Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
PODCAST
The GPT-x Revolution in Medicine, with Peter Lee
Microsoft Research’s Peter Lee recently sat down to discuss the impact of GPT-4 and large language models in medicine on physician-scientist Eric Topol’s Ground Truths podcast. Drawing from Lee’s recent book, The AI Revolution in Medicine, the conversation includes his early experimentation with GPT-4 and his views of its potential as well as its weaknesses.
For example:
GPT-4 excels at evaluating and reviewing content, insightfully spotting inconsistencies and missing citations, and perceiving a lack of inclusivity and diversity in terminology
GPT-4 can help reduce medical errors and coach physicians to consider different diagnoses and show greater empathy to patients
GPT-4 has the potential to empower patients with new tools and to democratize access to expert medical information
AI needs appropriate regulation, particularly in the field of medicine
AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Deploying machine learning models in production may allow adversaries to infer sensitive information about training data. Inference risks range from membership inference to data reconstruction attacks. Inspired by the success of games in cryptography to study security properties, some authors describe privacy inference risks in machine learning using a similar game-based formalism. However, adversary capabilities and goals are often stated in subtly different ways from one presentation to the next, which makes it hard to relate and compose results.
In a new research paper, SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning, researchers from Microsoft present a game-based framework to systematize the body of knowledge on privacy inference risks in machine learning. In the paper, which was presented at the 2023 IEEE Symposium on Security and Privacy, the authors use this framework to (1) provide a unifying structure for definitions of inference risks, (2) formally establish known relations among definitions, and (3) uncover hitherto unknown relations that would have been difficult to spot otherwise.
Analyzing Leakage of Personally Identifiable Information in Language Models
Language models (LMs) are widely deployed for performing several different downstream tasks. However, they have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking personally identifiable information (PII) has received less attention. Dataset curation techniques such as scrubbing reduce, but do not prevent, the risk of PII leakage—in practice, scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to what extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure.
In a new research paper, Analyzing Leakage of Personally Identifiable Information in Language Models, researchers from Microsoft introduce rigorous game-based definitions for three types of PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. In the paper, which was presented at the 2023 IEEE Symposium on Security and Privacy, they empirically evaluate the attacks against GPT-2 models fine-tuned with and without defenses in three domains: case law, health care, and e-mail.
Their findings show that differential privacy can largely, but not completely, mitigate PII leakage. Traditional data curation approaches such as PII scrubbing are still necessary to achieve sufficient protection. The authors advocate for the design of less aggressive PII scrubbing techniques that account for the protection afforded by DP and achieve a better privacy/utility trade-off.
Automatic Prompt Optimization with “Gradient Descent” and Beam Search
Large Language Models (LLMs) have shown impressive performance as general-purpose agents, but their abilities remain highly dependent on hand-written prompts, which require onerous trial-and-error work. Automatic or semiautomatic procedures would help people write the best prompts while reducing manual effort. In a recent research paper, Automatic Prompt Optimization with “Gradient Descent” and Beam Search, researchers from Microsoft propose a simple and nonparametric solution to this problem. Automatic Prompt Optimization (APO) is inspired by numerical gradient descent to automatically improve prompts, assuming access to training data and an LLM API. The algorithm uses minibatches of data to form natural language “gradients” that criticize the current prompt. The gradients are then “propagated” into the prompt by editing it in the opposite semantic direction of the gradient. These gradient descent steps are guided by a beam search and bandit selection procedure which significantly improves algorithmic efficiency. Preliminary results across three benchmark NLP tasks and the novel problem of LLM jailbreak detection suggest that APO can outperform prior prompt editing techniques and improve an initial prompt’s performance by up to 31%, by using data to rewrite vague task descriptions into more precise annotation instructions.
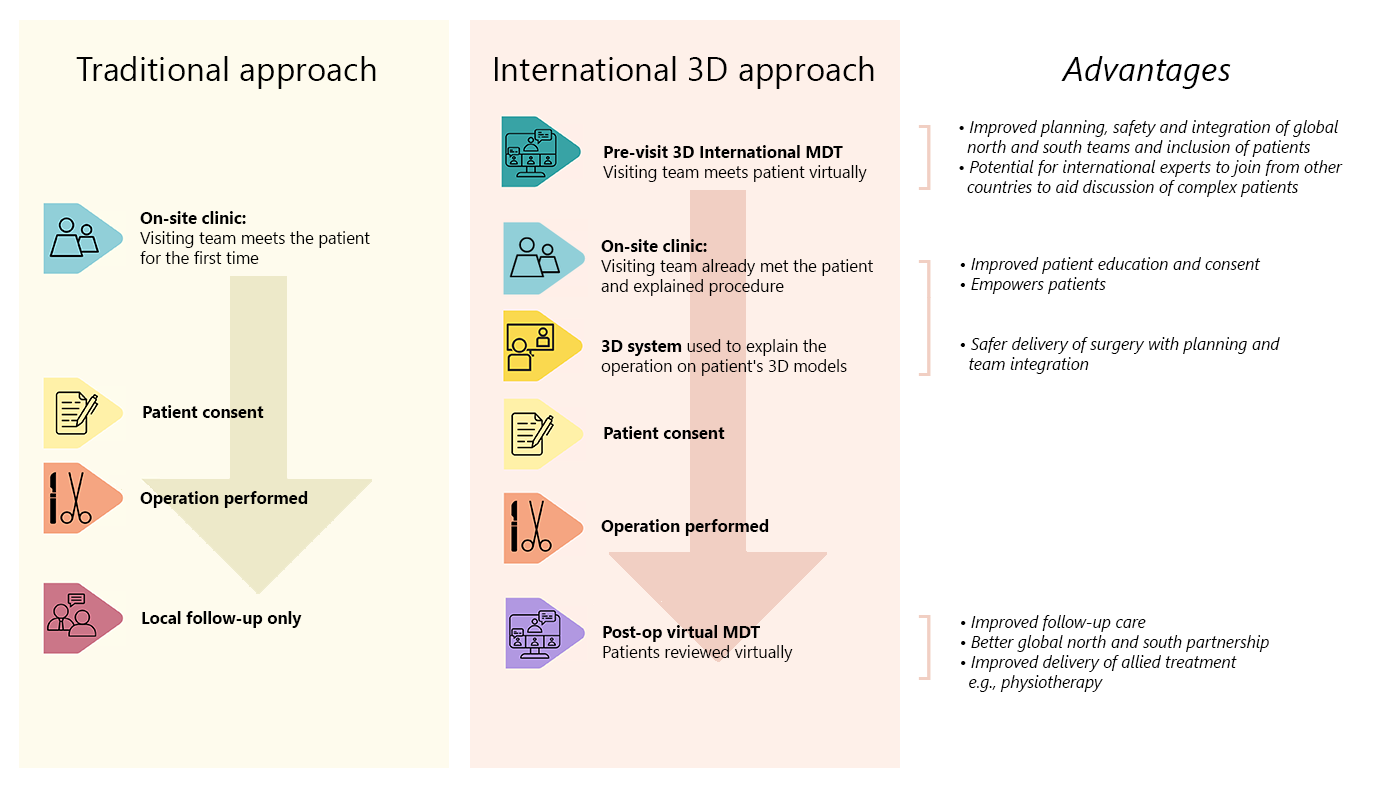
Providing healthcare in remote or rural areas is challenging, particularly specialized medicine and surgical procedures. Patients may need to travel long distances just to get to medical facilities and to communicate with caregivers. They may not arrive in time to receive essential information before their medical appointments and may have to return home before they can receive crucial follow-up care at the hospital. Some patients may wait several days just to meet with their surgeon. This is a very different experience from that of urban or suburban residents or people in more developed areas, where patients can get to a nearby clinic or hospital with relative ease.
In recent years, telemedicine has emerged as a potential solution for underserved remote populations. The COVID-19 pandemic, which prevented many caregivers and patients from meeting in person, helped popularize virtual medical appointments. Yet 2D telemedicine (2DTM) fails to fully replicate the experience of a face-to-face consultation.
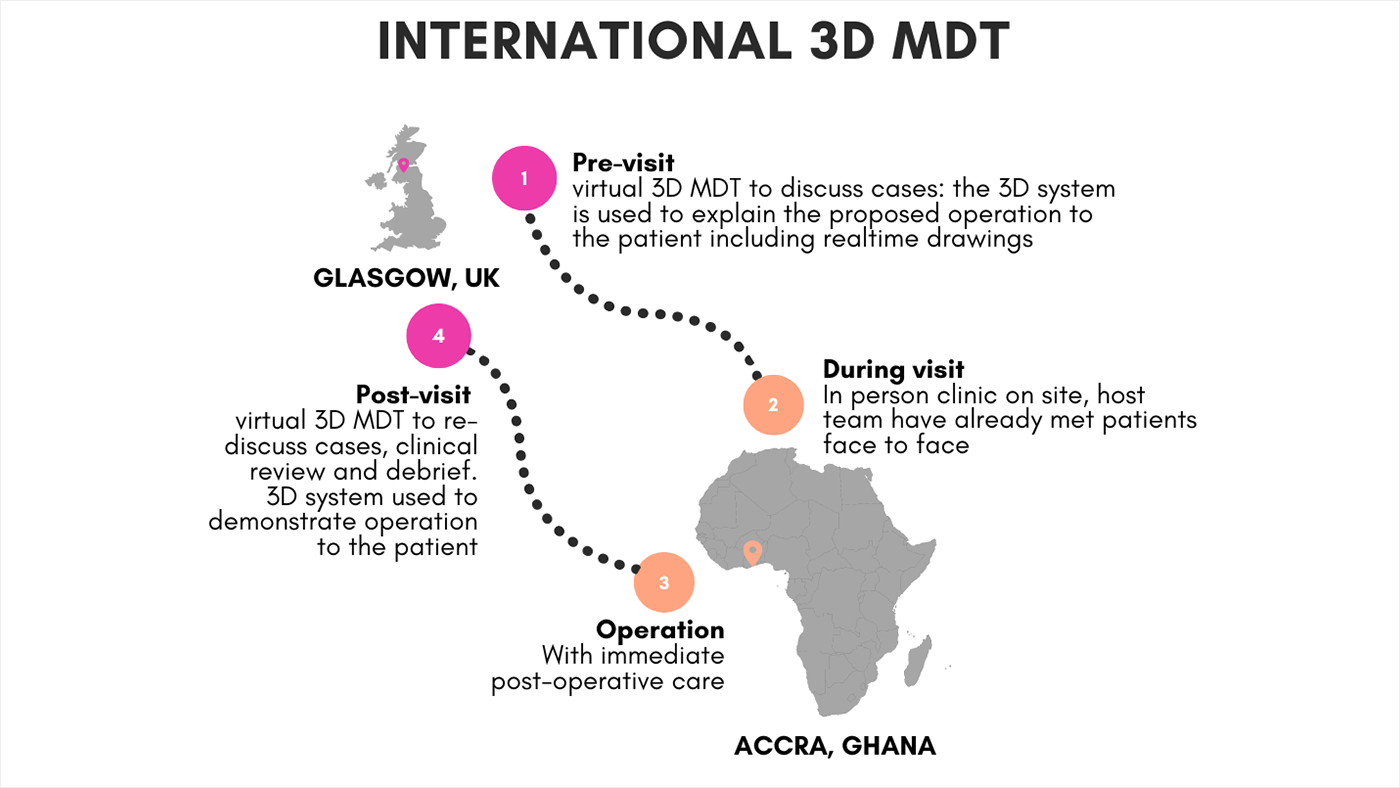
To improve the quality of virtual care, researchers from Microsoft worked with external partners in Scotland to conduct the first validated clinical use of a novel, real-time 360-degree 3D telemedicine system (3DTM). This work produced three studies beginning in 2020, in which 3DTM based on Microsoft’s HoloportationTM communication technology outperformed a 2DTM equivalent. Building on the success of this research, the collaborators conducted a follow-up trial in 2022 with partners in Ghana, where they demonstrated the first intercontinental use of 3DTM. This research provides critical progress toward increasing access to specialized healthcare for rural and underserved communities.
3DTM beats 2DTM in Scotland trials
The dramatic expansion of virtual medicine helped fill a void created by COVID restrictions, but it also underscored the need for more realistic remote consultations. While 2DTM can extend the reach of specialized medicine, it fails to provide doctors and surgeons with the same quantity and quality of information they get from an in-person consultation. Previous research efforts had theorized that 3DTM could raise the bar, but the advantages were purely speculative. Until now, real-time 3DTM had been proposed within a research setting only, because of constraints on complexity, bandwidth, and technology.
In December 2019, researchers from Microsoft began discussing the development of a 3DTM system leveraging Microsoft Holoportation communication technology with collaborators from the Canniesburn Plastic Surgery Unit in Glasgow, Scotland, and Korle Bu Teaching Hospital (KBTH) in Accra, Ghana.
With the emergence of COVID-19 in early 2020, this effort accelerated as part of Microsoft Research’s COVID response, with the recognition that it would allow patients, including those with weakened immune systems, to visit a specialist remotely from the relative safety of a local physician’s office, rather than having to travel to the specialist at a hospital with all the concurrent risk of infection.
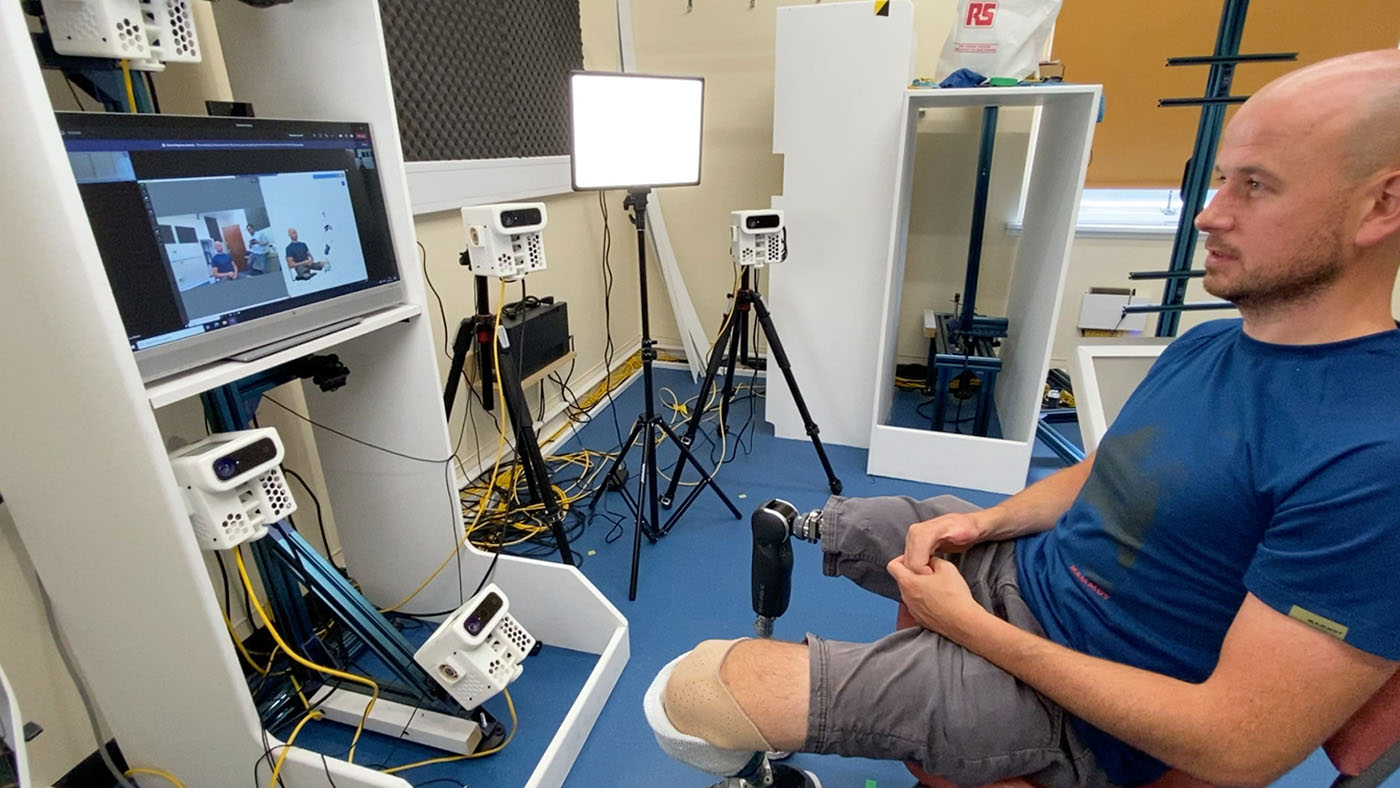
The initial research included a deployment in Scotland, with 10 specialized cameras capturing patient images, combining them into a 3D model, and transmitting the 3D image to a medical professional. The patient could view the same images as their doctor, which allowed them to discuss them in real time—almost as if they were in the same room.
Figure 1: A patient participates in a consultation with doctors using the 3D Telemedicine system. The screen allows the patient to view the same images as the clinician.
This work produced three separate studies: a clinician feedback study (23 clinicians, November–December 2020), a patient feedback study (26 patients, July–October 2021), and a study focusing on safety and reliability (40 patients, October 2021–March 2022).
Participatory testing demonstrated improved patient metrics with 3DTM versus 2DTM. Although patients still prefer face-to-face visits, 3DTM was rated significantly higher than 2DTM. Overall patient satisfaction increased to 88 percent with 3DTM from 51 percent with 2DTM; realism, or “presence,” rated higher at 80 percent for 3DTM versus 53 percent for 2DTM; and quality as measured by a Telehealth Usability Questionnaire came in at 85 percent for 3DTM compared with 77 percent for 2DTM. Safety and clinical concordance of 3DTM with a face-to-face consultation were 95 percent – equivalent to or exceeding estimates for 2DTM.
Figure 2: In three studies produced during a trial in Scotland, 3D telemedicine outperformed 2D telemedicine in satisfaction, realism and quality, with a direct correlation between realism and satisfaction.
One of the ultimate goals of telemedicine is to bring the quality of remote consultations closer to face-to-face experiences. This data provides the first evidence that Microsoft’s Holoportation communication technology moves 3DTM closer to this goal than a 2D equivalent.
“We showed that we can do it using off-the-shelf components, making it affordable. And we can deploy it and make it reliable enough so that a doctor or a clinical team could use it to conduct consultations,” said Spencer Fowers, Principal Researcher at Microsoft Research.
Ghana study: 3DTM brings doctors and patients closer
After the successful deployment in Scotland, the team turned its focus to Ghana. The research team visited KBTH in February 2022. That began the collaboration on the next phase of the project and the installation of the first known 3D telemedicine system on the African continent.
Ghana has a population of 31 million people but only 16 reconstructive surgeons, 14 of whom work at KBTH. It’s one of the largest hospitals in west Africa and the country’s main hospital for reconstructive surgery and burn treatment. Traveling to Accra can be difficult for people who live in rural areas of Ghana. It may require a 24-hour bus ride just to get to the clinic. Some patients can’t stay long enough to receive follow-up care or adequate pre-op preparation and counseling. Many people in need of surgery never receive treatment, and those that do may receive incomplete or sub-optimal follow-up care. They show up, have surgery, and go home.
“As a doctor, you typically take it for granted that a patient will come back to see you if they have complications. These are actually very complex operations. But too often in Ghana, the doctors may never see the patient again,” said Stephen Lo, a reconstructive surgeon at the Canniesburn Plastic Surgery and Burns Unit in Scotland. Lo has worked for years with KBTH and was the project’s clinical lead in Glasgow.
The researchers worked with surgical team members in Scotland and Ghana to build a portable system with enhanced lighting and camera upgrades compared to the original setup deployed in Scotland. This system would enable patients to meet in 3D with doctors in Scotland and in Ghana, both before and after their surgeries, using Microsoft Holoportation communication technology.
Figure 3: As part of a multidisciplinary team (MDT), doctors in Glasgow visit with patients virtually both before and after their in-person visits at the clinic in Accra. Clinicians in Accra manage follow-up care on site.
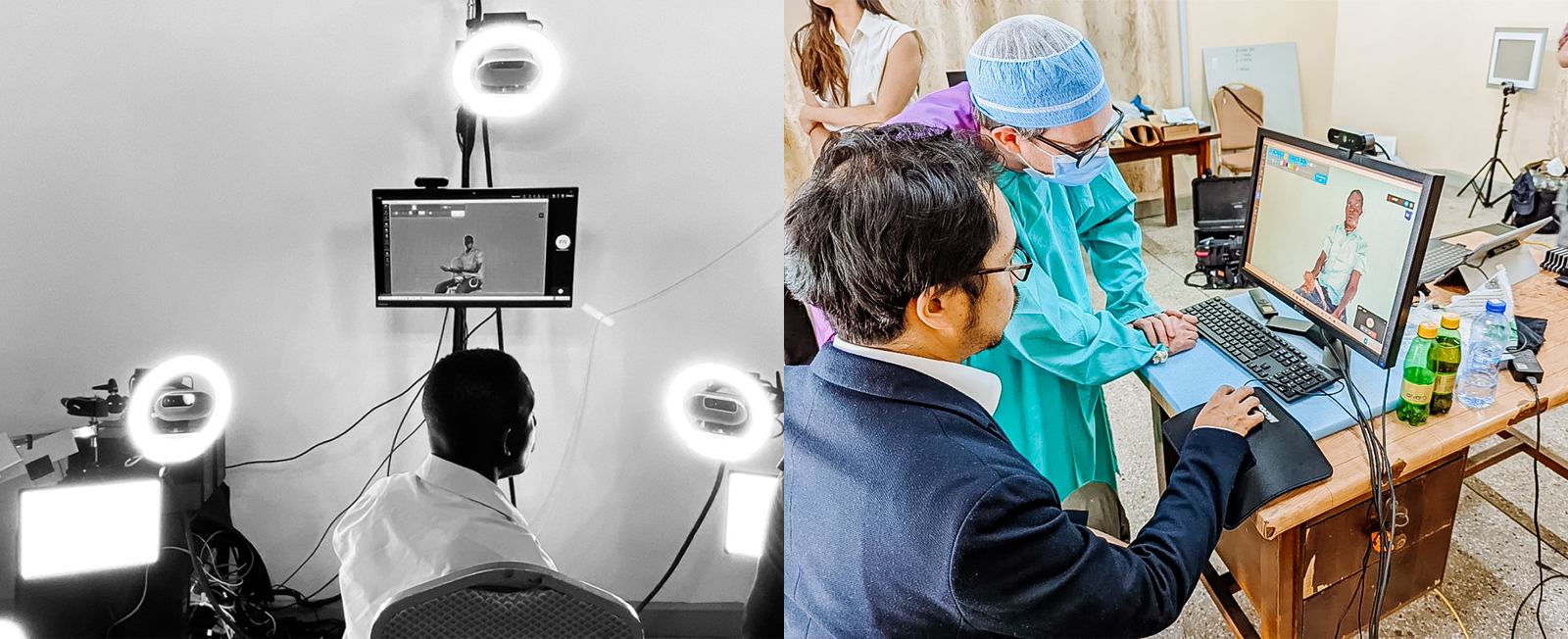
The results were multiple successful multidisciplinary team (MDT) engagements—both pre-operative and post-operative—supporting surgeries led by visiting doctors from Scotland at KBTH. The 3DTM system using Microsoft Holoportation communication technology helped doctors communicate to patients precisely what their surgery would entail ahead of time and then ensure that patients had access to any necessary follow-up procedures and post-operation therapy. The medical team in Glasgow used Microsoft Holoportation communication technology to manipulate and mark up 3D images of their patients. Patients watching from Accra could visualize the procedure, including the exact locations where the surgical incisions would occur.
Figure 4: 3DTM enables better planning, safety, and integration among the international team, plus better patient education and follow-up care.
For a patient who came to KBTH to address a chronic problem with his jaw, this visualization gave him a much better understanding than he had had with previous surgeries, said Levi Ankrah, a reconstructive surgeon at KBTH who participated in the remote consultations and the surgeries in Ghana.
“These are quite complex things to explain. But when the patient could actually see it for himself from the outside, that helped him feel more involved with his care and his follow-up plan,” Ankrah said.
Figure 5: A 3D consultation between a patient in Ghana using “the rig” and doctors in Scotland, who can see the patient and transmit details about his upcoming surgery.
Conclusion
One of the ultimate goals of telemedicine is for the quality of remote consultations to get closer to the experience of face-to-face consultations. The data presented in this research suggests significant potential in moving closer to the experience of face-to-face consultations, which is particularly relevant to specialties with a strong 3D focus, such as reconstructive surgery.
Nothing can replace the authenticity and confidence that come from a face-to-face visit with a doctor. But 3DTM shows great promise as a potential state-of-the-art solution for remote telemedicine, replacing current 2DTM virtual visits and driving better access and outcomes for patients.
Figure 6: Two views of medical team members. On the left (from left to right): Daniel Dromobi Nii Ntreh, Thiago Spina, Spencer Fowers, Chris O’Dowd, Steven Lo, Arnold Godonu, Andrea Britto. On the right, in medical gear (from left to right): Chris O’Dowd, Kwame Darko, Thiago Spina, Andrea Britto and Spencer Fowers.
Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Recent advances in scaling large language models (LLMs) have led to breakthroughs in AI capabilities, including writing code in programming languages, generating stories, poems, essays, and other texts, and strong performance in certain reasoning tasks. LLMs can even create plausible explanations for their outputs, and update their conclusions given new evidence.
At the same time, LLMs can make absurd claims and basic errors of logic, mathematics, and complex reasoning, which raises questions about their applicability in societally impactful domains such as medicine, science, law, and policy.
In a new paper: Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, researchers from Microsoft examine the causal capabilities of LLMs. They find that LLMs, on average, can outperform state-of-the-art causal algorithms in graph discovery and counterfactual inference, and can systematize nebulous concepts like necessity and sufficiency of cause by operating solely on natural language input. They show that by capturing commonsense and domain knowledge about causal mechanisms, LLMs open new frontiers for advancing the research, practice, and adoption of causality. The researchers envision pairing LLMs alongside existing causal methods to reduce the required manual effort that has been a major impediment to widespread adoption of causal analysis.
AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
DNA storage in thermoresponsive microcapsules for repeated random multiplexed data access
As the world generates more and more data, data storage capacity has not kept pace. Traditional long-term storage media such as hard disks or magnetic tape have limited durability and storage density. But DNA has an intrinsic capacity for information storage, durability, and high information density.
In DNA data storage, a large amount of data is stored together, and it is important to perform random access – selective retrieval of individual data files. This is achieved using polymerase chain reaction (PCR), a molecular process that can exponentially amplify a target file. However, this process can damage the data and cause errors. PCR amplification of multiple files simultaneously creates serious undesired DNA crosstalk. Currently one can only read one file at a time, but not a subset of files in a larger set.
In a recent paper: DNA storage in thermoresponsive microcapsules for repeated random multiplexed data access, researchers from Microsoft and external colleagues report on their work to develop a microcapsule-based PCR random access. By encapsulating individual files in each capsule, DNA files were physically separated, reducing undesired crosstalk. This enabled the simultaneous reading of all 25 files in the pool, without significant errors. The use of microcapsules also allowed DNA files to be recovered after random access, addressing the destructive reads problem and potentially making DNA data storage more economical.
Human-centered AI with Ben Shneiderman, Distinguished University Professor—University of Maryland Department of Computer Science
A new synthesis is emerging that integrates AI technologies with human-computer interaction (HCI) to produce human-centered AI (HCAI). Advocates of HCAI seek to amplify, augment, and enhance human abilities, so as to empower people, build their self-efficacy, support creativity, recognize responsibility, and promote social connections. Researchers, developers, business leaders, policy makers, and others are expanding the technology-centered scope of AI to include HCAI ways of thinking.
In this recent Microsoft Research Talk: Human-Centered AI: Ensuring Human Control While Increasing Automation Ben Shneiderman discusses his HCAI framework, design metaphors, and governance structures and other ideas drawn from his award-winning new book Human-Centered AI. The talk by Shneiderman, a Distinguished University Professor in the University of Maryland Department of Computer Science, is hosted by Mary Czerwinski, Partner Researcher and Research Manager with Microsoft Research.
OPPORTUNITIES
AI and the New Future of Work – call for proposals
The Microsoft New Future of Work Initiative is now accepting proposals to fund academic projects that help maximize the impact of LLMs and related AI systems on how work gets done. This call for proposals targets work that specifically supports the use of LLMs in productivity scenarios. The program plans to distribute five $50,000 USD unrestricted awards to support creative research that redefines what work might mean in various contexts.
For example: how can we ensure these new technologies truly accelerate productivity rather than having effects on the margins; how can LLMs achieve these gains by augmenting human labor; what is the future of a ‘document’ in a world where natural language can be so easily remixed and repurposed.
This research paper was accepted by the eighth ACM/IEEE Conference on Internet of Things Design and Implementation (IoTDI), which is a premier venue on IoT. The paper describes a framework that leverages cloud resources to execute large deep neural network (DNN) models with higher accuracy to improve the accuracy of models running on edge devices.
Leveraging the cloud and edge concurrently
The internet is evolving towards an edge-computing architecture to support latency-sensitive DNN workloads in the emerging Internet of Things and mobile computing applications domains. However, unlike cloud environments, the edge has limited computing resources and cannot run large, high accuracy DNN models. As a result, past work has focused on offloading some of the computation to the cloud to get around this limitation. However, this comes at the cost of increased latency.
For example, in edge video analytics use cases, such as road traffic monitoring, drone surveillance, and driver assist technology, one can transmit occasional frames to the cloud to perform object detection—a task ideally suited to models hosted on powerful GPUs. On the other hand, the edge handles the interpolating intermediate frames through object tracking—a relatively inexpensive computational task performed using general-purpose CPUs, a low-powered edge GPU, or other edge accelerators (e.g., Intel Movidius Neural Stick). However, for most real-time applications, processing data in the cloud is infeasible due to strict latency constraints.
Spotlight: On-demand video
AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
In our research paper, REACT: Streaming Video Analytics On The Edge With Asynchronous Cloud Support, we propose and demonstrate a novel architecture that leverages both the edge and the cloud concurrently to perform redundant computations at both ends. This helps retain the low latency of the edge while boosting accuracy with the power of the cloud. Our key technical contribution is in fusing the cloud inputs, which are received asynchronously, into the stream of computation at the edge, thereby improving the quality of detection without sacrificing latency.
Fusing edge and cloud detections
Figure 1(a): Orange and green boxes indicate detection from edge and cloud. Tracking performance degrades with every frame, indicated by the fading shades of blue.
Figure 1(b): REACT uses asynchronous cloud detections to correct the box labels and detect more objects.
We illustrate our fusion approach in REACT for object detection in videos. Figure 1 shows the result of object detection using a lightweight edge model. This suffers from both missed objects (e.g., cars in Frame 1 are not detected) and misclassified objects (e.g., the van on the right of the frame that has been misclassified as a car).
To address the challenges of limited edge computation capacity and the drop in accuracy from using edge models, we follow a two-pronged approach. First, since the sequence of video frames are spatiotemporally correlated, it suffices to call edge object detection only once every few frames. As illustrated in Figure 1(a), edge detection runs every fifth frame. As shown in the figure, to interpose the intermediate frames, we employ a comparatively lightweight operation of object tracking. Second, to improve the accuracy of inference, select frames are asynchronously transmitted to the cloud for inference. Depending on network delay and the availability of cloud resources, cloud detections reach the edge device only after a few frames. Next, the newer cloud detections—previously undetected—are merged with the current frame. To do this, we feed the cloud detection, which was made on an old frame, into another instance of the object tracker to “fast forward” to the current time. The newly detected objects can then be merged into the current frame so long as the scene does not change abruptly. Figure 1(b) shows a visual result of our approach on a dashcam video dataset.
Here’s a more detailed description of how REACT goes about combining the edge and the cloud detections. Each detection contains objects represented by a ⟨class_label, bounding_box, confidence_score⟩ tuple. Whenever we receive a new detection (either edge or cloud), we purge from the current list the objects that were previously obtained from the same detection source (either cloud or edge). Then we form a zero matrix of size (c, n). Here, c and n are the indices associated with detections from current list and new source, respectively. We populate the matrix cell with the Intersection over Union (IoU) values—if it is greater than 0.5—corresponding to specific current and new detections. We then perform a linear sum assignment, which matches two objects with the maximum overlap. For overlapped objects, we modify the confidence values, bounding box, and class label based on the new detections’ source. Specifically, our analysis reveals that edge detection models could correctly localize objects, but often had false positives, i.e., they assigned class labels incorrectly. In contrast, cloud detections have higher localization error but lower error for class labels. Finally, newer objects (unmatched ones) will then get added to the list of current objects with the returned confidence values, bounding boxes, and class labels. Thus, REACT’s fusion algorithm must consider multiple cases —such as misaligned bounding boxes, class label mismatch, etc. — to consolidate the edge and cloud detections into a single list.
Detector
Backbone
Where
#params
Faster R-CNN
ResNet50-FPN
Cloud
41.5M
RetinaNet
ResNet50-FPN
Cloud
36.1M
CenterNet
DLA34
Cloud
20.1M
TinyYOLOv3
DN19
Edge
8.7M
SSD
MobileNetV2
Edge
3.4M
Table 1: Models used in our evaluation
In our experimentation, we leveraged state-of-the-art computer vision algorithms for getting object detections at the edge and the cloud (see Table 1). Further, we use mAP@0.5 (mean average precision at 0.5 IoU), a metric popular in the computer vision community to measure the performance of object detections. Moreover, to evaluate the efficacy of REACT, we looked at two datasets:
Based on our evaluation, we observed that REACT outperforms baseline algorithms by as much as 50%. Also, we noted that edge and cloud models can complement each other, and overall performance improves due to our edge-cloud fusion algorithm.
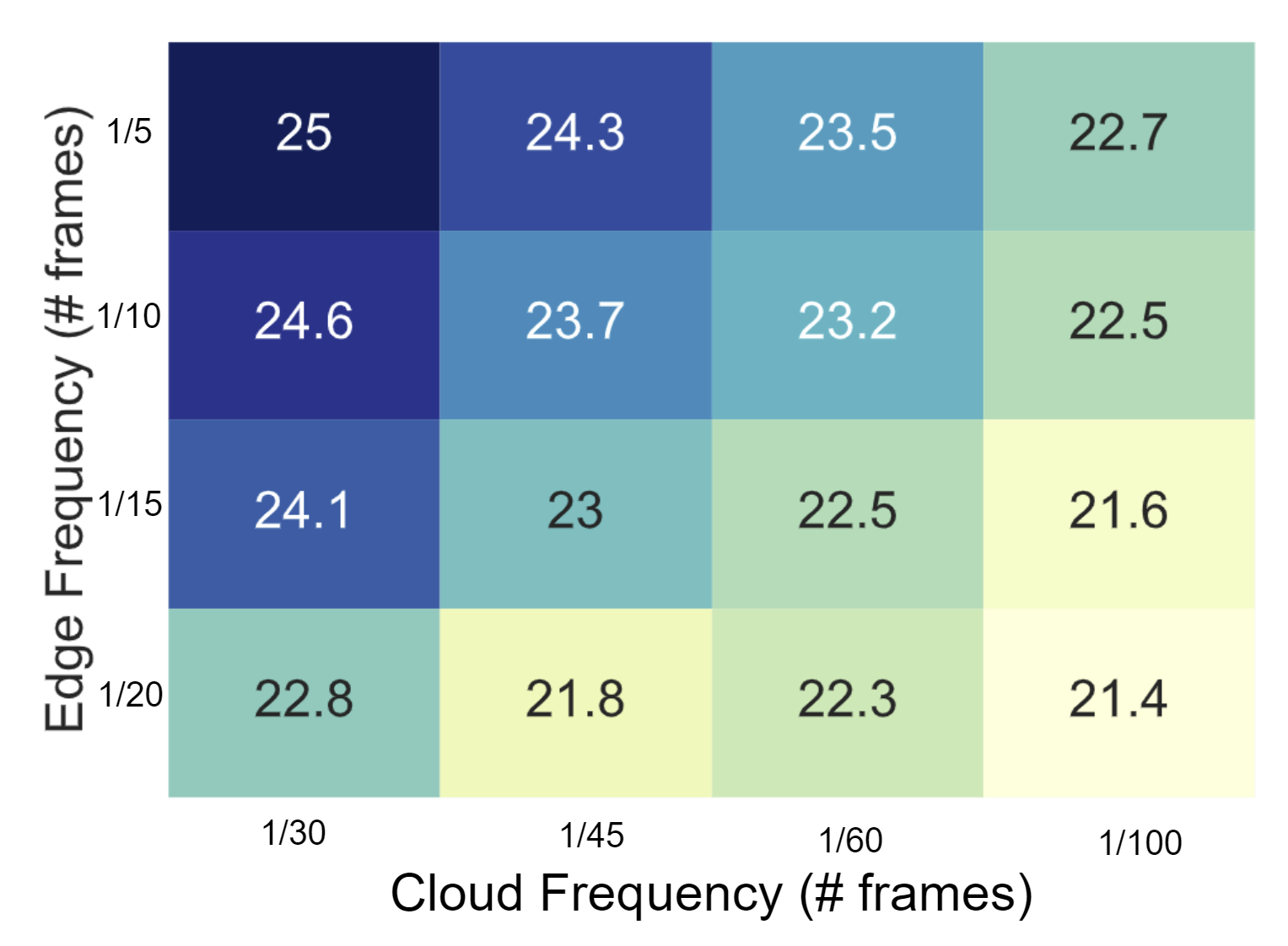
As already noted, the object detector runs only once every few frames and a lightweight object tracking is performed on intermediate frames. Running detection redundantly at both the edge and the cloud allows an application developer to flexibly trade off the frequency of edge versus cloud executions while achieving the same accuracy, as shown in Figure 2. For example, if the edge device experiences thermal throttling, we can pick a lower edge detection frequency (say, once every 20 frames) and complement it with cloud detection once every 30 frames to get mAP@0.5 of around 22.8. However, if there are fewer constraints at the edge, we can increase the edge detection frequency to once every five frames and reduce cloud detections to once every 120 frames to get similar performance (mAP@0.5 of 22.7). This provides a playground for fine-grained programmatic control.
Figure 2: mAP@0.5 values for varying cloud and edge detection frequency on the D2-City dataset. Similar shading corresponds to similar mAP@0.5.
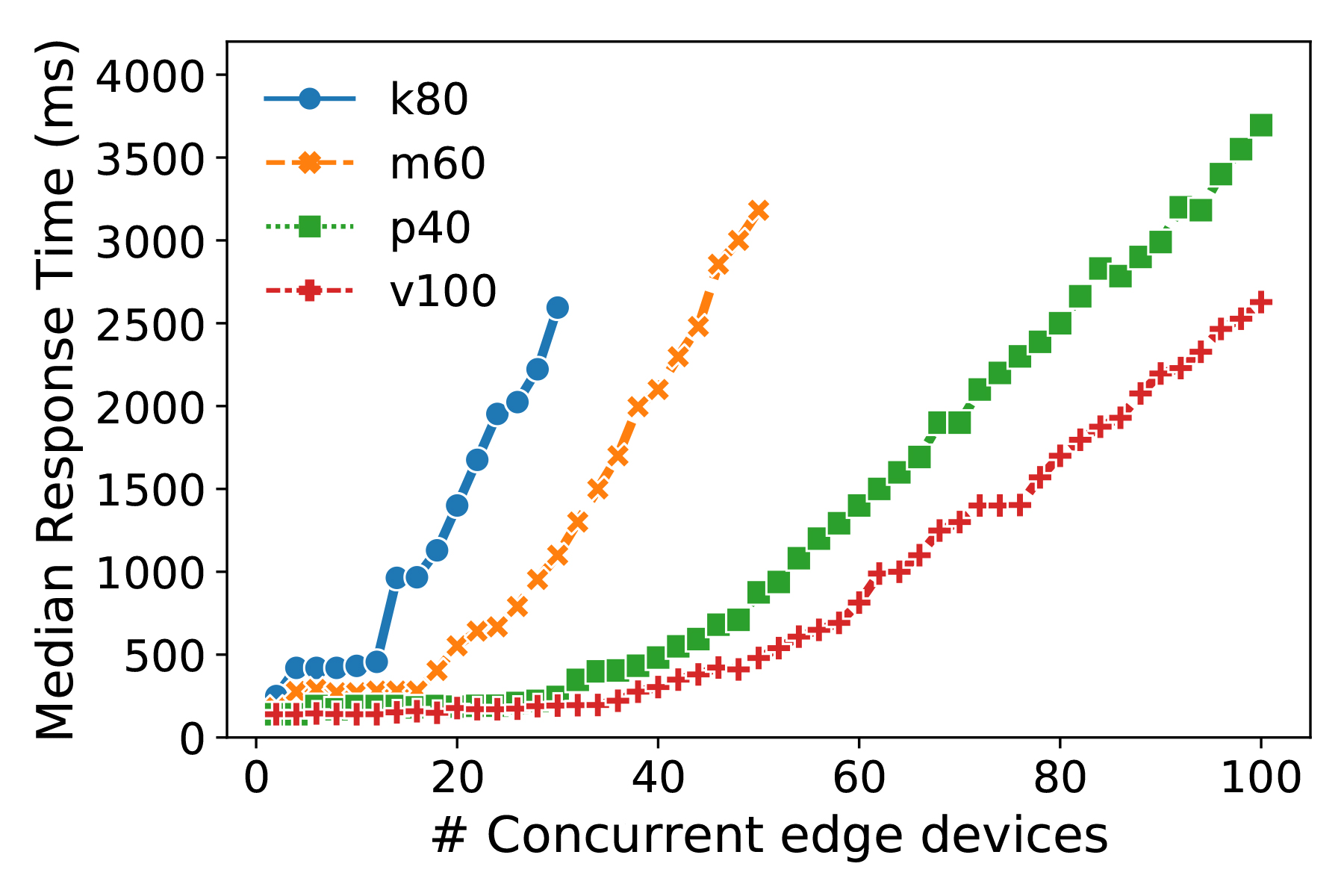
Further, one can amortize the cost of using cloud resources over multiple edge devices by having these share the same cloud hosted model. Specifically, if an application can tolerate a median latency of up to 500 ms, we can support over 60 concurrent devices at a time using the V100 GPU (Figure 3).
Figure 3: 50th percentile response time vs number of edge devices that concurrently share a cloud GPU
Conclusion
REACT represents a new paradigm of edge + cloud computing that leverages the resources of each to improve accuracy without sacrificing latency. As we have shown above, the choice between offloading and on-device inference is not binary, and redundant execution at cloud and edge locations complement each other when carefully employed. While we have focused on object detection, we believe that this approach could be employed in other contexts such as human pose-estimation, instance and semantic segmentation applications to have the “best of both worlds.”
Microsoft Editor provides AI-powered writing assistance to millions of users around the world. One of its features that writers of all levels and domains rely on is the grammar checker, which detects grammar errors in a user’s writing and offers suggested corrections and explanations of the detected errors.
The technology behind grammar checker has evolved significantly since the 1970s, when the first-generation tool was based on simple pattern matching. A major breakthrough occurred in 1997, when Microsoft Word 97 introduced a grammar checker that relied on a full-fledged natural language processing system (Heidorn, 2000), enabling more sophisticated and accurate error detection and correction. Another major breakthrough occurred in 2020, when Microsoft launched a neural grammar checker that leveraged deep neural networks with a novel fluency boost learning and inference mechanism, achieving state-of-the-art results on both CoNLL-2014 and JFLEG benchmark datasets[1,2]. In 2022, Microsoft released a highly optimized version of the Microsoft Editor neural grammar checker on expanded endpoints in Word Win32, Word Online, Outlook Online, and the Editor Browser Extension.
In this blog post, we will describe how we have optimized the Editor neural grammar checker model using the Aggressive Decoding algorithm pioneered by Microsoft Research (MSR) and accelerated with high performance ONNX Runtime (ORT). With the Aggressive Decoding algorithm and ORT optimizations, the server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality compared to the previous production model.
Spotlight: Microsoft Research Podcast
AI Frontiers: AI for health and the future of research with Peter Lee
Peter Lee, head of Microsoft Research, and Ashley Llorens, AI scientist and engineer, discuss the future of AI research and the potential for GPT-4 as a medical copilot.
But we did not stop there. We also implemented EdgeFormer, MSR’s cutting-edge on-device seq2seq modeling technology, to obtain a lightweight generative language model with competitive performance that can be run on a user’s device, allowing us to achieve the ultimate zero-cost-of-goods-sold (COGS) goal.
Shipping a client model offers three other key benefits in addition to achieving zero-COGS:
Increased privacy. A client model that runs locally on the user’s device does not need to send any personal data to a remote server.
Increased availability. A client model operates offline without relying on network connectivity, bandwidth, or server capacity.
Reduced cost and increased scalability. Shipping a client model to a user’s device removes all the computation that a server would be required to execute, which allows us to ship to more customers.
Additionally, we leveraged GPT-3.5 (the most advanced AI model at the time) to generate high-quality training data and identify and remove low-quality training examples, leading to a boost of model performance.
Innovation: Aggressive Decoding
Behind the AI-powered grammar checker in Microsoft Editor is the transformer model, enhanced by cutting-edge research innovations[1,2,3] from MSR for grammar correction. As with most seq2seq tasks, we used autoregressive decoding for high-quality grammar correction. However, conventional autoregressive decoding is very inefficient as it cannot fully utilize modern computing devices (CPUs, GPUs) due to its low computational parallelism, which results in high model serving costs and prevents us from scaling quickly to more (web/desktop) endpoints.
To address the challenge for serving cost reduction, we adopt the latest decoding innovation, Aggressive Decoding,[3] published by MSR researchers Tao Ge and Furu Wei at ACL 2021. Unlike the previous methods that speed up inference at the cost of prediction quality drop, Aggressive Decoding is the first efficient decoding algorithm for lossless speedup of seq2seq tasks, such as grammar checking and sentence rewriting. Aggressive Decoding works for tasks whose inputs and targeted outputs are highly similar. It uses inputs as the targeted outputs and verifies them in parallel instead of decoding sequentially, one-by-one, as in conventional autoregressive decoding. As a result, it can substantially speed up the decoding process, handling trillions of requests per year, without sacrificing quality by better utilizing the powerful parallel computing capabilities of modern computing devices, such PCs with graphics processing units (GPUs).
The figure above shows how Aggressive Decoding works. If we find a bifurcation during Aggressive Decoding, we discard all the predictions after the bifurcation and re-decode them using conventional one-by-one autoregressive decoding. If we find a suffix match (i.e., some advice highlighted with the blue dotted lines) between the output and the input during one-by-one re-decoding, we switch back to Aggressive Decoding by copying the tokens (highlighted with the orange dashed lines) and following the matched tokens in the input to the decoder input by assuming they will be the same. In this way, Aggressive Decoding can guarantee that the generated tokens are identical to autoregressive greedy decoding but with much fewer decoding steps, significantly improving the decoding efficiency.
Offline evaluations
We test Aggressive Decoding in grammar correction and other text rewriting tasks, such as text simplification, with a 6+6 standard transformer as well as a transformer with deep encoder and shallow decoder. All results confirm that Aggressive Decoding can introduce a significant speedup without quality loss.
CoNLL14
NLCC-18
Wikilarge
F0.5
speedup
F0.5
speedup
SARI
BLEU
speedup
6+6 Transformer (beam=1)
61.3
1
29.4
1
36.1
90.7
1
6+6 Transformer (AD)
61.3
6.8
29.4
7.7
36.1
90.7
8
CoNLL14
F0.5
speedup
12+2 Transformer (beam=1)
66.4
1
12+2 Transformer (AD)
66.4
4.2
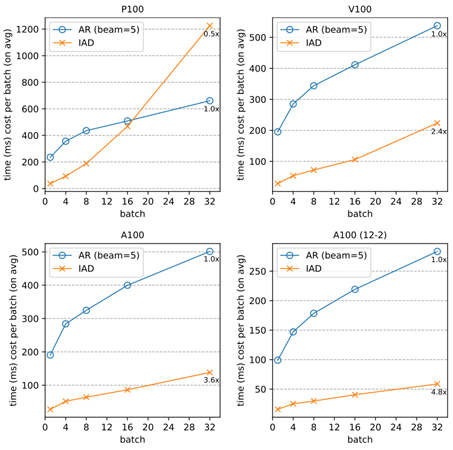
And it can work even better on more powerful computing devices that excel at parallel computing (e.g., A100):
Online evaluation
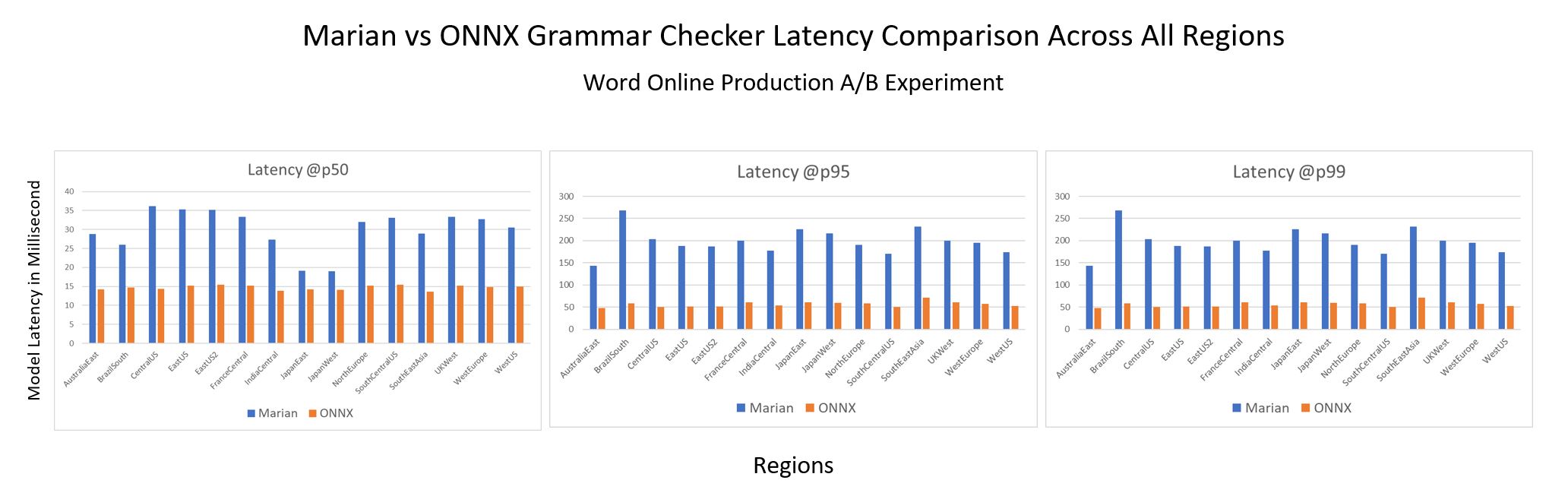
We ran an A/B experiment between a Marian server model and an equal size server model with Aggressive Decoding using ONNX Runtime. The latter shows 2x+ improvement @p50 and 3x+ improvement @p95 and @p99 over the Marian runtime, with conventional autoregressive decoding in CPU as shown in the graph below. Moreover, it offers better efficiency stability than the previous autoregressive decoding, which varies drastically in latency (approximately proportional to the sentence length), as Aggressive Decoding substantially reduces the decoding cost with only a few steps of parallel computing regardless of the sentence length. This substantial inference time speedup resulted in a two-thirds COGS reduction in the production endpoints.
Both offline/online evaluations confirm that Aggressive Decoding allows us to achieve significant COGS reduction without any loss of model prediction quality. Based on this intuition, we generalize[4]Aggressive Decoding to more general seq2seq tasks. Its high efficiency with lossless quality makes Aggressive Decoding likely to become the de facto decoding standard for seq2seq tasks and to play a vital role in the cost reduction of seq2seq model deployment.
Accelerate Grammar Checker with ONNX Runtime
ONNX Runtime is a high-performance engine, developed by Microsoft, that runs AI models across various hardware targets. A wide range of ML-powered Microsoft products leverage ONNX Runtime for inferencing performance acceleration. To further reduce the inferencing latency, the PyTorch Grammar Checker with Aggressive Decoding was exported to ONNX format using PyTorch-ONNX exporter, then inferenced with ONNX Runtime, which enables transformer optimizations and quantitation for CPU performance acceleration as well as model size reduction. A number of techniques are enabled in this end-to-end solution to run the advanced grammar checker model efficiently.
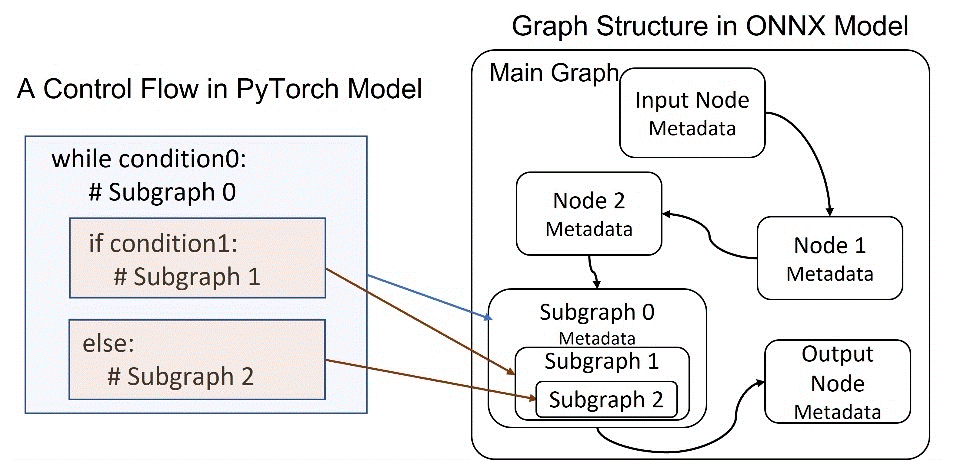
PyTorch provides a built-in function to export the PyTorch model to ONNX format with ease. To support the unique architecture of the grammar checker model, we enabled export of complex nested control flows to ONNX in the exporter. During this effort, we also extended the official ONNX specification on sequence type and operators to represent more complex scenarios (i.e., the autoregressive search algorithm). This eliminates the need to separately export model encoder and decoder components and stitch them together later with additional sequence generation implementation for production. With sequence type and operators support in PyTorch-ONNX exporter and ONNX Runtime, we were able to export one single ONNX graph, including encoder and decoder and sequence generation, which brings in both efficient computation and simpler inference logic. Furthermore, the shape type inference component of PyTorch ONNX exporter is enhanced to produce a valid ONNX model under stricter ONNX shape type constraints.
The innovative Aggressive Decoding algorithm introduced in the grammar checker model was originally implemented in Fairseq. To make it ONNX compatible, we reimplemented this Aggressive Decoding algorithm in HuggingFace for easy exporting. When diving into the implementation, we identified certain components that are not directly supported in the ONNX standard operator set (e.g., bifurcation detector). There are two approaches for exporting unsupported operators to ONNX and running with ONNX Runtime. We can either create a graph composing several standard ONNX operators that have equivalent semantics or implement a custom operator in ONNX Runtime with more efficient implementation. ONNX Runtime custom operator capability allows users to implement their own operators to run within ONNX Runtime with more flexibility. This is a tradeoff between implementation cost and performance. Considering the complexity of these components, the composition of standard ONNX operators might become a performance bottleneck. Hence, we introduced custom operators in ONNX Runtime to represent these components.
ONNX Runtime enables transformer optimizations and quantization, showing very promising performance gain on both CPU and GPU. We further enhanced encoder attention fusion and decoder reshape fusion for the grammar checker model. Another big challenge of supporting this model is multiple model subgraphs. We implemented subgraphs fusion in ONNX Runtime transformers optimizer and quantization tool. ONNX Runtime Quantization was applied to the whole model, further improving throughput and latency.
Quality Enhancement by GPT-3.5 LLMs
To further improve the precision and recall of the models in production, we employ the powerful GPT-3.5 as the teacher model. Specifically, the GPT-3.5 model works in the following two ways to help improve the result:
Training data augmentation: We fine-tune the GPT-3.5 model and use it to generate labels for massive unannotated texts. The annotations obtained are verified to be of high quality and can be used as augmented training data to enhance the performance of our model.
Training data cleaning: We leverage the powerful zero/few-shot capability of GPT-3.5 to distinguish between high-quality and low-quality training examples. The annotations of the identified low-quality examples are then regenerated by the GPT-3.5 model, resulting in a cleaner and higher-quality training set, which directly enhances the performance of our model.
EdgeFormer: Cost-effective parameterization for on-device seq2seq modeling
In recent years, the computational power of client devices has greatly increased, allowing for the use of deep neural networks to achieve the ultimate zero-COGS goal. However, running generative language models on these devices still poses a significant challenge, as the memory efficiency of these models must be strictly controlled. The traditional methods of compression used for neural networks in natural language understanding are often not applicable when it comes to generative language models.
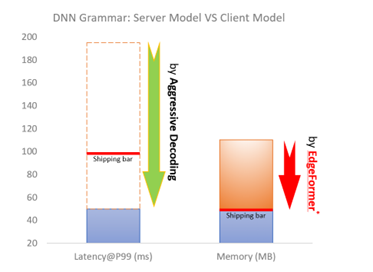
To ship a client grammar model, the model should be highly efficient (e.g., within 100ms latency), which has already been solved by Aggressive Decoding, mentioned earlier. Moreover, the client model must be memory-efficient (e.g., within a 50MB RAM footprint), which is the main bottleneck for a powerful (generative) transformer model (usually over 50 million parameters) to run on a client device.
To address this challenge, we introduce EdgeFormer[6], a cutting-edge on-device seq2seq modeling technology for obtaining lightweight generative language models with competitive performance that can be easily run on a user’s computer.
The main idea of EdgeFormer is two principles, which we proposed for cost-effective parameterization:
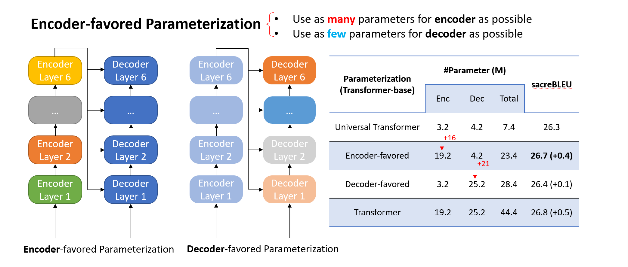
Encoder-favored parameterization
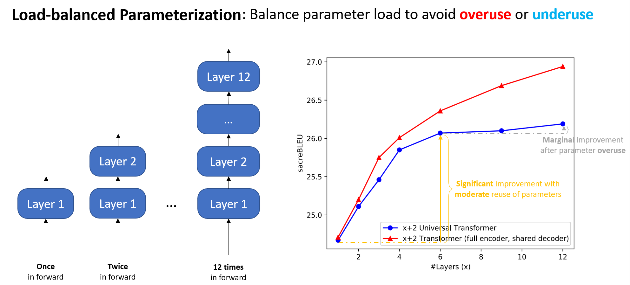
Load-balanced parameterization
We designed EdgeFormer with the above principles of cost-effective parameterization, allowing each parameter to be utilized to its maximum potential, which achieves competitive results despite the stringent computational and memory constraints of client devices.
Based on EdgeFormer, we further propose EdgeLM – the pretrained version of EdgeFormer, which is the first publicly available pretrained on-device seq2seq model that can be easily fine-tuned for seq2seq tasks with strong results. EdgeLM serves as the foundation model of the grammar client model to realize the zero-COGS goal, which achieves over 5x model size compression with minimal quality loss compared to the server model.
Inference cost reduction to empower client-device deployment
Model deployment on client devices has strict requirements on hardware usage, such as memory and disk size, to avoid interference with other user applications. ONNX Runtime shows advantages for on-device deployment along with its lightweight engine and comprehensive client-inference focused solutions, such as ONNX Runtime quantization and ONNX Runtime extensions. In addition, to maintain service quality while meeting shipping requirements, MSR introduced a series of optimization techniques, including system-aware model optimization, model metadata simplification, and deferred parameter loading as well as customized quantization strategy. Based on the EdgeFormer modeling, these system optimizations can further reduce the memory cost by 2.7x, without sacrificing model performance.
We will elaborate on each one in the following sections:
System-aware model optimization. As the model is represented as a dataflow graph, the major memory cost for this model is from the many subgraphs generated. As shown in the figure below, a branch in the PyTorch code is mapped as a subgraph. Therefore, we optimize the model implementation to reduce the usage of branch instructions. Particularly, we leverage greedy search as the decoder search algorithm, as beam search contains more branch instructions. The usage of this method can reduce memory cost by 38%.
Mapping of PyTorch model and ONNX model graph
Model metadata simplification. Also shown in the figure above, the model contains a lot of metadata that consumes memory, such as the node name and type, input and output, and parameters. To reduce the cost, we simplify the metadata to keep only the basic required information for inference. For example, the node name is simplified from a long string to an index. Besides that, we optimize the model graph implementation in ONNX Runtime to keep just one copy of the metadata, rather than duplicating all the available metadata each time a subgraph is generated.
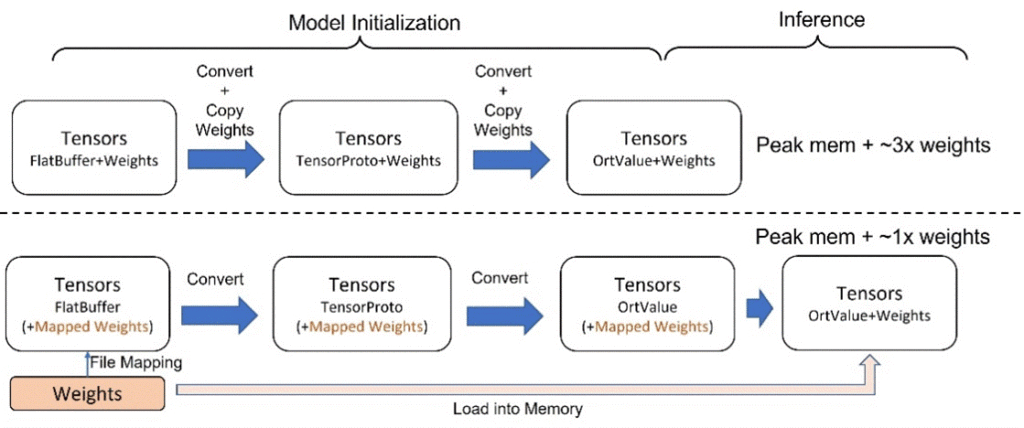
Deferred weight loading in ONNX Runtime. Current model files include both the model graphs and weights, which are then loaded into memory together during model initialization. However, this increases memory usage as shown in the figure below, because the weights will be copied repeatedly during model graph parsing and conversion. To avoid this, we save model graphs and weights separately. During initialization in ONNX Runtime, only the graphs are loaded into memory for actual parsing and conversion. The weights, on the other hand, still reside on disk with only the pointer kept in memory, through file mapping. The actual weight loading to memory will be deferred until the model inference. This technique can reduce the peak memory cost by 50%.
Deferred weights loading by file mapping during model initialization
ONNX Runtime quantization and ONNX Runtime extensions. Quantization is a well-known model compression technique that brings in both performance acceleration and model size reduction while sacrificing model accuracy. ONNX Runtime Quantization offers diverse tuning knobs to allow us to apply customized quantization strategy. Specifically, we customize the strategy as post-training, dynamic, UINT8, per-channel and all-operator quantization, for this model for minimum accuracy impact. Onnxruntime-extensions provides a set of ONNX Runtime custom operators to support the common pre- and post-processing operators for vision, text, and natural language processing models. With it, the pre- and post-processing for this model, including tokenization, string manipulation, and so on, can be integrated into one self-contained ONNX model file, leading to improved performance, simplified deployment, reduced memory usage, and better portability.
Conclusion
In this blog post, we have presented how we leveraged the cutting-edge research innovations from MSR and ONNX Runtime to optimize the server grammar checker model and achieve the ultimate zero-COGS goal with the client grammar checker model. The server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality. The client model has achieved over 5x model size compression with minimal quality loss compared to the server model. These optimizations have enabled us to scale quickly to more web and desktop endpoints and provide AI-powered writing assistance to millions of users around the world.
The innovation shared in this blog post is just the first milestone in our long-term continuous effort of COGS reduction for generative AI models. Our proposed approach is not limited to accelerating the neural grammar checker; it can be easily generalized and applied more broadly to scenarios such as abstractive summarization, translation, or search engines to accelerate large language models for COGS reduction[5,8], which is critical not only for Microsoft but also for the entire industry in the artificial general intelligence (AGI) era.
Reference
[1] Tao Ge, Furu Wei, Ming Zhou: Fluency Boost Learning and Inference for Neural Grammatical Error Correction. In ACL 2018.
[2] Tao Ge, Furu Wei, Ming Zhou: Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study. https://arxiv.org/abs/1807.01270
[3] Xin Sun, Tao Ge, Shuming Ma, Jingjing Li, Furu Wei, Houfeng Wang: A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-lingual Language Model. In IJCAI 2022.
[4] Xin Sun, Tao Ge, Furu Wei, Houfeng Wang: Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding. In ACL 2021.
[5] Tao Ge, Heming Xia, Xin Sun, Si-Qing Chen, Furu Wei: Lossless Acceleration for Seq2seq Generation with Aggressive Decoding. https://arxiv.org/pdf/2205.10350.pdf
[6] Tao Ge, Si-Qing Chen, Furu Wei: EdgeFormer: A Parameter-efficient Transformer for On-device Seq2seq Generation. In EMNLP 2022.
[7] Heidorn, George. “Intelligent Writing Assistance.” Handbook of Natural Language Processing. Robert Dale, Hermann L. Moisl, and H. L. Somers, editors. New York: Marcel Dekker, 2000: 181-207.
[8] Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei: Inference with Reference: Lossless Acceleration of Large Language Models. https://arxiv.org/abs/2304.04487
This research was accepted by the IEEE/ACM International Conference on Software Engineering (ICSE), which is a forum for researchers, practitioners, and educators to gather, present, and discuss the most recent innovations, trends, experiences, and issues in the field of software engineering.
The Microsoft 365 Systems Innovation research group has a paper accepted at the 45thInternational Conference on Software Engineering (ICSE), widely recognized as one of the most prestigious research conferences on software engineering. This paper, Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models, focuses on using state-of-the-art large language models (LLMs) to help generate recommendations for cloud incident root cause analysis and mitigation plans. With a rigorous study on real production incidents and analysis of several LLMs in different settings using semantic and lexical metrics as well as human evaluation, the research shows the efficacy and future potential of using AI for resolving cloud incidents.
Challenges of building reliable cloud services
Building highly reliable hyperscale cloud services such as Microsoft 365 (M365), which supports the productivity of hundreds of thousands of organizations, is very challenging. This includes the challenge of quickly detecting incidents, then performing root cause analysis and mitigation.
Our recent research starts with understanding the fundamentals of production incidents: we analyze the life cycle of incidents, then determine the common root causes, mitigations, and engineering efforts for resolution. In a previous paper: How to Fight Production Incidents? An Empirical Study on a Large-scale Cloud Service, which won a Best Paper award at SoCC’22, we provide a comprehensive, multi-dimensional empirical study of production incidents from Microsoft Teams. From this study, we envision that automation should support incident diagnosis and help identify the root cause and mitigation steps to quickly resolve an incident and minimize customer impact. We should also leverage past lessons to build resilience for future incidents. We posit that adopting AIOps and using state-of-the-art AI/ML technologies can help achieve both goals, as we show in the ICSE paper.
Spotlight: On-demand video
AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
Adapting large-language models for automated incident management
Recent breakthroughs in AI have enabled LLMs to develop a rich understanding of natural language. They can understand and reason over large volumes of data and complete a diverse set of tasks, such as code completion, translation, and Q&A. Given the complexities of incident management, we sought to evaluate the effectiveness of LLMs in analyzing the root cause of production incidents and generating mitigation steps.
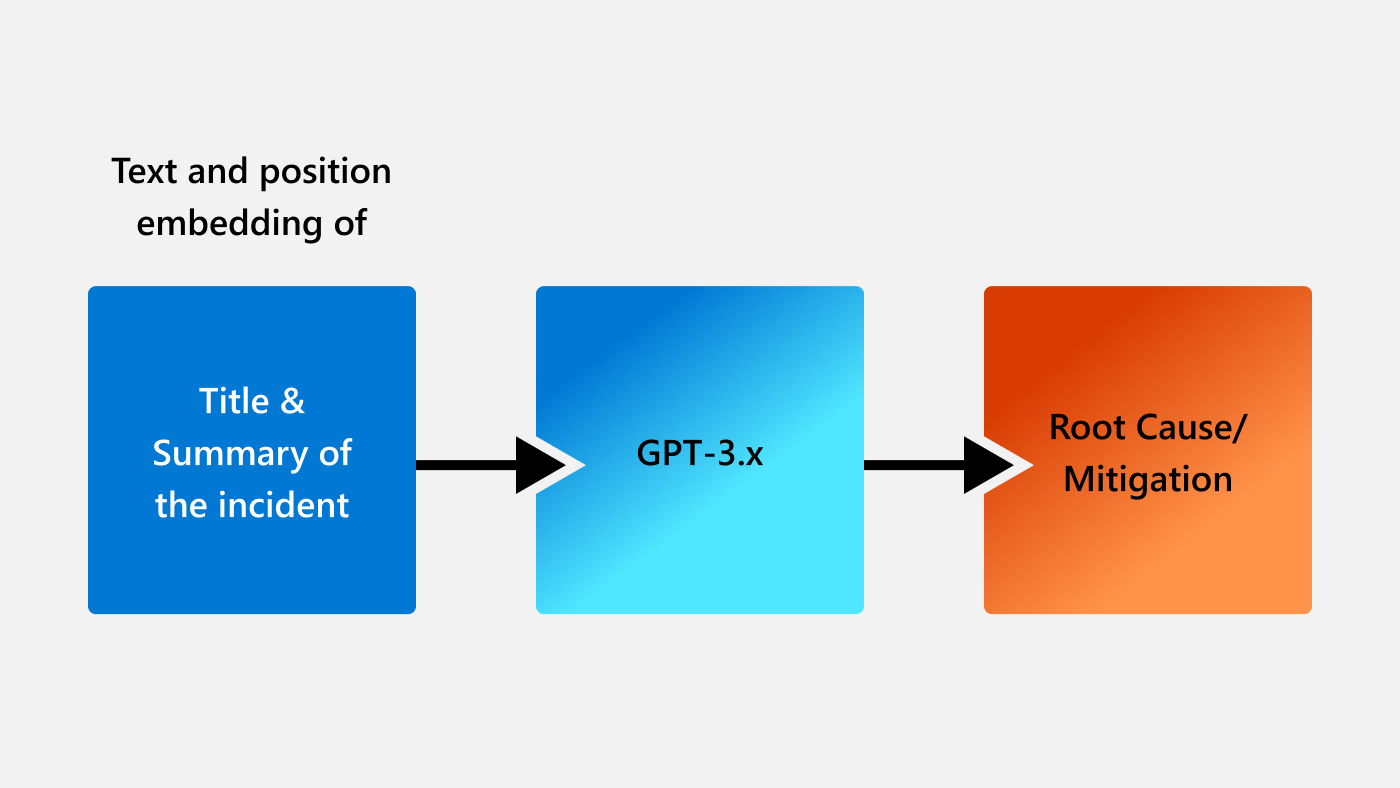
Figure 1: Leveraging GPT-3.x for root cause analysis and mitigation
In our recently published ICSE paper, we demonstrated the usefulness of LLMs for production incident diagnosis for the first time. When an incident ticket is created, the author specifies a title for each incident created and describes any relevant details, such as error messages, anomalous behavior, and other details which might help with resolution. We used the title and the summary of a given incident as the input for LLMs and generated root cause and mitigation steps, as shown in Figure 1.
We did a rigorous study on more than 40,000 incidents generated from more than 1000 services and compared several LLMs in zero-shot, fine-tuned, and multi-task settings. We find that fine-tuning the GPT-3 and GPT-3.5 models significantly improves the effectiveness of LLMs for incident data.
Effectiveness of GPT-3.x models at finding root causes
Model
BLEU-4
ROUGE-L
METEOR
BERTScore
BLEURT
NUBIA
Top1
Top5
Top1
Top5
Top1
Top5
Top1
Top5
Top1
Top5
Top1
Top5
RoBERTa
4.21
NA
12.83
NA
9.89
NA
85.38
NA
35.66
NA
33.94
NA
CodeBERT
3.38
NA
10.17
NA
6.58
NA
84.88
NA
33.19
NA
39.05
NA
Curie
3.40
6.29
19.04
15.44
7.21
13.65
84.90
86.36
32.62
40.08
33.52
49.76
Codex
3.44
6.25
8.98
15.51
7.33
13.82
84.85
86.33
32.50
40.11
33.64
49.77
Davinci
3.34
5.94
8.53
15.10
6.67
12.95
83.13
84.41
31.06
38.61
35.28
50.79
Davinci-002
4.24
7.15
11.43
17.2
10.42
16.8
85.42
86.78
36.77
42.87
32.3
51.34
%gain for Davinci-002
23.26
13.67
26.44
10.90
42.16
21.56
0.61
0.49
12.72
6.88
-8.45
1.08
Table 1: Lexical and semantic performance of different LLMs
In our offline evaluation, we compared the performance of GPT-3.5 against three GPT-3 models by computing several semantic and lexical metrics (which measures the text similarity) between the generated recommendations and the ground truth of root cause or mitigation steps mentioned in incident management (IcM) portal. The average gains for GPT-3.5 metrics for different tasks were as follows:
For root cause and mitigation recommendation tasks, Davinci-002 (GPT-3.5) provided at least 15.38% and 11.9% gains over all the GPT-3 models, respectively, as shown in Table 1.
When we generated mitigation plans by adding root cause as input to the model, GPT-3.5 model provided at least an 11.16% gain over the GPT-3 models.
LLMs performed better on machine reported incidents (MRIs) as opposed to customer reported incidents (CRIs), due to the repetitive nature of the MRIs.
Fine-tuning LLMs with incident data improved performance significantly. A fine-tuned GPT-3.5 model improved the average lexical similarity score by 45.5% for root cause generation and 131.3% for mitigation generation tasks over zero-shot (i.e., inferencing directly on pretrained GPT-3 or GPT-3.5 model) setting.
Looking through the incident owners’ eyes
In addition to analysis with semantic and lexical metrics, we also interviewed the incident owners to evaluate the effectiveness of the generated recommendations. Overall, GPT-3.5 outperforms GPT-3 in a majority of the metrics. More than 70% of on-call engineers gave a rating of 3 out of 5 or better for the usefulness of recommendations in a real-time production setting.
Looking forward
With future versions of LLMs coming, we expect the performance for automatic incident resolution will further improve, and the need for fine-tuning may decrease. Yet we are in the initial stage, with many open research questions in this field. For instance, how can we incorporate additional context about the incident, such as discussion entries, logs, service metrics, and even dependency graphs of the impacted services to improve the diagnosis? Another challenge is staleness since the models would need to be frequently retrained with the latest incident data. To solve these challenges, we are working on leveraging the latest LLMs combined with retrieval augmented approaches to improve incident diagnosis via a conversational interface, as shown in Figure 2.
Figure 2: Workflow of retrieval-augmented root cause analysis
Moreover, ChatGPT can be actively integrated into the “discussion” of the incident diagnosis. By collecting evidence from available documents and logs, the model can generate coherent, contextual, natural-sounding responses to inquiries and offer corresponding suggestions, thereby facilitating the discussion and accelerating the incident resolution process. We believe this could deliver a step function improvement in the overall incident management process with contextual and meaningful root causes analysis and mitigation, thereby reducing significant human effort required and bolstering reliability and customer satisfaction.
Acknowledgement
This post includes contributions from Toufique Ahmed during his internship at Microsoft.
The ways in which people are able to interact with technologies can have a profound effect on a technology’s utility and adoptability. Building computing tools and services around people’s natural styles of work, communication, and play can give technology the value it needs to have meaningful impact. For decades, human-computer interaction (HCI) has examined the relationship between people and computers to help maximize the capabilities of each across a range of experiences and situations.
The ACM CHI Conference on Human Factors in Computing Systems (CHI) is a renowned meeting ground for top talent in the HCI field and a showcase for some of its most compelling work. Hosted April 23 through April 28, this year’s conference drew more than 4,500 participants from 79 countries. Contributions from Microsoft researchers and their collaborators demonstrated the breadth of work inspired by the myriad and diverse ways people use computing today and will in the future.
Check out a few highlights from this year’s conference below, including researchers’ efforts to better understand the role of wellbeing in work, to augment memory through our sense of smell, and to bridge the gap between programmers and code-generating models, which received honorable mention at the conference.
Programming languages are an extremely powerful form of user interface. They also happen to be extremely difficult to learn, especially for non-expert end-user programmers who lack training in computing. What if end-user programmers could instead use a natural language they already know? This prospect can be realized through large language models (LLM): deep neural networks using the transformer architecture, trained on large corpora, and fine-tuned to generate code from natural language. Despite impressive benchmark performance, LLMs are beset with issues in practical use. Lab and field studies have shown that the mapping between natural language and code is poorly understood, that generated code can contain subtle bugs, and that generated code can be difficult to verify.
In their paper, researchers consider the specific problem of abstraction matching: when the user has well-formed intent, how do they select an utterance from the near infinite space of naturalistic utterances that they believe the system will reliably map to a satisfactory solution? This involves “matching” the utterance to the right level of “abstraction” by specifying the utterance at a level of granularity and detail that matches the set of actions the system can take and selecting suitable words and grammar.
Regularity in daily activities has been linked to positive wellbeing outcomes, but previous studies have mainly focused on clinical populations and traditional daily activities such as sleep and exercise. This research extends prior work by examining the regularity of both self-reported and digital activities of 49 information workers in a four-week naturalistic study. Findings suggest that greater variability in self-reported mood, job demands, lunch time, and sleep quality may be associated with increased stress, anxiety, and depression. However, when it comes to digital activity–based measures, greater variability in rhythm is associated with reduced emotional distress. This study expands our understanding of workers and the potential insights that can be gained from analyzing technology interactions and wellbeing.
This paper investigates how a smartphone-controlled olfactory wearable might improve memory recall. Researchers conducted a within-subjects experiment with 32 participants using the device and not using the device (control). In the experimental condition, bursts of odor were released during visuo-spatial memory navigation tasks, which also had a language learning component, and rereleased during sleep the following night in the subjects’ home. The researchers found that compared with control, there was an improvement in memory performance when using the scent wearable in memory tasks that involved walking in a physical space. Furthermore, participants recalled more objects and translations when re-exposed to the same scent during the recall test in addition to during sleep. These effects were statistically significant, and in the object recall task, they also persisted for more than a week. This experiment demonstrates a potential practical application of olfactory interfaces that can interact with a user during wake, as well as sleep, to support memory.
In their paper, researchers present AdHocProx, a system that uses device-relative, inside-out sensing to augment co-located collaboration across multiple devices without recourse to externally anchored beacons or even reliance on Wi-Fi connectivity.
AdHocProx achieves this via sensors, including dual ultra-wideband (UWB) radios for sensing distance and angle to other devices in dynamic, ad-hoc arrangements and capacitive grip to determine where the user’s hands hold the device and to partially correct for the resulting UWB signal attenuation. All spatial sensing and communication take place via the side-channel capability of the UWB radios, suitable for small-group collaboration across up to four devices (eight UWB radios).
Together, these sensors detect proximity and natural, socially meaningful device movements to enable contextual interaction techniques. Researchers find that AdHocProx can obtain 95 percent accuracy recognizing various ad-hoc device arrangements in an offline evaluation, with participants particularly appreciative of interaction techniques that automatically leverage proximity-awareness and relative orientation among multiple devices.
This paper introduces Escapement, a video prototyping tool that introduces a powerful new concept for prototyping screen-based interfaces by flexibly mapping sensor values to dynamic playback control of videos. This recasts the time dimension of video mockups as sensor-mediated interaction.
This abstraction of time as interaction, which the researchers dub video-escapement prototyping, empowers designers to rapidly explore and viscerally experience direct touch or sensor-mediated interactions across one or more device displays. The system affords cross-device and bidirectional remote (telepresent) experiences via cloud-based state sharing across multiple devices. This makes Escapement especially potent for exploring multi-device, dual-screen, or remote-work interactions for screen-based applications. Researchers share the results of observations of long-term usage of video-escapement techniques with experienced interaction designers and articulate design choices for supporting a reflective, iterative, and open-ended creative design process.
Andriana Boudouraki, Joel E. Fischer, Stuart Reeves, Sean Rintel
Organizations wishing to maintain employee satisfaction for hybrid collaboration need to explore flexible solutions that provide value for both remote and on-site employees. This case study reports on the roll-out of a telepresence robot pilot at Microsoft Research Cambridge to test whether robots would provide enjoyable planned and unplanned encounters between remote and on-site employees. Researchers describe the work that was undertaken to prepare for the roll-out, including the occupational health and safety assessment, systems for safety and security, and the information for employees on safe and effective use practices. The pilot ended after three months, and robot use has been discontinued after weighing the opportunities against low adoption and other challenges. The researchers discuss the pros and cons within this organizational setting and make suggestions for future work and roll-outs.
Having little time for focused work is a major challenge in information work. While research has explored computing-assisted user-facing solutions for protecting time for focused work, there’s limited empirical evidence about the effectiveness of these features on wellbeing and work engagement. Toward this problem, researchers study the effects of automatically scheduling time for focused work on people’s work calendars using the “focus time” feature on Outlook calendars. The researchers conducted an experimental study over six weeks with 15 treatment and 10 control participants, who responded to survey questions on wellbeing and work engagement throughout the study. The researchers found that the treatment participants showed higher wellbeing, including increased excitement, relaxation, and satisfaction, and decreased anger, frustration, tiredness, and stress. The researchers study the needs, benefits, and challenges of scheduling focus time and discuss the importance of and design recommendations for enabling mechanisms and tools supporting focused work.
Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
danah boyd, a partner researcher at Microsoft Research, has been awarded MIT’s Morison Prize in Science, Technology, and Society, for outstanding work combining humanistic values with effectiveness in the world of practical affairs, particular in science and technology.
Dr. boyd, who is also a Distinguished Visiting Professor at Georgetown University, is currently conducting a multi-year ethnographic study of the U.S. census to understand how data are made legitimate. Her previous studies have focused on media manipulation, algorithmic bias, privacy practices, social media, and teen culture.
Microsoft’s Nicole Immorlica receives 2023 SIGecom Test of Time Award
Nicole Immorlica, a Senior Principal Researcher with Microsoft Research New England, has been awarded the2023 SIGecom Test of Time Award for her work on a 2005 paper on matching markets. The award from the Association of Computing Machinery (ACM) recognizes “an influential paper or series of papers published between ten and twenty-five years ago that has significantly impacted research or applications exemplifying the interplay of economics and computation.”
In the award-winning paper: Marriage, honesty, and stability, Immorlica and a co-author explored centralized two-sided markets, such as the medical residency market, matching participants by running a stable marriage algorithm. While no matching mechanism based on a stable marriage algorithm can guarantee ‘truthfulness’ as a dominant strategy, the paper showed that in certain probabilistic settings, truthfulness is the best strategy for the participants.
On-Demand Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Microsoft’s Lorin Crawford named 2023 COPSS Emerging Leader
Lorin Crawford, a principal researcher at Microsoft Research New England, has been named a 2023 COPSS Emerging Leader by the Committee of Presidents of Statistical Societies. The award announcement cited Crawford’s path-breaking research combining theory and methods of mathematics, statistics and computing to generate new knowledge and insight about the genetic basis of disease, and exceptional mentoring of students from multiple scientific disciplines.
The award recognizes the important role of early-career statistical scientists in shaping the future of their discipline. The selection criteria are designed to highlight contributions in areas not traditionally recognized by other early-career awards in the statistical sciences.
Crawford, who is also a faculty member at Brown University’s School of Public Health, focuses on developing novel and efficient algorithms that address complex problems in quantitative genetics, cancer pharmacology, molecular genomics, and geometric morphometrics.
Microsoft researchers receive Test of Time award for personalized news recommendation work
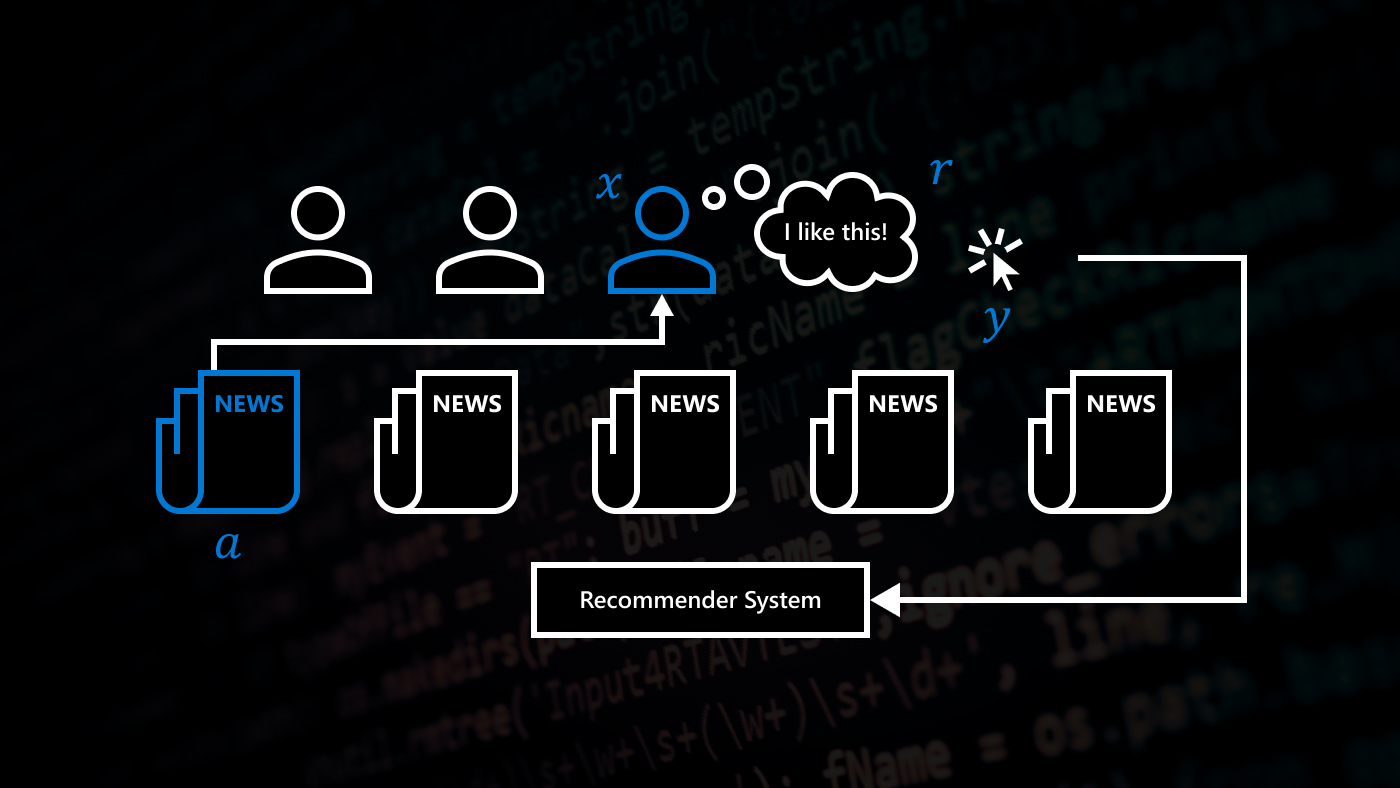
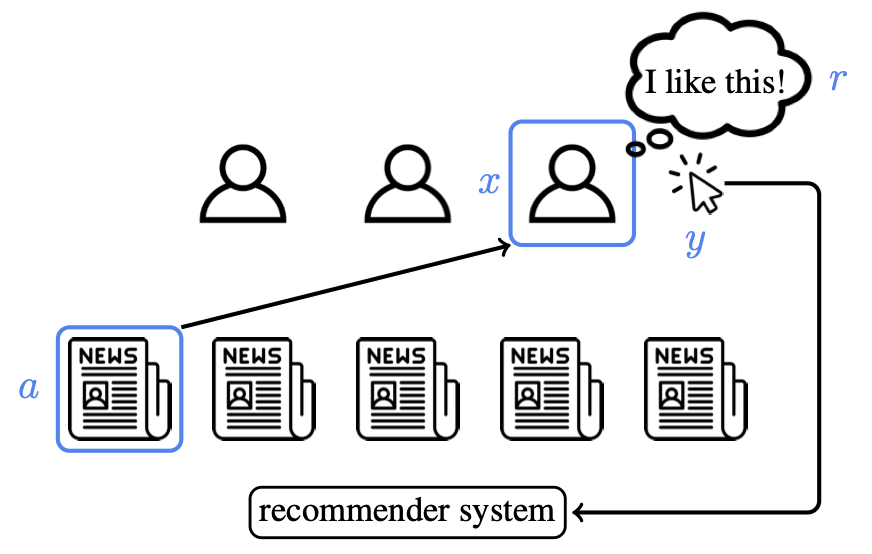
A paper co-authored by two Microsoft researchers has received a 2023 Seoul Test of Time Award from the International World Wide Web Conference Committee (IW3C2). The 2020 paper: A Contextual-Bandit Approach to Personalized News Article Recommendation, was written by John Langford and Robert Schapire, along with two industry colleagues. The authors proposed a new approach for personalized recommendation using contextual bandit algorithms. According to the IW3C2, the paper now has more than 2,730 citations and has become foundational research in the area of recommendation systems.
The award announcement also states: “The paper addressed fundamental challenges in real-world recommendation systems via computationally efficient algorithms grounded in learning theory. It also showed that recommendation algorithms can be reliably evaluated offline, enabling algorithm selection without operational impact, and that contextual bandits can yield significant gains in user engagement.”
A Frequency Domain Approach to Predict Power System Transients
The dynamics of power grids are governed by a large number of nonlinear differential and algebraic equations (DAEs). To safely run the system, operators need to check that the states described by these DAEs stay within prescribed limits after various potential faults. However, current numerical solvers of DAEs are often too slow for real-time system operations. In addition, detailed system parameters are often not exactly known. Machine learning approaches have been proposed to reduce the computational efforts, but existing methods generally suffer from overfitting and failures to predict unstable behaviors.
In a new paper: A Frequency Domain Approach to Predict Power System Transients, Microsoft researchers propose a novel framework to predict power system transients by learning in the frequency domain. The intuition is that although the system behavior is complex in the time domain, relatively few dominant modes exist in the frequency domain. Therefore, the researchers learn to predict by constructing neural networks with Fourier transform and filtering layers. System topology and fault information are encoded by taking a multi-dimensional Fourier transform, allowing researchers to leverage the fact that the trajectories are sparse both in time and spatial frequencies. This research shows that the proposed approach does not need detailed system parameters, greatly speeds up prediction computations and is highly accurate for different fault types.
Inference with Reference: Lossless Acceleration of Large Language Models
The growing use of large foundation models like GPT-3.5/4 for real-world applications has raised concerns about high deployment costs. While general methodologies such as quantization, pruning, compression, and distillation help reduce costs. At test time, output tokens must be decoded (sequentially) one by one, which poses significant challenges for LLMs to be deployed at scale.
In a new paper: Inference with Reference: Lossless Acceleration of Large Language Models, Microsoft researchers study accelerating LLM inference by improving the efficiency of autoregressive decoding. In multiple real-world applications, this research shows that an LLM’s output tokens often come from its context. For example, in a retrieval-augmented generation scenario for a search engine, an LLM’s context usually includes relevant documents retrieved from an external corpus as reference according to a query, and its output usually contains many text spans found in the reference (i.e., retrieved documents). Motivated by this observation, the researchers propose an LLM accelerator (LLMA) to losslessly speed inference with references. Its improved computational parallelism allows LLMA to achieve over 2x speed-up for LLMs, with identical generation results as greedy decoding, in many practical generation scenarios where significant overlap between in-context reference and outputs exists. The researchers are collaborating with the Bing search team to explore integrating this technique into snippet/caption generation, Bing chat, and other potential scenarios.
High-throughput ab initio reaction mechanism exploration in the cloud with automated multi-reference validation
Quantum chemical calculations on atomistic systems have evolved into a standard approach to studying molecular matter. But these calculations often involve a significant amount of manual input and expertise. Most of these calculations could be automated, alleviating the need for expertise in software and hardware accessibility.
This workflow i) uses density functional theory methods to deliver minimum and transition-state structures and corresponding energies and properties, (ii) launches coupled cluster calculations for optimized structures to provide more accurate energy and property estimates, and (iii) evaluates multi-reference diagnostics to back check the coupled cluster results and subjects them to automated multi-configurational calculations for potential multi-configurational cases.
All calculations take place in a cloud environment and support massive computational campaigns. Key features of all components of the AutoRXN workflow are autonomy, stability, and minimum operator interference.
Diffusion models have emerged as a powerful class of generative AI models. They have been used to generate photorealistic images and short videos, compose music, and synthesize speech. And their uses don’t stop there. In our new paper, Imitating Human Behaviour with Diffusion Models, we explore how they can be used to imitate human behavior in interactive environments.
This capability is valuable in many applications. For instance, it could help automate repetitive manipulation tasks in robotics, or it could be used to create humanlike AI in video games, which could lead to exciting new game experiences—a goal particularly dear to our team.
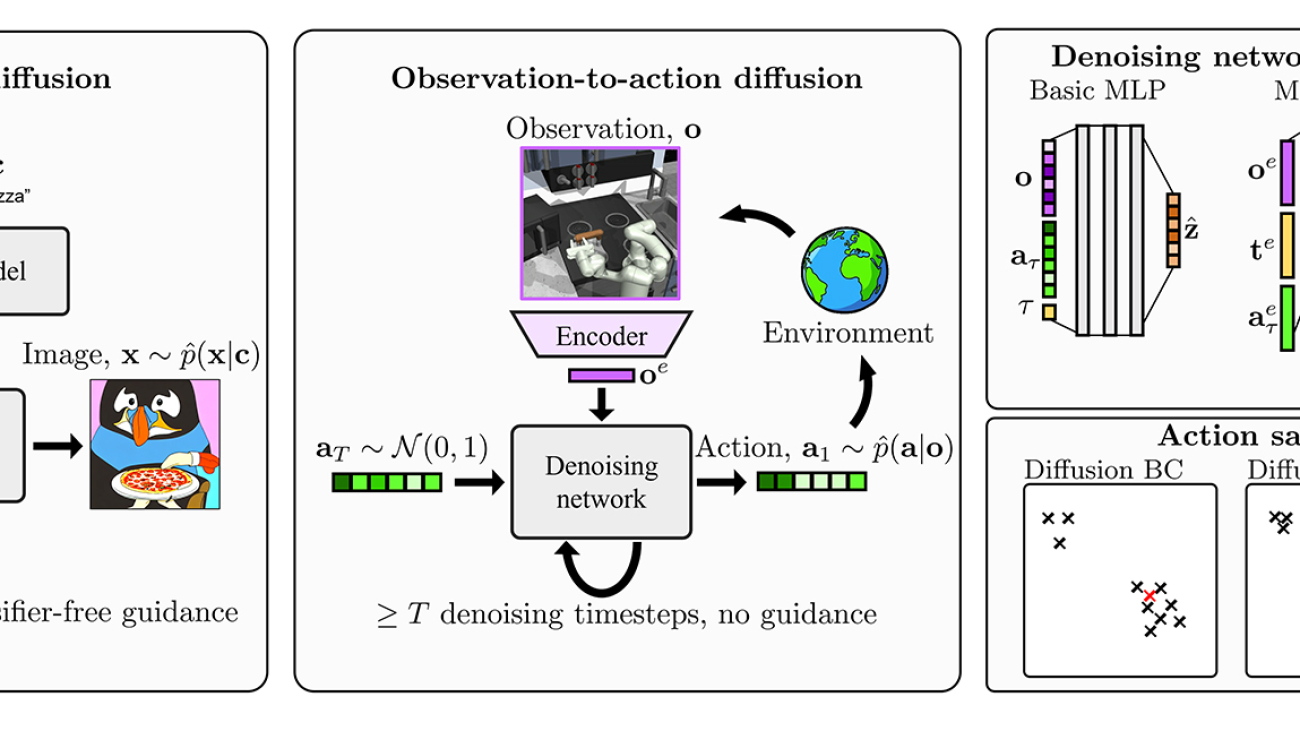
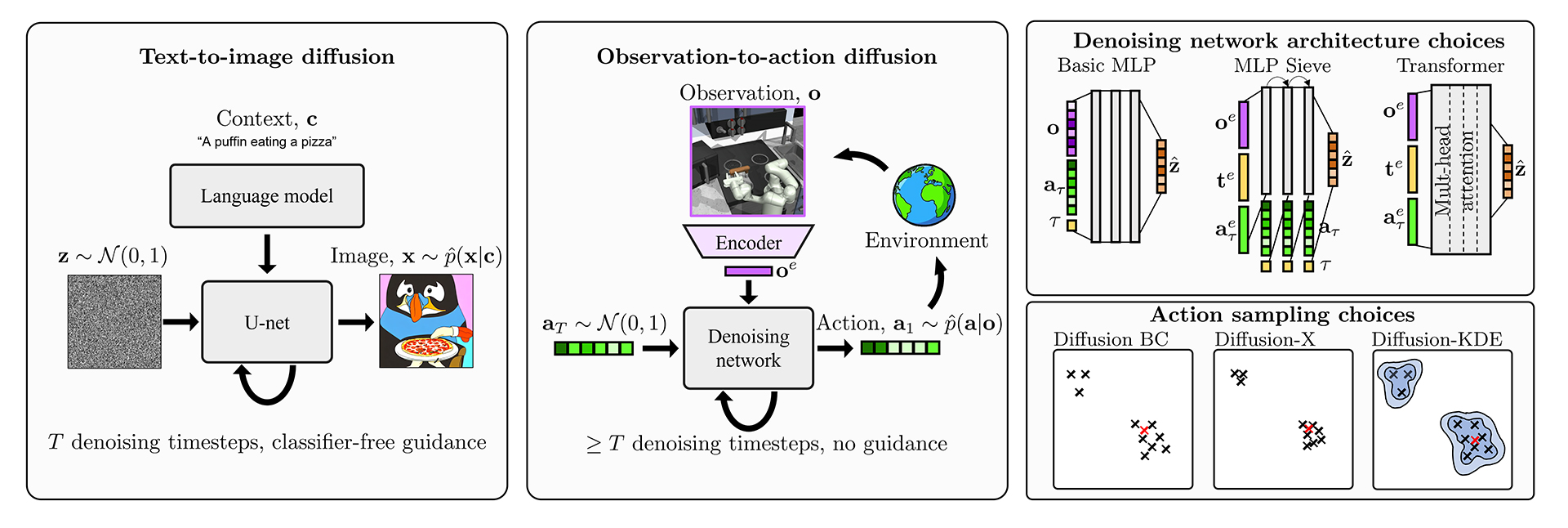
We follow a machine learning paradigm known as imitation learning (more specifically behavior cloning). In this paradigm, we are provided with a dataset containing observations a person saw, and the actions they took, when acting in an environment, which we would like an AI agent to mimic. In interactive environments, at each time step, an observation ( o_t ) is received (e.g. a screenshot of a video game), and an action ( a_t ) is then selected (e.g. the mouse movement). With this dataset of many ( o )’s and ( a )’s performed by some demonstrator, a model ( pi ) could try to learn this mapping of observation-to-action, ( pi(o) to a ).
Spotlight: Microsoft Research Podcast
AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
When the actions are continuous, training a model to learn this mapping introduces some interesting challenges. In particular, what loss function should be used? A simple choice is mean squared error, as often used in supervised regression tasks. In an interactive environment, this objective encourages an agent to learn the average of all the behaviors in the dataset.
If the goal of the application is to generate diverse human behaviors, the average might not be very useful. After all, humans are stochastic (they act on whims) and multimodal creatures (different humans might make different decisions). Figure 2 depicts the failure of mean squared error to mimic the true action distribution (marked in yellow) when it is multimodal. It also includes several other popular choices for the loss function when doing behavior cloning.
Figure 2: This toy example (based on an arcade claw game) shows an action space with two continuous action dimensions. Here the demonstration distribution is marked in yellow—it is both multimodal and has correlations between action dimensions. Diffusion models offer a good imitation of the full diversity in the dataset.
Ideally, we’d like our models to learn the full variety of human behaviors. And this is where generative models help. Diffusion models are a specific class of generative model that are both stable to train and easy to sample from. They have been very successful in the text-to-image domain, which shares this one-to-many challenge—a single text caption might be matched by multiple different images.
Our work adapts ideas that have been developed for text-to-image diffusion models, to this new paradigm of observation-to-action diffusion. Figure 1 highlights some differences. One obvious point is that the object we are generating is now a low-dimensional action vector (rather than an image). This calls for a new design for the denoising network architecture. In image generation, heavy convolutional U-Nets are in vogue, but these are less applicable for low-dimensional vectors. Instead, we innovated and tested three different architectures shown in Figure 1.
In observation-to-action models, sampling a single bad action during an episode can throw an agent off course, and hence we were motivated to develop sampling schemes that would more reliably return good action samples (also shown in Figure 1). This problem is less severe in text-to-image models, since users often have the luxury of selecting a single image from among several generated samples and ignoring any bad images. Figure 3 shows an example of this, where a user might cherry-pick their favorite, while ignoring the one with nonsensical text.
Figure 3: Four samples from a text-to-image diffusion model from Bing (note this is not our own work), using the prompt “A cartoon style picture of people playing with arcade claw machine”.
We tested our diffusion agents in two different environments. The first, a simulated kitchen environment, is a challenging high-dimensional continuous control problem where a robotic arm must manipulate various objects. The demonstration dataset is collected from a variety of humans performing various tasks in differing orders. Hence there is rich multimodality in the dataset.
We found that diffusion agents outperformed baselines in two aspects. 1) The diversity of behaviors they learned were broader, and closer to the human demonstrations. 2) The rate of task completion (a proxy for reward) was better.
The videos below highlight the ability of diffusion to capture multimodal behavior–starting from the same initial conditions, we roll out the diffusion agent eight times. Each time it selects a different sequence of tasks to complete.
The second environment tested was a modern 3D video game, Counter-strike. We refer interested readers to the paper for results.
In summary, our work has demonstrated how exciting recent advances in generative modeling can be leveraged to build agents that can behave in humanlike ways in interactive environments. We’re excited to continue exploring this direction – watch this space for future work.
For more detail on our work, please see our paper and code repo.
Reinforcement learning (RL) hinges on the power of rewards, driving agents—or the models doing the learning—to explore and learn valuable actions. The feedback received through rewards shapes their behavior, culminating in effective policies. Yet, crafting reward functions is a complex, laborious task, even for experts. A more appealing option, particularly for the people ultimately using systems that learn from feedback over time, is an agent that can automatically infer a reward function. The interaction-grounded learning (IGL) paradigm from Microsoft Research enables agents to infer rewards through the very process of interaction, utilizing diverse feedback signals rather than explicit numeric rewards. Despite the absence of a clear reward signal, the feedback relies on a binary latent reward through which the agent masters a policy that maximizes this unseen latent reward using environmental feedback.
In our paper “Personalized Reward Learning with Interaction-Grounded Learning,” which we’re presenting at the 2023 International Conference on Learning Representations (ICLR), we propose a novel approach to solve for the IGL paradigm: IGL-P. IGL-P is the first IGL strategy for context-dependent feedback, the first use of inverse kinematics as an IGL objective, and the first IGL strategy for more than two latent states. This approach provides a scalable alternative to current personalized agent learning methods, which can require expensive high-dimensional parameter tuning, handcrafted rewards, and/or extensive and costly user studies.
IGL-P is particularly useful for interactive learning applications such as recommender systems. Recommender systems help people navigate increasing volumes of content offerings by providing personalized content suggestions. However, without explicit feedback, recommender systems can’t detect for certain whether a person enjoyed the displayed content. To accommodate, modern recommender systems equate implicit feedback signals with user satisfaction. Despite the popularity of this approach, implicit feedback is not the true reward. Even the click-through rate (CTR) metric, the gold standard for recommender systems, is an imperfect reward, and its optimization naturally promotes clickbait.
Interaction-grounded learning (IGL) for the recommender system setting. The recommender system receives features describing a person (x), recommends an item (a), and observes implicit user feedback (y), which is dependent on the latent reward (r) but not r itself, to learn how to better recommend personalized content to the individual.
This problem has led to the handcrafting of reward functions with various implicit feedback signals in modern recommender systems. Recommendation algorithms will use hand-defined weights for different user interactions, such as replying to or liking content, when deciding how to recommend content to different people. This fixed weighting of implicit feedback signals might not generalize across a wide variety of people, and thus a personalized learning method can improve user experience by recommending content based on user preferences.
Spotlight: On-Demand EVENT
Microsoft Research Summit 2022
On-Demand Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
The choice of reward function is further complicated by differences in how people interact with recommender systems. A growing body of work shows that recommender systems don’t provide consistently good recommendations across demographic groups. Previous research suggests that this inconsistency has its roots in user engagement styles. In other words, a reward function that might work well for one type of user might (and often does) perform poorly for another type of user who interacts with the platform differently. For example, older adults have been found to click on clickbait more often. If the CTR is used as an objective, this group of users will receive significantly more clickbait recommendations than the general public, resulting in higher rates of negative user experiences and leading to user distrust in the recommender system.
IGL-P provides a novel approach to optimize content for latent user satisfaction—that is, rewards that a model doesn’t have direct access to—by learning personalized reward functions for different people rather than requiring a fixed, human-designed reward function. IGL-P learns representations of diverse user communication modalities and how these modalities depend on the underlying user satisfaction. It assumes that people may communicate their feedback in different ways but a given person expresses (dis)satisfaction or indifference to all content in the same way. This enables the use of inverse kinematics toward a solution for recovering the latent reward. With additional assumptions that rewards are rare when the agent acts randomly and some negatively labeled interactions are directly accessible to the agent, IGL-P recovers the latent reward function and leverages that to learn a personalized policy.
IGL-P successes
The success of IGL-P is demonstrated with experiments using simulations, as well as with real-world production traces. IGL-P is evaluated in three different settings:
A simulation using a supervised classification dataset shows that IGL-P can learn to successfully distinguish between different communication modalities.
A simulation for online news recommendation based on publicly available data from Facebook users shows that IGL-P leverages insights about different communication modalities to learn better policies and achieve consistent performance among diverse user groups (the dataset, created in 2016, consists of public posts from the official Facebook pages of news companies from 2012 to 2016 and aggregated user reactions; because of this aggregation, identifying information can’t be extracted).
A real-world experiment deployed in the Microsoft image recommendation product Windows Spotlight showcases that the proposed method outperforms the hand-engineered reward baseline and succeeds in a practical application serving millions of people.




 communication technology with collaborators from the
communication technology with collaborators from the