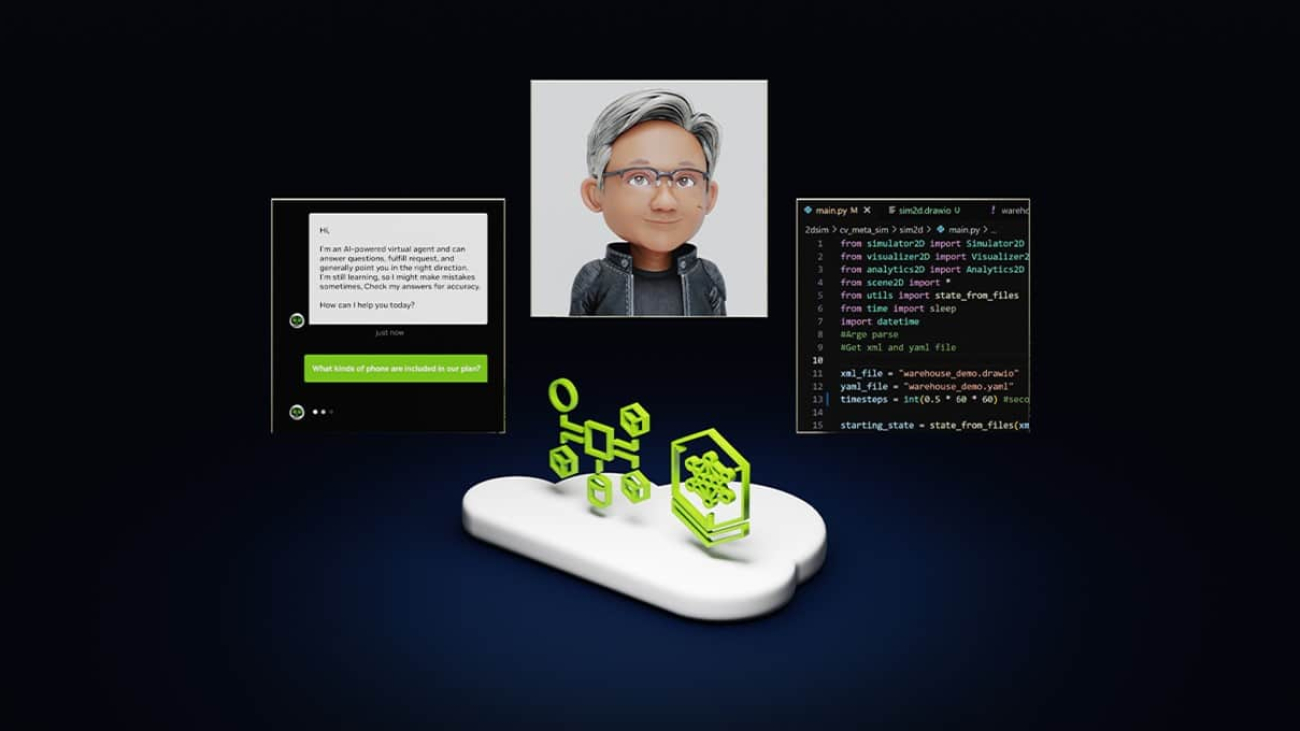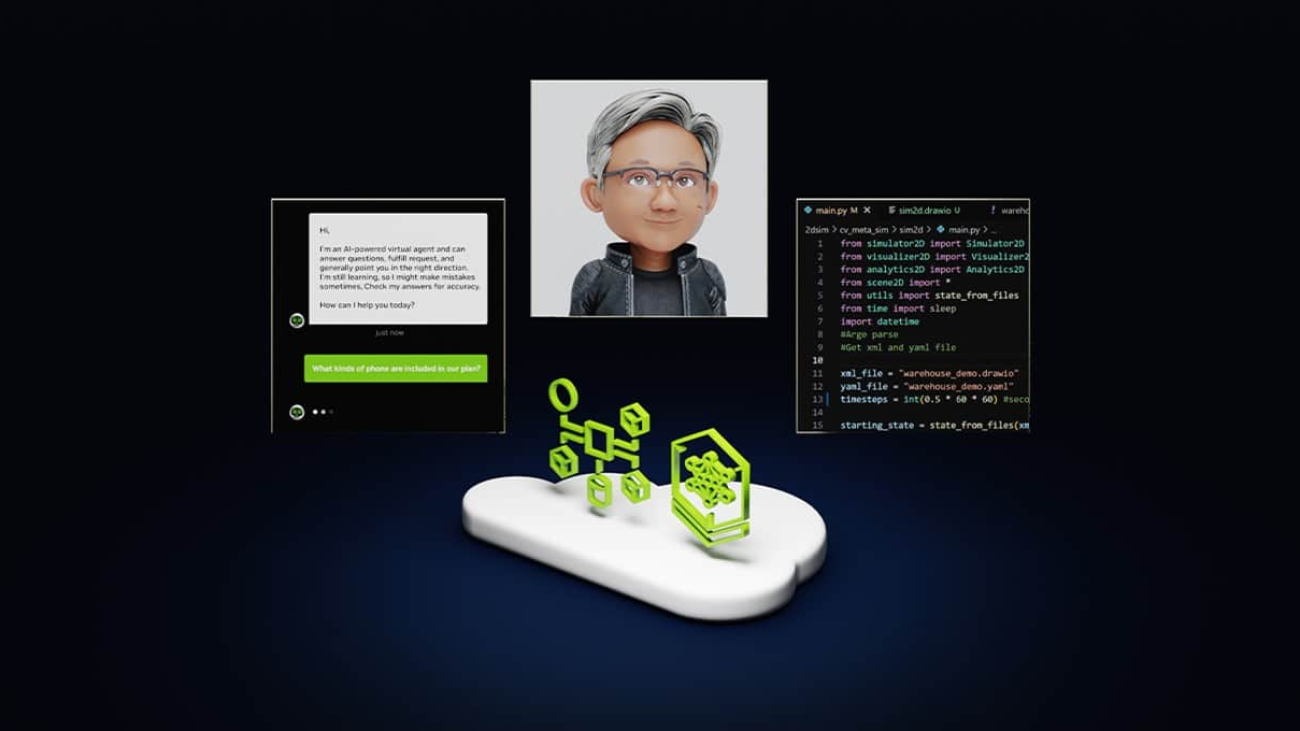
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
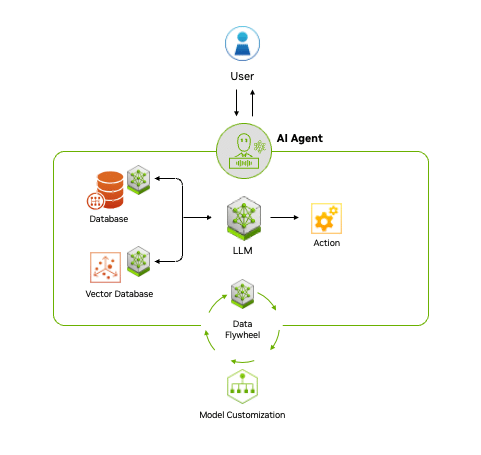 Fueling Agentic AI With Enterprise Data
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.

Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA NIM Agent Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NIM Agent Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.