 News on our bug bounty program specific to generative AI and how we’re supporting open source security for AI supply chainsRead More
News on our bug bounty program specific to generative AI and how we’re supporting open source security for AI supply chainsRead More

News on our bug bounty program specific to generative AI and how we’re supporting open source security for AI supply chainsRead More

Wildfires are becoming larger and affecting more and more communities around the world, often resulting in large-scale devastation. Just this year, communities have experienced catastrophic wildfires in Greece, Maui, and Canada to name a few. While the underlying causes leading to such an increase are complex — including changing climate patterns, forest management practices, land use development policies and many more — it is clear that the advancement of technologies can help to address the new challenges.
At Google Research, we’ve been investing in a number of climate adaptation efforts, including the application of machine learning (ML) to aid in wildfire prevention and provide information to people during these events. For example, to help map fire boundaries, our wildfire boundary tracker uses ML models and satellite imagery to map large fires in near real-time with updates every 15 minutes. To advance our various research efforts, we are partnering with wildfire experts and government agencies around the world.
Today we are excited to share more about our ongoing collaboration with the US Forest Service (USFS) to advance fire modeling tools and fire spread prediction algorithms. Starting from the newly developed USFS wildfire behavior model, we use ML to significantly reduce computation times, thus enabling the model to be employed in near real time. This new model is also capable of incorporating localized fuel characteristics, such as fuel type and distribution, in its predictions. Finally, we describe an early version of our new high-fidelity 3D fire spread model.
Today’s most widely used state-of-the-art fire behavior models for fire operation and training are based on the Rothermel fire model developed at the US Forest Service Fire Lab, by Rothermel et al., in the 1970s. This model considers many key factors that affect fire spread, such as the influence of wind, the slope of the terrain, the moisture level, the fuel load (e.g., the density of the combustible materials in the forest), etc., and provided a good balance between computational feasibility and accuracy at the time. The Rothermel model has gained widespread use throughout the fire management community across the world.
Various operational tools that employ the Rothermel model, such as BEHAVE, FARSITE, FSPro, and FlamMap, have been developed and improved over the years. These tools and the underlying model are used mainly in three important ways: (1) for training firefighters and fire managers to develop their insights and intuitions on fire behavior, (2) for fire behavior analysts to predict the development of a fire during a fire operation and to generate guidance for situation awareness and resource allocation planning, and (3) for analyzing forest management options intended to mitigate fire hazards across large landscapes. These models are the foundation of fire operation safety and efficiency today.
However, there are limitations on these state-of-the art models, mostly associated with the simplification of the underlying physical processes (which was necessary when these models were created). By simplifying the physics to produce steady state predictions, the required inputs for fuel sources and weather became practical but also more abstract compared to measurable quantities. As a result, these models are typically “adjusted” and “tweaked” by experienced fire behavior analysts so they work more accurately in certain situations and to compensate for uncertainties and unknowable environmental characteristics. Yet these expert adjustments mean that many of the calculations are not repeatable.
To overcome these limitations, USFS researchers have been working on a new model to drastically improve the physical fidelity of fire behavior prediction. This effort represents the first major shift in fire modeling in the past 50 years. While the new model continues to improve in capturing fire behavior, the computational cost and inference time makes it impractical to be deployed in the field or for applications with near real-time requirements. In a realistic scenario, to make this model useful and practical in training and operations, a speed up of at least 1000x would be needed.
In partnership with the USFS, we have undertaken a program to apply ML to decrease computation times for complex fire models. Researchers knew that many complex inputs and features could be characterized using a deep neural network, and if successful, the trained model would lower the computational cost and latency of evaluating new scenarios. Deep learning is a branch of machine learning that uses neural networks with multiple hidden layers of nodes that do not directly correspond to actual observations. The model’s hidden layers allow a rich representation of extremely complex systems — an ideal technique for modeling wildfire spread.
We used the USFS physics-based, numerical prediction models to generate many simulations of wildfire behavior and then used these simulated examples to train the deep learning model on the inputs and features to best capture the system behavior accurately. We found that the deep learning model can perform at a much lower computational cost compared to the original and is able to address behaviors resulting from fine-scale processes. In some cases, computation time for capturing the fine-scale features described above and providing a fire spread estimate was 100,000 times faster than running the physics-based numerical models.
This project has continued to make great progress since the first report at ICFFR in December 2022. The joint Google–USFS presentation at ICFFR 2022 and the USFS Fire Lab’s project page provides a glimpse into the ongoing work in this direction. Our team has expanded the dataset used for training by an order of magnitude, from 40M up to 550M training examples. Additionally, we have delivered a prototype ML model that our USFS Fire Lab partner is integrating into a training app that is currently being developed for release in 2024.
 |
| Google researchers visiting the USFS Fire Lab in Missoula, MT, stopping by Big Knife Fire Operation Command Center. |
Besides training, another key use-case of the new model is for operational fire prediction. To fully leverage the advantages of the new model’s capability to capture the detailed fire behavior changes from small-scale differences in fuel structures, high resolution fuel mapping and representation are needed. To this end, we are currently working on the integration of high resolution satellite imagery and geo information into ML models to allow fuel specific mapping at-scale. Some of the preliminary results will be presented at the upcoming 10th International Fire Ecology and Management Congress in November 2023.
Beyond the collaboration on the new fire spread model, there are many important and challenging problems that can help fire management and safety. Many such problems require even more accurate fire models that fully consider 3D flow interactions and fluid dynamics, thermodynamics and combustion physics. Such detailed calculations usually require high-performance computers (HPCs) or supercomputers.
These models can be used for research and longer-term planning purposes to develop insights on extreme fire development scenarios, build ML classification models, or establish a meaningful “danger index” using the simulated results. These high-fidelity simulations can also be used to supplement physical experiments that are used in expanding the operational models mentioned above.
In this direction, Google research has also developed a high-fidelity large-scale 3D fire simulator that can be run on Google TPUs. In the near future, there is a plan to further leverage this new capability to augment the experiments, and to generate data to build insights on the development of extreme fires and use the data to design a fire-danger classifier and fire-danger index protocol.
 |
| An example of 3D high-fidelity simulation. This is a controlled burn field experiment (FireFlux II) simulated using Google’s high fidelity fire simulator. |
We thank Mark Finney, Jason Forthofer, William Chatham and Issac Grenfell from US Forest Service Missoula Fire Science Laboratory and our colleagues John Burge, Lily Hu, Qing Wang, Cenk Gazen, Matthias Ihme, Vivian Yang, Fei Sha and John Anderson for core contributions and useful discussions. We also thank Tyler Russell for his assistance with program management and coordination.

Many people with questions about grammar turn to Google Search for guidance. While existing features, such as “Did you mean”, already handle simple typo corrections, more complex grammatical error correction (GEC) is beyond their scope. What makes the development of new Google Search features challenging is that they must have high precision and recall while outputting results quickly.
The conventional approach to GEC is to treat it as a translation problem and use autoregressive Transformer models to decode the response token-by-token, conditioning on the previously generated tokens. However, although Transformer models have proven to be effective at GEC, they aren’t particularly efficient because the generation cannot be parallelized due to autoregressive decoding. Often, only a few modifications are needed to make the input text grammatically correct, so another possible solution is to treat GEC as a text editing problem. If we could run the autoregressive decoder only to generate the modifications, that would substantially decrease the latency of the GEC model.
To this end, in “EdiT5: Semi-Autoregressive Text-Editing with T5 Warm-Start”, published at Findings of EMNLP 2022, we describe a novel text-editing model that is based on the T5 Transformer encoder-decoder architecture. EdiT5 powers the new Google Search grammar check feature that allows you to check if a phrase or sentence is grammatically correct and provides corrections when needed. Grammar check shows up when the phrase “grammar check” is included in a search query, and if the underlying model is confident about the correction. Additionally, it shows up for some queries that don’t contain the “grammar check” phrase when Search understands that is the likely intent.
 |
For low-latency applications at Google, Transformer models are typically run on TPUs. Due to their fast matrix multiplication units (MMUs), these devices are optimized for performing large matrix multiplications quickly, for example running a Transformer encoder on hundreds of tokens in only a few milliseconds. In contrast, Transformer decoding makes poor use of a TPU’s capabilities, because it forces it to process only one token at a time. This makes autoregressive decoding the most time-consuming part of a translation-based GEC model.
In the EdiT5 approach, we reduce the number of decoding steps by treating GEC as a text editing problem. The EdiT5 text-editing model is based on the T5 Transformer encoder-decoder architecture with a few crucial modifications. Given an input with grammatical errors, the EdiT5 model uses an encoder to determine which input tokens to keep or delete. The kept input tokens form a draft output, which is optionally reordered using a non-autoregressive pointer network. Finally, a decoder outputs the tokens that are missing from the draft, and uses a pointing mechanism to indicate where each new token should be placed to generate a grammatically correct output. The decoder is only run to produce tokens that were missing in the draft, and as a result, runs for much fewer steps than would be needed in the translation approach to GEC.
To further decrease the decoder latency, we reduce the decoder down to a single layer, and we compensate by increasing the size of the encoder. Overall, this decreases latency significantly because the extra work in the encoder is efficiently parallelized.
 |
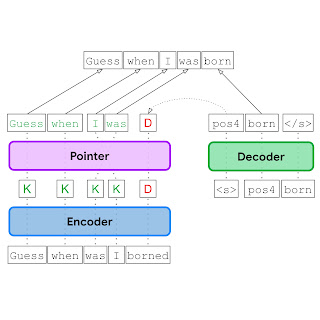
| Given an input with grammatical errors (“Guess when was I borned”), the EdiT5 model uses an encoder to determine which input tokens to keep (K) or delete (D), a pointer network (pointer) to reorder kept tokens, and a decoder to insert any new tokens that are needed to generate a grammatically correct output. |
We applied the EdiT5 model to the public BEA grammatical error correction benchmark, comparing different model sizes. The experimental results show that an EdiT5 large model with 391M parameters yields a higher F0.5 score, which measures the accuracy of the corrections, while delivering a 9x speedup compared to a T5 base model with 248M parameters. The mean latency of the EdiT5 model was merely 4.1 milliseconds.
 |
| Performance of the T5 and EdiT5 models of various sizes on the public BEA GEC benchmark plotted against mean latency. Compared to T5, EdiT5 offers a better latency-F0.5 trade-off. Note that the x axis is logarithmic. |
Our earlier research, as well as the results above, show that model size plays a crucial role in generating accurate grammatical corrections. To combine the advantages of large language models (LLMs) and the low latency of EdiT5, we leverage a technique called hard distillation. First, we train a teacher LLM using similar datasets used for the Gboard grammar model. The teacher model is then used to generate training data for the student EdiT5 model.
Training sets for grammar models consist of ungrammatical source / grammatical target sentence pairs. Some of the training sets have noisy targets that contain grammatical errors, unnecessary paraphrasing, or unwanted artifacts. Therefore, we generate new pseudo-targets with the teacher model to get cleaner and more consistent training data. Then, we re-train the teacher model with the pseudo-targets using a technique called self-training. Finally, we found that when the source sentence contains many errors, the teacher sometimes corrects only part of the errors. Thus, we can further improve the quality of the pseudo-targets by feeding them to the teacher LLM for a second time, a technique called iterative refinement.
 |
| Steps for training a large teacher model for grammatical error correction (GEC). Self-training and iterative refinement remove unnecessary paraphrasing, artifacts, and grammatical errors appearing in the original targets. |
Using the improved GEC data, we train two EdiT5-based models: a grammatical error correction model, and a grammaticality classifier. When the grammar check feature is used, we run the query first through the correction model, and then we check if the output is indeed correct with the classifier model. Only then do we surface the correction to the user.
The reason to have a separate classifier model is to more easily trade off between precision and recall. Additionally, for ambiguous or nonsensical queries to the model where the best correction is unclear, the classifier reduces the risk of serving erroneous or confusing corrections.
We have developed an efficient grammar correction model based on the state-of-the-art EdiT5 model architecture. This model allows users to check for the grammaticality of their queries in Google Search by including the “grammar check” phrase in the query.
We gratefully acknowledge the key contributions of the other team members, including Akash R, Aliaksei Severyn, Harsh Shah, Jonathan Mallinson, Mithun Kumar S R, Samer Hassan, Sebastian Krause, and Shikhar Thakur. We’d also like to thank Felix Stahlberg, Shankar Kumar, and Simon Tong for helpful discussions and pointers.

Google Ads infrastructure runs on an internal data warehouse called Napa. Billions of reporting queries, which power critical dashboards used by advertising clients to measure campaign performance, run on tables stored in Napa. These tables contain records of ads performance that are keyed using particular customers and the campaign identifiers with which they are associated. Keys are tokens that are used both to associate an ads record with a particular client and campaign (e.g., customer_id, campaign_id) and for efficient retrieval. A record contains dozens of keys, so clients use reporting queries to specify keys needed to filter the data to understand ads performance (e.g., by region, device and metrics such as clicks, etc.). What makes this problem challenging is that the data is skewed since queries require varying levels of effort to be answered and have stringent latency expectations. Specifically, some queries require the use of millions of records while others are answered with just a few.
To this end, in “Progressive Partitioning for Parallelized Query Execution in Napa”, presented at VLDB 2023, we describe how the Napa data warehouse determines the amount of machine resources needed to answer reporting queries while meeting strict latency targets. We introduce a new progressive query partitioning algorithm that can parallelize query execution in the presence of complex data skews to perform consistently well in a matter of a few milliseconds. Finally, we demonstrate how Napa allows Google Ads infrastructure to serve billions of queries every day.
When a client inputs a reporting query, the main challenge is to determine how to parallelize the query effectively. Napa’s parallelization technique breaks up the query into even sections that are equally distributed across available machines, which then process these in parallel to significantly reduce query latency. This is done by estimating the number of records associated with a specified key, and assigning more or less equal amounts of work to machines. However, this estimation is not perfect since reviewing all records would require the same effort as answering the query. A machine that processes significantly more than others would result in run-time skews and poor performance. Each machine also needs to have sufficient work since needless parallelism leads to underutilized infrastructure. Finally, parallelization has to be a per query decision that must be executed near-perfectly billions of times, or the query may miss the stringent latency requirements.
The reporting query example below extracts the records denoted by keys (i.e., customer_id and campaign_id) and then computes an aggregate (i.e., SUM(cost)) from an advertiser table. In this example the number of records is too large to process on a single machine, so Napa needs to use a subsequent key (e.g., adgroup_id) to further break up the collection of records so that equal distribution of work is achieved. It is important to note that at petabyte scale, the size of the data statistics needed for parallelization may be several terabytes. This means that the problem is not just about collecting enormous amounts of metadata, but also how it is managed.
SELECT customer_id, campaign_id, SUM(cost)
FROM advertiser_table
WHERE customer_id in (1, 7, ..., x )
AND campaign_id in (10, 20, ..., y)
GROUP BY customer_id, campaign_id;
This reporting query example extracts records denoted by keys (i.e., customer_id and campaign_id) and then computes an aggregate (i.e., SUM(cost)) from an advertiser table. The query effort is determined by the keys’ included in the query. Keys belonging to clients with larger campaigns may touch millions of records since the data volume directly correlates with the size of the ads campaign. This disparity of matching records based on keys reflects the skewness in data, which makes query processing a challenging problem. |
An effective solution minimizes the amount of metadata needed, focuses effort primarily on the skewed part of the key space to partition data efficiently, and works well within the allotted time. For example, if the query latency is a few hundred milliseconds, partitioning should take no longer than tens of milliseconds. Finally, a parallelization process should determine when it’s reached the best possible partitioning that considers query latency expectations. To this end, we have developed a progressive partitioning algorithm that we describe later in this article.
Tables in Napa are constantly updated, so we use log-structured merge forests (LSM tree) to organize the deluge of table updates. LSM is a forest of sorted data that is temporally organized with a B-tree index to support efficient key lookup queries. B-trees store summary information of the sub-trees in a hierarchical manner. Each B-tree node records the number of entries present in each subtree, which aids in the parallelization of queries. LSM allows us to decouple the process of updating the tables from the mechanics of query serving in the sense that live queries go against a different version of the data, which is atomically updated once the next batch of ingest (called delta) has been fully prepared for querying.
 |
The data partitioning problem in our context is that we have a massively large table that is represented as an LSM tree. In the figure below, Delta 1 and 2 each have their own B-tree, and together represent 70 records. Napa breaks the records into two pieces, and assigns each piece to a different machine. The problem becomes a partitioning problem of a forest of trees and requires a tree-traversal algorithm that can quickly split the trees into two equal parts.
To avoid visiting all the nodes of the tree, we introduce the concept of “good enough” partitioning. As we begin cutting and partitioning the tree into two parts, we maintain an estimate of how bad our current answer would be if we terminated the partitioning process at that instant. This is the yardstick of how close we are to the answer and is represented below by a total error margin of 40 (at this point of execution, the two pieces are expected to be between 15 and 35 records in size, the uncertainty adds up to 40). Each subsequent traversal step reduces the error estimate, and if the two pieces are approximately equal, it stops the partitioning process. This process continues until the desired error margin is reached, at which time we are guaranteed that the two pieces are more or less equal.
 |
Progressive partitioning encapsulates the notion of “good enough” in that it makes a series of moves to reduce the error estimate. The input is a set of B-trees and the goal is to cut the trees into pieces of more or less equal size. The algorithm traverses one of the trees (“drill down” in the figure) which results in a reduction of the error estimate. The algorithm is guided by statistics that are stored with each node of the tree so that it makes an informed set of moves at each step. The challenge here is to decide how to direct effort in the best possible way so that the error bound reduces quickly in the fewest possible steps. Progressive partitioning is conducive for our use-case since the longer the algorithm runs, the more equal the pieces become. It also means that if the algorithm is stopped at any point, one still gets good partitioning, where the quality corresponds to the time spent.
 |
Prior work in this space uses a sampled table to drive the partitioning process, while the Napa approach uses a B-tree. As mentioned earlier, even just a sample from a petabyte table can be massive. A tree-based partitioning method can achieve partitioning much more efficiently than a sample-based approach, which does not use a tree organization of the sampled records. We compare progressive partitioning with an alternative approach, where sampling of the table at various resolutions (e.g., 1 record sample every 250 MB and so on) aids the partitioning of the query. Experimental results show the relative speedup from progressive partitioning for queries requiring varying numbers of machines. These results demonstrate that progressive partitioning is much faster than existing approaches and the speedup increases as the size of the query increases.
 |
Napa’s progressive partitioning algorithm efficiently optimizes database queries, enabling Google Ads to serve client reporting queries billions of times each day. We note that tree traversal is a common technique that students in introductory computer science courses use, yet it also serves a critical use-case at Google. We hope that this article will inspire our readers, as it demonstrates how simple techniques and carefully designed data structures can be remarkably potent if used well. Check out the paper and a recent talk describing Napa to learn more.
This blog post describes a collaborative effort between Junichi Tatemura, Tao Zou, Jagan Sankaranarayanan, Yanlai Huang, Jim Chen, Yupu Zhang, Kevin Lai, Hao Zhang, Gokul Nath Babu Manoharan, Goetz Graefe, Divyakant Agrawal, Brad Adelberg, Shilpa Kolhar and Indrajit Roy.


Learning a language can open up new opportunities in a person’s life. It can help people connect with those from different cultures, travel the world, and advance their career. English alone is estimated to have 1.5 billion learners worldwide. Yet proficiency in a new language is difficult to achieve, and many learners cite a lack of opportunity to practice speaking actively and receiving actionable feedback as a barrier to learning.
We are excited to announce a new feature of Google Search that helps people practice speaking and improve their language skills. Within the next few days, Android users in Argentina, Colombia, India (Hindi), Indonesia, Mexico, and Venezuela can get even more language support from Google through interactive speaking practice in English — expanding to more countries and languages in the future. Google Search is already a valuable tool for language learners, providing translations, definitions, and other resources to improve vocabulary. Now, learners translating to or from English on their Android phones will find a new English speaking practice experience with personalized feedback.
 |
| A new feature of Google Search allows learners to practice speaking words in context. |
Learners are presented with real-life prompts and then form their own spoken answers using a provided vocabulary word. They engage in practice sessions of 3-5 minutes, getting personalized feedback and the option to sign up for daily reminders to keep practicing. With only a smartphone and some quality time, learners can practice at their own pace, anytime, anywhere.
Designed to be used alongside other learning services and resources, like personal tutoring, mobile apps, and classes, the new speaking practice feature on Google Search is another tool to assist learners on their journey.
We have partnered with linguists, teachers, and ESL/EFL pedagogical experts to create a speaking practice experience that is effective and motivating. Learners practice vocabulary in authentic contexts, and material is repeated over dynamic intervals to increase retention — approaches that are known to be effective in helping learners become confident speakers. As one partner of ours shared:
“Speaking in a given context is a skill that language learners often lack the opportunity to practice. Therefore this tool is very useful to complement classes and other resources.” – Judit Kormos, Professor, Lancaster University
We are also excited to be working with several language learning partners to surface content they are helping create and to connect them with learners around the world. We look forward to expanding this program further and working with any interested partner.
Every learner is different, so delivering personalized feedback in real time is a key part of effective practice. Responses are analyzed to provide helpful, real-time suggestions and corrections.
The system gives semantic feedback, indicating whether their response was relevant to the question and may be understood by a conversation partner. Grammar feedback provides insights into possible grammatical improvements, and a set of example answers at varying levels of language complexity give concrete suggestions for alternative ways to respond in this context.
 |
| The feedback is composed of three elements: Semantic analysis, grammar correction, and example answers. |
Among the several new technologies we developed, contextual translation provides the ability to translate individual words and phrases in context. During practice sessions, learners can tap on any word they don’t understand to see the translation of that word considering its context.
 |
| Example of contextual translation feature. |
This is a difficult technical task, since individual words in isolation often have multiple alternative meanings, and multiple words can form clusters of meaning that need to be translated in unison. Our novel approach translates the entire sentence, then estimates how the words in the original and the translated text relate to each other. This is commonly known as the word alignment problem.
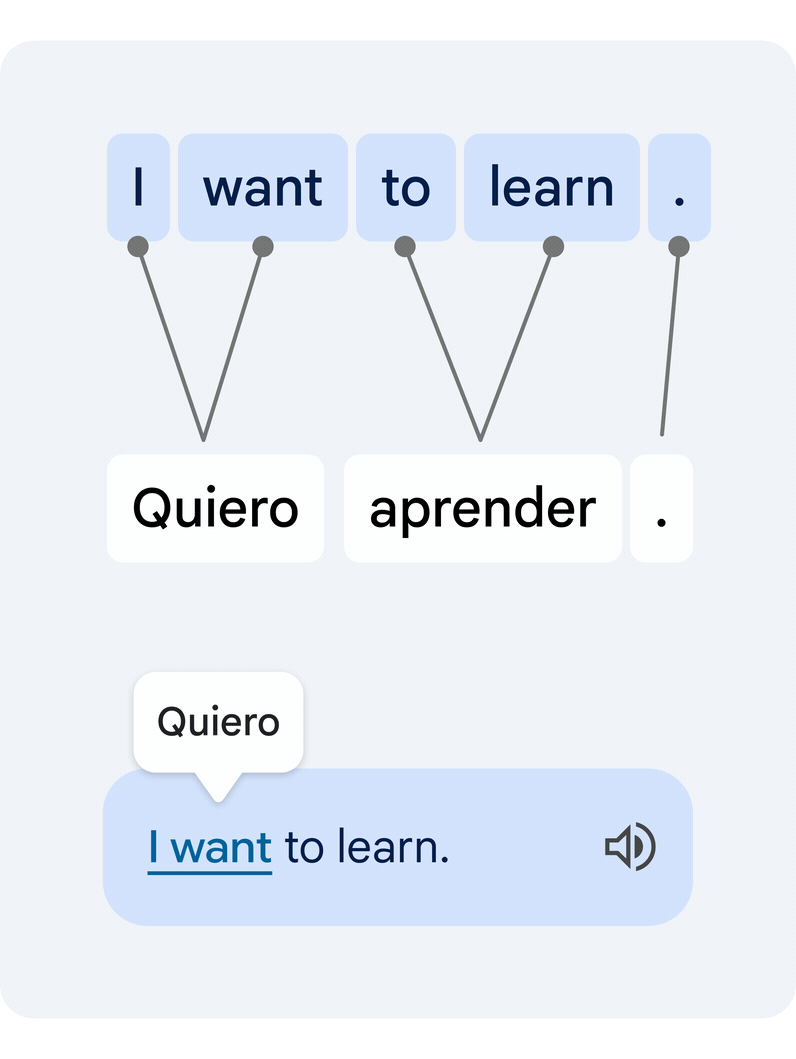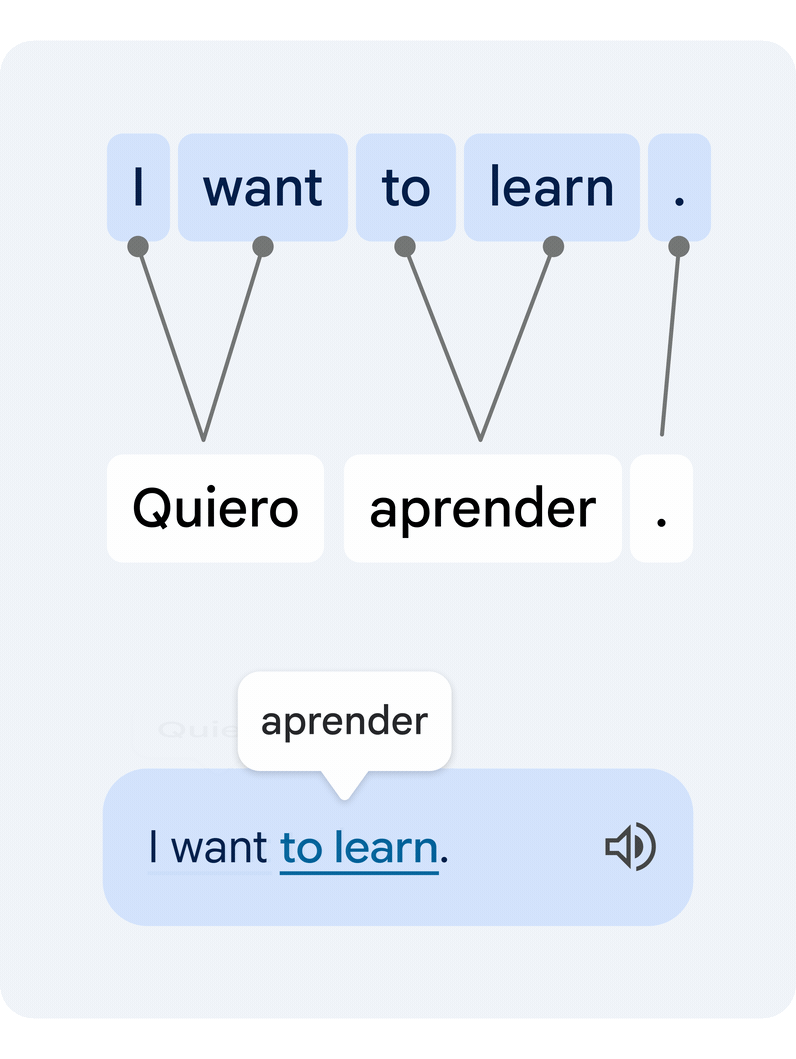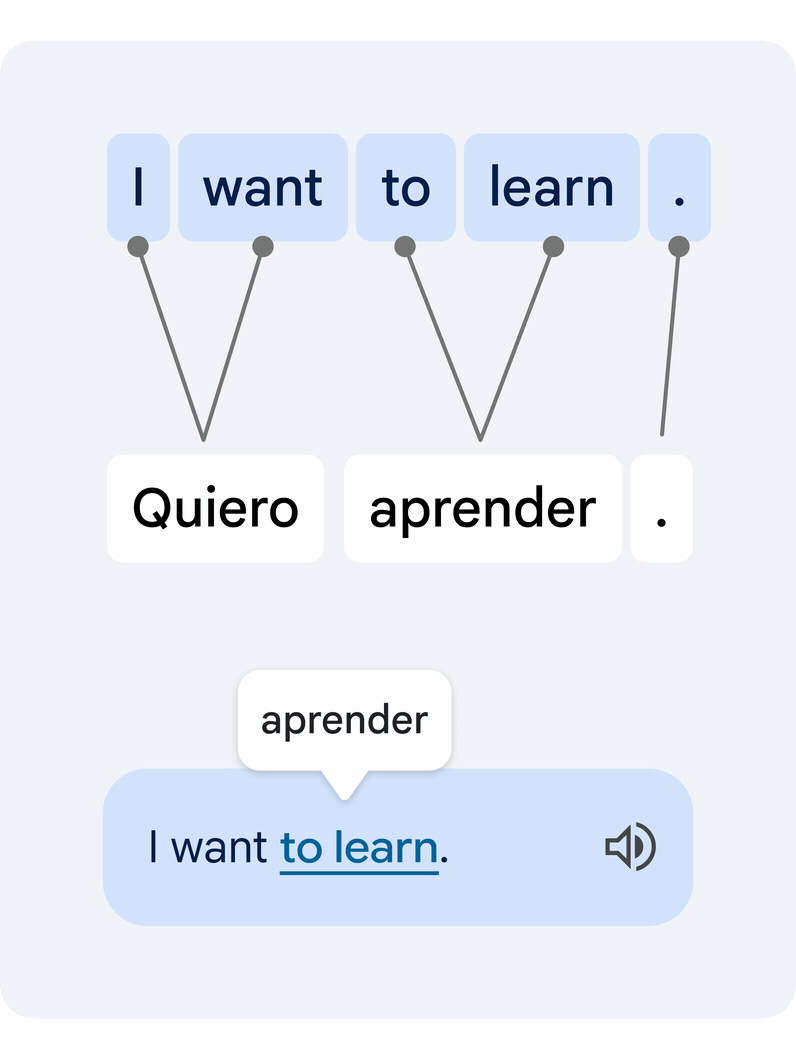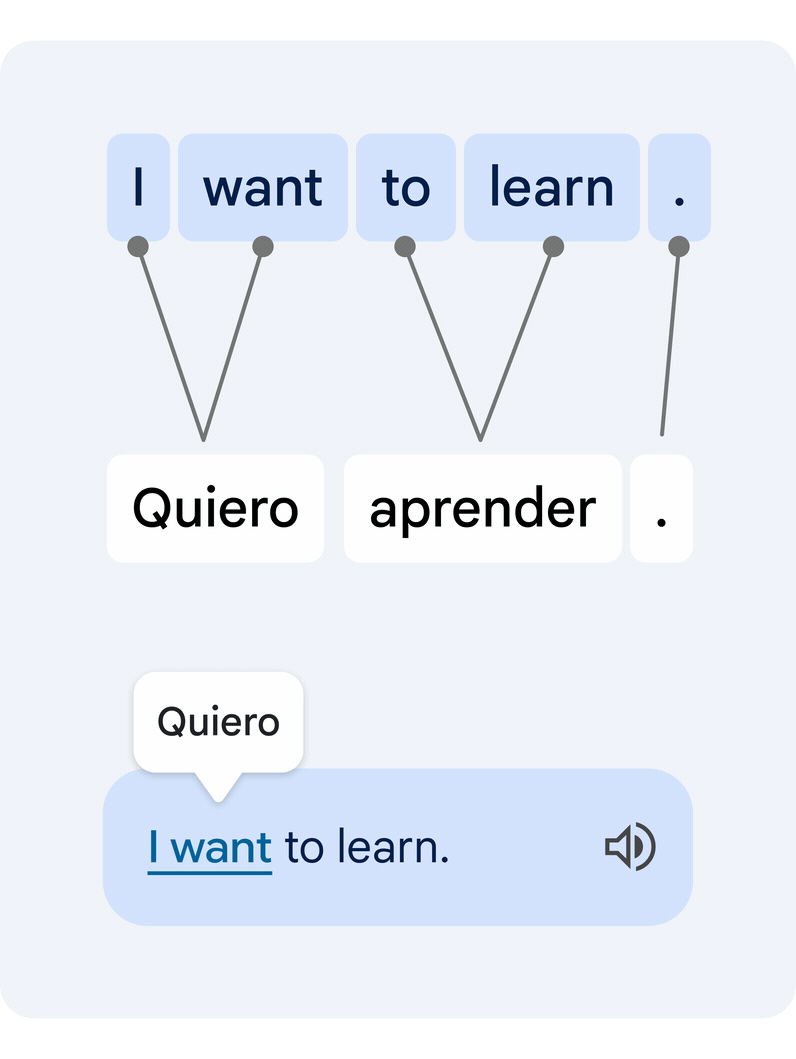 |
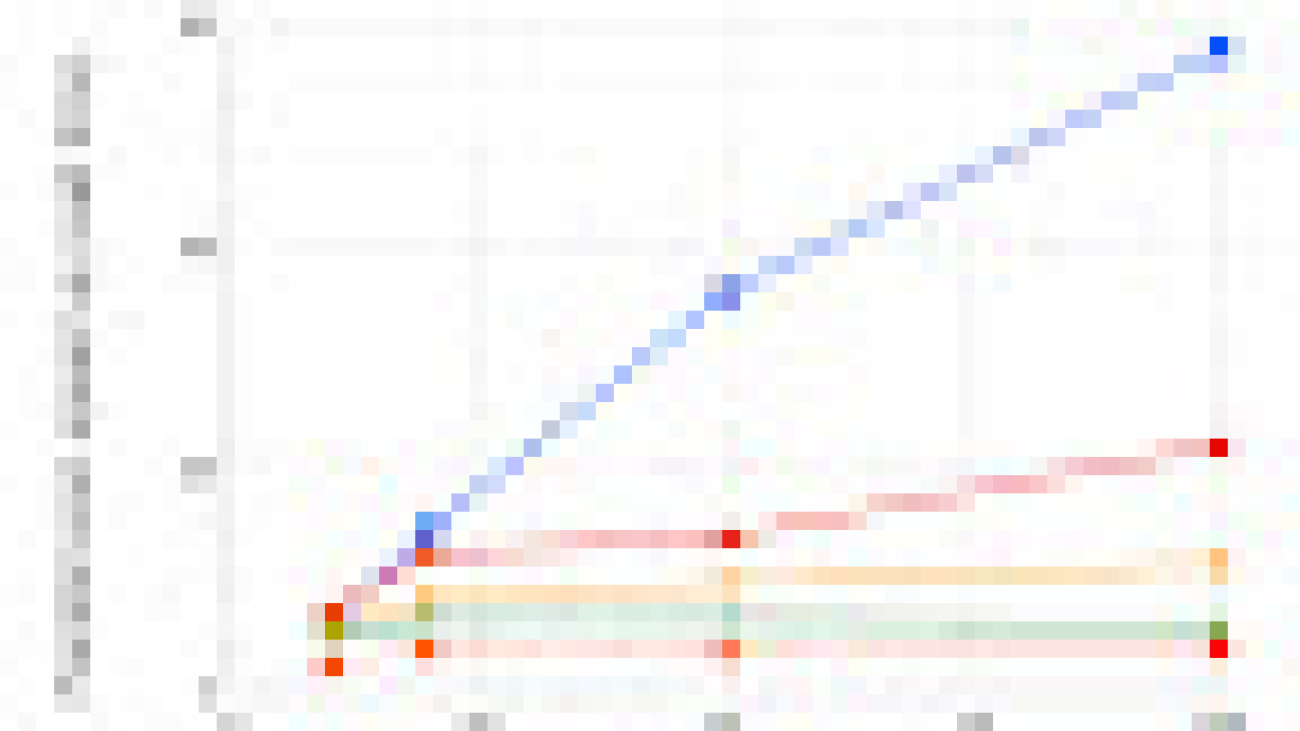
| Example of a translated sentence pair and its word alignment. A deep learning alignment model connects the different words that create the meaning to suggest a translation. |
The key technology piece that enables this functionality is a novel deep learning model developed in collaboration with the Google Translate team, called Deep Aligner. The basic idea is to take a multilingual language model trained on hundreds of languages, then fine-tune a novel alignment model on a set of word alignment examples (see the figure above for an example) provided by human experts, for several language pairs. From this, the single model can then accurately align any language pair, reaching state-of-the-art alignment error rate (AER, a metric to measure the quality of word alignments, where lower is better). This single new model has led to dramatic improvements in alignment quality across all tested language pairs, reducing average AER from 25% to 5% compared to alignment approaches based on Hidden Markov models (HMMs).
 |
| Alignment error rates (lower is better) between English (EN) and other languages. |
This model is also incorporated into Google’s translation APIs, greatly improving, for example, the formatting of translated PDFs and websites in Chrome, the translation of YouTube captions, and enhancing Google Cloud’s translation API.
To enable grammar feedback for accented spoken language, our research teams adapted grammar correction models for written text (see the blog and paper) to work on automatic speech recognition (ASR) transcriptions, specifically for the case of accented speech. The key step was fine-tuning the written text model on a corpus of human and ASR transcripts of accented speech, with expert-provided grammar corrections. Furthermore, inspired by previous work, the teams developed a novel edit-based output representation that leverages the high overlap between the inputs and outputs that is particularly well-suited for short input sentences common in language learning settings.
The edit representation can be explained using an example:
In the above, “at” is the word that is inserted at position 4 and “PREPOSITION” denotes this is an error involving prepositions. We used the error tag to select tag-dependent acceptance thresholds that improved the model further. The model increased the recall of grammar problems from 4.6% to 35%.
Some example output from our model and a model trained on written corpora:
| Example 1 | Example 2 | |||
| User input (transcribed speech) | I live of my profession. | I need a efficient card and reliable. | ||
| Text-based grammar model | I live by my profession. | I need an efficient card and a reliable. | ||
| New speech-optimized model | I live off my profession. | I need an efficient and reliable card. |
A primary goal of conversation is to communicate one’s intent clearly. Thus, we designed a feature that visually communicates to the learner whether their response was relevant to the context and would be understood by a partner. This is a difficult technical problem, since early language learners’ spoken responses can be syntactically unconventional. We had to carefully balance this technology to focus on the clarity of intent rather than correctness of syntax.
Our system utilizes a combination of two approaches:
 |
| The system provides feedback about whether the response was relevant to the prompt, and would be understood by a communication partner. |
Our available practice activities present a mix of human-expert created content, and content that was created with AI assistance and human review. This includes speaking prompts, focus words, as well as sets of example answers that showcase meaningful and contextual responses.
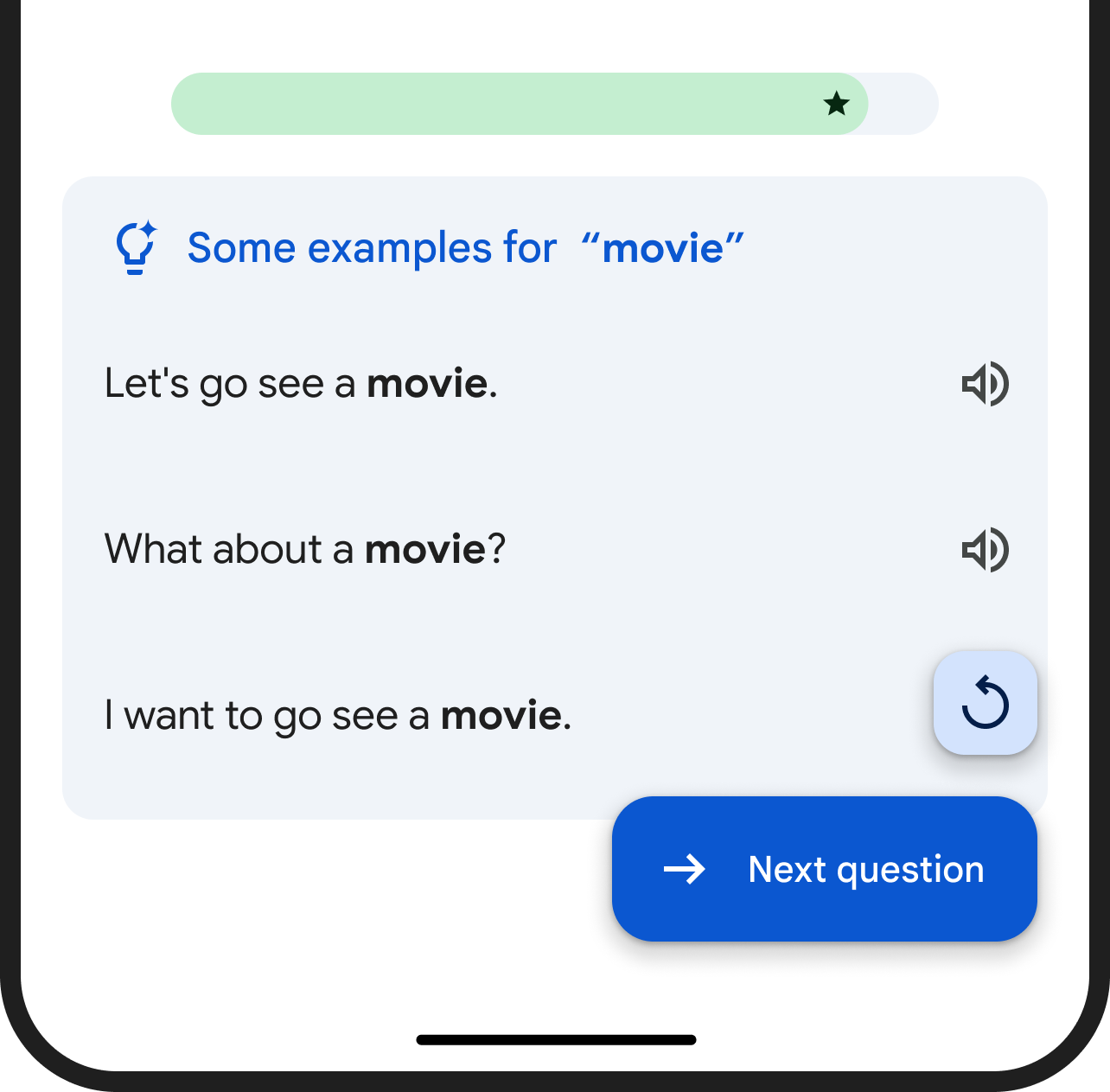 |
| A list of example answers is provided when the learner receives feedback and when they tap the help button. |
Since learners have different levels of ability, the language complexity of the content has to be adjusted appropriately. Prior work on language complexity estimation focuses on text of paragraph length or longer, which differs significantly from the type of responses that our system processes. Thus, we developed novel models that can estimate the complexity of a single sentence, phrase, or even individual words. This is challenging because even a phrase composed of simple words can be hard for a language learner (e.g., “Let’s cut to the chase”). Our best model is based on BERT and achieves complexity predictions closest to human expert consensus. The model was pre-trained using a large set of LLM-labeled examples, and then fine-tuned using a human expert–labeled dataset.
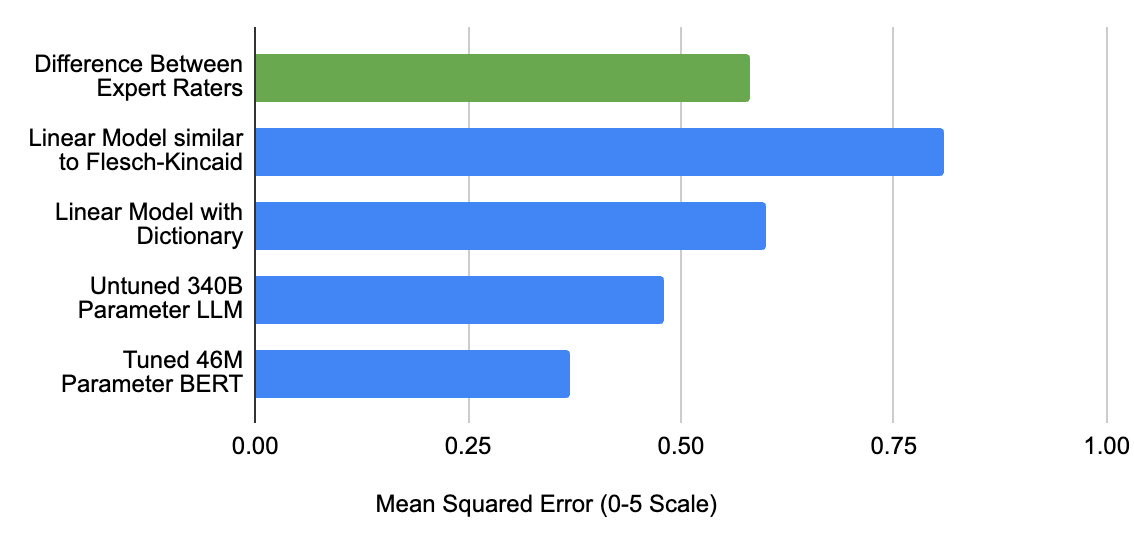 |
| Mean squared error of various approaches’ performance estimating content difficulty on a diverse corpus of ~450 conversational passages (text / transcriptions). Top row: Human raters labeled the items on a scale from 0.0 to 5.0, roughly aligned to the CEFR scale (from A1 to C2). Bottom four rows: Different models performed the same task, and we show the difference to the human expert consensus. |
Using this model, we can evaluate the difficulty of text items, offer a diverse range of suggestions, and most importantly challenge learners appropriately for their ability levels. For example, using our model to label examples, we can fine-tune our system to generate speaking prompts at various language complexity levels.
| Vocabulary focus words, to be elicited by the questions | ||||||
| guitar | apple | lion | ||||
| Simple | What do you like to play? | Do you like fruit? | Do you like big cats? | |||
| Intermediate | Do you play any musical instruments? | What is your favorite fruit? | What is your favorite animal? | |||
| Complex | What stringed instrument do you enjoy playing? | Which type of fruit do you enjoy eating for its crunchy texture and sweet flavor? | Do you enjoy watching large, powerful predators? | |||
Furthermore, content difficulty estimation is used to gradually increase the task difficulty over time, adapting to the learner’s progress.
With these latest updates, which will roll out over the next few days, Google Search has become even more helpful. If you are an Android user in India (Hindi), Indonesia, Argentina, Colombia, Mexico, or Venezuela, give it a try by translating to or from English with Google.
We look forward to expanding to more countries and languages in the future, and to start offering partner practice content soon.
Many people were involved in the development of this project. Among many others, we thank our external advisers in the language learning field: Jeffrey Davitz, Judit Kormos, Deborah Healey, Anita Bowles, Susan Gaer, Andrea Revesz, Bradley Opatz, and Anne Mcquade.


Quantum mechanics allows many phenomena that are classically impossible: a quantum particle can exist in a superposition of two states simultaneously or be entangled with another particle, such that anything you do to one seems to instantaneously also affect the other, regardless of the space between them. But perhaps no aspect of quantum theory is as striking as the act of measurement. In classical mechanics, a measurement need not affect the system being studied. But a measurement on a quantum system can profoundly influence its behavior. For example, when a quantum bit of information, called a qubit, that is in a superposition of both “0” and “1” is measured, its state will suddenly collapse to one of the two classically allowed states: it will be either “0” or “1,” but not both. This transition from the quantum to classical worlds seems to be facilitated by the act of measurement. How exactly it occurs is one of the fundamental unanswered questions in physics.
In a large system comprising many qubits, the effect of measurements can cause new phases of quantum information to emerge. Similar to how changing parameters such as temperature and pressure can cause a phase transition in water from liquid to solid, tuning the strength of measurements can induce a phase transition in the entanglement of qubits.
Today in “Measurement-induced entanglement and teleportation on a noisy quantum processor”, published in Nature, we describe experimental observations of measurement-induced effects in a system of 70 qubits on our Sycamore quantum processor. This is, by far, the largest system in which such a phase transition has been observed. Additionally, we detected “quantum teleportation” — when a quantum state is transferred from one set of qubits to another, detectable even if the details of that state are unknown — which emerged from measurements of a random circuit. We achieved this breakthrough by implementing a few clever “tricks” to more readily see the signatures of measurement-induced effects in the system.
Consider a system of qubits that start out independent and unentangled with one another. If they interact with one another , they will become entangled. You can imagine this as a web, where the strands represent the entanglement between qubits. As time progresses, this web grows larger and more intricate, connecting increasingly disparate points together.
A full measurement of the system completely destroys this web, since every entangled superposition of qubits collapses when it’s measured. But what happens when we make a measurement on only a few of the qubits? Or if we wait a long time between measurements? During the intervening time, entanglement continues to grow. The web’s strands may not extend as vastly as before, but there are still patterns in the web.
There is a balancing point between the strength of interactions and measurements, which compete to affect the intricacy of the web. When interactions are strong and measurements are weak, entanglement remains robust and the web’s strands extend farther, but when measurements begin to dominate, the entanglement web is destroyed. We call the crossover between these two extremes the measurement-induced phase transition.
In our quantum processor, we observe this measurement-induced phase transition by varying the relative strengths between interactions and measurement. We induce interactions by performing entangling operations on pairs of qubits. But to actually see this web of entanglement in an experiment is notoriously challenging. First, we can never actually look at the strands connecting the qubits — we can only infer their existence by seeing statistical correlations between the measurement outcomes of the qubits. So, we need to repeat the same experiment many times to infer the pattern of the web. But there’s another complication: the web pattern is different for each possible measurement outcome. Simply averaging all of the experiments together without regard for their measurement outcomes would wash out the webs’ patterns. To address this, some previous experiments used “post-selection,” where only data with a particular measurement outcome is used and the rest is thrown away. This, however, causes an exponentially decaying bottleneck in the amount of “usable” data you can acquire. In addition, there are also practical challenges related to the difficulty of mid-circuit measurements with superconducting qubits and the presence of noise in the system.
To address these challenges, we introduced three novel tricks to the experiment that enabled us to observe measurement-induced dynamics in a system of up to 70 qubits.
As counterintuitive as it may seem, interchanging the roles of space and time dramatically reduces the technical challenges of the experiment. Before this “space-time duality” transformation, we would have had to interleave measurements with other entangling operations, frequently checking the state of selected qubits. Instead, after the transformation, we can postpone all measurements until after all other operations, which greatly simplifies the experiment. As implemented here, this transformation turns the original 1-spatial-dimensional circuit we were interested in studying into a 2-dimensional one. Additionally, since all measurements are now at the end of the circuit, the relative strength of measurements and entangling interactions is tuned by varying the number of entangling operations performed in the circuit.
 |
| Exchanging space and time. To avoid the complication of interleaving measurements into our experiment (shown as gauges in the left panel), we utilize a space-time duality mapping to exchange the roles of space and time. This mapping transforms the 1D circuit (left) into a 2D circuit (right), where the circuit depth (T) now tunes the effective measurement rate. |
Since each combination of measurement outcomes on all of the qubits results in a unique web pattern of entanglement, researchers often use post-selection to examine the details of a particular web. However, because this method is very inefficient, we developed a new “decoding” protocol that compares each instance of the real “web” of entanglement to the same instance in a classical simulation. This avoids post-selection and is sensitive to features that are common to all of the webs. This common feature manifests itself into a combined classical–quantum “order parameter”, akin to the cross-entropy benchmark used in the random circuit sampling used in our beyond-classical demonstration.
This order parameter is calculated by selecting one of the qubits in the system as the “probe” qubit, measuring it, and then using the measurement record of the nearby qubits to classically “decode” what the state of the probe qubit should be. By cross-correlating the measured state of the probe with this “decoded” prediction, we can obtain the entanglement between the probe qubit and the rest of the (unmeasured) qubits. This serves as an order parameter, which is a proxy for determining the entanglement characteristics of the entire web.
 |
| In the decoding procedure we choose a “probe” qubit (pink) and classically compute its expected value, conditional on the measurement record of the surrounding qubits (yellow). The order parameter is then calculated by the cross correlation between the measured probe bit and the classically computed value. |
A key feature of the so-called “disentangling phase” — where measurements dominate and entanglement is less widespread — is its insensitivity to noise. We can therefore look at how the probe qubit is affected by noise in the system and use that to differentiate between the two phases. In the disentangling phase, the probe will be sensitive only to local noise that occurs within a particular area near the probe. On the other hand, in the entangling phase, any noise in the system can affect the probe qubit. In this way, we are turning something that is normally seen as a nuisance in experiments into a unique probe of the system.
We first studied how the order parameter was affected by noise in each of the two phases. Since each of the qubits is noisy, adding more qubits to the system adds more noise. Remarkably, we indeed found that in the disentangling phase the order parameter is unaffected by adding more qubits to the system. This is because, in this phase, the strands of the web are very short, so the probe qubit is only sensitive to the noise of its nearest qubits. In contrast, we found that in the entangling phase, where the strands of the entanglement web stretch longer, the order parameter is very sensitive to the size of the system, or equivalently, the amount of noise in the system. The transition between these two sharply contrasting behaviors indicates a transition in the entanglement character of the system as the “strength” of measurement is increased.
 |
| Order parameter vs. gate density (number of entangling operations) for different numbers of qubits. When the number of entangling operations is low, measurements play a larger role in limiting the entanglement across the system. When the number of entangling operations is high, entanglement is widespread, which results in the dependence of the order parameter on system size (inset). |
In our experiment, we also demonstrated a novel form of quantum teleportation that arises in the entangling phase. Typically, a specific set of operations are necessary to implement quantum teleportation, but here, the teleportation emerges from the randomness of the non-unitary dynamics. When all qubits, except the probe and another system of far away qubits, are measured, the remaining two systems are strongly entangled with each other. Without measurement, these two systems of qubits would be too far away from each other to know about the existence of each other. With measurements, however, entanglement can be generated faster than the limits typically imposed by locality and causality. This “measurement-induced entanglement” between the qubits (that must also be aided with a classical communications channel) is what allows for quantum teleportation to occur.
 |
| Proxy entropy vs. gate density for two far separated subsystems (pink and black qubits) when all other qubits are measured. There is a finite-size crossing at ~0.9. Above this gate density, the probe qubit is entangled with qubits on the opposite side of the system and is a signature of the teleporting phase. |
Our experiments demonstrate the effect of measurements on a quantum circuit. We show that by tuning the strength of measurements, we can induce transitions to new phases of quantum entanglement within the system and even generate an emergent form of quantum teleportation. This work could potentially have relevance to quantum computing schemes, where entanglement and measurements both play a role.
This work was done while Jesse Hoke was interning at Google from Stanford University. We would like to thank Katie McCormick, our Quantum Science Communicator, for helping to write this blog post.

 Google shares the report: Building a Secure Foundation for American Leadership in AI.Read More
Google shares the report: Building a Secure Foundation for American Leadership in AI.Read More

 Editor’s note: Today we’re building on our long-standing partnership with the University of Cambridge, with a multi-year research collaboration agreement and a Google gr…Read More
Editor’s note: Today we’re building on our long-standing partnership with the University of Cambridge, with a multi-year research collaboration agreement and a Google gr…Read More


Some cities or communities develop an evacuation plan to be used in case of an emergency. There are a number of reasons why city officials might enact their plan, a primary one being a natural disaster, such as a tornado, flood, or wildfire. An evacuation plan can help the community more effectively respond to an emergency, and so could help save lives. However, it can be difficult for a city to evaluate such a plan because it is not practical to have an entire town or city rehearse a full blown evacuation. For example, Mill Valley, a city in northern California, created a wildfire evacuation plan but lacked an estimate for how long the evacuation would take.
Today we describe a case study in which we teamed up with the city of Mill Valley to test and improve their evacuation plan. We outline our approach in our paper, “Mill Valley Evacuation Study”. We started by using a traffic simulator to model a citywide evacuation. The research goal was to provide the city with detailed estimates for how long it would take to evacuate the city, and, by studying the egress pattern, to find modifications to make the plan more effective. While our prior work on this subject provided an estimate for the evacuation time and showed how the time could be reduced if certain road changes were implemented, it turns out the recommendations in that paper — such as changing the number of outgoing lanes on an arterial — were not feasible. The current round of research improves upon the initial study by more accurately modeling the number and starting locations of vehicles, by using a more realistic map, and by working closely with city officials to ensure that recommended changes to the plan are deemed viable.
Mill Valley is in Marin County, California, north of San Francisco. Many of the residences are located on the steep hillsides of several valleys surrounded by dense redwood forests.
 |
 |
| Aerial views of Mill Valley, courtesy of the City of Mill Valley. |
Many of those residences are in areas that have only one exit direction, toward the town center. From there the best evacuation route is toward Highway 101, which is in the flat part of the city and is the most likely area to be far from potential wildfires. Some neighborhoods have other routes that lead away from both the city and Highway 101, but those routes pass through hilly forested areas, which could be dangerous or impassable during a wildfire. So, the evacuation plan directs all vehicles west of Highway 101 to head east, to the highway (see map below). The neighborhoods east of Highway 101 are not included in the simulation because they are away from areas with a high fire hazard rating, and are close to the highway.
Mill Valley has about 11,400 households west of Highway 101. Most Mill Valley households have two vehicles. Evacuation times scale with the number of vehicles, so it is in the common interest to minimize the number of vehicles used during an evacuation. To that end, Mill Valley has a public awareness campaign aimed at having each household evacuate in one vehicle. While no one knows how many vehicles would be used during an evacuation, it is safe to assume it is on average between one and two per household. The basic evacuation problem, then, is how to efficiently get between 11 and 23 thousand vehicles from the various residences onto one of the three sets of Highway 101 on-ramps.
 |
| The simulated part of Mill Valley west of Highway 101 is inside the blue border. Highway 101 is shown in green. The red squares indicate the three sets of Highway 101 on-ramps. The pink area has the highest fire hazard rating. |
The current work uses the same general methodology as the previous research, namely, running the open source SUMO agent-based traffic simulator on a map of Mill Valley. The traffic simulator models traffic by simulating each vehicle individually. The detailed behaviors of vehicles are dictated by a car-following model. Each vehicle is given a point and time at which to start and an initial route. The routes of most vehicles are updated throughout the simulation, depending on conditions. To consider potential changes in driver behavior under the high stress conditions of an evacuation, the effects of the “aggressiveness” of each car is also investigated, but in our case the impacts are minimal. Some simplifying assumptions are that vehicles originate at residential addresses and the roads and highways are initially empty. These assumptions correspond approximately to conditions that could be encountered if an evacuation happens in the middle of the night. The main inputs in the simulation are the road network, the household locations, the average number of vehicles per household, and a departure temporal distribution. We have to make assumptions about the departure distribution. After discussing with the city officials, we chose a distribution such that most vehicles depart within an hour.
Mill Valley has three sets of Highway 101 on-ramps: northern, middle, and southern. All the vehicles must use one of these sets of on-ramps to reach their destination (either the northernmost or southernmost segment of Highway 101 included in our map). Given that we are only concerned with the majority of Mill Valley that lies west of the highway, there are two lanes that approach the northern on-ramps, and one lane that approaches each of the middle and southern on-ramps. Since every vehicle has to pass over one of these four lanes to reach the highway, they are the bottlenecks. Given the geography and existing infrastructure, adding more lanes is infeasible. The aim of this research, then, is to try to modify traffic patterns to maximize the rate of traffic on each of the four lanes.
When we started this research, Mill Valley had a preliminary evacuation plan. It included modifying traffic patterns — disabling traffic lights and changing traffic rules — on a few road segments, as well as specifying the resources (traffic officers, signage) necessary to implement the changes. As an example, a two-way road may be changed to a one-way road to double the number of outgoing lanes. Temporarily changing the direction of traffic is called contraflow.
The plot below shows the simulated fraction of vehicles that have departed or reached their destinations versus time, for 1, 1.5, and 2 vehicles per household (left to right). The dashed line on the far left shows the fraction that have departed. The solid black lines show the preliminary evacuation plan results and the dotted lines indicate the normal road network (baseline) results. The preliminary evacuation plan significantly speeds up the evacuation.
 |
| The cumulative fraction of vehicles vs. time in hours. The demand curve is shown in the dashed line on the far left. The solid lines show the preliminary evacuation plan curves for 1, 1.5 and 2 vehicles per household (left to right). The dotted lines show the same for the baseline case. |
We can understand how effective the preliminary evacuation plan is by measuring the rates at the bottlenecks. The below plots show the rate of traffic on each of the four lanes leading to the highway on-ramps for the case of 1.5 vehicles per household for both the baseline case (the normal road rules; shown shaded in gray) and the preliminary evacuation plan (shown outlined in black). The average rate per lane varies greatly in the different cases. It is clear that, while the evacuation plan leads to increased evacuation rates, there is room for improvement. In particular, the middle on-ramps are quite underutilized.
 |
| The rates of traffic on the four lanes leading to Highway 101 on-ramps for both the baseline case (normal road rules; shown shaded in gray) and the preliminary evacuation plan (shown outlined in black). |
After studying the map and investigating different alternatives, we, working together with city officials, found a minimal set of new road changes that substantially lower the evacuation time compared to the preliminary evacuation plan (shown below). We call this the final evacuation plan. It extends the contraflow section of the preliminary plan 1000 feet further west, to a main intersection. Crucially, this allows for one of the (normally) two outgoing lanes to be dedicated to routing traffic to the middle on-ramps. It also creates two outgoing lanes from that main intersection clear through to the northern on-ramps, over ¾ of a mile to the east.
 |
| A map of the main changes in the final evacuation plan. The red line shows that traffic heading north on Camino Alto gets diverted to the middle Highway 101 on-ramps. The blue line shows traffic in the northern lane of E Blithedale Ave gets routed on the new contraflow section. |
The rate per lane plots comparing the preliminary and final evacuation plans are shown below for 1.5 vehicles per household. The simulation indicates that the final plan increases the average rate of traffic on the lane leading to the middle on-ramps from about 4 vehicles per minute to about 18. It also increases the through rate of the northern on-ramps by over 60%.
 |
| The rates of traffic on the four lanes leading to Highway 101 on-ramps for both the preliminary case (shown shaded in gray) and the final evacuation plan (shown outlined in black). |
The below plot shows the cumulative fraction of vehicles vs. time, comparing the cases of 1, 1.5 and 2 vehicles per household for the preliminary and final evacuation plans. The speedup is quite significant, on the scale of hours. For example, with 1.5 vehicles per household, it took 5.3 hours to evacuate the city using the preliminary evacuation plan, and only 3.5 hours using the final plan.
 |
| The cumulative fraction of vehicles vs. time in hours. The demand curve is shown in the dashed line on the far left. The solid lines show the final evacuation plan curves for 1, 1.5 and 2 vehicles per household (left to right). The dotted lines show the same for the preliminary evacuation plan. |
Evacuation plans can be crucial in quickly getting many people to safety in emergency situations. While some cities have traffic evacuation plans in place, it can be difficult for officials to learn how well the plan works or whether it can be improved. Google Research helped Mill Valley test and evaluate their evacuation plan by running traffic simulations. We found that, while the preliminary plan did speed up the evacuation time, some minor changes to the plan significantly expedited evacuation. We worked closely with the city during this research, and Mill Valley has adopted the final plan. We were able to provide the city with more simulation details, including results for evacuating the city one area at a time. Full details can be found in the paper.
Detailed recommendations for a particular evacuation plan are necessarily specific to the area under study. So, the specific road network changes we found for Mill Valley are not directly applicable for other cities. However, we used only public data (road network from OpenStreetMap; household information from census data) and an open source simulator (SUMO), so any city or agency could use the methodology used in our paper to obtain results for their area.
We thank former Mayor John McCauley and City of Mill Valley personnel Tom Welch, Lindsay Haynes, Danielle Staude, Rick Navarro and Alan Piombo for numerous discussions and feedback, and Carla Bromberg for program management.

 Launch of the new Google for Startups Growth Academy: AI for Cybersecurity program for companies based in Europe and the U.S.Read More
Launch of the new Google for Startups Growth Academy: AI for Cybersecurity program for companies based in Europe and the U.S.Read More