A full-scale error-corrected quantum computer will be able to solve some problems that are impossible for classical computers, but building such a device is a huge endeavor. We are proud of the milestones that we have achieved toward a fully error-corrected quantum computer, but that large-scale computer is still some number of years away. Meanwhile, we are using our current noisy quantum processors as flexible platforms for quantum experiments.
In contrast to an error-corrected quantum computer, experiments in noisy quantum processors are currently limited to a few thousand quantum operations or gates, before noise degrades the quantum state. In 2019 we implemented a specific computational task called random circuit sampling on our quantum processor and showed for the first time that it outperformed state-of-the-art classical supercomputing.
Although they have not yet reached beyond-classical capabilities, we have also used our processors to observe novel physical phenomena, such as time crystals and Majorana edge modes, and have made new experimental discoveries, such as robust bound states of interacting photons and the noise-resilience of Majorana edge modes of Floquet evolutions.
We expect that even in this intermediate, noisy regime, we will find applications for the quantum processors in which useful quantum experiments can be performed much faster than can be calculated on classical supercomputers — we call these “computational applications” of the quantum processors. No one has yet demonstrated such a beyond-classical computational application. So as we aim to achieve this milestone, the question is: What is the best way to compare a quantum experiment run on such a quantum processor to the computational cost of a classical application?
We already know how to compare an error-corrected quantum algorithm to a classical algorithm. In that case, the field of computational complexity tells us that we can compare their respective computational costs — that is, the number of operations required to accomplish the task. But with our current experimental quantum processors, the situation is not so well defined.
In “Effective quantum volume, fidelity and computational cost of noisy quantum processing experiments”, we provide a framework for measuring the computational cost of a quantum experiment, introducing the experiment’s “effective quantum volume”, which is the number of quantum operations or gates that contribute to a measurement outcome. We apply this framework to evaluate the computational cost of three recent experiments: our random circuit sampling experiment, our experiment measuring quantities known as “out of time order correlators” (OTOCs), and a recent experiment on a Floquet evolution related to the Ising model. We are particularly excited about OTOCs because they provide a direct way to experimentally measure the effective quantum volume of a circuit (a sequence of quantum gates or operations), which is itself a computationally difficult task for a classical computer to estimate precisely. OTOCs are also important in nuclear magnetic resonance and electron spin resonance spectroscopy. Therefore, we believe that OTOC experiments are a promising candidate for a first-ever computational application of quantum processors.
 |
| Plot of computational cost and impact of some recent quantum experiments. While some (e.g., QC-QMC 2022) have had high impact and others (e.g., RCS 2023) have had high computational cost, none have yet been both useful and hard enough to be considered a “computational application.” We hypothesize that our future OTOC experiment could be the first to pass this threshold. Other experiments plotted are referenced in the text. |
Random circuit sampling: Evaluating the computational cost of a noisy circuit
When it comes to running a quantum circuit on a noisy quantum processor, there are two competing considerations. On one hand, we aim to do something that is difficult to achieve classically. The computational cost — the number of operations required to accomplish the task on a classical computer — depends on the quantum circuit’s effective quantum volume: the larger the volume, the higher the computational cost, and the more a quantum processor can outperform a classical one.
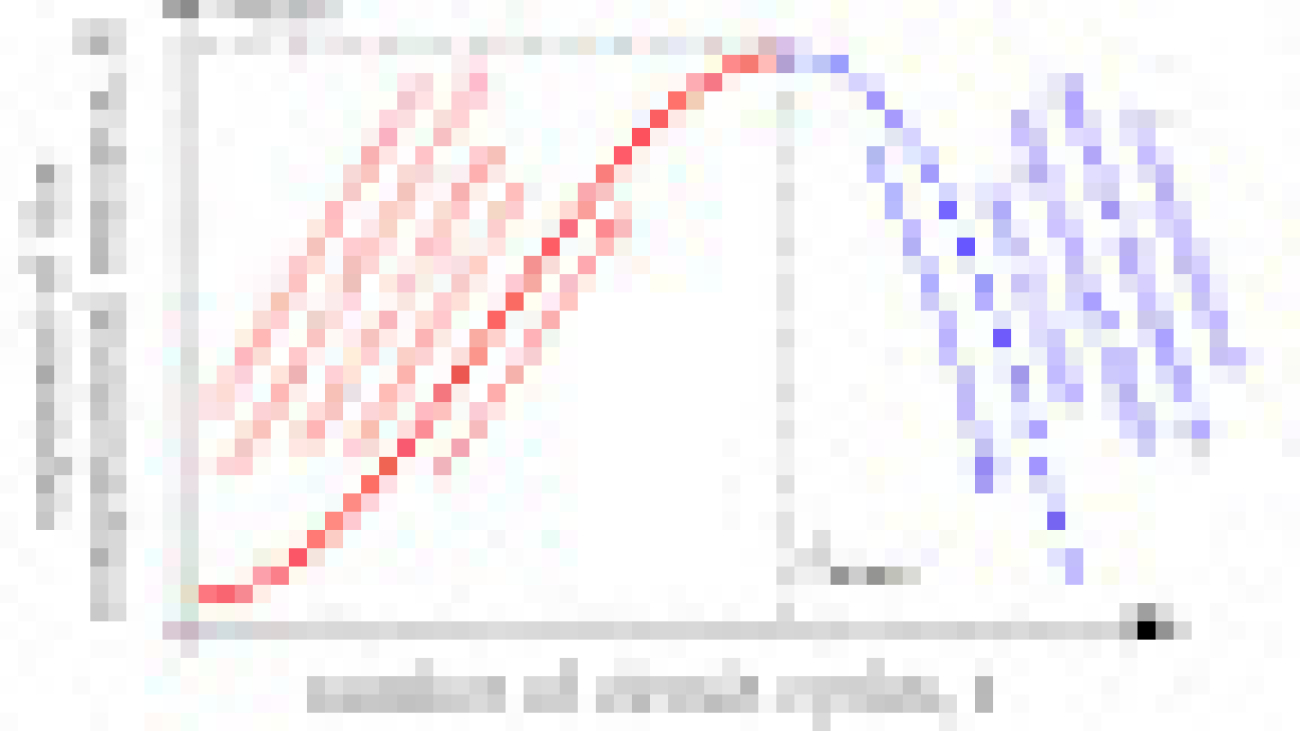
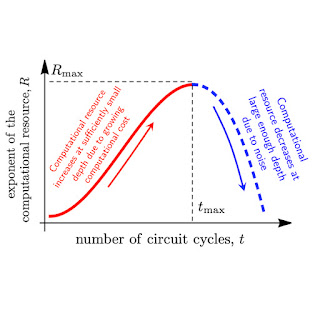
But on the other hand, on a noisy processor, each quantum gate can introduce an error to the calculation. The more operations, the higher the error, and the lower the fidelity of the quantum circuit in measuring a quantity of interest. Under this consideration, we might prefer simpler circuits with a smaller effective volume, but these are easily simulated by classical computers. The balance of these competing considerations, which we want to maximize, is called the “computational resource”, shown below.
 |
| Graph of the tradeoff between quantum volume and noise in a quantum circuit, captured in a quantity called the “computational resource.” For a noisy quantum circuit, this will initially increase with the computational cost, but eventually, noise will overrun the circuit and cause it to decrease. |
We can see how these competing considerations play out in a simple “hello world” program for quantum processors, known as random circuit sampling (RCS), which was the first demonstration of a quantum processor outperforming a classical computer. Any error in any gate is likely to make this experiment fail. Inevitably, this is a hard experiment to achieve with significant fidelity, and thus it also serves as a benchmark of system fidelity. But it also corresponds to the highest known computational cost achievable by a quantum processor. We recently reported the most powerful RCS experiment performed to date, with a low measured experimental fidelity of 1.7×10-3, and a high theoretical computational cost of ~1023. These quantum circuits had 700 two-qubit gates. We estimate that this experiment would take ~47 years to simulate in the world’s largest supercomputer. While this checks one of the two boxes needed for a computational application — it outperforms a classical supercomputer — it is not a particularly useful application per se.
OTOCs and Floquet evolution: The effective quantum volume of a local observable
There are many open questions in quantum many-body physics that are classically intractable, so running some of these experiments on our quantum processor has great potential. We typically think of these experiments a bit differently than we do the RCS experiment. Rather than measuring the quantum state of all qubits at the end of the experiment, we are usually concerned with more specific, local physical observables. Because not every operation in the circuit necessarily impacts the observable, a local observable’s effective quantum volume might be smaller than that of the full circuit needed to run the experiment.
We can understand this by applying the concept of a light cone from relativity, which determines which events in space-time can be causally connected: some events cannot possibly influence one another because information takes time to propagate between them. We say that two such events are outside their respective light cones. In a quantum experiment, we replace the light cone with something called a “butterfly cone,” where the growth of the cone is determined by the butterfly speed — the speed with which information spreads throughout the system. (This speed is characterized by measuring OTOCs, discussed later.) The effective quantum volume of a local observable is essentially the volume of the butterfly cone, including only the quantum operations that are causally connected to the observable. So, the faster information spreads in a system, the larger the effective volume and therefore the harder it is to simulate classically.
 |
| A depiction of the effective volume Veff of the gates contributing to the local observable B. A related quantity called the effective area Aeff is represented by the cross-section of the plane and the cone. The perimeter of the base corresponds to the front of information travel that moves with the butterfly velocity vB. |
We apply this framework to a recent experiment implementing a so-called Floquet Ising model, a physical model related to the time crystal and Majorana experiments. From the data of this experiment, one can directly estimate an effective fidelity of 0.37 for the largest circuits. With the measured gate error rate of ~1%, this gives an estimated effective volume of ~100. This is much smaller than the light cone, which included two thousand gates on 127 qubits. So, the butterfly velocity of this experiment is quite small. Indeed, we argue that the effective volume covers only ~28 qubits, not 127, using numerical simulations that obtain a larger precision than the experiment. This small effective volume has also been corroborated with the OTOC technique. Although this was a deep circuit, the estimated computational cost is 5×1011, almost one trillion times less than the recent RCS experiment. Correspondingly, this experiment can be simulated in less than a second per data point on a single A100 GPU. So, while this is certainly a useful application, it does not fulfill the second requirement of a computational application: substantially outperforming a classical simulation.
Information scrambling experiments with OTOCs are a promising avenue for a computational application. OTOCs can tell us important physical information about a system, such as the butterfly velocity, which is critical for precisely measuring the effective quantum volume of a circuit. OTOC experiments with fast entangling gates offer a potential path for a first beyond-classical demonstration of a computational application with a quantum processor. Indeed, in our experiment from 2021 we achieved an effective fidelity of Feff ~ 0.06 with an experimental signal-to-noise ratio of ~1, corresponding to an effective volume of ~250 gates and a computational cost of 2×1012.
While these early OTOC experiments are not sufficiently complex to outperform classical simulations, there is a deep physical reason why OTOC experiments are good candidates for the first demonstration of a computational application. Most of the interesting quantum phenomena accessible to near-term quantum processors that are hard to simulate classically correspond to a quantum circuit exploring many, many quantum energy levels. Such evolutions are typically chaotic and standard time-order correlators (TOC) decay very quickly to a purely random average in this regime. There is no experimental signal left. This does not happen for OTOC measurements, which allows us to grow complexity at will, only limited by the error per gate. We anticipate that a reduction of the error rate by half would double the computational cost, pushing this experiment to the beyond-classical regime.
Conclusion
Using the effective quantum volume framework we have developed, we have determined the computational cost of our RCS and OTOC experiments, as well as a recent Floquet evolution experiment. While none of these meet the requirements yet for a computational application, we expect that with improved error rates, an OTOC experiment will be the first beyond-classical, useful application of a quantum processor.

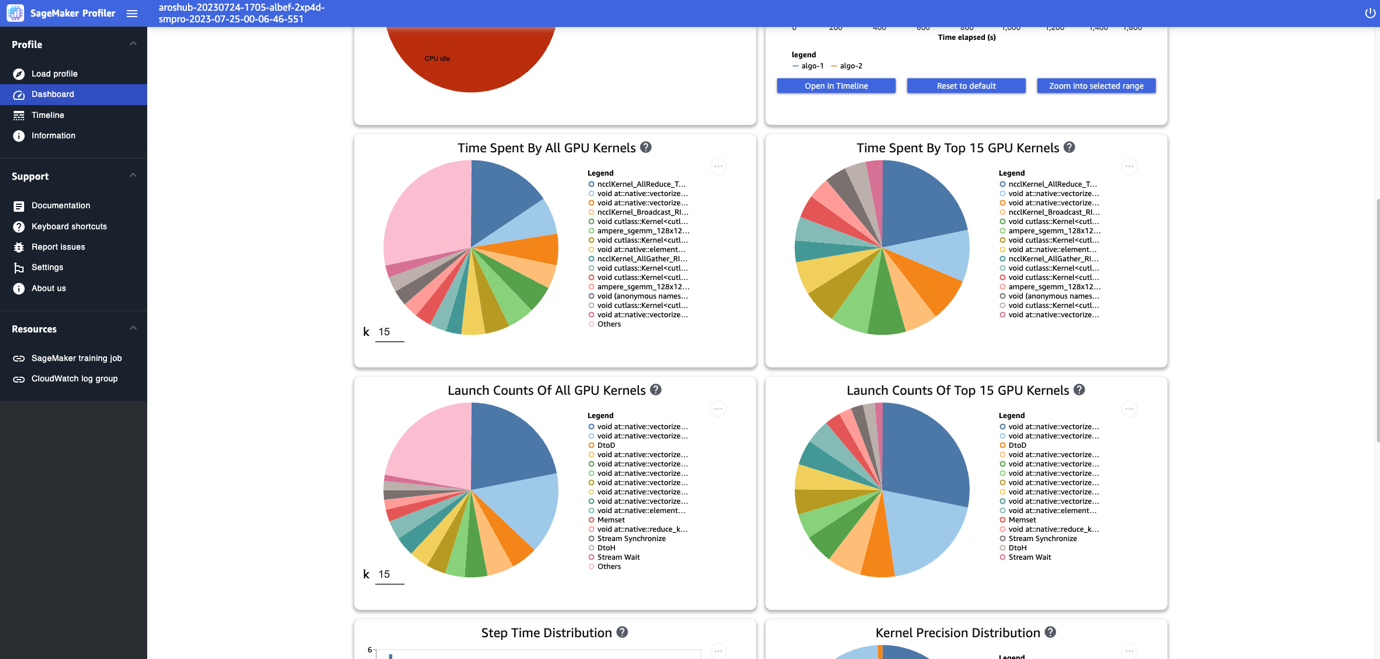
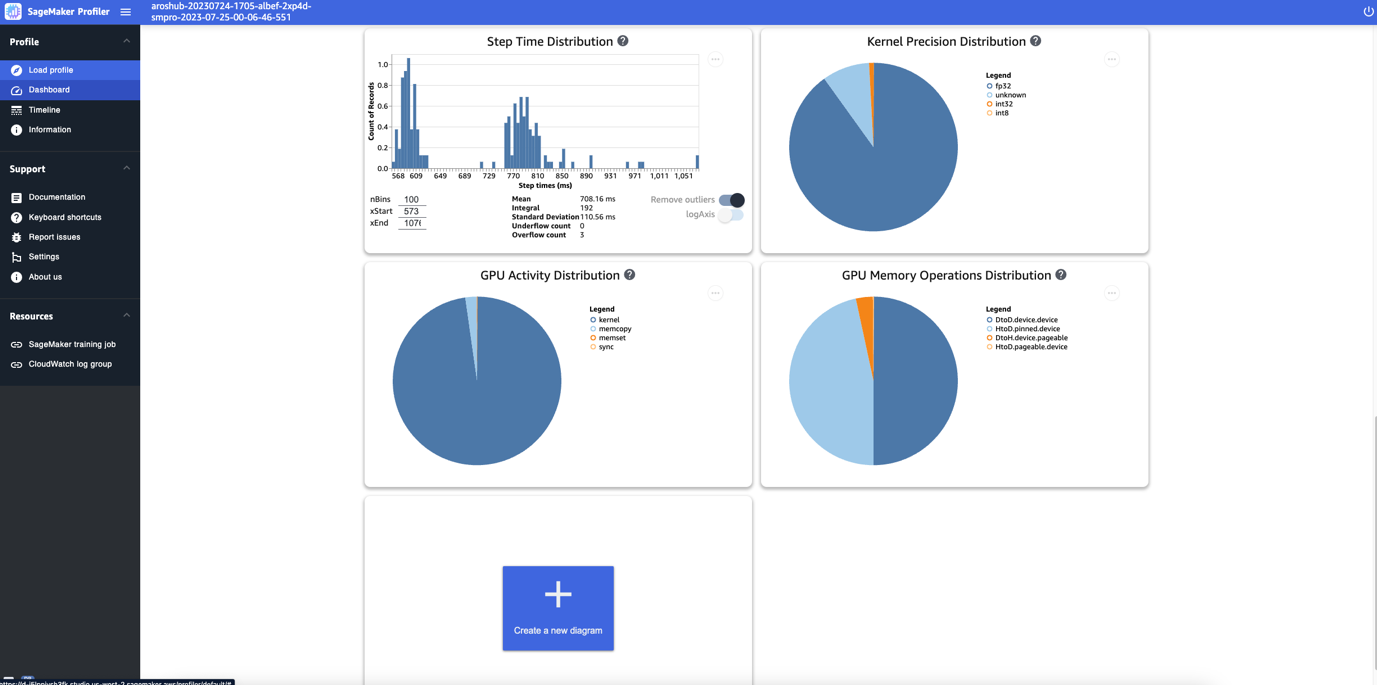
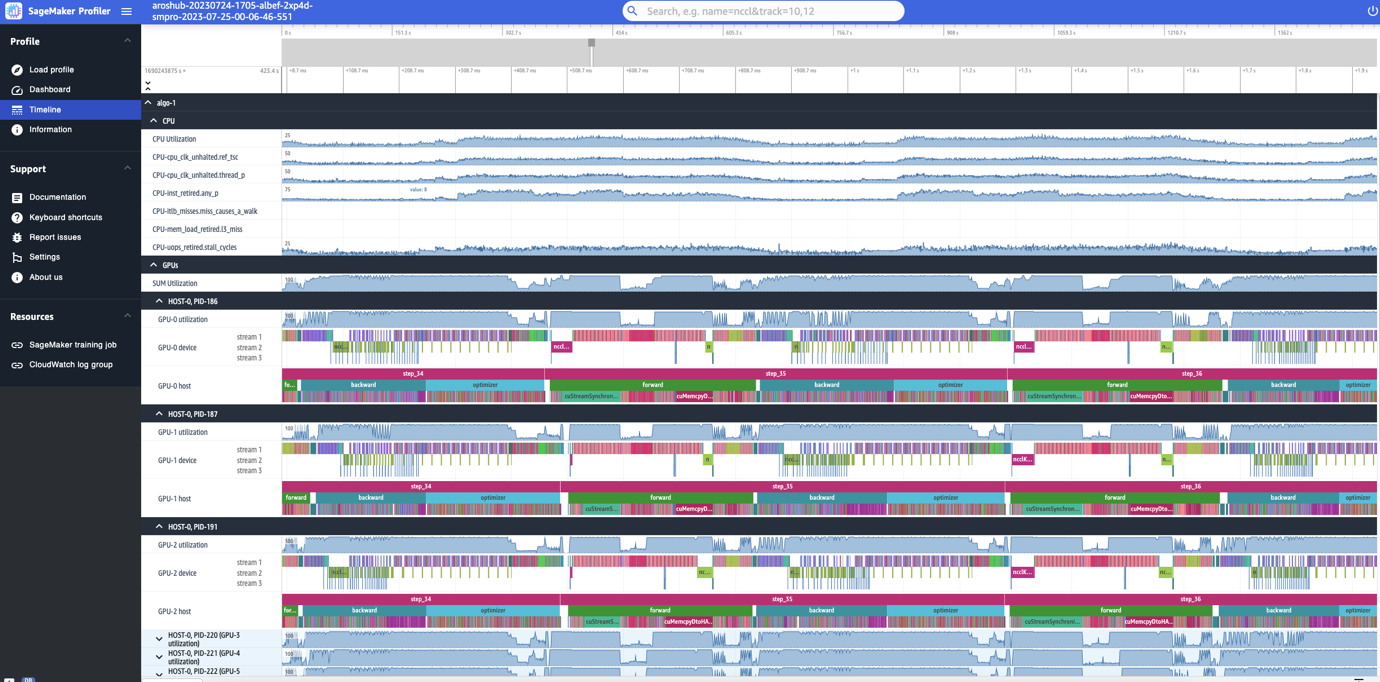
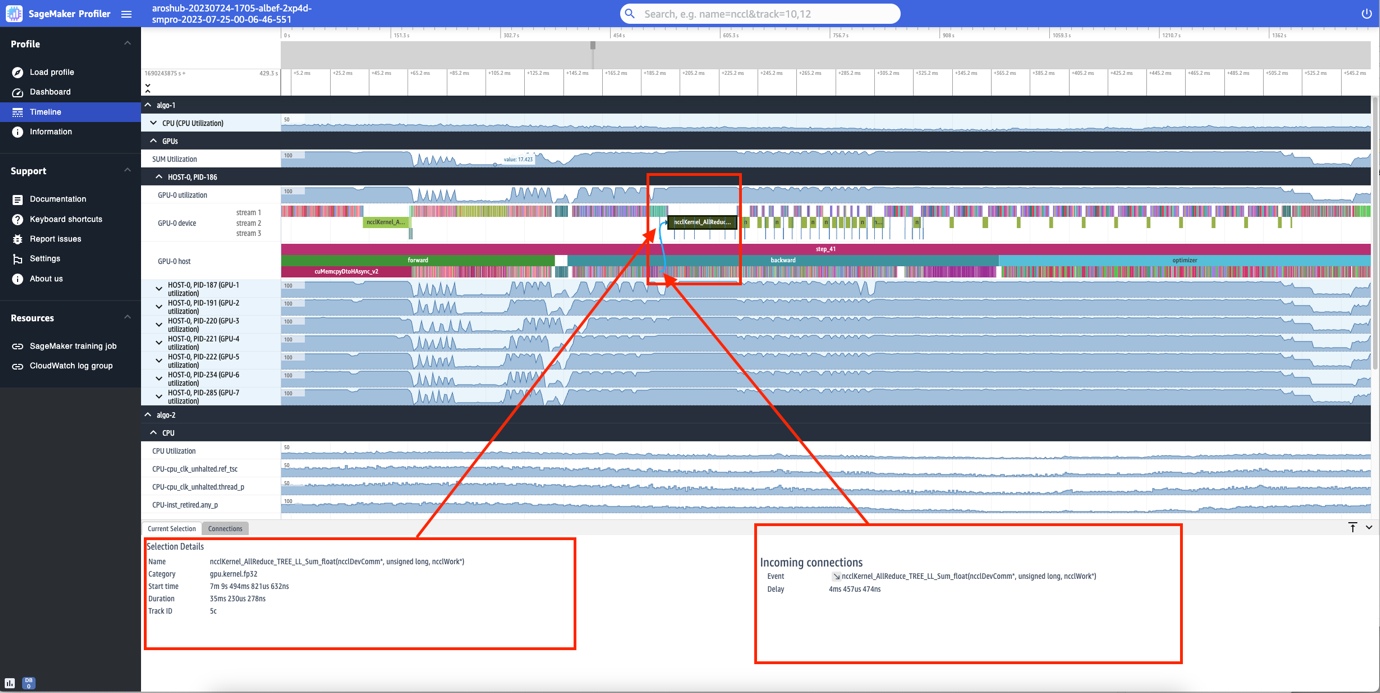
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads. Sushant Moon is a Data Scientist at AWS, India, specializing in guiding customers through their AI/ML endeavors. With a diverse background spanning retail, finance, and insurance domains, he delivers innovative and tailored solutions. Beyond his professional life, Sushant finds rejuvenation in swimming and seeks inspiration from his travels to diverse locales.
Sushant Moon is a Data Scientist at AWS, India, specializing in guiding customers through their AI/ML endeavors. With a diverse background spanning retail, finance, and insurance domains, he delivers innovative and tailored solutions. Beyond his professional life, Sushant finds rejuvenation in swimming and seeks inspiration from his travels to diverse locales. Diksha Sharma is an AI/ML Specialist Solutions Architect in the Worldwide Specialist Organization. She works with public sector customers to help them architect efficient, secure, and scalable machine learning applications including generative AI solutions on AWS. In her spare time, Diksha loves to read, paint, and spend time with her family.
Diksha Sharma is an AI/ML Specialist Solutions Architect in the Worldwide Specialist Organization. She works with public sector customers to help them architect efficient, secure, and scalable machine learning applications including generative AI solutions on AWS. In her spare time, Diksha loves to read, paint, and spend time with her family.






 Posted by
Posted by 
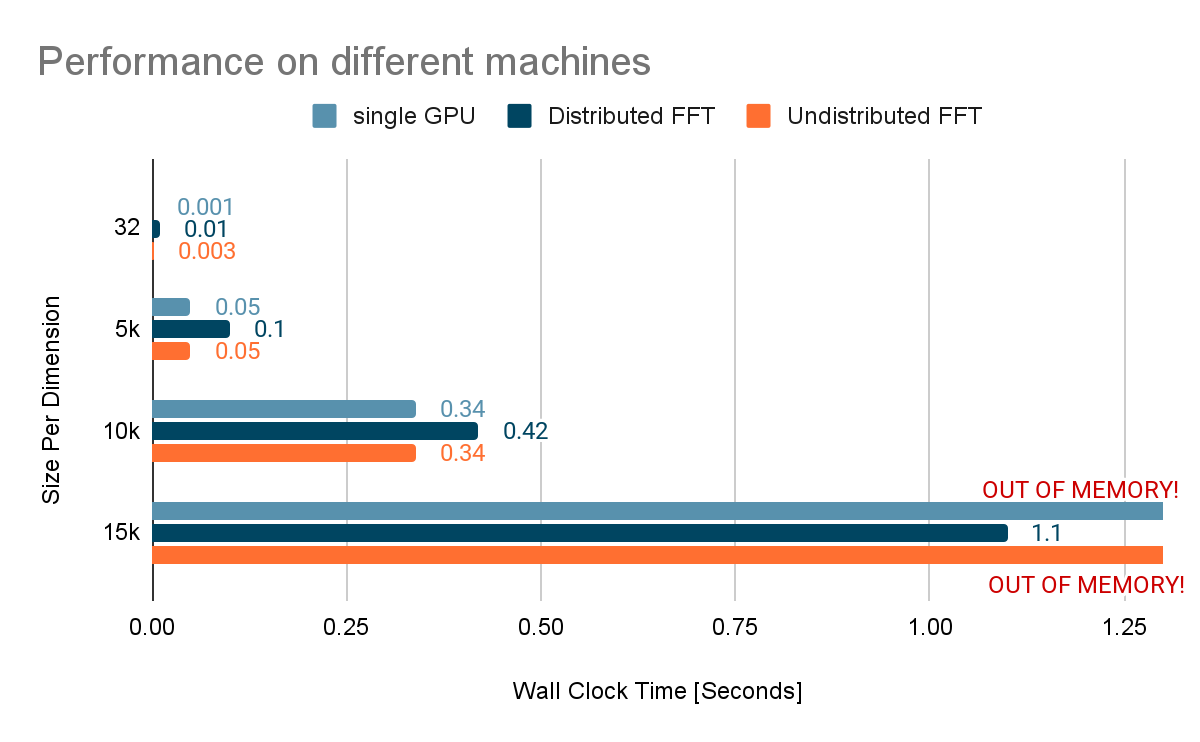
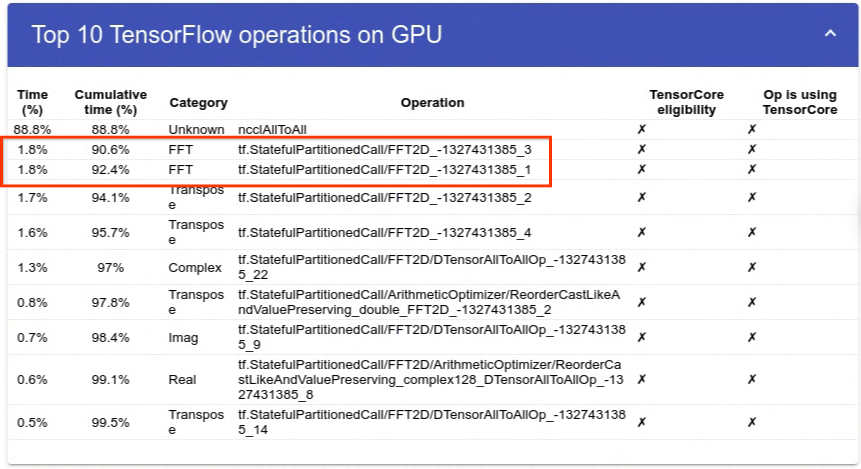







 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)