
Editor’s note: This is the first in a series of blogs on researchers advancing science in the expanding universe of high performance computing.
A perpetual shower of random raindrops falls inside a three-foot metal ring Dale Durran erected outside his front door (shown above). It’s a symbol of his passion for finding order in the seeming chaos of the planet’s weather.
A part-time sculptor and full-time professor of atmospheric science at the University of Washington, Durran has co-authored dozens of papers describing patterns in Earth’s ever-changing skies. It’s a field for those who crave a confounding challenge trying to express with math the endless dance of air and water.

In 2019, Durran acquired a new tool, AI. He teamed up with a grad student and a Microsoft researcher to build the first model to demonstrate deep learning’s potential to predict the weather.
Though crude, the model outperformed the complex equations used for the first computer-based forecasts. The descendants of those equations now run on the world’s biggest supercomputers. In contrast, AI slashes the traditional load of required calculations and works faster on much smaller systems.
“It was a dramatic revelation that said we better jump into this with both feet,” Durran recalled.
Sunny Outlook for AI
Last year, the team took their work to the next level. Their latest neural network can process 320 six-week forecasts in less than a minute on the four NVIDIA A100 Tensor Core GPUs in an NVIDIA DGX Station. That’s more than 6x the 51 forecasts today’s supercomputers synthesize to make weather predictions.
In a show of how rapidly the technology is evolving, the model was able to forecast, almost as well as traditional methods, what became the path of Hurricane Irma through the Caribbean in 2017. The same model also could crank out a week’s forecast in a tenth of a second on a single NVIDIA V100 Tensor Core GPU.
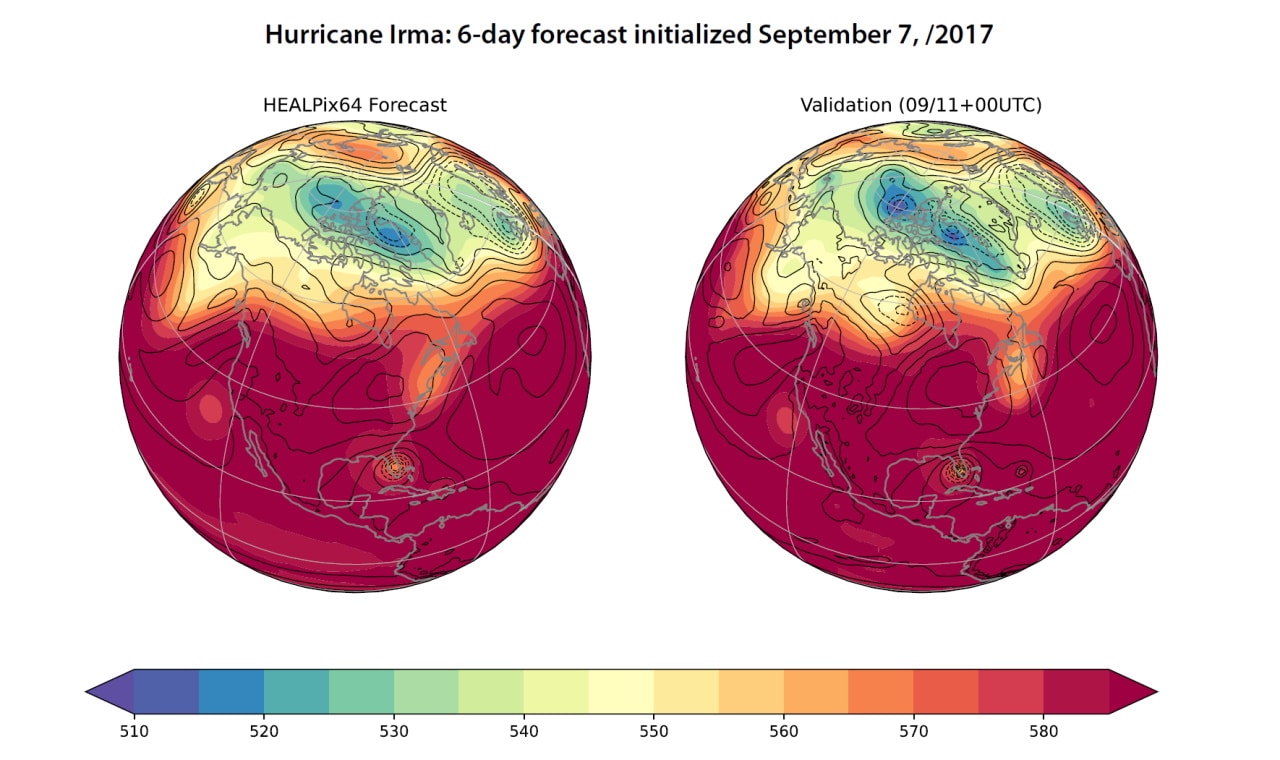
Durran foresees AI crunching thousands of forecasts simultaneously to deliver a clearer statistical picture with radically fewer resources than conventional equations. Some suggest the performance advances will be measured in as many as five orders of magnitude and use a fraction of the power.
AI Ingests Satellite Data
The next big step could radically widen the lens for weather watchers.
The complex equations today’s predictions use can’t readily handle the growing wealth of satellite data on details like cloud patterns, soil moisture and drought stress in plants. Durran believes AI models can.
One of his graduate students hopes to demonstrate this winter an AI model that directly incorporates satellite data on global cloud cover. If successful, it could point the way for AI to improve forecasts using the deluge of data types now being collected from space.
In a separate effort, researchers at the University of Washington are using deep learning to apply a grid astronomers use to track stars to their work understanding the atmosphere. The novel mesh could help map out a whole new style of weather forecasting, Durran said.
Harvest of a Good Season
In nearly 40 years as an educator, Durran has mentored dozens of students and wrote two highly rated textbooks on fluid dynamics, the math used to understand the weather and climate.
One of his students, Gretchen Mullendore, now heads a lab at the U.S. National Center for Atmospheric Research, working with top researchers to improve weather forecasting models.
“I was lucky to work with Dale in the late 1990s and early 2000s on adapting numerical weather prediction to the latest hardware at the time,” said Mullendore. “I am so thankful to have had an advisor that showed me it’s cool to be excited by science and computers.”
Carrying on a Legacy
Durran is slated to receive in January the American Meteorological Society’s most prestigious honor, the Jule G. Charney Medal. It’s named after the scientist who worked with John von Neumann to develop in the 1950s the algorithms weather forecasters still use today.
Charney was also author in 1979 of one of the earliest scientific papers on global warming. Following in his footsteps, Durran wrote two editorials last year for The Washington Post to help a broad audience understand the impacts of climate change and rising CO2 emissions.
The editorials articulate a passion he discovered at his first job in 1976, creating computer models of air pollution trends. “I decided I’d rather work on the front end of that problem,” he said of his career shift to meteorology.
It’s a field notoriously bedeviled by effects as subtle as a butterfly’s wings that motivates his passion to advance science.
The post Stormy Weather? Scientist Sharpens Forecasts With AI appeared first on NVIDIA Blog.
