
This post was co-written with Renato Nascimento, Felipe Viana, Andre Von Zuben from Articul8.
Generative AI is reshaping industries, offering new efficiencies, automation, and innovation. However, generative AI requires powerful, scalable, and resilient infrastructures that optimize large-scale model training, providing rapid iteration and efficient compute utilization with purpose-built infrastructure and automated cluster management.
In this post, we share how Articul8 is accelerating their training and deployment of domain-specific models (DSMs) by using Amazon SageMaker HyperPod and achieving over 95% cluster utilization and a 35% improvement in productivity.
What is SageMaker HyperPod?
SageMaker HyperPod is an advanced distributed training solution designed to accelerate the development of scalable, reliable, and secure generative AI model development. Articul8 uses SageMaker HyperPod to efficiently train large language models (LLMs) on diverse, representative data and uses its observability and resiliency features to keep the training environment stable over the long duration of training jobs. SageMaker HyperPod provides the following features:
- Fault-tolerant compute clusters with automated faulty node replacement during model training
- Efficient cluster utilization through observability and performance monitoring
- Seamless model experimentation with streamlined infrastructure orchestration using Slurm and Amazon Elastic Kubernetes Service (Amazon EKS)
Who is Articul8?
Articul8 was established to address the gaps in enterprise generative AI adoption by developing autonomous, production-ready products. For instance, they found that most general-purpose LLMs often fall short in delivering the accuracy, efficiency, and domain-specific knowledge needed for real-world business challenges. They are pioneering a set of DSMs that offer twofold better accuracy and completeness, compared to general-purpose models, at a fraction of the cost. (See their recent blog post for more details.)
The company’s proprietary ModelMesh technology serves as an autonomous layer that decides, selects, executes, and evaluates the right models at runtime. Think of it as a reasoning system that determines what to run, when to run it, and in what sequence, based on the task and context. It evaluates responses at every step to refine its decision-making, enabling more reliable and interpretable AI solutions while dramatically improving performance.
technology serves as an autonomous layer that decides, selects, executes, and evaluates the right models at runtime. Think of it as a reasoning system that determines what to run, when to run it, and in what sequence, based on the task and context. It evaluates responses at every step to refine its decision-making, enabling more reliable and interpretable AI solutions while dramatically improving performance.
Articul8’s ModelMesh supports:
- LLMs for general tasks
- Domain-specific models optimized for industry-specific applications
- Non-LLMs for specialized reasoning tasks or established domain-specific tasks (for example, scientific simulation)
Articul8’s domain-specific models are setting new industry standards across supply chain, energy, and semiconductor sectors. The A8-SupplyChain model, built for complex workflows, achieves 92% accuracy and threefold performance gains over general-purpose LLMs in sequential reasoning. In energy, A8-Energy models were developed with EPRI and NVIDIA as part of the Open Power AI Consortium, enabling advanced grid optimization, predictive maintenance, and equipment reliability. The A8-Semicon model has set a new benchmark, outperforming top open-source (DeepSeek-R1, Meta Llama 3.3/4, Qwen 2.5) and proprietary models (GPT-4o, Anthropic’s Claude) by twofold in Verilog code accuracy, all while running at 50–100 times smaller model sizes for real-time AI deployment.
Articul8 develops some of their domain-specific models using Meta’s Llama family as a flexible, open-weight foundation for expert-level reasoning. Through a rigorous fine-tuning pipeline with reasoning trajectories and curated benchmarks, general Llama models are transformed into domain specialists. To tailor models for areas like hardware description languages, Articul8 applies Reinforcement Learning with Verifiable Rewards (RLVR), using automated reward pipelines to specialize the model’s policy. In one case, a dataset of 50,000 documents was automatically processed into 1.2 million images, 360,000 tables, and 250,000 summaries, clustered into a knowledge graph of over 11 million entities. These structured insights fuel A8-DSMs across research, product design, development, and operations.
How SageMaker HyperPod accelerated the development of Articul8’s DSMs
Cost and time to train DSMs is critical for success for Articul8 in a rapidly evolving ecosystem. Training high-performance DSMs requires extensive experimentation, rapid iteration, and scalable compute infrastructure. With SageMaker HyperPod, Articul8 was able to:
- Rapidly iterate on DSM training – SageMaker HyperPod resiliency features enabled Articul8 to train and fine-tune its DSMs in a fraction of the time required by traditional infrastructure
- Optimize model training performance – By using the automated failure recovery feature in SageMaker HyperPod, Articul8 provided stable and resilient training processes
- Reduce AI deployment time by four times and lower total cost of ownership by five times – The orchestration capabilities of SageMaker HyperPod alleviated the manual overhead of cluster management, allowing Articul8’s research teams to focus on model optimization rather than infrastructure upkeep
These advantages contributed to record-setting benchmark results by Articul8, proving that domain-specific models deliver superior real-world performance compared to general-purpose models.
Distributed training challenges and the role of SageMaker HyperPod
Distributed training across hundreds of nodes faces several critical challenges beyond basic resource constraints. Managing massive training clusters requires robust infrastructure orchestration and careful resource allocation for operational efficiency. SageMaker HyperPod offers both managed Slurm and Amazon EKS orchestration experience that streamlines cluster creation, infrastructure resilience, job submission, and observability. The following details focus on the Slurm implementation for reference:
- Cluster setup – Although setting up a cluster is a one-time effort, the process is streamlined with a setup script that walks the administrator through each step of cluster creation. This post shows how this can be done in discrete steps.
- Resiliency – Fault tolerance becomes paramount when operating at scale. SageMaker HyperPod handles node failures and network interruptions by replacing faulty nodes automatically. You can add the flag
--auto-resume=1with the Slurm srun command, and the distributed training job will recover from the last checkpoint. - Job submission – SageMaker HyperPod managed Slurm orchestration is a powerful way for data scientists to submit and manage distributed training jobs. Refer to the following example in the AWS-samples distributed training repo for reference. For instance, a distributed training job can be submitted with a Slurm sbatch command:
sbatch 1.distributed-training-llama2.sbatch. You can usesqueueandscancelto view and cancel jobs, respectively. - Observability – SageMaker HyperPod uses Amazon CloudWatch and open source managed Prometheus and Grafana services for monitoring and logging. Cluster administrators can view the health of the infrastructure (network, storage, compute) and utilization.
Solution overview
The SageMaker HyperPod platform enables Articul8 to efficiently manage high-performance compute clusters without requiring a dedicated infrastructure team. The service automatically monitors cluster health and replaces faulty nodes, making the deployment process frictionless for researchers.
To enhance their experimental capabilities, Articul8 integrated SageMaker HyperPod with Amazon Managed Grafana, providing real-time observability of GPU resources through a single-pane-of-glass dashboard. They also used SageMaker HyperPod lifecycle scripts to customize their cluster environment and install required libraries and packages. This comprehensive setup empowers Articul8 to conduct rapid experimentation while maintaining high performance and reliability—they reduced their customers’ AI deployment time by four times and lowered their total cost of ownership by five times.
The following diagram illustrates the observability architecture.

The platform’s efficiency in managing computational resources with minimum downtime has been particularly valuable for Articul8’s research and development efforts, empowering them to quickly iterate on their generative AI solutions while maintaining enterprise-grade performance standards. The following sections describe the setup and results in detail.
For the setup for this post, we begin with the AWS published workshop for SageMaker HyperPod, and adjust it to suit our workload.
Prerequisites
The following two AWS CloudFormation templates address the prerequisites of the solution setup.
For SageMaker HyperPod
This CloudFormation stack addresses the prerequisites for SageMaker HyperPod:
- VPC and two subnets – A public subnet and a private subnet are created in an Availability Zone (provided as a parameter). The virtual private cloud (VPC) contains two CIDR blocks with 10.0.0.0/16 (for the public subnet) and 10.1.0.0/16 (for the private subnet). An internet gateway and NAT gateway are deployed in the public subnet.
- Amazon FSx for Lustre file system – An Amazon FSx for Lustre volume is created in the specified Availability Zone, with a default of 1.2 TB storage, which can be overridden by a parameter. For this case study, we increased the storage size to 7.2 TB.
- Amazon S3 bucket – The stack deploys endpoints for Amazon Simple Storage Service (Amazon S3) to store lifecycle scripts.
- IAM role – An AWS Identity and Access Management (IAM) role is also created to help execute SageMaker HyperPod cluster operations.
- Security group – The script creates a security group to enable EFA communication for multi-node parallel batch jobs.
For cluster observability
To get visibility into cluster operations and make sure workloads are running as expected, an optional CloudFormation stack has been used for this case study. This stack includes:
- Node exporter – Supports visualization of CPU load averages, memory and disk usage, network traffic, file system, and disk I/O metrics
- NVIDIA DCGM – Supports visualization of GPU utilization, temperatures, power usage, and memory usage
- EFA metrics – Supports visualization of EFA network and error metrics, EFA RDMA performance, and so on.
- FSx for Lustre – Supports visualization of file system read/write operations, free capacity, and metadata operations
Observability can be configured through YAML scripts to monitor SageMaker HyperPod clusters on AWS. Amazon Managed Service for Prometheus and Amazon Managed Grafana workspaces with associated IAM roles are deployed in the AWS account. Prometheus and exporter services are also set up on the cluster nodes.
Using Amazon Managed Grafana with SageMaker HyperPod helps you create dashboards to monitor GPU clusters and make sure they operate efficiently with minimum downtime. In addition, dashboards have become a critical tool to give you a holistic view of how specialized workloads consume different resources of the cluster, helping developers optimize their implementation.
Cluster setup
The cluster is set up with the following components (results might vary based on customer use case and deployment setup):
- Head node and compute nodes – For this case study, we use a head node and SageMaker HyperPod compute nodes. The head node has an ml.m5.12xlarge instance, and the compute queue consists of ml.p4de.24xlarge instances.
- Shared volume – The cluster has an FSx for Lustre file system mounted at /fsx on both the head and compute nodes.
- Local storage – Each node has 8 TB local NVME volume attached for local storage.
- Scheduler – Slurm is used as an orchestrator. Slurm is an open source and highly scalable cluster management tool and job scheduling system for high-performance computing (HPC) clusters.
- Accounting – As part of cluster configuration, a local MariaDB is deployed that keeps track of job runtime information.
Results
During this project, Articul8 was able to confirm the expected performance of A100 with the added benefit of creating a cluster using Slurm and providing observability metrics to monitor the health of various components (storage, GPU nodes, fiber). The primary validation was on the ease of use and rapid ramp-up of data science experiments. Furthermore, they were able to demonstrate near linear scaling with distributed training, achieving a 3.78 times reduction in time to train for Meta Llama-2 13B with 4x nodes. Having the flexibility to run multiple experiments, without losing development time from infrastructure overhead was an important accomplishment for the Articul8 data science team.
Clean up
If you run the cluster as part of the workshop, you can follow the cleanup steps to delete the CloudFormation resources after deleting the cluster.
Conclusion
This post demonstrated how Articul8 AI used SageMaker HyperPod to overcome the scalability and efficiency challenges of training multiple high-performing DSMs across key industries. By alleviating infrastructure complexity, SageMaker HyperPod empowered Articul8 to focus on building AI systems with measurable business outcomes. From semiconductor and energy to supply chain, Articul8’s DSMs are proving that the future of enterprise AI is not general—it’s purpose-built. Key takeaways include:
- DSMs significantly outperform general-purpose LLMs in critical domains
- SageMaker HyperPod accelerated the development of Articul8’s A8-Semicon, A8-SupplyChain, and Energy DSM models
- Articul8 reduced AI deployment time by four times and lowered total cost of ownership by five times using the scalable, automated training infrastructure of SageMaker HyperPod
Learn more about SageMaker HyperPod by following this workshop. Reach out to your account team on how you can use this service to accelerate your own training workloads.
About the Authors
 Yashesh A. Shroff, PhD. is a Sr. GTM Specialist in the GenAI Frameworks organization, responsible for scaling customer foundational model training and inference on AWS using self-managed or specialized services to meet cost and performance requirements. He holds a PhD in Computer Science from UC Berkeley and an MBA from Columbia Graduate School of Business.
Yashesh A. Shroff, PhD. is a Sr. GTM Specialist in the GenAI Frameworks organization, responsible for scaling customer foundational model training and inference on AWS using self-managed or specialized services to meet cost and performance requirements. He holds a PhD in Computer Science from UC Berkeley and an MBA from Columbia Graduate School of Business.
 Amit Bhatnagar is a Sr Technical Account Manager with AWS, in the Enterprise Support organization, with a focus on generative AI startups. He is responsible for helping key AWS customers with their strategic initiatives and operational excellence in the cloud. When he is not chasing technology, Amit loves to cook vegan delicacies and hit the road with his family to chase the horizon.
Amit Bhatnagar is a Sr Technical Account Manager with AWS, in the Enterprise Support organization, with a focus on generative AI startups. He is responsible for helping key AWS customers with their strategic initiatives and operational excellence in the cloud. When he is not chasing technology, Amit loves to cook vegan delicacies and hit the road with his family to chase the horizon.
 Renato Nascimento is the Head of Technology at Articul8, where he leads the development and execution of the company’s technology strategy. With a focus on innovation and scalability, he ensures the seamless integration of cutting-edge solutions into Articul8’s products, enabling industry-leading performance and enterprise adoption.
Renato Nascimento is the Head of Technology at Articul8, where he leads the development and execution of the company’s technology strategy. With a focus on innovation and scalability, he ensures the seamless integration of cutting-edge solutions into Articul8’s products, enabling industry-leading performance and enterprise adoption.
 Felipe Viana is the Head of Applied Research at Articul8, where he leads the design, development, and deployment of innovative generative AI technologies, including domain-specific models, new model architectures, and multi-agent autonomous systems.
Felipe Viana is the Head of Applied Research at Articul8, where he leads the design, development, and deployment of innovative generative AI technologies, including domain-specific models, new model architectures, and multi-agent autonomous systems.
 Andre Von Zuben is the Head of Architecture at Articul8, where he is responsible for designing and implementing scalable generative AI platform elements, novel generative AI model architectures, and distributed model training and deployment pipelines.
Andre Von Zuben is the Head of Architecture at Articul8, where he is responsible for designing and implementing scalable generative AI platform elements, novel generative AI model architectures, and distributed model training and deployment pipelines.



 Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market.
Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market. Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures.
Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures. Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact. Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning.
Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning. Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.
Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.













 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.

 Eshan Bhatnagar is the Director of Product Management for Amazon AGI at Amazon Web Services.
Eshan Bhatnagar is the Director of Product Management for Amazon AGI at Amazon Web Services. Amar Goel is Co-Founder and CEO of Bito. A serial entrepreneur, Amar previously founded PubMatic (went public in 2020), and formerly worked at Microsoft, McKinsey, and was a software engineer at Netscape, the original browser company. Amar attended Harvard University. He is excited about using GenAI to power the next generation of how software gets built!
Amar Goel is Co-Founder and CEO of Bito. A serial entrepreneur, Amar previously founded PubMatic (went public in 2020), and formerly worked at Microsoft, McKinsey, and was a software engineer at Netscape, the original browser company. Amar attended Harvard University. He is excited about using GenAI to power the next generation of how software gets built!






 Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund.
Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund. Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics.
Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics. Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London.
Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London. Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies.
Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies. Frederica Schrager is a Marketing Analyst at Gardenia Technologies.
Frederica Schrager is a Marketing Analyst at Gardenia Technologies. Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions. Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs. Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations.
Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations. Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.
Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.
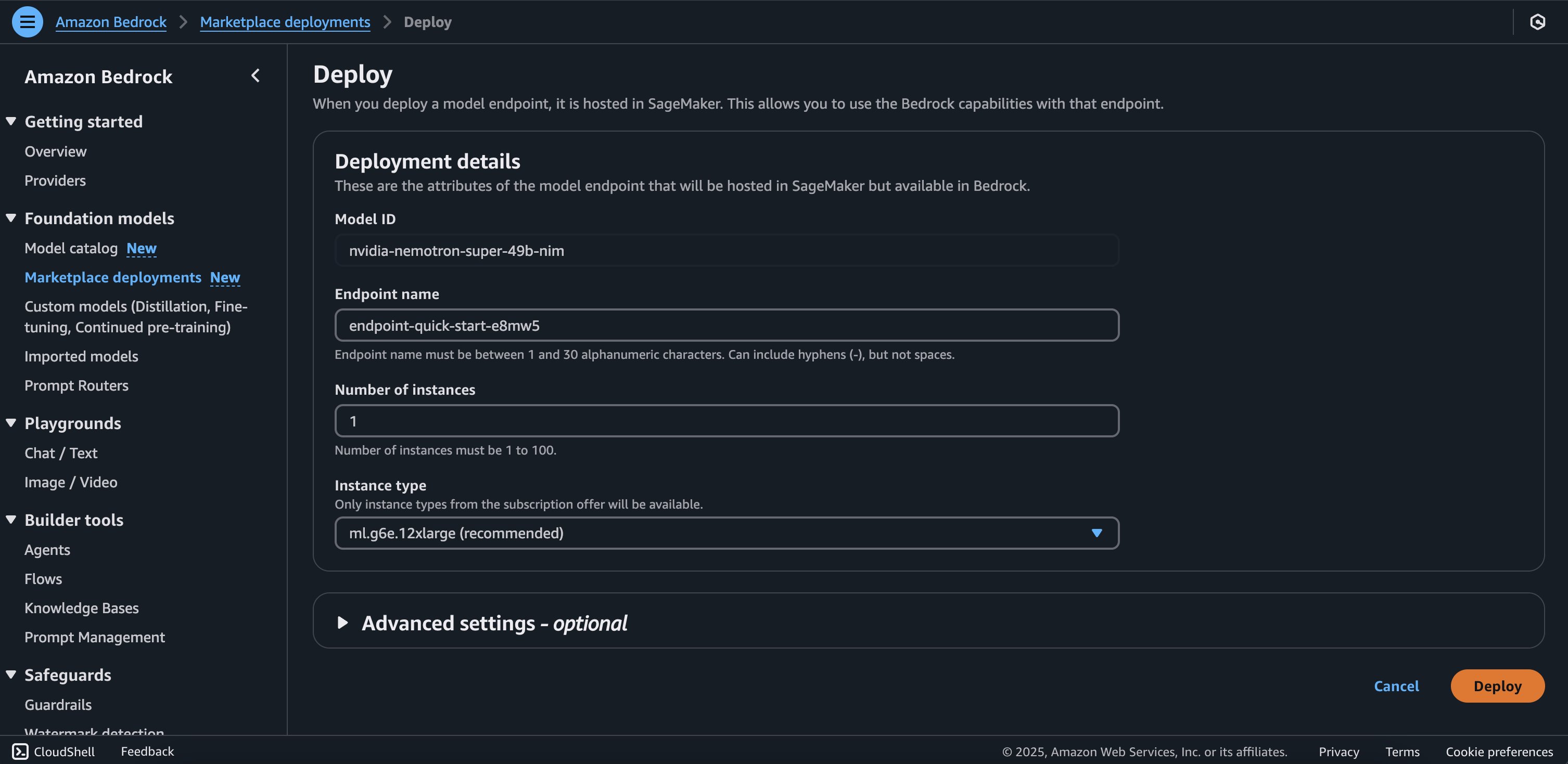
 Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.
Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. 
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics. Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography. Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City. Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player. Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing. Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
































 Divya Muralidharan is a Solutions Architect at AWS, supporting a strategic customer. Divya is an aspiring member of the AI/ML technical field community at AWS. She is passionate about using technology to accelerate growth, provide value to customers, and achieve business outcomes. Outside of work, she spends time cooking, singing, and growing plants.
Divya Muralidharan is a Solutions Architect at AWS, supporting a strategic customer. Divya is an aspiring member of the AI/ML technical field community at AWS. She is passionate about using technology to accelerate growth, provide value to customers, and achieve business outcomes. Outside of work, she spends time cooking, singing, and growing plants. Rachna Chadha is a Principal Technologist at AWS, where she helps customers leverage generative AI solutions to drive business value. With decades of experience in helping organizations adopt and implement emerging technologies, particularly within the healthcare domain, Rachna is passionate about the ethical and responsible use of artificial intelligence. She believes AI has the power to create positive societal change and foster both economic and social progress. Outside of work, Rachna enjoys spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Technologist at AWS, where she helps customers leverage generative AI solutions to drive business value. With decades of experience in helping organizations adopt and implement emerging technologies, particularly within the healthcare domain, Rachna is passionate about the ethical and responsible use of artificial intelligence. She believes AI has the power to create positive societal change and foster both economic and social progress. Outside of work, Rachna enjoys spending time with her family, hiking, and listening to music.



 Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS Cloud.
Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS Cloud.