Today, we’re excited to announce self-service quota management support for Amazon Textract via the AWS Service Quotas console, and higher default service quotas in select AWS Regions.
Customers tell us they need quick turnaround times to process their requests for quota increases and visibility into their service quotas so they may continue to scale their Amazon Textract usage. With this launch, we’re improving Amazon Textract support for service quotas by enabling you to self-manage your service quotas via the Service Quotas console. In addition to viewing the default service quotas, you can now view your account’s applied custom quotas for a specific Region, view your historical utilization metrics per applied quota, set up alarms to notify when utilization approaches a threshold, and add tags to your quotas for easier organization. Additionally, we’re launching the Amazon Textract Service Quota Calculator, which will help you quickly estimate service quota requirements for your workload prior to submitting a quota increase request.
In this post, we discuss the updated default service quotas, the new service quota management capabilities, and the service quota calculator for Amazon Textract.
Increased default service quotas for Amazon Textract
Amazon Textract now has higher service quotas for several asynchronous and synchronous APIs in multiple major AWS Regions. The updated default service quotas are available for US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai), and Europe (Ireland) Regions. The following table summarizes the before and after default quota numbers for each of these Regions for the respective synchronous and asynchronous APIs. You can refer to Amazon Textract endpoints and quotas to learn more about the current default quotas.
| Synchronous Operations |
API |
Region |
Before |
After |
| Transactions per second per account for synchronous operations |
AnalyzeDocument |
US East (Ohio) |
1 |
10 |
| Asia Pacific (Mumbai) |
1 |
5 |
| Europe (Ireland) |
1 |
5 |
| DetectDocumentText |
US East (Ohio) |
1 |
10 |
| US East (N. Virginia) |
10 |
25 |
| US West (Oregon) |
10 |
25 |
| Asia Pacific (Mumbai) |
1 |
5 |
| Europe (Ireland) |
1 |
5 |
| Asynchronous Operations |
API |
Region |
Before |
After |
| Transactions per second per account for all Start (asynchronous) operations |
StartDocumentAnalysis |
US East (Ohio) |
2 |
10 |
| Asia Pacific (Mumbai) |
2 |
5 |
| Europe (Ireland) |
2 |
5 |
| StartDocumentTextDetection |
US East (Ohio) |
1 |
5 |
| US East (N. Virginia) |
10 |
15 |
| US West (Oregon) |
10 |
15 |
| Asia Pacific (Mumbai) |
1 |
5 |
| Europe (Ireland) |
1 |
5 |
| Transactions per second per account for all Get (asynchronous) operations |
GetDocumentAnalysis |
US East (Ohio) |
5 |
10 |
| GetDocumentTextDetection |
US East (Ohio) |
5 |
10 |
| US East (N. Virginia) |
10 |
25 |
| US West (Oregon) |
10 |
25 |
Improved service quota support for Amazon Textract
Starting today, you can manage your Amazon Textract service quotas via the Service Quotas console. Requests may now be processed automatically, speeding up approval times. After a quota request for a specific Region is approved, the new quota is immediately available for scaling your Amazon Textract usage and also visible on the Service Quotas console. You can see the default and applied quota values for your account in a given Region, and view the historical utilization metrics via an integrated Amazon CloudWatch graph. This enables you to make informed decisions about whether a quota increase is required to scale your workload. You can also use CloudWatch alarms to notify whenever a specified quota reaches a predefined threshold, which can help investigate issues with your applications or monitor spikey workloads. You can also add tags to the quotas, which allows better administration and monitoring.
The following sections discusses the features that are now available via the Service Quotas console for Amazon Textract.
Default and applied quotas
You can now have visibility into the AWS default quota value and applied quota value of a specific quota for Amazon Textract on the Service Quotas console. The default quota value is the default value of the quota in that specific Region, and the applied quota value is the currently applied value for that quota for the account in that Region.
Monitoring via CloudWatch graphs
The Service Quotas console also displays a utilization against the total applied quota value. You can also view the weekly, daily, and hourly trend in utilization of the applied quota through an integrated CloudWatch graph, right from the Service Quotas console, for a given quota. You can add this graph to a custom CloudWatch dashboard for better monitoring and reporting of service usage and overall utilization.

We have also added the capability to set up CloudWatch alarms to notify you automatically whenever a specified quota reaches a certain configurable threshold. This helps you monitor the usage of Amazon Textract from your applications, analyze spikey workloads, make informed decisions about the overall utilization, control costs, and make improvements to the application’s architecture.
Quota tagging
With quota tagging, you can now add tags to applied quotas to simplify administration. Tags help you identify and organize AWS resources. With quota tags, you can manage the applied service quotas for Amazon Textract along with other AWS service quotas, as part of your administration and governance practices. You can better manage and monitor quotas and quota utilization for different environments based on tags. For example, you can use production or development tags to logically separate and monitor dev environment and production environment quotas and quota utilization for accounts under AWS Organizations and unified reporting.
Amazon Textract Service Quota Calculator
We’re introducing a new quota calculator on the Amazon Textract console. The quota calculator helps forecast service quota requirements based on answers to questions about your workload and usage of Amazon Textract. With calculations based on your usage patterns, such as number of documents and number of pages per document, it provides actionable recommendations in the form of a required quota value for the workload.
As shown in the following screenshot, the quota calculator is now accessible directly from the Amazon Textract console. You can also navigate to the Service Quotas console directly from the calculator, where you can manage the service quotas based on the calculated recommendations.

Quota calculator for synchronous operations
To view the current quota values and recommended quota values for synchronous operations, you start by selecting Synchronous under Processing type. For example, if you’re interested in calculating the desired quota values for your workload that uses the DetectDocumentText API, you select the Synchronous processing type, and then choose Detect Document Text on the Use case type drop-down menu.

After you specify your desired options, the quota calculator prompts for additional inputs, which include the maximum number of documents you expect to process via the API per day or per hour. The corresponding numbers of documents to be processed shown under View calculation is automatically calculated based on the input. Because synchronous processing allows text detection and analysis of single-page documents, the number of pages per document defaults to 1. For multi-page documents, we recommend using asynchronous processing.
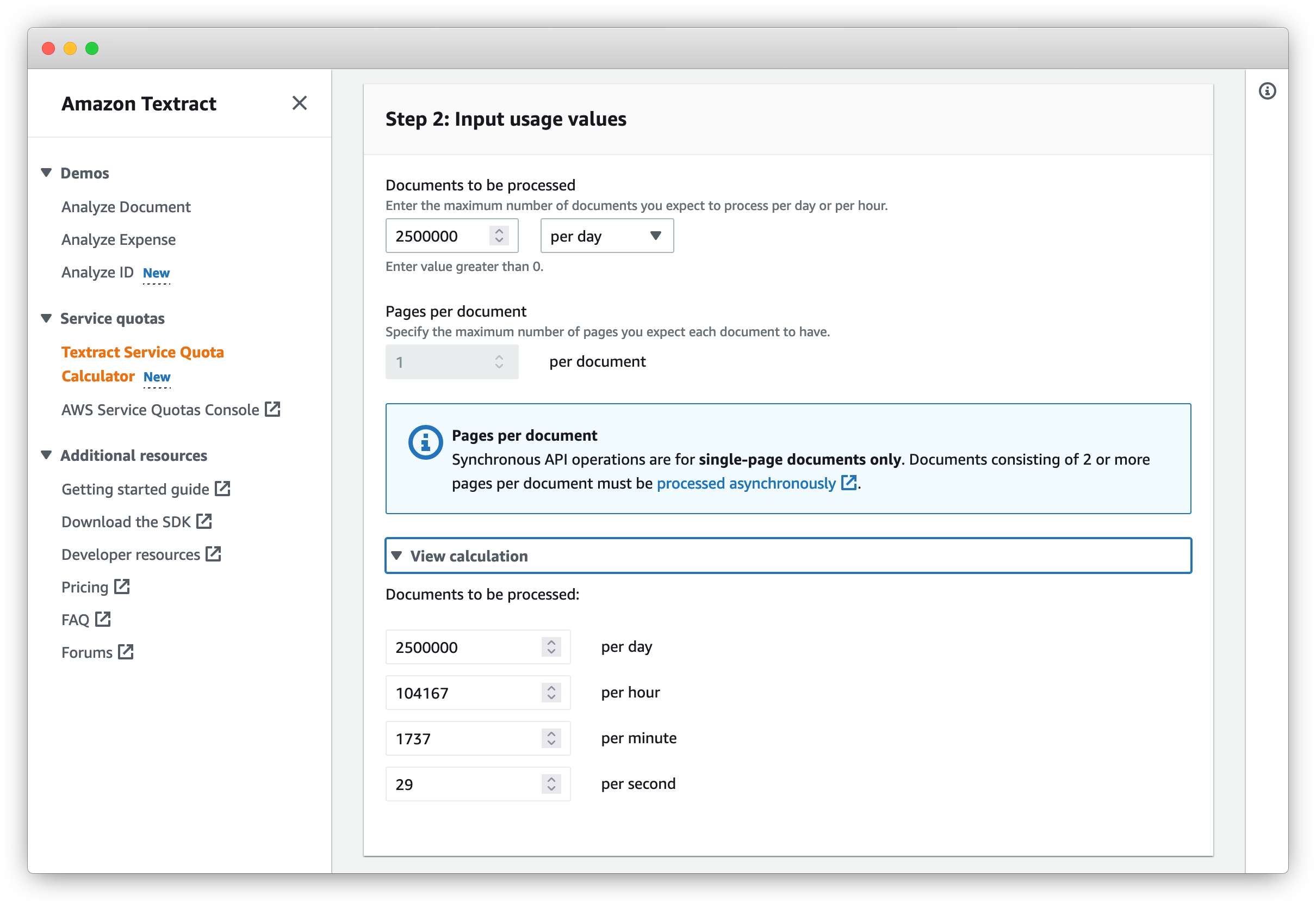
The output of this calculation is a current quota value applicable for that account in the current Region, and the recommended quota value, based on the quota type selected and the provided number of documents.

You can copy the recommended quota value within the calculator and use the Quota type (in this case, DetectDocumentText) deep link to navigate to the specific quota on the Service Quotas console to create a quota increase request.
Quota calculator for asynchronous operations
The way to view current quota values and recommended quota values for asynchronous operations is similar to that of the synchronous operations. Specify the use case type for your asynchronous operation usage, and answer a few questions relevant to your workload to view the current quotas and recommended quotas for all the asynchronous operations relevant to the use case.
For example, if you’re running asynchronous jobs using the StartDocumentTextDetection API and consecutively using the GetDocumentTextDetection API to get the results of the job in your workload, choose the Document Text Detection option as your use case. Because these two APIs are always used in conjunction to each other, the calculator provides recommendations for both the APIs. For asynchronous operations, there are limits on the total number of concurrent jobs that can be run per account in a given Region. Therefore, the calculator also calculates the recommended total number of concurrent asynchronous jobs recommended for your workload.

In addition to the processing type and use case type, you need to provide specific values relevant to your workload:
- The maximum number of documents you expect to process
- A processing time frame value in hours, which is the approximate length of time over which you expect to process the documents
- The maximum number of pages per document, because asynchronous operations allow processing multi-page documents

Quota calculation for asynchronous operations generates recommended quota values for all the asynchronous APIs relevant to the selected use case. In our example, the quota values for the StartDocumentTextDetection API, GetDocumentTextDetection API, and number of concurrent text detection jobs are generated by the calculator, as shown in the following screenshot. You can then use the required quota value to request quota increases via the Service Quotas console using the corresponding deep links under Quota type.

It’s worth noting that the all the quota-related information within the calculator is shown for the current AWS Region for the AWS Management Console. To view the quota information for a different Region, you can change the Region manually from the top navigation bar of the console. Recommendations generated by the calculator are based on the current applied quota for that account for the current Region, the selected processing type (asynchronous and synchronous), and other information relevant to your workload. You can use these recommendations to submit quota increase requests via the Service Quotas console. Although most requests are processed automatically, some requests may need additional manual review prior to being approved.
Conclusion
In this post, we announced the updated default service quotas in select AWS Regions and the self-service quota management capabilities of Amazon Textract. We also announced the availability of a new quota calculator, available on the Amazon Textract console. You can start taking advantage of the new default service quotas, and use the Amazon Textract quota calculator to generate recommended quota values to quickly scale your workload. With the improved Service Quotas console for Amazon Textract, you can request quota increases, monitor quota utilization and service usage, and set up alarms. With the features announced in this post, you can now easily monitor your quota utilization, manage costs, and follow best practices to scale your Amazon Textract usage.
To learn more about the Amazon Textract service quota calculator and extended features for quota management, visit Quotas in Amazon Textract.
About the authors
 Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
 Shashwat Sapre is a Senior Technical Product Manager with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers. In his spare time, he likes reading about new technologies, traveling and exploring different cuisines.
Shashwat Sapre is a Senior Technical Product Manager with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers. In his spare time, he likes reading about new technologies, traveling and exploring different cuisines.
Read More