Ström discusses his career journey in conversational AI, his published research, and where he sees the field of conversational AI headed nextRead More
New workshop, dataset will help promote safety in the skies
ICCV workshop hosted by Amazon Prime Air and AWS will announce results of challenge to detect airborne obstacles.Read More
Build a cognitive search and a health knowledge graph using AWS AI services
Medical data is highly contextual and heavily multi-modal, in which each data silo is treated separately. To bridge different data, a knowledge graph-based approach integrates data across domains and helps represent the complex representation of scientific knowledge more naturally. For example, three components of major electronic health records (EHR) are diagnosis codes, primary notes, and specific medications. Because these are represented in different data silos, secondary use of these documents for accurately identifying patients with a specific observable trait is a crucial challenge. By connecting those different sources, subject matter experts have a richer pool of data to understand how different concepts such as diseases and symptoms interact with one another and help conduct their research. This ultimately helps healthcare and life sciences researchers and practitioners create better insights from the data for a variety of use cases, such as drug discovery and personalized treatments.
In this post, we use Amazon HealthLake to export EHR data in the Fast Healthcare Interoperability Resources (FHIR) data format. We then build a knowledge graph based on key entities extracted and harmonized from the medical data. Amazon HealthLake also extracts and transforms unstructured medical data, such as medical notes, so it can be searched and analyzed. Together with Amazon Kendra and Amazon Neptune, we allow domain experts to ask a natural language question, surface the results and relevant documents, and show connected key entities such as treatments, inferred ICD-10 codes, medications, and more across records and documents. This allows for easy analysis of co-occurrence of key entities, co-morbidities analysis, and patient cohort analysis in an integrated solution. Combining effective search capabilities and data mining through graph networks reduces time and cost for users to find relevant information around patients and improve knowledge serviceability surrounding EHRs. The code base for this post is available on the GitHub repo.
Solution overview
In this post, we use the output from Amazon HealthLake for two purposes.
First, we index EHRs into Amazon Kendra for semantic and accurate document ranking out of patient notes, which help improve physician efficiency identifying patient notes and compare it with other patients sharing similar characteristics. This shifts from using a lexical search to a semantic search that introduces context around the query, which results in better search output (see the following screenshot).

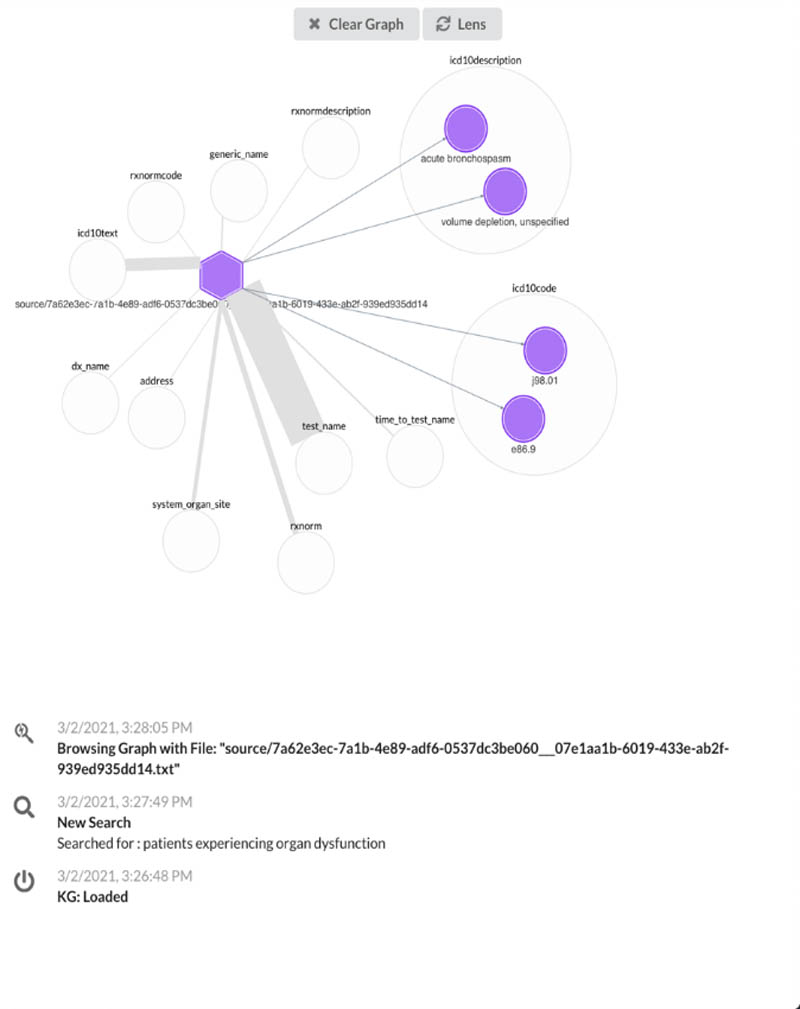
Second, we use Neptune to build knowledge graph applications for users to view metadata associated with patient notes in a more simple and normalized view, which allows us to highlight the important characteristics stemming from a document (see the following screenshot).
The following diagram illustrates our architecture.

The steps to implement the solution are as follows:
- Create and export Amazon HealthLake data.
- Extract patient visit notes and metadata.
- Load patient notes data into Amazon Kendra.
- Load the data into Neptune.
- Set up the backend and front end to run the web app.
Create and export Amazon HealthLake data
As a first step, create a data store using Amazon HealthLake either via the Amazon HealthLake console or the AWS Command Line Interface (AWS CLI). For this post, we focus on the AWS CLI approach.
- We use AWS Cloud9 to create a data store with the following code, replacing <<your data store name >> with a unique name:
aws healthlake create-fhir-datastore --region us-east-1 --datastore-type-version R4 --preload-data-config PreloadDataType="SYNTHEA" --datastore-name "<<your_data_store_name>>"The preceding code uses a preloaded dataset from Synthea, which is supported in FHIR version R4, to explore how to use Amazon HealthLake output. Running the code produces a response similar to the following code, and this step takes a few minutes to complete (approximately 30 minutes at the time of writing):
{
"DatastoreEndpoint": "https://healthlake.us-east-1.amazonaws.com/datastore/<<your_data_store_id>>/r4/",
"DatastoreArn": "arn:aws:healthlake:us-east-1:<<your_AWS_account_number>>:datastore/fhir/<<your_data_store_id>>",
"DatastoreStatus": "CREATING",
"DatastoreId": "<<your_data_store_id>>"
}
You can check the status of completion either on the Amazon HealthLake console or in the AWS Cloud9 environment.
- To check the status in AWS Cloud9, use the following code to check the status and wait until
DatastoreStatuschanges fromCREATINGtoACTIVE:
aws healthlake describe-fhir-datastore --datastore-id "<<your_data_store_id>>" --region us-east-1- When the status changes to
ACTIVE, get the role ARN from theHEALTHLAKE-KNOWLEDGE-ANALYZER-IAMROLEstack in AWS CloudFormation, associated with the physical IDAmazonHealthLake-Export-us-east-1-HealthDataAccessRole, and copy the ARN in the linked page. - In AWS Cloud9, use the following code to export the data from Amazon HealthLake to the Amazon Simple Storage Service (Amazon S3) bucket generated from AWS Cloud Development Kit (AWS CDK) and note the
job-idoutput:
aws healthlake start-fhir-export-job --output-data-config S3Uri="s3://hl-synthea-export-<<your_AWS_account_number>>/export-$(date +"%d-%m-%y")" --datastore-id <<your_data_store_id>> --data-access-role-arn arn:aws:iam::<<your_AWS_account_number>>:role/AmazonHealthLake-Export-us-east-1-HealthKnoMaDataAccessRole- Verify that the export job is complete using the following code with the
job-idobtained from the last code you ran. (when the export is complete,JobStatusin the output statesCOMPLETED):
aws healthlake describe-fhir-export-job --datastore-id <<your_data_store_id>> --job-id <<your_job_id>>Extract patient visit notes and metadata
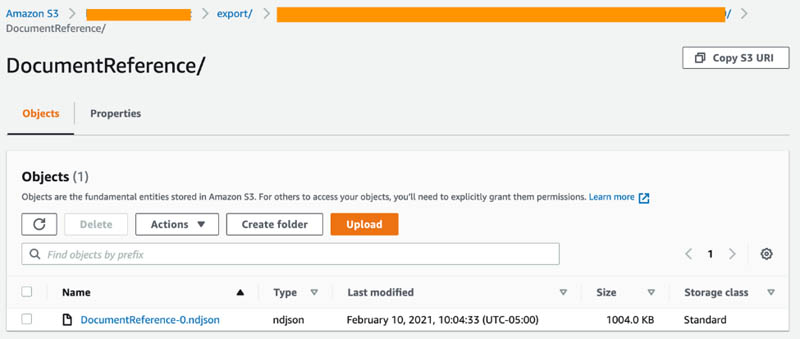
The next step involves decoding patient visits to obtain the raw texts. We will import the following file DocumentReference-0.ndjson (shown in the following screenshot of S3) from the Amazon HealthLake export step we previously completed into the CDK deployed Amazon SageMaker notebook instance. First, save the notebook provided from the Github repo into the SageMaker instance. Then, run the notebook to automatically locate and import the DocumentReference-0.ndjson files from S3.
For this step, use the resourced SageMaker to quickly run the notebook. The first part of the notebook creates a text file that contains notes from each patient’s visit and is saved to an Amazon S3 location. Because multiple visits could exist for a single patient, a unique identification combines the patient unique ID and the visit ID. These patients’ notes are used to perform semantic search against using Amazon Kendra.
The next step in the notebook involves creating triples based on the automatically extracted metadata. By creating and saving the metadata in an Amazon S3 location, an AWS Lambda function gets triggered to generate the triples surrounding the patient visit notes.
Load patient notes data into Amazon Kendra
The text files that are uploaded in the source path of the S3 bucket need to be crawled and indexed. For this post, a developer edition is created during the AWS CDK deployment, so the index is created to connect the raw patient notes.
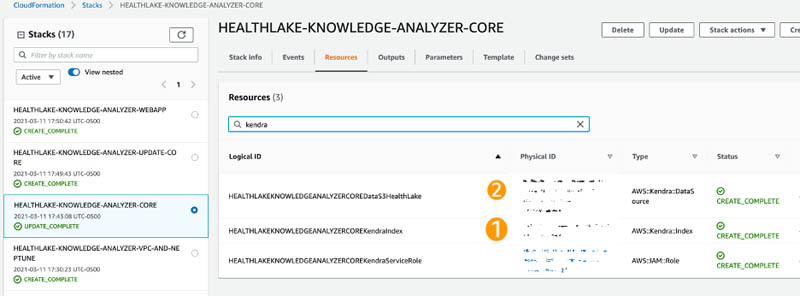
- On the AWS CloudFormation console under the HEALTHLAKE-KNOWLEDGE-ANALYZER-CORE stack, search for kendra on the Resources tab and take note of the index ID and data source ID (copy the first part of the physical ID before the pipe ( | )).
- Back in AWS Cloud9, run the following command to synchronize the patient notes in Amazon S3 to Amazon Kendra:
aws kendra start-data-source-sync-job --id <<data_source_id_2nd_circle>> --index-id <<index_id_1st_ circle>>- You can verify when the sync status is complete by running the following command:
aws kendra describe-data-source --id <<data_source_id_2nd_circle>> --index-id <<index_id_1st_circle>>Because the ingested data is very small, it should immediately show that Status is ACTIVE upon running the preceding command.
Load the data into Neptune
In this next step, we access the Amazon Elastic Compute Cloud (Amazon EC2) instance that was spun up and load the triples from Amazon S3 into Neptune using the following code:
curl -X POST
-H 'Content-Type: application/json'
https://healthlake-knowledge-analyzer-vpc-and-neptune-neptunedbcluster.cluster-<<your_unique_id>>.us-east-1.neptune.amazonaws.com:8182/loader -d '
{
"source": "s3://<<your_Amazon_S3_bucket>>/stdized-data/neptune_triples/nquads/",
"format": "nquads",
"iamRoleArn": "arn:aws:iam::<<your_AWS_account_number>>:role/KNOWLEDGE-ANALYZER-IAMROLE-ServiceRole",
"region": "us-east-1",
"failOnError": "TRUE"
}'
Set up the backend and front end to run the web app
The preceding step should take a few seconds to complete. In the meantime, configure the EC2 instance to access the web app. Make sure to have both Python and Node installed in the instance.
- Run the following code in the terminal of the instance:
sudo iptables -t nat -I PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 3000This routes the public address to the deployed app.
- Copy the two folders titled
ka-webappandka-server-webappand upload them to a folder nameddevin the EC2 instance. - For the front end, create a screen by running the following command:
screen -S back - In this screen, change the folder to
ka-webappand runnpminstall. - After installation, go into the file
.env.developmentand place the Amazon EC2 public IPv4 address and save the file. - Run
npmstart and then detach the screen. - For the backend, create another screen by entering:
screen -S back- Change the folder to
ka-server-webappand runpip install -r requirements.txt. - When the libraries are installed, enter the following code:
./run.sh- Detach from the current screen, and using any browser, go the Amazon EC2 Public IPv4 address to access the web app.
Try searching for a patient diagnosis and choose a document link to visualize the knowledge graph of that document.
Next steps
In this post, we integrate data output from Amazon HealthLake into both a search and graph engine to semantically search relevant information and highlight important entities linked to documents. You can further expand this knowledge graph and link it to other ontologies such as MeSH and MedDRA.
Furthermore, this provides a foundation to further integrate other clinical datasets and expand this knowledge graph to build a data fabric. You can make queries on historical population data, chaining structured and language-based searches for cohort selection to correlate disease with patient outcome.
Clean up
To clean up your resources, complete the following steps:
- To delete the stacks created, enter the following commands in the order given to properly remove all resources:
$ cdk destroy HEALTHLAKE-KNOWLEDGE-ANALYZER-UPDATE-CORE
$ cdk destroy HEALTHLAKE-KNOWLEDGE-ANALYZER-WEBAPP
$ cdk destroy HEALTHLAKE-KNOWLEDGE-ANALYZER-CORE
- While the preceding commands are in progress, delete the Amazon Kendra data source that was created:
$ cdk destroy HEALTHLAKE-KNOWLEDGE-ANALYZER-VPC-AND-NEPTUNE
$ cdk destroy HEALTHLAKE-KNOWLEDGE-ANALYZER-IAMROLE
$ aws healthlake delete-fhir-datastore --datastore-id <<your_data_store_id>> - To verify it’s been deleted, check the status by running the following command:
$ aws healthlake describe-fhir-datastore --datastore-id "<<your_data_store_id>>" --region us-east-1- Check the AWS CloudFormation console to ensure that all associated stacks starting with
HEALTHLAKE-KNOWLEDGE-ANALYZERhave all been deleted successfully.
Conclusion
Amazon HealthLake provides a managed service based on the FHIR standard to allow you to build health and clinical solutions. Connecting the output of Amazon HealthLake to Amazon Kendra and Neptune gives you the ability to build a cognitive search and a health knowledge graph to power your intelligent application.
Building on top of this approach can enable researchers and front-line physicians to easily search across clinical notes and research articles by simply typing their question into a web browser. Every clinical evidence is tagged, indexed, and structured using machine learning to provide evidence-based topics on things like transmission, risk factors, therapeutics, and incubation. This particular functionality is tremendously valuable for clinicians or scientists because it allows them to quickly ask a question to validate and advance their clinical decision support or research.
Try this out on your own! Deploy this solution using Amazon HealthLake in your AWS account by deploying the example on GitHub.
About the Authors
 Prithiviraj Jothikumar, PhD, is a Data Scientist with AWS Professional Services, where he helps customers build solutions using machine learning. He enjoys watching movies and sports and spending time to meditate.
Prithiviraj Jothikumar, PhD, is a Data Scientist with AWS Professional Services, where he helps customers build solutions using machine learning. He enjoys watching movies and sports and spending time to meditate.
 Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his fami
Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his fami
 Parminder Bhatia is a science leader in the AWS Health AI, currently building deep learning algorithms for clinical domain at scale. His expertise is in machine learning and large scale text analysis techniques in low resource settings, especially in biomedical, life sciences and healthcare technologies. He enjoys playing soccer, water sports and traveling with his family.
Parminder Bhatia is a science leader in the AWS Health AI, currently building deep learning algorithms for clinical domain at scale. His expertise is in machine learning and large scale text analysis techniques in low resource settings, especially in biomedical, life sciences and healthcare technologies. He enjoys playing soccer, water sports and traveling with his family.
 Garin Kessler is a Senior Data Science Manager at Amazon Web Services, where he leads teams of data scientists and application architects to deliver bespoke machine learning applications for customers. Outside of AWS, he lectures on machine learning and neural language models at Georgetown. When not working, he enjoys listening to (and making) music of questionable quality with friends and family.
Garin Kessler is a Senior Data Science Manager at Amazon Web Services, where he leads teams of data scientists and application architects to deliver bespoke machine learning applications for customers. Outside of AWS, he lectures on machine learning and neural language models at Georgetown. When not working, he enjoys listening to (and making) music of questionable quality with friends and family.
 Dr. Taha Kass-Hout is Director of Machine Learning and Chief Medical Officer at Amazon Web Services, and leads our Health AI strategy and efforts, including Amazon Comprehend Medical and Amazon HealthLake. Taha is also working with teams at Amazon responsible for developing the science, technology, and scale for COVID-19 lab testing. A physician and bioinformatician, Taha served two terms under President Obama, including the first Chief Health Informatics officer at the FDA. During this time as a public servant, he pioneered the use of emerging technologies and cloud (CDC’s electronic disease surveillance), and established widely accessible global data sharing platforms, the openFDA, that enabled researchers and the public to search and analyze adverse event data, and precisionFDA (part of the Presidential Precision Medicine initiative).
Dr. Taha Kass-Hout is Director of Machine Learning and Chief Medical Officer at Amazon Web Services, and leads our Health AI strategy and efforts, including Amazon Comprehend Medical and Amazon HealthLake. Taha is also working with teams at Amazon responsible for developing the science, technology, and scale for COVID-19 lab testing. A physician and bioinformatician, Taha served two terms under President Obama, including the first Chief Health Informatics officer at the FDA. During this time as a public servant, he pioneered the use of emerging technologies and cloud (CDC’s electronic disease surveillance), and established widely accessible global data sharing platforms, the openFDA, that enabled researchers and the public to search and analyze adverse event data, and precisionFDA (part of the Presidential Precision Medicine initiative).
Improve the streaming transcription experience with Amazon Transcribe partial results stabilization

Whether you’re watching a live broadcast of your favorite soccer team, having a video chat with a vendor, or calling your bank about a loan payment, streaming speech content is everywhere. You can apply a streaming transcription service to generate subtitles for content understanding and accessibility, to create metadata to enable search, or to extract insights for call analytics. These transcription services process streaming audio content and generate partial transcription results until it provides a final transcription for a segment of continuous speech. However, some words or phrases in these partial results might change, as the service further understands the context of the audio.
We’re happy to announce that Amazon Transcribe now allows you to enable and configure partial results stabilization for streaming audio transcriptions. Amazon Transcribe is an automatic speech recognition (ASR) service that enables developers to add real-time speech-to-text capabilities into their applications for on-demand and streaming content. Instead of waiting for an entire sentence to be transcribed, you can now control the stabilization level of partial results. Transcribe offers 3 settings: High, Medium and Low. Setting the stabilization “High” allows a greater portion of the partial results to be fixed with only the last few words changing during the transcription process. This feature helps you have more flexibility in your streaming transcription workflows based on the user experience you want to create.
In this post, we walk through the benefits of this feature and how to enable it via the Amazon Transcribe console or the API.
How partial results stabilization works
Let’s dive deeper into this with an example.
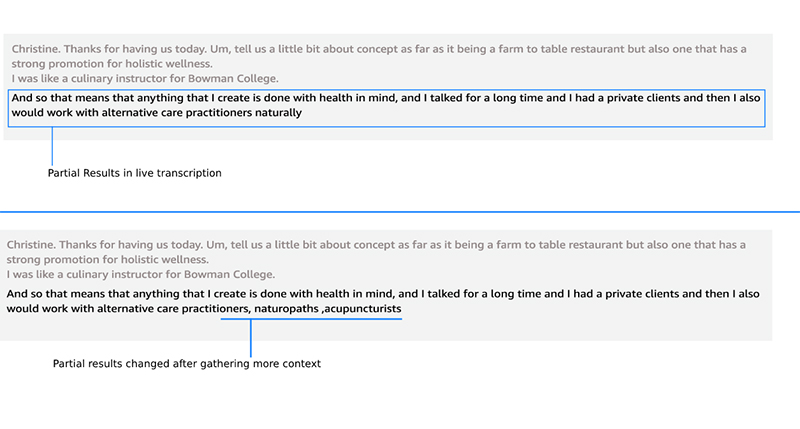
During your daily conversations, you may think you hear a certain word or phrase, but later realize that it was incorrect based on additional context. Let’s say you were talking to someone about food, and you heard them say “Tonight, I will eat a pear…” However, when the speaker finishes, you realize they actually said “Tonight I will eat a pair of pancakes.” Just as humans may change our understanding based on the information at hand, Amazon Transcribe uses machine learning (ML) to self-correct the transcription of streaming audio based on the context it receives. To enable this, Amazon Transcribe uses partial results.
During the streaming transcription process, Amazon Transcribe outputs chunks of the results with an isPartial flag. Results with this flag marked as true are the ones that Amazon Transcribe may change in the future depending on the additional context received. After Amazon Transcribe classifies that it has sufficient context to be over a certain confidence threshold, the results are stabilized and the isPartial flag for that specific partial result is marked false. The window size of these partial results could range from a few words to multiple sentences depending on the stream context.
The following image displays how the partial results are generated (and edited) in Amazon Transcribe for streaming transcription.
Results stabilization enables more control over the latency and accuracy of transcription results. Depending on the use case, you may prioritize one over the other. For example, when providing live subtitles, high stabilization of results may be preferred because speed is more important than accuracy. On the other hand for use cases like content moderation, lower stabilization is preferred because accuracy may be more important than latency.
A high stability level enables quicker stabilization of transcription results by limiting the window of context for stabilizing results, but can lead to lower overall accuracy. On the other hand, a low stability level leads to more accurate transcription results, but the partial transcription results are more likely to change.
With the streaming transcription API, you can now control the stability of the partial results in your transcription stream.
Now let’s look at how to use the feature.
Access partial results stabilization via the Amazon Transcribe console
To start using partial results stabilization on the Amazon Transcribe console, complete the following steps:
- On the Amazon Transcribe console, make sure you’re in a Region that supports Amazon Transcribe Streaming.
For this post, we use us-east-1.
- In the navigation pane, choose Real-time transcription.
- Under Additional settings, enable Partial results stabilization.
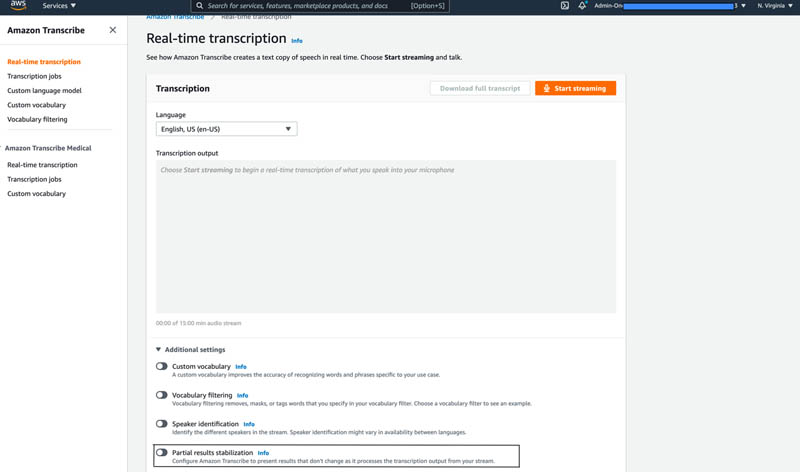
- Select your stability level.
You can choose between three levels:
- High – Provides the most stable partial transcription results with lower accuracy compared to Medium and Low settings. Results are less likely to change as additional context is gathered.
- Medium – Provides partial transcription results that have a balance between stability and accuracy
- Low – Provides relatively less stable partial transcription results with higher accuracy compared to High and Medium settings. Results get updated as additional context is gathered and utilized.

- Choose Start streaming to play a stream and check the results.
Access partial results stabilization via the API
In this section, we demonstrate streaming with HTTP/2. You can enable your preferred level of partial results stabilization in an API request.
You enable this feature via the enable-partial-results-stabilization flag and the partial-results-stability level input parameters:
POST /stream-transcription HTTP/2
x-amzn-transcribe-language-code: LanguageCode
x-amzn-transcribe-sample-rate: MediaSampleRateHertz
x-amzn-transcribe-media-encoding: MediaEncoding
x-amzn-transcribe-session-id: SessionId
x-amzn-transcribe-enable-partial-results-stabilization= true
x-amzn-transcribe-partial-results-stability = low | medium | high
Enabling partial results stabilization introduces the additional parameter flag Stable in the API response at the item level in the transcription results. If a partial results item in the streaming transcription result has the Stable flag marked as true, the corresponding item transcription in the partial results doesn’t change irrespective of any subsequent context identified by Amazon Transcribe. If the Stable flag is marked as false, there is still a chance that the corresponding item may change in the future, until the IsPartial flag is marked as false.
The following code shows our API response:
{
"Alternatives": [
{
"Items": [
{
"Confidence": 0,
"Content": "Amazon",
"EndTime": 1.22,
"Stable": true,
"StartTime": 0.78,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Confidence": 0,
"Content": "is",
"EndTime": 1.63,
"Stable": true,
"StartTime": 1.46,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Confidence": 0,
"Content": "the",
"EndTime": 1.76,
"Stable": true,
"StartTime": 1.64,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Confidence": 0,
"Content": "largest",
"EndTime": 2.31,
"Stable": true,
"StartTime": 1.77,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Confidence": 1,
"Content": "rainforest",
"EndTime": 3.34,
"Stable": true,
"StartTime": 2.4,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
],
"Transcript": "Amazon is the largest rainforest "
}
],
"EndTime": 4.33,
"IsPartial": false,
"ResultId": "f4b5d4dd-b685-4736-b883-795dc3f7f636",
"StartTime": 0.78
}
Conclusion
This post introduces the recently launched partial results stabilization feature in Amazon Transcribe. For more information, see the Amazon Transcribe Partial results stabilization documentation.
To learn more about the Amazon Transcribe Streaming Transcription API, check out Using Amazon Transcribe streaming With HTTP/2 and Using Amazon Transcribe streaming with WebSockets.
About the Author
 Alex Chirayath is an SDE in the Amazon Machine Learning Solutions Lab. He helps customers adopt AWS AI services by building solutions to address common business problems.
Alex Chirayath is an SDE in the Amazon Machine Learning Solutions Lab. He helps customers adopt AWS AI services by building solutions to address common business problems.
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Posted by Chao Jia and Yinfei Yang, Software Engineers, Google Research
Learning good visual and vision-language representations is critical to solving computer vision problems — image retrieval, image classification, video understanding — and can enable the development of tools and products that change people’s daily lives. For example, a good vision-language matching model can help users find the most relevant images given a text description or an image input and help tools such as Google Lens find more fine-grained information about an image.
To learn such representations, current state-of-the-art (SotA) visual and vision-language models rely heavily on curated training datasets that require expert knowledge and extensive labels. For vision applications, representations are mostly learned on large-scale datasets with explicit class labels, such as ImageNet, OpenImages, and JFT-300M. For vision-language applications, popular pre-training datasets, such as Conceptual Captions and Visual Genome Dense Captions, all require non-trivial data collection and cleaning steps, limiting the size of datasets and thus hindering the scale of the trained models. In contrast, natural language processing (NLP) models have achieved SotA performance on GLUE and SuperGLUE benchmarks by utilizing large-scale pre-training on raw text without human labels.
In “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision“, to appear at ICML 2021, we propose bridging this gap with publicly available image alt-text data (written copy that appears in place of an image on a webpage if the image fails to load on a user’s screen) in order to train larger, state-of-the-art vision and vision-language models. To that end, we leverage a noisy dataset of over one billion image and alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. We show that the scale of our corpus can make up for noisy data and leads to SotA representation, and achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new SotA results on Flickr30K and MS-COCO benchmarks, even when compared with more sophisticated cross-attention models, and enable zero-shot image classification and cross-modality search with complex text and text + image queries.
Creating the Dataset
Alt-texts usually provide a description of what the image is about, but the dataset is “noisy” because some text may be partly or wholly unrelated to its paired image.
 |
| Example image-text pairs randomly sampled from the training dataset of ALIGN. One clearly noisy text label is marked in italics. |
In this work, we follow the methodology of constructing the Conceptual Captions dataset to get a version of raw English alt-text data (image and alt-text pairs). While the Conceptual Captions dataset was cleaned by heavy filtering and post-processing, this work scales up visual and vision-language representation learning by relaxing most of the cleaning steps in the original work. Instead, we only apply minimal frequency-based filtering. The result is a much larger but noisier dataset of 1.8B image-text pairs.
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding
For the purpose of building larger and more powerful models easily, we employ a simple dual-encoder architecture that learns to align visual and language representations of the image and text pairs. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax) that pushes the embeddings of matched image-text pairs together while pushing those of non-matched image-text pairs (within the same batch) apart. The large-scale dataset makes it possible for us to scale up the model size to be as large as EfficientNet-L2 (image encoder) and BERT-large (text encoder) trained from scratch. The learned representation can be used for downstream visual and vision-language tasks.
 |
| Figure of ImageNet credit to (Krizhevsky et al. 2012) and VTAB figure credit to (Zhai et al. 2019) |
The resulting representation can be used for vision-only or vision-language task transfer. Without any fine-tuning, ALIGN powers cross-modal search – image-to-text search, text-to-image search, and even search with joint image+text queries, examples below.
 |
Evaluating Retrieval and Representation
The learned ALIGN model with BERT-Large and EfficientNet-L2 as text and image encoder backbones achieves SotA performance on multiple image-text retrieval tasks (Flickr30K and MS-COCO) in both zero-shot and fine-tuned settings, as shown below.
| Flickr30K (1K test set) R@1 | MS-COCO (5K test set) R@1 | ||||
| Setting | Model | image → text | text → image | image → text | text → image |
| Zero-shot | ImageBERT | 70.7 | 54.3 | 44.0 | 32.3 |
| UNITER | 83.6 | 68.7 | – | – | |
| CLIP | 88.0 | 68.7 | 58.4 | 37.8 | |
| ALIGN | 88.6 | 75.7 | 58.6 | 45.6 | |
| Fine-tuned | GPO | 88.7 | 76.1 | 68.1 | 52.7 |
| UNITER | 87.3 | 75.6 | 65.7 | 52.9 | |
| ERNIE-ViL | 88.1 | 76.7 | – | – | |
| VILLA | 87.9 | 76.3 | – | – | |
| Oscar | – | – | 73.5 | 57.5 | |
| ALIGN | 95.3 | 84.9 | 77.0 | 59.9 | |
| Image-text retrieval results (recall@1) on Flickr30K and MS-COCO datasets (both zero-shot and fine-tuned). ALIGN significantly outperforms existing methods including the cross-modality attention models that are too expensive for large-scale retrieval applications. |
ALIGN is also a strong image representation model. Shown below, with frozen features, ALIGN slightly outperforms CLIP and achieves a SotA result of 85.5% top-1 accuracy on ImageNet. With fine-tuning, ALIGN achieves higher accuracy than most generalist models, such as BiT and ViT, and is only worse than Meta Pseudo Labels, which requires deeper interaction between ImageNet training and large-scale unlabeled data.
| Model (backbone) | Acc@1 w/ frozen features | Acc@1 | Acc@5 |
| WSL (ResNeXt-101 32x48d) | 83.6 | 85.4 | 97.6 |
| CLIP (ViT-L/14) | 85.4 | – | – |
| BiT (ResNet152 x 4) | – | 87.54 | 98.46 |
| NoisyStudent (EfficientNet-L2) | – | 88.4 | 98.7 |
| ViT (ViT-H/14) | – | 88.55 | – |
| Meta-Pseudo-Labels (EfficientNet-L2) | – | 90.2 | 98.8 |
| ALIGN (EfficientNet-L2) | 85.5 | 88.64 | 98.67 |
| ImageNet classification results comparison with supervised training (fine-tuning). |
Zero-Shot Image Classification
Traditionally, image classification problems treat each class as independent IDs, and people have to train the classification layers with at least a few shots of labeled data per class. The class names are actually also natural language phrases, so we can naturally extend the image-text retrieval capability of ALIGN for image classification without any training data.
 |
| The pre-trained image and text encoder can directly be used in classifying an image into a set of classes by retrieving the nearest class name in the aligned embedding space. This approach does not require any training data for the defined class space. |
On the ImageNet validation dataset, ALIGN achieves 76.4% top-1 zero-shot accuracy and shows great robustness in different variants of ImageNet with distribution shifts, similar to the concurrent work CLIP. We also use the same text prompt engineering and ensembling as in CLIP.
| ImageNet | ImageNet-R | ImageNet-A | ImageNet-V2 | |
| CLIP | 76.2 | 88.9 | 77.2 | 70.1 |
| ALIGN | 76.4 | 92.2 | 75.8 | 70.1 |
| Top-1 accuracy of zero-shot classification on ImageNet and its variants. |
Application in Image Search
To illustrate the quantitative results above, we build a simple image retrieval system with the embeddings trained by ALIGN and show the top 1 text-to-image retrieval results for a handful of text queries from a 160M image pool. ALIGN can retrieve precise images given detailed descriptions of a scene, or fine-grained or instance-level concepts like landmarks and artworks. These examples demonstrate that the ALIGN model can align images and texts with similar semantics, and that ALIGN can generalize to novel complex concepts.
 |
| Image retrieval with fine-grained text queries using ALIGN’s embeddings. |
Multimodal (Image+Text) Query for Image Search
A surprising property of word vectors is that word analogies can often be solved with vector arithmetic. A common example, “king – man + woman = queen”. Such linear relationships between image and text embeddings also emerge in ALIGN.
Specifically, given a query image and a text string, we add their ALIGN embeddings together and use it to retrieve relevant images using cosine similarity, as shown below. These examples not only demonstrate the compositionality of ALIGN embeddings across vision and language domains, but also show the feasibility of searching with a multi-modal query. For instance, one could now look for the “Australia” or “Madagascar” equivalence of pandas, or turn a pair of black shoes into identically-looking beige shoes. Also, it is possible to remove objects/attributes from a scene by performing subtraction in the embedding space, shown below.
 |
| Image retrieval with image text queries. By adding or subtracting text query embedding, ALIGN retrieves relevant images. |
Social Impact and Future Work
While this work shows promising results from a methodology perspective with a simple data collection method, additional analysis of the data and the resulting model is necessary before the responsible use of the model in practice. For instance, considerations should be made towards the potential for the use of harmful text data in alt-texts to reinforce such harms. With regard to fairness, data balancing efforts may be required to prevent reinforcing stereotypes from the web data. Additional testing and training around sensitive religious or cultural items should be taken to understand and mitigate the impact from possibly mislabeled data.
Further analysis should also be taken to ensure that the demographic distribution of humans and related cultural items, such as clothing, food, and art, do not cause skewed model performance. Analysis and balancing would be required if such models will be used in production.
Conclusion
We have presented a simple method of leveraging large-scale noisy image-text data to scale up visual and vision-language representation learning. The resulting model, ALIGN, is capable of cross-modal retrieval and significantly outperforms SotA models. In visual-only downstream tasks, ALIGN is also comparable to or outperforms SotA models trained with large-scale labeled data.
Acknowledgement
We would like to thank our co-authors in Google Research: Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. This work was also done with invaluable help from other colleagues from Google. We would like to thank Jan Dlabal and Zhe Li for continuous support in training infrastructure, Simon Kornblith for building the zero-shot & robustness model evaluation on ImageNet variants, Xiaohua Zhai for help on conducting VTAB evaluation, Mingxing Tan and Max Moroz for suggestions on EfficientNet training, Aleksei Timofeev for the early idea of multimodal query retrieval, Aaron Michelony and Kaushal Patel for their early work on data generation, and Sergey Ioffe, Jason Baldridge and Krishna Srinivasan for the insightful feedback and discussion.

The Washington Post Launches Audio Articles Voiced by Amazon Polly
AWS is excited to announce that The Washington Post is integrating Amazon Polly to provide their readers with audio access to stories across The Post’s entire spectrum of web and mobile platforms, starting with technology stories. Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk, and build entirely new categories of speech-enabled products. Post subscribers live busy lives with limited time to read the news. The goal is to unlock the Post’s world-class written journalism in audio form and give readers a convenient way to stay up to date on the news, like listening while doing other things.
In The Post’s announcement, Kat Down Mulder, managing editor says, “Whether you’re listening to a story while multitasking or absorbing a compelling narrative while on a walk, audio unlocks new opportunities to engage with our journalism in more convenient ways. We saw that trend throughout last year as readers who listened to audio articles on our apps engaged more than three times longer with our content. We’re doubling-down on our commitment to audio and will be experimenting rapidly and boldly in this space. The full integration of Amazon Polly within our publishing ecosystem is a big step that offers readers this powerful convenience feature at scale, while ensuring a high-quality and consistent audio experience across all our platforms for our subscribers and readers.”
Integrating Amazon Polly into The Post’s publishing workflow has been easy and straightforward. When an article is ready for publication, the written content management system (CMS) publishes the text article and simultaneously sends the text to the audio CMS, where the article text is processed by Amazon Polly to produce an audio recording of the article. The audio is delivered as an mp3 and published in conjunction with the written portion of the article.
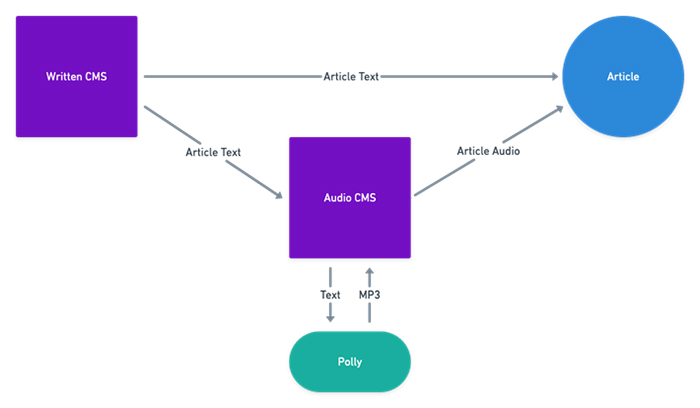
Figure 1 High-level architecture Washington Post article creation
Last year, The Post began testing article narration using the text-to-speech, accessibility capabilities in iOS and Android operating systems. While there were promising signs around engagement, some noted that the voices sounded robotic. The Post started testing other options and ended up choosing Amazon Polly because of its high-quality automated voices. “We’ve tested users’ perceptions to both human and automated voices and found high levels of satisfaction with Amazon Polly’s offering. Integrating Amazon Polly into our publishing workflow also gives us the ability to offer a consistent listening experience across platforms and experiment with new functions that we believe our subscribers will enjoy.” says Ryan Luu, senior product manager at The Post.
Over the coming months, The Post will be adding voice support for new sections, new languages and better usability. “We plan to introduce new features like more playback controls, text highlighting as you listen, and audio versions of Spanish articles,” said Luu. “We also hope to give readers the ability to create audio playlists to make it easy for subscribers to queue up stories they’re interested in and enjoy that content on the go.”
Amazon Polly is a text-to-speech service that powers audio access to news articles for media publishers like Gannett (the publisher of USA Today), The Globe and Mail (the biggest newspaper in Canada), and leading publishing companies such as BlueToad and Trinity Audio. In addition, Amazon Polly provides natural sounding voices in a variety of languages and personas to give content a voice in other sectors such as education, healthcare, and gaming.
For more information, see What Is Amazon Polly? and log in to the Amazon Polly console to try it out for free. To experience The Post’s new audio articles, listen to the story “Did you get enough steps in today? Maybe one day you’ll ask your ‘smart’ shirt.”
About the Author
 Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.
Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.
3 questions with Philip Resnik: Analyzing social media to understand the risks of suicide
Resnik is a featured speaker at the first virtual Amazon Web Services Machine Learning Summit on June 2.Read More
Keeping Games up to Date in the Cloud
GeForce NOW ensures your favorite games are automatically up to date, avoiding game updates and patches. Simply login, click PLAY, and enjoy an optimal cloud gaming experience.
Here’s an overview on how the service keeps your library game ready at all times.
Updating Games for All GeForce NOW Members
When a gamer downloads an update on their PC, all that matters is their individual download.
In the cloud, the GeForce NOW team goes through the steps of patching or maintenance and makes the updated game available for millions of members around the world.
Depending on when you happen to hop on GeForce NOW, you may not even see these updates taking place. In some cases, you’ll be able to keep playing your game while we’re updating game bits. In others, we may need to complete the backend work before it’s ready to play.
Patching in GeForce NOW
Patching is the process of making changes to a game or its supporting data to update, fix or improve it.
It typically takes a few minutes, sometimes longer for a game to patch on GeForce NOW.
When a developer releases a new version of a game, work is done on the backend of GeForce NOW to download that patch, replicate each bit to all of our storage systems, test for the proper security features, and finally copy it back onto all of our data centers worldwide, becoming available for gamers.
GeForce NOW handles this entire process so gamers and developers can focus on, well, gaming and developing.
Different Types of Patching
Three types of patching occur on GeForce NOW:
- On-seat patching allows you to play your game as-is while the patch is downloading in the background. Meaning you’re always game ready.
- Offline patching happens for games that don’t support on-seat patching. Our automated software system downloads the patch on the backend then updates. Offline patching can take minutes to hours.
- Distributed patching is a quicker type of patching. Specific bits are downloaded and installed, instead of the entire game (100 GB or so). We then finish updating and copy them onto the server. Typically this takes 30 minutes or less.
GeForce NOW continues to work with game developers requesting patch updates before releasing on PC, allowing for real-time preparations in the cloud, resulting in zero wait for gamers, period.
Maintenance Mode Explained
Maintenance mode is the status of a game that’s been taken offline for bigger fixes such as bugs that cause poor performance, issues with save games, or patches that need more time to deploy.
Depending on severity, a game in maintenance can be offline anywhere from days to weeks. We work to keep these maintenance times to a minimum, and often work directly with game developers to resolve these issues.
Eliminate Waiting for More Gaming
Our goal is to do all of the patching and maintenance behind the scenes — so that when you’re ready to play, you’re game ready and playing instantly.
Get started with your gaming adventures on GeForce NOW.
Follow GeForce NOW on Facebook and Twitter and stay up to date on the latest features and game launches.
The post Keeping Games up to Date in the Cloud appeared first on The Official NVIDIA Blog.
Create in Record Time with New NVIDIA Studio Laptops from Dell, HP, Lenovo, Gigabyte, MSI and Razer
New NVIDIA Studio laptops from Dell, HP, Lenovo, Gigabyte, MSI and Razer were announced today as part of the record-breaking GeForce laptop launch. The new Studio laptops are powered by GeForce RTX 30 Series and NVIDIA RTX professional laptop GPUs, including designs with the new GeForce RTX 3050 Ti and 3050 laptop GPUs, and the latest 11th Gen Intel mobile processors.
GeForce RTX 3050 Ti and 3050 Studio laptops are perfect for graphic designers, photographers and video editors, bringing high performance and affordable Studio laptops to artists and students.
The NVIDIA Broadcast app has been updated to version 1.2, bringing new room echo removal and video noise removal features, updated general noise removal and the ability to stack multiple effects for NVIDIA RTX users. The update can be downloaded here.
And it’s all supported by the May NVIDIA Studio Driver, also available today.
Creating Made Even Easier
With the latest NVIDIA Ampere architecture, Studio laptops accelerate creative workflows with real-time ray tracing, AI and dedicated video acceleration. Creative apps run faster than ever, taking full advantage of new AI features that save time and enable all creators to apply effects that previously were limited to the most seasoned experts.
The new line of NVIDIA Studio laptops introduces a wider range of options, making finding the perfect system easier than ever.
- Creative aficionados that are into photography, graphic design or video editing can do more, faster, with new GeForce RTX 3050 Ti and 3050 laptops, and RTX A2000 professional laptops. They introduce AI acceleration, best-in-class video hardware encoding and GPU acceleration in hundreds of apps. With reduced power consumption and 14-inch designs as thin as 16mm, they bring RTX to the mainstream, making them perfect for students and creators on the go.
- Advanced creators can step up to laptops powered by GeForce RTX 3070 and 3060 laptop GPUs or NVIDIA RTX A4000 and A3000 professional GPUs. They offer greater performance in up to 6K video editing and 3D rendering, providing great value in elegant Max-Q designs that can be paired with 1440p displays, widely available in laptops for the first time.
- Expert creators will enjoy the power provided by the GeForce RTX 3080 laptop GPU, available in two variants, with 8GB or 16GB of video memory, or the NVIDIA RTX A5000 professional GPU, with 16GB of video memory. The additional memory is perfect for working with large 3D assets or editing 8K HDR RAW videos. At 16GB, these laptops provide creators working across multiple apps with plenty of memory to ensure these apps run smoothly.
The laptops are powered by third-generation Max-Q technologies. Dynamic Boost 2.0 intelligently shifts power between the GPU, GPU memory and CPU to accelerate apps, improving battery life. WhisperMode 2.0 controls the acoustic volume for the laptop, using AI-powered algorithms to dynamically manage the CPU, GPU and fan speeds to deliver quieter acoustics. For 3D artists, NVIDIA DLSS 2.0 utilizes dedicated AI processors on RTX GPUs called Tensor Cores to boost frame rates in real-time 3D applications such as D5 Render, Unreal Engine 4 and NVIDIA Omniverse.
Meet the New NVIDIA Studio Laptops
Thirteen new Studio laptops were introduced today, including:
- Nine new models from Dell: The professional-grade Precision 5560, 5760, 7560 and 7760, creator dream team XPS 15 and XPS 17, redesigned Inspiron 15 Plus and 16 Inspiron Plus, and the ready for small business Vostro 7510. The Dell Precision 5560 and XPS 15 debut with elegant, thin, world-class designs featuring creator-grade panels.

- HP debuts the updated ZBook Studio G8, the world’s most powerful laptop of its size, featuring an incredible DreamColor display with a 120Hz refresh rate and a wide array of configuration options including GeForce RTX 3080 16GB and NVIDIA RTX A5000 laptop GPUs.
- Lenovo introduced the IdeaPad 5i Pro, with a factory-calibrated, 100 percent sRGB panel, available in 14 and 16-inch configurations with GeForce RTX 3050, as well as the ThinkBook 16p, powered by GeForce RTX 3060.



Gigabyte, MSI and Razer also refreshed their Studio laptops, originally launched earlier this year, with new Intel 11th Gen CPUs, including the Gigabyte AERO 15 OLED and 17 HDR, MSI Creator 15 and Razer Blade 15.
The Proof is in the Perf’ing
The Studio ecosystem is flush with support for top creative apps. In total, more than 60 have RTX-specific benefits.
GeForce RTX 30 Series and NVIDIA RTX professional Studio laptops save time (and money) by enabling creators to complete creative tasks faster.
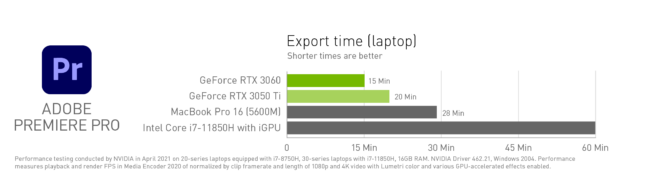
Video specialists can expect to edit 3.1x faster in Adobe Premiere Pro on Studio laptops with a GeForce RTX 3050 Ti, and 3.9x faster with a RTX 3060, compared to CPU alone.
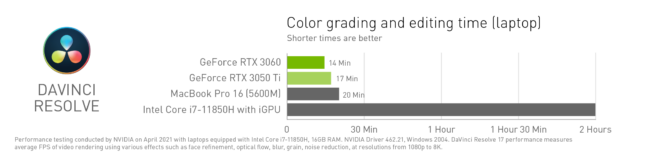
Color grading in Blackmagic Design’s DaVinci Resolve, and editing using features such as face refinement and optical flow, is 6.8x faster with a GeForce RTX 3050 Ti than on CPU alone.
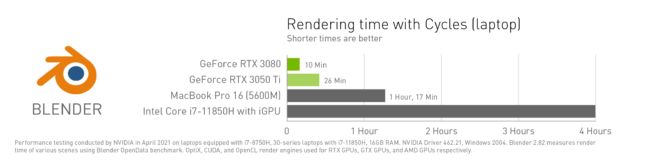
3D artists working with Blender who are equipped with a laptop featuring a GeForce RTX 3080-powered system can render an astonishing 24x faster than CPU alone.
Adobe Photoshop Lightroom completes Enhance Details on RAW photos 3.7x faster with a GeForce RTX 3050 Ti, compared to an 11th Gen Intel i7 CPU, while Adobe Illustrator users can zoom and pan canvases twice as fast with an RTX 3050.
Regardless of your creative field, Studio laptops with GeForce RTX 30 Series and RTX professional laptop GPUs will speed up your workflow.
May Studio Driver and Creative App Updates
Two popular creator applications added Tensor Core support, accelerating workflows, this month. Both, along with the new Studio laptops, are supported by the latest Studio Driver.
Topaz Labs Gigapixel enhances imagery up to 600 percent while maintaining impressive original image quality.
![]()
Video Enhance AI is a collection of upscaling, denoising and restoration features.
With Studio Driver support, both Topaz apps are at least 6x faster with a GeForce RTX 3060 than with a CPU alone.
Recent NVIDIA Omniverse updates include new app and connector betas, available to download now.
Omniverse Machinima offers a suite of tools and extensions that enable users to render realistic graphics and animation using scenes and characters from games. Omniverse Audio2Face creates realistic facial expressions and motions to match any voice-over track.
AVerMedia integrated the NVIDIA Broadcast virtual background and audio noise removal AI features natively into their software suite to improve broadcasting abilities without requiring special equipment.
Download the May Studio Driver (release 462.59) today through GeForce Experience or from the driver download page to get the latest optimizations for the new Studio laptops and applications.
Get regular updates for creators by subscribing to the NVIDIA Studio newsletter and following us on Facebook, Twitter and Instagram.
The post Create in Record Time with New NVIDIA Studio Laptops from Dell, HP, Lenovo, Gigabyte, MSI and Razer appeared first on The Official NVIDIA Blog.
OpenAI Scholars 2021: Final Projects
We’re proud to announce that the 2021 class of OpenAI Scholars has completed our six-month mentorship program and have produced an open-source research project with stipends and support from OpenAI.
Working alongside leading OpenAI researchers that created GPT-3 and DALL·E, our Scholars explored topics like AI safety, contrastive learning, generative modeling, scaling laws, auto-encoding multi-objective tasks, test time compute, NLP segmentation strategies, and summarization from human feedback.
To wrap up the program, our nine Scholars share their work and how the Scholars Program has impacted their careers. Read more about each of them and their projects below.
Introduction by Sam Altman
Scaling Laws for Language Transfer Learning
Christina Kim
Previously, I was the founding engineer at Sourceress, where I built the infrastructure for our machine learning pipeline and human-in-the-loop labeling system. My background is in software engineering and productionizing machine learning. Building upon OpenAI’s recent work on scaling laws, my project explores how much pre-training on English helps when transferring across different languages as we vary model size and dataset size. I found that a) pre-trained English models help most when learning German, then Spanish, and finally Chinese and b) transfer from English to Chinese, German, and Spanish scales predictably in terms of parameters, data, and compute.
My advice to someone starting in deep learning research is to take your time to understand insights from fundamental papers and remember that the field is still relatively new. There’s a lot of room for individuals to have an outsized impact.
Feedback Loops in Opinion Modeling
Danielle Ensign
I have a background in Software Development, AI Fairness, and VR Game Development. I was interested in the Scholars program as a way of strengthening my research skills, learning from other talented people in the field, and moving into industry research or engineering positions. My project is exploratory, investigating prior work on opinion modeling from the context of deep learning. As these models generate more and more text, it’s important to understand the impacts they’ll have on the ecosystem of opinions and future models. In addition, I investigated what happens when models are iteratively trained on outputs from previous models.
If you can, take a few months to carefully work through the 2019 fast.ai course (parts 1 and 2), Andrew Ng’s deep learning course on Coursera, David Silver’s RL Course, and Spinning Up in Deep RL. If you don’t have a background in statistics, building a more solid foundation in that would be useful as well. This will give you a headstart in learning how to do productive research as you need to spend less time learning the core concepts. In addition, if you haven’t yet, try to implement a few papers from scratch in pytorch. Pick old papers that have existing implementations, so you can reference those implementations if you get stuck. See if you can improve the paper by applying an idea from a later paper. This process will give you a better idea of what doing DL research is like.
Contrastive Language Encoding
Ellie Kitanidis
I’m a research scientist with a physics background and a focus on dark energy, dark matter, and large-scale structure of the Universe. For my project, I pre-trained a language representation model using a purely contrastive objective. I am interested in the generalizability and scalability of such models compared to models pre-trained with more traditional language modeling objectives. I am also curious about what factors influence the performance of contrastive language encoders. In this talk, I present our methodology and some preliminary results.
Navigating a career change during COVID-19 was daunting, but this program created the perfect environment for me to learn, gain hands-on experience, and orient myself in the field. Discussions with my mentor and others at OpenAI exposed me to expert insights and intuitions that can’t be found in a textbook. The most important thing I discovered, however, was how much I love doing AI research. I plan to continue growing my career in this direction.
Large Scale Reward Modeling
Jonathan Ward
I joined the Scholars Program to build computer systems that better understand what people really value. I live in Washington, D.C. and lately, I’ve really enjoyed building fantastic contraptions with K’nex. My recent work at OpenAI has demonstrated that reward models trained on human feedback can support Reinforcement Learning. My project demonstrates that reward models can be trained on large-scale structured feedback extracted from websites.
My advice to people looking to join: make open source projects! Find the simplest interesting idea that you can think of and build it!
Characterizing Test Time Compute on Graph Structured Problems
Kudzo Ahegbebu
I am a software engineer with an applied physics and aerospace background. My presentation explores the generalizability of models leveraging test time compute in a number of domains including autoregressive transformers, deep equilibrium models, and graph neural networks. In it, I ask: Given the constraints of limited training compute budget, can small adaptive models instead leverage test time compute to overcome the handicap of having a smaller number of learnable parameters? Lastly, we present mechanisms that show promise in reducing the computational cost and improving the performance of graph neural networks.
The Scholars program has given me the confidence to pursue new avenues of deep learning interest and research as well as an increased measure of competency so that I may operate with greater clarity, efficiency and ethical maturity. It’s also reignited a latent research interest which I hope to continue to nurture into the future.
Breaking Contrastive Models with the SET Card Game
Legg Yeung
I was formally trained as a data scientist and architect, but I pivoted my career because AI has a much higher agency on our environment than conventional industries, and there are many interesting research problems in this field. In my project, I extended the well-known card game “SET” to investigate the relationship between vector representation dimension and task composition. I found non-contrastive models of X parameters to solve games that contrastive models of 2X+ parameters cannot. What can a contrastive model learn with vector representations of size 16/32/64/128/256/512? And what not?
I came to the program with a few interests (reasoning, compositionality, multimodal). My mentor helped me a lot in terms of crystallizing these interests into concrete research questions and proposals. We explored multiple directions and kept iterating until we saw something promising. The process was intense, but the lessons were worth the effort.
Words to Bytes: Exploring Language Tokenizations
Sam Gbafa
I was drawn to the Scholar’s program because I’d seen some of what OpenAI’s models could do and I wanted to understand what it took to build and iterate such powerful models. Having the dedicated time to explore deep learning with great mentorship has been transformative in my ability to understand and contribute to the field! When I’m not working, I’m usually tinkering with gadgets or out seeking adrenaline with friends. My project explores the tradeoffs in using these other tokenization schemes and how these different tokenizations scale. I also consider an approach to learning a sequence’s segmentation instead of using a predefined one.
The Scholars program gave me the space to explore many different ideas in ML and deep learning, from “classical” stuff like CNNs and RNNs to understanding the tradeoffs of more recent transformer variants. Being able to have conversations with the researchers at OpenAI made me realize that the frontier of AI research is very accessible. I originally wanted to learn about the current state of the art, but being here for these past few months has let me understand that I can contribute meaningfully to advancing the state of deep learning and AI. Being at OpenAI has also caused me to think a lot about the implications of the models we create and ways to provide such models to the world while minimizing potential harm.
Studying Scaling Laws for Transformer Architecture Variants
Shola Oyedele
I almost majored in French in college because I’ve always loved language. I frequently watch movies and tv shows in other languages (yes – kdramas are at the top of that list) but I never imagined that my love of language would translate into me doing research in NLP. In my research, I explore the tradeoffs between model performance and the cost of training, and study scaling laws on different transformer architectures to understand the impact of transformer architecture on model performance.
Everything about my perspective has changed since joining the program. There are very few companies and institutions in the world that use machine learning at scale and have a vision of where the field of ML/AI is headed. Even fewer are opportunities for those who don’t have research experience and an advanced degree, let alone a program focused on underrepresented groups. Just the significance of joining this program at a time when the industry is discovering the potential of GPT3 has changed my vision of what the future of technology offers and what my place within that could be. I think people assume you need a technical degree to study AI but I was just curious about the future and wanted a part in building it.
Learning Multiple Modes of Behavior in a Continuous Control Environment
Florentine (Tyna) Eloundou
I applied to OpenAI because I wanted the profound privilege to wrestle with questions that shape ever-complex AI systems. As a Cameroonian native who grew up in the US, I navigate multiple perspectives (scholastically, culturally and linguistically) and was curious to learn how AI learns from human commonalities and differences. The arduous rewards and constraint engineering process can sometimes lead to misalignment between a designer’s idea of success and its analytic specification. Furthermore, many real-world tasks contain multiple objectives and current approaches in reinforcement learning do not offer a direct lever to choose between Pareto-equivalent strategies. To address these problems, in my project, I explain how we use “multiple experts, multiple objectives” (MEMO) to explore an agent’s ability to consume examples of success from multiple experts with different objectives, and learn a single conditional policy that can be oriented at the discretion of a supervisor.
For newcomers to the field, I would recommend slowly stepping through clean open source implementations of well-known algorithms while reading their theoretical grounding. Try to experiment with the designs often. Fast.ai and Andrew Ng’s courses are excellent resources for the journey.
OpenAI