 Last week at the inaugural Africa Climate Summit (ACS) in Nairobi, Kenya, we joined African leaders and shared our commitment to advance AI solutions to address the clim…Read More
Last week at the inaugural Africa Climate Summit (ACS) in Nairobi, Kenya, we joined African leaders and shared our commitment to advance AI solutions to address the clim…Read More

Last week at the inaugural Africa Climate Summit (ACS) in Nairobi, Kenya, we joined African leaders and shared our commitment to advance AI solutions to address the clim…Read More


Large language models (LLMs) have enabled a new data-efficient learning paradigm wherein they can be used to solve unseen new tasks via zero-shot or few-shot prompting. However, LLMs are challenging to deploy for real-world applications due to their sheer size. For instance, serving a single 175 billion LLM requires at least 350GB of GPU memory using specialized infrastructure, not to mention that today’s state-of-the-art LLMs are composed of over 500 billion parameters. Such computational requirements are inaccessible for many research teams, especially for applications that require low latency performance.
To circumvent these deployment challenges, practitioners often choose to deploy smaller specialized models instead. These smaller models are trained using one of two common paradigms: fine-tuning or distillation. Fine-tuning updates a pre-trained smaller model (e.g., BERT or T5) using downstream manually-annotated data. Distillation trains the same smaller models with labels generated by a larger LLM. Unfortunately, to achieve comparable performance to LLMs, fine-tuning methods require human-generated labels, which are expensive and tedious to obtain, while distillation requires large amounts of unlabeled data, which can also be hard to collect.
In “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes”, presented at ACL2023, we set out to tackle this trade-off between model size and training data collection cost. We introduce distilling step-by-step, a new simple mechanism that allows us to train smaller task-specific models with much less training data than required by standard fine-tuning or distillation approaches that outperform few-shot prompted LLMs’ performance. We demonstrate that the distilling step-by-step mechanism enables a 770M parameter T5 model to outperform the few-shot prompted 540B PaLM model using only 80% of examples in a benchmark dataset, which demonstrates a more than 700x model size reduction with much less training data required by standard approaches.
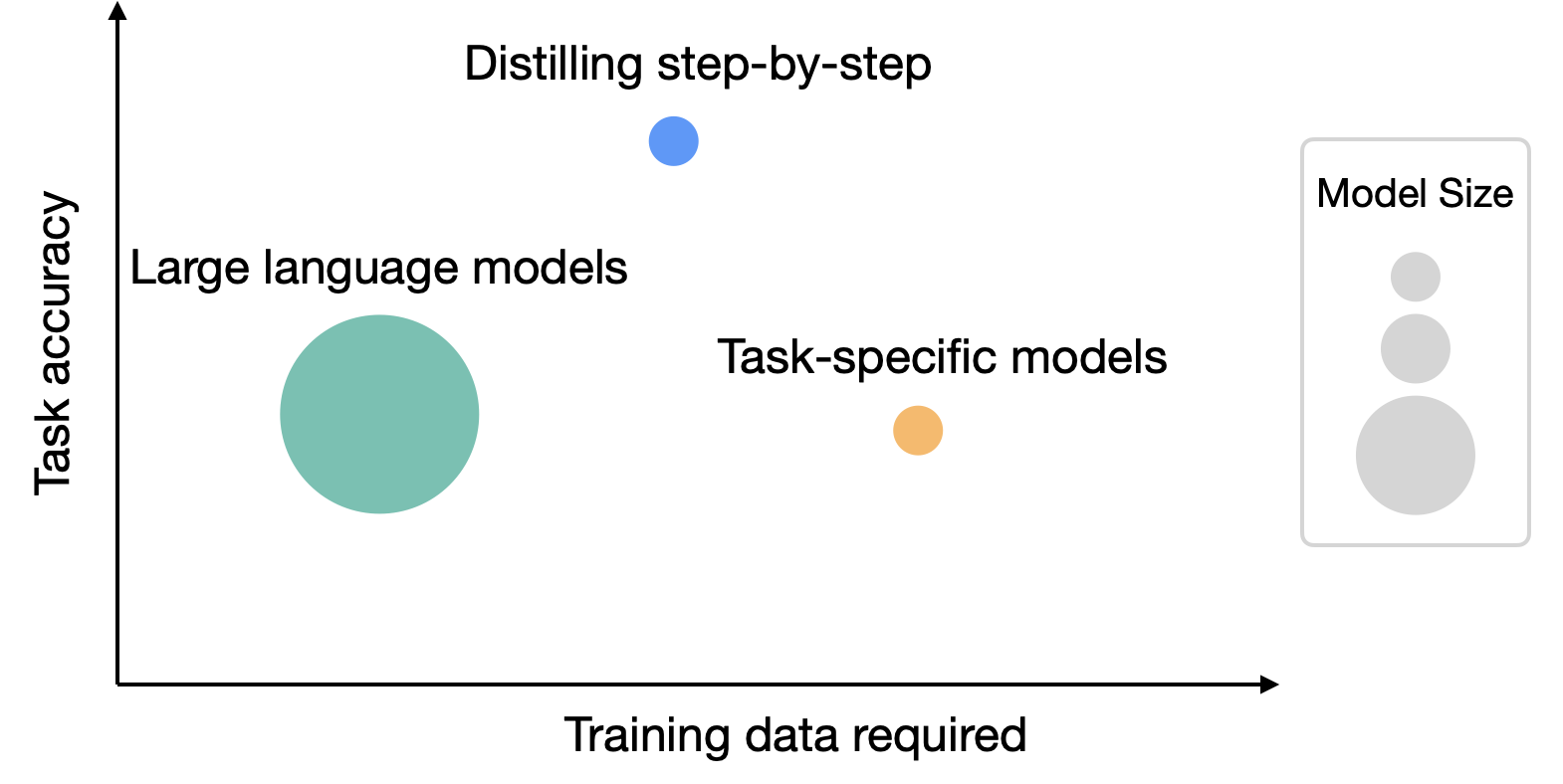 |
| While LLMs offer strong zero and few-shot performance, they are challenging to serve in practice. On the other hand, traditional ways of training small task-specific models require a large amount of training data. Distilling step-by-step provides a new paradigm that reduces both the deployed model size as well as the number of data required for training. |
The key idea of distilling step-by-step is to extract informative natural language rationales (i.e., intermediate reasoning steps) from LLMs, which can in turn be used to train small models in a more data-efficient way. Specifically, natural language rationales explain the connections between the input questions and their corresponding outputs. For example, when asked, “Jesse’s room is 11 feet long and 15 feet wide. If she already has 16 square feet of carpet, how much more carpet does she need to cover the whole floor?”, an LLM can be prompted by the few-shot chain-of-thought (CoT) prompting technique to provide intermediate rationales, such as, “Area = length * width. Jesse’s room has 11 * 15 square feet.” That better explains the connection from the input to the final answer, “(11 * 15 ) – 16”. These rationales can contain relevant task knowledge, such as “Area = length * width”, that may originally require many data for small models to learn. We utilize these extracted rationales as additional, richer supervision to train small models, in addition to the standard task labels.
 |
| Overview on distilling step-by-step: First, we utilize CoT prompting to extract rationales from an LLM. We then use the generated rationales to train small task-specific models within a multi-task learning framework, where we prepend task prefixes to the input examples and train the model to output differently based on the given task prefix. |
Distilling step-by-step consists of two main stages. In the first stage, we leverage few-shot CoT prompting to extract rationales from LLMs. Specifically, given a task, we prepare few-shot exemplars in the LLM input prompt where each example is composed of a triplet containing: (1) input, (2) rationale, and (3) output. Given the prompt, an LLM is able to mimic the triplet demonstration to generate the rationale for any new input. For instance, in a commonsense question answering task, given the input question “Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock”, distilling step-by-step provides the correct answer to the question, “(a) populated areas”, paired with the rationale that provides better connection from the question to the answer, “The answer must be a place with a lot of people. Of the above choices, only populated areas have a lot of people.” By providing CoT examples paired with rationales in the prompt, the in-context learning ability allows LLMs to output corresponding rationales for future unseen inputs.
 |
| We use the few-shot CoT prompting, which contains both an example rationale (highlighted in green) and a label (highlighted in blue), to elicit rationales from an LLM on new input examples. The example is from a commonsense question answering task. |
After the rationales are extracted, in the second stage, we incorporate the rationales in training small models by framing the training process as a multi-task problem. Specifically, we train the small model with a novel rationale generation task in addition to the standard label prediction task. The rationale generation task enables the model to learn to generate the intermediate reasoning steps for the prediction, and guides the model to better predict the resultant label. We prepend task prefixes (i.e., [label] and [rationale] for label prediction and rationale generation, respectively) to the input examples for the model to differentiate the two tasks.
In the experiments, we consider a 540B PaLM model as the LLM. For task-specific downstream models, we use T5 models. For CoT prompting, we use the original CoT prompts when available and curate our own examples for new datasets. We conduct the experiments on four benchmark datasets across three different NLP tasks: e-SNLI and ANLI for natural language inference; CQA for commonsense question answering; and SVAMP for arithmetic math word problems. We include two sets of baseline methods. For comparison to few-shot prompted LLMs, we compare to few-shot CoT prompting with a 540B PaLM model. In the paper, we also compare standard task-specific model training to both standard fine-tuning and standard distillation. In this blogpost, we will focus on the comparisons to standard fine-tuning for illustration purposes.
Compared to standard fine-tuning, the distilling step-by-step method achieves better performance using much less training data. For instance, on the e-SNLI dataset, we achieve better performance than standard fine-tuning when using only 12.5% of the full dataset (shown in the upper left quadrant below). Similarly, we achieve a dataset size reduction of 75%, 25% and 20% on ANLI, CQA, and SVAMP.
 |
| Distilling step-by-step compared to standard fine-tuning using 220M T5 models on varying sizes of human-labeled datasets. On all datasets, distilling step-by-step is able to outperform standard fine-tuning, trained on the full dataset, by using much less training examples. |
Compared to few-shot CoT prompted LLMs, distilling step-by-step achieves better performance using much smaller model sizes. For instance, on the e-SNLI dataset, we achieve better performance than 540B PaLM by using a 220M T5 model. On ANLI, we achieve better performance than 540B PaLM by using a 770M T5 model, which is over 700X smaller. Note that on ANLI, the same 770M T5 model struggles to match PaLM’s performance using standard fine-tuning.
 |
| We perform distilling step-by-step and standard fine-tuning on varying sizes of T5 models and compare their performance to LLM baselines, i.e., Few-shot CoT and PINTO Tuning. Distilling step-by-step is able to outperform LLM baselines by using much smaller models, e.g., over 700× smaller models on ANLI. Standard fine-tuning fails to match LLM’s performance using the same model size. |
Finally, we explore the smallest model sizes and the least amount of data for distilling step-by-step to outperform PaLM’s few-shot performance. For instance, on ANLI, we surpass the performance of the 540B PaLM using a 770M T5 model. This smaller model only uses 80% of the full dataset. Meanwhile, we observe that standard fine-tuning cannot catch up with PaLM’s performance even using 100% of the full dataset. This suggests that distilling step-by-step simultaneously reduces the model size as well as the amount of data required to outperform LLMs.
 |
| We show the minimum size of T5 models and the least amount of human-labeled examples required for distilling step-by-step to outperform LLM’s few-shot CoT by a coarse-grained search. Distilling step-by-step is able to outperform few-shot CoT using not only much smaller models, but it also achieves so with much less training examples compared to standard fine-tuning. |
We propose distilling step-by-step, a novel mechanism that extracts rationales from LLMs as informative supervision in training small, task-specific models. We show that distilling step-by-step reduces both the training dataset required to curate task-specific smaller models and the model size required to achieve, and even surpass, a few-shot prompted LLM’s performance. Overall, distilling step-by-step presents a resource-efficient paradigm that tackles the trade-off between model size and training data required.
Distilling step-by-step is available for private preview on Vertex AI. If you are interested in trying it out, please contact vertex-llm-tuning-preview@google.com with your Google Cloud Project number and a summary of your use case.
This research was conducted by Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Thanks to Xiang Zhang and Sergey Ioffe for their valuable feedback.
About this CFPRead More
Setting the standard for cryptography and privacy at Amazon.Read More
Advancing the frontiers of machine learning.Read More
Systems assurance by mathematical proofRead More

In this post, we discuss how United Airlines, in collaboration with the Amazon Machine Learning Solutions Lab, build an active learning framework on AWS to automate the processing of passenger documents.
“In order to deliver the best flying experience for our passengers and make our internal business process as efficient as possible, we have developed an automated machine learning-based document processing pipeline in AWS. In order to power these applications, as well as those using other data modalities like computer vision, we need a robust and efficient workflow to quickly annotate data, train and evaluate models, and iterate quickly. Over the course a couple months, United partnered with the Amazon Machine Learning Solutions Labs to design and develop a reusable, use case-agnostic active learning workflow using AWS CDK. This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to data drift.”
– Jon Nelson, Senior Manager of Data Science and Machine Learning at United Airlines.
United’s Digital Technology team is made up of globally diverse individuals working together with cutting-edge technology to drive business outcomes and keep customer satisfaction levels high. They wanted to take advantage of machine learning (ML) techniques such as computer vision (CV) and natural language processing (NLP) to automate document processing pipelines. As part of this strategy, they developed an in-house passport analysis model to verify passenger IDs. The process relies on manual annotations to train ML models, which are very costly.
United wanted to create a flexible, resilient, and cost-efficient ML framework for automating passport information verification, validating passenger’s identities and detecting possible fraudulent documents. They engaged the ML Solutions Lab to help achieve this goal, which allows United to continue delivering world-class service in the face of future passenger growth.
Our joint team designed and developed an active learning framework powered by the AWS Cloud Development Kit (AWS CDK), which programmatically configures and provisions all necessary AWS services. The framework uses Amazon SageMaker to process unlabeled data, creates soft labels, launches manual labeling jobs with Amazon SageMaker Ground Truth, and trains an arbitrary ML model with the resulting dataset. We used Amazon Textract to automate information extraction from specific document fields such as name and passport number. On a high level, the approach can be described with the following diagram.
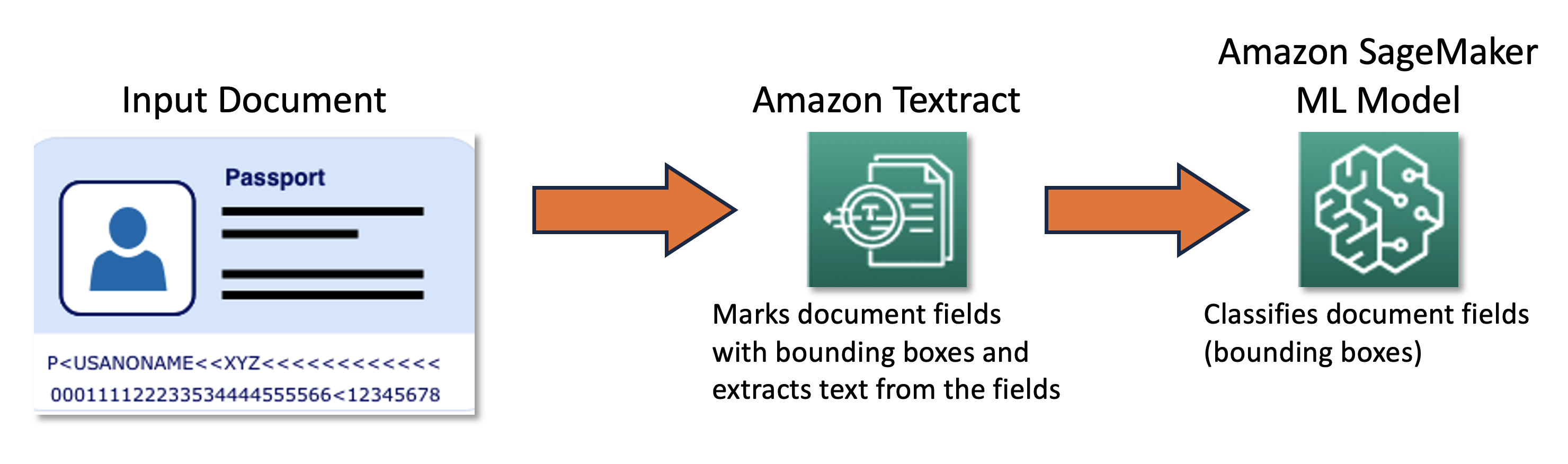
The primary dataset for this problem is comprised of tens of thousands of main-page passport images from which personal information (name, date of birth, passport number, and so on) must be extracted. Image size, layout, and structure vary depending on the document issuing country. We normalize these images into a set of uniform thumbnails, which constitute the functional input for the active learning pipeline (auto-labeling and inference).
The second dataset contains JSON line formatted manifest files that relate raw passport images, thumbnail images, and label information such as soft labels and bounding box positions. Manifest files serve as a metadata set storing results from various AWS services in a unified format, and decouple the active learning pipeline from downstream services used by United. The following diagram illustrates this architecture.
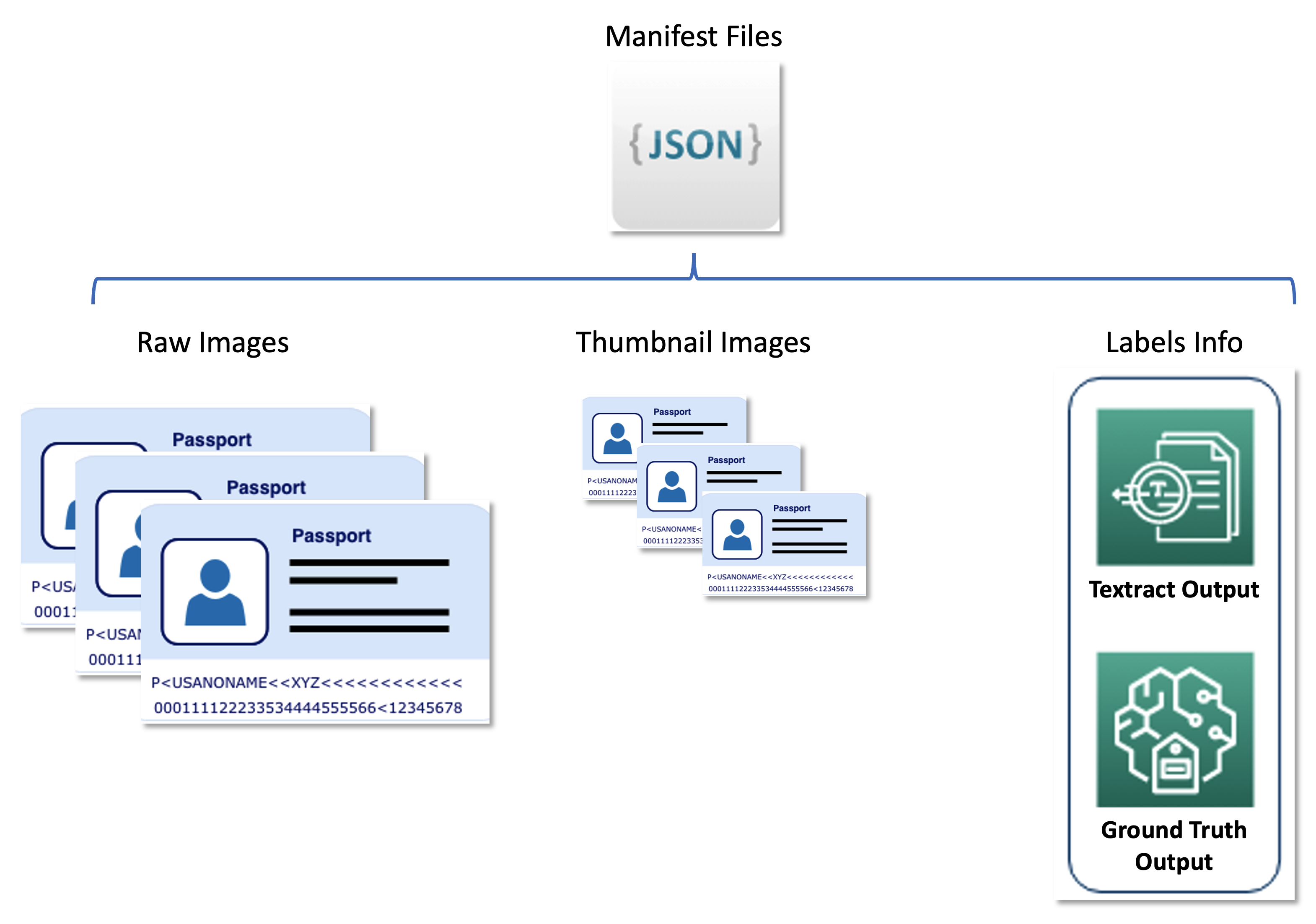
The following code is an example manifest file:
The solution includes two main components:
The ML framework is responsible for training the ML model and deploying it as a SageMaker endpoint. The auto-labeling pipeline focuses on automating SageMaker Ground Truth jobs and sampling images for labeling through those jobs.
The two components are decoupled from each other and only interact through the set of labeled images produced by the auto-labeling pipeline. That is, the labeling pipeline creates labels that are later used by the ML framework to train the ML model.
The ML Solutions Lab team built the ML framework using the Hugging Face implementation of the state-of-art LayoutLMV2 model (LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, Yang Xu, et al.). Training was based on Amazon Textract outputs, which served as a preprocessor and produced bounding boxes around text of interest. The framework uses distributed training and runs on a custom Docker container based on the SageMaker pre-built Hugging Face image with additional dependencies (dependencies that are missing in the pre-built SageMaker Docker image but required for Hugging Face LayoutLMv2).
The ML model was trained to classify document fields in the following 11 classes:
The training pipeline can be summarized in the following diagram.
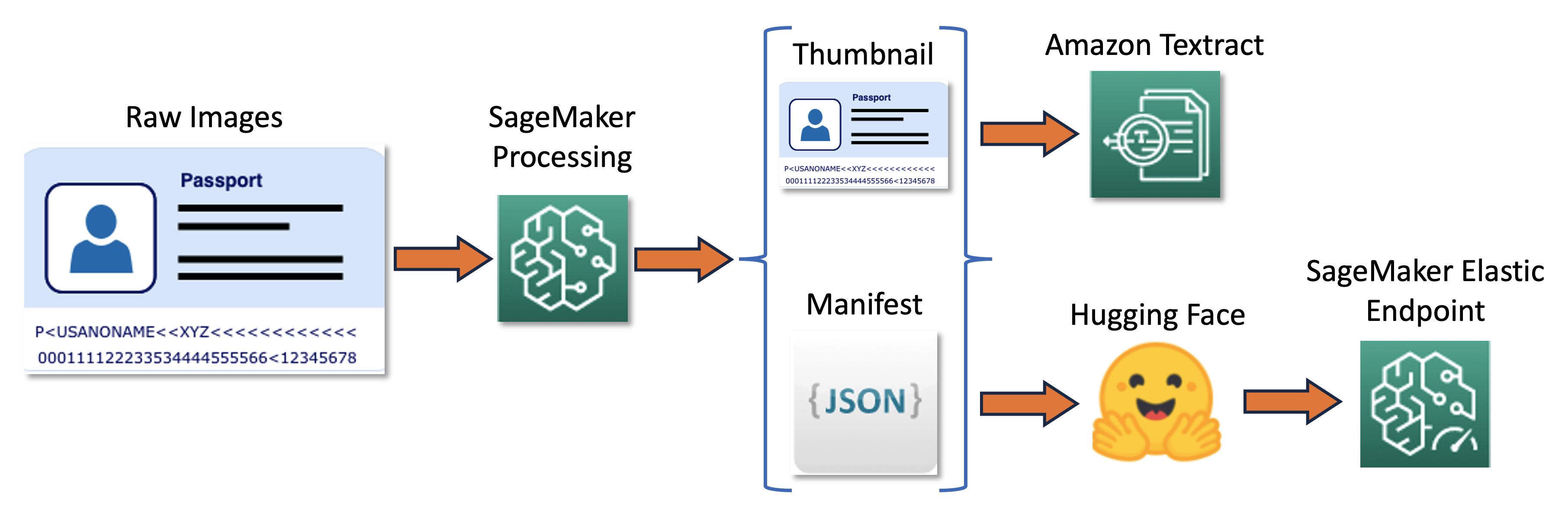
First, we resize and normalize a batch of raw images into thumbnails. At the same time, a JSON line manifest file with one line per image is created with information about raw and thumbnail images from the batch. Next, we use Amazon Textract to extract text bounding boxes in the thumbnail images. All information produced by Amazon Textract is recorded in the same manifest file. Finally, we use the thumbnail images and manifest data to train a model, which is later deployed as a SageMaker endpoint.
We developed an auto-labeling pipeline designed to perform the following functions:
The uncertainty sampling strategy reduces the number of images sent to the human labeling job by selecting images that would likely contribute the most to improving model accuracy. Because human labeling is an expensive task, such sampling is an important cost reduction technique. We support four sampling strategies, which can be selected as a parameter stored in Parameter Store, a capability of AWS Systems Manager:
The entire auto-labeling workflow was implemented with AWS Step Functions, which orchestrates the processing job (called the elastic endpoint for batch inference), uncertainty sampling, and SageMaker Ground Truth. The following diagram illustrates the Step Functions workflow.

The main factor influencing labeling costs is manual annotation. Before deploying this solution, the United team had to use a rule-based approach, which required expensive manual data annotation and third-party parsing OCR techniques. With our solution, United reduced their manual labeling workload by manually labeling only images that would result in the largest model improvements. Because the framework is model-agnostic, it can be used in other similar scenarios, extending its value beyond passport images to a much broader set of documents.
We performed a cost analysis based on the following assumptions:
Our analysis shows that training cost remains constant and high without active learning. Incorporating active learning results in exponentially decreasing costs with each new batch of data.
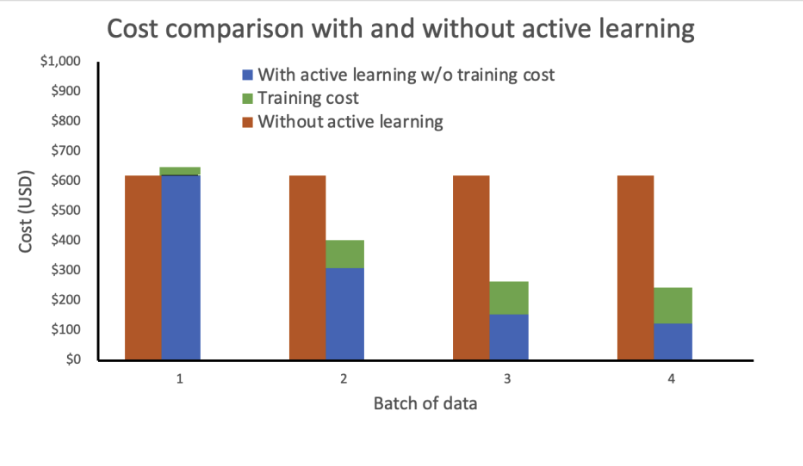
We further reduced costs by deploying the inference endpoint as an elastic endpoint by adding an auto scaling policy. The endpoint resources can scale up or down between zero and a configured maximum number of instances.
Our focus was to help the United team meet their functional requirements while building a scalable and flexible cloud application. The ML Solutions Lab team developed the complete production-ready solution with help of AWS CDK, automating management and provisioning of all cloud resources and services. The final cloud application was deployed as a single AWS CloudFormation stack with four nested stacks, each represented a single functional component.
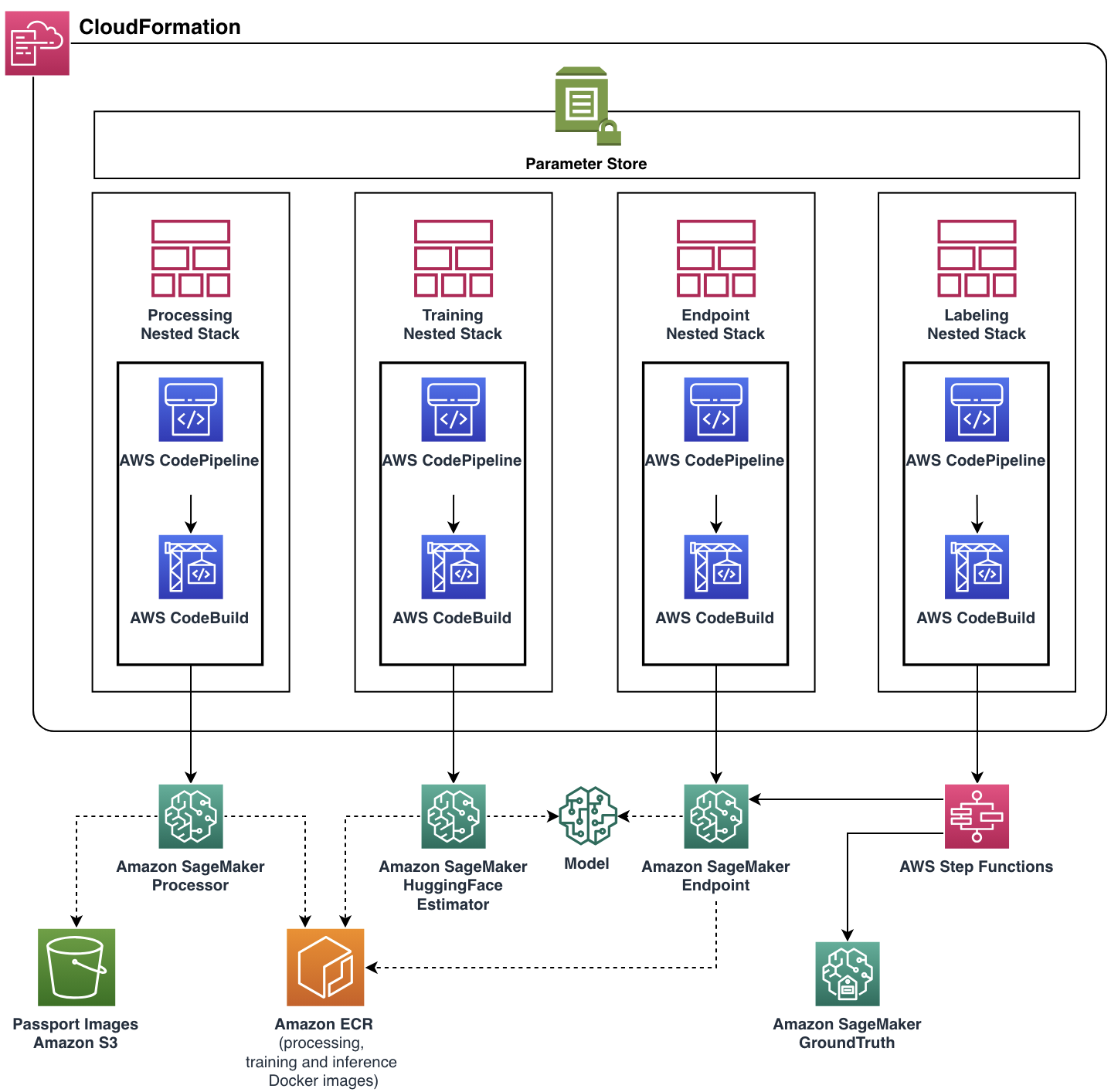
Almost every pipeline feature, including Docker images, endpoint auto scaling policy, and more, was parameterized through Parameter Store. With such flexibility, the same pipeline instance could be run with a broad range of settings, adding the ability to experiment.
In this post, we discussed how United Airlines, in collaboration with the ML Solutions Lab, built an active learning framework on AWS to automate the processing of passenger documents. The solution had great impact on two important aspects of United’s automation goals:
If you are interested in implementing a similar solution or want to learn more about the ML Solutions Lab, contact your account manager or visit us at Amazon Machine Learning Solutions Lab.
 Xin Gu is the Lead Data Scientist – Machine Learning at United Airlines’ Advanced Analytics and Innovation division. She contributed significantly to designing machine-learning-assisted document understanding automation and played a key role in expanding data annotation active learning workflows across diverse tasks and models. Her expertise lies in elevating AI efficacy and efficiency, achieving remarkable progress in the field of intelligent technological advancements at United Airlines.
Xin Gu is the Lead Data Scientist – Machine Learning at United Airlines’ Advanced Analytics and Innovation division. She contributed significantly to designing machine-learning-assisted document understanding automation and played a key role in expanding data annotation active learning workflows across diverse tasks and models. Her expertise lies in elevating AI efficacy and efficiency, achieving remarkable progress in the field of intelligent technological advancements at United Airlines.
 Jon Nelson is the Senior Manager of Data Science and Machine Learning at United Airlines.
Jon Nelson is the Senior Manager of Data Science and Machine Learning at United Airlines.
 Alex Goryainov is Machine Learning Engineer at Amazon AWS. He builds architecture and implements core components of active learning and auto-labeling pipeline powered by AWS CDK. Alex is an expert in MLOps, cloud computing architecture, statistical data analysis and large scale data processing.
Alex Goryainov is Machine Learning Engineer at Amazon AWS. He builds architecture and implements core components of active learning and auto-labeling pipeline powered by AWS CDK. Alex is an expert in MLOps, cloud computing architecture, statistical data analysis and large scale data processing.
 Vishal Das is an Applied Scientist at the Amazon ML Solutions Lab. Prior to MLSL, Vishal was a Solutions Architect, Energy, AWS. He received his PhD in Geophysics with a PhD minor in Statistics from Stanford University. He is committed to working with customers in helping them think big and deliver business results. He is an expert in machine learning and its application in solving business problems.
Vishal Das is an Applied Scientist at the Amazon ML Solutions Lab. Prior to MLSL, Vishal was a Solutions Architect, Energy, AWS. He received his PhD in Geophysics with a PhD minor in Statistics from Stanford University. He is committed to working with customers in helping them think big and deliver business results. He is an expert in machine learning and its application in solving business problems.
 Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services.
Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services.
 Yunzhi Shi is an Applied Scientist at the Amazon ML Solutions Lab, where he works with customers across different industry verticals to help them ideate, develop, and deploy AI/ML solutions built on AWS Cloud services to solve their business challenges. He has worked with customers in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The University of Texas at Austin.
Yunzhi Shi is an Applied Scientist at the Amazon ML Solutions Lab, where he works with customers across different industry verticals to help them ideate, develop, and deploy AI/ML solutions built on AWS Cloud services to solve their business challenges. He has worked with customers in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The University of Texas at Austin.
 Diego Socolinsky is a Senior Applied Science Manager with the AWS Generative AI Innovation Center, where he leads the delivery team for the Eastern US and Latin America regions. He has over twenty years of experience in machine learning and computer vision, and holds a PhD degree in mathematics from The Johns Hopkins University.
Diego Socolinsky is a Senior Applied Science Manager with the AWS Generative AI Innovation Center, where he leads the delivery team for the Eastern US and Latin America regions. He has over twenty years of experience in machine learning and computer vision, and holds a PhD degree in mathematics from The Johns Hopkins University.
 Xin Chen is currently the Head of People Science Solutions Lab at Amazon People eXperience Technology (PXT, aka HR) Central Science. He leads a team of applied scientists to build production grade science solutions to proactively identify and launch mechanisms and process improvements. Previously, he was head of Central US, Greater China Region, LATAM and Automotive Vertical in AWS Machine Learning Solutions Lab. He helped AWS customers identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin is adjunct faculty at Northwestern University and Illinois Institute of Technology. He obtained his PhD in Computer Science and Engineering at the University of Notre Dame.
Xin Chen is currently the Head of People Science Solutions Lab at Amazon People eXperience Technology (PXT, aka HR) Central Science. He leads a team of applied scientists to build production grade science solutions to proactively identify and launch mechanisms and process improvements. Previously, he was head of Central US, Greater China Region, LATAM and Automotive Vertical in AWS Machine Learning Solutions Lab. He helped AWS customers identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin is adjunct faculty at Northwestern University and Illinois Institute of Technology. He obtained his PhD in Computer Science and Engineering at the University of Notre Dame.
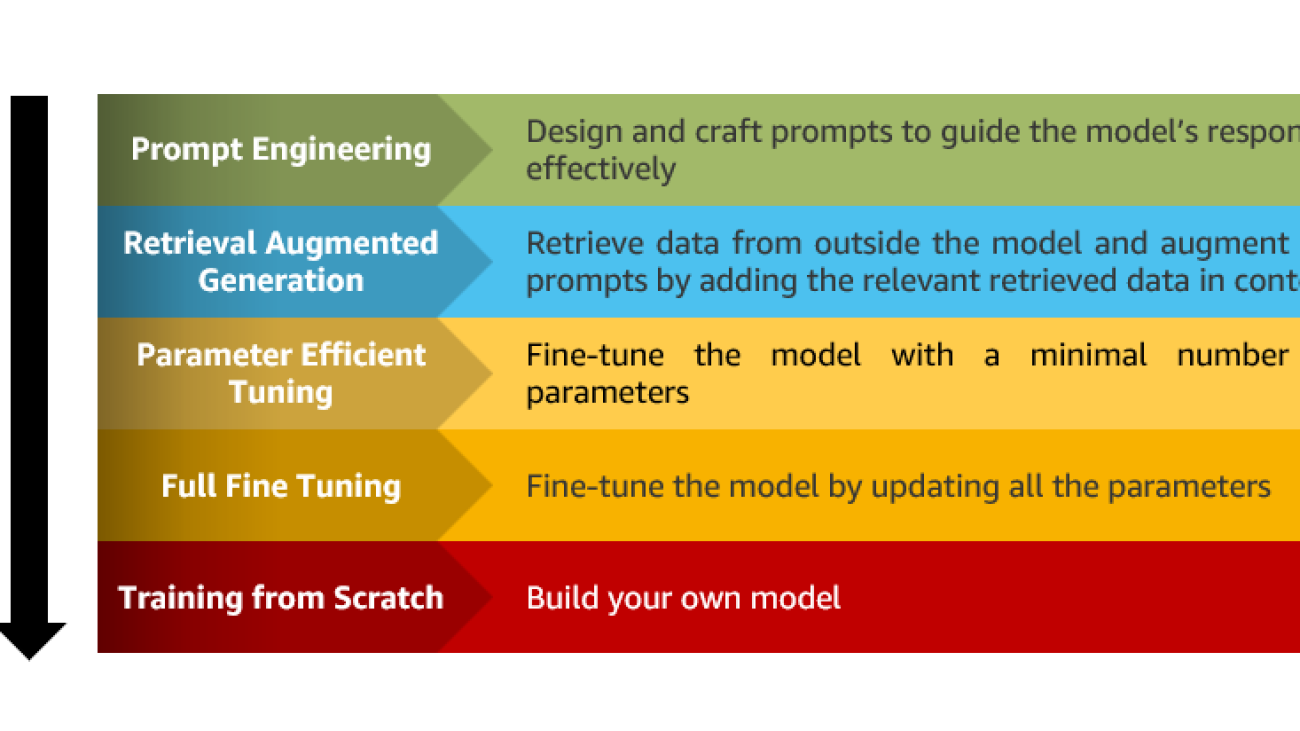
The adoption of generative AI is rapidly expanding, reaching an ever-growing number of industries and users worldwide. With the increasing complexity and scale of generative AI models, it is crucial to work towards minimizing their environmental impact. This involves a continuous effort focused on energy reduction and efficiency by achieving the maximum benefit from the resources provisioned and minimizing the total resources required.
To add to our guidance for optimizing deep learning workloads for sustainability on AWS, this post provides recommendations that are specific to generative AI workloads. In particular, we provide practical best practices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering. Although this post primarily focuses on large language models (LLM), we believe most of the recommendations can be extended to other foundation models.
When framing your generative AI problem, consider the following:

In this section, we share best practices for model customization.
Selecting the appropriate base model is a critical step in customizing generative AI workloads and can help reduce the need for extensive fine-tuning and associated resource usage. Consider the following factors:
Effective prompt engineering can enhance the performance and efficiency of generative AI models. By carefully crafting prompts, you can guide the model’s behavior, reducing unnecessary iterations and resource requirements. Consider the following guidelines:
Retrieval Augmented Generation (RAG) is a highly effective approach for augmenting model capabilities by retrieving and integrating pertinent external information from a predefined dataset. Because existing LLMs are used as is, this strategy avoids the energy and resources needed to train the model on new data or build a new model from scratch. Use tools such as Amazon Kendra or Amazon OpenSearch Service and LangChain to successfully build RAG-based solutions with Amazon Bedrock or SageMaker JumpStart.
Parameter-Efficient Fine-Tuning (PEFT) is a fundamental aspect of sustainability in generative AI. It aims to achieve performance comparable to fine-tuning, using fewer trainable parameters. By fine-tuning only a small number of model parameters while freezing most parameters of the pre-trained LLMs, we can reduce computational resources and energy consumption.
Use public libraries such as the Parameter-Efficient Fine-Tuning library to implement common PEFT techniques such as Low Rank Adaptation (LoRa), Prefix Tuning, Prompt Tuning, or P-Tuning. As an example, studies show the utilization of LoRa can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times, depending on the size of your model, with similar or better performance.
Fine-tune the entire pre-trained model with the additional data. This approach may achieve higher performance but is more resource-intensive than PEFT. Use this strategy when the available data significantly differs from the pre-training data.
By selecting the right fine-tuning approach, you can maximize the reuse of your model and avoid the resource usage associated with fine-tuning multiple models for each use case. For example, if you anticipate reusing the model within a specific domain or business unit in your organization, you may prefer domain adaptation. On the other hand, instruction-based fine-tuning is better suited for general use across multiple tasks.
In some cases, training an LLM model from scratch may be necessary. However, this approach can be computationally expensive and energy-intensive. To ensure optimal training, consider the following best practices:
Consider the following best practices for model inference and deployment:
temperature, top_p, top_k, and max_length.Implement an improvement process to track the impact of your optimizations over time. The goal of your improvements is to use all the resources you provision and complete the same work with the minimum resources possible. To operationalize this process, collect metrics about the utilization of your cloud resources. These metrics, combined with business metrics, can be used as proxy metrics for your carbon emissions.
To consistently monitor your environment, you can use Amazon CloudWatch to monitor system metrics like CPU, GPU, or memory utilization. If you are using NVIDIA GPU, consider NVIDIA System Management Interface (nvidia-smi) to monitor GPU utilization and performance state. For Trainium and AWS Inferentia accelerator, you can use AWS Neuron Monitor to monitor system metrics. Consider also SageMaker Profiler, which provides a detailed view into the AWS compute resources provisioned during training deep learning models on SageMaker. The following are some key metrics worth monitoring:
CPUUtilization, GPUUtilization, GPUMemoryUtilization, MemoryUtilization, and DiskUtilization in CloudWatchnvidia_smi.gpu_utilization, nvidia_smi.gpu_memory_utilization, and nvidia_smi.gpu_performance_state in nvidia-smi logs.vcpu_usage, memory_info, and neuroncore_utilization in Neuron Monitor.As generative AI models are becoming bigger, it is essential to consider the environmental impact of our workloads.
In this post, we provided guidance for optimizing the compute, storage, and networking resources required to run your generative AI workloads on AWS while minimizing their environmental impact. Because the field of generative AI is continuously progressing, staying updated with the latest courses, research, and tools can help you find new ways to optimize your workloads for sustainability.
 Dr. Wafae Bakkali is a Data Scientist at AWS, based in Paris, France. As a generative AI expert, Wafae is driven by the mission to empower customers in solving their business challenges through the utilization of generative AI techniques, ensuring they do so with maximum efficiency and sustainability.
Dr. Wafae Bakkali is a Data Scientist at AWS, based in Paris, France. As a generative AI expert, Wafae is driven by the mission to empower customers in solving their business challenges through the utilization of generative AI techniques, ensuring they do so with maximum efficiency and sustainability.
 Benoit de Chateauvieux is a Startup Solutions Architect at AWS, based in Montreal, Canada. As a former CTO, he enjoys helping startups build great products using the cloud. He also supports customers in solving their sustainability challenges through the cloud. Outside of work, you’ll find Benoit in canoe-camping expeditions, paddling across Canadian rivers.
Benoit de Chateauvieux is a Startup Solutions Architect at AWS, based in Montreal, Canada. As a former CTO, he enjoys helping startups build great products using the cloud. He also supports customers in solving their sustainability challenges through the cloud. Outside of work, you’ll find Benoit in canoe-camping expeditions, paddling across Canadian rivers.