Computer vision (CV) is one of the most common applications of machine learning (ML) and deep learning. Use cases range from self-driving cars, content moderation on social media platforms, cancer detection, and automated defect detection. Amazon Rekognition is a fully managed service that can perform CV tasks like object detection, video segment detection, content moderation, and more to extract insights from data without the need of any prior ML experience. In some cases, a more custom solution might be needed along with the service to solve a very specific problem.
In this post, we address areas where CV can be applied to use cases where the pose of objects, their position, and orientation is important. One such use case would be customer-facing mobile applications where an image upload is required. It might be for compliance reasons or to provide a consistent user experience and improve engagement. For example, on online shopping platforms, the angle at which products are shown in images has an effect on the rate of buying this product. One such case is to detect the position of a car. We demonstrate how you can combine well-known ML solutions with postprocessing to address this problem on the AWS Cloud.
We use deep learning models to solve this problem. Training ML algorithms for pose estimation requires a lot of expertise and custom training data. Both requirements are hard and costly to obtain. Therefore, we present two options: one that doesn’t require any ML expertise and uses Amazon Rekognition, and another that uses Amazon SageMaker to train and deploy a custom ML model. In the first option, we use Amazon Rekognition to detect the wheels of the car. We then infer the car orientation from the wheel positions using a rule-based system. In the second option, we detect the wheels and other car parts using the Detectron model. These are again used to infer the car position with rule-based code. The second option requires ML experience but is also more customizable. It can be used for further postprocessing on the image, for example, to crop out the whole car. Both of the options can be trained on publicly available datasets. Finally, we show how you can integrate this car pose detection solution into your existing web application using services like Amazon API Gateway and AWS Amplify.
Solution overview
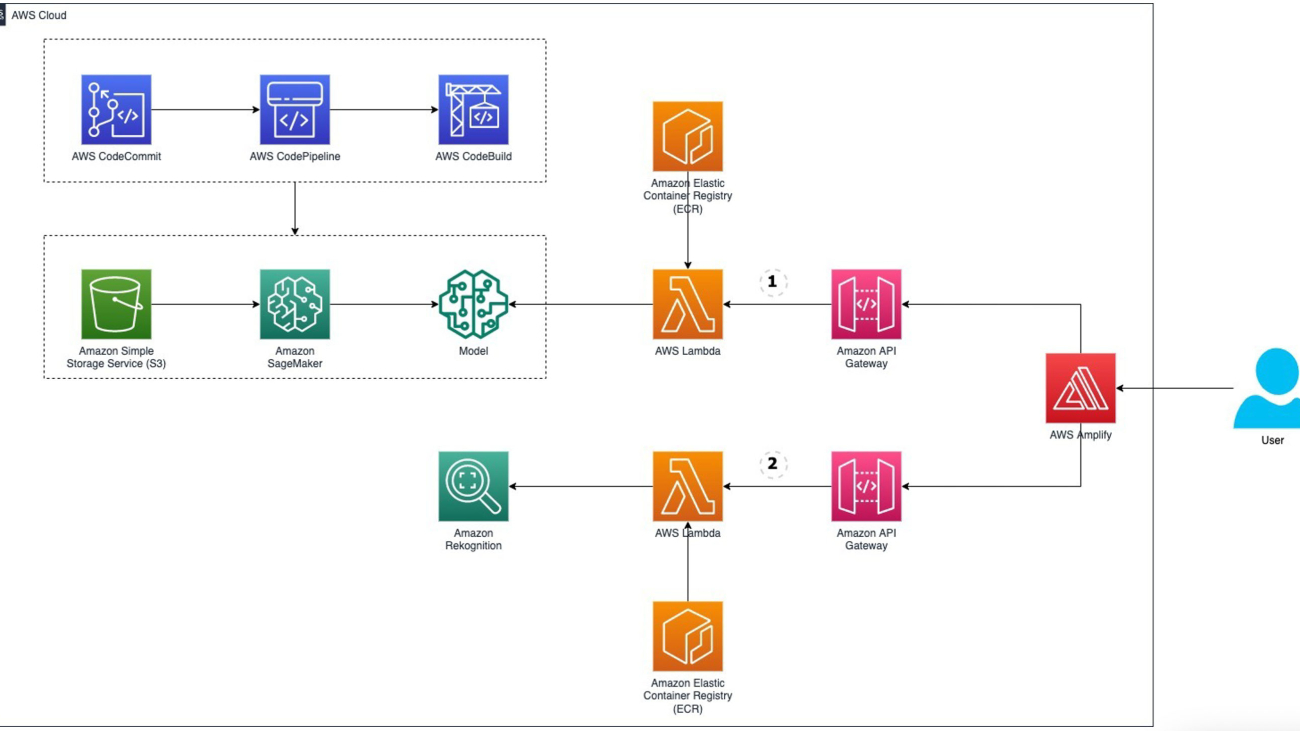
The following diagram illustrates the solution architecture.

The solution consists of a mock web application in Amplify where a user can upload an image and invoke either the Amazon Rekognition model or the custom Detectron model to detect the position of the car. For each option, we host an AWS Lambda function behind an API Gateway that is exposed to our mock application. We configured our Lambda function to run with either the Detectron model trained in SageMaker or Amazon Rekognition.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Create a serverless app using Amazon Rekognition
Our first option demonstrates how you can detect car orientations in images using Amazon Rekognition. The idea is to use Amazon Rekognition to detect the location of the car and its wheels and then do postprocessing to derive the orientation of the car from this information. The whole solution is deployed using Lambda as shown in the Github repository. This folder contains two main files: a Dockerfile that defines the Docker image that will run in our Lambda function, and the app.py file, which will be the main entry point of the Lambda function:
def lambda_handler(event, context):
body_bytes = json.loads(event["body"])["image"].split(",")[-1]
body_bytes = base64.b64decode(body_bytes)
rek = boto3.client('rekognition')
response = rek.detect_labels(Image={'Bytes': body_bytes}, MinConfidence=80)
angle, img = label_image(img_string=body_bytes, response=response)
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_str = "data:image/jpeg;base64," + base64.b64encode(buffered.getvalue()).decode('utf-8')
The Lambda function expects an event that contains a header and body, where the body should be the image needed to be labeled as base64 decoded object. Given the image, the Amazon Rekognition detect_labels function is invoked from the Lambda function using Boto3. The function returns one or more labels for each object in the image and bounding box details for all of the detected object labels as part of the response, along with other information like confidence of the assigned label, the ancestor labels of the detected label, possible aliases for the label, and the categories the detected label belongs to. Based on the labels returned by Amazon Rekognition, we run the function label_image, which calculates the car angle from the detected wheels as follows:
n_wheels = len(wheel_instances)
wheel_centers = [np.array(_extract_bb_coords(wheel, img)).mean(axis=0)
for wheel in wheel_instances]
wheel_center_comb = list(combinations(wheel_centers, 2))
vecs = [(k, pair[0] - pair[1]) for k,pair in enumerate(wheel_center_comb)]
vecs = sorted(vecs, key = lambda vec: np.linalg.norm(vec[1]))
vec_rel = vecs[1] if n_wheels == 3 else vecs[0]
angle = math.degrees(math.atan(vec_rel[1][1]/vec_rel[1][0]))
wheel_centers_rel = [tuple(wheel.tolist()) for wheel in
wheel_center_comb[vec_rel[0]]]
Note that the application requires that only one car is present in the image and returns an error if that’s not the case. However, the postprocessing can be adapted to provide more granular orientation descriptions, cover several cars, or calculate the orientation of more complex objects.
Improve wheel detection
To further improve the accuracy of the wheel detection, you can use Amazon Rekognition Custom Labels. Similar to fine-tuning using SageMaker to train and deploy a custom ML model, you can bring your own labeled data so that Amazon Rekognition can produce a custom image analysis model for you in just a few hours. With Rekognition Custom Labels, you only need a small set of training images that are specific to your use case, in this case car images with specific angles, because it uses the existing capabilities in Amazon Rekognition of being trained on tens of millions of images across many categories. Rekognition Custom Labels can be integrated with only a few clicks and small adaptations to the Lambda function we use for the standard Amazon Rekognition solution.
Train a model using a SageMaker training job
In our second option, we train a custom deep learning model on SageMaker. We use the Detectron2 framework for the segmentation of car parts. These segments are then used to infer the position of the car.
The Detectron2 framework is a library that provides state-of-the-art detection and segmentation algorithms. Detectron provides a variety of Mask R-CNN models that were trained on the famous COCO (Common objects in Context) dataset. To build our car objects detection model, we use transfer learning to fine-tune a pretrained Mask R-CNN model on the car parts segmentation dataset. This dataset allows us to train a model that can detect wheels but also other car parts. This additional information can be further used in the car angle computations relative to the image.
The dataset contains annotated data of car parts to be used for object detection and semantic segmentation tasks: approximately 500 images of sedans, pickups, and sports utility vehicles (SUVs), taken in multiple views (front, back, and side views). Each image is annotated by 18 instance masks and bounding boxes representing the different parts of a car like wheels, mirrors, lights, and front and back glass. We modified the base annotations of the wheels such that each wheel is considered an individual object instead of considering all the available wheels in the image as one object.
We use Amazon Simple Storage Service (Amazon S3) to store the dataset used for training the Detectron model along with the trained model artifacts. Moreover, the Docker container that runs in the Lambda function is stored in Amazon Elastic Container Registry (Amazon ECR). The Docker container in the Lambda function is needed to include the required libraries and dependencies for running the code. We could alternatively use Lambda layers, but it’s limited to an unzipped deployment packaged size quota of 250 MB and a maximum of five layers can be added to a Lambda function.
Our solution is built on SageMaker: we extend prebuilt SageMaker Docker containers for PyTorch to run our custom PyTorch training code. Next, we use the SageMaker Python SDK to wrap the training image into a SageMaker PyTorch estimator, as shown in the following code snippets:
d2_estimator = Estimator(
image_uri=training_image_uri,
role=role,
sagemaker_session=sm_session,
instance_count=1,
instance_type=training_instance,
output_path=f"s3://{session_bucket}/{prefix_model}",
base_job_name=f"detectron2")
d2_estimator.fit({
"training": training_channel,
"validation": validation_channel,
},
wait=True)
Finally, we start the training job by calling the fit() function on the created PyTorch estimator. When the training is finished, the trained model artifact is stored in the session bucket in Amazon S3 to be used for the inference pipeline.
Deploy the model using SageMaker and inference pipelines
We also use SageMaker to host the inference endpoint that runs our custom Detectron model. The full infrastructure used to deploy our solution is provisioned using the AWS CDK. We can host our custom model through a SageMaker real-time endpoint by calling deploy on the PyTorch estimator. This is the second time we extend a prebuilt SageMaker PyTorch container to include PyTorch Detectron. We use it to run the inference script and host our trained PyTorch model as follows:
model = PyTorchModel(
name="d2-sku110k-model",
model_data=d2_estimator.model_data,
role=role,
sagemaker_session=sm_session,
entry_point="predict.py",
source_dir="src",
image_uri=serve_image_uri,
framework_version="1.6.0")
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge",
endpoint_name="detectron-endpoint",
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer(),
wait=True)
Note that we used an ml.g4dn.xlarge GPU for deployment because it’s the smallest GPU available and sufficient for this demo. Two components need to be configured in our inference script: model loading and model serving. The function model_fn() is used to load the trained model that is part of the hosted Docker container and can also be found in Amazon S3 and return a model object that can be used for model serving as follows:
def model_fn(model_dir: str) -> DefaultPredictor:
for p_file in Path(model_dir).iterdir():
if p_file.suffix == ".pth":
path_model = p_file
cfg = get_cfg()
cfg.MODEL.WEIGHTS = str(path_model)
return DefaultPredictor(cfg)
The function predict_fn() performs the prediction and returns the result. Besides using our trained model, we use a pretrained version of the Mask R-CNN model trained on the COCO dataset to extract the main car in the image. This is an extra postprocessing step to deal with images where more than one car exists. See the following code:
def predict_fn(input_img: np.ndarray, predictor: DefaultPredictor) -> Mapping:
pretrained_predictor = _get_pretraind_model()
car_mask = get_main_car_mask(pretrained_predictor, input_img)
outputs = predictor(input_img)
fmt_out = {
"image_height": input_object.shape[0],
"image_width": input_object.shape[1],
"pred_boxes": outputs["instances"].pred_boxes.tensor.tolist(),
"scores": outputs["instances"].scores.tolist(),
"pred_classes": outputs["instances"].pred_classes.tolist(),
"car_mask": car_mask.tolist()
}
return fmt_out
Similar to the Amazon Rekognition solution, the bounding boxes predicted for the wheel class are filtered from the detection outputs and supplied to the postprocessing module to assess the car position relative to the output.
Finally, we also improved the postprocessing for the Detectron solution. It also uses the segments of different car parts to infer the solution. For example, whenever a front bumper is detected, but no back bumper, it is assumed that we have a front view of the car and the corresponding angle is calculated.
Connect your solution to the web application
The steps to connect the model endpoints to Amplify are as follows:
- Clone the application repository that the AWS CDK stack created, named
car-angle-detection-website-repo. Make sure you are looking for it in the Region you used for deployment.
- Copy the API Gateway endpoints for each of the deployed Lambda functions into the
index.html file in the preceding repository (there are placeholders where the endpoint needs to be placed). The following code is an example of what this section of the .html file looks like:
<td align="center" colspan="2">
<select id="endpoint">
<option value="https://ey82aaj8ch.execute-api.eu-central-1.amazonaws.com/prod/">
Amazon Rekognition</option>
<option value="https://nhq6q88xjg.execute-api.eu-central-1.amazonaws.com/prod/">
Amazon SageMaker Detectron</option>
</select>
<input class="btn" type="file" id="ImageBrowse" />
<input class="btn btn-primary" type="submit" value="Upload">
</td>
- Save the HTML file and push the code change to the remote main branch.
This will update the HTML file in the deployment. The application is now ready to use.
- Navigate to the Amplify console and locate the project you created.
The application URL will be visible after the deployment is complete.
- Navigate to the URL and have fun with the UI.

Conclusion
Congratulations! We have deployed a complete serverless architecture in which we used Amazon Rekognition, but also gave an option for your own custom model, with this example available on GitHub. If you don’t have ML expertise in your team or enough custom data to train a model, you could select the option that uses Amazon Rekognition. If you want more control over your model, would like to customize it further, and have enough data, you can choose the SageMaker solution. If you have a team of data scientists, they might also want to enhance the models further and pick a more custom and flexible option. You can put the Lambda function and the API Gateway behind your web application using either of the two options. You can also use this approach for a different use case for which you might want to adapt the code.
The advantage of this serverless architecture is that the building blocks are completely exchangeable. The opportunities are almost limitless. So, get started today!
As always, AWS welcomes feedback. Please submit any comments or questions.
About the Authors
 Michael Wallner is a Senior Consultant Data & AI with AWS Professional Services and is passionate about enabling customers on their journey to become data-driven and AWSome in the AWS cloud. On top, he likes thinking big with customers to innovate and invent new ideas for them.
Michael Wallner is a Senior Consultant Data & AI with AWS Professional Services and is passionate about enabling customers on their journey to become data-driven and AWSome in the AWS cloud. On top, he likes thinking big with customers to innovate and invent new ideas for them.
 Aamna Najmi is a Data Scientist with AWS Professional Services. She is passionate about helping customers innovate with Big Data and Artificial Intelligence technologies to tap business value and insights from data. She has experience in working on data platform and AI/ML projects in the healthcare and life sciences vertical. In her spare time, she enjoys gardening and traveling to new places.
Aamna Najmi is a Data Scientist with AWS Professional Services. She is passionate about helping customers innovate with Big Data and Artificial Intelligence technologies to tap business value and insights from data. She has experience in working on data platform and AI/ML projects in the healthcare and life sciences vertical. In her spare time, she enjoys gardening and traveling to new places.
 David Sauerwein is a Senior Data Scientist at AWS Professional Services, where he enables customers on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the University of Innsbruck, Austria. He was also a doctoral and post-doctoral researcher at the Max-Planck-Institute for Quantum Optics in Germany. In his free time he loves to read, ski and spend time with his family.
David Sauerwein is a Senior Data Scientist at AWS Professional Services, where he enables customers on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the University of Innsbruck, Austria. He was also a doctoral and post-doctoral researcher at the Max-Planck-Institute for Quantum Optics in Germany. In his free time he loves to read, ski and spend time with his family.
 Srikrishna Chaitanya Konduru is a Senior Data Scientist with AWS Professional services. He supports customers in prototyping and operationalising their ML applications on AWS. Srikrishna focuses on computer vision and NLP. He also leads ML platform design and use case identification initiatives for customers across diverse industry verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen university, Germany, with a focus on Medical Imaging.
Srikrishna Chaitanya Konduru is a Senior Data Scientist with AWS Professional services. He supports customers in prototyping and operationalising their ML applications on AWS. Srikrishna focuses on computer vision and NLP. He also leads ML platform design and use case identification initiatives for customers across diverse industry verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen university, Germany, with a focus on Medical Imaging.
 Ahmed Mansour is a Data Scientist at AWS Professional Services. He provide technical support for customers through their AI/ML journey on the AWS cloud. Ahmed focuses on applications of NLP to the protein domain along with RL. He has a PhD in Engineering from the Technical University of Munich, Germany. In his free time he loves to go to the gym and play with his kids.
Ahmed Mansour is a Data Scientist at AWS Professional Services. He provide technical support for customers through their AI/ML journey on the AWS cloud. Ahmed focuses on applications of NLP to the protein domain along with RL. He has a PhD in Engineering from the Technical University of Munich, Germany. In his free time he loves to go to the gym and play with his kids.
Read More



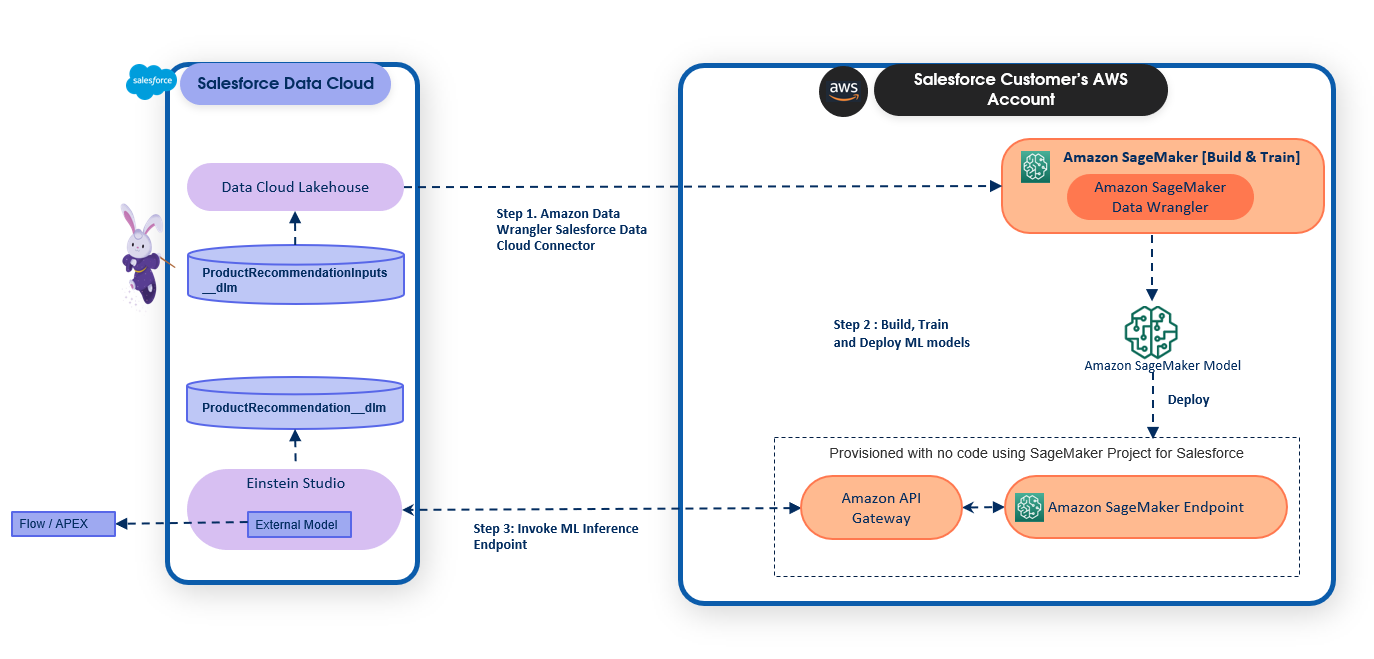
 Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City.
Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field. Maninder (Mani) Kaur is the AI/ML Specialist lead for Strategic ISVs at AWS. With her customer-first approach, Mani helps strategic customers shape their AI/ML strategy, fuel innovation, and accelerate their AI/ML journey. Mani is a firm believer of ethical and responsible AI, and strives to ensure that her customers’ AI solutions align with these principles.
Maninder (Mani) Kaur is the AI/ML Specialist lead for Strategic ISVs at AWS. With her customer-first approach, Mani helps strategic customers shape their AI/ML strategy, fuel innovation, and accelerate their AI/ML journey. Mani is a firm believer of ethical and responsible AI, and strives to ensure that her customers’ AI solutions align with these principles.

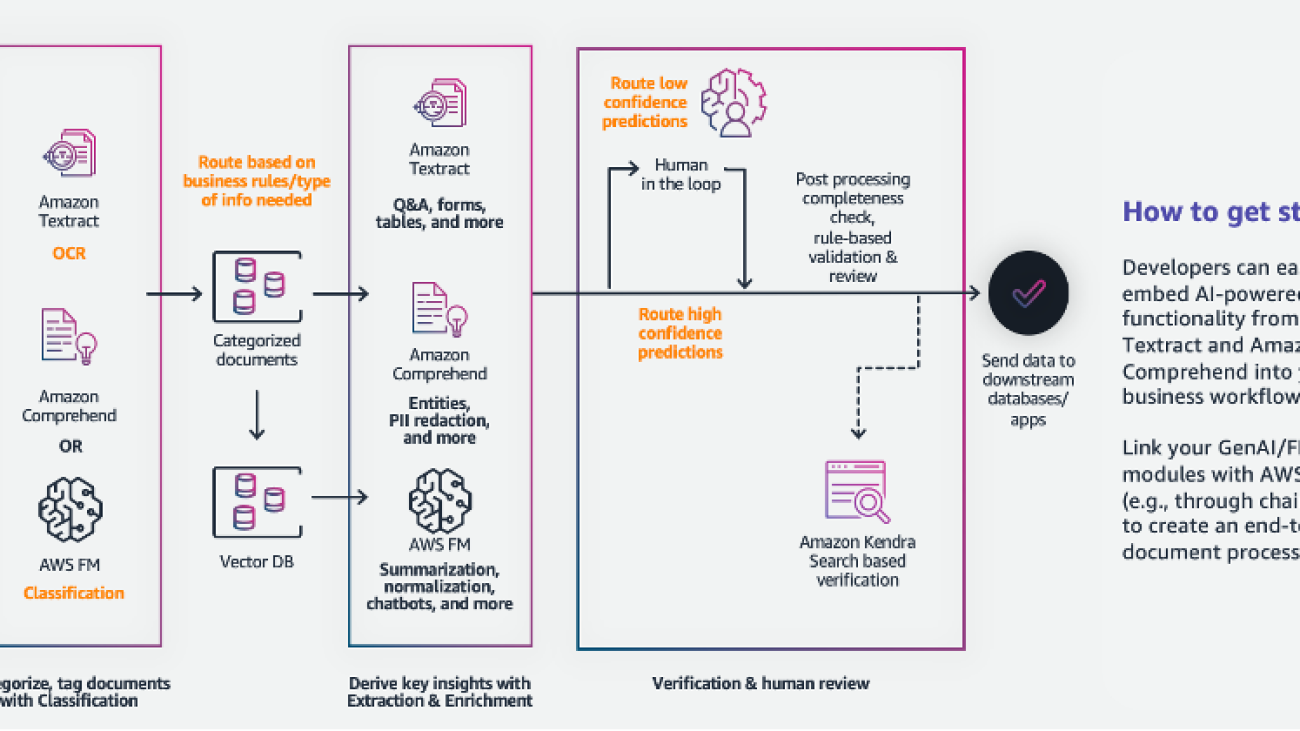






 Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance. Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington.
Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington. Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence.
Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence. Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers.
Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers. Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.
Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.







 Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then. Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.
Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family. Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc. Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling. Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.
Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.