Many customers, including those in creative advertising, media and entertainment, ecommerce, and fashion, often need to change the background in a large number of images. Typically, this involves manually editing each image with photo software. This can take a lot of effort, especially for large batches of images. However, Amazon Bedrock and AWS Step Functions make it straightforward to automate this process at scale.
Amazon Bedrock offers the generative AI foundation model Amazon Titan Image Generator G1, which can automatically change the background of an image using a technique called outpainting. Step Functions allows you to create an automated workflow that seamlessly connects with Amazon Bedrock and other AWS services. Together, Amazon Bedrock and Step Functions streamline the entire process of automatically changing backgrounds across multiple images.
This post introduces a solution that simplifies the process of changing backgrounds in multiple images. By harnessing the capabilities of generative AI with Amazon Bedrock and the Titan Image Generator G1 model, combined with Step Functions, this solution efficiently generates images with the desired background. This post provides insight into the inner workings of the solution and helps you understand the design choices made to build this own custom solution.
See the GitHub repository for detailed instructions on deploying this solution.
Solution overview
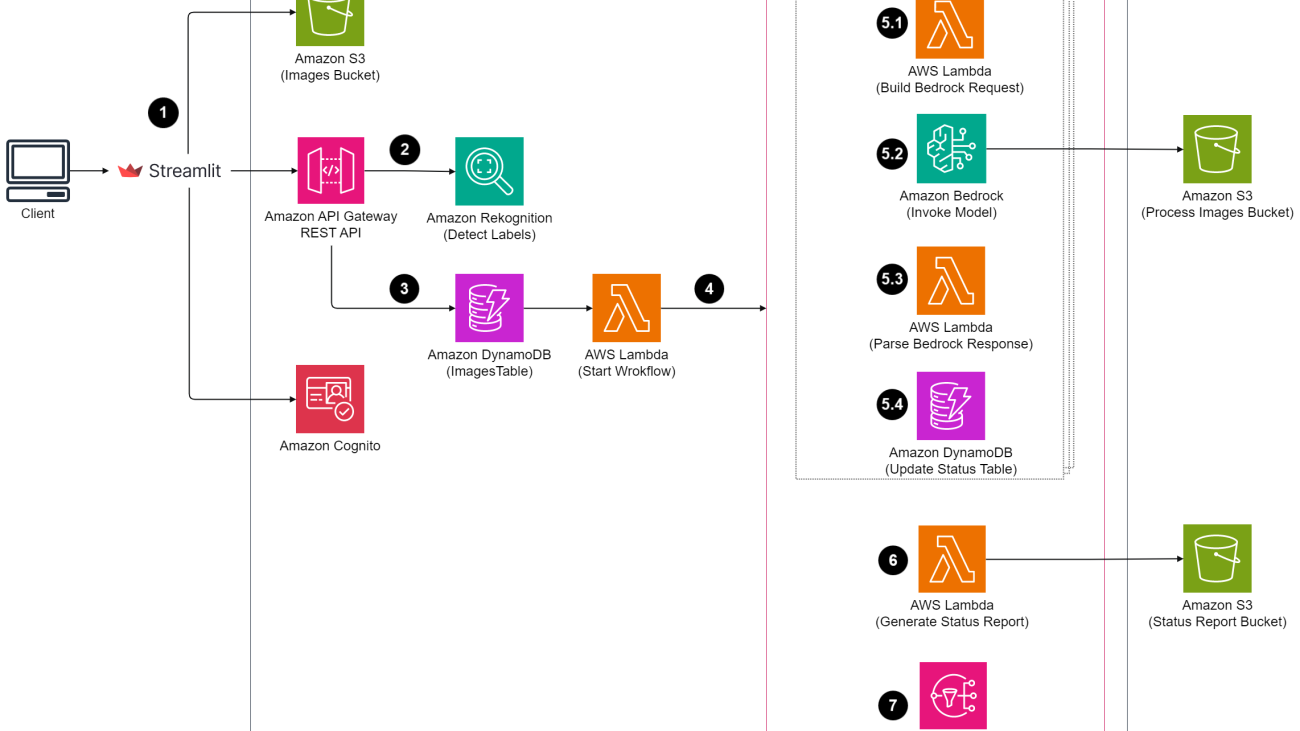
Let’s look at how the solution works at a high level before diving deeper into specific elements and the AWS services used. The following diagram provides a simplified view of the solution architecture and highlights the key elements.

The workflow consists of the following steps:
- A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application.
- The Streamlit web application calls an Amazon API Gateway REST API endpoint integrated with the Amazon Rekognition DetectLabels API, which detects labels for each image.
- Upon submission, the Streamlit web application updates an Amazon DynamoDB table with image details.
- The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow.
- The Step Functions workflow runs the following steps for each image:
5.1 Constructs a request payload for the Amazon BedrockInvokeModelAPI.
5.2 Invokes the Amazon BedrockInvokeModelAPI action.
5.3 Parses an image from the response and saves it to an S3 location.
5.4 Updates the image status in a DynamoDB table. - The Step Functions workflow invokes a Lambda function to generate a status report.
- The workflow sends an email using Amazon Simple Notification Service (Amazon SNS).
As shown in the following screenshot, the Streamlit web application allows you to upload images and enter text prompts to specify desired backgrounds, negative prompts, and outpainting mode for image generation. You can also view and remove unwanted labels associated with each uploaded image that you don’t want to keep in the final generated images.

In this example, the prompt for the background is “London city background.” The automation process generates new images based on the original uploaded images with London as the background.

Streamlit web application and images uploads
A Streamlit web application serves as the frontend for this solution. To protect the application from unauthorized access, it integrates with an Amazon Cognito user pool. API Gateway uses an Amazon Cognito authorizer to authenticate requests. The web application completes the following steps:
- For each selected image, it retrieves labels via Amazon Rekognition using an API Gateway REST API endpoint.
- Upon submission, the application uploads images to an S3 bucket.
- The application updates a DynamoDB table with relevant parameters, image names, and associated labels for each image using another API Gateway REST API endpoint.
Image processing workflow
When the DynamoDB table is updated, DynamoDB Streams triggers a Lambda function to start a new Step Functions workflow. The following is a sample request for the workflow:
The Step Functions workflow subsequently performs the following three steps:
- Replace the background for all images.
- Generate a status report.
- Send an email via Amazon SNS.
The following screenshot illustrates the Step Functions workflow.

Let’s look at each step in more detail.
Replace background for all images
Step Functions uses a Distributed Map to process each image in parallel child workflows. The Distributed Map allows high-concurrency processing. Each child workflow has its own separate run history from that of the parent workflow.
Step Functions uses an InvokeModel optimized API action for Amazon Bedrock. The API accepts requests and responses that are up to 25 MB. However, Step Functions has a 256 KB limit on state payload input and output. To support larger images, the solution uses an S3 bucket where the InvokeModel API reads data from and writes the result to. The following is the configuration for the InvokeModel API for Amazon Bedrock integration:
The Input S3Uri parameter specifies the source location to retrieve the input data. The Output S3Uri parameter specifies the destination to write the API response.
A Lambda function saves the request payload as a JSON file in the specified Input S3Uri location. The InvokeModel API uses this input payload to generate images with the specified background:
The Titan Image Generator G1 model supports the following parameters for image generation:
- taskType – Specifies the outpainting method to replace background of image.
- text – A text prompt to define the background.
- negativeText – A text prompt to define what not to include in the image.
- maskPrompt – A text prompt that defines the mask. It corresponds to labels that you want to retain in the final generated images.
- maskImage – The JPEG or PNG image encoded in base64.
- outPaintingMode – Specifies whether to allow modification of the pixels inside the mask or not. DEFAULT allows modification of the image inside the mask in order to keep it consistent with the reconstructed background. PRECISE prevents modification of the image inside the mask.
- numberOfImages – The number of images to generate.
- quality – The quality of the generated images:
standardorpremium. - cfgScale – Specifies how strongly the generated image should adhere to the prompt.
- height – The height of the image in pixels.
- width – The width of the image in pixels.
The Amazon Bedrock InvokeModel API generates a response with an encoded image in the Output S3Uri location. Another Lambda function parses the image from the response, decodes it from base64, and saves the image file in the following location: s3://<Image Bucket>/generated-image-file/<year>/<month>/<day>/<timestamp>/.
Finally, a child workflow updates a DynamoDB table with image generation status, marking it as either Succeeded or Failed, and including details such as ImageName, Cause, Error, and Status.
Generate a status report
After the image generation process, a Lambda function retrieves the status details from DynamoDB. It dynamically compiles these details into a comprehensive status report in JSON format. It then saves the generated status report a JSON file in the following location: s3://<Image Bucket>/status-report-files/<year>/<month>/<day>/<timestamp>/. The ITOps team can integrate this report with their existing notification system to track if image processing completed successfully. For business users, you can expand this further to generate a report in CSV format.
Send an email via Amazon SNS
Step Functions invokes an Amazon SNS API action to send an email. The email contains details including the S3 location for the status report and final images files. The following is the sample notification email.

Conclusion
In this post, we provided an overview of a sample solution demonstrating the automation of changing image backgrounds at scale using Amazon Bedrock and Step Functions. We also explained each element of the solution in detail. By using the Step Functions optimized integration with Amazon Bedrock, Distributed Map, and the Titan Image Generator G1 model, the solution efficiently replaces the backgrounds of images in parallel, enhancing productivity and scalability.
To deploy the solution, refer to the instructions in the GitHub repository.
Resources
To learn more about Amazon Bedrock, see the following resources:
- Using generative AI on AWS for diverse content types Workshop
- Amazon Bedrock Workshop
- Amazon Bedrock User Guide
- Amazon Bedrock with Amazon Titan Image Generator G1
- Amazon Bedrock InvokeModel API
To learn more about the Titan Image Generator G1 model, see the following resources:
To learn more about using Amazon Bedrock with Step Functions, see the following resources:
- Build generative AI apps using AWS Step Functions and Amazon Bedrock
- Amazon Bedrock Optimized Integration for Step Functions
About the Author
 Chetan Makvana is a Senior Solutions Architect with Amazon Web Services. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture and implementing strategies to drive adoption of AWS services. He is a technology enthusiast and a builder with a core area of interest on generative AI, serverless, and DevOps. Outside of work, he enjoys watching shows, traveling, and music.
Chetan Makvana is a Senior Solutions Architect with Amazon Web Services. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture and implementing strategies to drive adoption of AWS services. He is a technology enthusiast and a builder with a core area of interest on generative AI, serverless, and DevOps. Outside of work, he enjoys watching shows, traveling, and music.














 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)