This has been a year of incredible progress in the field of Artificial Intelligence (AI) research and its practical applications.Read More
This has been a year of incredible progress in the field of Artificial Intelligence (AI) research and its practical applications.Read More

Great customer experience provides a competitive edge and helps create brand differentiation. As per the Forrester report, The State Of Customer Obsession, 2022, being customer-first can make a sizable impact on an organization’s balance sheet, as organizations embracing this methodology are surpassing their peers in revenue growth. Despite contact centers being under constant pressure to do more with less while improving customer experiences, 80% of companies plan to increase their level of investment in Customer Experience (CX) to provide a differentiated customer experience. Rapid innovation and improvement in generative AI has captured our mind and attention and as per McKinsey & Company’s estimate, applying generative AI to customer care functions could increase productivity at a value ranging from 30–45% of current function costs.
Amazon SageMaker Canvas provides business analysts with a visual point-and-click interface that allows you to build models and generate accurate machine learning (ML) predictions without requiring any ML experience or coding. In October 2023, SageMaker Canvas announced support for foundation models among its ready-to-use models, powered by Amazon Bedrock and Amazon SageMaker JumpStart. This allows you to use natural language with a conversational chat interface to perform tasks such as creating novel content including narratives, reports, and blog posts; summarizing notes and articles; and answering questions from a centralized knowledge base—all without writing a single line of code.
A call center agent’s job is to handle inbound and outbound customer calls and provide support or resolve issues while fielding dozens of calls daily. Keeping up with this volume while giving customers immediate answers is challenging without time to research between calls. Typically, call scripts guide agents through calls and outline addressing issues. Well-written scripts improve compliance, reduce errors, and increase efficiency by helping agents quickly understand problems and solutions.
In this post, we explore how generative AI in SageMaker Canvas can help solve common challenges customers may face when dealing with contact centers. We show how to use SageMaker Canvas to create a new call script or improve an existing call script, and explore how generative AI can help with reviewing existing interactions to bring insights that are difficult to obtain from traditional tools. As part of this post, we provide the prompts used to solve the tasks and discuss architectures to integrate these results in your AWS Contact Center Intelligence (CCI) workflows.
Generative AI foundation models can help create powerful call scripts in contact centers and enable organizations to do the following:
With SageMaker Canvas, you can choose from a larger selection of foundation models to create compelling call scripts. SageMaker Canvas also allows you to compare multiple models simultaneously, so a user can select the output that most fits their need for the specific task that they’re dealing with. To use generative AI-powered chatbots, the user first needs to provide a prompt, which is an instruction to tell the model what you intend to do.
In this post, we address four common use cases:
Throughout the post, we use large language models (LLMs) available in SageMaker Canvas powered by Amazon Bedrock. Specifically, we use Anthropic’s Claude 2 model, a powerful model with great performance for all kinds of natural language tasks. The examples are in English; however, Anthropic Claude 2 supports multiple languages. Refer to Anthropic Claude 2 to learn more. Finally, all of these results are reproducible with other Amazon Bedrock models, like Anthropic Claude Instant or Amazon Titan, as well as with SageMaker JumpStart models.
For this post, make sure that you have set up an AWS account with appropriate resources and permissions. In particular, complete the following prerequisite steps:
Note that the services that SageMaker Canvas uses to solve generative AI tasks are available in SageMaker JumpStart and Amazon Bedrock. To use Amazon Bedrock, make sure you are using SageMaker Canvas in the Region where Amazon Bedrock is supported. Refer to Supported Regions to learn more.
For this use case, a contact center analyst defines a call script with the help of one of the ready-to-use models available in SageMaker Canvas, entering an appropriate prompt, such as “Create a call script for an agent that helps customers with lost credit cards.” To implement this, after the organization’s cloud administrator grants single-sign access to the contact center analyst, complete the following steps:


The script obtained through generative AI is included in a document (such as TXT, HTML, or PDF), and added to a knowledge base that will guide contact center agents in their interactions with customers.

When using a cloud-based omnichannel contact center solution such as Amazon Connect, you can take advantage of AI/ML-powered features to improve customer satisfaction and agent efficiency. Amazon Connect Wisdom reduces the time agents spend searching for answers and enables quick resolution of customer issues by providing knowledge search and real-time recommendations while agents talk with customers. In this particular example, Amazon Connect Wisdom can synchronize with Amazon Simple Storage Service (Amazon S3) as a source of content for the knowledge base, thereby incorporating the call script generated with the help of SageMaker Canvas. For more information, refer to Amazon Connect Wisdom S3 Sync.
The following diagram illustrates this architecture.

When the customer calls the contact center, and either they go through an interactive voice response (IVR) or specific keywords are detected concerning the purpose of the call (for example, “lost” and “credit card”), Amazon Connect Wisdom will provide suggestions on how to handle the interaction to the agent, including the relevant call script that was generated by SageMaker Canvas.
With SageMaker Canvas generative AI, contact center analysts save time in the creation of call scripts, and are able to quickly try new prompts to tweak the scripts creation.
As per the following survey, 78% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. SageMaker Canvas can use generative AI help you analyze the existing call script and suggest improvements to improve the quality of call scripts. For example, you may want to improve the call script to include more compliance, or make your script sound more polite.
To do so, choose New chat and select Claude 2 as your model. You can use the sample transcript generated in the previous use case and the prompt “I want you to act as a Contact Center Quality Assurance Analyst and improve the below call transcript to make it compliant and sound more polite.”

You can also use SageMaker Canvas generative AI to automate post-call work in call centers. Common use cases are call summarization, assistance in call logs completion, and personalized follow-up message creation. This can improve agent productivity and reduce the risk of errors, allowing them to focus on higher-value tasks such as customer engagement and relationship-building.
Choose New chat and select Claude 2 as your model. You can use the sample transcript generated in the previous use case and the prompt “Summarize the below Call transcript to highlight Customer issue, Agent actions, Call outcome and Customer sentiment.”

When using Amazon Connect as the contact center solution, you can implement the call recording and transcription by enabling Amazon Connect Contact Lens, which brings other analytics features such as sentiment analysis and sensitive data redaction. It also has summarization by highlighting key sentences in the transcript and labeling the issues, outcomes, and action items.
Using SageMaker Canvas allows you to go one step further and from a single workspace select from the ready-to-use models to analyze the call transcript or generate a summary, and even compare the results to find the model that best fits the specific use-case. The following diagram illustrates this solution architecture.

Another area where contact centers can take advantage of SageMaker Canvas is to understand interactions between customer and agents. As per the 2022 NICE WEM Global Survey, 58% of call center agents say they benefit very little from company coaching sessions. Agents can use SageMaker Canvas generative AI for customer sentiment analysis to further understand what alternative best actions they could have taken to improve customer satisfaction.
We follow similar steps as in the previous use cases. Choose New chat and select Claude 2. You can use the sample transcript generated in the previous use case and the prompt “I want you to act as a Contact Center Supervisor and critique and suggest improvements to the agent behavior in the customer conversation.”

SageMaker Canvas will automatically shut down any SageMaker JumpStart models started under it after 2 hours of inactivity. Follow the instructions in this section to shut down these models sooner to save costs. Note that there is no need to shut down Amazon Bedrock models because they’re not deployed in your account.
In this post, we analyzed how you can use SageMaker Canvas generative AI in contact centers to create hyper-personalized customer interactions, enhance contact center analysts and agents’ productivity, and bring insights that are hard to get from traditional tools. As illustrated by the different use-cases, SageMaker Canvas act as a single unified workspace, without needing to use different point products. With SageMaker Canvas generative AI, contact centers can improve customer satisfaction, reduce costs, and increase efficiency. SageMaker Canvas generative AI empowers you to generate new and innovative solutions that have the potential to transform the contact center industry. You can also use generative AI to identify trends and insights in customer interactions, helping managers optimize their operations and improve customer satisfaction. Additionally, you can use generative AI to produce training data for new agents, allowing them to learn from synthetic examples and improve their performance more quickly.
Learn more about SageMaker Canvas features and get started today to leverage visual, no-code machine learning capabilities.
 Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML. He is based in Brussels and works closely with customers all around the globe that are looking to adopt Low-Code/No-Code Machine Learning technologies, and Generative AI. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML. He is based in Brussels and works closely with customers all around the globe that are looking to adopt Low-Code/No-Code Machine Learning technologies, and Generative AI. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
 Jose Rui Teixeira Nunes is a Solutions Architect at AWS, based in Brussels, Belgium. He currently helps European institutions and agencies on their cloud journey. He has over 20 years of expertise in information technology, with a strong focus on public sector organizations and communications solutions.
Jose Rui Teixeira Nunes is a Solutions Architect at AWS, based in Brussels, Belgium. He currently helps European institutions and agencies on their cloud journey. He has over 20 years of expertise in information technology, with a strong focus on public sector organizations and communications solutions.
 Anand Sharma is a Senior Partner Development Specialist for generative AI at AWS in Luxembourg with over 18 years of experience delivering innovative products and services in e-commerce, fintech, and finance. Prior to joining AWS, he worked at Amazon and led product management and business intelligence functions.
Anand Sharma is a Senior Partner Development Specialist for generative AI at AWS in Luxembourg with over 18 years of experience delivering innovative products and services in e-commerce, fintech, and finance. Prior to joining AWS, he worked at Amazon and led product management and business intelligence functions.

AI made a splash this year — from Wall Street to the U.S. Congress — driven by a wave of developers aiming to make the world better.
Here’s a look at AI in 2023 across agriculture, natural disasters, medicine and other areas worthy of a cocktail party conversation.
California has recently seen record wildfires. With scorching heat late into the summer, the state’s crispy foliage becomes a tinderbox that can ignite and quickly blaze out of control. Burning for solutions, developers are embracing AI for early detection.
DigitalPath, based in Chico, California, has refined a convolutional neural network to spot wildfires. The model, run on NVIDIA GPUs, enables thousands of cameras across the state to detect wildfires in real time for the ALERTCalifornia initiative, a collaboration between the University of California, San Diego, and the CAL FIRE wildfire agency.
The mission is near and dear to DigitalPath employees, whose office sits not far from the town of Paradise, where California’s deadliest wildfire killed 85 people in 2018.
“It’s one of the main reasons we’re doing this,” said CEO Jim Higgins. “We don’t want people to lose their lives.”
A team from the University of California, Santa Cruz; University of California, Berkeley; and the Technical University of Munich released a paper this year on a new deep learning model for earthquake forecasts.
Shaking up the status quo around the ETAS model standard, developed in 1988, the new RECAST model, trained on NVIDIA GPUs, is capable of using larger datasets and holds promise for making better predictions during earthquake sequences.
“There’s a ton of room for improvement within the forecasting side of things,” said Kelian Dascher-Cousineau, one of the paper’s authors.
Verdant, based in the San Francisco Bay Area, is supporting organic farming. The startup develops AI for tractor implements that can weed, fertilize and spray, providing labor support while lowering production costs for farmers and boosting yields.
The NVIDIA Jetson Orin-based robots-as-a-service business provides farmers with metrics on yield gains and chemical reduction. “We wanted to do something meaningful to help the environment,” said Lawrence Ibarria, chief operating officer at Verdant.
Ge Dong is living out her childhood dream, following in her mother’s footsteps by pursuing physics. She cofounded Energy Singularity, a startup that aims to lower the cost of building a commercial tokamak — which can cost billions of dollars —for fusion energy development.
It brings the promise of cleaner energy.
“We’ve been using NVIDIA GPUs for all our research — they’re one of the most important tools in plasma physics these days,” she said.
Chaofeng Wang, a University of Florida assistant professor of artificial intelligence, is enlisting deep learning and images from Google Street View to evaluate urban buildings. By automating the process, the work is intended to assist governments in supporting building structures and post-disaster recovery.
“Without NVIDIA GPUs, we wouldn’t have been able to do this,” Wang said. “They significantly accelerate the process, ensuring timely results.”
A Gordon Bell prize-winning model, GenSLMs has shown it can generate gene sequences closely resembling real-world variants of SARS-CoV-2, the virus behind COVID-19. Researchers trained the model using NVIDIA A100 Tensor Core GPU-powered supercomputers, including NVIDIA’s Selene, the U.S. Department of Energy’s Perlmutter and Argonne’s Polaris system.
“The AI’s ability to predict the kinds of gene mutations present in recent COVID strains — despite having only seen the Alpha and Beta variants during training — is a strong validation of its capabilities,” said Arvind Ramanathan, lead researcher on the project and a computational biologist at Argonne.
Kabilan KB, an undergraduate student from the Karunya Institute of Technology and Sciences in Coimbatore, India, is developing an NVIDIA Jetson-enabled autonomous wheelchair. To help boost development, he’s been using NVIDIA Omniverse, a platform for building and operating 3D tools and applications based on the OpenUSD framework.
“Using Omniverse for simulation, I don’t need to invest heavily in prototyping models for my robots, because I can use synthetic data generation instead,” he said. “It’s the software of the future.”
Atlas Meditech is using the MONAI medical imaging framework and the NVIDIA Omniverse 3D development platform to help build AI-powered decision support and high-fidelity surgery rehearsal platforms — all in an effort to improve surgical outcomes and patient safety.
“With accelerated computing and digital twins, we want to transform this mental rehearsal into a highly realistic rehearsal in simulation,” said Dr. Aaron Cohen-Gadol, founder of the company.
Artificial intelligence is helping optimize solar and wind farms, simulate climate and weather, and support power grid reliability and other areas of the energy market.
Check out this installment of the I AM AI video series to learn about how NVIDIA is enabling these technologies and working with energy-conscious collaborators to drive breakthroughs for a cleaner, safer, more sustainable future.
Many patients in lower- and middle-income countries lack access to cataract surgery because of a shortage of ophthalmologists. But more than 2,000 doctors a year in lower-income countries can now treat cataract blindness — the world’s leading cause of blindness —using GPU-powered surgical simulation with the help of nonprofit HelpMeSee.
“We’re lowering the barrier for healthcare practitioners to learn these specific skills that can have a profound impact on patients,” said Bonnie An Henderson, CEO of the New York-based nonprofit.
Afresh, based in San Francisco, helps stores reduce food waste. The startup has developed machine learning and AI models using data on fresh produce to help grocers make informed inventory-purchasing decisions. It has also launched software that enables grocers to save time and increase data accuracy with inventory tracking.
“The most impactful thing we can do is reduce food waste to mitigate climate change,” said Nathan Fenner, cofounder and president of Afresh, on the NVIDIA AI podcast.

Time to gear up, hunters — Capcom’s Monster Hunter: World joins the GeForce NOW library, bringing members the ultimate hunting experience on any device.
It’s all part of an adventurous week, with nearly a dozen new games joining the cloud gaming service.

Join the Fifth Fleet on an epic adventure to the New World, a land full of monstrous creatures, in the acclaimed action role-playing game (RPG) Monster Hunter: World. It’s the latest in the series to join the cloud, following Monster Hunter Rise.
Members can unleash their inner hunter and slay ferocious monsters in a living, breathing ecosystem. Explore the unique landscape and encounter diverse monster inhabitants in ferocious hunting battles. Hunt alone or with up to three other players, and use materials collected from fallen foes to craft new gear and take on bigger, badder beasts.
Step up to the Quest Board and hunt monsters in the cloud at up to 4K resolution and 120 frames per second as an Ultimate member — or discover the New World at ultrawide resolutions. Members don’t need to wait for downloads or worry about storage space, and can take the action with them across nearly all devices.
One of the best ways to stream top PC games on the go — even the stunning neon lights of Cyberpunk 2077 — is with a Chromebook Plus. NVIDIA invited Cyberpunk 2077 fans well-versed on the graphics-intensive game to try it out on an unknown, hidden system.
They were shocked to realize they were playing on a Chromebook Plus with GeForce NOW’s Ultimate tier.
NVIDIA brought the same activation to attendees of The Game Awards, one of the industry’s most-watched award shows.
With the ability to stream from powerful GeForce RTX 4080 GPU-powered servers in the cloud with the Ultimate tier — paired with the cloud gaming Chromebook Plus’ high refresh rates, high-resolution displays, gaming keyboards, fast WiFi 6 connectivity and immersive audio — it’s no surprise participants gave the same surprised and delighted response.
To experience the power of gaming on a Chromebook with GeForce NOW, Google and NVIDIA are offering Chromebook owners three free months of a premium GeForce NOW membership. Find more details on how to redeem the offer on the Chromebook Perks page.

The latest update from opular open-world action RPG Genshin Impact from miHoYo is now available for members to stream. It brings two new characters, new events and a whole host of new features. Get to know the Geo Claymore character Navia, as well as Chevreuse, a new Pyro Polearm user, and more during the Fontinalia Festival event.
Don’t miss the 11 newly supported games joining the GeForce NOW library this week:
And there’s still time to give the gift of cloud gaming with the latest membership bundle, which includes a free, three-month PC Game Pass subscription with the purchase of a six-month GeForce NOW Ultimate membership.
What are you planning to play this weekend? Let us know on Twitter or in the comments below.
—
NVIDIA GeForce NOW (@NVIDIAGFN) December 20, 2023
Today we are excited to announce that the Llama Guard model is now available for customers using Amazon SageMaker JumpStart. Llama Guard provides input and output safeguards in large language model (LLM) deployment. It’s one of the components under Purple Llama, Meta’s initiative featuring open trust and safety tools and evaluations to help developers build responsibly with AI models. Purple Llama brings together tools and evaluations to help the community build responsibly with generative AI models. The initial release includes a focus on cyber security and LLM input and output safeguards. Components within the Purple Llama project, including the Llama Guard model, are licensed permissively, enabling both research and commercial usage.
Now you can use the Llama Guard model within SageMaker JumpStart. SageMaker JumpStart is the machine learning (ML) hub of Amazon SageMaker that provides access to foundation models in addition to built-in algorithms and end-to-end solution templates to help you quickly get started with ML.
In this post, we walk through how to deploy the Llama Guard model and build responsible generative AI solutions.
Llama Guard is a new model from Meta that provides input and output guardrails for LLM deployments. Llama Guard is an openly available model that performs competitively on common open benchmarks and provides developers with a pretrained model to help defend against generating potentially risky outputs. This model has been trained on a mix of publicly available datasets to enable detection of common types of potentially risky or violating content that may be relevant to a number of developer use cases. Ultimately, the vision of the model is to enable developers to customize this model to support relevant use cases and to make it effortless to adopt best practices and improve the open ecosystem.
Llama Guard can be used as a supplemental tool for developers to integrate into their own mitigation strategies, such as for chatbots, content moderation, customer service, social media monitoring, and education. By passing user-generated content through Llama Guard before publishing or responding to it, developers can flag unsafe or inappropriate language and take action to maintain a safe and respectful environment.
Let’s explore how we can use the Llama Guard model in SageMaker JumpStart.
SageMaker JumpStart provides access to a range of models from popular model hubs, including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your ML development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and are adaptable to a wide category of use cases, such as text summarization, digital art generation, and language translation. Because these models are expensive to train, customers want to use existing pre-trained foundation models and fine-tune them as needed, rather than train these models themselves. SageMaker provides a curated list of models that you can choose from on the SageMaker console.
You can now find foundation models from different model providers within SageMaker JumpStart, enabling you to get started with foundation models quickly. You can find foundation models based on different tasks or model providers, and easily review model characteristics and usage terms. You can also try out these models using a test UI widget. When you want to use a foundation model at scale, you can do so easily without leaving SageMaker by using pre-built notebooks from model providers. Because the models are hosted and deployed on AWS, you can rest assured that your data, whether used for evaluating or using the model at scale, is never shared with third parties.
Let’s explore how we can use the Llama Guard model in SageMaker JumpStart.
You can access Code Llama foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in Amazon SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions.

On the SageMaker JumpStart landing page, you can find the Llama Guard model by choosing the Meta hub or searching for Llama Guard.

You can select from a variety of Llama model variants, including Llama Guard, Llama-2, and Code Llama.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find a Deploy option, which will take you to a landing page where you can test inference with an example payload.

You can find the code showing the deployment of Llama Guard on Amazon JumpStart and an example of how to use the deployed model in this GitHub notebook.
In the following code, we specify the SageMaker model hub model ID and model version to use when deploying Llama Guard:
You can now deploy the model using SageMaker JumpStart. The following code uses the default instance ml.g5.2xlarge for the inference endpoint. You can deploy the model on other instance types by passing instance_type in the JumpStartModel class. The deployment might take a few minutes. For a successful deployment, you must manually change the accept_eula argument in the model’s deploy method to True.
This model is deployed using the Text Generation Inference (TGI) deep learning container. Inference requests support many parameters, including the following:
max_length. If specified, it must be a positive integer.max_new_tokens. If specified, it must be a positive integer.num_return_sequences.no_repeat_ngram_size is not repeated in the output sequence. If specified, it must be a positive integer greater than 1.temperature results in an output sequence with low-probability words, and a lower temperature results in an output sequence with high-probability words. If temperature is 0, it results in greedy decoding. If specified, it must be a positive float.True, text generation is finished when all beam hypotheses reach the end of the sentence token. If specified, it must be Boolean.True, the model samples the next word as per the likelihood. If specified, it must be Boolean.top_k most likely words. If specified, it must be a positive integer.top_p. If specified, it must be a float between 0–1.True, the input text will be part of the output generated text. If specified, it must be Boolean. The default value is False.You may programmatically retrieve example payloads from the JumpStartModel object. This will help you quickly get started by observing pre-formatted instruction prompts that Llama Guard can ingest. See the following code:
After you run the preceding example, you can see how your input and output would be formatted by Llama Guard:
Similar to Llama-2, Llama Guard uses special tokens to indicate safety instructions to the model. In general, the payload should follow the below format:
User prompt shown as {user_prompt} above, can further include sections for content category definitions and conversations, which looks like the following:
In the next section, we discuss the recommended default values for the task, content category, and instruction definitions. The conversation should alternate between User and Agent text as follows:
You can now deploy a Llama-2 7B Chat model endpoint for conversational chat and then use Llama Guard to moderate input and output text coming from Llama-2 7B Chat.
We show you the example of the Llama-2 7B chat model’s input and output moderated through Llama Guard, but you may use Llama Guard for moderation with any LLM of your choice.
Deploy the model with the following code:
You can now define the Llama Guard task template. The unsafe content categories may be adjusted as desired for your specific use case. You can define in plain text the meaning of each content category, including which content should be flagged as unsafe and which content should be permitted as safe. See the following code:
Next, we define helper functions format_chat_messages and format_guard_messages to format the prompt for the chat model and for the Llama Guard model that required special tokens:
You can then use these helper functions on an example message input prompt to run the example input through Llama Guard to determine if the message content is safe:
The following output indicates that the message is safe. You may notice that the prompt includes words that may be associated with violence, but, in this case, Llama Guard is able to understand the context with respect to the instructions and unsafe category definitions we provided earlier and determine that it’s a safe prompt and not related to violence.
Now that you have confirmed that the input text is determined to be safe with respect to your Llama Guard content categories, you can pass this payload to the deployed Llama-2 7B model to generate text:
The following is the response from the model:
Finally, you may wish to confirm that the response text from the model is determined to contain safe content. Here, you extend the LLM output response to the input messages and run this whole conversation through Llama Guard to ensure the conversation is safe for your application:
You may see the following output, indicating that response from the chat model is safe:
After you have tested the endpoints, make sure you delete the SageMaker inference endpoints and the model to avoid incurring charges.
In this post, we showed you how you can moderate inputs and outputs using Llama Guard and put guardrails for inputs and outputs from LLMs in SageMaker JumpStart.
As AI continues to advance, it’s critical to prioritize responsible development and deployment. Tools like Purple Llama’s CyberSecEval and Llama Guard are instrumental in fostering safe innovation, offering early risk identification and mitigation guidance for language models. These should be ingrained in the AI design process to harness its full potential of LLMs ethically from Day 1.
Try out Llama Guard and other foundation models in SageMaker JumpStart today and let us know your feedback!
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses, and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties, or guarantees that any information in this guidance will result in a particular outcome or result.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
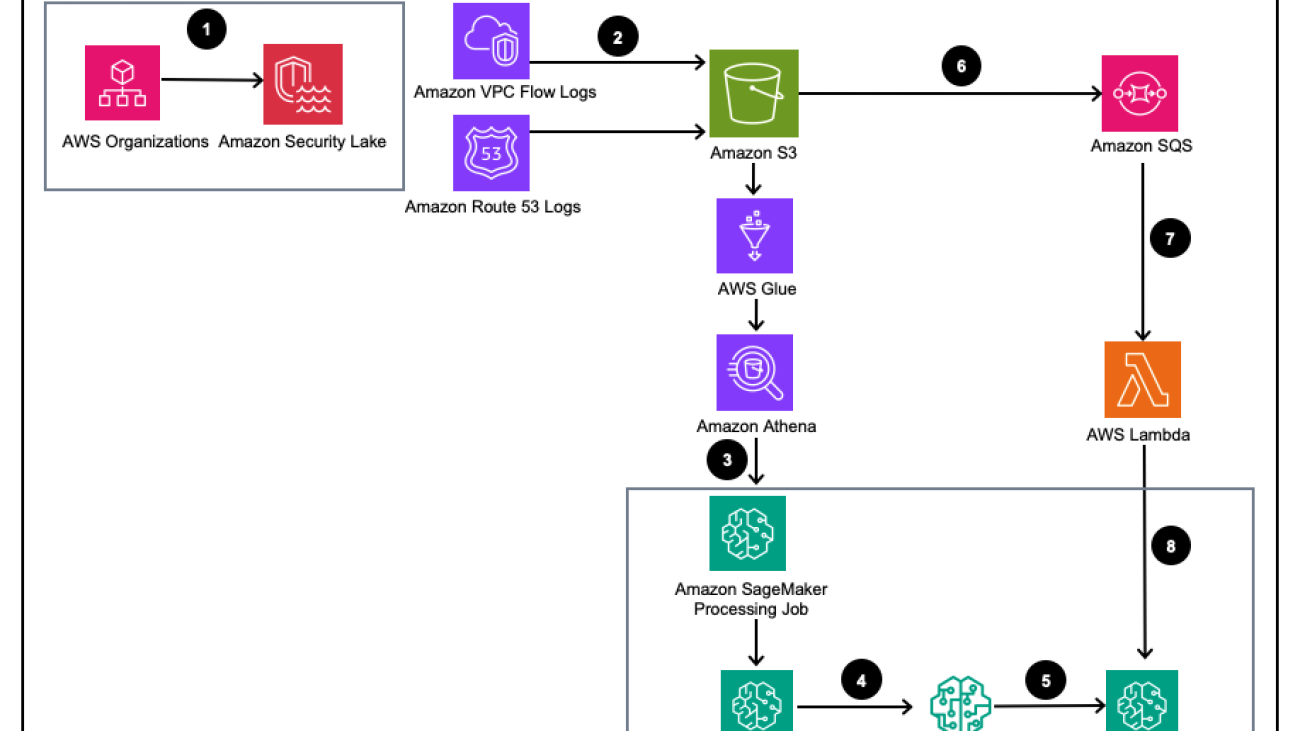
Customers are faced with increasing security threats and vulnerabilities across infrastructure and application resources as their digital footprint has expanded and the business impact of those digital assets has grown. A common cybersecurity challenge has been two-fold:
Furthermore, the analytics for identifying security threats must be capable of scaling and evolving to meet a changing landscape of threat actors, security vectors, and digital assets.
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Amazon Security Lake is a purpose-built service that automatically centralizes an organization’s security data from cloud and on-premises sources into a purpose-built data lake stored in your AWS account. Amazon Security Lake automates the central management of security data, normalizes logs from integrated AWS services and third-party services and manages the lifecycle of data with customizable retention and also automates storage tiering. Amazon Security Lake ingests log files in the Open Cybersecurity Schema Framework (OCSF) format, with support for partners such as Cisco Security, CrowdStrike, Palo Alto Networks, and OCSF logs from resources outside your AWS environment. This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal data pipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. An effective approach to analyzing the security log data is using ML; specifically, anomaly detection, which examines activity and traffic data and compares it against a baseline. The baseline defines what activity is statistically normal for that environment. Anomaly detection scales beyond an individual event signature, and it can evolve with periodic retraining; traffic classified as abnormal or anomalous can then be acted upon with prioritized focus and urgency. Amazon SageMaker is a fully managed service that enables customers to prepare data and build, train, and deploy ML models for any use case with fully managed infrastructure, tools, and workflows, including no-code offerings for business analysts. SageMaker supports two built-in anomaly detection algorithms: IP Insights and Random Cut Forest. You can also use SageMaker to create your own custom outlier detection model using algorithms sourced from multiple ML frameworks.
In this post, you learn how to prepare data sourced from Amazon Security Lake, and then train and deploy an ML model using an IP Insights algorithm in SageMaker. This model identifies anomalous network traffic or behavior which can then be composed as part of a larger end-to-end security solution. Such a solution could invoke a multi-factor authentication (MFA) check if a user is signing in from an unusual server or at an unusual time, notify staff if there is a suspicious network scan coming from new IP addresses, alert administrators if unusual network protocols or ports are used, or enrich the IP insights classification result with other data sources such as Amazon GuardDuty and IP reputation scores to rank threat findings.
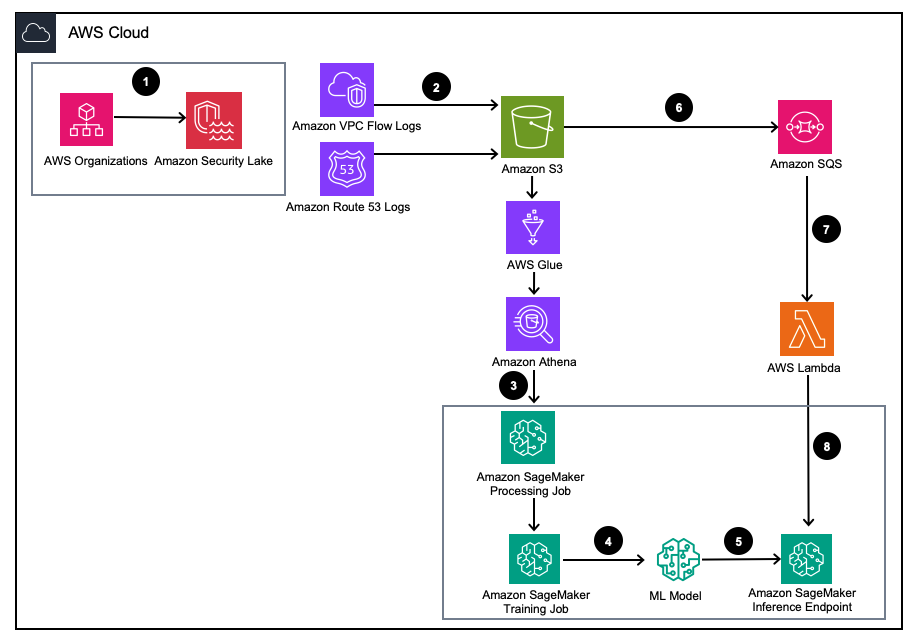
Figure 1 – Solution Architecture
To deploy the solution, you must first complete the following prerequisites:
To set up the environment, complete the following steps:
ml.m5.large instance. Note: Instance size is dependent on the datasets you use.01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy.This blog walks through the relevant portion of code within the notebook after it’s deployed in your environment.
Use the following code to install dependencies, import the required libraries, and create the SageMaker S3 bucket needed for data processing and model training. One of the required libraries, awswrangler, is an AWS SDK for pandas dataframe that is used to query the relevant tables within the AWS Glue Data Catalog and store the results locally in a dataframe.
This portion of code uses the AWS SDK for pandas to query the AWS Glue table related to VPC Flow Logs. As mentioned in the prerequisites, Amazon Security Lake tables are managed by AWS Lake Formation, so all proper permissions must be granted to the role used by the SageMaker notebook. This query will pull multiple days of VPC flow log traffic. The dataset used during development of this blog was small. Depending on the scale of your use case, you should be aware of the limits of the AWS SDK for pandas. When considering terabyte scale, you should consider AWS SDK for pandas support for Modin.
When you view the data frame, you will see an output of a single column with common fields that can be found in the Network Activity (4001) class of the OCSF.
The IP Insights algorithm requires that the training data be in CSV format and contain two columns. The first column must be an opaque string that corresponds to an entity’s unique identifier. The second column must be the IPv4 address of the entity’s access event in decimal-dot notation. In the sample dataset for this blog, the unique identifier is the Instance IDs of EC2 instances associated to the instance_id value within the dataframe. The IPv4 address will be derived from the src_endpoint. Based on the way the Amazon Athena query was created, the imported data is already in the correct format for training an IP Insights model, so no additional feature engineering is required. If you modify the query in another way, you may need to incorporate additional feature engineering.
Just as you did above, the next step of the notebook runs a similar query against the Amazon Security Lake Route 53 resolver table. Since you will be using all OCSF compliant data within this notebook, any feature engineering tasks remain the same for Route 53 resolver logs as they were for VPC Flow Logs. You then combine the two data frames into a single data frame that is used for training. Since the Amazon Athena query loads the data locally in the correct format, no further feature engineering is required.
In this next portion of the notebook, you train an ML model based on the IP Insights algorithm and use the consolidated dataframe of OCSF from different types of logs. A list of the IP Insights hyperparmeters can be found here. In the example below we selected hyperparameters that outputted the best performing model, for example, 5 for epoch and 128 for vector_dim. Since the training dataset for our sample was relatively small, we utilized a ml.m5.large instance. Hyperparameters and your training configurations such as instance count and instance type should be chosen based on your objective metrics and your training data size. One capability that you can utilize within Amazon SageMaker to find the best version of your model is Amazon SageMaker automatic model tuning that searches for the best model across a range of hyperparameter values.
After the model has been trained, you deploy the model to a SageMaker endpoint and send a series of unique identifier and IPv4 address combinations to test your model. This portion of code assumes you have test data saved in your S3 bucket. The test data is a .csv file, where the first column is instance ids and the second column is IPs. It is recommended to test valid and invalid data to see the results of the model. The following code deploys your endpoint.
Now that your endpoint is deployed, you can now submit inference requests to identify if traffic is potentially anomalous. Below is a sample of what your formatted data should look like. In this case, the first column identifier is an instance id and the second column is an associated IP address as shown in the following:
After you have your data in CSV format, you can submit the data for inference using the code by reading your .csv file from an S3 bucket.:
The output for an IP Insights model provides a measure of how statistically expected an IP address and online resource are. The range for this address and resource is unbounded however, so there are considerations on how you would determine if an instance ID and IP address combination should be considered anomalous.
In the preceding example, four different identifier and IP combinations were submitted to the model. The first two combinations were valid instance ID and IP address combinations that are expected based on the training set. The third combination has the correct unique identifier but a different IP address within the same subnet. The model should determine there is a modest anomaly as the embedding is slightly different from the training data. The fourth combination has a valid unique identifier but an IP address of a nonexistent subnet within any VPC in the environment.
Note: Normal and abnormal traffic data will change based on your specific use case, for example: if you want to monitor external and internal traffic you would need a unique identifier aligned to each IP address and a scheme to generate the external identifiers.
To determine what your threshold should be to determine whether traffic is anomalous can be done using known normal and abnormal traffic. The steps outlined in this sample notebook are as follows:
dot_product scores for the model on normal traffic and the abnormal traffic.To demonstrate how this new ML model could be use with Amazon Security Lake in a proactive manner, we will configure a Lambda function to be invoked on each PutObject event within the Amazon Security Lake managed bucket, specifically the VPC flow log data. Within Amazon Security Lake there is the concept of a subscriber, that consumes logs and events from Amazon Security Lake. The Lambda function that responds to new events must be granted a data access subscription. Data access subscribers are notified of new Amazon S3 objects for a source as the objects are written to the Security Lake bucket. Subscribers can directly access the S3 objects and receive notifications of new objects through a subscription endpoint or by polling an Amazon SQS queue.
inferencelambda for Subscriber name and an optional Description.To create and deploy the Lambda function you can either complete the following steps or deploy the prebuilt SAM template 01_ipinsights/01.02-ipcheck.yaml in the GitHub repo. The SAM template requires you provide the SQS ARN and the SageMaker endpoint name.
ipcheck.ENDPOINT_NAME and for value enter the endpoint ARN that was outputted during deployment of the SageMaker endpoint./aws/lambda/ipcheck.{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
This Lambda function continually analyzes the network traffic being ingested by Amazon Security Lake. This allows you to build mechanisms to notify your security teams when a specified threshold is violated, which would indicate an anomalous traffic in your environment.
When you’re finished experimenting with this solution and to avoid charges to your account, clean up your resources by deleting the S3 bucket, SageMaker endpoint, shutting down the compute attached to the SageMaker Jupyter notebook, deleting the Lambda function, and disabling Amazon Security Lake in your account.
In this post you learned how to prepare network traffic data sourced from Amazon Security Lake for machine learning, and then trained and deployed an ML model using the IP Insights algorithm in Amazon SageMaker. All of the steps outlined in the Jupyter notebook can be replicated in an end-to-end ML pipeline. You also implemented an AWS Lambda function that consumed new Amazon Security Lake logs and submitted inferences based on the trained anomaly detection model. The ML model responses received by AWS Lambda could proactively notify security teams of anomalous traffic when certain thresholds are met. Continuous improvement of the model can be enabled by including your security team in the loop reviews to label whether traffic identified as anomalous was a false positive or not. This could then be added to your training set and also added to your normal traffic dataset when determining an empirical threshold. This model can identify potentially anomalous network traffic or behavior whereby it can be included as part of a larger security solution to initiate an MFA check if a user is signing in from an unusual server or at an unusual time, alert staff if there is a suspicious network scan coming from new IP addresses, or combine the IP insights score with other sources such as Amazon Guard Duty to rank threat findings. This model can include custom log sources such as Azure Flow Logs or on-premises logs by adding in custom sources to your Amazon Security Lake deployment.
In part 2 of this blog post series, you will learn how to build an anomaly detection model using the Random Cut Forest algorithm trained with additional Amazon Security Lake sources that integrate network and host security log data and apply the security anomaly classification as part of an automated, comprehensive security monitoring solution.
 Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), helping Enterprise customers across the Midwest US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance
Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), helping Enterprise customers across the Midwest US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance
 Bishr Tabbaa is a solutions architect at Amazon Web Services. Bishr specializes in helping customers with machine learning, security, and observability applications. Outside of work, he enjoys playing tennis, cooking, and spending time with family.
Bishr Tabbaa is a solutions architect at Amazon Web Services. Bishr specializes in helping customers with machine learning, security, and observability applications. Outside of work, he enjoys playing tennis, cooking, and spending time with family.
 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.

 A roundup of Google’s best tips from 2023 for saving time and money, being more creative and putting AI to work in the New Year.Read More
A roundup of Google’s best tips from 2023 for saving time and money, being more creative and putting AI to work in the New Year.Read More

Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.

Deep Neural Networks (DNNs) are essentially stacked transformation functions (layers) that generate progressively complex features/encoding. This makes them universal approximators and allows for unprecedented success in complex tasks. This inferential effectiveness comes at the cost of increased computational complexity, making DNNs hard to scale for operational efficiency in AI applications, especially when running on resource-constrained hardware.
In a recent paper: NASerEx: Optimizing Early Exits via AutoML for Scalable Efficient Inference in Big Image Streams, researchers from Microsoft and their collaborators propose a new framework to address this problem. NASerEX leverages neural architecture search (NAS) with a novel saliency-constrained search space and exit decision metric to learn suitable early exit structures to augment deep neural models for scalable efficient inference on big image streams. Optimized exit-augmented models, with the power of smart adaptive inference, perform ~2.5x faster having ~4x aggregated lower effective FLOPs, with no significant accuracy loss.
Spotlight: On-demand video

Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
Effective data exploration requires in-depth knowledge of the dataset and the user intent, and expertise in data analysis techniques. Not being familiar with either can create obstacles that make the process time-consuming and overwhelming.
In a recent paper, InsightPilot: An LLM-Empowered Automated Data Exploration System, researchers from Microsoft address this issue. InsightPilot is a large language model (LLM)-based, automated system designed to simplify the data exploration process. It features a set of carefully designed analysis actions that streamline the data exploration process. Given a natural language question, InsightPilot collaborates with the LLM to issue a sequence of analysis actions, explore the data, and generate insights. The authors demonstrate the effectiveness of InsightPilot in a user study and a case study, showing how it can help users gain valuable insights from their datasets.
Microsoft’s cloud system serves as the backbone for the daily operations of hundreds of thousands of organizations, driving productivity and collaboration. The foundational infrastructure demands both high reliability and efficiency. In a new blog post, Microsoft’s Systems Innovation team explores some recent innovations to continually enhance hyper-scale cloud capacity efficiency, delivering substantial operational cost savings for customers.
Systems Innovation is a collaboration between Microsoft 365, Microsoft Research and Azure. The research group is focused on leveraging their shared deep workload understanding and combining algorithmic research with AI/machine learning techniques and hardware innovation to improve operational reliability and efficiency.
Large language models (LLMs) trained on large bodies of text can solve tasks with few supervised examples. These few-shot models have shown state-of-the-art success across natural language processing (NLP) tasks, language translation, standardized exams, and coding challenges, as well as in subjective domains such as chatbots. All of these domains involve bootstrapping a single LLM referred to as a foundation model with examples of specific knowledge from the associated task.
The process of updating a model with limited domain-specific data is known as fine-tuning. However, the costs of accessing, fine-tuning and querying foundation models to perform new tasks can be large.
To help democratize access to language models, Microsoft and other industry leaders were pleased to sponsor the NeurIPS Large Language Model Efficiency Challenge, (opens in new tab) which addressed three major issues:
The challenge to the community was to adapt a foundation model to specific tasks by fine-tuning on a single GPU of either 4090 or A100 (40GB) within a 24-hour (1-day) time frame, while maintaining high accuracy for these desired tasks.
Each submission was evaluated for accuracy and computational performance tradeoffs at commodity hardware scales. Insights and lessons were distilled into a set of well documented steps and easy-to-follow tutorials. The machine learning community will have documentation on how to achieve the same performance as winning entries, which will serve as the starting point to help them build their own LLM solutions.
The post Research Focus: Week of December 18, 2023 appeared first on Microsoft Research.

 Explore our collection looking back on some of our biggest moments and milestones from 2023.Read More
Explore our collection looking back on some of our biggest moments and milestones from 2023.Read More
Novel architectures and carefully prepared training data enable state-of-the-art performance.Read More
