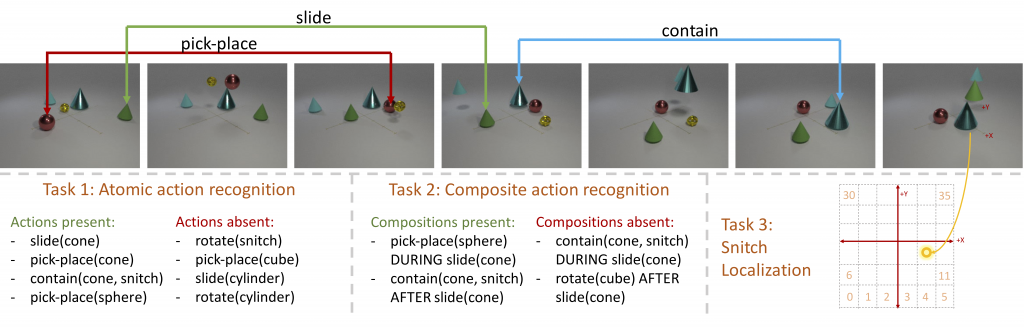
Carnegie Mellon University is proud to present 44 papers at the 37th International Conference on Machine Learning (ICML 2020), which will be held virtually this week. CMU is also involved in organizing 5 workshops at the conference, and our faculty and researchers are giving invited talks at 6 workshops.
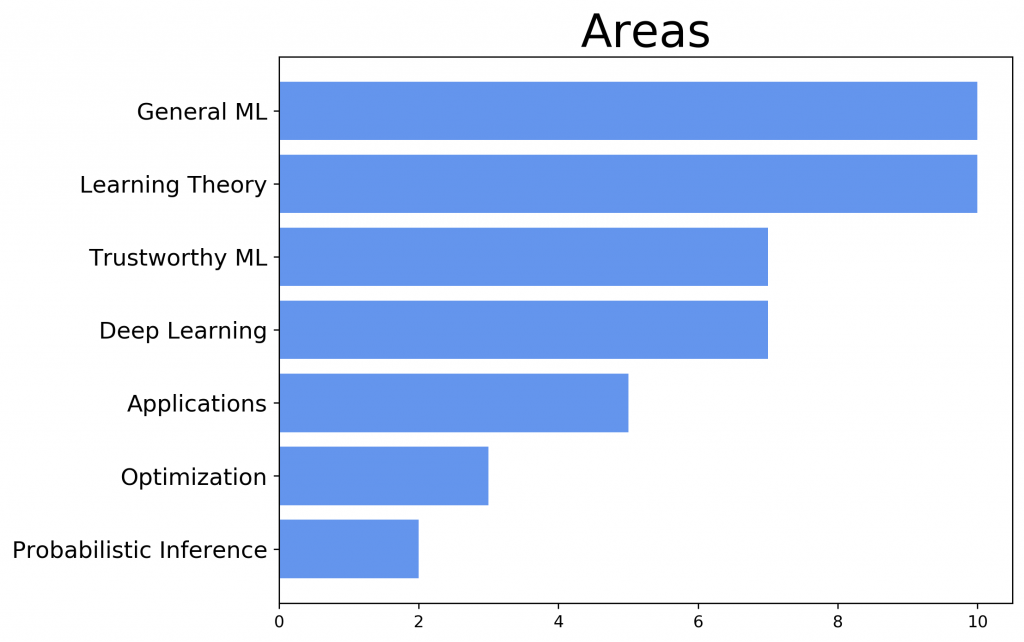
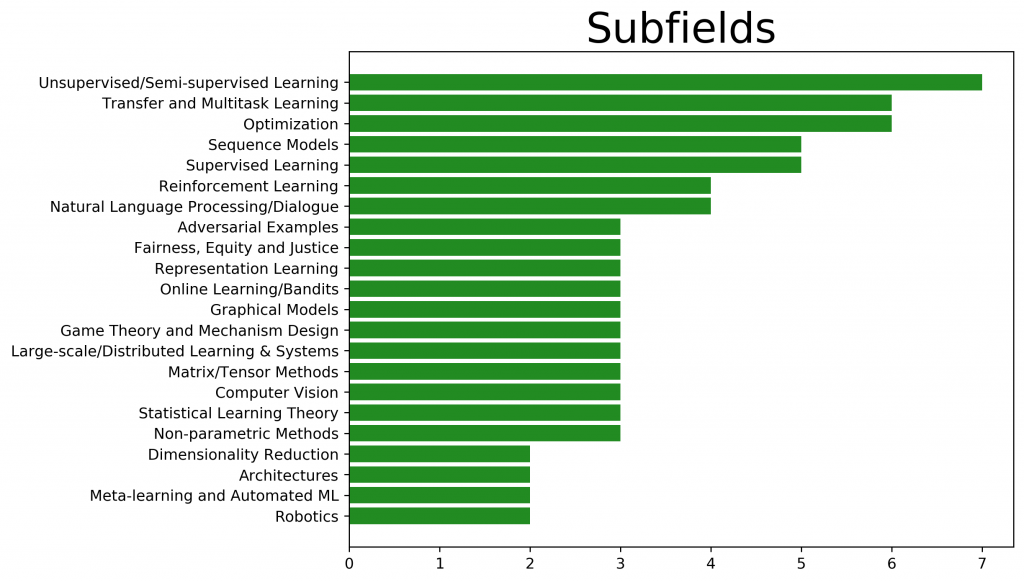
Here is a quick overview of the areas our researchers are working on:
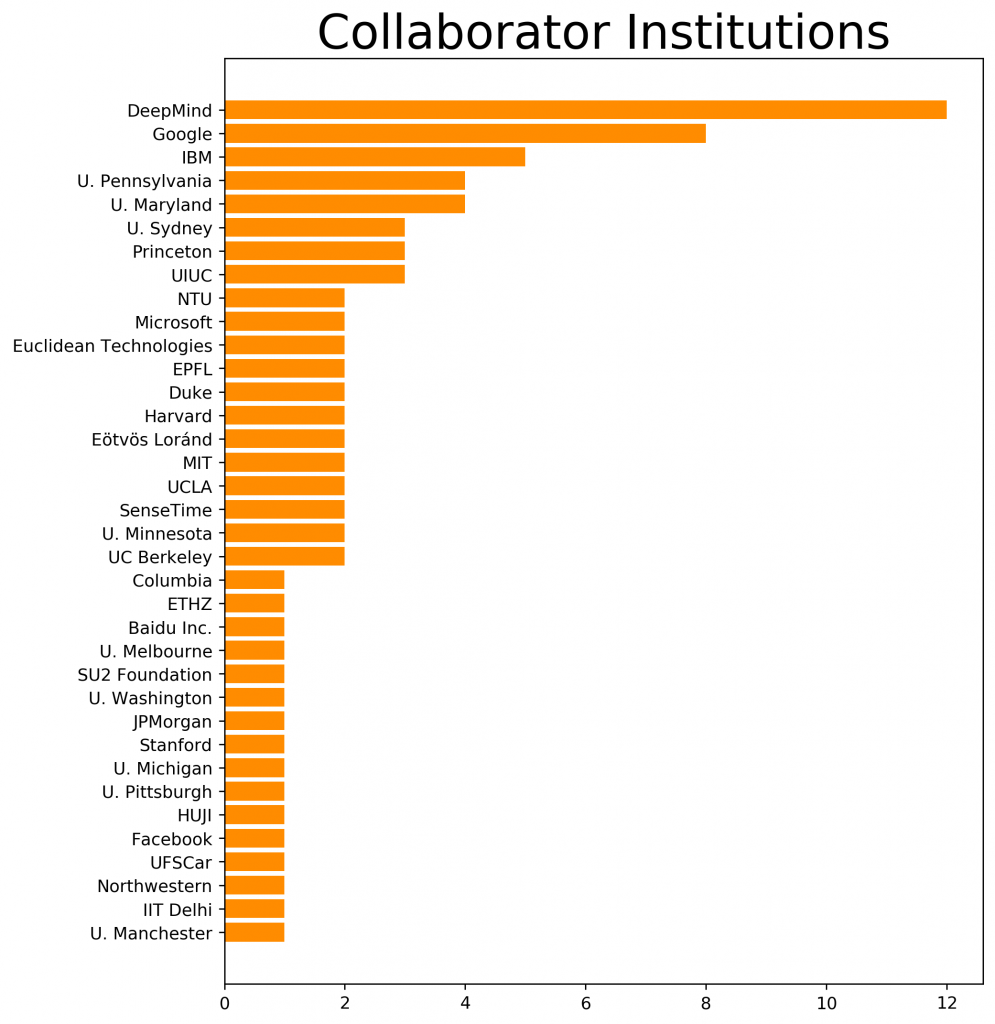
We are also proud to collaborate with many other researchers in academia and industry:
Publications
Check out the full list of papers below, along with their presentation times and links to preprints/code so you can check out our work.
Learning Theory
Familywise Error Rate Control by Interactive Unmasking
Boyan Duan (Carnegie Mellon University); Aaditya Ramdas (Carnegie Mellon University); Larry Wasserman (Carnegie Mellon University)
Learning Theory, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 06:00 PM — 06:45 PM (PDT)
Stochastic Regret Minimization in Extensive-Form Games
Gabriele Farina (Carnegie Mellon University); Christian Kroer (Columbia University); Tuomas Sandholm (CMU, Strategy Robot, Inc., Optimized Markets, Inc., Strategic Machine, Inc.)
Learning Theory, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 06:00 PM — 06:45 PM (PDT)
Strategyproof Mean Estimation from Multiple-Choice Questions
Anson Kahng (Carnegie Mellon University); Gregory Kehne (Carnegie Mellon University); Ariel D Procaccia (Harvard University)
Learning Theory, Tue Jul 14 08:00 AM — 08:45 AM & Tue Jul 14 07:00 PM — 07:45 PM (PDT)
On Learning Language-Invariant Representations for Universal Machine Translation
Han Zhao (Carnegie Mellon University); Junjie Hu (Carnegie Mellon University); Andrej Risteski (CMU)
Learning Theory, Wed Jul 15 05:00 AM — 05:45 AM & Wed Jul 15 04:00 PM — 04:45 PM (PDT)
Class-Weighted Classification: Trade-offs and Robust Approaches
Ziyu Xu (Carnegie Mellon University); Chen Dan (Carnegie Mellon University); Justin Khim (Carnegie Mellon University); Pradeep Ravikumar (Carnegie Mellon University)
Learning Theory, Wed Jul 15 08:00 AM — 08:45 AM & Wed Jul 15 09:00 PM — 09:45 PM (PDT)
Sparsified Linear Programming for Zero-Sum Equilibrium Finding
Brian H Zhang (Carnegie Mellon University); Tuomas Sandholm (CMU, Strategy Robot, Inc., Optimized Markets, Inc., Strategic Machine, Inc.)
Learning Theory, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Sharp Statistical Guarantees for Adversarially Robust Gaussian Classification
Chen Dan (Carnegie Mellon University); Yuting Wei (CMU); Pradeep Ravikumar (Carnegie Mellon University)
Learning Theory, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Uniform Convergence of Rank-weighted Learning
Justin Khim (Carnegie Mellon University); Liu Leqi (Carnegie Mellon University); Adarsh Prasad (Carnegie Mellon University); Pradeep Ravikumar (Carnegie Mellon University)
Learning Theory, Thu Jul 16 07:00 AM — 07:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Online Control of the False Coverage Rate and False Sign Rate
Asaf Weinstein (The Hebrew University of Jerusalem); Aaditya Ramdas (Carnegie Mellon University)
Online Learning, Active Learning, and Bandits, Tue Jul 14 10:00 AM — 10:45 AM & Tue Jul 14 09:00 PM — 09:45 PM (PDT)
On conditional versus marginal bias in multi-armed bandits
Jaehyeok Shin (Carnegie Mellon University); Aaditya Ramdas (Carnegie Mellon University); Alessandro Rinaldo (Carnegie Mellon University)
Online Learning, Active Learning, and Bandits, Wed Jul 15 08:00 AM — 08:45 AM & Wed Jul 15 07:00 PM — 07:45 PM (PDT)
General Machine Learning
Influence Diagram Bandits: Variational Thompson Sampling for Structured Bandit Problems
Tong Yu (Carnegie Mellon University); Branislav Kveton (Google Research); Zheng Wen (DeepMind); Ruiyi Zhang (Duke University); Ole J. Mengshoel (Carnegie Mellon University)
Online Learning, Active Learning, and Bandits, Tue Jul 14 10:00 AM — 10:45 AM & Tue Jul 14 10:00 PM — 10:45 PM (PDT)
The Implicit Regularization of Stochastic Gradient Flow for Least Squares
Alnur Ali (Stanford University); Edgar Dobriban (University of Pennsylvania); Ryan Tibshirani (Carnegie Mellon University)
Supervised Learning, Thu Jul 16 09:00 AM — 09:45 AM & Thu Jul 16 08:00 PM — 08:45 PM (PDT)
Near Input Sparsity Time Kernel Embeddings via Adaptive Sampling
David Woodruff (CMU); Amir Zandieh (EPFL)
General Machine Learning Techniques, Tue Jul 14 02:00 PM — 02:45 PM & Wed Jul 15 03:00 AM — 03:45 AM (PDT)
InfoGAN-CR and Model Centrality: Self-supervised Model Training and Selection for Disentangling GANs [code]Zinan Lin (Carnegie Mellon University); Kiran K Thekumparampil (University of Illinois at Urbana-Champaign); Giulia Fanti (CMU); Sewoong Oh (University of Washington)
Representation Learning, Wed Jul 15 08:00 AM — 08:45 AM & Wed Jul 15 08:00 PM — 08:45 PM (PDT)
LTF: A Label Transformation Framework for Correcting Label Shift
Jiaxian Guo (The University of Sydney); Mingming Gong (University of Melbourne); Tongliang Liu (The University of Sydney); Kun Zhang (Carnegie Mellon University); Dacheng Tao (The University of Sydney)
Transfer, Multitask and Meta-learning, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 07:00 PM — 07:45 PM (PDT)
Optimizing Dynamic Structures with Bayesian Generative Search
Minh Hoang (Carnegie Mellon University); Carleton Kingsford (Carnegie Mellon University)
Transfer, Multitask and Meta-learning, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 05:00 PM — 05:45 PM (PDT)
Label-Noise Robust Domain Adaptation
Xiyu Yu (Baidu Inc.); Tongliang Liu (The University of Sydney); Mingming Gong (University of Melbourne); Kun Zhang (Carnegie Mellon University); Kayhan Batmanghelich (University of Pittsburgh); Dacheng Tao (The University of Sydney)
Unsupervised and Semi-Supervised Learning, Wed Jul 15 05:00 AM — 05:45 AM & Wed Jul 15 07:00 PM — 07:45 PM (PDT)
Input-Sparsity Low Rank Approximation in Schatten Norm
Yi Li (Nanyang Technological University); David Woodruff (Carnegie Mellon University)
Unsupervised and Semi-Supervised Learning, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
A Pairwise Fair and Community-preserving Approach to k-Center Clustering
Brian Brubach (University of Maryland); Darshan Chakrabarti (Carnegie Mellon University); John P Dickerson (University of Maryland); Samir Khuller (Northwestern University); Aravind Srinivasan (University of Maryland College Park); Leonidas Tsepenekas (University of Maryland, College Park)
Unsupervised and Semi-Supervised Learning, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 05:00 PM — 05:45 PM (PDT)
Poisson Learning: Graph Based Semi-Supervised Learning At Very Low Label Rates
Jeff Calder (University of Minnesota); Brendan Cook (University of Minnesota); Matthew Thorpe (University of Manchester); Dejan Slepcev (Carnegie Mellon University)
Unsupervised and Semi-Supervised Learning, Thu Jul 16 07:00 AM — 07:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Trustworthy Machine Learning
Explaining Groups of Points in Low-Dimensional Representations [code]Gregory Plumb CMU); Jonathan Terhorst (U-M LSA); Sriram Sankararaman (UCLA); Ameet Talwalkar (CMU)
Accountability, Transparency and Interpretability, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 06:00 PM — 06:45 PM (PDT)
Overfitting in adversarially robust deep learning [code]Leslie Rice (Carnegie Mellon University); Eric Wong (Carnegie Mellon University); Zico Kolter (Carnegie Mellon University)
Adversarial Examples, Tue Jul 14 08:00 AM — 08:45 AM & Tue Jul 14 07:00 PM — 07:45 PM (PDT)
Adversarial Robustness Against the Union of Multiple Perturbation Models
Pratyush Maini (IIT Delhi); Eric Wong (Carnegie Mellon University); Zico Kolter (Carnegie Mellon University)
Adversarial Examples, Wed Jul 15 09:00 AM — 09:45 AM & Wed Jul 15 09:00 PM — 09:45 PM (PDT)
Characterizing Distribution Equivalence and Structure Learning for Cyclic and Acyclic Directed Graphs
AmirEmad Ghassami (UIUC); Alan Yang (University of Illinois at Urbana-Champaign); Negar Kiyavash (École Polytechnique Fédérale de Lausanne); Kun Zhang (Carnegie Mellon University)
Causality, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 08:00 PM — 08:45 PM (PDT)
Certified Robustness to Label-Flipping Attacks via Randomized Smoothing
Elan Rosenfeld (Carnegie Mellon University); Ezra Winston (Carnegie Mellon University); Pradeep Ravikumar (Carnegie Mellon University); Zico Kolter (Carnegie Mellon University)
Trustworthy Machine Learning, Tue Jul 14 09:00 AM — 09:45 AM & Tue Jul 14 08:00 PM — 08:45 PM (PDT)
FACT: A Diagnostic for Group Fairness Trade-offs
Joon Sik Kim (Carnegie Mellon University); Jiahao Chen (JPMorgan AI Research); Ameet Talwalkar (CMU)
Fairness, Equity, Justice, and Safety, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 05:00 PM — 05:45 PM (PDT)
Is There a Trade-Off Between Fairness and Accuracy? A Perspective Using Mismatched Hypothesis Testing
Sanghamitra Dutta (CMU); Dennis Wei (IBM Research); Hazar Yueksel (IBM Research); Pin-Yu Chen (IBM Research); Sijia Liu (IBM Research); Kush R Varshney (IBM Research)
Fairness, Equity, Justice, and Safety, Thu Jul 16 07:00 AM — 07:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Deep Learning
Combining Differentiable PDE Solvers and Graph Neural Networks for Fluid Flow Prediction [code]Filipe de Avila Belbute-Peres (Carnegie Mellon University); Thomas D. Economon (SU2 Foundation); Zico Kolter (Carnegie Mellon University)
Deep Learning – General, Wed Jul 15 05:00 AM — 05:45 AM & Wed Jul 15 04:00 PM — 04:45 PM (PDT)
Optimizing Data Usage via Differentiable Rewards
Xinyi Wang (Carnegie Mellon University); Hieu Pham (Carnegie Mellon University); Paul Michel (Carnegie Mellon University); Antonios Anastasopoulos (Carnegie Mellon University); Jaime Carbonell (Carnegie Mellon University); Graham Neubig (Carnegie Mellon University)
Deep Learning – Algorithms, Thu Jul 16 08:00 AM — 08:45 AM & Thu Jul 16 07:00 PM — 07:45 PM (PDT)
A Sample Complexity Separation between Non-Convex and Convex Meta-Learning
Nikunj Saunshi (Princeton University); Yi Zhang (Princeton); Mikhail Khodak (Carnegie Mellon University); Sanjeev Arora (Princeton University)
Deep Learning – Theory, Tue Jul 14 10:00 AM — 10:45 AM & Tue Jul 14 09:00 PM — 09:45 PM (PDT)
Stabilizing Transformers for Reinforcement Learning
Emilio Parisotto (Carnegie Mellon University); Francis Song (DeepMind); Jack Rae (Deepmind); Razvan Pascanu (Google Deepmind); Caglar Gulcehre (DeepMind); Siddhant Jayakumar (DeepMind); Max Jaderberg (DeepMind); Raphaël Lopez Kaufman (DeepMind); Aidan Clark (DeepMind); Seb Noury (DeepMind); Matthew Botvinick (Google); Nicolas Heess (DeepMind); Raia Hadsell (Deepmind)
Reinforcement Learning – Deep RL, Wed Jul 15 05:00 AM — 05:45 AM & Wed Jul 15 04:00 PM — 04:45 PM (PDT)
Planning to Explore via Self-Supervised World Models [code]Ramanan Sekar (University of Pennsylvania); Oleh Rybkin (University of Pennsylvania); Kostas Daniilidis (University of Pennsylvania); Pieter Abbeel (UC Berkeley); Danijar Hafner (Google); Deepak Pathak (CMU, FAIR)
Reinforcement Learning – Deep RL, Wed Jul 15 08:00 AM — 08:45 AM & Wed Jul 15 07:00 PM — 07:45 PM (PDT)
One Policy to Control Them All: Shared Modular Policies for Agent-Agnostic Control [code]Wenlong Huang (UC Berkeley); Igor Mordatch (Google); Deepak Pathak (CMU, FAIR)
Reinforcement Learning – Deep RL, Thu Jul 16 08:00 AM — 08:45 AM & Thu Jul 16 08:00 PM — 08:45 PM (PDT)
VideoOneNet: Bidirectional Convolutional Recurrent OneNet with Trainable Data Steps for Video Processing
“Zoltán Á Milacski (Eötvös Loránd University); Barnabas Poczos (Carnegie Mellon University); Andras Lorincz (Eötvös Loránd University)
Sequential, Network, and Time-Series Modeling, Wed Jul 15 02:00 PM — 02:45 PM & Thu Jul 16 01:00 AM — 01:45 AM (PDT)
Applications
An EM Approach to Non-autoregressive Conditional Sequence Generation
Zhiqing Sun (Carnegie Mellon University); Yiming Yang (Carnegie Mellon University)
Applications – Language, Speech and Dialog, Tue Jul 14 08:00 AM — 08:45 AM & Tue Jul 14 07:00 PM — 07:45 PM (PDT)
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalisation [code]Junjie Hu (Carnegie Mellon University); Sebastian Ruder (DeepMind); Aditya Siddhant (Google Research); Graham Neubig (Carnegie Mellon University); Orhan Firat (Google); Melvin Johnson (Google)
Applications – Language, Speech and Dialog, Tue Jul 14 10:00 AM — 10:45 AM & Tue Jul 14 09:00 PM — 09:45 PM (PDT)
Learning Factorized Weight Matrix for Joint Filtering
Xiangyu Xu (Carnegie Mellon University); Yongrui Ma (SenseTime); Wenxiu Sun (SenseTime Research)
Applications – Computer Vision, Thu Jul 16 03:00 PM — 03:45 PM & Fri Jul 17 04:00 AM — 04:45 AM (PDT)
Uncertainty-Aware Lookahead Factor Models for Quantitative Investing
Lakshay Chauhan (Euclidean Technologies); John Alberg (Euclidean Technologies LLC); Zachary Lipton (Carnegie Mellon University)
Applications – Other, Tue Jul 14 08:00 AM — 08:45 AM & Tue Jul 14 08:00 PM — 08:45 PM (PDT)
Learning Robot Skills with Temporal Variational Inference
Tanmay Shankar (Facebook AI Research); Abhinav Gupta (CMU/FAIR)
Applications – Other, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 05:00 PM — 05:45 PM (PDT)
Optimization
Nearly Linear Row Sampling Algorithm for Quantile Regression
Yi Li (Nanyang Technological University); Ruosong Wang (Carnegie Mellon University); Lin Yang (UCLA); Hanrui Zhang (Duke University)
Optimization – Large Scale, Parallel and Distributed, Tue Jul 14 09:00 AM — 09:45 AM & Tue Jul 14 08:00 PM — 08:45 PM (PDT)
The Non-IID Data Quagmire of Decentralized Machine Learning
Kevin Hsieh (Microsoft Research); Amar Phanishayee (Microsoft Research); Onur Mutlu (ETH Zurich); Phillip B Gibbons (CMU)
Optimization – Large Scale, Parallel and Distributed, Wed Jul 15 08:00 AM — 08:45 AM & Wed Jul 15 09:00 PM — 09:45 PM (PDT)
Refined bounds for algorithm configuration: The knife-edge of dual class approximability
Maria-Florina Balcan (Carnegie Mellon University); Tuomas Sandholm (CMU, Strategy Robot, Inc., Optimized Markets, Inc., Strategic Machine, Inc.); Ellen Vitercik (Carnegie Mellon University)
Optimization – General, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 06:00 PM — 06:45 PM (PDT)
Probabilistic Inference
Confidence Sets and Hypothesis Testing in a Likelihood-Free Inference Setting [code]Niccolo Dalmasso (Carnegie Mellon University); Rafael Izbicki (UFSCar); Ann Lee (Carnegie Mellon University)
Probabilistic Inference – Models and Probabilistic Programming, Tue Jul 14 07:00 AM — 07:45 AM & Tue Jul 14 06:00 PM — 06:45 PM (PDT)
Empirical Study of the Benefits of Overparameterization in Learning Latent Variable Models [code]Rares-Darius Buhai (MIT); Yoni Halpern (Google); Yoon Kim (Harvard University); Andrej Risteski (CMU); David Sontag (MIT)
Probabilistic Inference – Models and Probabilistic Programming, Thu Jul 16 06:00 AM — 06:45 AM & Thu Jul 16 05:00 PM — 05:45 PM (PDT)
Workshops
Check out the full list of organized workshops below, along with their times and links to the program.
Invited Speakers
Participatory Approaches to Machine Learning
Alexandra Chouldechova (CMU)
Fri Jul 17 06:00 AM — 01:45 PM (PDT)
Workshop on AI for Autonomous Driving
Drew Bagnell (Aurora and CMU)
Fri Jul 17 05:00 AM — 03:00 PM (PDT)
Bridge Between Perception and Reasoning: Graph Neural Networks & Beyond
Zico Kolter (CMU)
Sat Jul 18 05:50 AM — 02:30 PM (PDT)
Real World Experiment Design and Active Learning
Aaditya Ramdas (CMU)
Sat Jul 18 07:00 AM — 03:35 PM (PDT)
Incentives in Machine Learning
Nihar Shah (CMU)
Sat Jul 18 08:00 AM — 11:00 AM (PDT)
2nd ICML Workshop on Human in the Loop Learning (HILL)
Christian Lebiere (CMU); Pradeep Ravikumar, (CMU)
Sat Jul 18 11:00 AM — 03:00 AM (PDT)
Organizers
Federated Learning for User Privacy and Data Confidentiality
Nathalie Baracaldo (IBM Research Almaden, USA); Olivia Choudhury (Amazon, USA); Gauri Joshi (Carnegie Mellon University, USA); Ramesh Raskar (MIT Media Lab, USA); Shiqiang Wang (IBM T. J. Watson Research Center, USA); Han Yu (Nanyang Technological University, Singapore)
Sat Jul 18 05:45 AM — 02:35 PM (PDT)
MLRetrospectives: A Venue for Self-Reflection in ML Research
Ryan Lowe, (Mila / McGill University); Jessica Forde, (Brown University); Jesse Dodge, CMU); Mayoore Jaiswal, IBM Research); Rosanne Liu, (Uber AI Labs); Joelle Pineau, (Mila / McGill University / Facebook AI); Yoshua Bengio, (Mila)
Sat Jul 18 05:50 AM — 02:30 PM (PDT)
Bridge Between Perception and Reasoning: Graph Neural Networks & Beyond
Jian Tang (HEC Montreal & MILA); Le Song (Georgia Institute of Technology); Jure Leskovec (Stanford University); Renjie Liao (University of Toronto); Yujia Li (DeepMimd); Sanja Fidler (University of Toronto, NVIDIA); Richard Zemel (U Toronto); Ruslan Salakhutdinov (CMU)
Sat Jul 18 05:50 AM — 02:30 PM (PDT)
Workshop on Learning in Artificial Open Worlds
William H. Guss (CMU and OpenAI); Katja Hofmann (Microsoft); Brandon Houghton (CMU and OpenAI); Noburu (Sean) Kuno (Microsoft); Ruslan Salakhutdinov (CMU); Kavya Srinet (Facebook AI Research); Arthur Szlam (Facebook AI Research)
Sat Jul 18 07:00 AM — 02:00 PM (PDT)
Real World Experiment Design and Active Learning
Ilija Bogunovic (ETH Zurich); Willie Neiswanger (Carnegie Mellon University); Yisong Yue (Caltech)
Sat Jul 18 07:00 AM — 03:35 PM (PDT)