Ongoing collaboration includes Amazon joining the UW Center for the Future of Cloud Infrastructure.Read More

Capture public health insights more quickly with no-code machine learning using Amazon SageMaker Canvas
Public health organizations have a wealth of data about different types of diseases, health trends, and risk factors. Their staff has long used statistical models and regression analyses to make important decisions such as targeting populations with the highest risk factors for a disease with therapeutics, or forecasting the progression of concerning outbreaks.
When public health threats emerge, data velocity increases, incoming datasets can grow larger, and data management becomes more challenging. This makes it more difficult to analyze data holistically and capture insights from it. And when time is of the essence, speed and agility in analyzing data and drawing insights from it are key blockers to forming rapid and robust health responses.
Typical questions public health organizations face during times of stress include:
- Will there be sufficient therapeutics in a certain location?
- What risk factors are driving health outcomes?
- Which populations have a higher risk of reinfection?
Because answering these questions requires understanding complex relationships between many different factors—often changing and dynamic—one powerful tool we have at our disposal is machine learning (ML), which can be deployed to analyze, predict, and solve these complex quantitative problems. We have increasingly seen ML applied to address difficult health-related problems such as classifying brain tumors with image analysis and predicting the need for mental health to deploy early intervention programs.
But what happens if public health organizations are in short supply of the skills required to apply ML to these questions? The application of ML to public health problems is impeded, and public health organizations lose the ability to apply powerful quantitative tools to address their challenges.
So how do we remove these bottlenecks? The answer is to democratize ML and allow a larger number of health professionals with deep domain expertise to use it and apply it to the questions they want to solve.
Amazon SageMaker Canvas is a no-code ML tool that empowers public health professionals such as epidemiologists, informaticians, and bio-statisticians to apply ML to their questions, without requiring a data science background or ML expertise. They can spend their time on the data, apply their domain expertise, quickly test hypothesis, and quantify insights. Canvas helps make public health more equitable by democratizing ML, allowing health experts to evaluate large datasets and empowering them with advanced insights using ML.
In this post, we show how public health experts can forecast on-hand demand for a certain therapeutic for the next 30 days using Canvas. Canvas provides you with a visual interface that allows you to generate accurate ML predictions on your own without requiring any ML experience or having to write a single line of code.
Solution overview
Let’s say we are working on data that we collected from states across the US. We may form a hypothesis that a certain municipality or location doesn’t have enough therapeutics in the coming weeks. How can we test this quickly and with a high degree of accuracy?
For this post, we use a publicly available dataset from the US Department of Health and Human Services, which contains state-aggregated time series data related to COVID-19, including hospital utilization, availability of certain therapeutics, and much more. The dataset (COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries (RAW)) is downloadable from healthdata.gov, and has 135 columns and over 60,000 rows. The dataset is updated periodically.
In the following sections, we demonstrate how to perform exploratory data analysis and preparation, build the ML forecasting model, and generate predictions using Canvas.
Perform exploratory data analysis and preparation
When doing a time series forecast in Canvas, we need to reduce the number of features or columns according to the service quotas. Initially, we reduce the number of columns to the 12 that are likely to be the most relevant. For example, we dropped the age-specific columns because we’re looking to forecast total demand. We also dropped columns whose data was similar to other columns we kept. In future iterations, it is reasonable to experiment with retaining other columns and using feature explainability in Canvas to quantify the importance of these features and which we want to keep. We also rename the state column to location.
Looking at the dataset, we also decide to remove all the rows for 2020, because there were limited therapeutics available at that time. This allows us to reduce the noise and improve the quality of the data for the ML model to learn from.
Reducing the number of columns can be done in different ways. You can edit the dataset in a spreadsheet, or directly inside Canvas using the user interface.
You can import data into Canvas from various sources, including from local files from your computer, Amazon Simple Storage Service (Amazon S3) buckets, Amazon Athena, Snowflake (see Prepare training and validation dataset for facies classification using Snowflake integration and train using Amazon SageMaker Canvas), and over 40 additional data sources.
After our data has been imported, we can explore and visualize our data to get additional insights into it, such as with scatterplots or bar charts. We also look at the correlation between different features to ensure that we have selected what we think are the best ones. The following screenshot shows an example visualization.
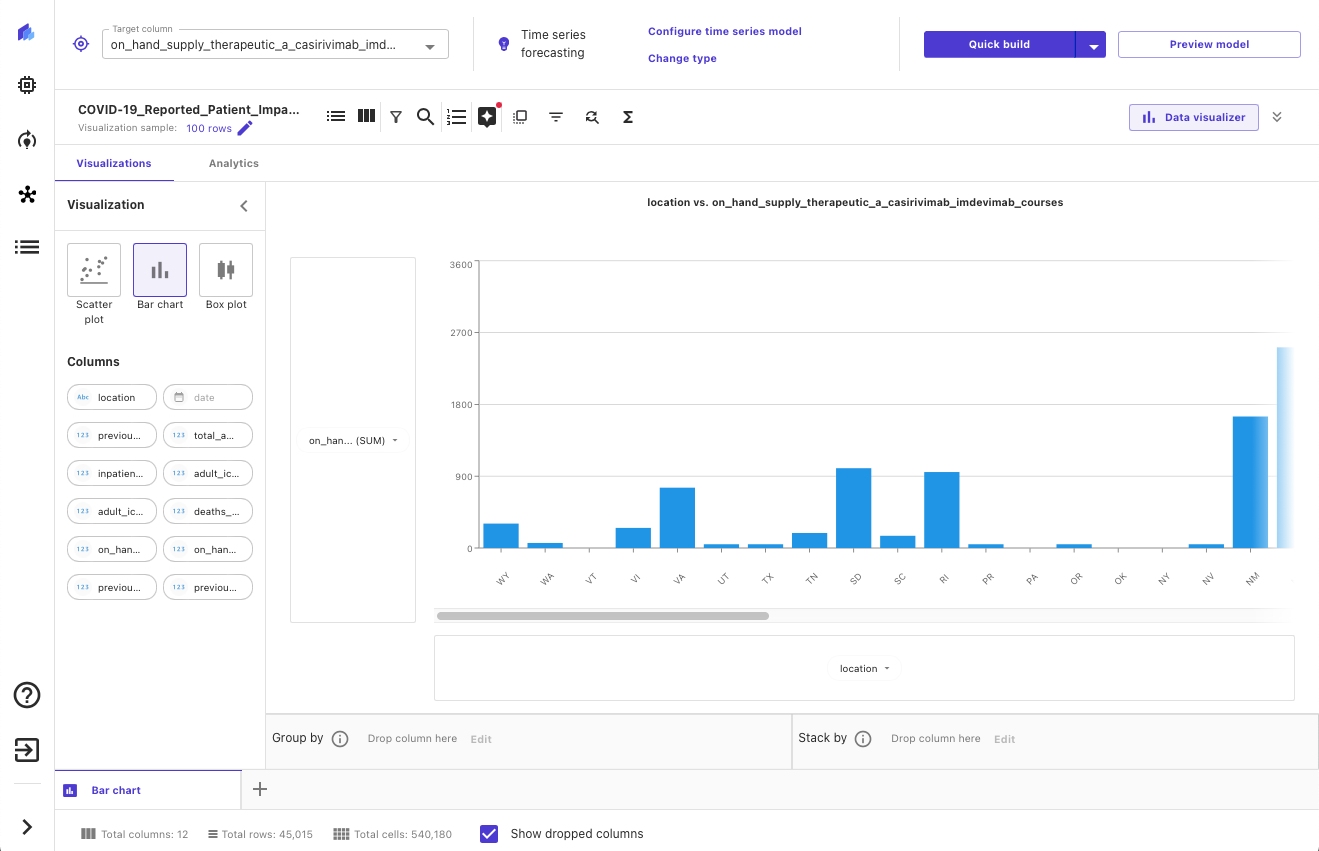
Build the ML forecasting model
Now we’re ready to create our model, which we can do with just a few clicks. We choose the column identifying on-hand therapeutics as our target. Canvas automatically identifies our problem as a time series forecast based on the target column we just selected, and we can configure the parameters needed.
We configure the item_id, the unique identifier, as location because our dataset is provided by location (US states). Because we’re creating a time series forecast, we need to select a time stamp, which is date in our dataset. Finally, we specify how many days into the future we want to forecast (for this example, we choose 30 days). Canvas also offers the ability to include a holiday schedule to improve accuracy. In this case, we use US holidays because this is a US-based dataset.
With Canvas, you can get insights from your data before you build a model by choosing Preview model. This saves you time and cost by not building a model if the results are unlikely to be satisfactory. By previewing our model, we realize that the impact of some columns is low, meaning the expected value of the column to the model is low. We remove columns by deselecting them in Canvas (red arrows in the following screenshot) and see an improvement in an estimated quality metric (green arrow).
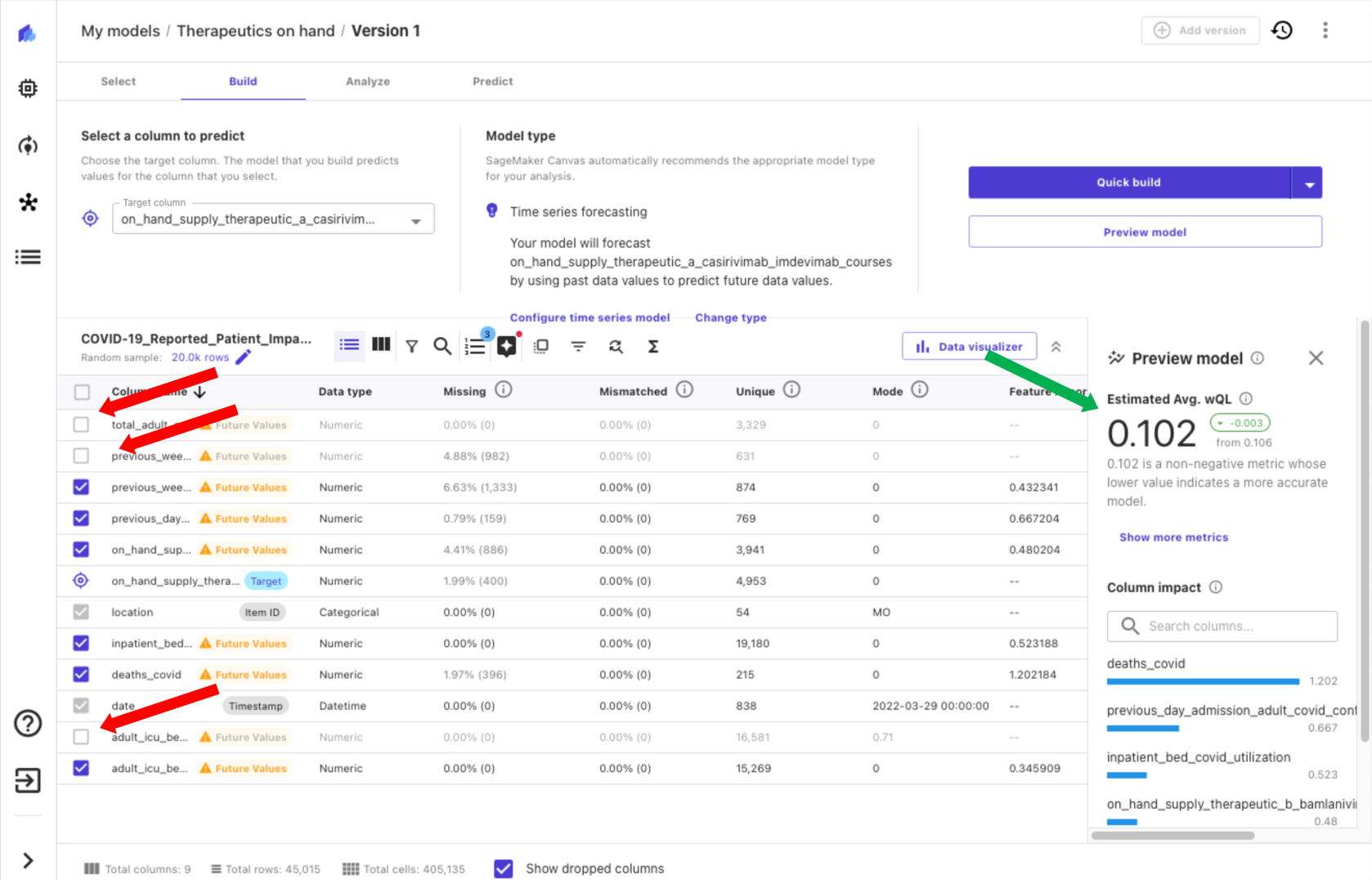
Moving on to building our model, we have two options, Quick build and Standard build. Quick build produces a trained model in less than 20 minutes, prioritizing speed over accuracy. This is great for experimentation, and is a more thorough model than the preview model. Standard build produces a trained model in under 4 hours, prioritizing accuracy over latency, iterating through a number of model configurations to automatically select the best model.
First, we experiment with Quick build to validate our model preview. Then, because we’re happy with the model, we choose Standard build to have Canvas help build the best possible model for our dataset. If the Quick build model had produced unsatisfactory results, then we would go back and adjust the input data to capture a higher level of accuracy. We could accomplish this by, for instance, adding or removing columns or rows in our original dataset. The Quick build model supports rapid experimentation without having to rely on scarce data science resources or wait for a full model to be completed.
Generate predictions
Now that the model has been built, we can predict the availability of therapeutics by location. Let’s look at what our estimated on-hand inventory looks like for the next 30 days, in this case for Washington, DC.
Canvas outputs probabilistic forecasts for therapeutic demand, allowing us to understand both the median value as well as upper and lower bounds. In the following screenshot, you can see the tail end of the historical data (the data from the original dataset). You can then see three new lines: the median (50th quantile) forecast in purple, the lower bound (10th quantile) in light blue, and upper bound (90th quantile) in dark blue.
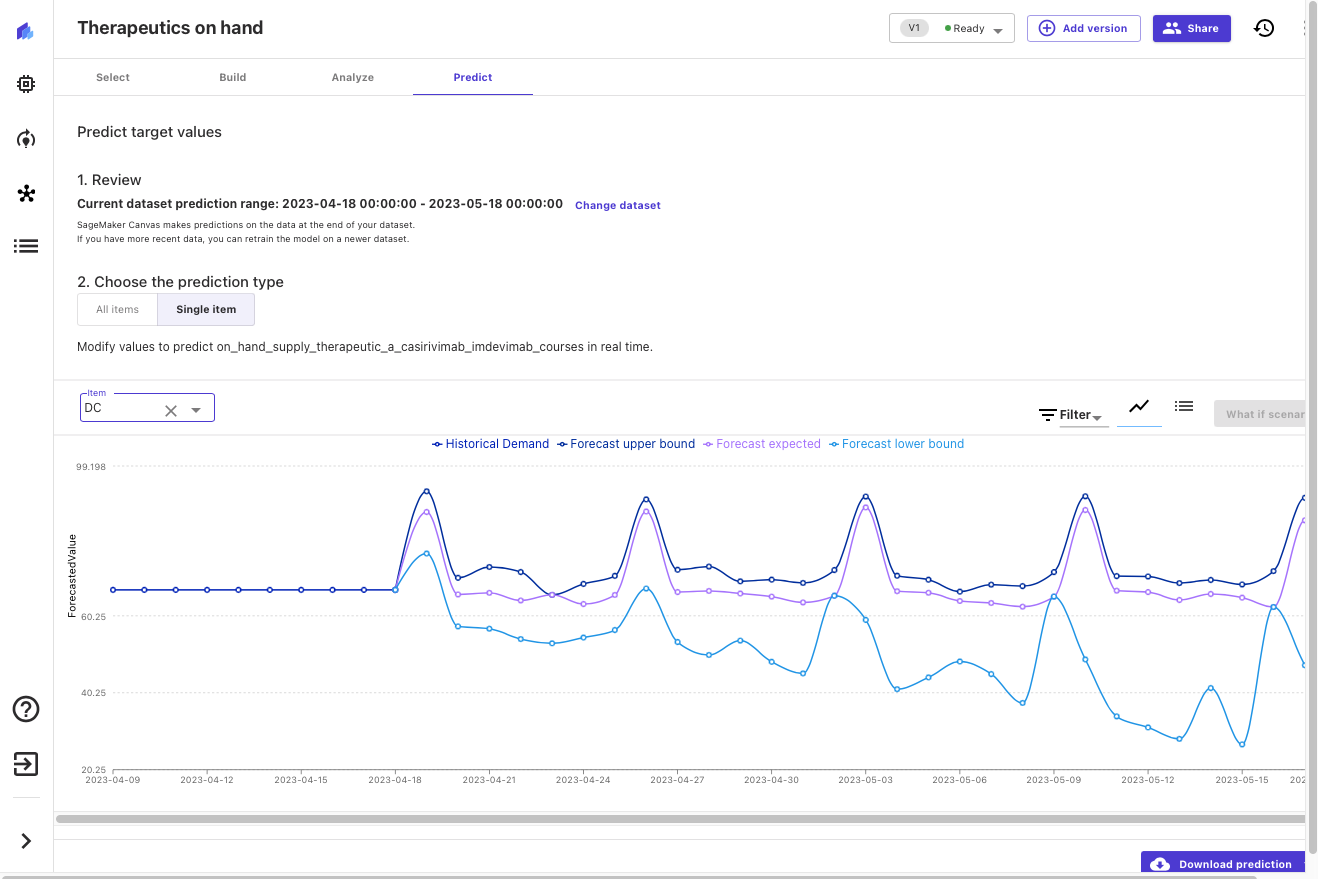
Examining upper and lower bounds provides insight into the probability distribution of the forecast and allows us to make informed decisions about desired levels of local inventory for this therapeutic. We can add this insight to other data (for example, disease progression forecasts, or therapeutic efficacy and uptake) to make informed decisions about future orders and inventory levels.
Conclusion
No-code ML tools empower public health experts to quickly and effectively apply ML to public health threats. This democratization of ML makes public health organizations more agile and more efficient in their mission of protecting public health. Ad hoc analyses that can identify important trends or inflection points in public health concerns can now be performed directly by specialists, without having to compete for limited ML expert resources and slowing down response times and decision-making.
In this post, we showed how someone without any knowledge of ML can use Canvas to forecast the on-hand inventory of a certain therapeutic. This analysis can be performed by any analyst in the field, through the power of cloud technologies and no-code ML. Doing so distributes capabilities broadly and allows public health agencies to be more responsive, and to more efficiently use centralized and field office resources to deliver better public health outcomes.
What are some of the questions you might be asking, and how may low-code/no-code tools be able to help you answer them? If you are interested in learning more about Canvas, refer to Amazon SageMaker Canvas and start applying ML to your own quantitative health questions.
About the authors
 Henrik Balle is a Sr. Solutions Architect at AWS supporting the US Public Sector. He works closely with customers on a range of topics from machine learning to security and governance at scale. In his spare time, he loves road biking, motorcycling, or you might find him working on yet another home improvement project.
Henrik Balle is a Sr. Solutions Architect at AWS supporting the US Public Sector. He works closely with customers on a range of topics from machine learning to security and governance at scale. In his spare time, he loves road biking, motorcycling, or you might find him working on yet another home improvement project.
 Dan Sinnreich leads Go to Market product management for Amazon SageMaker Canvas and Amazon Forecast. He is focused on democratizing low-code/no-code machine learning and applying it to improve business outcomes. Previous to AWS Dan built enterprise SaaS platforms and time-series risk models used by institutional investors to manage risk and construct portfolios. Outside of work, he can be found playing hockey, scuba diving, traveling, and reading science fiction.
Dan Sinnreich leads Go to Market product management for Amazon SageMaker Canvas and Amazon Forecast. He is focused on democratizing low-code/no-code machine learning and applying it to improve business outcomes. Previous to AWS Dan built enterprise SaaS platforms and time-series risk models used by institutional investors to manage risk and construct portfolios. Outside of work, he can be found playing hockey, scuba diving, traveling, and reading science fiction.

Safe image generation and diffusion models with Amazon AI content moderation services
Generative AI technology is improving rapidly, and it’s now possible to generate text and images based on text input. Stable Diffusion is a text-to-image model that empowers you to create photorealistic applications. You can easily generate images from text using Stable Diffusion models through Amazon SageMaker JumpStart.
The following are examples of input texts and the corresponding output images generated by Stable Diffusion. The inputs are “A boxer dancing on a table,” “A lady on the beach in swimming wear, water color style,” and “A dog in a suit.”

Although generative AI solutions are powerful and useful, they can also be vulnerable to manipulation and abuse. Customers using them for image generation must prioritize content moderation to protect their users, platform, and brand by implementing strong moderation practices to create a safe and positive user experience while safeguarding their platform and brand reputation.
In this post, we explore using AWS AI services Amazon Rekognition and Amazon Comprehend, along with other techniques, to effectively moderate Stable Diffusion model-generated content in near-real time. To learn how to launch and generate images from text using a Stable Diffusion model on AWS, refer to Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart.
Solution overview
Amazon Rekognition and Amazon Comprehend are managed AI services that provide pre-trained and customizable ML models via an API interface, eliminating the need for machine learning (ML) expertise. Amazon Rekognition Content Moderation automates and streamlines image and video moderation. Amazon Comprehend utilizes ML to analyze text and uncover valuable insights and relationships.
The following reference illustrates the creation of a RESTful proxy API for moderating Stable Diffusion text-to-image model-generated images in near-real time. In this solution, we launched and deployed a Stable Diffusion model (v2-1 base) using JumpStart. The solution uses negative prompts and text moderation solutions such as Amazon Comprehend and a rule-based filter to moderate input prompts. It also utilizes Amazon Rekognition to moderate the generated images. The RESTful API will return the generated image and the moderation warnings to the client if unsafe information is detected.

The steps in the workflow are as follows:
- The user send a prompt to generate an image.
- An AWS Lambda function coordinates image generation and moderation using Amazon Comprehend, JumpStart, and Amazon Rekognition:
- Apply a rule-based condition to input prompts in Lambda functions, enforcing content moderation with forbidden word detection.
- Use the Amazon Comprehend custom classifier to analyze the prompt text for toxicity classification.
- Send the prompt to the Stable Diffusion model through the SageMaker endpoint, passing both the prompts as user input and negative prompts from a predefined list.
- Send the image bytes returned from the SageMaker endpoint to the Amazon Rekognition
DetectModerationLabelAPI for image moderation. - Construct a response message that includes image bytes and warnings if the previous steps detected any inappropriate information in the prompt or generative image.
- Send the response back to the client.
The following screenshot shows a sample app built using the described architecture. The web UI sends user input prompts to the RESTful proxy API and displays the image and any moderation warnings received in the response. The demo app blurs the actual generated image if it contains unsafe content. We tested the app with the sample prompt “A sexy lady.”

You can implement more sophisticated logic for a better user experience, such as rejecting the request if the prompts contain unsafe information. Additionally, you could have a retry policy to regenerate the image if the prompt is safe, but the output is unsafe.
Predefine a list of negative prompts
Stable Diffusion supports negative prompts, which lets you specify prompts to avoid during image generation. Creating a predefined list of negative prompts is a practical and proactive approach to prevent the model from producing unsafe images. By including prompts like “naked,” “sexy,” and “nudity,” which are known to lead to inappropriate or offensive images, the model can recognize and avoid them, reducing the risk of generating unsafe content.
The implementation can be managed in the Lambda function when calling the SageMaker endpoint to run inference of the Stable Diffusion model, passing both the prompts from user input and the negative prompts from a predefined list.
Although this approach is effective, it could impact the results generated by the Stable Diffusion model and limit its functionality. It’s important to consider it as one of the moderation techniques, combined with other approaches such as text and image moderation using Amazon Comprehend and Amazon Rekognition.
Moderate input prompts
A common approach to text moderation is to use a rule-based keyword lookup method to identify whether the input text contains any forbidden words or phrases from a predefined list. This method is relatively easy to implement, with minimal performance impact and lower costs. However, the major drawback of this approach is that it’s limited to only detecting words included in the predefined list and can’t detect new or modified variations of forbidden words not included in the list. Users can also attempt to bypass the rules by using alternative spellings or special characters to replace letters.
To address the limitations of a rule-based text moderation, many solutions have adopted a hybrid approach that combines rule-based keyword lookup with ML-based toxicity detection. The combination of both approaches allows for a more comprehensive and effective text moderation solution, capable of detecting a wider range of inappropriate content and improving the accuracy of moderation outcomes.
In this solution, we use an Amazon Comprehend custom classifier to train a toxicity detection model, which we use to detect potentially harmful content in input prompts in cases where no explicit forbidden words are detected. With the power of machine learning, we can teach the model to recognize patterns in text that may indicate toxicity, even when such patterns aren’t easily detectable by a rule-based approach.
With Amazon Comprehend as a managed AI service, training and inference are simplified. You can easily train and deploy Amazon Comprehend custom classification with just two steps. Check out our workshop lab for more information about the toxicity detection model using an Amazon Comprehend custom classifier. The lab provides a step-by-step guide to creating and integrating a custom toxicity classifier into your application. The following diagram illustrates this solution architecture.

This sample classifier uses a social media training dataset and performs binary classification. However, if you have more specific requirements for your text moderation needs, consider using a more tailored dataset to train your Amazon Comprehend custom classifier.
Moderate output images
Although moderating input text prompts is important, it doesn’t guarantee that all images generated by the Stable Diffusion model will be safe for the intended audience, because the model’s outputs can contain a certain level of randomness. Therefore, it’s equally important to moderate the images generated by the Stable Diffusion model.
In this solution, we utilize Amazon Rekognition Content Moderation, which employs pre-trained ML models, to detect inappropriate content in images and videos. In this solution, we use the Amazon Rekognition DetectModerationLabel API to moderate images generated by the Stable Diffusion model in near-real time. Amazon Rekognition Content Moderation provides pre-trained APIs to analyze a wide range of inappropriate or offensive content, such as violence, nudity, hate symbols, and more. For a comprehensive list of Amazon Rekognition Content Moderation taxonomies, refer to Moderating content.
The following code demonstrates how to call the Amazon Rekognition DetectModerationLabel API to moderate images within an Lambda function using the Python Boto3 library. This function takes the image bytes returned from SageMaker and sends them to the Image Moderation API for moderation.
For additional examples of the Amazon Rekognition Image Moderation API, refer to our Content Moderation Image Lab.
Effective image moderation techniques for fine-tuning models
Fine-tuning is a common technique used to adapt pre-trained models to specific tasks. In the case of Stable Diffusion, fine-tuning can be used to generate images that incorporate specific objects, styles, and characters. Content moderation is critical when training a Stable Diffusion model to prevent the creation of inappropriate or offensive images. This involves carefully reviewing and filtering out any data that could lead to the generation of such images. By doing so, the model learns from a more diverse and representative range of data points, improving its accuracy and preventing the propagation of harmful content.
JumpStart makes fine-tuning the Stable Diffusion Model easy by providing the transfer learning scripts using the DreamBooth method. You just need to prepare your training data, define the hyperparameters, and start the training job. For more details, refer to Fine-tune text-to-image Stable Diffusion models with Amazon SageMaker JumpStart.
The dataset for fine-tuning needs to be a single Amazon Simple Storage Service (Amazon S3) directory including your images and instance configuration file dataset_info.json, as shown in the following code. The JSON file will associate the images with the instance prompt like this: {'instance_prompt':<<instance_prompt>>}.
Obviously, you can manually review and filter the images, but this can be time-consuming and even impractical when you do this at scale across many projects and teams. In such cases, you can automate a batch process to centrally check all the images against the Amazon Rekognition DetectModerationLabel API and automatically flag or remove images so they don’t contaminate your training.
Moderation latency and cost
In this solution, a sequential pattern is used to moderate text and images. A rule-based function and Amazon Comprehend are called for text moderation, and Amazon Rekognition is used for image moderation, both before and after invoking Stable Diffusion. Although this approach effectively moderates input prompts and output images, it may increase the overall cost and latency of the solution, which is something to consider.
Latency
Both Amazon Rekognition and Amazon Comprehend offer managed APIs that are highly available and have built-in scalability. Despite potential latency variations due to input size and network speed, the APIs used in this solution from both services offer near-real-time inference. Amazon Comprehend custom classifier endpoints can offer a speed of less than 200 milliseconds for input text sizes of less than 100 characters, while the Amazon Rekognition Image Moderation API serves approximately 500 milliseconds for average file sizes of less than 1 MB. (The results are based on the test conducted using the sample application, which qualifies as a near-real-time requirement.)
In total, the moderation API calls to Amazon Rekognition and Amazon Comprehend will add up to 700 milliseconds to the API call. It’s important to note that the Stable Diffusion request usually takes longer depending on the complexity of the prompts and the underlying infrastructure capability. In the test account, using an instance type of ml.p3.2xlarge, the average response time for the Stable Diffusion model via a SageMaker endpoint was around 15 seconds. Therefore, the latency introduced by moderation is approximately 5% of the overall response time, making it a minimal impact on the overall performance of the system.
Cost
The Amazon Rekognition Image Moderation API employs a pay-as-you-go model based on the number of requests. The cost varies depending on the AWS Region used and follows a tiered pricing structure. As the volume of requests increases, the cost per request decreases. For more information, refer to Amazon Rekognition pricing.
In this solution, we utilized an Amazon Comprehend custom classifier and deployed it as an Amazon Comprehend endpoint to facilitate real-time inference. This implementation incurs both a one-time training cost and ongoing inference costs. For detailed information, refer to Amazon Comprehend Pricing.
Jumpstart enables you to quickly launch and deploy the Stable Diffusion model as a single package. Running inference on the Stable Diffusion model will incur costs for the underlying Amazon Elastic Compute Cloud (Amazon EC2) instance as well as inbound and outbound data transfer. For detailed information, refer to Amazon SageMaker Pricing.
Summary
In this post, we provided an overview of a sample solution that showcases how to moderate Stable Diffusion input prompts and output images using Amazon Comprehend and Amazon Rekognition. Additionally, you can define negative prompts in Stable Diffusion to prevent generating unsafe content. By implementing multiple moderation layers, the risk of producing unsafe content can be greatly reduced, ensuring a safer and more dependable user experience.
Learn more about content moderation on AWS and our content moderation ML use cases, and take the first step towards streamlining your content moderation operations with AWS.
About the Authors
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing and advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing and advertising industries.
 Kevin Carlson is a Principal AI/ML Specialist with a focus on Computer Vision at AWS, where he leads Business Development and GTM for Amazon Rekognition. Prior to joining AWS, he led Digital Transformation globally at Fortune 500 Engineering company AECOM, with a focus on artificial intelligence and machine learning for generative design and infrastructure assessment. He is based in Chicago, where outside of work he enjoys time with his family, and is passionate about flying airplanes and coaching youth baseball.
Kevin Carlson is a Principal AI/ML Specialist with a focus on Computer Vision at AWS, where he leads Business Development and GTM for Amazon Rekognition. Prior to joining AWS, he led Digital Transformation globally at Fortune 500 Engineering company AECOM, with a focus on artificial intelligence and machine learning for generative design and infrastructure assessment. He is based in Chicago, where outside of work he enjoys time with his family, and is passionate about flying airplanes and coaching youth baseball.
 John Rouse is a Senior AI/ML Specialist at AWS, where he leads global business development for AI services focused on Content Moderation and Compliance use cases. Prior to joining AWS, he has held senior level business development and leadership roles with cutting edge technology companies. John is working to put machine learning in the hands of every developer with AWS AI/ML stack. Small ideas bring about small impact. John’s goal for customers is to empower them with big ideas and opportunities that open doors so they can make a major impact with their customer.
John Rouse is a Senior AI/ML Specialist at AWS, where he leads global business development for AI services focused on Content Moderation and Compliance use cases. Prior to joining AWS, he has held senior level business development and leadership roles with cutting edge technology companies. John is working to put machine learning in the hands of every developer with AWS AI/ML stack. Small ideas bring about small impact. John’s goal for customers is to empower them with big ideas and opportunities that open doors so they can make a major impact with their customer.
Long-form-video understanding and synthesis
Four CVPR papers from Prime Video examine a broad set of topics related to efficient model training for understanding and synthesizing long-form cinematic content.Read More
Use proprietary foundation models from Amazon SageMaker JumpStart in Amazon SageMaker Studio
Amazon SageMaker JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. With SageMaker JumpStart, you can discover and deploy publicly available and proprietary foundation models to dedicated Amazon SageMaker instances for your generative AI applications. SageMaker JumpStart allows you to deploy foundation models from a network isolated environment, and doesn’t share customer training and inference data with model providers.
In this post, we walk through how to get started with proprietary models from model providers such as AI21, Cohere, and LightOn from Amazon SageMaker Studio. SageMaker Studio is a notebook environment where SageMaker enterprise data scientist customers evaluate and build models for their next generative AI applications.
Foundation models in SageMaker
Foundation models are large-scale ML models that contain billions of parameters and are pre-trained on terabytes of text and image data so you can perform a wide range of tasks, such as article summarization and text, image, or video generation. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case.
SageMaker JumpStart provides two types of foundation models:
- Proprietary models – These models are from providers such as AI21 with Jurassic-2 models, Cohere with Cohere Command, and LightOn with Mini trained on proprietary algorithms and data. You can’t view model artifacts such as weight and scripts, but you can still deploy to SageMaker instances for inferencing.
- Publicly available models – These are from popular model hubs such as Hugging Face with Stable Diffusion, Falcon, and FLAN trained on publicly available algorithms and data. For these models, users have access to model artifacts and are able to fine-tune with their own data prior to deployment for inferencing.
Discover models
You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in the SageMaker Studio UI.
SageMaker Studio is a web-based integrated development environment (IDE) for ML that lets you build, train, debug, deploy, and monitor your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
Once you’re on the SageMaker Studio UI, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions.
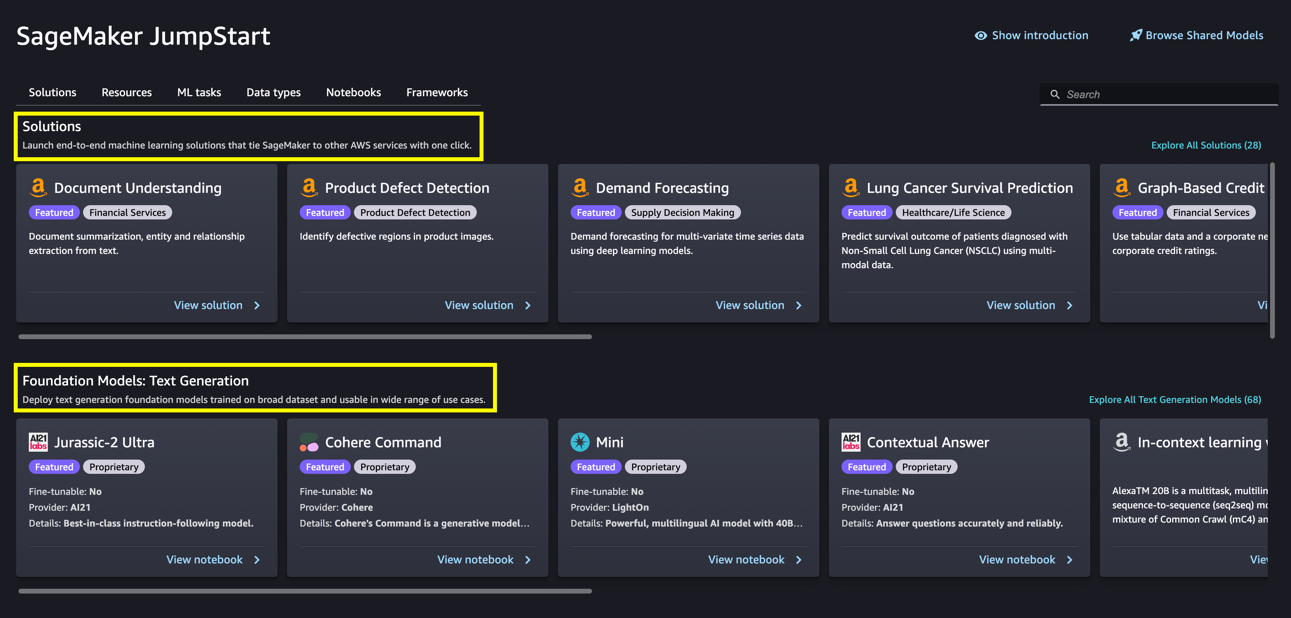
From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources. The following screenshot shows an example of the landing page with solutions and foundation models listed.
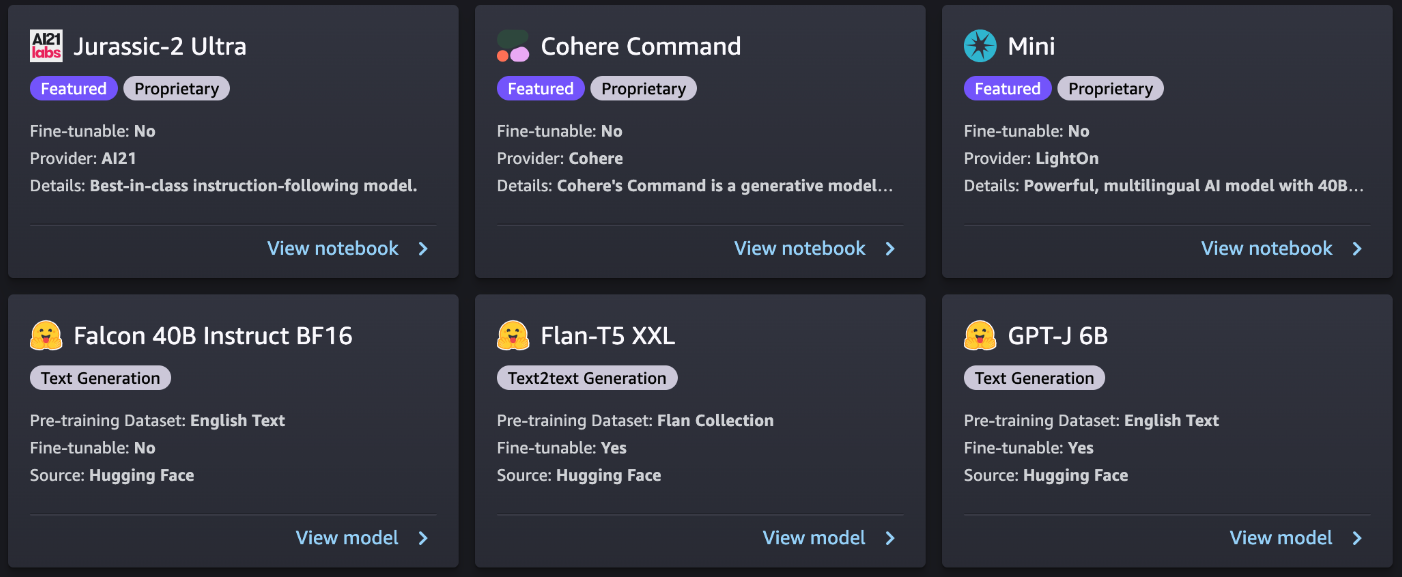
Each model has a model card, as shown in the following screenshot, which contains the model name, if it is fine-tunable or not, the provider name, and a short description about the model. You can also open the model card to learn more about the model and start training or deploying.
Subscribe in AWS Marketplace
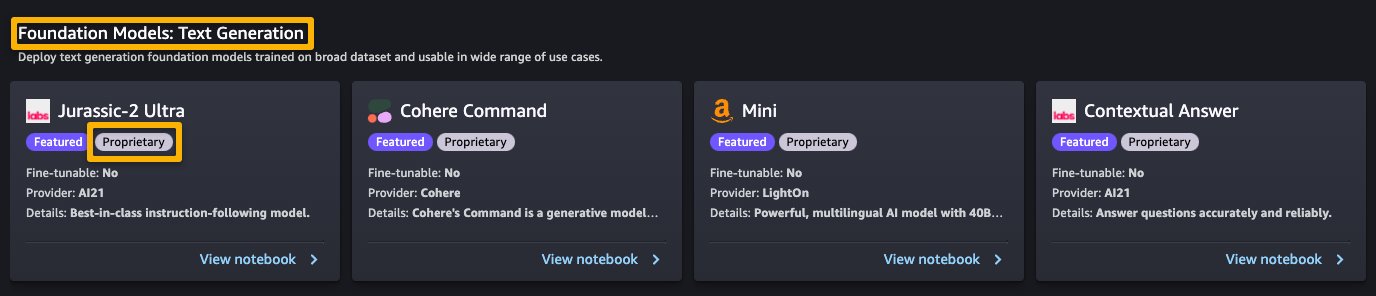
Proprietary models in SageMaker JumpStart are published by model providers such as AI21, Cohere, and LightOn. You can identify proprietary models by the “Proprietary” tag on model cards, as shown in the following screenshot.
You can choose View notebook on the model card to open the notebook in read-only mode, as shown in the following screenshot. You can read the notebook for important information regarding prerequisites and other usage instructions.
After importing the notebook, you need to select the appropriate notebook environment (image, kernel, instance type, and so on) before running codes. You should also follow the subscription and usage instructions per the selected notebook.
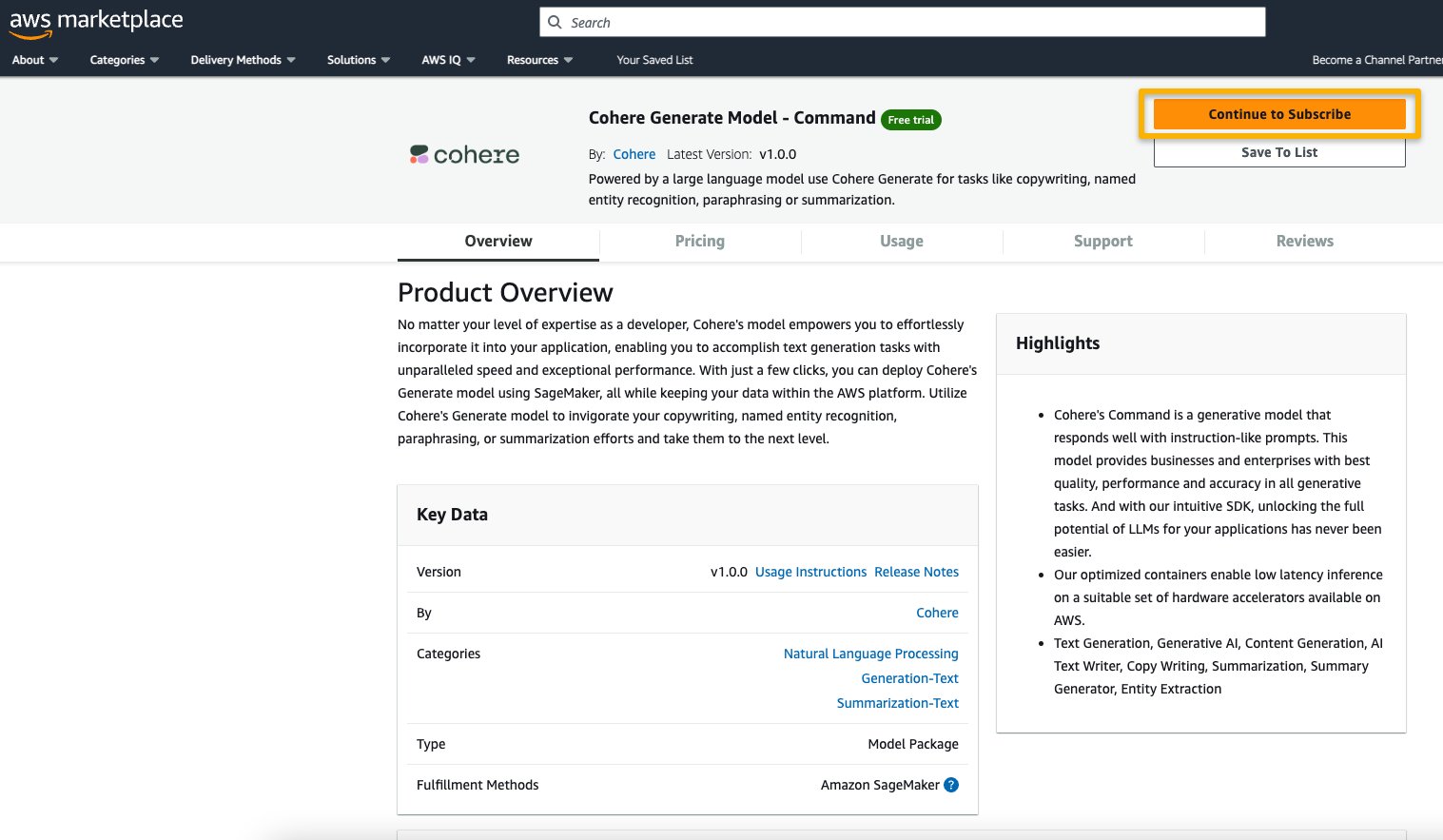
Before using a proprietary model, you need to first subscribe to the model from AWS Marketplace:
- Open the model listing page in AWS Marketplace.
The URL is provided in the Important section of the notebook, or you can access it from the SageMaker JumpStart service page. The listing page shows the overview, pricing, usage, and support information about the model.
- On the AWS Marketplace listing, choose Continue to subscribe.
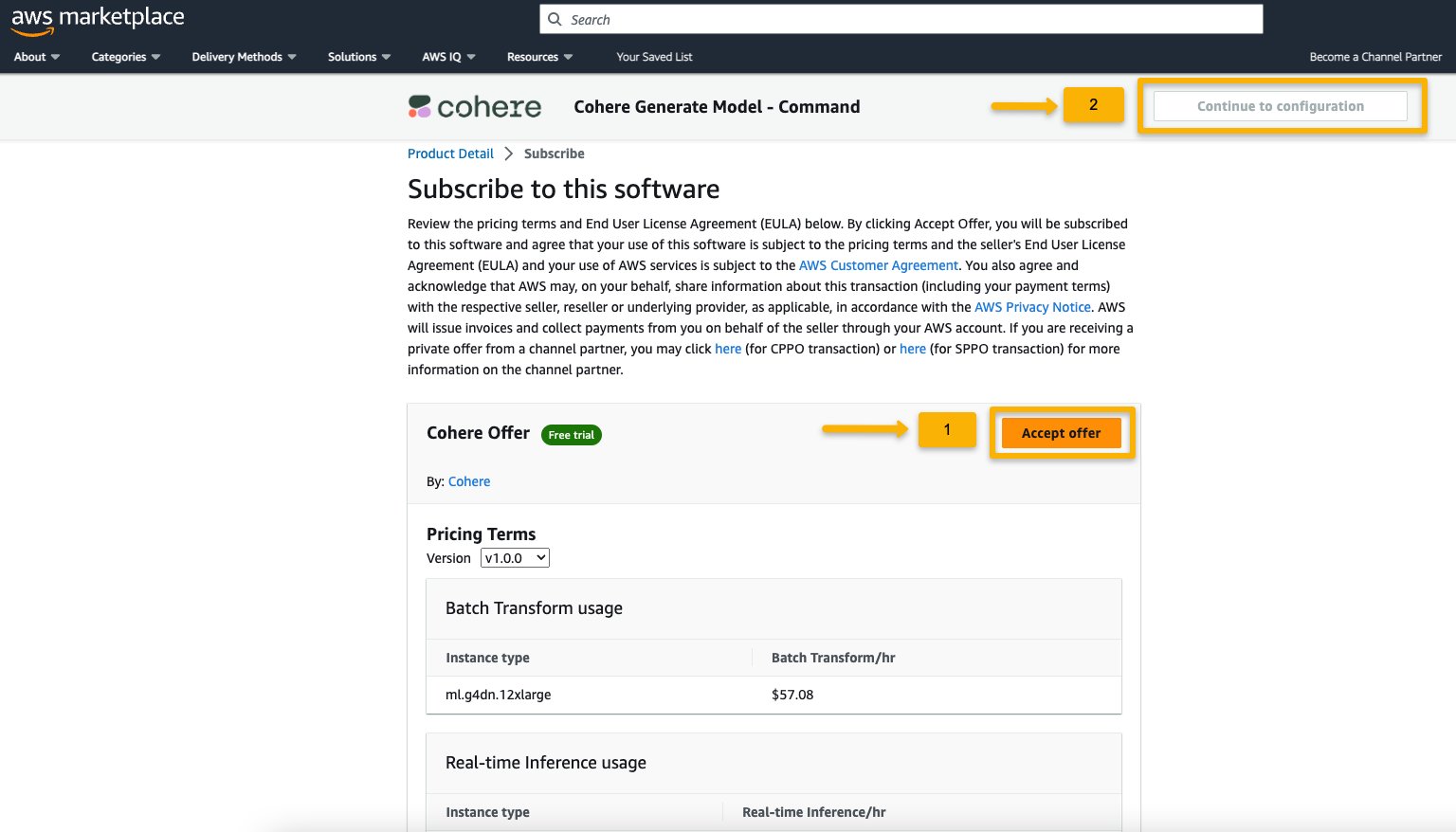
If you don’t have the necessary permissions to view or subscribe to the model, reach out to your IT admin or procurement point of contact to subscribe to the model for you. Many enterprises may limit AWS Marketplace permissions to control the actions that someone with those permissions can take in the AWS Marketplace Management Portal.
- On the Subscribe to this software page, review the details and choose Accept offer if you and your organization agree with the EULA, pricing, and support terms.
If you have any questions or a request for volume discount, reach out to the model provider directly via the support email provided on the detail page or reach out to your AWS account team.
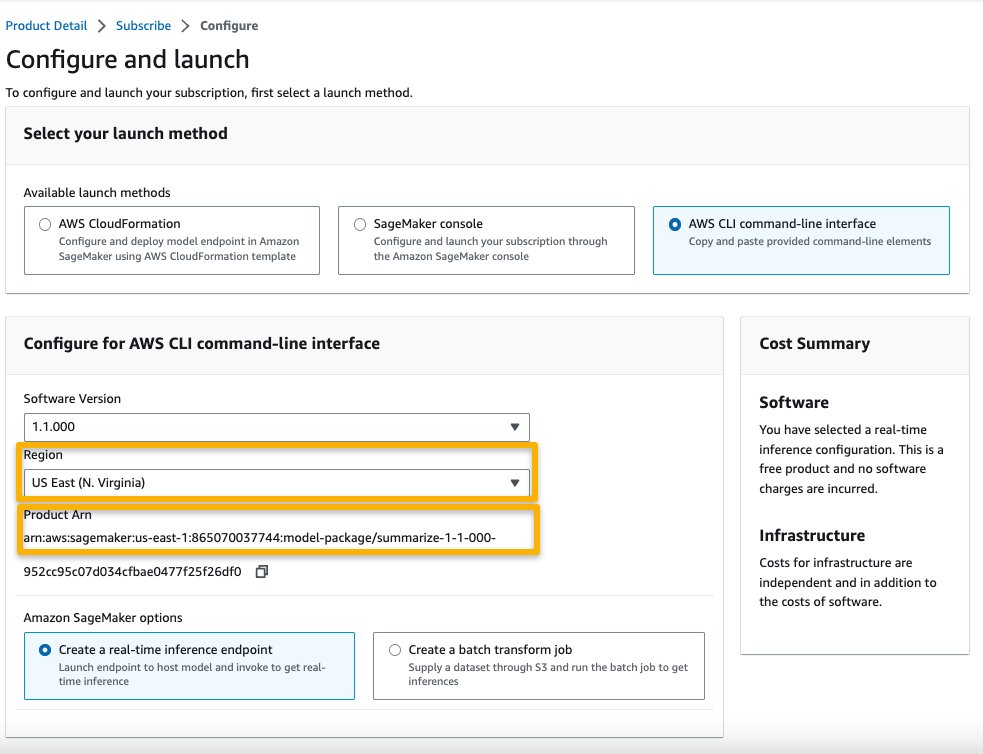
- Choose Continue to configuration and choose a Region.
You will see a product ARN displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
- Copy the ARN corresponding to your Region and specify the same in the notebook’s cell instruction.
Sample inferencing with sample prompts
Let’s look at some of the sample foundation models from A21 Labs, Cohere, and LightOn that are discoverable from SageMaker JumpStart in SageMaker Studio. All of them have same the instructions to subscribe from AWS Marketplace and import and configure the notebook.
AI21 Summarize
The Summarize model by A121 Labs condenses lengthy texts into short, easy-to-read bites that remain factually consistent with the source. The model is trained to generate summaries that capture key ideas based on a body of text. It doesn’t require any prompting. You simply input the text that needs to be summarized. Your source text can contain up to 50,000 characters, translating to roughly 10,000 words, or an impressive 40 pages.
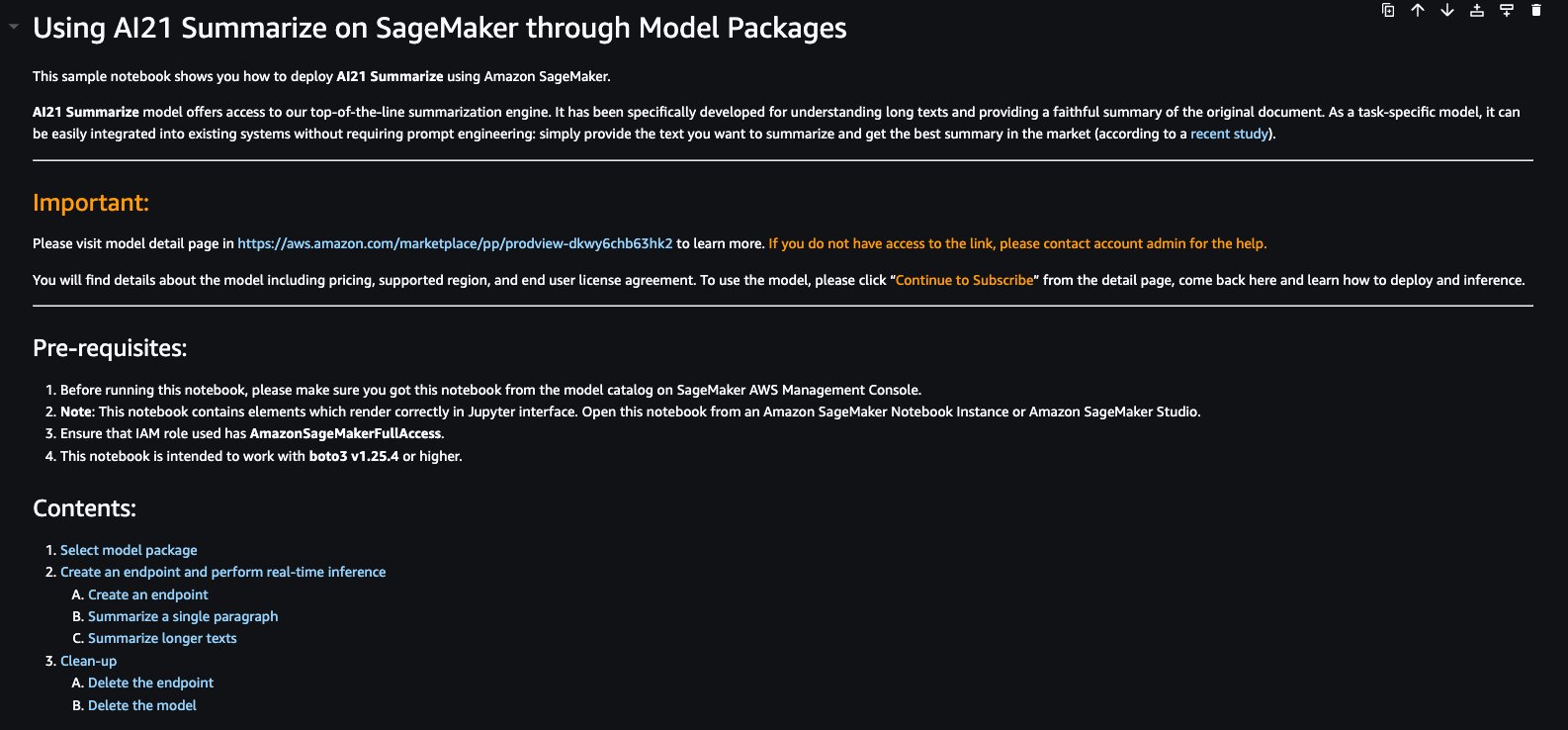
The sample notebook for AI21 Summarize model provides important prerequisites that needs to be followed. For example the model is subscribed from AWS Marketplace , have appropriate IAM roles permissions, and required boto3 version etc. It walks you through how to select the model package, create endpoints for real-time inference, and then clean up.
The selected model package contains the mapping of ARNs to Regions. This is the information you captured after choosing Continue to configuration on the AWS Marketplace subscription page (in the section Evaluate and subscribe in Marketplace) and then selecting a Region for which you will see the corresponding product ARN.
The notebook may already have ARN prepopulated.

You then import some libraries required to run this notebook and install wikipedia, which is a Python library that makes it easy to access and parse data from Wikipedia. The notebook uses this later to showcase how to summarize a long text from Wikipedia.
The notebook also proceeds to install the ai21 Python SDK, which is a wrapper around SageMaker APIs such as deploy and invoke endpoint.
The next few cells of the notebook walk through the following steps:
- Select the Region and fetch the model package ARN from model package map
- Create your inference endpoint by selecting an instance type (depending on your use case and supported instance for the model; see Task-specific models for more details) to run the model on
- Create a deployable model from the model package
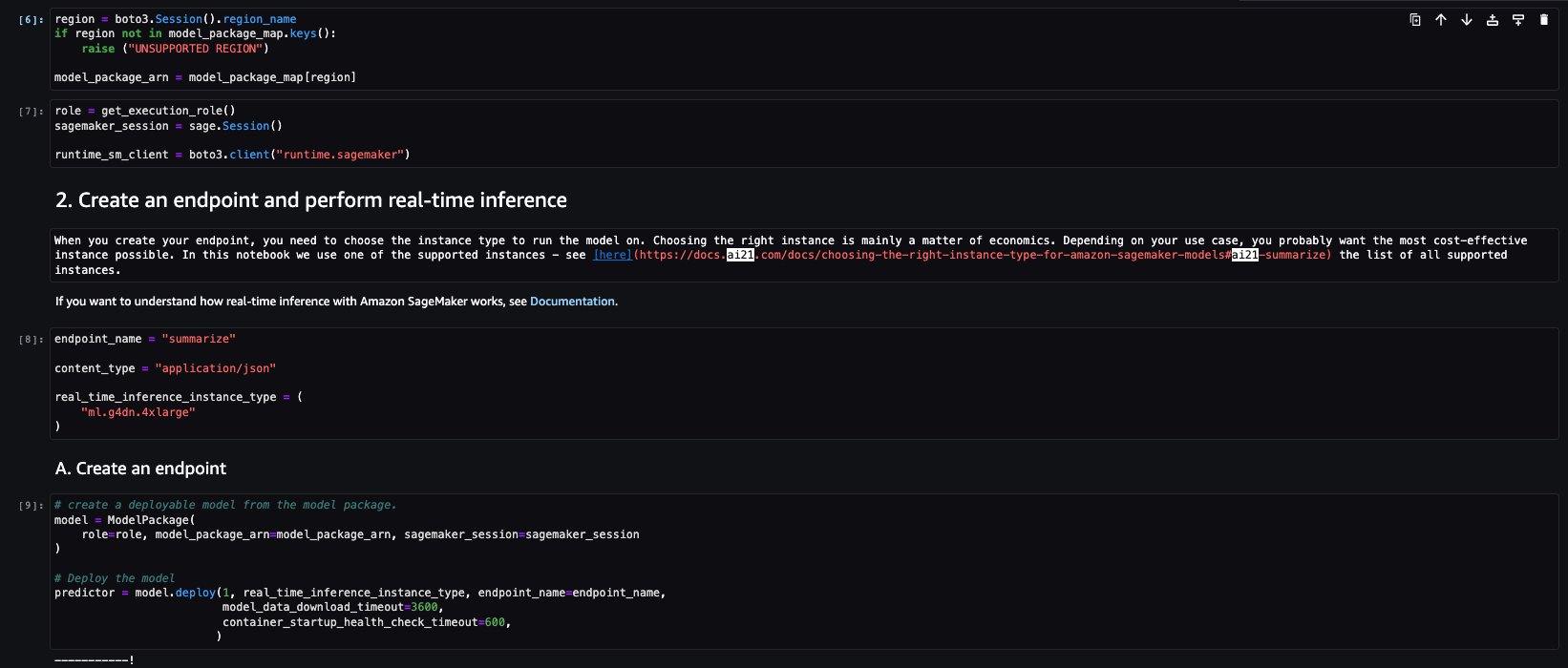
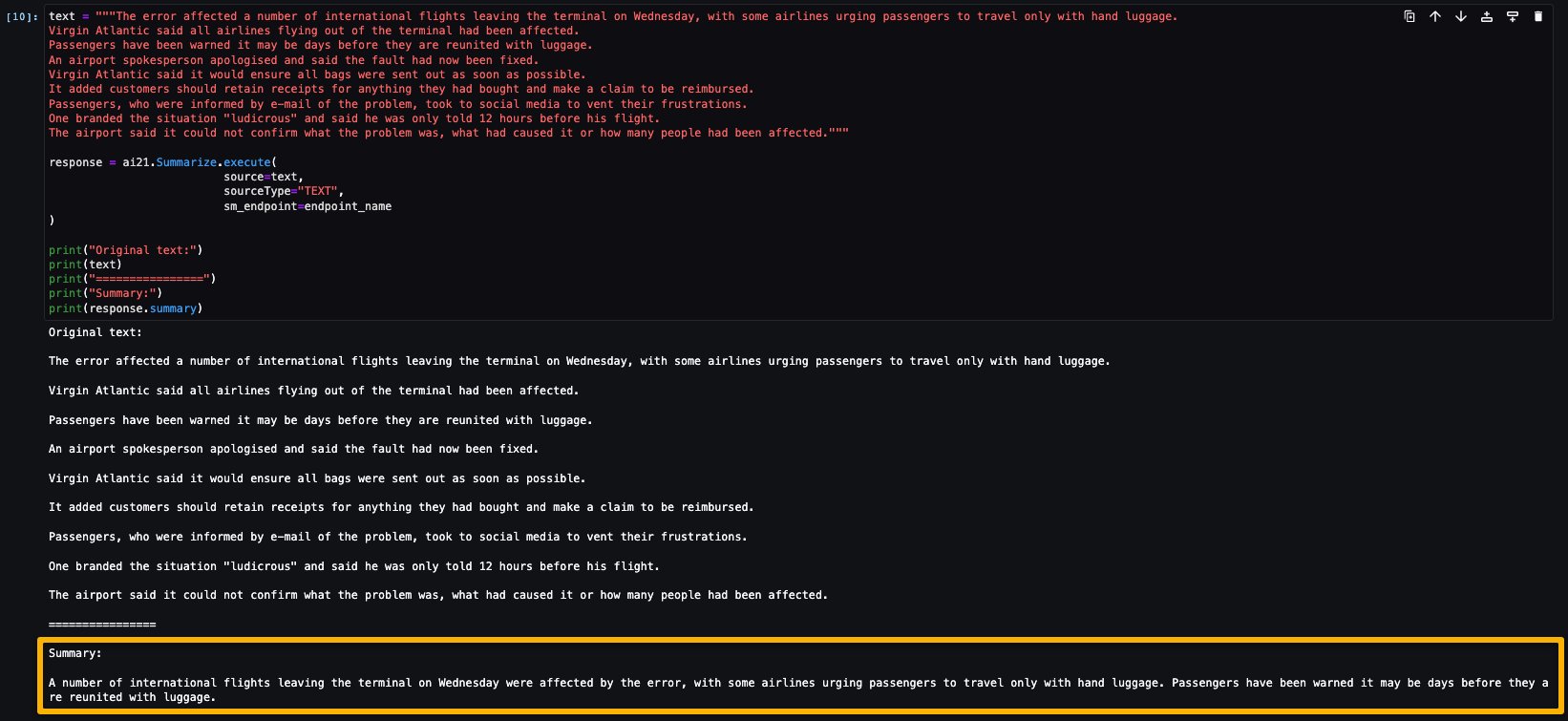
Let’s run the inference to generate a summary of a single paragraph taken from a news article. As you can see in the output, the summarized text is presented as an output by the model.
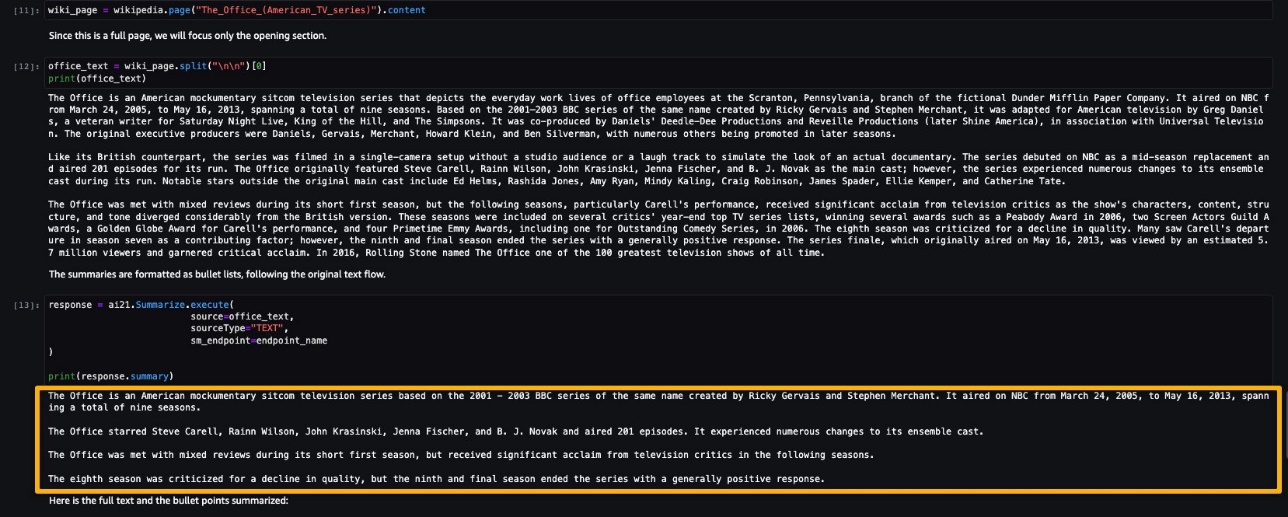
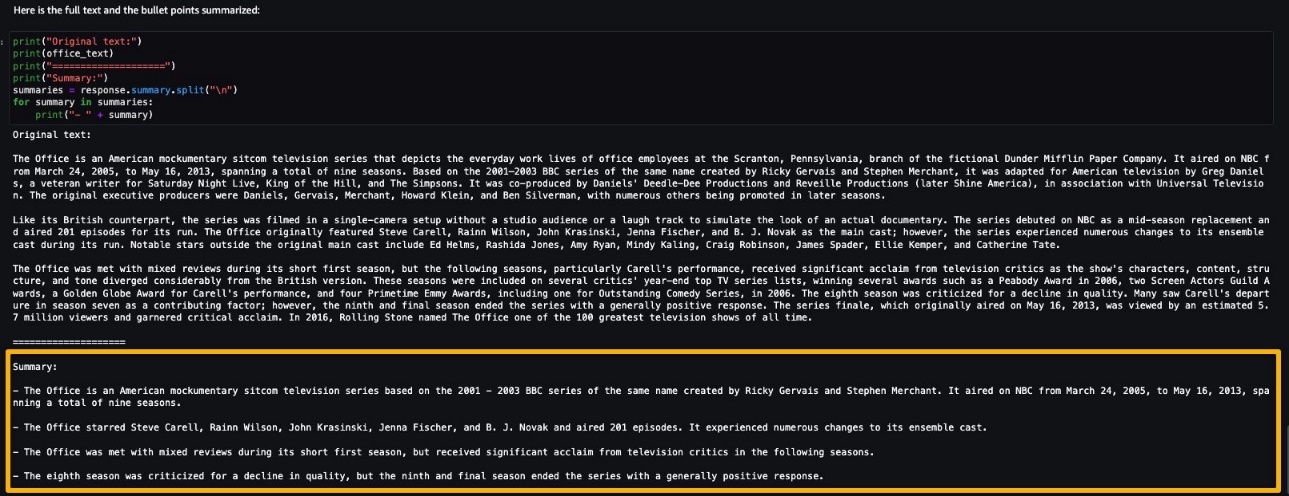
AI21 Summarize can handle inputs up to 50,000 characters. This translates into roughly 10,000 words, or 40 pages. As a demonstration of the model’s behavior, we load a page from Wikipedia.
Now that you have performed a real-time inference for testing, you may not need the endpoint anymore. You can delete the endpoint to avoid being charged.
Cohere Command
Cohere Command is a generative model that responds well with instruction-like prompts. This model provides businesses and enterprises with best quality, performance, and accuracy in all generative tasks. You can use Cohere’s Command model to invigorate your copywriting, named entity recognition, paraphrasing, or summarization efforts and take them to the next level.
The sample notebook for Cohere Command model provides important prerequisites that needs to be followed. For example the model is subscribed from AWS Marketplace, have appropriate IAM roles permissions, and required boto3 version etc. It walks you through how to select the model package, create endpoints for real-time inference, and then clean up.
Some of the tasks are similar to those covered in the previous notebook example, like installing Boto3, installing cohere-sagemaker (the package provides functionality developed to simplify interfacing with the Cohere model), and getting the session and Region.
Let’s explore creating the endpoint. You provide the model package ARN, endpoint name, instance type to be used, and number of instances. Once created, the endpoint appears in your endpoint section of SageMaker.

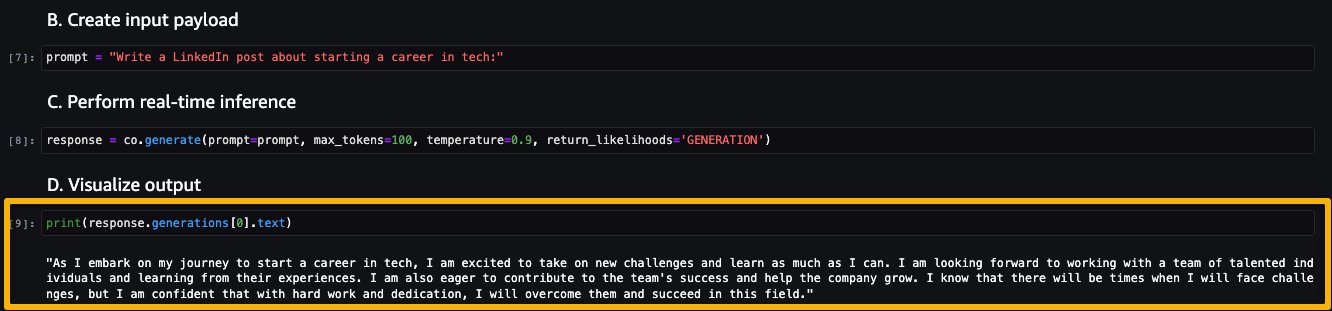
Now let’s run the inference to see some of the outputs from the Command model.
The following screenshot shows a sample example of generating a job post and its output. As you can see, the model generated a post from the given prompt.
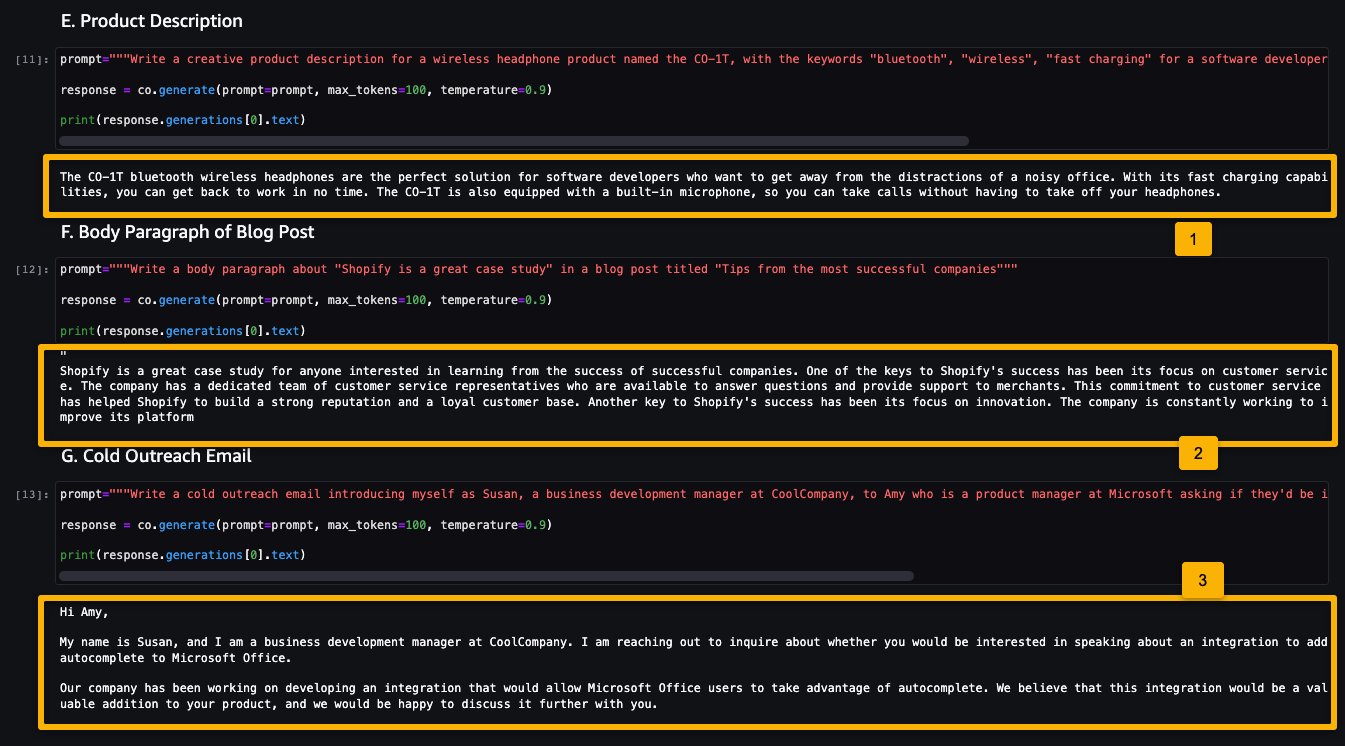
Now let’s look at the following examples:
- Generate a product description
- Generate a body paragraph of a blog post
- Generate an outreach email
As you can see, the Cohere Command model generated text for various generative tasks.
Now that you have performed real-time inference for testing, you may not need the endpoint anymore. You can delete the endpoint to avoid being charged.
LightOn Mini-instruct
Mini-instruct, an AI model with 40 billion billion parameters created by LightOn, is a powerful multilingual AI system that has been trained using high-quality data from numerous sources. It is built to understand natural language and react to commands that are specific to your needs. It performs admirably in consumer products like voice assistants, chatbots, and smart appliances. It also has a wide range of business applications, including agent assistance and natural language production for automated customer care.
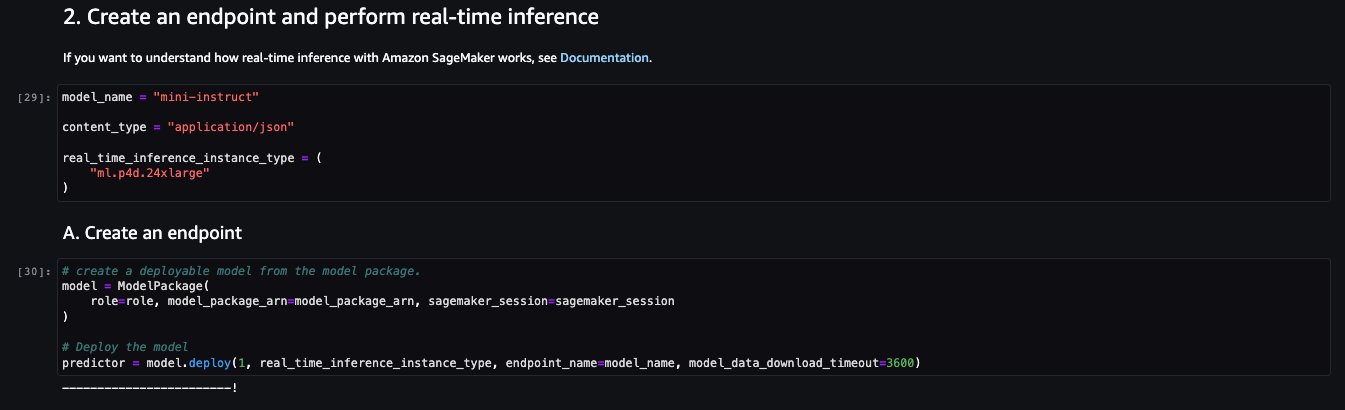
The sample notebook for LightOn Mini-instruct model provides important prerequisites that needs to be followed. For example the model is subscribed from AWS Marketplace, have appropriate IAM roles permissions, and required boto3 version etc. It walks you through how to select the model package, create endpoints for real-time inference, and then clean up.
Some of the tasks are similar to those covered in the previous notebook example, like installing Boto3 and getting the session Region.
Let’s look at creating the endpoint. First, provide the model package ARN, endpoint name, instance type to be used, and number of instances. Once created, the endpoint appears in your endpoint section of SageMaker.
Now let’s try inferencing the model by asking it to generate a list of ideas for articles for a topic, in this case watercolor.
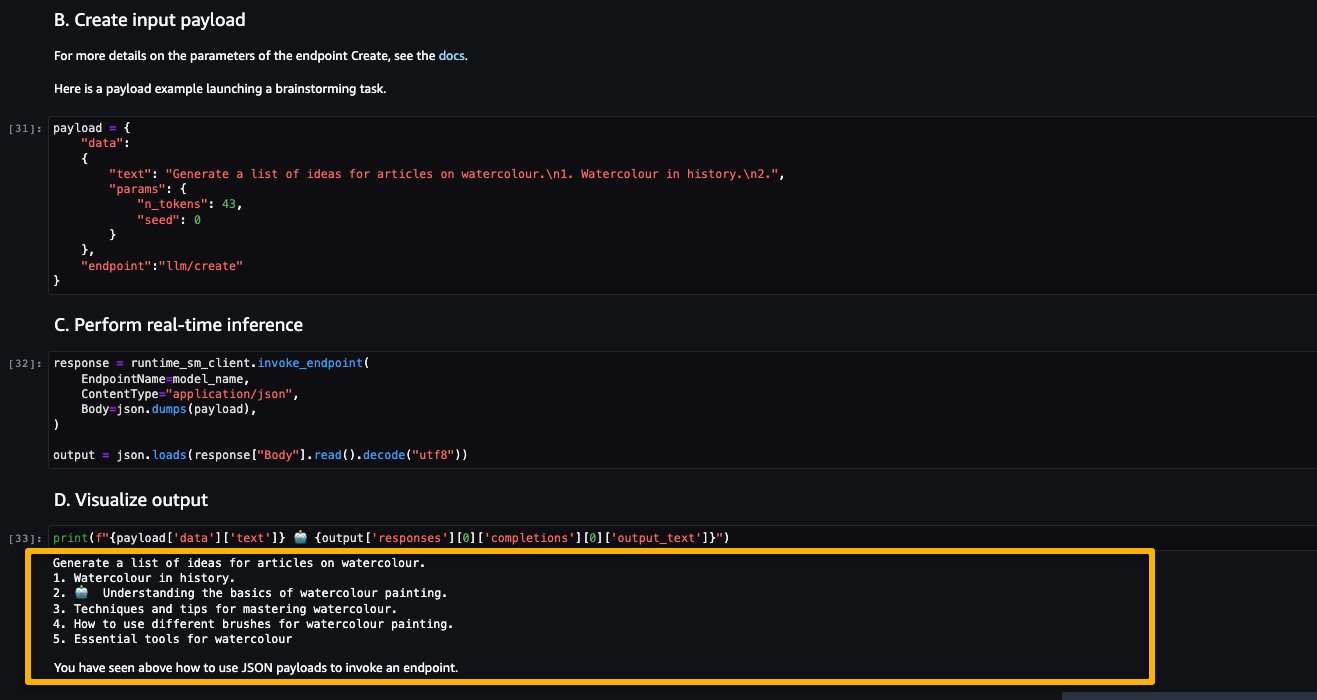
As you can see, the LightOn Mini-instruct model was able to provide generated text based on the given prompt.
Clean up
After you have tested the models and created endpoints above for the example proprietary Foundation Models, make sure you delete the SageMaker inference endpoints and delete the models to avoid incurring charges.
Conclusion
In this post, we showed you how to get started with proprietary models from model providers such as AI21, Cohere, and LightOn in SageMaker Studio. Customers can discover and use proprietary Foundation Models in SageMaker JumpStart from Studio, the SageMaker SDK, and the SageMaker Console. With this, they have access to large-scale ML models that contain billions of parameters and are pretrained on terabytes of text and image data so customers can perform a wide range of tasks such as article summarization and text, image, or video generation. Because foundation models are pretrained, they can also help lower training and infrastructure costs and enable customization for your use case.
Resources
- SageMaker JumpStart documentation
- SageMaker JumpStart Foundation Models documentation
- SageMaker JumpStart product detail page
- SageMaker JumpStart model catalog
About the authors
 June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications.
June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications.
 Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spends lot of her free time.
Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spends lot of her free time.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with experience in Software Engineering , Enterprise Architecture and AI/ML. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with experience in Software Engineering , Enterprise Architecture and AI/ML. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
How Earth.com and Provectus implemented their MLOps Infrastructure with Amazon SageMaker
This blog post is co-written with Marat Adayev and Dmitrii Evstiukhin from Provectus.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. Machine Learning Operations (MLOps) provides the technical solution to this issue, assisting organizations in managing, monitoring, deploying, and governing their models on a centralized platform.
At-scale, real-time image recognition is a complex technical problem that also requires the implementation of MLOps. By enabling effective management of the ML lifecycle, MLOps can help account for various alterations in data, models, and concepts that the development of real-time image recognition applications is associated with.
One such application is EarthSnap, an AI-powered image recognition application that enables users to identify all types of plants and animals, using the camera on their smartphone. EarthSnap was developed by Earth.com, a leading online platform for enthusiasts who are passionate about the environment, nature, and science.
Earth.com’s leadership team recognized the vast potential of EarthSnap and set out to create an application that utilizes the latest deep learning (DL) architectures for computer vision (CV). However, they faced challenges in managing and scaling their ML system, which consisted of various siloed ML and infrastructure components that had to be maintained manually. They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market. That is where Provectus, an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
This post explains how Provectus and Earth.com were able to enhance the AI-powered image recognition capabilities of EarthSnap, reduce engineering heavy lifting, and minimize administrative costs by implementing end-to-end ML pipelines, delivered as part of a managed MLOps platform and managed AI services.
Challenges faced in the initial approach
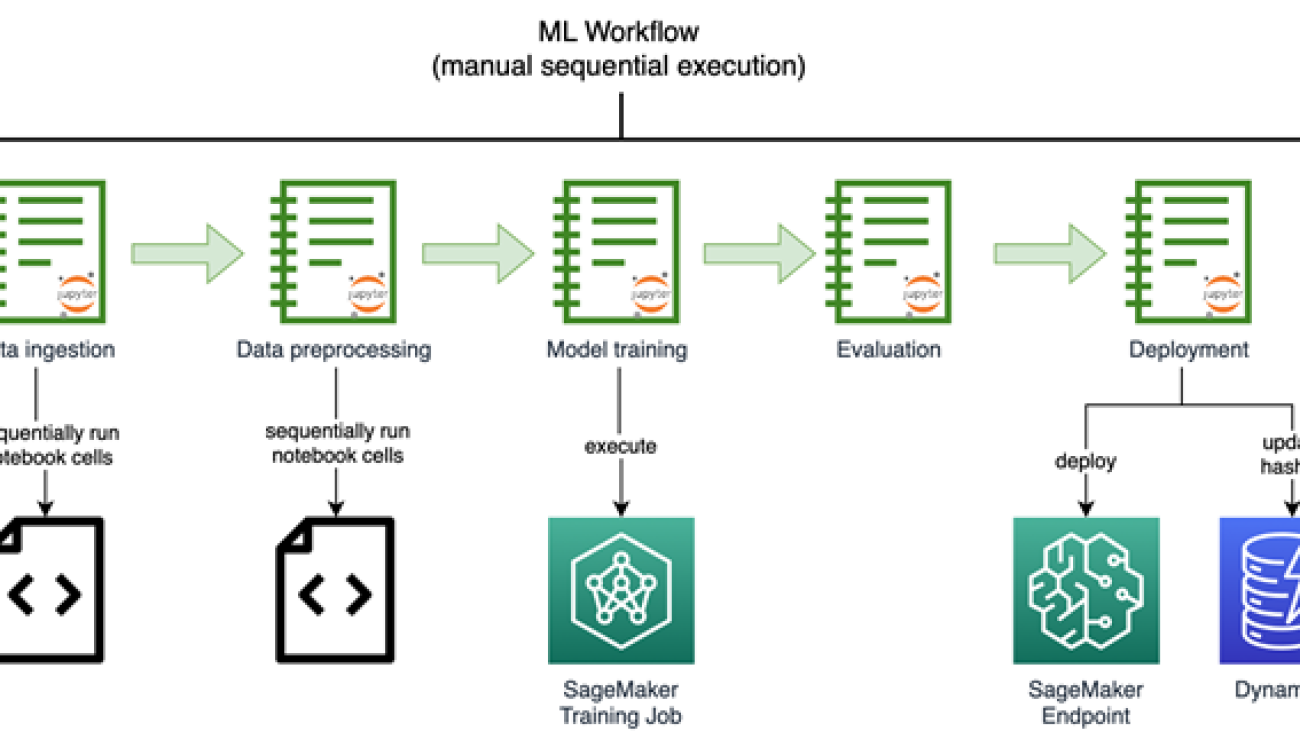
The executive team at Earth.com was eager to accelerate the launch of EarthSnap. They swiftly began to work on AI/ML capabilities by building image recognition models using Amazon SageMaker. The following diagram shows the initial image recognition ML workflow, run manually and sequentially.
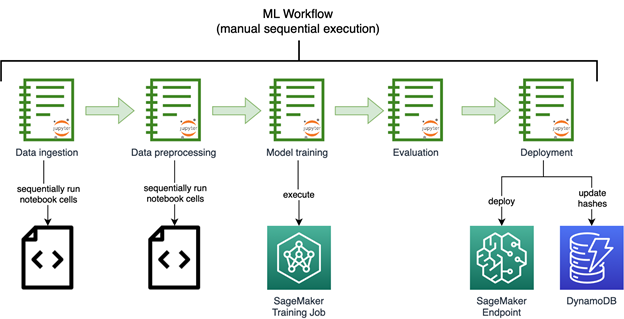
The models developed by Earth.com lived across various notebooks. They required the manual sequential execution run of a series of complex notebooks to process the data and retrain the model. Endpoints had to be deployed manually as well.
Earth.com didn’t have an in-house ML engineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system.
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers.
The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
First iteration of the solution
Provectus served as a valuable collaborator for Earth.com, playing a crucial role in augmenting the AI-driven image recognition features of EarthSnap. The application’s workflows were automated by implementing end-to-end ML pipelines, which were delivered as part of Provectus’s managed MLOps platform and supported through managed AI services.
A series of project discovery sessions were initiated by Provectus to examine EarthSnap’s existing codebase and inventory the notebook scripts, with the goal of reproducing the existing model results. After the model results had been restored, the scattered components of the ML workflow were merged into an automated ML pipeline using Amazon SageMaker Pipelines, a purpose-built CI/CD service for ML.
The final pipeline includes the following components:
- Data QA & versioning – This step run as a SageMaker Processing job, ingests the source data from Amazon Simple Storage Service (Amazon S3) and prepares the metadata for the next step, containing only valid images (URI and label) that are filtered according to internal rules. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
- Data preprocessing – This includes multiple steps wrapped as SageMaker processing jobs, and run sequentially. The steps preprocess the images, convert them to RecordIO format, split the images into datasets (full, train, test and validation), and prepare the images to be consumed by SageMaker training jobs.
- Hyperparameter tuning – A SageMaker hyperparameter tuning job takes as input a subset of the training and validation set and runs a series of small training jobs under the hood to determine the best parameters for the full training job.
- Full training – A step SageMaker training job launches the training job on the entire data, given the best parameters from the hyperparameter tuning step.
- Model evaluation – A step SageMaker processing job is run after the final model has been trained. This step produces an expanded report containing the model’s metrics.
- Model creation – The SageMaker ModelCreate step wraps the model into the SageMaker model package and pushes it to the SageMaker model registry.
All steps are run in an automated manner after the pipeline has been run. The pipeline can be run via any of following methods:
- Automatically using AWS CodeBuild, after the new changes are pushed to a primary branch and a new version of the pipeline is upserted (CI)
- Automatically using Amazon API Gateway, which can be triggered with a certain API call
- Manually in Amazon SageMaker Studio
After the pipeline run (launched using one of preceding methods), a trained model is produced that is ready to be deployed as a SageMaker endpoint. This means that the model must first be approved by the PM or engineer in the model registry, then the model is automatically rolled out to the stage environment using Amazon EventBridge and tested internally. After the model is confirmed to be working as expected, it’s deployed to the production environment (CD).
The Provectus solution for EarthSnap can be summarized in the following steps:
- Start with fully automated, end-to-end ML pipelines to make it easier for Earth.com to release new models
- Build on top of the pipelines to deliver a robust ML infrastructure for the MLOps platform, featuring all components for streamlining AI/ML
- Support the solution by providing managed AI services (including ML infrastructure provisioning, maintenance, and cost monitoring and optimization)
- Bring EarthSnap to its desired state (mobile application and backend) through a series of engagements, including AI/ML work, data and database operations, and DevOps
After the foundational infrastructure and processes were established, the model was trained and retrained on a larger dataset. At this point, however, the team encountered an additional issue when attempting to expand the model with even larger datasets. We needed to find a way to restructure the solution architecture, making it more sophisticated and capable of scaling effectively. The following diagram shows the EarthSnap AI/ML architecture.
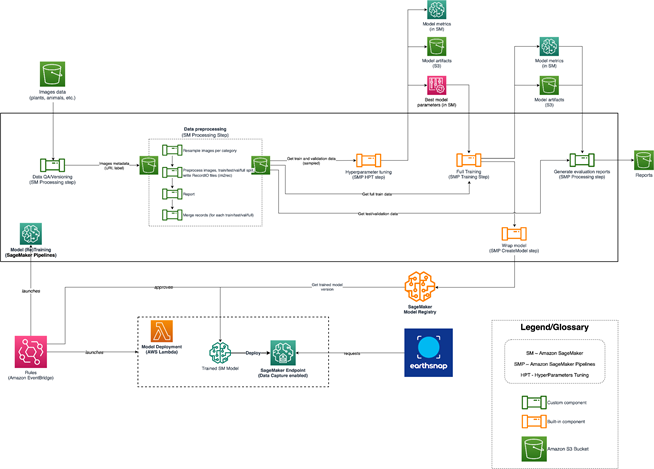
The AI/ML architecture for EarthSnap is designed around a series of AWS services:
- Sagemaker Pipeline runs using one of the methods mentioned above (CodeBuild, API, manual) that trains the model and produces artifacts and metrics. As a result, the new version of the model is pushed to the Sagemaker Model registry
- Then the model is reviewed by an internal team (PM/engineer) in model registry and approved/rejected based on metrics provided
- Once the model is approved, the model version is automatically deployed to the stage environment using the Amazon EventBridge that tracks the model status change
- The model is deployed to the production environment if the model passes all tests in the stage environment
Final solution
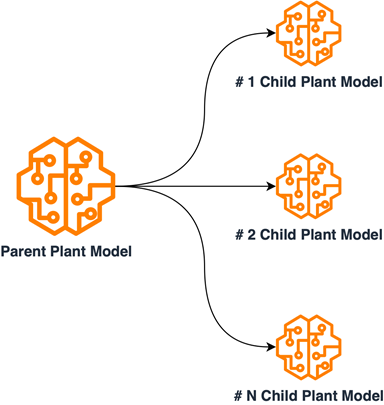
To accommodate all necessary sets of labels, the solution for EarthSnap’s model required substantial modifications, because incorporating all species within a single model proved to be both costly and inefficient. The plant category was selected first for implementation.
A thorough examination of plant data was conducted, to organize it into subsets based on shared internal characteristics. The solution for the plant model was redesigned by implementing a multi-model parent/child architecture. This was achieved by training child models on grouped subsets of plant data and training the parent model on a set of data samples from each subcategory. The Child models were employed for accurate classification within the internally grouped species, while the parent model was utilized to categorize input plant images into subgroups. This design necessitated distinct training processes for each model, leading to the creation of separate ML pipelines. With this new design, along with the previously established ML/MLOps foundation, the EarthSnap application was able to encompass all essential plant species, resulting in improved efficiency concerning model maintenance and retraining. The following diagram illustrates the logical scheme of parent/child model relations.
Upon completing the redesign, the ultimate challenge was to guarantee that the AI solution powering EarthSnap could manage the substantial load generated by a broad user base. Fortunately, the managed AI onboarding process encompasses all essential automation, monitoring, and procedures for transitioning the solution into a production-ready state, eliminating the need for any further capital investment.
Results
Despite the pressing requirement to develop and implement the AI-driven image recognition features of EarthSnap within a few months, Provectus managed to meet all project requirements within the designated time frame. In just 3 months, Provectus modernized and productionized the ML solution for EarthSnap, ensuring that their mobile application was ready for public release.
The modernized infrastructure for ML and MLOps allowed Earth.com to reduce engineering heavy lifting and minimize the administrative costs associated with maintenance and support of EarthSnap. By streamlining processes and implementing best practices for CI/CD and DevOps, Provectus ensured that EarthSnap could achieve better performance while improving its adaptability, resilience, and security. With a focus on innovation and efficiency, we enabled EarthSnap to function flawlessly, while providing a seamless and user-friendly experience for all users.
As part of its managed AI services, Provectus was able to reduce the infrastructure management overhead, establish well-defined SLAs and processes, ensure 24/7 coverage and support, and increase overall infrastructure stability, including production workloads and critical releases. We initiated a series of enhancements to deliver managed MLOps platform and augment ML engineering. Specifically, it now takes Earth.com minutes, instead of several days, to release new ML models for their AI-powered image recognition application.
With assistance from Provectus, Earth.com was able to release its EarthSnap application at the Apple Store and Playstore ahead of schedule. The early release signified the importance of Provectus’ comprehensive work for the client.
”I’m incredibly excited to work with Provectus. Words can’t describe how great I feel about handing over control of the technical side of business to Provectus. It is a huge relief knowing that I don’t have to worry about anything other than developing the business side.”
– Eric Ralls, Founder and CEO of EarthSnap.
The next steps of our cooperation will include: adding advanced monitoring components to pipelines, enhancing model retraining, and introducing a human-in-the-loop step.
Conclusion
The Provectus team hopes that Earth.com will continue to modernize EarthSnap with us. We look forward to powering the company’s future expansion, further popularizing natural phenomena, and doing our part to protect our planet.
To learn more about the Provectus ML infrastructure and MLOps, visit Machine Learning Infrastructure and watch the webinar for more practical advice. You can also learn more about Provectus managed AI services at the Managed AI Services.
If you’re interested in building a robust infrastructure for ML and MLOps in your organization, apply for the ML Acceleration Program to get started.
Provectus helps companies in healthcare and life sciences, retail and CPG, media and entertainment, and manufacturing, achieve their objectives through AI.
Provectus is an AWS Machine Learning Competency Partner and AI-first transformation consultancy and solutions provider helping design, architect, migrate, or build cloud-native applications on AWS.
Contact Provectus | Partner Overview
About the Authors
Marat Adayev is an ML Solutions Architect at Provectus
Dmitrii Evstiukhin is the Director of Managed Services at Provectus
James Burdon is a Senior Startups Solutions Architect at AWS
Amazon and Max Planck Society announce sustainability awards
Two Max Planck Society researchers receive funding for projects to develop new ways to advance a more circular economy.Read More
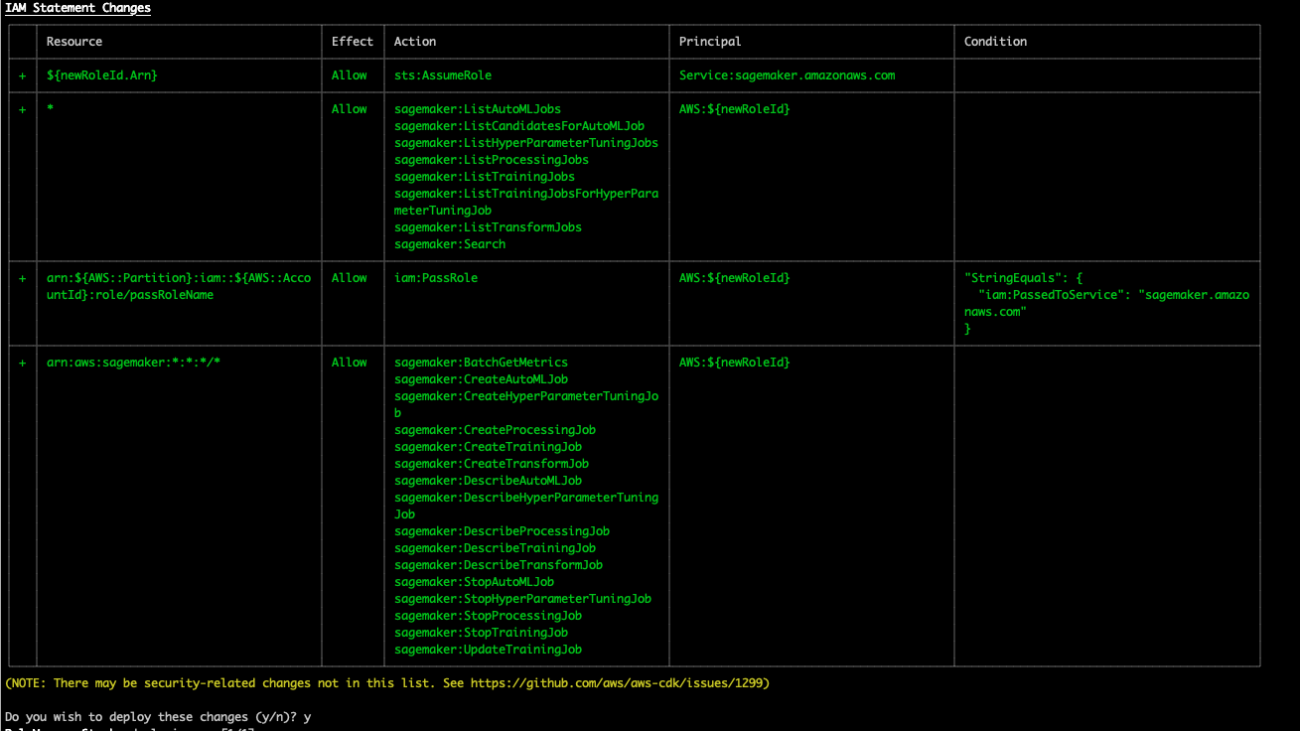
Define customized permissions in minutes with Amazon SageMaker Role Manager via the AWS CDK
Machine learning (ML) administrators play a critical role in maintaining the security and integrity of ML workloads. Their primary focus is to ensure that users operate with the utmost security, adhering to the principle of least privilege. However, accommodating the diverse needs of different user personas and creating appropriate permission policies can sometimes impede agility. To address this challenge, AWS introduced Amazon SageMaker Role Manager in December 2022. SageMaker Role Manager is a powerful tool can you can use to swiftly develop persona-based roles, which can be easily customized to meet specific requirements.
With SageMaker Role Manager, administrators can efficiently define persona-based roles tailored to distinct user groups. This approach ensures that individuals have access only to the resources and actions essential for their tasks, reducing the risk of unauthorized actions or breaches. SageMaker Role Manager also allows for fine-grained customization. ML administrators can tailor the roles to meet specific requirements by modifying the permissions associated with each persona. This flexibility ensures that the permissions align precisely with the tasks and responsibilities of individual users, providing a robust security framework while accommodating unique use cases.
SageMaker Role Manager is currently available on the Amazon SageMaker console of all commercial Regions. Today, we are launching the ability to define customized permissions in minutes with SageMaker Role Manager via the AWS Cloud Development Kit (AWS CDK). This addresses a critical obstacle to wider adoption because ML administrators can now automate their tasks programmatically. With the power of the AWS CDK, ML administrators can streamline workflows, reduce manual efforts, and ensure consistency in managing permissions for their ML infrastructure.
Solution overview
With the release of the SageMaker Role Manager CDK, we are launching two new infrastructure as code (IaC) capabilities:
- Create fine-grained permissions for ML personas
- Create fine-grained permissions for automated jobs through Amazon SageMaker Pipelines, AWS Lambda, and other AWS services
You can create fine-grained AWS Identity and Access Management (IAM) roles for ML personas such as data scientist, ML engineer, or data engineer. SageMaker Role Manager offers predefined personas and ML activities combined to streamline your permission generation process, allowing your ML practitioners to perform their responsibilities with the least privilege permissions. For secure access to your ML resources, SageMaker Role Manager allows you to specify networking and encryption permissions for Amazon Virtual Private Cloud (Amazon VPC) resources and AWS Key Management Service (AWS KMS) encryption keys. Furthermore, you can customize permissions by attaching your own customer managed policies.
The SageMaker Role Manager CDK lets you define custom permissions for SageMaker users in minutes. It comes with a set of predefined policy templates for different personas and ML activities. Personas represent the different types of users that need permissions to perform ML activities in SageMaker, such as data scientists or MLOps engineers. ML activities are a set of permissions to accomplish a common ML task, such as running Amazon SageMaker Studio applications or managing experiments, models, or pipelines. After you have selected the persona type and the set of ML activities, the SageMaker Role Manager CDK automatically creates the required IAM role and policies that you can assign to SageMaker users. Similarly, you can also create IAM roles with fine-grained permissions for automated jobs such as running SageMaker Pipelines.
Prerequisites
To start using the SageMaker Role Manager CDK, you need to complete the following prerequisite steps:
- Set up a role for your ML administrator to create and manage personas, as well as the IAM permissions for those users. For a sample admin policy, refer to the prerequisite section in Define customized permissions in minutes with Amazon SageMaker Role Manager blog post.
- Create a compute-only persona role (if you don’t have any) for passing to jobs and endpoints. For instructions to set up that role, refer to Using the role manager.
- Set up your AWS CDK development environment. For instructions, refer to Getting started with the AWS CDK.
Install and run the SageMaker Role Manager CDK
Complete the following steps to set up the SageMaker Role Manager CDK:
- Create your AWS CDK app and give it a name; for example,
RoleManager. - Navigate to the
RoleManagerfolder and run the following command to create a blank typescript AWS CDK project: - Open
package.jsonand add the highlighted package as shown in the following code: - Run the following command to install the new
cdk-aws-sagemaker-role-managerpackage: - Navigate to the lib folder and replace
role_manager_stack.tswith the following code: - Replace
passRoleId,passRoleName,newRoleId,newRoleName, andnewRoleDescriptionbased on your requirements for role creation. - Navigate back to your AWS CDK app home folder and run the following command to verify the generated AWS CloudFormation template:
- Finally, run the following command to run the CloudFormation stack in your AWS account:
You should see an AWS CDK deployment output similar to the one in the following screenshot.

More SageMaker Role Manager CDK examples are available in the following GitHub repo.
ML persona and activity CDK reference
Administrators can define ML activities using one of the ML activity static functions of the ML activity class. For a list of the latest versions, refer to ML activity reference.
The ML persona class supports the following methods:
- customizeVPC(subnets, securityGroups) – Customizes the VPC of all activities that support VPC customization of personas.
- customizeKMS(dataKeys, volumeKeys) – Customizes KMS keys of all activities that support KMS key customization of personas.
- createRole(scope, id, roleNameSuffix, roleDescription) – Creates a role with the persona’s activities’ permissions similar to the UI in the scope with ID, with the name
SageMaker-${roleNameSuffix}and optionally with the passed role description. - grantPermissionsTo(identity) – Grants the persona’s activities’ permissions to the identity. The passed identity can be a role or an AWS resource associated with a role (for example, a Lambda function with the role of the Lambda function describing which resources the Lambda function can access).
- grantPermissionsTo() – Updates the role of the passed identity to have the permissions specified in the ML activity.
The ML activity class supports the same set of functions as ML personas; however, the difference is an ML activity is constrained to a single activity when using this interface to create IAM roles.
Conclusion
SageMaker Role Manager enables you to create customized roles based on personas, pre-built ML activities, and custom policies, significantly reducing the time required. Now, with this latest AWS CDK support, the ability to define roles is further expanded to support infrastructure as code. This empowers ML practitioners to work programmatically in SageMaker, enhancing efficiency and enabling seamless integration into their workflows.
We would like to hear from you on how this new feature is helping you. Try out the new AWS CDK support for SageMaker Role Manager and send us your feedback!
To learn more about how to use SageMaker Role Manager, refer to the SageMaker Role Manager Developer Guide.
About The Authors
 Akash Bhatia is a Principal Solution Architect with experience spanning multiple industries, including Manufacturing, Automotive, Retail ,and Space and Technology. Currently working in Amazon Web Services Enterprise Segments, Akash works closely with a diverse range of clients, including Fortune 100 companies and start-ups, to facilitate their cloud migration journey. In addition to his technical expertise, Akash has led product and program management, having successfully overseen numerous large-scale initiatives throughout his career.
Akash Bhatia is a Principal Solution Architect with experience spanning multiple industries, including Manufacturing, Automotive, Retail ,and Space and Technology. Currently working in Amazon Web Services Enterprise Segments, Akash works closely with a diverse range of clients, including Fortune 100 companies and start-ups, to facilitate their cloud migration journey. In addition to his technical expertise, Akash has led product and program management, having successfully overseen numerous large-scale initiatives throughout his career.
 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys riding motorcycle, playing tennis, and photography.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys riding motorcycle, playing tennis, and photography.
 Ozan Eken is a Senior Product Manager at Amazon Web Services. He has over 15 years of experience in consulting and product management. He is passionate about building governance products, and Admin capabilities in Machine Learning for enterprise customers. Outside of work, he likes exploring different outdoor activities and watching soccer.
Ozan Eken is a Senior Product Manager at Amazon Web Services. He has over 15 years of experience in consulting and product management. He is passionate about building governance products, and Admin capabilities in Machine Learning for enterprise customers. Outside of work, he likes exploring different outdoor activities and watching soccer.
The science behind the improved Fire TV voice search
How phonetically blended results (PBR) help ensure customers find the content they were actually asking for.Read More
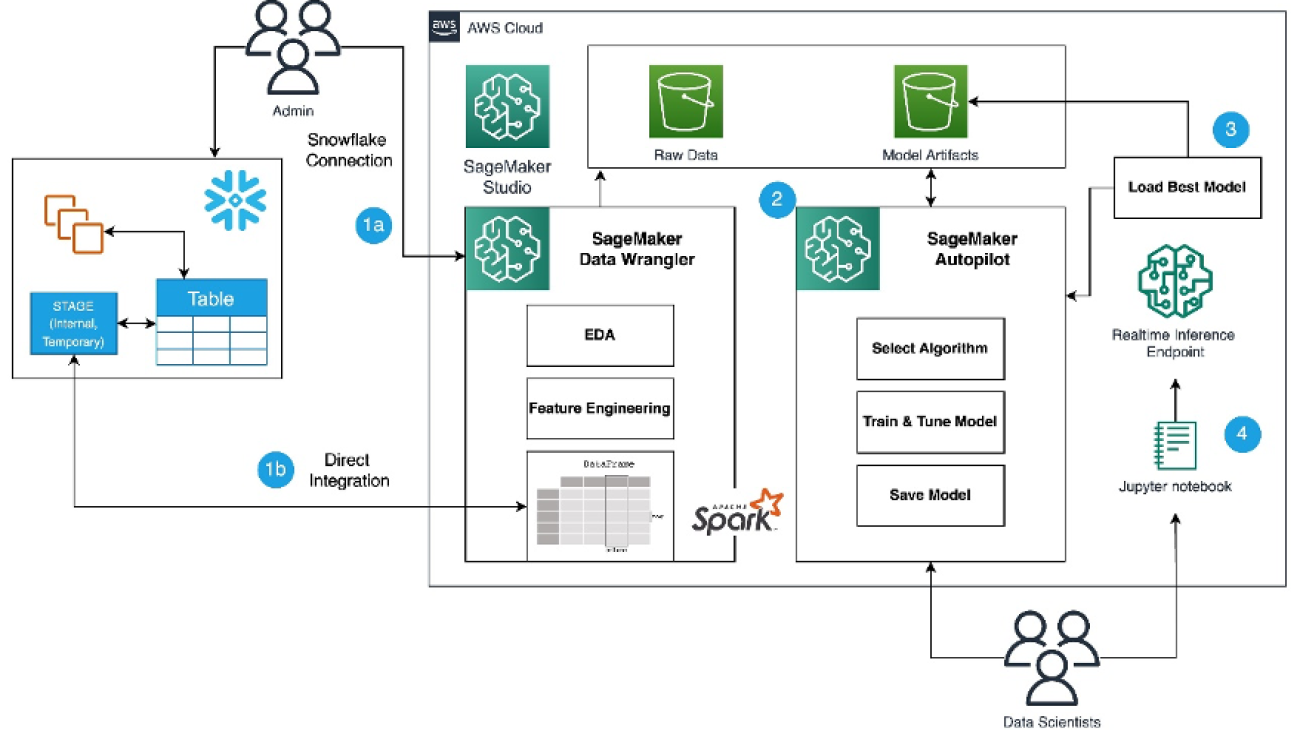
Accelerate time to business insights with the Amazon SageMaker Data Wrangler direct connection to Snowflake
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
SageMaker Data Wrangler supports Snowflake, a popular data source for users who want to perform ML. We launch the Snowflake direct connection from the SageMaker Data Wrangler in order to improve the customer experience. Before the launch of this feature, administrators were required to set up the initial storage integration to connect with Snowflake to create features for ML in Data Wrangler. This includes provisioning Amazon Simple Storage Service (Amazon S3) buckets, AWS Identity and Access Management (IAM) access permissions, Snowflake storage integration for individual users, and an ongoing mechanism to manage or clean up data copies in Amazon S3. This process is not scalable for customers with strict data access control and a large number of users.
In this post, we show how Snowflake’s direct connection in SageMaker Data Wrangler simplifies the administrator’s experience and data scientist’s ML journey from data to business insights.
Solution overview
In this solution, we use SageMaker Data Wrangler to speed up data preparation for ML and Amazon SageMaker Autopilot to automatically build, train, and fine-tune the ML models based on your data. Both services are designed specifically to increase productivity and shorten time to value for ML practitioners. We also demonstrate the simplified data access from SageMaker Data Wrangler to Snowflake with direct connection to query and create features for ML.
Refer to the diagram below for an overview of the low-code ML process with Snowflake, SageMaker Data Wrangler, and SageMaker Autopilot.
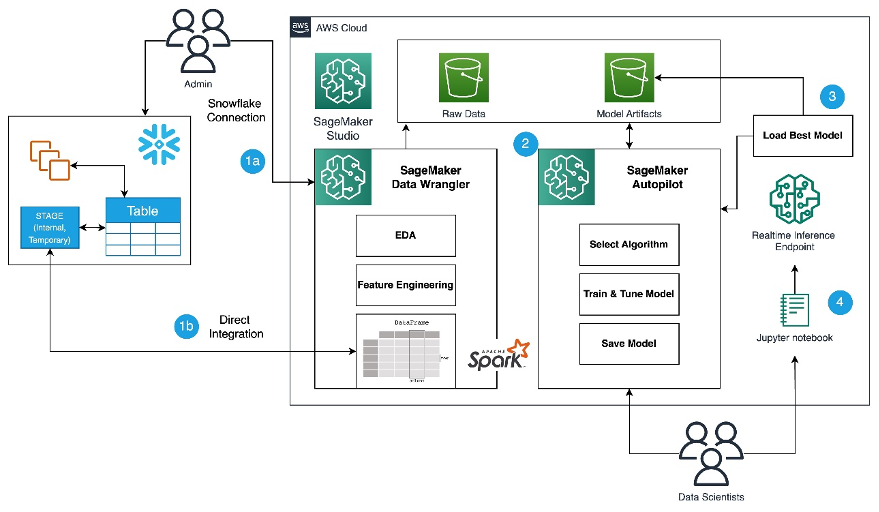
The workflow includes the following steps:
- Navigate to SageMaker Data Wrangler for your data preparation and feature engineering tasks.
- Set up the Snowflake connection with SageMaker Data Wrangler.
- Explore your Snowflake tables in SageMaker Data Wrangler, create a ML dataset, and perform feature engineering.
- Train and test the models using SageMaker Data Wrangler and SageMaker Autopilot.
- Load the best model to a real-time inference endpoint for predictions.
- Use a Python notebook to invoke the launched real-time inference endpoint.
Prerequisites
For this post, the administrator needs the following prerequisites:
- A Snowflake user with administrator permission to create a Snowflake virtual warehouse, user, and role, and grant access to this user to create a database. For more details on the administration setup, refer to Import data from Snowflake.
- An AWS account with admin access.
- A Snowflake Enterprise Account in your preferred AWS Region with
ACCOUNTADMINaccess. - Optionally, if you’re using Snowflake OAuth access in SageMaker Data Wrangler, refer to Import data from Snowflake to set up an OAuth identity provider.
- Familiarity with Snowflake, basic SQL, the Snowsight UI, and Snowflake objects.
Data scientists should have the following prerequisites
- Access to Amazon SageMaker, an instance of Amazon SageMaker Studio, and a user for SageMaker Studio. For more information about prerequisites, see Get Started with Data Wrangler.
- Familiarity with AWS services, networking, and the AWS Management Console.
Basic knowledge of Python, Jupyter notebooks, and ML.
Lastly, you should prepare your data for Snowflake
- We use credit card transaction data from Kaggle to build ML models for detecting fraudulent credit card transactions, so customers are not charged for items that they didn’t purchase. The dataset includes credit card transactions in September 2013 made by European cardholders.
- You should use the SnowSQL client and install it in your local machine, so you can use it to upload the dataset to a Snowflake table.
The following steps show how to prepare and load the dataset into the Snowflake database. This is a one-time setup.
Snowflake table and data preparation
Complete the following steps for this one-time setup:
- First, as the administrator, create a Snowflake virtual warehouse, user, and role, and grant access to other users such as the data scientists to create a database and stage data for their ML use cases:
- As the data scientist, let’s now create a database and import the credit card transactions into the Snowflake database to access the data from SageMaker Data Wrangler. For illustration purposes, we create a Snowflake database named
SF_FIN_TRANSACTION: - Download the dataset CSV file to your local machine and create a stage to load the data into the database table. Update the file path to point to the downloaded dataset location before running the PUT command for importing the data to the created stage:
- Create a table named
credit_card_transactions: - Import the data into the created table from the stage:
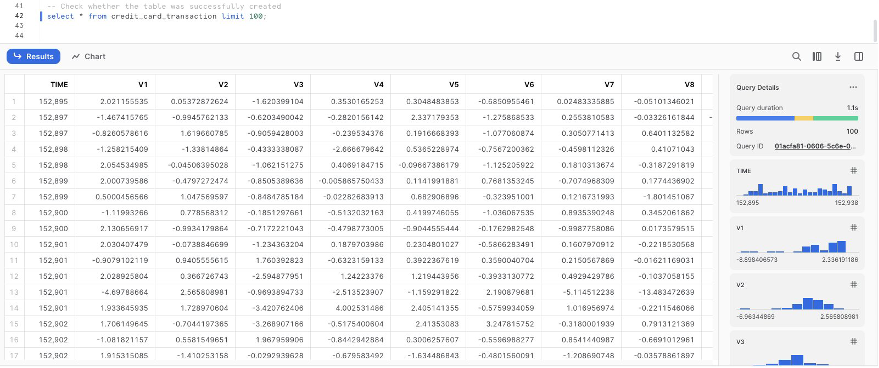
Set up the SageMaker Data Wrangler and Snowflake connection
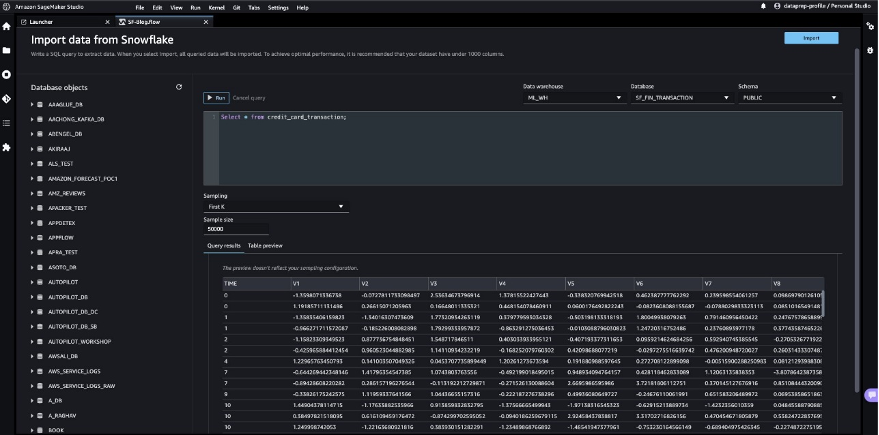
After we prepare the dataset to use with SageMaker Data Wrangler, let us create a new Snowflake connection in SageMaker Data Wrangler to connect to the sf_fin_transaction database in Snowflake and query the credit_card_transaction table:
- Choose Snowflake on the SageMaker Data Wrangler Connection page.
- Provide a name to identify your connection.
- Select your authentication method to connect with the Snowflake database:
- If using basic authentication, provide the user name and password shared by your Snowflake administrator. For this post, we use basic authentication to connect to Snowflake using the user credentials we created in the previous step.
- If you are using OAuth, provide your identity provider credentials.
SageMaker Data Wrangler by default queries your data directly from Snowflake without creating any data copies in S3 buckets. SageMaker Data Wrangler’s new usability enhancement uses Apache Spark to integrate with Snowflake to prepare and seamlessly create a dataset for your ML journey.
So far, we have created the database on Snowflake, imported the CSV file into the Snowflake table, created Snowflake credentials, and created a connector on SageMaker Data Wrangler to connect to Snowflake. To validate the configured Snowflake connection, run the following query on the created Snowflake table:
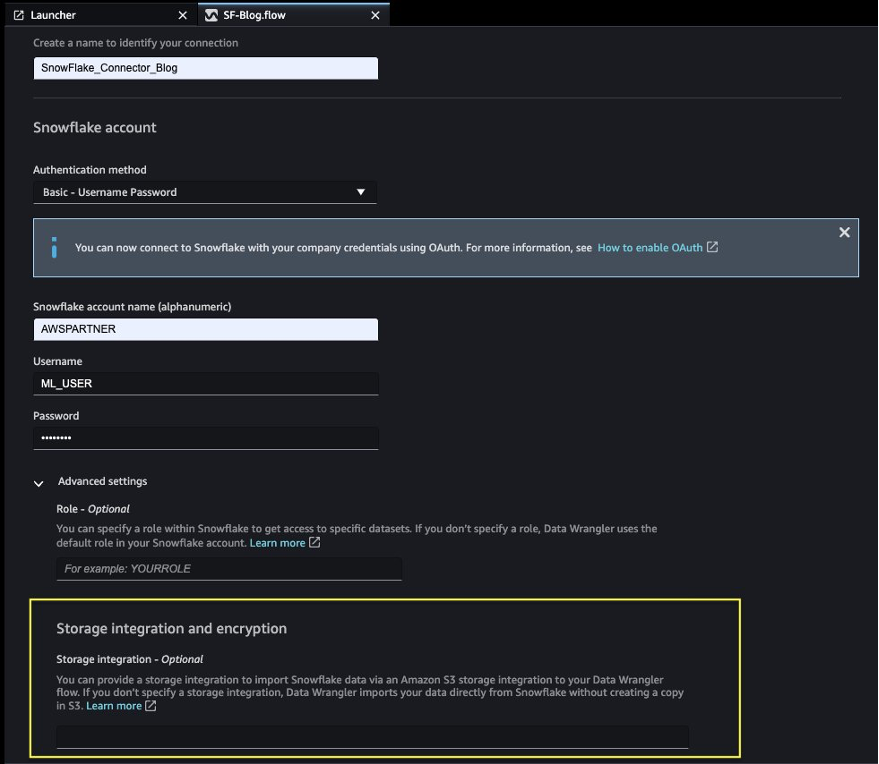
Note that the storage integration option that was required before is now optional in the advanced settings.
Explore Snowflake data
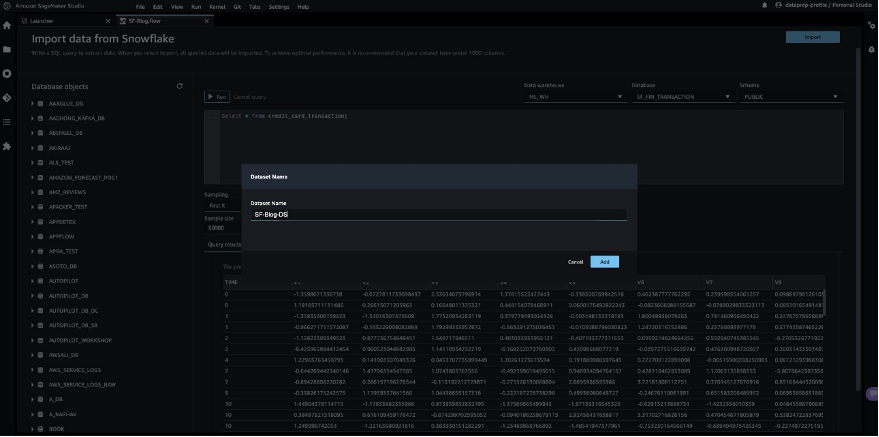
After you validate the query results, choose Import to save the query results as the dataset. We use this extracted dataset for exploratory data analysis and feature engineering.
You can choose to sample the data from Snowflake in the SageMaker Data Wrangler UI. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs.
Perform exploratory data analysis in SageMaker Data Wrangler
The data within Data Wrangler needs to be engineered before it can be trained. In this section, we demonstrate how to perform feature engineering on the data from Snowflake using SageMaker Data Wrangler’s built-in capabilities.
First, let’s use the Data Quality and Insights Report feature within SageMaker Data Wrangler to generate reports to automatically verify the data quality and detect abnormalities in the data from Snowflake.
You can use the report to help you clean and process your data. It gives you information such as the number of missing values and the number of outliers. If you have issues with your data, such as target leakage or imbalance, the insights report can bring those issues to your attention. To understand the report details, refer to Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler.
After you check out the data type matching applied by SageMaker Data Wrangler, complete the following steps:
- Choose the plus sign next to Data types and choose Add analysis.
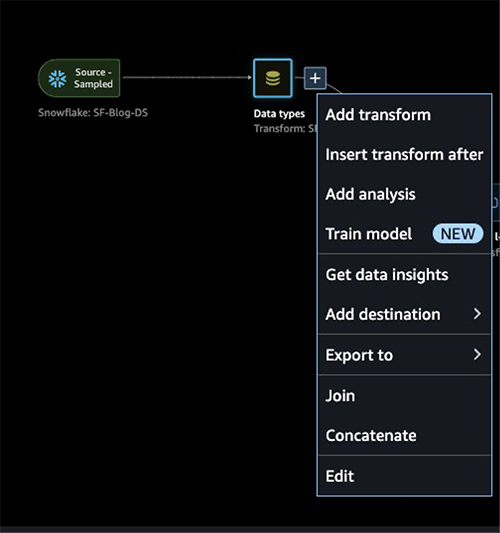
- For Analysis type, choose Data Quality and Insights Report.
- Choose Create.
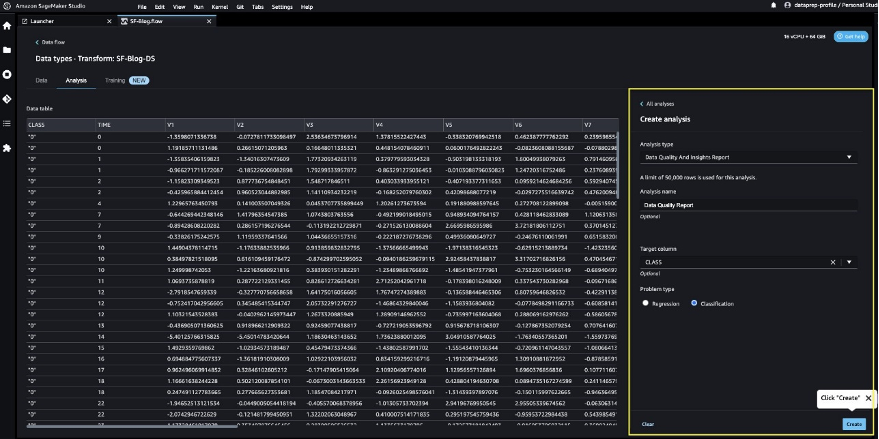
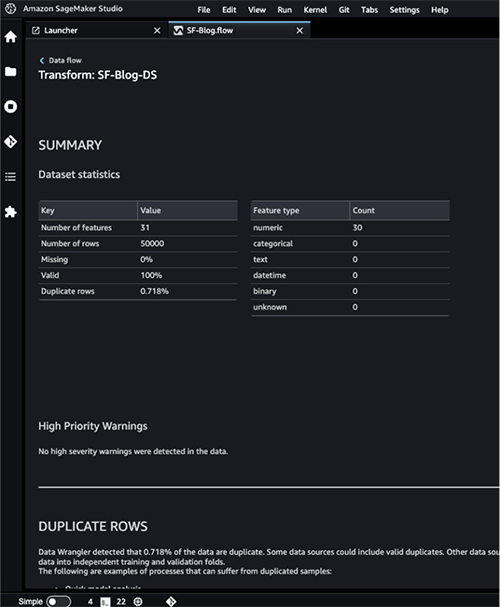
- Refer to the Data Quality and Insights Report details to check out high-priority warnings.
You can choose to resolve the warnings reported before proceeding with your ML journey.
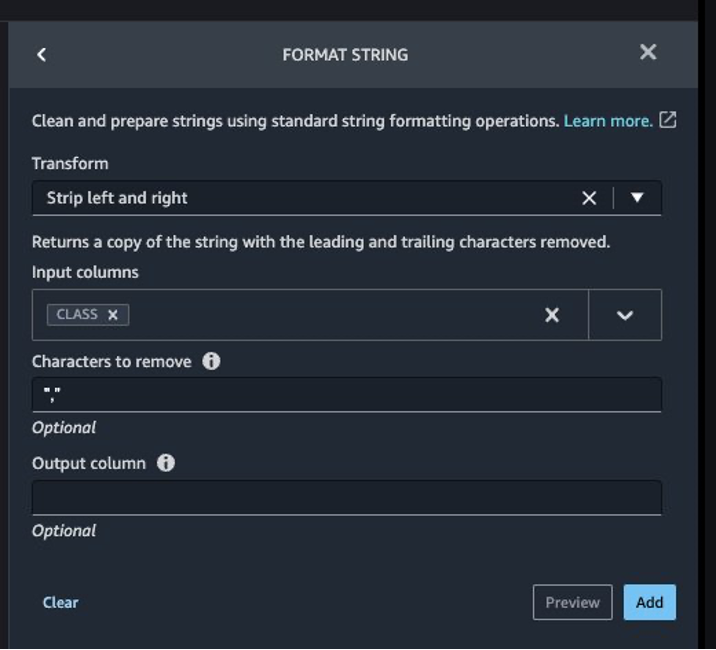
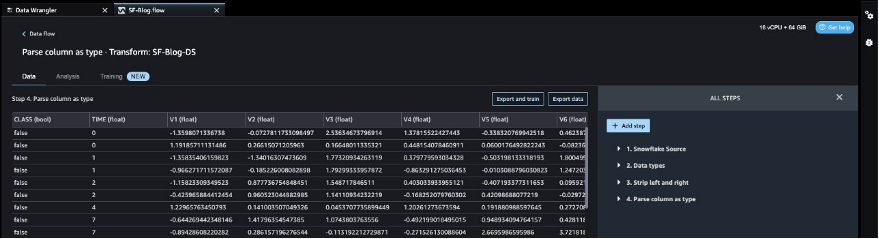
The target column Class to be predicted is classified as a string. First, let’s apply a transformation to remove the stale empty characters.
- Choose Add step and choose Format string.
- In the list of transforms, choose Strip left and right.
- Enter the characters to remove and choose Add.
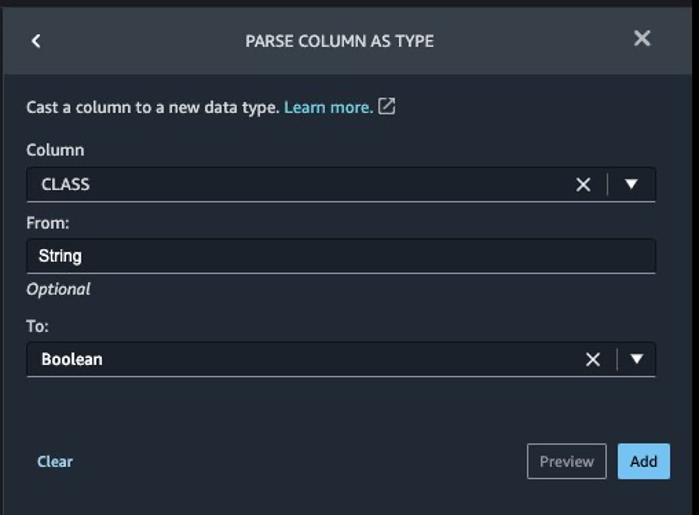
Next, we convert the target column Class from the string data type to Boolean because the transaction is either legitimate or fraudulent.
- Choose Add step.
- Choose Parse column as type.
- For Column, choose
Class. - For From, choose String.
- For To, choose Boolean.
- Choose Add.
After the target column transformation, we reduce the number of feature columns, because there are over 30 features in the original dataset. We use Principal Component Analysis (PCA) to reduce the dimensions based on feature importance. To understand more about PCA and dimensionality reduction, refer to Principal Component Analysis (PCA) Algorithm.
- Choose Add step.
- Choose Dimensionality Reduction.
- For Transform, choose Principal component analysis.
- For Input columns, choose all the columns except the target column
Class.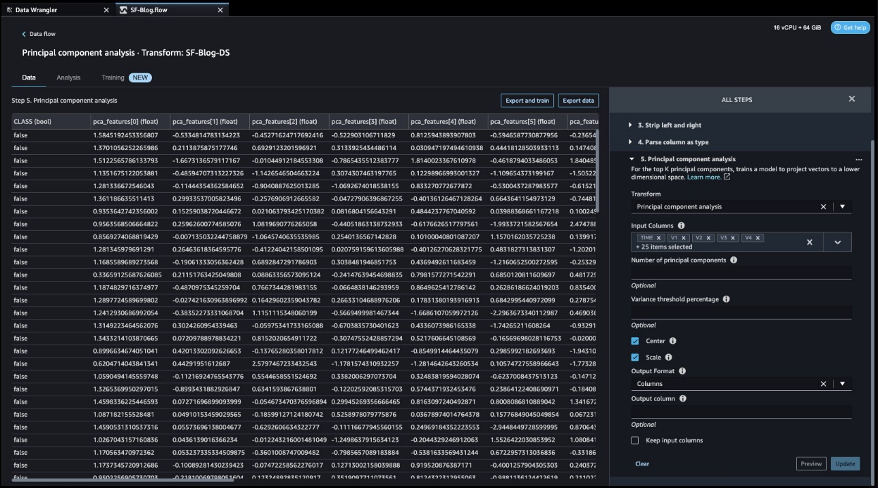
- Choose the plus sign next to Data flow and choose Add analysis.
- For Analysis type, choose Quick Model.
- For Analysis name, enter a name.
- For Label, choose
Class.
- Choose Run.
Based on the PCA results, you can decide which features to use for building the model. In the following screenshot, the graph shows the features (or dimensions) ordered based on highest to lowest importance to predict the target class, which in this dataset is whether the transaction is fraudulent or valid.
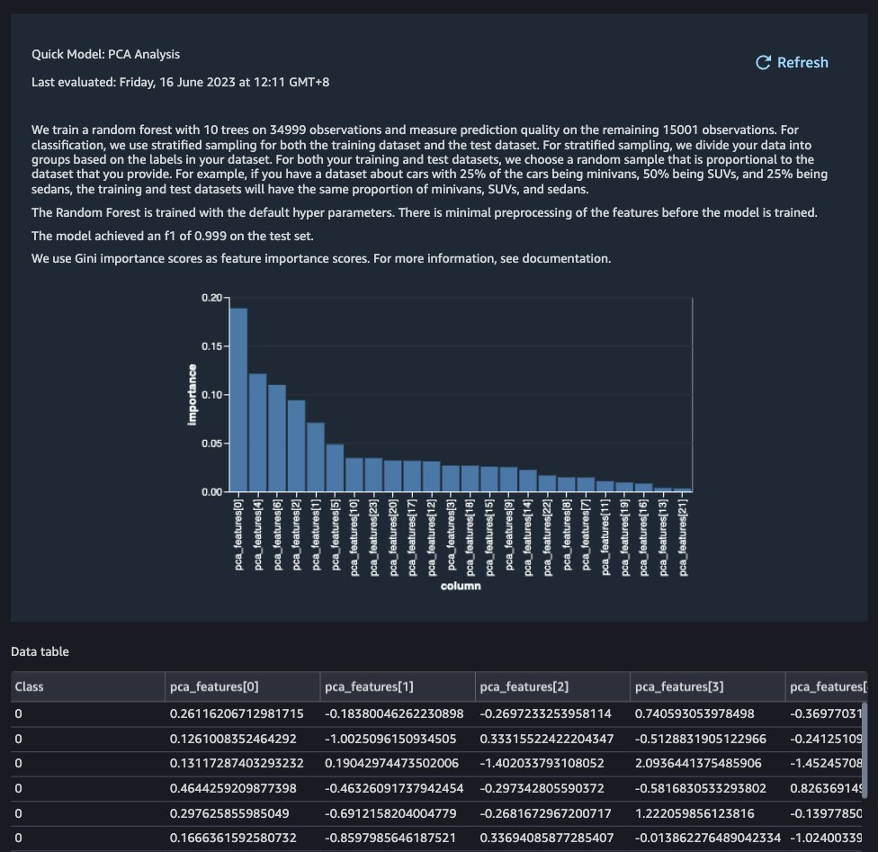
You can choose to reduce the number of features based on this analysis, but for this post, we leave the defaults as is.
This concludes our feature engineering process, although you may choose to run the quick model and create a Data Quality and Insights Report again to understand the data before performing further optimizations.
Export data and train the model
In the next step, we use SageMaker Autopilot to automatically build, train, and tune the best ML models based on your data. With SageMaker Autopilot, you still maintain full control and visibility of your data and model.
Now that we have completed the exploration and feature engineering, let’s train a model on the dataset and export the data to train the ML model using SageMaker Autopilot.
- On the Training tab, choose Export and train.
We can monitor the export progress while we wait for it to complete.
Let’s configure SageMaker Autopilot to run an automated training job by specifying the target we want to predict and the type of problem. In this case, because we’re training the dataset to predict whether the transaction is fraudulent or valid, we use binary classification.
- Enter a name for your experiment, provide the S3 location data, and choose Next: Target and features.
- For Target, choose
Classas the column to predict. - Choose Next: Training method.
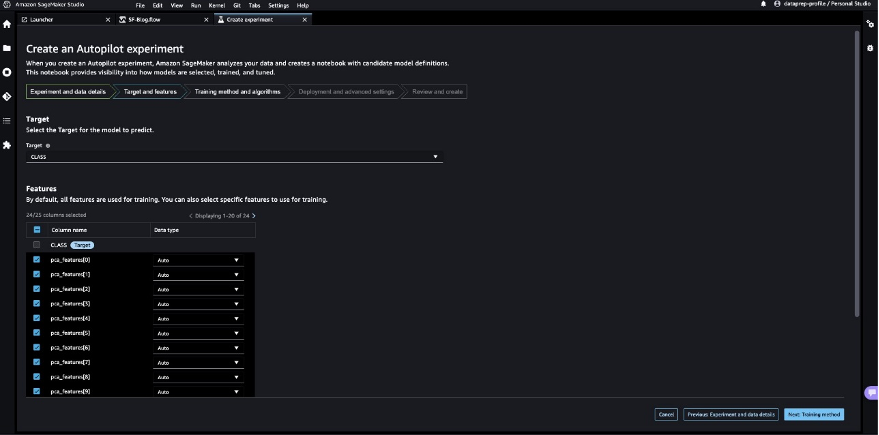
Let’s allow SageMaker Autopilot to decide the training method based on the dataset.
- For Training method and algorithms, select Auto.
To understand more about the training modes supported by SageMaker Autopilot, refer to Training modes and algorithm support.
- Choose Next: Deployment and advanced settings.
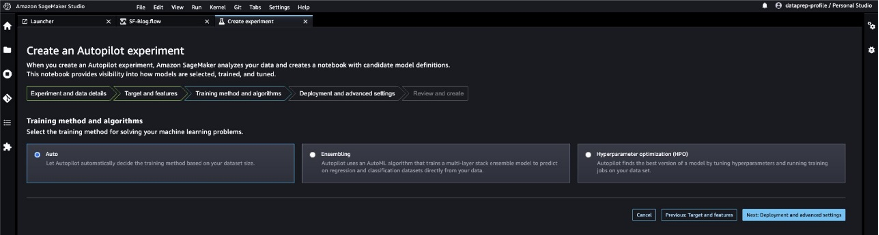
- For Deployment option, choose Auto deploy the best model with transforms from Data Wrangler, which loads the best model for inference after the experimentation is complete.
- Enter a name for your endpoint.
- For Select the machine learning problem type, choose Binary classification.
- For Objection metric, choose F1.
- Choose Next: Review and create.
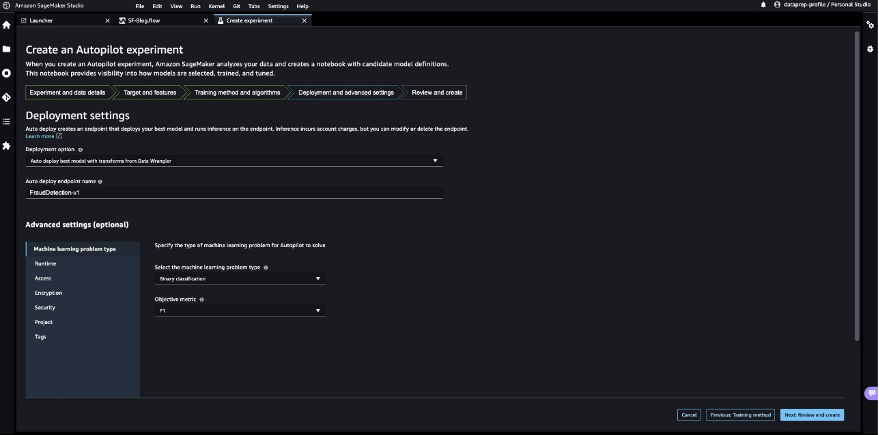
- Choose Create experiment.
This starts an SageMaker Autopilot job that creates a set of training jobs that uses combinations of hyperparameters to optimize the objective metric.
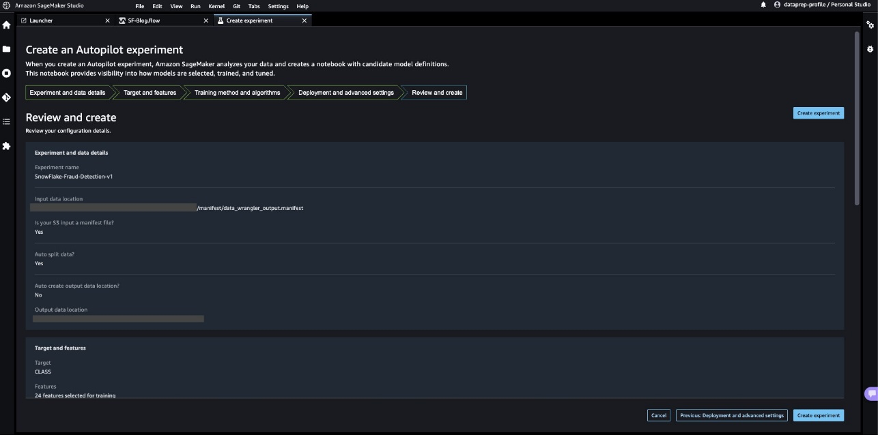
Wait for SageMaker Autopilot to finish building the models and evaluation of the best ML model.
Launch a real-time inference endpoint to test the best model
SageMaker Autopilot runs experiments to determine the best model that can classify credit card transactions as legitimate or fraudulent.
When SageMaker Autopilot completes the experiment, we can view the training results with the evaluation metrics and explore the best model from the SageMaker Autopilot job description page.
- Select the best model and choose Deploy model.
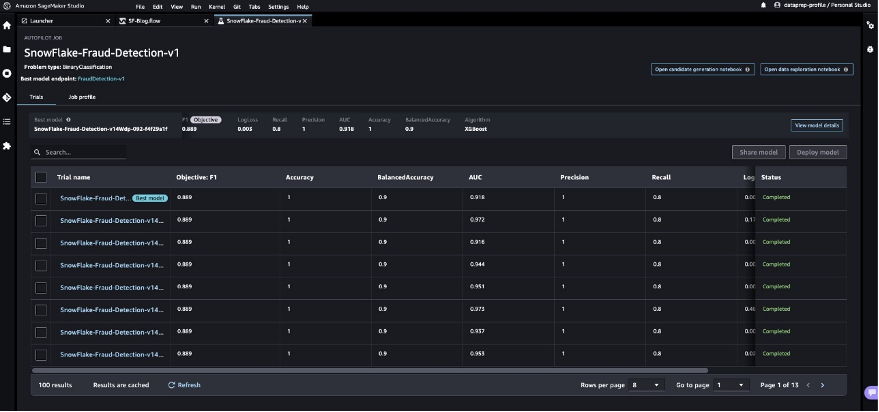
We use a real-time inference endpoint to test the best model created through SageMaker Autopilot.
- Select Make real-time predictions.
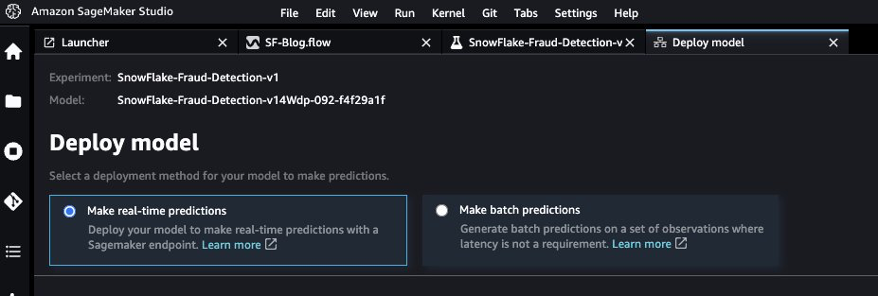
When the endpoint is available, we can pass the payload and get inference results.
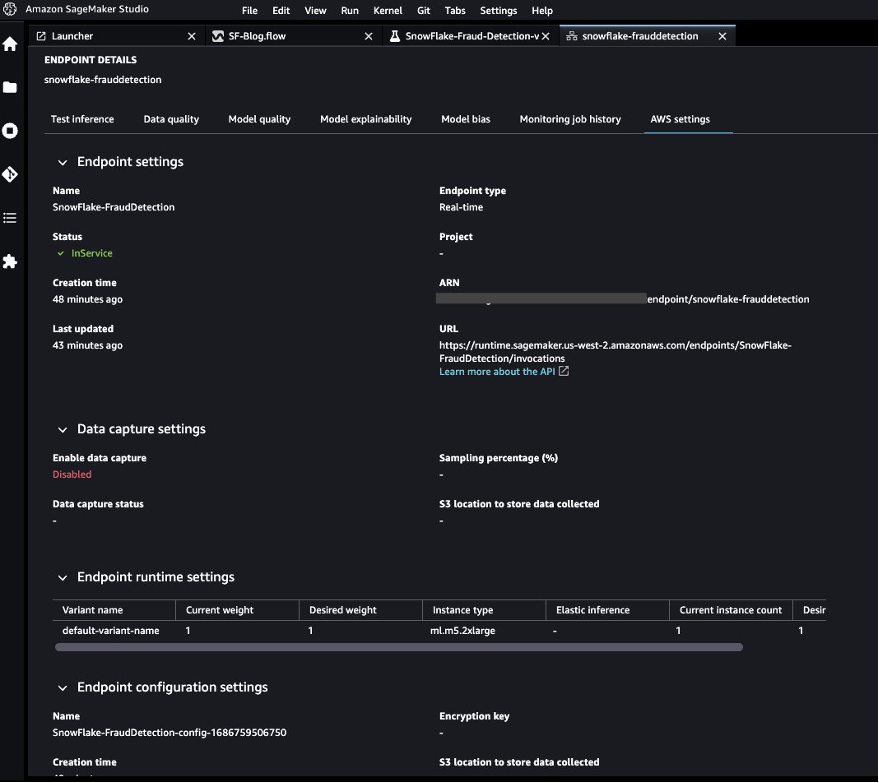
Let’s launch a Python notebook to use the inference endpoint.
- On the SageMaker Studio console, choose the folder icon in the navigation pane and choose Create notebook.
- Use the following Python code to invoke the deployed real-time inference endpoint:
The output shows the result as false, which implies the sample feature data is not fraudulent.

Clean up
To make sure you don’t incur charges after completing this tutorial, shut down the SageMaker Data Wrangler application and shut down the notebook instance used to perform inference. You should also delete the inference endpoint you created using SageMaker Autopilot to prevent additional charges.
Conclusion
In this post, we demonstrated how to bring your data from Snowflake directly without creating any intermediate copies in the process. You can either sample or load your complete dataset to SageMaker Data Wrangler directly from Snowflake. You can then explore the data, clean the data, and perform featuring engineering using SageMaker Data Wrangler’s visual interface.
We also highlighted how you can easily train and tune a model with SageMaker Autopilot directly from the SageMaker Data Wrangler user interface. With SageMaker Data Wrangler and SageMaker Autopilot integration, we can quickly build a model after completing feature engineering, without writing any code. Then we referenced SageMaker Autopilot’s best model to run inferences using a real-time endpoint.
Try out the new Snowflake direct integration with SageMaker Data Wrangler today to easily build ML models with your data using SageMaker.
About the authors
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys.
Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys.
 Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
 Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience in working with database and analytics products from enterprise database vendors and cloud providers. He has helped large technology companies design data analytics solutions and has led engineering teams in designing and implementing data analytics platforms and data products.
Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience in working with database and analytics products from enterprise database vendors and cloud providers. He has helped large technology companies design data analytics solutions and has led engineering teams in designing and implementing data analytics platforms and data products.