The IMDb and Box Office Mojo Movies/TV/OTT licensable data package provides a wide range of entertainment metadata, including over 1 billion user ratings; credits for more than 11 million cast and crew members; 9 million movie, TV, and entertainment titles; and global box office reporting data from more than 60 countries. Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention.
In this three-part series, we demonstrate how to transform and prepare IMDb data to power out-of-catalog search for your media and entertainment use cases. In this post, we discuss how to prepare IMDb data and load the data into Amazon Neptune for querying. In Part 2, we discuss how to use Amazon Neptune ML to train graph neural network (GNN) embeddings from the IMDb graph. In Part 3, we walk through a demo application out-of-catalog search that is powered by the GNN embeddings.
Solution overview
In this series, we use the IMDb and Box Office Mojo Movies/TV/OTT licensed data package to show how you can built your own applications using graphs.
This licensable data package consists of JSON files with IMDb metadata for more than 9 million titles (including movies, TV and OTT shows, and video games) and credits for more than 11 million cast, crew, and entertainment professionals. IMDb’s metadata package also includes over 1 billion user ratings, as well as plots, genres, categorized keywords, posters, credits, and more.
IMDb delivers data through AWS Data Exchange, which makes it incredibly simple for you to access data to power your entertainment experiences and seamlessly integrate with other AWS services. IMDb licenses data to a wide range of media and entertainment customers, including pay TV, direct-to-consumer, and streaming operators, to improve content discovery and increase customer engagement and retention. Licensing customers also use IMDb data to enhance in-catalog and out-of-catalog title search and power relevant recommendations.
We use the following services as part of this solution:
- AWS Lambda
- Amazon Neptune
- Amazon Neptune ML
- Amazon OpenSearch Service
- AWS Glue
- Amazon SageMaker notebooks
- Amazon SageMaker Processing
- Amazon SageMaker Training
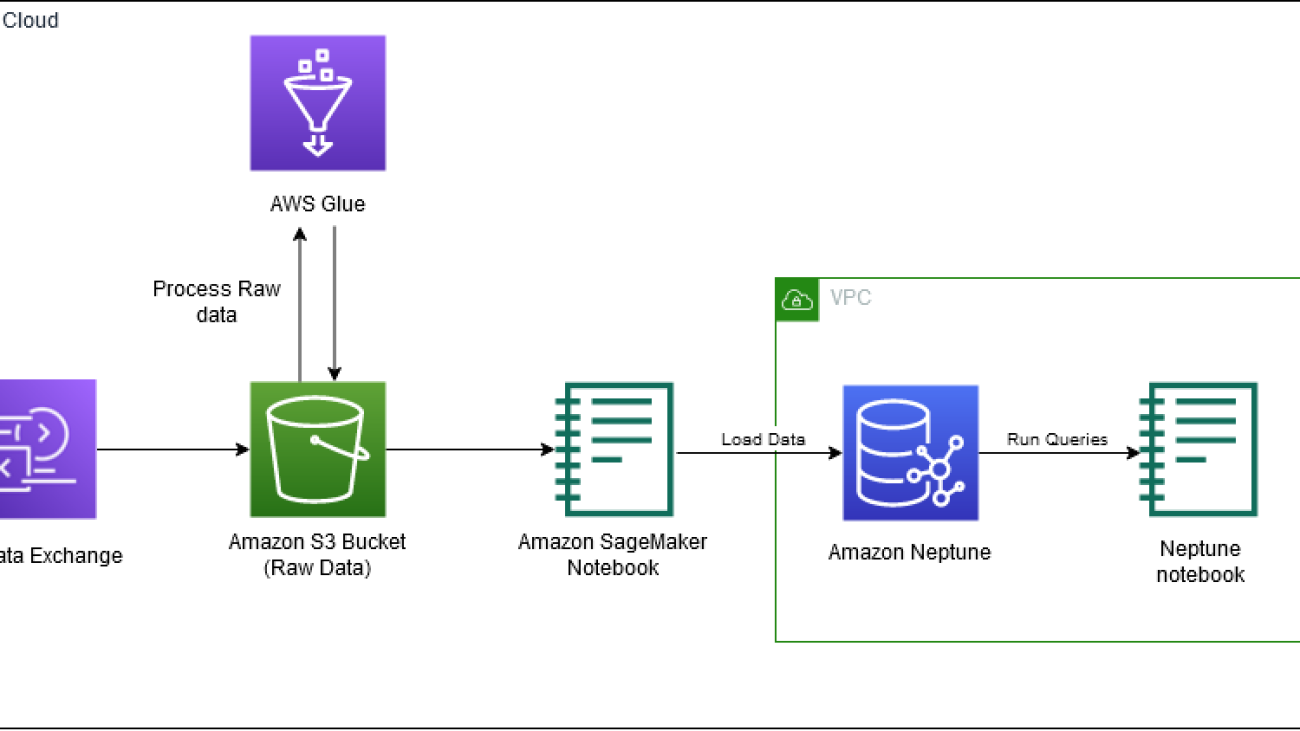
The following diagram depicts the workflow for part 1 of the 3 part blog series.

In this post, we walk through the following high-level steps:
- Provision Neptune resources with AWS CloudFormation.
- Access the IMDb data from AWS Data Exchange.
- Clone the GitHub repo.
- Process the data in Neptune Gremlin format.
- Load the data into a Neptune cluster.
- Query the data using Gremlin Query Language.
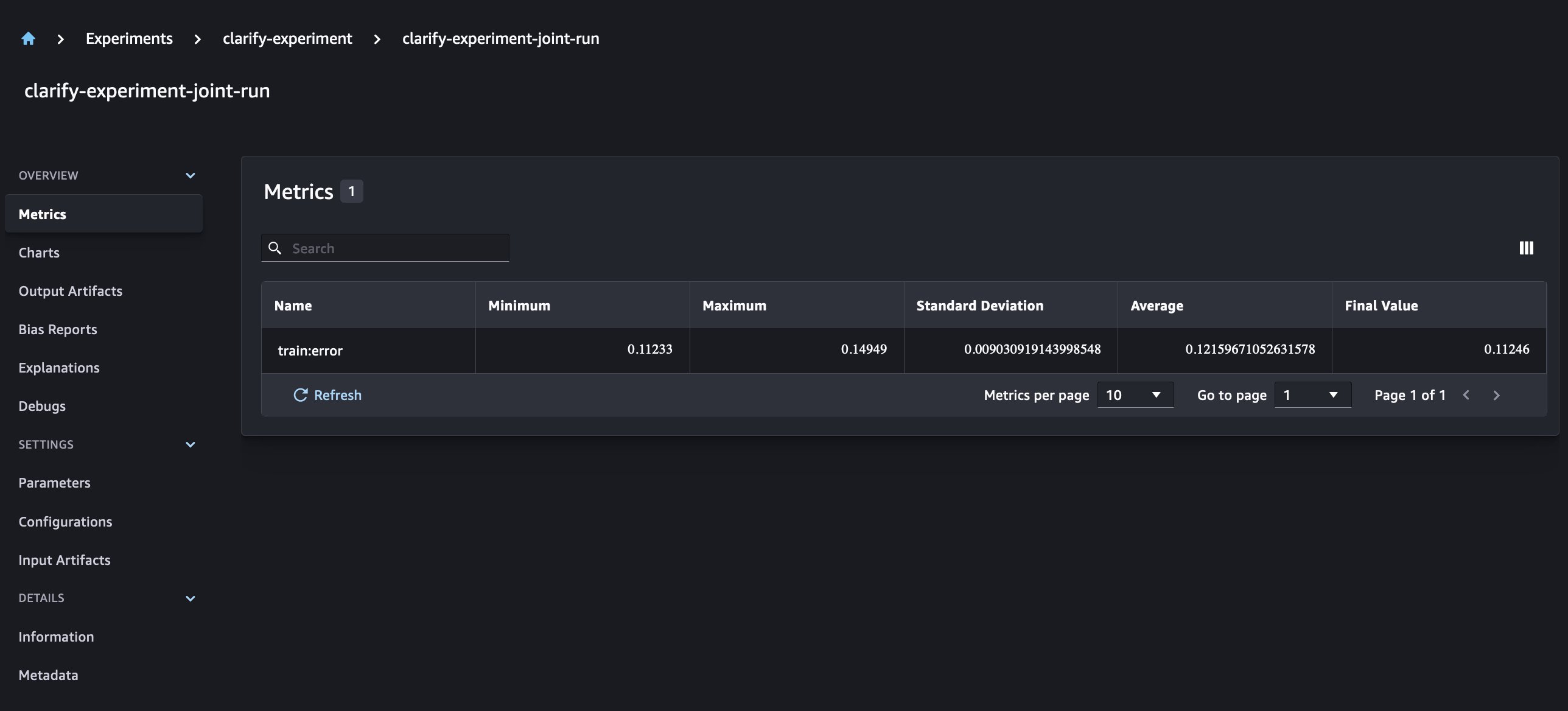
Prerequisites
The IMDb data used in this post requires an IMDb content license and paid subscription to the IMDb and Box Office Mojo Movies/TV/OTT licensing package in AWS Data Exchange. To inquire about a license and access sample data, visit developer.imdb.com.
Additionally, to follow along with this post, you should have an AWS account and familiarity with Neptune, the Gremlin query language, and SageMaker.
Provision Neptune resources with AWS CloudFormation
Now that you’ve seen the structure of the solution, you can deploy it into your account to run an example workflow.
You can launch the stack in AWS Region us-east-1 on the AWS CloudFormation console by choosing Launch Stack:
![]()
To launch the stack in a different Region, refer to Using the Neptune ML AWS CloudFormation template to get started quickly in a new DB cluster.
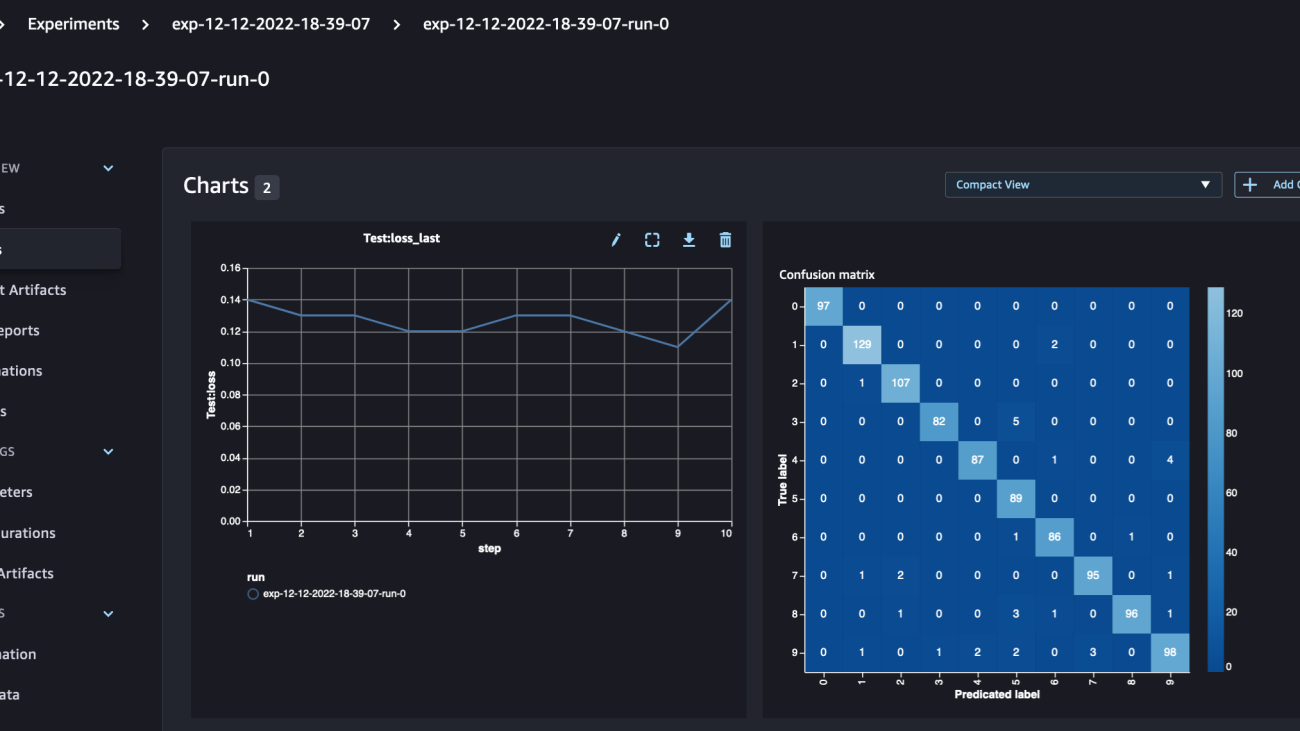
The following screenshot shows the stack parameters to provide.

Stack creation takes approximately 20 minutes. You can monitor the progress on the AWS CloudFormation console.
When the stack is complete, you’re now ready to process the IMDb data. On the Outputs tab for the stack, note the values for NeptuneExportApiUri and NeptuneLoadFromS3IAMRoleArn. Then proceed to the following steps to gain access to the IMDb dataset.
Access the IMDb data
IMDb publishes its dataset once a day on AWS Data Exchange. To use the IMDb data, you first subscribe to the data in AWS Data Exchange, then you can export the data to Amazon Simple Storage Service (Amazon S3). Complete the following steps:
- On the AWS Data Exchange console, choose Browse catalog in the navigation pane.
- In the search field, enter
IMDb. - Subscribe to either IMDb and Box Office Mojo Movie/TV/OTT Data (SAMPLE) or IMDb and Box Office Mojo Movie/TV/OTT Data.
- Complete the steps in the following workshop to export the IMDb data from AWS Data Exchange to Amazon S3.
Clone the GitHub repository
Complete the following steps:
- Open the SageMaker instance that you created from the CloudFormation template.
- Clone the GitHub repository.
Process IMDb data in Neptune Gremlin format
To add the data into Amazon Neptune, we process the data in Neptune gremlin format. From the GitHub repository, we run process_imdb_data.py to process the files. The script creates the CSVs to load the data into Neptune. Upload the data to an S3 bucket and note the S3 URI location.
Note that for this post, we filter the dataset to include only movies. You need either an AWS Glue job or Amazon EMR to process the full data.
To process the IMDb data using AWS Glue, complete the following steps:
- On the AWS Glue console, in the navigation pane, choose Jobs.
- On the Jobs page, choose Spark script editor.
- Under Options, choose Upload and edit existing script and upload the
1_process_imdb_data.pyfile. - Choose Create.
- On the editor page, choose Job Details.
- On the Job Details page, add the following options:
- For Name, enter
imdb-graph-processor. - For Description, enter
processing IMDb dataset and convert to Neptune Gremlin Format. - For IAM role, use an existing AWS Glue role or create an IAM role for AWS Glue. Make sure you give permission to your Amazon S3 location for the raw data and output data path.
- For Worker type, choose G 2X.
- For Requested number of workers, enter 20.
- For Name, enter
- Expand Advanced properties.
- Under Job Parameters, choose Add new parameter and enter the following key value pair:
- For the key, enter
--output_bucket_path. - For the value, enter the S3 path where you want to save the files. This path is also used to load the data into the Neptune cluster.
- For the key, enter
- To add another parameter, choose Add new parameter and enter the following key value pair:
- For the key, enter
--raw_data_path. - For the value, enter the S3 path where the raw data is stored.
- For the key, enter
- Choose Save and then choose Run.
This job takes about 2.5 hours to complete.
The following table provide details about the nodes for the graph data model.
| Description | Label |
| Principal cast members | Person |
| Long format movie | Movie |
| Genre of movies | Genre |
| Keyword descriptions of movies | Keyword |
| Shooting locations of movies | Place |
| Ratings for movies | rating |
| Awards event where movie received an award | awards |
Similarly, the following table shows some of the edges included in the graph. There will be in total 24 edge types.
| Description | Label | From | To |
| Movies an actress has acted in | casted-by-actress | Movie | Person |
| Movies an actor has acted in | casted-by-actor | Movie | Person |
| Keywords in a movie by character | described-by-character-keyword | Movie | keyword |
| Genre of a movie | is-genre | Movie | Genre |
| Place where the movie was shot | Filmed-at | Movie | Place |
| Composer of a movie | Crewed-by-composer | Movie | Person |
| award nomination | Nominated_for | Movie | Awards |
| award winner | Has_won | Movie | Awards |
Load the data into a Neptune cluster
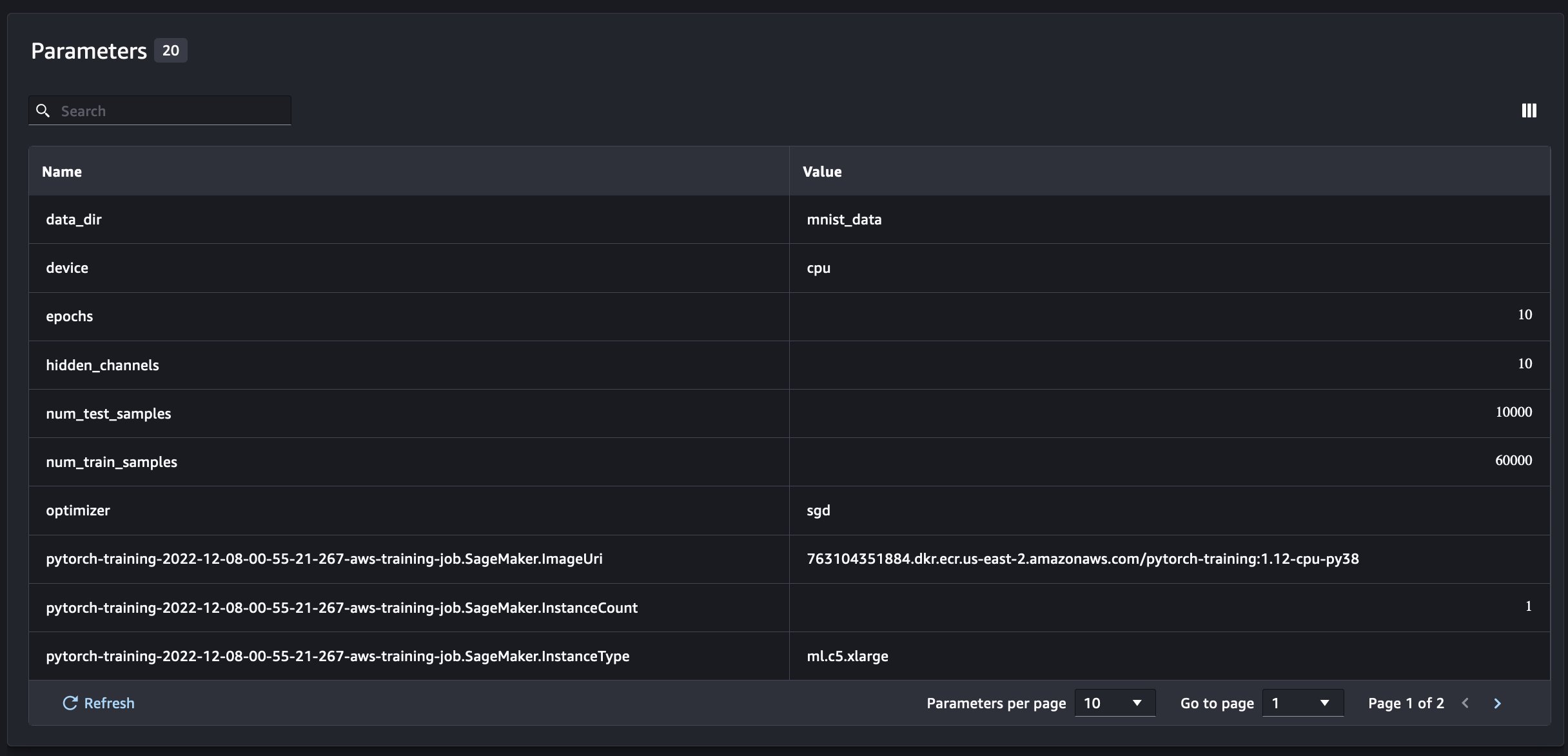
In the repo, navigate to the graph_creation folder and run the 2_load.ipynb. To load the data to Neptune, use the %load command in the notebook, and provide your AWS Identity and Access Management (IAM) role ARN and Amazon S3 location of your processed data.
The following screen shot shows the output of the command.

Note that the data load takes about 1.5 hours to complete. To check the status of the load, use the following command:
When the load is complete, the status displays LOAD_COMPLETED, as shown in the following screenshot.

All the data is now loaded into graphs, and you can start querying the graph.

Fig: Sample Knowledge graph representation of movies in IMDb dataset. Movies “Saving Private Ryan” and “Bridge of Spies” have common connections like actor and director as well as indirect connections through movies like “The Catcher was a Spy” in the graph network.
Query the data using Gremlin
To access the graph in Neptune, we use the Gremlin query language. For more information, refer to Querying a Neptune Graph.
The graph consists of a rich set of information that can be queried directly using Gremlin. In this section, we show a few examples of questions that you can answer with the graph data. In the repo, navigate to the graph_creation folder and run the 3_queries.ipynb notebook. The following section goes over all the queries from the notebook.
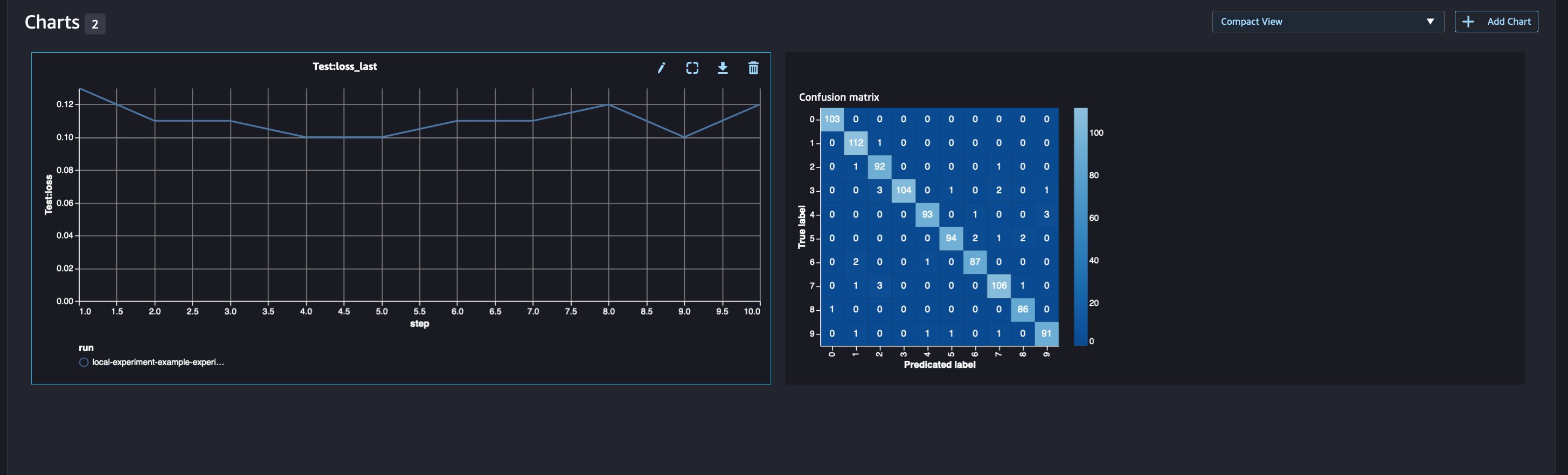
Worldwide gross of movies that have been shot in New Zealand, with minimum 7.5 rating
The following query returns the worldwide gross of movies filmed in New Zealand, with a minimum rating of 7.5:
The following screenshot shows the query results.

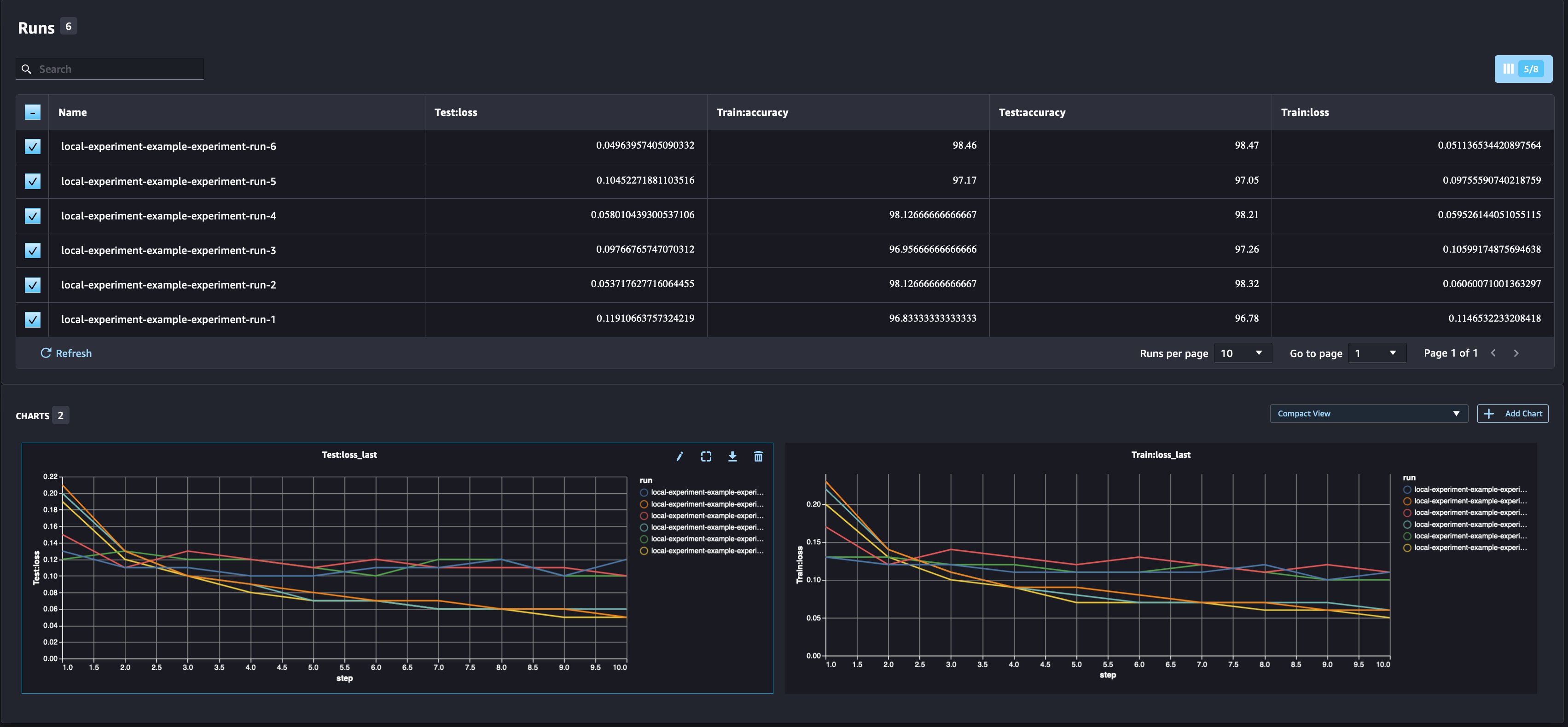
Top 50 movies that belong to action and drama genres and have Oscar-winning actors
In the following example, we want to find the top 50 movies in two different genres (action and drama) with Oscar-winning actors. We can do this by using three different queries and merging the information using Pandas:
The following screenshot shows our results.

Top movies that have common keywords “tattoo” and “assassin”
The following query returns movies with keywords “tattoo” and “assassin”:
The following screenshot shows our results.

Movies that have common actors
In the following query, we find movies that have Leonardo DiCaprio and Tom Hanks:
We get the following results.

Conclusion
In this post, we showed you the power of the IMDb and Box Office Mojo Movies/TV/OTT dataset and how you can use it in various use cases by converting the data into a graph using Gremlin queries. In Part 2 of this series, we show you how to create graph neural network models on this data that can be used for downstream tasks.
For more information about Neptune and Gremlin, refer to Amazon Neptune Resources for additional blog posts and videos.
About the Authors
 Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
 Matthew Rhodes is a Data Scientist I working in the Amazon ML Solutions Lab. He specializes in building Machine Learning pipelines that involve concepts such as Natural Language Processing and Computer Vision.
Matthew Rhodes is a Data Scientist I working in the Amazon ML Solutions Lab. He specializes in building Machine Learning pipelines that involve concepts such as Natural Language Processing and Computer Vision.
 Divya Bhargavi is a Data Scientist and Media and Entertainment Vertical Lead at the Amazon ML Solutions Lab, where she solves high-value business problems for AWS customers using Machine Learning. She works on image/video understanding, knowledge graph recommendation systems, predictive advertising use cases.
Divya Bhargavi is a Data Scientist and Media and Entertainment Vertical Lead at the Amazon ML Solutions Lab, where she solves high-value business problems for AWS customers using Machine Learning. She works on image/video understanding, knowledge graph recommendation systems, predictive advertising use cases.
 Karan Sindwani is a Data Scientist at Amazon ML Solutions Lab, where he builds and deploys deep learning models. He specializes in the area of computer vision. In his spare time, he enjoys hiking.
Karan Sindwani is a Data Scientist at Amazon ML Solutions Lab, where he builds and deploys deep learning models. He specializes in the area of computer vision. In his spare time, he enjoys hiking.
 Soji Adeshina is an Applied Scientist at AWS where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud & abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.
Soji Adeshina is an Applied Scientist at AWS where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud & abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.
 Vidya Sagar Ravipati is a Manager at the Amazon ML Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Manager at the Amazon ML Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.























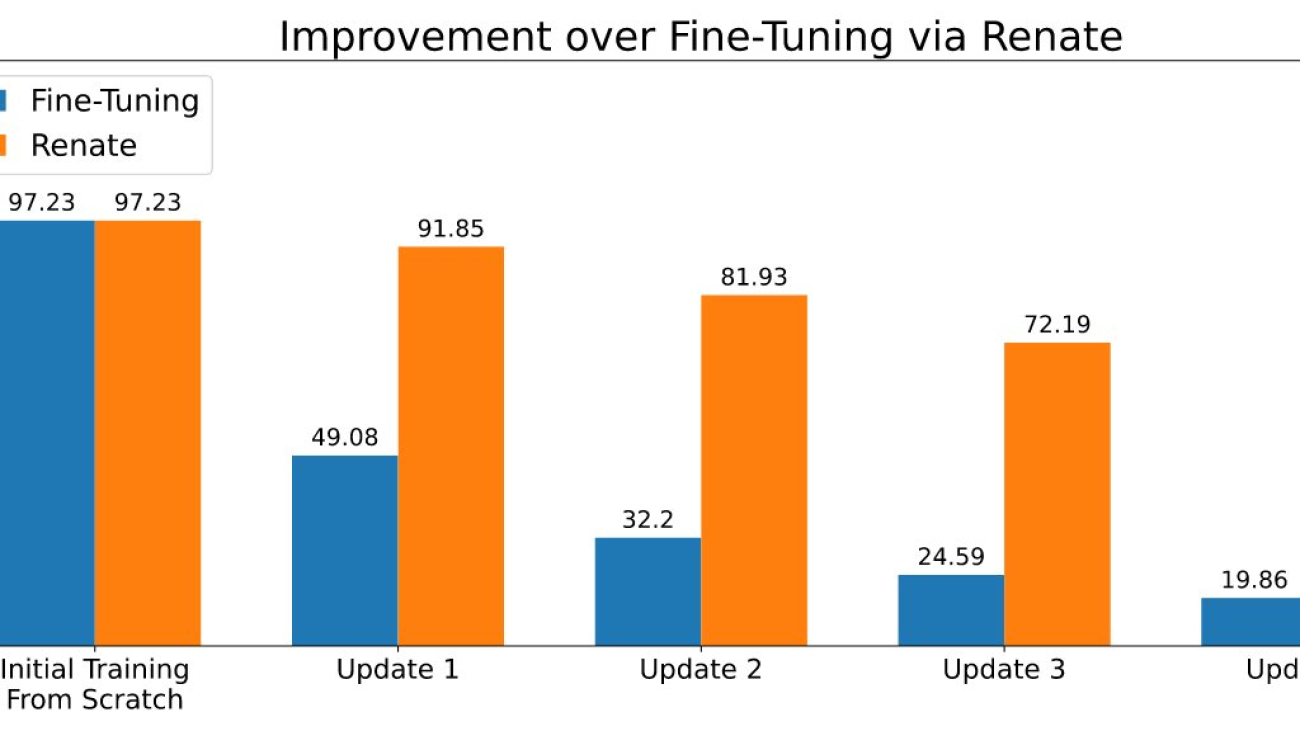

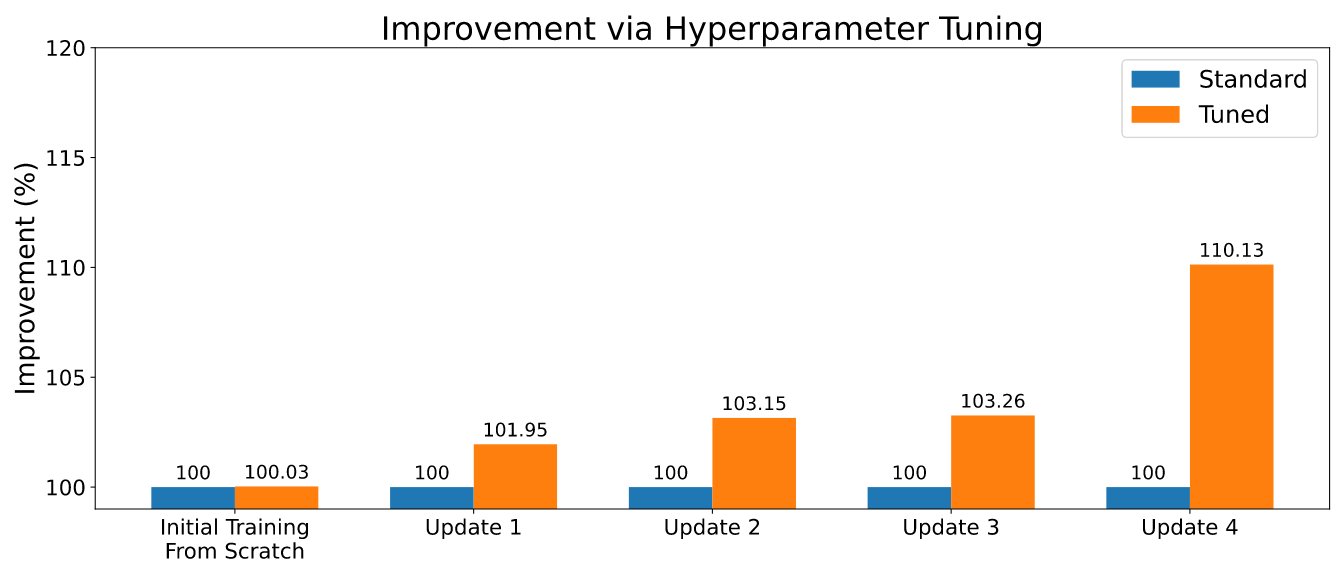
 Giovanni Zappella is a Sr. Applied Scientist working on Long-term science at AWS Sagemaker. He currently works on continual learning, model monitoring and AutoML. Before that he worked on applications of multi-armed bandits for large-scale recommendations systems at Amazon Music.
Giovanni Zappella is a Sr. Applied Scientist working on Long-term science at AWS Sagemaker. He currently works on continual learning, model monitoring and AutoML. Before that he worked on applications of multi-armed bandits for large-scale recommendations systems at Amazon Music. Martin Wistuba is an Applied Scientist in the Long-term science team at AWS Sagemaker. His research focuses on automatic machine learning.
Martin Wistuba is an Applied Scientist in the Long-term science team at AWS Sagemaker. His research focuses on automatic machine learning. Lukas Balles is an Applied Scientist at AWS. He works on continual learning and topics relating to model monitoring.
Lukas Balles is an Applied Scientist at AWS. He works on continual learning and topics relating to model monitoring. Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.
Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.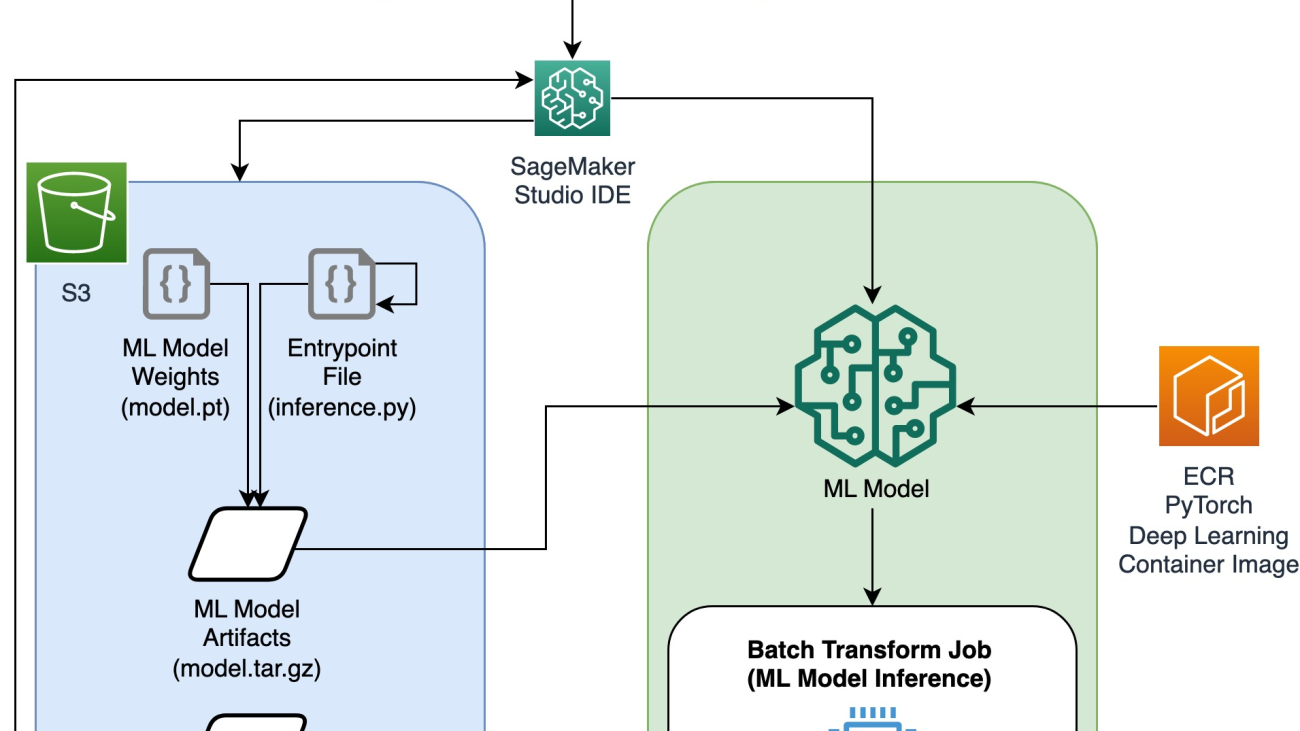







 Dipika Khullar is an ML Engineer in the
Dipika Khullar is an ML Engineer in the  Marcelo Aberle is an ML Engineer in the AWS AI organization. He is leading MLOps efforts at the
Marcelo Aberle is an ML Engineer in the AWS AI organization. He is leading MLOps efforts at the  Ninad Kulkarni is an Applied Scientist in the
Ninad Kulkarni is an Applied Scientist in the  Yash Shah is a Science Manager in the
Yash Shah is a Science Manager in the