GEHRKE: We just had a discussion maybe a couple of years ago, right, when you were just in transition to Africa. So it’s really great to have you here and both learn a little bit what’s happening there, but also to learn a bit more about your story. Where did you grow up, and how did you end up here at Microsoft?
O’NEILL: Yeah, thanks for asking that. I’ve had a very, well, it’s definitely not been a straight road to get here, but the windy roads are the most interesting ones. I grew up in Plymouth, which is a dockyard and naval town in the southwest of England, so a socially deprived working-class town. So when I was growing up, it was a thriving working-class town, but of course with those industries, you know, they didn’t, they didn’t pass so well through those years. So, you know, by the time I was leaving school, it was quite a deprived city and still is. I think that it’s really important to be in those type of places, though, because you get a very rich view of life, and I left them as soon as I could, [LAUGHS] so …
GEHRKE: When you went to university?
O’NEILL: Went to, well, I went and I was a cook for a year in the Lake District, which is a very beautiful part of the UK, and then went to university.
GEHRKE: Where’s the Lake District?
O’NEILL: It is northwest, and it’s all hills. It’s, like, Wordsworth Country. It’s all hills and poetry and beautiful houses. And, yeah, it was a fantastic time working as a cook there. And then I went to Manchester to do my degree.
GEHRKE: OK. And what is your degree in?
O’NEILL: Ah, so, yes, I had, I did a social science degree to start with. I started at the time when you could get a degree in anything and get any job at the end of it. But by the time I came out of my degree, it was a recession.
GEHRKE: But did you have, did you have specific plans while you were studying of what you want, you know, what profession you wanted to go into?
O’NEILL: Not really. I didn’t. I think I’d, I think like many young people, I didn’t really know, but I felt that I would find something interesting when I came out. And then, you know, I just worked lots of different jobs. [LAUGHS]
GEHRKE: What is your favorite college course?
O’NEILL: My favorite college course—in my degree? Gosh, that’s a good question. It was all so long ago. [LAUGHS]
GEHRKE: OK …
O’NEILL: My favorite, I guess, yeah, no, I, so, I did … my degree was in psychology. I worked, and then I did my master’s in computer science and then my PhD in human-computer interaction.
GEHRKE: That’s quite a change, right, from psychology into computer science, then.
O’NEILL: Yes, yes. And I just, you know, I’d always just wanted to do computing, but when I was at school, it was … we had one computer in the school, and so it was, like, a computer at home or you don’t do computer science. So, you know, I didn’t do it.
GEHRKE: Right.
O’NEILL: So then as computers became more prominent, more available, you know, I was working in libraries, and they started computerizing, and I worked on that project, and then that led me to do a master’s. And so I was like, hey, this is the opportunity to really get into this area, and I loved it. It was fantastic. And Manchester’s computer science department is one of the top departments, and I had an amazing … Carole Goble was my thesis supervisor. She was absolutely amazing and strong for women in computing. But at the end of it, I was like, OK, so I didn’t want to do pure social science and I didn’t want to do pure computer science. What I want to do is do human-computer science, so where you really merge the two. And that’s how I got into HCI, and I think that’s where I started finding my favorite courses. You know, I loved the research methods. I loved those types of things.
GEHRKE: And what is your PhD about?
O’NEILL: Ooh, it was very boring. [LAUGHTER] My PhD was in computer-supported cooperative work [CSCW], and …
GEHRKE: OK. Oh, yeah. Very relevant now, right?
O’NEILL: Yeah, very relevant now. And that was a really exciting time for CSCW, as well, because there were so many different labs. There were Sun Systems, there was Xerox, there was Microsoft—all doing really cool, like, collaborative technologies. So it seemed like a brilliant area to go into. But I was looking at, can we support networking events for businesses?
GEHRKE: Wow. Uh-huh …
O’NEILL: So it was just at the time of the first, you know, things like Webex and things, you know, the first collaborative seminar-y …
GEHRKE: Yeah, so you’re way ahead of the social networks, right, and everything, right?
O’NEILL: Yeah, yeah.
GEHRKE: And there was a whole conference at that point in time, right? CSCW, I think I remember. Wasn’t there …
O’NEILL: Yes, yes, yes.
GEHRKE: So it was and still is, I think, a really big field.
O’NEILL: Yes, it’s a, it’s a, it’s really interesting. And I think one of the things that’s interesting with the foundational models now is many of the things that people like me, HCI people, have been wanting to happen—”Oh, if only we can enable people to interact with technology like this”—are now suddenly possible, which is quite exciting.
GEHRKE: Yeah, so we’ll get to that in a little bit because I think, you know, as you said, the whole field of HCI is now changing with foundational models and what the interfaces are, will be. I think it’s a really interesting, deep research question right now. So, so, OK, so you got your PhD; you’re in Manchester. What’s the next step in your career? Where did you go next?
O’NEILL: Yeah, I actually got a job before I finished my PhD. So I took quite a long time to do my PhD. I think it was seven years in the end, partly because I was teaching. When I was doing—like, lecturing when I was doing my PhD, and I also had a job as a consultant occasionally, working with, I think, I worked with the Co-op Bank. I worked with some usability companies, and you could, I could make enough money to live for a term on, like, two weeks’ consultancy because I didn’t have very high costs. [LAUGHS]
GEHRKE: Right. You lived as a grad student, right?
O’NEILL: Yes. Yeah. Yeah. And, actually, you know, I was living in Manchester. I was living in a squat, so I wasn’t paying any rent, [LAUGHS] so …
GEHRKE: Oh, really?
O’NEILL: Yes. So I didn’t have very many costs.
GEHRKE: OK.
O’NEILL: Which was very handy. So I didn’t have any real incentive to finish my PhD until I got a job, you know. When I finished my master’s, I looked at the job market, and with my computer science master’s, the main job was database manager, [LAUGHS] which didn’t appeal.
GEHRKE: That sounds now really interesting. [LAUGHTER]
O’NEILL: Yeah. So I, actually, that’s why I ended up doing a PhD, because I was like, I don’t want to go back to work yet. You know, I’ve been working for five years before. So, so, yeah, I just was enjoying doing a PhD and doing pieces of work here and there. And then I got a job at Xerox in Cambridge, and then that’s when I got motivated to finish my PhD because working and doing a PhD at the same time is not much fun.
GEHRKE: Right, right. So you got your PhD, had your job lined up, and then you’re starting at Xerox. What were you doing in Xerox?
O’NEILL: Human-computer interaction. Yeah, it was a really exciting time. There was so much going on in the industry. I was so delighted. It was like my dream job to be in industry and to maybe create cool interfaces and, you know, cool collaborative systems. So … and then they closed the lab [LAUGHS] within six months. It wasn’t my fault.
GEHRKE: So quickly?
O’NEILL: Mm-hmm.
GEHRKE: Wow. And what did you do then? I mean, this is your first big job, and …
O’NEILL: Yes …
GEHRKE: … such a quick setback.
O’NEILL: They offered me a job in their lab in France. So I stayed in the UK for a while and worked half in France, half in the UK, and then I shifted to France full time.
GEHRKE: OK. Oh, wow. So do you … where in France did you live then?
O’NEILL: Grenoble.
GEHRKE: OK, yeah. In the middle of …
O’NEILL: In the French Alps.
GEHRKE: … the French Alps. Exactly. Beautiful place.
O’NEILL: Absolutely … yes. Yeah. Skiing, climbing, hiking. So much fun.
GEHRKE: And, OK, so you’re at Xerox PARC in the French Alps. What’s, what’s next?
O’NEILL: They were opening, Xerox was opening a research lab in India. And I’d always wanted to travel. You know, I’d always wanted … and I never really had the money or the opportunity to travel. So when they said they were opening it, I just went to my boss and said, hey, I don’t know what you’d want me to do, but if there’s any opportunities for me to do anything to help …
GEHRKE: Wow.
O’NEILL: … the opening of India, I’d love to. And I went out for a month and then I went out for three months.
GEHRKE: I mean, both of these sound like really bold steps to me. First of all, I mean, Grenoble is probably pure French speaking, right? And, I don’t know, did you have high school French or you were good … [LAUGHS]
O’NEILL: I had high school French, yes, and then we drove, we drove from the UK to Grenoble listening to “learn French” tapes [LAUGHS] …
GEHRKE: OK, wow … [LAUGHS]
O’NEILL: …in the car. Yeah.
GEHRKE: Wow. And that was enough then to get by with a daily …
O’NEILL: Actually, so it was great in France because they expect you to learn the language, so you have French lessons at work. And then, actually, I did an evening class, as well, that was paid for by work, a really intensive one-month, like two hours a night, every night of the week. And that really helped. Yeah, it was, it’s fantastic.
GEHRKE: Wow, that’s really great. And then, and then you took the even bigger step to move to India, right. How was that like, and what was your experience there?
O’NEILL: Yeah, India is just magical. You know, initially, I just went for one month, then three months, and it was just—the people, the culture, the work I was doing, the research I was doing was like no research … you know, I’d spent a lot of time in call centers around Europe doing studies, ethnographic studies, and designing technology. Lots of time looking at photocopiers because I was with Xerox. [LAUGHS] And then so going to India, suddenly, you know, I’m looking at social enterprises. I’m looking at all sorts of businesses and different ways of life and different people. And it was just so rich and so amazing that I was like, OK, I really want to do this. And that’s actually when I applied to Microsoft because Microsoft had the Technology for Emerging Markets group there, which is world-class research in that space. So I was like, OK, if I want to keep on doing this, then that’s what I’m going to apply to. And luckily enough, I got the job, and that’s how I joined Microsoft.
GEHRKE: Wow. So, so, OK, so you’re now at Microsoft in India. That was in Bangalore, right, where our research lab there is?
O’NEILL: Mm-hmm.
GEHRKE: And so what, what were you working on there for the next few years?
O’NEILL: Yeah. So initially, I looked at a few different things. I joined some existing projects. So I was on MEC, which was the educational platform, looking at whether we could bring the power of MOOCs [Massive Open Online Courses] to Indian education to improve the level of education because they have amazing colleges at the top, but, actually, the vast majority of students go to these intermediate colleges, and the teaching level really varies. And so the idea was, can you help with blended learning? Can you help the teachers teach better? That turns out to be really challenging. And, actually, the system ended up being used by the students to teach themselves.
GEHRKE: Oh, like for independent learning?
O’NEILL: Mm-hmm. Mm-hmm. And that was really, so that was interesting, doing some studies there. I looked at … Indrani [Medhi Thies] had done an amazing project where they’d built “Facebook for Farmers.” So I did a study of that, which was really, really fun. And then I worked in financial inclusion, one of my big areas. I spent about five years working with auto-rickshaw drivers in Bangalore, designing technologies to help them understand the loans they’d taken out, which was really, really fun. They’re a very great community to work [with]. You don’t get any nonsense from an auto-rickshaw driver. [LAUGHS]
GEHRKE: Well, I was just thinking, what was it like to, like, live in India and just move there and start out there?
O’NEILL: Uh, it was, I mean, it was fantastic. It’s a great place to live. The people are amazing. The food is amazing. Moving with Microsoft makes it very easy because Microsoft takes care of you when you move so you’re not, you know, some of the stresses that you might have around the move are taken care of. I had a young family. I had a 2-year-old son when we moved out there and within a year had another one, which was not 100 percent planned, because you don’t usually move to a new company and then have a baby. You’re like, oh, sorry. [LAUGHS] But that was all fine. Yeah.
GEHRKE: And, and, you know, you worked with all of these different communities in India, right. How did you connect to the communities? I mean, these were teachers …
O’NEILL: Yeah, you need to, you really need to go with people, so you have to convince some organization that what you’re going to do is going to be beneficial to them and useful for them. And then if they’re trusted by the community, they give you access. And that’s really great because you do have access that you wouldn’t otherwise have. You know, if you’re really wanting to build technologies to support people, you really need to understand what they care about—what do they want help with?—and you only get that if you’ve got a trusted relationship with them. So we worked with, there was one organization that worked with the auto-rickshaw drivers’ wives. It was about empowering women, and we got access to the drivers initially through that organization.
GEHRKE: That’s amazing. I mean, you know, I’ve visited India many times, but I can only imagine how it is to live there, actually. So do you have some of the stories of what is, sort of, most surprising for you given that you’ve lived there?
O’NEILL: Yeah … what’s most surprising? I think, so one thing is, one thing is people want to tell you what they think you want to hear. So if you’re lost, you need to ask quite a few people for directions and then make some sort of assessment about whether the person was just saying “yes, yes, that way” because he knew the way or “yes, yes that way” because he just didn’t want to tell you that he didn’t know. And so you have to, sort of, judge. [LAUGHS] So that’s one, like, useful piece of …
GEHRKE: So the first few times you went in the wrong direction? [LAUGHS]
O’NEILL: Yes, exactly. And then you’re like, “But they said …”; you ask someone else, and they’re like, “No, it’s over there.” And then someone … so that’s … the most useful piece of advice I could give to anyone who’s visiting India, is when you cross the road, just find someone else who’s already crossing the road and cross with them.
GEHRKE: Because it’s so dangerous if you go by yourself potentially?
O’NEILL: Yes, yeah. You get used to it quite quickly, and there’s obviously something that changes in you when you’ve been there a while. You know, when you first go there, all the auto-rickshaw drivers are going to overcharge you and drive around the block twice and all of those things. And I find after about four to five weeks when you’ve been there, they know, like, there must be something that changes in your attitude because they actually know that you’re there longer term and you’re not going to take any nonsense.
GEHRKE: So, so do you behave differently? What’s the change there?
O’NEILL: I don’t know. That’s, I’ve tried to think about this, but I think, I don’t know, it must be just an air of confidence or an air of certainty or something. But, yeah, it’s like something just clicks or changes.
GEHRKE: That’s so interesting. Is it only for the drivers, or is it in other aspects of your life, as well, where, sort of, you get treated differently because you suddenly have become a native?
O’NEILL: I think you notice it most in the drivers because they’re the ones that you’re interacting so much with to get about, you know, to get … you’re always getting a tuk-tuk to go from here to there. And they really do, you know, if they can make extra money out of you, they are going to make extra money out of you.
GEHRKE: They smell it, that you’re a tourist.
O’NEILL: Yeah, yeah, yes. [LAUGHS]
GEHRKE: And then so you were in India and then another opportunity came along. So tell us a little bit about that opportunity, where you ended up now.
O’NEILL: Yes, yes. So when I heard that the ADCs were opening—the Africa Development Center, so our software engineering center in Nairobi and Lagos—I thought that that was a great time to pitch for research in Africa for Microsoft. It seemed like a bit of a hole in our portfolio. I have family connections to Africa. So, actually, one of the reasons for joining Microsoft was partly because I thought there might be opportunities eventually in Africa because we had a great Africa startup program, for example. So, you know, but there wasn’t any research there. And so when I heard the ADCs were open, I just put together a, like, pitch for setting up research in Africa within the ADCs, and, you know, all sorts of people really helped me hone that pitch. And then I flew at the end of February 2020. I flew …
GEHRKE: Oh, just right before the pandemic.
O’NEILL: Mm-hmm. I flew to … I was in Barcelona for a Future of Work event, and then I flew to Nairobi and then Lagos to meet the people who were running the ADCs and to think about where, which one I would want to set up research in if such a thing were to happen. And I did that. I decided that Nairobi was the right one. And when I went there, Jack Ngare ran the ADC, and he was so enthusiastic about having research there. So I did a pitch and got some funding just—I think if it had been two weeks later, I’m not sure. But, you know, it was just before we knew how bad COVID was going to be, so I was very lucky with timing.
GEHRKE: And, I mean, you’ve made these amazing moves throughout your career, right. You, sort of, raised your hand for India when the lab was open; now here in Africa. Why, and how? I’m just, I mean, so curious because people make the most unexpected turns in their careers from time to time. But it’s more like because, you know, they lose their current job or they, their manager moves away and they really think about their career. But you, like, raise your hand from time to time and make these really bold and amazing moves.
O’NEILL: Yeah, I mean, life’s meant to be exciting, isn’t it?
GEHRKE: OK …
O’NEILL: I think. You know, life’s meant to be exciting. I love living in different places and, you know, as an ethnographer, as a person interested in human-computer interaction, it’s, like, those experiences are what help us innovate better and design things that are, like, taking another point of view, more creative, I think. Like, just sparks things in your, in your head. And, I mean, it’s so much fun. Like, I don’t understand why everyone doesn’t do it. [LAUGHS]
GEHRKE: So it’s just really amazing. So if I think about, you know, India, where you said, right, the experience for you was that the drivers were treating you suddenly differently. Did you have a similar experience in Africa, or what is one of the or a few of the defining experiences and stories there?
O’NEILL: Yeah, I think … so the animals are amazing in Kenya. They’ve done such an amazing job at conservation. I imagine that they would, you would only see, like, these big animals in the national parks, but—they’re not everywhere. They’re not going to be, you’re not going to find a hippo walking down the road in Nairobi. But they are all over the place. So you can go camping in Lake Naivasha, which is just an hour and a half from Nairobi, and I was camping with a friend, and the kids were in their tent, and my friend was in her tent, and I was just sitting by the fire. It’s about 10 o’clock. I said, yeah, I might go to bed in a minute. And then I just heard this snort, and I get up with my torch, and I look, and there’s a hippo, [LAUGHS] like, probably less than a meter and a half …
GEHRKE: Wow …
O’NEILL: … away from me. So I carefully went and sat back down by the fire and waited for a while before I moved. [LAUGHS]
GEHRKE: So are they dangerous in that aspect, if you’ve startled them or so … ?
O’NEILL: Yeah, I think … they say that you should never get between a hippo and the water. So, luckily, I was on the other side of the, [LAUGHS] of the hippo and the water. But they are big. I mean, they can be very grumpy.
GEHRKE: And so you should, just, shouldn’t startle them or … ? I’m just trying to understand what’s the recommended behavior. Don’t get between the hippo and the water.
O’NEILL: Yes, that’s recommended, and don’t, yeah, don’t startle them, and just, you know, stay very, stay very calm. So, actually, when you’re camping, if you don’t have an electric fence around the campsite, then you shouldn’t come out of your tent at night. So don’t drink too much beer before you go to bed, [LAUGHTER] because it’s the “zip.” When you unzip it, you can really startle … If there’s any wild animals, lions, or whatever around, then you can really scare them. And you don’t want to scare a lion.
GEHRKE: Yeah, I was thinking, just, actually, about the lions or so, right. I mean, they could be probably even more dangerous than the hippos or, or not really?
O’NEILL: Hippos are actually more dangerous than lions. Yeah, lions will generally not attack you. And apparently, the thing—I haven’t had to try this, I’m glad to say—but the thing you should do if you encounter a lion is just look them in the eye, and then they’ll go off.
GEHRKE: Stare them down.
O’NEILL: Mm-hmm.
GEHRKE: OK.
O’NEILL: I hope I never have to try that because they are quite scary … [LAUGHS]
GEHRKE: I hope I never have to do that but good advice …
O’NEILL: Yes, yeah, yeah. I think hippos are more likely to charge at you. Like, a lion’s more likely to go off in the other direction.
GEHRKE: And what’s the daily life like, you know, living in Nairobi, right? I mean, is it, I mean, it must be very, very different from living in both India, as well as, you know, Great Britain or here.
O’NEILL: Yeah. I mean it is very different. The traffic’s bad but not as crazy as India. Like, I drive in Kenya. I didn’t drive in India because it was a bit too scary with the bikes and everything. It’s a really, it’s a really nice pace, I think, in Nairobi. It’s a beautiful city. There’s nightlife, and there’s cafes and restaurants, but you’ve got countryside so close. You know, compared to Bangalore, it’s quite a small city. And the weather is amazing, and the people are really friendly and kind, and, you know, it’s just, it’s a very nice, it’s a very nice place to live.
GEHRKE: That’s amazing, and you now are leading the Microsoft Africa Research Institute there, right?
O’NEILL: Yes.
GEHRKE: What is the focus of the institute, and what are you studying there?
O’NEILL: Mm-hmm. Yeah, we’re mainly focused on foundational models. It won’t be a surprise to anybody. [LAUGHS] Which actually, you know, it’s worked out very well for us because, you know, we have a mixed disciplinary team. We have HCI and AI and ML and data science.
GEHRKE: And all local?
O’NEILL: All local. Yeah. And, yeah, we’re looking at multilingual languages in models. So we’re working with MSR [Microsoft Research] India, thinking about how can you benchmark these models for different languages. And we’re thinking all the way along the scale from your high-resource, you know, French and German, to your mid-resource Swahili, Hindi, all the way to your low-resource languages because, you know, the vast majority of training data is in English. So we’ve been working a lot. That’s nice because we’re having, you know, in a very short amount of time, you know, four or five months, we’re having both scientific impact with papers but also product impact, working with the Copilot Language Globalization team as they’re rolling out Copilot in different languages.
GEHRKE: I see. So the research that you have will go into, let’s say, Word or PowerPoint or so to make it available in some of the languages from the continent.
O’NEILL: Yes, exactly. Because it’s not just about translation. It’s also if you think about RAI, responsible AI, you know, a lot of that is language based. And so how do … you can’t just translate this to words. You have to find the right list of words in those languages. And then what about things like tone and stuff? So that’s one area. And then related to that, it’s in a much bigger space of equity, the models and equity. You know, what’s going to happen to the digital divide with these models? In some ways, you could imagine that they may be flattening it, but in other ways, they could be increasing it. So we really are trying to map out how … the different elements of the digital divide as it plays out in these models. Because you obviously have your traditional things like access to devices, access to, you know, infrastructure, and things like that. But there’s also the data divide. So not only is most of the training material in English; it’s also mostly from America and the Global North. So it embodies very particular world views. And if you think about data on Africa, data on Africa tends to be collected by particular organizations. So there’s lots of data on poverty and disease and forced migration and things like that. Not much data on, like, the stories, the creativity, wealth, innovation. So what does that mean? Even if the models can speak perfectly, which they can’t yet, but they’ll eventually get quite good at, you know, even smaller languages like Luo, if that model is just translating English content into Luo, that’s not necessarily what we want from a model. So there’s some really interesting questions there to be answered.
GEHRKE: Well, it seems to me like it’s clearly also a question of, like, getting the right kind of data. So where do you get the data, and how do you get the data?
O’NEILL: Yeah, that’s a big question. And it was already a challenge, you know, before these models. You know, many people have been working with Masakhane, which is one of the African NLP communities which is around creating datasets in African languages for training the models. So that was, you know, getting good quality training data is already a challenge. Sriram [Rajamani] from MSR India, though, was telling me of a really interesting project they’ve got going on in India with the Indian government where they are trying to collect data from each region of India so that they can use it to train the OpenAI models, which would be really cool. And we should think about, is that what we can do for different African countries and contexts?
GEHRKE: Exactly. It seems to be very much like a citizen science project, right, where you, sort of, involve the citizens that speak different dialects and then involve them in collecting the right kind of data.
O’NEILL: Yeah, yeah. And maybe collecting the stories, you know, and the cultural attributes and assets from different places.
GEHRKE: That’ll be really, really exciting probably also about preservation of the culture and history, right.
O’NEILL: Yes, yes. But challenging.
GEHRKE: But challenging. [LAUGHTER]
O’NEILL: Yeah.
GEHRKE: So that’s one big aspect of the work. Anything else that’s happening there?
O’NEILL: Yeah. So we’re doing a lot of work, you’ll be unsurprised to hear, on Future of Work and AI. And so we’ve got a project on modern work and LLMs, so looking at the work that enterprise workers, frontline and knowledge workers, are doing and then what bits of their job they would like to get rid of if they could and what bits they would keep and how we can use LLMs to support them. And we’ve also, like, Maxamed [Axmed] on my team, also worked with The Garage to train them up in foundational models, both the LLMs and the vision models, and then they’ve introduced them to a whole load of small businesses in Kenya.
GEHRKE: Oh, wow.
O’NEILL: So that’s really interesting. You got everyone from like car salespeople to lawyers who are now using, like, LLMs as part of their everyday work, which is amazing.
GEHRKE: As part of like composing messages or part of … what’s …
O’NEILL: Yeah. Writing contracts, sales documents for cars, all sorts of really interesting things.
GEHRKE: Oh, wow.
O’NEILL: So we’re going to go out and look at what they’re doing and think about how, you know, what else is needed, what, what more do they need.
GEHRKE: What’s the prevalent form factor in terms of if I think about, like, a computer there? Is it my, is it a mobile phone? Is it a tablet?
O’NEILL: Yeah.
GEHRKE: It’s a mobile phone?
O’NEILL: It’s a mobile phone. Yeah.
GEHRKE: So you have to rethink also, probably, all the interfaces.
O’NEILL: Yes, I mean …
GEHRKE: You mentioned that early on, right, as you think about the next generation of HCI with AI in it, right.
O’NEILL: Yes, yes. I mean conversational interfaces. The idea that you can talk to your phone or enter existing text, you know. If you look at small businesses, a lot of their interactions with customers are on chat. If you can enter that chat into an LLM and extract structured data from it, then suddenly you’ve got all this data that’s been lost to the business becomes usable. So it’s a really exciting space, and I think voice interfaces are going to become really, really, really big. And that’s why there’s opportunities for leapfrogging, because suddenly everyone with a mobile phone potentially has a really powerful office productivity tool in their hand and can do things … you know, many of the small businesses, they don’t employ a designer; they don’t employ an accountant. But now they could maybe have an accountant or a designer in their pocket, which enables them to do more, which is definitely the more positive side of the future of work than some of the …
GEHRKE: Right. You know, this whole enablement story of people is just really amazing, what you can do with LLMs and especially with voice interfaces, as well. Let me conclude maybe with a question about your career. I mean, it seems like you’ve always amazingly managed to somewhat align your career moves with your passion. You moved to India because you’re just excited to live in India. You moved then to, you know, Microsoft Research, but then you moved to Africa again for, what I hear, is a little bit the adventure, as well, right?
O’NEILL: Yes.
GEHRKE: So what’s your advice for people who want to, sort of, align these two and who want to not only work but also want to work on something they’re really passionate about? How do you manage to create that alignment?
O’NEILL: That is a good question. I don’t know. It just, sort of, happens. I mean, I think you have to, you have to be passionate about it; you have to talk about it and decide what you want to do. You know, I never really imagined MARI would happen. But I just started talking to people, and people were saying, before I did the pitch, people were saying to me, oh, what would you like to do in five years, Jacki? And I was like, oh, you know what? If I had my way, I’d love to run a research center in Africa. And then within a couple of years … it was nothing more than an idea in my head. So I think that you have to have the ideas, verbalize it, and maybe it can happen.
GEHRKE: And why a research center in Africa? What’s personal for you there?
O’NEILL: So my children are African; my children are Cameroonian. So I wanted them to grow, spend some time on the continent, and, you know, as a family, we’d always had that idea of moving to the continent eventually. So that was part, that was a personal motivation in there as well as the passion. Yeah.
GEHRKE: So it’s, well, sort of, the confluence of, I guess, opportunity but then also drive on your side? Because that’s what I’ve heard. Very often in careers, that it’s not only about, well, this is what I finally want to do but also watching out for that opportunity.
O’NEILL: Yes.
GEHRKE: So it seems like that played a big role here, as well. And so when you heard about, you know, that there was an Africa Development Center, how did you, what were your next steps then? I mean, you must have been excited, but you also had to take some action.
O’NEILL: Yeah, I mean, I created, [LAUGHS] I created a small pitch, a small set of slides, and then I just started talking to everybody I knew who was doing anything. I didn’t have any contact with the ADCs.
GEHRKE: So you created that energy and excitement about it?
O’NEILL: I just started to, you know, every time anyone would come to India, you know, I was just like, oh, this is what I’d like to do. And you just almost talk it into being, I think.
GEHRKE: And were there some setbacks, or was it just like a straight line from, sort of, the excitement all the way up to realization?
O’NEILL: No, I mean, I didn’t, I don’t think I ever really imagined it would happen, you know. But you’re just doing it, and you’re plugging away, and then taking the, you know, taking the advice of people.
GEHRKE: Really an awesome story. So maybe as a last question, where do you see the center being in like three to five years? I mean, you’re starting off right now, but I’m sure you have really big ambitions for the center, and there’s so much to do on the whole continent.
O’NEILL: No, absolutely. I think that I have a few ambitions. So the most important, I think, I want it to be really established as this thing that’s really beneficial to Microsoft, that Microsoft is like, really, “Yeah, the guys at MARI, they’re doing great research. We really like them.” So that it, sort of, exists without me, you know. At the moment, I think I’m the driver of it. I would …
GEHRKE: So you want to grow the next generation that is basically going to be the next generation of leaders?
O’NEILL: Yes, exactly, exactly. And then I think also grow, I would love to help in growing Microsoft’s market in Africa. We don’t have a particularly big market in Africa, but I think there’s a lot of opportunity, especially now with these, with these large language models. I think that we … so that would be really exciting, you know, if we can help. I don’t see our success only being about growing the African market, but I think it’s part of what we can do, and if we can grow that market, as well as do research that’s relevant for Redmond and relevant globally, that’s really, that’s really exciting, I think, you know. So everything we do, I think, has to have a relevance globally. And I think, you know, at the beginning I was talking about different ways of viewing the world and how that leads to innovation. I think by having researchers who are African, based in Africa, doing this great research, we can create better products for everyone.
GEHRKE: That’s such a great finishing note. Thank you so much for the great conversation, Jacki.
O’NEILL: Thank you, Johannes. It’s been fun.
[MUSIC]
To learn more about Jacki or to see photos of Jacki living and working abroad, visit aka.ms/ResearcherStories (opens in new tab).
[MUSIC FADES]






























![[On the left] Image of VASIM user interface. On the left panel, it has options to select from “Simulation Run”, “Simulation Tuning”, “Simulation Tuning History”. Option “Simulation Run” is selected. Below user has loaded a trace from csv file on disk (c_26742_perf_event_log.csv), algorithm C, metadata config json file from disk. Button “Visualize workload” was clicked and loaded trace is displayed.
[On the right] On the right panel, user picked other parameters for simulation run (lag – how often recommender gives decision and initial core count) and algorithm parameter from json are shown for edit.
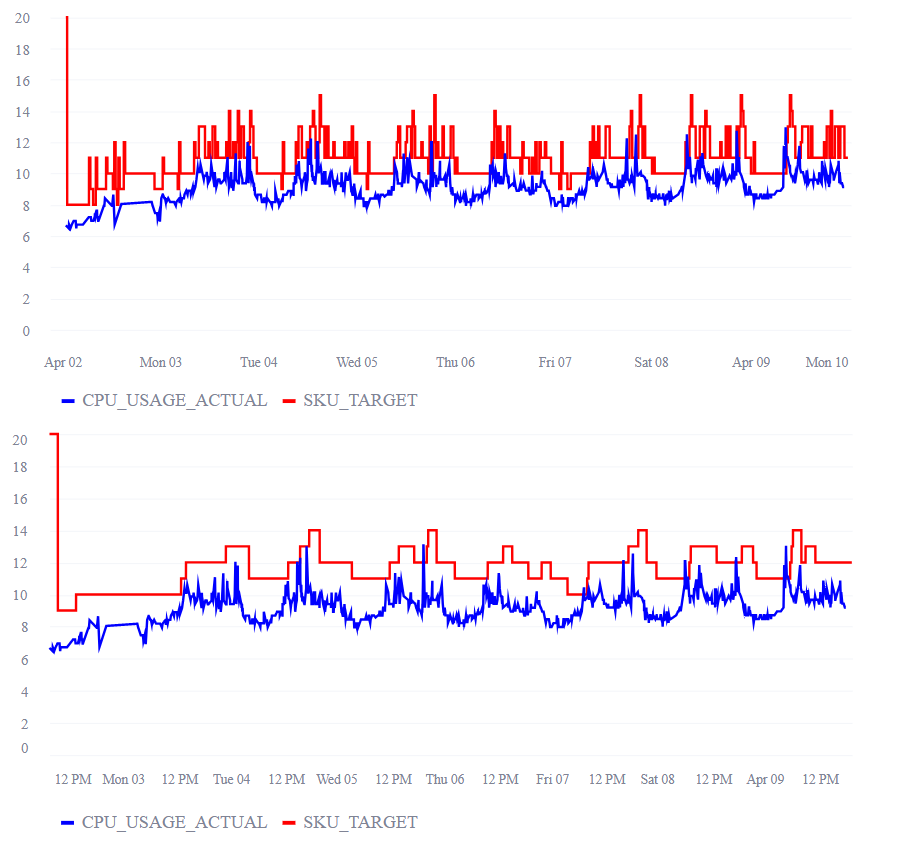
Image of VASIM UI when simulation was run for selected algorithm, trace and parameter setting. It shows a graph with cpu usage in blue and the limit calculated by selected algorithm in red. It is different from the trace plot that was shown before because calculated limits were below cpu utilization, so the latter was cut off. On top of the plot it shows metrics of the simulation like average slack, average insufficient CPU, sum slack, sum insufficient CPU, number of scalings, number of times of insufficient CPU etc.](https://www.microsoft.com/en-us/research/uploads/prodnew/2024/04/VASIM_Fig1.png)
![[On the left] A graph that plots the average slack on the Y axis and the average insufficient cpu on the X axis. It shows that the more average insufficient cpu decreases, the more average slack increases. There are six points in red that are pareto frontier points, all on the very edge of the graph but not too close to each other, showing some possible choices of configuration.
[On the right] A 3D scatter plot displays the total slack on the X axis, cpu total throttle on the Y axis, and the amount of scalings in Z axis. It shows that as you aim to lower total slack and throttle, the amount of scalings increases.](https://www.microsoft.com/en-us/research/uploads/prodnew/2024/04/VASIM_Fig2.png)