Natural language processing (NLP) is the field in machine learning (ML) concerned with giving computers the ability to understand text and spoken words in the same way as human beings can. Recently, state-of-the-art architectures like the transformer architecture are used to achieve near-human performance on NLP downstream tasks like text summarization, text classification, entity recognition, and more.
Large language models (LLMs) are transformer-based models trained on a large amount of unlabeled text with hundreds of millions (BERT) to over a trillion parameters (MiCS), and whose size makes single-GPU training impractical. Due to their inherent complexity, training an LLM from scratch is a very challenging task that very few organizations can afford. A common practice for NLP downstream tasks is to take a pre-trained LLM and fine-tune it. For more information about fine-tuning, refer to Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data and Fine-tune transformer language models for linguistic diversity with Hugging Face on Amazon SageMaker.
Zero-shot learning in NLP allows a pre-trained LLM to generate responses to tasks that it hasn’t been explicitly trained for (even without fine-tuning). Specifically speaking about text classification, zero-shot text classification is a task in natural language processing where an NLP model is used to classify text from unseen classes, in contrast to supervised classification, where NLP models can only classify text that belong to classes in the training data.
We recently launched zero-shot classification model support in Amazon SageMaker JumpStart. SageMaker JumpStart is the ML hub of Amazon SageMaker that provides access to pre-trained foundation models (FMs), LLMs, built-in algorithms, and solution templates to help you quickly get started with ML. In this post, we show how you can perform zero-shot classification using pre-trained models in SageMaker Jumpstart. You will learn how to use the SageMaker Jumpstart UI and SageMaker Python SDK to deploy the solution and run inference using the available models.
Zero-shot learning
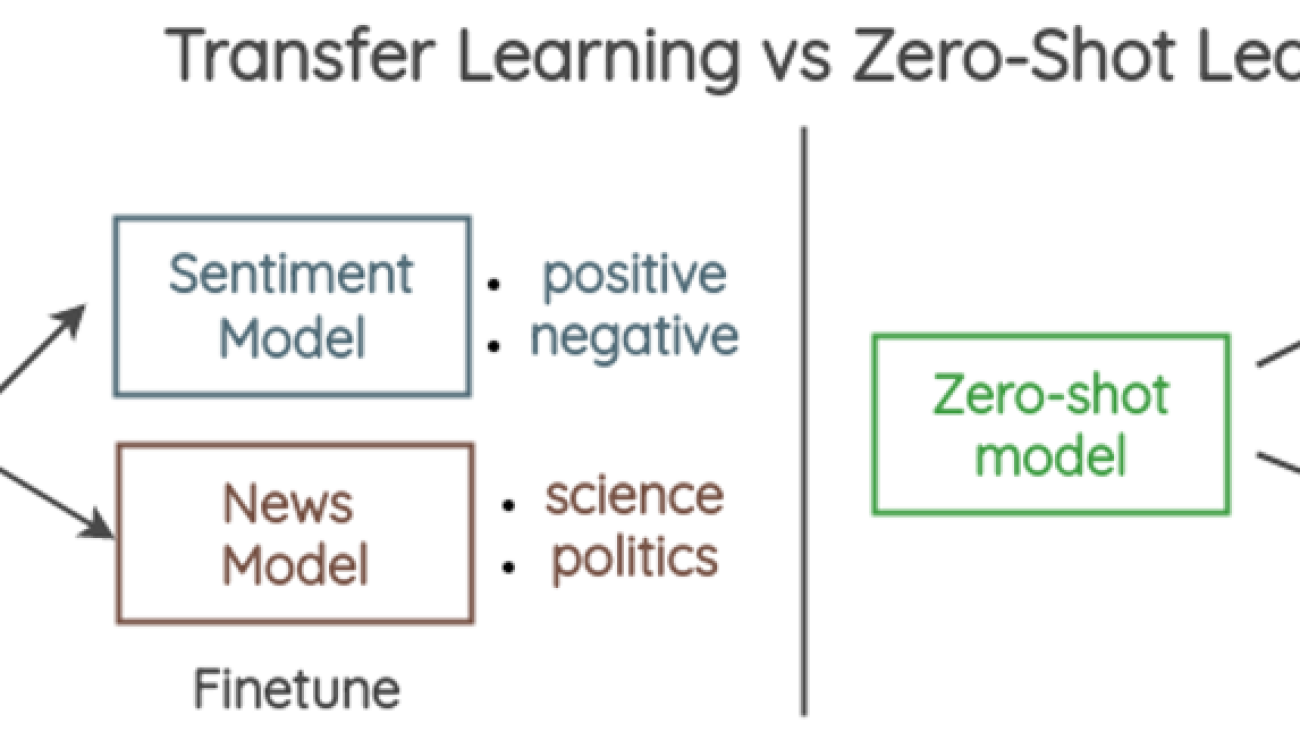
Zero-shot classification is a paradigm where a model can classify new, unseen examples that belong to classes that were not present in the training data. For example, a language model that has beed trained to understand human language can be used to classify New Year’s resolutions tweets on multiple classes like career, health, and finance, without the language model being explicitly trained on the text classification task. This is in contrast to fine-tuning the model, since the latter implies re-training the model (through transfer learning) while zero-shot learning doesn’t require additional training.
The following diagram illustrates the differences between transfer learning (left) vs. zero-shot learning (right).

Yin et al. proposed a framework for creating zero-shot classifiers using natural language inference (NLI). The framework works by posing the sequence to be classified as an NLI premise and constructs a hypothesis from each candidate label. For example, if we want to evaluate whether a sequence belongs to the class politics, we could construct a hypothesis of “This text is about politics.” The probabilities for entailment and contradiction are then converted to label probabilities. As a quick review, NLI considers two sentences: a premise and a hypothesis. The task is to determine whether the hypothesis is true (entailment) or false (contradiction) given the premise. The following table provides some examples.
| Premise | Label | Hypothesis |
| A man inspects the uniform of a figure in some East Asian country. | Contradiction | The man is sleeping. |
| An older and younger man smiling. | Neutral | Two men are smiling and laughing at the cats playing on the floor. |
| A soccer game with multiple males playing. | entailment | Some men are playing a sport. |
Solution overview
In this post, we discuss the following:
- How to deploy pre-trained zero-shot text classification models using the SageMaker JumpStart UI and run inference on the deployed model using short text data
- How to use the SageMaker Python SDK to access the pre-trained zero-shot text classification models in SageMaker JumpStart and use the inference script to deploy the model to a SageMaker endpoint for a real-time text classification use case
- How to use the SageMaker Python SDK to access pre-trained zero-shot text classification models and use SageMaker batch transform for a batch text classification use case
SageMaker JumpStart provides one-click fine-tuning and deployment for a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. These features remove the heavy lifting from each step of the ML process, simplifying the development of high-quality models and reducing time to deployment. The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets.
The JumpStart model hub provides access to a large number of NLP models that enable transfer learning and fine-tuning on custom datasets. As of this writing, the JumpStart model hub contains over 300 text models across a variety of popular models, such as Stable Diffusion, Flan T5, Alexa TM, Bloom, and more.
Note that by following the steps in this section, you will deploy infrastructure to your AWS account that may incur costs.
Deploy a standalone zero-shot text classification model
In this section, we demonstrate how to deploy a zero-shot classification model using SageMaker JumpStart. You can access pre-trained models through the JumpStart landing page in Amazon SageMaker Studio. Complete the following steps:
- In SageMaker Studio, open the JumpStart landing page.
Refer to Open and use JumpStart for more details on how to navigate to SageMaker JumpStart. - In the Text Models carousel, locate the “Zero-Shot Text Classification” model card.
- Choose View model to access the
facebook-bart-large-mnlimodel.
Alternatively, you can search for the zero-shot classification model in the search bar and get to the model in SageMaker JumpStart. - Specify a deployment configuration, SageMaker hosting instance type, endpoint name, Amazon Simple Storage Service (Amazon S3) bucket name, and other required parameters.
- Optionally, you can specify security configurations like AWS Identity and Access Management (IAM) role, VPC settings, and AWS Key Management Service (AWS KMS) encryption keys.
- Choose Deploy to create a SageMaker endpoint.
This step takes a couple of minutes to complete. When it’s complete, you can run inference against the SageMaker endpoint that hosts the zero-shot classification model.
In the following video, we show a walkthrough of the steps in this section.
Use JumpStart programmatically with the SageMaker SDK
In the SageMaker JumpStart section of SageMaker Studio, under Quick start solutions, you can find the solution templates. SageMaker JumpStart solution templates are one-click, end-to-end solutions for many common ML use cases. As of this writing, over 20 solutions are available for multiple use cases, such as demand forecasting, fraud detection, and personalized recommendations, to name a few.
The “Zero Shot Text Classification with Hugging Face” solution provides a way to classify text without the need to train a model for specific labels (zero-shot classification) by using a pre-trained text classifier. The default zero-shot classification model for this solution is the facebook-bart-large-mnli (BART) model. For this solution, we use the 2015 New Year’s Resolutions dataset to classify resolutions. A subset of the original dataset containing only the Resolution_Category (ground truth label) and the text columns is included in the solution’s assets.

The input data includes text strings, a list of desired categories for classification, and whether the classification is multi-label or not for synchronous (real-time) inference. For asynchronous (batch) inference, we provide a list of text strings, the list of categories for each string, and whether the classification is multi-label or not in a JSON lines formatted text file.

The result of the inference is a JSON object that looks something like the following screenshot.

We have the original text in the sequence field, the labels used for the text classification in the labels field, and the probability assigned to each label (in the same order of appearance) in the field scores.
To deploy the Zero Shot Text Classification with Hugging Face solution, complete the following steps:
- On the SageMaker JumpStart landing page, choose Models, notebooks, solutions in the navigation pane.
- In the Solutions section, choose Explore All Solutions.

- On the Solutions page, choose the Zero Shot Text Classification with Hugging Face model card.
- Review the deployment details and if you agree, choose Launch.



The deployment will provision a SageMaker real-time endpoint for real-time inference and an S3 bucket for storing the batch transformation results.
The following diagram illustrates the architecture of this method.

Perform real-time inference using a zero-shot classification model
In this section, we review how to use the Python SDK to run zero-shot text classification (using any of the available models) in real time using a SageMaker endpoint.
- First, we configure the inference payload request to the model. This is model dependent, but for the BART model, the input is a JSON object with the following structure:
- Note that the BART model is not explicitly trained on the
candidate_labels. We will use the zero-shot classification technique to classify the text sequence to unseen classes. The following code is an example using text from the New Year’s resolutions dataset and the defined classes: - Next, you can invoke a SageMaker endpoint with the zero-shot payload. The SageMaker endpoint is deployed as part of the SageMaker JumpStart solution.
- The inference response object contains the original sequence, the labels sorted by score from max to min, and the scores per label:
Run a SageMaker batch transform job using the Python SDK
This section describes how to run batch transform inference with the zero-shot classification facebook-bart-large-mnli model using the SageMaker Python SDK. Complete the following steps:
- Format the input data in JSON lines format and upload the file to Amazon S3.
SageMaker batch transform will perform inference on the data points uploaded in the S3 file. - Set up the model deployment artifacts with the following parameters:
- model_id – Use
huggingface-zstc-facebook-bart-large-mnli. - deploy_image_uri – Use the
image_urisPython SDK function to get the pre-built SageMaker Docker image for themodel_id. The function returns the Amazon Elastic Container Registry (Amazon ECR) URI. - deploy_source_uri – Use the
script_urisutility API to retrieve the S3 URI that contains scripts to run pre-trained model inference. We specify thescript_scopeasinference. - model_uri – Use
model_urito get the model artifacts from Amazon S3 for the specifiedmodel_id.
- model_id – Use
- Use
HF_TASKto define the task for the Hugging Face transformers pipeline andHF_MODEL_IDto define the model used to classify the text:For a complete list of tasks, see Pipelines in the Hugging Face documentation.
- Create a Hugging Face model object to be deployed with the SageMaker batch transform job:
- Create a transform to run a batch job:
- Start a batch transform job and use S3 data as input:
You can monitor your batch processing job on the SageMaker console (choose Batch transform jobs under Inference in the navigation pane). When the job is complete, you can check the model prediction output in the S3 file specified in output_path.
For a list of all the available pre-trained models in SageMaker JumpStart, refer to Built-in Algorithms with pre-trained Model Table. Use the keyword “zstc” (short for zero-shot text classification) in the search bar to locate all the models capable of doing zero-shot text classification.
Clean up
After you’re done running the notebook, make sure to delete all resources created in the process to ensure that the costs incurred by the assets deployed in this guide are stopped. The code to clean up the deployed resources is provided in the notebooks associated with the zero-shot text classification solution and model.
Default security configurations
The SageMaker JumpStart models are deployed using the following default security configurations:
- The models are deployed with a default SageMaker execution role. You can specify your own role or use an existing one. For more information, refer to SageMaker Roles.
- The model will not connect to a VPC and no VPC will be provisioned for your model. You can specify VPC configuration to connect to your model from within the security options. For more information, see Give SageMaker Hosted Endpoints Access to Resources in Your Amazon VPC.
- Default KMS keys will be used to encrypt your model’s artifacts. You can specify your own KMS keys or use existing one. For more information, refer to Using server-side encryption with AWS KMS keys (SSE-KMS).
To learn more about SageMaker security-related topics, check out Configure security in Amazon SageMaker.
Conclusion
In this post, we showed you how to deploy a zero-shot classification model using the SageMaker JumpStart UI and perform inference using the deployed endpoint. We used the SageMaker JumpStart New Year’s resolutions solution to show how you can use the SageMaker Python SDK to build an end-to-end solution and implement zero-shot classification application. SageMaker JumpStart provides access to hundreds of pre-trained models and solutions for tasks like computer vision, natural language processing, recommendation systems, and more. Try out the solution on your own and let us know your thoughts.
About the authors
 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.





 Jie Dong is an AWS Cloud Architect based in Sydney, Australia. Jie is passionate about automation, and loves to develop solutions to help customer improve productivity. Event-driven system and serverless framework are his expertise. In his own time, Jie loves to work on building smart home and explore new smart home gadgets.
Jie Dong is an AWS Cloud Architect based in Sydney, Australia. Jie is passionate about automation, and loves to develop solutions to help customer improve productivity. Event-driven system and serverless framework are his expertise. In his own time, Jie loves to work on building smart home and explore new smart home gadgets. Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends. Gordon Wang, is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.
Gordon Wang, is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.





 Fabian Benitez-Quiroz is a IoT Edge Data Scientist in AWS Professional Services. He holds a PhD in Computer Vision and Pattern Recognition from The Ohio State University. Fabian is involved in helping customers run their machine learning models with low latency on IoT devices and in the cloud across various industries.
Fabian Benitez-Quiroz is a IoT Edge Data Scientist in AWS Professional Services. He holds a PhD in Computer Vision and Pattern Recognition from The Ohio State University. Fabian is involved in helping customers run their machine learning models with low latency on IoT devices and in the cloud across various industries. Romil Shah is a Sr. Data Scientist at AWS Professional Services. Romil has more than 6 years of industry experience in computer vision, machine learning, and IoT edge devices. He is involved in helping customers optimize and deploy their machine learning models for edge devices and on the cloud. He works with customers to create strategies for optimizing and deploying foundation models.
Romil Shah is a Sr. Data Scientist at AWS Professional Services. Romil has more than 6 years of industry experience in computer vision, machine learning, and IoT edge devices. He is involved in helping customers optimize and deploy their machine learning models for edge devices and on the cloud. He works with customers to create strategies for optimizing and deploying foundation models. Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and GenAI solutions on AWS.
Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and GenAI solutions on AWS.













 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football. Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with customers of any size, helping them understand their technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His field of expertice includes machine learning end to end, machine learning endustrialization, and generative AI. He enjoys spending time with his friends and exploring new places, as well as traveling to new destinations.
Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with customers of any size, helping them understand their technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His field of expertice includes machine learning end to end, machine learning endustrialization, and generative AI. He enjoys spending time with his friends and exploring new places, as well as traveling to new destinations.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family. Nikhil Kulkarni is a software developer with AWS Machine Learning, focusing on making machine learning workloads more performant on the cloud, and is a co-creator of AWS Deep Learning Containers for training and inference. He’s passionate about distributed Deep Learning Systems. Outside of work, he enjoys reading books, fiddling with the guitar, and making pizza.
Nikhil Kulkarni is a software developer with AWS Machine Learning, focusing on making machine learning workloads more performant on the cloud, and is a co-creator of AWS Deep Learning Containers for training and inference. He’s passionate about distributed Deep Learning Systems. Outside of work, he enjoys reading books, fiddling with the guitar, and making pizza. Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers to design, build, and operate ML workloads at scale. In his spare time, he enjoys cycling, backpacking, and backpropagating.
Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers to design, build, and operate ML workloads at scale. In his spare time, he enjoys cycling, backpacking, and backpropagating. Eliuth Triana Isaza is a Developer Relations Manager on the NVIDIA-AWS team. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
Eliuth Triana Isaza is a Developer Relations Manager on the NVIDIA-AWS team. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
 James Poquiz is a Data Scientist with AWS Professional Services based in Orange County, California. He has a BS in Computer Science from the University of California, Irvine and has several years of experience working in the data domain having played many different roles. Today he works on implementing and deploying scalable ML solutions to achieve business outcomes for AWS clients.
James Poquiz is a Data Scientist with AWS Professional Services based in Orange County, California. He has a BS in Computer Science from the University of California, Irvine and has several years of experience working in the data domain having played many different roles. Today he works on implementing and deploying scalable ML solutions to achieve business outcomes for AWS clients. Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and GenAI solutions on AWS.
Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and GenAI solutions on AWS. Safa Tinaztepe is a full-stack data scientist with AWS Professional Services. He has a BS in computer science from Emory University and has interests in MLOps, distributed systems, and web3.
Safa Tinaztepe is a full-stack data scientist with AWS Professional Services. He has a BS in computer science from Emory University and has interests in MLOps, distributed systems, and web3.



















 Munish Dabra is a Principal Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn:
Munish Dabra is a Principal Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn:  Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.
Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.