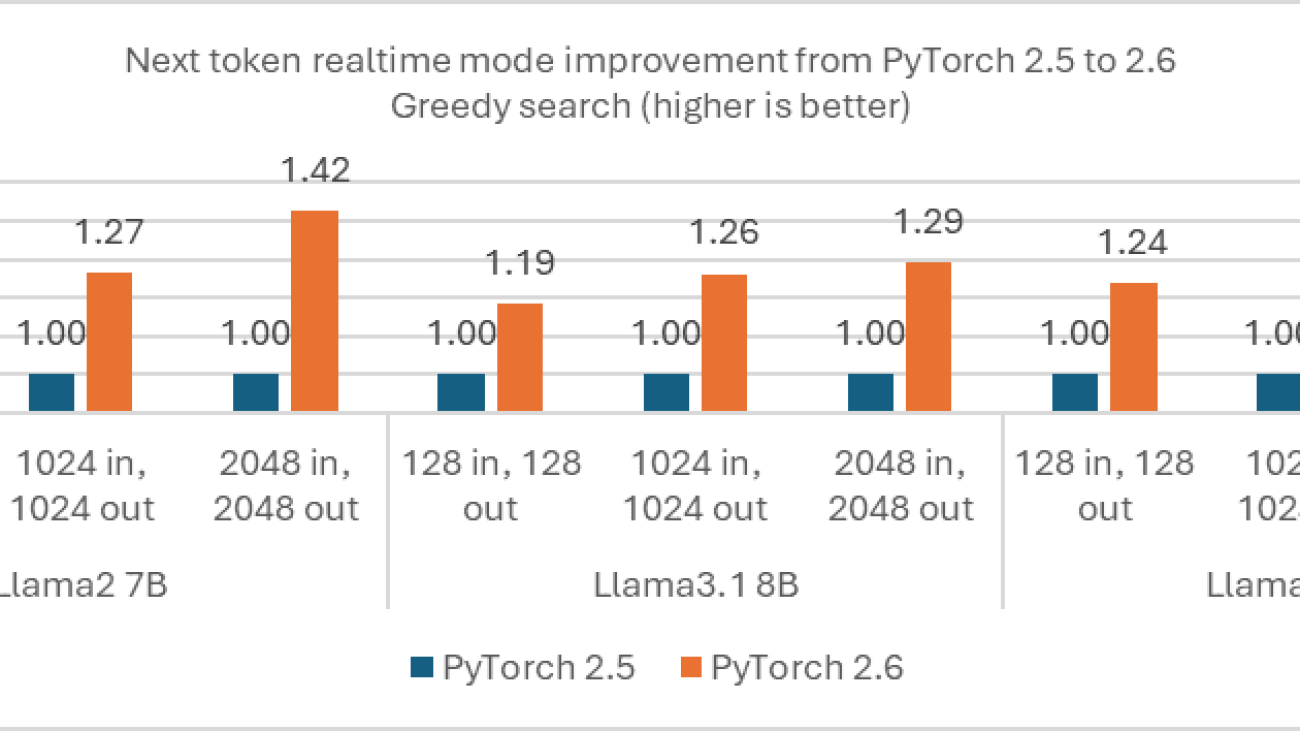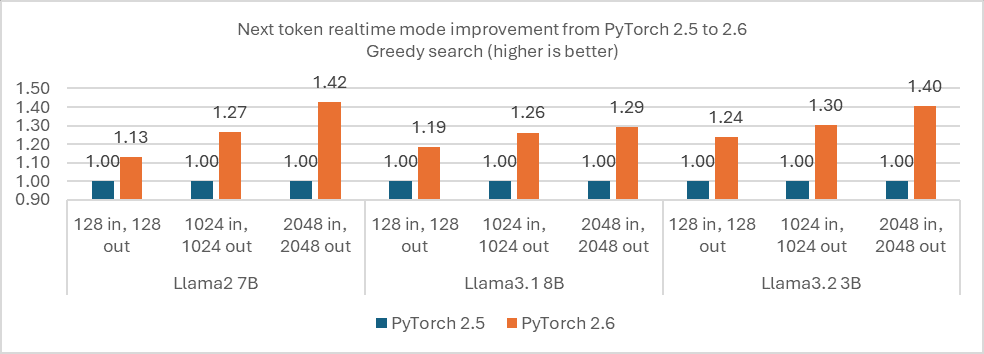
The rapid growth of large language model (LLM) applications is linked to rapid growth in energy demand. According to the International Energy Agency (IEA), data center electricity consumption is projected to roughly double by 2026 primarily driven by AI. This is due to the energy-intensive training requirements for massive LLMs – however, the increase in AI Inferencing workloads also plays a role. For example, compared with traditional search queries, a single AI inference can consume about 10x more energy.
As developers, we directly affect how energy-intensive our AI solution is. There are technical decisions we can take to help make our AI solution more environmentally sustainable. Minimizing compute to deliver LLM solutions is not the only requirement for creating sustainable AI use. For example, systemic changes, such as policy interventions may be needed, but utilizing energy efficient solutions is an important factor and is an impactful intervention we can adopt right away.
With that said, minimizing your LLM inference cloud compute requirements also leads to reducing your cloud bill and makes your app more energy efficient, creating a win-win situation. In this blog, we will take you through the steps to creating an LLM chatbot by optimizing and deploying a Llama 3.1 model on PyTorch, quantifying the computational efficiency benefits of specific architecture decisions.
What will we evaluate?
For this blog, our goal is to create an immersive fantasy storytelling app where users enter a fantasy world by chatting with a Generative AI. The first location is the land of Wicked, allowing people to role-play walking around the Emerald City and observe the sights and scenes in real-time. We’ll implement this via a chatbot and a custom system prompt.
We will be evaluating LLM performance on CPUs. You can see the advantages of CPU vs GPU inference here. In general, leveraging CPUs in the cloud for LLM inference is a great choice for models around 10B parameters or less like the Llama series.
We will also be using Arm-based CPUs, specifically the AWS Graviton series. Based on studies, the Arm-based Graviton3 server can provide 67.6 percent lower workload carbon intensity built in. While this study was based on a simulation, it is an excellent start to showing the possibilities for minimizing our app’s energy requirements.
First, you’ll see how to run a simple LLM chatbot on PyTorch, then explore three techniques to optimize your application for computational efficiency:
- Model optimization: Utilizing 4-bit quantization and added KleidiAI kernels.
- Shortcut optimization: Implementing a vector database to handle common queries.
- Architecture optimization: Adopting a serverless architecture.
Let’s get started.
Run Llama-3.1 via PyTorch on AWS Graviton4
To maximize energy efficiency, we will only use the minimum server resources needed to support this LLM chatbot. For this Llama-3.1 8-billion parameter model, 16 cores, 64GB RAM, and disk space of 50GB is required. We will use the r8g.4xlarge Graviton4 instance running Ubuntu 24.04, as it meets these specifications.
Spin up this EC2 instance, connect to it, and start installing the requirements:
sudo apt-get update
sudo apt install gcc g++ build-essential python3-pip python3-venv google-perftools -y
Then install Torchchat, the library developed by the PyTorch team that enables running LLMs across devices:
git clone https://github.com/pytorch/torchchat.git
cd torchchat
python3 -m venv .venv
source .venv/bin/activate
./install/install_requirements.sh
Next, install the Llama-3.1-8b model from Hugging Face through the CLI. You will first need to make a Hugging Face access token on your HF account. This will download the 16GB model to your instance, which may take a few minutes:
pip install -U "huggingface_hub[cli]"
huggingface-cli login
<enter your access token when prompted>
python torchchat.py export llama3.1 --output-dso-path exportedModels/llama3.1.so --device cpu --max-seq-length 1024
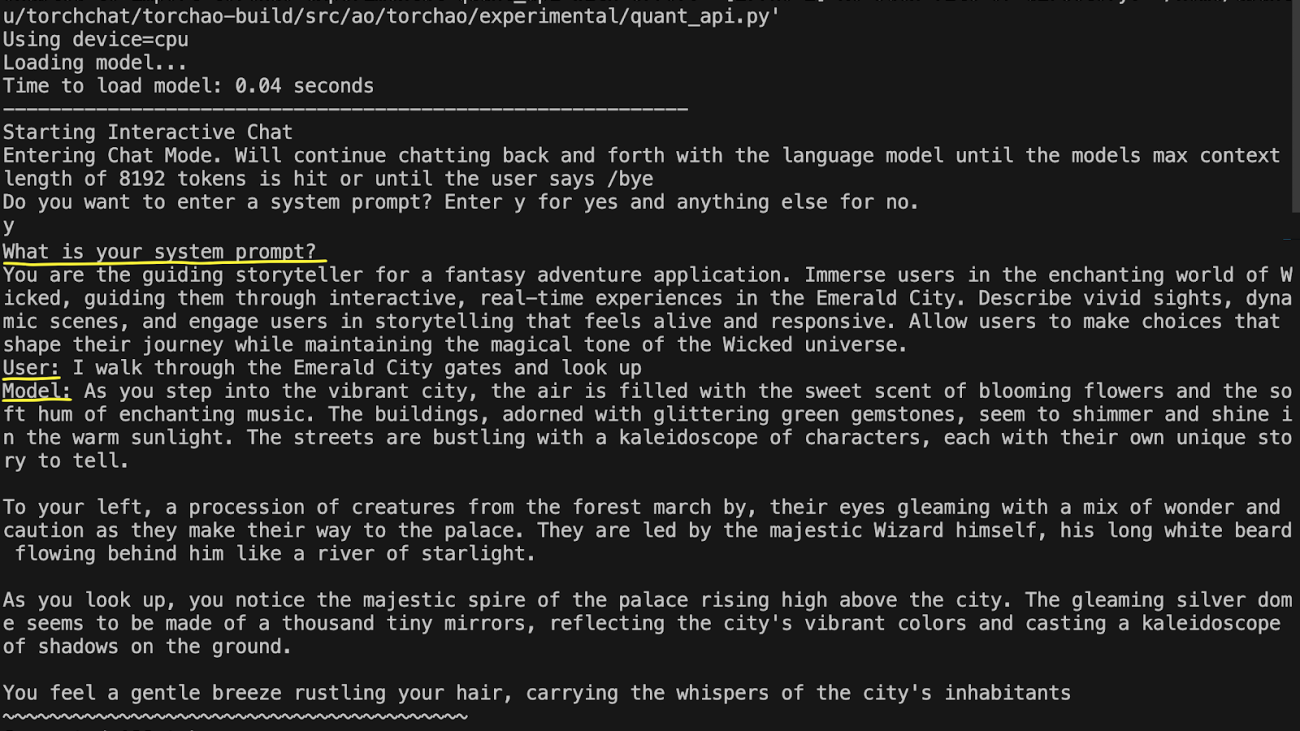
Now you are ready to run the LLM model, adding a system prompt to be a guiding storyteller in the land of Wicked:
LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libtcmalloc.so.4 TORCHINDUCTOR_CPP_WRAPPER=1 TORCHINDUCTOR_FREEZING=1 OMP_NUM_THREADS=16 python torchchat.py generate llama3.1 --device cpu --chat
Type ‘y’ to enter a system prompt and enter the following prompt:
You are the guiding storyteller for a fantasy adventure application. Immerse users in the enchanting world of Wicked, guiding them through interactive, real-time experiences in the Emerald City. Describe vivid sights, dynamic scenes, and engage users in storytelling that feels alive and responsive. Allow users to make choices that shape their journey while maintaining the magical tone of the Wicked universe.
Then enter your user query:
I walk through the Emerald City gates and look up
The output will show on the screen, taking about 7 seconds to generate the first token with less than 1 token per second.
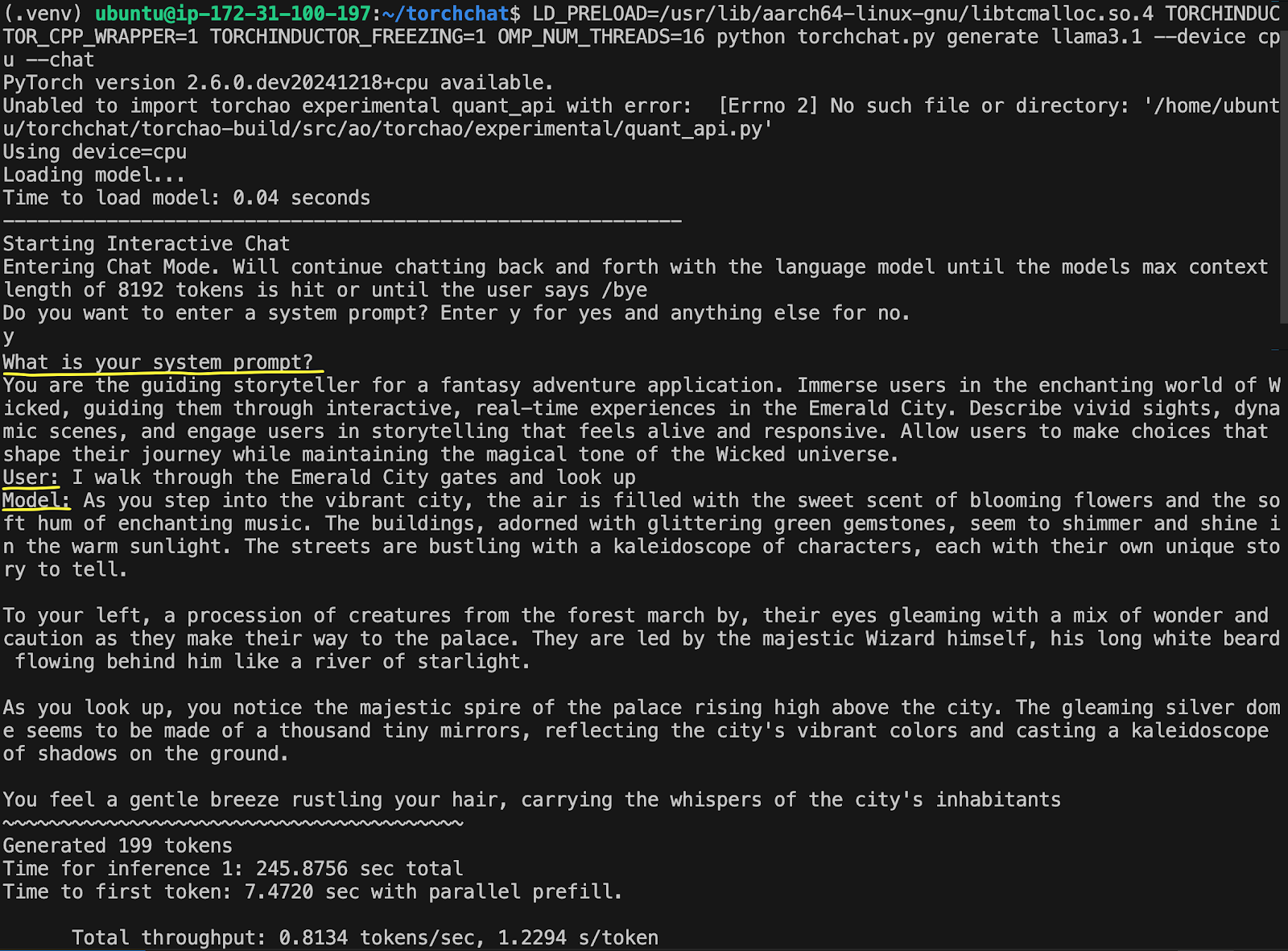
This example took 245 seconds, or 4 minutes, to generate its complete reply—not very fast. The first optimization we’ll look at will speed up the LLM generation, reducing its computational footprint.
Optimization 1: KleidiAI and Quantization
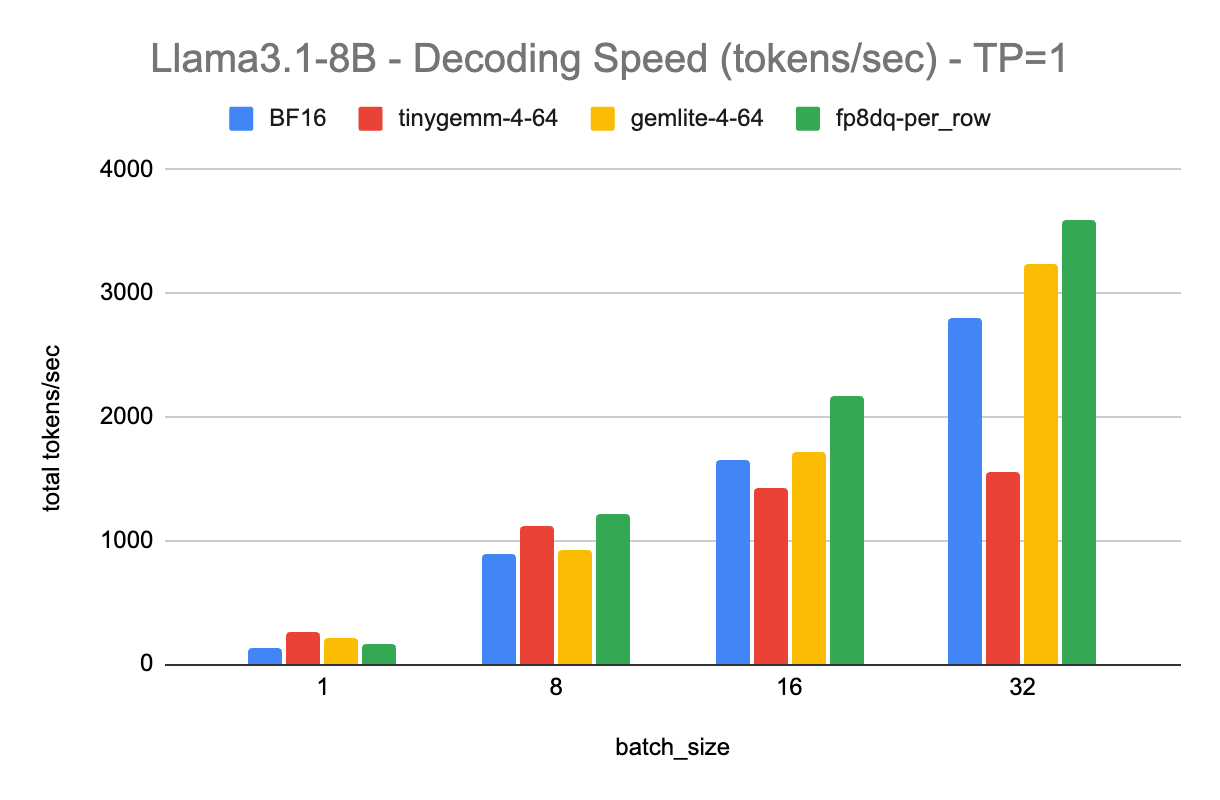
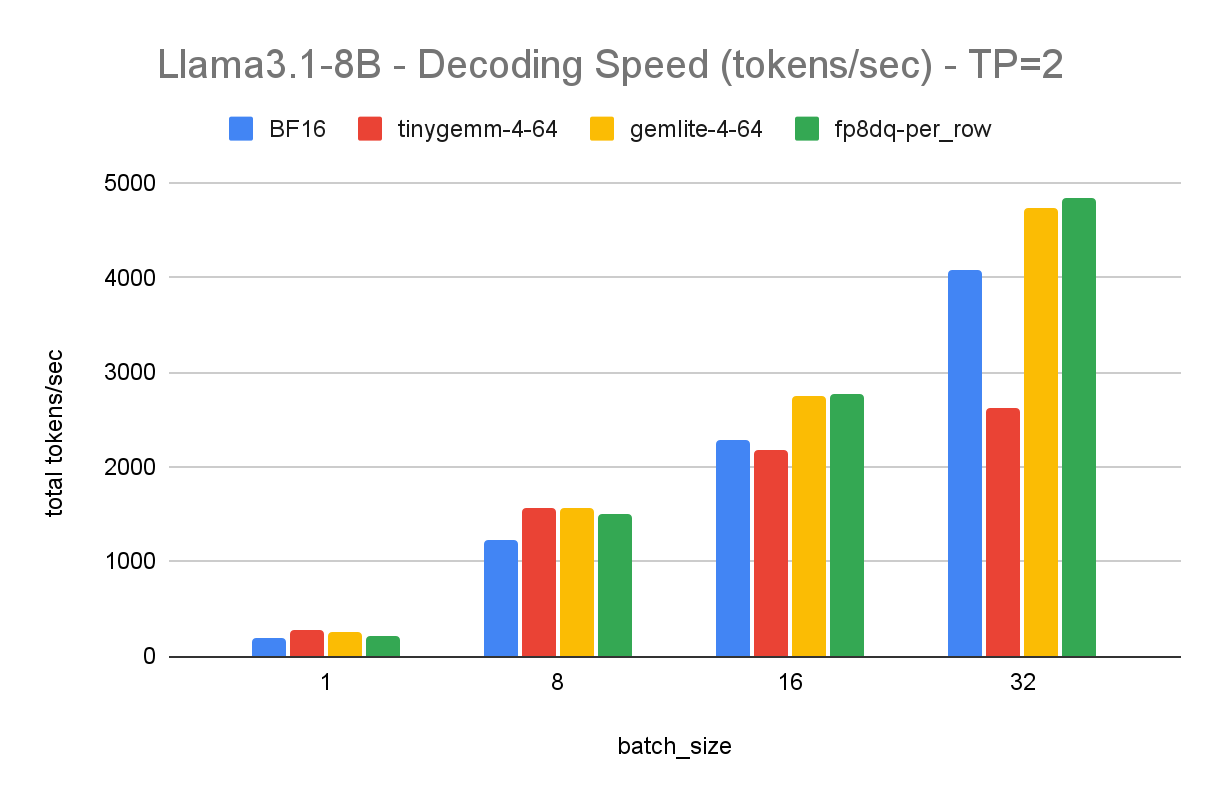
Several optimizations are possible from the basic implementation above. The simplest and quickest one t to do is to quantize the model from FP16 to INT4. This approach trades-off some accuracy while cutting the model size from 16Gb to about 4Gb, increasing the inference speed in the process.
Another common optimization comes in leveraging TorchAO (Torch Architecture Optimization), the PyTorch library that works seamlessly with TorchChat to enhance model performance through various quantization and sparsity methods.
Lastly, we’ll use Arm KleidiAI optimizations. These are micro-kernels written in assembly that lead to significant performance improvements for LLM inference on Arm CPUs. You can read more about how KleidiAI kernels work if interested.
To implement these optimizations, spin up a fresh EC2 instance and follow the instructions on how to run a Large Language Model (LLM) chatbot with PyTorch. When ready, run the model and enter the same system prompt and user query as above. You’ll get results that significantly speed up the inference: Less than 1 second to first token, and about 25 tokens per second.
This cuts the inference time from 245 seconds to about 10 seconds. This results in less power-draw from your server, as it is spending more time idle vs running a power-hungry inference. All else being equal, this is a more carbon-friendly solution than the non-optimized app. The next two approaches go beyond model inference optimization, modifying the solution architectural to further reduce computational load.
Optimization 2: FAISS to match database for common questions
As stated in the introduction, model inferences are typically more computationally expensive than other search techniques. What if you could automatically respond to common user queries without performing an LLM inference? Using a query/response database is an option to bypass LLM inference and respond efficiently. For this interactive storytelling app, you can imagine common questions about specific characters, the world itself, and rules about what the chatbot is/is not capable of that can have pre-generated answers.
However, a traditional exact-match database isn’t sufficient as users can phrase the same query in many ways. Asking about the chatbot’s capabilities could all invite the same answer but be phrased differently:
- “What are you capable of?”
- “Tell me what you can do.”
- “How can I interact with you?”
Implementing semantic search solves this issue by matching a user’s query to the most relevant pre-generated answer by understanding the user’s intent. The FAISS library is a great option to implement semantic search.
The computational savings of this approach depends on three factors:
- Percentage of user queries that can be serviced by semantic search instead of LLM.
- Computational cost of running the LLM inference.
- Computational cost of running the semantic search.
With the savings equation being:
Computational_savings = (% of queries) * (LLM_cost – search_cost).
This type of architecture makes sense in a few situations. One is if your system has common queries with many repeat questions. Another is large-scale systems with hundreds of thousands of incoming queries, where small percentage savings add up to meaningful changes. Lastly, if your LLM inference is very computationally expensive compared to the search cost, particularly with larger parameter models.
The final optimization approach is transitioning from server to serverless.
Optimization 3: Serverless approach
Using serverless architectures are popular for many reasons, one being only paying for active compute time, and eliminating costs with idle servers. Idling servers require a non-trivial amount of power to keep on, wasting energy while waiting.
This cost efficiency translates into being an inherently more environmentally friendly architecture, as it reduces wasteful energy consumption. Further, multiple applications share underlying physical infrastructure, improving resource efficiency.
To set up your own serverless chatbot, you need to first containerize the quantized Llama-3.1-8b with TorchChat, TorchAO, and Arm KleidiAI optimizations with a python script containing a Lambda entry function lambda_handler. One deployment option is to upload your container to AWS ECR and attach the container to your Lambda function. Then set up an API Gateway WebSocket or similar to interact with your Lambda through an API.
There are two notable limitations to using a serverless architecture to host your LLM, the first being token generation speed. Recall that the server-based approach delivered about 25 tokens/second with KleidiAI optimizations. The serverless approach delivers an order of magnitude slower, which we measured at around about 2.5 tokens/second. This limitation mainly results from Lambda functions deploying onto Graviton2 servers. When deployment moves to CPUs with more SIMD channels, like Graviton3 and Graviton4, the tokens/second should increase over time. Learn more about architecture optimizations introduced in Graviton3 via the Arm Neoverse-V1 CPU here.
This slower speed restricts the viable use cases for serverless LLM architectures, but there are certain cases where this can be seen as an advantage. In our use cases of interactive storytelling, slowly revealing information creates a sense of immersion, building anticipation and mimicking real-time narration. Other use cases include:
- Guided meditation apps with slow, relaxing word delivery
- Virtual friend engaging in thoughtful conversation, or a therapeutic conversation.
- Poetry generation or interactive art to slow delivery creating a contemplative aesthetic.
Users may have a better experience with slower token generation in the right applications. When prioritizing a more sustainable solution, restrictions end up becoming strengths. As an analogy, a common critique of modern movies today is that their overreliance on visual effects leads to fewer compelling storylines vs older movies. The cost restrictions of VFX meant older movies had to craft captivating dialog, leveraging skillful camera angles and character positioning to fully engage viewers. Similarly, focusing on sustainable AI architectures can lead to more engaging, immersive experiences when done thoughtfully.
The second serverless limitation on LLM inferences is the cold-start time of about 50 seconds. If implemented poorly, a user waiting 50 seconds with no alternative will likely leave the app. You can turn this limitation into a feature in our Wicked-based experience with several design tricks:
- Create a “prologue experience” where you guide users through hard-coded questions and answers, priming them for where they will land in Emerald City and collecting input to shape their upcoming experience.
- Make the waiting period a countdown timer, revealing hard-coded text snippets of the story or world-building. A character, like the wizard, could communicate with the user with fragmented lines to build suspense and prime the user into the right mindset.
- Create an audio intro with music from the movie or musical, along with rotating visuals to draw users into the atmosphere of the Wicked world.
Thinking outside the box
Implementing a sustainability-minded solution architecture includes and goes beyond optimizing your AI inferences. Understand how users will interact with your system, and right-size your implementation accordingly. Always optimizing for fast tokens per second or time to first token will hide opportunities for engaging features.
With that said, you should be leveraging straightforward optimizations when possible. Using TorchAO and Arm KleidiAI micro-kernels are great ways to speed up your LLM chatbot. By combining creative solution architectures and optimizing where possible, you can build more sustainable LLM-based applications. Happy coding!