Some weeks, GFN Thursday reveals new or unique features. Other weeks, it’s a cool reward. And every week, it offers its members new games.
This week, it’s all of the above.
First, Saints Row marches into GeForce NOW. Be your own boss in the new reboot of the classic open-world criminal adventure series, now available to stream from nearly any device.
Plus, members asked, and we listened: Genshin Impact is now streaming to iOS, iPadOS and Android mobile devices with touch controls. It’s part of the big Genshin Impact Version 3.0 update, adding a brand-new nation, characters and more.
But that’s not all. Guild Wars 2 comes to Steam, and GeForce NOW members can celebrate with a free in-game reward. Dragons, anyone?
And don’t forget about the 13 new games joining the GeForce NOW library, because the action never stops.
It’s Good to Be the King(pin)
Build a criminal empire and rise up from “Newbie” to “Boss” in Saints Row, streaming today for all GeForce NOW members.
The highly anticipated reboot of the Saints Row franchise follows the Saints, a group of three gang members turned friends who combine forces to take on three warring criminal gangs in the vibrant new city of Santo Ileso. Players can become whoever they want with the all-new “Boss Factory.” Customize characters, their weapons, vehicles and more in true Saints Row fashion.
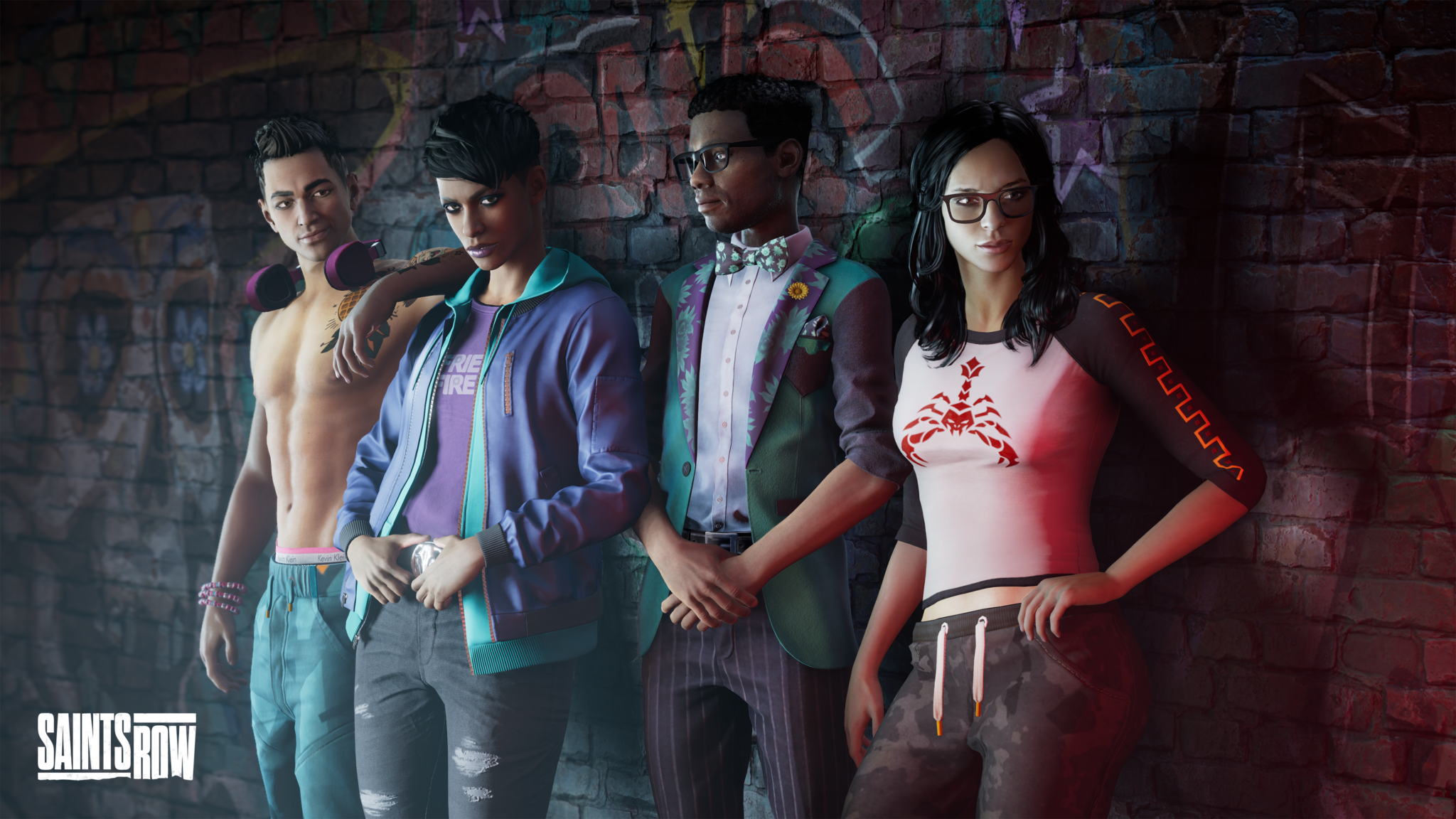
Stream every side hustle, criminal venture and blockbuster mission across PCs, Macs, SHIELD TVs, iOS Safari and Android mobile devices and more. Recruiting a friend on a low-powered device into your crew has never been easier.

Plus, without any wait times for game downloads, members can jump right into Santo Ileso and spend more time being a boss. The game runs on AMD Threadripper Pro CPUs for GeForce NOW, allowing members to enjoy high-quality graphics. And RTX 3080 members get the added benefits of ultra-low latency, higher streaming frame rates, maximized eight-hour sessions and dedicated RTX 3080 servers.
Tap Into Tevyat With ‘Genshin Impact’ Version 3.0
Travelers rejoice: Genshin Impact is now streaming to iOS, iPadOS and Android mobile devices with touch controls.
The launch of game developer HoYoverse’s free-to-play, open-world, action role-playing game on GeForce NOW has been hugely successful, and members can now continue their journeys with their PCs, Macs or Chromebooks.
Mobile touch controls for Genshin Impact are now available for all GeForce NOW members who prefer gaming on their phones and tablets or only have time to play on the go. Jump in to start playing at PC quality. No downloads or accessories needed – just fingers!

The timing for touch controls couldn’t be better, as HoYoverse just released Genshin Impact’s biggest update of the year, “The Morn a Thousand Roses Brings.” It adds Sumeru, the fourth of the game’s seven major nations, and Dendro, the last of the game’s seven-element system. A new nation to explore and Dendro playable characters to recruit for the first time ever — it’s all available to stream on GeForce NOW from nearly any device.
Learn more about how to use touch controls for Genshin Impact on GeForce NOW.

Dragons Are Coming
Guild War 2 comes to Steam this week, and for a limited time members can redeem the “Emblazoned Dragon Throne” in-game reward for free. It’s a heroic seat fit for an adventurer and another perk of being a GeForce NOW member.

Getting membership rewards for streaming games on the cloud is easy. Log in to your NVIDIA account and select “GEFORCE NOW” from the header. Then, scroll down to “REWARDS” and click the “UPDATE REWARDS SETTINGS” button. Check the box in the dialogue window that shows up to start receiving special offers and in-game goodies.
Sign up for the GeForce NOW newsletter, including notifications for when rewards are available, by logging into your NVIDIA account and selecting “PREFERENCES” from the header. Check the “Gaming & Entertainment” box and “GeForce NOW” under topic preferences.
Non-Stop Action

Check out the 13 new games available to stream on GeForce NOW this week:
- Destiny 2 (New release on Epic Games Store)
- Fallen Legion Revenants (New release on Steam)
- Guild Wars 2 (New release on Steam)
- Saints Row (New release on Epic Games Store)
- Ultimate Fishing Simulator 2 (New release on Steam)
- The Bridge Curse: Road to Salvation (New release on Steam, Aug. 25)
- Century: Age of Ashes (Epic Games Store)
- Coromon (Epic Games Store)
- Dark Deity (Steam)
- HYPERCHARGE: Unboxed (Epic Games Store)
- Last Call BBS (Steam)
- Plague Inc: Evolved (Steam)
- Rebel Inc: Escalation (Steam)
With all of these new games to choose from, there’s an option for everyone. Speaking of options, we’ve got a question for you. Let us know your pick on Twitter or in the comments below.

Three doors appear in front of you.
Left: You become a crime boss
Center: Everything you touch becomes a cloud
Right: You get a pet dragonWhich door do you open?
—
NVIDIA GeForce NOW (@NVIDIAGFN) August 24, 2022
The post GFN Thursday Adds ‘Saints Row,’ ‘Genshin Impact’ on Mobile With Touch Controls appeared first on NVIDIA Blog.








 Dvij Bajpai is a Senior Product Manager at AWS. He works on developing EC2 instances for workloads in machine learning and high-performance computing.
Dvij Bajpai is a Senior Product Manager at AWS. He works on developing EC2 instances for workloads in machine learning and high-performance computing. Amr Ragab is a Principal Solutions Architect at AWS. He provides technical guidance to help customers run complex computational workloads at scale.
Amr Ragab is a Principal Solutions Architect at AWS. He provides technical guidance to help customers run complex computational workloads at scale. Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.