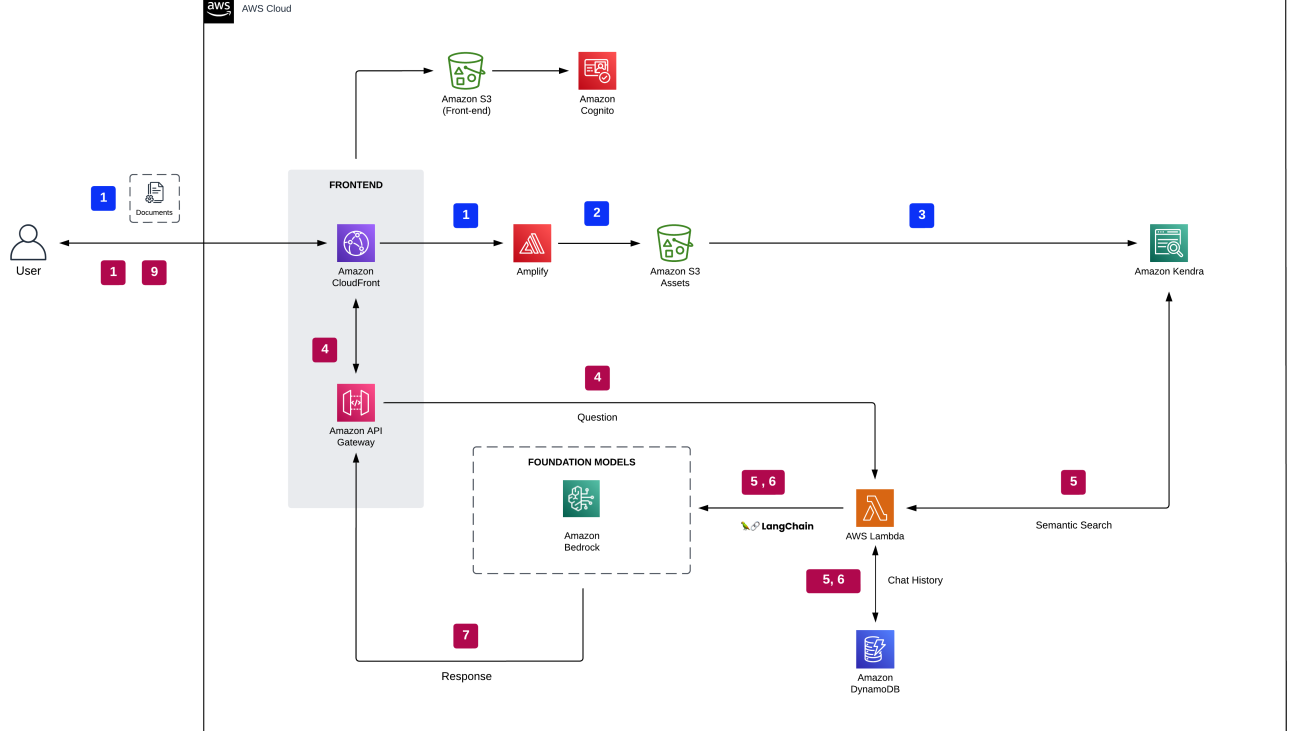
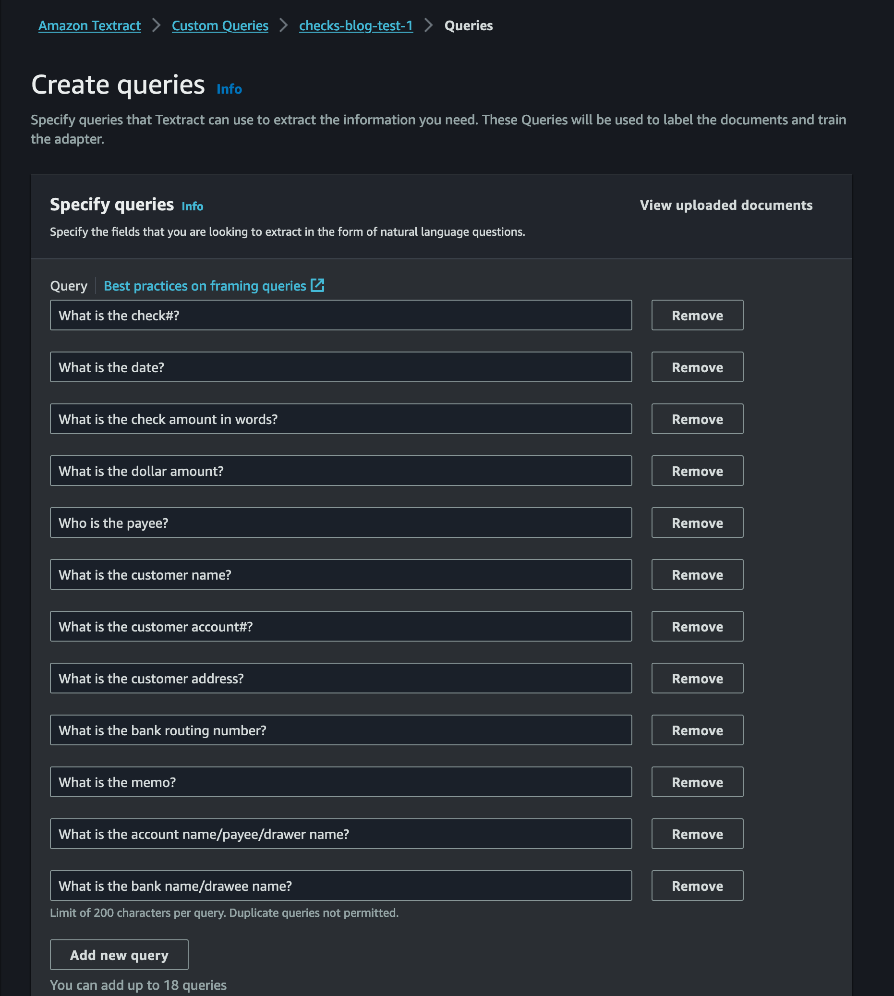
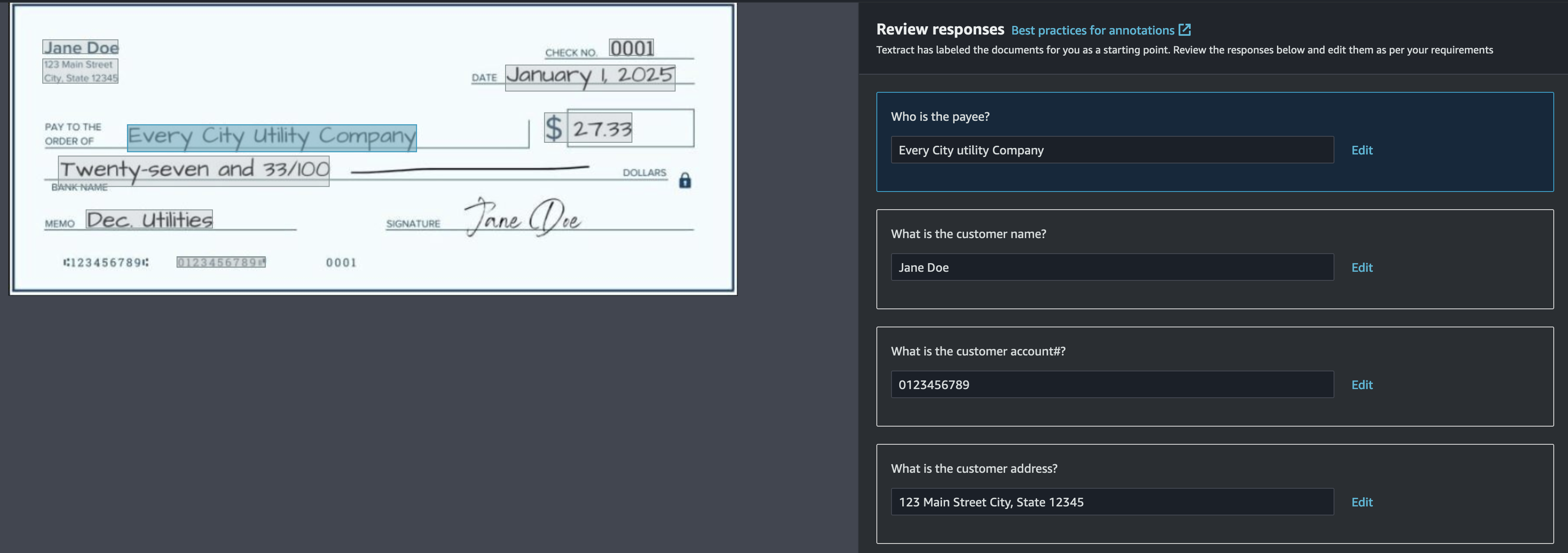
Contemporary deep learning models have been remarkably successful in many domains, ranging from natural language to computer vision. Transformer neural networks (transformers) are a popular deep learning architecture that today comprise the foundation for most tasks in natural language processing and also are starting to extend to applications in other domains, such as computer vision, robotics, and autonomous driving. Moreover, they form the backbone of all the current state-of-the-art language models.
Increasing scale in Transformer networks has led to improved performance and the emergence of behavior not present in smaller networks. However, this increase in scale often comes with prohibitive increases in compute cost and inference latency. A natural question is whether we can reap the benefits of larger models without incurring the computational burden.
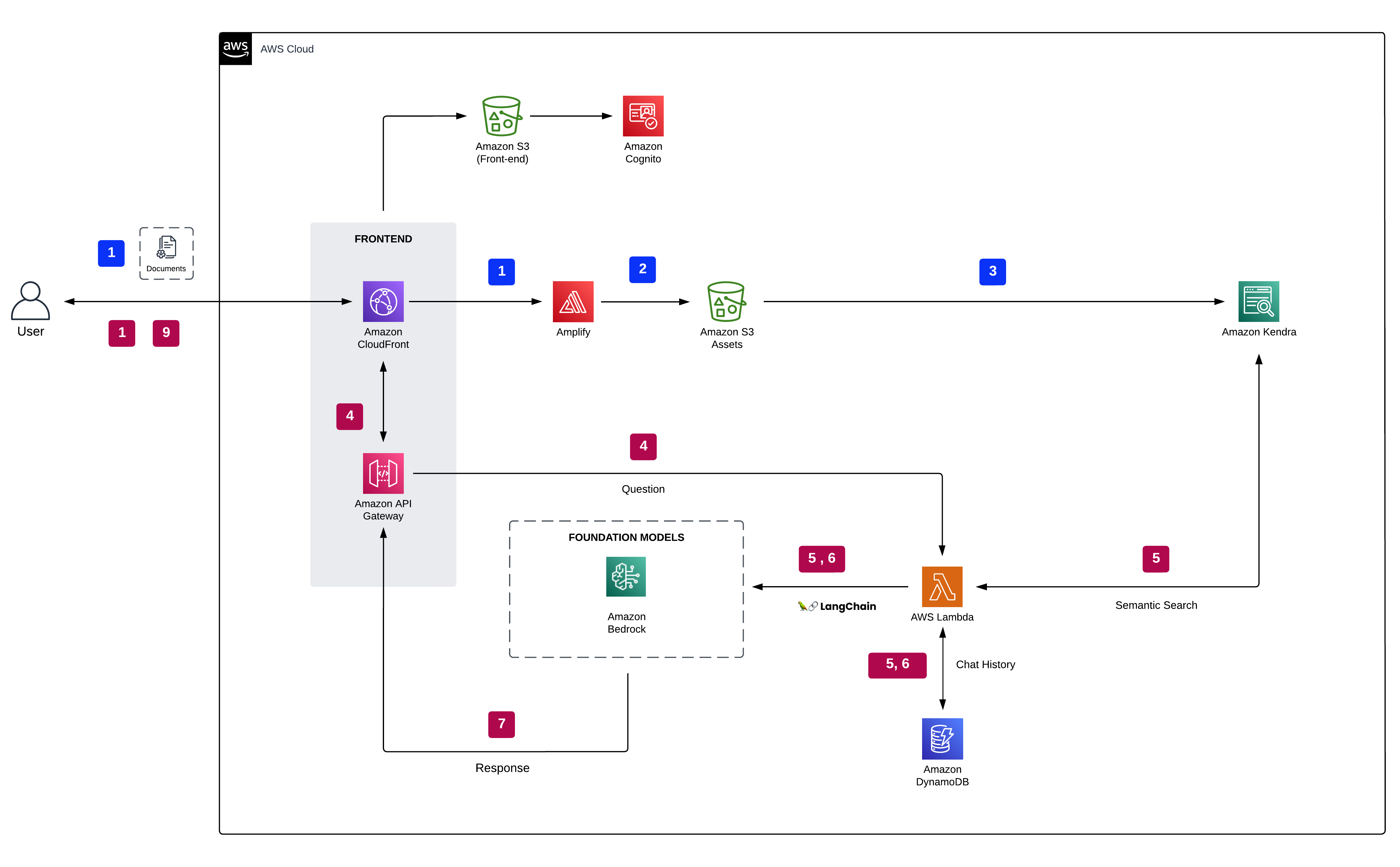
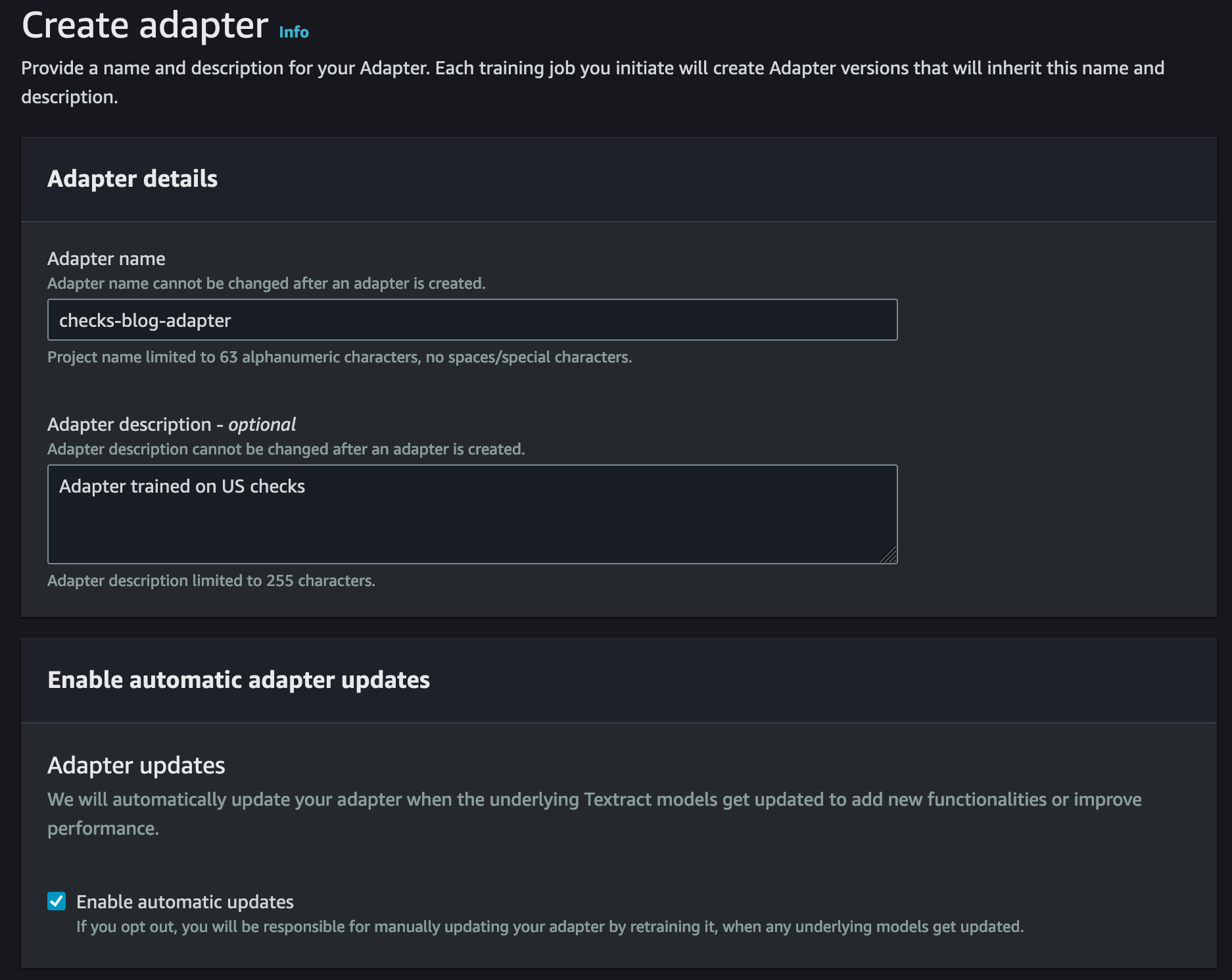
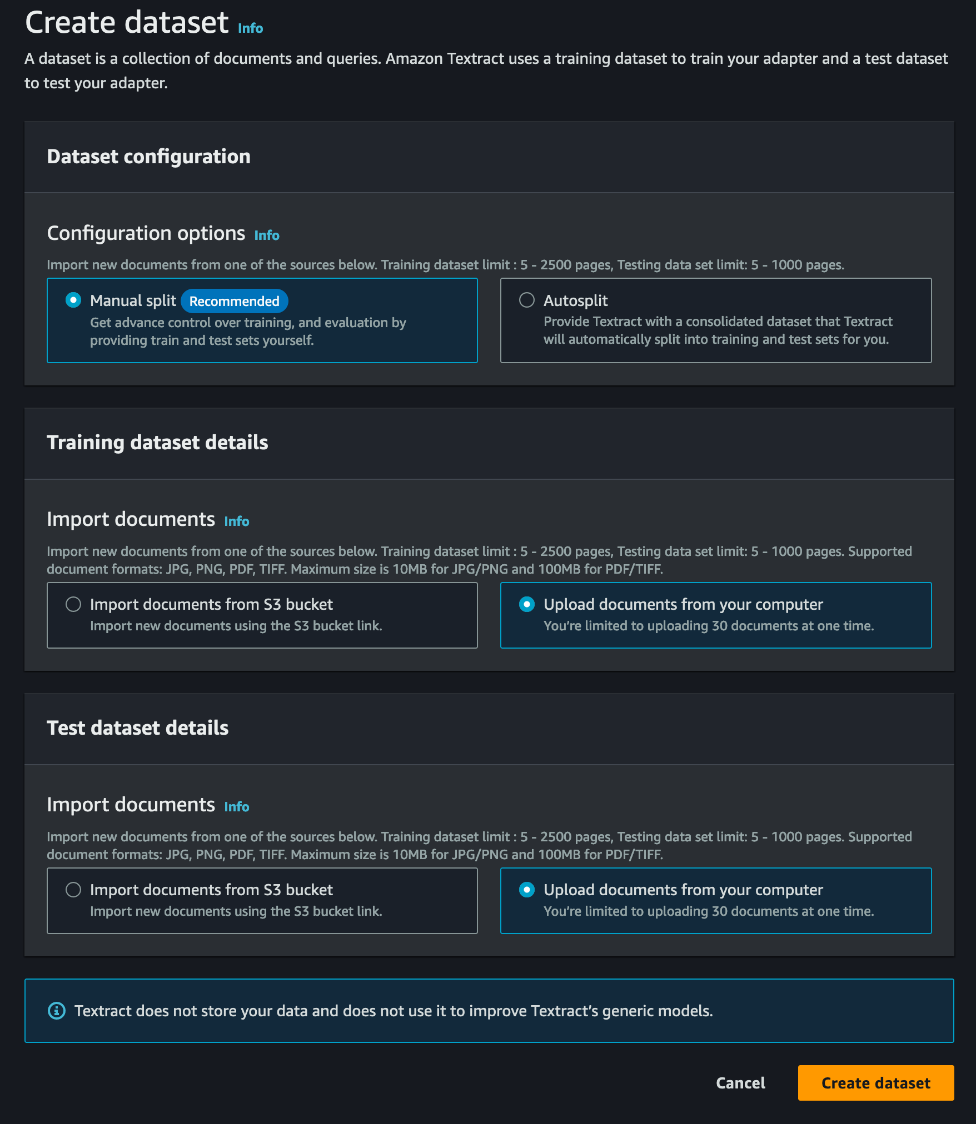
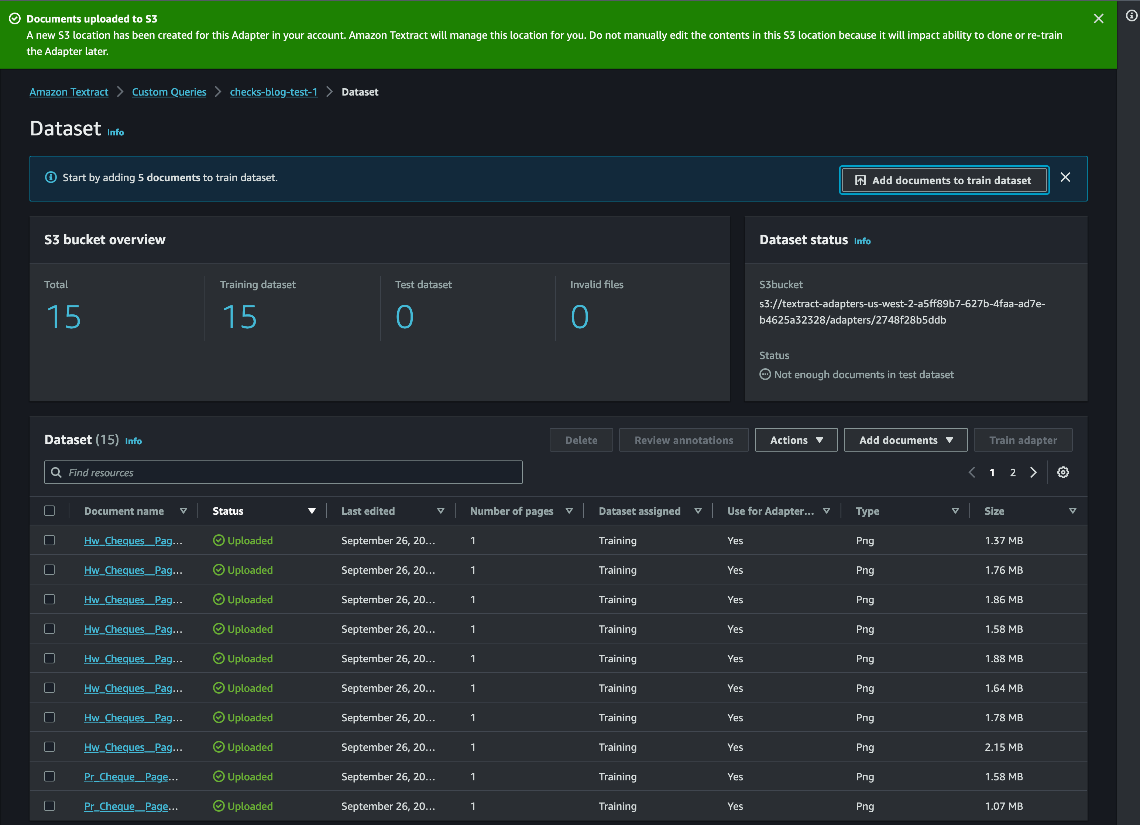
In “Alternating Updates for Efficient Transformers”, accepted as a Spotlight at NeurIPS 2023, we introduce AltUp, a method to take advantage of increased token representation without increasing the computation cost. AltUp is easy to implement, widely applicable to any transformer architecture, and requires minimal hyperparameter tuning. For instance, using a variant of AltUp on a 770M parameter T5-Large model, the addition of ~100 parameters yields a model with a significantly better quality.
Background
To understand how we can achieve this, we dig into how transformers work. First, they partition the input into a sequence of tokens. Each token is then mapped to an embedding vector (via the means of an embedding table) called the token embedding. We call the dimension of this vector the token representation dimension. The Transformer then operates on this sequence of token embeddings by applying a series of computation modules (called layers) using its network parameters. The number of parameters in each transformer layer is a function of the layer’s width, which is determined by the token representation dimension.
To achieve benefits of scale without incurring the compute burden, prior works such as sparse mixture-of-experts (Sparse MoE) models (e.g., Switch Transformer, Expert Choice, V-MoE) have predominantly focused on efficiently scaling up the network parameters (in the self-attention and feedforward layers) by conditionally activating a subset based on the input. This allows us to scale up network size without significantly increasing compute per input. However, there is a research gap on scaling up the token representation dimension itself by conditionally activating parts of the token representation vector.
Recent works (for example, scaling laws and infinite-width networks) have empirically and theoretically established that a wider token representation helps in learning more complicated functions. This phenomenon is also evident in modern architectures of increasing capability. For instance, the representation dimension grows from 512 (small) to 768 (base) and 1024 (corresponding to models with 770M, 3B, and 11B parameters respectively) in T5 models, and from 4096 (8B) to 8192 (64B) and 18432 (540B) in PaLM models. A widened representation dimension also significantly improves performance for dual encoder retrieval models. However, naïvely widening the representation vector requires one to increase the model dimension accordingly, which quadratically1 increases the amount of computation in the feedforward computation.
Method
AltUp works by partitioning a widened representation vector into equal sized blocks, processing only a single block at each layer, and using an efficient prediction-correction mechanism to infer the outputs of the other blocks (shown below on the right). This allows AltUp to simultaneously keep the model dimension, hence the computation cost, roughly constant and take advantage of using an increased token dimension. The increased token dimension allows the model to pack more information into each token’s embedding. By keeping the width of each transformer layer constant, AltUp avoids incurring the quadratic increase in computation cost that would otherwise be present with a naïve expansion of the representation.
 |
| An illustration of widening the token representation without (left) and with AltUp (right). This widening causes a near-quadratic increase in computation in a vanilla transformer due to the increased layer width. In contrast, Alternating Updates keeps the layer width constant and efficiently computes the output by operating on a sub-block of the representation at each layer. |
More specifically, the input to each layer is two or more blocks, one of which is passed into the 1x width transformer layer (see figure below). We refer to this block as the “activated” block. This computation results in the exact output for the activated block. In parallel, we invoke a lightweight predictor that computes a weighted combination of all the input blocks. The predicted values, along with the computed value of the activated block, are passed on to a lightweight corrector that updates the predictions based on the observed values. This correction mechanism enables the inactivated blocks to be updated as a function of the activated one. Both the prediction and correction steps only involve a limited number of vector additions and multiplications and hence are much faster than a regular transformer layer. We note that this procedure can be generalized to an arbitrary number of blocks.
 |
| The predictor and corrector computations: The predictor mixes sub-blocks with trainable scalar coefficients; the corrector returns a weighted average of the predictor output and the transformer output. The predictor and corrector perform scalar-vector multiplications and incur negligible computation cost compared to the transformer. The predictor outputs a linear mixing of blocks with scalar mixing coefficients pi, j , and the corrector combines predictor output and transformer output with weights gi. |
At a higher level, AltUp is similar to sparse MoE in that it is a method to add capacity to a model in the form of conditionally accessed (external) parameters. In sparse MoE, the additional parameters take the form of feed forward network (FFN) experts and the conditionality is with respect to the input. In AltUp, the external parameters come from the widened embedding table and the conditionality takes the form of alternating block-wise activation of the representation vector, as in the figure above. Hence, AltUp has the same underpinning as sparse MoE models.
An advantage of AltUp over sparse MoE is that it does not necessitate sharding since the number of additional parameters introduced is a factor2 of the embedding table size, which typically makes up a small fraction of the overall model size. Moreover, since AltUp focuses on conditionally activating parts of a wider token representation, it can be applied synergistically with orthogonal techniques like MoE to obtain complementary performance gains.
Evaluation
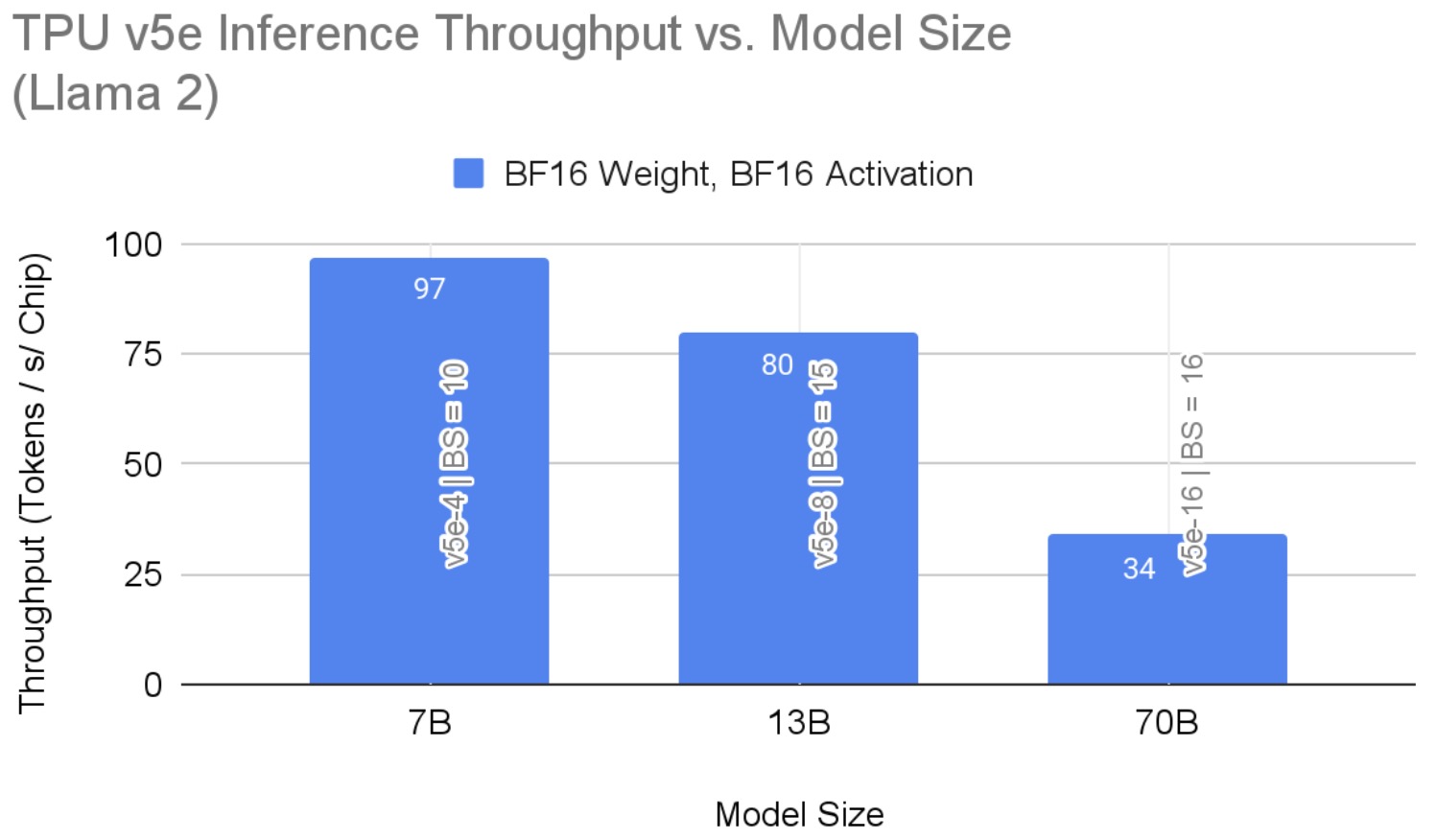
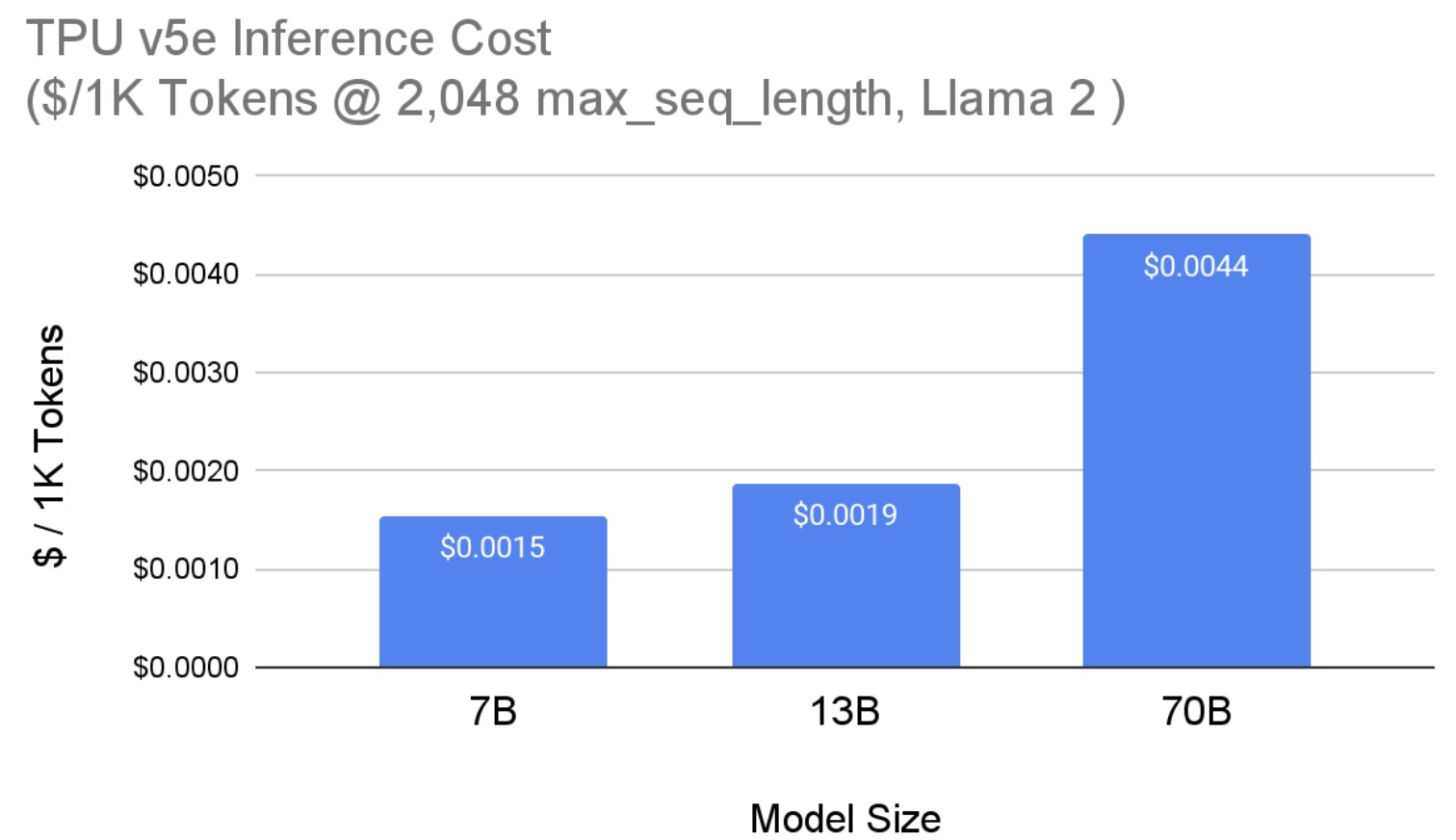
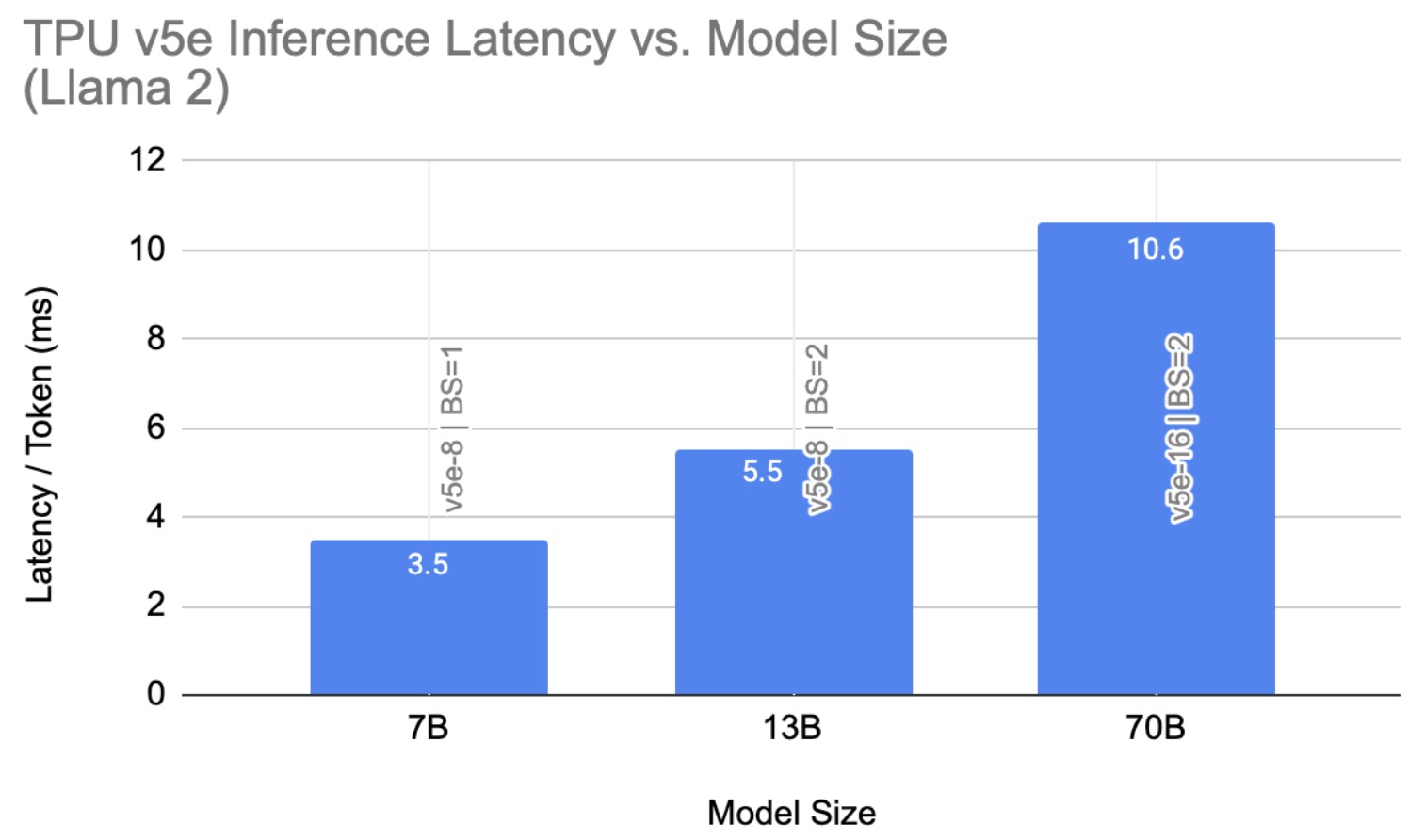
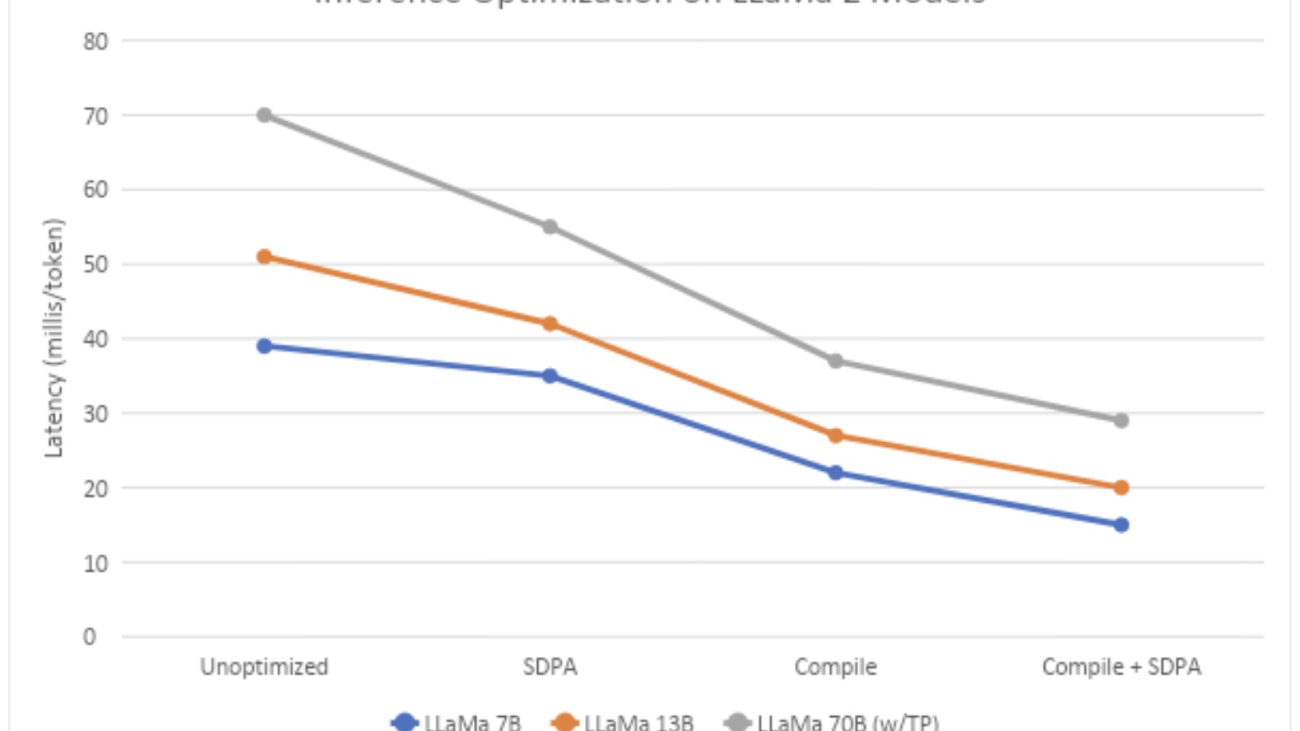
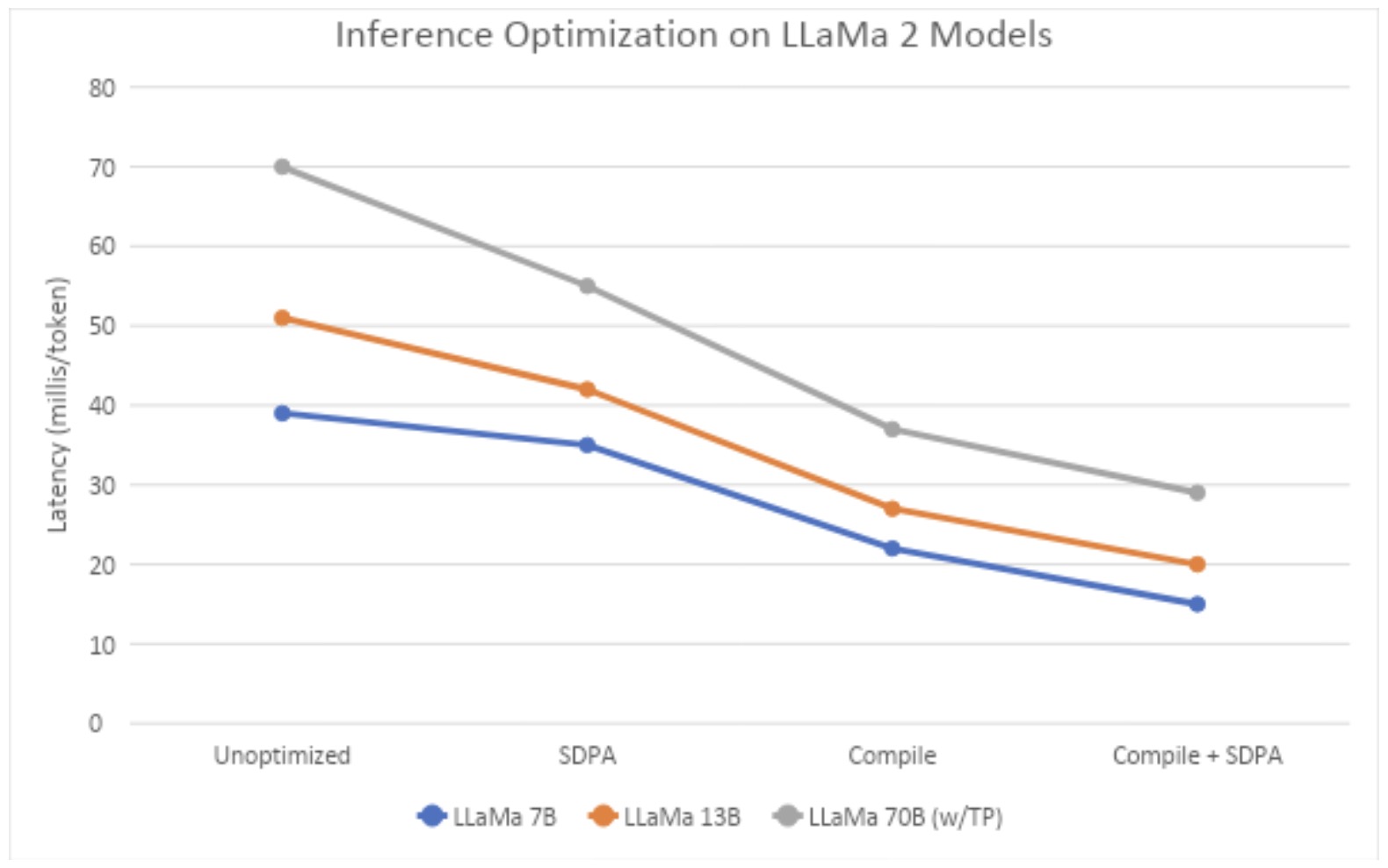
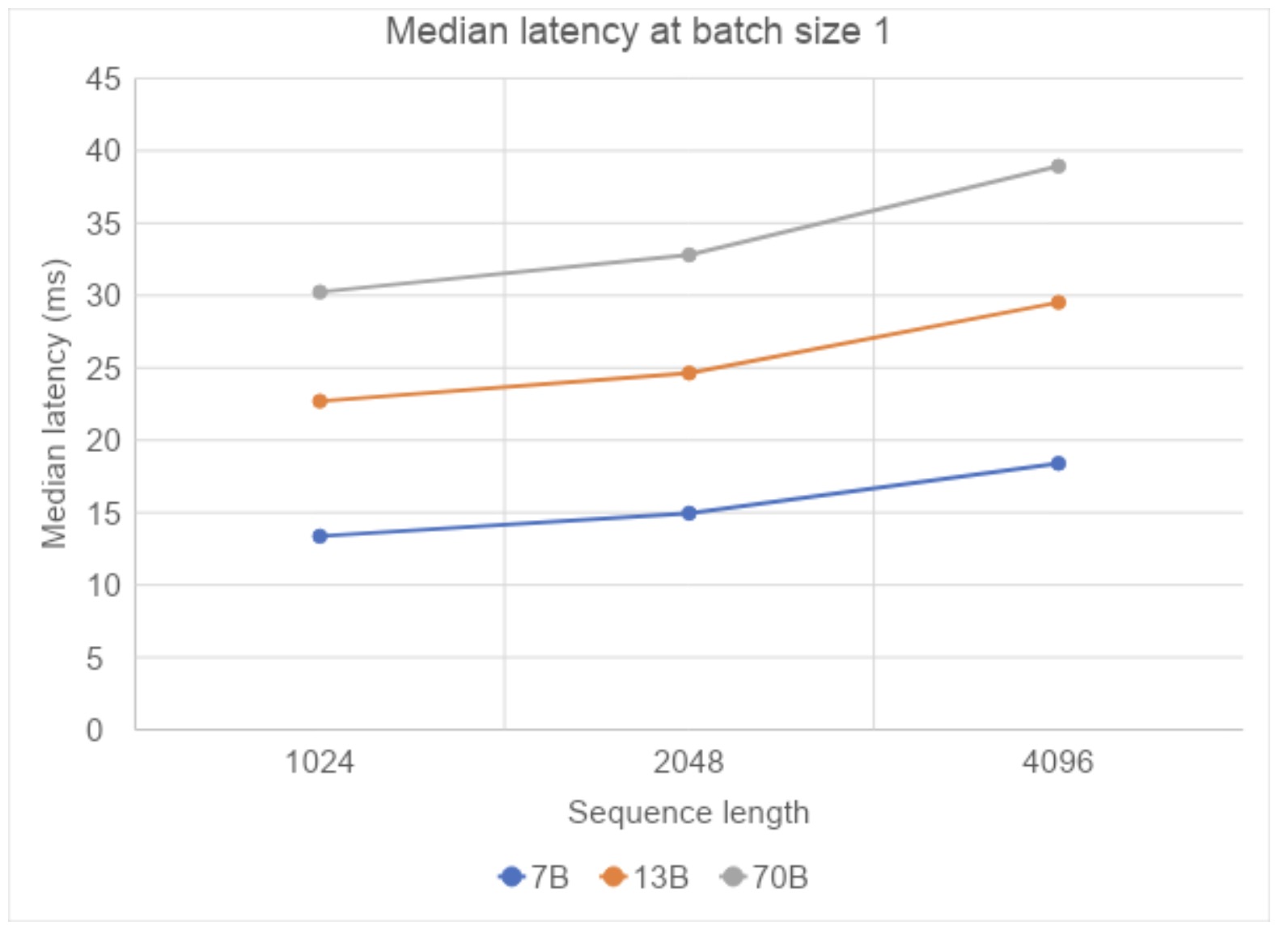
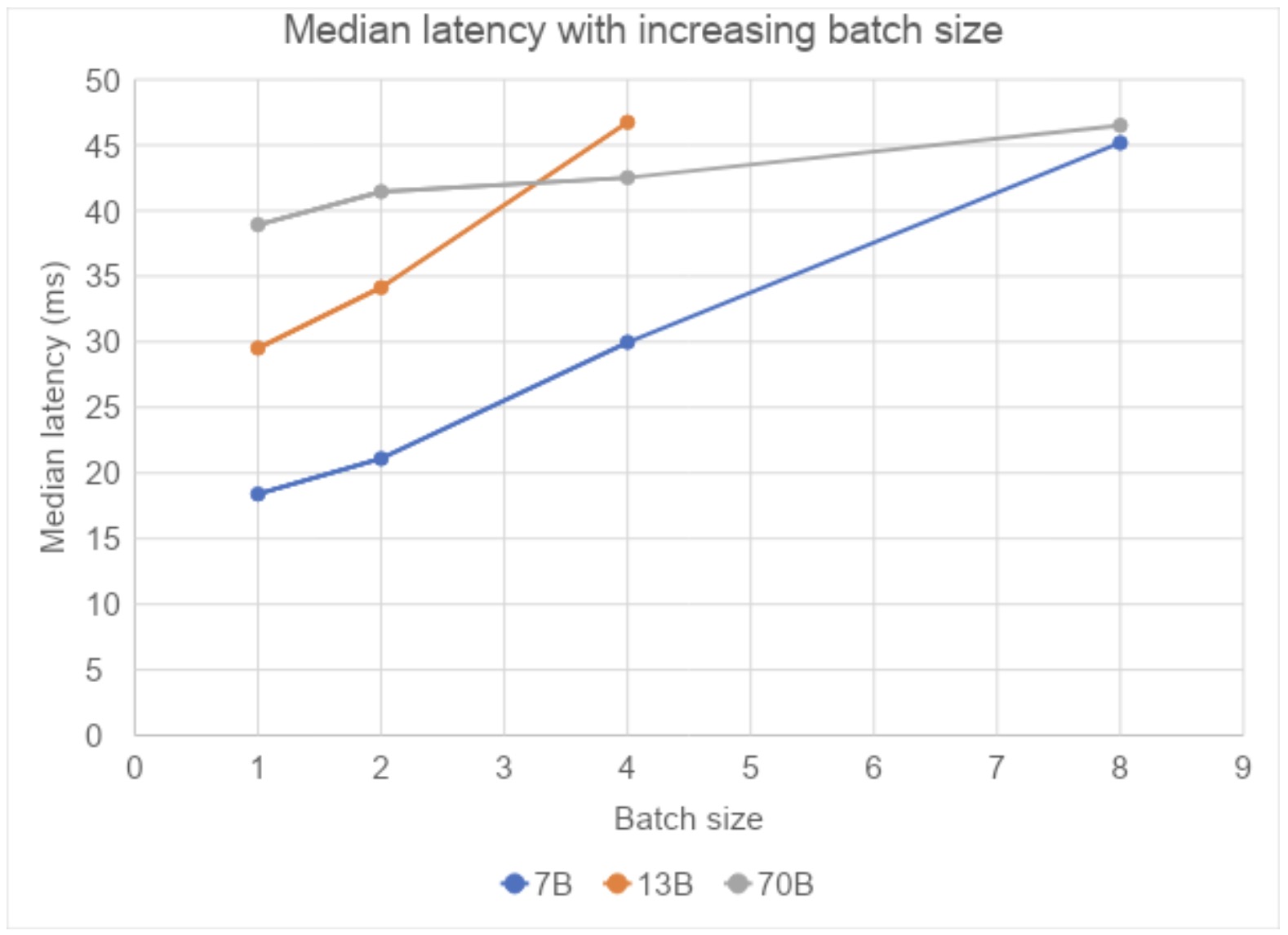
AltUp was evaluated on T5 models on various benchmark language tasks. Models augmented with AltUp are uniformly faster than the extrapolated dense models at the same accuracy. For example, we observe that a T5 Large model augmented with AltUp leads to a 27%, 39%, 87%, and 29% speedup on GLUE, SuperGLUE, SQuAD, and Trivia-QA benchmarks, respectively.
 |
| Evaluations of AltUp on T5 models of various sizes and popular benchmarks. AltUp consistently leads to sizable speedups relative to baselines at the same accuracy. Latency is measured on TPUv3 with 8 cores. Speedup is defined as the change in latency divided by the AltUp latency (B = T5 Base, L = T5 Large, XL = T5 XL models). |
AltUp’s relative performance improves as we apply it to larger models — compare the relative speedup of T5 Base + AltUp to that of T5 Large + AltUp. This demonstrates the scalability of AltUp and its improved performance on even larger models. Overall, AltUp consistently leads to models with better predictive performance than the corresponding baseline models with the same speed on all evaluated model sizes and benchmarks.
Extensions: Recycled AltUp
The AltUp formulation adds an insignificant amount of per-layer computation, however, it does require using a wider embedding table. In certain scenarios where the vocabulary size (i.e., the number of distinct tokens the tokenizer can produce) is very large, this may lead to a non-trivial amount of added computation for the initial embedding lookup and the final linear + softmax operation. A very large vocabulary may also lead to an undesirable amount of added embedding parameters. To address this, Recycled-AltUp is an extension of AltUp that avoids these computational and parameter costs by keeping the embedding table’s width the same.
 |
| Illustration of the Architecture for Recycled-AltUp with K = 2. |
In Recycled-AltUp, instead of widening the initial token embeddings, we replicate the embeddings K times to form a wider token representation. Hence, Recycled-AltUp adds virtually no additional parameters relative to the baseline transformer, while benefiting from a wider token representation.
 |
| Recycled-AltUp on T5-B/L/XL compared to baselines. Recycled-AltUp leads to strict improvements in pre-training performance without incurring any perceptible slowdown. |
We also evaluate the lightweight extension of AltUp, Recycled-AltUp, with K = 2 on T5 base, large, and XL models and compare its pre-trained accuracy and speed to those of baselines. Since Recycled-AltUp does not require an expansion in the embedding table dimension, the models augmented with it have virtually the same number of trainable parameters as the baseline models. We again observe consistent improvements compared to the dense baselines.
Why does AltUp work?
AltUp increases a model’s capacity by adding and efficiently leveraging auxiliary parameters to the embedding table, and maintaining the higher dimensional representation across the layers. We believe that a key ingredient in this computation lies in AltUp’s prediction mechanism that performs an ensemble of the different blocks. This weighted combination enables continuous message passing to the entire vector despite activating only sub-blocks of it in each layer. Recycled-AltUp, on the other hand, does not add any additional parameters to the token embeddings. However, it still confers the benefit of simulating computation in a higher dimensional representation space since a higher dimensional representation vector is maintained when moving from one transformer layer to another. We conjecture that this aids the training by augmenting the flow of information through the network. An interesting research direction is to explore whether the benefits of Recycled-AltUp can be explained entirely by more favorable training dynamics.
Acknowledgements
We thank our collaborators Cenk Baykal, Dylan Cutler, and Rina Panigrahy at Google Research, and Nikhil Ghosh at University of California, Berkeley (work done during research internship at Google).
1This is because the feedforward layers of a Transformer are typically scaled quadratically with the model dimension. ↩
2This factor depends on the user-specified expansion factor, but is typically 1, i.e., we double the embedding table dimension. ↩


 Jin Tan Ruan is a Prototyping Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, specializing in NLP and generative AI. With a background in software development and nine AWS certifications, Jin brings a wealth of experience to assist AWS customers in materializing their AI/ML and generative AI visions using the AWS platform. He holds a master’s degree in Computer Science & Software Engineering from the University of Syracuse. Outside of work, Jin enjoys playing video games and immersing himself in the thrilling world of horror movies.
Jin Tan Ruan is a Prototyping Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, specializing in NLP and generative AI. With a background in software development and nine AWS certifications, Jin brings a wealth of experience to assist AWS customers in materializing their AI/ML and generative AI visions using the AWS platform. He holds a master’s degree in Computer Science & Software Engineering from the University of Syracuse. Outside of work, Jin enjoys playing video games and immersing himself in the thrilling world of horror movies. Aravind Kodandaramaiah is a Senior Prototyping full stack solution builder within the AWS Industries Prototyping and Customer Engineering (PACE) team. He focuses on helping AWS customers turn innovative ideas into solutions with measurable and delightful outcomes. He is passionate about a range of topics, including cloud security, DevOps, and AI/ML, and can be usually found tinkering with these technologies.
Aravind Kodandaramaiah is a Senior Prototyping full stack solution builder within the AWS Industries Prototyping and Customer Engineering (PACE) team. He focuses on helping AWS customers turn innovative ideas into solutions with measurable and delightful outcomes. He is passionate about a range of topics, including cloud security, DevOps, and AI/ML, and can be usually found tinkering with these technologies. Arjun Shakdher is a Developer on the AWS Industries Prototyping (PACE) team who is passionate about blending technology into the fabric of life. Holding a master’s degree from Purdue University, Arjun’s current role revolves around architecting and building cutting-edge prototypes that span an array of domains, presently prominently featuring the realms of AI/ML and IoT. When not immersed in code and digital landscapes, you’ll find Arjun indulging in the world of coffee, exploring the intricate mechanics of horology, or reveling in the artistry of automobiles.
Arjun Shakdher is a Developer on the AWS Industries Prototyping (PACE) team who is passionate about blending technology into the fabric of life. Holding a master’s degree from Purdue University, Arjun’s current role revolves around architecting and building cutting-edge prototypes that span an array of domains, presently prominently featuring the realms of AI/ML and IoT. When not immersed in code and digital landscapes, you’ll find Arjun indulging in the world of coffee, exploring the intricate mechanics of horology, or reveling in the artistry of automobiles.











 Smriti Ranjan is a Principal Product Manager in the AWS AI/ML team focusing on language and search services. Prior to joining AWS, she worked at Amazon Devices and other technology startups leading product and growth functions. Smriti lives in Boston, MA and enjoys hiking, attending concerts and traveling the world.
Smriti Ranjan is a Principal Product Manager in the AWS AI/ML team focusing on language and search services. Prior to joining AWS, she worked at Amazon Devices and other technology startups leading product and growth functions. Smriti lives in Boston, MA and enjoys hiking, attending concerts and traveling the world.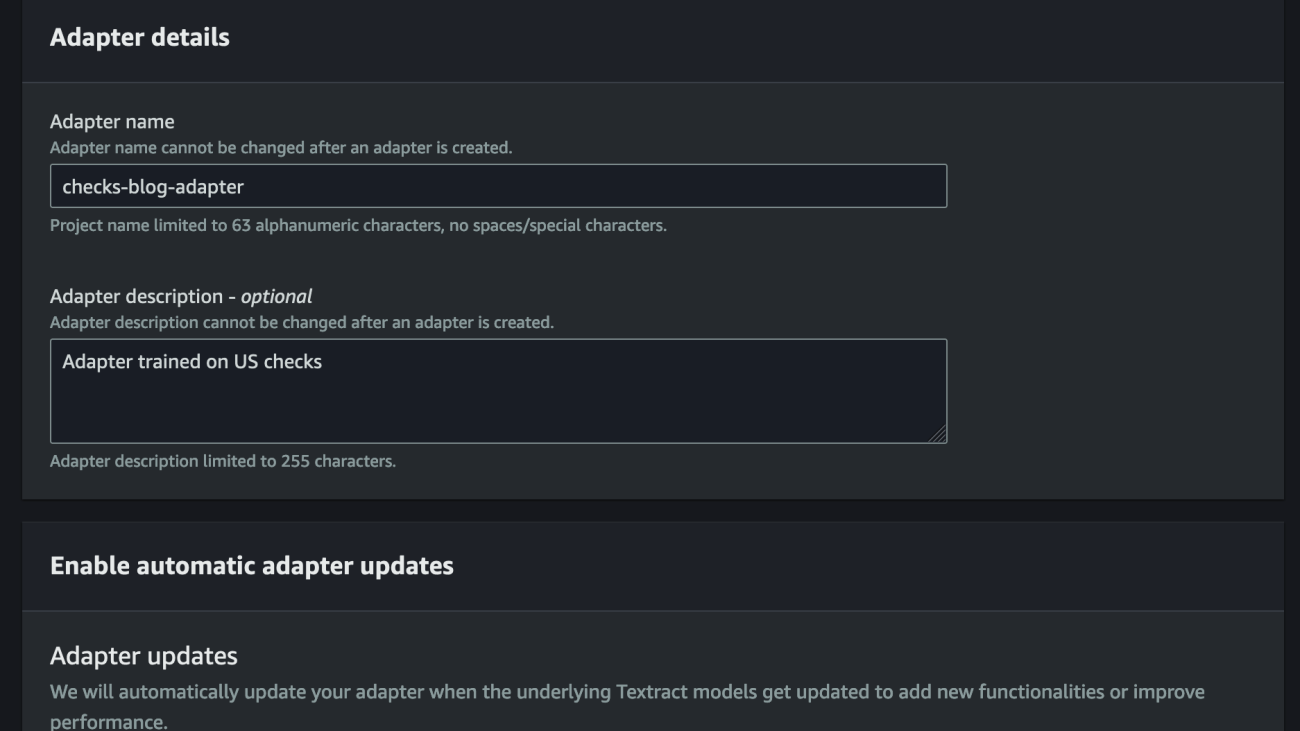





 Shibin Michaelraj is a Sr. Product Manager with the Amazon Textract team. He is focused on building AI/ML-based products for AWS customers. He is excited helping customers solve their complex business challenges by leveraging AI and ML technologies. In his spare time, he enjoys running, tuning into podcasts, and refining his amateur tennis skills.
Shibin Michaelraj is a Sr. Product Manager with the Amazon Textract team. He is focused on building AI/ML-based products for AWS customers. He is excited helping customers solve their complex business challenges by leveraging AI and ML technologies. In his spare time, he enjoys running, tuning into podcasts, and refining his amateur tennis skills. Keith Mascarenhas is a Sr. Solutions Architect with the Amazon Textract service team. He is passionate about solving business problems at scale using machine learning, and currently helps our worldwide customers automate their document processing to achieve faster time to market with reduced operational costs.
Keith Mascarenhas is a Sr. Solutions Architect with the Amazon Textract service team. He is passionate about solving business problems at scale using machine learning, and currently helps our worldwide customers automate their document processing to achieve faster time to market with reduced operational costs.
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Dr. Kyle Ulrich is an Applied Scientist with the
Dr. Kyle Ulrich is an Applied Scientist with the  Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.