 A look back at 2023 at Google, from AI announcements to hardware launches and more.Read More
A look back at 2023 at Google, from AI announcements to hardware launches and more.Read More

A look back at 2023 at Google, from AI announcements to hardware launches and more.Read More

Outside the glare of the klieg lights that ChatGPT commanded this year, a troupe of autonomous machines nudged the frontiers of robotics forward.
Here are six that showed special prowess — swimming, diving, gripping, seeing, strolling and flying through 2023.
Ella — a smart stroller from startup Glüxkind Technologies, of Vancouver, Canada — kicked off the year when it was named an honoree in the CES 2023 Innovation Awards.
The canny carriage uses computer vision running on the NVIDIA Jetson edge AI platform to follow parents. Its AI-powered abilities, like smart braking and a rock-my-baby mode, captured the attention of media outlets like Good Morning America and The Times of London as well as an NVIDIA AI Podcast interview with its husband-and-wife cofounders.
A member of NVIDIA Inception, a free program for cutting-edge startups, Glüxkind was one of seven companies with NVIDIA-powered products recognized at the Las Vegas event in January. They included:
Inception startup Soft Robotics, of Bedford, Mass., introduced its mGripAI system to an $8 trillion food industry hungry for automation. It combines 3D vision and AI to grasp delicate items such as chicken wings, attracting investors that include Tyson Foods and Johnsonville.
Soft Robotics uses the NVIDIA Omniverse platform and NVIDIA Isaac Sim robotics simulator to create 3D renderings of chicken parts on conveyor belts or in bins. With help from AI and the ray-tracing capabilities of NVIDIA RTX technology, they help the robot gripper handle as many as 100 picks per minute, even under glare or changing light conditions.
“We’re all in on Omniverse and Isaac Sim, and that’s been working great for us,” said David Weatherwax, senior director of software engineering at Soft Robotics.
In a very different example of industrial digitalization, leading electronics manufacturer Quanta is inspecting the quality of its products using the TM25S, an AI-enabled robot from its subsidiary, Techman Robot.
Using Omniverse, Techman built a digital twin of the inspection robot — as well as the product to be inspected — in Isaac Sim. Programming the robot in simulation reduced time spent on the task by over 70%, compared to programming manually on the real robot.
Then, with powerful optimization tools in Isaac Sim, Techman explored a massive number of program options in parallel on NVIDIA GPUs. The end result, shown in the video below, was an efficient solution that reduced the cycle time of each inspection by 20%.
For its part, Saildrone, an Inception startup in Alameda, Calif., created uncrewed watercraft that can cost-effectively gather data for science, fisheries, weather forecasting and more. NVIDIA Jetson modules process data streams from their sensors, some with help from NVIDIA Metropolis vision AI software such as NVIDIA DeepStream, a development kit for intelligent video analytics.
The video below shows how three of its smart sailboats are helping evaluate ocean health around the Hawaiian Islands.
The next stop for one autonomous vehicle may be the red planet.
Caltech’s Multi-Modal Mobility Morphobot, or M4, can configure itself to walk, fly or drive at speeds up to 40 mph (video below). An M42 version is now under development at NASA as a Mars rover candidate and has attracted interest for other uses like reconnaissance in fire zones.
Since releasing a paper on it in Nature Communications, the team has been inundated with proposals for the shape-shifting drone built on the NVIDIA Jetson platform.
The year ended on a high note with San Francisco-based Zipline announcing its delivery drones flew more than 55 million miles and made more than 800,000 deliveries since the company’s start in 2011. Zipline now completes one delivery every 70 seconds, globally.
That’s a major milestone for the Inception startup, the field it’s helping pioneer and the customers who can receive everything from pizza to vitamins 7x faster than by truck.
Zipline’s latest drone uses two Jetson Orin NX modules. It can carry eight pounds of cargo for 10 miles at up to 70 mph to deliver packages in single-digit minutes while reducing carbon emissions 97% compared to gasoline-based delivery vehicles.
Individual makers designed two autonomous vehicles this year worth special mentions.

Kabilan KB, a robotics developer and student in Coimbatore, India, built an autonomous wheelchair using Jetson to run computer vision models that find and navigate a path to a user’s desired destination. The undergrad at the Karunya Institute of Technology and Sciences aspires to one day launch a robotics startup.
Finally, an engineering manager in Copenhagen who’s a self-described Star Wars fanatic designed an AI-powered droid based on an NVIDIA Jetson Orin Nano Developer Kit. Goran Vuksic shared his step-by-step technical guide, so others can build their own sci-fi companions.
More than 6,500 companies and 1.2 million developers — as well as a community of makers and enthusiasts — use the NVIDIA Jetson and Isaac platforms for edge AI and robotics.
To get a look at where autonomous machines will go next, see what’s coming at CES in 2024.

Thomson Reuters, the global content and technology company, is transforming the legal industry with generative AI.
In the latest episode of NVIDIA’s AI Podcast, host Noah Kravitz spoke with Thomson Reuters Chief Product Officer David Wong about its potential — and implications.
Many of Thomson Reuters offerings for the legal industry either address an information retrieval problem or help generate written content.
It has aN AI-driven digital solution that enables law practitioners to search laws and cases intelligently within different jurisdictions. It also provides AI-powered tools that are set to be integrated with commonly used products like Microsoft 365 to automate the time-consuming processes of drafting and analyzing legal documents.
These technologies increase the productivity of legal professionals, enabling them to focus their time on higher-value work. According to Wong, ultimately these tools also have the potential to help deliver better access to justice.
To address ethical concerns, the company has created publicly available AI development guidelines, as well as privacy and data protection policies. And it’s participating in the drafting of ethical guidelines for the industries it serves.
There’s still a wide range of reactions surrounding AI use in the legal field, from optimism about its potential to fears of job replacement. But Wong underscored that no matter what the outlook, “it is very likely that professionals that use AI are going to replace professionals that don’t use AI.”
Looking ahead, Thomson Reuters aims to further integrate generative AI, as well as retrieval-augmented generation techniques into its flagship research products to help lawyers synthesize, read and respond to complicated technical and legal questions. Recently, Thomson Reuters acquired Casetext, which developed the first AI legal assistant, CoCounsel.
In 2024 Thomson Reuters is building on this with the launch of an AI assistant that will be the interface across Thomson Reuters products with GenAI capabilities, including those in other fields such as tax and accounting.
Driver’s Ed: How Waabi Uses AI Simulation to Teach Autonomous Vehicles to Drive
Teaching the AI brains of autonomous vehicles to understand the world as humans do requires billions of miles of driving experience—the road to achieving this astronomical level of driving leads to the virtual world. Learn how Waabi uses powerful high-fidelity simulations to train and develop production-level autonomous vehicles.
Polestar’s Dennis Nobelius on the Sustainable Performance Brand’s Plans
Driving enjoyment and autonomous driving capabilities can complement one another in intelligent, sustainable vehicles. Learn about the automaker’s plans to unveil its third vehicle, the Polestar 3, the tech inside it, and what the company’s racing heritage brings to the intersection of smarts and sustainability.
GANTheftAuto: Harrison Kinsley on AI-Generated Gaming Environments
Humans playing games against machines is nothing new, but now computers can develop games for people to play. Programming enthusiast and social media influencer Harrison Kinsley created GANTheftAuto, an AI-based neural network that generates a playable chunk of the classic video game Grand Theft Auto V.
The AI Podcast is now available through Amazon Music.
In addition, get the AI Podcast through iTunes, Google Podcasts, Google Play, Castbox, DoggCatcher, Overcast, PlayerFM, Pocket Casts, Podbay, PodBean, PodCruncher, PodKicker, Soundcloud, Spotify, Stitcher and TuneIn.
Make the AI Podcast better: Have a few minutes to spare? Fill out this listener survey.

Editor’s note: This post is part of Into the Omniverse, a series focused on how artists, developers and enterprises can transform their workflows using the latest advances in OpenUSD and NVIDIA Omniverse.
3D designers and creators are embracing Universal Scene Description, aka OpenUSD, to transform their workflows.
Creative software company Foundry’s latest release of Nuke, a powerful compositing tool for visual effects (VFX), is bringing increased support for OpenUSD, a framework that provides a unified and extensible ecosystem for describing, composing, simulating and collaborating within 3D worlds.
With advanced compositing and improved interoperability capabilities, artists are showcasing the immense potential of Nuke and OpenUSD for visual storytelling.
YouTuber Jacob Zirkle is one such 3D artist.
Inspired by his 10th watch through the Star Wars films, Zirkle wanted to create a sci-fi ship of his own. He first combined computer graphics elements in Blender and Unreal Engine before using USD to bring the scene into Nuke for compositing.
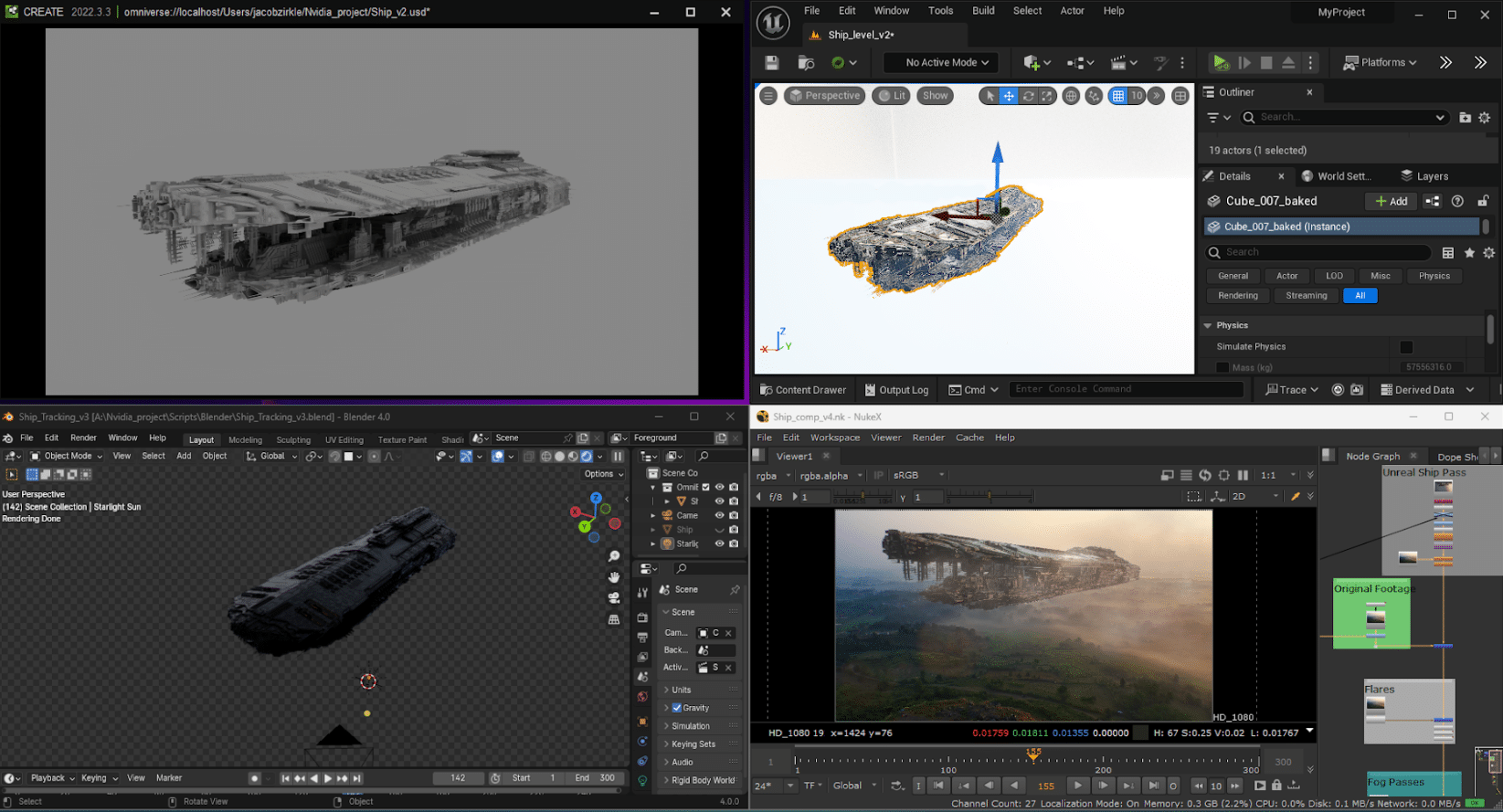 Zirkle’s ship, built using Blender, Nuke, Unreal Engine and USD Composer.
Zirkle’s ship, built using Blender, Nuke, Unreal Engine and USD Composer.
OpenUSD was the glue that held his workflow together.
“Usually, I have to deal with multiple, varying file types in my VFX pipeline, and as soon as something gets updated, it can be a real pain to apply the change across the board,” Zirkle said. “But because I was using the same OpenUSD file for all of my programs, I could save the file once, and changes get automatically propagated through the pipeline — saving me a ton of time.”

Edward McEvenue, an associate creative director at NVIDIA, is using OpenUSD and Nuke to create his short film with the working title: “Dare to Dream.”
Through the project, McEvenue hopes to visualize aspects of automated manufacturing. He uses Autodesk 3ds Max and SideFX Houdini for 3D scene creation, Chaos V-Ray for rendering arbitrary output variables and extended dynamic range sequences, and Nuke for compositing elements for final renders.

OpenUSD helps streamline data transfer between applications, speeding the iteration process. “Nuke’s USD capabilities allow me to seamlessly transition 3D assets between digital content-creation apps, providing a powerful tool for achieving advanced compositing techniques,” he said.
Other NVIDIA creatives have integrated OpenUSD and Nuke into their 3D workflows. A team of 10 artists developed a fully OpenUSD-based pipeline and custom tooling on NVIDIA Omniverse — a development platform for building OpenUSD-based tools and applications — to bring to life the “Da Vinci Workshop,” a project to inspire greater OpenUSD use among pipeline developers.
The artists also used Adobe Substance Painter, Autodesk 3ds Max, Autodesk Maya, DaVinci Resolve, SideFX Houdini, Pixelogic Zbrush and Omniverse USD Composer. OpenUSD served as the backbone of the team’s internal pipeline, offering the flexibility needed to collaborate across applications with ease.
The “Da Vinci Workshop” OpenUSD dataset is now available on the Omniverse launcher — free for developers and artists.
Foundry Nuke representatives, Omniverse community members and the NVIDIA creative team recently joined a livestream to discuss their 3D workflows and the impact of OpenUSD. Learn more by watching the replay:
The 15.0 and 14.1 updates to Nuke bring significant workflow enhancements to those working with OpenUSD.
The updated GeoMerge node now offers four new modes: Merge Layers, Duplicate Prims, Flatten Layers and Flatten to Single Layer. These give users greater control over geometry and OpenUSD layers, allowing for quick merging of complex structures, the duplication of workflows and more effective layer management.
The OpenUSD-based 3D system introduced in Nuke 14.0 enables users to handle large, intricate scenes with greater ease. And the new Scene Graph Popup feature in Nuke 15.0 allows users to easily filter through 3D scene data, reducing time and energy needed to spend searching for specific assets.
In addition, the main 3D scene graph now includes a search and filter feature, simplifying workspace navigation.
Foundry is also embracing OpenUSD across its other products, including the latest updates to Katana 7.0, which boost pipeline efficiency by integrating USD-native workflows already aligned with Nuke’s 3D system architecture.
NVIDIA and Foundry are both members of the Alliance for OpenUSD (AOUSD), an organization dedicated to an open-source future using the powerful framework. To learn more, explore the AOUSD forum and check out these resources on OpenUSD.
Share your Nuke and Omniverse work as part of the latest community #WinterArtChallenge. Use the hashtag for a chance to be featured on the @NVIDIAStudio and @NVIDIAOmniverse social channels.
Winter has returned and so has our #WinterArtChallenge!
Share your winter-themed art (like this incredible one created on an RTX GPU by @rafianimates) using the hashtag for a chance to be featured on our social channels!
We can’t wait to see what you create!
pic.twitter.com/Ml4cUAUgW3
— NVIDIA Studio (@NVIDIAStudio) December 4, 2023
Get started with NVIDIA Omniverse by downloading the standard license free, access OpenUSD resources, and learn how Omniverse Enterprise can connect your team. Stay up to date on Instagram, Medium and Twitter. For more, join the Omniverse community on the forums, Discord server, Twitch and YouTube channels.

A recent wave of video generation models has burst onto the scene, in many cases showcasing stunning picturesque quality. One of the current bottlenecks in video generation is in the ability to produce coherent large motions. In many cases, even the current leading models either generate small motion or, when producing larger motions, exhibit noticeable artifacts.
To explore the application of language models in video generation, we introduce VideoPoet, a large language model (LLM) that is capable of a wide variety of video generation tasks, including text-to-video, image-to-video, video stylization, video inpainting and outpainting, and video-to-audio. One notable observation is that the leading video generation models are almost exclusively diffusion-based (for one example, see Imagen Video). On the other hand, LLMs are widely recognized as the de facto standard due to their exceptional learning capabilities across various modalities, including language, code, and audio (e.g., AudioPaLM). In contrast to alternative models in this space, our approach seamlessly integrates many video generation capabilities within a single LLM, rather than relying on separately trained components that specialize on each task.
The diagram below illustrates VideoPoet’s capabilities. Input images can be animated to produce motion, and (optionally cropped or masked) video can be edited for inpainting or outpainting. For stylization, the model takes in a video representing the depth and optical flow, which represent the motion, and paints contents on top to produce the text-guided style.
 |
| An overview of VideoPoet, capable of multitasking on a variety of video-centric inputs and outputs. The LLM can optionally take text as input to guide generation for text-to-video, image-to-video, video-to-audio, stylization, and outpainting tasks. Resources used: Wikimedia Commons and DAVIS. |
One key advantage of using LLMs for training is that one can reuse many of the scalable efficiency improvements that have been introduced in existing LLM training infrastructure. However, LLMs operate on discrete tokens, which can make video generation challenging. Fortunately, there exist video and audio tokenizers, which serve to encode video and audio clips as sequences of discrete tokens (i.e., integer indices), and which can also be converted back into the original representation.
VideoPoet trains an autoregressive language model to learn across video, image, audio, and text modalities through the use of multiple tokenizers (MAGVIT V2 for video and image and SoundStream for audio). Once the model generates tokens conditioned on some context, these can be converted back into a viewable representation with the tokenizer decoders.
 |
| A detailed look at the VideoPoet task design, showing the training and inference inputs and outputs of various tasks. Modalities are converted to and from tokens using tokenizer encoder and decoders. Each modality is surrounded by boundary tokens, and a task token indicates the type of task to perform. |
Some examples generated by our model are shown below.
 |
| Videos generated by VideoPoet from various text prompts. For specific text prompts refer to the website. |
For text-to-video, video outputs are variable length and can apply a range of motions and styles depending on the text content. To ensure responsible practices, we reference artworks and styles in the public domain e.g., Van Gogh’s “Starry Night”.
| Text Input | “A Raccoon dancing in Times Square” | “A horse galloping through Van-Gogh’s ‘Starry Night’” | “Two pandas playing cards” | “A large blob of exploding splashing rainbow paint, with an apple emerging, 8k” | ||||
| Video Output |  |
 |
 |
 |
For image-to-video, VideoPoet can take the input image and animate it with a prompt.
 |
| An example of image-to-video with text prompts to guide the motion. Each video is paired with an image to its left. Left: “A ship navigating the rough seas, thunderstorm and lightning, animated oil on canvas”. Middle: “Flying through a nebula with many twinkling stars”. Right: “A wanderer on a cliff with a cane looking down at the swirling sea fog below on a windy day”. Reference: Wikimedia Commons, public domain**. |
For video stylization, we predict the optical flow and depth information before feeding into VideoPoet with some additional input text.
 |
| Examples of video stylization on top of VideoPoet text-to-video generated videos with text prompts, depth, and optical flow used as conditioning. The left video in each pair is the input video, the right is the stylized output. Left: “Wombat wearing sunglasses holding a beach ball on a sunny beach.” Middle: “Teddy bears ice skating on a crystal clear frozen lake.” Right: “A metal lion roaring in the light of a forge.” |
VideoPoet is also capable of generating audio. Here we first generate 2-second clips from the model and then try to predict the audio without any text guidance. This enables generation of video and audio from a single model.
| An example of video-to-audio, generating audio from a video example without any text input. |
By default, the VideoPoet model generates videos in portrait orientation to tailor its output towards short-form content. To showcase its capabilities, we have produced a brief movie composed of many short clips generated by VideoPoet. For the script, we asked Bard to write a short story about a traveling raccoon with a scene-by-scene breakdown and a list of accompanying prompts. We then generated video clips for each prompt, and stitched together all resulting clips to produce the final video below.
When we developed VideoPoet, we noticed some nice properties of the model’s capabilities, which we highlight below.
We are able to generate longer videos simply by conditioning on the last 1 second of video and predicting the next 1 second. By chaining this repeatedly, we show that the model can not only extend the video well but also faithfully preserve the appearance of all objects even over several iterations.
Here are two examples of VideoPoet generating long video from text input:
| Text Input | “An astronaut starts dancing on Mars. Colorful fireworks then explode in the background.” | “FPV footage of a very sharp elven city of stone in the jungle with a brilliant blue river, waterfall, and large steep vertical cliff faces.” | |||
| Video Output |  |
 |
It is also possible to interactively edit existing video clips generated by VideoPoet. If we supply an input video, we can change the motion of objects to perform different actions. The object manipulation can be centered at the first frame or the middle frames, which allow for a high degree of editing control.
For example, we can randomly generate some clips from the input video and select the desired next clip.
 |
| An input video on the left is used as conditioning to generate four choices given the initial prompt: “Closeup of an adorable rusty broken-down steampunk robot covered in moss moist and budding vegetation, surrounded by tall grass”. For the first three outputs we show what would happen for unprompted motions. For the last video in the list below, we add to the prompt, “powering up with smoke in the background” to guide the action. |
Similarly, we can apply motion to an input image to edit its contents towards the desired state, conditioned on a text prompt.
 |
| Animating a painting with different prompts. Left: “A woman turning to look at the camera.” Right: “A woman yawning.” ** |
We can also accurately control camera movements by appending the type of desired camera motion to the text prompt. As an example, we generated an image by our model with the prompt, “Adventure game concept art of a sunrise over a snowy mountain by a crystal clear river”. The examples below append the given text suffix to apply the desired motion.
 |
| Prompts from left to right: “Zoom out”, “Dolly zoom”, “Pan left”, “Arc shot”, “Crane shot”, “FPV drone shot”. |
We evaluate VideoPoet on text-to-video generation with a variety of benchmarks to compare the results to other approaches. To ensure a neutral evaluation, we ran all models on a wide variation of prompts without cherry-picking examples and asked people to rate their preferences. The figure below highlights the percentage of the time VideoPoet was chosen as the preferred option in green for the following questions.
 |
| User preference ratings for text fidelity, i.e., what percentage of videos are preferred in terms of accurately following a prompt. |
 |
| User preference ratings for motion interestingness, i.e., what percentage of videos are preferred in terms of producing interesting motion. |
Based on the above, on average people selected 24–35% of examples from VideoPoet as following prompts better than a competing model vs. 8–11% for competing models. Raters also preferred 41–54% of examples from VideoPoet for more interesting motion than 11–21% for other models.
Through VideoPoet, we have demonstrated LLMs’ highly-competitive video generation quality across a wide variety of tasks, especially in producing interesting and high quality motions within videos. Our results suggest the promising potential of LLMs in the field of video generation. For future directions, our framework should be able to support “any-to-any” generation, e.g., extending to text-to-audio, audio-to-video, and video captioning should be possible, among many others.
To view more examples in original quality, see the website demo.
This research has been supported by a large body of contributors, including Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, Yong Cheng, Ming-Chang Chiu, Josh Dillon, Irfan Essa, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, David Ross, Grant Schindler, Mikhail Sirotenko, Kihyuk Sohn, Krishna Somandepalli, Huisheng Wang, Jimmy Yan, Ming-Hsuan Yang, Xuan Yang, Bryan Seybold, and Lu Jiang.
We give special thanks to Alex Siegman and Victor Gomes for managing computing resources. We also give thanks to Aren Jansen, Marco Tagliasacchi, Neil Zeghidour, John Hershey for audio tokenization and processing, Angad Singh for storyboarding in “Rookie the Raccoon”, Cordelia Schmid for research discussions, Alonso Martinez for graphic design, David Salesin, Tomas Izo, and Rahul Sukthankar for their support, and Jay Yagnik as architect of the initial concept.
**
(a) The Storm on the Sea of Galilee, by Rembrandt 1633, public domain.
(b) Pillars of Creation, by NASA 2014, public domain.
(c) Wanderer above the Sea of Fog, by Caspar David Friedrich, 1818, public domain
(d) Mona Lisa, by Leonardo Da Vinci, 1503, public domain.

 An overview of how we’re expanding code assistance features to all Colab users.Read More
An overview of how we’re expanding code assistance features to all Colab users.Read More
Four professors awarded for research in machine learning and robotics; two doctoral candidates awarded fellowships.Read More

In the lead-up to next month’s CES trade show in Las Vegas, NVIDIA will unveil its latest advancements in artificial intelligence — including generative AI — and a spectrum of other cutting-edge technologies.
Scheduled for Monday, Jan. 8, at 8 a.m. PT, the company’s special address will be publicly streamed. Save the date and plan to tune in to the virtual address, which will focus on consumer technologies and robotics, on NVIDIA’s website, YouTube or Twitch.
AI and NVIDIA technologies will be the focus of 14 conference sessions, including four at CES Digital Hollywood, “Reshaping Retail – AI Creating Opportunity,” “Robots at Work” and “Cracking the Smart Car.”
And throughout CES, NVIDIA’s story will be enriched by the presence of over 85 NVIDIA customers and partners.
For the investment community, NVIDIA will participate in a CES Virtual Fireside Chat hosted by J.P. Morgan on Tuesday, Jan. 9, at 8 a.m. PT. Listen to the live audio webcast at investor.nvidia.com.
Visit NVIDIA’s event web page for a complete list of sessions and a view of our extensive partner ecosystem at the show.
This post was written in collaboration with Ankur Goyal and Karthikeyan Chokappa from PwC Australia’s Cloud & Digital business.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices. Many businesses already have data scientists and ML engineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. Manual workflows limit ML lifecycle operations to slow down the development process, increase costs, and compromise the quality of the final product.
Machine learning operations (MLOps) applies DevOps principles to ML systems. Just like DevOps combines development and operations for software engineering, MLOps combines ML engineering and IT operations. With the rapid growth in ML systems and in the context of ML engineering, MLOps provides capabilities that are needed to handle the unique complexities of the practical application of ML systems. Overall, ML use cases require a readily available integrated solution to industrialize and streamline the process that takes an ML model from development to production deployment at scale using MLOps.
To address these customer challenges, PwC Australia developed Machine Learning Ops Accelerator as a set of standardized process and technology capabilities to improve the operationalization of AI/ML models that enable cross-functional collaboration across teams throughout ML lifecycle operations. PwC Machine Learning Ops Accelerator, built on top of AWS native services, delivers a fit-for-purpose solution that easily integrates into the ML use cases with ease for customers across all industries. In this post, we focus on building and deploying an ML use case that integrates various lifecycle components of an ML model, enabling continuous integration (CI), continuous delivery (CD), continuous training (CT), and continuous monitoring (CM).
In MLOps, a successful journey from data to ML models to recommendations and predictions in business systems and processes involves several crucial steps. It involves taking the result of an experiment or prototype and turning it into a production system with standard controls, quality, and feedback loops. It’s much more than just automation. It’s about improving organization practices and delivering outcomes that are repeatable and reproducible at scale.
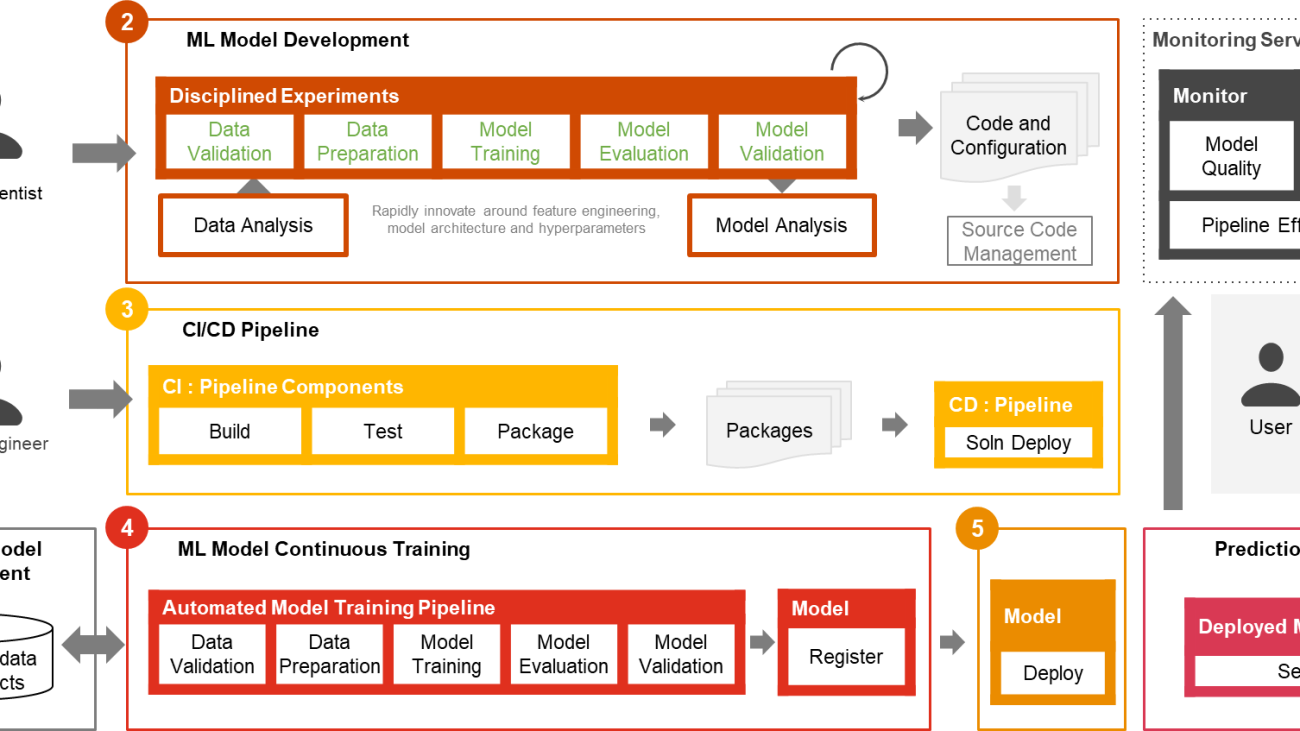
Only a small fraction of a real-world ML use case comprises the model itself. The various components needed to build an integrated advanced ML capability and continuously operate it at scale is shown in Figure 1. As illustrated in the following diagram, PwC MLOps Accelerator comprises seven key integrated capabilities and iterative steps that enable CI, CD, CT, and CM of an ML use case. The solution takes advantage of AWS native features from Amazon SageMaker, building a flexible and extensible framework around this.
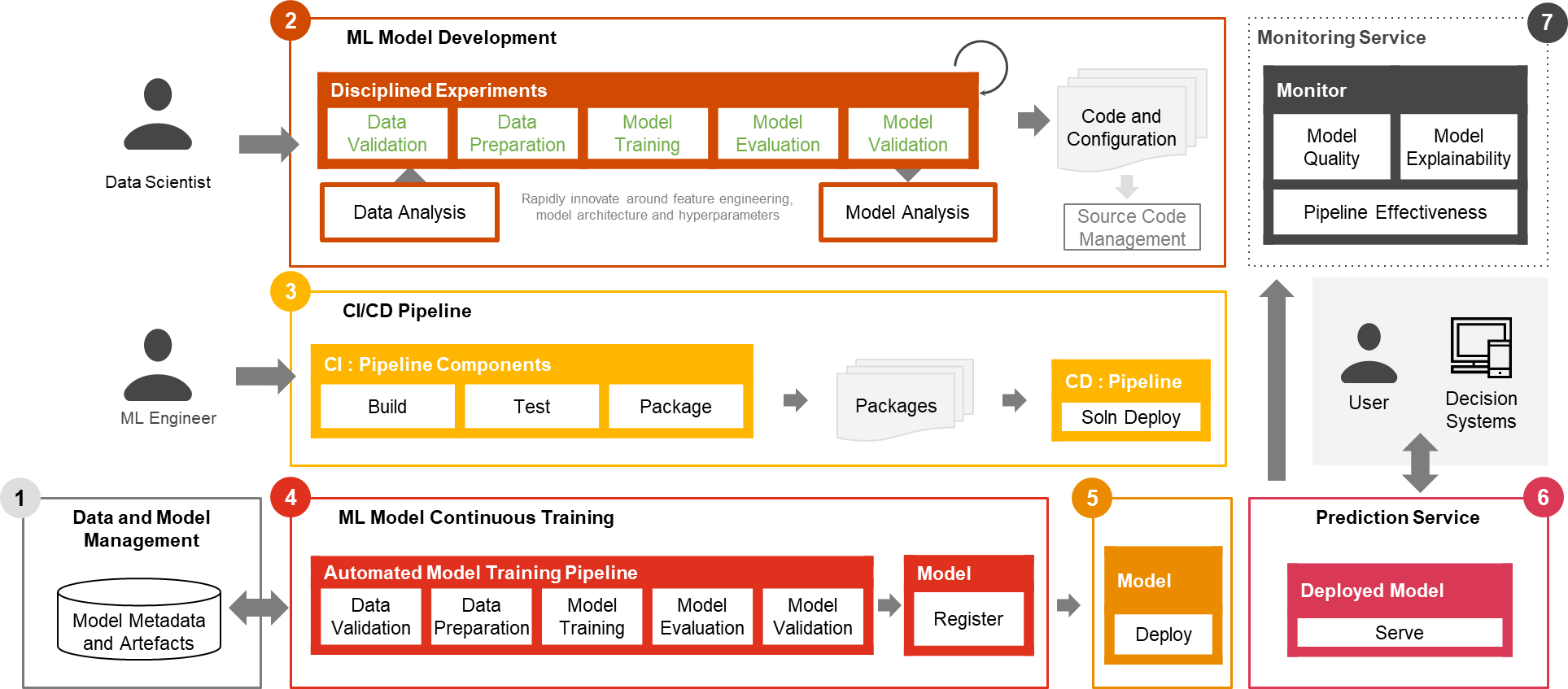
Figure 1 -– PwC Machine Learning Ops Accelerator capabilities
In a real enterprise scenario, additional steps and stages of testing may exist to ensure rigorous validation and deployment of models across different environments.
The solution is built on top of AWS-native services using Amazon SageMaker and serverless technology to keep performance and scalability high and running costs low.
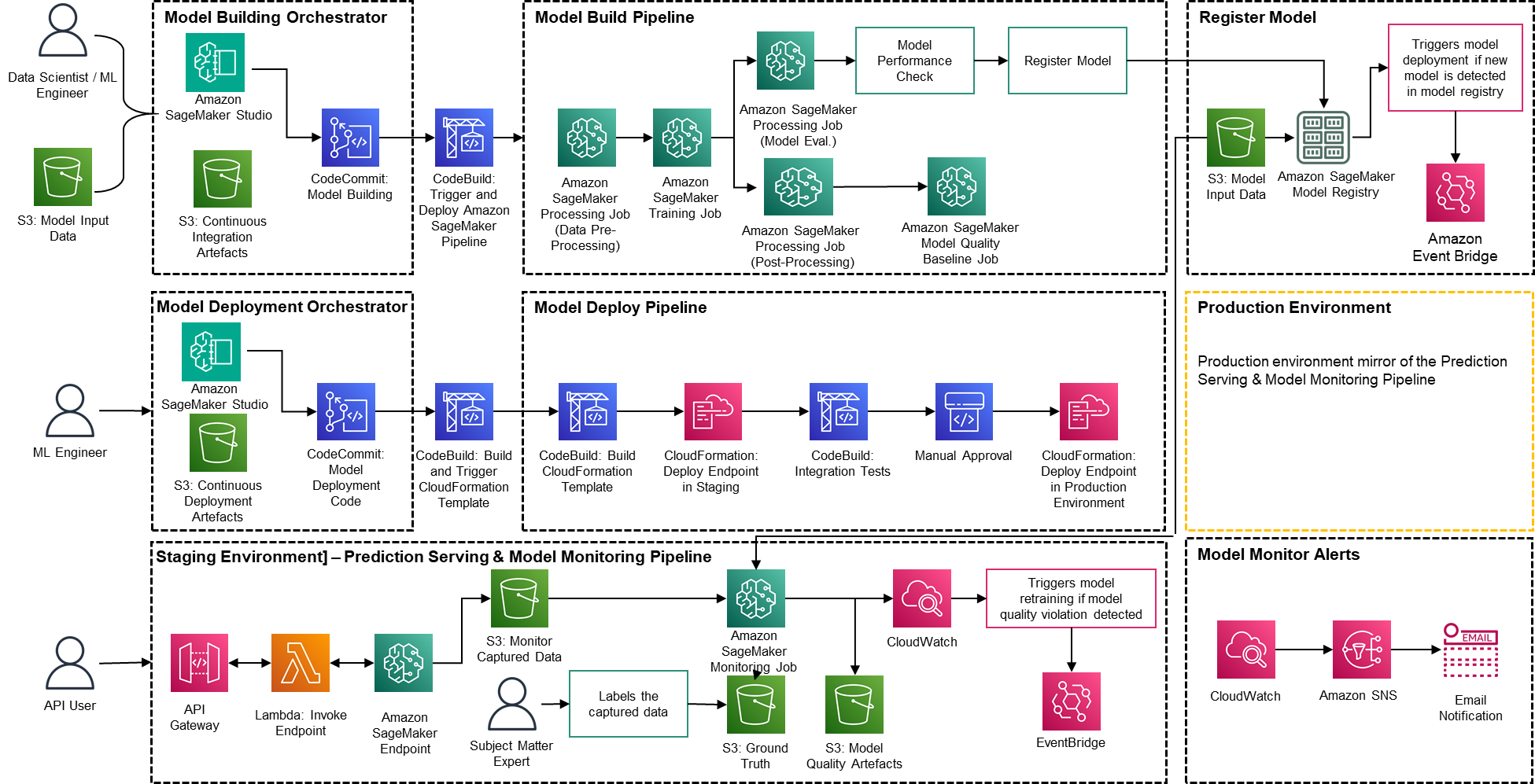
Figure 2 – PwC Machine Learning Ops Accelerator architecture
The following walkthrough dives into the standard steps to create the MLOps process for a model using PwC MLOps Accelerator. This walkthrough describes a use case of an MLOps engineer who wants to deploy the pipeline for a recently developed ML model using a simple definition/configuration file that is intuitive.
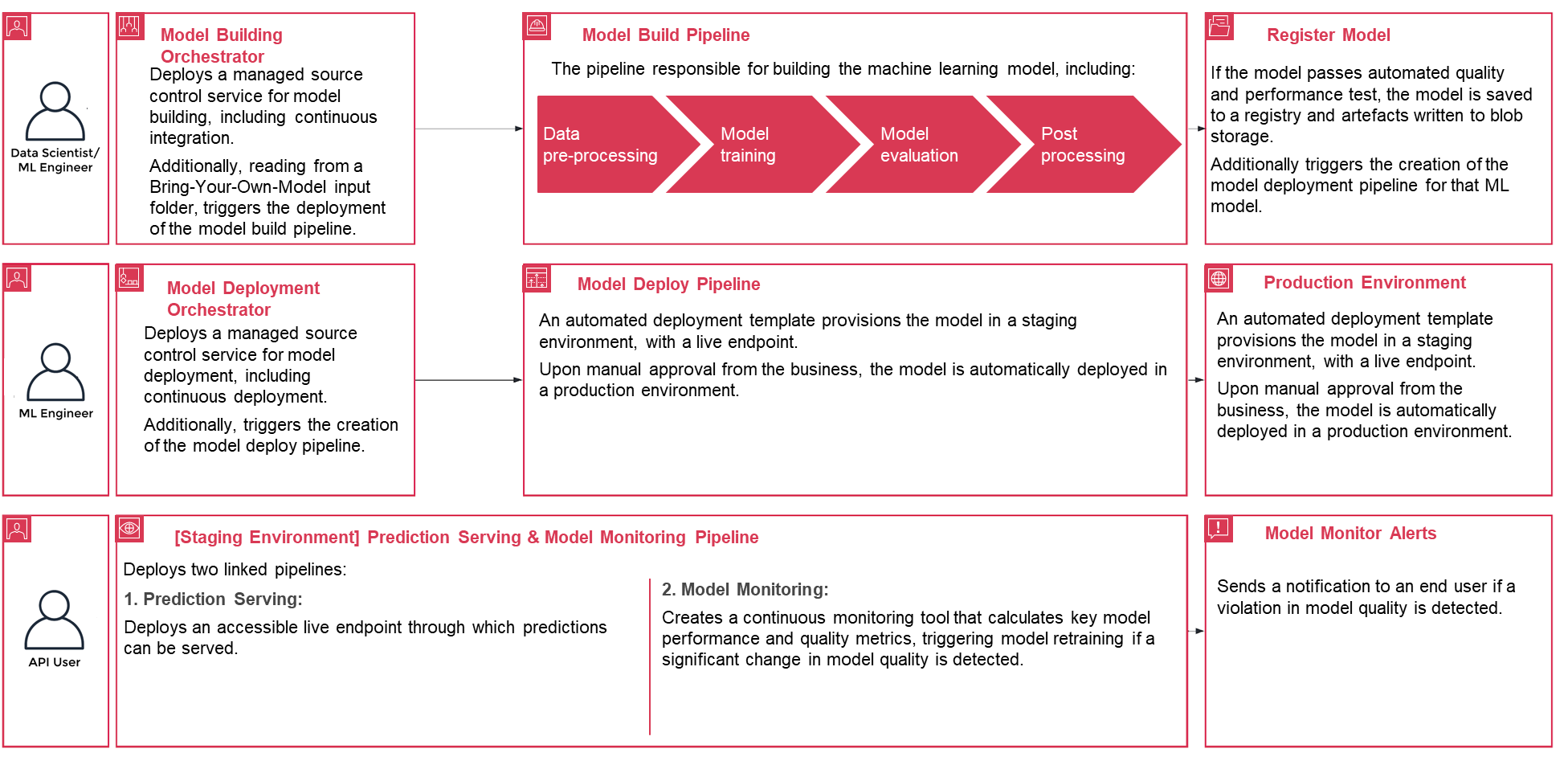
Figure 3 – PwC Machine Learning Ops Accelerator process lifecycle
config.yaml) per model. All the details required to run the solution are contained within that config file and stored along with the model in a Git repository. The configuration file will serve as input to automate workflow steps by externalizing important parameters and settings outside of code.config.yaml file and trigger the MLOps pipeline. Customers can configure an AWS account, the repository, the model, the data used, the pipeline name, the training framework, the number of instances to use for training, the inference framework, and any pre- and post-processing steps and several other configurations to check the model quality, bias, and explainability.
Figure 4 – Machine Learning Ops Accelerator configuration YAML
config.yaml is configured appropriately and saved alongside the model in its own Git repository, the model-building orchestrator is invoked. It also can read from a Bring-Your-Own-Model that can be configured through YAML to trigger deployment of the model build pipeline.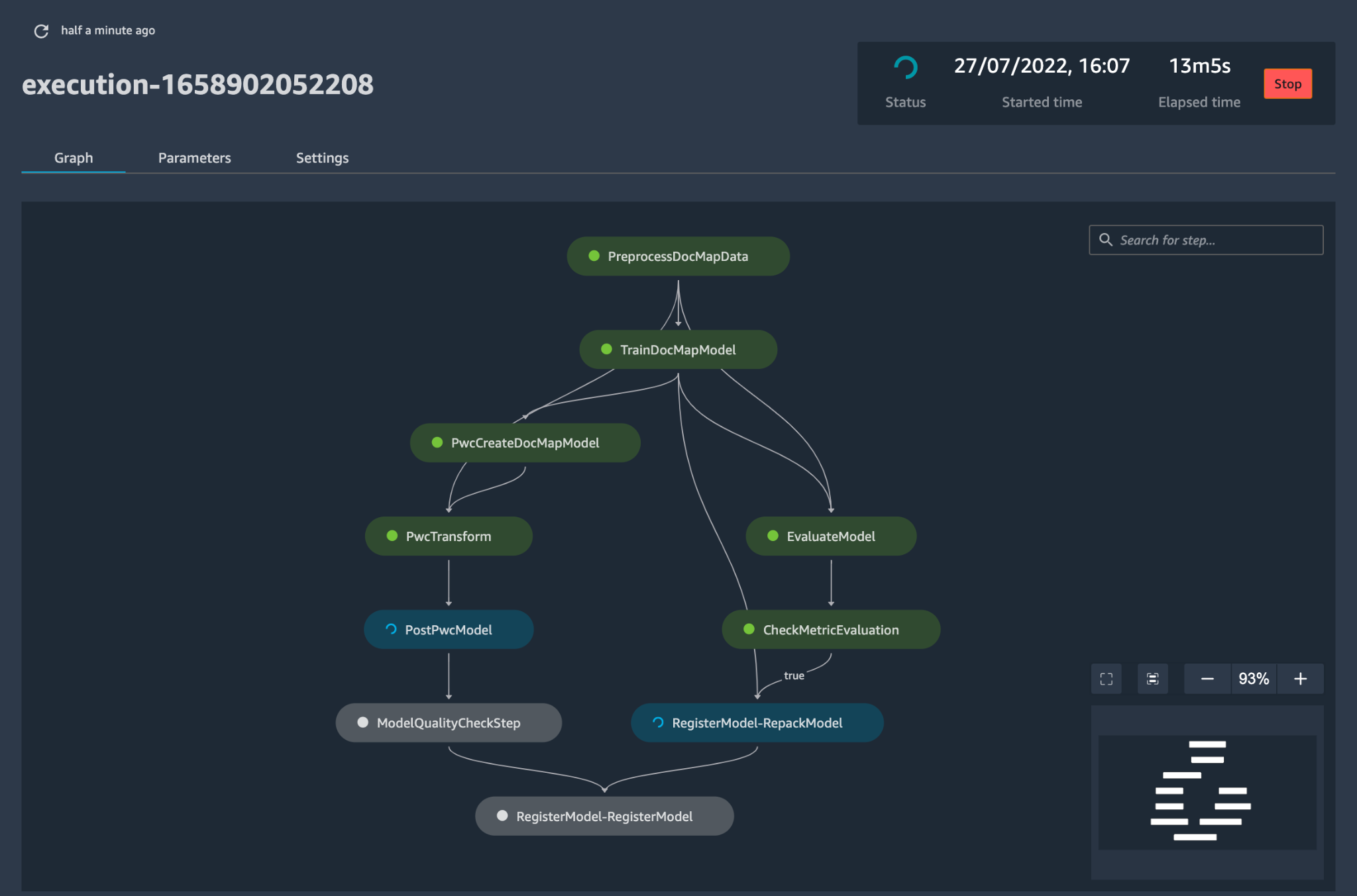
Figure 5 – Sample model deployment workflow
In summary, MLOps is critical for any organization that aims to deploy ML models in production systems at scale. PwC developed an accelerator to automate building, deploying, and maintaining ML models via integrating DevOps tools into the model development process.
In this post, we explored how the PwC solution is powered by AWS native ML services and helps to adopt MLOps practices so that businesses can speed up their AI journey and gain more value from their ML models. We walked through the steps a user would take to access the PwC Machine Learning Ops Accelerator, run the pipelines, and deploy an ML use case that integrates various lifecycle components of an ML model.
To get started with your MLOps journey on AWS Cloud at scale and run your ML production workloads, enroll in PwC Machine Learning Operations.
 Kiran Kumar Ballari is a Principal Solutions Architect at Amazon Web Services (AWS). He is an evangelist who loves to help customers leverage new technologies and build repeatable industry solutions to solve their problems. He is especially passionate about software engineering , Generative AI and helping companies with AI/ML product development.
Kiran Kumar Ballari is a Principal Solutions Architect at Amazon Web Services (AWS). He is an evangelist who loves to help customers leverage new technologies and build repeatable industry solutions to solve their problems. He is especially passionate about software engineering , Generative AI and helping companies with AI/ML product development.
 Ankur Goyal is a director in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. Ankur has extensive experience in supporting public and private sector organizations in driving technology transformations and designing innovative solutions by leveraging data assets and technologies.
Ankur Goyal is a director in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. Ankur has extensive experience in supporting public and private sector organizations in driving technology transformations and designing innovative solutions by leveraging data assets and technologies.
 Karthikeyan Chokappa (KC) is a Manager in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. KC is passionate about designing, developing, and deploying end-to-end analytics solutions that transform data into valuable decision assets to improve performance and utilization and reduce the total cost of ownership for connected and intelligent things.
Karthikeyan Chokappa (KC) is a Manager in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. KC is passionate about designing, developing, and deploying end-to-end analytics solutions that transform data into valuable decision assets to improve performance and utilization and reduce the total cost of ownership for connected and intelligent things.
 Rama Lankalapalli is a Sr. Partner Solutions Architect at AWS, working with PwC to accelerate their clients’ migrations and modernizations into AWS. He works across diverse industries to accelerate their adoption of AWS Cloud. His expertise lies in architecting efficient and scalable cloud solutions, driving innovation and modernization of customer applications by leveraging AWS services, and establishing resilient cloud foundations.
Rama Lankalapalli is a Sr. Partner Solutions Architect at AWS, working with PwC to accelerate their clients’ migrations and modernizations into AWS. He works across diverse industries to accelerate their adoption of AWS Cloud. His expertise lies in architecting efficient and scalable cloud solutions, driving innovation and modernization of customer applications by leveraging AWS services, and establishing resilient cloud foundations.
 Jeejee Unwalla is a Senior Solutions Architect at AWS who enjoys guiding customers in solving challenges and thinking strategically. He is passionate about tech and data and enabling innovation.
Jeejee Unwalla is a Senior Solutions Architect at AWS who enjoys guiding customers in solving challenges and thinking strategically. He is passionate about tech and data and enabling innovation.


Fifteen minutes. That’s how long it took to empty the Colosseum, an engineering marvel that’s still standing as the largest amphitheater in the world. Two thousand years later, this design continues to work well to move enormous crowds out of sporting and entertainment venues.
But of course, exiting the arena is only the first step. Next, people must navigate the traffic that builds up in the surrounding streets. This is an age-old problem that remains unsolved to this day. In Rome, they addressed the issue by prohibiting private traffic on the street that passes directly by the Colosseum. This policy worked there, but what if you’re not in Rome? What if you’re at the Superbowl? Or at a Taylor Swift concert?
An approach to addressing this problem is to use simulation models, sometimes called “digital twins”, which are virtual replicas of real-world transportation networks that attempt to capture every detail from the layout of streets and intersections to the flow of vehicles. These models allow traffic experts to mitigate congestion, reduce accidents, and improve the experience of drivers, riders, and walkers alike. Previously, our team used these models to quantify sustainability impact of routing, test evacuation plans and show simulated traffic in Maps Immersive View.
Calibrating high-resolution traffic simulations to match the specific dynamics of a particular setting is a longstanding challenge in the field. The availability of aggregate mobility data, detailed Google Maps road network data, advances in transportation science (such as understanding the relationship between segment demands and speeds for road segments with traffic signals), and calibration techniques which make use of speed data in physics-informed traffic models are paving the way for compute-efficient optimization at a global scale.
To test this technology in the real world, Google Research partnered with the Seattle Department of Transportation (SDOT) to develop simulation-based traffic guidance plans. Our goal is to help thousands of attendees of major sports and entertainment events leave the stadium area quickly and safely. The proposed plan reduced average trip travel times by 7 minutes for vehicles leaving the stadium region during large events. We deployed it in collaboration with SDOT using Dynamic Message Signs (DMS) and verified impact over multiple events between August and November, 2023.
 |
 |
| One policy recommendation we made was to divert traffic from S Spokane St, a major thoroughfare that connects the area to highways I-5 and SR 99, and is often congested after events. Suggested changes improved the flow of traffic through highways and arterial streets near the stadium, and reduced the length of vehicle queues that formed behind traffic signals. (Note that vehicles are larger than reality in this clip for demonstration.) |
For this project, we created a new simulation model of the area around Seattle’s stadiums. The intent for this model is to replay each traffic situation for a specified day as closely as possible. We use an open-source simulation software, Simulation of Urban MObility (SUMO). SUMO’s behavioral models help us describe traffic dynamics, for instance, how drivers make decisions, like car-following, lane-changing and speed limit compliance. We also use insights from Google Maps to define the network’s structure and various static segment attributes (e.g., number of lanes, speed limit, presence of traffic lights).
 |
| Overview of the Simulation framework. |
Travel demand is an important simulator input. To compute it, we first decompose the road network of a given metropolitan area into zones, specifically level 13 S2 cells with 1.27 km2 area per cell. From there, we define the travel demand as the expected number of trips that travel from an origin zone to a destination zone in a given time period. The demand is represented as aggregated origin–destination (OD) matrices.
To get the initial expected number of trips between an origin zone and a destination zone, we use aggregated and anonymized mobility statistics. Then we solve the OD calibration problem by combining initial demand with observed traffic statistics, like segment speeds, travel times and vehicular counts, to reproduce event scenarios.
We model the traffic around multiple past events in Seattle’s T-Mobile Park and Lumen Field and evaluate the accuracy by computing aggregated and anonymized traffic statistics. Analyzing these event scenarios helps us understand the effect of different routing policies on congestion in the region.
 |
| Heatmaps demonstrate a substantial increase in numbers of trips in the region after a game as compared to the same time on a non-game day. |
 |
| The graph shows observed segment speeds on the x-axis and simulated speeds on the y-axis for a modeled event. The concentration of data points along the red x=y line demonstrates the ability of the simulation to reproduce realistic traffic conditions. |
SDOT and the Seattle Police Department’s (SPD) local knowledge helped us determine the most congested routes that needed improvement:
We developed routing policies and evaluated them using the simulation model. To disperse traffic faster, we tried policies that would route northbound/southbound traffic from the nearest ramps to further highway ramps, to shorten the wait times. We also experimented with opening HOV lanes to event traffic, recommending alternate routes (e.g., SR 99), or load sharing between different lanes to get to the nearest stadium ramps.


We model multiple events with different traffic conditions, event times, and attendee counts. For each policy, the simulation reproduces post-game traffic and reports the travel time for vehicles, from departing the stadium to reaching their destination or leaving the Seattle SODO area. The time savings are computed as the difference of travel time before/after the policy, and are shown in the below table, per policy, for small and large events. We apply each policy to a percentage of traffic, and re-estimate the travel times. Results are shown if 10%, 30%, or 50% of vehicles are affected by a policy.

Based on these simulation results, the feasibility of implementation, and other considerations, SDOT has decided to implement the “Northbound Cherry St ramp” and “Southbound S Spokane St ramp” policies using DMS during large events. The signs suggest drivers take alternative routes to reach their destinations. The combination of these two policies leads to an average of 7 minutes of travel time savings per vehicle, based on rerouting 30% of traffic during large events.
This work demonstrates the power of simulations to model, identify, and quantify the effect of proposed traffic guidance policies. Simulations allow network planners to identify underused segments and evaluate the effects of different routing policies, leading to a better spatial distribution of traffic. The offline modeling and online testing show that our approach can reduce total travel time. Further improvements can be made by adding more traffic management strategies, such as optimizing traffic lights. Simulation models have been historically time consuming and hence affordable only for the largest cities and high stake projects. By investing in more scalable techniques, we hope to bring these models to more cities and use cases around the world.
In collaboration with Alex Shashko, Andrew Tomkins, Ashley Carrick, Carolina Osorio, Chao Zhang, Damien Pierce, Iveel Tsogsuren, Sheila de Guia, and Yi-fan Chen. Visual design by John Guilyard. We would like to thank our SDOT partners Carter Danne, Chun Kwan, Ethan Bancroft, Jason Cambridge, Laura Wojcicki, Michael Minor, Mohammed Said, Trevor Partap, and SPD partners Lt. Bryan Clenna and Sgt. Brian Kokesh.




{kind=link}
{kind=link}
{kind=link}
{kind=link}