 Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…Read More
Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…Read More

Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…Read More

 The best of Google AI is now included in Workspace with significant nonprofit discounts.Read More
The best of Google AI is now included in Workspace with significant nonprofit discounts.Read More

 James Manyika and Kent Walker share three scientific imperatives for the AI era.Read More
James Manyika and Kent Walker share three scientific imperatives for the AI era.Read More
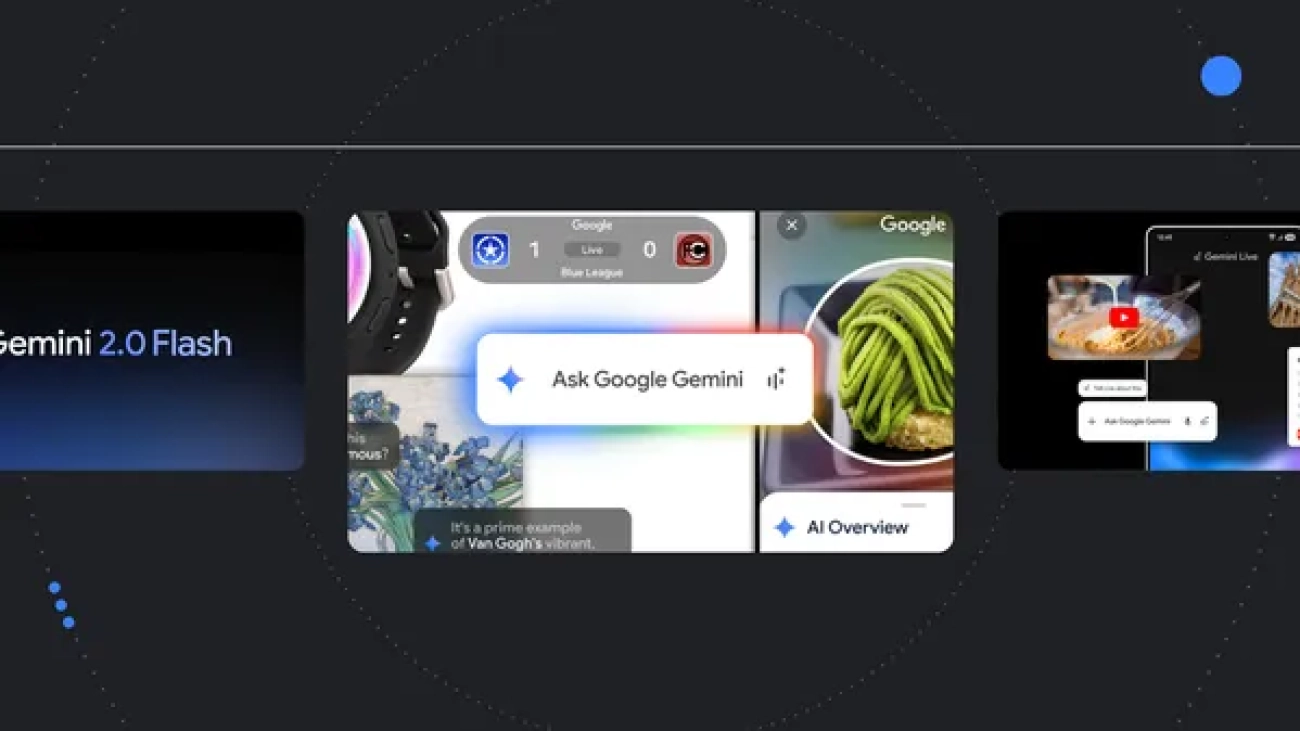
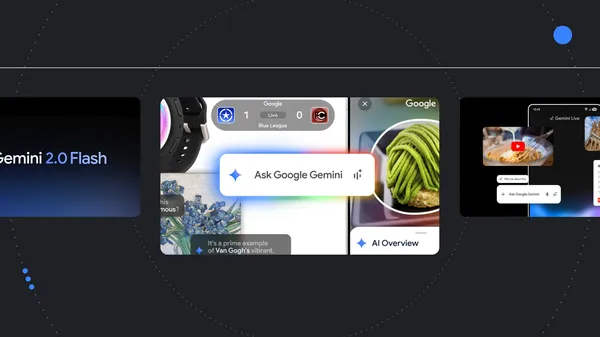 Here are Google’s latest AI updates from January.Read More
Here are Google’s latest AI updates from January.Read More
We’re publishing our 2024 Responsible AI Progress Report and updating our Frontier Safety Framework and AI Principles.Read More

 Yinka Ilori, a British-Nigerian artist, has partnered with Google Arts & Culture to create his first digital artwork, a musical playground.Read More
Yinka Ilori, a British-Nigerian artist, has partnered with Google Arts & Culture to create his first digital artwork, a musical playground.Read More
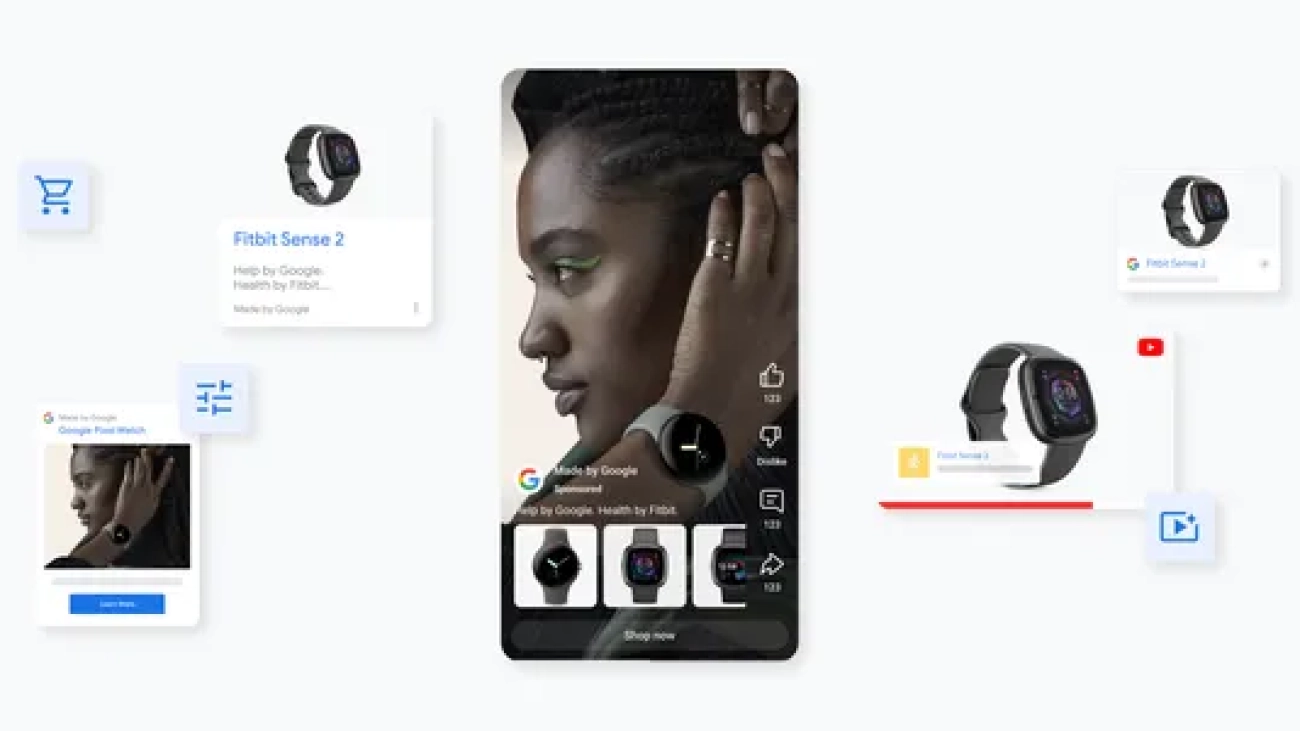
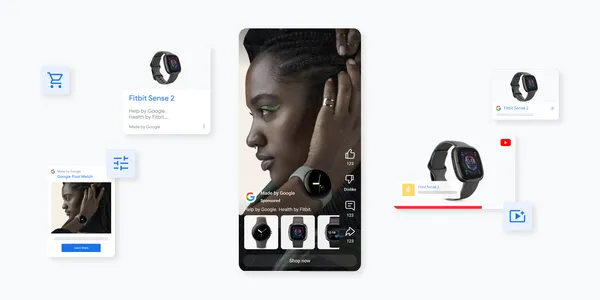 New features are coming to Demand Gen to help you create and convert demand across YouTube and Google’s visual surfaces.Read More
New features are coming to Demand Gen to help you create and convert demand across YouTube and Google’s visual surfaces.Read More

 Google is partnering with UK trade union Community Union to ensure that everyone reaps the benefits of generative AI at work.Read More
Google is partnering with UK trade union Community Union to ensure that everyone reaps the benefits of generative AI at work.Read More
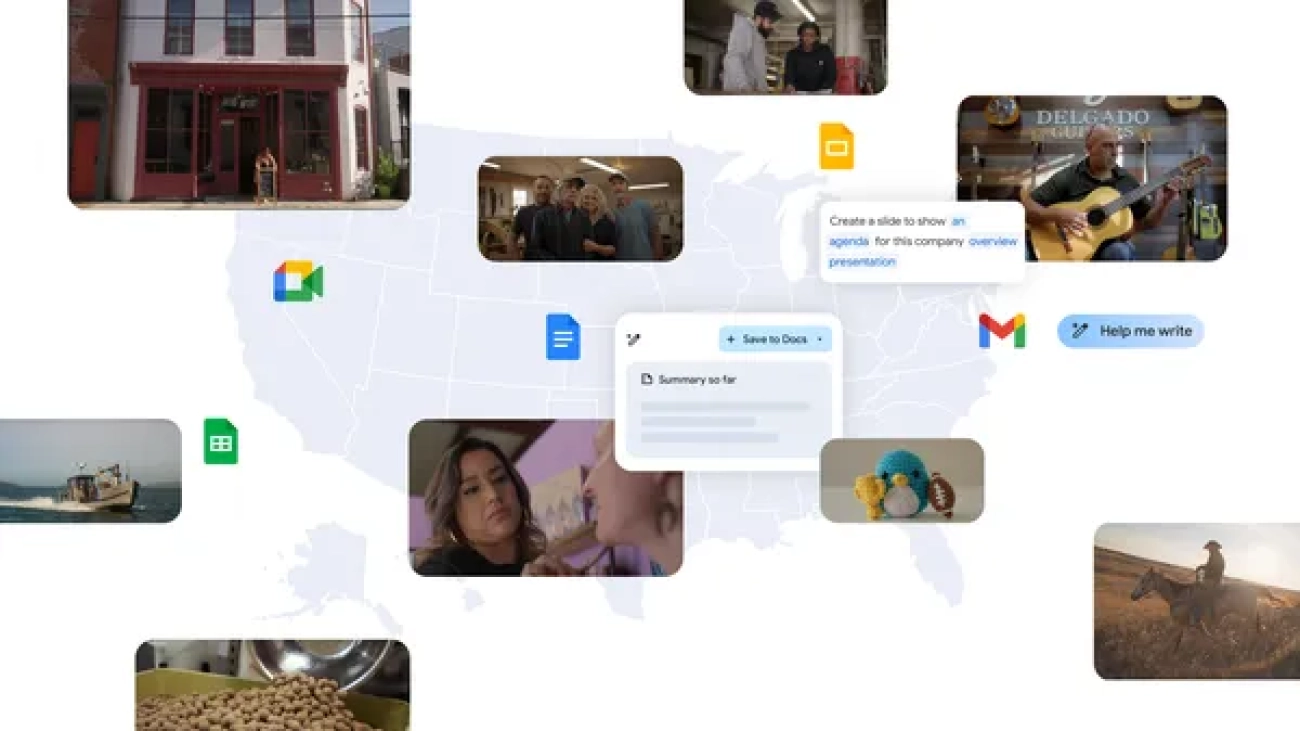
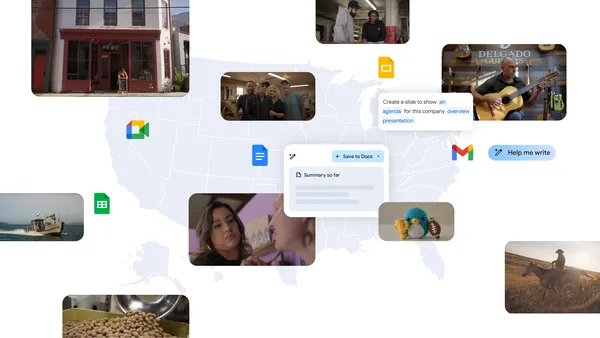 Learn more about Google’s new local ad spots highlighting small businesses using Gemini for Workspace.Read More
Learn more about Google’s new local ad spots highlighting small businesses using Gemini for Workspace.Read More

 Kent Walker shares three national security imperatives for the AI era.Read More
Kent Walker shares three national security imperatives for the AI era.Read More