Large Language Models (LLMs) have made substantial progress in the past several months, shattering state-of-the-art benchmarks in many domains. This paper investigates LLMs’ behavior with respect to gender stereotypes, a known stumbling block for prior models. We propose a simple paradigm to test the presence of gender bias, building on but differing from WinoBias, a commonly used gender bias dataset which is likely to be included in the training data of current LLMs. We test four recently published LLMs and demonstrate that they express biased assumptions about men and women, specifically…Apple Machine Learning Research
Reinforce Data, Multiply Impact: Improved Model Accuracy and Robustness with Dataset Reinforcement
We propose Dataset Reinforcement, a strategy to improve a dataset once such that the accuracy of any model architecture trained on the reinforced dataset is improved at no additional training cost for users. We propose a Dataset Reinforcement strategy based on data augmentation and knowledge distillation. Our generic strategy is designed based on extensive analysis across CNN- and transformer-based models and performing large-scale study of distillation with state-of-the-art models with various data augmentations. We create a reinforced version of the ImageNet training dataset, called…Apple Machine Learning Research
Self-Supervised Object Goal Navigation with In-Situ Finetuning
A household robot should be able to navigate to target locations without requiring users to first annotate everything in their home. Current approaches to this object navigation challenge do not test on real robots and rely on expensive semantically labeled 3D meshes. In this work, our aim is an agent that builds self-supervised models of the world via exploration, the same as a child might. We propose an end-to-end self-supervised embodied agent that leverages exploration to train a semantic segmentation model of 3D objects, and uses those representations to learn an object navigation policy…Apple Machine Learning Research
Pre-processing temporal data made easier with TensorFlow Decision Forests and Temporian
 Posted by Google: Mathieu Guillame-Bert, Richard Stotz, Robert Crowe, Luiz GUStavo Martins (Gus), Ashley Oldacre, Kris Tonthat, Glenn Cameron, and Tryolabs: Ian Spektor, Braulio Rios, Guillermo Etchebarne, Diego Marvid, Lucas Micol, Gonzalo Marín, Alan Descoins, Agustina Pizarro, Lucía Aguilar, Martin Alcala Rubi
Posted by Google: Mathieu Guillame-Bert, Richard Stotz, Robert Crowe, Luiz GUStavo Martins (Gus), Ashley Oldacre, Kris Tonthat, Glenn Cameron, and Tryolabs: Ian Spektor, Braulio Rios, Guillermo Etchebarne, Diego Marvid, Lucas Micol, Gonzalo Marín, Alan Descoins, Agustina Pizarro, Lucía Aguilar, Martin Alcala Rubi

Temporal data is omnipresent in applied machine learning applications. Data often changes over time or is only available or valuable at a certain point in time. For example, market prices and weather conditions change constantly. Temporal data is also often highly discriminative in decision-making tasks. For example, the rate of change and interval between two consecutive heartbeats provides valuable insights into a person’s physical health, and temporal patterns of network logs are used to detect configuration issues and intrusions. Hence, it is essential to incorporate temporal data and temporal information in ML applications.
This blog post demonstrates how to train a forecasting model on transactional data. Specifically, we will show how to forecast the total weekly sales from individual sales records. For the modeling part, we will use TensorFlow Decision Forests as they are well suited to handle temporal data. To feed the transaction data to our model, and to compute temporal specific features, we will use Temporian, a newly released library designed for ingesting and aggregating transactional data from multiple non-synchronized sources.


 |
Time series are the most commonly used representation for temporal data. They consist of uniformly sampled values, which can be useful for representing aggregate signals. However, time series are sometimes not sufficient to represent the richness of available data. Instead, multivariate time series can represent multiple signals together, while time sequences or event sets can represent non-uniformly sampled measurements. Multi-index time sequences can be used to represent relations between different time sequences. In this blog post, we will use the multivariate multi-index time sequence, also known as event sets. Don’t worry, they’re not as complex as they sound.
|
Examples of temporal data include:
|
A simple example
Let’s start with a simple example. We have collected sales records from a fictitious online shop. Each time a client makes a purchase, we record the following information: time of the purchase, client id, product purchased, and price of the product.
The dataset is stored in a single CSV file, with one transaction per line:
$ head -n 5 sales.csv |
Looking at data is crucial to understand the data and spot potential issues. Our first task is to load the sales data into an EventSet and plot it.
|
INFO: A Temporian |
# Import Temporian |
This code snippet load and print the data:

We can also plot the data:
# Plot "price" feature of the EventSet |
 |
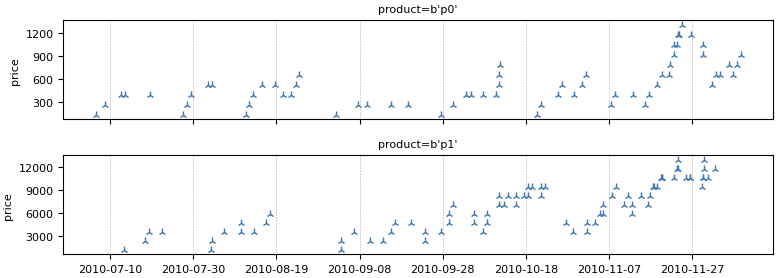
We have shown how to load and visualize temporal data in just a few lines of code. However, the resulting plot is very busy, as it shows all transactions for all clients in the same view.
A common operation on temporal data is to calculate the moving sum. Let’s calculate and plot the sum of sales for each transaction in the previous seven days. The moving sum can be computed using the moving_sum operator.
weekly_sales = sales["price"].moving_sum(tp.duration.days(7))
|
 |
|
BONUS: To make the plots interactive, you can add the |
Sales per products
In the previous step, we computed the overall moving sum of sales for the entire shop. However, what if we wanted to calculate the rolling sum of sales for each product or client separately?
For this task, we can use an index.
# Index the data by "product" |
 |
|
NOTE: Many operators such as |
Aggregate transactions into time series
Our dataset contains individual client transactions. To use this data with a machine learning model, it is often useful to aggregate it into time series, where the data is sampled uniformly over time. For example, we could aggregate the sales weekly, or calculate the total sales in the last week for each day.
However, it is important to note that aggregating transaction data into time series can result in some data loss. For example, the individual transaction timestamps and values would be lost. This is because the aggregated time series would only represent the total sales for each time period.
Let’s compute the total sales in the last week for each day for each product individually.
# The data is sampled daily |
 |
|
NOTE: The current plot is a continuous line, while the previous plots have markers. This is because Temporian uses continuous lines by default when the data is uniformly sampled, and markers otherwise. |
After the data preparation stage is finished, the data can be exported to a Pandas DataFrame as a final step.
tp.to_pandas(weekly_sales_daily) |

Train a forecasting model with TensorFlow model
A key application of Temporian is to clean data and perform feature engineering for machine learning models. It is well suited for forecasting, anomaly detection, fraud detection, and other tasks where data comes continuously.
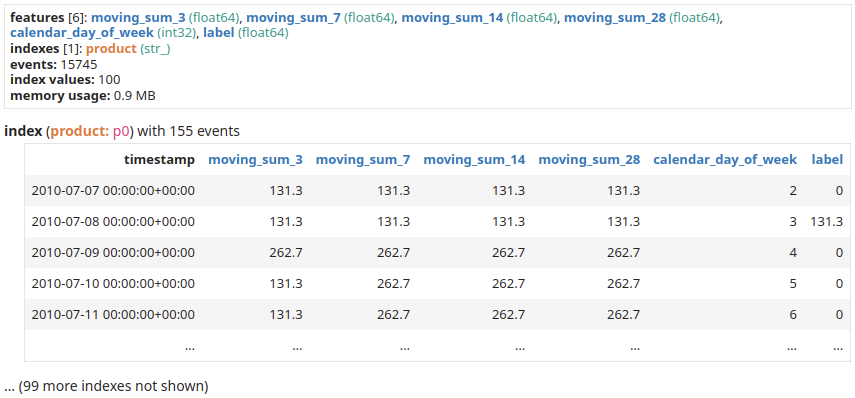
In this example, we show how to train a TensorFlow model to predict the next day’s sales using past sales for each product individually. We will feed the model various levels of aggregations of sales as well as calendar information.
Let’s first augment our dataset and convert it to a dataset compatible with a tabular ML model.
sales_per_product = sales.add_index("product")
|
 |
We can then convert the dataset from EventSet to TensorFlow Dataset format, and train a Random Forest.
import tensorflow_decision_forests as tfdf
|
And that’s it, we have a model trained to forecast sales. We now can look at the variable importance of the model to understand what features matter the most.
model.summary() |
In the summary, we can find the INV_MEAN_MIN_DEPTH variable importance:
Type: "RANDOM_FOREST" |
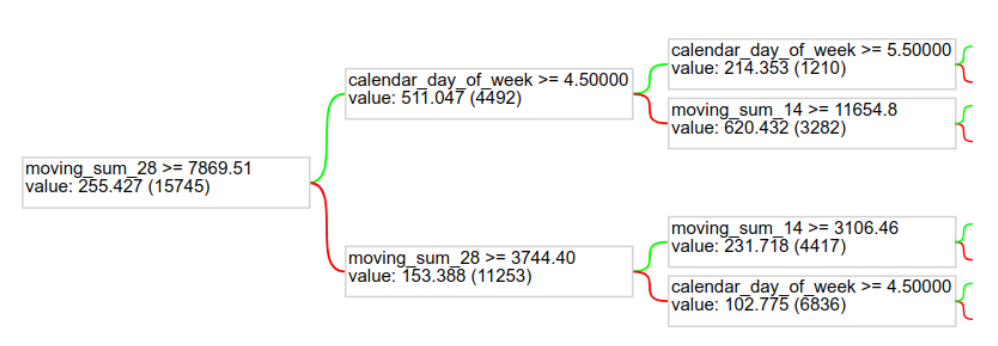
We see that moving_sum_28 is the feature with the highest importance (0.342231). This indicates that the sum of sales in the last 28 days is very important to the model. To further improve our model, we should probably add more temporal aggregation features. The product feature also matters a lot.
And to get an idea of the model itself, we can plot one of the trees of the Random Forest.
tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0, max_depth=2) |
 |
More on temporal data preprocessing
We demonstrated some simple data preprocessing. If you want to see other examples of temporal data preprocessing on different data domains, check the Temporian tutorials. Notably:
- Heart rate analysis ❤️ detects individual heartbeats and derives heart rate related features on raw ECG signals from Physionet.
- M5 Competition 🛒 predicts retail sales in the M5 Makridakis Forecasting competition.
- Loan outcomes prediction 🏦 prepares relational SQL data to predict outcomes for finished loans.
- Detecting payment card fraud 💳 detects fraudulent payment card transactions in real time.
- Supervised and unsupervised anomaly detection 🔎 perform data analysis and feature engineering to detect anomalies in a group of server’s resource usage metrics.
Next Steps
We demonstrated how to handle temporal data such as transactions in TensorFlow using the Temporian library. Now you can try it too!
- Join our Discord server, to share your feedback or ask for help.
- Read the 3 minutes to Temporian guide for a quick introduction.
- Check the User guide.
- Visit the GitHub repository.
To learn more about model training with TensorFlow Decision Forests:
- Visit the official website.
- Follow the beginner notebook.
- Check the various guides and tutorials.
- Check the TensorFlow Forum.
Falcon 180B foundation model from TII is now available via Amazon SageMaker JumpStart
Today, we are excited to announce that the Falcon 180B foundation model developed by Technology Innovation Institute (TII) is available for customers through Amazon SageMaker JumpStart to deploy with one-click for running inference. With a 180-billion-parameter size and trained on a massive 3.5-trillion-token dataset, Falcon 180B is the largest and one of the most performant models with openly accessible weights. You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. In this post, we walk through how to discover and deploy the Falcon 180B model via SageMaker JumpStart.
What is Falcon 180B
Falcon 180B is a model released by TII that follows previous releases in the Falcon family. It’s a scaled-up version of Falcon 40B, and it uses multi-query attention for better scalability. It’s an auto-regressive language model that uses an optimized transformer architecture. It was trained on 3.5 trillion tokens of data, primarily consisting of web data from RefinedWeb (approximately 85%). The model has two versions: 180B and 180B-Chat. 180B is a raw, pre-trained model, which should be further fine-tuned for most use cases. 180B-Chat is better suited to taking generic instructions. The Chat model has been fine-tuned on chat and instructions datasets together with several large-scale conversational datasets.
The model is made available under the Falcon-180B TII License and Acceptable Use Policy.
Falcon 180B was trained by TII on Amazon SageMaker, on a cluster of approximately 4K A100 GPUs. It used a custom distributed training codebase named Gigatron, which uses 3D parallelism with ZeRO, and custom, high-performance Triton kernels. The distributed training architecture used Amazon Simple Storage Service (Amazon S3) as the sole unified service for data loading and checkpoint writing and reading, which particularly contributed to the workload reliability and operational simplicity.
What is SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. ML practitioners can deploy foundation models to dedicated SageMaker instances within a network isolated environment, and customize models using Amazon SageMaker for model training and deployment.
You can now discover and deploy Falcon 180B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your VPC controls, helping ensure data security. Falcon 180B is discoverable and can be deployed in Regions where the requisite instances are available. At present, ml.p4de instances are available in US East (N. Virginia) and US West (Oregon).
Discover models
You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
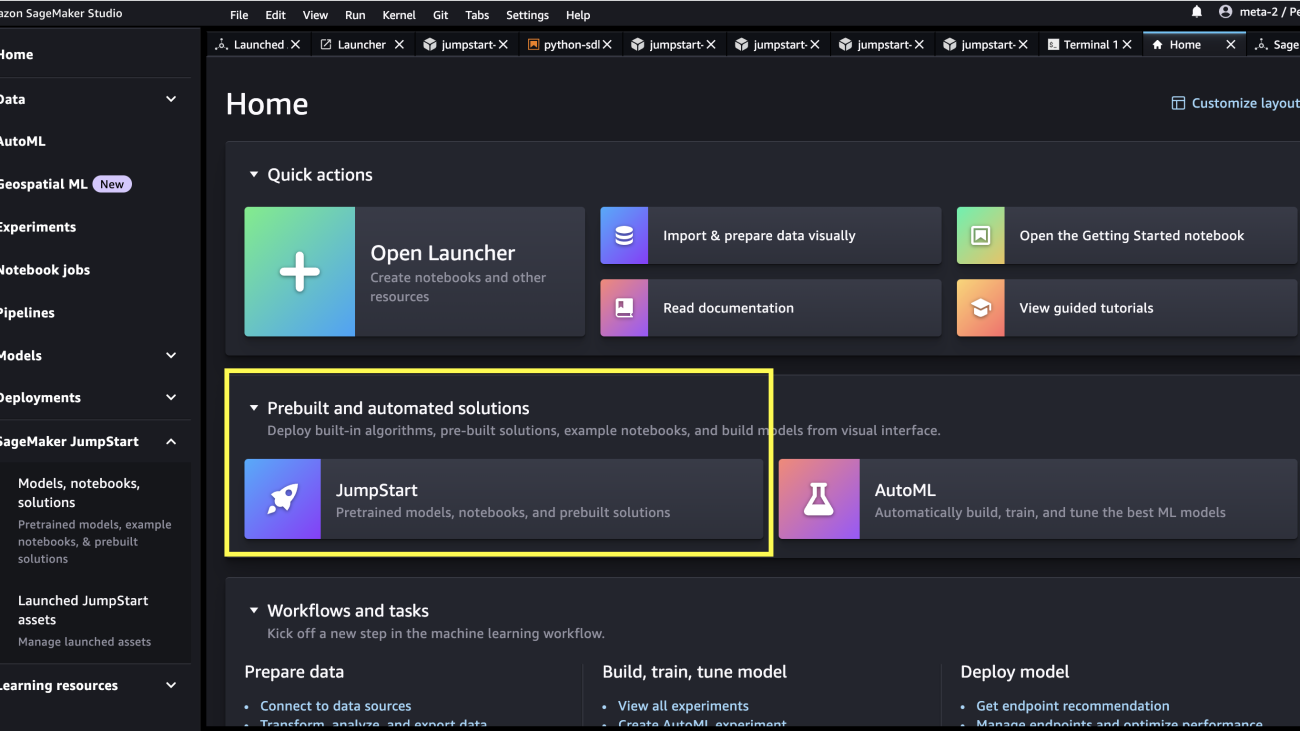
In SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions.

From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources. You can find Falcon 180B in the Foundation Models: Text Generation carousel.

You can also find other model variants by choosing Explore all Text Generation Models or searching for Falcon.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find two buttons, Deploy and Open Notebook, which will help you use the model (the following screenshot shows the Deploy option).

Deploy models
When you choose Deploy, the model deployment will start. Alternatively, you can deploy through the example notebook that shows up by choosing Open Notebook. The example notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy using a notebook, we start by selecting an appropriate model, specified by the model_id. You can deploy any of the selected models on SageMaker with the following code:
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel. To learn more, refer to the API documentation. After it’s deployed, you can run inference against the deployed endpoint through a SageMaker predictor. See the following code:
Inference parameters control the text generation process at the endpoint. The max new tokens control refers to the size of the output generated by the model. Note that this is not the same as the number of words because the vocabulary of the model is not the same as the English language vocabulary and each token may not be an English language word. Temperature controls the randomness in the output. Higher temperature results in more creative and hallucinated outputs. All the inference parameters are optional.
This 180B parameter model is 335GB and requires even more GPU memory to sufficiently perform inference in 16-bit precision. Currently, JumpStart only supports this model on ml.p4de.24xlarge instances. It is possible to deploy an 8-bit quantized model on a ml.p4d.24xlarge instance by providing the env={"HF_MODEL_QUANTIZE": "bitsandbytes"} keyword argument to the JumpStartModel constructor and specifying instance_type="ml.p4d.24xlarge" to the deploy method. However, please note that per-token latency is approximately 5x slower for this quantized configuration.
The following table lists all the Falcon models available in SageMaker JumpStart along with the model IDs, default instance types, maximum number of total tokens (sum of the number of input tokens and number of generated tokens) supported, and the typical response latency per token for each of these models.
| Model Name | Model ID | Default Instance Type | Max Total Tokens | Latency per Token* |
| Falcon 7B | huggingface-llm-falcon-7b-bf16 |
ml.g5.2xlarge | 2048 | 34 ms |
| Falcon 7B Instruct | huggingface-llm-falcon-7b-instruct-bf16 |
ml.g5.2xlarge | 2048 | 34 ms |
| Falcon 40B | huggingface-llm-falcon-40b-bf16 |
ml.g5.12xlarge | 2048 | 57 ms |
| Falcon 40B Instruct | huggingface-llm-falcon-40b-instruct-bf16 |
ml.g5.12xlarge | 2048 | 57 ms |
| Falcon 180B | huggingface-llm-falcon-180b-bf16 |
ml.p4de.24xlarge | 2048 | 45 ms |
| Falcon 180B Chat | huggingface-llm-falcon-180b-chat-bf16 |
ml.p4de.24xlarge | 2048 | 45 ms |
*per-token latency is provided for the median response time of the example prompts provided in this blog; this value will vary based on length of input and output sequences.
Inference and example prompts for Falcon 180B
Falcon models can be used for text completion for any piece of text. Through text generation, you can perform a variety of tasks, such as answering questions, language translation, sentiment analysis, and many more. The endpoint accepts the following input payload schema:
You can explore the definition of these client parameters and their default values within the text-generation-inference repository.
The following are some sample example prompts and the text generated by the model. All outputs here are generated with inference parameters {"max_new_tokens": 768, "stop": ["<|endoftext|>", "###"]}.
Building a website can be done in 10 simple steps:
You may notice this pretrained model generates long text sequences that are not necessarily ideal for dialog use cases. Before we show how the fine-tuned chat model performs for a larger set of dialog-based prompts, the next two examples illustrate how to use Falcon models with few-shot in-context learning, where we provide training samples available to the model. Note that “few-shot learning” does not adjust model weights — we only perform inference on the deployed model during this process while providing a few examples within the input context to help guild model output.
Inference and example prompts for Falcon 180B-Chat
With Falcon 180B-Chat models, optimized for dialogue use cases, the input to the chat model endpoints may contain previous history between the chat assistant and the user. You can ask questions contextual to the conversation that has happened so far. You can also provide the system configuration, such as personas, which define the chat assistant’s behavior. Input payload to the endpoint is the same as the Falcon 180B model except the inputs string value should use the following format:
The following are some sample example prompts and the text generated by the model. All outputs are generated with inference parameters {"max_new_tokens":256, "stop": ["nUser:", "<|endoftext|>", " User:", "###"]}.
In the following example, the user has had a conversation with the assistant about tourist sites in Paris. Next, the user is inquiring about the first option recommended by the chat assistant.
Clean up
After you’re done running the notebook, make sure to delete all resources that you created in the process so your billing is stopped. Use the following code:
Conclusion
In this post, we showed you how to get started with Falcon 180B in SageMaker Studio and deploy the model for inference. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
Resources
- SageMaker JumpStart documentation
- SageMaker JumpStart Foundation Models documentation
- SageMaker JumpStart product detail page
- SageMaker JumpStart model catalog
About the Authors
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Olivier Cruchant is a Principal Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Principal Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
 Karl Albertsen leads Amazon SageMaker’s foundation model hub, algorithms, and partnerships teams.
Karl Albertsen leads Amazon SageMaker’s foundation model hub, algorithms, and partnerships teams.
Amazon SageMaker Domain in VPC only mode to support SageMaker Studio with auto shutdown Lifecycle Configuration and SageMaker Canvas with Terraform
Amazon SageMaker Domain supports SageMaker machine learning (ML) environments, including SageMaker Studio and SageMaker Canvas. SageMaker Studio is a fully integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models, improving data science team productivity by up to 10x. SageMaker Canvas expands access to machine learning by providing business analysts with a visual interface that allows them to generate accurate ML predictions on their own—without requiring any ML experience or having to write a single line of code.
HashiCorp Terraform is an infrastructure as code (IaC) tool that lets you organize your infrastructure in reusable code modules. AWS customers rely on IaC to design, develop, and manage their cloud infrastructure, such as SageMaker Domains. IaC ensures that customer infrastructure and services are consistent, scalable, and reproducible while following best practices in the area of development operations (DevOps). Using Terraform, you can develop and manage your SageMaker Domain and its supporting infrastructure in a consistent and repeatable manner.
In this post, we demonstrate the Terraform implementation to deploy a SageMaker Domain and the Amazon Virtual Private Cloud (Amazon VPC) it associates with. The solution will use Terraform to create:
- A VPC with subnets, security groups, as well as VPC endpoints to support VPC only mode for the SageMaker Domain.
- A SageMaker Domain in VPC only mode with a user profile.
- An AWS Key Management Service (AWS KMS) key to encrypt the SageMaker Studio’s Amazon Elastic File System (Amazon EFS) volume.
- A Lifecycle Configuration attached to the SageMaker Domain to automatically shut down idle Studio notebook instances.
- A SageMaker Domain execution role and IAM policies to enable SageMaker Studio and Canvas functionalities.
The solution described in this post is available at this GitHub repo.
Solution overview
The following image shows SageMaker Domain in VPC only mode.
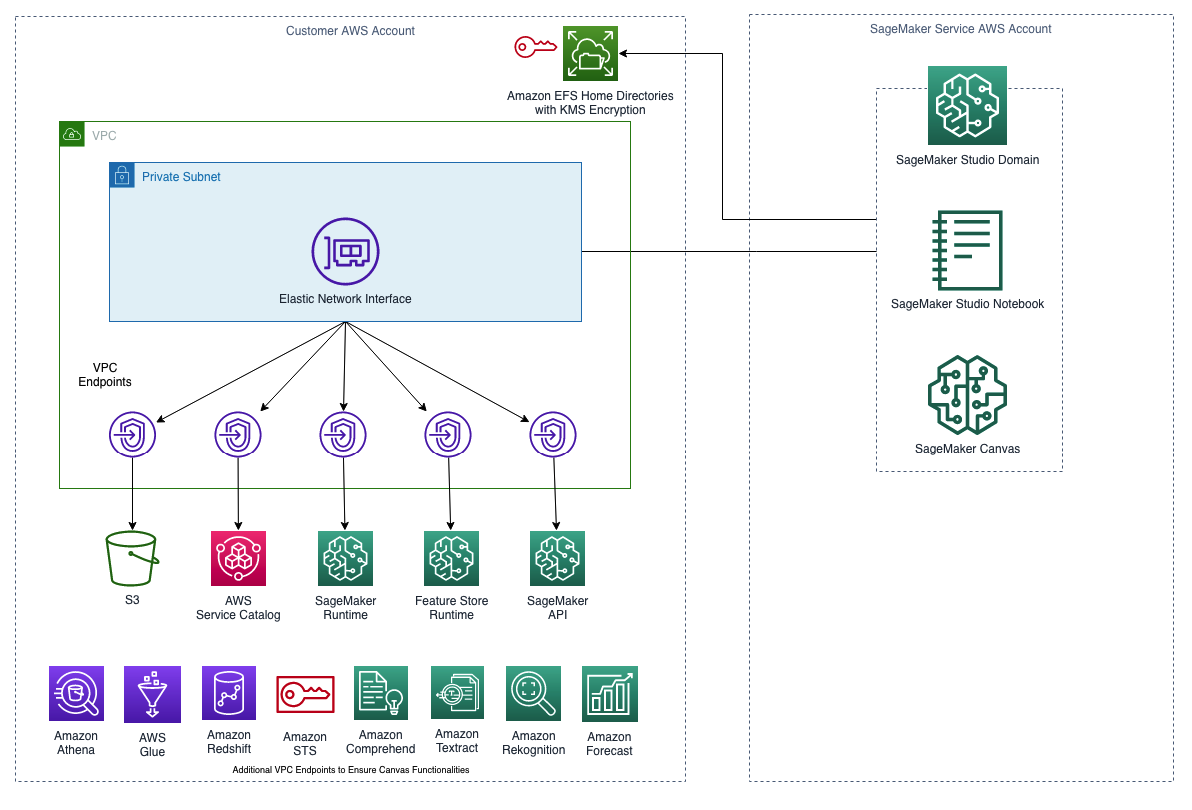
By launching SageMaker Domain in your VPC, you can control the data flow from your SageMaker Studio and Canvas environments. This allows you to restrict internet access, monitor and inspect traffic using standard AWS networking and security capabilities, and connect to other AWS resources through VPC endpoints.
VPC requirements to use VPC only mode
Creating a SageMaker Domain in VPC only mode requires a VPC with the following configurations:
- At least two private subnets, each in a different Availability Zone, to ensure high availability.
- Ensure your subnets have the required number of IP addresses needed. We recommend between two and four IP addresses per user. The total IP address capacity for a Studio domain is the sum of available IP addresses for each subnet provided when the domain is created.
- Set up one or more security groups with inbound and outbound rules that together allow the following traffic:
- NFS traffic over TCP on port 2049 between the domain and the Amazon EFS volume.
- TCP traffic within the security group. This is required for connectivity between the JupyterServer app and the KernelGateway apps. You must allow access to at least ports in the range 8192–65535.
- Create a gateway endpoint for Amazon Simple Storage Service (Amazon S3). SageMaker Studio needs to access Amazon S3 from your VPC using Gateway VPC endpoints. After you create the gateway endpoint, you need to add it as a target in your route table for traffic destined from your VPC to Amazon S3.
- Create interface VPC endpoints (AWS PrivateLink) to allow Studio to access the following services with the corresponding service names. You must also associate a security group for your VPC with these endpoints to allow all inbound traffic from port 443:
- SageMaker API:
com.amazonaws.region.sagemaker.api. This is required to communicate with the SageMaker API. - SageMaker runtime:
com.amazonaws.region.sagemaker.runtime. This is required to run Studio notebooks and to train and host models. - SageMaker Feature Store:
com.amazonaws.region.sagemaker.featurestore-runtime. This is required to use SageMaker Feature Store. - SageMaker Projects:
com.amazonaws.region.servicecatalog. This is required to use SageMaker Projects.
- SageMaker API:
Additional VPC endpoints to use SageMaker Canvas
In addition to the previously mentioned VPC endpoints, to use SageMaker Canvas, you need to also create the following interface VPC endpoints:
- Amazon Forecast and Amazon Forecast Query:
com.amazonaws.region.forecastandcom.amazonaws.region.forecastquery. These are required to use Amazon Forecast. - Amazon Rekognition:
com.amazonaws.region.rekognition. This is required to use Amazon Rekognition. - Amazon Textract:
com.amazonaws.region.textract. This is required to use Amazon Textract. - Amazon Comprehend:
com.amazonaws.region.comprehend. This is required to use Amazon Comprehend. - AWS Security Token Service (AWS STS):
com.amazonaws.region.sts. This is required because SageMaker Canvas uses AWS STS to connect to data sources. - Amazon Athena and AWS Glue:
com.amazonaws.region.athenaandcom.amazonaws.region.glue. This is required to connect to AWS Glue Data Catalog through Amazon Athena. - Amazon Redshift:
com.amazonaws.region.redshift-data. This is required to connect to the Amazon Redshift data source.
To view all VPC endpoints for each service you can use with SageMaker Canvas, please go to Configure Amazon SageMaker Canvas in a VPC without internet access.
AWS KMS encryption for SageMaker Studio’s EFS volume
The first time a user on your team onboards to SageMaker Studio, SageMaker creates an EFS volume for the team. A home directory is created in the volume for each user who onboards to Studio as part of your team. Notebook files and data files are stored in these directories.
You can encrypt your SageMaker Studio’s EFS volume with a KMS key so your home directories’ data are encrypted at rest. This Terraform solution creates a KMS key and uses it to encrypt SageMaker Studio’s EFS volume.
SageMaker Domain Lifecycle Configuration to automatically shut down idle Studio notebooks
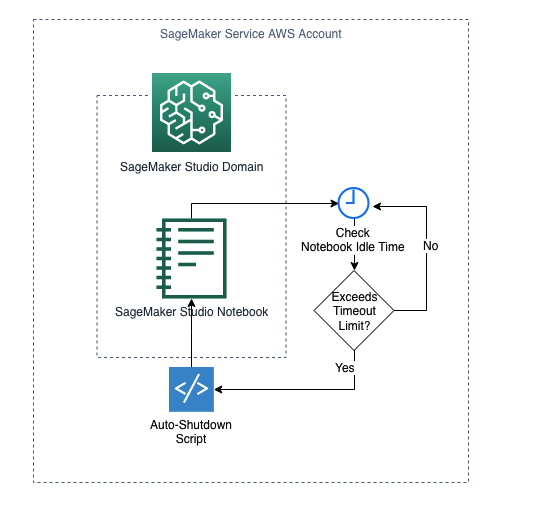
Lifecycle Configurations are shell scripts triggered by Amazon SageMaker Studio lifecycle events, such as starting a new Studio notebook. You can use Lifecycle Configurations to automate customization for your Studio environment.
This Terraform solution creates a SageMaker Lifecycle Configuration to detect and stop idle resources that incur costs within Studio using an auto-shutdown Jupyter extension. Under the hood, the following resources are created or configured to achieve the desired result:
- Create an S3 bucket and upload the latest version of the auto-shutdown extension
sagemaker_studio_autoshutdown-0.1.5.tar.gz. Later, the auto-shutdown script will run thes3 cpcommand to download the extension file from the S3 bucket on Jupyter Server start-ups. Please refer to the following GitHub repos for more information regarding the auto-shutdown extension and auto-shutdown script. - Create an aws_sagemaker_studio_lifecycle_config resource “
auto_shutdown”. This resource will encode theautoshutdown-script.shwith base 64 and create a Lifecycle Configuration for the SageMaker Domain. - For SageMaker Domain default user settings, specify the Lifecycle Configuration arn and set it as default.
SageMaker execution role IAM permissions
As a managed service, SageMaker performs operations on your behalf on the AWS hardware that is managed by SageMaker. SageMaker can perform only operations that the user permits.
A SageMaker user can grant these permissions with an IAM role (referred to as an execution role). When you create a SageMaker Studio domain, SageMaker allows you to create the execution role by default. You can restrict access to user profiles by changing the SageMaker user profile role. This Terraform solution attaches the following IAM policies to the SageMaker execution role:
- SageMaker managed
AmazonSageMakerFullAccesspolicy. This policy grants the execution role full access to use SageMaker Studio. - A customer managed IAM policy to access the KMS key used to encrypt the SageMaker Studio’s EFS volume.
- SageMaker managed
AmazonSageMakerCanvasFullAccessandAmazonSageMakerCanvasAIServicesAccesspolicies. These policies grant the execution role full access to use SageMaker Canvas. - In order to enable time series analysis in SageMaker Canvas, you also need to add the IAM trust policy for Amazon Forecast.
Solution walkthrough
In this blog post, we demonstrate how to deploy the Terraform solution. Prior to making the deployment, please ensure to satisfy the following prerequisites:
Prerequisites
- An AWS account
- An IAM user with administrative access
Deployment steps
To give users following this guide a unified deployment experience, we demonstrate the deployment process with AWS CloudShell. Using CloudShell, a browser-based shell, you can quickly run scripts with the AWS Command Line Interface (AWS CLI), experiment with service APIs using the AWS CLI, and use other tools to increase your productivity.
To deploy the Terraform solution, complete the following steps:
CloudShell launch settings
- Sign in to the AWS Management Console and select the CloudShell service.
- In the navigation bar, in the Region selector, choose US East (N. Virginia).
Your browser will open the CloudShell terminal.
Install Terraform
The next steps should be executed in a CloudShell terminal.
Check this Hashicorp guide for up-to-date instructions to install Terraform for Amazon Linux:
- Install
yum-config-managerto manage your repositories.
- Use
yum-config-managerto add the official HashiCorp Linux repository.
- Install Terraform from the new repository.
- Verify that the installation worked by listing Terraform’s available subcommands.
Expected output:
Clone the code repo
Perform the following steps in a CloudShell terminal.
- Clone the repo and navigate to the sagemaker-domain-vpconly-canvas-with-terraform folder:
- Download the auto-shutdown extension and place it in the
assets/auto_shutdown_templatefolder:
Deploy the Terraform solution
In the CloudShell terminal, run the following Terraform commands:
You should see a success message like:
Now you can run:
After you are satisfied with the resources the plan outlines to be created, you can run:
Enter “yes“ when prompted to confirm the deployment.
If successfully deployed, you should see an output that looks like:
Accessing SageMaker Studio and Canvas
We now have a Studio domain associated with our VPC and a user profile in this domain.

To use the SageMaker Studio console, on the Studio Control Panel, locate your user name (it should be defaultuser) and choose Open Studio.
We made it! Now you can use your browser to connect to the SageMaker Studio environment. After a few minutes, Studio finishes creating your environment, and you’re greeted with the launcher screen.

To use the SageMaker Canvas console, on the Canvas Control Panel, locate your user name (should be defaultuser) and choose Open Canvas.
Now you can use your browser to connect to the SageMaker Canvas environment. After a few minutes, Canvas finishes creating your environment, and you’re greeted with the launcher screen.

Feel free to explore the full functionality SageMaker Studio and Canvas has to offer! Please refer to the Conclusion section for additional workshops and tutorials you can use to learn more about SageMaker.
Clean up
Run the following command to clean up your resources:
Tip: If you set the Amazon EFS retention policy as “Retain” (the default), you will run into issues during “terraform destroy” because Terraform is trying to delete the subnets and VPC when the EFS volume as well as its associated security groups (created by SageMaker) still exist. To fix this, first delete the EFS volume manually and then delete the subnets and VPC manually in the AWS console.
Conclusion
The solution in this post provides you the ability to create a SageMaker Domain to support ML environments, including SageMaker Studio and SageMaker Canvas with Terraform. SageMaker Studio provides a fully managed IDE that removes the heavy lifting in the ML process. With SageMaker Canvas, our business users can easily explore and build ML models to make accurate predictions without writing any code. With the ability to launch Studio and Canvas inside a VPC and the use of a KMS key to encrypt the EFS volume, customers can use SageMaker ML environments with enhanced security. Auto shutdown Lifecycle Configuration helps customers save costs on idle Studio notebook instances.
Go test this solution and let us know what you think. For more information about how to use SageMaker Studio and Sagemaker Canvas, see the following:
About the Author
 Chen Yang is a Machine Learning Engineer at Amazon Web Services. She is part of the AWS Professional Services team, and has been focusing on building secure machine learning environments for customers. In her spare time, she enjoys running and hiking in the Pacific Northwest.
Chen Yang is a Machine Learning Engineer at Amazon Web Services. She is part of the AWS Professional Services team, and has been focusing on building secure machine learning environments for customers. In her spare time, she enjoys running and hiking in the Pacific Northwest.

NVIDIA Grace Hopper Superchip Sweeps MLPerf Inference Benchmarks
In its debut on the MLPerf industry benchmarks, the NVIDIA GH200 Grace Hopper Superchip ran all data center inference tests, extending the leading performance of NVIDIA H100 Tensor Core GPUs.
The overall results showed the exceptional performance and versatility of the NVIDIA AI platform from the cloud to the network’s edge.
Separately, NVIDIA announced inference software that will give users leaps in performance, energy efficiency and total cost of ownership.
GH200 Superchips Shine in MLPerf
The GH200 links a Hopper GPU with a Grace CPU in one superchip. The combination provides more memory, bandwidth and the ability to automatically shift power between the CPU and GPU to optimize performance.
Separately, NVIDIA HGX H100 systems that pack eight H100 GPUs delivered the highest throughput on every MLPerf Inference test in this round.
Grace Hopper Superchips and H100 GPUs led across all MLPerf’s data center tests, including inference for computer vision, speech recognition and medical imaging, in addition to the more demanding use cases of recommendation systems and the large language models (LLMs) used in generative AI.
Overall, the results continue NVIDIA’s record of demonstrating performance leadership in AI training and inference in every round since the launch of the MLPerf benchmarks in 2018.
The latest MLPerf round included an updated test of recommendation systems, as well as the first inference benchmark on GPT-J, an LLM with six billion parameters, a rough measure of an AI model’s size.
TensorRT-LLM Supercharges Inference
To cut through complex workloads of every size, NVIDIA developed TensorRT-LLM, generative AI software that optimizes inference. The open-source library — which was not ready in time for August submission to MLPerf — enables customers to more than double the inference performance of their already purchased H100 GPUs at no added cost.
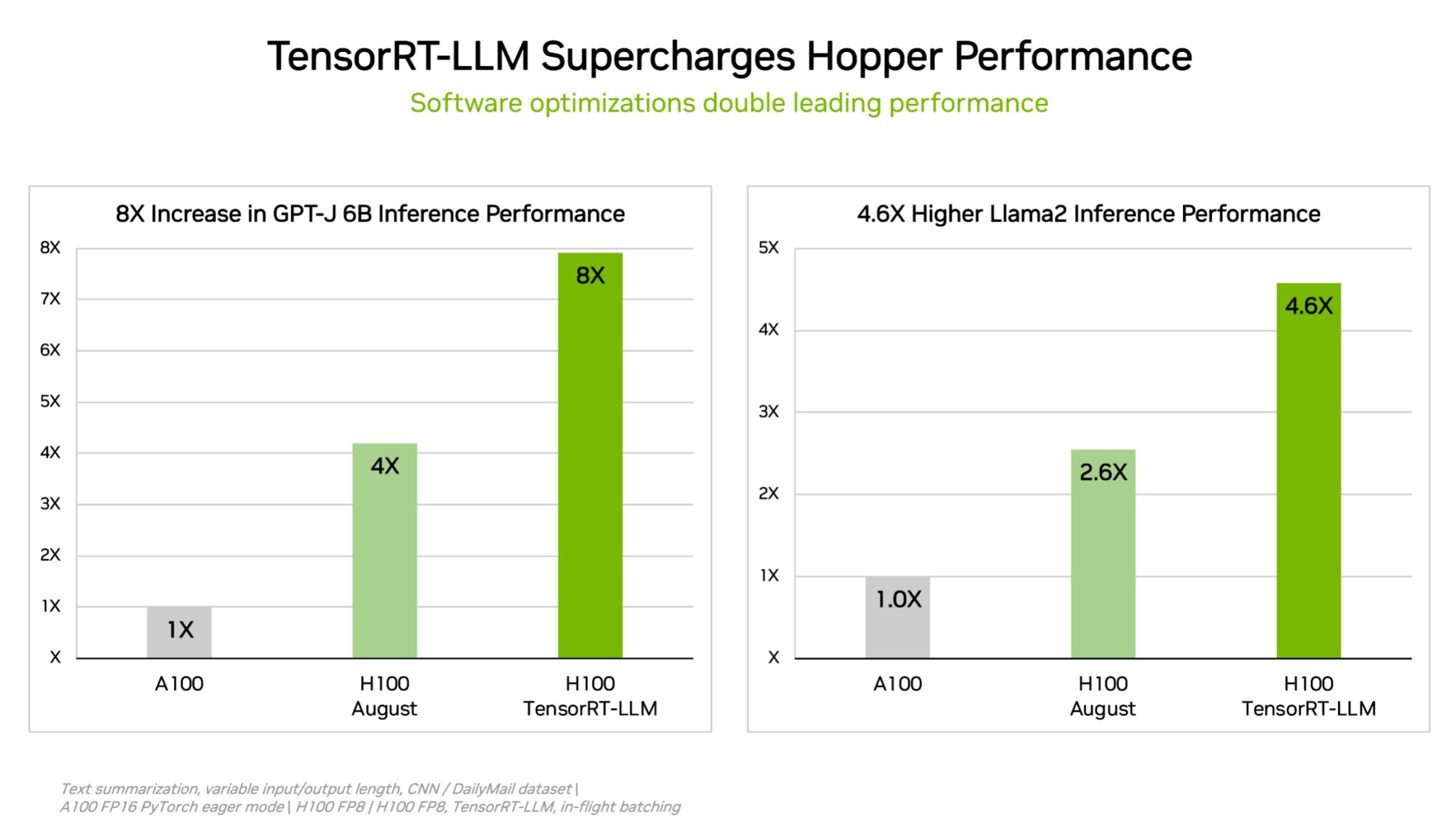
NVIDIA’s internal tests show that using TensorRT-LLM on H100 GPUs provides up to an 8x performance speedup compared to prior generation GPUs running GPT-J 6B without the software.
The software got its start in NVIDIA’s work accelerating and optimizing LLM inference with leading companies including Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (now part of Databricks), OctoML, Tabnine and Together AI.
MosaicML added features that it needs on top of TensorRT-LLM and integrated them into its existing serving stack. “It’s been an absolute breeze,” said Naveen Rao, vice president of engineering at Databricks.
“TensorRT-LLM is easy-to-use, feature-packed and efficient,” Rao said. “It delivers state-of-the-art performance for LLM serving using NVIDIA GPUs and allows us to pass on the cost savings to our customers.”
TensorRT-LLM is the latest example of continuous innovation on NVIDIA’s full-stack AI platform. These ongoing software advances give users performance that grows over time at no extra cost and is versatile across diverse AI workloads.
L4 Boosts Inference on Mainstream Servers
In the latest MLPerf benchmarks, NVIDIA L4 GPUs ran the full range of workloads and delivered great performance across the board.
For example, L4 GPUs running in compact, 72W PCIe accelerators delivered up to 6x more performance than CPUs rated for nearly 5x higher power consumption.
In addition, L4 GPUs feature dedicated media engines that, in combination with CUDA software, provide up to 120x speedups for computer vision in NVIDIA’s tests.
L4 GPUs are available from Google Cloud and many system builders, serving customers in industries from consumer internet services to drug discovery.
Performance Boosts at the Edge
Separately, NVIDIA applied a new model compression technology to demonstrate up to a 4.7x performance boost running the BERT LLM on an L4 GPU. The result was in MLPerf’s so-called “open division,” a category for showcasing new capabilities.
The technique is expected to find use across all AI workloads. It can be especially valuable when running models on edge devices constrained by size and power consumption.
In another example of leadership in edge computing, the NVIDIA Jetson Orin system-on-module showed performance increases of up to 84% compared to the prior round in object detection, a computer vision use case common in edge AI and robotics scenarios.
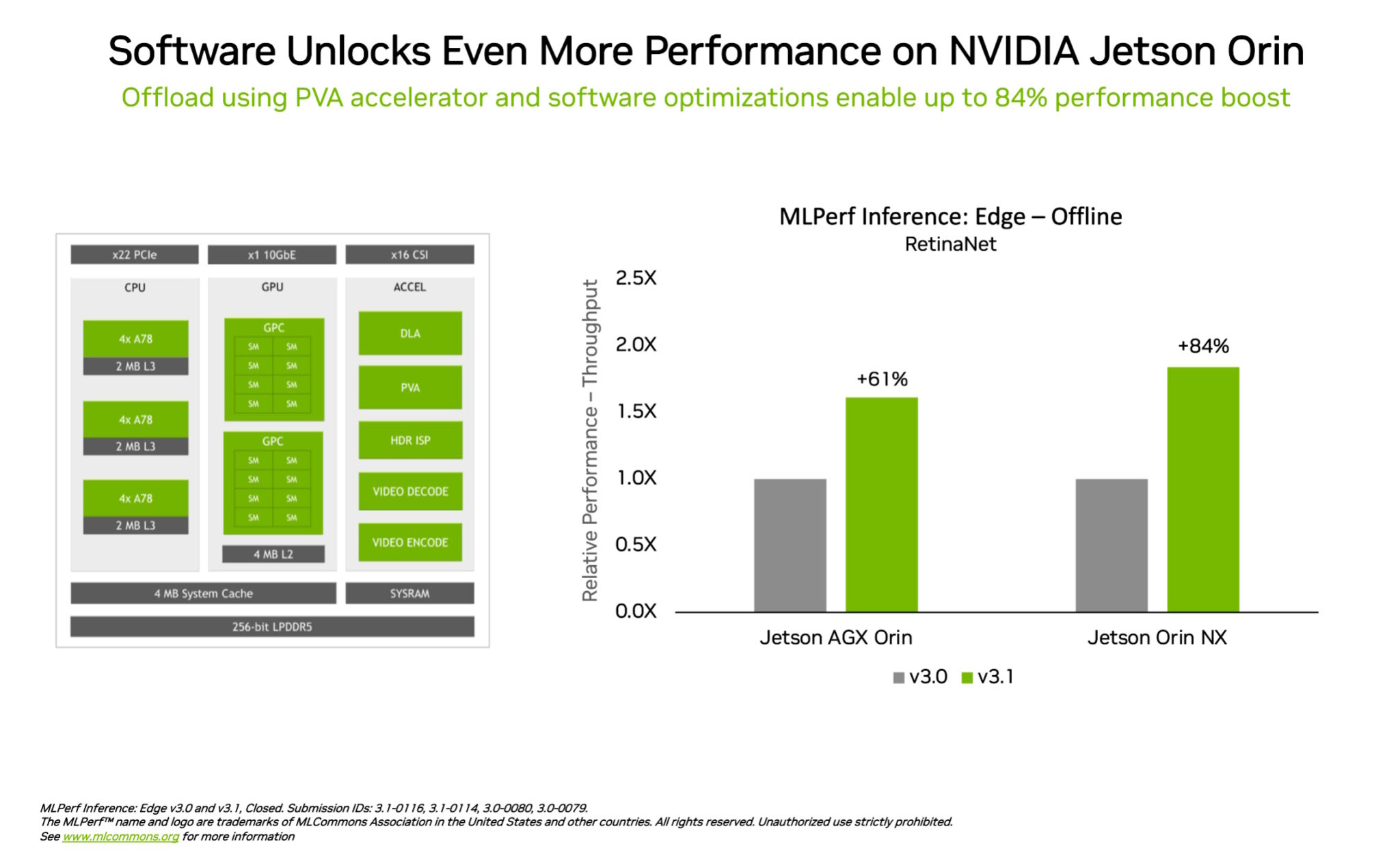
The Jetson Orin advance came from software taking advantage of the latest version of the chip’s cores, such as a programmable vision accelerator, an NVIDIA Ampere architecture GPU and a dedicated deep learning accelerator.
Versatile Performance, Broad Ecosystem
The MLPerf benchmarks are transparent and objective, so users can rely on their results to make informed buying decisions. They also cover a wide range of use cases and scenarios, so users know they can get performance that’s both dependable and flexible to deploy.
Partners submitting in this round included cloud service providers Microsoft Azure and Oracle Cloud Infrastructure and system manufacturers ASUS, Connect Tech, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, QCT and Supermicro.
Overall, MLPerf is backed by more than 70 organizations, including Alibaba, Arm, Cisco, Google, Harvard University, Intel, Meta, Microsoft and the University of Toronto.
Read a technical blog for more details on how NVIDIA achieved the latest results.
All the software used in NVIDIA’s benchmarks is available from the MLPerf repository, so everyone can get the same world-class results. The optimizations are continuously folded into containers available on the NVIDIA NGC software hub for GPU applications.
All About Sample-Size Calculations for A/B Testing: Novel Extensions and Practical Guide
While there exists a large amount of literature on the general challenges and best practices for trustworthy online A/B testing, there are limited studies on sample size estimation, which plays a crucial role in trustworthy and efficient A/B testing that ensures the resulting inference has a sufficient power and type I error control. For example, when the sample size is under-estimated the statistical inference, even with the correct analysis methods, will not be able to detect the true significant improvement leading to misinformed and costly decisions. This paper addresses this fundamental…Apple Machine Learning Research
Intelligent Assistant Language Understanding On-device
It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper, we describe a design for a natural language understanding system that runs on-device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may…Apple Machine Learning Research
Accelerated CPU Inference with PyTorch Inductor using torch.compile
Story at a Glance
- Although the PyTorch* Inductor C++/OpenMP* backend has enabled users to take advantage of modern CPU architectures and parallel processing, it has lacked optimizations, resulting in the backend performing worse than eager mode in terms of end-to-end performance.
- Intel optimized the Inductor backend using a hybrid strategy that classified operations into two categories: Conv/GEMM and non-Conv/GEMM element-wise and reduction ops.
- For popular deep learning models, this hybrid strategy demonstrates promising performance improvements compared to eager mode and improves the C++/OpenMP backend’s efficiency and reliability for PyTorch models.
Inductor Backend Challenges
The PyTorch Inductor C++/OpenMP backend enables users to take advantage of modern CPU architectures and parallel processing to accelerate computations.
However, during the early stages of its development, the backend lacked some optimizations, which prevented it from fully utilizing the CPU computation capabilities. As a result, for most models the C++/OpenMP backend performed worse than eager mode in terms of end-to-end performance, with 45% of TorchBench, 100% of Hugging Face, and 75% of TIMM models performing worse than eager mode.
In this post, we highlight Intel’s optimizations to the Inductor CPU backend, including the technologies and results.
We optimized the backend by using a hybrid strategy that classified operations into two categories: Conv/GEMM and non-Conv/GEMM element-wise and reduction ops. Post-op fusion and weight prepacking using the oneDNN performance library were utilized to optimize the former, while explicit vectorization in C++ codegen was used to optimize the latter.
This hybrid strategy demonstrated promising performance improvements compared to eager mode, particularly on popular deep learning models such as Inductor Hugging Face, Inductor TorchBench and Inductor TIMM. Overall, Intel’s optimizations improve the C++/OpenMP backend’s efficiency and reliability for PyTorch models.
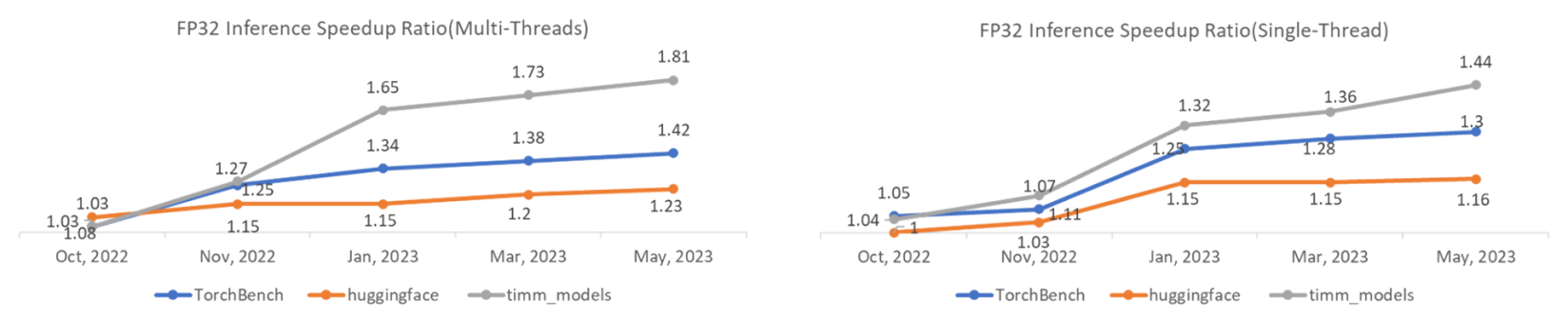
Figure 1: Performance Speedup Ratio Trend
Performance Status of Intel Hybrid Optimizations
Compared to eager mode with the hybrid optimizations, the C++/OpenMP backend shows promising performance improvements. We measured the performance of the three Inductor benchmark suites—TorchBench, Hugging Face, and TIMM—and the results are as follows. (Note: we publish our performance data twice per week on GitHub.)
Overall, these optimizations help to ensure that the C++/OpenMP backend provides efficient and reliable support for PyTorch models.
Passrate
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 93%, 56/60 | 96%, 44/46 | 100%, 61/61 |
+----------+------------+-------------+-------------+
Geometric mean speedup (Single-Socket Multi-threads)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.39x | 1.20x | 1.73x |
+----------+------------+-------------+-------------+
Individual Model Performance
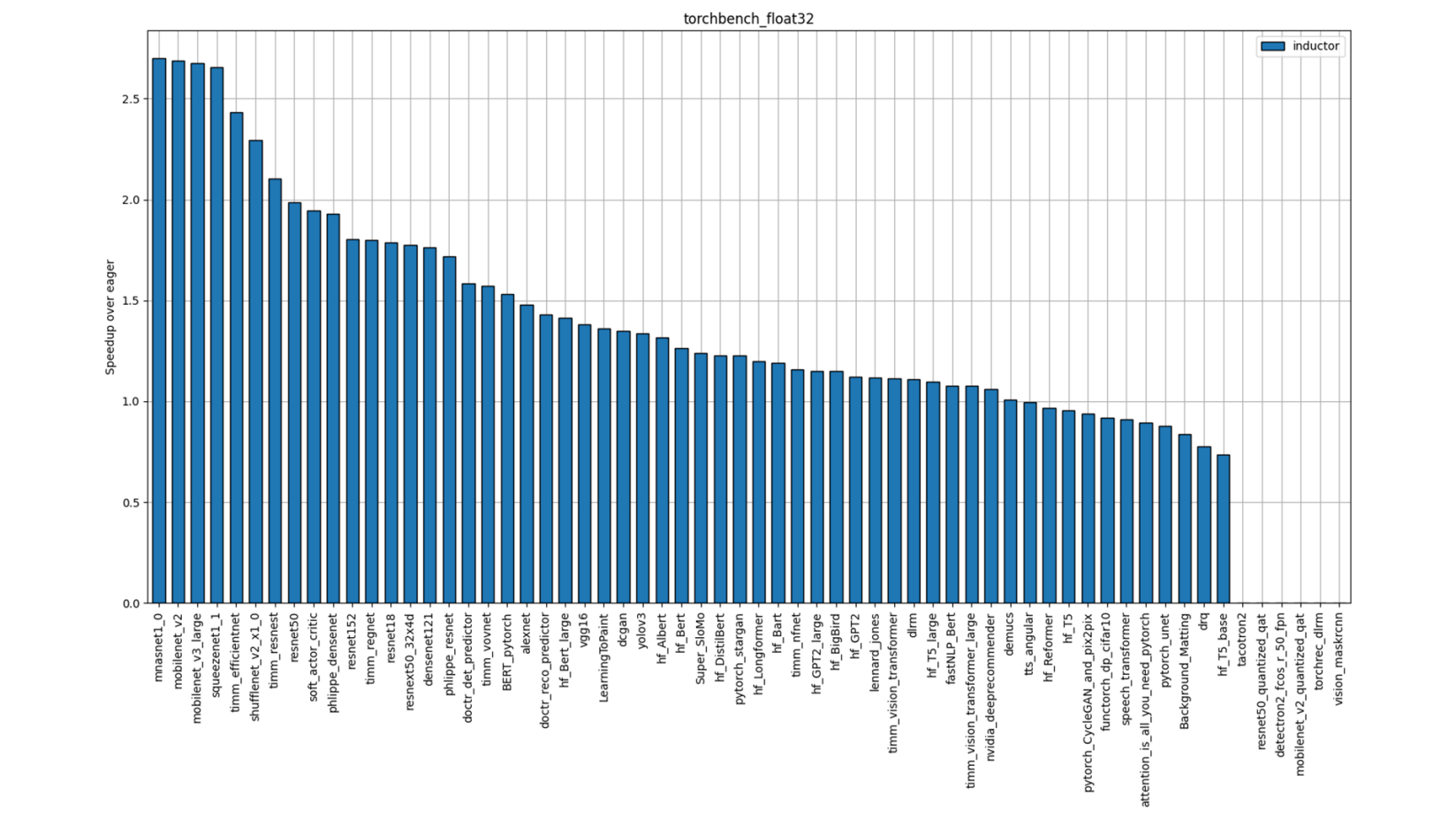
Figure 2: TorchBench FP32 Performance (Single-Socket Multi-threads)
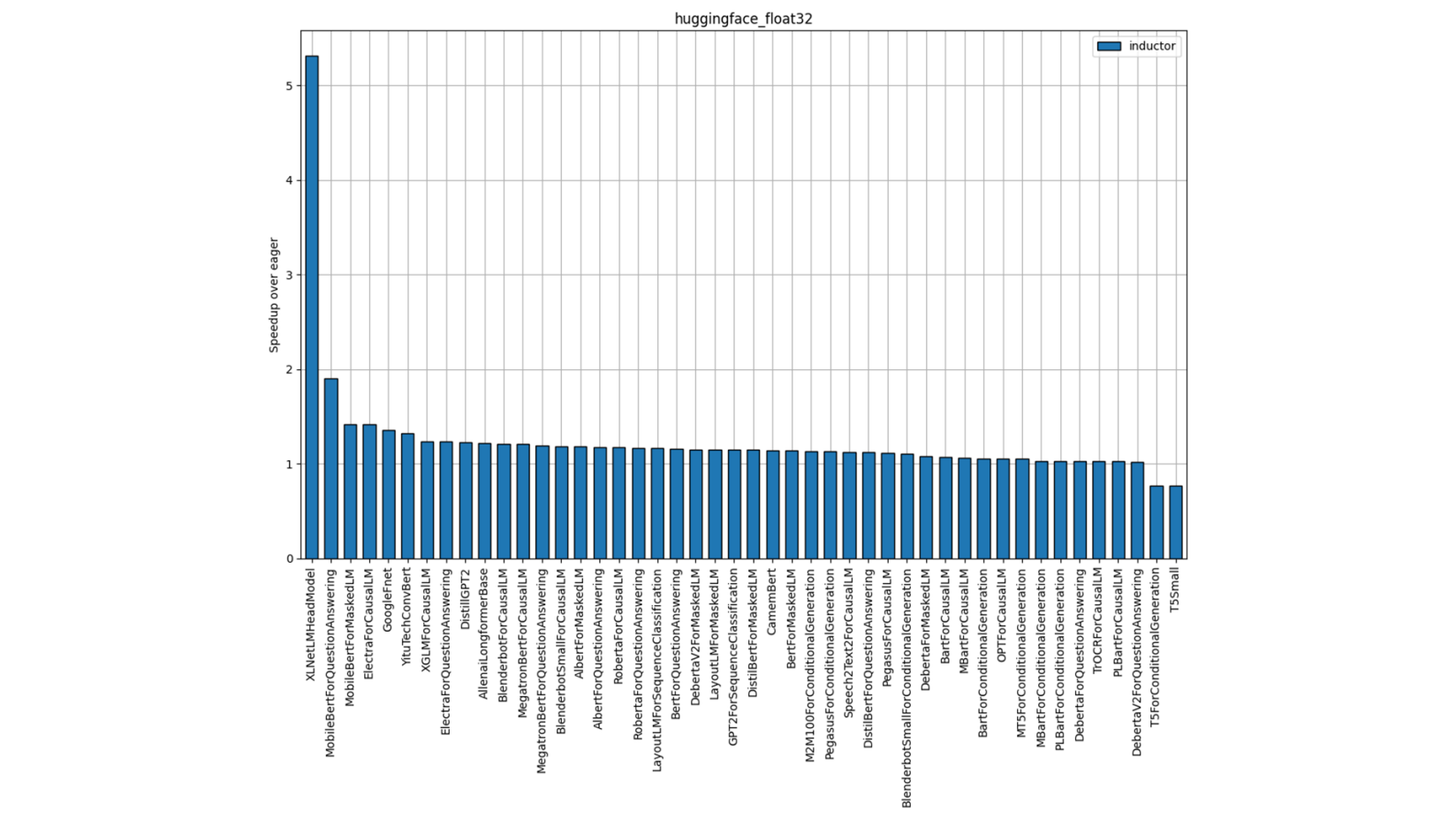
Figure 3: Hugging Face FP32 Performance (Single-Socket Multi-thread)
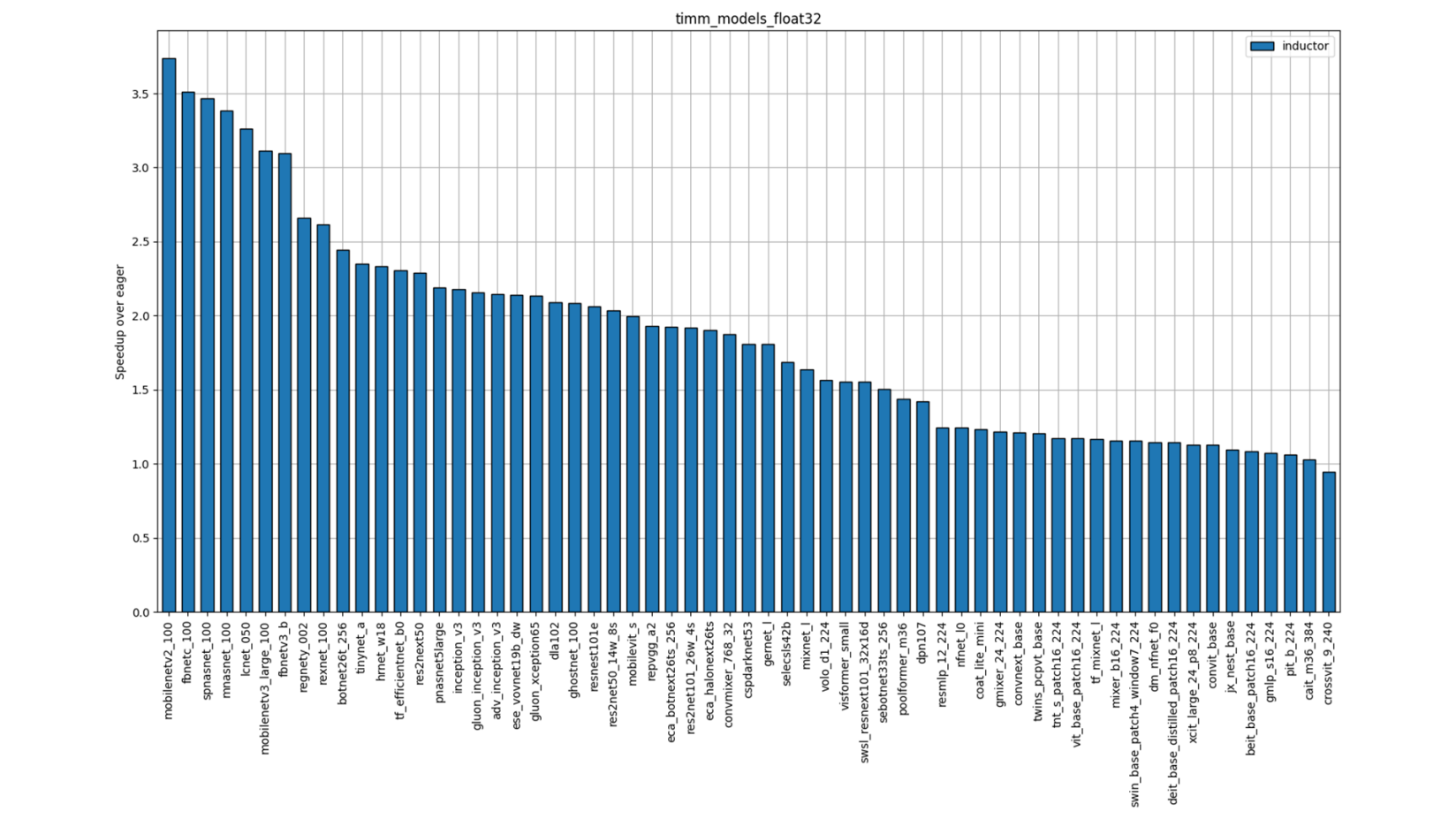
Figure 4: TIMM FP32 Performance (Single-Socket Multi-threads)
Geometric mean speedup (Single-core Single-thread)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.29x | 1.15x | 1.37x |
+----------+------------+-------------+-------------+
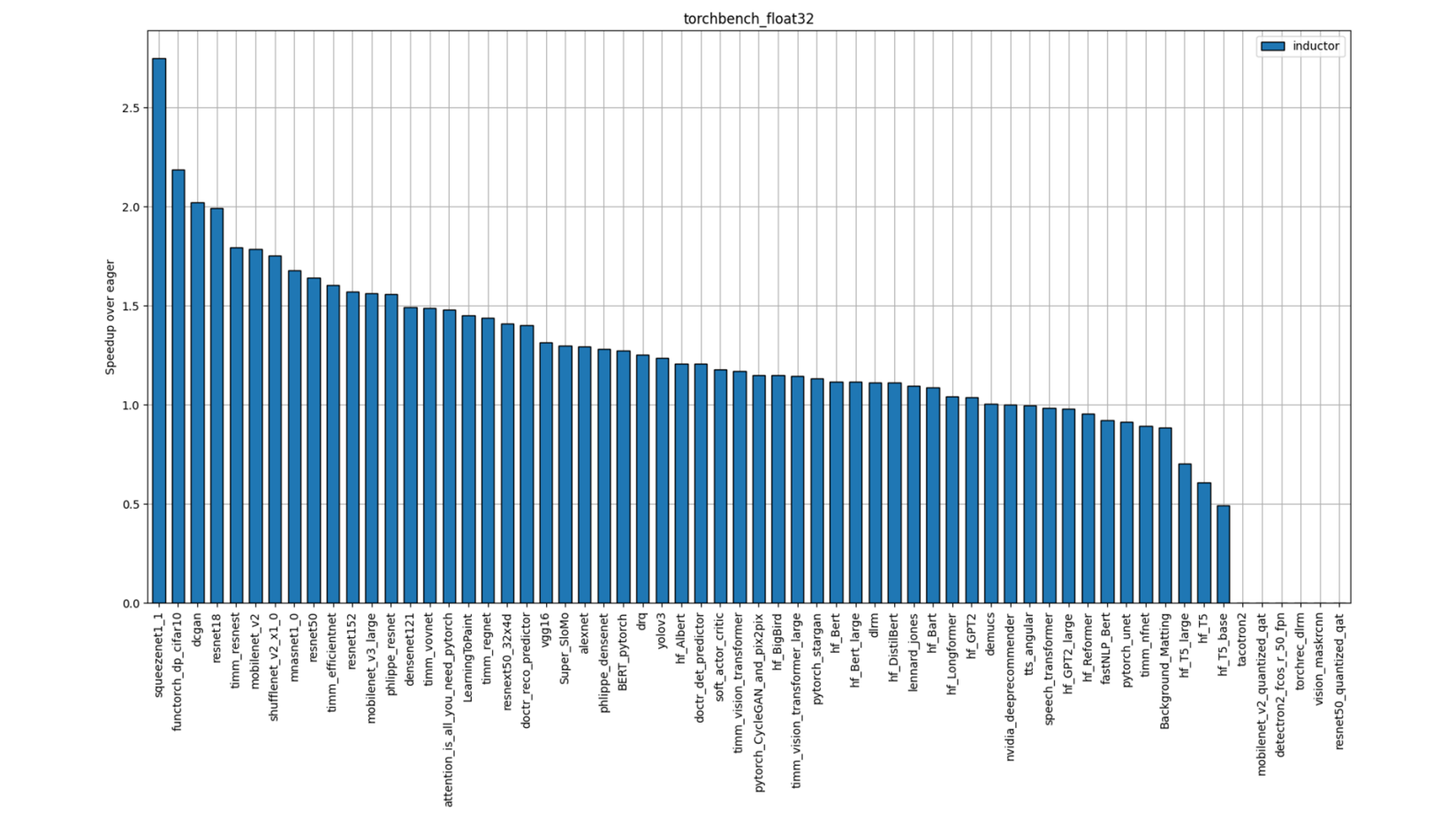
Figure 5: TorchBench FP32 Performance (Single-Socket Single-thread)
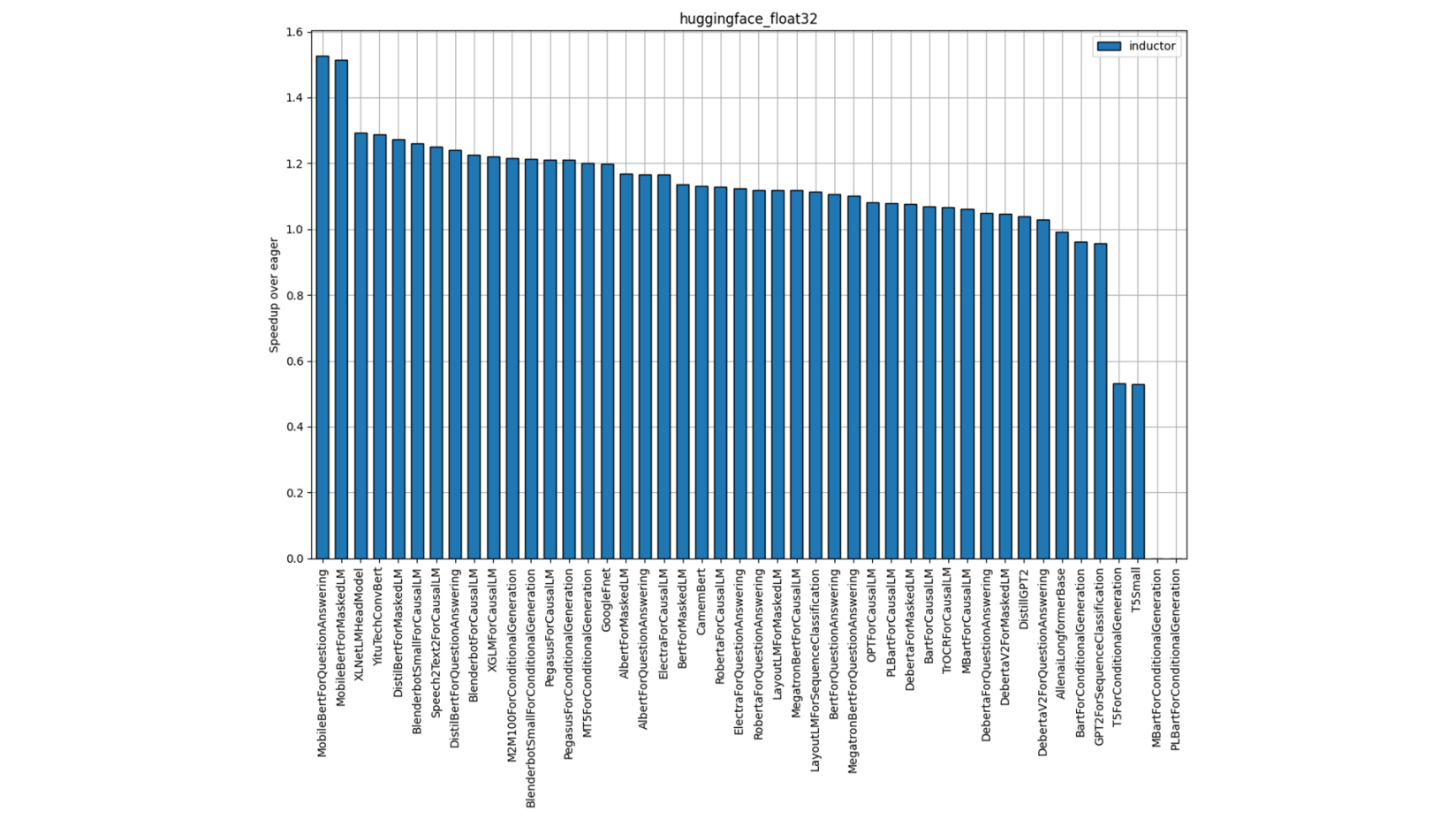
Figure 6: Hugging Face FP32 Performance (Single-Socket Single Thread)
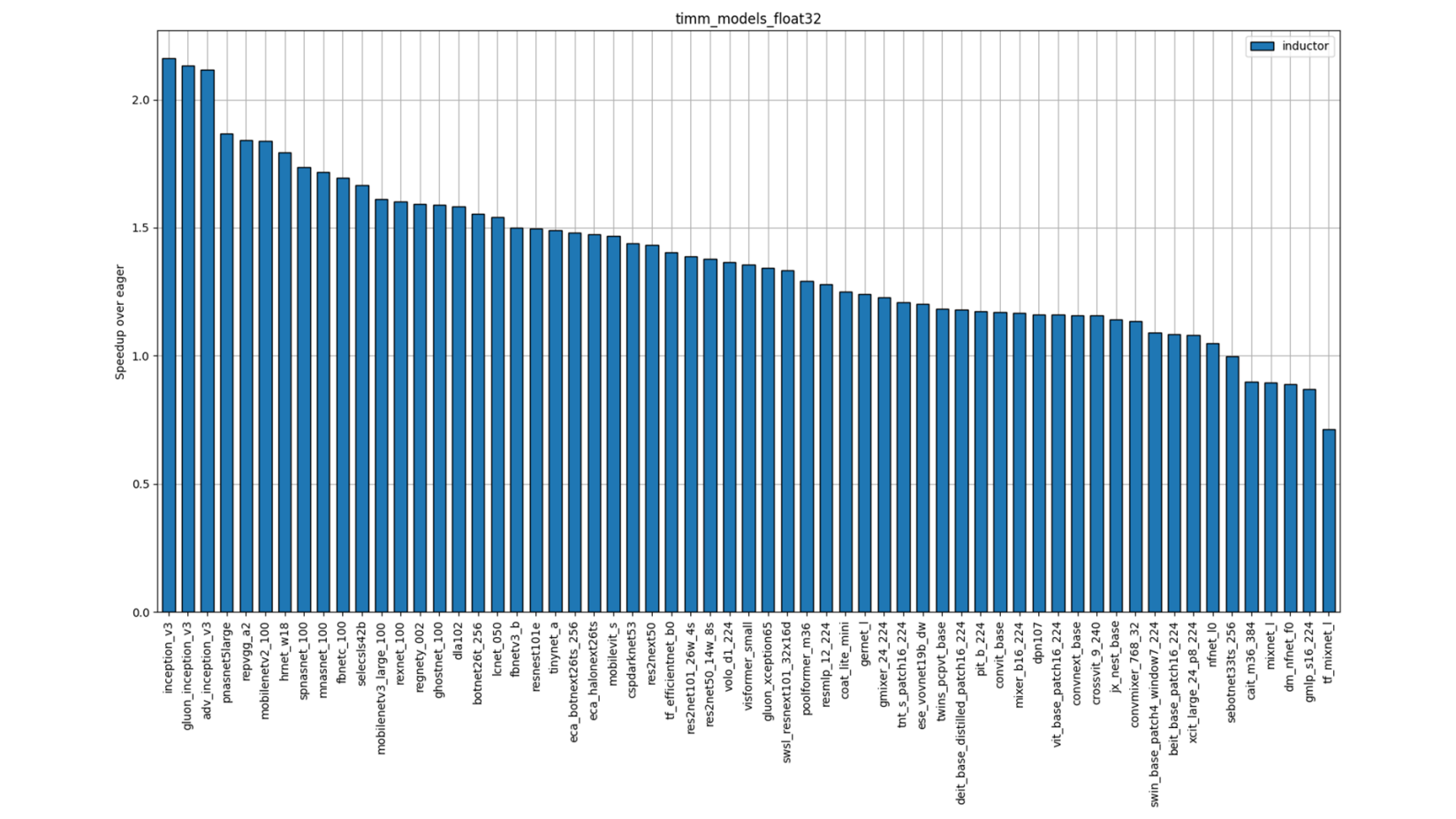
Figure 7: TIMM FP32 Performance (Single-Socket Single-thread)
Technical Deep Dive
Now, let’s take a closer look at the two primary optimizations used in the Inductor C++/OpenMP backend:
- weight prepacking and post-operation fusion via oneDNN library
- explicit vectorization in Inductor C++ codegen
Weight Prepackaging & Post-op Fusion via oneDNN
Shorthand for Intel® oneAPI Deep Neural Network Library, oneDNN library provides a range of post-op fusions (i.e., fuse convolution and matmal with its consecutive operation) that can benefit popular models. The Intel® Extension for PyTorch has implemented most of these fusions and has achieved significant performance improvements. As a result, we have upstreamed all of these fusions that have been applied in Intel’s PyTorch extension to Inductor, enabling a wider range of models to benefit from these optimizations. We have defined these fusions as operators under the mkldnn namespace. This allows the Python module to invoke these mkldnn operations directly.
Currently, the defined fused operations are as follows. You can find these defined fused operations at RegisterMkldnnOpContextClass.cpp.
_linear_pointwise: Fuses Linear and its post-unary element-wise operations_linear_pointwise.binary: Fuses Linear and its post-binary element-wise operations_convolution_pointwise: Fuses Convolution and its post-unary element-wise operations_convolution_pointwise.binary: Fuses Convolution and its post-binary element-wise operations
The detailed fusion patterns are defined in the mkldnn.py file: convolution/linear + sigmoid/hardsigmoid/tanh/hardtanh/hardswish/leaky_relu/gelu/relu/relu6/siluconvolution/linear + add/add_/iadd/sub/sub_
On the Inductor side, we apply these fusions on the FX graph that has been lowered. We have defined mkldnn_fuse_fx as the entry point to apply all the fusions. The code snippet for this is as follows:
def mkldnn_fuse_fx(gm: torch.fx.GraphModule, example_inputs):
...
gm = fuse_unary(gm)
gm = fuse_binary(gm)
...
if config.cpp.weight_prepack:
gm = pack_module(gm)
return gm
In the mkldnn_fuse_fx function, we apply fusion on the FX graph that hasn’t been lowered yet. To fuse convolution/linear and its consecutive elementwise operations, we invoke fuse_unary and fuse_binary as follows:
gm = fuse_unary(gm)
gm = fuse_binary(gm)
In addition to the post-op fusion, we apply weight prepacking to improve the Conv/GEMM performance further:
gm = pack_module(gm)
Weight prepacking involves rearranging the weight tensor in a blocked layout, which:
- can improve vectorization and cache reuse compared to plain formats like NCHW or NHWC and;
- can help avoid weight reordering at runtime, which can reduce overhead and improve performance and;
- increases memory usage as the tradeoff.
For these reasons, we provide config.cpp.weight_prepack flag in Inductor to provide users with more control over this optimization, allowing them to enable it based on their specific needs.
Explicit Vectorization in Inductor C++ Codegen
Vectorization is a key optimization technique that can significantly improve the performance of numerical computations. By utilizing SIMD (Single Instruction, Multiple Data) instructions, vectorization enables multiple computations to be performed simultaneously on a single processor core, which can lead to significant performance improvements.
In the Inductor C++/OpenMP backend, we use Intel® AVX2 and Intel® AVX-512 ISA (Instruction Set Architecture) options for vectorization by leveraging the aten vectorization library to facilitate the implementation. Aten vectorization supports multiple platforms, including x86 and Arm, as well as multiple data types. It can be extended to support other ISAs easily by adding more VecISA sub-classes. This allows Inductor to easily support other platforms and data types in the future.
Due to differences in platforms, the C++/OpenMP backend of Inductor starts by detecting the CPU features to determine the vectorization bit width at the beginning of code generation. By default, if the machine supports both AVX-512 and AVX2, the backend will choose 512-bit vectorization.
If the hardware supports vectorization, the C++/OpenMP backend first detects if the loop body can be vectorized or not. There are primarily three scenarios that we are not able to generate kernel with vectorization:
- Loop body lacks vector intrinsics support, e.g.,
randandatomic_add. - Loop body lacks efficient vector intrinsics support, e.g., non-contiguous
load/store. - Data types with vectorization not yet supported but work in progress, e.g., integer, double, half, and bfloat16.
To address this issue, the C++/OpenMP backend uses CppVecKernelChecker to detect whether all operations in a particular loop body can be vectorized or not. In general, we classified the operations into two categories by identifying if they depend on the context.
For most elementwise operations such as add, sub, relu, vectorization is straightforward, and their execution does not depend on context.
However, for certain other operations, their semantics are more complex and their execution depends on context through static analysis.
For example, let’s consider the where operation that takes in mask, true_value, and false_value while the mask value is loaded from a uint8 tensor. The fx graph could be as follows:
graph():
%ops : [#users=9] = placeholder[target=ops]
%get_index : [#users=1] = call_module[target=get_index](args = (index0,), kwargs = {})
%load : [#users=1] = call_method[target=load](args = (%ops, arg1_1, %get_index), kwargs = {})
%to_dtype : [#users=1] = call_method[target=to_dtype](args = (%ops, %load, torch.bool), kwargs = {})
...
%where : [#users=1] = call_method[target=where](args = (%ops, %to_dtype, %to_dtype_2, %to_dtype_3), kwargs = {})
Regarding uint8, it is a general data type and could be used for computation but is not limited to being used as Boolean for mask. Hence, we need to analyze its context statically. In particular, the CppVecKernelChecker will check whether a uint8 tensor is only used by to_dtype and to_dtype is only used by where. If yes, it could be vectorized. Otherwise, it will fall back to the scalar version. The generated code could be as follows:
Scalar Version
auto tmp0 = in_ptr0[i1 + (17*i0)];
auto tmp3 = in_ptr1[i1 + (17*i0)];
auto tmp1 = static_cast<bool>(tmp0);
auto tmp2 = static_cast<float>(-33.0);
auto tmp4 = tmp1 ? tmp2 : tmp3;
tmp5 = std::max(tmp5, tmp4);
Vectorization Version
float g_tmp_buffer_in_ptr0[16] = {0};
// Convert the flag to float for vectorization.
flag_to_float(in_ptr0 + (16*i1) + (17*i0), g_tmp_buffer_in_ptr0, 16);
auto tmp0 = at::vec::Vectorized<float>::loadu(g_tmp_buffer_in_ptr0);
auto tmp3 = at::vec::Vectorized<float>::loadu(in_ptr1 + (16*i1) + (17*i0));
auto tmp1 = (tmp0);
auto tmp2 = at::vec::Vectorized<float>(static_cast<float>(-33.0));
auto tmp4 = decltype(tmp2)::blendv(tmp3, tmp2, tmp1);
In addition to context analysis, the C++/OpenMP backend also incorporates several other vectorization-related optimizations. These include:
- Tiled kernel implementation for supporting transpose load – cpp.py
- Data type demotion based on value range – cpp.py
- Replacement of sleef implementation with oneDNN/oneMKL implementation for optimizing aten vectorization – #94577, #92289, #91613
In summary, we examined vectorization optimization in Inductor C++ backend for FP32 training and inference of 150 benchmark models with 90% of inference kernels and 71% of training kernels being vectorized.
In terms of inference, a total of 28,185 CPP kernels were generated, with 25,579 (90%) of them being vectorized, while the remaining 10% were scalar. As for training, 103,084 kernels were generated, with 73,909 (71%) being vectorized and 29% not vectorized.
The results indicate that the vectorization of inference kernels is quite impressive (there is still some work to be done in training kernels since we just started to work on the training). The remaining non-vectorized kernels are analyzed in different categories, highlighting the next steps to improve vectorization coverage: index-related operations, int64 support, vertical reduction, vectorization with fallback, and more.
In addition, we also optimized the C++/OpenMP backend with other optimizations like buffer-reuse and CppWrapper.
Future Work
The next step, we will continue optimizing the C++/OpenMP backend and extend it to support more data types as the next step. This includes:
- Improve vectorization coverage
- Support and optimize low precision kernel including BF16, FP16, Quantization
- Training optimization
- Loop tiling
- Autotune
- Further fusion optimization of Conv/GEMM kernels.
- Explore alternative codegen paths: clang/llvm/triton
Summary
Inductor C++/OpenMP backend is a flexible and efficient backend for the CPU. This blog describes the optimizations used in the C++/OpenMP backend of Inductor for inference and training of three benchmark suites – TorchBench, Hugging
Face and TIMM. The primary optimizations include weight prepacking and post-operation fusion via the oneDNN library, as well as explicit vectorization in Inductor C++ codegen using AVX2 and AVX-512 instructions.
The results show that 90% of inference kernels and 71% of training kernels are vectorized, indicating impressive vectorization for inference and room for improvement in training. In addition, we also applied other optimizations like buffer-reuse and CppWrapper. And we will continuously focus on the future work mentioned above to further improve the performance.
Acknowledgements
The results presented in this blog post are the culmination of a collaborative effort between the Intel PyTorch team and Meta. We would like to express our sincere gratitude to @jansel, @desertfire, and @Chillee for their invaluable contributions and unwavering support throughout the development process. Their expertise and dedication have been instrumental in achieving the optimizations and performance improvements discussed here.
Configuration Details
Hardware Details
| Item | Value |
| Manufacturer | Amazon EC2 |
| Product Name | c6i.16xlarge |
| CPU Model | Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz |
| Installed Memory | 128GB (1x128GB DDR4 3200 MT/s [Unknown]) |
| OS | Ubuntu 22.04.2 LTS |
| Kernel | 5.19.0-1022-aws |
| Microcode | 0xd000389 |
| GCC | gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0 |
| GLIBC | ldd (Ubuntu GLIBC 2.35-0ubuntu3.1) 2.35 |
| Binutils | GNU ld (GNU Binutils for Ubuntu) 2.38 |
| Python | Python 3.10.6 |
| OpenSSL | OpenSSL 3.0.2 15 Mar 2022 (Library: OpenSSL 3.0.2 15 Mar 2022) |
Software Details
| SW | Nightly commit | Main commit |
| Pytorch | a977a12 | 0b1b063 |
| Torchbench | / | a0848e19 |
| torchaudio | 0a652f5 | d5b2996 |
| torchtext | c4ad5dd | 79100a6 |
| torchvision | f2009ab | b78d98b |
| torchdata | 5cb3e6d | f2bfd3d |
| dynamo_benchmarks | fea73cb | / |
Configuration
- Intel OpenMP
- Jemalloc – oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:-1,muzzy_decay_ms:-1
- Single-Socket Multi-threads: #of Instances: 1; Cores/Instance: 32
- Single-Core Single-thread: #of Instances: 1; Cores/Instance: 1