This post is co-written with Eliuth Triana Isaza, Abhishek Sawarkar, and Abdullahi Olaoye from NVIDIA.
Today, we are excited to announce that the Llama 3.3 Nemotron Super 49B V1 and Llama 3.1 Nemotron Nano 8B V1 are available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can now deploy NVIDIA’s newest reasoning models to build, experiment, and responsibly scale your generative AI ideas on AWS.
In this post, we demonstrate how to get started with these models on Amazon Bedrock Marketplace and SageMaker JumpStart.
About NVIDIA NIMs on AWS
NVIDIA NIM inference microservices integrate closely with AWS managed services such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon SageMaker AI, to enable the deployment of generative AI models at scale. As part of NVIDIA AI Enterprise, available in the AWS Marketplace, NVIDIA NIM is a set of easy-to-use microservices designed to accelerate the deployment of generative AI. These prebuilt containers support a broad spectrum of generative AI models from open source community models to NVIDIA AI Foundation and custom models. NIM microservices are deployed with a single command for easy integration into generative AI applications using industry-standard APIs and just a few lines of code, or with a few actions in the SageMaker JumpStart console. Engineered to facilitate seamless generative AI inferencing at scale, NIM ensures generative AI applications can be deployed anywhere.
Overview of NVIDIA Nemotron models
In this section, we provide an overview of the NVIDIA Nemotron Super and Nano NIM microservices discussed in this post.
Llama 3.3 Nemotron Super 49B V1
Llama-3.3-Nemotron-Super-49B-v1 is an LLM which is a derivative of Meta Llama-3.3-70B-Instruct (the reference model). It is a reasoning model that is post-trained for reasoning, human chat preferences, and task executions, such as Retrieval-Augmented Generation (RAG) and tool calling. The model supports a context length of 128K tokens. Using a novel Neural Architecture Search (NAS) approach, we greatly reduced the model’s memory footprint and increased efficiency to support larger workloads and for the model to fit onto a single Hopper GPU (P5 instances) at high workloads (H200).
Llama 3.1 Nemotron Nano 8B V1
Llama-3.1-Nemotron-Nano-8B-v1 is an LLM which is a derivative of Meta Llama-3.1-8B-Instruct (the reference model). It is a reasoning model that is post trained for reasoning, human chat preferences, and task execution, such as RAG and tool calling. The model supports a context length of 128K tokens. It is created from Llama 3.1 8B Instruct and offers improvements in model accuracy. The model fits on a single H100 or A100 GPU (P5 or P4 instances) and can be used locally.
About Amazon Bedrock Marketplace
Amazon Bedrock Marketplace plays a pivotal role in democratizing access to advanced AI capabilities through several key advantages:
- Comprehensive model selection – Amazon Bedrock Marketplace offers an exceptional range of models, from proprietary to publicly available options, allowing organizations to find the perfect fit for their specific use cases.
- Unified and secure experience – By providing a single access point for all models through the Amazon Bedrock APIs, Bedrock Marketplace significantly simplifies the integration process. Organizations can use these models securely, and for models that are compatible with the Amazon Bedrock Converse API, you can use the robust toolkit of Amazon Bedrock, including Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Flows.
- Scalable infrastructure – Amazon Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Deploy NVIDIA Llama Nemotron models in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace gives you access to over 100 popular, emerging, and specialized foundation models (FMs) through Amazon Bedrock. To access the Nemotron reasoning models in Amazon Bedrock, complete the following steps:
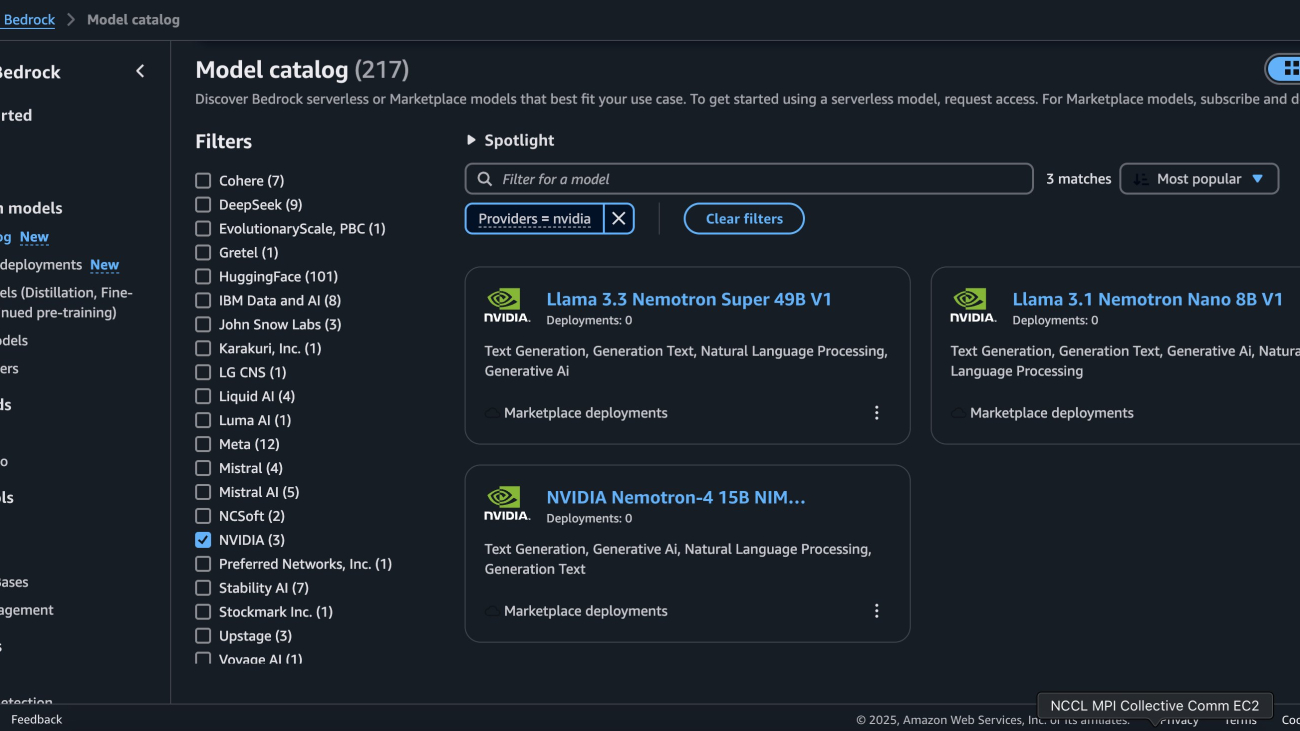
- On the Amazon Bedrock console, in the navigation pane under Foundation models, choose Model catalog.
You can also use the InvokeModel API to invoke the model. The InvokeModel API doesn’t support Converse APIs and other Amazon Bedrock tooling.
- On the Model catalog page, filter for NVIDIA as a provider and choose the Llama 3.3 Nemotron Super 49B V1 model.
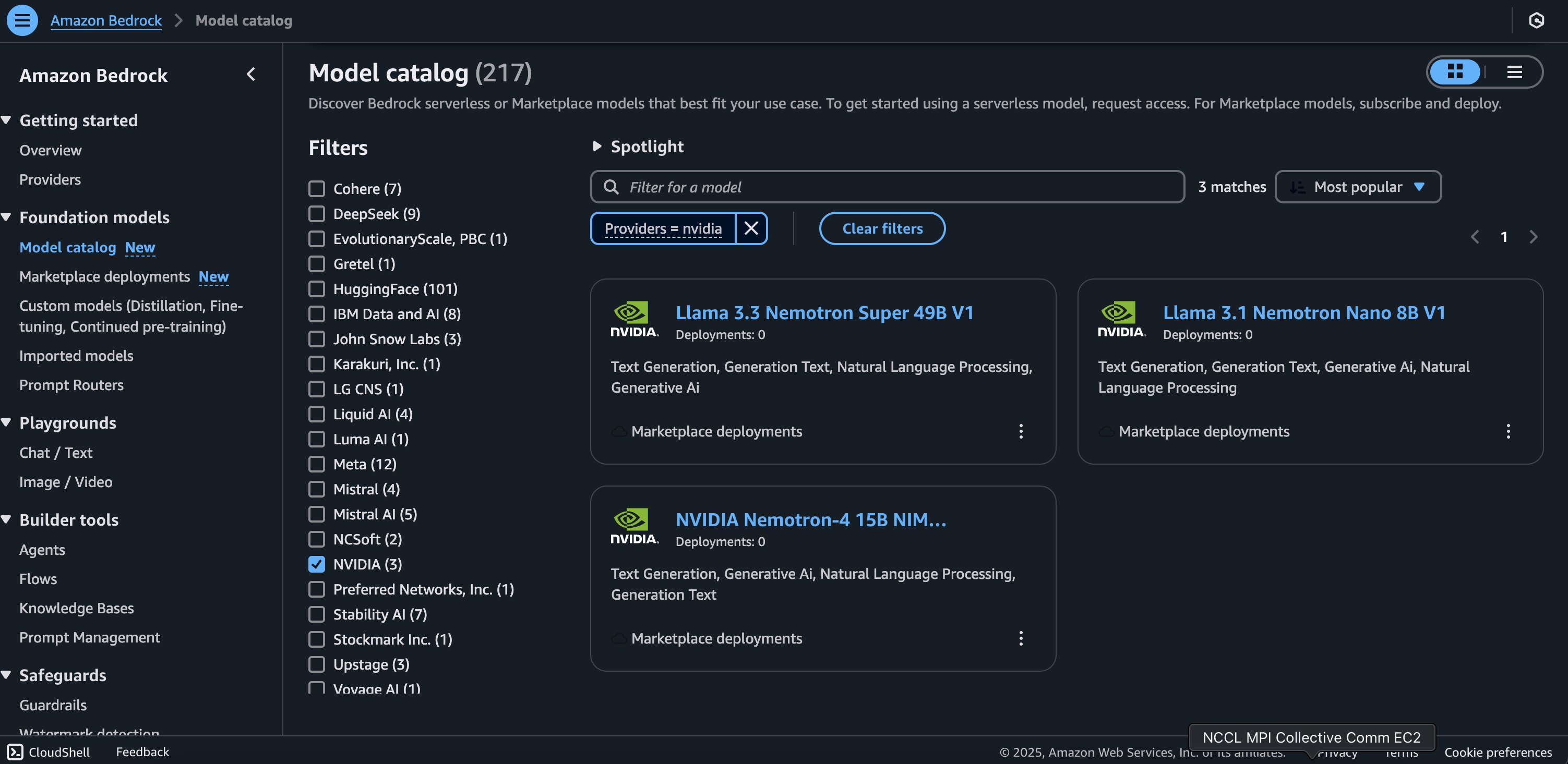
The Model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.
- To begin using the Llama 3.3 Nemotron Super 49B V1 model, choose Subscribe to subscribe to the marketplace offer.
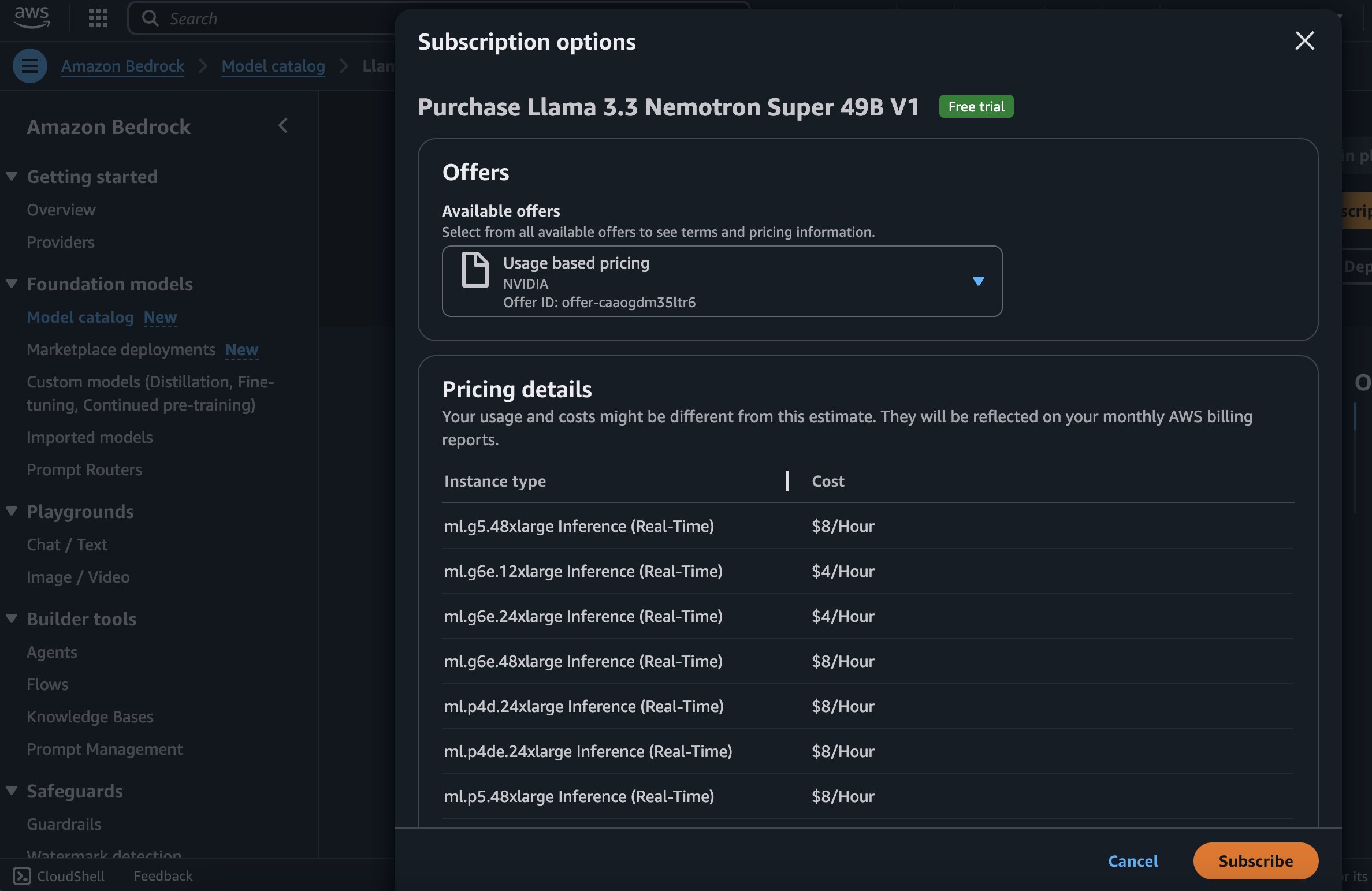
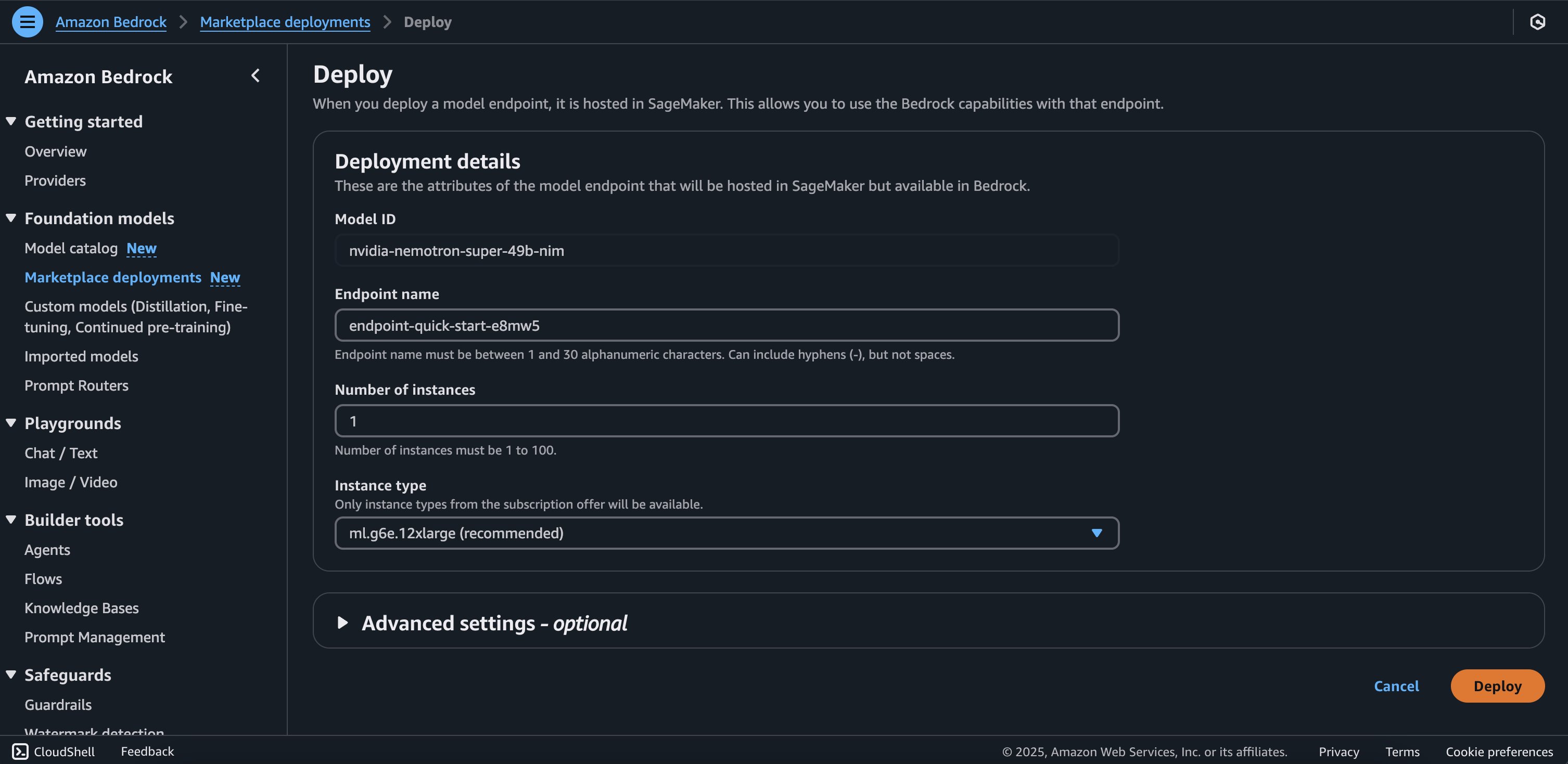
- On the model detail page, choose Deploy.
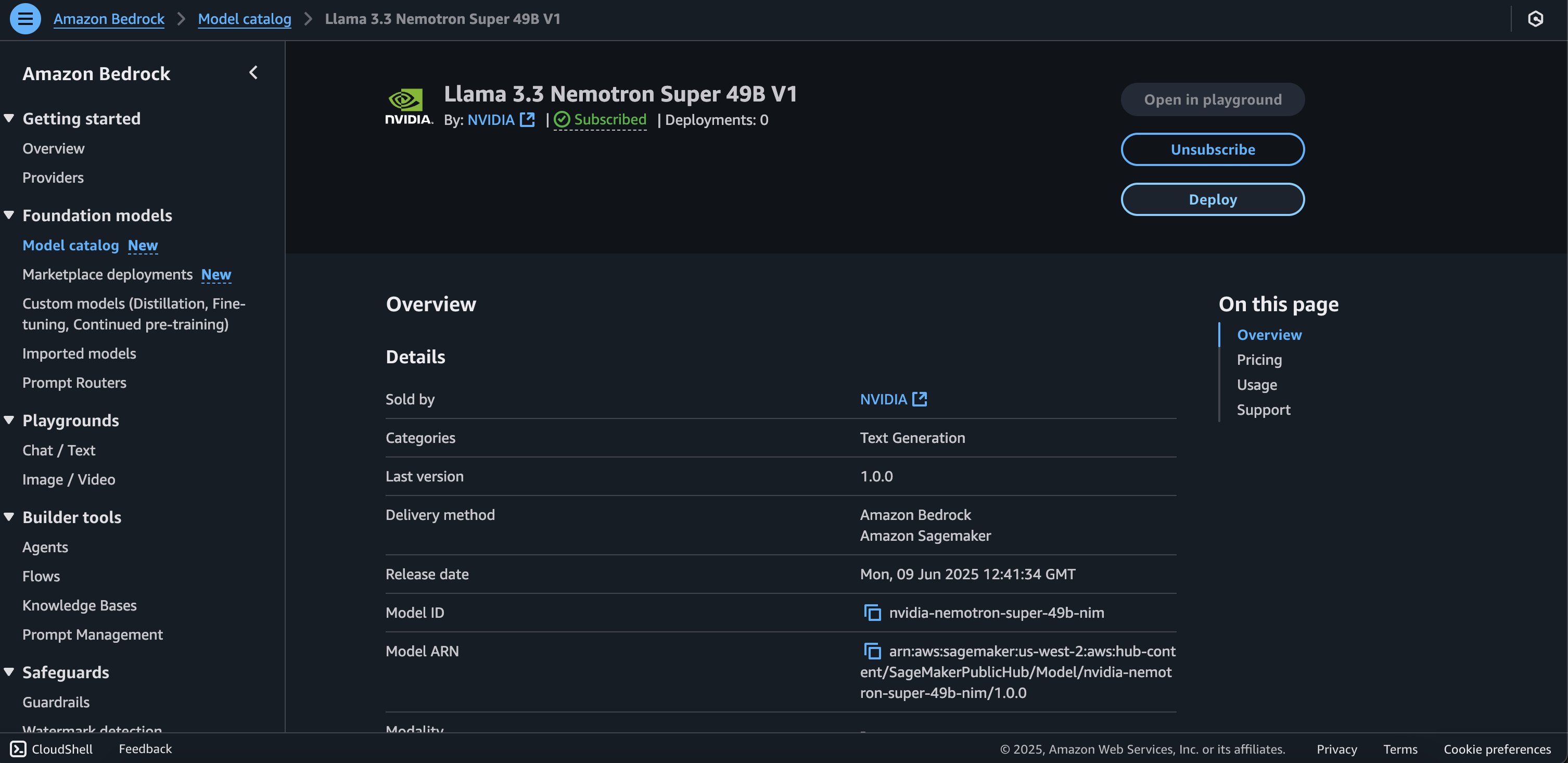
You will be prompted to configure the deployment details for the model. The model ID will be pre-populated.
- For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters).
- For Number of instances, enter a number of instances (between 1–100).
- For Instance type, choose your instance type. For optimal performance with Nemotron Super, a GPU-based instance type like
ml.g6e.12xlarge is recommended.
Optionally, you can configure advanced security and infrastructure settings, including virtual private cloud (VPC) networking, service role permissions, and encryption settings. For most use cases, the default settings will work well. However, for production deployments, you should review these settings to align with your organization’s security and compliance requirements.
- Choose Deploy to begin using the model.
When the deployment is complete, you can test its capabilities directly in the Amazon Bedrock playground.This is an excellent way to explore the model’s reasoning and text generation abilities before integrating it into your applications. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results. A similar process can be followed for deploying the Llama 3.1 Nemotron Nano 8B V1 model as well.
Run inference with the deployed Nemotron endpoint
The following code example demonstrates how to perform inference using a deployed model through Amazon Bedrock using the InvokeModel api. The script initializes the bedrock_runtime client, configures inference parameters, and sends a request to generate text based on a user prompt. With Nemotron Super and Nano models, we can use a soft switch to toggle reasoning on and off. In the content field, set detailed thinking on or detailed thinking off.
Request
import boto3
import json
# Initialize Bedrock client
bedrock_runtime = boto3.client("bedrock-runtime")
# Configuration
MODEL_ID = "" # Replace with Bedrock Marketplace endpoint arn
def invoke_model(prompt, max_tokens=1000, temperature=0.6, top_p=0.9):
"""
Simple Bedrock model invocation
"""
# Prepare model input
body = {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"messages": [
{
"role": "system",
"content": "detailed thinking on" # to turn thinking off, simply toggle this
},
{
"role": "user",
"content": prompt # Use the prompt parameter
}
],
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p
}
# Invoke model
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps(body)
)
# Parse and return response
model_output = json.loads(response['body'].read())
print(json.dumps(model_output, indent=2))
# Example usage
if __name__ == "__main__":
prompt = "Explain how a transformer neural network works."
result = invoke_model(prompt)
print(result)
Response body
{
"id": "chat-43c35c87d5a646c9b3dcaba461eefeaa",
"object": "chat.completion",
"created": 1749566119,
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<think>nOkay, I need to explain how a transformer neural network works. Let me start by recalling what I know about transformers. They were introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017, right? Before transformers, sequence models like RNNs and LSTMs were common, but they had issues with parallelization because of their sequential processing. Transformers changed that by using self-attention mechanisms, which allow parallel processing of the entire input sequence at once.nnSo, the main components of a transformer are the encoder and the decoder. Each encoder layer has two main sub-layers: multi-head self-attention and a fully connected feed-forward network. The decoder has these two plus an additional multi-head attention layer to interact with the encoder's output.nnLet me break down the encoder first. The self-attention mechanism is key here. Self-attention allows the model to attend to all positions in the input sequence simultaneously and weigh their importance. The multi-head part means that instead of just one attention mechanism, you have multiple (like 8 or 12) running in parallel, each with a different linear projection. This helps capture different types of relationships between tokens.nnEach head computes attention by using Query (Q), Key (K), and Value (V) matrices. These are derived from the input by linear transformations. The attention weights are computed as the dot product of Q and K transposed, divided by the square root of the key's dimensionality (for stability). Then, these weights are used to compute a weighted sum of the Value vectors. This gives the output for one attention head. Since there are multiple heads, their outputs are concatenated and then linearly transformed.nnAfter the multi-head attention, there's a feed-forward network (FFN) applied individually to each position. It's a simple neural network with a ReLU activation in the middle. Both the attention and FFN layers use residual connections followed by layer normalization.nnThe decoder is similar but has an extra attention layer that attends to the encoder's output. Also, in the decoder's self-attention, they use masking to prevent looking ahead in the sequence, which is important for tasks like translation where you generate one token at a time.nnPositional encodings are added to the input embeddings because transformers don't have recurrence or convolution, so they need a way to preserve sequence order. The encodings are fixed and based on sine and cosine functions, which allows the model to handle sequences of varying lengths.nnI should also mention the overall architecture: the input goes through an embedding layer plus positional encoding, then through a stack of encoder layers. The output from the encoder goes into the decoder's stack of layers, and the final output goes through a linear layer and softmax for tasks like machine translation.nnWait, maybe I should explain each part step by step. Start with the overall structure, then dive into encoder and decoder layers, then the self-attention mechanism, positional encodings, and how it's different from RNNs.nnPotential pitfalls: Confusing encoder and decoder layers, not explaining why multi-head attention is useful, or omitting the role of layer normalization and residual connections. Also, ensuring that the explanation of attention weights calculation is clear.nnLet me check if I missed anything. Oh, the decoder's structure: after self-attention, there's encoder-decoder attention, then FFN. And the output linear layer. Also, the training process involves teacher forcing, but maybe that's beyond the basic explanation.nnI need to make sure the explanation is clear for someone who knows basics of neural networks but not transformers. Use analogies if possible, like how attention is like selectively focusing on different parts of the input when processing each element.nnAnother point: the efficiency. Since attention is O(n^2) with sequence length n, but it's parallelizable, which is better than O(n) for RNNs which can't be parallelized. But for very long sequences, transformers can be computationally expensive.nnAlso, the difference between BERT-style transformers (encoder-only) and sequence-to-sequence models (both encoder and decoder). But the question is about transformer neural networks in general, so covering the basic encoder-decoder structure is sufficient.nnOkay, putting it all together in a structured way: introduction, architecture overview, encoder details, decoder details, key components (self-attention, positional encodings), advantages, and maybe an example application.n</think>nnA transformer neural network is a revolutionary architecture introduced in 2017 for sequence-to-sequence tasks, replacing recurrent neural networks (RNNs) with self-attention mechanisms for parallel processing. Here's a structured explanation:nn### **1. Architecture Overview**n- **Encoder**: Takes in a sequence (e.g., text) and outputs a continuous representation.n- **Decoder**: Generates an output sequence (e.g., translated text) one token at a time, conditioned on the"
},
"logprobs": null,
"finish_reason": "length",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 29,
"total_tokens": 1029,
"completion_tokens": 1000
},
"prompt_logprobs": null
}
Amazon SageMaker JumpStart overview
SageMaker JumpStart is a fully managed service that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks. You can now discover and deploy Llama 3.3 Nemotron Super 49B V1 and Llama-3.1-Nemotron-Nano-8B-v1 in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, so you can derive model performance and MLOps controls with Amazon SageMaker AI features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in a secure AWS environment and in your VPC, helping to support data security for enterprise security needs.
Prerequisites
Before getting started with deployment, make sure your AWS Identity and Access Management (IAM) service role for Amazon SageMaker has the AmazonSageMakerFullAccess permission policy attached. To deploy the NVIDIA Llama Nemotron models successfully, confirm one of the following:
- Make sure your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- If your account is already subscribed to the model, you can skip to the Deploy section below. Otherwise, please start by subscribing to the model package and then move to the Deploy section.
Subscribe to the model package
To subscribe to the model package, complete the following steps:
- Open the model package listing page and choose Llama 3.3 Nemotron Super 49B V1 or Llama 3.1 Nemotron Nano 8B V1.
- On the AWS Marketplace listing, choose Continue to subscribe.
- On the Subscribe to this software page, review and choose Accept Offer if you and your organization agree with EULA, pricing, and support terms.
- Choose Continue to with the configuration and then choose an AWS Region where you have the service quota for the desired instance type.
A product ARN will be displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
(Option-1) Deploy NVIDIA Llama Nemotron Super and Nano models on SageMaker JumpStart
For those new to SageMaker Jumpstart, we will go to SageMaker Studio to access models on SageMaker Jumpstart. The Llama 3.3 Nemotron Super 49B V1and Llama 3.1 Nemotron Nano 8B V1 models are available on SageMaker Jumpstart. Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.
Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. 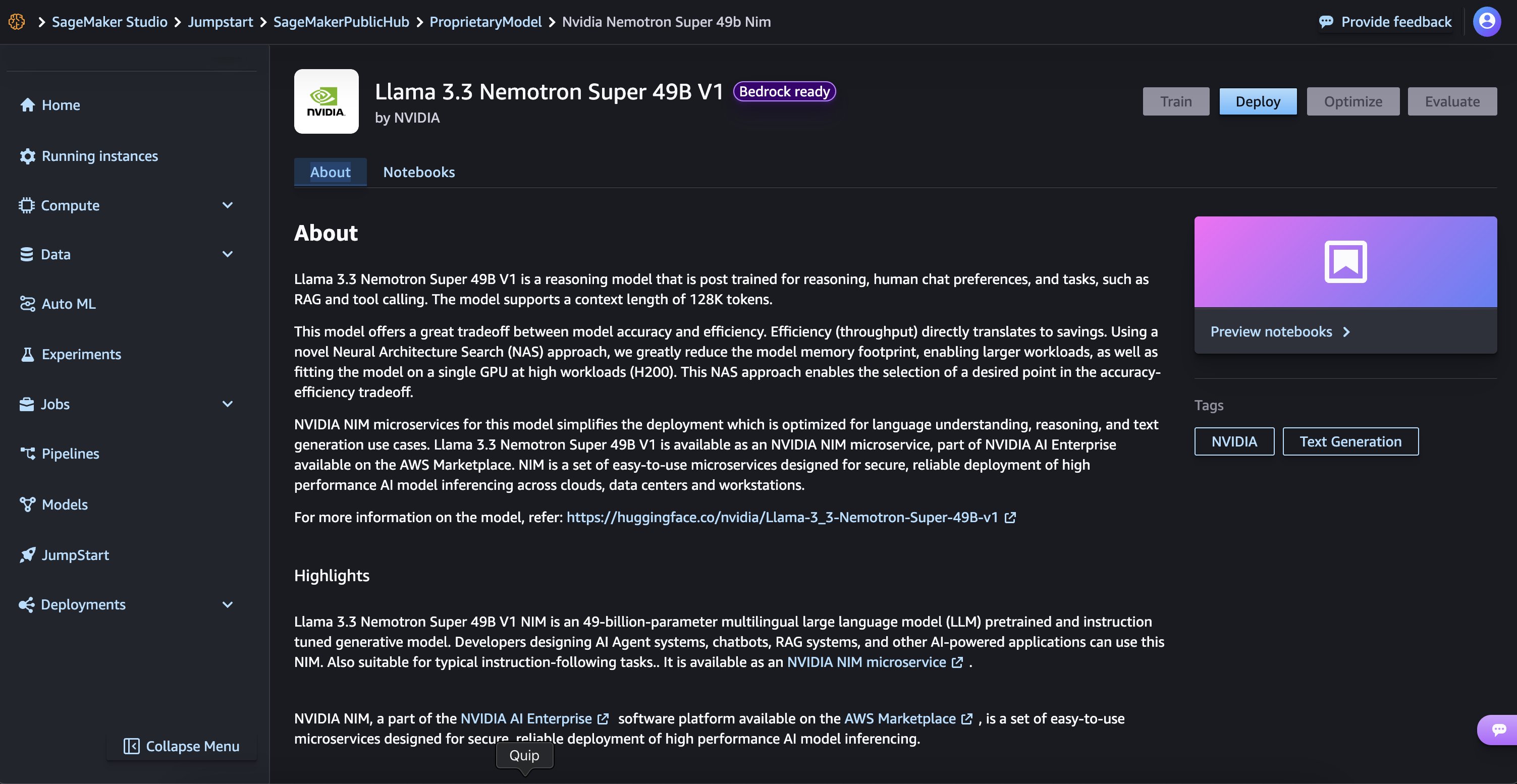
(Option-2) Deploy NVIDIA Llama Nemotron using the SageMaker SDK
In this section we will walk through deploying the Llama 3.3 Nemotron Super 49B V1 model through the SageMaker SDK. A similar process can be followed for deploying the Llama 3.1 Nemotron Nano 8B V1 model as well.
Define the SageMaker model using the Model Package ARN
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
sm_model_name "nim-llama-3-3-nemotron-super-49b-v1"
create_model_response smcreate_model(
ModelNamesm_model_name,
PrimaryContainer{
'ModelPackageName': model_package_arn
},
ExecutionRoleArnrole,
EnableNetworkIsolation
)
print("Model Arn: " create_model_response["ModelArn"])
Create the endpoint configuration
Next, we can create endpoint configuration by specifying instance type, in this case it’s ml.g6e.12xlarge. Make sure you have the account-level service limit for using ml.g6e.12xlarge for endpoint usage as one or more instances. NVIDIA also provides a list of supported instance types that supports deployment. Refer to the AWS Marketplace listing for both of these models to see supported instance types. To request a service quota increase, see AWS service quotas.
endpoint_config_name sm_model_name
create_endpoint_config_response smcreate_endpoint_config(
EndpointConfigNameendpoint_config_name,
ProductionVariants[
{
'VariantName': 'AllTraffic',
'ModelName': sm_model_name,
'InitialInstanceCount': 1,
'InstanceType': 'ml.g6e.12xlarge',
'InferenceAmiVersion': 'al2-ami-sagemaker-inference-gpu-2',
'RoutingConfig': {'RoutingStrategy': 'LEAST_OUTSTANDING_REQUESTS'},
'ModelDataDownloadTimeoutInSeconds': 3600,
'ContainerStartupHealthCheckTimeoutInSeconds': 3600,
}
]
)
print("Endpoint Config Arn: " create_endpoint_config_response["EndpointConfigArn"])
Create the endpoint
Using the previous endpoint configuration we create a new SageMaker endpoint and add a wait and loop as shown below until the deployment finishes. This typically takes around 5-10 minutes. The status will change to InService once the deployment is successful.
endpoint_name endpoint_config_name
create_endpoint_response smcreate_endpoint(
EndpointNameendpoint_name,
EndpointConfigNameendpoint_config_name
)
print("Endpoint Arn: " create_endpoint_response["EndpointArn"
Deploy the endpoint
Let’s now deploy and track the status of the endpoint.
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
while status == "Creating":
time.sleep(60)
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
print("Arn: " + resp["EndpointArn"])
print("Status: " + status)
Run Inference with Llama 3.3 Nemotron Super 49B V1
Once we have the model, we can use a sample text to do an inference request. NIM on SageMaker supports the OpenAI API inference protocol inference request format. For explanation of supported parameters please see Creates a model in the NVIDIA documentation.
Real-Time inference example
The following code examples illustrate how to perform real-time inference using the Llama 3.3 Nemotron Super 49B V1 model in non-reasoning and reasoning mode.
Non-reasoning mode
Perform real-time inference in non-reasoning mode:
payload_model "nvidia/llama-3.3-nemotron-super-49b-v1"
messages [
{
"role": "system",
"content": "detailed thinking off"
},
{
"role":"user",
"content":"Explain how a transformer neural network works."
}
]
payload {
"model": payload_model,
"messages": messages,
"max_tokens": 3000
}
response clientinvoke_endpoint(
EndpointNameendpoint_name, ContentType"application/json", Bodyjsondumps(payload)
)
output jsonloads(response["Body"]read()decode("utf8"))
print(jsondumps(output, indent2))
Reasoning mode
Perform real-time inference in reasoning mode:
payload_model "nvidia/llama-3.3-nemotron-super-49b-v1"
messages [
{
"role": "system",
"content": "detailed thinking on"
},
{
"role":"user",
"content":"Explain how a transformer neural network works."
}
]
payload {
"model": payload_model,
"messages": messages,
"max_tokens": 3000
}
response clientinvoke_endpoint(
EndpointNameendpoint_name, ContentType"application/json", Bodyjsondumps(payload)
)
output jsonloads(response["Body"]read()decode("utf8"))
print(jsondumps(output, indent2))
Streaming inference
NIM on SageMaker also supports streaming inference and you can enable that by setting stream as True in the payload and by using the invoke_endpoint_with_response_stream method.
Streaming inference:
payload_model = "nvidia/llama-3.3-nemotron-super-49b-v1"
messages = [
{
"role": "system",
"content": "detailed thinking on"# this can be toggled off to disable reasoning
},
{
"role":"user",
"content":"Explain how a transformer neural network works."
}
]
payload = {
"model": payload_model,
"messages": messages,
"max_tokens": 3000,
"stream": True
}
response = client.invoke_endpoint_with_response_stream(
EndpointName=endpoint_name,
Body=json.dumps(payload),
ContentType="application/json",
Accept="application/jsonlines",
)
We can use some post-processing code for the streaming output that reads the byte-chunks coming from the endpoint, pieces them into full JSON messages, extracts any new text the model produced, and immediately prints that text to output.
event_stream = response['Body']
accumulated_data = ""
start_marker = 'data:'
end_marker = '"finish_reason":null}]}'
for event in event_stream:
try:
payload = event.get('PayloadPart', {}).get('Bytes', b'')
if payload:
data_str = payload.decode('utf-8')
accumulated_data += data_str
# Process accumulated data when a complete response is detected
while start_marker in accumulated_data and end_marker in accumulated_data:
start_idx = accumulated_data.find(start_marker)
end_idx = accumulated_data.find(end_marker) + len(end_marker)
full_response = accumulated_data[start_idx + len(start_marker):end_idx]
accumulated_data = accumulated_data[end_idx:]
try:
data = json.loads(full_response)
content = data.get('choices', [{}])[0].get('delta', {}).get('content', "")
if content:
print(content, end='', flush=True)
except json.JSONDecodeError:
continue
except Exception as e:
print(f"nError processing event: {e}", flush=True)
continue
Clean up
To avoid unwanted charges, complete the steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, in the navigation pane in the Foundation models section, choose Marketplace deployments.
- In the Managed deployments section, locate the endpoint you want to delete.
- Select the endpoint, and on the Actions menu, choose Delete.
- Verify the endpoint details to make sure you’re deleting the correct deployment:
- Endpoint name
- Model name
- Endpoint status
- Choose Delete to delete the endpoint.
- In the Delete endpoint confirmation dialog, review the warning message, enter
confirm, and choose Delete to permanently remove the endpoint.
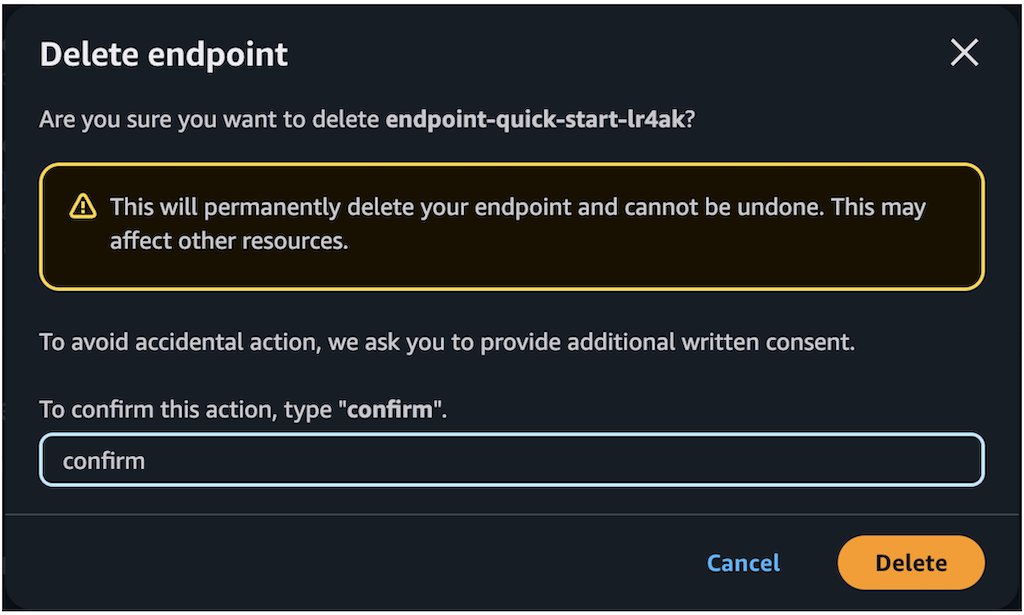
Delete the SageMaker JumpStart Endpoint
The SageMaker JumpStart model you deployed will incur costs if you leave it running. Use the following code to delete the endpoint if you want to stop incurring charges. For more details, see Delete Endpoints and Resources.
sm.delete_model(ModelName=sm_model_name)
sm.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm.delete_endpoint(EndpointName=endpoint_name)
Conclusion
NVIDIA’s Nemotron Llama3 models deliver optimized AI reasoning capabilities and are now available on AWS through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. The Llama 3.3 Nemotron Super 49B V1, derived from Meta’s 70B model, uses Neural Architecture Search (NAS) to achieve a reduced 49B parameter count while maintaining high accuracy, enabling deployment on a single H200 GPU despite its sophisticated capabilities. Meanwhile, the compact Llama 3.1 Nemotron Nano 8B V1 fits on a single fits on a single H100 or A100 GPU (P5 or P4 instances) while improving on Meta’s reference model accuracy, making it ideal for efficiency-conscious applications. Both models support extensive 128K token context windows and are post-trained for enhanced reasoning, RAG capabilities, and tool calling, offering organizations flexible options to balance performance and computational requirements for enterprise AI applications.
With this launch, organizations can now leverage the advanced reasoning capabilities of these models while benefiting from the scalable infrastructure of AWS. Through either the intuitive UI or just a few lines of code, you can quickly deploy these powerful language models to transform your AI applications with minimal effort. These complementary platforms provide straightforward access to NVIDIA’s robust technologies, allowing teams to immediately begin exploring and implementing sophisticated reasoning capabilities in their enterprise solutions.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
 Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
 Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
 Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
 Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
 Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
 Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Read More

 Nicholas Switzer is an AI/ML Specialist Solutions Architect at Amazon Web Services. He joined AWS in 2022 and specializes in AI/ML, generative AI, IoT, and edge AI. He is based in the US and enjoys building intelligent products that improve everyday life.
Nicholas Switzer is an AI/ML Specialist Solutions Architect at Amazon Web Services. He joined AWS in 2022 and specializes in AI/ML, generative AI, IoT, and edge AI. He is based in the US and enjoys building intelligent products that improve everyday life. Jane Ridge is Senior Solutions Architect at Amazon Web Services with over 20 years of technology experience. She joined AWS in 2020 and is based in the US. She is passionate around enabling growth of her customers through innovative solutions combined with her deep technical expertise in the AWS ecosystem. She is known for her ability to guide customers through all stages of their cloud journey and deliver impactful solutions.
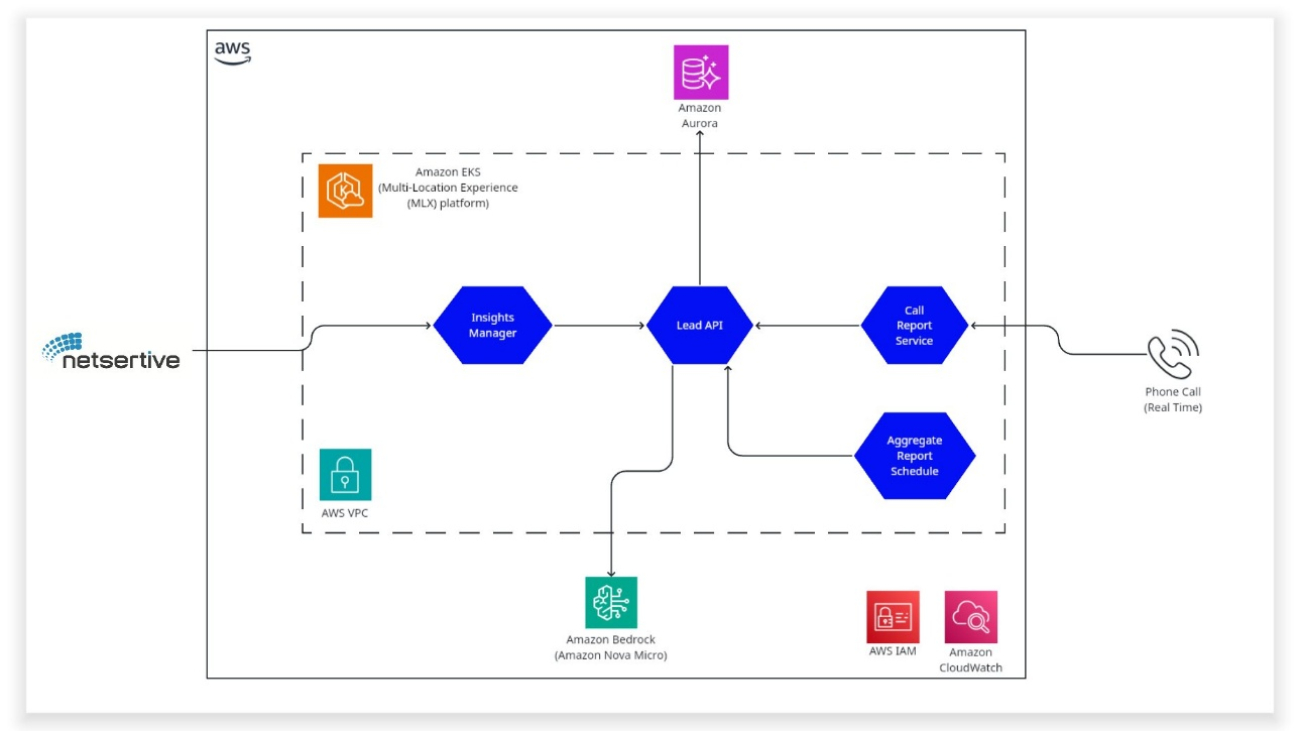
Jane Ridge is Senior Solutions Architect at Amazon Web Services with over 20 years of technology experience. She joined AWS in 2020 and is based in the US. She is passionate around enabling growth of her customers through innovative solutions combined with her deep technical expertise in the AWS ecosystem. She is known for her ability to guide customers through all stages of their cloud journey and deliver impactful solutions. Herb Brittner is the Vice President of Product & Engineering at Netsertive, where he leads the development of AI-driven digital marketing solutions for multi-location brands and franchises. With a strong background in product innovation and scalable engineering, he specializes in using machine learning and cloud technologies to drive business insights and customer engagement. Herb is passionate about building data-driven platforms that enhance marketing performance and operational efficiency.
Herb Brittner is the Vice President of Product & Engineering at Netsertive, where he leads the development of AI-driven digital marketing solutions for multi-location brands and franchises. With a strong background in product innovation and scalable engineering, he specializes in using machine learning and cloud technologies to drive business insights and customer engagement. Herb is passionate about building data-driven platforms that enhance marketing performance and operational efficiency.



 Dylan Martin is an AWS Solutions Architect, working primarily in the generative AI space helping AWS Technical Field teams build AI/ML workloads on AWS. He brings his experience as both a security solutions architect and software engineer. Outside of work he enjoys motorcycling, the French Riviera and studying languages.
Dylan Martin is an AWS Solutions Architect, working primarily in the generative AI space helping AWS Technical Field teams build AI/ML workloads on AWS. He brings his experience as both a security solutions architect and software engineer. Outside of work he enjoys motorcycling, the French Riviera and studying languages. Ankit Patel is an AWS Solutions Developer, part of the Prototyping And Customer Engineering (PACE) team. Ankit helps customers bring their innovative ideas to life by rapid prototyping; using the AWS platform to build, orchestrate, and manage custom applications.
Ankit Patel is an AWS Solutions Developer, part of the Prototyping And Customer Engineering (PACE) team. Ankit helps customers bring their innovative ideas to life by rapid prototyping; using the AWS platform to build, orchestrate, and manage custom applications.












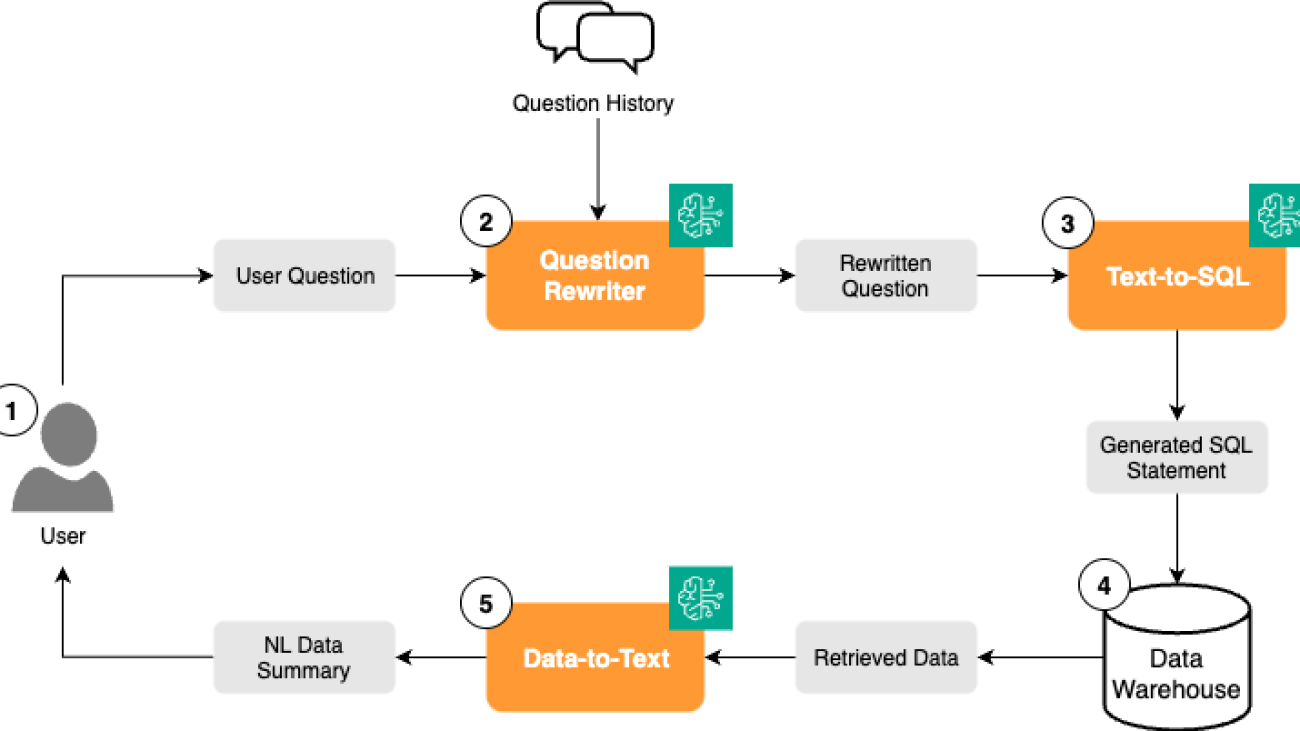
 technology serves as an autonomous layer that decides, selects, executes, and evaluates the right models at runtime. Think of it as a reasoning system that determines what to run, when to run it, and in what sequence, based on the task and context. It evaluates responses at every step to refine its decision-making, enabling more reliable and interpretable AI solutions while dramatically improving performance.
technology serves as an autonomous layer that decides, selects, executes, and evaluates the right models at runtime. Think of it as a reasoning system that determines what to run, when to run it, and in what sequence, based on the task and context. It evaluates responses at every step to refine its decision-making, enabling more reliable and interpretable AI solutions while dramatically improving performance.








 Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market.
Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market. Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures.
Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures. Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact. Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning.
Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning. Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.
Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.













 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.

 Eshan Bhatnagar is the Director of Product Management for Amazon AGI at Amazon Web Services.
Eshan Bhatnagar is the Director of Product Management for Amazon AGI at Amazon Web Services. Amar Goel is Co-Founder and CEO of Bito. A serial entrepreneur, Amar previously founded PubMatic (went public in 2020), and formerly worked at Microsoft, McKinsey, and was a software engineer at Netscape, the original browser company. Amar attended Harvard University. He is excited about using GenAI to power the next generation of how software gets built!
Amar Goel is Co-Founder and CEO of Bito. A serial entrepreneur, Amar previously founded PubMatic (went public in 2020), and formerly worked at Microsoft, McKinsey, and was a software engineer at Netscape, the original browser company. Amar attended Harvard University. He is excited about using GenAI to power the next generation of how software gets built!






 Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund.
Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund. Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics.
Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics. Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London.
Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London. Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies.
Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies. Frederica Schrager is a Marketing Analyst at Gardenia Technologies.
Frederica Schrager is a Marketing Analyst at Gardenia Technologies. Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions. Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs. Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations.
Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations. Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.
Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.