This post demonstrates how to create a serverless Machine Learning Operations (MLOps) pipeline to develop and visualize a forecasting model built with Amazon Forecast. Because Machine Learning (ML) workloads need to scale, it’s important to break down the silos among different stakeholders to capture business value. The MLOps model makes sure that the data science, production, and operations teams work together seamlessly across workflows that are as automated as possible, ensuring smooth deployments and effective ongoing monitoring.
Similar to the DevOps model in software development, the MLOps model in ML helps build code and integration across ML tools and frameworks. You can automate, operationalize, and monitor data pipelines without having to rewrite custom code or rethink existing infrastructures. MLOps helps scale existing distributed storage and processing infrastructures to deploy and manage ML models at scale. It can also be implemented to track and visualize drift over time for all models across the organization in one central location and implement automatic data validation policies.
MLOps combines best practices from DevOps and the ML world by applying continuous integration, continuous deployment, and continuous training. MLOps helps streamline the lifecycle of ML solutions in production. For more information, see the whitepaper Machine Learning Lens: AWS Well-Architected Framework.
In the following sections you will build, train, and deploy a time-series forecasting model leveraging an MLOps pipeline encompassing Amazon Forecast, AWS Lambda, and AWS Step Functions. To visualize the generated forecast, you will use a combination of AWS serverless analytics services such as Amazon Athena and Amazon QuickSight.
Solution architecture
In this section, you deploy an MLOps architecture that you can use as a blueprint to automate your Amazon Forecast usage and deployments. The provided architecture and sample code help you build an MLOps pipeline for your time series data, enabling you to generate forecasts to define future business strategies and fulfil customer needs.
You can build this serverless architecture using AWS-managed services, which means you don’t need to worry about infrastructure management while creating your ML pipeline. This helps iterate through a new dataset and adjust your model by tuning features and hyperparameters to optimize performance.
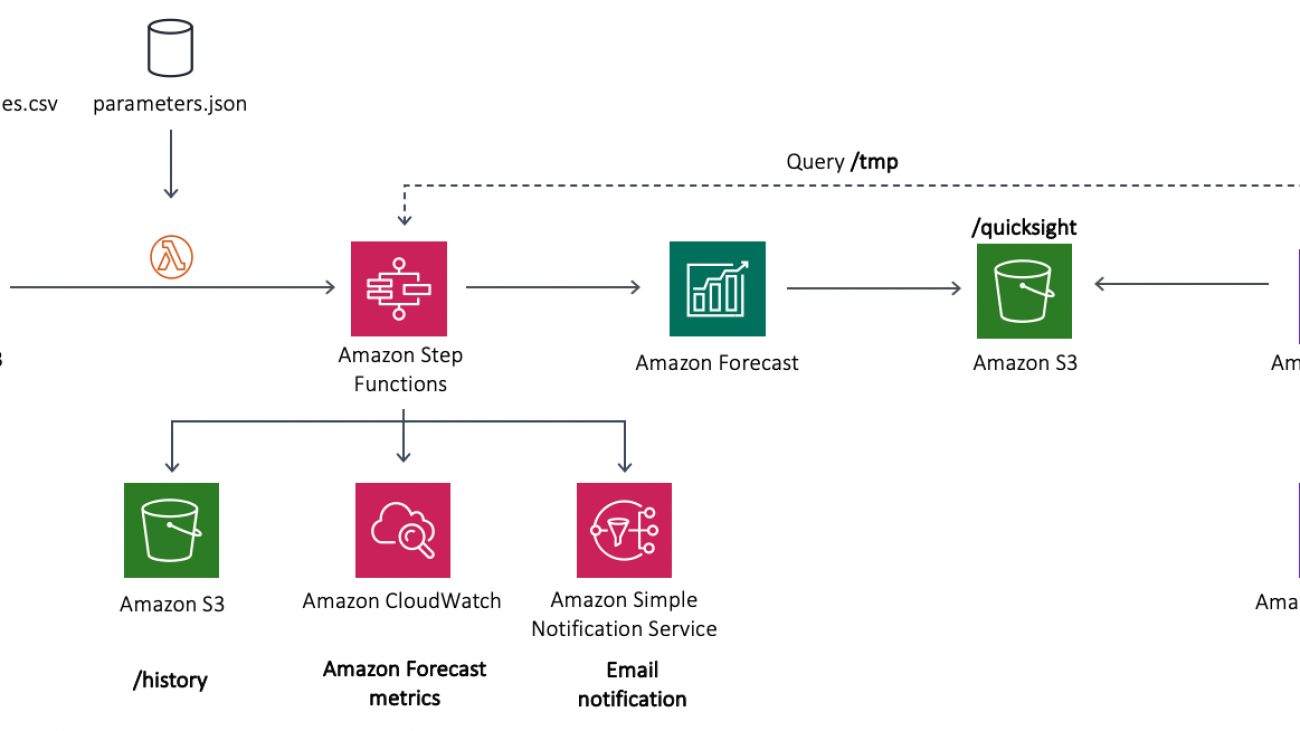
The following diagram illustrates the components you will build throughout this post.

In the preceding diagram, the serverless MLOps pipeline is deployed using a Step Functions workflow, in which Lambda functions are stitched together to orchestrate the steps required to set up Amazon Forecast and export the results to Amazon Simple Storage Service (Amazon S3).
The architecture contains the following components:
- The time series dataset is uploaded to the Amazon S3 cloud storage under the
/traindirectory (prefix). - The uploaded file triggers Lambda, which initiates the MLOps pipeline built using a Step Functions state machine.
- The state machine stitches together a series of Lambda functions to build, train, and deploy a ML model in Amazon Forecast. You will learn more details about the state machine’s Lambda components in the next section.
- For log analysis, the state machine uses Amazon CloudWatch, which captures Forecast metrics. You use Amazon Simple Notification Service (Amazon SNS) to send email notifications when the final forecasts become available in the source Amazon S3 bucket in the
/forecastdirectory. The ML pipeline saves any old forecasts in the/historydirectory. - Finally, you will use Athena and QuickSight to provide a visual presentation of the current forecast.
In this post, you use the Individual household electric power consumption dataset available in the UCI Machine Learning Repository. The time series dataset aggregates hourly energy consumption for various customers households and shows spikes in energy utilization over weekdays. You can replace the sample data as needed for later use cases.
Now that you are familiar with the architecture, you’re ready to explore the details of each Lambda component in the state machine.
Building an MLOps pipeline using Step Functions
In the previous section, you learned that the Step Functions state machine is the core of the architecture automating the entire MLOps pipeline. The following diagram illustrates the workflow deployed using the state machine.

As shown in preceding diagram, the Lambda functions from the Step Functions workflow are as follows (the steps also highlight the mapping between Lambda functions and the parameters used from the params.json file stored in Amazon S3):
- Create-Dataset – Creates a Forecast dataset. The information about the dataset helps Forecast understand how to consume the data for model training.
- Create-DatasetGroup – Creates a dataset group.
- Import-Data – Imports your data into a dataset that resides inside a dataset group.
- Create-Predictor – Creates a predictor with a forecast horizon that the parameters file specifies.
- Create-Forecast – Creates the forecast and starts an export job to Amazon S3, including quantiles specified in the parameters file.
- Update-Resources – Creates the necessary Athena resources and transforms the exported forecasts to the same format as the input dataset.
- Notify Success – Sends an email alerting when the job is finished by posting a message to Amazon SNS.
- Strategy-Choice – Checks whether to delete the Forecast resources, according to the parameters file.
- Delete-Forecast – Deletes the forecast and keeps the exported data.
- Delete-Predictor – Deletes the predictor.
- Delete-ImportJob – Deletes the
Import-Datajob in Forecast.
In Amazon Forecast, a dataset group is an abstraction that contains all the datasets for a particular collection of forecasts. There is no information sharing between dataset groups; to try out various alternatives to the schemas, you create a new dataset group and make changes inside its corresponding datasets. For more information, see Datasets and Dataset Groups. For this use case, the workflow imports a target time series dataset into a dataset group.
After completing these steps, the workflow triggers the predictor training job. A predictor is a Forecast-trained model used for making forecasts based on time series data. For more information, see Predictors.
When your predictor is trained, the workflow triggers the creation of a forecast using that predictor. During forecast creation, Amazon Forecast trains a model on the entire dataset before hosting the model and making inferences. For more information, see Forecasts.
The state machine sends a notification email to the address specified at the deployment of a successful forecast export. After exporting your forecast, the Update-Resources step reformats the exported data so Athena and QuickSight can easily consume it.
You can reuse this MLOps pipeline to build, train, and deploy other ML models by replacing the algorithms and datasets in the Lambda function for each step.
Prerequisites
Before you deploy the architecture, complete the following prerequisite steps:
- Install Git.
- Install the AWS Serverless Application Model (AWS SAM) CLI on your system. For instructions, see Installing the AWS SAM CLI. Make sure the latest version is installed with the following code:
sam --version
Deploying the sample architecture to your AWS account
To simplify deployment, this post provides the entire architecture as infrastructure as code using AWS CloudFormation and is available in the Forecast Visualization Automation Blogpost GitHub repo. You use AWS SAM to deploy this solution.
- Clone the Git repo. See the following code:
git clone https://github.com/aws-samples/amazon-forecast-samples.gitThe code is also available on the Forecast Visualization Automation Blogpost GitHub repo.
- Navigate to the newly created
amazon-forecast-samples/ml_ops/visualization_blogdirectory and enter the following code to start solution deployment:cd amazon-forecast-samples/ml_ops/visualization_blog sam build && sam deploy --guidedAt this stage, AWS SAM builds a CloudFormation template change set. After a few seconds, AWS SAM prompts you to deploy the CloudFormation stack.
- Provide parameters for the stack deployment. This post uses the following parameters; you can keep the default parameters:
Setting default arguments for 'sam deploy' ========================================= Stack Name [ForecastSteps]: <Enter Stack Name e.g. - forecast-blog-stack> AWS Region [us-east-1]: <Enter region e.g. us-east-1> Parameter Email [youremail@yourprovider.com]: <Enter valid e-mail id> Parameter ParameterFile [params.json]: <Leave Default> #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [Y/n]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: y Save arguments to samconfig.toml [Y/n]: nAWS SAM creates an AWS CloudFormation change set and asks for confirmation.
- Enter
Y.
For more information about change sets, see Updating Stacks Using Change Sets.
After a successful deployment, you see the following output:
CloudFormation outputs from the deployed stack
------------------------------------------------------------
Outputs
-------------------------------------------------------------
Key AthenaBucketName
Description Athena bucket name to drop your files
Value forecast-blog-stack-athenabucket-1v6qnz7n5f13w
Key StepFunctionsName
Description Step Functions Name
Value arn:aws:states:us-east-1:789211807855:stateMachine:DeployStateMachine-5qfVJ1kycEOj
Key ForecastBucketName
Description Forecast bucket name to drop your files
Value forecast-blog-stack-forecastbucket-v61qpov2cy8c
-------------------------------------------------------------
Successfully created/updated stack - forecast-blog-stack in us-east-1
- On the AWS CloudFormation console, on the Outputs tab, record the value of
ForecastBucketName, which you use in the testing step.

Testing the sample architecture
The following steps outline how to test the sample architecture. To trigger the Step Functions workflow, you need to upload two files to the newly created S3 bucket: a parameter file and the time series training dataset.
- Under the same directory in which you cloned the GitHub repo, enter the following code, replacing YOURBUCKETNAME with the value from the AWS CloudFormation Outputs tab that you copied earlier:
aws s3 cp ./testing-data/params.json s3://{YOURBUCKETNAME}The preceding command copied the parameters file that the Lambda functions use to configure your Forecast API calls.
- Upload the time series dataset by entering the following code:
aws s3 sync ./testing-data/ s3://{YOURBUCKETNAME} - On the Step Functions dashboard, locate the state machine named DeployStateMachine-<random string>.
- Choose the state machine to explore the workflow in execution.

In the preceding screenshot, all successfully executed steps (Lambda functions) are in a green box. The blue box indicates that a step is still in progress. All boxes without colors are steps that are pending execution. It can take up to 2 hours to complete all the steps of this workflow.
After the successful completion of the workflow, you can go to the Amazon S3 console and find an Amazon S3 bucket with the following directories:
/params.json # Your parameters file.
/train/ # Where the training CSV files are stored
/history/ # Where the previous forecasts are stored
/history/raw/ # Contains the raw Amazon Forecast exported files
/history/clean/ # Contains the previous processed Amazon Forecast exported files
/quicksight/ # Contains the most updated forecasts according to the train dataset
/tmp/ # Where the Amazon Forecast files are temporarily stored before processing
The parameter file params.json stores attributes to call Forecast APIs from the Lambda functions. These parameter configurations contain information such as forecast type, predictor setting, and dataset setting, in addition to forecast domain, frequency, and dimension. For more information about API actions, see Amazon Forecast Service.
Now that your data is in Amazon S3, you can visualize your results.
Analyzing forecasted data with Athena and QuickSight
To complete your forecast pipeline, you need to query and visualize your data. Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. QuickSight is a fast, cloud-powered business intelligence service that makes it easy to uncover insights through data visualization. To start analyzing your data, you first ingest your data into QuickSight using Athena as a data source.
If you’re new to AWS, set up QuickSight to create a QuickSight account. If you have an AWS account, subscribe to QuickSight to create an account.
If this is your first time using Athena on QuickSight, you have to give permissions to QuickSight to query Amazon S3 using Athena. For more information, see Insufficient Permissions When Using Athena with Amazon QuickSight.
- On the QuickSight console, choose New Analysis.
- Choose New Data Set.
- Choose Athena.
- In the New Athena data source window, for Data source name, enter a name; for example,
Utility Prediction. - Choose Validate connection.
- Choose Create data source.

The Choose your table window appears.
- Choose Use custom SQL.

- In the Enter custom SQL query window, enter a name for your query; for example,
Query to merge Forecast result with training data. - Enter the following code into the query text box:
SELECT LOWER(forecast.item_id) as item_id, forecast.target_value, date_parse(forecast.timestamp, '%Y-%m-%d %H:%i:%s') as timestamp, forecast.type FROM default.forecast UNION ALL SELECT LOWER(train.item_id) as item_id, train.target_value, date_parse(train.timestamp, '%Y-%m-%d %H:%i:%s') as timestamp, 'history' as type FROM default.train - Choose Confirm query.

You now have the option to import your data to SPICE or query your data directly.
- Choose either option, then choose Visualize.
You see the following fields under Fields list:
item_idtarget_valuetimestamptype
The exported forecast contains the following fields:
item_iddate- The requested quantiles (P10, P50, P90)
The type field contains the quantile type (P10, P50, P90) for your forecasted window and history as its value for your training data. This was done through the custom query to have a consistent historical line between your historical data and the exported forecast.
You can customize the quantiles by using the CreateForecast API optional parameter called ForecastType. For this post, you can configure this in the params.json file in Amazon S3.
- For X axis, choose timestamp.
- For Value, choose target_value.
- For Color, choose type.
In your parameters, you specified a 72-hour horizon. To visualize results, you need to aggregate the timestamp field on an hourly frequency.
- From the timestamp drop-down menu, choose Aggregate and Hour.

The following screenshot is your final forecast prediction. The graph shows a future projection in the quantiles p10, p50m, and p90, at which probabilistic forecasts are generated.

Conclusion
Every organization can benefit from more accurate forecasting to better predict product demand, optimize planning and supply chains, and more. Forecasting demand is a challenging task, and ML can narrow the gap between predictions and reality.
This post showed you how to create a repeatable, AI-powered, automated forecast generation process. You also learned how to implement an ML operation pipeline using serverless technologies and used a managed analytics service to get data insights by querying the data and creating a visualization.
There’s even more that you can do with Forecast. For more information about energy consumption predictions, see Making accurate energy consumption predictions with Amazon Forecast. For more information about quantiles, see Amazon Forecast now supports the generation of forecasts at a quantile of your choice.
If this post helps you or inspires you to solve a problem, share your thoughts and questions in the comments. You can use and extend the code on the GitHub repo.
About the Author
 Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
 Saurabh Shrivastava is a solutions architect leader and AI/ML specialist working with global systems integrators. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.
Saurabh Shrivastava is a solutions architect leader and AI/ML specialist working with global systems integrators. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.
 Pedro Sola Pimentel is an R&D solutions architect working with the AWS Brazil commercial team. He works with AWS to innovate and develop solutions using new technologies and services. He’s interested in recent computer science research topics and enjoys traveling and watching movies.
Pedro Sola Pimentel is an R&D solutions architect working with the AWS Brazil commercial team. He works with AWS to innovate and develop solutions using new technologies and services. He’s interested in recent computer science research topics and enjoys traveling and watching movies.
































 Leonardo Gómez is a Big Data Specialist Solutions Architect at AWS. Based in Toronto, Canada, He works with customers across Canada to design and build big data architectures.
Leonardo Gómez is a Big Data Specialist Solutions Architect at AWS. Based in Toronto, Canada, He works with customers across Canada to design and build big data architectures.















 Emily Webber is a machine learning specialist SA at AWS, who alternates between data scientist, machine learning architect, and research scientist based on the day of the week. She lives in Chicago, and you can find her on YouTube, LinkedIn, GitHub, or Twitch. When not helping customers and attempting to invent the next generation of machine learning experiences, she enjoys running along beautiful Lake Shore Drive, escaping into her Kindle, and exploring the road less traveled.
Emily Webber is a machine learning specialist SA at AWS, who alternates between data scientist, machine learning architect, and research scientist based on the day of the week. She lives in Chicago, and you can find her on YouTube, LinkedIn, GitHub, or Twitch. When not helping customers and attempting to invent the next generation of machine learning experiences, she enjoys running along beautiful Lake Shore Drive, escaping into her Kindle, and exploring the road less traveled. Tom Faulhaber is a Principal Engineer on the Amazon SageMaker team. Lately, he has been focusing on unlocking all the potential uses of the richness of Jupyter notebooks and how they can add to the data scientist’s toolbox in non-traditional ways. In his spare time, Tom is usually found biking and hiking to discover all the wild spaces around Seattle with his kids.
Tom Faulhaber is a Principal Engineer on the Amazon SageMaker team. Lately, he has been focusing on unlocking all the potential uses of the richness of Jupyter notebooks and how they can add to the data scientist’s toolbox in non-traditional ways. In his spare time, Tom is usually found biking and hiking to discover all the wild spaces around Seattle with his kids.




 Jyothi Nookula is a Principal Product Manager for AWS AI devices. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.
Jyothi Nookula is a Principal Product Manager for AWS AI devices. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.



