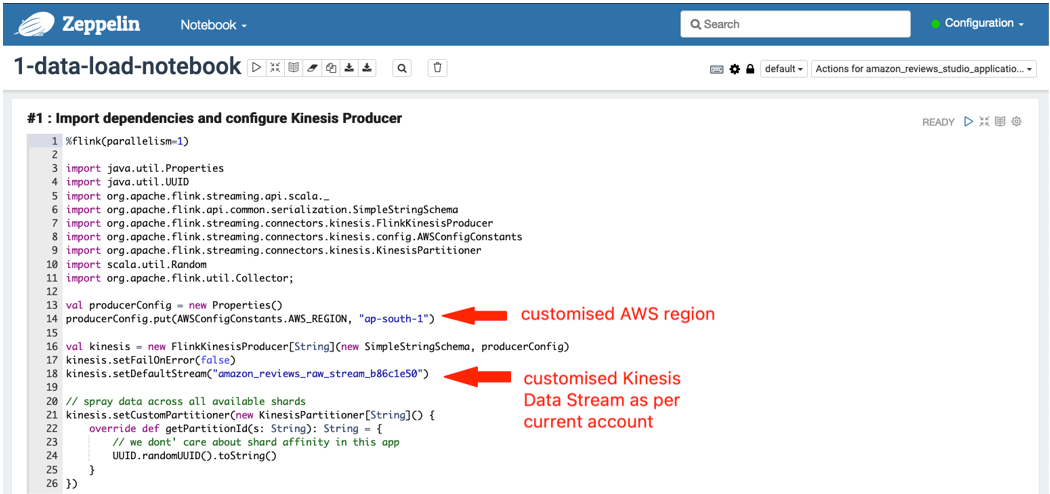
1-data-load-notebook
Choose the play icon at the top of each cell (#1 and #2) to load data into a Kinesis data stream.
Cell #1 imports the dependencies into the runtime and configures the Kinesis producer with Kinesis data stream name and Region for ingestion. The Region and stream name variables are pre-populated as per the AWS account in which the CloudFormation stack was deployed.
Cell #2 loads the trimmed-down version of the Amazon Customer Reviews dataset into the Kinesis data stream. 2-base-SQL-notebook
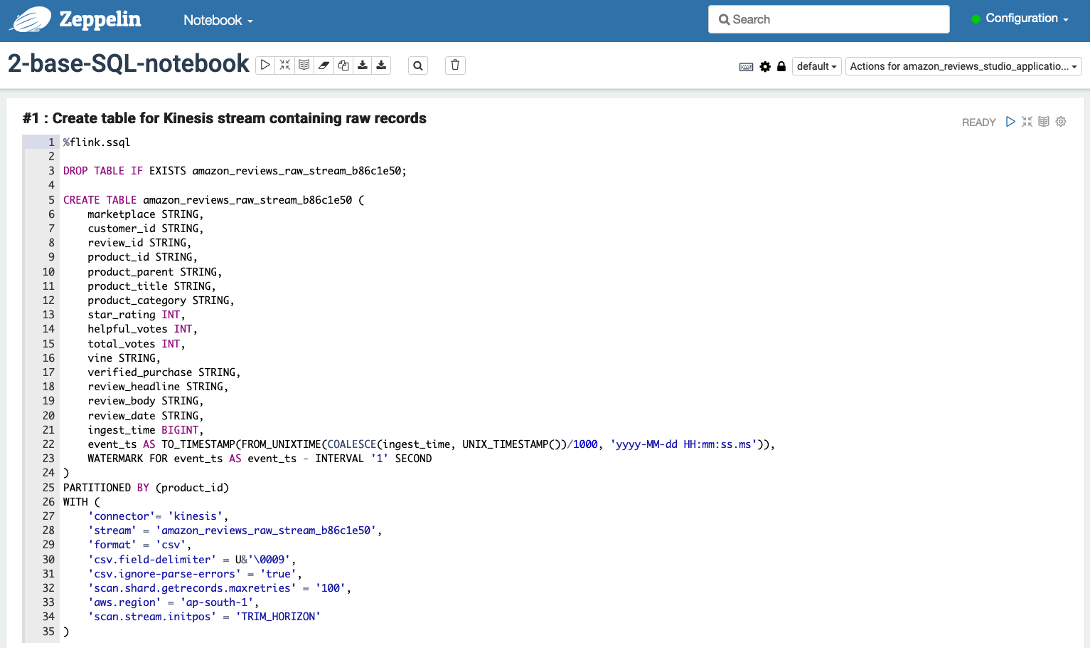
2-base-SQL-notebook
Choose the play icon at the top of each cell (#1 and #2) to run the notebook.
Cell #1 creates a table schema in the AWS Glue Data Catalog for the Kinesis data stream.
Cell #2 creates the view amazon_reviews_enriched on the streaming data and runs the UDF to enrich additional columns in the schema (review_body_in_french and review_body_detected_language).
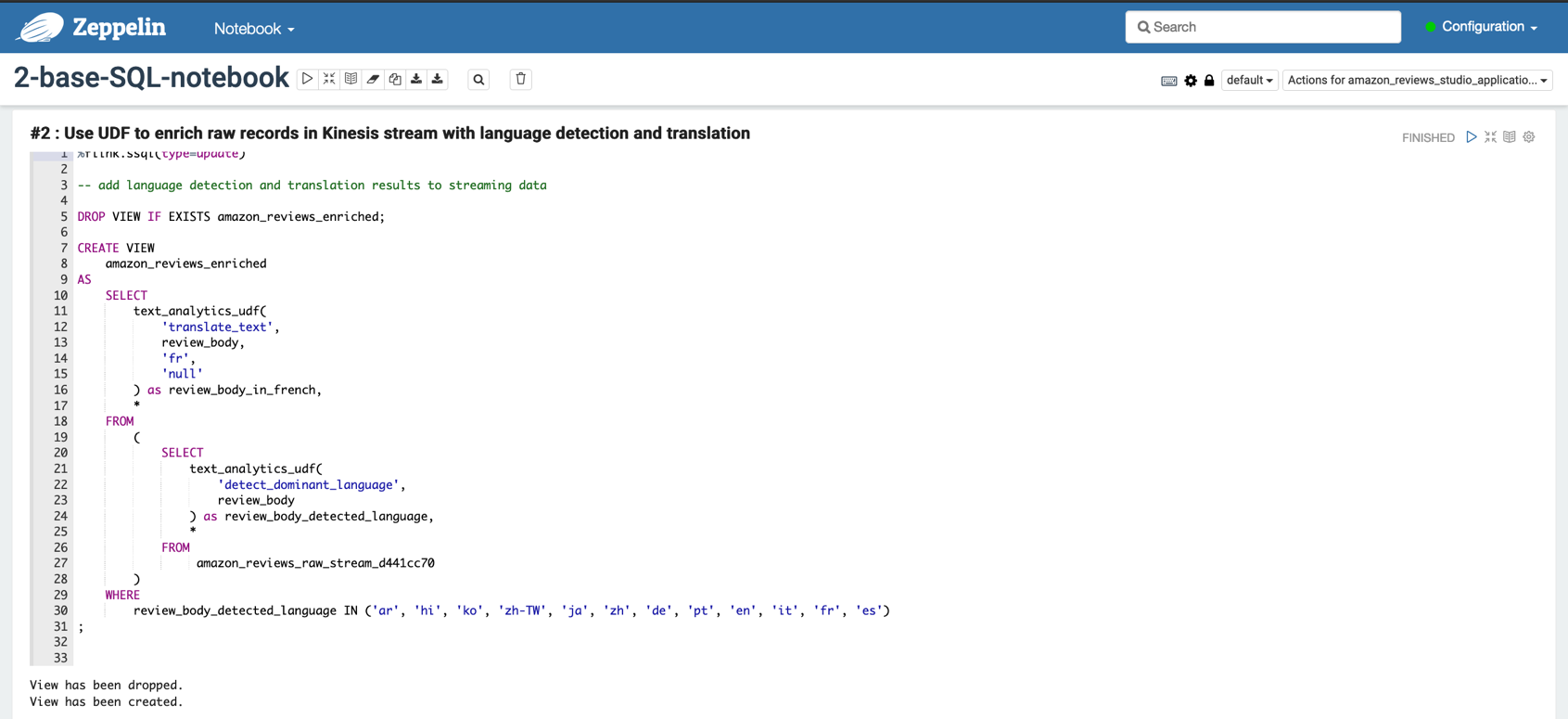
Cell #3 is optional for understanding the modifications on the base schema.
3-sentiments-notebook
Choose the play icon at the top of each cell (#1–3) to run the notebook.
Cell #1 creates another view named sentiment_view on top of the amazon_reviews_enriched view to further determine the sentiments of the product reviews.
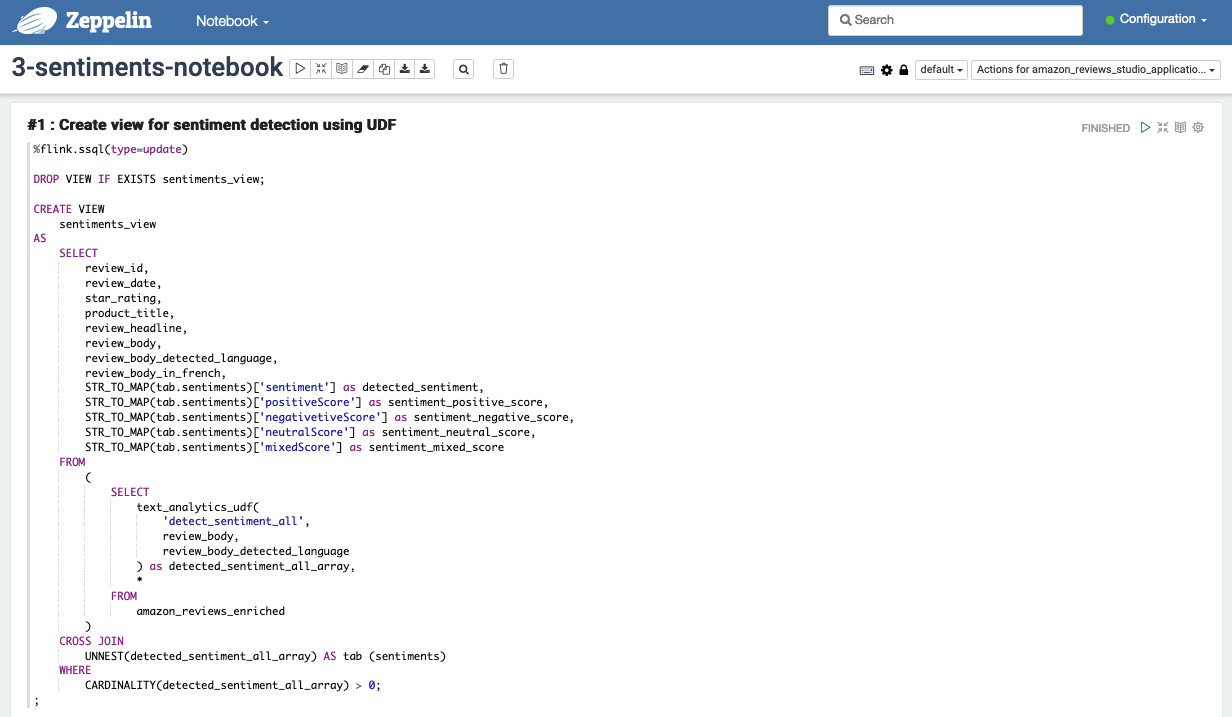
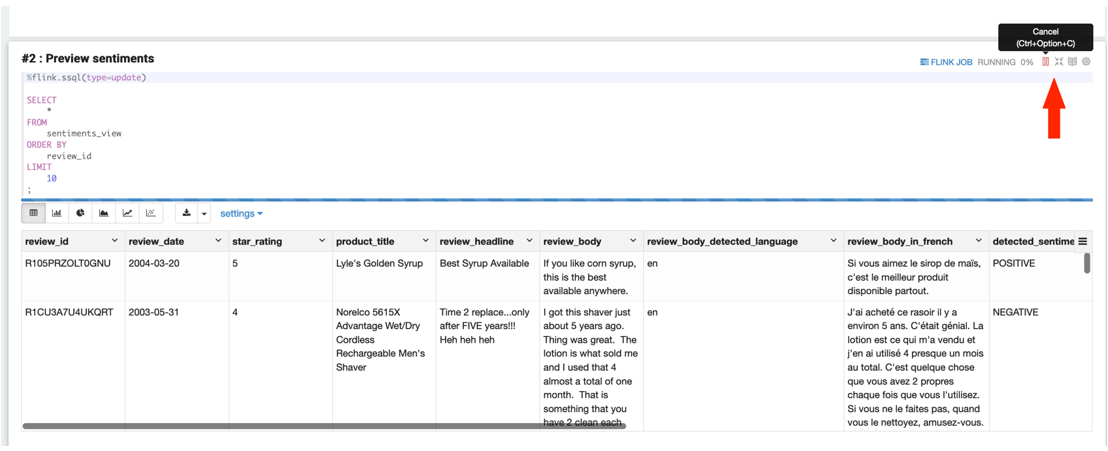
Because the intention of cell #2 is to have a quick preview of rows expected in the destination S3 bucket and we don’t need the corresponding Flink job to run forever, choose the cancel icon in cell #2 to stop the job after you get sufficient rows as output. You can expect the notebook cell to populate with results in approximately 2–3 minutes. This duration is a one-time investment to start the Flink job, after which the job continues to process streaming data as it arrives.
Cell #3 creates a table called amazon_reviews_sentiments to store the UDF modified streaming data in an S3 bucket.
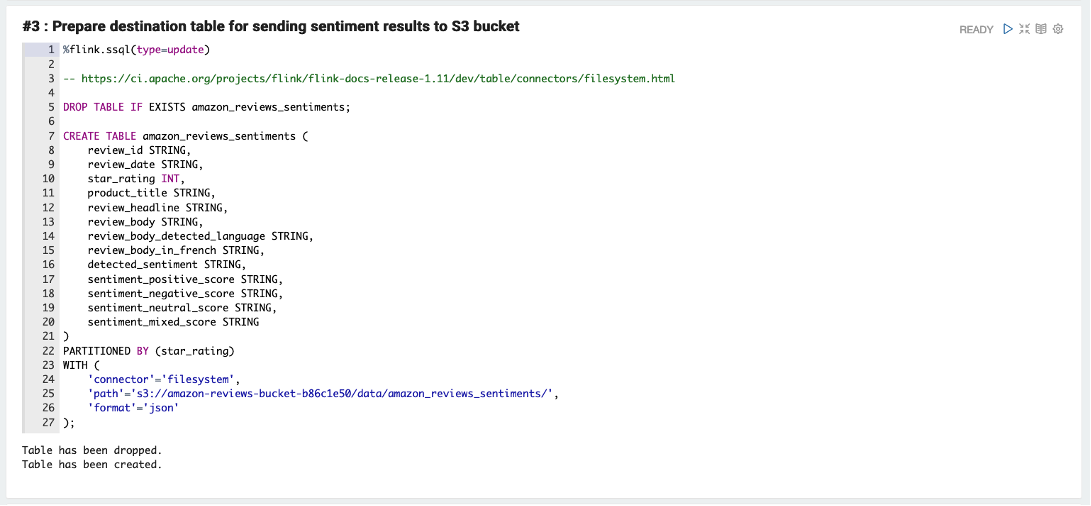
Run cell #4 to send sentiments to the S3 destination bucket. This cell creates an Apache Flink job that reads dataset records from the Kinesis data stream, applies the UDF transformations, and stores the modified records in Amazon S3.
You can expect the notebook cell to populate the S3 bucket with results in approximately 5 minutes. Note, this duration is a one-time investment to start the Flink job, after which the job continues to process streaming data as it arrives. You can stop the notebook cell to stop this Flink job after you review the end results in the S3 bucket.
Query the file using S3 Select to validate the contents.
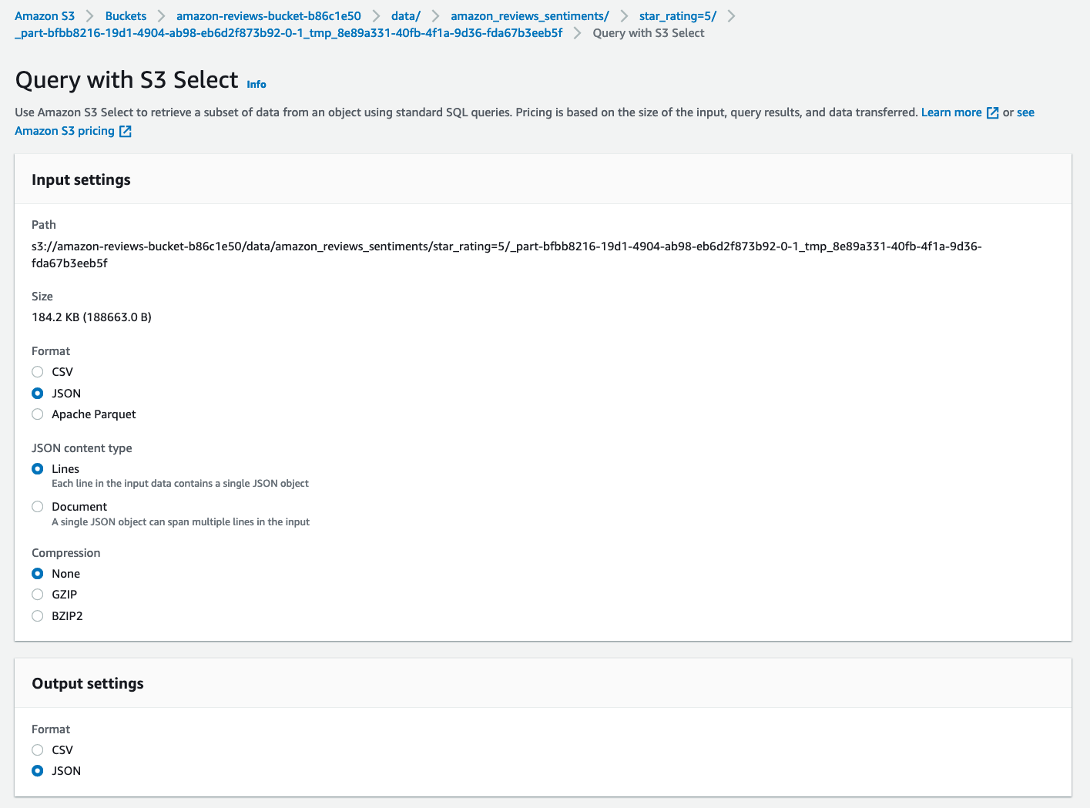
The following screenshot shows your query input and output settings.
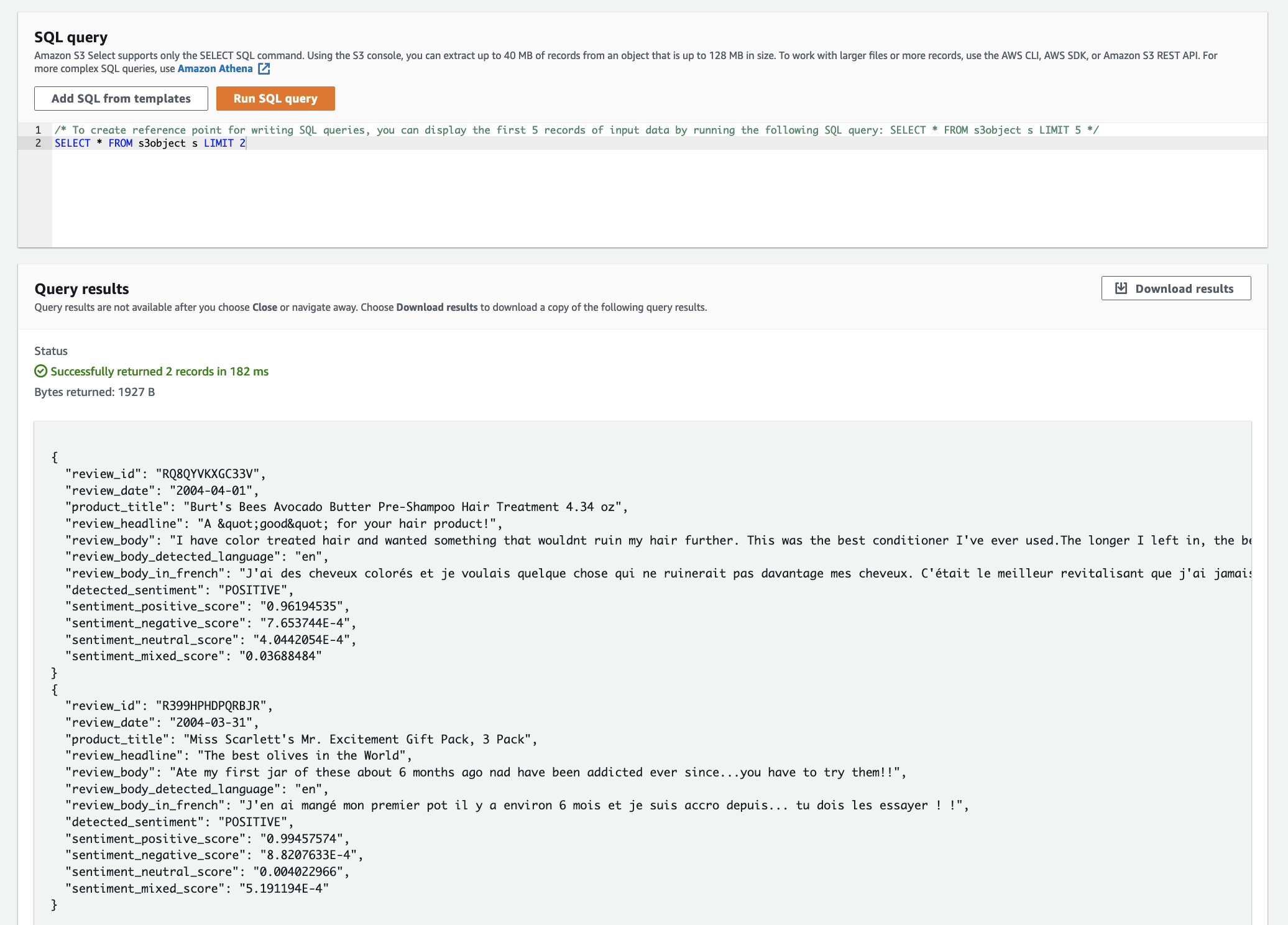
The following screenshot shows the query results for sentiment detection.
The following are equivalent results of 4-entities-notebook in the S3 bucket.
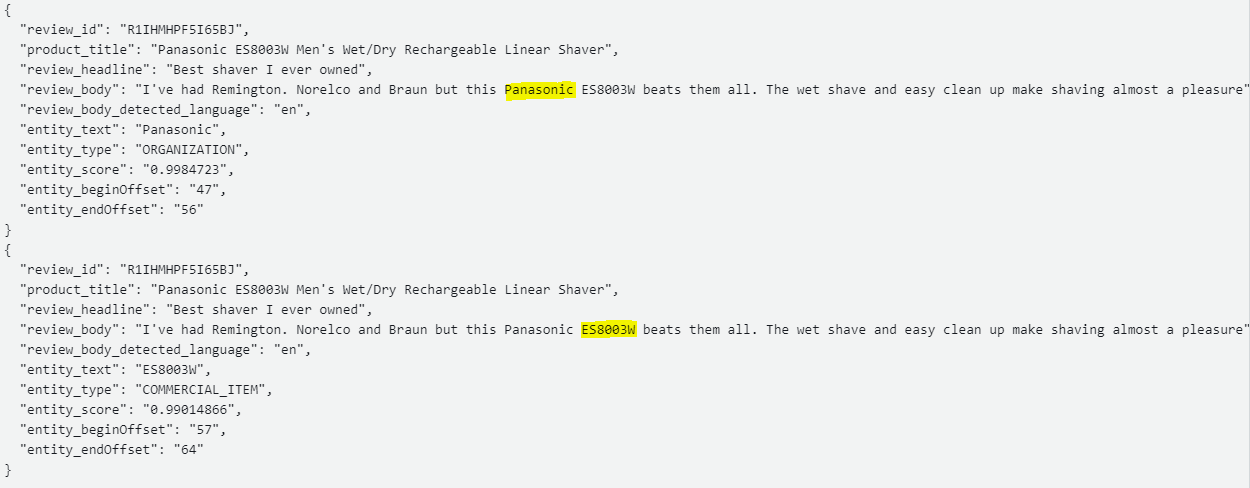
The following are equivalent results of 5-redact-entities-notebook in the S3 bucket.
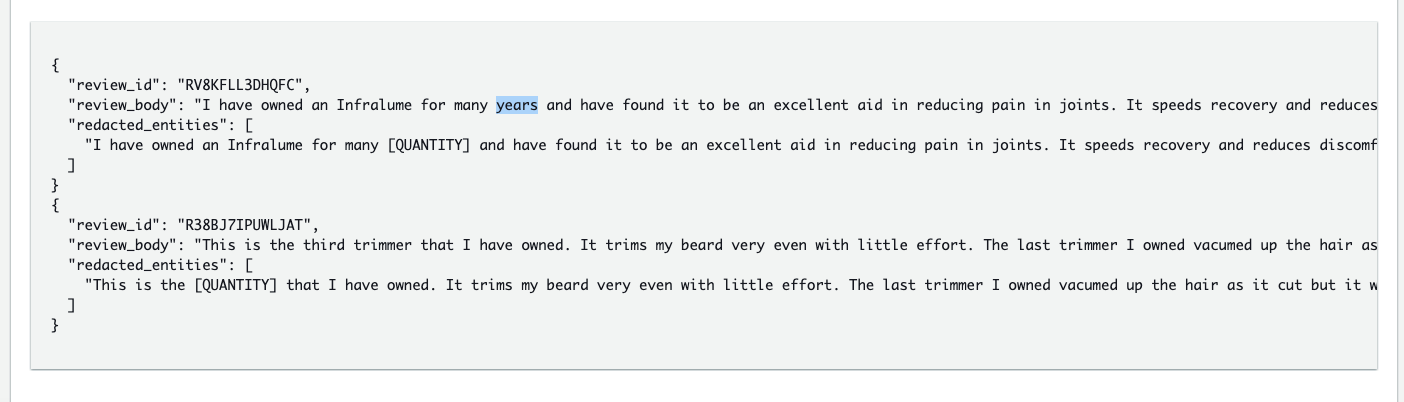
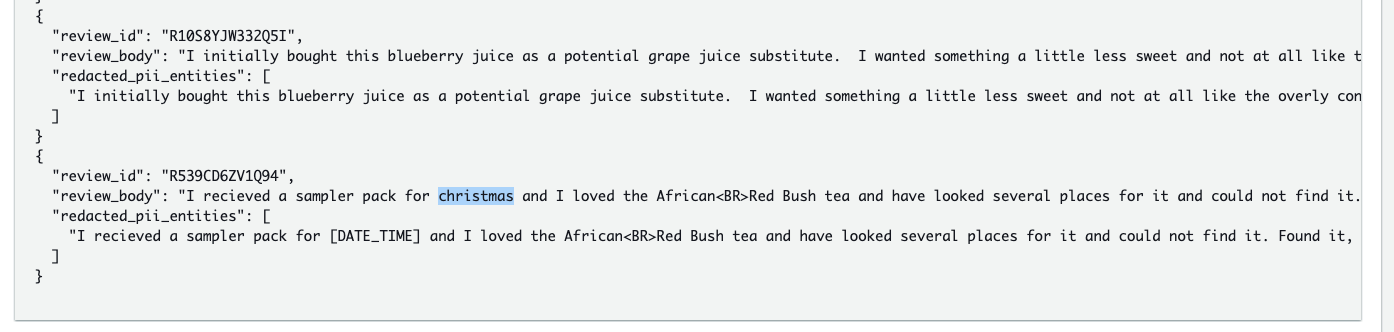
The following are equivalent results of 6-redact-pii-entities-notebook in the S3 bucket.
Export the Studio notebook as a Kinesis Data Analytics application
There are two modes of running an Apache Flink application on Kinesis Data Analytics:
- Create notes within a Studio notebook. This provides the ability to develop your code interactively, view results of your code in real time, and visualize it within your note. We have already achieved this in previous steps.
-
Deploy a note to run in streaming mode.
After you deploy a note to run in streaming mode, Kinesis Data Analytics creates an application for you that runs continuously, reads data from your sources, writes to your destinations, maintains a long-running application state, and scales automatically based on the throughput of your source streams.
The CloudFormation stack already configured a Kinesis Data Analytics Studio notebook to store the exported application artifacts in the amazon-reviews-bucket-<your-stack-id>/zeppelin-code/ S3 prefix. The SQL criteria for Studio notebook export prevents the presence of simple SELECT statements in cells of the notebook to export. Therefore, we can’t export 3-sentiments-notebook because the notebook contains SELECT statements under cell #2: Preview sentiments. To export the end result, complete the following steps:
- Navigate to the Apache Zeppelin UI for the notebook instance.
- Open
3-sentiments-notebook and copy the last cell’s SQL query:
%flink.ssql(type=update, parallelism=1)
INSERT INTO
amazon_reviews_sentiments
SELECT
*
FROM
sentiments_view;
- Create a new notebook (named
dep_to_kda in this post) and enter the copied content into a new cell.
- On the Actions menu, choose Build and export to Amazon S3.
- Enter an application name, confirm the S3 destination path, and choose Build and export.
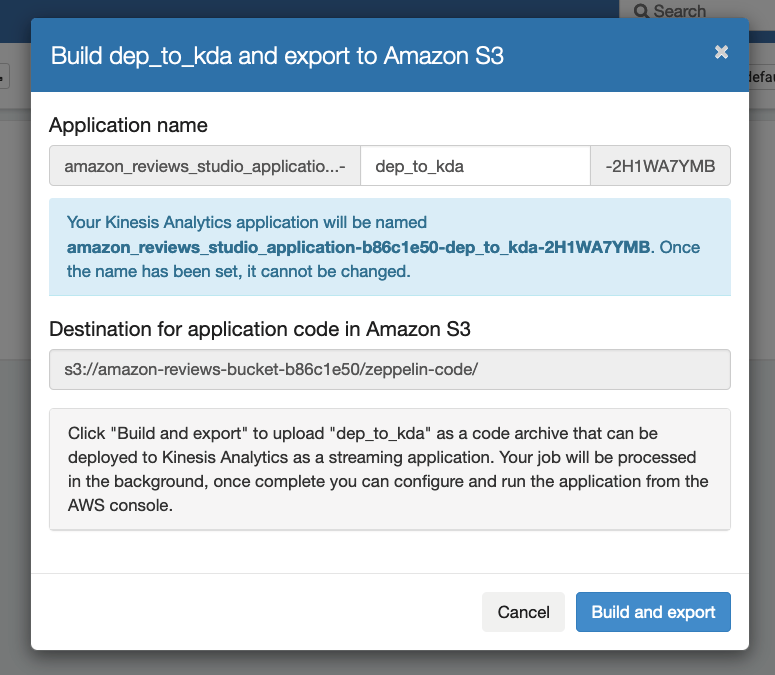
The process of building and exporting the artifacts is complete in approximately 5 minutes. You can monitor the progress on the console.


- Validate the creation of the required ZIP export in the S3 bucket.

- Navigate back to the Apache Zeppelin UI for the notebook instance and open the newly created notebook (named
dep-to-kda in this post).
- On the Actions menu, choose Deploy export as Kinesis Analytics application.
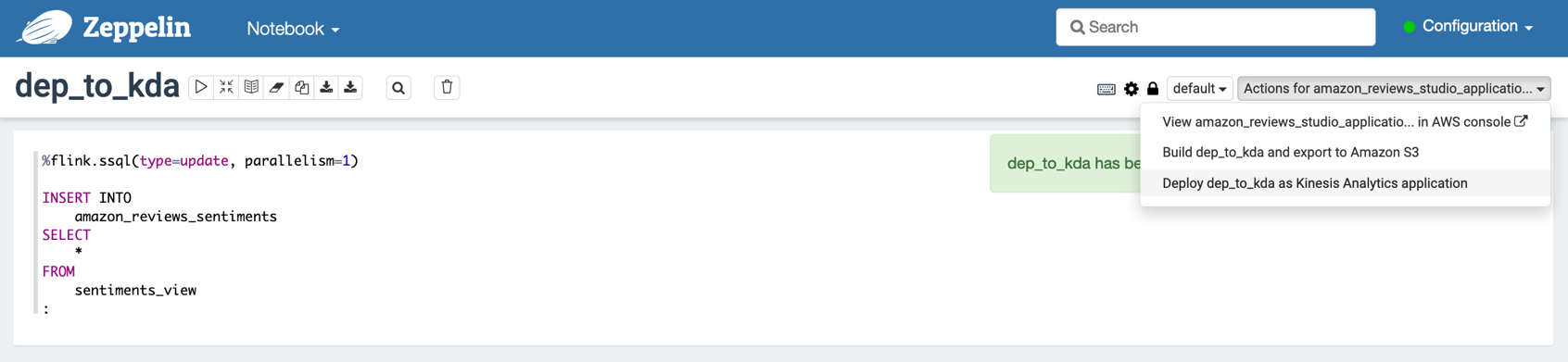
- Choose Deploy using AWS console to continue with the deployment.
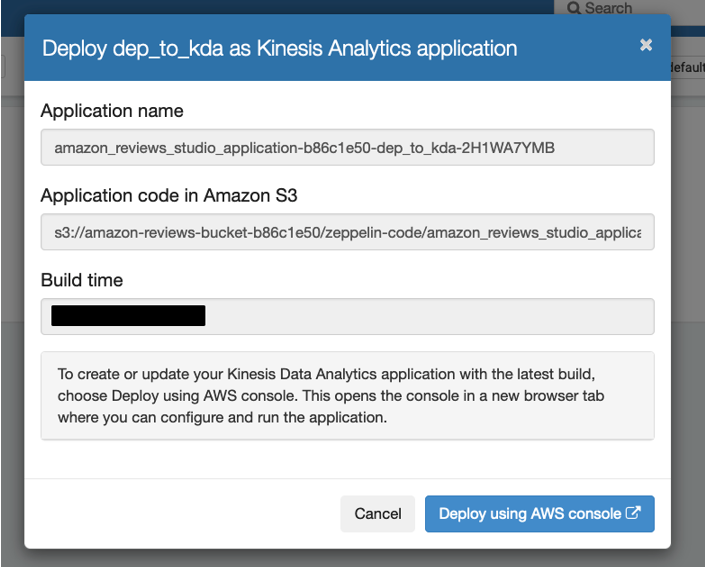
You’re automatically redirected to the Kinesis Data Analytics console.
- On the Kinesis Data Analytics console, select Choose from IAM roles that Kinesis Data Analytics can assume and choose the
KDAExecutionRole-<stack-id> role.

- Leave the remaining configurations at default and choose Create streaming application.
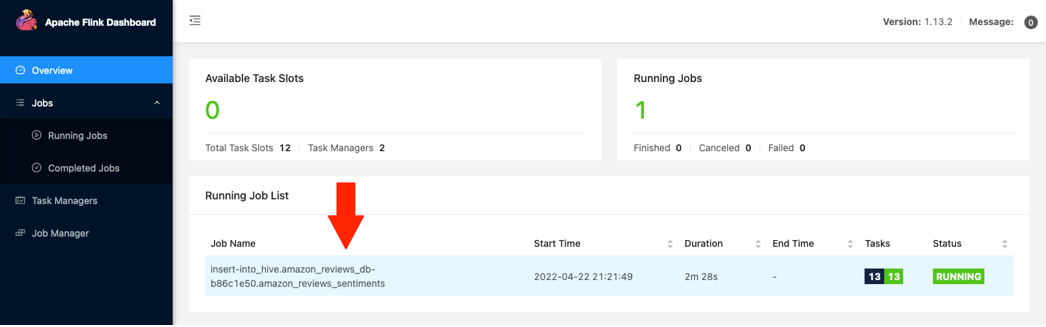
- Navigate back to the Kinesis Analytics application and choose Run to run the application.

- When the status shows as
Running, choose Open Apache Flink Dashboard.

You can now review the progress of the running Flink job.
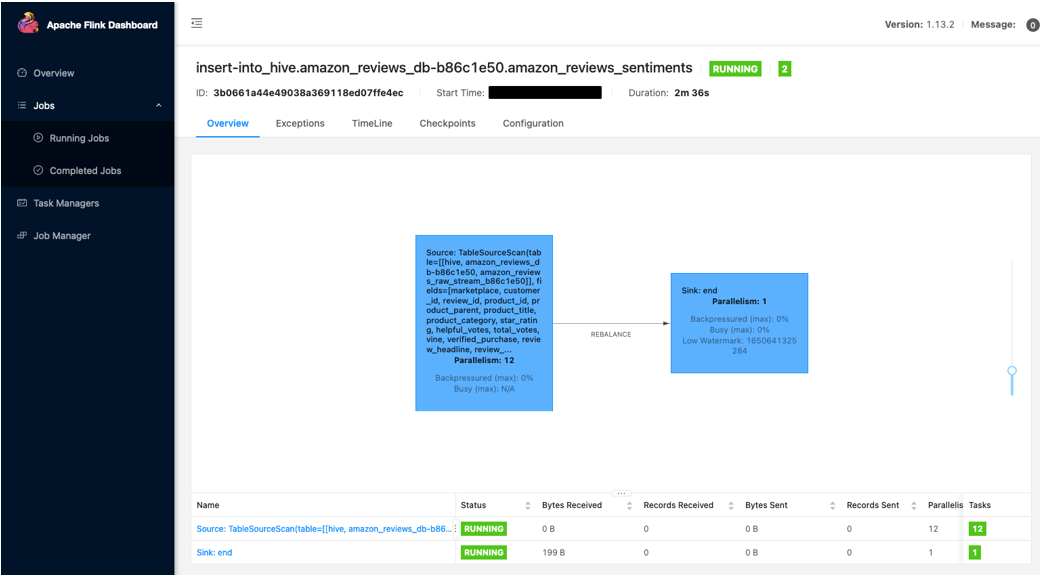
Troubleshooting
If your query fails, check the Amazon CloudWatch logs generated by the Kinesis Data Analytics for Flink application:
- On the Kinesis Data Analytics console, choose the exported application in previous steps and navigate to the Configuration
- Scroll down and choose Logging and Monitoring.
- Choose the hyperlink under Log Group to open the log streams for additional troubleshooting insights.
For more information about viewing CloudWatch logs, see Logging and Monitoring in Amazon Kinesis Data Analytics for Apache Flink.
Additional use cases
There are many use cases for the discussed text analytics functions. In addition to the example shown in this post, consider the following:
- Prepare research-ready datasets by redacting PII from customer or patient interactions.
- Simplify extract, transform, and load (ETL) pipelines by using incremental SQL queries to enrich text data with sentiment and entities, such as streaming social media streams ingested by Amazon Kinesis Data Firehose.
- Use SQL queries to explore sentiment and entities in your customer support texts, emails, and support cases.
- Standardize many languages to a single common language.
You may have additional use cases for these functions, or additional capabilities you want to see added, such as the following:
- SQL functions to call custom entity recognition and custom classification models in Amazon Comprehend.
- SQL functions for de-identification—extending the entity and PII redaction functions to replace entities with alternate unique identifiers.
The implementation is open source, which means that you can clone the repo, modify and extend the functions as you see fit, and (hopefully) send us pull requests so we can merge your improvements back into the project and make it better for everyone.
Clean up
After you complete this tutorial, you might want to clean up any AWS resources you no longer want to use. Active AWS resources can continue to incur charges in your account.
Because the deployed Kinesis Data Analytics application is independent of the CloudFormation stack, we need to delete the application individually.
- On the Kinesis Data Analytics console, select the application.
- On the Actions drop-down menu, choose Delete.
- On the AWS CloudFormation console, choose the stack deployed earlier and choose Delete.

Conclusion
We have shown you how to install the sample text analytics UDF function for Kinesis Data Analytics, so that you can use simple SQL queries to translate text using Amazon Translate, generate insights from text using Amazon Comprehend, and redact sensitive information. We hope you find this useful, and share examples of how you can use it to simplify your architectures and implement new capabilities for your business.
The SQL functions described in this post are also available for Amazon Athena and Amazon Redshift. For more information, see Translate, redact, and analyze text using SQL functions with Amazon Athena, Amazon Translate, and Amazon Comprehend and Translate and analyze text using SQL functions with Amazon Redshift, Amazon Translate, and Amazon Comprehend.
Please share your thoughts with us in the comments section, or in the issues section of the project’s GitHub repository.
Appendix: Available function reference
This section summarizes the example queries and results on non-streaming static data. To access these functions in your CloudFormation deployed environment, refer to cells #3–13 of 0-UDF-notebook.
Detect language
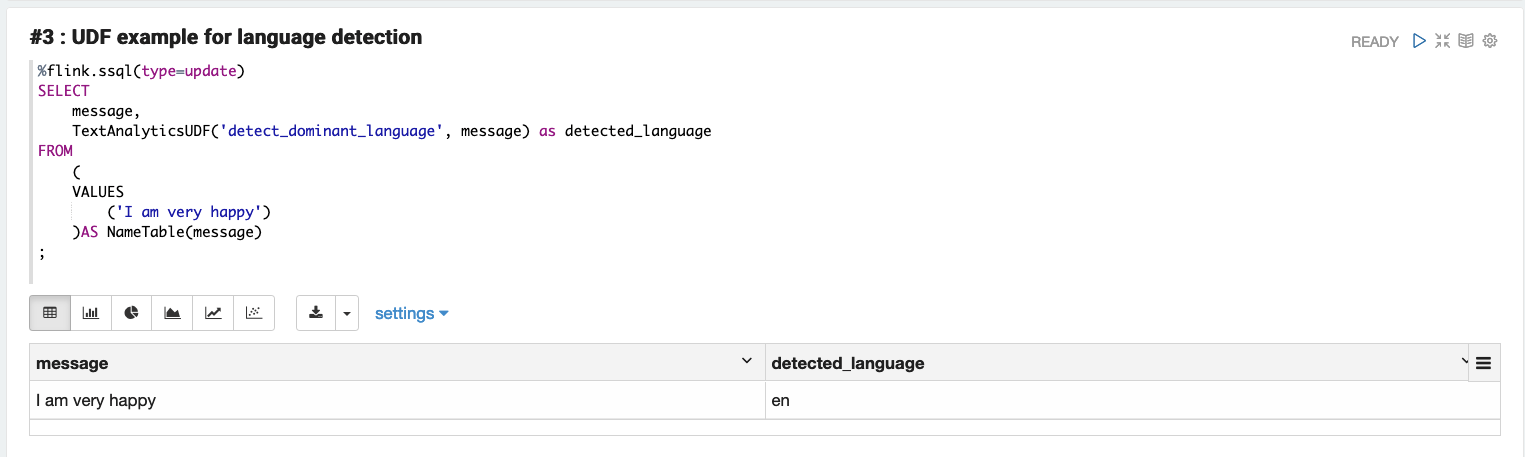
This function uses the Amazon Comprehend DetectDominantLanguage API to identify the dominant language and return a language code, such as fr for French or en for English:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_dominant_language', message) as detected_language
FROM
(
VALUES
('I am very happy')
)AS NameTable(message)
;
message | detected_language
=====================================
I am very happy | en
The following code returns a comma-separated string of language codes and corresponding confidence scores:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_dominant_language_all', message) as detected_language
FROM
(
VALUES
('I am very happy et joyeux')
)AS NameTable(message)
;
message | detected_language
============================================================================
I am very happy et joyeux | lang_code=fr,score=0.5603816,lang_code=en,score=0.30602336
Detect sentiment
This function uses the Amazon Comprehend DetectSentiment API to identify the sentiment and return results as POSITIVE, NEGATIVE, NEUTRAL, or MIXED:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF(‘detect_sentiment’, message, ‘en’) as sentiment
FROM
(
VALUES
(‘I am very happy’)
)AS NameTable(message)
;
message | sentiment
================================
I am very happy | [POSITIVE]
The following code returns a comma-separated string containing detected sentiment and confidence scores for each sentiment value:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_sentiment_all', message, 'en') as sentiment
FROM
(
VALUES
('I am very happy')
)AS NameTable(message)
;
message | sentiment
=============================================================================================================================================
I am very happy | [sentiment=POSITIVE,positiveScore=0.999519,negativetiveScore=7.407639E-5,neutralScore=2.7478999E-4,mixedScore=1.3210243E-4]
Detect entities
This function uses the Amazon Comprehend DetectEntities API to identify entities:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_entities', message, 'en') as entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | entities
=============================================================================================
I am Bob, I live in Herndon VA, and I love cars | [[["PERSON","Bob"],["LOCATION","Herndon VA"]]]
The following code returns a comma-separated string containing entity types and values:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_entities_all', message, 'en') as entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | entities
=============================================================================================
I am Bob, I live in Herndon VA, and I love cars |[score=0.9976127,type=PERSON,text=Bob,beginOffset=5,endOffset=8, score=0.995559,type=LOCATION,text=Herndon VA,beginOffset=20,endOffset=30]
Detect PII entities
This function uses the DetectPiiEntities API to identify PII:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_pii_entities', message, 'en') as pii_entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | pii_entities
=============================================================================================
I am Bob, I live in Herndon VA, and I love cars | [[["NAME","Bob"],["ADDRESS","Herndon VA"]]]
The following code returns a comma-separated string containing PII entity types, with their scores and character offsets:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('detect_pii_entities_all', message, 'en') as pii_entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | pii_entities
=============================================================================================
I am Bob, I live in Herndon VA, and I love cars | [score=0.9999832,type=NAME,beginOffset=5,endOffset=8, score=0.9999931,type=ADDRESS,beginOffset=20,endOffset=30]
Redact entities
This function replaces entity values for the specified entity types with “[ENTITY_TYPE]”:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('redact_entities', message, 'en') as redacted_entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | redacted_entities
=====================================================================================================
I am Bob, I live in Herndon VA, and I love cars | [I am [PERSON], I live in [LOCATION], and I love cars]
Redact PII entities
This function replaces PII entity values for the specified entity types with “[PII_ENTITY_TYPE]”:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF('redact_pii_entities', message, 'en') as redacted_pii_entities
FROM
(
VALUES
('I am Bob, I live in Herndon VA, and I love cars')
)AS NameTable(message)
;
message | redacted_pii_entities
=====================================================================================================
I am Bob, I live in Herndon VA, and I love cars | [I am [NAME], I live in [ADDRESS], and I love cars]
Translate text
This function translates text from the source language to the target language:
%flink.ssql(type=update)
SELECT
message,
TextAnalyticsUDF(‘translate_text’, message, ‘fr’, ‘null’) as translated_text_to_french
FROM
(
VALUES
(‘It is a beautiful day in neighborhood’)
)AS NameTable(message)
;
Message | translated_text_to_french
==================================================================================
It is a beautiful day in neighborhood | C'est une belle journée dans le quartier
About the Authors
 Nikhil Khokhar is a Solutions Architect at AWS. He joined AWS in 2016 and specializes in building and supporting data streaming solutions that help customers analyze and get value out of their data. In his free time, he makes use of his 3D printing skills to solve everyday problems.
Nikhil Khokhar is a Solutions Architect at AWS. He joined AWS in 2016 and specializes in building and supporting data streaming solutions that help customers analyze and get value out of their data. In his free time, he makes use of his 3D printing skills to solve everyday problems.
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Read More


























 Aditi Rajnish is a second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found playing badminton, learning new songs on the piano, or hiking in North America’s national parks.
Aditi Rajnish is a second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found playing badminton, learning new songs on the piano, or hiking in North America’s national parks. Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision. Mason Force is a Solutions Architect based in Seattle. He specializes in Analytics and helps enterprise customers across the western and central United States develop efficient data strategies. Outside of work, Mason enjoys bouldering, snowboarding and exploring the wilderness across the Pacific Northwest.
Mason Force is a Solutions Architect based in Seattle. He specializes in Analytics and helps enterprise customers across the western and central United States develop efficient data strategies. Outside of work, Mason enjoys bouldering, snowboarding and exploring the wilderness across the Pacific Northwest.






 Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.







