Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
Self-supervised Multi-task pretrAining with contRol Transformers (SMART)
Many real-world applications require sequential decision making, where an agent interacts with a stochastic environment to perform a task. For example, a navigating robot is expected to control itself and move to a target using sensory information it receives along the way. Learning the proper control policy can be complicated by environmental uncertainty and high-dimensional perceptual information, such as raw-pixel spaces. More importantly, the learned strategy is specific to the task (e.g. which target to reach) and the agent (e.g., a two-leg robot or a four-leg robot). That means that a good strategy for one task does not necessarily apply to a new task or a different agent.
Pre-training a foundation model can help improve overall efficiency when facing a large variety of control tasks and agents. However, although foundation models have achieved incredible success in language domains, different control tasks and agents can have large discrepancies, making it challenging to find a universal foundation. It becomes even more challenging in real-world scenarios that lack supervision or high-quality behavior data.
In a new paper: SMART: Self-supervised Multi-task pretrAining with contRol Transformers, Microsoft researchers tackle these challenges and propose a generic pre-training framework for control problems. Their research demonstrates that a single pre-trained SMART model can be fine-tuned for various visual-control tasks and agents, either seen or unseen, with significantly improved performance and learning efficiency. SMART is also resilient to low-quality datasets and works well even when random behaviors comprise the pre-training data.
On-Demand Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Reinforcement learning relies on environmental reward feedback to learn meaningful behaviors. Since reward specification is a hard problem, imitation learning (IL) may be used to bypass reward specification and learn from expert data, often via Inverse Reinforcement Learning (IRL) techniques. In IL, while near-optimal expert data is very informative, it can be difficult to obtain. Even with infinite data, expert data cannot imply a total ordering over trajectories as preferences can. On the other hand, learning from preferences alone is challenging, as a large number of preferences are required to infer a high-dimensional reward function, though preference data is typically much easier to collect than expert demonstrations. The classical IRL formulation learns from expert demonstrations but provides no mechanism to incorporate learning from offline preferences.
In a new paper: A Ranking Game for Imitation Learning accepted at TMLR 2023, researchers from UT Austin, Microsoft Research, and UMass Amherst create a unified algorithmic framework for IRL that incorporates both expert and suboptimal information for imitation learning. They propose a new framework for imitation learning called “rank-game” which treats imitation as a two-player ranking-based game between a policy and a reward. In this game, the reward agent learns to satisfy pairwise performance rankings between behaviors, while the policy agent learns to maximize this reward. A novel ranking loss function is proposed, giving an algorithm that can simultaneously learn from expert demonstrations and preferences, gaining the advantages of both modalities. Experimental results in the paper show that the proposed method achieves state-of-the-art sample efficiency and can solve previously unsolvable tasks in the Learning from Observation (LfO) setting. Project video and code can be found on GitHub.
Figure 1: rank-game: The Policy agent maximizes the reward function by interacting with the environment. The Reward agent satisfies a set of behavior rankings obtained from various sources: generated by the policy agent (vanilla), automatically generated (auto), or offline annotated rankings obtained from a human or offline dataset (pref). Treating this game in the Stackelberg framework leads to either Policy being a leader and Reward being a follower, or vice versa.
Microsoft helps GoodLeaf Farms drive agricultural innovation with data
Vertical indoor farming uses extensive technology to manage production and optimize growing conditions. This includes movement of grow benches, lighting, irrigation, and air and temperature controls. Data and analytics can help vertical farms produce the highest possible yields and quality.
GoodLeaf is also collaborating with Microsoft Research through Project FarmVibes, using GoodLeaf’s data to support research into controlled environment agriculture.
GoodLeaf’s farm in Guelph, Ontario, and two currently under construction in Calgary and Montreal, use a connected system of cameras and sensors to manage plant seeding, growing mediums, germination, temperature, humidity, nutrients, lighting, and air flow. Data science and analytics help the company grow microgreens and baby greens in Canada year-round, no matter the weather using a hydroponics system and specialized LED lights.
Proposals are now being accepted for Reinforcement Learning (RL) Open Source Fest 2023, a global online program that introduces students to open-source RL programs and software development. Our goal is to bring together a diverse group of students from around the world to help solve open-source RL problems and advance state-of-the-art research and development. The program produces open-source code written and released to benefit all.
Accepted students will join a four-month research project from May to August 2023, working virtually alongside researchers, data scientists, and engineers on the Microsoft Research New York City Real World Reinforcement Learning team. Students will also receive a $10,000 USD stipend. At the end of the program, students will present each of their projects to the Microsoft Research Real World Reinforcement Learning team online.
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
Behind the Tech podcast with Tobi Lütke: CEO and Founder, Shopify
In the latest episode of Behind the Tech, Microsoft CTO Kevin Scott is joined by Tobi Lütke, CEO and founder of the Canadian multinational e-commerce platform Shopify. Since his early days running an online snowboard shop from his carport, Tobi has envisioned himself as a craftsman first and a business exec second, a mindset he has used to solve a wide variety of problems. He and Kevin discuss applying computer science and engineering techniques to build and scale a company, the idea of bringing an ‘apprentice mindset’ to his work, and how Tobi’s daily practice of writing code and tinkering in his home lab inspires him to be a more creative leader.
Distribution inference risks: Identifying and mitigating sources of leakage
Distribution inference (or property inference) attacks allow an adversary to infer distributional information about the training data of a machine learning model, which can cause significant problems. For example, leaking distribution of sensitive attributes such as gender or race can create a serious privacy concern. This kind of attack has been shown to be feasible on different types of models and datasets. However, little attention has been given to identifying the potential causes of such leakages and to proposing mitigations.
A new paper, Distribution Inference Risks: Identifying and Mitigating Sources of Leakage, focuses on theoretically and empirically analyzing the sources of information leakage that allow an adversary to perpetrate distribution inference attacks. The researchers identified three sources of leakage: (1) memorizing specific information about the value of interest to the adversary; (2) wrong inductive bias of the model; and (3) finiteness of the training data. Next, based on their analysis, the researchers propose principled mitigation techniques against distribution inference attacks. Specifically, they demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk — distributional membership inference — than associative learning methods. And lastly, they present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.
In their paper: SCALE: Automatically Finding RFC Compliance Bugs in DNS Nameservers, Kakarla and his colleagues introduce the first approach for finding RFC (request for comment) compliance errors in DNS nameserver implementations through automatic test generation. Their approach, called Small-scope Constraint-driven Automated Logical Execution, or SCALE, generates high-coverage tests for covering RFC behaviors.
The Applied Networking Research Prize acknowledges advances in applied networking, interesting new research ideas of potential relevance to the internet standards community, and people that are likely to have an impact on internet standards and technologies.
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
Revolutionizing Document AI with multimodal document foundation models
Organizations must digitize various documents, many with charts and images, to manage and streamline essential functions. Yet manually digitized documents are often of uneven quality, while web pages and electronic documents can come with multiple layouts.
Document AI technology is designed to efficiently extract, organize and analyze the information in different documents, freeing employees and companies from this repetitive and tedious work. The results are automated extraction, classification and understanding of information with rich typesetting formats from webpages, digital-born documents, or scanned documents, along with lower costs and reduced errors.
Microsoft Research Asia has been studying Document AI since 2019, working at the intersection of natural language processing and computer vision and using deep learning techniques. In their most recent work, researchers have developed new skills for Document AI, unveiled industry-leading models, and begun developing general-purpose and unified frameworks.
Tapping into Large Language Models with Microsoft’s Turing Academic Program
Large language models (LLMs) deliver impressive performance with difficult tasks and across various applications. As AI researchers explore LLMs, many questions persist. Answering these questions will require a range of different perspectives and proficiencies from experts from industry, research, and government.
A key theme of the panel was the need to expand access to LLMs, which requires large amounts of data and computing resources. The Microsoft Turing Academic Program (MS-TAP) supports this effort through multiple in-depth collaborations with partner universities.
You can learn more about MS-TAP and the panel discussion in this recent blog post.
This award, which recognizes the top 1% of ACM members for accomplishments in computing and information technology and/or outstanding service to ACM and the larger computing community, was presented to the following Microsoft researchers:
Ranveer Chandra For contributions to software-defined wireless networking and applications to agriculture and rural broadband
Marc Pollefeys For contributions to geometric computer vision and applications to AR/VR/MR, robotics and autonomous vehicles
Jaime Teevan For contributions to human-computer interaction, information retrieval, and productivity
The ACM Fellows program was launched in 1993. Candidates are nominated by their peers and then reviewed by a selection committee. ACM is the world’s largest educational and scientific computing society, uniting educators, researchers, and professionals to inspire dialogue, share resources, and address challenges.
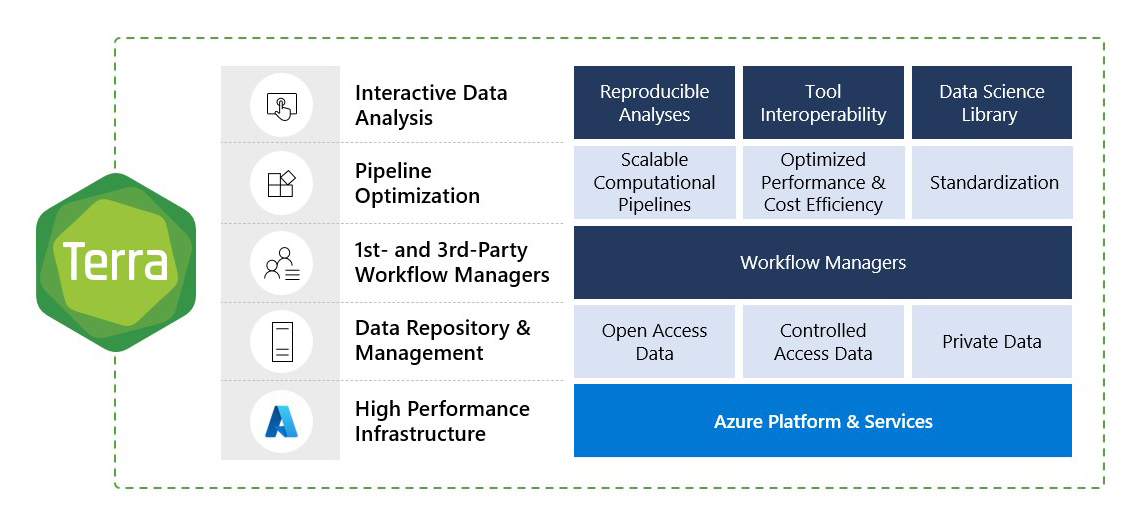
We stand at the threshold of a new era of precision medicine, where health and life sciences data hold the potential to dramatically propel and expand our understanding and treatment of human disease. One of the tools that we believe will help to enable precision medicine is Terra, the secure biomedical research platform co-developed by Broad Institute of MIT and Harvard, Microsoft, and Verily. Today, we are excited to share that Terra is available for preview on Microsoft Azure.
Starting today, any researcher can bring their data, access publicly available datasets, run analyses, and collaborate with others on Terra using Microsoft Azure. Learn more about accessing Terra and exploring its capabilities on the Terra blog.
By joining forces on Terra, the Broad Institute, Microsoft, and Verily are accelerating the next generation of collaborative biomedical research to positively impact health outcomes now and in the future. Terra’s cloud-based platform offers a secure, centralized location for biomedical research, connecting researchers to each other and to the datasets and tools they need to collaborate effectively, advance their work, and achieve scientific breakthroughs. Terra on Azure will also provide valuable support for enterprise organizations across industries.
Terra on Azure is built to be enterprise-ready and natively supports single sign-on (SSO) with Azure Active Directory. Operating as platform as a service (PaaS), Terra deploys resources into an end-user’s Azure tenant, allowing customers to apply their Enterprise Agreements to their use of Terra and giving them more control over the cloud resources running in their environment as well as the different types of tools and data they can use within their Terra workspace.
Figure 1: Terra brings together components of the Microsoft Genomics and healthcare ecosystems to offer optimized, secure, and collaborative biomedical research.
At Microsoft, with our focus on standards-driven data interoperability, we are building seamless connections between Terra and Azure Health Data Services to enable multi-modal data analysis—across clinical, genomics, imaging, and other modes—and to accelerate precision medicine research, discovery, development, and delivery. Terra on Azure can connect to other Azure services, allowing customers to draw on Azure innovations that are beneficial to biomedical analysis, such as those in Azure Confidential Computing for data privacy, Azure Synapse for data analytics, Azure Purview for data governance, and Azure ML for machine learning.
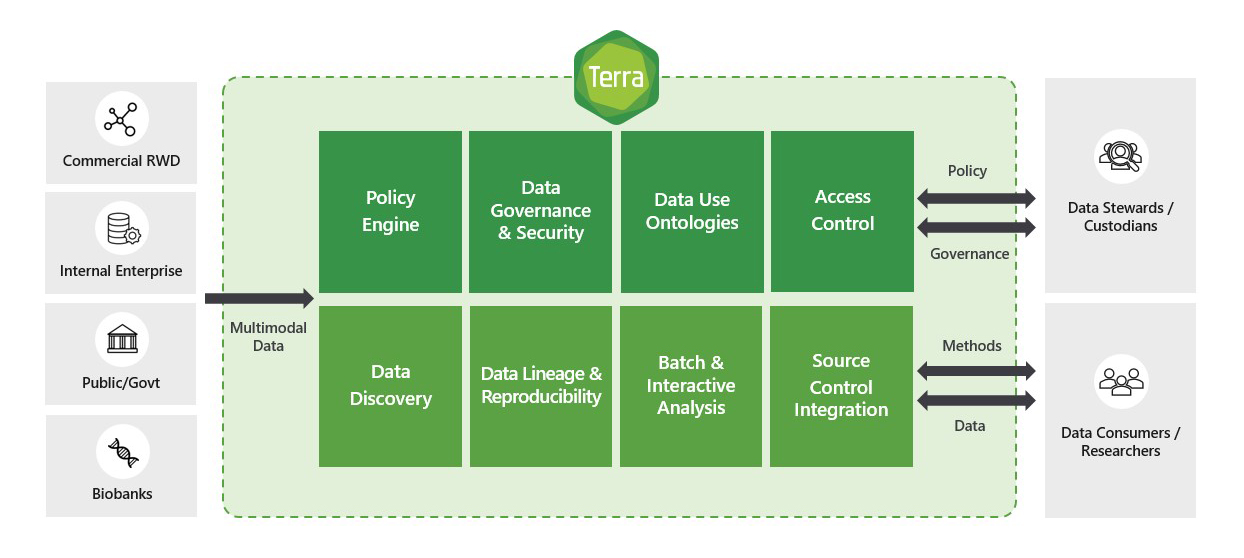
How does the biomedical research community benefit from Terra?
Data and partnerships form the bedrock of biomedical research, but researchers often face significant challenges on the path to effective collaboration. Part of the challenge for data scientists and researchers is accessing large and diverse sample sizes. Although the volume and availability of data is increasing, silos are growing stronger as data becomes more globally distributed. Different regions and organizations have their own unique data access policies, making access to data nearly impossible and collaboration a sometimes daunting challenge.
Terra powers research collaborations within and across organizational boundaries by giving researchers and data stewards new tools and capabilities to help them overcome those challenges and achieve their goals. As a biomedical research platform, Terra provides a foundation for data stewards to manage dataset access and use policies across the research lifecycle, and it enables researchers to access, build, and analyze larger datasets much faster.
Figure 2: Terra is built to support researchers and data custodians.
Through Terra on Azure, researchers can operate in secure environments purpose-built for health and life sciences; retrieve and examine public, controlled-access, and private data; reproduce analyses; and share hypotheses and analysis results. Analyses are performed within a security perimeter that enables data-access and data-use policies and compliance standards to be met.
How does Terra on Azure advance Health Futures’ goals?
Microsoft Health Futures is focused on empowering every person on the planet to live healthier lives and create a healthier future. We are responsible for research, incubations, and moonshots that drive cross-company strategy to support that goal. We believe the future of medicine is data-driven, predictive, and precise. Yet one of the major barriers to scientific discovery is access to data—at scale, longitudinally, and in multiple modalities.
Innovation within the life sciences is a core Health Futures priority, and we partner with leading organizations to advance and build infrastructure for emerging precision health modalities, including genomics, immunomics, and beyond. The Terra collaboration is a key piece of this broader priority and sets the foundation to scale real-world impact through our customers, partners, and the life sciences ecosystem.
It is an honor to partner with the Broad Institute and Verily to help researchers around the world understand and treat our toughest human diseases. Terra is a powerful platform that will enhance biomedical research collaboration and scientific exploration for the betterment of humankind.
Editor’s note: All papers referenced here represent collaborations throughout Microsoft and across academia and industry that include authors who contribute to Aether, the Microsoft internal advisory body for AI Ethics and Effects in Engineering and Research.
Learn how considering potential benefits and harms to people and society helps create better AI in the keynote “Challenges and opportunities in responsible AI” (2022 ACM SIGIR Conference on Human Information Interaction and Retrieval).
Artificial intelligence, like all tools we build, is an expression of human creativity. As with all creative expression, AI manifests the perspectives and values of its creators. A stance that encourages reflexivity among AI practitioners is a step toward ensuring that AI systems are human-centered, developed and deployed with the interests and well-being of individuals and society front and center. This is the focus of research scientists and engineers affiliated with Aether, the advisory body for Microsoft leadership on AI ethics and effects. Central to Aether’s work is the question of who we’re creating AI for—and whether we’re creating AI to solve real problems with responsible solutions. With AI capabilities accelerating, our researchers work to understand the sociotechnical implications and find ways to help on-the-ground practitioners envision and realize these capabilities in line with Microsoft AI principles.
The following is a glimpse into the past year’s research for advancing responsible AI with authors from Aether. Throughout this work are repeated calls for reflexivity in AI practitioners’ processes—that is, self-reflection to help us achieve clarity about who we’re developing AI systems for, who benefits, and who may potentially be harmed—and for tools that help practitioners with the hard work of uncovering assumptions that may hinder the potential of human-centered AI. The research discussed here also explores critical components of responsible AI, such as being transparent about technology limitations, honoring the values of the people using the technology, enabling human agency for optimal human-AI teamwork, improving effective interaction with AI, and developing appropriate evaluation and risk-mitigation techniques for multimodal machine learning (ML) models.
Considering who AI systems are for
The need to cultivate broader perspectives and, for society’s benefit, reflect on why and for whom we’re creating AI is not only the responsibility of AI development teams but also of the AI research community. In the paper “REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research,” the authors point out that machine learning publishing often exhibits a bias toward emphasizing exciting progress, which tends to propagate misleading expectations about AI. They urge reflexivity on the limitations of ML research to promote transparency about findings’ generalizability and potential impact on society—ultimately, an exercise in reflecting on who we’re creating AI for. The paper offers a set of guided activities designed to help articulate research limitations, encouraging the machine learning research community toward a standard practice of transparency about the scope and impact of their work.
Walk through REAL ML’s instructional guide and worksheet that help researchers with defining the limitations of their research and identifying societal implications these limitations may have in the practical use of their work.
Despite many organizations formulating principles to guide the responsible development and deployment of AI, a recent survey highlights that there’s a gap between the values prioritized by AI practitioners and those of the general public. The survey, which included a representative sample of the US population, found AI practitioners often gave less weight than the general public to values associated with responsible AI. This raises the question of whose values should inform AI systems and shifts attention toward considering the values of the people we’re designing for, aiming for AI systems that are better aligned with people’s needs.
Supporting human agency and emphasizing transparency in AI systems are proven approaches to building appropriate trust with the people systems are designed to help. In human-AI teamwork, interactive visualization tools can enable people to capitalize on their own domain expertise and let them easily edit state-of-the-art models. For example, physicians using GAM Changer can edit risk prediction models for pneumonia and sepsis to incorporate their own clinical knowledge and make better treatment decisions for patients.
A study examining how AI can improve the value of rapidly growing citizen-science contributions found that emphasizing human agency and transparency increased productivity in an online workflow where volunteers provide valuable information to help AI classify galaxies. When choosing to opt in to using the new workflow and receiving messages that stressed human assistance was necessary for difficult classification tasks, participants were more productive without sacrificing the quality of their input and they returned to volunteer more often.
Failures are inevitable in AI because no model that interacts with the ever-changing physical world can be complete. Human input and feedback are essential to reducing risks. Investigating reliability and safety mitigations for systems such as robotic box pushing and autonomous driving, researchers formalize the problem of negative side effects (NSEs), the undesirable behavior of these systems. The researchers experimented with a framework in which the AI system uses immediate human assistance in the form of feedback—either about the user’s tolerance for an NSE occurrence or their decision to modify the environment. Results demonstrate that AI systems can adapt to successfully mitigate NSEs from feedback, but among future considerations, there remains the challenge of developing techniques for collecting accurate feedback from individuals using the system.
The goal of optimizing human-AI complementarity highlights the importance of engaging human agency. In a large-scale study examining how bias in models influences humans’ decisions in a job recruiting task, researchers made a surprising discovery: when working with a black-box deep neural network (DNN) recommender system, people made significantly fewer gender-biased decisions than when working with a bag-of-words (BOW) model, which is perceived as more interpretable. This suggests that people tend to reflect and rely on their own judgment before accepting a recommendation from a system for which they can’t comfortably form a mental model of how its outputs are derived. Researchers call for exploring techniques to better engage human reflexivity when working with advanced algorithms, which can be a means for improving hybrid human-AI decision-making and mitigating bias.
How we design human-AI interaction is key to complementarity and empowering human agency. We need to carefully plan how people will interact with AI systems that are stochastic in nature and present inherently different challenges than deterministic systems. Designing and testing human interaction with AI systems as early as possible in the development process, even before teams invest in engineering, can help avoid costly failures and redesign. Toward this goal, researchers propose early testing of human-AI interaction through factorial surveys, a method from the social sciences that uses short narratives for deriving insights about people’s perceptions.
But testing for optimal user experience before teams invest in engineering can be challenging for AI-based features that change over time. The ongoing nature of a person adapting to a constantly updating AI feature makes it difficult to observe user behavior patterns that can inform design improvements before deploying a system. However, experiments demonstrate the potential of HINT (Human-AI INtegration Testing), a framework for uncovering over-time patterns in user behavior during pre-deployment testing. Using HINT, practitioners can design test setup, collect data via a crowdsourced workflow, and generate reports of user-centered and offline metrics.
Check out the 2022 anthology of this annual workshop that brings human-computer interaction (HCI) and natural language processing (NLP) research together for improving how people can benefit from NLP apps they use daily.
Building responsible AI tools for foundation models
Although we’re still in the early stages of understanding how to responsibly harness the potential of large language and multimodal models that can be used as foundations for building a variety of AI-based systems, researchers are developing promising tools and evaluation techniques to help on-the-ground practitioners deliver responsible AI. The reflexivity and resources required for deploying these new capabilities with a human-centered approach are fundamentally compatible with business goals of robust services and products.
Natural language generation with open-ended vocabulary has sparked a lot of imagination in product teams. Challenges persist, however, including for improving toxic language detection; content moderation tools often over-flag content that mentions minority groups without respect to context while missing implicit toxicity. To help address this, a new large-scale machine-generated dataset, ToxiGen, enables practitioners to fine-tune pretrained hate classifiers for improving detection of implicit toxicity for 13 minority groups in both human- and machine-generated text.
Download the large-scale machine-generated ToxiGen dataset and install source code for fine-tuning toxic language detection systems for adversarial and implicit hate speech for 13 demographic minority groups. Intended for research purposes.
Multimodal models are proliferating, such as those that combine natural language generation with computer vision for services like image captioning. These complex systems can surface harmful societal biases in their output and are challenging to evaluate for mitigating harms. Using a state-of-the-art image captioning service with two popular image-captioning datasets, researchers isolate where in the system fairness-related harms originate and present multiple measurement techniques for five specific types of representational harm: denying people the opportunity to self-identify, reifying social groups, stereotyping, erasing, and demeaning.
The commercial advent of AI-powered code generators has introduced novice developers alongside professionals to large language model (LLM)-assisted programming. An overview of the LLM-assisted programming experience reveals unique considerations. Programming with LLMs invites comparison to related ways of programming, such as search, compilation, and pair programming. While there are indeed similarities, the empirical reports suggest it is a distinct way of programming with its own unique blend of behaviors. For example, additional effort is required to craft prompts that generate the desired code, and programmers must check the suggested code for correctness, reliability, safety, and security. Still, a user study examining what programmers value in AI code generation shows that programmers do find value in suggested code because it’s easy to edit, increasing productivity. Researchers propose a hybrid metric that combines functional correctness and similarity-based metrics to best capture what programmers value in LLM-assisted programming, because human judgment should determine how a technology can best serve us.
Organizational culture and business goals can often be at odds with what practitioners need for mitigating fairness and other responsible AI issues when their systems are deployed at scale. Responsible, human-centered AI requires a thoughtful approach: just because a technology is technically feasible does not mean it should be created.
Similarly, just because a dataset is available doesn’t mean it’s appropriate to use. Knowing why and how a dataset was created is crucial for helping AI practitioners decide on whether it should be used for their purposes and what its implications are for fairness, reliability, safety, and privacy. A study focusing on how AI practitioners approach datasets and documentation reveals current practices are informal and inconsistent. It points to the need for data documentation frameworks designed to fit within practitioners’ existing workflows and that make clear the responsible AI implications of using a dataset. Based on these findings, researchers iterated on Datasheets for Datasets and proposed the revised Aether Data Documentation Template.
Use this flexible template to reflect and help document underlying assumptions, potential risks, and implications of using your dataset.
AI practitioners find themselves balancing the pressures of delivering to meet business goals and the time requirements necessary for the responsible development and evaluation of AI systems. Examining these tensions across three technology companies, researchers conducted interviews and workshops to learn what practitioners need for measuring and mitigating AI fairness issues amid time pressure to release AI-infused products to wider geographic markets and for more diverse groups of people. Participants disclosed challenges in collecting appropriate datasets and finding the right metrics for evaluating how fairly their system will perform when they can’t identify direct stakeholders and demographic groups who will be affected by the AI system in rapidly broadening markets. For example, hate speech detection may not be adequate across cultures or languages. A look at what goes into AI practitioners’ decisions around what, when, and how to evaluate AI systems that use natural language generation (NLG) further emphasizes that when practitioners don’t have clarity about deployment settings, they’re limited in projecting failures that could cause individual or societal harm. Beyond concerns for detecting toxic speech, other issues of fairness and inclusiveness—for example, erasure of minority groups’ distinctive linguistic expression—are rarely a consideration in practitioners’ evaluations.
Coping with time constraints and competing business objectives is a reality for teams deploying AI systems. There are many opportunities for developing integrated tools that can prompt AI practitioners to think through potential risks and mitigations for sociotechnical systems.
Thinking about it: Reflexivity as an essential for society and industry goals
As we continue to envision what all is possible with AI’s potential, one thing is clear: developing AI designed with the needs of people in mind requires reflexivity. We have been thinking about human-centered AI as being focused on users and stakeholders. Understanding who we are designing for, empowering human agency, improving human-AI interaction, and developing harm mitigation tools and techniques are as important as ever. But we also need to turn a mirror toward ourselves as AI creators. What values and assumptions do we bring to the table? Whose values get to be included and whose are left out? How do these values and assumptions influence what we build, how we build, and for whom? How can we navigate complex and demanding organizational pressures as we endeavor to create responsible AI? With technologies as powerful as AI, we can’t afford to be focused solely on progress for its own sake. While we work to evolve AI technologies at a fast pace, we need to pause and reflect on what it is that we are advancing—and for whom.
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
High-throughput ab initio reaction mechanism exploration in the cloud with automated multi-reference validation
Jan P. Unsleber, Hongbin Liu, Leopold Talirz, Thomas Weymuth, Maximilian Mörchen, Adam Grofe, Dave Wecker, Christopher J. Stein, Ajay Panyala, Bo Peng, Karol Kowalski, Matthias Troyer, Markus Reiher
Quantum chemical calculations on atomistic systems have evolved into a standard approach to studying molecular matter. These calculations often involve a significant amount of manual input and specific process considerations, which could be automated and allow for further efficiencies. In our recent paper: High-throughput ab initio reaction mechanism exploration in the cloud with automated multi-reference validation, we present the AutoRXN workflow, an automated workflow for exploratory high-throughput electronic structure calculations of molecular systems. In this workflow, (i) density functional theory methods are exploited to deliver minimum and transition-state structures and corresponding energies and properties, (ii) coupled cluster calculations are then launched for optimized structures to provide more accurate energy and property estimates, and (iii) multi-reference diagnostics are evaluated to back check the coupled cluster results and subject them to automated multi-configurational calculations for potential multi-configurational cases. All calculations are carried out in a cloud environment and support massive computational campaigns. Key features of all components of the AutoRXN workflow are autonomy, stability, and minimum operator interference. We highlight the AutoRXN workflow at the example of an autonomous reaction mechanism exploration of the mode of action of a homogeneous catalyst for the asymmetric reduction of ketones.
On-Demand Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Despite efforts to close the long-term and emergent health equity gap, studies during the COVID-19 pandemic show that socioeconomically and environmentally disadvantaged subpopulations have been disproportionately harmed by the disease[1]. Digital access to health services and information has also emerged as an important factor modulating health outcomes. During the pandemic, digital engagement in resources across health, educational, economic, and social needs became a necessity due to lockdown mandates and increased use of internet-based communication by public institutions. Unfortunately, disparities in digital access also reflect socioeconomic and environmental dimensions, which can lead to negative offline consequences, creating a “digital vicious cycle”[2]. Therefore, it is a public health priority to identify vulnerable populations and to understand potential barriers to critical digital resources.
In a new paper: Disparate Impacts on Online Information Access during the COVID-19 Pandemic, published in Nature Communications, researchers from Microsoft Research and the University of Washington have collaborated to harness the centrality of web search engines for online information access to observe digital disparities during the pandemic. They analyzed over 55 billion web search interactions on Bing during the pandemic across 25,150 U.S. ZIP codes to reveal that socioeconomic and environmental factors are associated with the differential use of digital resources across different communities – even if they were digitally connected.
DeepSpeed has released a new Data Efficiency library to optimize deep learning training efficiency and cost. The library offers new algorithms on efficient data sampling/scheduling via curriculum learning and efficient data routing via random layerwise token dropping, together with composable and customizable library support. The library greatly reduces training cost while maintaining model quality (1.5-2x less data and time for GPT-3/BERT pretraining), or further improves model quality under the same training cost (>1 point gain for GPT-3-1.3B zero/few-shot evaluation). The code is open-sourced at https://github.com/microsoft/DeepSpeed.
You can learn more in our blog post and in the papers below.
Research Fellows Program at Microsoft Research India – Apply now
The Research Fellows Program at Microsoft Research India is now accepting applications for Fall 2023. This is an opportunity to work with world-class researchers on state-of-the-art technology. The program prepares students for careers in research, engineering, and entrepreneurship, while pushing the frontiers of computer science and technology. Previous Research Fellows have contributed to all aspects of the research lifecycle, spanning ideation, implementation, evaluation, and deployment.
Selected candidates spend one to two years with Microsoft Research India. Candidates should have completed BS/BE/BTech or MS/ME/MTech in Computer Science or related areas, graduating by summer 2023. Apply before February 3, 2023.
2022 has seen remarkable progress in foundational technologies that have helped to advance human knowledge and create new possibilities to address some of society’s most challenging problems. Significant advances in AI have also enabled Microsoft to bring new capabilities to customers through our products and services, including GitHub Copilot, an AI pair programmer capable of turning natural language prompts into code, and a preview of Microsoft Designer, a graphic design app that supports the creation of social media posts, invitations, posters, and one-of-a-kind images.
These offerings provide an early glimpse of how new AI capabilities, such as large language models, can enable people to interact with machines in increasingly powerful ways. They build on a significant, long-term commitment to fundamental research in computing and across the sciences, and the research community at Microsoft plays an integral role in advancing the state of the art in AI, while working closely with engineering teams and other partners to transform that progress into tangible benefits.
In 2022, Microsoft Research established AI4Science, a global organization applying the latest advances in AI and machine learning toward fundamentally transforming science; added to and expanded the capabilities of the company’s family of foundation models; worked to make these models and technologies more adaptable, collaborative, and efficient; further developed approaches to ensure that AI is used responsibly and in alignment with human needs; and pursued different approaches to AI, such as causal machine learning and reinforcement learning.
We shared our advances across AI and many other disciplines during our second annual Microsoft Research Summit, where members of our research community gathered virtually with their counterparts across industry and academia to discuss how emerging technologies are being explored and deployed to bring the greatest possible benefits to humanity.
Plenary sessions at the event focused on the transformational impact of deep learning on the way we practice science, research that empowers medical practitioners and reduces inequities in healthcare, and emerging foundations for planet-scale computing. Further tracks and sessions over three days provided deeper dives into the future of the cloud; efficient large-scale AI; amplifying human productivity and creativity; delivering precision healthcare; building user trust through privacy, identity, and responsible AI; and enabling a resilient and sustainable world.
In June, the Microsoft Climate Research Initiative (MCRI) announced its first phase of collaborations among multidisciplinary researchers working together to accelerate cutting-edge research and transformative innovation in climate science and technology.
In May, researchers across Microsoft published the New Future of Work Report 2022, which summarizes important recent research developments related to hybrid work. It highlights themes that have emerged in the findings of the past year and resurfaces older research that has become newly relevant.
In this blog post, we look back at some of the key achievements and notable work in AI and highlight other advances across our diverse, multidisciplinary, and global organization.
Advancing AI foundations and accelerating progress
Researchers from Microsoft Research Asia and the Microsoft Turing team also introduced BEiT-3, a general-purpose multimodal foundation model that achieves state-of-the-art transfer performance on both vision and vision-language tasks. In BEiT-3, researchers introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, BEiT-3 performs masked “language” modeling on images (Imglish), texts (English), and image-text pairs (“parallel sentences”) in a unified manner. The code and pretrained models will be available at GitHub.
One of the most crucial accelerators of progress in AI is the ability to optimize training and inference for large-scale models. In 2022, the DeepSpeed team made a number of breakthroughs to improve mixture of experts (MoE) models, making them more efficient, faster, and less costly. Specifically, they were able to reduce training cost by 5x, reduce MoE parameter size by up to 3.7x, and reduce MoE inference latency by 7.3x while offering up to 4.5x faster and 9x cheaper inference for MoE models compared to quality-equivalent dense models.
Transforming scientific discovery and adding societal value
Our ability to comprehend and reason about the natural world has advanced over time, and the new AI4Science organization, announced in July, represents another turn in the evolution of scientific discovery. Machine learning is already being used in the natural sciences to model physical systems using observational data. AI4Science aims to dramatically accelerate our ability to model and predict natural phenomena by creating deep learning emulators that learn by using computational solutions to fundamental equations as training data.
This new paradigm can help scientists gain greater insight into natural phenomena, right down to their smallest components. Such molecular understanding and powerful computational tools can help accelerate the discovery of new materials to combat climate change, and new drugs to help support the prevention and treatment of disease.
For instance, AI4Science’s Project Carbonix is working on globally accessible, at-scale solutions for decarbonizing the world economy, including reverse engineering materials that can pull carbon out of the environment and recycling carbon into materials. Collaborating on these efforts through the Microsoft Climate Research Initiative (MCRI) are domain experts from academia, industry, and government. Announced in June, MCRI is focused on areas such as carbon accounting, climate risk assessments, and decarbonization.
As part of the Generative Chemistry project, Microsoft researchers have been working with the global medicines company Novartis to develop and execute machine learning tools and human-in-the-loop approaches to enhance the entire drug discovery process. In April, they introduced MoLeR, a graph-based generative model for designing compounds that is more reflective of how chemists think about the process and is more efficient and practical than an earlier generative model the team developed.
Making AI more adaptable, collaborative, and efficient
To help accelerate the capabilities of large-scale AI while building a landscape in which everyone can benefit from it, the research community at Microsoft aimed to drive progress in three areas: adaptability, collaboration, and efficiency.
To provide consistent value, AI systems must respond to changes in task and environment. Research in this area includes multi-task learning with task-aware routing of inputs, knowledge-infused decoding, model repurposing with data-centric ML, pruning and cognitive science or brain-inspired AI. A good example of our work toward adaptability is GODEL, or Grounded Open DialogueLanguage Model, which ushers in a new class of pretrained language models that enable chatbots to help with tasks and then engage in more general conversations.
Microsoft’s research into more collaborative AI includes AdaTest, which leverages human expertise alongside the generative power of large language models to help people more efficiently find and correct bugs in natural language processing models. Researchers have also explored expanding the use of AI in creative processes, including a project in which science fiction writer Gabrielle Loisel used OpenAI’s GPT-3 to co-author a novella and other stories.
To enable more people to make use of AI in an efficient and sustainable way, Microsoft researchers are pursuing several new architectures and training paradigms. This includes new modular architectures and novel techniques, such as DeepSpeed Compression, a composable library for extreme compression and zero-cost quantization, and Z-Code Mixture of Experts models, which boost translation efficiency and were deployed in Microsoft Translator in 2022.
In December, researchers unveiled AutoDistil, a new technique that leverages knowledge distillation and neural architecture search to improve the balance between cost and performance when generating compressed models. They also introduced AdaMix, which improves the fine-tuning of large pretrained models for downstream tasks using mixture of adaptations modules for parameter-efficient model tuning. And vision-language model compression research on the lottery ticket hypothesis showed that pretrained language models can be significantly compressed without hurting their performance.
Cloud Intelligence/AIOps is a rapidly emerging technology trend and an interdisciplinary research direction across system, software engineering, and AI/ML communities. In this blog post from November, the researchers behind Microsoft’s AIOps work outline a research vision to make the cloud more autonomous, proactive, and manageable.
Building and deploying AI responsibly
Building AI that maximizes its benefit to humanity, and does so equitably, requires considering both the opportunities and risks that come with each new advancement in line with our guiding principles: fairness, reliability and safety, privacy and security, inclusiveness, transparency, and accountability.
Helping to put these principles into practice is Microsoft’s Responsible AI Standard, which the company made publicly available in June. The standard comprises tools and steps that AI practitioners can execute in their workflows today to help ensure that building AI responsibly is baked into every stage of development. These standards will evolve as the tools and resources to responsibly build AI evolve in response to the rapid pace of AI advancement, particularly pertaining to the growing size of AI models and the new challenges they bring.
The responsible development of AI also means deploying technologies that operate the way they were designed to—and the way people expect them to. In a pair of blog posts, researchers draw on their respective experiences developing a technology to support social agency in children who are born blind and another to support mental health practitioners in guiding patient treatment to stress the need for multiple measures of performance in determining the readiness of increasingly complex AI systems and the incorporation of domain experts and user research throughout the development process.
Advancing AI for decision making
Building the next generation of AI requires continuous research into fundamental new AI innovations. Two significant areas of study in 2022 were causal ML and reinforcement learning.
Causal ML
Identifying causal effects is an integral part of scientific inquiry. It helps us understand everything from educational outcomes to the effects of social policies to risk factors for diseases. Questions of cause and effect are also critical for the design and data-driven evaluation of many technological systems we build today.
This year, Microsoft Research continued its work on causal ML, which combines traditional machine learning with causal inference methods. To help data scientists better understand and deploy causal inference, Microsoft researchers built the DoWhy library, an end-to-end causal inference tool, in 2018. To broaden access to this critical knowledge base, DoWhy has now migrated to an independent open-source governance model in a new PyWhy GitHub organization. As part of this new collaborative model, Amazon Web Services is contributing new technology based on structural causal models.
At this year’s Conference on Neural Information Processing Systems (NeurIPS), researchers presented a suite of open-source causal tools and libraries that aims to simultaneously provide core causal AI functionality to practitioners and create a platform for research advances to be rapidly deployed. This includes ShowWhy, a no-code user interface suite that empowers domain experts to become decision scientists. We hope that our work accelerates use-inspired basic research for improvement of causal AI.
Reinforcement learning (RL)
Reinforcement learning is a powerful tool for learning which behaviors are likely to produce the best outcomes in a given scenario, typically through trial and error. But this powerful tool faces some challenges. Trial and error can consume enormous resources when applied to large datasets. And for many real-time applications, there’s no room to learn from mistakes.
To address RL’s computational bottleneck, Microsoft researchers developed Path Predictive Elimination, a reinforcement learning method that is robust enough to remove noise from continuously changing environments. Also in 2022, a Microsoft team released MoCapAct, a library of pretrained simulated models to enable advanced research on artificial humanoid control at a fraction of the compute resources currently required.
Researchers also developed a new method for using offline RL to augment human-designed strategies for making critical decisions. This team deployed game theory to design algorithms that can use existing data to learn policies that improve on current strategies.
2022 was an exciting year for research, and we look forward to the future breakthroughs our global research community will deliver. In the coming year, you can expect to hear more from us about our vision, and the impact we hope to achieve. We appreciate the opportunity to share our work with you, and we hope you will subscribe to the Microsoft Research Newsletter for the latest developments.
Writers and Editors Elise Ballard Kristina Dodge Kate Forster Chris Stetkiewicz Larry West
For more than six years, Microsoft Research has been honored to develop the Soundscape research project, which was designed to deliver information about a person’s location and points of interest and has guided individuals to desired places and in unfamiliar spaces using augmented-reality and three-dimensional audio. While not a traditional turn-by-turn navigation mobile app, the Soundscape research project allowed us to explore ways that audio can enhance mobility and expand navigation experiences without the need to follow directions on a small display.
Beginning January 3, 2023, the Soundscape code will be available as open-source software, so that anyone can continue to build on, and find new ways to leverage, this novel feature set for the growing navigation opportunities in today’s world. As Microsoft Research continues to expand into new accessibility innovation areas, we hope the open-source software release of the Soundscape code supports the community in further developing confidence and utility of spatial audio navigation experiences.
Also on January 3, 2023, the Microsoft Soundscape iOS app will no longer be available for download from the App Store, although existing installations can continue to be used until the end of June 2023. We are grateful to all of those who have tried and found value in the Microsoft Soundscape app and appreciate all the feedback and stories you have shared with us over the years.
Through the Microsoft Soundscape journey, we were delighted to discover the many valuable experiences Soundscape enabled, from empowering mobility instructors, to understanding the role of audio in adaptive sports, to supporting blind or low-vision individuals to go places and do essential activities for their lives. By making the Soundscape code available as open-source software, we hope the interest and potential continues to grow. Documentation on how to build and use the system from the new GitHub Soundscape page will be shared on January 3, 2023.
Frequently asked questions on Soundscape
Q: What is changing for Microsoft Soundscape? A: It is now time to transition the Soundscape research project to the next phase, where we will share it to allow for broader development. Soundscape code will be available on GitHub as open-source software on January 3, 2023.
Q: What will happen to the Microsoft Soundscape app on iOS? A: As of January 3, 2023, the app will not be available for download. Existing installations can continue to be used until the end of June 2023.
Q: Will the Azure services that enable the Microsoft Soundscape app continue to be supported? A: Yes, until the end of June 2023. Beyond that, entities can build new cloud-based services from our open-source release.
Q: Will user feedback on the Microsoft Soundscape app continue to work? A: Yes, until the end of June 2023. We will focus on bug fixes and repairing service disruptions, but we will not address requests for new features or capabilities.
Q: Will the Soundscape open-source release run only on iOS, or will it also support Android? A: The original Microsoft Soundscape app only supports iOS, and that is also true for the open-source release.
Q: Why has Microsoft Research decided to release Soundscape as open-source? A: As we evolve our research portfolio, it is natural to end or transition some projects. We feel the community can benefit from the novel experiences we developed for the Soundscape research project, and that is why we are releasing the code as open-source software.
Q: What will happen to the Microsoft Soundscape Authoring app? A: Use of the Microsoft Soundscape Authoring app will end on January 17, 2023.
Q: Are other Microsoft offerings implicated in this change for Soundscape or following a similar path at this time? A: No, this change is specific to Soundscape. There is no impact or implication on other Microsoft offerings.
Microsoft is home to a diverse team of researchers focused on supporting a healthy global society, including finding ways technology can address human rights problems affecting the most vulnerable populations around the world. With a multi-disciplinary background in human-computer interaction, data science, and the social sciences, the research team partners with community, governmental, and nongovernmental organizations to create open technologies that enable scalable responses to such challenges.
The United Nations’ International Organization for Migration (IOM) provides direct assistance and support to migrants around the world, as well as victims and survivors of human trafficking. IOM is dedicated to promoting humane and orderly migration by providing services to governments and migrants in its 175 member countries. It recently reported 50 million victims of forced labor globally, including 3.3 million children, 6.3 million in commercial sexual exploitation, and 22 million trapped in forced marriages. Understanding and addressing problems at this scale requires technology to help anti-trafficking actors and domain experts gather and translate real-world data into evidence that can inform policies and build support systems.
On-Demand Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Today, using software developed by Microsoft researchers, IOM released its second synthetic dataset from trafficking victim case records, the first ever public dataset to describe victim-perpetrator relations. The synthetic dataset is also the first of its kind to be generated with differential privacy, providing an additional security guarantee for multiple data releases, which enables the sharing of more data and allows more rigorous research to be conducted while protecting privacy and civil liberties.
The new data release builds on several years of collaboration between Microsoft and IOM to support safe data sharing of victim case records in ways that can inform collective action across the anti-trafficking community. This collaboration began in July 2019 when IOM joined the accelerator program of the Tech Against Trafficking (TAT) coalition, with the goal of advancing the privacy and utility of data made available through the Counter Trafficking Data Collaborative (CTDC) data hub – the first global portal on human trafficking case data. Since then, IOM and Microsoft have collaborated to improve the ways data on identified victims and survivors—as well as their accounts of perpetrators—can be used to combat the proliferation of human trafficking.
“We are grateful to Microsoft Research for our partnership over almost four years to share data while protecting the safety and privacy of victims and survivors of trafficking.”
– Monica Goracci, IOM’s Director of Programme Support and Migration Management
The critical importance of data privacy when working with vulnerable populations
When publishing data on victims of trafficking, all efforts must be taken to ensure that traffickers are wholly prevented from identifying known victims in published datasets. It is also important to protect individuals’ privacy to avoid stigma or other potential forms of harm or (re)traumatization. Data statistics accuracy is another concern: the statistics must simultaneously enable researchers and analysts to guarantee victims’ privacy and extract useful insights from the dataset containing personal information. This is critically important: if a privacy method were to over- or under-report a given pattern in victim cases, it could mislead decision makers to misdirect scarce resources and therefore fail to tackle the originating problem.
The collaboration between IOM and Microsoft was founded on the idea that rather than redacting sensitive data to create privacy, synthetic datasets can be generated in ways that accurately capture the structure and statistics of underlying sensitive datasets, while remaining private by design. But not all synthetic data comes with formal guarantees of data privacy or accuracy. Therefore, building trust in synthetic data requires communicating how well the synthetic data represents the actual sensitive data, while ensuring that these comparisons do not create privacy risks themselves.
From this founding principle, along with the need to accurately report case counts broken down by different combinations of attributes (e.g., age range, gender, nationality), a solution emerged: to release synthetic data alongside privacy-preserving counts of cases, matching all short combinations of case attributes. The aggregate data thereby supports both evaluation of synthetic data quality and retrieval of accurate counts for official reporting. Through this collaboration and the complementary nature of synthetic data and aggregate data—together with interactive interfaces with which to view and explore both datasets—the open-source Synthetic Data Showcase software was developed.
In September 2021, IOM used Synthetic Data Showcase to release its first downloadable Global Synthetic Dataset, representing data from over 156,000 victims and survivors of trafficking across 189 countries and territories (where victims were first identified and supported by CTDC partners). The new Global Victim-Perpetrator Synthetic Dataset, released today, is CTDC’s second synthetic dataset produced using an updated version of Synthetic Data Showcase with added support for differential privacy. This new dataset includes IOM data from over 17,000 trafficking victim case records and their accounts of over 37,000 perpetrators who facilitated the trafficking process from 2005 to 2022. Together, these datasets provide vital first-hand information on the socio-demographic profiles of victims, their accounts of perpetrators, types of exploitation, and the overall trafficking process—all of which are critical to better assist survivors and prosecute perpetrators.
“Data privacy is crucial to the pursuit of efficient, targeted counter-trafficking policies and good migration governance.”
– Irina Todorova, Head of the Assistance to Vulnerable Migrants Unit at IOM’s Protection Division
A differentially private dataset
In 2006, Microsoft researchers led the initial development of differential privacy, and today it represents the gold standard in privacy protection. It helps ensure that answers to data queries are similar, whether or not any individual data subject is in the dataset, and therefore cannot be used to infer the presence of specific individuals, either directly or indirectly.
Existing algorithms for differentially private data synthesis typically create privacy by “hiding” actual combinations of attributes in a sea of fabricated or spurious attribute combinations that don’t specifically reflect what was in the original sensitive dataset.
This can be problematic if the presence of these fabricated attribute combinations misrepresents the real-world situation and misleads downstream decision making, policy making, or resource allocation to the detriment of the underlying population (e.g., encouraging policing of trafficking routes that have not actually been observed).
When the research team encountered these challenges with existing differentially private synthesizers, they engaged fellow researchers at Microsoft to explore possible solutions. They explained the critical importance of reporting accurate counts of actual attribute combinations in support of statistical reporting and evidence-based intervention, and how the “feature” of fabricating unobserved combinations as a way of preserving privacy could be harmful when attempting to understand real-world patterns of exploitation.
Those colleagues had recently solved a similar problem in a different context: how to extract accurate counts of n-gram word combinations from a corpus of private text data. Their solution, recently published at the 2021 Conference on Neural Information Processing Systems, significantly outperformed the state of the art. In collaboration with the research team working with IOM, they adapted this solution into a new approach to generating differentially private marginals—counts of all short combinations of attributes that represented a differentially-private aggregate dataset.
Because differentially private data has the property that subsequent processing cannot increase privacy loss, any datasets generated from such aggregates retain the same level of privacy. This enabled the team to modify their existing approach to data synthesis—creating synthetic records by sampling attribute combinations until all attributes are accounted for—to extrapolate these noisily reported attribute combinations into full, differentially-private synthetic records. The result is precisely what IOM and similar organizations need to create a thriving data ecosystem in the fight against human trafficking and other human rights violations: accurate aggregate data for official reporting, synthetic data for interactive exploration and machine learning, and differential privacy guarantees that provide protection even over multiple overlapping data releases.
This new synthesizer is now available to the community via Microsoft’s SmartNoise library within the OpenDP initiative. Unlike existing synthesizers, it provides strong control over the extent to which fabrication of spurious attribute combinations is allowed and augments synthetic datasets with “actual” aggregate data protected by differential privacy.
Access to private-yet-accurate patterns of attributes characterizing victim-perpetrator relationships allows stakeholders to advance the understanding of risk factors for vulnerability and carry out effective counter-trafficking interventions, all while keeping the victims’ identities private.
“The new dataset represents the first global collection of case data linking the profiles of trafficking victims and perpetrators ever made available to the public, while enabling strong privacy guarantees. It provides critical information to better assist survivors and prosecute offenders.” – Claire Galez-Davis, Data Scientist at IOM’s Protection Division.
An intuitive new interface and public utility web application
Solving problems at a global scale requires tools that make safe data sharing accessible wherever there is a need and in a way that is understandable by all stakeholders. The team wanted to construct an intuitive interface to help develop a shared evidence base and motivate collective action by the anti-trafficking community. They also wanted to ensure that the solution was available to anyone with a need to share sensitive data safely and responsibly. The new user interface developed through this work is now available as a public utility web application in which private data aggregation and synthesis are performed locally in the web browser, with no data ever leaving the user’s machine.
“I find the locally run web application incredibly interactive and intuitive. It is a lot easier for me to explain the data generation process and teach others to use the new web interface. As the data is processed locally in our computers, I don’t need to worry about data leaks.” – Lorraine Wong, Research Officer at IOM’s Protection Division.
What’s next for the IOM and Microsoft collaboration
Microsoft and IOM have made the solution publicly accessible for other organizations, including central government agencies. It can be used by any stakeholder who wants to collect and publish sensitive data while protecting individual privacy.
Through workshops and guidance on how to produce high-quality administrative data, the organizations plan to share evidence on exploitation and abuse to support Member States, other UN agencies, and counter-trafficking organizations around the world. This kind of administrative data is a key source of information providing baseline statistics that can be used to understand patterns, risk factors, trends, and modus operandi that are critical for policy response formulation.
For example, IOM has been collaborating with the UN Office on Drugs and Crime (UNODC) to establish international standards and guidance to support governments in producing high-quality administrative data. It has also been collaborating with the UN International Labour Organization (ILO) to index policy-oriented research on trafficking in a bibliography. Finally, IOM is producing an online course, including a module that includes guidance on synthetic data, to encourage safe data sharing from governments and frontline counter-trafficking agencies.
“Being able to publish more data than we have done in the past, and in an even safer way, is a great achievement,” explained Phineas Jasi, Data Management and Research Specialist at IOM’s Protection Division. He added that “The aim is for these data to inform the evidence base on human trafficking, which in turns helps devise efficient and targeted counter-trafficking policies and achieve good migration governance.”
Translating data into evidence is the goal of the related ShowWhy application from the same Microsoft research team, which guides domain experts through the end-to-end process of developing causal evidence from observational data. Just like Synthetic Data Showcase, it makes advanced data science capabilities accessible to domain experts through a suite of interactive, no-code user interfaces.
“Driving a coordinated global response against human trafficking requires removing traditional barriers to both data access and data analysis,” said Darren Edge, Director at Microsoft Research. “With our Synthetic Data Showcase and ShowWhy applications, we are aiming to empower domain experts to develop causal evidence for themselves, from sensitive data that couldn’t otherwise be shared, and use this to inform collective action with a precision and scale that couldn’t otherwise be imagined.”
This special edition of Research Focus highlights some of the 100+ papers from Microsoft Research that were accepted for publication at NeurIPS 2022 – the thirty-sixth annual Conference on Neural Information Processing Systems.
In this issue, we continue to feature some of our 100+ papers accepted at NeurIPS 2022.
Outstanding paper: Gradient Estimation with Discrete Stein Operators
Gradient estimation — approximating the gradient of an expectation with respect to the parameters of a distribution — is central to the solution of many machine learning problems. However, when the distribution is discrete, most common gradient estimators suffer from excessive variance. To improve the quality of gradient estimation, we introduce a variance reduction technique based on Stein operators for discrete distributions in our paper: Gradient Estimation with Discrete Stein Operators. We then use this technique to build flexible control variates for the REINFORCE leave-one-out estimator. Our control variates can be adapted online to minimize variance and do not require extra evaluations of the target function. In benchmark generative modeling tasks such as training binary variational autoencoders, our gradient estimator achieves substantially lower variance than state-of-the-art estimators with the same number of function evaluations.
Data-driven simulations have emerged as an effective alternative to building simulators from scratch, which involves complex handcrafting and expert knowledge. However, complex real-life systems are often decomposable into modular subsystems and are usually designed in such a manner for engineering tractability. Unfortunately, current data-driven methods tend to learn monolithic blocks in an end-to-end fashion, which often results in simulators that only work for a particular configuration and are not generalizable. In our paper: Learning Modular Simulations for Homogeneous Systems, we present a modular simulation framework for modeling homogeneous multibody systems, which combines ideas from graph neural networks and neural differential equations. We propose the Message-Passing Neural Ordinary Differential Equation (MP-NODE), a paradigm for modeling individual subsystems as neural ODEs along with spatio-temporal message-passing capability, which is then used to orchestrate full simulations. We evaluate our framework on a variety of systems and show that message passing allows coordination between multiple modules over time for accurate predictions and can also enable zero-shot generalization to new system configurations. Furthermore, we show that our models can be transferred to new system configurations with lower data requirement and training effort, compared to those trained from scratch.
Deep learning has shown high predictive accuracy in a wide range of tasks, but its inner working mechanisms are obscured by complex model designs. This raises important questions about whether a deep model is ethical, trustworthy, or capable of performing as intended under various conditions.
In our paper, Self-explaining deep models with logic rule reasoning, we present SELOR, a framework for integrating self-explaining capabilities into a given deep model to achieve both high prediction performance and human precision. By “human precision”, we refer to the degree to which humans agree with the reasons models provide for their predictions. Human precision affects user trust and allows users to collaborate closely with the model. We demonstrate that logic rule explanations naturally satisfy human precision with the expressive power required for good predictive performance. We then show how to enable a deep model to predict and explain with logic rules. Our method does not require predefined logic rule sets or human annotations and can be learned efficiently and easily with widely-used deep learning modules in a differentiable way. Extensive experiments show that our method gives explanations closer to human decision logic than other methods while maintaining the performance of deep learning models.
Computer vision models such as classification and object detection are known to fail in many different ways. While the importance of recognizing and addressing such shortcomings is well understood, we lack a scalable and efficient means of identifying such failure cases. To address this issue, we introduce 3DB: an extendable, unified framework for testing and debugging vision models using photorealistic simulation. In our paper, 3DB: A Framework for Debugging Computer Vision Models, we show how 3DB enables users to test vision models on synthetic images, where a diverse set of factors can be controlled. We demonstrate, through a wide range of use cases, that 3DB allows users to discover shortcomings in computer vision systems and gain insights into how models make decisions. 3DB captures and generalizes many robustness analyses from prior work and enables one to study their interplay. Finally, we find that the insights generated by the system transfer to the physical world. We are releasing 3DB as a library alongside a set of example analyses, guides, and documentation: https://3db.github.io/3db/.