Launched under the auspices of the KDD Cup at KDD 2022, the competition included the release of a new product query dataset.Read More
Achieve low-latency hosting for decision tree-based ML models on NVIDIA Triton Inference Server on Amazon SageMaker
Machine learning (ML) model deployments can have very demanding performance and latency requirements for businesses today. Use cases such as fraud detection and ad placement are examples where milliseconds matter and are critical to business success. Strict service level agreements (SLAs) need to be met, and a typical request may require multiple steps such as preprocessing, data transformation, model selection logic, model aggregation, and postprocessing. At scale, this often means maintaining a huge volume of traffic while maintaining low latency. Common design patterns include serial inference pipelines, ensembles (scatter-gather), and business logic workflows, which result in realizing the entire workflow of the request as a Directed Acyclic Graph (DAG). However, as workflows get more complex, this can lead to an increase in overall response times, which in turn can negatively impact the end-user experience and jeopardize business goals. Triton can address these use cases where multiple models are composed in a pipeline with input and output tensors connected between them, helping you address these workloads.
As you evaluate your goals in relation to ML model inference, many options can be considered, but few are as capable and proven as Amazon SageMaker with Triton Inference Server. SageMaker with Triton Inference Server has been a popular choice for many customers because it’s purpose-built to maximize throughput and hardware utilization with ultra-low (single-digit milliseconds) inference latency. It has wide range of supported ML frameworks (including TensorFlow, PyTorch, ONNX, XGBoost, and NVIDIA TensorRT) and infrastructure backends, including NVIDIA GPUs, CPUs, and AWS Inferentia. Additionally, Triton Inference Server is integrated with SageMaker, a fully managed end-to-end ML service, providing real-time inference options for model hosting.
In this post, we walk through deploying a fraud detection ensemble workload to SageMaker with Triton Inference Server.
Solution overview
It’s essential for any project to have a list of requirements and an effort estimation, in order to approximate the total cost of the project. It’s important to estimate the return on investment (ROI) that supports the decision of an organization. Some considerations to take account when moving a workload to Triton include:
- Costs – The engineering effort to experiment, code, and test with existing ML models maintained by the company, in order to migrate ML model inferences to SageMaker with Triton Inference Server
- Benefits – Your organization may aim to reduce the latency from tens of milliseconds to single-digit milliseconds for 99% of the traffic for your workload, for example, because it has learned from internal reports that the conversion rate drops 1% with every 100 milliseconds of latency
Effort estimation is key in software development, and its measurement is often based on incomplete, uncertain, and noisy inputs. ML workloads are no different. Multiple factors will affect an architecture for ML inference, some of which include:
- Client-side latency budget – It specifies the client-side round-trip maximum acceptable waiting time for an inference response, commonly expressed in percentiles. For workloads that require a latency budget near tens of milliseconds, network transfers could become expensive, so using models at the edge would be a better fit.
- Data payload distribution size – Payload, often referred to as message body, is the request data transmitted from the client to the model, as well as the response data transmitted from the model to the client. The payload size often has a major impact on latency and should be taken into consideration.
- Data format – This specifies how the payload is sent to the ML model. Format can be human-readable, such as JSON and CSV, however there are also binary formats, which are often compressed and smaller in size. This is a trade-off between compression overhead and transfer size, meaning that CPU cycles and latency is added to compress or decompress, in order to save bytes transferred over the network. This post shows how to utilize both JSON and binary formats.
- Software stack and components required – A stack is a collection of components that operate together to support an ML application, including operating system, runtimes, and software layers. Triton comes with built-in popular ML frameworks, called backends, such as ONNX, TensorFlow, FIL, OpenVINO, native Python, and others. You can also author a custom backend for your own homegrown components. This post goes over an XGBoost model and data preprocessing, which we migrate to the NVIDIA provided FIL and Python Triton backends, respectively.
All these factors should play a vital part in evaluating how your workloads perform, but in this use case we focus on the work needed to move your ML models to be hosted in SageMaker with Triton Inference Server. Specifically, we use an example of a fraud detection ensemble composed of an XGBoost model with preprocessing logic written in Python.
NVIDIA Triton Inference Server
Triton Inference Server has been designed from the ground up to enable teams to deploy, run, and scale trained AI models from any framework on GPU or CPU based infrastructure. In addition, it has been optimized to offer high-performance inference at scale with features like dynamic batching, concurrent runs, optimal model configuration, model ensemble, and support for streaming inputs.
The following diagram shows an example NVIDIA Triton ensemble pipeline.
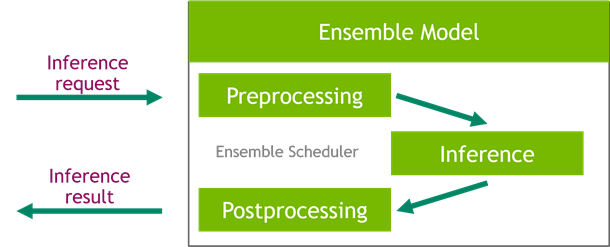
Workloads should take into account the capabilities that Triton provides along with SageMaker hosting to maximize the benefits offered. For example, Triton supports both HTTP and gRPC protocols as well a C API, which allow for flexibility as well as payload optimization when needed. As previously mentioned, Triton supports several popular frameworks out of the box, including TensorFlow, PyTorch, ONNX, XGBoost, and NVIDIA TensorRT. These frameworks are supported through Triton backends, and in the rare event that a backend doesn’t support your use case, Triton allows you to implement your own and integrate it easily.
The following diagram shows an example of the NVIDIA Triton architecture.
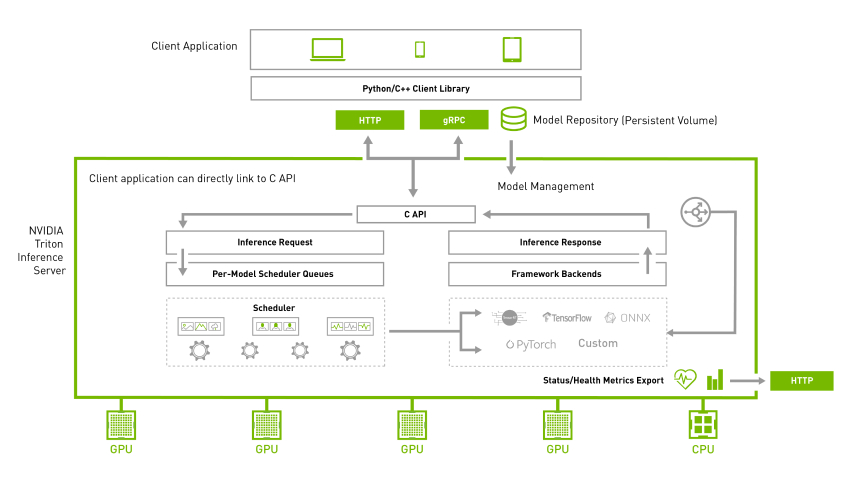
NVIDIA Triton on SageMaker
SageMaker hosting services are the set of SageMaker features aimed at making model deployment and serving easier. It provides a variety of options to easily deploy, auto scale, monitor, and optimize ML models tailored for different use cases. This means that you can optimize your deployments for all types of usage patterns, from persistent and always available with serverless options, to transient, long-running, or batch inference needs.
Under the SageMaker hosting umbrella is also the set of SageMaker inference Deep Learning Containers (DLCs), which come prepackaged with the appropriate model server software for their corresponding supported ML framework. This enables you to achieve high inference performance with no model server setup, which is often the most complex technical aspect of model deployment and in general isn’t part of a data scientist’s skill set. Triton inference server is now available on SageMaker DLCs.
This breadth of options, modularity, and ease of use of different serving frameworks makes SageMaker and Triton a powerful match.
NVIDIA FIL backend support
With the 22.05 version release of Triton, NVIDIA now supports forest models trained by several popular ML frameworks, including XGBoost, LightGBM, Scikit-learn, and cuML. When using the FIL backend for Triton, you should ensure that the model artifacts that you provide are supported. For example, FIL supports model_type xgboost, xgboost_json, lightgbm, or treelite_checkpoint, indicating whether the provided model is in XGBoost binary format, XGBoost JSON format, LightGBM text format, or Treelite binary format, respectively.
This backend support is essential for us to use in our example because FIL supports XGBoost models. The only consideration to check is to ensure that the model that we deploy supports binary or JSON formats.
In addition to ensuring that you have the proper model format, other considerations should be taken. The FIL backend for Triton provides configurable options for developers to tune their workloads and optimize model run performance. The configuration dynamic_batching allows Triton to hold client-side requests and batch them on the server side, in order to efficiently use FIL’s parallel computation to inference the entire batch together. The option max_queue_delay_microseconds offers a fail-safe control of how long Triton waits to form a batch. FIL comes with Shapley explainer, which can be activated by the configuration treeshap_output; however, you should keep in mind that Shapley outputs hurt performance due to its output size. Another important aspect is storage_type in order to trade-off between memory footprint and runtime. For example, using storage as SPARSE can reduce the memory consumption, whereas DENSE can reduce your model run performance at the expense of higher memory usage. Deciding the best choice for each of these depends on your workload and your latency budget, so we recommend a deeper look into all options in the FIL backend FAQ and the list of configurations available in FIL.
Steps to host a model on triton
Let’s look at our fraud detection use case as an example of what to consider when moving a workload to Triton.
Identify your workload
In this use case, we have a fraud detection model used during the checkout process of a retail customer. The inference pipeline is using an XGBoost algorithm with preprocessing logic that includes data preparation for preprocessing.
Identify current and target performance metrics and other goals that may apply
You may find that your end-to-end inference time is taking too long to be acceptable. Your goal could be to go from tens of milliseconds of latency to single-digit latency for the same volume of requests and respective throughput. You determine that the bulk of the time is consumed by data preprocessing and the XGBoost model. Other factors such as network and payload size play a minimal role in the overhead associated with the end-to-end inference time.
Work backward to determine if Triton can host your workload based on your requirements
To determine if Triton can meet your requirements, you want to pay attention to two main areas of concern. The first is to ensure that Triton can serve with an acceptable front end option such as HTTP or C API.
As mentioned previously, it’s also critical to determine if Triton supports a backend that can serve your artifacts. Triton supports a number of backends that are tailor-made to support various frameworks like PyTorch and TensorFlow. Check to ensure that your models are supported and that you have the proper model format that Triton expects. To do this, first check to see what model formats the Triton backend supports. In many cases, this doesn’t require any changes for the model. In other cases, your model may require transformation to a different format. Depending on the source and target format, various options exist, such as transforming a Python pickle file to use Treelite’s binary checkpoint format.
For this use case, we determine the FIL backend can support the XGBoost model with no changes needed and that we can use the Python backend for the preprocessing. With the ensemble feature of Triton, you can further optimize your workload by avoiding costly network calls between hosting instances.
Create a plan and estimate the effort required to use Triton for hosting
Let’s talk about the plan to move your models to Triton. Every Triton deployment requires the following:
- Model artifacts required by Triton backends
- Triton configuration files
- A model repository folder with the proper structure
We show an example of how to create these deployment dependencies later in this post.
Run the plan and validate the results
After you create the required files and artifacts in the properly structured model repository, you need to tune your deployment and test it to validate that you have now hit your target metrics.
At this point, you can use SageMaker Inference Recommender to determine what endpoint instance type is best for you based upon your requirements. In addition, Triton provides tools to make build optimizations to get better performance.
Implementation
Now let’s look at the implementation details. For this we have prepared two notebooks that provide an example of what can be expected. The first notebook shows the training of the given XGBoost model as well as the preprocessing logic that is used for both training and inference time. The second notebook shows how we prepare the artifacts needed for deployment on Triton.
The first notebook shows an existing notebook your organization has that uses the RAPIDS suite of libraries and the RAPIDS Conda kernel. This instance runs on a G4DN instance type provided by AWS, which is GPU accelerated by using NVIDIA T4 processors.

Preprocessing tasks in this example benefit from GPU acceleration and heavily use the cuML and cuDF libraries. An example of this is in the following code, where we show categorical label encoding using cuML. We also generate a label_encoders.pkl file that we can use to serialize the encoders and use them for preprocessing during inference time.

The first notebook concludes by training our XGBoost model and saving the artifacts accordingly.


In this scenario, the training code already existed and no changes are needed for the model at training time. Additionally, although we used GPU acceleration for preprocessing during training, we plan to use CPUs for preprocessing at inference time. We explain more later in the post.
Let’s now move on to the second notebook and recall what we need for a successful Triton deployment.
First, we need the model artifacts required by backends. The files that we need to create for this ensemble include:
- Preprocessing artifacts (
model.py,label_encoders.pkl) - XGBoost model artifacts (
xgboost.json)
The Python backend in Triton requires us to use a Conda environment as a dependency. In this case, we use the Python backend to preprocess the raw data before feeding it into the XGBoost model being run in the FIL backend. Even though we originally used RAPIDS cuDF and cuML libraries to do the data preprocessing (as referenced earlier using our GPU), here we use Pandas and Scikit-learn as preprocessing dependencies for inference time (using our CPU). We do this for three reasons:
- To show how to create a Conda environment for your dependencies and how to package it in the format expected by Triton’s Python backend.
- By showing the preprocessing model running in the Python backend on the CPU while the XGBoost model runs on the GPU in the FIL backend, we illustrate how each model in Triton’s ensemble pipeline can run on a different framework backend, and run on different hardware with different configurations.
- It highlights how the RAPIDS libraries (cuDF, cuML) are compatible with their CPU counterparts (Pandas, Scikit-learn). This way, we can show how
LabelEncoderscreated in cuML can be used in Scikit-learn and vice-versa. Note that if you expect to preprocess large amounts of tabular data during inference time, you can still use RAPIDS to GPU-accelerate it.
Recall that we created the label_encoders.pkl file in the first notebook. There’s nothing more to do for category encoding other than include it in our model.py file for preprocessing.

To create the model.py file required by the Triton Python backend, we adhere to the formatting required by the backend and include our Python logic to process the incoming tensor and use the label encoder referenced earlier. You can review the file used for preprocessing.
For the XGBoost model, nothing more needs to be done. We trained the model in the first notebook and Triton’s FIL backend requires no additional effort for XGBoost models.
Next, we need the Triton configuration files. Each model in the Triton ensemble requires a config.pbtxt file. In addition, we also create a config.pbtxt file for the ensemble as a whole. These files allow Triton to know metadata about the ensemble with information such as the inputs and outputs we expect as well as help defining the DAG associated with the ensemble.
Lastly, to deploy a model on Triton, we need our model repository folder to have the proper folder structure. Triton has specific requirements for model repository layout. Within the top-level model repository directory, each model has its own sub-directory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric sub-directory representing a version of the model. For our use case, the resulting structure should look like the following.

After we have these three prerequisites, we create a compressed file as packaging for deployment and upload it to Amazon Simple Storage Service (Amazon S3).

We can now create a SageMaker model from the model repository we uploaded to Amazon S3 in the previous step.
In this step, we also provide the additional environment variable SAGEMAKER_TRITON_DEFAULT_MODEL_NAME, which specifies the name of the model to be loaded by Triton. The value of this key should match the folder name in the model package uploaded to Amazon S3. This variable is optional in the case of a single model. In the case of ensemble models, this key has to be specified for Triton to start up in SageMaker.
Additionally, you can set SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT and SAGEMAKER_TRITON_THREAD_COUNT for optimizing the thread counts. Both configuration values help tune the number of threads that are running on your CPUs, so you can possibly gain better utilization by increasing these values for CPUs with a greater number of cores. In the majority of cases, the default values often work well, but it may be worth experimenting see if further efficiency can be gained for your workloads.

With the preceding model, we create an endpoint configuration where we can specify the type and number of instances we want in the endpoint.

Lastly, we use the preceding endpoint configuration to create a new SageMaker endpoint and wait for the deployment to finish. The status changes to InService after the deployment is successful.

That’s it! Your endpoint is now ready for testing and validation. At this point, you may want to use various tools to help optimize your instance types and configuration to get the best possible performance. The following figure provides an example of the gains that can be achieved by using the FIL backend for an XGBoost model on Triton.

Summary
In this post, we walked you through deploying an XGBoost ensemble workload to SageMaker with Triton Inference Server. Moving workloads to Triton on SageMaker can be a highly beneficial return on investment. As with any adoption of technology, a vetting process and plan are key, and we detailed a five-step process to guide you through what to consider when moving your workloads. In addition, we dove deep into the steps needed to deploy an ensemble that uses using Python preprocessing and an XGBoost model on Triton on SageMaker.
SageMaker provides the tools to remove the undifferentiated heavy lifting from each stage of the ML lifecycle, thereby facilitating the rapid experimentation and exploration needed to fully optimize your model deployments. SageMaker hosting support for Triton Inference Server enables low-latency, high transactions per second (TPS) workloads.
We highly recommend evaluating Triton Inference Server on SageMaker hosting for your inference needs; it can be well worth the effort to move your existing models to take advantage of this technology.
You can find the notebooks used for this example on GitHub.
About the author
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
 Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
 Bruno Aguiar de Melo is a Software Development Engineer at Amazon.com, where he helps science teams to build, deploy and release ML workloads. He is interested in instrumentation and controllable aspects within the ML modelling/design phase that must be considered and measured with the insight that model execution performance is just as important as model quality performance, particularly in latency constrained use cases. In his spare time, he enjoys wine, board games and cooking.
Bruno Aguiar de Melo is a Software Development Engineer at Amazon.com, where he helps science teams to build, deploy and release ML workloads. He is interested in instrumentation and controllable aspects within the ML modelling/design phase that must be considered and measured with the insight that model execution performance is just as important as model quality performance, particularly in latency constrained use cases. In his spare time, he enjoys wine, board games and cooking.
 Eliuth Triana is a Developer Relations Manager at NVIDIA. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
Eliuth Triana is a Developer Relations Manager at NVIDIA. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
Build a multi-lingual document translation workflow with domain-specific and language-specific customization
In the digital world, providing information in a local language isn’t novel, but it can be a tedious and expensive task. Advancements in machine learning (ML) and natural language processing (NLP) have made this task much easier and less expensive.
We have seen increased adoption of ML for multi-lingual data and document processing workloads. Enterprise and government customers are migrating their manual translation workloads to take advantage of automated ML translation services. Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation between several thousand language pairings that can be used for synchronous (real-time) or asynchronous translation tasks. For a complete list of available translation pairs, refer to Supported languages and language codes.
Customers migrating and modernizing their translation workloads need the ability to customize translations for their business domain. A translation workload may also need the ability to adapt to regional language dialects or usage. For example, the Spanish translation of “elderly” is anciano(a) but in Puerto Rico the word envejeciente is preferred.
In this post, we demonstrate how to incorporate Amazon Translate’s Active Custom Translation (ACT) feature. We propose a solution to create a multi-lingual document translation workflow with domain- and language-specific customizations that you can review and augment as needed to continuously improve results and delight end-users.
Solution overview
ACT produces custom-translated output without the need to build and maintain a custom translation model. Using ACT, Amazon Translate will use your preferred translation examples as parallel data to customize your translation result, eliminating the time and cost of required to build and train a new machine learning model.
The solution covered in this post explains how to create a human-in-the-loop workflow using Amazon Augmented AI (Amazon A2I) to continuously improve the customized translation. Amazon A2I provides a simple way to integrate human oversight into your ML workflows, with no ML experience required. Amazon A2I makes it straightforward to integrate human judgement and AI into any ML application, regardless of whether it’s run on AWS or on another platform.
For more information refer to Designing human review workflows with Amazon Translate and Amazon Augmented AI post.
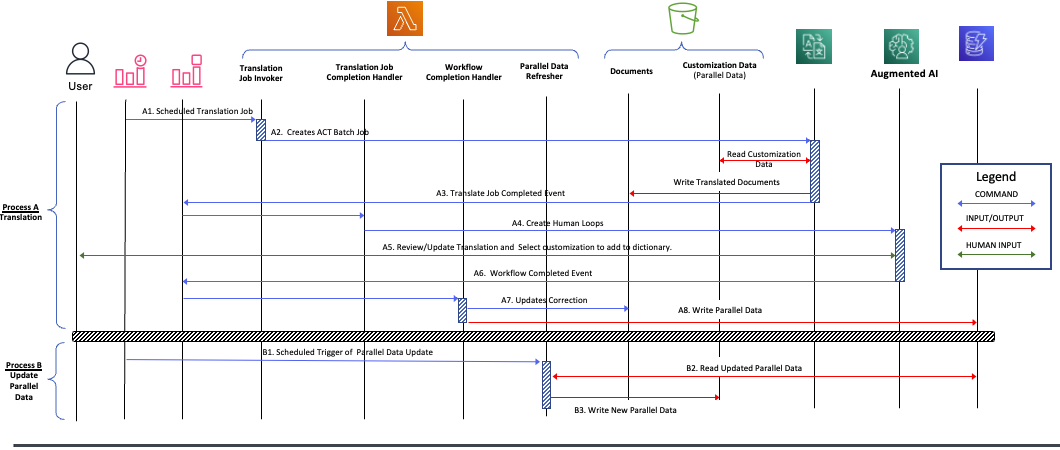
The following diagram displays the command flow and data flow of the solution. The command flow shows the logical sequence of events in the workflow. A data flow indicates how data is being created or used by various components in the solution.

The following sequence diagram shows two separate processes in the solution: the translation workflow (A) and the process to update parallel data (B).
The translation workflow is initiated by an Amazon CloudWatch scheduled event which starts the Translation Job Invoker AWS Lambda function. This function creates an asynchronous translation job in Amazon Translate, passing along the document to translate and the location of the parallel data to customize the translation. The translation job reads the parallel data, performs the translation, and writes the translated result back to an Amazon S3 bucket. As of this writing, only asynchronous translation jobs can use parallel data.
When the translation job is complete, an event is generated that triggers the Translation Job Completion Handler Lambda function. This function creates a human workflow loop—the main component of the Amazon A2I portion of the workflow.
Human reviewers assess the translation and accept or modify the translation. Any corrections are used to update the translated document and also added to a customization dictionary. When the review is finalized, another event is generated to trigger the Workflow Completion Handler function. This function writes the latest translated document back to Amazon S3. The customization data is used to update an Amazon DynamoDB table with the source and translated text pairs.
To close the loop, we must incorporate this customization data stored in DynamoDB back into the parallel data stored in Amazon S3. To accomplish this, we use a scheduled CloudWatch event to trigger the Parallel Data Refresher function, which reads the data from the DynamoDB table, reformats it as parallel data, and updates the S3 bucket, storing the parallel data.
Deploy the solution with AWS CloudFormation
Launch the provided AWS CloudFormation template to deploy the solution in your account. This stack only works in the us-east-1 Region. If you want to deploy this solution in other Regions, refer to the following GitHub repo.
- Choose Launch Stack:

- Follow the instructions to populate the necessary parameters. If you’re running this stack for the first time, SNS Email is the only required parameter.
- On the Review page, in the Capabilities section, select the check box and choose Create stack.
The stack creates the following key components:
-
Customization data – A DynamoDB table (
translate_parallel_data) to maintain the customization data. You migrate the existing customization data to this table. This table is used to continuously add and update customizations. - Parallel Data Refresher – The Lambda function to convert the customization data in the DynamoDB table to a parallel data format—CSV, TSV, or TMX—and store it in Amazon S3. It creates and updates parallel data with the new parallel data file in Amazon S3.
- Translation Job Invoker – The Lambda function to start the Amazon Translate batch job with parallel data.
- Translation Job Completion Handler – This Lambda function is triggered when the Amazon Translate batch job is complete. The function creates one human loop per document (we’ll refine this in the future to create a human loop only for a select percentage of documents processed). It uses the original and translated documents to create the human loop.
- Amazon A2I customized template – This template is used to render the translation pair for human review. The template has the Add option for every translation segment. Users can select this option to add the corrections to the customization data. The new customization data is used in the next batch translation job.
- Workflow Completion Handler – This Lambda function is triggered when the human workflow is complete. The function updates the translated document with corrections and checks for parallel data updates. New parallel data is added to the DynamoDB table.
- Amazon A2I private team – An Amazon A2I private team is created with a human worker using the email provided. Initial credentials are emailed upon successful creation of the private team. You use this email and credential to log in to the Amazon A2I worker portal.
Test the solution
The sample_text.txt file would have been created under the input prefix of the S3 bucket created by the stack. We use this file for our testing. It contains the following content:
To test the solution, complete the following steps:
- Invoke the Translation Job Invoker function manually, or wait for it to be triggered by CloudWatch based on the cron schedule you specified.
This function triggers the Amazon Translate batch job. You can observe the progress of the job on the Amazon Translate console.
 This batch job takes approximately 30 minutes to complete. When it’s complete, the
This batch job takes approximately 30 minutes to complete. When it’s complete, the TextTranslationJobstate change event triggers the Translation Job Completion Handler function. This function creates one human loop per translated document. - Navigate to the Amazon A2I workforces page.
- Choose the Private tab.

- Log in to the Amazon A2I worker portal by choosing the link for Labelling portal sign-in URL.
- Select the task
Human review taskin the jobs list. - Choose Start working.

You can see the following page displayed.

- Follow the instructions to make domain- and language-specific corrections.
In the preceding screenshot, the phrase “The use of health status in any group health insurance policy is prohibited by law” has been translated to “La ley prohíbe el uso del estado de salud en cualquier póliza de seguro médico de grupo.” Although the translation is accurate, the phrases have been rearranged. - Let’s modify this to “El uso del estado de salud en cualquier póliza de seguro de salud grupal está prohibido por ley” to make this a more direct translation reflecting the original phraseology.
- Select Add to add this to the dictionary.
- When you’re done, choose Submit.

This triggers the Workflow Completion Handler function, and the customization data is updated in the DynamoDB table. The function also stores the corrected translation under the post-edits prefix.
You can observe the customizations being added to translate_parallel_data table on the DynamoDB console.

Command flow
The Parallel Data Refresher function is triggered every hour by a CloudWatch scheduled event. This function checks for new updates in the translate_parallel_data table, creates a new parallel data TMX file in Amazon S3 under the parallel_data prefix, and updates the Amazon Translate parallel data component. You can trigger this function manually if you don’t want to wait for the scheduled event trigger.
You can observe the parallel data being updated on the Amazon Translate console.
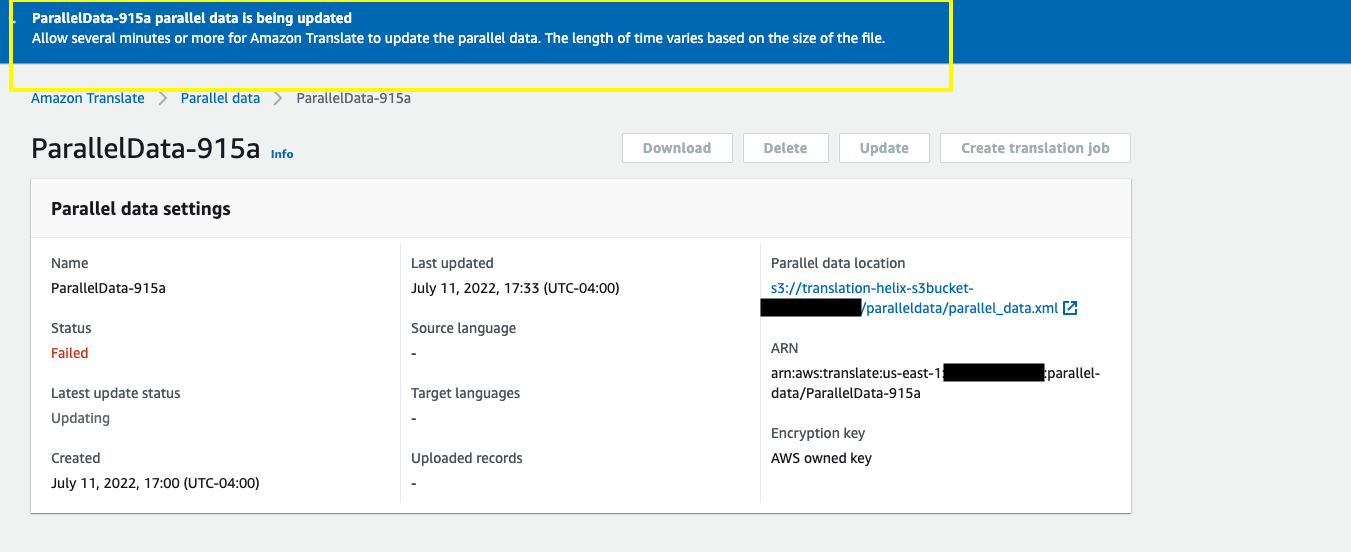
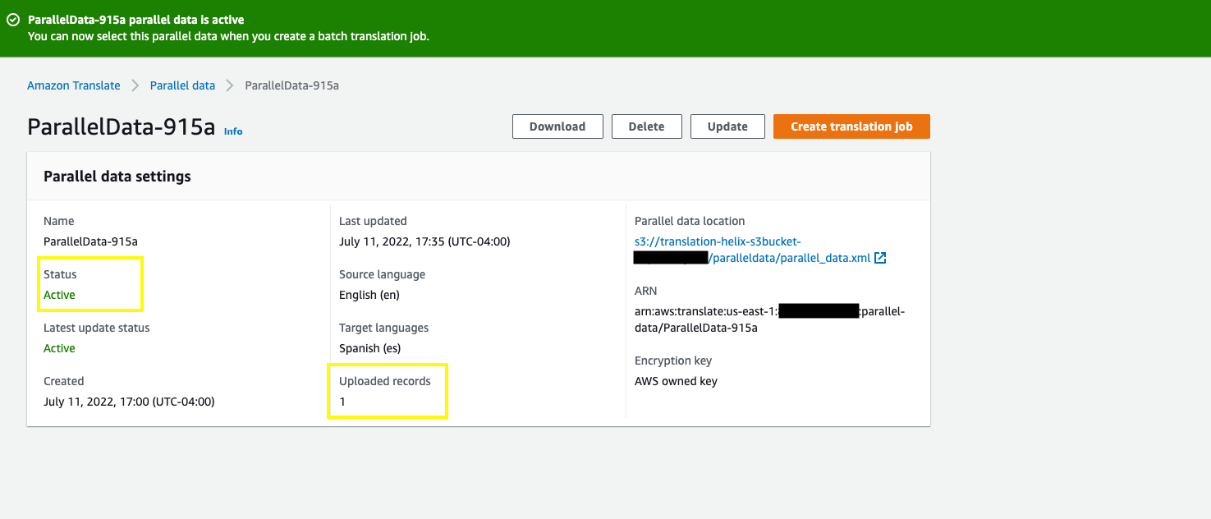
When it’s complete, the job status should be Active and the value for Updated records should reflect the number of customizations you added (in this case 1).
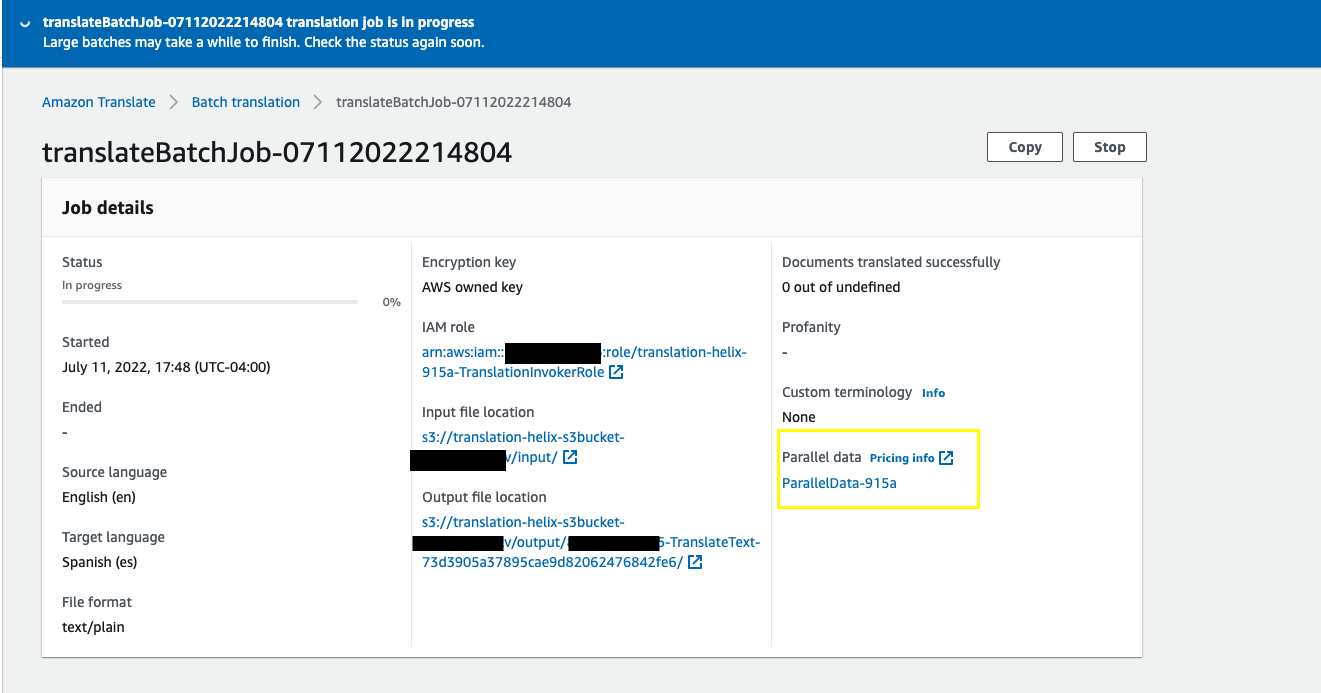
Now we can run the translation job again with the updated data. Trigger the Translation Job Invoker function again to observe the customization being added to the translation in the second iteration. Amazon Translate now uses the parallel data provided to customize the translation.
You can observe the change in the translation output in the labeling portal. Instead of the default translation, we see the customized translation being applied.

This workflow helps create a virtuous cycle to continuously improve translation output using Amazon A2I and Amazon Translate customization features.
Cost
With Amazon Translate and Amazon A2I, you pay as you go based on the number of text characters that you processed and for each human-reviewed object. We use DynamoDB on-demand mode for this example. DynamoDB charges you for the reads and writes performed on your tables. Refer to the pricing pages for Amazon Translate, Amazon A2I, and Amazon DynamoDB for actual costs.
Clean up
When you’re finished experimenting with this solution, clean up your resources by using the AWS CloudFormation console to delete all the resources deployed in this example. This helps you avoid continuing costs in your account.
Conclusion
You can use the solution presented in this post to build a multi-lingual translation workflow that uses and augments domain-specific customization incrementally to continuously improve translation results. We provided a simple mechanism to integrate your existing customization assets with managed AI services like Amazon Translate and Amazon A2I to build a robust translation service for your application. Amazon Translate can help you scale this solution to support over 5,550 translation pairs out of the box. Amazon A2I can help you easily integrate with your in-house linguistic expert or take advantage of an external workforce to scale the solution.
For more information about Amazon Translate, visit Amazon Translate resources to find video resources and blog posts, and refer to AWS Translate FAQs. Please share your thoughts with us in the comments section, or in the issues section of the project’s Github repository.
About the Authors
 Sathya Balakrishnan is a Sr Customer Delivery Architect in the Professional Services team at AWS, specializing in Data/ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr Customer Delivery Architect in the Professional Services team at AWS, specializing in Data/ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Paul W. Joireman is a Sr Customer Delivery Architect in Professional Services at AWS, specializing in Application Migration and working with US federal financial clients. Paul enjoys creating technology solutions, traveling with family and hiking in the Shenandoah National Park, as long as the hike finishes at a local craft brewery.
Paul W. Joireman is a Sr Customer Delivery Architect in Professional Services at AWS, specializing in Application Migration and working with US federal financial clients. Paul enjoys creating technology solutions, traveling with family and hiking in the Shenandoah National Park, as long as the hike finishes at a local craft brewery.
High-Definition Segmentation in Google Meet
In recent years video conferencing has played an increasingly important role in both work and personal communication for many users. Over the past two years, we have enhanced this experience in Google Meet by introducing privacy-preserving machine learning (ML) powered background features, also known as “virtual green screen”, which allows users to blur their backgrounds or replace them with other images. What is unique about this solution is that it runs directly in the browser without the need to install additional software.
So far, these ML-powered features have relied on CPU inference made possible by leveraging neural network sparsity, a common solution that works across devices, from entry level computers to high-end workstations. This enables our features to reach the widest audience. However, mid-tier and high-end devices often have powerful GPUs that remain untapped for ML inference, and existing functionality allows web browsers to access GPUs via shaders (WebGL).
With the latest update to Google Meet, we are now harnessing the power of GPUs to significantly improve the fidelity and performance of these background effects. As we detail in “Efficient Heterogeneous Video Segmentation at the Edge”, these advances are powered by two major components: 1) a novel real-time video segmentation model and 2) a new, highly efficient approach for in-browser ML acceleration using WebGL. We leverage this capability to develop fast ML inference via fragment shaders. This combination results in substantial gains in accuracy and latency, leading to crisper foreground boundaries.
 |
| CPU segmentation vs. HD segmentation in Meet. |
Moving Towards Higher Quality Video Segmentation Models
To predict finer details, our new segmentation model now operates on high definition (HD) input images, rather than lower-resolution images, effectively doubling the resolution over the previous model. To accommodate this, the model must be of higher capacity to extract features with sufficient detail. Roughly speaking, doubling the input resolution quadruples the computation cost during inference.
Inference of high-resolution models using the CPU is not feasible for many devices. The CPU may have a few high-performance cores that enable it to execute arbitrary complex code efficiently, but it is limited in its ability for the parallel computation required for HD segmentation. In contrast, GPUs have many, relatively low-performance cores coupled with a wide memory interface, making them uniquely suitable for high-resolution convolutional models. Therefore, for mid-tier and high-end devices, we adopt a significantly faster pure GPU pipeline, which is integrated using WebGL.
This change inspired us to revisit some of the prior design decisions for the model architecture.
- Backbone: We compared several widely-used backbones for on-device networks and found EfficientNet-Lite to be a better fit for the GPU because it removes the squeeze-and-excitation block, a component that is inefficient on WebGL (more below).
- Decoder: We switched to a multi-layer perceptron (MLP) decoder consisting of 1×1 convolutions instead of using simple bilinear upsampling or the more expensive squeeze-and-excitation blocks. MLP has been successfully adopted in other segmentation architectures, like DeepLab and PointRend, and is efficient to compute on both CPU and GPU.
- Model size: With our new WebGL inference and the GPU-friendly model architecture, we were able to afford a larger model without sacrificing the real-time frame rate necessary for smooth video segmentation. We explored the width and the depth parameters using a neural architecture search.
 |
| HD segmentation model architecture. |
In aggregate, these changes substantially improve the mean Intersection over Union (IoU) metric by 3%, resulting in less uncertainty and crisper boundaries around hair and fingers.
We have also released the accompanying model card for this segmentation model, which details our fairness evaluations. Our analysis shows that the model is consistent in its performance across the various regions, skin-tones, and genders, with only small deviations in IoU metrics.
| Model | Resolution | Inference | IoU | Latency (ms) | ||||
| CPU segmenter | 256×144 | Wasm SIMD | 94.0% | 8.7 | ||||
| GPU segmenter | 512×288 | WebGL | 96.9% | 4.3 |
| Comparison of the previous segmentation model vs. the new HD segmentation model on a Macbook Pro (2018). |
Accelerating Web ML with WebGL
One common challenge for web-based inference is that web technologies can incur a performance penalty when compared to apps running natively on-device. For GPUs, this penalty is substantial, only achieving around 25% of native OpenGL performance. This is because WebGL, the current GPU standard for Web-based inference, was primarily designed for image rendering, not arbitrary ML workloads. In particular, WebGL does not include compute shaders, which allow for general purpose computation and enable ML workloads in mobile and native apps.
To overcome this challenge, we accelerated low-level neural network kernels with fragment shaders that typically compute the output properties of a pixel like color and depth, and then applied novel optimizations inspired by the graphics community. As ML workloads on GPUs are often bound by memory bandwidth rather than compute, we focused on rendering techniques that would improve the memory access, such as Multiple Render Targets (MRT).
MRT is a feature in modern GPUs that allows rendering images to multiple output textures (OpenGL objects that represent images) at once. While MRT was originally designed to support advanced graphics rendering such as deferred shading, we found that we could leverage this feature to drastically reduce the memory bandwidth usage of our fragment shader implementations for critical operations, like convolutions and fully connected layers. We do so by treating intermediate tensors as multiple OpenGL textures.
In the figure below, we show an example of intermediate tensors having four underlying GL textures each. With MRT, the number of GPU threads, and thus effectively the number of memory requests for weights, is reduced by a factor of four and saves memory bandwidth usage. Although this introduces considerable complexities in the code, it helps us reach over 90% of native OpenGL performance, closing the gap with native applications.
 |
| Left: A classic implementation of Conv2D with 1-to-1 correspondence of tensor and an OpenGL texture. Red, yellow, green, and blue boxes denote different locations in a single texture each for intermediate tensor A and B. Right: Our implementation of Conv2D with MRT where intermediate tensors A and B are realized with a set of 4 GL textures each, depicted as red, yellow, green, and blue boxes. Note that this reduces the request count for weights by 4x. |
Conclusion
We have made rapid strides in improving the quality of real-time segmentation models by leveraging the GPU on mid-tier and high-end devices for use with Google Meet. We look forward to the possibilities that will be enabled by upcoming technologies like WebGPU, which bring compute shaders to the web. Beyond GPU inference, we’re also working on improving the segmentation quality for lower powered devices with quantized inference via XNNPACK WebAssembly.
Acknowledgements
Special thanks to those on the Meet team and others who worked on this project, in particular Sebastian Jansson, Sami Kalliomäki, Rikard Lundmark, Stephan Reiter, Fabian Bergmark, Ben Wagner, Stefan Holmer, Dan Gunnarsson, Stéphane Hulaud, and to all our team members who made this possible: Siargey Pisarchyk, Raman Sarokin, Artsiom Ablavatski, Jamie Lin, Tyler Mullen, Gregory Karpiak, Andrei Kulik, Karthik Raveendran, Trent Tolley, and Matthias Grundmann.
3D Artist Creates Blooming, Generative Sculptures With NVIDIA RTX and AI
Looking for a change of art? Try using AI — that’s what 3D artist Nikola Damjanov is doing.
Based in Serbia, Damjanov has over 15 years of experience in the graphics industry, from making 3D models and animations to creating high-quality visual effects for music videos and movies. Now an artist at game developer company Nordeus, Damajanov’s hobbies include dabbling in creative projects using the latest technologies, like NVIDIA RTX and AI.
Recently, Damjanov has been experimenting with generative art, which is the process of using algorithms to create new ideas, forms, shapes, colors or patterns. And when Damjanov was invited to participate in his country’s Art Biennale, an exhibit that features creative pieces from local artists, he decided to design something new — a 3D-printed sculpture.

With the help of NVIDIA RTX and AI, Damjanov accelerated his creative workflows and produced a physical 3D sculpture of a flower with intricate details and designs.
An AI for Art
To bring his sculpture to life, Damjanov started with the 3D digital design. His floral sculpture was inspired by the aesthetics of microfossils and radiolaria, which are intricate mineral skeletons.
 To capture such elaborate details, Damjanov used the NVIDIA Quadro RTX 6000 GPU, and tapped into the power of NVIDIA RTX rendering and AI denoising. These capabilities helped him easily create the 3D model and achieve the complex details of the flower for the sculpture.
To capture such elaborate details, Damjanov used the NVIDIA Quadro RTX 6000 GPU, and tapped into the power of NVIDIA RTX rendering and AI denoising. These capabilities helped him easily create the 3D model and achieve the complex details of the flower for the sculpture.
“NVIDIA RTX-powered AI denoising just makes look development way easier, because the feedback loop is much shorter now,” he said. “You can quickly get a very decent approximation of what the final render will look like.”
Damjanov then accomplished most of the RTX rendering and generative modeling in SideFX Houdini, a 3D animation application software, and the OTOY OctaneRender engine.
In generative art, it’s important to set up rules that provide boundaries for the creative process, so the computer can follow those rules to create the new artwork.
For Damjanov, setting up these rules and relationships in the system helped with iterations and design changes. With the rules in place, he could change minor details and aspects, and immediately see how the rest of the design would be affected by the tweaks. For example, Damjanov could alter a petal on the flower to be twice the current size, and everything else connected to the petal would react to the new size.
 Once he finalized the design, the most challenging part of the project was testing all the physical parts of the sculpture, the artist said.
Once he finalized the design, the most challenging part of the project was testing all the physical parts of the sculpture, the artist said.
“Because it was a very intricate design, we had to test out and print specific parts to see what comes out,” he said. “I ran simulations to try to find an approximate center of mass. I also had to print specific parts to find a design that would be structurally sound when printed.”
 After three weeks of printing, Damjanov reached a 3D design that would produce the flower sculpture he envisioned for the Art Biennale.
After three weeks of printing, Damjanov reached a 3D design that would produce the flower sculpture he envisioned for the Art Biennale.
Damjanov uses RTX-powered AI denoising and rendering in most of his projects. He’s also experimenting with using game engines for his work, and implementing NVIDIA Deep Learning Super Sampling for increased graphics performance.
“I remember when most of my time was spent on waiting for something to finish, such as renders completed, maps baked, mesh processed — it was always a pain,” he said. “But with the sheer power and speed of RTX, artists have more time to spend on creative tasks.”
Check out Damjanov’s work on ArtStation and learn more about NVIDIA RTX.
The post 3D Artist Creates Blooming, Generative Sculptures With NVIDIA RTX and AI appeared first on NVIDIA Blog.
Join us in the AI Test Kitchen
As AI technologies continue to advance, they have the potential to unlock new experiences that support more natural human-computer interactions. We see a future where you can find the information you’re looking for in the same conversational way you speak to friends and family. While there’s still lots of work to be done before this type of human-computer interaction is possible, recent research breakthroughs in generative language models — inspired by the natural conversations of people — are accelerating our progress. One of our most promising models is called LaMDA (Language Model for Dialogue Applications), and as we move ahead with development, we feel a great responsibility to get this right.
That’s why we introduced an app called AI Test Kitchen at Google I/O earlier this year. It provides a new way for people to learn about, experience, and give feedback on emerging AI technology, like LaMDA. Starting today, you can register your interest for the AI Test Kitchen as it begins to gradually roll out to small groups of users in the US, launching on Android today and iOS in the coming weeks.
Our goal is to learn, improve and innovate responsibly on AI together.
Similar to a real test kitchen, AI Test Kitchen will serve a rotating set of experimental demos. These aren’t finished products, but they’re designed to give you a taste of what’s becoming possible with AI in a responsible way. Our first set of demos explore the capabilities of our latest version of LaMDA, which has undergone key safety improvements. The first demo, “Imagine It,” lets you name a place and offers paths to explore your imagination. With the “List It” demo, you can share a goal or topic, and LaMDA will break it down into a list of helpful subtasks. And in the “Talk About It (Dogs Edition)” demo, you can have a fun, open-ended conversation about dogs and only dogs, which explores LaMDA’s ability to stay on topic even if you try to veer off-topic.
Evaluating LaMDA’s potential and its risks
As you try each demo, you’ll see LaMDA’s ability to generate creative responses on the fly. This is one of the model’s strengths, but it can also pose challenges since some responses can be inaccurate or inappropriate. We’ve been testing LaMDA internally over the last year, which has produced significant quality improvements. More recently, we’ve run dedicated rounds of adversarial testing to find additional flaws in the model. We enlisted expert red teaming members — product experts who intentionally stress test a system with an adversarial mindset — who have uncovered additional harmful, yet subtle, outputs. For example, the model can misunderstand the intent behind identity terms and sometimes fails to produce a response when they’re used because it has difficulty differentiating between benign and adversarial prompts. It can also produce harmful or toxic responses based on biases in its training data, generating responses that stereotype and misrepresent people based on their gender or cultural background. These areas and more continue to be under active research.
In response to these challenges, we’ve added multiple layers of protection to the AI Test Kitchen. This work has minimized the risk, but not eliminated it. We’ve designed our systems to automatically detect and filter out words or phrases that violate our policies, which prohibit users from knowingly generating content that is sexually explicit; hateful or offensive; violent, dangerous, or illegal; or divulges personal information. In addition to these safety filters, we made improvements to LaMDA around quality, safety, and groundedness — each of which are carefully measured. We have also developed techniques to keep conversations on topic, acting as guardrails for a technology that can generate endless, free-flowing dialogue. As you’re using each demo, we hope you see LaMDA’s potential, but also keep these challenges in mind.
Responsible progress, together
In accordance with our AI Principles, we believe responsible progress doesn’t happen in isolation. We’re at a point where external feedback is the next, most helpful step to improve LaMDA. When you rate each LaMDA reply as nice, offensive, off topic, or untrue, we’ll use this data — which is not linked to your Google account — to improve and develop our future products. We intend for AI Test Kitchen to be safe, fun, and educational, and we look forward to innovating in a responsible and transparent way together.
MoCapAct: Training humanoid robots to “Move Like Jagger”
What would it take to get humanoid, bipedal robots to dance like Mick Jagger? Indeed, for something more mundane, what does it take to get them to simply stand still? Sit down? Walk? Move in myriads of other ways many people take for granted? Bipedalism provides unparalleled versatility in an environment designed for and by humans. By mixing and matching a wide range of basic motor skills, from walking to jumping to balancing on one foot, people routinely dance, play soccer, carry heavy objects, and perform other complex high-level motions. If robots are ever to reach their full potential as an assistive technology, mastery of diverse bipedal motion is a requirement, not a luxury. However, even the simplest of these skills can require a fine orchestration of dozens of joints. Sophisticated engineering can rein in some of this complexity, but endowing bipedal robots with the generality to cope with our messy, weakly structured world, or a metaverse that takes after it, requires learning. Training AI agents with humanoid morphology to match human performance across the entire diversity of human motion is one of the biggest challenges of artificial physical intelligence. Due to the vagaries of experimentation on physical robots, research in this direction is currently done mostly in simulation.
Unfortunately, it involves computationally intensive methods, effectively restricting participation to research institutions with large compute budgets. In an effort to level the playing field and make this critical research area more inclusive, Microsoft Research’s Robot Learning group is releasing MoCapAct, a large library of pre-trained humanoid control models along with enriched data for training new ones. This will enable advanced research on artificial humanoid control at a fraction of the compute resources currently required.
The reason why humanoid control research has been so computationally demanding is subtle and, at the first glance, paradoxical. The prominent avenue for learning locomotive skills is based on using motion capture (MoCap) data. MoCap is an animation technique widely used in the entertainment industry for decades. It involves recording the motion of several keypoints on a human actor’s body, such as their elbows, shoulders, and knees, while the actor is performing a task of interest, such as jogging. Thus, a MoCap clip can be thought of as a very concise and precise summary of an activity’s video clip. Thanks to this, useful information can be extracted from MoCap clips with much less computation than from the much more high-dimensional, ambiguous training data in other major areas of machine learning, which comes in the form of videos, images, and text. On top of this, MoCap data is widely available. Repositories such as CMU Motion Capture Dataset contain hours of clips for just about any common motion of a human body, with visualizations of several examples shown below. Why, then, is it so hard to make physical and simulated humanoid robots mimic a person’s movements?
The caveat is that MoCap clips don’t contain all the information necessary to imitate the demonstrated motions on a physical robot or in a simulation that models physical forces. They only show us what a motion skill looks like, not the underlying muscular movements that caused the actor’s muscles to yield that motion. Even if MoCap systems recorded these signals, it wouldn’t be of much help: simulated humanoids and real robots typically use motors instead of muscles, which is a dramatically different form of articulation. Nonetheless, actuation in artificial humanoids is also driven by a type of control signal. MoCap clips are a valuable aid in computing these control signals, if combined with additional learning and optimization methods that use MoCap data as guidance. The computational bottleneck that our MoCapAct release aims to remove is created exactly by these methods, collectively known as reinforcement learning (RL). In simulation, where much of AI locomotion research is currently focused, RL can recover the sequence of control inputs that takes a humanoid agent through the sequence of poses from a given MoCap clip. What results is a locomotion behavior that is indistinguishable from the clip’s. The availability of control policies for individual basic behaviors learned from separate MoCap clips can open the doors for fascinating locomotion research, e.g., in methods for combining these behaviors into a single “multi-skilled” neural network and training higher-level locomotion capabilities by switching among them. However, with thousands of basic locomotion skills to learn, RL’s expensive trial-and-error approach creates a massive barrier to entry on this research path. It is this scalability issue that our dataset release aims to address.
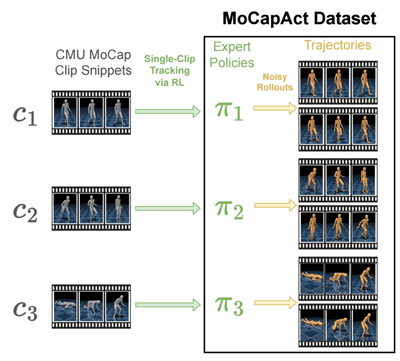
Our MoCapAct dataset, designed to be compatible with the highly popular dm_control humanoid simulation environment and the extensive CMU Motion Capture Dataset, serves the research community in two ways:
- For each of over 2500 MoCap clip snippets from the CMU Motion Capture Dataset, it provides an RL-trained “expert” control policy (represented as a PyTorch model) that enables dm_control’s simulated humanoid to faithfully recreate the skill depicted in that clip snippet, as shown in these videos of the experts’ behaviors:
Training this model zoo has taken the equivalent of 50 years over many GPU-equipped Azure NC6v2 virtual machines (excluding hyperparameter tuning and other required experiments) – a testament to the computational hurdle MoCapAct removes for other researchers.
- For each of the trained skill policies above, MoCapAct supplies a set of recorded trajectories generated by executing that skill’s control policy on the dm_control’s humanoid agent. These trajectories can be thought of as MoCap clips of the trained experts but, in a crucial difference from the original MoCap data, they contain both low-level sensory measurements (e.g., touch measurements) and control signals for the humanoid agent. Unlike typical MoCap data, these trajectories are suitable for learning to match and improve on skill experts via direct imitation – a much more efficient class of techniques than RL.
We give two examples of how we used the MoCapAct dataset.
First, we train a hierarchical policy based on the neural probabilistic motor primitive. To achieve this, we combine the thousands of MoCapAct’s clip-specialized policies together into a single policy that is capable of executing many different skills. This agent has a high-level component that takes MoCap frames as input and outputs a learned skill. The low-level component takes the learned skill and sensory measurement from the humanoid as input and outputs the motor action.
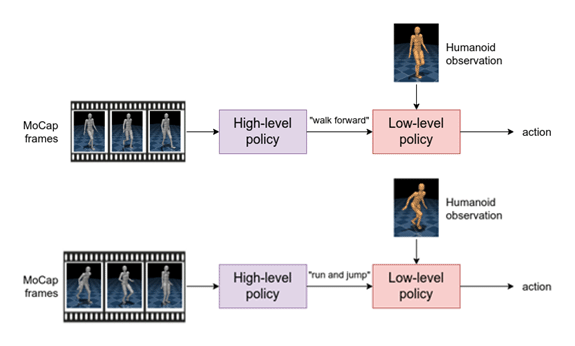
This hierarchical structure offers an appealing benefit. If we keep the low-level component, we can instead control the humanoid by inputting different skills to the low-level policy (e.g., “walk” instead of the corresponding motor actions). Therefore, we can re-use the low-level policy to efficiently learn new tasks.
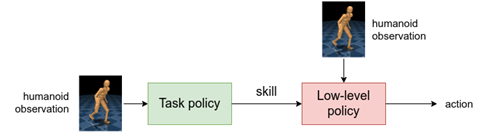
In light of that, we replace the high-level policy with a task policy that is then trained to steer the low-level policy towards achieving some task. As an example, we train a task policy to have the humanoid reach a target. Notice that the humanoid uses many low-level skills, like running, turning, and side-stepping.
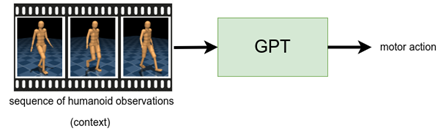
Our second example centers on motion completion, which is inspired by the task of sentence completion. Here, we use the GPT architecture, which accepts a sequence of sensory measurements (the “context”) and outputs a motor action. We train a control policy to take one second of sensory measurements from the dataset and output the corresponding motor actions from the specialized expert. Then, before executing the policy on our humanoid, we first generate a “prompt” (red humanoid in the videos) by executing a specialized expert for one second. Afterwards, we let the policy control the humanoid (bronze humanoid in the videos), at each time step, where it constantly takes the previous second of sensory measurements and predicts the motor actions. We find that this policy can reliably repeat the underlying motion of the clip, which is demonstrated in the first two videos. On other MoCap clips, we find that the policy can deviate from the underlying clip in a plausible way, such as in the third video, where the humanoid transitions from side-stepping to walking backwards.
On top of the dataset, we also release the code used to generate the policies and results. We hope the community can build off of our dataset and work to do incredible research in the control of humanoid robots.
Our paper is available here. You can read more at our website.
The data used in this project was obtained from mocap.cs.cmu.edu.
The database was created with funding from NSF EIA-0196217.
The post MoCapAct: Training humanoid robots to “Move Like Jagger” appeared first on Microsoft Research.
Fintech Company Blocks Fraud Attacks for Financial Institutions With AI and NVIDIA GPUs
E-commerce sales have skyrocketed as more people shop remotely, spurred by the pandemic. But this surge has also led fraudsters to use the opportunity to scam retailers and customers, according to David Sutton, director of analytical technology at fintech company Featurespace.
The company, headquartered in the U.K., has developed AI-powered technology to increase the speed and accuracy of fraud detection and prevention. Called ARIC Risk Hub, the platform uses deep learning models trained using NVIDIA GPUs to distinguish between valid and fraudulent transactional behavior.
“Online transactions are a prime target for criminals, as they don’t need to have the physical card to transact,” Sutton said. “With compromised card details readily available through the dark web, fraudsters can target large volumes of cards to commit fraud with very little effort.”
ARIC Risk Hub builds complex behavioral profiles of what it calls “genuine” customers by converging transaction and third-party data from across their lifecycle within a financial institution.
Fraud prevention has traditionally been limited by delays in detection — with customers being notified only after money had already left their bank accounts. But ARIC Risk Hub in less than 30 milliseconds determines anomalies in even the slightest changes in a customer’s behavior. It compares each financial event of a customer to their profile using AI-powered adaptive behavioral analytics.
The technology is deployed across 70 major financial institutions globally — and some have reported that it’s blocked 75% of its fraud attacks, Sutton said.
ARIC Risk Hub helps these institutions identify criminal behavior in near-real time — reducing their financial losses and operational costs, and protecting more than 500 million consumers from fraud and financial crime.
Featurespace is a member of NVIDIA Inception, a free, global program that nurtures cutting-edge startups.
100x Model Training Acceleration With NVIDIA GPUs
Featurespace got its start over a decade ago as a machine learning consultancy. It was rooted in the research of University of Cambridge professor Bill Fitzgerald, who was looking to make a commercial impact with adaptive behavioral analytics, a technology he created.
Applied to the financial services industry, the technology quickly took flight.
“With this technology, you could build a deep learning model that learns from and understands what sorts of actions a person normally takes so that it can look for changes in those actions,” said Sutton.
In the past, it would take weeks for Featurespace to set up and train different deep learning models. With NVIDIA A100 Tensor Core GPUs, the company has seen up to a 100x speedup in model training, Sutton said.
“Compared to when we used CPUs, NVIDIA GPUs give us a really quick research-to-impact loop,” he added. “It’s electrifying to work with something that can have an impact that quickly.”
In the time that they used to run just 10 trials, Featurespace’s researchers and data scientists can now run thousands of tests, which bolsters the statistical confidence of their results, enabling them to deploy only the best, tried-and-tested models.
Sutton said even a 1% increase in fraud detection discovered using the deep learning model could save large enterprises $20 million a year.
Featurespace typically uses recurrent neural-network architectures on data from streams of transactions. This model pipeline allows an individual’s new actions to be assessed via behavioral context learned from their past actions.
Financial Fortifications for All
Featurespace’s deep learning models have prevented all sorts of fraud, including those that involve credit cards, payments, applications and money laundering.
The ARIC Risk Hub interface is customizable, so customers can select the most suitable subset of components for their specific needs. Users can then change analytics settings or review suspicious cases. If upon review a case is deemed to be a false positive, the deep learning model learns from its errors, increasing future accuracy.
Featurespace technology has been making a splash for payment processing companies like TSYS and Worldpay — as well as large banks including Danske Bank, HSBC and NatWest.
As Sutton put it, “Featurespace is using AI to make the world a safer place to transact.”
“Our work is what brings a lot of people at Featurespace into the office every morning,” he said. “If you’re able to reduce the amount of money laundering in the world, for example, you can turn crime into something that doesn’t pay as much, making it a less profitable industry to be in.”
Featurespace will host sessions on preventing fraud, money laundering and cryptocrime at Money 20/20, a fintech conference running Oct. 23-26 in Las Vegas.
Register free for NVIDIA GTC, running online Sept. 19-22, to learn more about the latest technology breakthroughs for the era of AI and the metaverse.
Subscribe to NVIDIA financial services news.
The post Fintech Company Blocks Fraud Attacks for Financial Institutions With AI and NVIDIA GPUs appeared first on NVIDIA Blog.
NeILF: Neural Incident Light Field for Material and Lighting Estimation
We present a differentiable rendering framework for material and lighting estimation from multi-view images and a reconstructed geometry. In the framework, we represent scene lightings as the Neural Incident Light Field (NeILF) and material properties as the surface BRDF modelled by multi-layer perceptrons. Compared with recent approaches that approximate scene lightings as the 2D environment map, NeILF is a fully 5D light field that is capable of modelling illuminations of any static scenes. In addition, occlusions and indirect lights can be handled naturally by the NeILF representation…Apple Machine Learning Research
Identifying the sponsored-product ads most useful to customers
Large language models improve click-through-rate prediction for sponsored products on Amazon product pages.Read More