Researchers and developers working with Machine Learning (ML) models and algorithms using PyTorch can now use AMD ROCm 5.7 on Ubuntu® Linux® to tap into the parallel computing power of the Radeon™ RX 7900 XTX and the Radeon™ PRO W7900 graphics cards which are based on the AMD RDNA™ 3 GPU architecture.
A client solution built on these two high-end GPUs enables a local, private, and cost-effective workflow for ML training and inference for those who previously relied on cloud-based solutions alone.
Accelerate Machine Learning With Pytorch On Your Desktop
A local PC or workstation system running PyTorch with a Radeon 7900 series GPU presents a capable, yet affordable solution to address these growing workflow challenges thanks to large GPU memory sizes of 24GB and even 48GB.
Unified Software Stack For The Desktop And The Datacenter
The latest AMD ROCm 5.7 software stack for GPU programming unlocks the massively parallel compute power of these RDNA™ 3 architecture-based GPUs for use with PyTorch, one of the leading ML frameworks. The same unified software stack also supports the CDNA™ GPU architecture of the AMD Instinct™ MI series accelerators.
Freedom To Customize
The AMD ROCm platform is primarily Open-Source Software (OSS). It allows developers the freedom to customize and tailor their GPU software for their own needs while collaborating with a community of other developers, and helping each other find solutions in an agile, flexible, and rapid manner. The AMD ROCm platform’s goal is to allow users to maximize their GPU hardware investment. The AMD ROCm platform is designed to help develop, test, and deploy GPU accelerated HPC, AI, scientific computing, CAD, and other applications in a free, open source, integrated and secure software ecosystem.
As the industry moves towards an ecosystem that supports a broad set of systems, frameworks and accelerators, AMD is determined to continue to make AI more accessible to PyTorch developers and researchers that benefit from a local client-based setup for ML development using RDNA™ 3 architecture-based desktop GPUs.
Radeon™ AI technology is compatible with all AMD Radeon 7000 Series graphics cards and newer. Please check with your system manufacturer for feature availability prior to purchase. GD-232.
Based on AMD internal measurements, November 2022, comparing the Radeon RX 7900 XTX at 2.5GHz boost clock with 96 CUs issuing 2X the Bfloat16 math operations per clocks vs. the RX 6900 XT GPU at 2.25 GHz boost clock and 80 CUs issue 1X the Bfloat16 math operations per clock. RX-821
*=Equal Contributors
Controversy is a reflection of our zeitgeist, and an important aspect to any discourse. The rise of large language models (LLMs) as conversational systems has increased public reliance on these systems for answers to their various questions. Consequently, it is crucial to systematically examine how these models respond to questions that pertaining to ongoing debates. However, few such datasets exist in providing human-annotated labels reflecting the contemporary discussions. To foster research in this area, we propose a novel construction of a controversial questions…Apple Machine Learning Research
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. You can choose from various FMs from Amazon and leading AI startups such as AI21 Labs, Anthropic, Cohere, and Stability AI to find the model that’s best suited for your use case. With the Amazon Bedrock serverless experience, you can quickly get started, easily experiment with FMs, privately customize them with your own data, and seamlessly integrate and deploy them into your applications using AWS tools and capabilities.
Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data. When accessing Amazon Bedrock APIs, customers are looking for mechanism to set up a data perimeter without exposing their data to internet so they can mitigate potential threat vectors from internet exposure. The Amazon Bedrock VPC endpoint powered by AWS PrivateLink allows you to establish a private connection between the VPC in your account and the Amazon Bedrock service account. It enables VPC instances to communicate with service resources without the need for public IP addresses.
In this post, we demonstrate how to set up private access on your AWS account to access Amazon Bedrock APIs over VPC endpoints powered by PrivateLink to help you build generative AI applications securely with your own data.
Solution overview
You can use generative AI to develop a diverse range of applications, such as text summarization, content moderation, and other capabilities. When building such generative AI applications using FMs or base models, customers want to generate a response without going over the public internet or based on their proprietary data that may reside in their enterprise databases.
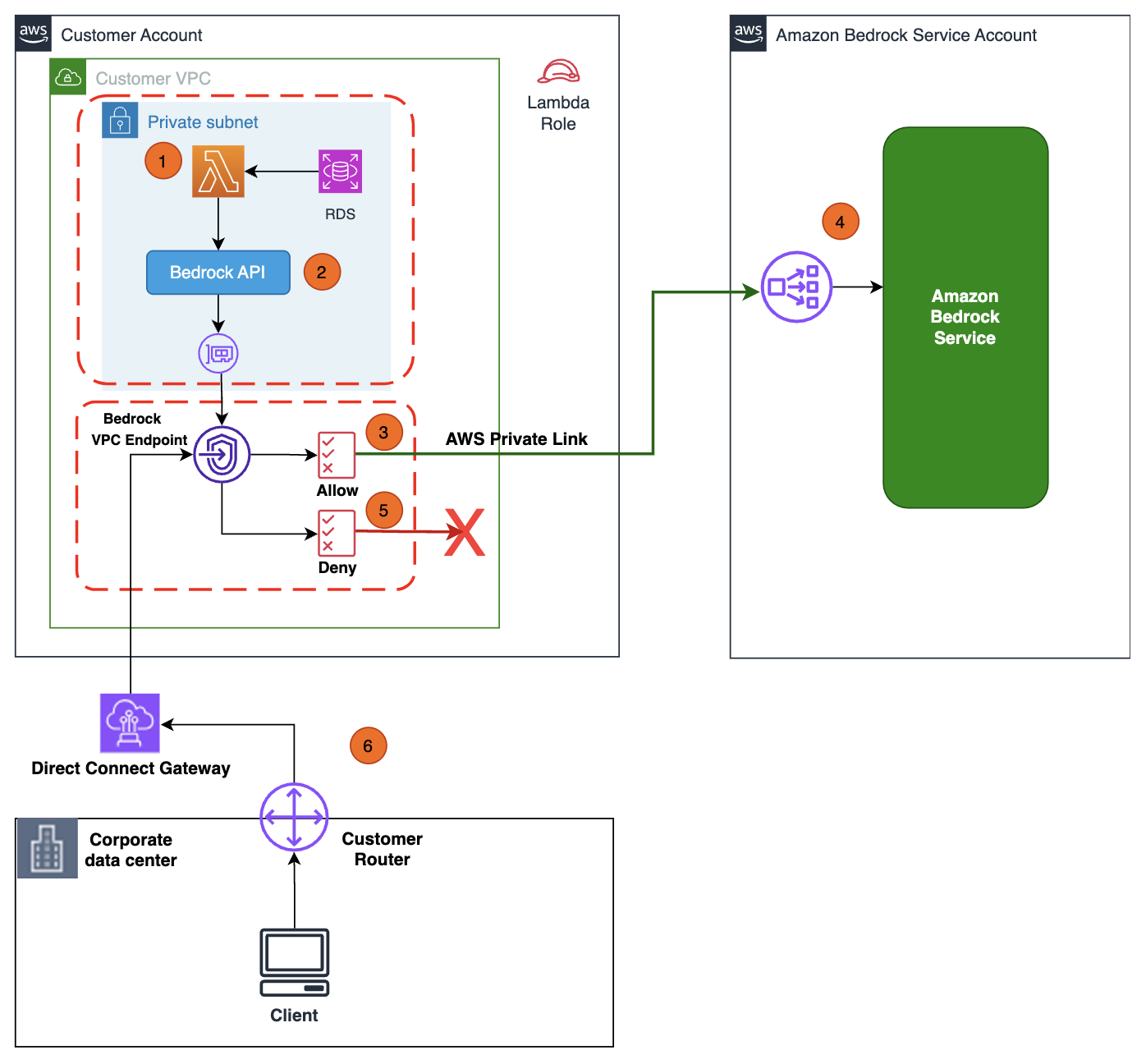
In the following diagram, we depict an architecture to set up your infrastructure to read your proprietary data residing in Amazon Relational Database Service (Amazon RDS) and augment the Amazon Bedrock API request with product information when answering product-related queries from your generative AI application. Although we use Amazon RDS in this diagram for illustration purposes, you can test the private access of the Amazon Bedrock APIs end to end using the instructions provided in this post.
The workflow steps are as follows:
AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
Lambda makes a call to proprietary RDS database and augments the prompt query context (for example, adding product information) and invokes the Amazon Bedrock API with the augmented query request.
The API call is routed to the Amazon Bedrock VPC endpoint that is associated to the VPC endpoint policy with Allow permissions to Amazon Bedrock APIs.
The Amazon Bedrock service API endpoint receives the API request over PrivateLink without traversing the public internet.
You can change the Amazon Bedrock VPC endpoint policy to Deny permissions to validate that Amazon Bedrock APIs calls are denied.
You can also privately access Amazon Bedrock APIs over the VPC endpoint from your corporate network through an AWS Direct Connect gateway.
Prerequisites
Before you get started, make sure you have the following prerequisites:
In this section, we use Amazon Virtual Private Cloud (Amazon VPC) to set up the VPC endpoint for Amazon Bedrock to facilitate private connectivity from your VPC to Amazon Bedrock.
On the Amazon VPC console, under Virtual private cloud in the navigation pane, choose Endpoints.
Choose Create endpoint.
For Name tag, enter bedrock-vpce.
Under Services, search for bedrock-runtime and select com.amazonaws.<region>.bedrock-runtime.
For VPC, specify the VPC Bedrock-GenAI-Project-vpc that you created through the CloudFormation stack in the previous section.
In the Subnets section, and select the Availability Zones and choose the corresponding subnet IDs from the drop-down menu.
For Security groups, select the security group with the group name Bedrock-GenAI-Stack-VPCEndpointSecurityGroup- and description Allow TLS for VPC Endpoint.
A security group acts as a virtual firewall for your instance to control inbound and outbound traffic. Note that this VPC endpoint security group only allows traffic originating from the security group attached to your VPC private subnets, adding a layer of protection.
Choose Create endpoint.
In the Policy section, select Custom and enter the following least privilege policy to ensure only certain actions are allowed on the specified foundation model resource, arn:aws:bedrock:*::foundation-model/anthropic.claude-instant-v1 for a given principal (such as Lambda function IAM role).
It may take up to 2 minutes until the interface endpoint is created and the status changes to Available. You can refresh the page to check the latest status.
Set up the Lambda function over private VPC subnets
Complete the following steps to configure the Lambda function:
On the Lambda console, choose Functions in the navigation pane.
Choose the function gen-ai-lambda-stack-BedrockTestLambdaFunction-XXXXXXXXXXXX.
On the Configuration tab, choose Permissions in the left pane.
Under Execution role¸ choose the link for the role gen-ai-lambda-stack-BedrockTestLambdaFunctionRole-XXXXXXXXXXXX.
You’re redirected to the IAM console.
In the Permissions policies section, choose Add permissions and choose Create inline policy.
Return to the Lambda function page and on the Code tab, choose Test.
As shown in the following screenshot, the access request to Amazon Bedrock over the VPC endpoint was denied (Status: Failed).
Through this testing process, we demonstrated how traffic from your VPC to the Amazon Bedrock API endpoint is traversing over the PrivateLink connection and not through the internet connection.
Clean up
Follow these steps to avoid incurring future charges:
In this post, we demonstrated how to set up and operationalize a private connection between a generative AI workload deployed on your customer VPC and Amazon Bedrock using an interface VPC endpoint powered by PrivateLink. When using the architecture discussed in this post, the traffic between your customer VPC and Amazon Bedrock will not leave the Amazon network, ensuring your data is not exposed to the public internet and thereby helping with your compliance requirements.
As a next step, try the solution out in your account and share your feedback.
About the Authors
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle!
Ray Khorsandi is an AI/ML specialist at AWS, supporting strategic customers with AI/ML best practices. With an M.Sc. and Ph.D. in Electrical Engineering and Computer Science, he leads enterprises to build secure, scalable AI/ML and big data solutions to optimize their cloud adoption. His passions include computer vision, NLP, generative AI, and MLOps. Ray enjoys playing soccer and spending quality time with family.
Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his Ph.D. from the Univ. of Texas and his M.Sc. in Computer Science specialization in Machine Learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations, while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding in the mountains.
We are excited to announce a simplified version of the Amazon SageMaker JumpStart SDK that makes it straightforward to build, train, and deploy foundation models. The code for prediction is also simplified. In this post, we demonstrate how you can use the simplified SageMaker Jumpstart SDK to get started with using foundation models in just a couple of lines of code.
SageMaker JumpStart provides pre-trained, open-source models for a wide range of problem types to help you get started with machine learning (ML). You can incrementally train and fine-tune these models before deployment. JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker. You can access the pre-trained models, solution templates, and examples through the SageMaker JumpStart landing page in Amazon SageMaker Studio or use the SageMaker Python SDK.
To demonstrate the new features of the SageMaker JumpStart SDK, we show you how to use the pre-trained Flan T5 XL model from Hugging Face for text generation for summarization tasks. We also showcase how, in just a few lines of code, you can fine-tune the Flan T5 XL model for summarization tasks. You can use any other model for text generation like Llama2, Falcon, or Mistral AI.
You can find the notebook for this solution using Flan T5 XL in the GitHub repo.
Deploy and invoke the model
Foundation models hosted on SageMaker JumpStart have model IDs. For the full list of model IDs, refer to Built-in Algorithms with pre-trained Model Table. For this post, we use the model ID of the Flan T5 XL text generation model. We instantiate the model object and deploy it to a SageMaker endpoint by calling its deploy method. See the following code:
from sagemaker.jumpstart.model import JumpStartModel
# Replace with larger model if needed
pretrained_model = JumpStartModel(model_id="huggingface-text2text-flan-t5-base")
pretrained_predictor = pretrained_model.deploy()
Next, we invoke the model to create a summary of the provided text using the Flan T5 XL model. The new SDK interface makes it straightforward for you to invoke the model: you just need to pass the text to the predictor and it returns the response from the model as a Python dictionary.
text = """Summarize this content - Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases.
You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. You can run real-time analysis for small workloads or you can start asynchronous analysis jobs for large document sets. You can use the pre-trained models that Amazon Comprehend provides, or you can train your own custom models for classification and entity recognition. """
query_response = pretrained_predictor.predict(text)
print(query_response["generated_text"])
The following is the output of the summarization task:
Understand how Amazon Comprehend works. Use Amazon Comprehend to analyze documents.
Fine-tune and deploy the model
The SageMaker JumpStart SDK provides you with a new class, JumpStartEstimator, which simplifies fine-tuning. You can provide the location of fine-tuning data and optionally pass validations datasets as well. After you fine-tune the model, use the deploy method of the Estimator object to deploy the fine-tuned model:
The new SDK makes it straightforward to deploy and fine-tune JumpStart models by defaulting many parameters. You still have the option to override the defaults and customize the deployment and invocation based on your requirements. For example, you can customize input payload format type, instance type, VPC configuration, and more for your environment and use case.
The following code shows how to override the instance type while deploying your model:
The SageMaker JumpStart SDK deploy function will automatically select a default content type and serializer for you. If you want to change the format type of the input payload, you can use serializers and content_types objects to introspect the options available to you by passing the model_id of the model you are working with. In the following code, we set the payload input format as JSON by setting JSONSerializer as serializer and application/json as content_type:
Next, you can invoke the Flan T5 XL model for the summarization task with a payload of the JSON format. In the following code, we also pass inference parameters in the JSON payload for making responses more accurate:
from sagemaker import serializers
input_text= """Summarize this content - Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases.
You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. You can run real-time analysis for small workloads or you can start asynchronous analysis jobs for large document sets. You can use the pre-trained models that Amazon Comprehend provides, or you can train your own custom models for classification and entity recognition. """
parameters = {
"max_length": 600,
"num_return_sequences": 1,
"top_p": 0.01,
"do_sample": False,
}
payload = {"text_inputs": input_text, **parameters} #JSON Input format
pretrained_predictor.serializer = serializers.JSONSerializer()
query_response = pretrained_predictor.predict(payload)
print(query_response["generated_texts"][0])
If you’re looking for more ways to customize the inputs and other options for hosting and fine-tuning, refer to the documentation for the JumpStartModel and JumpStartEstimator classes.
Conclusion
In this post, we showed you how you can use the simplified SageMaker JumpStart SDK for building, training, and deploying task-based and foundation models in just a few lines of code. We demonstrated the new classes like JumpStartModel and JumpStartEstimator using the Hugging Face Flan T5-XL model as an example. You can use any of the other SageMaker JumpStart foundation models for use cases such as content writing, code generation, question answering, summarization, classification, information retrieval, and more. To see the whole list of models available with SageMaker JumpStart, refer to Built-in Algorithms with pre-trained Model Table. SageMaker JumpStart also supports task-specific models for many popular problem types.
We hope the simplified interface of the SageMaker JumpStart SDK will help you get started quickly and enable you to deliver faster. We look forward to hearing how you use the simplified SageMaker JumpStart SDK to create exciting applications!
About the authors
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
A research paper released today describes ways generative AI can assist one of the most complex engineering efforts: designing semiconductors.
The work demonstrates how companies in highly specialized fields can train large language models (LLMs) on their internal data to build assistants that increase productivity.
Few pursuits are as challenging as semiconductor design. Under a microscope, a state-of-the-art chip like an NVIDIA H100 Tensor Core GPU (above) looks like a well-planned metropolis, built with tens of billions of transistors, connected on streets 10,000x thinner than a human hair.
Multiple engineering teams coordinate for as long as two years to construct one of these digital megacities.
Some groups define the chip’s overall architecture, some craft and place a variety of ultra-small circuits, and others test their work. Each job requires specialized methods, software programs and computer languages.
A Broad Vision for LLMs
“I believe over time large language models will help all the processes, across the board,” said Mark Ren, an NVIDIA Research director and lead author on the paper.
Bill Dally, NVIDIA’s chief scientist, announced the paper today in a keynote at the International Conference on Computer-Aided Design, an annual gathering of hundreds of engineers working in the field called electronic design automation, or EDA.
“This effort marks an important first step in applying LLMs to the complex work of designing semiconductors,” said Dally at the event in San Francisco. “It shows how even highly specialized fields can use their internal data to train useful generative AI models.”
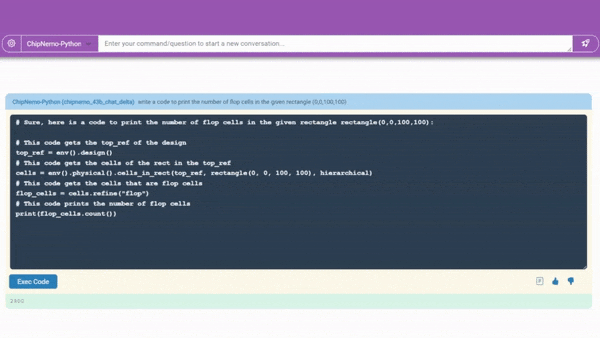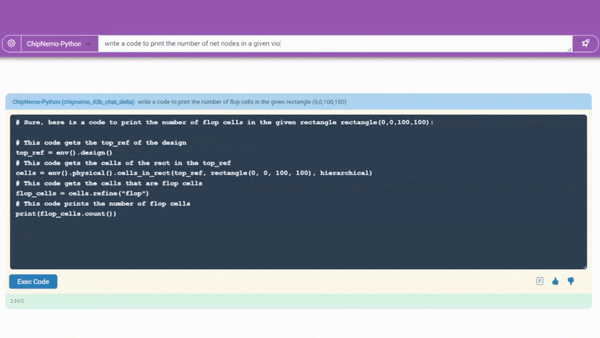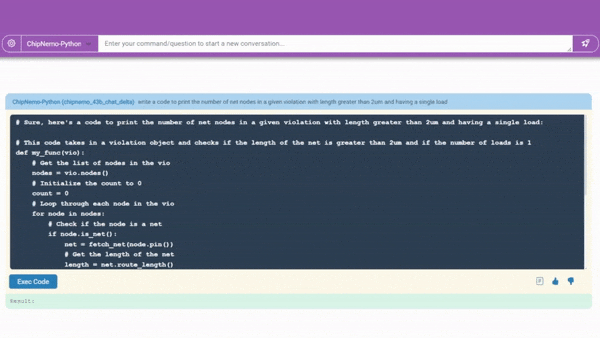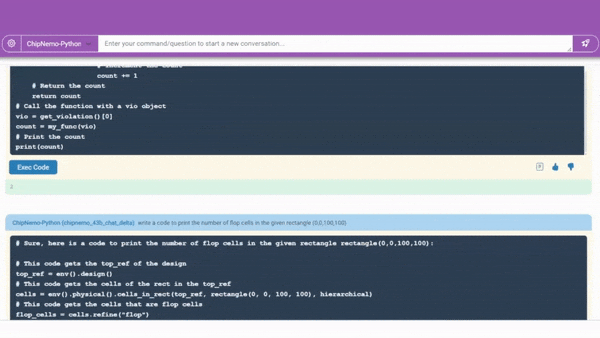
ChipNeMo Surfaces
The paper details how NVIDIA engineers created for their internal use a custom LLM, called ChipNeMo, trained on the company’s internal data to generate and optimize software and assist human designers.
Long term, engineers hope to apply generative AI to each stage of chip design, potentially reaping significant gains in overall productivity, said Ren, whose career spans more than 20 years in EDA.
After surveying NVIDIA engineers for possible use cases, the research team chose three to start: a chatbot, a code generator and an analysis tool.
Initial Use Cases
The latter — a tool that automates the time-consuming tasks of maintaining updated descriptions of known bugs — has been the most well-received so far.
A prototype chatbot that responds to questions about GPU architecture and design helped many engineers quickly find technical documents in early tests.
A code generator will help designers write software for a chip design.
A code generator in development (demonstrated above) already creates snippets of about 10-20 lines of software in two specialized languages chip designers use. It will be integrated with existing tools, so engineers have a handy assistant for designs in progress.
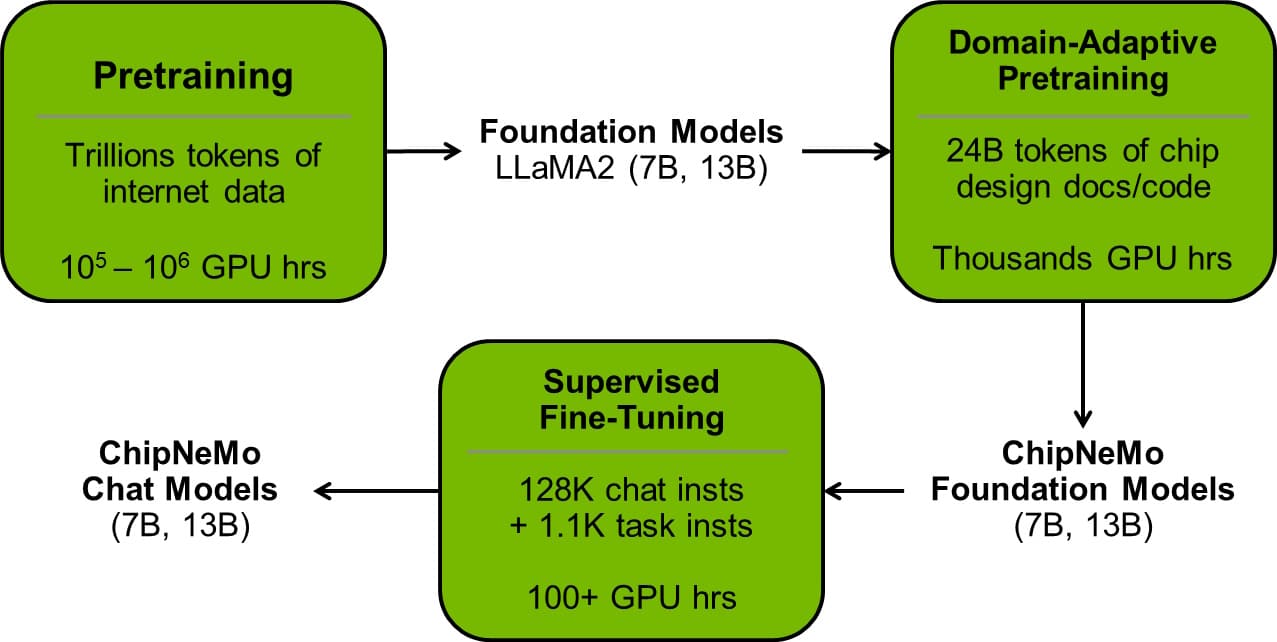
Customizing AI Models With NVIDIA NeMo
The paper mainly focuses on the team’s work gathering its design data and using it to create a specialized generative AI model, a process portable to any industry.
As its starting point, the team chose a foundation model and customized it with NVIDIA NeMo, a framework for building, customizing and deploying generative AI models that’s included in the NVIDIA AI Enterprise software platform. The selected NeMo model sports 43 billion parameters, a measure of its capability to understand patterns. It was trained using more than a trillion tokens, the words and symbols in text and software.
ChipNeMo provides an example of how one deeply technical team refined a pretrained model with its own data.
The team then refined the model in two training rounds, the first using about 24 billion tokens worth of its internal design data and the second on a mix of about 130,000 conversation and design examples.
The work is among several examples of research and proofs of concept of generative AI in the semiconductor industry, just beginning to emerge from the lab.
Sharing Lessons Learned
One of the most important lessons Ren’s team learned is the value of customizing an LLM.
On chip-design tasks, custom ChipNeMo models with as few as 13 billion parameters match or exceed performance of even much larger general-purpose LLMs like LLaMA2 with 70 billion parameters. In some use cases, ChipNeMo models were dramatically better.
Along the way, users need to exercise care in what data they collect and how they clean it for use in training, he added.
Finally, Ren advises users to stay abreast of the latest tools that can speed and simplify the work.
NVIDIA Research has hundreds of scientists and engineers worldwide focused on topics such as AI, computer graphics, computer vision, self-driving cars and robotics. Other recent projects in semiconductors include using AI to design smaller, faster circuits and to optimize placement of large blocks.
Enterprises looking to build their own custom LLMs can get started today using NeMo framework available from GitHub and NVIDIA NGC catalog.
Teachers are the backbone of any educational system. They are not just educators; they are indispensable navigators, mentors, and leaders. Teachers around the world face many challenges, which vary from country to country or even within a city or town. But some challenges are universal, including time management, classroom organization, and creating effective lesson plans.
Advances in AI present new opportunities to enhance teachers’ abilities and empower students to learn more effectively. That’s the goal of a new project from Microsoft Research, which uses generative AI to help teachers quickly develop personalized learning experiences, design assignments, create hands-on activities, and more, while giving them back hours of time that they spend on daily planning today.
Shiksha copilot is a research project which is an interdisciplinary collaboration between Microsoft Research India and teams across Microsoft. Shiksha (Sanskrit: शिक्षा, IAST and ISO: śikṣā) is a Sanskrit word, which means “instruction, lesson, learning, study of skill”. The project aims to improve learning outcomes and empower teachers to create comprehensive, age-appropriate lesson plans combining the best available online resources, including textbooks, videos, classroom activities, and student assessment tools. To help curate these resources, the project team built a copilot—an AI-powered digital assistant—centered around teachers’ specific needs, which were identified right at the start through multiple interviews and workshops.
Working with Sikshana Foundation (opens in new tab), a local non-governmental organization focused on improving public education, the researchers are piloting this program at several public schools in and around Bengaluru, India, to build and improve the underlying tools. This post gives an overview of the project, including interviews with three teachers who have used Shiksha copilot in their own classrooms.
Spotlight: Microsoft research newsletter
Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
A lesson plan is like a road map charting what students need to learn and how to efficiently cover the material during class time. It includes three key components:
Objectives for student learning, based on grade level and subject
Teaching and learning tactics, including tutorials and activities to help students understand the topic
Strategies to assess student understanding, both in class and through homework
Parimala H V teaches science in grades 6-8 at Government Higher Primary School, Santhe Beedhi in Bengaluru. She teaches in the local language, Kannada, and in English. For each class she teaches, she spends an hour or more each day scanning textbooks and printed materials to put together an effective lesson plan. She also searches the internet for ideas, but sifting through the growing body of online content could take just as long. Often she would work till midnight planning the next day’s activities, which left her feeling tired and stressed.
“Lesson planning can be a struggle, but it’s very important,” Parimala said. “If the planning goes well, everything goes well.”
With Shiksha copilot, Parimala was able to develop a complete lesson plan in 60 to 90 seconds, instead of 60 to 90 minutes. The simple interface asks basic questions about the curriculum, language of delivery, grade level, and subject. It then compiles engaging learning materials to achieve the teacher’s classroom objectives. Parimala finds better ideas and hands-on activities using Shiksha copilot than through other online tools. She feels well rested and better prepared for her day, which also makes her happier in the classroom. And with the time she saves, she can focus more on coaching her students and improving her teaching practices.
“I was thrilled to have the opportunity to use Shiksha copilot,” Parimala said. “It could be very useful for new teachers just learning their profession. I think it could revolutionize the way teachers teach.”
Parimala H.V., Teacher, Government Higher Primary School, Santhee Beedhi
At Parimala’s school and others in the Bengaluru area, teachers face some significant challenges. Classrooms can have up to 70 students of varying abilities. Teachers often need to prepare lessons and give instruction in both English and Kannada. As the Covid pandemic brought about remote learning on a large scale, technology began to rapidly change how teachers and students interact. Most students now have computers or smartphones, expanding teachers’ options. But it also makes it harder to keep students focused on a traditional classroom blackboard.
“These children are addicted to their mobile phones and social media. If I use the ‘chalk and talk’ method in class, they may get bored,” said Gireesh K S, who relies heavily on his blackboard to teach math and physics at Government High School, Jalige. Gireesh has used web search tools to find digital resources like interactive PowerPoint slides that will hold his students’ attention longer. With Shiksha copilot, he can zero in more quickly on videos or classroom activities that help him connect better with all 40+ students in his class.
“Here lies the teacher’s job. The teacher has to select whichever activity, whichever video, or whichever questions to use,” Gireesh said. “There are so many questions and videos (to choose from), but as a teacher for my class, I know my students. So, I have to select the suitable ones.”
Other learning platforms were less flexible and less dynamic, returning static content options that were not always useful for a diverse group of learners. Shiksha copilot, on the other hand, does a much better job of customizing and adapting its recommendations based on teacher input, Gireesh said.
“Shiksha copilot is very easy to use when compared to other AI we have tried, because it is mapped with our own syllabus and our own curriculum.”
Gireesh K S, Teacher, Government High School, Jalige
Behind the technology
Designing and building Shiksha copilot requires various technological innovations. Educational content is mainly multimodal, including text, images, tables, videos, charts, and interactive materials. Therefore, for developing engaging learning experiences, it is essential to build generative AI models which have unified multimodal capabilities. Also, these experiences are most impactful when delivered in native languages, which requires improving the multilingual capabilities of generative AI models.
Shiksha copilot includes a range of powerful features that address those challenges and enhance the educational experience. It’s grounded in specific curricula and learning objectives, to ensure that all generated content aligns with desired educational outcomes, according to Akshay Nambi (opens in new tab), principal researcher at Microsoft Research. “This grounding is enabled by ingesting relevant data with the help of state-of-the-art optical character recognition (OCR), computer vision (CV) and generative AI models. It was also important to use natural language and support voice-based interactions while including options for English and Kannada speakers,” Nambi said.
Shiksha copilot supports connectivity to both public and private resource content, enabling educators to tap into a vast array of materials and tailor them to their unique teaching requirements. Shiksha copilot can be accessed through different modalities, such as WhatsApp, Telegram, and web applications, enabling seamless integration with teachers’ current workflows.
To help create content more quickly and efficiently, the system leverages semantic caching with LLMs. Storing and reusing previously processed educational content reduces computational resources required to deliver a scalable, and affordable copilot experience. Throughout development, the project team followed established protocols regarding safety, reliability and trustworthiness.
“Extensive prompt designing, testing and rigorous responsible AI procedures, including content filtering and moderation, red team assessments and jailbreaking simulations, have been deployed to maximize safety and reliability. These measures are in place so that Shiksha copilot consistently produces factual and trustworthy content,” said Tanuja Ganu, principal research SDE manager at Microsoft Research.
Convincing the skeptics
Before the initial workshop, some teachers expressed skepticism about using AI for lesson planning. Students already have multiple digital learning tools. But for Mahalakshmi A, who teaches standard science in grades 4-8 at rural Government Higher Primary School, Basavana Halli, outside Bengaluru, the value for teachers was less clear. However, during a two-hour initial workshop session, Mahalakshmi found she could easily create multiple lesson plans using Shiksha copilot that would work well in her classroom.
“I felt very happy because it’s a totally different concept. Before now, I could see that technology could work for the students. But this is the first time that it felt like the teachers also had a tool for themselves.”
Mahalakshmi A., Teacher, Government Higher Primary School, Basavana Halli
Mahalakshmi could also see how the content assembled using Shiksha copilot would make her class more interesting for her students, which is an important goal. “Instead of giving them the same problems, the same experiments, and the same videos, we make learning interesting. And then they learn what we call shashwatha kalike, or permanent learning. With Shiksha copilot, we can make that permanent learning happen in our classroom,” she added.
Next steps
The initial pilot program for Shiksha copilot is underway at more than 10 schools in and around Bengaluru. The goal is to let the teachers experience how Shiksha copilot can best be used in their daily workflows to improve learning experiences and collect feedback. The early response has been highly positive, with teachers expressing great satisfaction in both the quality of the content generated and the time savings. To build on this successful pilot, researchers are gearing up to scale Shiksha copilot in schools across the state of Karnataka and beyond, in collaboration with Sikshana Foundation.
This copilot is being developed as part of Project VeLLM (Universal Empowerment with Large Language Models) at Microsoft Research India. VeLLM’s goal is to make inclusive and accessible copilots available to everyone by building a platform for developing population-scale copilots. Inclusive copilots must address various real-world challenges, such as a multilingual user base, varied skillsets, limited devices and connectivity, domain-specific understanding, guardrails, and safety principles. Shiksha is the first copilot developed using the VeLLM platform. The VeLLM team is working with collaborators across diverse domains, such as agriculture and healthcare, to develop tailored domain-specific copilot experiences utilizing the platform and addressing associated research problems.
This paper was accepted at the EMNLP Workshop on Computational Approaches to Linguistic Code-Switching (CALCS).
Code-switching (CS), i.e. mixing different languages in a single sentence, is a common phenomenon in communication and can be challenging in many Natural Language Processing (NLP) settings. Previous studies on CS speech have shown promising results for end-to-end speech translation (ST), but have been limited to offline scenarios and to translation to one of the languages present in the source (monolingual transcription).
In this paper, we focus on two essential yet unexplored areas…Apple Machine Learning Research
Posted by Xiaoran “Van” Fan, Experimental Scientist, and Trausti Thormundsson, Director, Google
The market for true wireless stereo (TWS) active noise canceling (ANC) hearables (headphones and earbuds) has been soaring in recent years, and the global shipment volume will nearly double that of smart wristbands and watches in 2023. The on-head time for hearables has extended significantly due to the recent advances in ANC, transparency mode, and artificial intelligence. Users frequently wear hearables not just for music listening, but also for exercising, focusing, or simply mood adjustment. However, hearable health is still mostly uncharted territory for the consumer market.
In “APG: Audioplethysmography for Cardiac Monitoring in Hearables,” presented at MobiCom 2023, we introduce a novel active in-ear health sensing modality. Audioplethysmography (APG) enables ANC hearables to monitor a user’s physiological signals, such as heart rate and heart rate variability, without adding extra sensors or compromising battery life. APG exhibits high resilience to motion artifacts, adheres to safety regulations with an 80 dB margin below the limit, remains unaffected by seal conditions, and is inclusive of all skin tones.
APG sends a low intensity ultrasound transmitting wave (TX wave) using an ANC headphone’s speakers and collects the receiving wave (RX wave) via the on-board feedback microphones. The APG signal is a pulse-like waveform that synchronizes with heartbeat and reveals rich cardiac information, such as dicrotic notches.
Health sensing in the ear canal
The auditory canal receives its blood supply from the arteria auricularis profunda, also known as the deep ear artery. This artery forms an intricate network of smaller vessels that extensively permeate the auditory canal. Slight variations in blood vessel shape caused by the heartbeat (and blood pressure) can lead to subtle changes in the volume and pressure of the ear canals, making the ear canal an ideal location for health sensing.
Recent research has explored using hearables for health sensing by packaging together a plethora of sensors — e.g., photoplethysmograms (PPG) and electrocardiograms (ECG) — with a microcontroller to enable health applications, such as sleep monitoring, heart rate and blood pressure tracking. However, this sensor mounting paradigm inevitably adds cost, weight, power consumption, acoustic design complexity, and form factor challenges to hearables, constituting a strong barrier to its wide adoption.
Existing ANC hearables deploy feedback and feedforward microphones to navigate the ANC function. These microphones create new opportunities for various sensing applications as they can detect or record many bio-signals inside and outside the ear canal. For example, feedback microphones can be used to listen to heartbeats and feedforward microphones can hear respirations. Academic research on this passive sensing paradigm has prompted many mobile applications, including heart rate monitoring, ear disease diagnosis, respiration monitoring, and body activity recognition. However, microphones in consumer-grade ANC headphones come with built-in high-pass filters to prevent saturation from body motions or strong wind noise. The signal quality of passive listening in the ear canal also heavily relies on the earbud seal conditions. As such, it is challenging to embed health features that rely on the passive listening of low frequency signals (≤ 50 Hz) on commercial ANC headphones.
Measuring tiny physiological signals
APG bypasses the aforementioned ANC headphone hardware constraints by sending a low intensity ultrasound probing signal through an ANC headphone’s speakers. This signal triggers echoes, which are received via on-board feedback microphones. We observe that the tiny ear canal skin displacement and heartbeat vibrations modulate these ultrasound echoes.
We build a cylindrical resonance model to understand APG’s underlying physics. This phenomenon happens at an extremely small scale, which makes the raw pulse signal invisible in the raw received ultrasound. We adopt coherent detection to retrieve this micro physiological modulation under the noise floor (we term this retrieved signal as mixed-down signal, see the paper for more details). The final APG waveform looks strikingly similar to a PPG waveform, but provides an improved view of cardiac activities with more pronounced dicrotic notches (i.e., pressure waveforms that provide rich insights about the central artery system, such as blood pressure).
A cylindrical model with cardiac activities ℎ(𝑡) that modulates both the phase and amplitude of the mixed-down signal. Based on the simulation from our analytical model, the amplitude 𝑅(𝑡) and phase Φ(𝑡) of the mixed-down APG signals both reflect the cardiac activities ℎ(𝑡).
APG sensing in practice
During our initial experiments, we observed that APG works robustly with bad earbuds seals and with music playing. However, we noticed the APG signal can sometimes be very noisy and could be heavily disturbed by body motion. At that point, we determined that in order to make APG useful, we had to make it more robust to compete with more than 80 years of PPG development.
While PPGs are widely used and highly advanced, they do have some limitations. For example, PPGs sensors typically use two to four diodes to send and receive light frequencies for sensing. However, due to the ultra high-frequency nature (hundreds of Terahertz) of the light, it’s difficult for a single diode to send multiple colors with different frequencies. On the other hand, we can easily design a low-cost and low-power system that generates and receives more than ten audio tones (frequencies). We leverage channel diversity, a physical phenomenon that describes how wireless signals (e.g., light and audio) at different frequencies have different characters (e.g., different attenuation and reflection coefficients) when the signal propagates in a medium, to enable a higher quality APG signal and motion resilience.
Next, we experimentally demonstrate the effectiveness of using multiple frequencies in the APG signaling. We transmit three probing signals concurrently with their frequencies spanning evenly from 30 KHz to 32 KHz. A participant was asked to shake their head four times during the experiment to introduce interference. The figure below shows that different frequencies can be transmitted simultaneously to gather various information with coherent detection, a unique advantage to APG.
The 30 kHz phase shows the four head movements and the magnitude (amplitude) of 31 kHz shows the pulse wave signal. This observation shows that some ultrasound frequencies might be sensitive to cardiac activities while others might be sensitive to motion. Therefore, we can use the multi-tone APG as a calibration signal to find the best frequency that measures heart rate, and use only the best frequency to get high-quality pulse waveform.
The mixed-down amplitude (upper row) and phase (bottom row) for a customized multi-tone APG signal that spans from 30 kHz to 32 kHz. With channel diversity, the cardiac activities are captured in some frequencies (e.g., magnitude of 31 kHz) and head movements are captured in other frequencies (e.g., magnitude of 30 kHz, 30 kHz, and phase of 31 kHz).
After choosing the best frequency to measure heart rate, the APG pulse waveform becomes more visible with pronounced dicrotic notches , and enables accurate heart rate variability measurement.
The final APG signal used in the measurement phase (left) and chest ECG signal (right).
Multi-tone translates to multiple simultaneous observations, which enable the development of array signal processing techniques. We demonstrate the spectrogram of a running session APG experiment before and after applying blind source separation (see the paper for more details). We also show the ground truth heart rate measurement in the same running experiment using a Polar ECG chest strap. In the raw APG, we see the running cadence (around 3.3 Hz) as well as two dim lines (around 2 Hz and 4 Hz) that indicate the user’s heart rate frequency and its harmonics. The heart rate frequencies are significantly enhanced in signal to noise ratio (SNR) after the blind source separation, which align with the ground truth heart rate frequencies. We also show the calculated heart rate and running cadence from APG and ECG. We can see that APG tracks the growth of heart rate during the running session accurately.
APG tracks the heart rate accurately during the running session and also measures the running cadence.
Field study and closing thoughts
We conducted two rounds of user experience (UX) studies with 153 participants. Our results demonstrate that APG achieves consistently accurate heart rate (3.21% median error across participants in all activity scenarios) and heart rate variability (2.70% median error in inter-beat interval) measurements. Unlike PPG, which exhibits variable performance across skin tones, our study shows that APG is resilient to variation in: skin tone, sub-optimal seal conditions, and ear canal size. More detailed evaluations can be found in the paper.
APG transforms any TWS ANC headphones into smart sensing headphones with a simple software upgrade, and works robustly across various user activities. The sensing carrier signal is completely inaudible and not impacted by music playing. More importantly, APG represents new knowledge in biomedical and mobile research and unlocks new possibilities for low-cost health sensing.
Acknowledgements
APG is the result of collaboration across Google Health, product, UX and legal teams. We would like to thank David Pearl, Jesper Ramsgaard, Cody Wortham, Octavio Ponce, Patrick Amihood, Sam Sheng, Michael Pate, Leonardo Kusumo, Simon Tong, Tim Gladwin, Russ Mirov, Kason Walker, Govind Kannan, Jayvon Timmons, Dennis Rauschmayer, Chiong Lai, Shwetak Patel, Jake Garrison, Anran Wang, Shiva Rajagopal, Shelten Yuen, Seobin Jung, Yun Liu, John Hernandez, Issac Galatzer-Levy, Isaiah Fischer-Brown, Jamie Rogers, Pramod Rudrapatna, Andrew Barakat, Jason Guss, Ethan Grabau, Pol Peiffer, Bill Park, Helen O’Connor, Mia Cheng, Keiichiro Yumiba, Felix Bors, Priyanka Jantre, Luzhou Xu, Jian Wang, Jaime Lien, Gerry Pallipuram, Nicholas Gillian, Michal Matuszak, Jakub Wojciechowski, Bryan Allen, Jane Hilario, and Phil Carmack for their invaluable insights and support. Thanks to external collaborators Longfei Shangguan and Rich Howard, Rutgers University and University of Pittsburgh.
Generative artificial intelligence is transforming how enterprises do business. Organizations are using AI to improve data-driven decisions, enhance omnichannel experiences, and drive next-generation product development. Enterprises are using generative AI specifically to power their marketing efforts through emails, push notifications, and other outbound communication channels. Gartner predicts that “by 2025, 30% of outbound marketing messages from large organizations will be synthetically generated.” However, generative AI alone isn’t enough to deliver engaging customer communication. Research shows that the most impactful communication is personalized—showing the right message to the right user at the right time. According to McKinsey, “71% of consumers expect companies to deliver personalized interactions.” Customers can use Amazon Personalize and generative AI to curate concise, personalized content for marketing campaigns, increase ad engagement, and enhance conversational chatbots.
Developers can use Amazon Personalize to build applications powered by the same type of machine learning (ML) technology used by Amazon.com for real-time personalized recommendations. With Amazon Personalize, developers can improve user engagement through personalized product and content recommendations with no ML expertise required. Using recipes (algorithms prepared to support specific uses cases) provided by Amazon Personalize, customers can deliver a wide array of personalization, including specific product or content recommendations, personalized ranking, and user segmentation. Additionally, as a fully managed artificial intelligence service, Amazon Personalize accelerates customers’ digital transformations with ML, making it easier to integrate personalized recommendations into existing websites, applications, email marketing systems, and so on.
In this post, we illustrate how you can elevate your marketing campaigns using Amazon Personalize and generative AI with Amazon Bedrock. Together, Amazon Personalize and generative AI help you tailor your marketing to individual consumer preferences.
How exactly do Amazon Personalize and Amazon Bedrock work together to achieve this? Imagine as a marketer that you want to send tailored emails to users recommending movies they would enjoy based on their interactions across your platform. Or perhaps you want to send targeted emails to a segment of users promoting a new shoe they might be interested in. The following use cases use generative AI to enhance two common marketing emails.
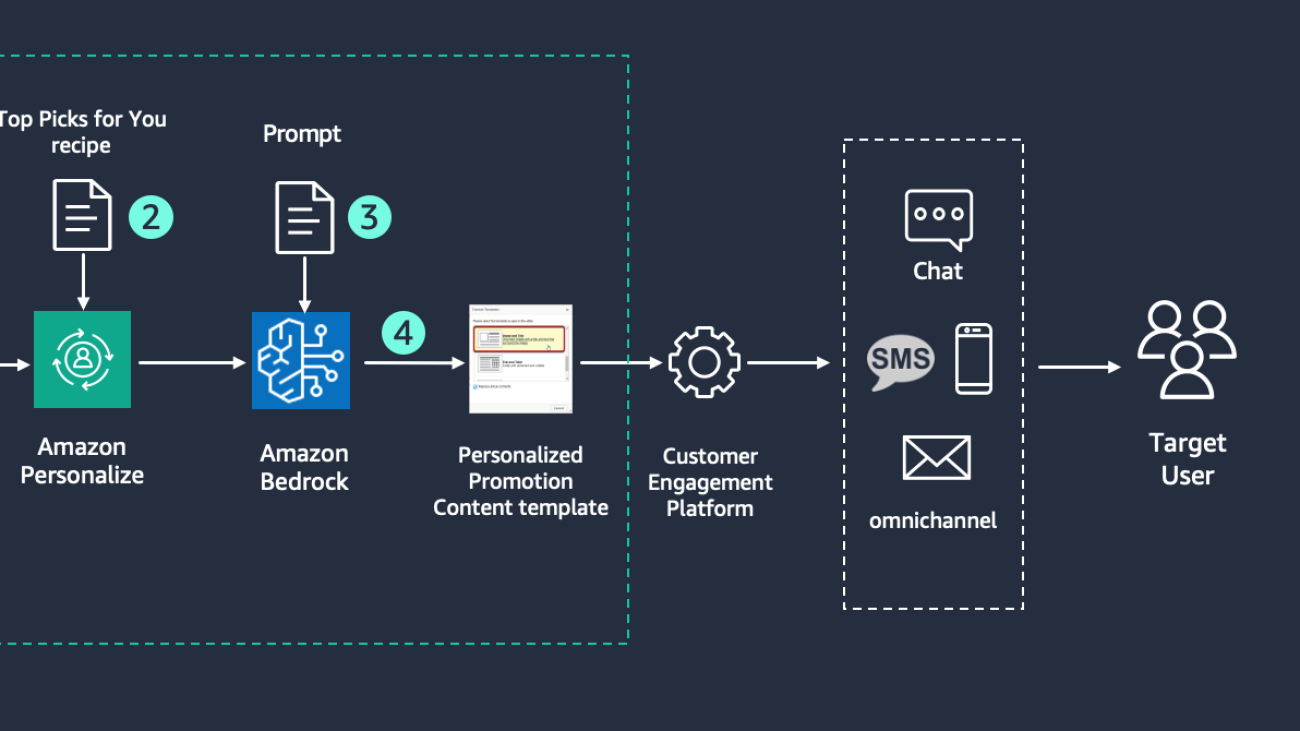
Use Case 1: Use generative AI to deliver targeted one-to-one personalized emails
With Amazon Personalize and Amazon Bedrock, you can generate personalized recommendations and create outbound messages with a personal touch tailored to each of your users.
The following diagram illustrates the architecture and workflow for delivering targeted personalized emails powered by generative AI.
First, import your dataset of users’ interactions into Amazon Personalize for training. Amazon Personalize automatically trains a model using the Top Picks for You recipe. As an output, Amazon Personalize provides recommendations that align with the users’ preferences.
You can use the following code to identify recommended items for users:
The provided output of recommendations is ingested by Amazon Bedrock using a prompt, which includes your user preferences, demographics, and Amazon Personalize recommended items.
For example, a marketer who wants to create a personalized email that is charming and fun for a user might use the following prompt:
Create a personalized email which is charming and fun so that the user is engaged. The user has recently watched family-friendly films. These are the recommended items – The Little Mermaid, Encanto, Spider-Man: Into the Spider-Verse.
By invoking one of the foundation models (FM) provided in Amazon Bedrock, such as Claude 2, with the prompt and sample code that follows, you can create a personalized email for a user:
personalized_email_response = bedrock_client.invoke_model(
body = prompt,
modelId = identifier_of_the_model)
Amazon Bedrock returns a personalized email for the user:
Subject: Fall in love with this recommended selection for movie night!
Dear <user name>,
Desiring the cozy feel of fall? No problem! Check our top three recommendations for movies that will have you cozy on the couch with your loved ones:
1. The Little Mermaid: This classic Disney movie is all about a mermaid princess named Ariel, who dreams of the human world. Because of her fascination, she makes a deal with the sea witch Ursula and learns a major lesson.
2. Encanto: This Disney movie is about the Madrigals, a Colombian family who lives in a magical house. Each member of the family has a unique gift, except for young Maribel who must help save her family.
3. Spider-Man: Into the Spider-Verse: This animated superhero movie is a must-see action movie. Spider-man, a Brooklyn teen named Miles Morales, teams up with other spider-powered people to save the multiverse.
With lovable characters, catchy tunes, and moving stories, you really can’t go wrong with any of these three. Grab the popcorn because you’re in for a treat!
Use case 2: Use generative AI to elevate one-to-many marketing campaigns
When it comes to one-to-many email marketing, generic content can result in low engagement (that is, low open rates and unsubscribes). One way companies circumvent this outcome is to manually craft variations of outbound messages with compelling subjects. This can lead to inefficient use of time. By integrating Amazon Personalize and Amazon Bedrock into your workflow, you can quickly identify the interested segment of users and create variations of email content with greater relevance and engagement.
The following diagram illustrates the architecture and workflow for elevating marketing campaigns powered by generative AI.
To compose one-to-many emails, first import your dataset of users’ interactions into Amazon Personalize for training. Amazon Personalize trains the model using the user segmentation recipe. With the user segmentation recipe, Amazon Personalize automatically identifies the individual users that demonstrate a propensity for the chosen items as the target audience.
To identify the target audience and retrieve metadata for an item you can use the following sample code:
Amazon Personalize delivers a list of recommended users to target for each item to batch_output_path. You can then invoke the user segment into Amazon Bedrock using one of the FMs along with your prompt.
For this use case, you might want to market a newly released sneaker through email. An example prompt might include the following:
For the user segment “sneaker heads”, create a catchy email that promotes the latest sneaker “Ultra Fame II”. Provide users with discount code FAME10 to save 10%.
Similar to the first use case, you’ll use the following code in Amazon Bedrock:
personalized_email_response = bedrock_client.invoke_model(
body = prompt,
modelId = identifier_of_the_model)
Amazon Bedrock returns a personalized email based on the items chosen for each user as shown:
Subject: <<name>>, your ticket to the Hall of Fame awaits
Hey <<name>>,
The wait is over. Check out the new Ultra Fame II! It’s the most innovative and comfortable Ultra Fame shoe yet. Its new design will have you turning heads with every step. Plus, you’ll get a mix of comfort, support, and style that’s just enough to get you into the Hall of Fame.
Don’t wait until it’s too late. Use the code FAME10 to save 10% on your next pair.
To test and determine the email that leads to the highest engagement, you can use Amazon Bedrock to generate a variation of catchy subject lines and content in a fraction of the time it would take to manually produce test content.
Conclusion
By integrating Amazon Personalize and Amazon Bedrock, you are enabled to deliver personalized promotional content to the right audience.
Generative AI powered by FMs is changing how businesses build hyper-personalized experiences for consumers. AWS AI services, such as Amazon Personalize and Amazon Bedrock, can help recommend and deliver products, content, and compelling marketing messages personalized to your users. For more information on working with generative AI on AWS, see to Announcing New Tools for Building with Generative AI on AWS.
About the Authors
Ba’Carri Johnson is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. With a background in computer science and strategy, she is passionate about product innovation. In her spare time, she enjoys traveling and exploring the great outdoors.
Ragini Prasad is a Software Development Manager with the Amazon Personalize team focused on building AI-powered recommender systems at scale. In her spare time, she enjoys art and travel.
Jingwen Hu is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
Anna Grüebler is a Specialist Solutions Architect at AWS focusing on artificial intelligence. She has more than 10 years of experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone and solving difficult problems by taking advantage of using AI in the cloud.
Tim Wu Kunpeng is a Sr. AI Specialist Solutions Architect with extensive experience in end-to-end personalization solutions. He is a recognized industry expert in e-commerce and media and entertainment, with expertise in generative AI, data engineering, deep learning, recommendation systems, responsible AI, and public speaking.
Effective data visualization plays a crucial role in data analysis. It enables data analysts and others to explore complex datasets, comprehend patterns, and convey meaningful insights to various stakeholders. Today, there are numerous tools for creating visual representations of data. However, these tools only work with tidy data, meaning that data points must be organized according to the specific categories required by the tool’s visualization format. This poses significant challenges for data analysts, requiring the use of additional tools to transform raw data into a compatible format before it is entered into one of these visualization tools.
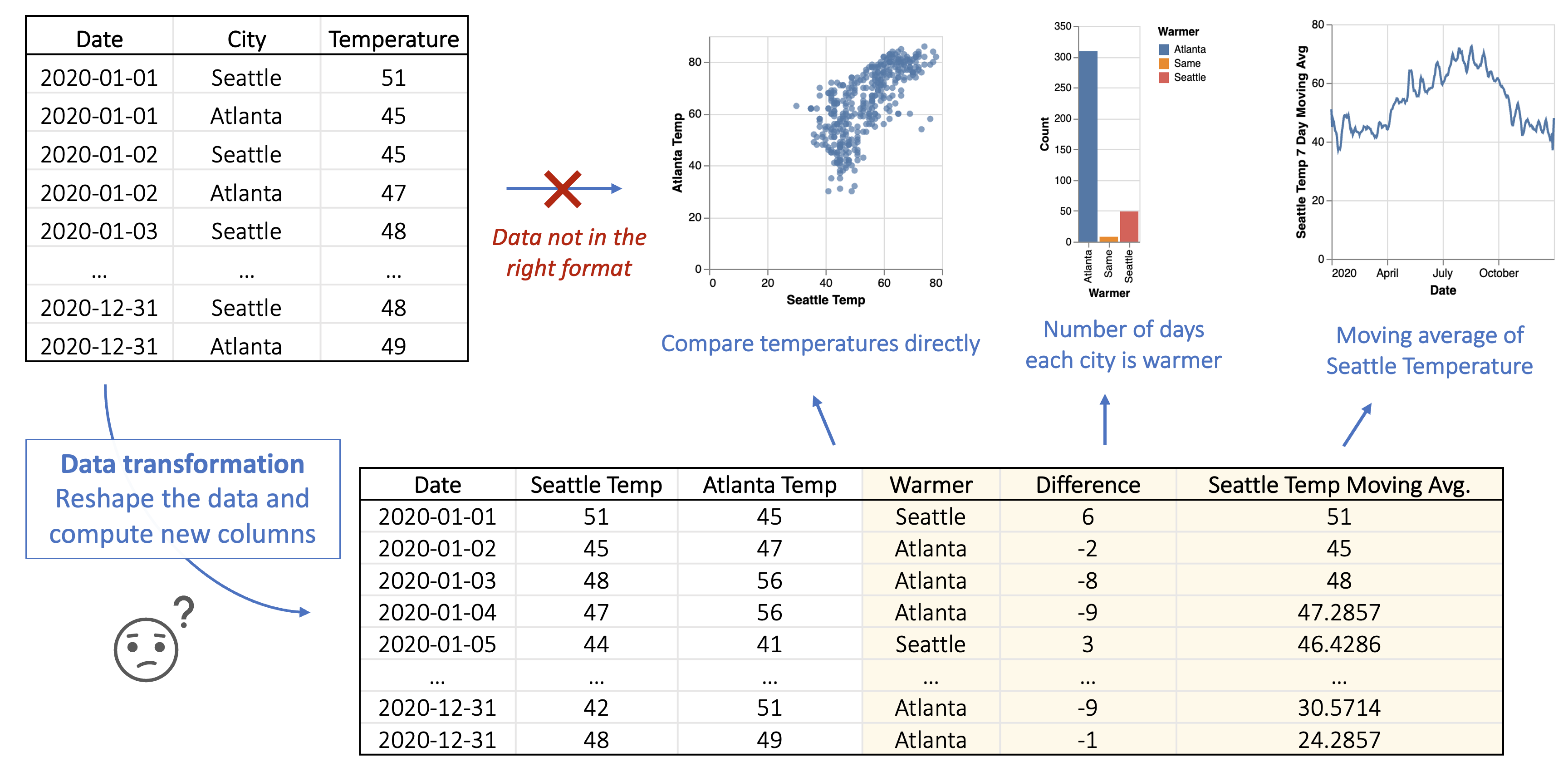
For instance, consider a dataset displaying 2020 temperatures in Seattle and Atlanta. If an analyst aims to create a scatter plot comparing the temperatures of these two US cities on the x/y-axes, data transformation is essential. The visualization tool mandates separate columns for Seattle and Atlanta temperatures to map to the scatter plot’s axes. Consequently, the analyst must pivot the input table to generate these columns. Moreover, if the analyst intends to compare which city experiences warmer days or create a smoothed line chart illustrating Seattle’s 7-day moving average temperature, further computations on the transformed data are necessary. Fields like “Warmer” and “Seattle 7-day Moving Avg” need to be calculated to facilitate the visualization, as depicted in Figure 1. This intricate process highlights the complexity and expertise currently needed to prepare raw data for effective visualization.
Figure 1. A data analyst wants to compare 2020 temperatures in Seattle and Atlanta using visualizations like scatter plots and histograms. However, the original dataset lacks necessary columns (“Seattle Temp,” “Atlanta Temp,” “Warmer,” and “Seattle Temp Moving Average”) for these visualizations. Data transformation is needed to include these fields.
This hurdle is particularly daunting because it necessitates a certain level of programming expertise or familiarity with additional data processing tools. It highlights the complexities of data visualization and underscores the need for an easier and more seamless process for data analysts, enabling them to create impactful visualizations regardless of their technical background.
Against the backdrop of rapid advancements in learning language models (LLMs) and programming-by-example techniques, researchers have made significant strides in breaking down these barriers. In this context, we share our paper, “Data Formulator: AI-powered Concept-driven Visualization Authoring (opens in new tab),” presented at VIS 2023 (opens in new tab) and winner of the Best Paper Honorable Mention (opens in new tab) award. Data Formulator is an AI-powered visualization authoring tool developed through a collaboration between researchers studying AI and those studying human-computer interaction (HCI). The result is a new visualization paradigm that separates high-level visualization intents from low-level data transformation steps. The process begins with data analysts articulating their visualization ideas as data concepts. These concepts refer to specific data categories, or fields, that analysts want to visualize, even though they are not present in the raw input data. This way, they effectively convey their visualization intent with the AI agent, which, in turn, assists them in implementing their visualization.
Defining data concepts and creating visualizations
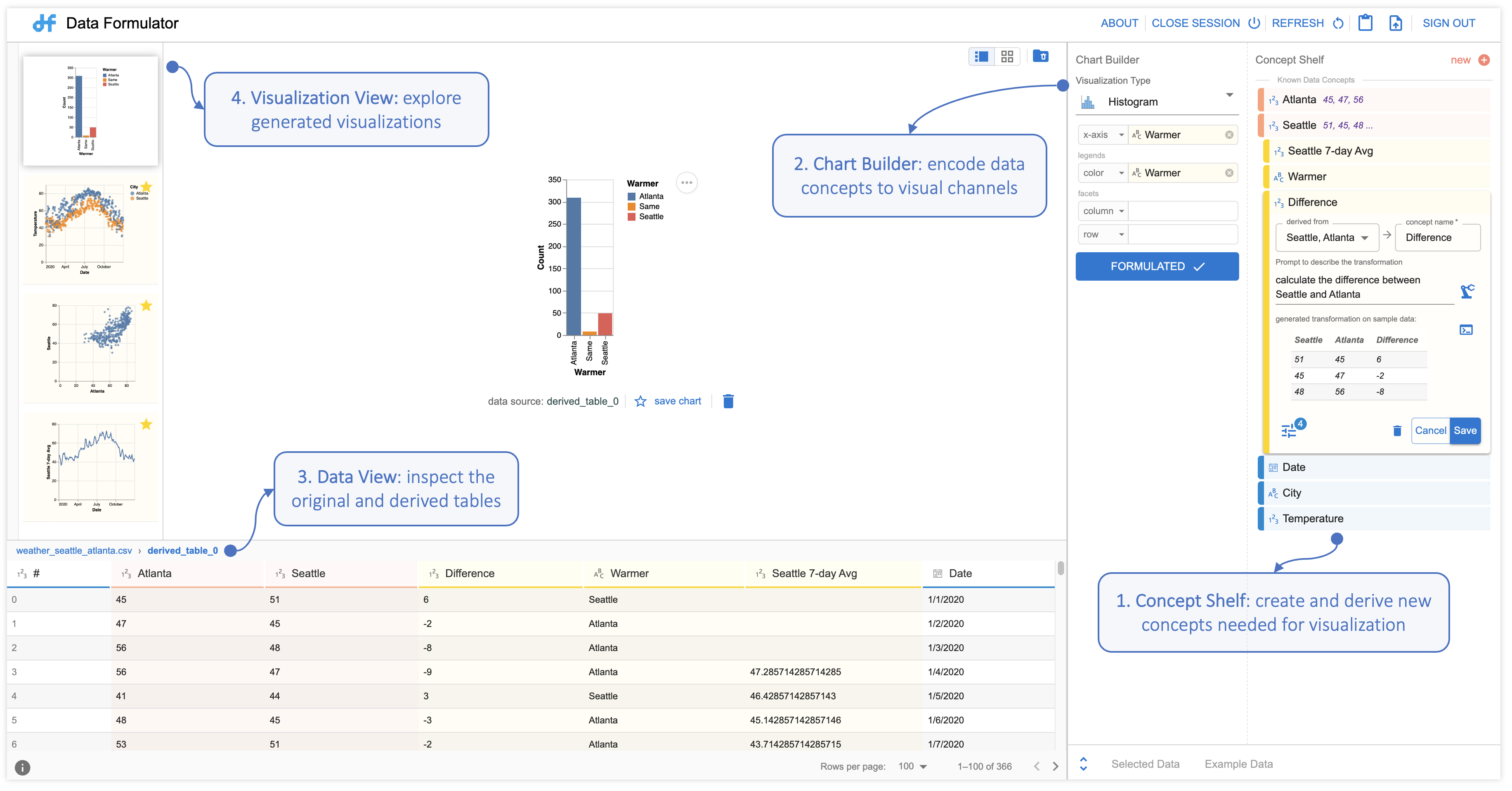
The way Data Formula operates is straightforward. The analyst defines the specific data concepts they plan to visualize, either through natural language queries or by providing categories, or example entries for the concept. Once these concepts are defined, they are linked to appropriate visual representation, as illustrated in Figure 2.
Figure 2. The Data Formulator user interface. Data Formulator has four panels: (1) the Concept Shelf, for defining new data concepts to be visualized, (2) the Chart Builder, for specifying the visualization type, (3) the Table View, for analysts to inspect data automatically generated by Data Formulator, and (4) the Visualization Panel, for presenting final visualizations.
If the analyst defines concepts through examples, Data Formulator engages a program synthesizer, which generates a specialized data reshaping program, transforming the provided data to bring out the required data fields. Conversely, when an analyst introduces a new concept using natural language queries, Data Formulator calls on LLMs to generate code, which facilitates the creation of a new data category based on the provided description. In both cases, Data Formulator compiles the transformed data into a structured table and creates corresponding visualizations.
We recognize that analyst specifications can be ambiguous, so we designed Data Formulator to generate multiple visualization options to help them identify what they want. The tool also provides analysts with the AI-generated transformation program and the transformed data for inspection. This transparency helps analysts refine their intent for future iterations.
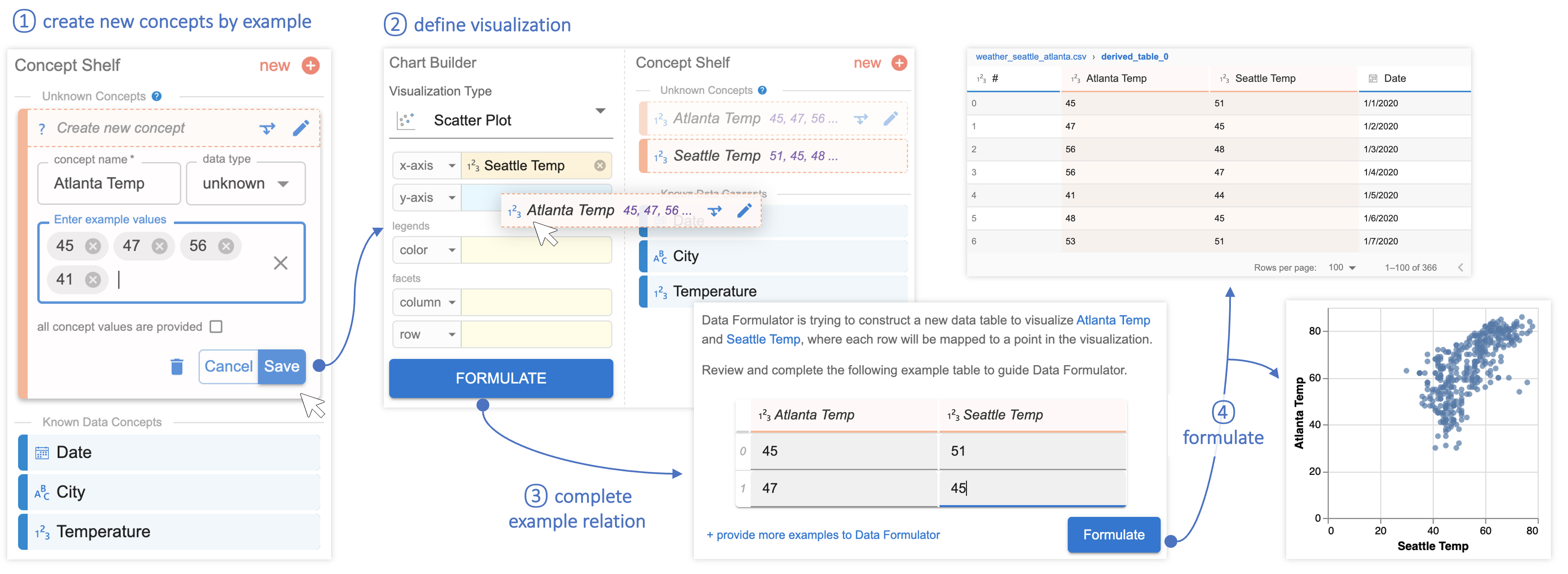
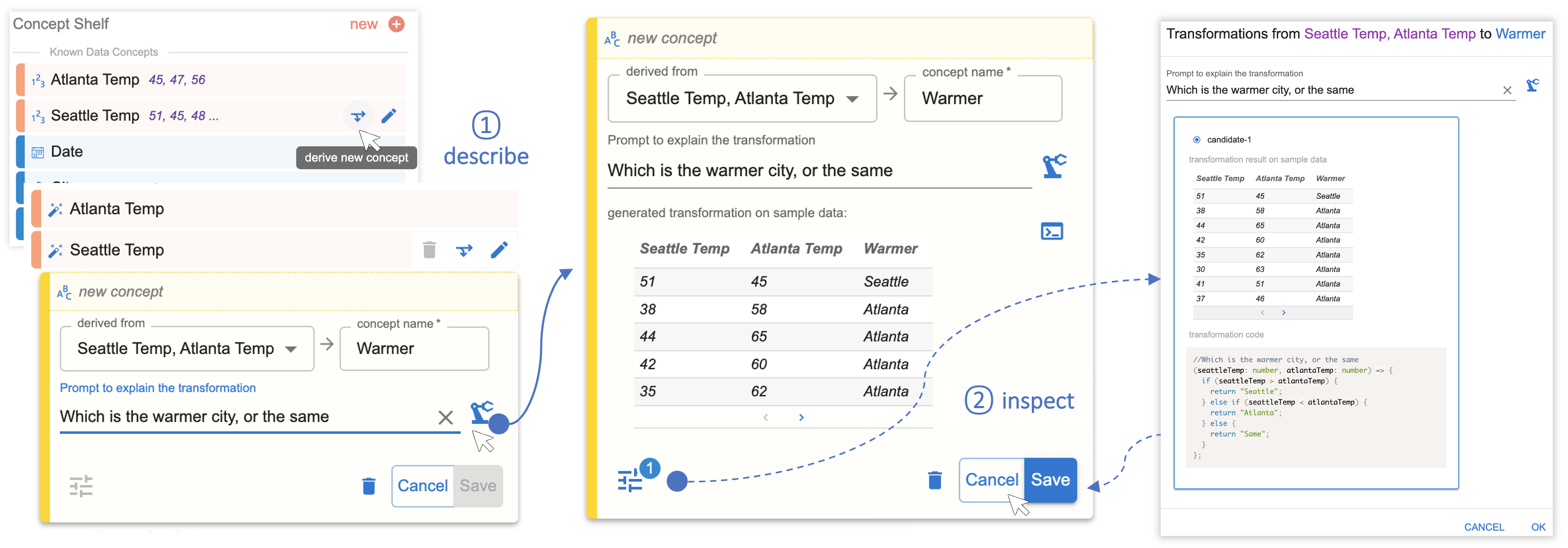
In continuing our Seattle/Atlanta temperatures example, the following two figures show how analysts can use Data Formulator to create visualizations without reformatting raw data using an external tool. Instead, the analyst provides example entries in the form of temperature values to create new the data concepts “Seattle Temp” and “Atlanta Temp,” shown in Figure 3. The analyst uses these natural language queries to create the new concept “Warmer” and instructs Data Formulator to format the data so that it can be visualized, shown in Figure 4.
Figure 3. The analyst creates new data concepts “Atlanta Temp”, “Seattle Temp” using examples. The AI agent solves a programming-by-example problem to create the new concepts for visualization.Figure 4. The analyst creates a new data concept “Warmer” using natural language description. Data Formulator calls LLMs to generate a transformation program to derive the new concept.
Looking ahead: Analyst-AI collaboration in data analysis
AI-powered data analysis tools have the potential to significantly streamline the entire data analysis process by consolidating various tasks into a single tool. Beyond just visualization, this concept-driven technique can be applied to data cleaning, data integration, visual data exploration, and visual storytelling. Our vision is for an AI system to take high-level instruction from the user and automatically recommend the necessary steps across the entire data analysis pipeline, enabling collaboration between the user and the AI agent to achieve their data visualization goals.
Inevitably, data analysts will need to tackle more complex tasks beyond the scope mentioned here. For this reason, it’s crucial to consider how to design AI-powered tools that effectively convey results to the analyst that are uncertain, ambiguous, or incorrect. This ensures that the analyst can trust the tool and collaborate effectively with AI to accomplish their objectives.


















 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle! Ray Khorsandi is an AI/ML specialist at AWS, supporting strategic customers with AI/ML best practices. With an M.Sc. and Ph.D. in Electrical Engineering and Computer Science, he leads enterprises to build secure, scalable AI/ML and big data solutions to optimize their cloud adoption. His passions include computer vision, NLP, generative AI, and MLOps. Ray enjoys playing soccer and spending quality time with family.
Ray Khorsandi is an AI/ML specialist at AWS, supporting strategic customers with AI/ML best practices. With an M.Sc. and Ph.D. in Electrical Engineering and Computer Science, he leads enterprises to build secure, scalable AI/ML and big data solutions to optimize their cloud adoption. His passions include computer vision, NLP, generative AI, and MLOps. Ray enjoys playing soccer and spending quality time with family. Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his Ph.D. from the Univ. of Texas and his M.Sc. in Computer Science specialization in Machine Learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations, while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding in the mountains.
Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his Ph.D. from the Univ. of Texas and his M.Sc. in Computer Science specialization in Machine Learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations, while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding in the mountains.
 Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City. Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY.
Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.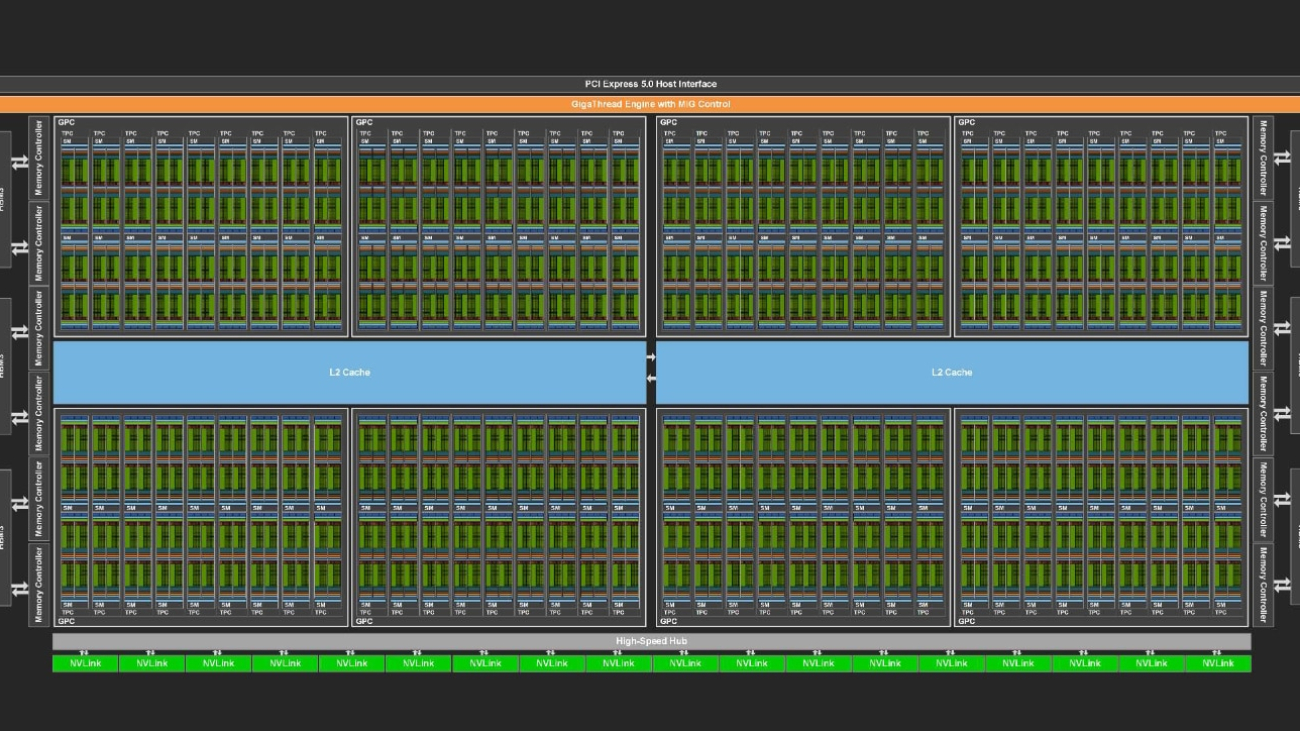
















 Ba’Carri Johnson is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. With a background in computer science and strategy, she is passionate about product innovation. In her spare time, she enjoys traveling and exploring the great outdoors.
Ba’Carri Johnson is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. With a background in computer science and strategy, she is passionate about product innovation. In her spare time, she enjoys traveling and exploring the great outdoors. Ragini Prasad is a Software Development Manager with the Amazon Personalize team focused on building AI-powered recommender systems at scale. In her spare time, she enjoys art and travel.
Ragini Prasad is a Software Development Manager with the Amazon Personalize team focused on building AI-powered recommender systems at scale. In her spare time, she enjoys art and travel. Jingwen Hu is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
Jingwen Hu is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food. Anna Grüebler is a Specialist Solutions Architect at AWS focusing on artificial intelligence. She has more than 10 years of experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone and solving difficult problems by taking advantage of using AI in the cloud.
Anna Grüebler is a Specialist Solutions Architect at AWS focusing on artificial intelligence. She has more than 10 years of experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone and solving difficult problems by taking advantage of using AI in the cloud. Tim Wu Kunpeng is a Sr. AI Specialist Solutions Architect with extensive experience in end-to-end personalization solutions. He is a recognized industry expert in e-commerce and media and entertainment, with expertise in generative AI, data engineering, deep learning, recommendation systems, responsible AI, and public speaking.
Tim Wu Kunpeng is a Sr. AI Specialist Solutions Architect with extensive experience in end-to-end personalization solutions. He is a recognized industry expert in e-commerce and media and entertainment, with expertise in generative AI, data engineering, deep learning, recommendation systems, responsible AI, and public speaking.