Students will receive funding to pursue independent research projects in robotics and adjacent areas in AI.Read More
Improve data extraction and document processing with Amazon Textract
Intelligent document processing (IDP) has seen widespread adoption across enterprise and government organizations. Gartner estimates the IDP market will grow more than 100% year over year, and is projected to reach $4.8 billion in 2022.
IDP helps transform structured, semi-structured, and unstructured data from a variety of document formats into actionable information. Processing unstructured data has become much easier with the advancements in optical character recognition (OCR), machine learning (ML), and natural language processing (NLP).
IDP techniques have grown tremendously, allowing us to extract, classify, identify, and process unstructured data. With AI/ML powered services such as Amazon Textract, Amazon Transcribe, and Amazon Comprehend, building an IDP solution has become much easier and doesn’t require specialized AI/ML skills.
In this post, we demonstrate how to use Amazon Textract to extract meaningful, actionable data from a wide range of complex multi-format PDF files. PDF files are challenging; they can have a variety of data elements like headers, footers, tables with data in multiple columns, images, graphs, and sentences and paragraphs in different formats. We explore the data extraction phase of IDP, and how it connects to the steps involved in a document process, such as ingestion, extraction, and postprocessing.
Solution overview
Amazon Textract provides various options for data extraction, based on your use case. You can use forms, tables, query-based extractions, handwriting recognition, invoices and receipts, identity documents, and more. All the extracted data is returned with bounding box coordinates. This solution uses Amazon Textract IDP CDK constructs to build the document processing workflow that handles Amazon Textract asynchronous invocation, raw response extraction, and persistence in Amazon Simple Storage Service (Amazon S3). This solution adds an Amazon Textract postprocessing component to the base workflow to handle paragraph-based text extraction.
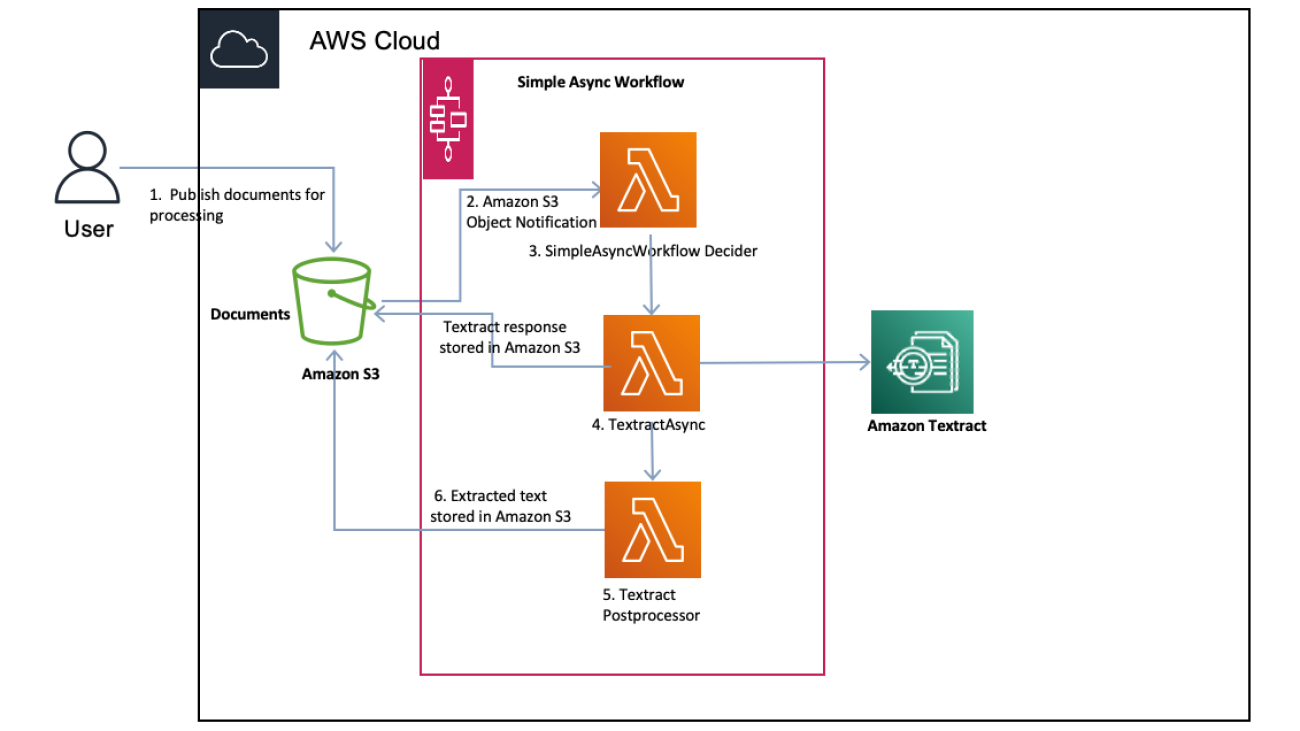
The following diagram shows the document processing flow.

The document processing flow contains the following steps:
- The document extraction flow is initiated when a user uploads a PDF document to Amazon S3.
- An S3 object notification event triggered by new the S3 object with an
uploads/prefix, which triggers the AWS Step Functions asynchronous workflow. - The AWS Lambda function
SimpleAsyncWorkflowDecider validates the PDF document. This step prevents processing invalid documents. - TextractAsync is an IDP CDK construct that abstracts the invocation of the Amazon Textract
AsyncAPI, handling Amazon Simple Notification Service (Amazon SNS) messages and workflow processing. The following are some high-level steps:- The construct invokes the asynchronous Amazon Textract StartDocumentTextDetection API.
- Amazon Textract processes the PDF file and publishes a completion status event to an Amazon SNS topic.
- Amazon Textract stores the paginated results in Amazon S3.
- Construct handles the Amazon Textract completion event, returns the paginated results output prefix to the main workflow.
- The Textract Postprocessor Lambda function uses the extracted content in the results Amazon S3 bucket to retrieve the document data. This function iterates through all the files, and extracts data using bounding boxes and other metadata. It performs various postprocessing optimizations to aggregate paragraph data, identify and ignore headers and footers, combine sentences spread across pages, process data in multiple columns, and more.
- The Textract Postprocessor Lambda function persists the aggregated paragraph data as a CSV file in Amazon S3.
Deploy the solution with the AWS CDK
To deploy the solution, launch the AWS Cloud Development Kit (AWS CDK) using AWS Cloud9 or from your local system. If you’re launching from your local system, you need to have the AWS CDK and Docker installed. Follow the instructions in the GitHub repo for deployment.
The stack creates the key components depicted in the architecture diagram.
Test the solution
The GitHub repo contains the following sample files:
- sample_climate_change.pdf – Contains headers, footers, and sentences flowing across pages
- sample_multicolumn.pdf – Contains data in two columns, headers, footers, and sentences flowing across pages
To test the solution, complete the following steps:
- Upload the sample PDF files to the S3 bucket created by the stack: The file upload triggers the Step Functions workflow via S3 event notification.
- Open the Step Functions console to view the workflow status. You should find one workflow instance per document.

- Wait for all three steps to complete.
- On the Amazon S3 console, browse to the S3 prefix mentioned in the JSON path
TextractTempOutputJsonPath. The below screenshot of the Amazon S3 console shows the Amazon Textract paginated results (in this case objects 1 and 2) created by Amazon Textract. The postprocessing task stores the extracted paragraphs from the sample PDF asextracted-text.csv.
- Download the
extracted-text.csvfile to view the extracted content.
The sample_climate_change.pdf file has sentences flowing across pages, as shown in the following screenshot.

The postprocessor identifies and ignores the header and footer, and combines the text across pages into one paragraph. The extracted text for the combined paragraph should look like:
“Impacts on this scale could spill over national borders, exacerbating the damage further. Rising sea levels and other climate-driven changes could drive millions of people to migrate: more than a fifth of Bangladesh could be under water with a 1m rise in sea levels, which is a possibility by the end of the century. Climate-related shocks have sparked violent conflict in the past, and conflict is a serious risk in areas such as West Africa, the Nile Basin and Central Asia.”
The sample_multi_column.pdf file has two columns of text with headers and footers, as shown in the following screenshot.

The postprocessor identifies and ignores the header and footer, processes the text in the columns from left to right, and combines incomplete sentences across pages. The extracted text should construct paragraphs from text in the left column and separate paragraphs from text in the right column. The last line in the right column is incomplete on that page and continues in the left column of the next page; the postprocessor should combine them as one paragraph.
Cost
With Amazon Textract, you pay as you go based on the number of pages in the document. Refer to Amazon Textract pricing for actual costs.
Clean up
When you’re finished experimenting with this solution, clean up your resources by using the AWS CloudFormation console to delete all the resources deployed in this example. This helps you avoid continuing costs in your account.
Conclusion
You can use the solution presented in this post to build an efficient document extraction workflow and process the extracted document according to your needs. If you’re building an intelligent document processing system, you can further process the extracted document using Amazon Comprehend to get more insights about the document.
For more information about Amazon Textract, visit Amazon Textract resources to find video resources and blog posts, and refer to Amazon Textract FAQs. For more information about the IDP reference architecture, refer to Intelligent Document Processing. Please share your thoughts with us in the comments section, or in the issues section of the project’s GitHub repository.
About the Author
 Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
3 ways AI is scaling helpful technologies worldwide
I was first introduced to neural networks as an undergraduate in 1990. Back then, many people in the AI community were excited about the potential of neural networks, which were impressive, but couldn’t yet accomplish important, real-world tasks. I was excited, too! I did my senior thesis on using parallel computation to train neural networks, thinking we only needed 32X more compute power to get there. I was way off. At that time, we needed 1 million times as much computational power.
A short 21 years later, with exponentially more computational power, it was time to take another crack at neural networks. In 2011, I and a few others at Google started training very large neural networks using millions of randomly selected frames from videos online. The results were remarkable. Without explicit training, the system automatically learned to recognize different objects (especially cats, the Internet is full of cats). This was one transformational discovery in AI among a long string of successes that is still ongoing — at Google and elsewhere.
I share my own history of neural networks to illustrate that, while progress in AI might feel especially fast right now, it’s come from a long arc of progress. In fact, prior to 2012, computers had a really difficult time seeing, hearing, or understanding spoken or written language. Over the past 10 years we’ve made especially rapid progress in AI.
Today, we’re excited about many recent advances in AI that Google is leading — not just on the technical side, but in responsibly deploying it in ways that help people around the world. That means deploying AI in Google Cloud, in our products from Pixel phones to Google Search, and in many fields of science and other human endeavors.
We’re aware of the challenges and risks that AI poses as an emerging technology. We were the first major company to release and operationalize a set of AI Principles, and following them has actually (and some might think counterintuitively) allowed us to focus on making rapid progress on technologies that can be helpful to everyone. Getting AI right needs to be a collective effort — involving not just researchers, but domain experts, developers, community members, businesses, governments and citizens.
I’m happy to make announcements in three transformative areas of AI today: first, using AI to make technology accessible in many more languages. Second, exploring how AI might bolster creativity. And third, in AI for Social Good, including climate adaptation.
1. Supporting 1,000 languages with AI
Language is fundamental to how people communicate and make sense of the world. So it’s no surprise it’s also the most natural way people engage with technology. But more than 7,000 languages are spoken around the world, and only a few are well represented online today. That means traditional approaches to training language models on text from the web fail to capture the diversity of how we communicate globally. This has historically been an obstacle in the pursuit of our mission to make the world’s information universally accessible and useful.
That’s why today we’re announcing the 1,000 Languages Initiative, an ambitious commitment to build an AI model that will support the 1,000 most spoken languages, bringing greater inclusion to billions of people in marginalized communities all around the world. This will be a many years undertaking – some may even call it a moonshot – but we are already making meaningful strides here and see the path clearly. Technology has been changing at a rapid clip – from the way people use it to what it’s capable of. Increasingly, we see people finding and sharing information via new modalities like images, videos, and speech. And our most advanced language models are multimodal – meaning they’re capable of unlocking information across these many different formats. With these seismic shifts come new opportunities.

As part of our this initiative and our focus on multimodality, we’ve developed a Universal Speech Model — or USM — that’s trained on over 400 languages, making it the largest language coverage seen in a speech model to date. As we expand on this work, we’re partnering with communities across the world to source representative speech data. We recently announced voice typing for 9 more African languages on Gboard by working closely with researchers and organizations in Africa to create and publish data. And in South Asia, we are actively working with local governments, NGOs, and academic institutions to eventually collect representative audio samples from across all the regions’ dialects and languages.
2. Empowering creators and artists with AI
AI-powered generative models have the potential to unlock creativity, helping people across cultures express themselves using video, imagery, and design in ways that they previously could not.
Our researchers have been hard at work developing models that lead the field in terms of quality, generating images that human raters prefer over other models. We recently shared important breakthroughs, applying our diffusion model to video sequences and generating long coherent videos for a sequence of text prompts. We can combine these techniques to produce video — for the first time, today we’re sharing AI-generated super-resolution video:
We’ll soon be bringing our text-to-image generation technologies to AI Test Kitchen, which provides a way for people to learn about, experience, and give feedback on emerging AI technology. We look forward to hearing feedback from users on these demos in AI Test Kitchen Season 2. You’ll be able to build themed cities with “City Dreamer” and design friendly monster characters that can move, dance, and jump with “Wobble” — all by using text prompts.
In addition to 2D images, text-to-3D is now a reality with DreamFusion, which produces a three-dimensional model that can be viewed from any angle and can be composited into any 3D environment. Researchers are also making significant progress in the audio generation space with AudioLM, a model that learns to generate realistic speech and piano music by listening to audio only. In the same way a language model might predict the words and sentences that follow a text prompt, AudioLM can predict which sounds should follow after a few seconds of an audio prompt.
We’re collaborating with creative communities globally as we develop these tools. For example, we’re working with writers using Wordcraft, which is built on our state-of-the-art dialog system LaMDA, to experiment with AI-powered text generation. You can read the first volume of these stories at the Wordcraft Writers Workshop.
3. Addressing climate change and health challenges with AI
AI also has great potential to address the effects of climate change, including helping people adapt to new challenges. One of the worst is wildfires, which affect hundreds of thousands of people today, and are increasing in frequency and scale.
Today, I’m excited to share that we’ve advanced our use of satellite imagery to train AI models to identify and track wildfires in real time, helping predict how they will evolve and spread. We’ve launched this wildfire tracking system in the U.S., Canada, Mexico, and are rolling out in parts of Australia, and since July we’ve covered more than 30 big wildfire events in the U.S. and Canada, helping inform our users and firefighting teams with over 7 million views in Google Search and Maps.
We’re also using AI to forecast floods, another extreme weather pattern exacerbated by climate change. We’ve already helped communities to predict when floods will hit and how deep the waters will get — in 2021, we sent 115 million flood alert notifications to 23 million people over Google Search and Maps, helping save countless lives. Today, we’re sharing that we’re now expanding our coverage to more countries in South America (Brazil and Colombia), Sub-Saharan Africa (Burkina Faso, Cameroon, Chad, Democratic Republic of Congo, Ivory Coast, Ghana, Guinea, Malawi, Nigeria, Sierra Leone, Angola, South Sudan, Namibia, Liberia, and South Africa), and South Asia (Sri Lanka). We’ve used an AI technique called transfer learning to make it work in areas where there’s less data available. We’re also announcing the global launch of Google FloodHub, a new platform that displays when and where floods may occur. We’ll also be bringing this information to Google Search and Maps in the future to help more people to reach safety in flooding situations.
Finally, AI is helping provide ever more access to healthcare in under-resourced regions. For example, we’re researching ways AI can help read and analyze outputs from low-cost ultrasound devices, giving parents the information they need to identify issues earlier in a pregnancy. We also plan to continue to partner with caregivers and public health agencies to expand access to diabetic retinopathy screening through our Automated Retinal Disease Assessment tool (ARDA). Through ARDA, we’ve successfully screened more than 150,000 patients in countries like India, Thailand, Germany, the United States, and the United Kingdom across deployed use and prospective studies — more than half of those in 2022 alone. Further, we’re exploring how AI can help your phone detect respiratory and heart rates. This work is part of Google Health’s broader vision, which includes making healthcare more accessible for anyone with a smartphone.
AI in the years ahead
Our advancements in neural network architectures, machine learning algorithms and new approaches to hardware for machine learning have helped AI solve important, real-world problems for billions of people. Much more is to come. What we’re sharing today is a hopeful vision for the future — AI is letting us reimagine how technology can be helpful. We hope you’ll join us as we explore these new capabilities and use this technology to improve people’s lives around the world.

Robots That Write Their Own Code
<!– –><!–
–><!– –>
–>
A common approach used to control robots is to program them with code to detect objects, sequencing commands to move actuators, and feedback loops to specify how the robot should perform a task. While these programs can be expressive, re-programming policies for each new task can be time consuming, and requires domain expertise.
What if when given instructions from people, robots could autonomously write their own code to interact with the world? It turns out that the latest generation of language models, such as PaLM, are capable of complex reasoning and have also been trained on millions of lines of code. Given natural language instructions, current language models are highly proficient at writing not only generic code but, as we’ve discovered, code that can control robot actions as well. When provided with several example instructions (formatted as comments) paired with corresponding code (via in-context learning), language models can take in new instructions and autonomously generate new code that re-composes API calls, synthesizes new functions, and expresses feedback loops to assemble new behaviors at runtime. More broadly, this suggests an alternative approach to using machine learning for robots that (i) pursues generalization through modularity and (ii) leverages the abundance of open-source code and data available on the Internet.
 |
| Given code for an example task (left), language models can re-compose API calls to assemble new robot behaviors for new tasks (right) that use the same functions but in different ways. |
To explore this possibility, we developed Code as Policies (CaP), a robot-centric formulation of language model-generated programs executed on physical systems. CaP extends our prior work, PaLM-SayCan, by enabling language models to complete even more complex robotic tasks with the full expression of general-purpose Python code. With CaP, we propose using language models to directly write robot code through few-shot prompting. Our experiments demonstrate that outputting code led to improved generalization and task performance over directly learning robot tasks and outputting natural language actions. CaP allows a single system to perform a variety of complex and varied robotic tasks without task-specific training.
| We demonstrate, across several robot systems, including a robot from Everyday Robots, that language models can autonomously interpret language instructions to generate and execute CaPs that represent reactive low-level policies (e.g., proportional-derivative or impedance controllers) and waypoint-based policies (e.g., vision-based pick and place, trajectory-based control). |
A Different Way to Think about Robot Generalization
To generate code for a new task given natural language instructions, CaP uses a code-writing language model that, when prompted with hints (i.e., import statements that inform which APIs are available) and examples (instruction-to-code pairs that present few-shot “demonstrations” of how instructions should be converted into code), writes new code for new instructions. Central to this approach is hierarchical code generation, which prompts language models to recursively define new functions, accumulate their own libraries over time, and self-architect a dynamic codebase. Hierarchical code generation improves state-of-the-art on both robotics as well as standard code-gen benchmarks in natural language processing (NLP) subfields, with 39.8% pass@1 on HumanEval, a benchmark of hand-written coding problems used to measure the functional correctness of synthesized programs.
Code-writing language models can express a variety of arithmetic operations and feedback loops grounded in language. Pythonic language model programs can use classic logic structures, e.g., sequences, selection (if/else), and loops (for/while), to assemble new behaviors at runtime. They can also use third-party libraries to interpolate points (NumPy), analyze and generate shapes (Shapely) for spatial-geometric reasoning, etc. These models not only generalize to new instructions, but they can also translate precise values (e.g., velocities) to ambiguous descriptions (“faster” and “to the left”) depending on the context to elicit behavioral commonsense.
|
| Code as Policies uses code-writing language models to map natural language instructions to robot code to complete tasks. Generated code can call existing perception action APIs, third party libraries, or write new functions at runtime. |
CaP generalizes at a specific layer in the robot: interpreting natural language instructions, processing perception outputs (e.g., from off-the-shelf object detectors), and then parameterizing control primitives. This fits into systems with factorized perception and control, and imparts a degree of generalization (acquired from pre-trained language models) without the magnitude of data collection needed for end-to-end robot learning. CaP also inherits language model capabilities that are unrelated to code writing, such as supporting instructions with non-English languages and emojis.
 |
| CaP inherits the capabilities of language models, such as multilingual and emoji support. |
By characterizing the types of generalization encountered in code generation problems, we can also study how hierarchical code generation improves generalization. For example, “systematicity” evaluates the ability to recombine known parts to form new sequences, “substitutivity” evaluates robustness to synonymous code snippets, while “productivity” evaluates the ability to write policy code longer than those seen in the examples (e.g., for new long horizon tasks that may require defining and nesting new functions). Our paper presents a new open-source benchmark to evaluate language models on a set of robotics-related code generation problems. Using this benchmark, we find that, in general, bigger models perform better across most metrics, and that hierarchical code generation improves “productivity” generalization the most.
 |
| Performance on our RoboCodeGen Benchmark across different generalization types. The larger model (Davinci) performs better than the smaller model (Cushman), with hierarchical code generation improving productivity the most. |
We’re also excited about the potential for code-writing models to express cross-embodied plans for robots with different morphologies that perform the same task differently depending on the available APIs (perception action spaces), which is an important aspect of any robotics foundation model.
 |
| Language model code-generation exhibits cross-embodiment capabilities, completing the same task in different ways depending on the available APIs (that define perception action spaces). |
Limitations
Code as policies today are restricted by the scope of (i) what the perception APIs can describe (e.g., few visual-language models to date can describe whether a trajectory is “bumpy” or “more C-shaped”), and (ii) which control primitives are available. Only a handful of named primitive parameters can be adjusted without over-saturating the prompts. Our approach also assumes all given instructions are feasible, and we cannot tell if generated code will be useful a priori. CaPs also struggle to interpret instructions that are significantly more complex or operate at a different abstraction level than the few-shot examples provided to the language model prompts. Thus, for example, in the tabletop domain, it would be difficult for our specific instantiation of CaPs to “build a house with the blocks” since there are no examples of building complex 3D structures. These limitations point to avenues for future work, including extending visual language models to describe low-level robot behaviors (e.g., trajectories) or combining CaPs with exploration algorithms that can autonomously add to the set of control primitives.
Open-Source Release
We have released the code needed to reproduce our experiments and an interactive simulated robot demo on the project website, which also contains additional real-world demos with videos and generated code.
Conclusion
Code as policies is a step towards robots that can modify their behaviors and expand their capabilities accordingly. This can be enabling, but the flexibility also raises potential risks since synthesized programs (unless manually checked per runtime) may result in unintended behaviors with physical hardware. We can mitigate these risks with built-in safety checks that bound the control primitives that the system can access, but more work is needed to ensure new combinations of known primitives are equally safe. We welcome broad discussion on how to minimize these risks while maximizing the potential positive impacts towards more general-purpose robots.
Acknowledgements
This research was done by Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng. Special thanks to Vikas Sindhwani, Vincent Vanhoucke for helpful feedback on writing, Chad Boodoo for operations and hardware support. An early preprint is available on arXiv.

How we’re using AI to help address the climate crisis
Communities around the world are facing the effects of climate change — from devastating floods and wildfires to challenges around food security. As global leaders meet in Egypt for COP27, a key area of focus will be on how we can work together to adapt to climate change and implement sustainable solutions. At Google, we’re investing in technologies that can help communities prepare for and respond to climate-related disasters and threats.
Tools to alert people and governments about immediate risks
Natural disasters are increasing in frequency and intensity due to climate change. As part of our Crisis Response efforts, we’re working to bring trusted information to people in critical moments to keep them safe and informed. To do so, we rely on the research and development of our AI-powered technologies and longstanding partnerships with frontline emergency workers and organizations. Here’s a look at some of our crisis response efforts and new ways we’re expanding these tools.
- Floods: Catastrophic damage from flooding affects more than 250 million people every year. In 2018, we launched our flood forecasting initiative that uses machine learning models to provide people with detailed alerts. In 2021, we sent 115 million flood alert notifications to 23 million people over Search and Maps, helping save countless lives. Today, we’re expanding our flood forecasts to river basins in 18 additional countries across Africa, Latin America and Southeast Asia. We’re also announcing the global launch of the new FloodHub, a platform that displays flood forecasts and shows when and where floods may occur to help people directly at risk and provide critical information to aid organizations and governments. This expansion in geographic coverage is possible thanks to our recent breakthroughs in AI-based flood forecasting models, and we’re committed to expanding to more countries.
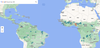
The new Google FloodHub at g.co/floodhub shows forecasts for riverine floods. Forecasts are now available in 18 additional countries: Brazil, Colombia, Sri Lanka, Burkina Faso, Cameroon, Chad, Democratic Republic of Congo, Ivory Coast, Ghana, Guinea, Malawi, Nigeria, Sierra Leone, Angola, South Sudan, Namibia, Liberia, South Africa.
- Wildfires: Wildfires affect hundreds of thousands of people each year, and are increasing in frequency and size. I experienced firsthand the need for accurate information when wildfires occur and this inspired our crisis response work. We detect wildfire boundaries using new AI models based on satellite imagery and show their real-time location in Search and Maps. Since July, we’ve covered more than 30 big wildfire events in the U.S. and Canada, helping inform people and firefighting teams with over 7 million views in Search and Maps. Today, wildfire detection is now available in the U.S., Canada, Mexico and Australia.
The location of the Pukatawagan fire in Manitoba, Canada.
- Hurricanes: Access to authoritative forecasts and safety information about hurricanes can be life-saving. In the days before a hurricane in North America or a typhoon in Japan, detailed forecasts from authoritative sources appear on SOS Alerts in Search and Maps to show a storm’s predicted trajectory. We’re also using machine learning to analyze satellite imagery after disasters and identify which areas need help. When Hurricane Ian hit Florida in September, this technology was deployed in partnership with Google.org grantee GiveDirectly to quickly allocate aid to those most affected.
Managing current and future climate impacts
Climate change poses a threat to our world’s natural resources and food security. We’re working with governments, organizations and communities to provide information and technologies to help adapt to these changes.
- Keeping cities greener and healthier: Extreme temperatures and poor air quality are increasingly common in cities and can impact public health. To mitigate this, our Project Green Light uses AI to optimize traffic lights at intersections around the world with the aim to help minimize congestion and related pollution. Project Air View also brings detailed air quality maps to scientists, policymakers and communities. And we’re working to expand our Environmental Insights Explorer’s Tree Canopy Insights tool to hundreds of cities by the end of this year so they can use trees to lower street-level temperatures and improve quality of life.
- Meeting the world’s growing demand for food: Mineral — a project from X, Alphabet’s moonshot factory — is working to build a more sustainable and productive food system. The team is joining diverse data sets in radically new ways — from soil and weather data to drone and satellite images — and using AI to reveal insights never before possible about what’s happening with crops. As part of our Startups For Sustainable Development program, we’re also supporting startups addressing food security. These include startups like OKO, which provides crop insurance to keep farmers in business in case of adverse weather events and has reached tens of thousands of farmers in Mali and Uganda.
- Helping farmers protect their crops: Pest infestations can threaten entire crops and impact the livelihoods of millions. In collaboration with InstaDeep and the Food and Agriculture Organization of the United Nations, our team at the Google AI Center in Ghana is using AI to better detect locust outbreaks so that it’s possible to implement control measures. In India, Google.org Fellows worked with Wadhwani AI to create an AI-powered app that helps identify and treat infestations of pests, resulting in a 20% reduction in pesticide sprays and a 26% increase in profit margins for farmers. Google Cloud is also working with agricultural technology companies to use machine learning and cloud services to improve crop yields.
- Analyzing a changing planet: Using Google Cloud and Google Earth Engine, organizations and businesses can better assess and manage climate risks. For example, the U.S. Forest Service uses these tools to analyze land-cover changes to better respond to new wildfire threats and monitor the impacts of invasive insects, diseases and droughts. Similarly, the Bank of Montreal is integrating climate data — like precipitation trends — into its business strategy and risk management for clients.
AI already plays a critical role in addressing many urgent, climate-related challenges. It is important that we continue to invest in research and raise awareness about why we are doing this work. Google Arts and Culture has collaborated with artists on the Culture meets Climate collection so everyone can explore more perspectives on climate change. And at COP27 we hope to generate more awareness and engage in productive discussions about how to use AI, innovations, and shared data to help global communities address the changing climate.
Reality Labs Research’s audio team sponsors competition to encourage algorithm development for future AR glasses that amplify human hearing
Reality Labs Research Audio sponsors competition to encourage algorithm development for AR glasses that amplify human hearingRead More
Reality Labs Research’s audio team sponsors competition to encourage algorithm development for future AR glasses that amplify human hearing
Reality Labs Research Audio sponsors competition to encourage algorithm development for AR glasses that amplify human hearingRead More
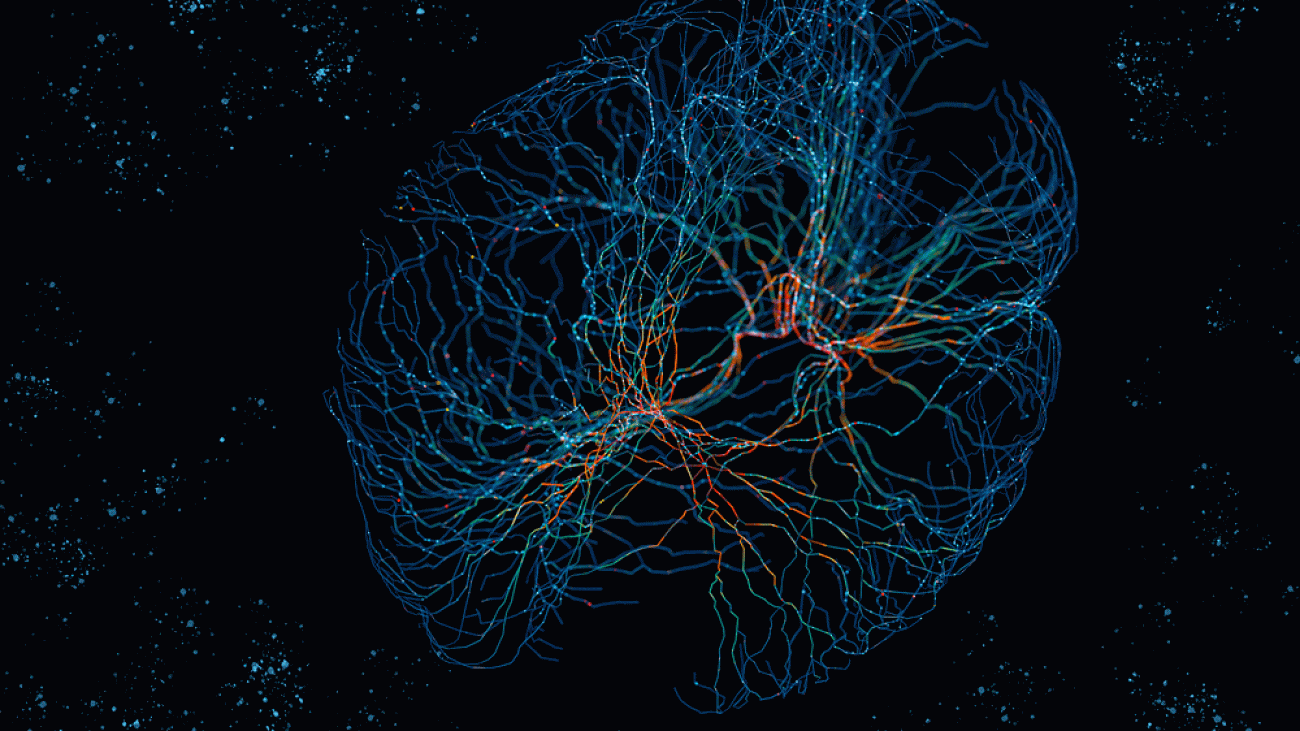
Study urges caution when comparing neural networks to the brain
Neural networks, a type of computing system loosely modeled on the organization of the human brain, form the basis of many artificial intelligence systems for applications such speech recognition, computer vision, and medical image analysis.
In the field of neuroscience, researchers often use neural networks to try to model the same kind of tasks that the brain performs, in hopes that the models could suggest new hypotheses regarding how the brain itself performs those tasks. However, a group of researchers at MIT is urging that more caution should be taken when interpreting these models.
In an analysis of more than 11,000 neural networks that were trained to simulate the function of grid cells — key components of the brain’s navigation system — the researchers found that neural networks only produced grid-cell-like activity when they were given very specific constraints that are not found in biological systems.
“What this suggests is that in order to obtain a result with grid cells, the researchers training the models needed to bake in those results with specific, biologically implausible implementation choices,” says Rylan Schaeffer, a former senior research associate at MIT.
Without those constraints, the MIT team found that very few neural networks generated grid-cell-like activity, suggesting that these models do not necessarily generate useful predictions of how the brain works.
Schaeffer, who is now a graduate student in computer science at Stanford University, is the lead author of the new study, which will be presented at the 2022 Conference on Neural Information Processing Systems this month. Ila Fiete, a professor of brain and cognitive sciences and a member of MIT’s McGovern Institute for Brain Research, is the senior author of the paper. Mikail Khona, an MIT graduate student in physics, is also an author.
Modeling grid cells
Neural networks, which researchers have been using for decades to perform a variety of computational tasks, consist of thousands or millions of processing units connected to each other. Each node has connections of varying strengths to other nodes in the network. As the network analyzes huge amounts of data, the strengths of those connections change as the network learns to perform the desired task.
In this study, the researchers focused on neural networks that have been developed to mimic the function of the brain’s grid cells, which are found in the entorhinal cortex of the mammalian brain. Together with place cells, found in the hippocampus, grid cells form a brain circuit that helps animals know where they are and how to navigate to a different location.
Place cells have been shown to fire whenever an animal is in a specific location, and each place cell may respond to more than one location. Grid cells, on the other hand, work very differently. As an animal moves through a space such as a room, grid cells fire only when the animal is at one of the vertices of a triangular lattice. Different groups of grid cells create lattices of slightly different dimensions, which overlap each other. This allows grid cells to encode a large number of unique positions using a relatively small number of cells.
This type of location encoding also makes it possible to predict an animal’s next location based on a given starting point and a velocity. In several recent studies, researchers have trained neural networks to perform this same task, which is known as path integration.
To train neural networks to perform this task, researchers feed into it a starting point and a velocity that varies over time. The model essentially mimics the activity of an animal roaming through a space, and calculates updated positions as it moves. As the model performs the task, the activity patterns of different units within the network can be measured. Each unit’s activity can be represented as a firing pattern, similar to the firing patterns of neurons in the brain.
In several previous studies, researchers have reported that their models produced units with activity patterns that closely mimic the firing patterns of grid cells. These studies concluded that grid-cell-like representations would naturally emerge in any neural network trained to perform the path integration task.
However, the MIT researchers found very different results. In an analysis of more than 11,000 neural networks that they trained on path integration, they found that while nearly 90 percent of them learned the task successfully, only about 10 percent of those networks generated activity patterns that could be classified as grid-cell-like. That includes networks in which even only a single unit achieved a high grid score.
The earlier studies were more likely to generate grid-cell-like activity only because of the constraints that researchers build into those models, according to the MIT team.
“Earlier studies have presented this story that if you train networks to path integrate, you’re going to get grid cells. What we found is that instead, you have to make this long sequence of choices of parameters, which we know are inconsistent with the biology, and then in a small sliver of those parameters, you will get the desired result,” Schaeffer says.
More biological models
One of the constraints found in earlier studies is that the researchers required the model to convert velocity into a unique position, reported by one network unit that corresponds to a place cell. For this to happen, the researchers also required that each place cell correspond to only one location, which is not how biological place cells work: Studies have shown that place cells in the hippocampus can respond to up to 20 different locations, not just one.
When the MIT team adjusted the models so that place cells were more like biological place cells, the models were still able to perform the path integration task, but they no longer produced grid-cell-like activity. Grid-cell-like activity also disappeared when the researchers instructed the models to generate different types of location output, such as location on a grid with X and Y axes, or location as a distance and angle relative to a home point.
“If the only thing that you ask this network to do is path integrate, and you impose a set of very specific, not physiological requirements on the readout unit, then it’s possible to obtain grid cells,” Fiete says. “But if you relax any of these aspects of this readout unit, that strongly degrades the ability of the network to produce grid cells. In fact, usually they don’t, even though they still solve the path integration task.”
Therefore, if the researchers hadn’t already known of the existence of grid cells, and guided the model to produce them, it would be very unlikely for them to appear as a natural consequence of the model training.
The researchers say that their findings suggest that more caution is warranted when interpreting neural network models of the brain.
“When you use deep learning models, they can be a powerful tool, but one has to be very circumspect in interpreting them and in determining whether they are truly making de novo predictions, or even shedding light on what it is that the brain is optimizing,” Fiete says.
Kenneth Harris, a professor of quantitative neuroscience at University College London, says he hopes the new study will encourage neuroscientists to be more careful when stating what can be shown by analogies between neural networks and the brain.
“Neural networks can be a useful source of predictions. If you want to learn how the brain solves a computation, you can train a network to perform it, then test the hypothesis that the brain works the same way. Whether the hypothesis is confirmed or not, you will learn something,” says Harris, who was not involved in the study. “This paper shows that ‘postdiction’ is less powerful: Neural networks have many parameters, so getting them to replicate an existing result is not as surprising.”
When using these models to make predictions about how the brain works, it’s important to take into account realistic, known biological constraints when building the models, the MIT researchers say. They are now working on models of grid cells that they hope will generate more accurate predictions of how grid cells in the brain work.
“Deep learning models will give us insight about the brain, but only after you inject a lot of biological knowledge into the model,” Khona says. “If you use the correct constraints, then the models can give you a brain-like solution.”
The research was funded by the Office of Naval Research, the National Science Foundation, the Simons Foundation through the Simons Collaboration on the Global Brain, and the Howard Hughes Medical Institute through the Faculty Scholars Program. Mikail Khona was supported by the MathWorks Science Fellowship.
MAEEG: Masked Auto-encoder for EEG Representation Learning
This paper was accepted at the Workshop on Learning from Time Series for Health at NeurIPS 2022.
Decoding information from bio-signals such as EEG, using machine learning has been a challenge due to the small data-sets and difficulty to obtain labels. We propose a reconstruction-based self-supervised learning model, the masked auto-encoder for EEG (MAEEG), for learning EEG representations by learning to reconstruct the masked EEG features using a transformer architecture. We found that MAEEG can learn representations that significantly improve sleep stage classification (∼ 5% accuracy…Apple Machine Learning Research