Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides.
Valuable data in organizations is stored in both structured and unstructured repositories. An enterprise search solution should be able to index and search across several structured and unstructured repositories.
Alfresco Content Services provides open, flexible, highly scalable enterprise content management (ECM) capabilities with the added benefits of a content services platform, making content accessible wherever and however you work through easy integrations with the business applications you use every day. Many organizations use the Alfresco content management platform to store their content. One of the key requirements for enterprise customers using Alfresco is the ability to easily and securely find accurate information across all the stored documents.
We are excited to announce that you can now use the new Amazon Kendra Alfresco connector to search documents stored in your Alfresco repositories and sites. In this post, we show how to use the new connector to retrieve documents stored in Alfresco for indexing purposes and securely use the Amazon Kendra intelligent search function. In addition, the ML-powered intelligent search can accurately find information from unstructured documents with natural language narrative content, for which keyword search is not very effective.
What’s new in the Amazon Kendra Alfresco connector
The Amazon Kendra Alfresco connector offers support for the following:
- Basic and OAuth2 authentication mechanisms for the Alfresco On-Premises (On-Prem) platform
- Basic and OAuth2 authentication mechanisms for the Alfresco PaaS platform
- Aspect-based crawling of Alfresco repository documents
Solution overview
With Amazon Kendra, you can configure multiple data sources to provide a central place to search across your document repositories and sites. The solution in this post demonstrates the following:
- Retrieval of documents and comments from Alfresco private sites and public sites
- Retrieval of documents and comments from Alfresco repositories using Amazon Kendra-specific aspects
- Authentication against Alfresco On-Prem and PaaS platforms using Basic and OAuth2 mechanisms, respectively
- The Amazon Kendra search capability with access control across sites and repositories
If you are going to use only one of the platforms, you can still follow this post to build the example solution; just ignore the steps corresponding to the platform that you are not using.
The following is a summary of the steps to build the example solution:
- Upload documents to the three Alfresco sites and the repository folder. Make sure the uploaded documents are unique across sites and repository folders.
- For the two private sites and repository, use document-level Alfresco permission management to set access permissions. For the public site, you don’t need to set up permissions at the document level. Note that permissions information is retrieved by the Amazon Kendra Alfresco connector and used for access control by the Amazon Kendra search function.
- For the two private sites and repository, create a new Amazon Kendra index (you use the same index for both the private sites and the repository). For the public site, create a new Amazon Kendra index.
- For the On-Prem private site, create an Amazon Kendra Alfresco data source using Basic authentication, within the Amazon Kendra index for private sites.
- For the On-Prem repository documents with Amazon Kendra-specific aspects, create a data source using Basic authentication, within the Amazon Kendra index for private sites.
- For the PaaS private site, create a data source using Basic authentication, within the Amazon Kendra index for private sites.
- For the PaaS public site, create a data source using OAuth2 authentication, within the Amazon Kendra index for public sites.
- Perform a sync for each data source.
- Run a test query in the Amazon Kendra index meant for private sites and the repository using access control.
- Run a test query in the Amazon Kendra index meant for public sites without access control.
Prerequisites
You need an AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies. You need to have a basic knowledge of AWS and how to navigate the AWS Management Console.
For the Alfresco On-Prem platform, complete the following steps:
- Create a private site or use an existing site.
- Create a repository folder or use an existing repository folder.
- Get the repository URL.
- Get Basic authentication credentials (user ID and password).
- Make sure authentication are part of the
ALFRESCO_ADMINISTRATORSgroup. - Get the public X509 certificate in .pem format and save it locally.
For the Alfresco PaaS platform, complete the following steps:
- Create a private site or use an existing site.
- Create a public site or use an existing site.
- Get the repository URL.
- Get Basic authentication credentials (user ID and password).
- Get OAuth2 credentials (client ID, client secret, and token URL).
- Confirm that authentication users are part of the
ALFRESCO_ADMINISTRATORSgroup.
Step 1: Upload example documents
Each uploaded document must have 5 MB or less in text. For more information, see Amazon Kendra Service Quotas. You can upload example documents or use existing documents within each site.
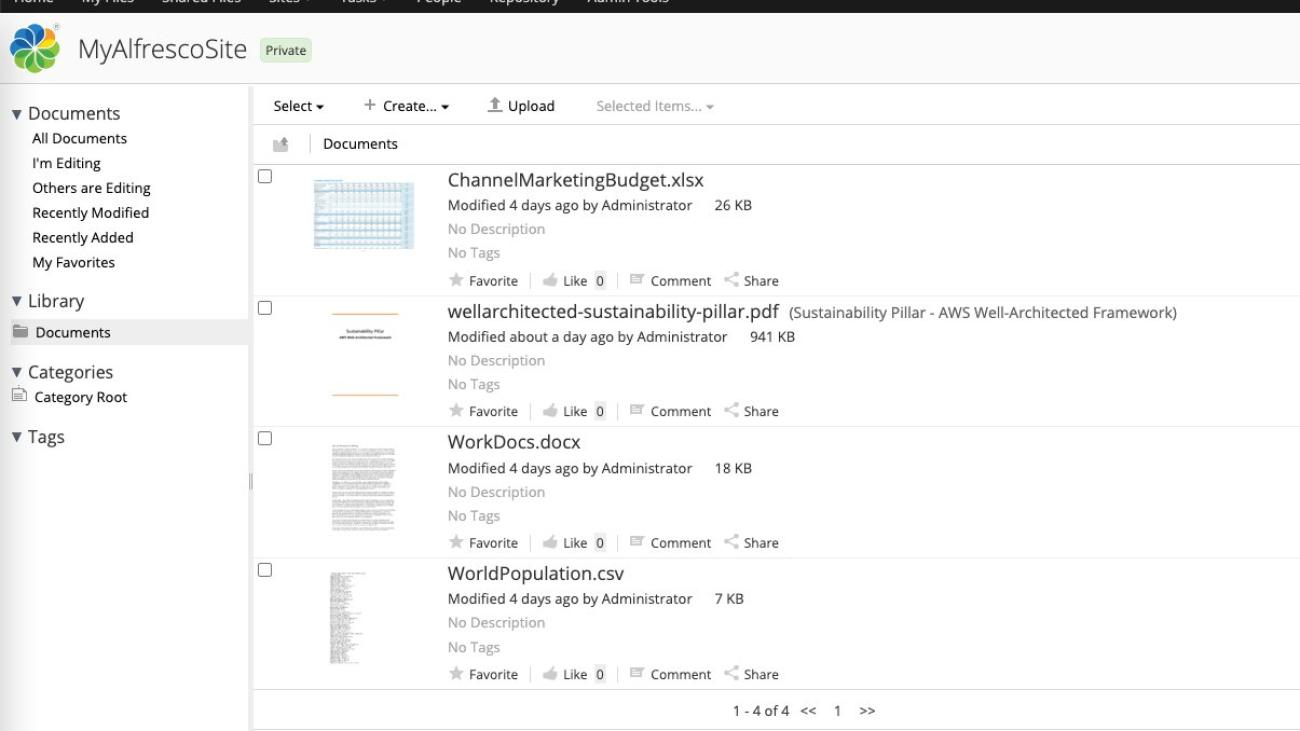
As shown in the following screenshot, we have uploaded four documents to the Alfresco On-Prem private site.

We have uploaded three documents to the Alfresco PaaS private site.

We have uploaded five documents to the Alfresco PaaS public site.

We have uploaded two documents to the Alfresco On-Prem repository.

Assign the aspect awskendra:indexControl to one or more documents in the repository folder.

Step 2: Configure Alfresco permissions
Use the Alfresco Permissions Management feature to give access rights to example users for viewing uploaded documents. It is assumed that you have some example Alfresco user names, with email addresses, that can be used for setting permissions at the document level in private sites. These users are not used for crawling the sites.
In the following example for the On-Prem private site, we have provided users My Dev User1 and My Dev User2 with site-consumer access to the example document. Repeat the same procedure for the other uploaded documents.

In the following example for the PaaS private site, we have provided user Kendra User 3 with site-consumer access to the example document. Repeat the same procedure for the other uploaded documents.

For the Alfresco repository documents, we have provided user My Dev user1 with consumer access to the example document.

The following table lists the site or repository names, document names, and permissions.
| Platform | Site or Repository Name | Document Name | User IDs |
| On-Prem | MyAlfrescoSite | ChannelMarketingBudget.xlsx | My Manager User3 |
| On-Prem | MyAlfrescoSite | wellarchitected-sustainability-pillar.pdf | My Dev User1, My Dev User2 |
| On-Prem | MyAlfrescoSite | WorkDocs.docx | My Dev User1, My Dev User2, My Manager User3 |
| On-Prem | MyAlfrescoSite | WorldPopulation.csv | My Dev User1, My Dev User2, My Manager User3 |
| PaaS | MyAlfrescoCloudSite2 | DDoS_White_Paper.pdf | Kendra User3 |
| PaaS | MyAlfrescoCloudSite2 | wellarchitected-framework.pdf | Kendra User3 |
| PaaS | MyAlfrescoCloudSite2 | ML_Training.pptx | Kendra User1 |
| PaaS | MyAlfrescoCloudPublicSite | batch_user.pdf | Everyone |
| PaaS | MyAlfrescoCloudPublicSite | Amazon Simple Storage Service – User Guide.pdf | Everyone |
| PaaS | MyAlfrescoCloudPublicSite | AWS Batch – User Guide.pdf | Everyone |
| PaaS | MyAlfrescoCloudPublicSite | Amazon Detective.docx | Everyone |
| PaaS | MyAlfrescoCloudPublicSite | Pricing.xlsx | Everyone |
| On-Prem | Repo: MyAlfrescoRepoFolder1 | Polly-dg.pdf (aspect awskendra:indexControl) | My Dev User1 |
| On-Prem | Repo: MyAlfrescoRepoFolder1 | Transcribe-api.pdf (aspect awskendra:indexControl) | My Dev User1 |
Step 3: Set up Amazon Kendra indexes
You can create a new Amazon Kendra index or use an existing index for indexing documents hosted in Alfresco private sites. To create a new index, complete the following steps:
- On the Amazon Kendra console, create an index called
Alfresco-Private. - Create a new IAM role, then choose Next.
- For Access Control, choose Yes.
- For Token Type¸ choose JSON.
- Keep the user name and group as default.
- Choose None for user group expansion because we are assuming no integration with AWS IAM Identity Center (successor to AWS Single Sign-On).
- Choose Next.
- Choose Developer Edition for this example solution.
- Choose Create to create a new index.
The following screenshot shows the Alfresco-Private index after it has been created.

- You can verify the access control configuration on the User access control tab.

- Repeat these steps to create a second index called
Alfresco-Public.

Step 4: Create a data source for the On-Prem private site
To create a data source for the On-Prem private site, complete the following steps:
- On the Amazon Kendra console, navigate to the
Alfresco-Privateindex. - Choose Data sources in the navigation pane.
- Choose Add data source.

- Choose Add connector for the Alfresco connector.

- For Data source name, enter
Alfresco-OnPrem-Private. - Optionally, add a description.
- Keep the remaining settings as default and choose Next.

To connect to the Alfresco On-Prem site, the connector needs access to the public certificate corresponding to the On-Prem server. This was one of the prerequisites.
- Use a different browser tab to upload the .pem file to an Amazon Simple Storage Service (Amazon S3) bucket in your account.
You use this S3 bucket name in the next steps.
- Return to the data source creation page.
- For Source, select Alfresco server.
- For Alfresco repository URL, enter the repository URL (created as a prerequisite).
- For Alfresco user application URL, enter the same value as the repository URL.
- For SSL certificate location, choose Browse S3 and choose the S3 bucket where you uploaded the .pem file.
- For Authentication, select Basic authentication.
- For AWS Secrets Manager secret, choose Create and add new secret.

A pop-up window opens to create an AWS Secrets Manager secret.
- Enter a name for your secret, user name, and password, then choose Save.

- For Virtual Private Cloud (VPC), choose No VPC.
- Turn the identity crawler on.
- For IAM role, choose Create a new IAM role.
- Choose Next.

You can configure the data source to synchronize contents from one or more Alfresco sites. For this post, we sync to the on-prem private site.
- For Content to sync, select Single Alfresco site sync and choose
MyAlfrescoSite. - Select Include comments to retrieve comments in addition to documents.
- For Sync mode, select Full sync.
- For Frequency, choose Run on demand (or a different frequency option as needed).
- Choose Next.

- Map the Alfresco document fields to the Amazon Kendra index fields (you can keep the defaults), then choose Next.

- On the Review and Create page, verify all the information, then choose Add data source.
After the data source has been created, the data source page is displayed as shown in the following screenshot.

Step 5: Create a data source for the On-Prem repository documents with Amazon Kendra-specific aspects
Similarly to the previous steps, create a data source for the On-Prem repository documents with Amazon Kendra-specific aspects:
- On the Amazon Kendra console, navigate to the
Alfresco-Privateindex. - Choose Data sources in the navigation pane.
- Choose Add data source.
- Choose Add connector for the Alfresco connector.
- For Data source name, enter
Alfresco-OnPrem-Aspects. - Optionally, add a description.
- Keep the remaining settings as default and choose Next.
- For Source, select Alfresco server.
- For Alfresco repository URL, enter the repository URL (created as a prerequisite).
- For Alfresco user application URL, enter the same value as the repository URL.
- For SSL certificate location, choose Browse S3 and choose the S3 bucket where you uploaded the .pem file.
- For Authentication, select Basic authentication.
- For AWS Secrets Manager secret, choose the secret you created earlier.
- For Virtual Private Cloud (VPC), choose No VPC.
- Turn the identity crawler off.
- For IAM role, choose Create a new IAM role.
- Choose Next.
For this scope, the connector retrieves only those On-Prem server repository documents that have been assigned an aspect called awskendra:indexControl.
- For Content to sync, select Alfresco aspects sync.
- For Sync mode, select Full sync.
- For Frequency, choose Run on demand (or a different frequency option as needed).
- Choose Next.
- Map the Alfresco document fields to the Amazon Kendra index fields (you can keep the defaults), then choose Next.
- On the Review and Create page, verify all the information, then choose Add data source.
After the data source has been created, the data source page is displayed as shown in the following screenshot.

Step 6: Create a data source for the PaaS private site
Follow similar steps as the previous sections to create a data source for the PaaS private site:
- On the Amazon Kendra console, navigate to the
Alfresco-Privateindex. - Choose Data sources in the navigation pane.
- Choose Add data source.
- Choose Add connector for the Alfresco connector.
- For Data source name, enter
Alfresco-Cloud-Private. - Optionally, add a description.
- Keep the remaining settings as default and choose Next.
- For Source, select Alfresco cloud.
- For Alfresco repository URL, enter the repository URL (created as a prerequisite).
- For Alfresco user application URL, enter the same value as the repository URL.
- For Authentication, select Basic authentication.
- For AWS Secrets Manager secret, choose Create and add new secret.
- Enter a name for your secret, user name, and password, then choose Save.
- For Virtual Private Cloud (VPC), choose No VPC.
- Turn the identity crawler off.
- For IAM role, choose Create a new IAM role.
- Choose Next.
We can configure the data source to synchronize contents from one or more Alfresco sites. For this post, we configure the data source to sync from the PaaS private site MyAlfrescoCloudSite2.
- For Content to sync, select Single Alfresco site sync and choose
MyAlfrescoCloudSite2. - Select Include comments.
- For Sync mode, select Full sync.
- For Frequency, choose Run on demand (or a different frequency option as needed).
- Choose Next.
- Map the Alfresco document fields to the Amazon Kendra index fields (you can keep the defaults) and choose Next.
- On the Review and Create page, verify all the information, then choose Add data source.
After the data source has been created, the data source page is displayed as shown in the following screenshot.

Step 7: Create a data source for the PaaS public site
We follow similar steps as before to create a data source for the PaaS public site:
- On the Amazon Kendra console, navigate to the Alfresco-Public index.
- Choose Data sources in the navigation pane.
- Choose Add data source.
- Choose Add connector for the Alfresco connector.
- For Data source name, enter
Alfresco-Cloud-Public. - Optionally, add a description.
- Keep the remaining settings as default and choose Next.
- For Source, select Alfresco cloud.
- For Alfresco repository URL, enter the repository URL (created as a prerequisite).
- For Alfresco user application URL, enter the same value as the repository URL.
- For Authentication, select OAuth2.0 authentication.
- For AWS Secrets Manager secret, choose Create and add new secret.
- Enter a name for your secret, client ID, client secret, and token URL, then choose Save.
- For Virtual Private Cloud (VPC), choose No VPC.
- Turn the identity crawler off.
- For IAM role, choose Create a new IAM role.
- Choose Next.
We configure this data source to sync to the PaaS public site MyAlfrescoCloudPublicSite.
- For Content to sync, select Single Alfresco site sync and choose
MyAlfrescoCloudPublicSite. - Optionally, select Include comments.
- For Sync mode, select Full sync.
- For Frequency, choose Run on demand (or a different frequency option as needed).
- Choose Next.
- Map the Alfresco document fields to the Amazon Kendra index fields (you can keep the defaults) and choose Next.
- On the Review and Create page, verify all the information, then choose Add data source.
After the data source has been created, the data source page is displayed as shown in the following screenshot.

Step 8: Perform a sync for each data source
Navigate to each of the data sources and choose Sync now. Complete only one synchronization at a time.

Wait for synchronization to be complete for all data sources. When each synchronization is complete for a data source, you see the status as shown in the following screenshot.

You can also view Amazon CloudWatch logs for a specific sync under Sync run history.
Step 9: Run a test query in the private index using access control
Now it’s time to test the solution. We first run a query in the private index using access control:
- On the Amazon Kendra console, navigate to the
Alfresco-Privateindex and choose Search indexed content.

- Enter a query in the search field.
As shown in the following screenshot, Amazon Kendra didn’t return any results.

- Choose Apply token.
- Enter the email address corresponding to the My Dev User1 user and choose Apply.
Note that Amazon Kendra access control works based on the email address associated with an Alfresco user name.

- Run the search again.
The search results in a document list (containing wellarchitected-sustainability-pillar.pdf in the following example) based on the access control setup.

If you run the same query again and provide an email address that doesn’t have access to either of these documents, you should not see these documents in the results list.
- Enter another query to search in the documents based on the aspect
awskendra:indexControl. - Choose Apply token, enter the email address corresponding to My Dev User1 user, and choose Apply.
- Rerun the query.

Step 10: Run a test query in the public index without access control.
Similarly, we can test our solution by running queries in the public index without access control:
- On the Amazon Kendra console, navigate to the Alfresco-Public index and choose Search indexed content.
- Run a search query.
Because this example Alfresco public site has not been set up with any access control, we don’t use an access token.

Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. Delete newly added Alfresco data sources within the indexes. If you created new Amazon Kendra indexes while testing this solution, delete them as well.
Conclusion
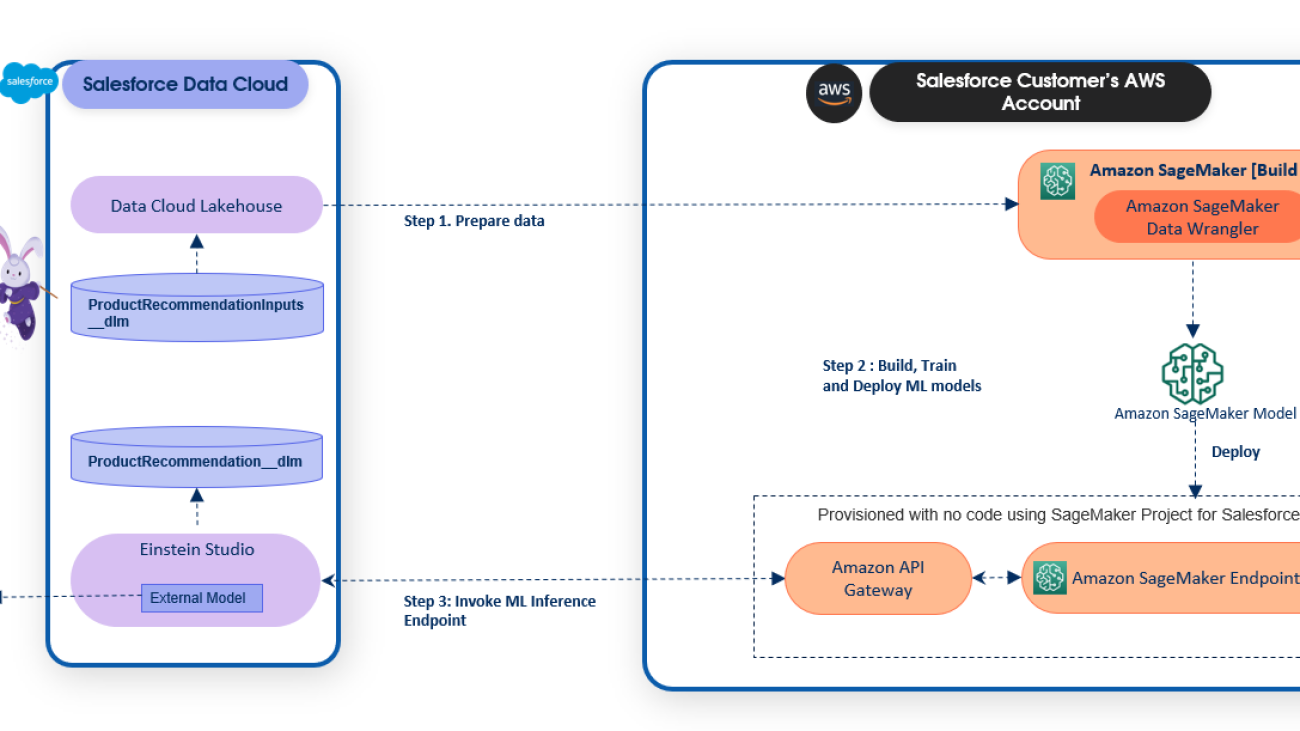
With the new Alfresco connector for Amazon Kendra, organizations can tap into the repository of information stored in their account securely using intelligent search powered by Amazon Kendra.
To learn about these possibilities and more, refer to the Amazon Kendra Developer Guide. For more information on how you can create, modify, or delete metadata and content when ingesting your data from Alfresco, refer to Enriching your documents during ingestion and Enrich your content and metadata to enhance your search experience with custom document enrichment in Amazon Kendra.
About the Authors
 Arun Anand is a Senior Solutions Architect at Amazon Web Services based in Houston area. He has 25+ years of experience in designing and developing enterprise applications. He works with partners in Energy & Utilities segment providing architectural and best practice recommendations for new and existing solutions.
Arun Anand is a Senior Solutions Architect at Amazon Web Services based in Houston area. He has 25+ years of experience in designing and developing enterprise applications. He works with partners in Energy & Utilities segment providing architectural and best practice recommendations for new and existing solutions.
 Rajnish Shaw is a Senior Solutions Architect at Amazon Web Services, with a background as a Product Developer and Architect. Rajnish is passionate about helping customers build applications on the cloud. Outside of work Rajnish enjoys spending time with family and friends, and traveling.
Rajnish Shaw is a Senior Solutions Architect at Amazon Web Services, with a background as a Product Developer and Architect. Rajnish is passionate about helping customers build applications on the cloud. Outside of work Rajnish enjoys spending time with family and friends, and traveling.
 Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.
Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.







































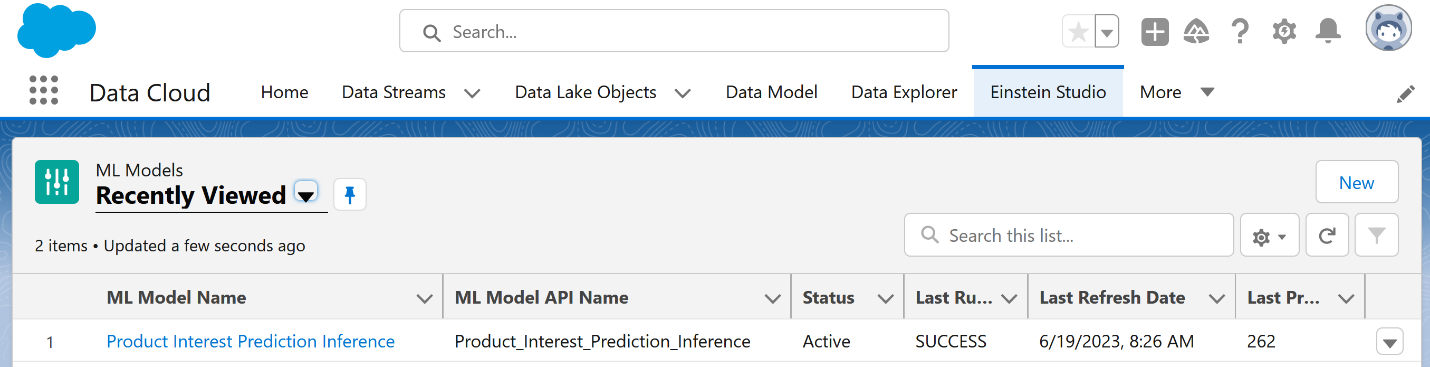
 Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Follow him on
Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Follow him on  Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field. Dharmendra Kumar Rai (DK Rai) is a Sr. Data Architect, Data Lake & AI/ML, serving strategic customers. He works closely with customers to understand how AWS can help them solve problems, especially in the AI/ML and analytics space. DK has many years of experience in building data-intensive solutions across a range of industry verticals, including high-tech, FinTech, insurance, and consumer-facing applications.
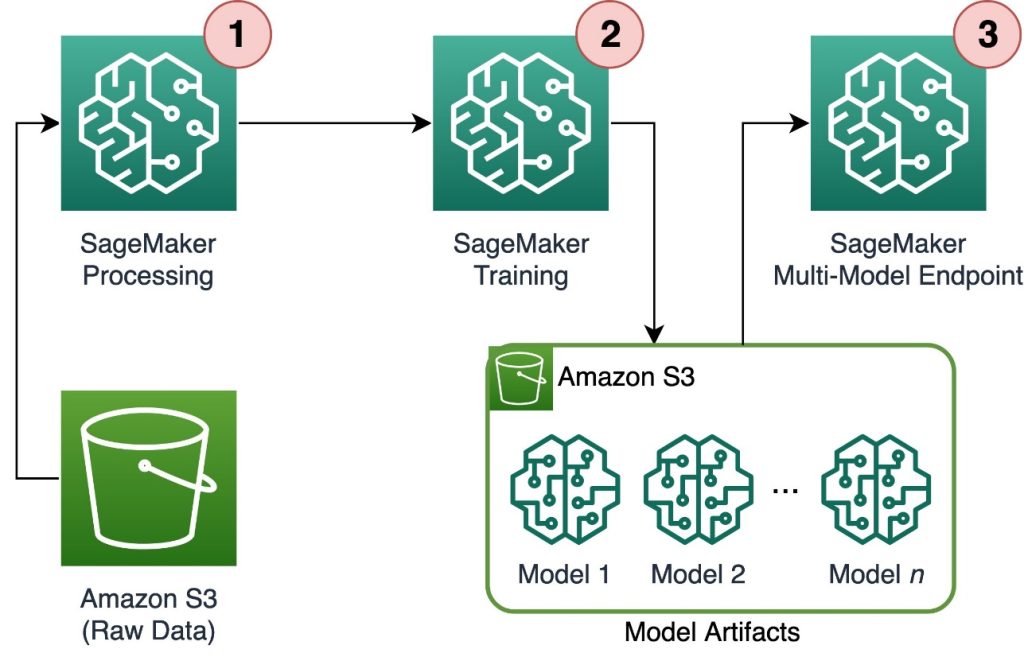
Dharmendra Kumar Rai (DK Rai) is a Sr. Data Architect, Data Lake & AI/ML, serving strategic customers. He works closely with customers to understand how AWS can help them solve problems, especially in the AI/ML and analytics space. DK has many years of experience in building data-intensive solutions across a range of industry verticals, including high-tech, FinTech, insurance, and consumer-facing applications. Marc Karp is an ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.

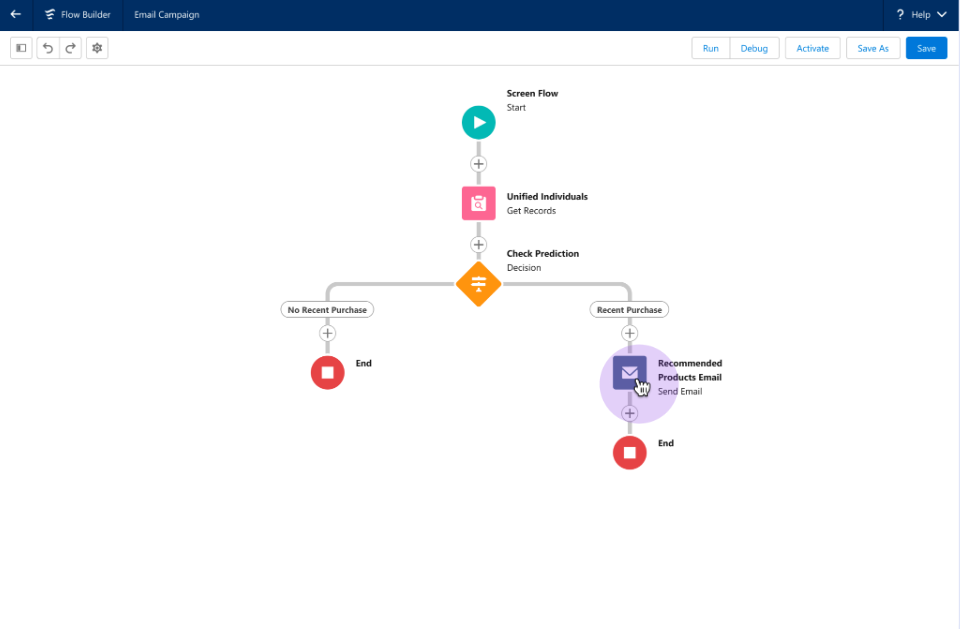

 Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City.
Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Maninder (Mani) Kaur is the AI/ML Specialist lead for Strategic ISVs at AWS. With her customer-first approach, Mani helps strategic customers shape their AI/ML strategy, fuel innovation, and accelerate their AI/ML journey. Mani is a firm believer of ethical and responsible AI, and strives to ensure that her customers’ AI solutions align with these principles.
Maninder (Mani) Kaur is the AI/ML Specialist lead for Strategic ISVs at AWS. With her customer-first approach, Mani helps strategic customers shape their AI/ML strategy, fuel innovation, and accelerate their AI/ML journey. Mani is a firm believer of ethical and responsible AI, and strives to ensure that her customers’ AI solutions align with these principles.






 Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance. Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington.
Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington. Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence.
Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence. Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers.
Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers. Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.
Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.
 Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then. Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.
Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family. Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc. Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling. Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.
Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.


 Michael Wallner is a Senior Consultant Data & AI with AWS Professional Services and is passionate about enabling customers on their journey to become data-driven and AWSome in the AWS cloud. On top, he likes thinking big with customers to innovate and invent new ideas for them.
Michael Wallner is a Senior Consultant Data & AI with AWS Professional Services and is passionate about enabling customers on their journey to become data-driven and AWSome in the AWS cloud. On top, he likes thinking big with customers to innovate and invent new ideas for them.
 David Sauerwein is a Senior Data Scientist at AWS Professional Services, where he enables customers on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the University of Innsbruck, Austria. He was also a doctoral and post-doctoral researcher at the Max-Planck-Institute for Quantum Optics in Germany. In his free time he loves to read, ski and spend time with his family.
David Sauerwein is a Senior Data Scientist at AWS Professional Services, where he enables customers on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the University of Innsbruck, Austria. He was also a doctoral and post-doctoral researcher at the Max-Planck-Institute for Quantum Optics in Germany. In his free time he loves to read, ski and spend time with his family. Srikrishna Chaitanya Konduru is a Senior Data Scientist with AWS Professional services. He supports customers in prototyping and operationalising their ML applications on AWS. Srikrishna focuses on computer vision and NLP. He also leads ML platform design and use case identification initiatives for customers across diverse industry verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen university, Germany, with a focus on Medical Imaging.
Srikrishna Chaitanya Konduru is a Senior Data Scientist with AWS Professional services. He supports customers in prototyping and operationalising their ML applications on AWS. Srikrishna focuses on computer vision and NLP. He also leads ML platform design and use case identification initiatives for customers across diverse industry verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen university, Germany, with a focus on Medical Imaging. Ahmed Mansour is a Data Scientist at AWS Professional Services. He provide technical support for customers through their AI/ML journey on the AWS cloud. Ahmed focuses on applications of NLP to the protein domain along with RL. He has a PhD in Engineering from the Technical University of Munich, Germany. In his free time he loves to go to the gym and play with his kids.
Ahmed Mansour is a Data Scientist at AWS Professional Services. He provide technical support for customers through their AI/ML journey on the AWS cloud. Ahmed focuses on applications of NLP to the protein domain along with RL. He has a PhD in Engineering from the Technical University of Munich, Germany. In his free time he loves to go to the gym and play with his kids.








 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects. Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.