As generative AI and large language models (LLMs) continue to drive innovations, compute requirements for training and inference have grown at an astonishing pace.
To meet that need, Google Cloud today announced the general availability of its new A3 instances, powered by NVIDIA H100 Tensor Core GPUs. These GPUs bring unprecedented performance to all kinds of AI applications with their Transformer Engine — purpose-built to accelerate LLMs.
Availability of the A3 instances comes on the heels of NVIDIA being named Google Cloud’s Generative AI Partner of the Year — an award that recognizes the companies’ deep and ongoing collaboration to accelerate generative AI on Google Cloud.
The joint effort takes multiple forms, from infrastructure design to extensive software enablement, to make it easier to build and deploy AI applications on the Google Cloud platform.
At the Google Cloud Next conference, NVIDIA founder and CEO Jensen Huang joined Google Cloud CEO Thomas Kurian for the event keynote to celebrate the general availability of NVIDIA H100 GPU-powered A3 instances and speak about how Google is using NVIDIA H100 and A100 GPUs for internal research and inference in its DeepMind and other divisions.
During the discussion, Huang pointed to the deeper levels of collaboration that enabled NVIDIA GPU acceleration for the PaxML framework for creating massive LLMs. This Jax-based machine learning framework is purpose-built to train large-scale models, allowing advanced and fully configurable experimentation and parallelization.
PaxML has been used by Google to build internal models, including DeepMind as well as research projects, and will use NVIDIA GPUs. The companies also announced that PaxML is available immediately on the NVIDIA NGC container registry.
Generative AI Startups Abound
Today, there are over a thousand generative AI startups building next-generation applications, many using NVIDIA technology on Google Cloud. Some notable ones include Writer and Runway.
Writer uses transformer-based LLMs to enable marketing teams to quickly create copy for web pages, blogs, ads and more. To do this, the company harnesses NVIDIA NeMo, an application framework from NVIDIA AI Enterprise that helps companies curate their training datasets, build and customize LLMs, and run them in production at scale.
Using NeMo optimizations, Writer developers have gone from working with models with hundreds of millions of parameters to 40-billion parameter models. The startup’s customer list includes household names like Deloitte, L’Oreal, Intuit, Uber and many other Fortune 500 companies.
Runway uses AI to generate videos in any style. The AI model imitates specific styles prompted by given images or through a text prompt. Users can also use the model to create new video content using existing footage. This flexibility enables filmmakers and content creators to explore and design videos in a whole new way.
Google Cloud was the first CSP to bring the NVIDIA L4 GPU to the cloud. In addition, the companies have collaborated to enable Google’s Dataproc service to leverage the RAPIDS Accelerator for Apache Spark to provide significant performance boosts for ETL, available today with Dataproc on the Google Compute Engine and soon for Serverless Dataproc.
Maintaining machine learning (ML) workflows in production is a challenging task because it requires creating continuous integration and continuous delivery (CI/CD) pipelines for ML code and models, model versioning, monitoring for data and concept drift, model retraining, and a manual approval process to ensure new versions of the model satisfy both performance and compliance requirements.
In this post, we describe how to create an MLOps workflow for batch inference that automates job scheduling, model monitoring, retraining, and registration, as well as error handling and notification by using Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon Simple Notification Service (Amazon SNS), HashiCorp Terraform, and GitLab CI/CD. The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production.
Solution overview
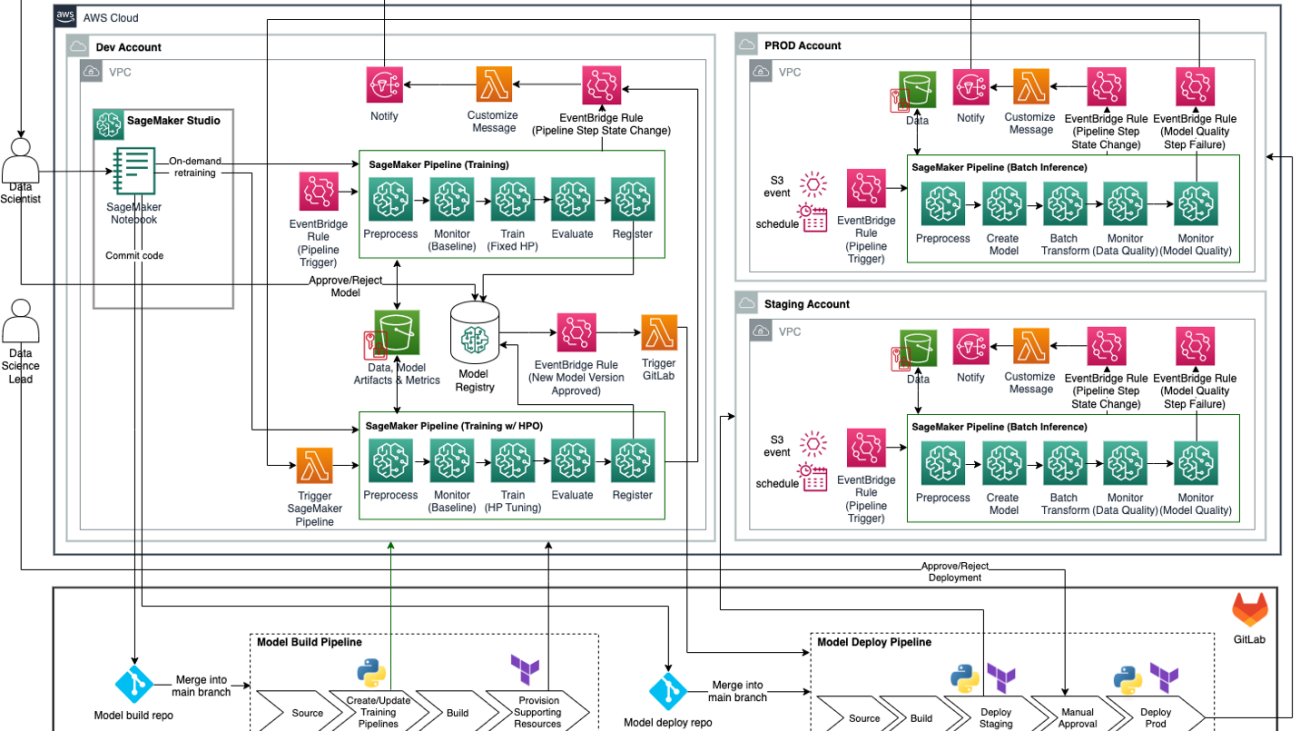
The following figure illustrates the proposed target MLOps architecture for enterprise batch inference for organizations who use GitLab CI/CD and Terraform infrastructure as code (IaC) in conjunction with AWS tools and services. GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform. SageMaker Python SDK is used to create or update SageMaker pipelines for training, training with hyperparameter optimization (HPO), and batch inference. Terraform is used to create additional resources such as EventBridge rules, Lambda functions, and SNS topics for monitoring SageMaker pipelines and sending notifications (for example, when a pipeline step fails or succeeds). SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a data science development account (which has more controls than a typical application development account). Then, inference pipelines are deployed to staging and production accounts using automation from DevOps tools such as GitLab CI/CD. The central model registry could optionally be placed in a shared services account as well. Refer to Operating model for best practices regarding a multi-account strategy for ML.
In the following subsections, we discuss different aspects of the architecture design in detail.
Infrastructure as code
IaC offers a way to manage IT infrastructure through machine-readable files, ensuring efficient version control. In this post and the accompanying code sample, we demonstrate how to use HashiCorp Terraform with GitLab CI/CD to manage AWS resources effectively. This approach underscores the key benefit of IaC, offering a transparent and repeatable process in IT infrastructure management.
Model training and retraining
In this design, the SageMaker training pipeline runs on a schedule (via EventBridge) or based on an Amazon Simple Storage Service (Amazon S3) event trigger (for example, when a trigger file or new training data, in case of a single training data object, is placed in Amazon S3) to regularly recalibrate the model with new data. This pipeline does not introduce structural or material changes to the model because it uses fixed hyperparameters that have been approved during the enterprise model review process.
The training pipeline registers the newly trained model version in the Amazon SageMaker Model Registry if the model exceeds a predefined model performance threshold (for example, RMSE for regression and F1 score for classification). When a new version of the model is registered in the model registry, it triggers a notification to the responsible data scientist via Amazon SNS. The data scientist then needs to review and manually approve the latest version of the model in the Amazon SageMaker Studio UI or via an API call using the AWS Command Line Interface (AWS CLI) or AWS SDK for Python (Boto3) before the new version of model can be utilized for inference.
The SageMaker training pipeline and its supporting resources are created by the GitLab model build pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model build Git repository.
Batch inference
The SageMaker batch inference pipeline runs on a schedule (via EventBridge) or based on an S3 event trigger as well. The batch inference pipeline automatically pulls the latest approved version of the model from the model registry and uses it for inference. The batch inference pipeline includes steps for checking data quality against a baseline created by the training pipeline, as well as model quality (model performance) if ground truth labels are available.
If the batch inference pipeline discovers data quality issues, it will notify the responsible data scientist via Amazon SNS. If it discovers model quality issues (for example, RMSE is greater than a pre-specified threshold), the pipeline step for the model quality check will fail, which will in turn trigger an EventBridge event to start the training with HPO pipeline.
The SageMaker batch inference pipeline and its supporting resources are created by the GitLab model deploy pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model deploy Git repository.
Model tuning and retuning
The SageMaker training with HPO pipeline is triggered when the model quality check step of the batch inference pipeline fails. The model quality check is performed by comparing model predictions with the actual ground truth labels. If the model quality metric (for example, RMSE for regression and F1 score for classification) doesn’t meet a pre-specified criterion, the model quality check step is marked as failed. The SageMaker training with HPO pipeline can also be triggered manually (in the SageMaker Studio UI or via an API call using the AWS CLI or SageMaker Python SDK) by the responsible data scientist if needed. Because the model hyperparameters are changing, the responsible data scientist needs to obtain approval from the enterprise model review board before the new model version can be approved in the model registry.
The SageMaker training with HPO pipeline and its supporting resources are created by the GitLab model build pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model build Git repository.
Model monitoring
Data statistics and constraints baselines are generated as part of the training and training with HPO pipelines. They are saved to Amazon S3 and also registered with the trained model in the model registry if the model passes evaluation. The proposed architecture for the batch inference pipeline uses Amazon SageMaker Model Monitor for data quality checks, while using custom Amazon SageMaker Processing steps for model quality check. This design decouples data and model quality checks, which in turn allows you to only send a warning notification when data drift is detected; and trigger the training with HPO pipeline when a model quality violation is detected.
Model approval
After a newly trained model is registered in the model registry, the responsible data scientist receives a notification. If the model has been trained by the training pipeline (recalibration with new training data while hyperparameters are fixed), there is no need for approval from the enterprise model review board. The data scientist can review and approve the new version of the model independently. On the other hand, if the model has been trained by the training with HPO pipeline (retuning by changing hyperparameters), the new model version needs to go through the enterprise review process before it can be used for inference in production. When the review process is complete, the data scientist can proceed and approve the new version of the model in the model registry. Changing the status of the model package to Approved will trigger a Lambda function via EventBridge, which will in turn trigger the GitLab model deploy pipeline via an API call. This will automatically update the SageMaker batch inference pipeline to utilize the latest approved version of the model for inference.
There are two main ways to approve or reject a new model version in the model registry: using the AWS SDK for Python (Boto3) or from the SageMaker Studio UI. By default, both the training pipeline and training with HPO pipeline set ModelApprovalStatus to PendingManualApproval. The responsible data scientist can update the approval status for the model by calling the update_model_package API from Boto3. Refer to Update the Approval Status of a Model for details about updating the approval status of a model via the SageMaker Studio UI.
Data I/O design
SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The following diagram illustrates how different Python scripts, raw and processed training data, raw and processed inference data, inference results and ground truth labels (if available for model quality monitoring), model artifacts, training and inference evaluation metrics (model quality monitoring), as well as data quality baselines and violation reports (for data quality monitoring) can be organized within an S3 bucket. The direction of arrows in the diagram indicates which files are inputs or outputs from their respective steps in the SageMaker pipelines. Arrows have been color-coded based on pipeline step type to make them easier to read. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
The data engineer is responsible for the following:
Uploading labeled training data to the appropriate path in Amazon S3. This includes adding new training data regularly to ensure the training pipeline and training with HPO pipeline have access to recent training data for model retraining and retuning, respectively.
Uploading input data for inference to the appropriate path in S3 bucket before a planned run of the inference pipeline.
Uploading ground truth labels to the appropriate S3 path for model quality monitoring.
The data scientist is responsible for the following:
Preparing ground truth labels and providing them to the data engineering team for uploading to Amazon S3.
Taking the model versions trained by the training with HPO pipeline through the enterprise review process and obtaining necessary approvals.
Manually approving or rejecting newly trained model versions in the model registry.
Approving the production gate for the inference pipeline and supporting resources to be promoted to production.
Sample code
In this section, we present a sample code for batch inference operations with a single-account setup as shown in the following architecture diagram. The sample code can be found in the GitHub repository, and can serve as a starting point for batch inference with model monitoring and automatic retraining using quality gates often required for enterprises. The sample code differs from the target architecture in the following ways:
It uses a single GitLab CI/CD pipeline for building and deploying the ML model and supporting resources.
When a new version of the model is trained and approved, the GitLab CI/CD pipeline is not triggered automatically and needs to be run manually by the responsible data scientist to update the SageMaker batch inference pipeline with the latest approved version of the model.
It only supports S3 event-based triggers for running the SageMaker training and inference pipelines.
Prerequisites
You should have the following prerequisites before deploying this solution:
An AWS account
SageMaker Studio
A SageMaker execution role with Amazon S3 read/write and AWS Key Management Service (AWS KMS) encrypt/decrypt permissions
An S3 bucket for storing data, scripts, and model artifacts
/code/lambda_function/ – This directory contains the Python file for a Lambda function that prepares and sends notification messages (via Amazon SNS) about the SageMaker pipelines’ step state changes
/data/ – This directory includes the raw data files (training, inference, and ground truth data)
/env_files/ – This directory contains the Terraform input variables file
/pipeline_scripts/ – This directory contains three Python scripts for creating and updating training, inference, and training with HPO SageMaker pipelines, as well as configuration files for specifying each pipeline’s parameters
/scripts/ – This directory contains additional Python scripts (such as preprocessing and evaluation) that are referenced by the training, inference, and training with HPO pipelines
.gitlab-ci.yml – This file specifies the GitLab CI/CD pipeline configuration
/events.tf – This file defines EventBridge resources
/main.tf – This file defines Terraform data sources and local variables
/sns.tf – This file defines Amazon SNS resources
/tags.json – This JSON file allows you to declare custom tag key-value pairs and append them to your Terraform resources using a local variable
/variables.tf – This file declares all the Terraform variables
Variables and configuration
The following table shows the variables that are used to parameterize this solution. Refer to the ./env_files/dev_env.tfvars file for more details.
Name
Description
bucket_name
S3 bucket that is used to store data, scripts, and model artifacts
bucket_prefix
S3 prefix for the ML project
bucket_train_prefix
S3 prefix for training data
bucket_inf_prefix
S3 prefix for inference data
notification_function_name
Name of the Lambda function that prepares and sends notification messages about SageMaker pipelines’ step state changes
custom_notification_config
The configuration for customizing notification message for specific SageMaker pipeline steps when a specific pipeline run status is detected
email_recipient
The email address list for receiving SageMaker pipelines’ step state change notifications
pipeline_inf
Name of the SageMaker inference pipeline
pipeline_train
Name of the SageMaker training pipeline
pipeline_trainwhpo
Name of SageMaker training with HPO pipeline
recreate_pipelines
If set to true, the three existing SageMaker pipelines (training, inference, training with HPO) will be deleted and new ones will be created when GitLab CI/CD is run
model_package_group_name
Name of the model package group
accuracy_mse_threshold
Maximum value of MSE before requiring an update to the model
role_arn
IAM role ARN of the SageMaker pipeline execution role
kms_key
KMS key ARN for Amazon S3 and SageMaker encryption
subnet_id
Subnet ID for SageMaker networking configuration
sg_id
Security group ID for SageMaker networking configuration
upload_training_data
If set to true, training data will be uploaded to Amazon S3, and this upload operation will trigger the run of the training pipeline
upload_inference_data
If set to true, inference data will be uploaded to Amazon S3, and this upload operation will trigger the run of the inference pipeline
user_id
The employee ID of the SageMaker user that is added as a tag to SageMaker resources
Deploy the solution
Complete the following steps to deploy the solution in your AWS account:
Clone the GitHub repository into your working directory.
Review and modify the GitLab CI/CD pipeline configuration to suit your environment. The configuration is specified in the ./gitlab-ci.yml file.
Refer to the README file to update the general solution variables in the ./env_files/dev_env.tfvars file. This file contains variables for both Python scripts and Terraform automation.
Check the additional SageMaker Pipelines parameters that are defined in the YAML files under ./batch_scoring_pipeline/pipeline_scripts/. Review and update the parameters if necessary.
Review the SageMaker pipeline creation scripts in ./pipeline_scripts/ as well as the scripts that are referenced by them in the ./scripts/ folder. The example scripts provided in the GitHub repo are based on the Abalone dataset. If you are going to use a different dataset, ensure you update the scripts to suit your particular problem.
Put your data files into the ./data/ folder using the following naming convention. If you are using the Abalone dataset along with the provided example scripts, ensure the data files are headerless, the training data includes both independent and target variables with the original order of columns preserved, the inference data only includes independent variables, and the ground truth file only includes the target variable.
training-data.csv
inference-data.csv
ground-truth.csv
Commit and push the code to the repository to trigger the GitLab CI/CD pipeline run (first run). Note that the first pipeline run will fail on the pipeline stage because there’s no approved model version yet for the inference pipeline script to use. Review the step log and verify a new SageMaker pipeline named TrainingPipeline has been successfully created.
Open the SageMaker Studio UI, then review and run the training pipeline.
After the successful run of the training pipeline, approve the registered model version in the model registry, then rerun the entire GitLab CI/CD pipeline.
Review the Terraform plan output in the build stage. Approve the manual apply stage in the GitLab CI/CD pipeline to resume the pipeline run and authorize Terraform to create the monitoring and notification resources in your AWS account.
Finally, review the SageMaker pipelines’ run status and output in the SageMaker Studio UI and check your email for notification messages, as shown in the following screenshot. The default message body is in JSON format.
SageMaker pipelines
In this section, we describe the three SageMaker pipelines within the MLOps workflow.
Training pipeline
The training pipeline is composed of the following steps:
Preprocessing step, including feature transformation and encoding
Data quality check step for generating data statistics and constraints baseline using the training data
Training step
Training evaluation step
Condition step to check whether the trained model meets a pre-specified performance threshold
Model registration step to register the newly trained model in the model registry if the trained model meets the required performance threshold
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to True in the training pipeline. These parameters instruct the pipeline to skip the data quality check and just create and register new data statistics or constraints baselines using the training data. The following figure depicts a successful run of the training pipeline.
Batch inference pipeline
The batch inference pipeline is composed of the following steps:
Creating a model from the latest approved model version in the model registry
Preprocessing step, including feature transformation and encoding
Batch inference step
Data quality check preprocessing step, which creates a new CSV file containing both input data and model predictions to be used for the data quality check
Data quality check step, which checks the input data against baseline statistics and constraints associated with the registered model
Condition step to check whether ground truth data is available. If ground truth data is available, the model quality check step will be performed
Model quality calculation step, which calculates model performance based on ground truth labels
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to False in the inference pipeline. These parameters instruct the pipeline to perform a data quality check using the data statistics or constraints baseline associated with the registered model (supplied_baseline_statistics_data_quality and supplied_baseline_constraints_data_quality) and skip creating or registering new data statistics and constraints baselines during inference. The following figure illustrates a run of the batch inference pipeline where the data quality check step has failed due to poor performance of the model on the inference data. In this particular case, the training with HPO pipeline will be triggered automatically to fine-tune the model.
Training with HPO pipeline
The training with HPO pipeline is composed of the following steps:
Preprocessing step (feature transformation and encoding)
Data quality check step for generating data statistics and constraints baseline using the training data
Hyperparameter tuning step
Training evaluation step
Condition step to check whether the trained model meets a pre-specified accuracy threshold
Model registration step if the best trained model meets the required accuracy threshold
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to True in the training with HPO pipeline. The following figure depicts a successful run of the training with HPO pipeline.
Clean up
Complete the following steps to clean up your resources:
Employ the destroy stage in the GitLab CI/CD pipeline to eliminate all resources provisioned by Terraform.
Use the AWS CLI to list and remove any remaining pipelines that are created by the Python scripts.
Optionally, delete other AWS resources such as the S3 bucket or IAM role created outside the CI/CD pipeline.
Conclusion
In this post, we demonstrated how enterprises can create MLOps workflows for their batch inference jobs using Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon SNS, HashiCorp Terraform, and GitLab CI/CD. The presented workflow automates data and model monitoring, model retraining, as well as batch job runs, code versioning, and infrastructure provisioning. This can lead to significant reductions in complexities and costs of maintaining batch inference jobs in production. For more information about implementation details, review the GitHub repo.
About the Authors
Hasan Shojaei is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history.
Wenxin Liu is a Sr. Cloud Infrastructure Architect. Wenxin advises enterprise companies on how to accelerate cloud adoption and supports their innovations on the cloud. He’s a pet lover and is passionate about snowboarding and traveling.
Vivek Lakshmanan is a Machine Learning Engineer at Amazon. He has a Master’s degree in Software Engineering with specialization in Data Science and several years of experience as an MLE. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers on cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking road trips.
Andy Cracchiolo is a Cloud Infrastructure Architect. With more than 15 years in IT infrastructure, Andy is an accomplished and results-driven IT professional. In addition to optimizing IT infrastructure, operations, and automation, Andy has a proven track record of analyzing IT operations, identifying inconsistencies, and implementing process enhancements that increase efficiency, reduce costs, and increase profits.
In the previous posts in this series, we introduced our research vision for Cloud Intelligence/AIOps (part 1) and how advanced AI can help design, build, and manage large-scale cloud platforms effectively and efficiently; we looked at solutions that are making many aspects of cloud operations more autonomous and proactive (part 2); and we discussed an important aspect of cloud management: RL-based tuning of application configuration parameters (part 3). In this post, we focus on the broader challenges of autonomously managing the entire cloud platform.
In an ideal world, almost all operations of a large-scale cloud platform would be autonomous, and the platform would always be at, or converging to, the operators’ desired state. However, this is not possible for a variety of reasons. Cloud applications and infrastructure are incredibly complex, and they change too much, too fast. For the foreseeable future, there will continue to be problems that are novel and/or too complex for automated solutions, no matter how intelligent, to address. These may arise due to complex cascading or unlikely simultaneous failures, unexpected interactions between components, challenging (or malicious) changes in workloads such as the rapid increase in traffic due to the COVID pandemic, or even external factors such as the need to reduce power usage in a particular region.
At the same time, rapid advances in machine learning and AI are enabling an increase in the automation of several aspects of cloud operations. Our second post in this series listed a number of these, including detection or problematic deployments, fault localization, log parsing, diagnosis of failures, prediction of capacity, and optimized container reallocation.
Spotlight: Microsoft research newsletter
Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
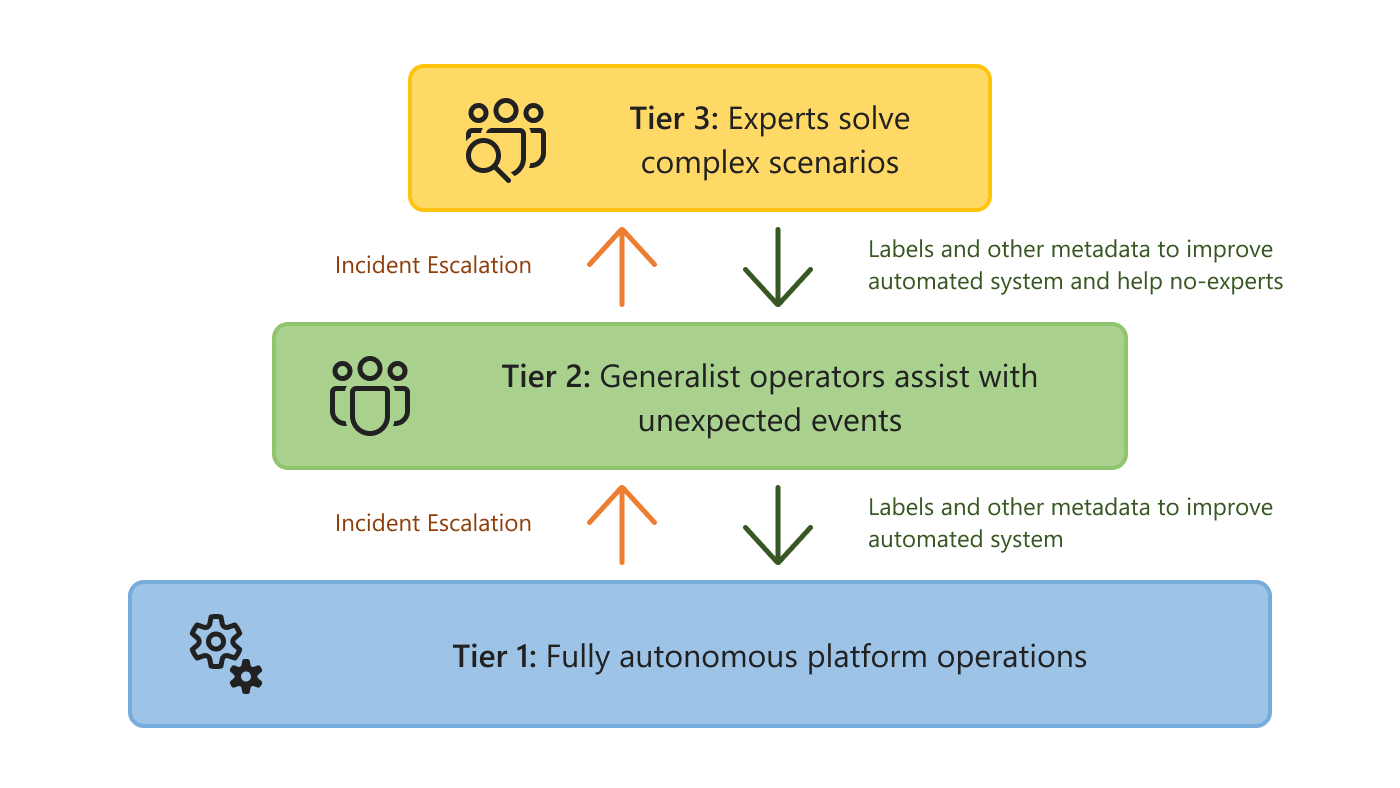
To reconcile these two realities, we introduce the concept of Tiered AIOps. The idea is to separate systems and issues into tiers of different levels of automation and human intervention. This separation comes in stages (Figure 1). The first stage has only two tiers: one where AI progressively automates routine operations and can mitigate and solve simple incidents without a human in the loop, and a second tier where expert human operators manage the long tail of incidents and scenarios that the AI systems cannot handle. As the AI in the first tier becomes more powerful, the same number of experts can manage larger and more complex cloud systems. However, this is not enough.
Figure 2: Tiered AIOps. Incidents not resolved by a tier get escalated to the next one. As upper tiers solve these incidents, this knowledge propagates to the previous tiers to improve their coverage with new models and labeled data.
New AI tools enable a final, even more scalable stage, where human expertise can also be separated into two tiers. In this stage, the middle tier involves situations and problems that the AI in the first level cannot handle, but which can be solved by non-expert, generalist human operators. AI in this second tier helps these operators manage the platform by lowering the level of expertise needed to respond to incidents. For example, the AI could automatically localize the source of an incident, recommend mitigation actions, and provide risk estimates and explanations to help operators reason about the best mitigating action to take. Finally, the last tier relies on expert engineers for complex and high-impact incidents that automated systems and generalists are unable to solve. In other words, we have the following tiers (Figure 2):
Tier 1: Fully autonomous platform operation. Automates what can be learned or predicted. Includes intelligent and proactive systems to prevent failures and resolution of incidents that follow patterns of past incidents.
Tier 2: Infrastructure for non-expert operators to manage systems and incidents. Receives context from events and incidents that are not handled in the first tier. AI systems provide context, summaries, and mitigation recommendations to generalist operators.
Tier 3: Infrastructure for experts to manage systems and incidents that are novel or highly complex. Receives context from events and incidents not handled in the first two tiers. Can enable experts to interact and manage a remote installation.
There are two types of AI systems involved: first, those that enable increasing levels of automation in the first and second tiers, and; second, the AI systems (different types of co-pilots) that assist operators. It is the latter type that enables the division between the second and third tiers, and also reduces the risk of imperfect or incomplete systems in the first tier. This separation between the top two tiers is also crucial for the operation of air-gapped clouds and makes it more feasible to deploy new datacenters in locations where there might not be the same level of expert operators.
The key idea in the Tiered AIOps concept is to simultaneously expand automation and increase the number of incidents that can be handled by the first tier, while recognizing that all three tiers are critical. The research agenda is to build systems and models to support automation and incident response in all three tiers.
Escalating incidents. Each tier must have safeguards to (automatically or not) escalate an issue to the next tier. For example, when the first tier detects that there is insufficient data, or that the confidence (risk) in a prediction is lower (higher) than a threshold, it should escalate, with the right context, to the next tier.
Migrating learnings. On the other hand, over time and with gained experience (which can be encoded in troubleshooting guides, new monitors, AI models, or better training data), repeated incidents and operations migrate toward the lower tiers, allowing operators to allocate costly expertise to highly complex and impactful incidents and decisions.
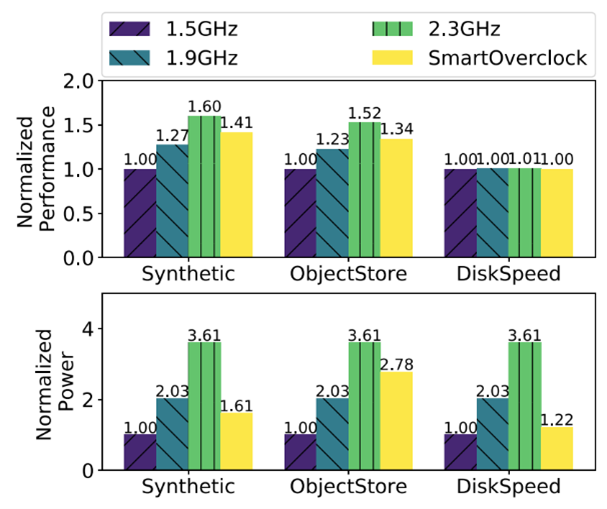
Figure 3: Performance and power of the SmartOverclock agent, showing near peak performance at significantly less power.
We will now discuss some work on extending the first tier with on-node learning, how to use new AI systems (large language models or simply LLMs) to assist operators in mitigating incidents and to move toward enabling the second tier, and, finally, how the third tier enables air-gapped clouds.
Tier 1: On-node learning
Managing a cloud platform requires control loops and agents with many different granularities and time scales. Some agents need to be located on individual nodes, either because of latency requirements of the decisions they make, or because they depend on telemetry that is too fine-grained and large to leave the node. Examples of these agents include configuration (credentials, firewalls, operating system updates), services like virtual machine (VM) creation, monitoring and logging, watchdogs, resource controls (e.g., power, memory, or CPU allocation), and access daemons.
Any agent that can use data about current workload characteristics or system state to guide dynamic adjustment of their behavior can potentially take advantage of machine learning (ML). However, current ML solutions such as Resource Central (SOSP’17) require data and decisions to run in a dedicated service outside of the server nodes. The problem is that for some agents this is not feasible, as they either have to make fast decisions or require data that cannot leave the node.
In SOL: Safe On-Node Learning in Cloud Platforms (ASPLOS’22), we proposed a framework that allows local agents to use modern ML techniques in a safe, robust, and effective way. We identified three classes of local agents that can benefit from ML. First, agents that assign resources (CPU, memory, power) benefit from near real-time workload information. Making these decisions quickly and with fine-grained telemetry enables better assignments with smaller impact to customer quality of service (QoS). Second, monitoring and logging agents, which must run on each node, can benefit from online learning algorithms, such as multi-armed bandits to smartly decide which telemetry data to sample and at which frequency, while staying within a sampling budget. Lastly, watchdogs, which monitor for metrics that indicate failures, can benefit from learning algorithms to detect problems and take mitigating actions sooner, as well as detect and diagnose more complex problems that simpler systems would not detect.
SOL makes it easy to integrate protections against invalid data, inaccurate or drifting AI models, and delayed predictions, and to add safeguards in the actions the models can take, through a simple interface. As examples, we developed agents to do CPU overclocking, CPU harvesting, and memory page hotness classification. In our experiments (Figure 3), the overclocking agent, for example, achieved near-peak normalized performance for different workloads, at nearly half of the power draw, while responding well to many failure conditions in the monitoring itself. See our paper for more details.
Tier 2: Incident similarity and mitigation with LLMs
As an example of how AI systems can enable the second tier, we are exploring how LLMs can help in mitigating and finding the root cause of incidents in cloud operations. When an incident happens in a cloud system, either generated by automated alarms or by customer-reported issues, a team of one or more on-call engineers must quickly find ways to mitigate the incident (resolving the symptoms), and then find the cause of the incident for a permanent fix and to avoid the incident in the future.
There are many steps involved in this process, and they are highly variable. There is also context that relates to the incident, which grows as both automated systems and on-call engineers perform tests, look at logs, and go through a cycle of forming, testing, and validating hypotheses. We are investigating using LLMs to help with several of these steps, including automatically generating summaries of the cumulative status of an incident, finding similar incidents in the database of past incidents, and proposing mitigation steps based on these similar incidents. There is also an ever-growing library of internal troubleshooting guides (TSGs) created by engineers, together with internal and external documentation on the systems involved. We are using LLMs to extract and summarize information from these combined sources in a way that is relevant to the on-call engineer.
We are also using LLMs to find the root cause of incidents. In a recent paper published in ISCE (2023), the Microsoft 365 Systems Innovation research group demonstrated the usefulness of LLMs in determining the root cause of incidents from the title and summary of the incident. In a survey conducted as part of the work, more than 70% of the on-call engineers gave a rating of 3 out of 5 or better on the usefulness of the recommendations in a real-time incident resolution setting.
There is still enormous untapped potential in using these methods, along with some interesting challenges. In aggregate, these efforts are a great step toward the foundation for the second tier in our vision. They can assist on-call engineers, enable junior engineers to be much more effective in handling more incidents, reduce the time to mitigation, and, finally, give room for the most expert engineers to work on the third tier, focusing on complex, atypical, and novel incidents.
Tier 3: Air-gapped clouds
We now turn to an example where the separation between the second and third tiers could enable significantly simplified operations. Air-gapped datacenters, characterized by their isolated nature and restricted access, provide a secure environment for managing sensitive data while prioritizing privacy. In such datacenters, direct access is limited and highly controlled, being operated locally by authorized employees, ensuring that data is handled with utmost care and confidentiality. However, this level of isolation also presents unique challenges when it comes to managing the day-to-day operations and addressing potential issues, as Microsoft’s expert operators do not have physical or direct access to the infrastructure.
In such an environment, future tiered AIOps could improve operations, while maintaining the strict data and communication isolation requirements. The first tier would play a critical role by significantly reducing the occurrence of incidents through the implementation of automated operations. However, the second and third tiers would be equally vital. The second tier would empower local operators on-site to address most issues that the first tier cannot. Even with AI assistance, there would be instances requiring additional expertise beyond that which is available locally. Unfortunately, the experts in the third tier may not even have access to remote desktops, or to the results of queries or commands. LLMs would serve a crucial role here, as they could become an ideal intermediary between tiers 2 and 3, sharing high-level descriptions of problems without sending sensitive information.
Figure 4: LLM-intermediated communication between remote experts (Tier 3) and generalist operators (Tier 2) to solve problems in an air-gapped datacenter.
In an interactive session (Figure 4), an LLM with access to the air-gapped datacenter systems could summarize and sanitize the problem description in natural language (①). A remote expert in Tier 3 would then formulate hypotheses and send high-level instructions in natural language for more investigation or for mitigation (②). The LLM could use the high-level instructions to form a specialized plan. For example, it could query devices with a knowledge of the datacenter topology that the expert does not have; interpret, summarize, and sanitize the results (with or without the help of the generalist, on-site operators) (③); and send the interpretation of the results back to the experts, again in natural language (④). Depending on the problem, this cycle could repeat until the problem is solved (⑤). Crucially, while the operators at the air-gapped cloud would be in the loop, they wouldn’t need deep expertise in all systems to perform the required actions and interpret the results.
Conclusion
Cloud platform operators have seen massive, continuous growth in scale. To remain competitive and viable, we must decouple the scaling of human support operations from this growth. AI offers great hope in increasing automation of platform management, but because of constant change in the systems, environment, and demands, there will likely always be decisions and incidents requiring expert human input. In this post, we described our vision of Tiered AIOps as the way to enable and achieve this decoupling and maximize the effectiveness of both AI tools and human expertise.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep-diving on new GeForce RTX 40 Series GPU features, technologies and resources and how they dramatically accelerate content creation.
As beautiful and extraordinary as art forms can be, it can be easy to forget the simple joy and comforting escapism that content creation can provide for artists across creative fields.
Janice K. Lee, a.k.a Janice.Journal — the subject of this week’s In the NVIDIA Studio installment — is a TikTok sensation using AI to accelerate her creative process, find inspiration and automate repetitive tasks.
Also this week, NVIDIA Studio technology is powering some of the most popular mobile and desktop apps — driving creative workflows of both aspiring artists and creative professionals.
TikTok and CapCut, Powered by NVIDIA and the Cloud
Week by week, AI becomes more ubiquitous within content creation.
Take the popular social media app TikTok. All of its mobile app features, including AI Green Screen, are accelerated by GeForce RTX GPUs in the cloud. Other parts of TikTok creator workflows are also accelerated — Descript AI, a popular generative AI-powered video editing app, runs 50% faster on the latest NVIDIA L4 Tensor Core GPUs versus T4 Tensor Core GPUs.
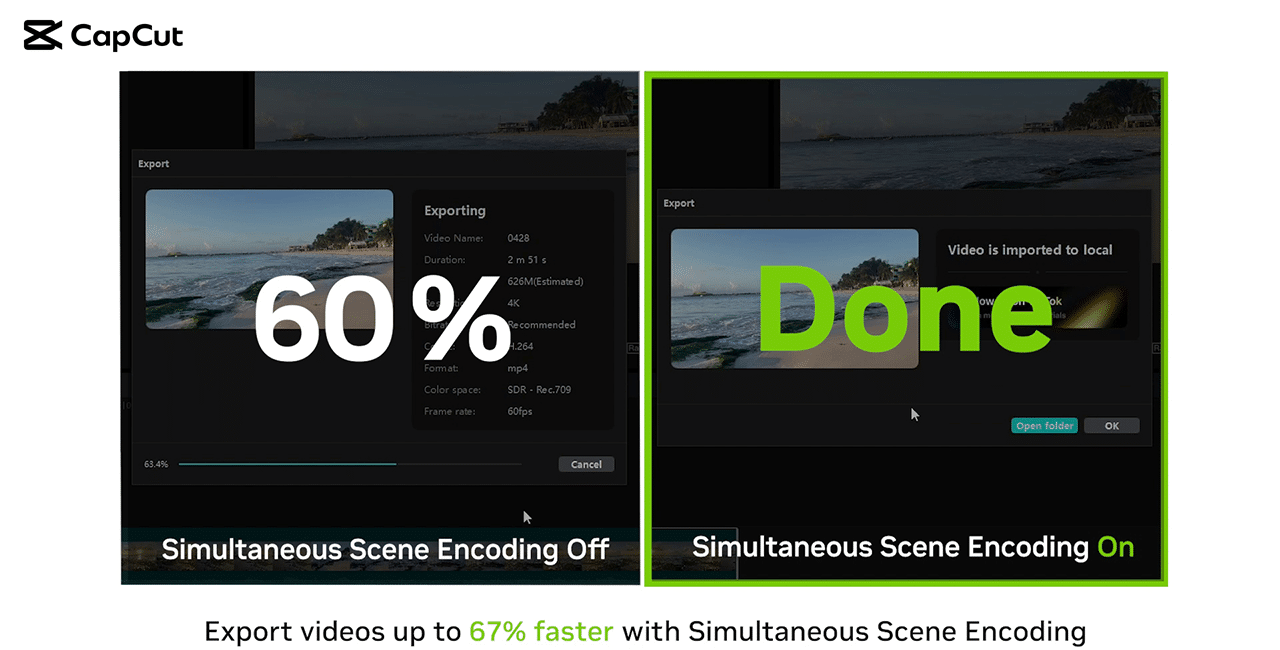
CapCut, the most widely used video editor by TikTok users, enables Simultaneous Scene Encoding, a functionality that sends independent groups of scenes to an NVIDIA Encoder (NVENC), contributing to shorter video export times without affecting image quality. This technology performs over 2x faster on NVIDIA GeForce RTX 4080 graphics cards versus on Apple’s M2 Ultra.
Tests were conducted by CapCut using CapCut v2.2.0 (beta) on desktops equipped with GeForce RTX 4090 to export 180s 4K 60fps H.264 video. Video exporting was accelerated.
Advanced users can move footage to their preferred desktop video editing app using native GPU-acceleration and RTX technology. This includes AV1 dual encoders (NVIDIA GeForce RTX 4070 Ti graphics cards or higher required) for 40% better video quality for livestreamers, while video editors can slash export times nearly in half.
Janice.Journal Gets AI Art Blanche
Janice.Journal, a self-taught 3D creator, was motivated to learn new art skills as a way to cope with her busy schedule.
“I was going through a tough time during my junior year of college with classes and clubs,” she said. “With no time to hang out with friends or decompress, my only source of comfort was learning something new every night for 20 minutes.”
Her passion for 3D creation quickly became evident. While Janice.Journal does consulting work during the day, she deep-dives into 3D creation at night, creating stunning scenes and tutorials to help other artists get started.
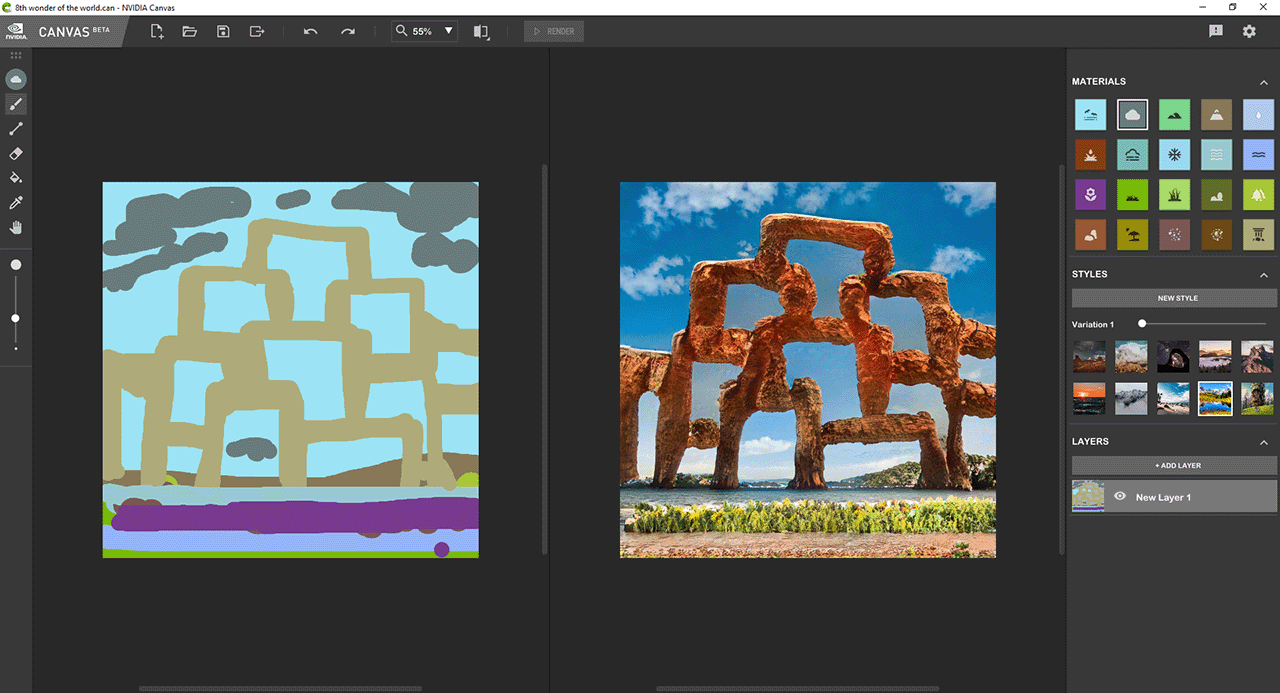
One of her recent projects involved using the free NVIDIA Canvas beta app, which uses AI to interpret basic lines and shapes, translating them into realistic landscape images and textures.
In the above video, Janice.Journal aimed to create the “Eighth Wonder of the World,” a giant arch inspired by the natural sandstone formations in Arches National Park in Utah.
“I wanted to create something that looked familiar enough where you could conceive to see it on ‘National Geographic’ but would still seem fantastical, awe-inspiring and simultaneously make the viewer question if it was real or fake,” said Janice.Journal.
NVIDIA Canvas AI-assisted painting.
Using Canvas’s 20 material brushes and nine style images, each with 10 variations, Janice.Journal got to work.
She said she “got a bit carried away” on Canvas, resulting in an incredible masterpiece.
Janice.Journal then had the option to export her painting into either a PNG or layered PSD file format to import into graphic design apps like Adobe Photoshop.
“The Eighth Wonder of the World.”
Canvas is especially useful for concept artists looking to rapidly explore new ideas and for architects aiming to quickly draft backdrops and environments for buildings. With Canvas, Janice.Journal could rapidly paint a landscape without having to search for hours for the perfect stock photo, saving her valuable time to hone her 3D skills instead.
“I’m still blown away trying it out for myself,” said Janice.Journal. “Seeing my simple drawings turn into fully HD images is wild — it really reminds me that the future is now.”
Janice.Journal’s portfolio features bright, vibrant visuals with a soft touch. Her 3D scene “Gameboy” features two levels — no, not gaming levels, but living quarters built into a Gameboy, bringing to life every child’s dream.
Would you love to live here?
Most artists start with a rough physical sketch to get concepts on paper, then move to Blender to block out basic shapes and sculpt models in finer detail.
AI shines at this point in the workflow. Janice.Journal’s GeForce RTX 3090 GPU-powered system unlocks Blender’s Cycles RTX-accelerated OptiX ray tracing in the viewport, reducing noise and improving interactivity in the viewport for fluid movement with photorealistic visuals.
Work-in-progress ‘Gameboy’ render.
“Simply put, GPU acceleration and AI allow me to see renders in real time as they process modeling, lighting and the entire environment, enabling a preview as if I were to hit ‘render’ right away,” said Janice.Journal. “It makes life 10 times easier for me.”
Janice.Journal has also been experimenting with AI-generated images as a way to brainstorm concepts and push creative boundaries — in her opinion, the most optimal use of AI.
Once everything has been modeled, Janice.Journal adds textures by playing around in Blender, applying clay shaders or displacement modifiers for “bumpier” textures. Then, she adds lighting and finishing touches to complete the ambience of the scene.
Today, in partnership with Google Cloud, we’re beta launching SynthID, a new tool for watermarking and identifying AI-generated images. It’s being released to a limited number of Vertex AI customers using Imagen, one of our latest text-to-image models that uses input text to create photorealistic images. This technology embeds a digital watermark directly into the pixels of an image, making it imperceptible to the human eye, but detectable for identification. While generative AI can unlock huge creative potential, it also presents new risks, like creators spreading false information — both intentionally or unintentionally. Being able to identify AI-generated content is critical to empowering people with knowledge of when they’re interacting with generated media, and for helping prevent the spread of misinformation.Read More
As part of the 2023 Data Science Conference (DSCO 23), AWS partnered with the Data Institute at the University of San Francisco (USF) to conduct a datathon. Participants, both high school and undergraduate students, competed on a data science project that focused on air quality and sustainability. The Data Institute at the USF aims to support cross-disciplinary research and education in the field of data science. The Data Institute and the Data Science Conference provide a distinctive fusion of cutting-edge academic research and the entrepreneurial culture of the technology industry in the San Francisco Bay Area.
The students used Amazon SageMaker Studio Lab, which is a free platform that provides a JupyterLab environment with compute (CPU and GPU) and storage (up to 15GB). Because most of the students were unfamiliar with machine learning (ML), they were given a brief tutorial illustrating how to set up an ML pipeline: how to conduct exploratory data analysis, feature engineering, model building, and model evaluation, and how to set up inference and monitoring. The tutorial referenced Amazon Sustainability Data Initiative (ASDI) datasets from the National Oceanic and Atmospheric Administration (NOAA) and OpenAQ to build an ML model to predict air quality levels using weather data via a binary classification AutoGluon model. Next, the students were turned loose to work on their own projects in their teams. The winning teams were led by Peter Ma, Ben Welner, and Ei Coltin, who were all awarded prizes at the opening ceremony of the Data Science Conference at USF.
Response from the event
“This was a fun event, and a great way to work with others. I learned some Python coding in class but this helped make it real. During the datathon, my team member and I conducted research on different ML models (LightGBM, logistic regression, SVM models, Random Forest Classifier, etc.) and their performance on an AQI dataset from NOAA aimed at detecting the toxicity of the atmosphere under specific weather conditions. We built a gradient boosting classifier to predict air quality from weather statistics.”
– Anay Pant, a junior at the Athenian School, Danville, California, and one of the winners of the datathon.
“AI is becoming increasingly important in the workplace, and 82% of companies need employees with machine learning skills. It’s critical that we develop the talent needed to build products and experiences that we will all benefit from, this includes software engineering, data science, domain knowledge, and more. We were thrilled to help the next generation of builders explore machine learning and experiment with its capabilities. Our hope is that they take this forward and expand their ML knowledge. I personally hope to one day use an app built by one of the students at this datathon!”
– Sherry Marcus, Director of AWS ML Solutions Lab.
“This is the first year we used SageMaker Studio Lab. We were pleased by how quickly high school/undergraduate students and our graduate student mentors could start their projects and collaborate using SageMaker Studio.”
– Diane Woodbridge from the Data Institute of the University of San Francisco.
Get started with Studio Lab
If you missed this datathon, you can still register for your own Studio Lab account and work on your own project. If you’re interested in running your own hackathon, reach out to your AWS representative for a Studio Lab referral code, which will give your participants immediate access to the service. Finally, you can look for next year’s challenge at the USF Data Institute.
About the Authors
Neha Narwal is a Machine Learning Engineer at AWS Bedrock where she contributes to development of large language models for generative AI applications. Her focus lies at the intersection of science and engineering to influence research in Natural Language Processing domain.
Vidya Sagar Ravipati is a Applied Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Posted by Dahun Kim and Weicheng Kuo, Research Scientists, Google
The ability to detect objects in the visual world is crucial for computer vision and machine intelligence, enabling applications like adaptive autonomous agents and versatile shopping systems. However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. To overcome this, the open-vocabulary detection task (OVD) has emerged, utilizing image-text pairs for training and incorporating new category names at test time by associating them with the image content. By treating categories as text embeddings, open-vocabulary detectors can predict a wide range of unseen objects. Various techniques such as image-text pre-training, knowledge distillation, pseudo labeling, and frozen models, often employing convolutional neural network (CNN) backbones, have been proposed. With the growing popularity of vision transformers (ViTs), it is important to explore their potential for building proficient open-vocabulary detectors.
The existing approaches assume the availability of pre-trained vision-language models (VLMs) and focus on fine-tuning or distillation from these models to address the disparity between image-level pre-training and object-level fine-tuning. However, as VLMs are primarily designed for image-level tasks like classification and retrieval, they do not fully leverage the concept of objects or regions during the pre-training phase. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
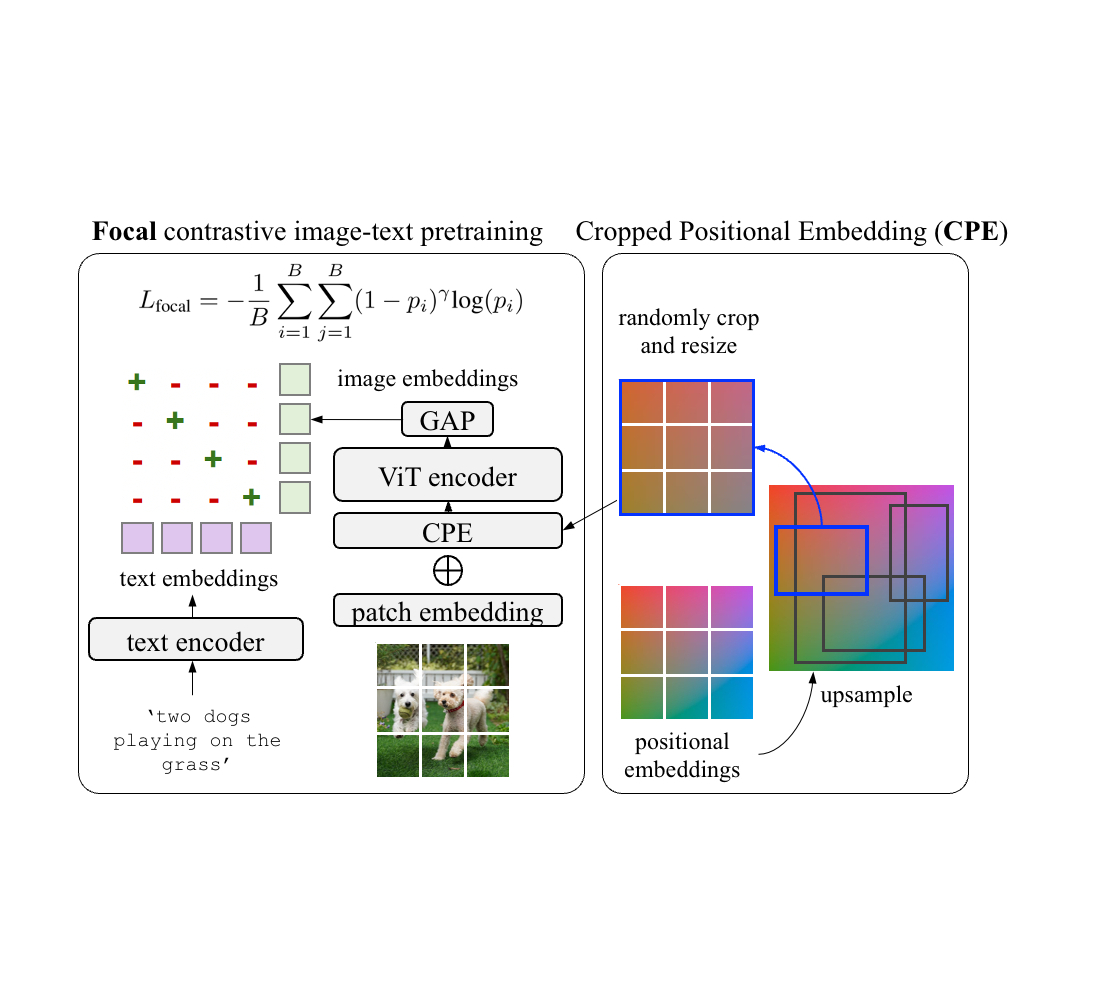
In “RO-ViT: Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers”, presented at CVPR 2023, we introduce a simple method to pre-train vision transformers in a region-aware manner to improve open-vocabulary detection. In vision transformers, positional embeddings are added to image patches to encode information about the spatial position of each patch within the image. Standard pre-training typically uses full-image positional embeddings, which does not generalize well to detection tasks. Thus, we propose a new positional embedding scheme, called “cropped positional embedding”, that better aligns with the use of region crops in detection fine-tuning. In addition, we replace the softmax cross entropy loss with focal loss in contrastive image-text learning, allowing us to learn from more challenging and informative examples. Finally, we leverage recent advances in novel object proposals to enhance open-vocabulary detection fine-tuning, which is motivated by the observation that existing methods often miss novel objects during the proposal stage due to overfitting to foreground categories. We are also releasing the code here.
Region-aware image-text pre-training
Existing VLMs are trained to match an image as a whole to a text description. However, we observe there is a mismatch between the way the positional embeddings are used in the existing contrastive pre-training approaches and open-vocabulary detection. The positional embeddings are important to transformers as they provide the information of where each element in the set comes from. This information is often useful for downstream recognition and localization tasks. Pre-training approaches typically apply full-image positional embeddings during training, and use the same positional embeddings for downstream tasks, e.g., zero-shot recognition. However, the recognition occurs at region-level for open-vocabulary detection fine-tuning, which requires the full-image positional embeddings to generalize to regions that they never see during the pre-training.
To address this, we propose cropped positional embeddings (CPE). With CPE, we upsample positional embeddings from the image size typical for pre-training, e.g., 224×224 pixels, to that typical for detection tasks, e.g., 1024×1024 pixels. Then we randomly crop and resize a region, and use it as the image-level positional embeddings during pre-training. The position, scale, and aspect ratio of the crop is randomly sampled. Intuitively, this causes the model to view an image not as a full image in itself, but as a region crop from some larger unknown image. This better matches the downstream use case of detection where recognition occurs at region- rather than image-level.
For the pre-training, we propose cropped positional embedding (CPE) which randomly crops and resizes a region of positional embeddings instead of using the whole-image positional embedding (PE). In addition, we use focal loss instead of the common softmax cross entropy loss for contrastive learning.
We also find it beneficial to learn from hard examples with a focal loss. Focal loss enables finer control over how hard examples are weighted than what the softmax cross entropy loss can provide. We adopt the focal loss and replace it with the softmax cross entropy loss in both image-to-text and text-to-image losses. Both CPE and focal loss introduce no extra parameters and minimal computation costs.
Open-vocabulary detector fine-tuning
An open-vocabulary detector is trained with the detection labels of ‘base’ categories, but needs to detect the union of ‘base’ and ‘novel’ (unlabeled) categories at test time. Despite the backbone features pre-trained from the vast open-vocabulary data, the added detector layers (neck and heads) are newly trained with the downstream detection dataset. Existing approaches often miss novel/unlabeled objects in the object proposal stage because the proposals tend to classify them as background. To remedy this, we leverage recent advances in a novel object proposal method and adopt the localization quality-based objectness (i.e., centerness score) instead of object-or-not binary classification score, which is combined with the detection score. During training, we compute the detection scores for each detected region as the cosine similarity between the region’s embedding (computed via RoI-Align operation) and the text embeddings of the base categories. At test time, we append the text embeddings of novel categories, and the detection score is now computed with the union of the base and novel categories.
The pre-trained ViT backbone is transferred to the downstream open-vocabulary detection by replacing the global average pooling with detector heads. The RoI-Align embeddings are matched with the cached category embeddings to obtain the VLM score, which is combined with the detection score into the open-vocabulary detection score.
Results
We evaluate RO-ViT on the LVIS open-vocabulary detection benchmark. At the system-level, our best model achieves 33.6 box average precision on rare categories (APr) and 32.1 mask APr, which outperforms the best existing ViT-based approach OWL-ViT by 8.0 APr and the best CNN-based approach ViLD-Ens by 5.8 mask APr. It also exceeds the performance of many other approaches based on knowledge distillation, pre-training, or joint training with weak supervision.
RO-ViT outperforms both the state-of-the-art (SOTA) ViT-based and CNN-based methods on LVIS open-vocabulary detection benchmark. We show mask AP on rare categories (APr) , except for SOTA ViT-based (OwL-ViT) where we show box AP.
Apart from evaluating region-level representation through open-vocabulary detection, we evaluate the image-level representation of RO-ViT in image-text retrieval through the MS-COCO and Flickr30K benchmarks. Our model with 303M ViT outperforms the state-of-the-art CoCa model with 1B ViT on MS COCO, and is on par on Flickr30K. This shows that our pre-training method not only improves the region-level representation but also the global image-level representation for retrieval.
We show zero-shot image-text retrieval on MS COCO and Flickr30K benchmarks, and compare with dual-encoder methods. We report recall@1 (top-1 recall) on image-to-text (I2T) and text-to-image (T2I) retrieval tasks. RO-ViT outperforms the state-of-the-art CoCa with the same backbone.
RO-ViT open-vocabulary detection on LVIS. We only show the novel categories for clarity. RO-ViT detects many novel categories that it has never seen during detection training: “fishbowl”, “sombrero”, “persimmon”, “gargoyle”.
Visualization of positional embeddings
We visualize and compare the learned positional embeddings of RO-ViT with the baseline. Each tile is the cosine similarity between positional embeddings of one patch and all other patches. For example, the tile in the top-left corner (marked in red) visualizes the similarity between the positional embedding of the location (row=1, column=1) and those positional embeddings of all other locations in 2D. The brightness of the patch indicates how close the learned positional embeddings of different locations are. RO-ViT forms more distinct clusters at different patch locations showing symmetrical global patterns around the center patch.
Each tile shows the cosine similarity between the positional embedding of the patch (at the indicated row-column position) and the positional embeddings of all other patches. ViT-B/16 backbone is used.
Conclusion
We present RO-ViT, a contrastive image-text pre-training framework to bridge the gap between image-level pre-training and open-vocabulary detection fine-tuning. Our methods are simple, scalable, and easy to apply to any contrastive backbones with minimal computation overhead and no increase in parameters. RO-ViT achieves the state-of-the-art on LVIS open-vocabulary detection benchmark and on the image-text retrieval benchmarks, showing the learned representation is not only beneficial at region-level but also highly effective at the image-level. We hope this study can help the research on open-vocabulary detection from the perspective of image-text pre-training which can benefit both region-level and image-level tasks.
Acknowledgements
Dahun Kim, Anelia Angelova, and Weicheng Kuo conducted this work and are now at Google DeepMind. We would like to thank our colleagues at Google Research for their advice and helpful discussions.










 Hasan Shojaei is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history.
Hasan Shojaei is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history. Wenxin Liu is a Sr. Cloud Infrastructure Architect. Wenxin advises enterprise companies on how to accelerate cloud adoption and supports their innovations on the cloud. He’s a pet lover and is passionate about snowboarding and traveling.
Wenxin Liu is a Sr. Cloud Infrastructure Architect. Wenxin advises enterprise companies on how to accelerate cloud adoption and supports their innovations on the cloud. He’s a pet lover and is passionate about snowboarding and traveling. Vivek Lakshmanan is a Machine Learning Engineer at Amazon. He has a Master’s degree in Software Engineering with specialization in Data Science and several years of experience as an MLE. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers on cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking road trips.
Vivek Lakshmanan is a Machine Learning Engineer at Amazon. He has a Master’s degree in Software Engineering with specialization in Data Science and several years of experience as an MLE. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers on cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking road trips. Andy Cracchiolo is a Cloud Infrastructure Architect. With more than 15 years in IT infrastructure, Andy is an accomplished and results-driven IT professional. In addition to optimizing IT infrastructure, operations, and automation, Andy has a proven track record of analyzing IT operations, identifying inconsistencies, and implementing process enhancements that increase efficiency, reduce costs, and increase profits.
Andy Cracchiolo is a Cloud Infrastructure Architect. With more than 15 years in IT infrastructure, Andy is an accomplished and results-driven IT professional. In addition to optimizing IT infrastructure, operations, and automation, Andy has a proven track record of analyzing IT operations, identifying inconsistencies, and implementing process enhancements that increase efficiency, reduce costs, and increase profits.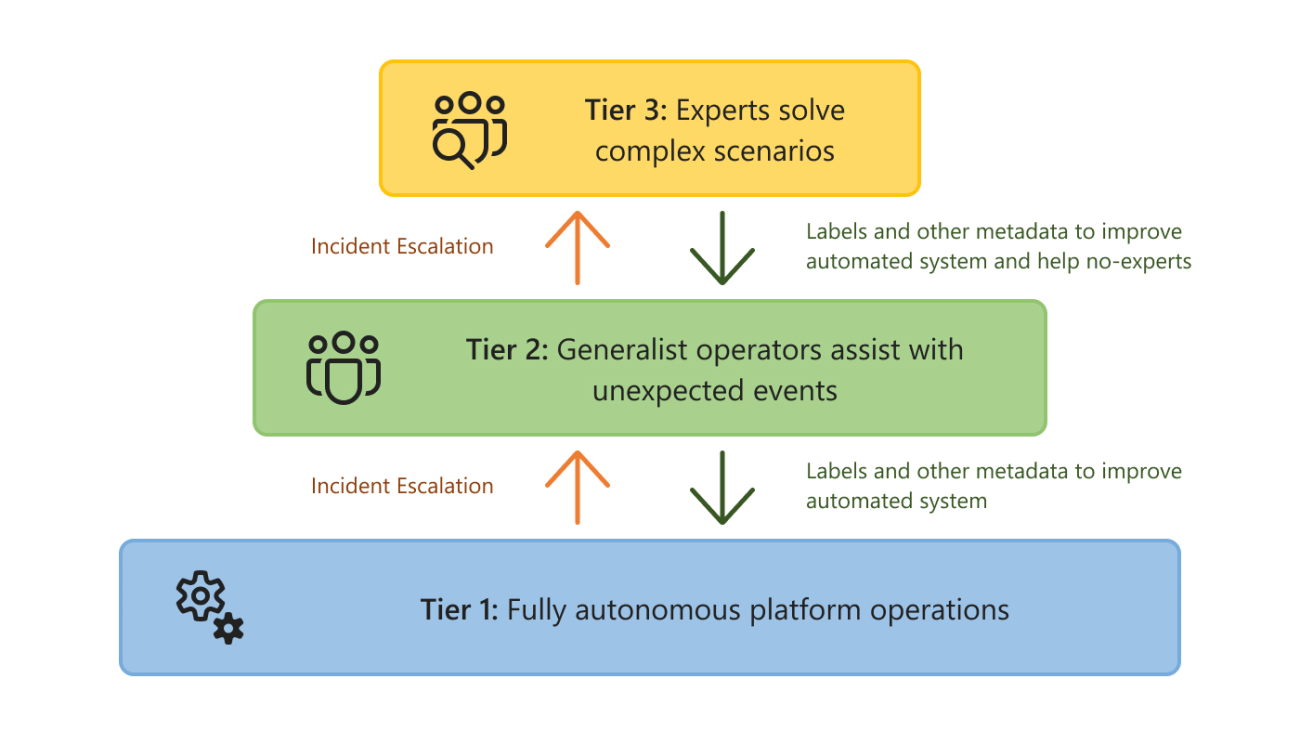




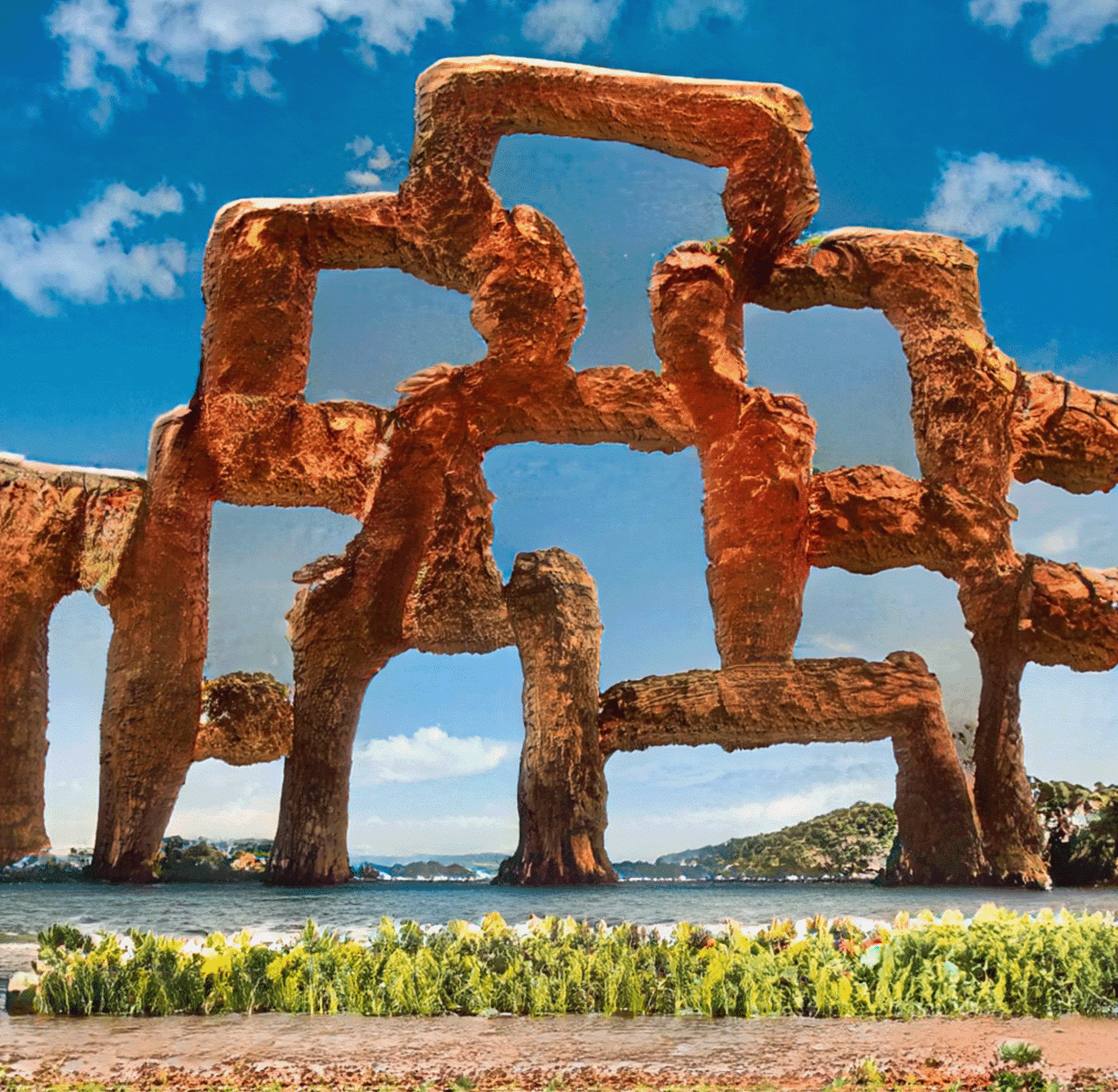



 We’re introducing Google Cloud healthcare customers using Med-PaLM 2 and other generative AI solutions.
We’re introducing Google Cloud healthcare customers using Med-PaLM 2 and other generative AI solutions.



 Neha Narwal is a Machine Learning Engineer at AWS Bedrock where she contributes to development of large language models for generative AI applications. Her focus lies at the intersection of science and engineering to influence research in Natural Language Processing domain.
Neha Narwal is a Machine Learning Engineer at AWS Bedrock where she contributes to development of large language models for generative AI applications. Her focus lies at the intersection of science and engineering to influence research in Natural Language Processing domain. Vidya Sagar Ravipati is a Applied Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Applied Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.