Summit offered Day One fellows the opportunity to interact with leaders in the robotics field.Read More
Detect patterns in text data with Amazon SageMaker Data Wrangler
In this post, we introduce a new analysis in the Data Quality and Insights Report of Amazon SageMaker Data Wrangler. This analysis assists you in validating textual features for correctness and uncovering invalid rows for repair or omission.
Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes. You can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization, from a single visual interface.
Solution overview
Data preprocessing often involves cleaning textual data such as email addresses, phone numbers, and product names. This data can have underlying integrity constraints that may be described by regular expressions. For example, to be considered valid, a local phone number may need to follow a pattern like [1-9][0-9]{2}-[0-9]{4}, which would match a non-zero digit, followed by two more digits, followed by a dash, followed by four more digits.
Common scenarios resulting in invalid data may include inconsistent human entry, for example phone numbers in various formats (5551234 vs. 555 1234 vs. 555-1234) or unexpected data, such as 0, 911, or 411. For a customer call center, it’s important to omit numbers such as 0, 911, or 411, and validate (and potentially correct) entries such as 5551234 or 555 1234.
Unfortunately, although textual constraints exist, they may not be provided with the data. Therefore, a data scientist preparing a dataset must manually uncover the constraints by looking at the data. This can be tedious, error prone, and time consuming.
Pattern learning automatically analyzes your data and surfaces textual constraints that may apply to your dataset. For the example with phone numbers, pattern learning can analyze the data and identify that the vast majority of phone numbers follow the textual constraint [1-9][0-9]{2}-[0-9][4]. It can also alert you that there are examples of invalid data so that you can exclude or correct them.
In the following sections, we demonstrate how to use pattern learning in Data Wrangler using a fictional dataset of product categories and SKU (stock keeping unit) codes.
This dataset contains features that describe products by company, brand, and energy consumption. Notably, it includes a feature SKU that is ill-formatted. All the data in this dataset is fictional and created randomly using random brand names and appliance names.
Prerequisites
Before you get started using Data Wrangler, download the sample dataset and upload it to a location in Amazon Simple Storage Service (Amazon S3). For instructions, refer to Uploading objects.
Import your dataset
To import your dataset, complete the following steps:
- In Data Wrangler, choose Import & Explore Data for ML.

- Choose Import.

- For Import data, choose Amazon S3.

- Locate the file in Amazon S3 and choose Import.
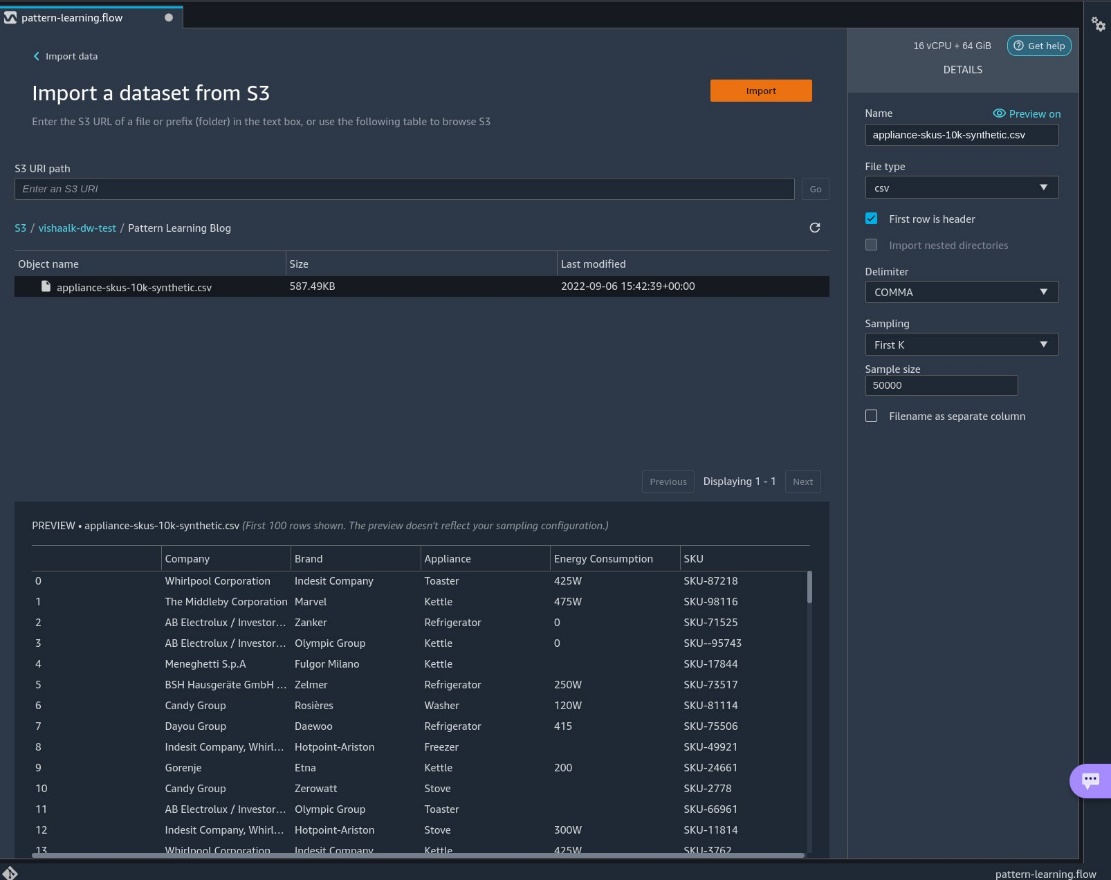
After importing, we can navigate to the data flow.
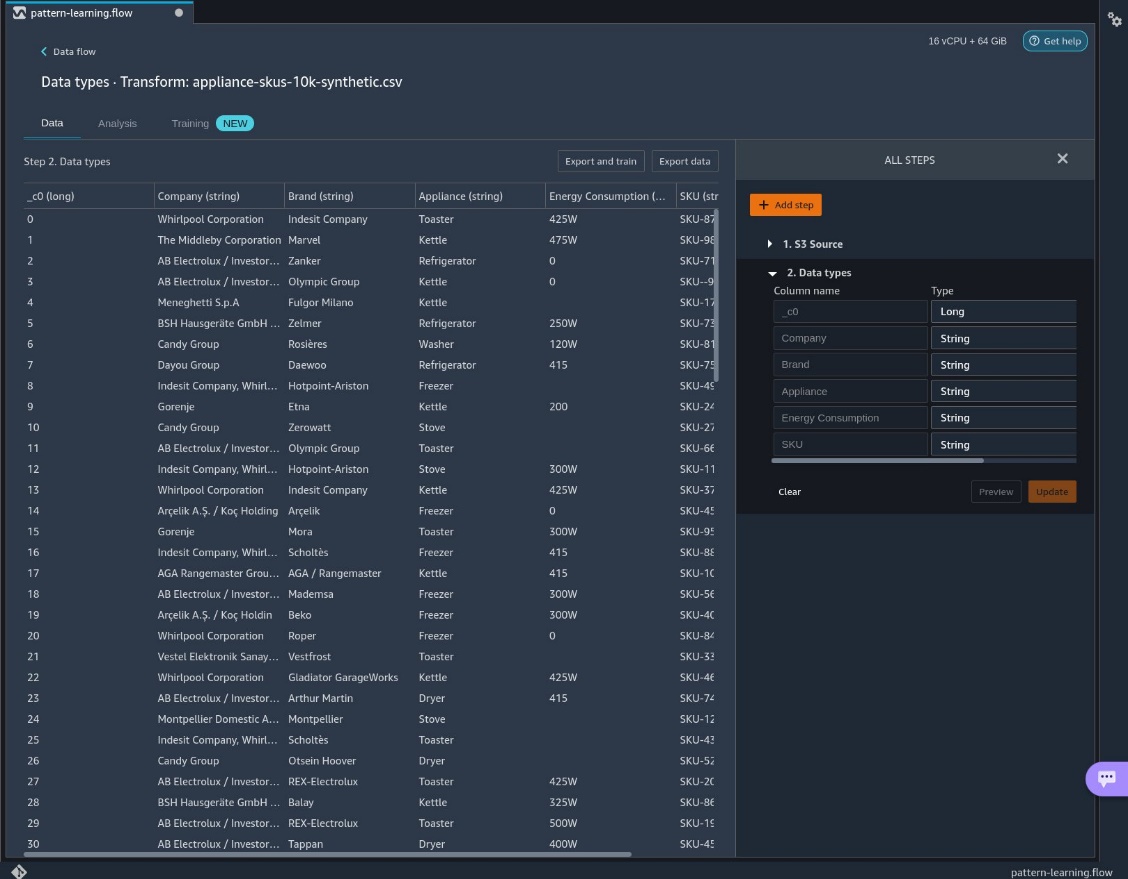
Get data insights
In this step, we create a data insights report that includes information about data quality. For more information, refer to Get Insights On Data and Data Quality. Complete the following steps:
- On the Data Flow tab, choose the plus sign next to Data types.
- Choose Get data insights.

- For Analysis type, choose Data Quality and Insights Report.
- For this post, leave Target column and Problem type blank.If you plan to use your dataset for a regression or classification task with a target feature, you can select those options and the report will include analysis on how your input features relate to your target. For example, it can produce reports on target leakage. For more information, refer to Target column.
- Choose Create.

We now have a Data Quality and Data Insights Report. If we scroll down to the SKU section, we can see an example of pattern learning describing the SKU. This feature appears to have some invalid data, and actionable remediation is required.

Before we clean the SKU feature, let’s scroll up to the Brand section to see some more insights. Here we see two patterns have been uncovered, indicating that that majority of brand names are single words consisting of word characters or alphabetic characters. A word character is either an underscore or a character that may appear in a word in any language. For example, the strings Hello_world and écoute both consist of word characters: H and é.
For this post, we don’t clean this feature.
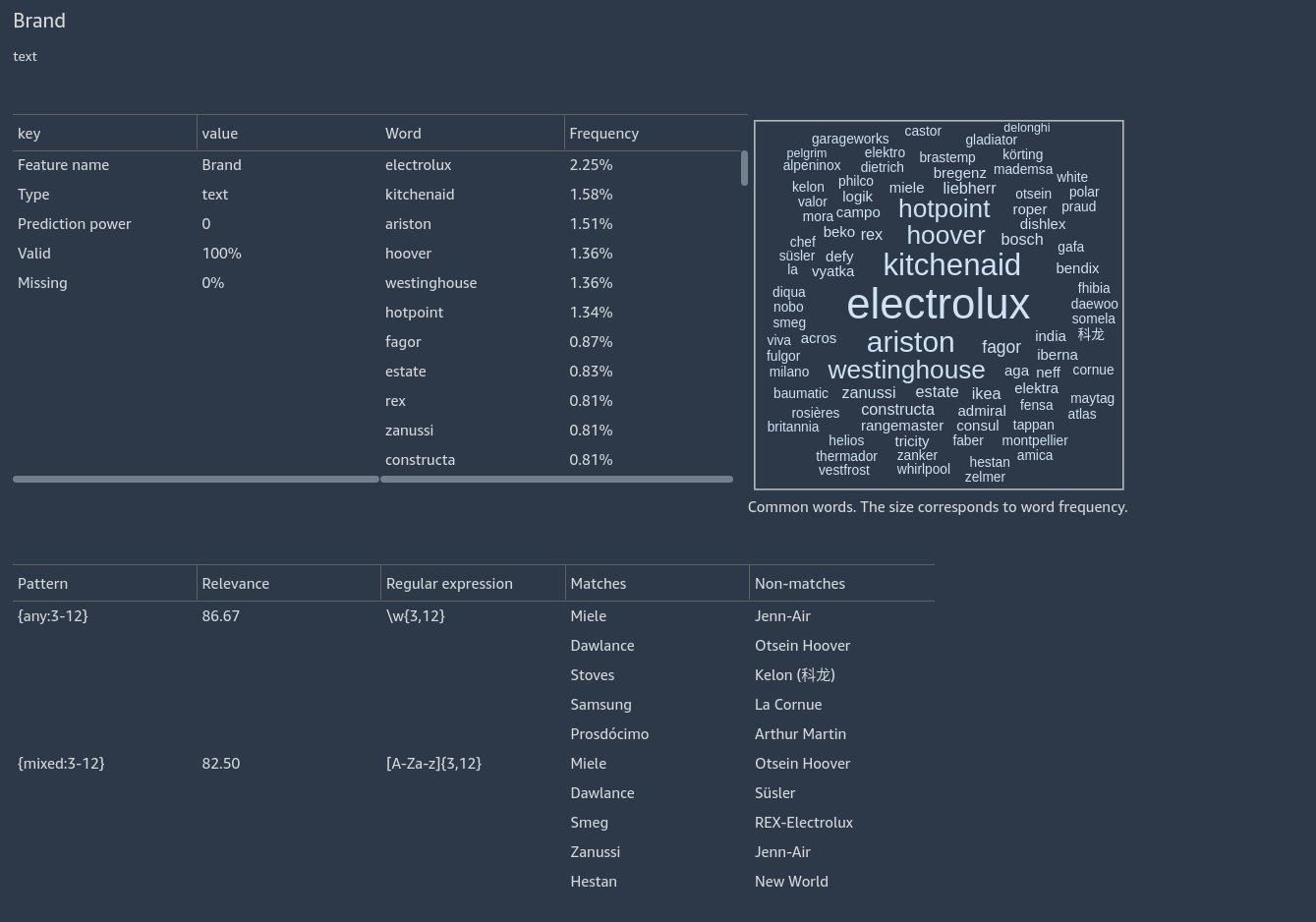
View pattern learning insights
Let’s return to cleaning SKUs and zoom in on the pattern and the warning message.
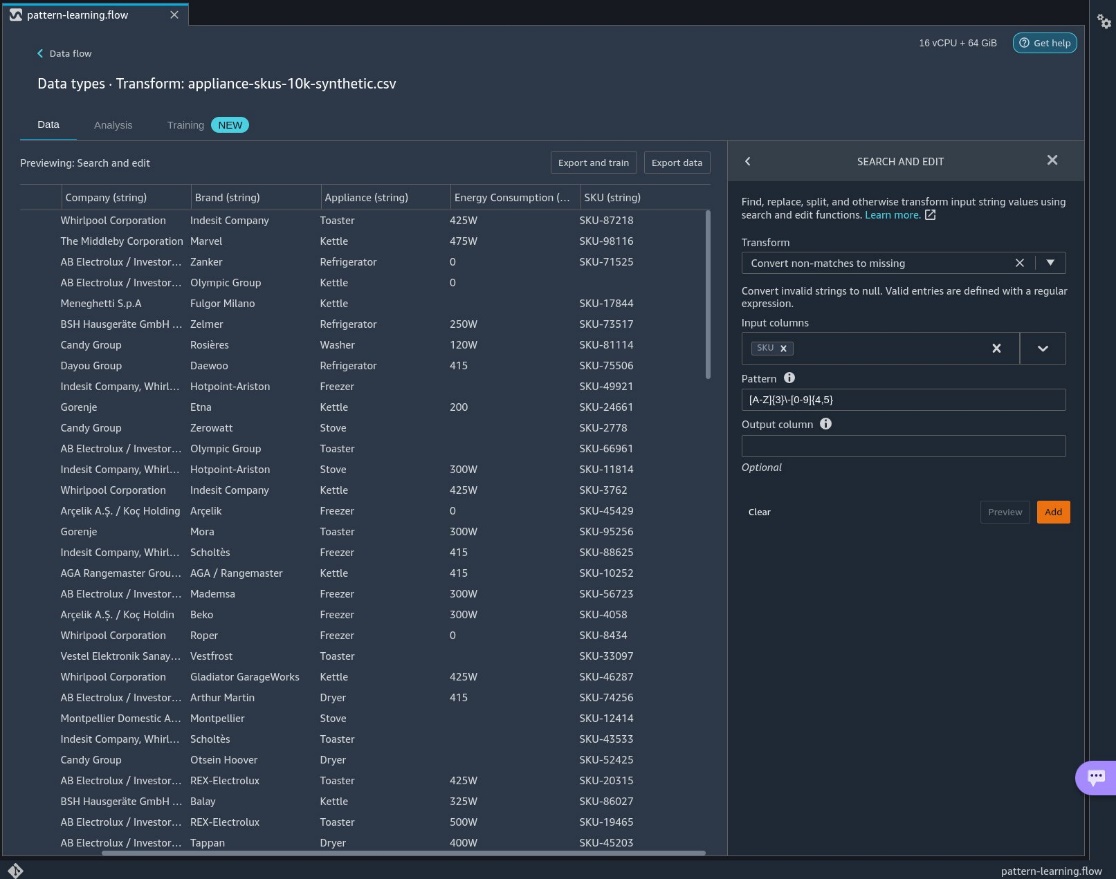
As shown in the following screenshot, pattern learning surfaces a high-accuracy pattern matching 97.78% of the data. It also displays some examples matching the pattern as well as examples that don’t match the pattern. In the non-matches, we see some invalid SKUs.
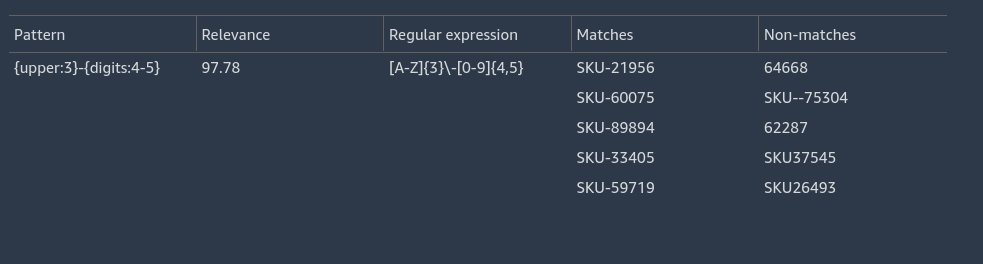
In addition to the surfaced patterns, a warning may appear indicating a potential action to clean up data if there is a high accuracy pattern as well as some data that doesn’t conform to the pattern.

We can omit the invalid data. If we choose (right-click) on the regular expression, we can copy the expression [A-Z]{3}-[0-9]{4,5}.
Remove invalid data
Let’s create a transform to omit non-conforming data that doesn’t match this pattern.
- On the Data Flow tab, choose the plus sign next to Data types.
- Choose Add transform.

- Choose Add step.
- Search for
regexand choose Search and edit.

- For Transform, choose Convert non-matches to missing.
- For Input columns, choose
SKU. - For Pattern, enter our regular expression.
- Choose Preview, then choose Add.
Now the extraneous data has been removed from the features. - To remove the rows, add the step Handle missing and choose the transform Drop missing.
- Choose
SKUas the input column.
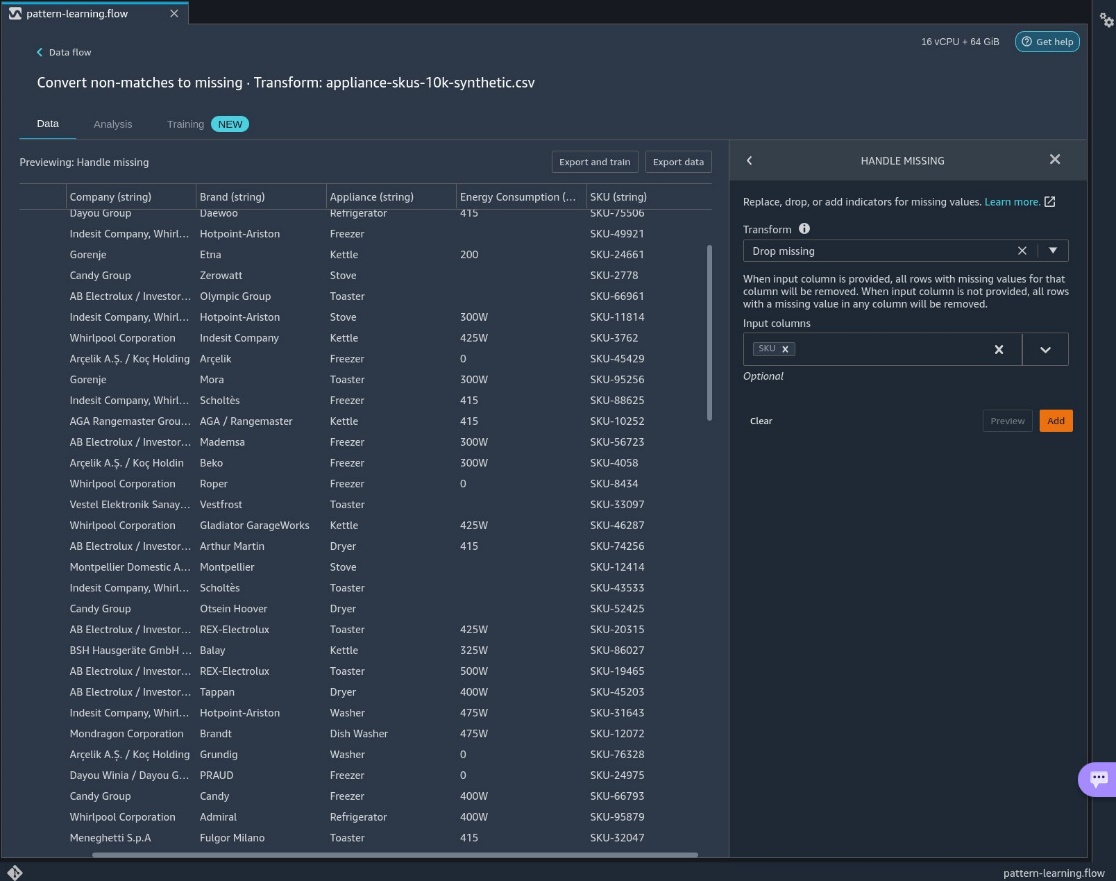
We return to our data flow with the erroneous data removed.

Conclusion
In this post, we showed you how to use the pattern learning feature in data insights to find invalid textual data in your dataset, as well as how to correct or omit that data.
Now that you’ve cleaned up a textual column, you can visualize your dataset using an analysis or you can apply built-in transformations to further process your data. When you’re satisfied with your data, you can train a model with Amazon SageMaker Autopilot, or export your data to a data source such as Amazon S3.
We would like to thank Nikita Ivkin for his thoughtful review.
About the authors
 Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
 Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
 Ajai Sharma is a Principal Product Manager for Amazon SageMaker where he focuses on Data Wrangler, a visual data preparation tool for data scientists. Prior to AWS, Ajai was a Data Science Expert at McKinsey and Company, where he led ML-focused engagements for leading finance and insurance firms worldwide. Ajai is passionate about data science and loves to explore the latest algorithms and machine learning techniques.
Ajai Sharma is a Principal Product Manager for Amazon SageMaker where he focuses on Data Wrangler, a visual data preparation tool for data scientists. Prior to AWS, Ajai was a Data Science Expert at McKinsey and Company, where he led ML-focused engagements for leading finance and insurance firms worldwide. Ajai is passionate about data science and loves to explore the latest algorithms and machine learning techniques.
 Derek Baron is a software development manager for Amazon SageMaker Data Wrangler
Derek Baron is a software development manager for Amazon SageMaker Data Wrangler
Reduce deep learning training time and cost with MosaicML Composer on AWS
In the past decade, we have seen Deep learning (DL) science adopted at a tremendous pace by AWS customers. The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. In this post, we highlight challenges commonly reported specifically in DL training, and how the open-source library MosaicML Composer helps solve them.
The challenge with DL training
DL models are trained iteratively, in a nested for loop. A loop iterates through the training dataset chunk by chunk and, if necessary, this loop is repeated several times over the whole dataset. ML practitioners working on DL training face several challenges:
- Training duration grows with data size. With permanently-growing datasets, training times and costs grow too, and the rhythm of scientific discovery slows down.
- DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs.
- The paradox of choice: several training optimization papers and libraries are published, yet it’s unclear which one to test first, and how to combine their effects.
In the past few years, several open-source libraries such as Keras, PyTorch Lightning, Hugging Face Transformers, and Ray Train have been attempting to make DL training more accessible, notably by reducing code verbosity, thereby simplifying how neural networks are programmed. Most of those libraries have focused on developer experience and code compactness.
In this post, we present a new open-source library that takes a different stand on DL training: MosaicML Composer is a speed-centric library whose primary objective is to make neural network training scripts faster via algorithmic innovation. In the cloud DL world, it’s wise to focus on speed, because compute infrastructure is often paid per use—even down to the second on Amazon SageMaker Training—and improvements in speed can translate into money savings.
Historically, speeding up DL training has mostly been done by increasing the number of machines computing model iterations in parallel, a technique called data parallelism. Although data parallelism sometimes accelerates training (not guaranteed because it disturbs convergence, as highlighted in Goyal et al.), it doesn’t reduce overall job cost. In practice, it tends to increase it, due to inter-machine communication overhead and higher machine unit cost, because distributed DL machines are equipped with high-end networking and in-server GPU interconnect.
Although MosaicML Composer supports data parallelism, its core philosophy is different from the data parallelism movement. Its goal is to accelerate training without requiring more machines, by innovating at the science implementation level. Therefore, it aims to achieve time savings which would result in cost savings due to AWS’ pay-per-use fee structure.
Introducing the open-source library MosaicML Composer
MosaicML Composer is an open-source DL training library purpose-built to make it simple to bring the latest algorithms and compose them into novel recipes that speed up model training and help improve model quality. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks
Composer is available via pip:
pip install mosaicmlSpeedup techniques implemented in Composer can be accessed with its functional API. For example, the following snippet applies the BlurPool technique to a TorchVision ResNet:
import logging
from composer import functional as CF
import torchvision.models as models
logging.basicConfig(level=logging.INFO)
model = models.resnet50()
CF.apply_blurpool(model)Optionally, you can also use a Trainer to compose your own combination of techniques:
from composer import Trainer
from composer.algorithms import LabelSmoothing, CutMix, ChannelsLast
trainer = Trainer(
model=.. # must be a composer.ComposerModel
train_dataloader=...,
max_duration="2ep", # can be a time, a number of epochs or batches
algorithms=[
LabelSmoothing(smoothing=0.1),
CutMix(alpha=1.0),
ChannelsLast(),
]
)
trainer.fit()Examples of methods implemented in Composer
Some of the methods available in Composer are specific to computer vision, for example image augmentation techniques ColOut, Cutout, or Progressive Image Resizing. Others are specific to sequence modeling, such as Sequence Length Warmup or ALiBi. Interestingly, several are agnostic of the use case and can be applied to a variety of PyTorch neural networks beyond computer vision and NLP. Those generic neural network training acceleration methods include Label Smoothing, Selective Backprop, Stochastic Weight Averaging, Layer Freezing, and Sharpness Aware Minimization (SAM).
Let’s dive deep into a few of them that were found particularly effective by the MosaicML team:
- Sharpness Aware Minimization (SAM) is an optimizer than minimizes both the model loss function and its sharpness by computing a gradient twice for each optimization step. To limit the extra compute to penalize the throughput, SAM can be run periodically.
- Attention with Linear Biases (ALiBi), inspired by Press et al., is specific to Transformers models. It removes the need for positional embeddings, replacing them with a non-learned bias to attention weights.
- Selective Backprop, inspired by Jiang et al., allows you to run back-propagation (the algorithms that improve model weights by following its error slope) only on records with high loss function. This method helps you avoid unnecessary compute and helps improve throughput.
Having those techniques available in a single compact training framework is a significant value added for ML practitioners. What is also valuable is the actionable field feedback the MosaicML team produces for each technique, tested and rated. However, given such a rich toolbox, you may wonder: what method shall I use? Is it safe to combine the use of multiple methods? Enter MosaicML Explorer.
MosaicML Explorer
To quantify the value and compatibility of DL training methods, the MosaicML team maintains Explorer, a first-of-its kind live dashboard picturing dozens of DL training experiments over five datasets and seven models. The dashboard pictures the pareto optimal frontier in the cost/time/quality trade-off, and allows you to browse and find top-scoring combinations of methods—called recipes in the MosaicML world—for a given model and dataset. For example, the following graphs show that for a 125M parameter GPT2 training, the cheapest training maintaining a perplexity of 24.11 is obtained by combining AliBi, Sequence Length Warmup, and Scale Schedule, reaching a cost of about $145.83 in the AWS Cloud! However, please note that this cost calculation and the ones that follow in this post are based on an EC2 on-demand compute only, other cost considerations may be applicable, depending on your environment and business needs.
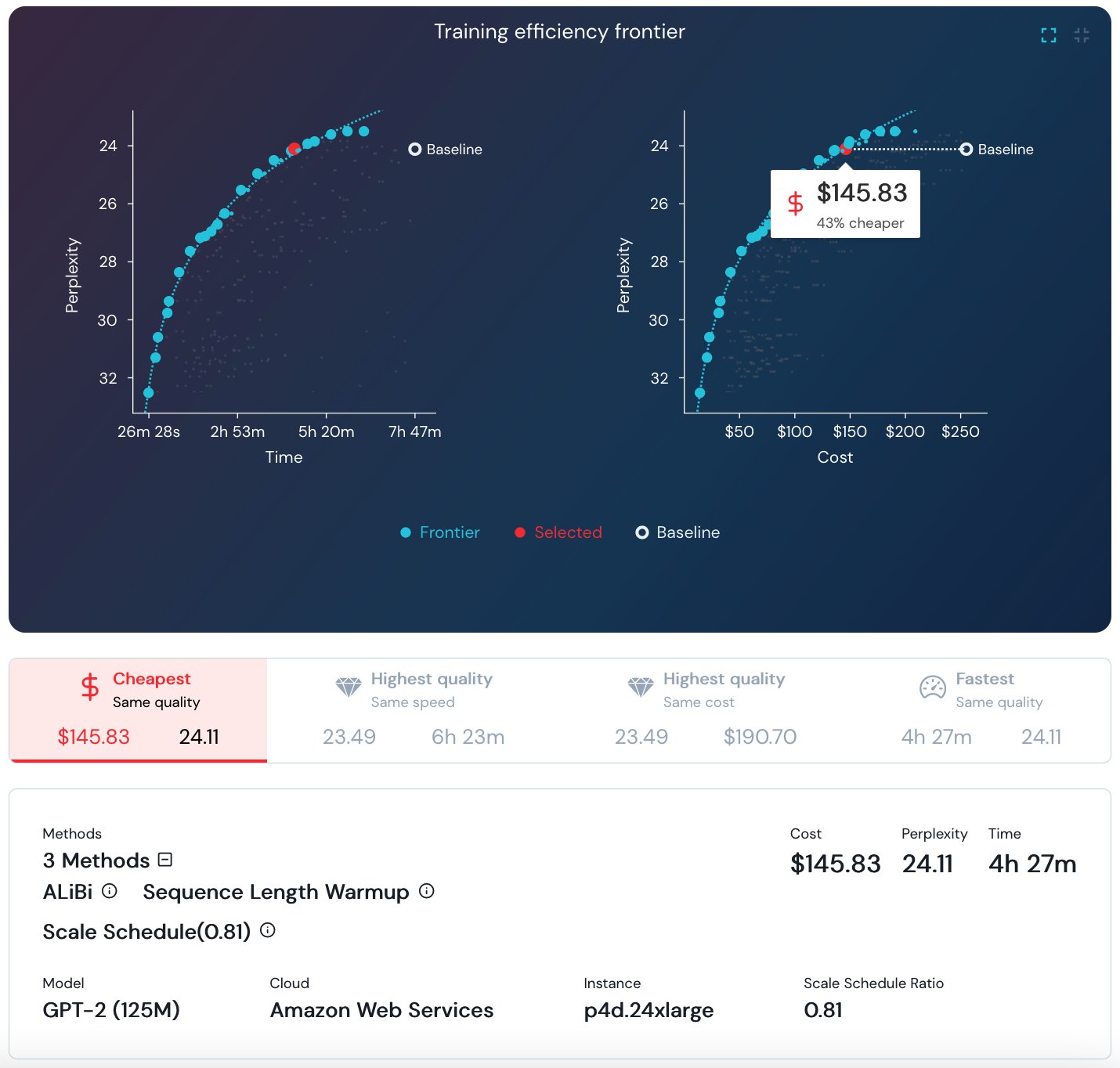
Screenshot of MosaicML Explorer for GPT-2 training
Notable achievements with Composer on AWS
By running the Composer library on AWS, the MosaicML team achieved a number of impressive results. Note that costs estimates reported by MosaicML team consist of on-demand compute charge only.
- ResNet-50 training on ImageNet to 76.6% top-one accuracy for ~$15 in 27 minutes (MosaicML Explorer link)
- GPT-2 125M parameter training to a perplexity of 24.11 for ~$145 (MosaicML Explorer link)
- BERT-Base training to Average Dev-Set Accuracy of 83.13% for ~$211 (MosaicML Explorer link)
Conclusion
You can get started with Composer on any compatible platform, from your laptop to large GPU-equipped cloud servers. The library features intuitive Welcome Tour and Getting Started documentation pages. Using Composer in AWS allows you to cumulate Composer cost-optimization science with AWS cost-optimization services and programs, including Spot compute (Amazon EC2, Amazon SageMaker), Savings Plan, SageMaker automatic model tuning, and more. The MosaicML team maintains a tutorial of Composer on AWS. It provides a step-by-step demonstration of how you can reproduce MLPerf results and train ResNet-50 on AWS to the standard 76.6% top-1 accuracy in just 27 minutes.
If you’re struggling with neural networks that are training too slow, or if you’re looking to keep your DL training costs under control, give MosaicML on AWS a try and let us know what you build!
About the authors
 Bandish Shah is an Engineering Manager at MosaicML, working to bridge efficient deep learning with large scale distributed systems and performance computing. Bandish has over a decade of experience building systems for machine learning and enterprise applications. He enjoys spending time with friends and family, cooking and watching Star Trek on repeat for inspiration.
Bandish Shah is an Engineering Manager at MosaicML, working to bridge efficient deep learning with large scale distributed systems and performance computing. Bandish has over a decade of experience building systems for machine learning and enterprise applications. He enjoys spending time with friends and family, cooking and watching Star Trek on repeat for inspiration.
 Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
The quest to deploy autonomous robots within Amazon fulfillment centers
Company is testing a new class of robots that use artificial intelligence and computer vision to move freely throughout facilities.Read More
Lessons learned from 10 years of DynamoDB
Prioritizing predictability over efficiency, adapting data partitioning to traffic, and continuous verification are a few of the principles that help ensure stability, availability, and efficiency.Read More
Create synthetic data for computer vision pipelines on AWS
Collecting and annotating image data is one of the most resource-intensive tasks on any computer vision project. It can take months at a time to fully collect, analyze, and experiment with image streams at the level you need in order to compete in the current marketplace. Even after you’ve successfully collected data, you still have a constant stream of annotation errors, poorly framed images, small amounts of meaningful data in a sea of unwanted captures, and more. These major bottlenecks are why synthetic data creation needs to be in the toolkit of every modern engineer. By creating 3D representations of the objects we want to model, we can rapidly prototype algorithms while concurrently collecting live data.
In this post, I walk you through an example of using the open-source animation library Blender to build an end-to-end synthetic data pipeline, using chicken nuggets as an example. The following image is an illustration of the data generated in this blog post.
What is Blender?
Blender is an open-source 3D graphics software primarily used in animation, 3D printing, and virtual reality. It has an extremely comprehensive rigging, animation, and simulation suite that allows the creation of 3D worlds for nearly any computer vision use case. It also has an extremely active support community where most, if not all, user errors are solved.
Set up your local environment
We install two versions of Blender: one on a local machine with access to a GUI, and the other on an Amazon Elastic Compute Cloud (Amazon EC2) P2 instance.
Install Blender and ZPY
Install Blender from the Blender website.
Then complete the following steps:
- Run the following commands:
- Copy the necessary Python headers into the Blender version of Python so that you can use other non-Blender libraries:
- Override your Blender version and force installs so that the Blender-provided Python works:
- Download
zpyand install from source: - Change the NumPy version to
>=1.19.4andscikit-image>=0.18.1to make the install on3.10.2possible and so you don’t get any overwrites: - To ensure compatibility with Blender 3.2, go into
zpy/render.pyand comment out the following two lines (for more information, refer to Blender 3.0 Failure #54): - Next, install the
zpylibrary: - Download the add-ons version of
zpyfrom the GitHub repo so you can actively run your instance: - Save a file called
enable_zpy_addon.pyin your/homedirectory and run the enablement command, because you don’t have a GUI to activate it:If
zpy-addondoesn’t install (for whatever reason), you can install it via the GUI. - In Blender, on the Edit menu, choose Preferences.
- Choose Add-ons in the navigation pane and activate
zpy.
You should see a page open in the GUI, and you’ll be able to choose ZPY. This will confirm that Blender is loaded.
AliceVision and Meshroom
Install AliceVision and Meshrooom from their respective GitHub repos:
FFmpeg
Your system should have ffmpeg, but if it doesn’t, you’ll need to download it.
Instant Meshes
You can either compile the library yourself or download the available pre-compiled binaries (which is what I did) for Instant Meshes.
Set up your AWS environment
Now we set up the AWS environment on an EC2 instance. We repeat the steps from the previous section, but only for Blender and zpy.
- On the Amazon EC2 console, choose Launch instances.
- Choose your AMI.There are a few options from here. We can either choose a standard Ubuntu image, pick a GPU instance, and then manually install the drivers and get everything set up, or we can take the easy route and start with a preconfigured Deep Learning AMI and only worry about installing Blender.For this post, I use the second option, and choose the latest version of the Deep Learning AMI for Ubuntu (Deep Learning AMI (Ubuntu 18.04) Version 61.0).
- For Instance type¸ choose p2.xlarge.
- If you don’t have a key pair, create a new one or choose an existing one.
- For this post, use the default settings for network and storage.
- Choose Launch instances.
- Choose Connect and find the instructions to log in to our instance from SSH on the SSH client tab.
- Connect with SSH:
ssh -i "your-pem" ubuntu@IPADDRESS.YOUR-REGION.compute.amazonaws.com
Once you’ve connected to your instance, follow the same installation steps from the previous section to install Blender and zpy.
Data collection: 3D scanning our nugget
For this step, I use an iPhone to record a 360-degree video at a fairly slow pace around my nugget. I stuck a chicken nugget onto a toothpick and taped the toothpick to my countertop, and simply rotated my camera around the nugget to get as many angles as I could. The faster you film, the less likely you get good images to work with depending on the shutter speed.
After I finished filming, I sent the video to my email and extracted the video to a local drive. From there, I used ffmepg to chop the video into frames to make Meshroom ingestion much easier:
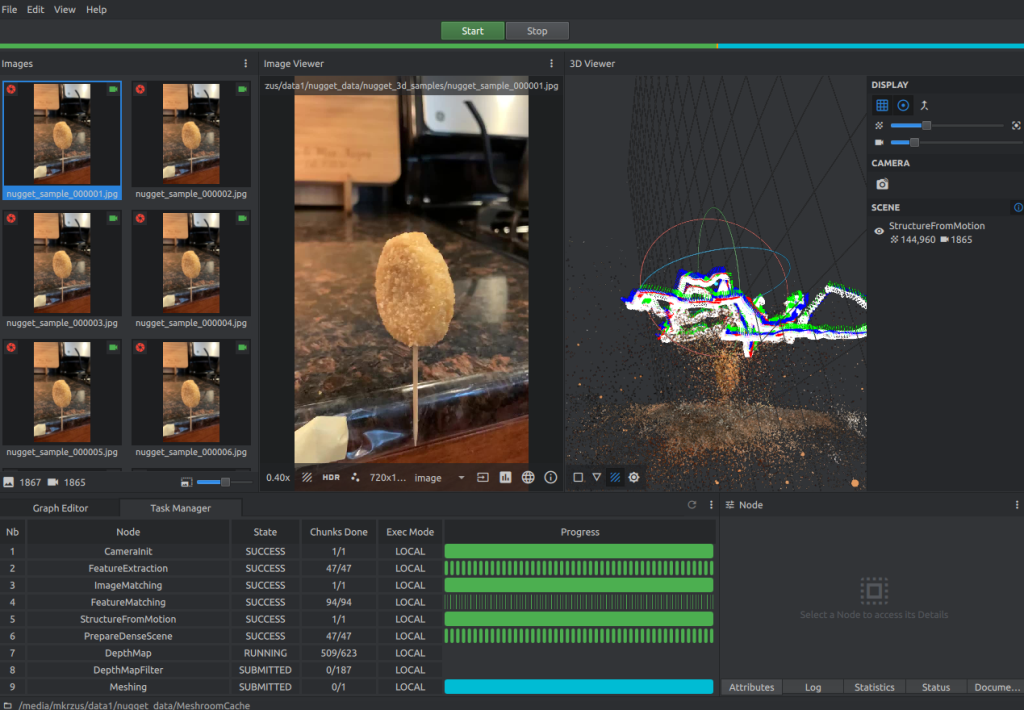
Open Meshroom and use the GUI to drag the nugget_images folder to the pane on the left. From there, choose Start and wait a few hours (or less) depending on the length of the video and if you have a CUDA-enabled machine.
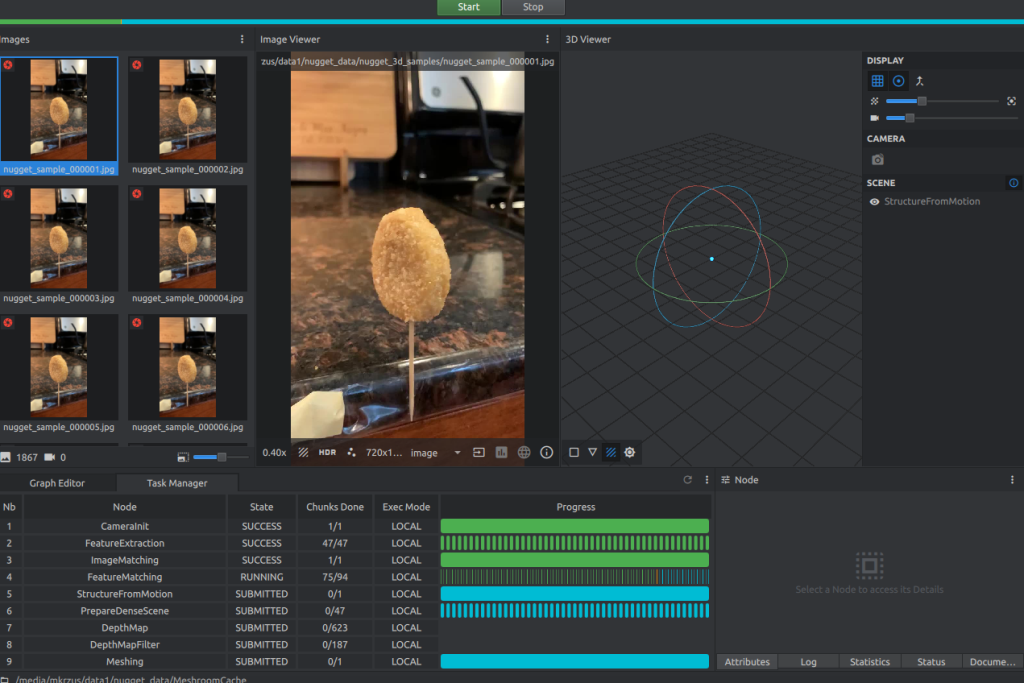
You should see something like the following screenshot when it’s almost complete.
Data collection: Blender manipulation
When our Meshroom reconstruction is complete, complete the following steps:
- Open the Blender GUI and on the File menu, choose Import, then choose Wavefront (.obj) to your created texture file from Meshroom.
The file should be saved inpath/to/MeshroomCache/Texturing/uuid-string/texturedMesh.obj. - Load the file and observe the monstrosity that is your 3D object.
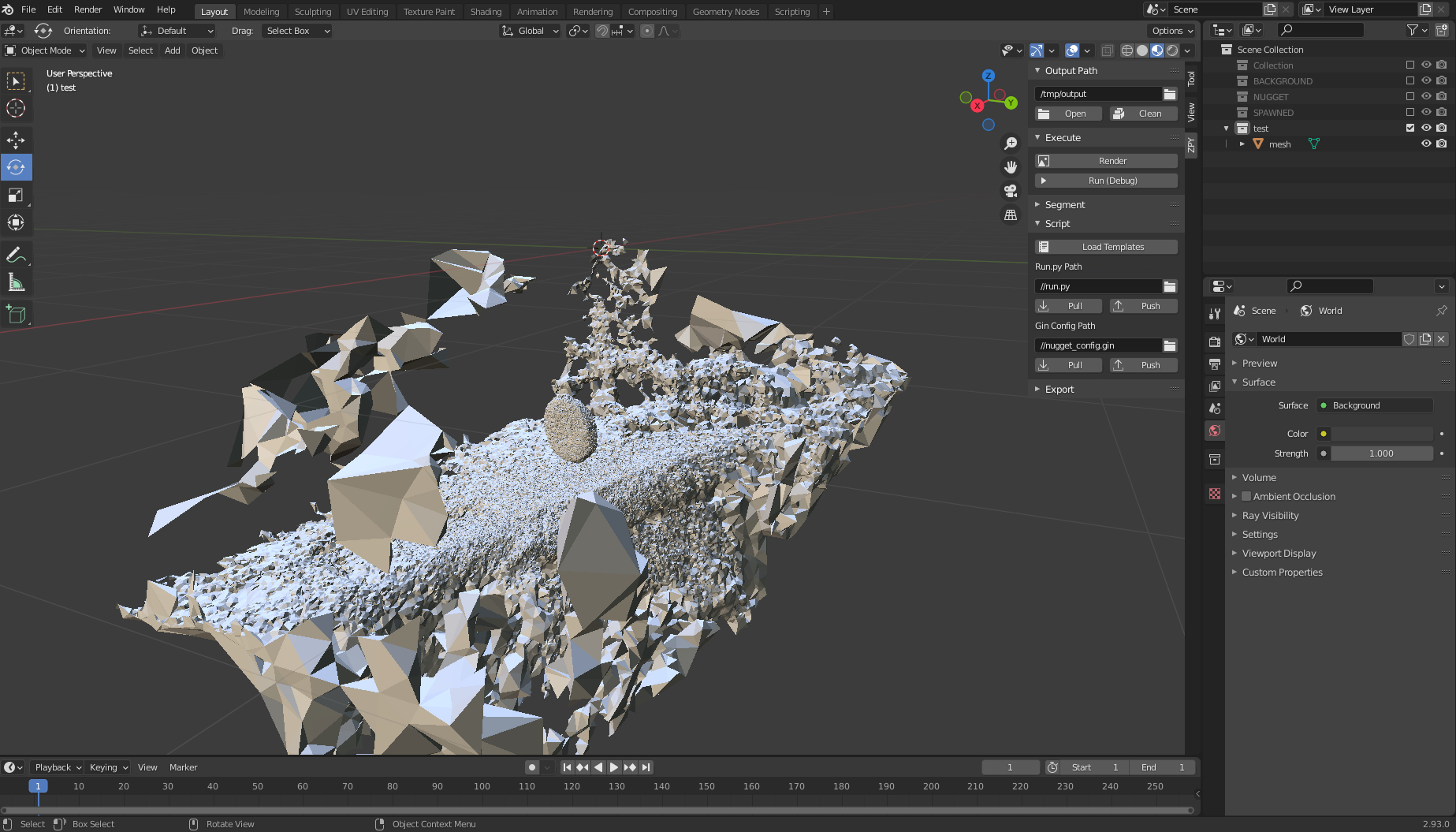
Here is where it gets a bit tricky. - Scroll to the top right side and choose the Wireframe icon in Viewport Shading.
- Select your object on the right viewport and make sure it’s highlighted, scroll over to the main layout viewport, and either press Tab or manually choose Edit Mode.
- Next, maneuver the viewport in such a way as to allow yourself to be able to see your object with as little as possible behind it. You’ll have to do this a few times to really get it correct.
- Click and drag a bounding box over the object so that only the nugget is highlighted.
- After it’s highlighted like in the following screenshot, we separate our nugget from the 3D mass by left-clicking, choosing Separate, and then Selection.
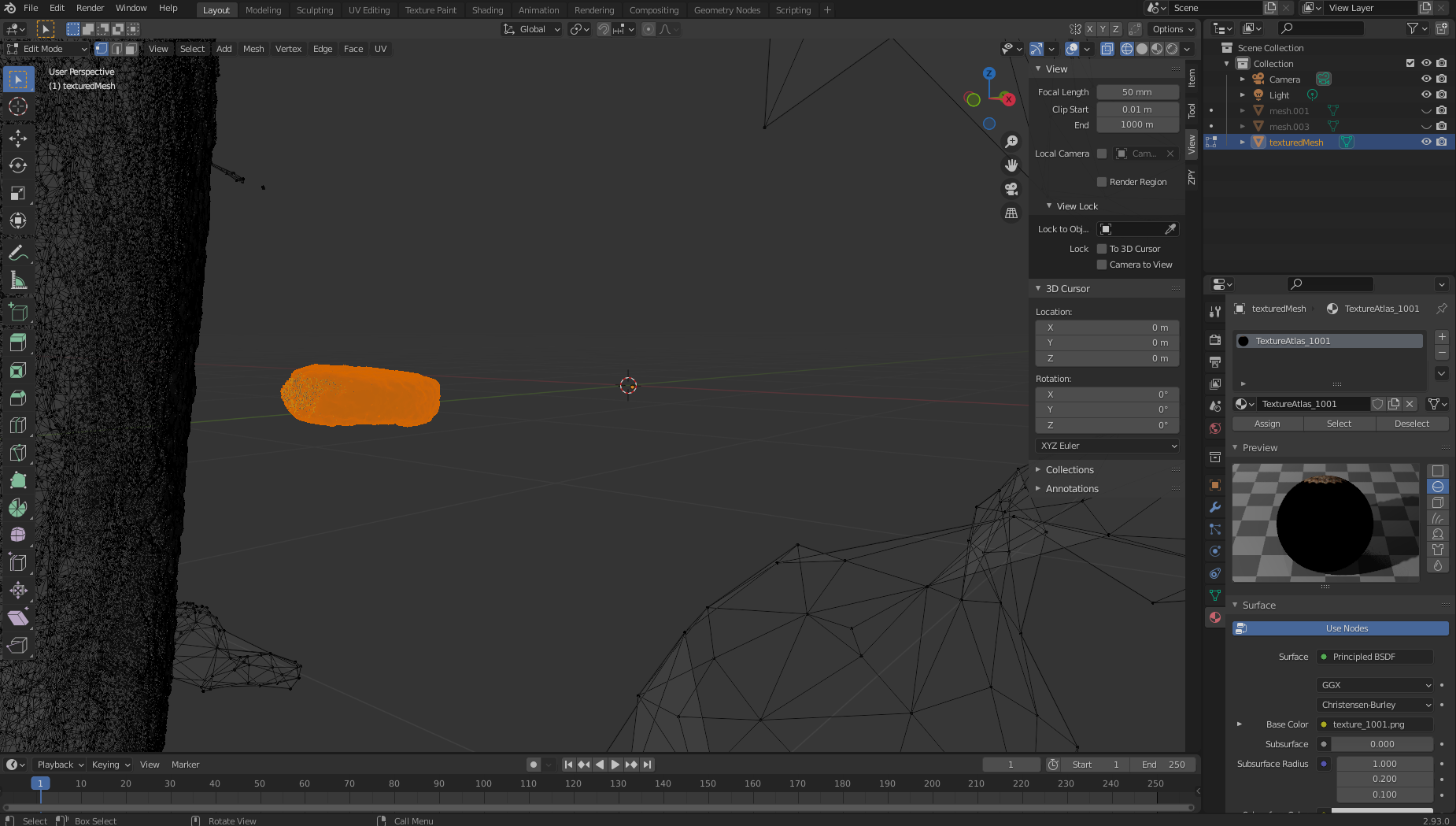
We now move over to the right, where we should see two textured objects:texturedMeshandtexturedMesh.001. - Our new object should be
texturedMesh.001, so we choosetexturedMeshand choose Delete to remove the unwanted mass.
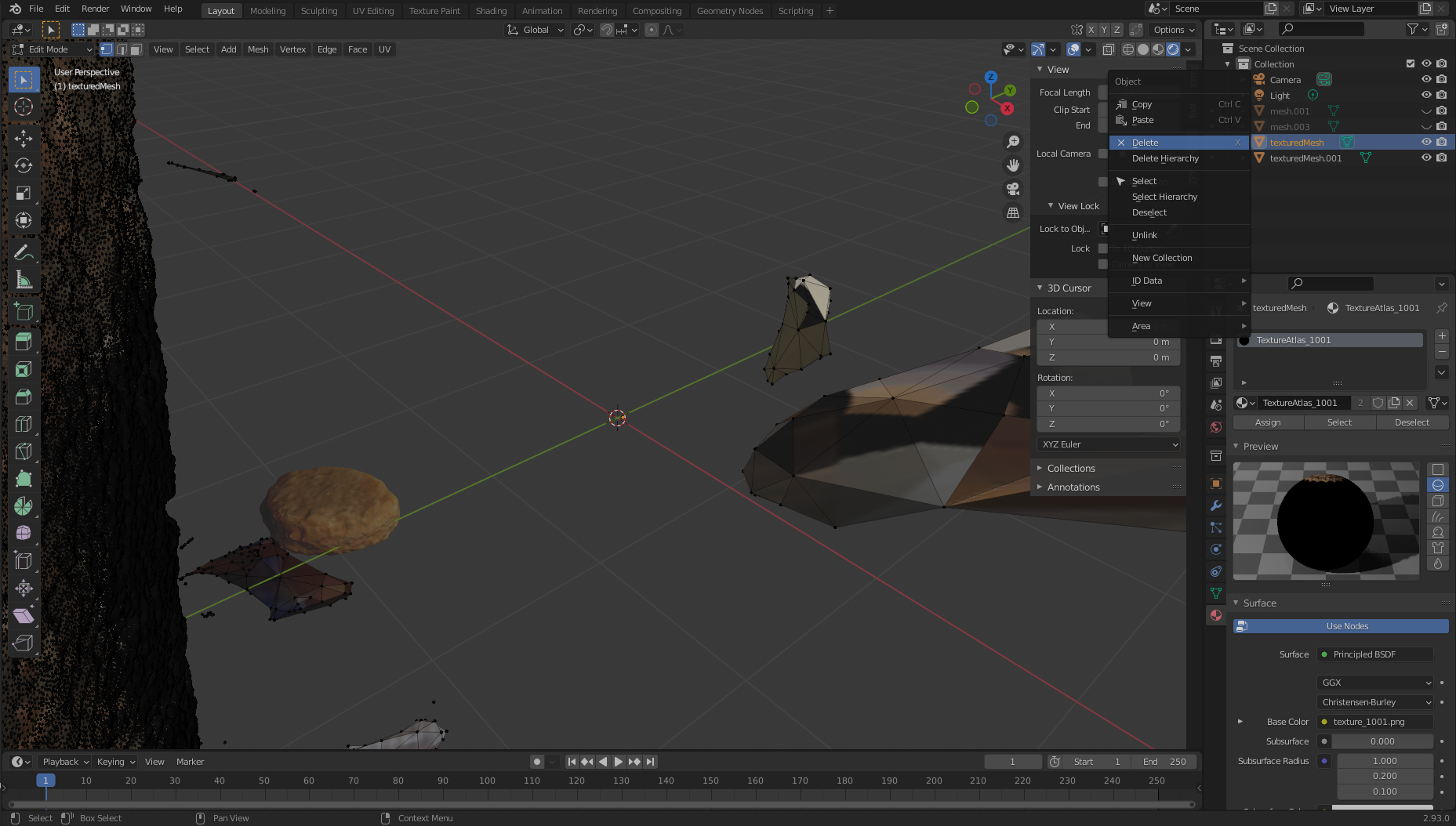
- Choose the object (
texturedMesh.001) on the right, move to our viewer, and choose the object, Set Origin, and Origin to Center of Mass.
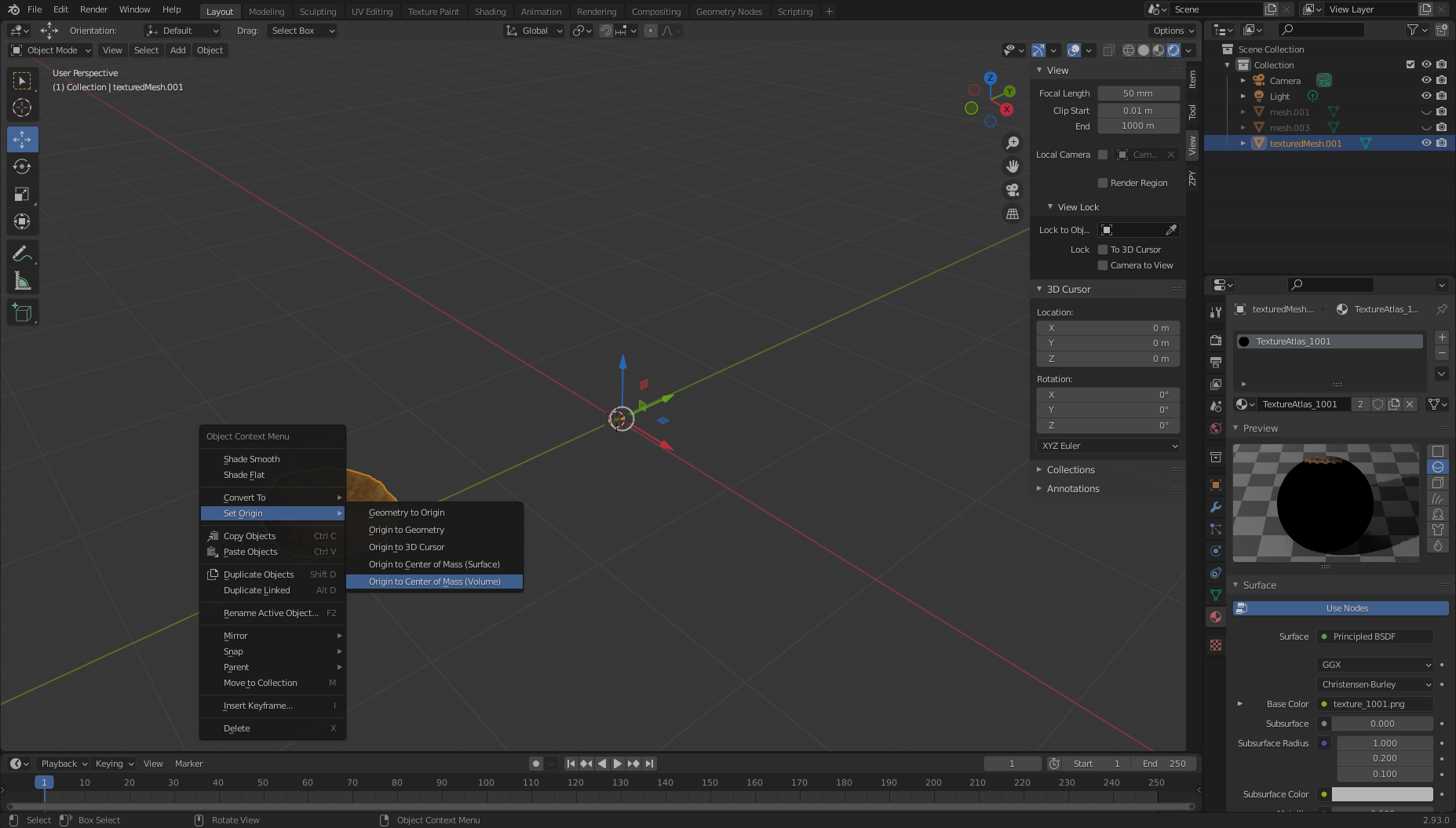
Now, if we want, we can move our object to the center of the viewport (or simply leave it where it is) and view it in all its glory. Notice the large black hole where we didn’t really get good film coverage from! We’re going to need to correct for this.
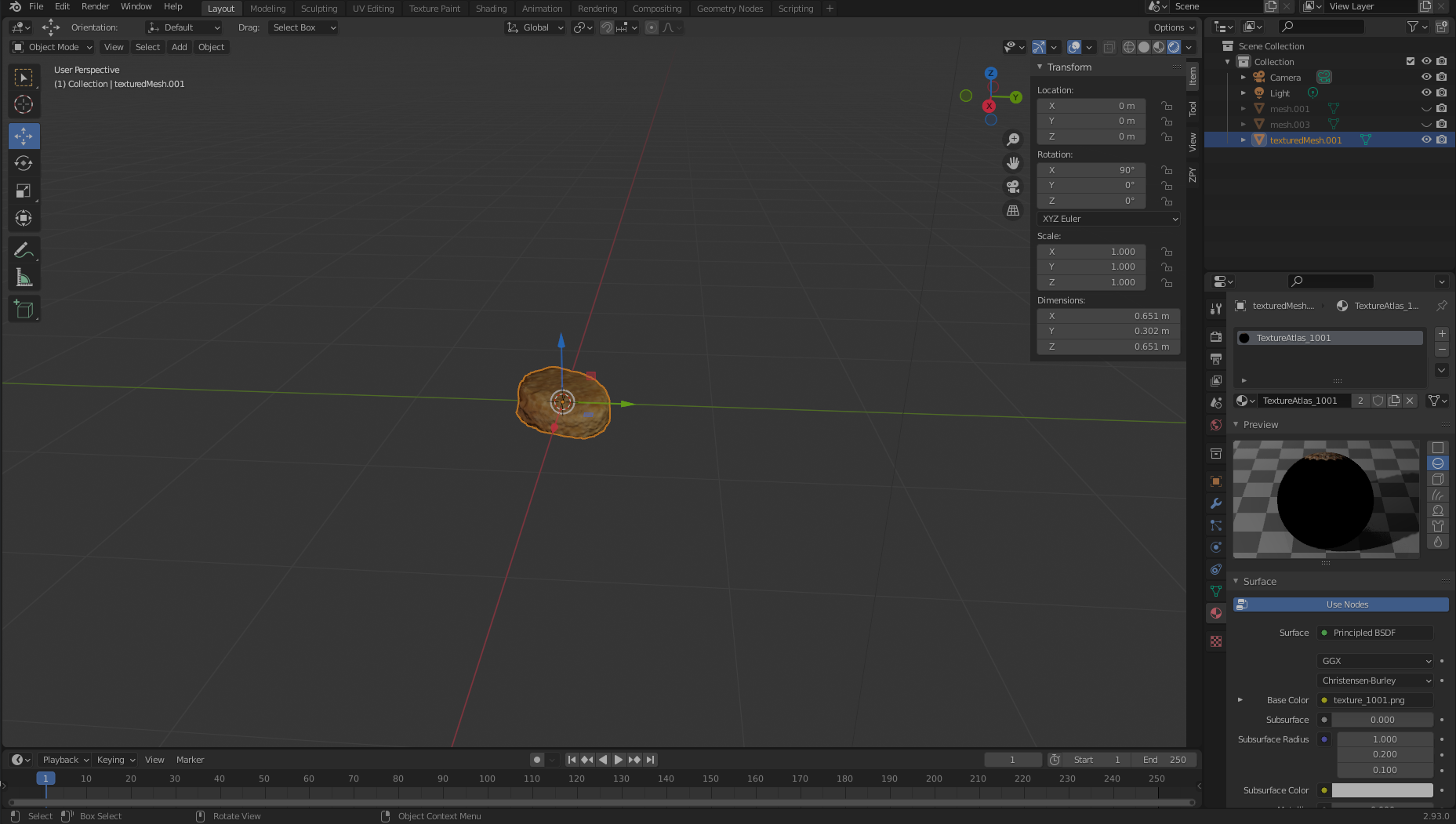
To clean our object of any pixel impurities, we export our object to an .obj file. Make sure to choose Selection Only when exporting.
Data collection: Clean up with Instant Meshes
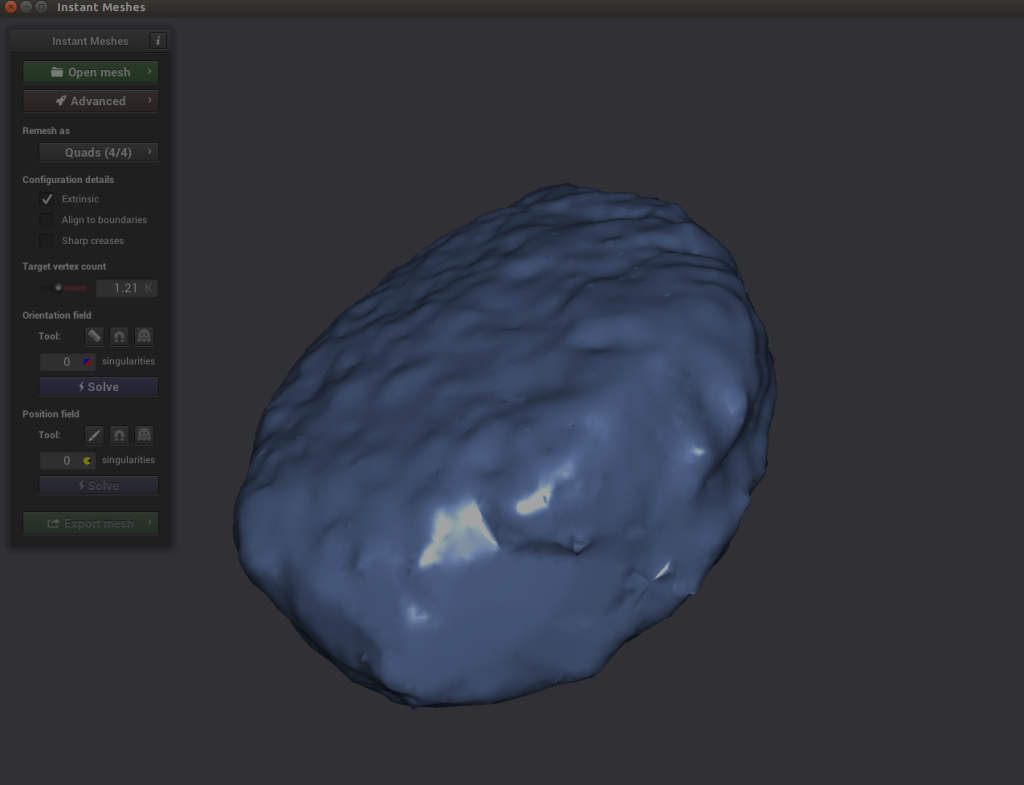
Now we have two problems: our image has a pixel gap creating by our poor filming that we need to clean up, and our image is incredibly dense (which will make generating images extremely time-consuming). To tackle both issues, we need to use a software called Instant Meshes to extrapolate our pixel surface to cover the black hole and also to shrink the total object to a smaller, less dense size.
- Open Instant Meshes and load our recently saved
nugget.objfile.
- Under Orientation field, choose Solve.
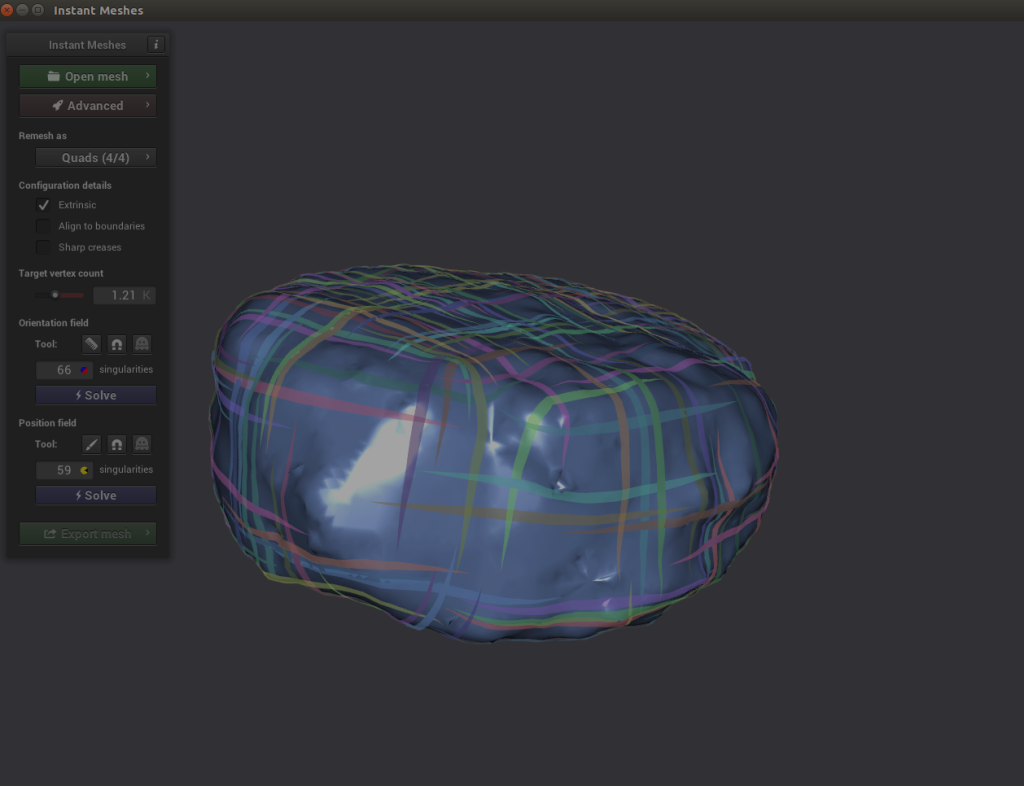
- Under Position field, choose Solve.
 Here’s where it gets interesting. If you explore your object and notice that the criss-cross lines of the Position solver look disjointed, you can choose the comb icon under Orientation field and redraw the lines properly.
Here’s where it gets interesting. If you explore your object and notice that the criss-cross lines of the Position solver look disjointed, you can choose the comb icon under Orientation field and redraw the lines properly. - Choose Solve for both Orientation field and Position field.
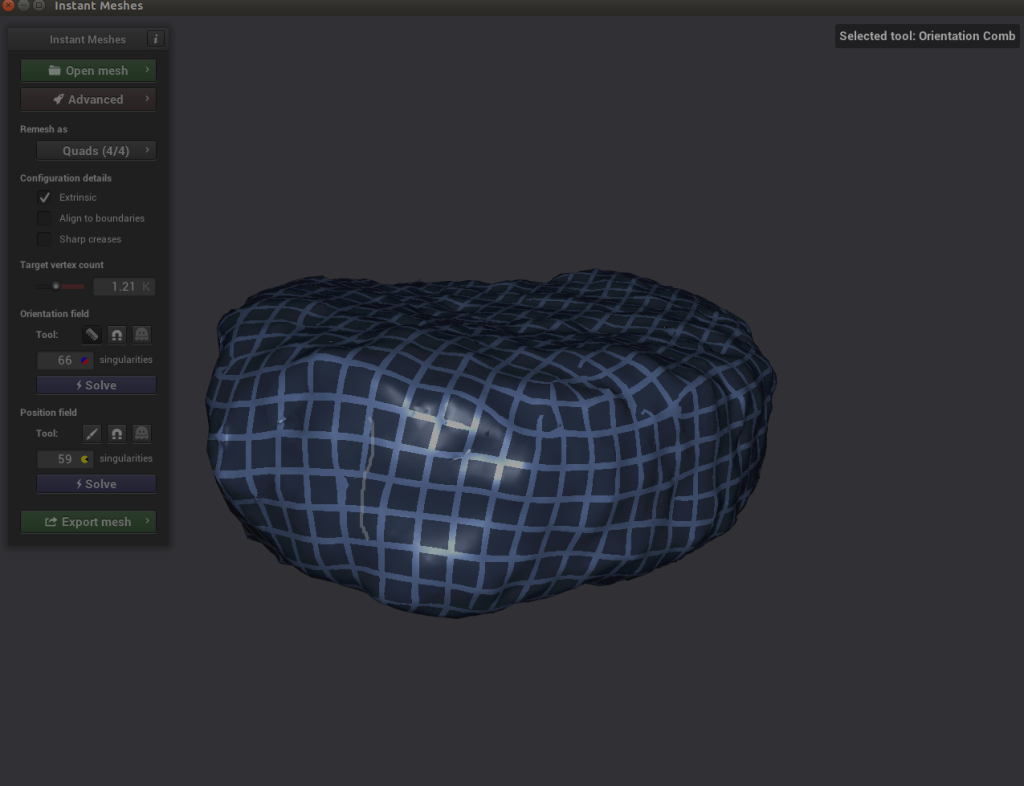
- If everything looks good, export the mesh, name it something like
nugget_refined.obj, and save it to disk.
Data collection: Shake and bake!
Because our low-poly mesh doesn’t have any image texture associated with it and our high-poly mesh does, we either need to bake the high-poly texture onto the low-poly mesh, or create a new texture and assign it to our object. For sake of simplicity, we’re going to create an image texture from scratch and apply that to our nugget.
I used Google image search for nuggets and other fried things in order to get a high-res image of the surface of a fried object. I found a super high-res image of a fried cheese curd and made a new image full of the fried texture.

With this image, I’m ready to complete the following steps:
- Open Blender and load the new
nugget_refined.objthe same way you loaded your initial object: on the File menu, choose Import, Wavefront (.obj), and choose thenugget_refined.objfile. - Next, go to the Shading tab.
At the bottom you should notice two boxes with the titles Principled BDSF and Material Output. - On the Add menu, choose Texture and Image Texture.
An Image Texture box should appear. - Choose Open Image and load your fried texture image.
- Drag your mouse between Color in the Image Texture box and Base Color in the Principled BDSF box.
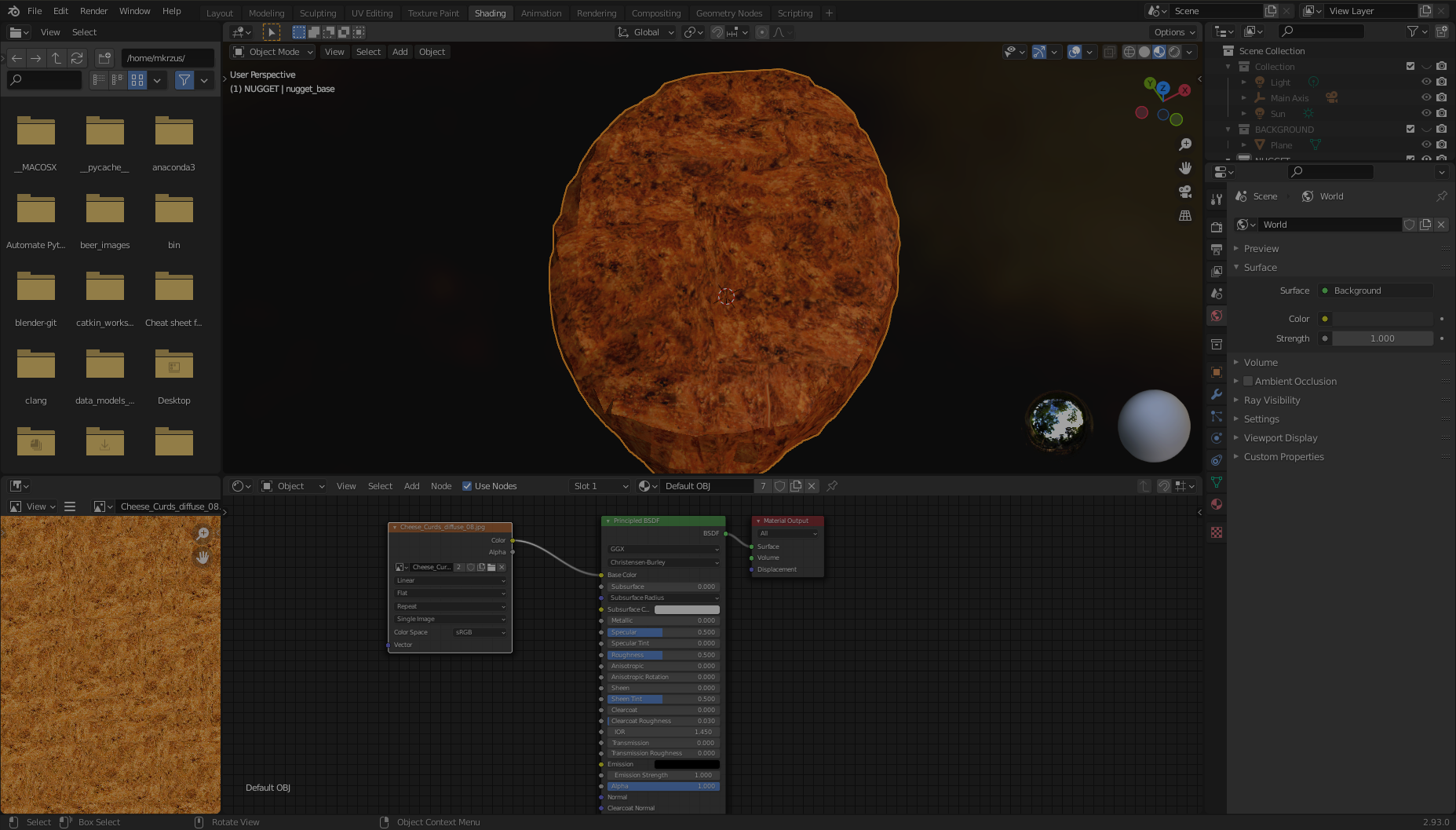
Now your nugget should be good to go!
Data collection: Create Blender environment variables
Now that we have our base nugget object, we need to create a few collections and environment variables to help us in our process.
- Left-click on the hand scene area and choose New Collection.
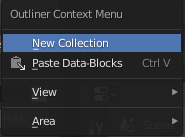
- Create the following collections: BACKGROUND, NUGGET, and SPAWNED.
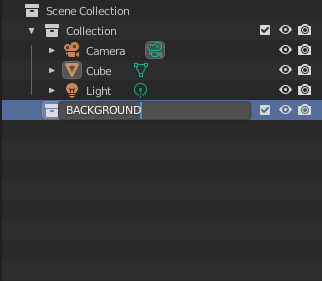
- Drag the nugget to the NUGGET collection and rename it nugget_base.
Data collection: Create a plane
We’re going to create a background object from which our nuggets will be generated when we’re rendering images. In a real-world use case, this plane is where our nuggets are placed, such as a tray or bin.
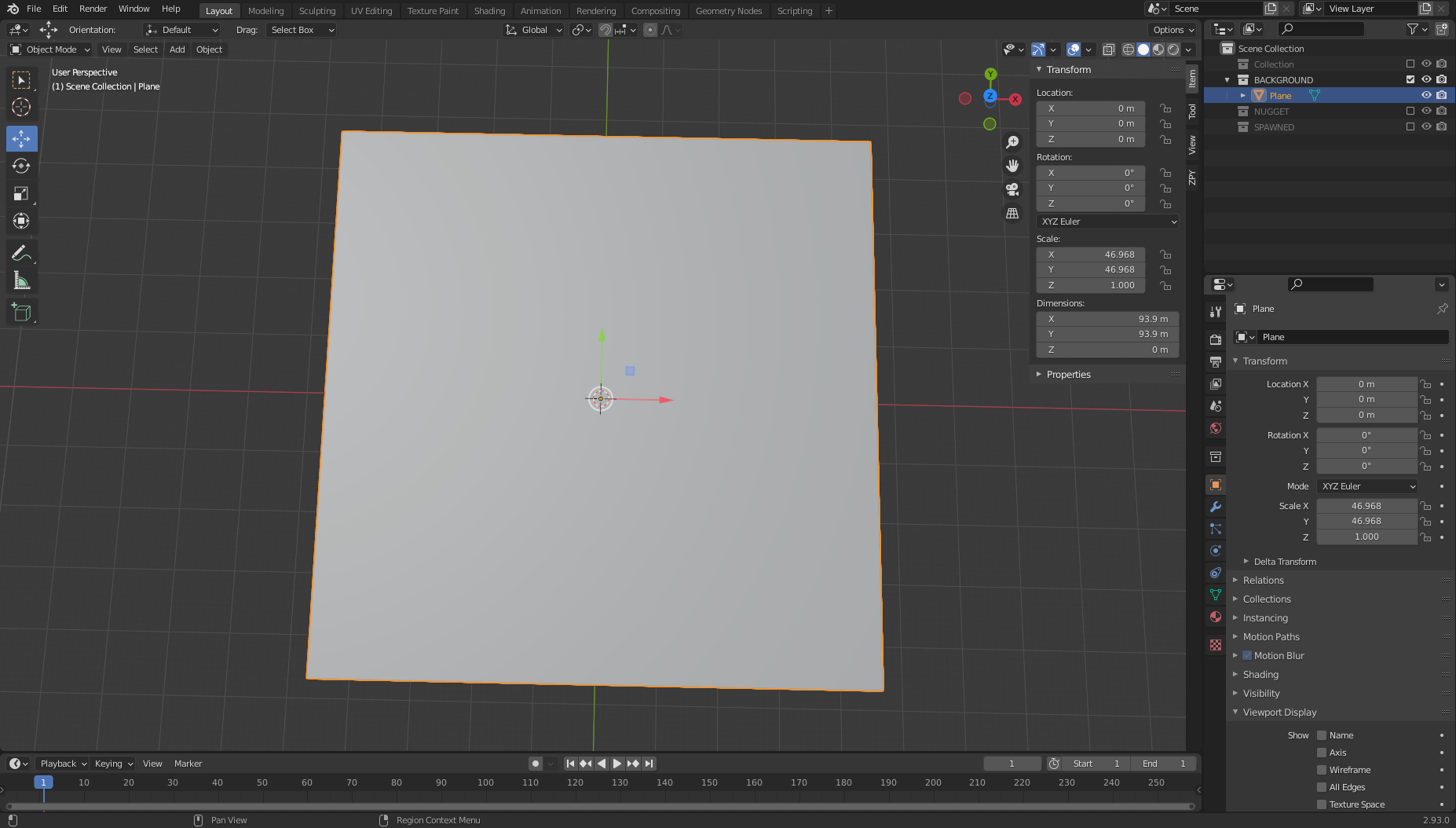
- On the Add menu, choose Mesh and then Plane.
From here, we move to the right side of the page and find the orange box (Object Properties). - In the Transform pane, for XYZ Euler, set X to 46.968, Y to 46.968, and Z to 1.0.
- For both Location and Rotation, set X, Y, and Z to 0.
Data collection: Set the camera and axis
Next, we’re going to set our cameras up correctly so that we can generate images.
- On the Add menu, choose Empty and Plain Axis.
- Name the object Main Axis.
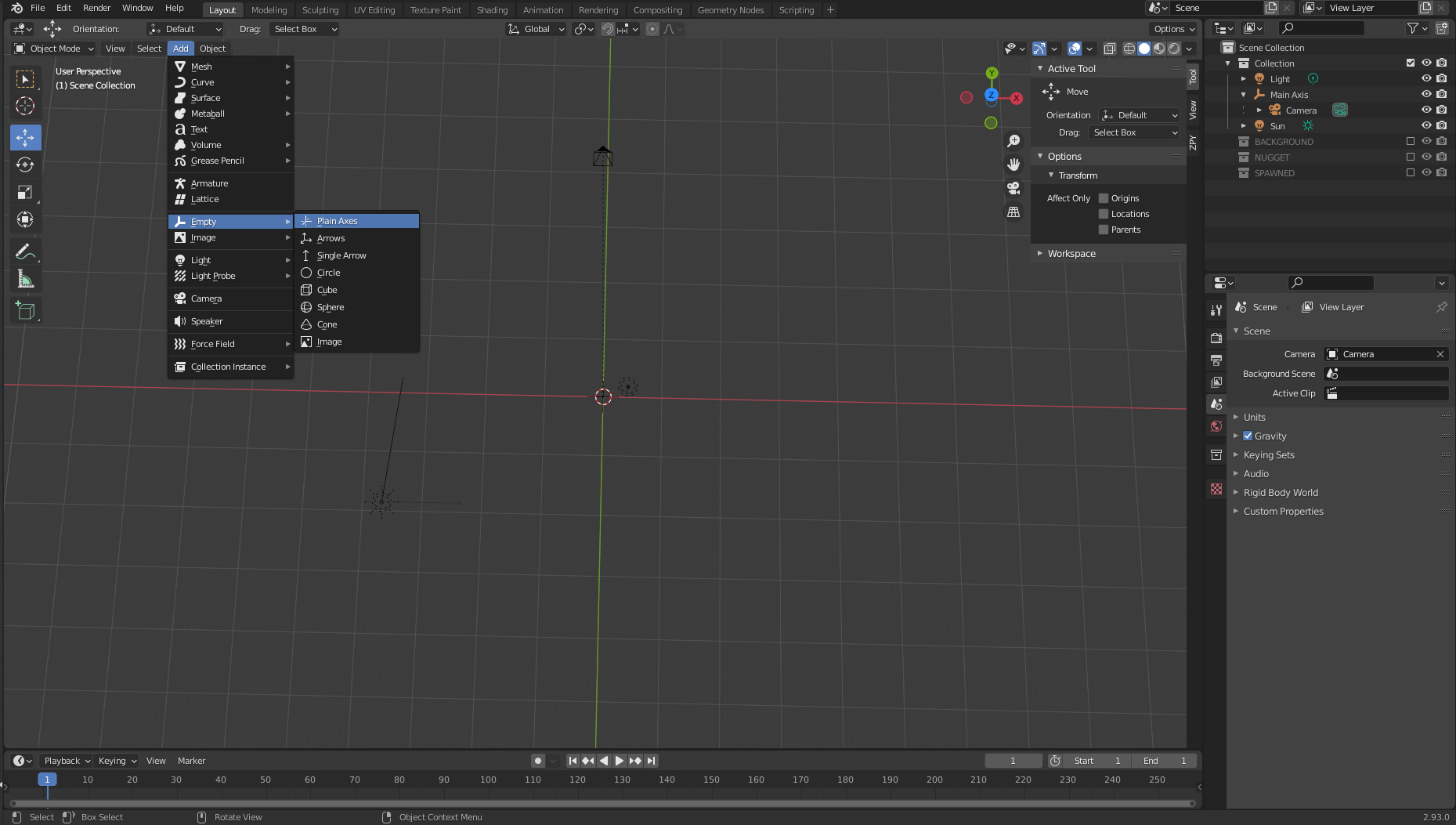
- Make sure our axis is 0 for all the variables (so it’s directly in the center).
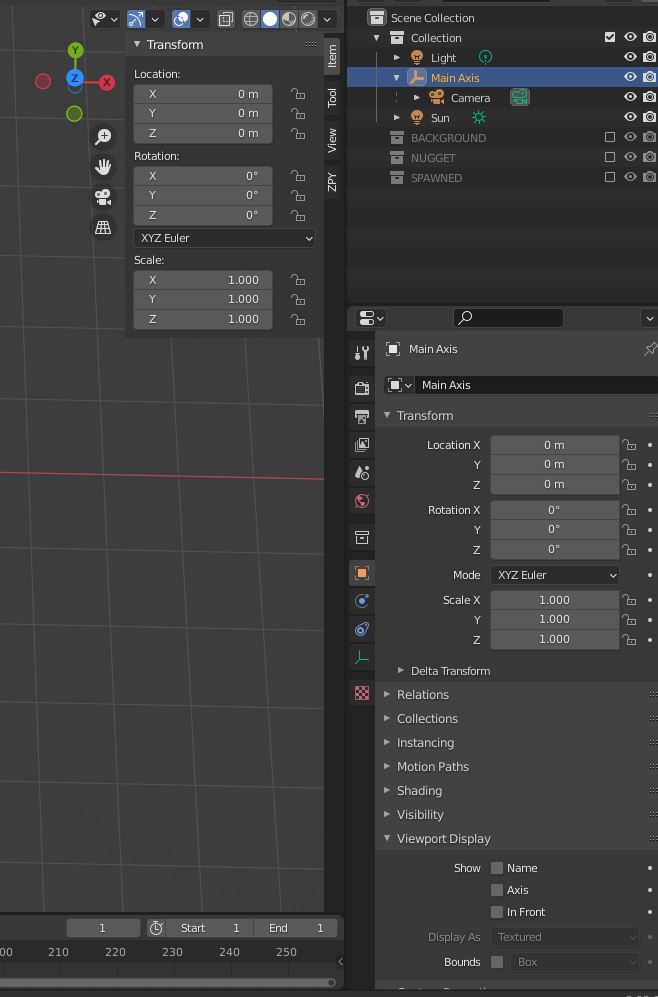
- If you have a camera already created, drag that camera to under Main Axis.
- Choose Item and Transform.
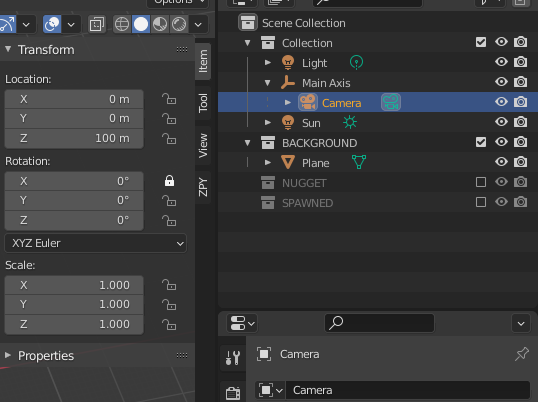
- For Location, set X to 0, Y to 0, and Z to 100.
Data collection: Here comes the sun
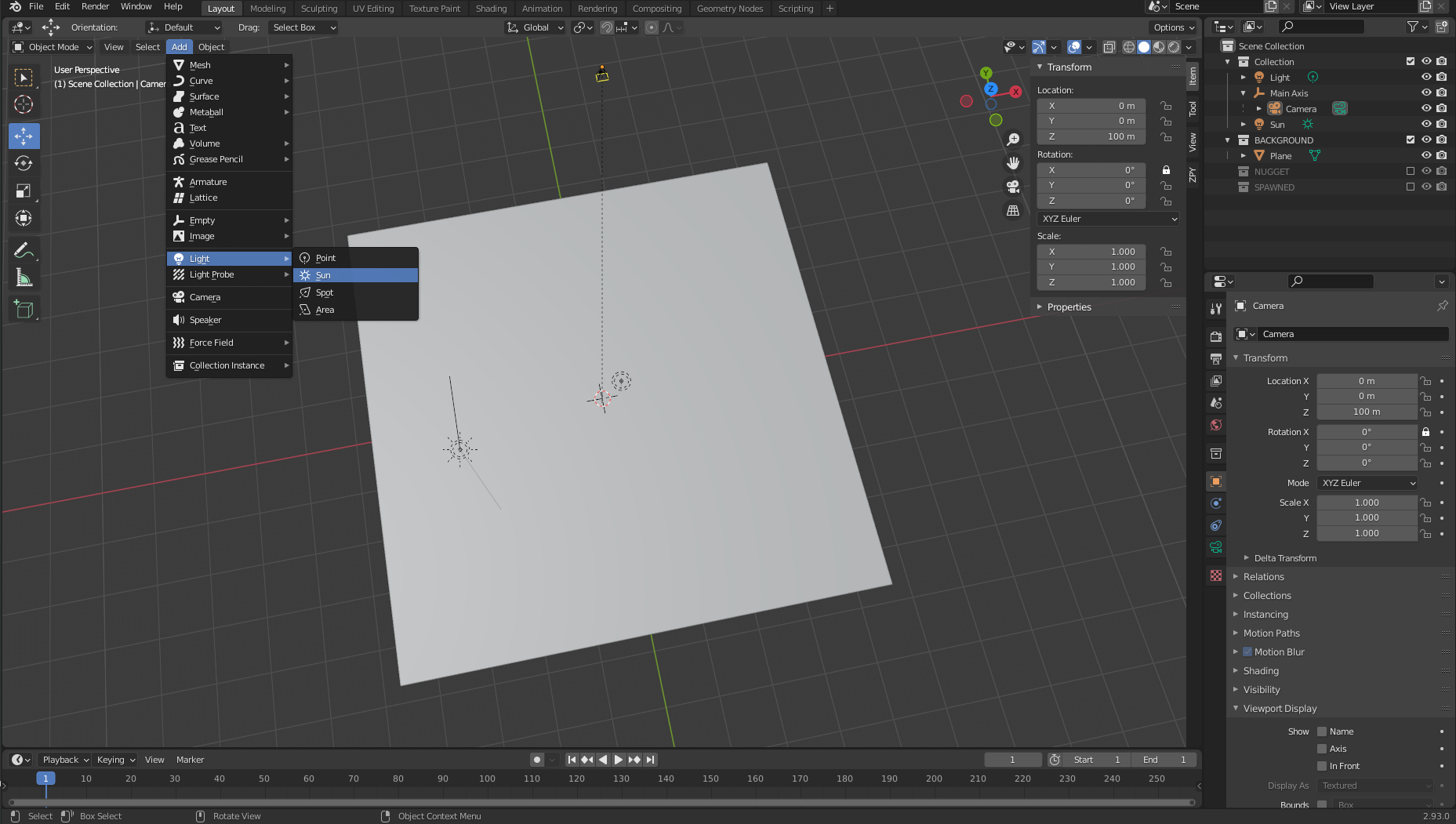
Next, we add a Sun object.
- On the Add menu, choose Light and Sun.
The location of this object doesn’t necessarily matter as long as it’s centered somewhere over the plane object we’ve set. - Choose the green lightbulb icon in the bottom right pane (Object Data Properties) and set the strength to 5.0.
- Repeat the same procedure to add a Light object and put it in a random spot over the plane.
Data collection: Download random backgrounds
To inject randomness into our images, we download as many random textures from texture.ninja as we can (for example, bricks). Download to a folder within your workspace called random_textures. I downloaded about 50.

Generate images
Now we get to the fun stuff: generating images.
Image generation pipeline: Object3D and DensityController
Let’s start with some code definitions:
We first define a basic container Class with some important properties. This class mainly exists to allow us to create a BVH tree (a way to represent our nugget object in 3D space), where we’ll need to use the BVHTree.overlap method to see if two independent generated nugget objects are overlapping in our 3D space. More on this later.
The second piece of code is our density controller. This serves as a way to bound ourselves to the rules of reality and not the 3D world. For example, in the 3D Blender world, objects in Blender can exist inside each other; however, unless someone is performing some strange science on our chicken nuggets, we want to make sure no two nuggets are overlapping by a degree that makes it visually unrealistic.
We use our Plane object to spawn a set of bounded invisible cubes that can be queried at any given time to see if the space is occupied or not.
See the following code:
In the following snippet, we select the nugget and create a bounding cube around that nugget. This cube represents the size of a single pseudo-voxel of our psuedo-kdtree object. We need to use the bpy.context.view_layer.update() function because when this code is being run from inside a function or script vs. the blender-gui, it seems that the view_layer isn’t automatically updated.
Next, we slightly update our cube object so that its length and width are square, as opposed to the natural size of the nugget it was created from:
Now we use our updated cube object to create a plane that can volumetrically hold num_objects amount of nuggets:
We take our plane object and create a giant cube of the same length and width as our plane, with the height of our nugget cube, CUBE1:
From here, we want to create voxels from our cube. We take the number of cubes we would to fit num_objects and then cut them from our cube object. We look for the upward-facing mesh-face of our cube, and then pick that face to make our cuts. See the following code:
Lastly, we calculate the center of the top-face of each cut we’ve made from our big cube and create actual cubes from those cuts. Each of these newly created cubes represents a single piece of space to spawn or move nuggets around our plane. See the following code:
Next, we develop an algorithm that understands which cubes are occupied at any given time, finds which objects overlap with each other, and moves overlapping objects separately into unoccupied space. We won’t be able get rid of all overlaps entirely, but we can make it look real enough.



See the following code:
Image generation pipeline: Cool runnings
In this section, we break down what our run function is doing.
We initialize our DensityController and create something called a saver using the ImageSaver from zpy. This allows us to seemlessly save our rendered images to any location of our choosing. We then add our nugget category (and if we had more categories, we would add them here). See the following code:
Next, we need to make a source object from which we spawn copy nuggets from; in this case, it’s the nugget_base that we created:
Now that we have our base nugget, we’re going to save the world poses (locations) of all the other objects so that after each rendering run, we can use these saved poses to reinitialize a render. We also move our base nugget completely out of the way so that the kdtree doesn’t sense a space being occupied. Finally, we initialize our kdtree-cube objects. See the following code:
The following code collects our downloaded backgrounds from texture.ninja, where they’ll be used to be randomly projected onto our plane:
Here is where the magic begins. We first regenerate out kdtree-cubes for this run so that we can start fresh:
We use our density controller to generate a random spawn point for our nugget, create a copy of nugget_base, and move the copy to the randomly generated spawn point:
Next, we randomly jitter the size of the nugget, the mesh of the nugget, and the scale of the nugget so that no two nuggets look the same:
We turn our nugget copy into an Object3D object where we use the BVH tree functionality to see if our plane intersects or overlaps any face or vertices on our nugget copy. If we find an overlap with the plane, we simply move the nugget upwards on its Z axis. See the following code:
Now that all nuggets are created, we use our DensityController to move nuggets around so that we have a minimum number of overlaps, and those that do overlap aren’t hideous looking:
In the following code: we restore the Camera and Main Axis poses and randomly select how far the camera is to the Plane object:
We decide how randomly we want the camera to travel along the Main Axis. Depending on if we want it to be mainly overhead or if we care very much about the angle from which it sees the board, we can adjust the top_down_mostly parameter depending on how well our training model is picking up the signal of “What even is a nugget anyway?”
In the following code, we do the same thing with the Sun object, and randomly pick a texture for the Plane object:
Finally, we hide all our objects that we don’t want to be rendered: the nugget_base and our entire cube structure:
Lastly, we use zpy to render our scene, save our images, and then save our annotations. For this post, I made some small changes to the zpy annotation library for my specific use case (annotation per image instead of one file per project), but you shouldn’t have to for the purpose of this post).
Voila!
Run the headless creation script
Now that we have our saved Blender file, our created nugget, and all the supporting information, let’s zip our working directory and either scp it to our GPU machine or uploaded it via Amazon Simple Storage Service (Amazon S3) or another service:
Log in to your EC2 instance and decompress your working_blender folder:
Now we create our data in all its glory:
The script should run for 500 images, and the data is saved in /path/to/working_blender_dir/nugget_data.
The following code shows a single annotation created with our dataset:



Conclusion
In this post, I demonstrated how to use the open-source animation library Blender to build an end-to-end synthetic data pipeline.
There are a ton of cool things you can do in Blender and AWS; hopefully this demo can help you on your next data-starved project!
References
- Easily Clean Your 3D Scans (blender)
- Instant Meshes: A free quad-based autoretopology program
- How to 3D Scan an Object for Synthetic Data
- Generate synthetic data with Blender and Python
About the Author
 Matt Krzus is a Sr. Data Scientist at Amazon Web Service in the AWS Professional Services group
Matt Krzus is a Sr. Data Scientist at Amazon Web Service in the AWS Professional Services group
Enable CI/CD of multi-Region Amazon SageMaker endpoints
Amazon SageMaker and SageMaker inference endpoints provide a capability of training and deploying your AI and machine learning (ML) workloads. With inference endpoints, you can deploy your models for real-time or batch inference. The endpoints support various types of ML models hosted using AWS Deep Learning Containers or your own containers with custom AI/ML algorithms. When you launch SageMaker inference endpoints with multiple instances, SageMaker distributes the instances across multiple Availability Zones (in a single Region) for high availability.
In some cases, however, to ensure lowest possible latency for customers in diverse geographical areas, you may require deploying inference endpoints in multiple Regions. Multi-Regional deployment of SageMaker endpoints and other related application and infrastructure components can also be part of a disaster recovery strategy for your mission-critical workloads aimed at mitigating the risk of a Regional failure.
SageMaker Projects implements a set of pre-built MLOps templates that can help manage endpoint deployments. In this post, we show how you can extend an MLOps SageMaker Projects pipeline to enable multi-Regional deployment of your AI/ML inference endpoints.
Solution overview
SageMaker Projects deploys both training and deployment MLOPs pipelines; you can use these to train a model and deploy it using an inference endpoint. To reduce complexity and cost of a multi-Region solution, we assume that you train the model in a single Region and deploy inference endpoints in two or more Regions.
This post presents a solution that slightly modifies a SageMaker project template to support multi-Region deployment. To better illustrate the changes, the following figure displays both a standard MLOps pipeline created automatically by SageMaker (Steps 1-5) as well as changes required to extend it to a secondary Region (Steps 6-11).

The SageMaker Projects template automatically deploys a boilerplate MLOps solution, which includes the following components:
- Amazon EventBridge monitors AWS CodeCommit repositories for changes and starts a run of AWS CodePipeline if a code commit is detected.
- If there is a code change, AWS CodeBuild orchestrates the model training using SageMaker training jobs.
- After the training job is complete, the SageMaker model registry registers and catalogs the trained model.
- To prepare for the deployment stage, CodeBuild extends the default AWS CloudFormation template configuration files with parameters of an approved model from the model registry.
- Finally, CodePipeline runs the CloudFormation templates to deploy the approved model to the staging and production inference endpoints.
The following additional steps modify the MLOps Projects template to enable the AI/ML model deployment in the secondary Region:
- A replica of the Amazon Simple Storage Service (Amazon S3) bucket in the primary Region storing model artifacts is required in the secondary Region.
- The CodePipeline template is extended with more stages to run a cross-Region deployment of the approved model.
- As part of the cross-Region deployment process, the CodePipeline template uses a new CloudFormation template to deploy the inference endpoint in a secondary Region. The CloudFormation template deploys the model from the model artifacts from the S3 replica bucket created in Step 6.
9–11 optionally, create resources in Amazon Route 53, Amazon API Gateway, and AWS Lambda to route application traffic to inference endpoints in the secondary Region.
Prerequisites
Create a SageMaker project in your primary Region (us-east-2 in this post). Complete the steps in Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines until the section Modifying the sample code for a custom use case.
Update your pipeline in CodePipeline
In this section, we discuss how to add manual CodePipeline approval and cross-Region model deployment stages to your existing pipeline created for you by SageMaker.
- On the CodePipeline console in your primary Region, find and select the pipeline containing your project name and ending with deploy. This pipeline has already been created for you by SageMaker Projects. You modify this pipeline to add AI/ML endpoint deployment stages for the secondary Region.
- Choose Edit.
- Choose Add stage.
- For Stage name, enter
SecondaryRegionDeployment. - Choose Add stage.
- In the
SecondaryRegionDeploymentstage, choose Add action group.In this action group, you add a manual approval step for model deployment in the secondary Region. - For Action name, enter
ManualApprovaltoDeploytoSecondaryRegion. - For Action provider, choose Manual approval.
- Leave all other settings at their defaults and choose Done.
- In the
SecondaryRegionDeploymentstage, choose Add action group (afterManualApprovaltoDeploytoSecondaryRegion).In this action group, you add a cross-Region AWS CloudFormation deployment step. You specify the names of build artifacts that you create later in this post. - For Action name, enter
DeploytoSecondaryRegion. - For Action provider, choose AWS Cloud Formation.
- For Region, enter your secondary Region name (for example,
us-west-2). - For Input artifacts, enter
BuildArtifact. - For ActionMode, enter
CreateorUpdateStack. - For StackName, enter
DeploytoSecondaryRegion. - Under Template, for Artifact Name, select
BuildArtifact. - Under Template, for File Name, enter
template-export-secondary-region.yml. - Turn Use Configuration File on.
- Under Template, for Artifact Name, select
BuildArtifact. - Under Template, for File Name, enter
secondary-region-config-export.json. - Under Capabilities, choose
CAPABILITY_NAMED_IAM. - For Role, choose
AmazonSageMakerServiceCatalogProductsUseRolecreated by SageMaker Projects. - Choose Done.
- Choose Save.
- If a Save pipeline changes dialog appears, choose Save again.
Modify IAM role
We need to add additional permissions to the AWS Identity and Access Management (IAM) role AmazonSageMakerServiceCatalogProductsUseRole created by AWS Service Catalog to enable CodePipeline and S3 bucket access for cross-Region deployment.
- On the IAM console, choose Roles in the navigation pane.
- Search for and select
AmazonSageMakerServiceCatalogProductsUseRole. - Choose the IAM policy under Policy name:
AmazonSageMakerServiceCatalogProductsUseRole-XXXXXXXXX. - Choose Edit Policy and then JSON.
- Modify the AWS CloudFormation permissions to allow CodePipeline to sync the S3 bucket in the secondary Region. You can replace the existing IAM policy with the updated one from the following GitHub repo (see lines:16-18, 198, 213)
- Choose Review policy.
- Choose Save changes.
Add the deployment template for the secondary Region
To spin up an inference endpoint in the secondary Region, the SecondaryRegionDeployment stage needs a CloudFormation template (for endpoint-config-template-secondary-region.yml) and a configuration file (secondary-region-config.json).
The CloudFormation template is configured entirely through parameters; you can further modify it to fit your needs. Similarly, you can use the config file to define the parameters for the endpoint launch configuration, such as the instance type and instance count:
To add these files to your project, download them from the provided links and upload them to Amazon SageMaker Studio in the primary Region. In Studio, choose File Browser and then the folder containing your project name and ending with modeldeploy.
Upload these files to the deployment repository’s root folder by choosing the upload icon. Make sure the files are located in the root folder as shown in the following screenshot.

Modify the build Python file
Next, we need to adjust the deployment build.py file to enable SageMaker endpoint deployment in the secondary Region to do the following:
- Retrieve the location of model artifacts and Amazon Elastic Container Registry (Amazon ECR) URI for the model image in the secondary Region
- Prepare a parameter file that is used to pass the model-specific arguments to the CloudFormation template that deploys the model in the secondary Region
You can download the updated build.py file and replace the existing one in your folder. In Studio, choose File Browser and then the folder containing your project name and ending with modeldeploy. Locate the build.py file and replace it with the one you downloaded.
The CloudFormation template uses the model artifacts stored in a S3 bucket and the Amazon ECR image path to deploy the inference endpoint in the secondary Region. This is different from the deployment from the model registry in the primary Region, because you don’t need to have a model registry in the secondary Region.

Modify the buildspec file
buildspec.yml contains instructions run by CodeBuild. We modify this file to do the following:
- Install the SageMaker Python library needed to support the code run
- Pass through the –secondary-region and model-specific parameters to
build.py - Add the S3 bucket content sync from the primary to secondary Regions
- Export the secondary Region CloudFormation template and associated parameter file as artifacts of the CodeBuild step
Open the buildspec.yml file from the model deploy folder and make the highlighted modifications as shown in the following screenshot.

Alternatively, you can download the following buildspec.yml file to replace the default file.
Add CodeBuild environment variables
In this step, you add configuration parameters required for CodeBuild to create the model deployment configuration files in the secondary Region.
- On the CodeBuild console in the primary Region, find the project containing your project name and ending with deploy. This project has already been created for you by SageMaker Projects.

- Choose the project and on the Edit menu, choose Environment.

- In the Advanced configuration section, deselect Allow AWS CodeBuild to modify this service role so it can be used with this build project.
- Add the following environment variables, defining the names of the additional CloudFormation templates, secondary Region, and model-specific parameters:
-
EXPORT_TEMPLATE_NAME_SECONDARY_REGION – For Value, enter
template-export-secondary-region.ymland for Type, choose PlainText. -
EXPORT_TEMPLATE_SECONDARY_REGION_CONFIG – For Value, enter
secondary-region-config-export.jsonand for Type, choose PlainText. - AWS_SECONDARY_REGION – For Value, enter us-west-2 and for Type, choose PlainText.
-
FRAMEWORK – For Value, enter
xgboost(replace with your framework) and for Type, choose PlainText. - MODEL_VERSION – For Value, enter 1.0-1 (replace with your model version) and for Type, choose PlainText.
-
EXPORT_TEMPLATE_NAME_SECONDARY_REGION – For Value, enter
- Copy the value of
ARTIFACT_BUCKETinto Notepad or another text editor. You need this value in the next step. - Choose Update environment.
You need the values you specified for model training for FRAMEWORK and MODEL_VERSION. For example, to find these values for the Abalone model used in MLOps boilerplate deployment, open Studio and on the File Browser menu, open the folder with your project name and ending with modelbuild. Navigate to pipelines/abalone and open the pipeline.py file. Search for sagemaker.image_uris.retrieve and copy the relevant values.

Create an S3 replica bucket in the secondary Region
We need to create an S3 bucket to hold the model artifacts in the secondary Region. SageMaker uses this bucket to get the latest version of model to spin up an inference endpoint. You only need to do this one time. CodeBuild automatically syncs the content of the bucket in the primary Region to the replication bucket with each pipeline run.
- On the Amazon S3 console, choose Create bucket.
- For Bucket name, enter the value of
ARTEFACT_BUCKETcopied in the previous step and append-replicato the end (for example,sagemaker-project-X-XXXXXXXX-replica. - For AWS Region, enter your secondary Region (
us-west-2). - Leave all other values at their default and choose Create bucket.
Approve a model for deployment
The deployment stage of the pipeline requires an approved model to start. This is required for the deployment in the primary Region.
- In Studio (primary Region), choose SageMaker resources in the navigation pane.
- For Select the resource to view, choose Model registry.
- Choose model group name starting with your project name.
- In the right pane, check the model version, stage and status.
- If the status shows pending, choose the model version and then choose Update status.
- Change status to Approved, then choose Update status.
Deploy and verify the changes
All the changes required for multi-Region deployment of your SageMaker inference endpoint are now complete and you can start the deployment process.
- In Studio, save all the files you edited, choose Git, and choose the repository containing your project name and ending with deploy.
- Choose the plus sign to make changes.
- Under Changed, add
build.pyandbuildspec.yml. - Under Untracked, add
endpoint-config-template-secondary-region.ymlandsecondary-region-config.json. - Enter a comment in the Summary field and choose Commit.
- Push the changes to the repository by choosing Push.
Pushing these changes to the CodeCommit repository triggers a new pipeline run, because an EventBridge event monitors for pushed commits. After a few moments, you can monitor the run by navigating to the pipeline on the CodePipeline console.
Make sure to provide manual approval for deployment to production and the secondary Region.
You can verify that the secondary Region endpoint is created on the SageMaker console, by choosing Dashboard in the navigation pane and confirming the endpoint status in Recent activity.

Add API Gateway and Route 53 (Optional)
You can optionally follow the instructions in Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda to expose the SageMaker inference endpoint in the secondary Region as an API using API Gateway and Lambda.
Clean up
To delete the SageMaker project, see Delete an MLOps Project using Amazon SageMaker Studio. To ensure the secondary inference endpoint is destroyed, go to the AWS CloudFormation console and delete the related stacks in your primary and secondary Regions; this destroys the SageMaker inference endpoints.
Conclusion
In this post, we showed how a MLOps specialist can modify a preconfigured MLOps template for their own multi-Region deployment use case, such as deploying workloads in multiple geographies or as part of implementing a multi-Regional disaster recovery strategy. With this deployment approach, you don’t need to configure services in the secondary Region and can reuse the CodePipeline and CloudBuild setups in the primary Region for cross-Regional deployment. Additionally, you can save on costs by continuing the training of your models in the primary Region while utilizing SageMaker inference in multiple Regions to scale your AI/ML deployment globally.
Please let us know your feedback in the comments section.
About the Authors
 Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on AI/ML and SaaS solutions at Scale.
Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on AI/ML and SaaS solutions at Scale.
 Steven Alyekhin is a Senior Solutions Architect for AWS focused on MLOps at Scale.
Steven Alyekhin is a Senior Solutions Architect for AWS focused on MLOps at Scale.
Detect fraudulent transactions using machine learning with Amazon SageMaker
Businesses can lose billions of dollars each year due to malicious users and fraudulent transactions. As more and more business operations move online, fraud and abuses in online systems are also on the rise. To combat online fraud, many businesses have been using rule-based fraud detection systems.
However, traditional fraud detection systems rely on a set of rules and filters hand-crafted by human specialists. The filters can often be brittle and the rules may not capture the full spectrum of fraudulent signals. Furthermore, while fraudulent behaviors are ever-evolving, the static nature of predefined rules and filters makes it difficult to maintain and improve traditional fraud detection systems effectively.
In this post, we show you how to build a dynamic, self-improving, and maintainable credit card fraud detection system with machine learning (ML) using Amazon SageMaker.
Alternatively, if you’re looking for a fully managed service to build customized fraud detection models without writing code, we recommend checking out Amazon Fraud Detector. Amazon Fraud Detector enables customers with no ML experience to automate building fraud detection models customized for their data, leveraging more than 20 years of fraud detection expertise from AWS and Amazon.com.
Solution overview
This solution builds the core of a credit card fraud detection system using SageMaker. We start by training an unsupervised anomaly detection model using the algorithm Random Cut Forest (RCF). Then we train two supervised classification models using the algorithm XGBoost, one as a baseline model and the other for making predictions, using different strategies to address the extreme class imbalance in data. Lastly, we train an optimal XGBoost model with hyperparameter optimization (HPO) to further improve the model performance.
For the sample dataset, we use the public, anonymized credit card transactions dataset that was originally released as part of a research collaboration of Worldline and the Machine Learning Group of ULB (Université Libre de Bruxelles). In the walkthrough, we also discuss how you can customize the solution to use your own data.
The outputs of the solution are as follows:
- An unsupervised SageMaker RCF model. The model outputs an anomaly score for each transaction. A low score value indicates that the transaction is considered normal (non-fraudulent). A high value indicates that the transaction is fraudulent. The definitions of low and high depend on the application, but common practice suggests that scores beyond three standard deviations from the mean score are considered anomalous.
- A supervised SageMaker XGBoost model trained using its built-in weighting schema to address the highly unbalanced data issue.
- A supervised SageMaker XGBoost model trained using the Sythetic Minority Over-sampling Technique (SMOTE).
- A trained SageMaker XGBoost model with HPO.
- Predictions of the probability for each transaction being fraudulent. If the estimated probability of a transaction is over a threshold, it’s classified as fraudulent.
To demonstrate how you can use this solution in your existing business infrastructures, we also include an example of making REST API calls to the deployed model endpoint, using AWS Lambda to trigger both the RCF and XGBoost models.
The following diagram illustrates the solution architecture.

Prerequisites
To try out the solution in your own account, make sure that you have the following in place:
- You need an AWS account to use this solution. If you don’t have an account, you can sign up for one.
- The solution outlined in this post is part of Amazon SageMaker JumpStart. To run this SageMaker JumpStart 1P Solution and have the infrastructure deploy to your AWS account, you need to create an active Amazon SageMaker Studio instance (see Onboard to Amazon SageMaker Domain).
When the Studio instance is ready, you can launch Studio and access JumpStart. JumpStart solutions are not available in SageMaker notebook instances, and you can’t access them through SageMaker APIs or the AWS Command Line Interface (AWS CLI).
Launch the solution
To launch the solution, complete the following steps:
- Open JumpStart by using the JumpStart launcher in the Get Started section or by choosing the JumpStart icon in the left sidebar.
- Under Solutions, choose Detect Malicious Users and Transactions to open the solution in another Studio tab.

- On the solution tab, choose Launch to launch the solution.

The solution resources are provisioned and another tab opens showing the deployment progress. When the deployment is finished, an Open Notebook button appears. - Choose Open Notebook to open the solution notebook in Studio.



Investigate and process the data
The default dataset contains only numerical features, because the original features have been transformed using Principal Component Analysis (PCA) to protect user privacy. As a result, the dataset contains 28 PCA components, V1–V28, and two features that haven’t been transformed, Amount and Time. Amount refers to the transaction amount, and Time is the seconds elapsed between any transaction in the data and the first transaction.
The Class column corresponds to whether or not a transaction is fraudulent.
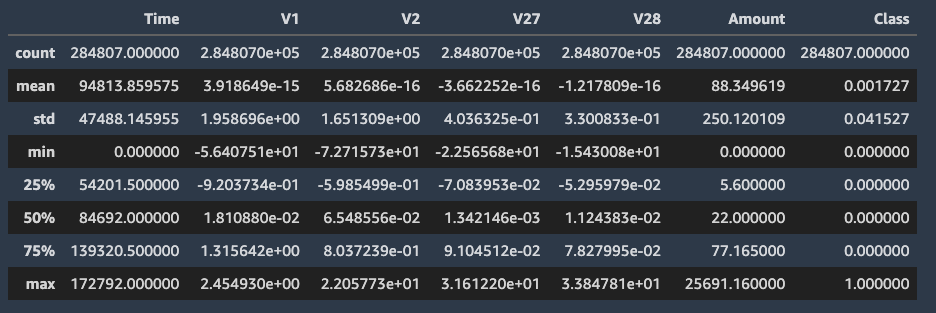
We can see that the majority is non-fraudulent, because out of the total 284,807 examples, only 492 (0.173%) are fraudulent. This is a case of extreme class imbalance, which is common in fraud detection scenarios.

We then prepare our data for loading and training. We split the data into a train set and a test set, using the former to train and the latter to evaluate the performance of our model. It’s important to split the data before applying any techniques to alleviate the class imbalance. Otherwise, we might leak information from the test set into the train set and hurt the model’s performance.
If you want to bring in your own training data, make sure that it’s tabular data in CSV format, upload the data to an Amazon Simple Storage Service (Amazon S3) bucket, and edit the S3 object path in the notebook code.

If your data includes categorical columns with non-numerical values, you need to one-hot encode these values (using, for example, sklearn’s OneHotEncoder) because the XGBoost algorithm only supports numerical data.
Train an unsupervised Random Cut Forest model
In a fraud detection scenario, we commonly have very few labeled examples, and labeling fraud can take a lot of time and effort. Therefore, we also want to extract information from the unlabeled data at hand. We do this using an anomaly detection algorithm, taking advantage of the high data imbalance that is common in fraud detection datasets.
Anomaly detection is a form of unsupervised learning where we try to identify anomalous examples based solely on their feature characteristics. Random Cut Forest is a state-of-the-art anomaly detection algorithm that is both accurate and scalable. With each data example, RCF associates an anomaly score.
We use the SageMaker built-in RCF algorithm to train an anomaly detection model on our training dataset, then make predictions on our test dataset.
First, we examine and plot the predicted anomaly scores for positive (fraudulent) and negative (non-fraudulent) examples separately, because the numbers of positive and negative examples differ significantly. We expect the positive (fraudulent) examples to have relatively high anomaly scores, and the negative (non-fraudulent) ones to have low anomaly scores. From the histograms, we can see the following patterns:
- Almost half of the positive examples (left histogram) have anomaly scores higher than 0.9, whereas most of the negative examples (right histogram) have anomaly scores lower than 0.85.
- The unsupervised learning algorithm RCF has limitations to identify fraudulent and non-fraudulent examples accurately. This is because no label information is used. We address this issue by collecting label information and using a supervised learning algorithm in later steps.

Then, we assume a more real-world scenario where we classify each test example as either positive (fraudulent) or negative (non-fraudulent) based on its anomaly score. We plot the score histogram for all test examples as follows, choosing a cutoff score of 1.0 (based on the pattern shown in the histogram) for classification. Specifically, if an example’s anomaly score is less than or equal to 1.0, it’s classified as negative (non-fraudulent). Otherwise, the example is classified as positive (fraudulent).

Lastly, we compare the classification result with the ground truth labels and compute the evaluation metrics. Because our dataset is imbalanced, we use the evaluation metrics balanced accuracy, Cohen’s Kappa score, F1 score, and ROC AUC, because they take into account the frequency of each class in the data. For all of these metrics, a larger value indicates a better predictive performance. Note that in this step we can’t compute the ROC AUC yet, because there is no estimated probability for positive and negative classes from the RCF model on each example. We compute this metric in later steps using supervised learning algorithms.
| . | RCF |
| Balanced accuracy | 0.560023 |
| Cohen’s Kappa | 0.003917 |
| F1 | 0.007082 |
| ROC AUC | – |
From this step, we can see that the unsupervised model can already achieve some separation between the classes, with higher anomaly scores correlated with fraudulent examples.
Train an XGBoost model with the built-in weighting schema
After we’ve gathered an adequate amount of labeled training data, we can use a supervised learning algorithm to discover relationships between the features and the classes. We choose the XGBoost algorithm because it has a proven track record, is highly scalable, and can deal with missing data. We need to handle the data imbalance this time, otherwise the majority class (the non-fraudulent, or negative examples) will dominate the learning.
We train and deploy our first supervised model using the SageMaker built-in XGBoost algorithm container. This is our baseline model. To handle the data imbalance, we use the hyperparameter scale_pos_weight, which scales the weights of the positive class examples against the negative class examples. Because the dataset is highly skewed, we set this hyperparameter to a conservative value: sqrt(num_nonfraud/num_fraud).
We train and deploy the model as follows:
- Retrieve the SageMaker XGBoost container URI.
- Set the hyperparameters we want to use for the model training, including the one we mentioned that handles data imbalance,
scale_pos_weight. - Create an XGBoost estimator and train it with our train dataset.
- Deploy the trained XGBoost model to a SageMaker managed endpoint.
- Evaluate this baseline model with our test dataset.
Then we evaluate our model with the same four metrics as mentioned in the last step. This time we can also calculate the ROC AUC metric.
| . | RCF | XGBoost |
| Balanced accuracy | 0.560023 | 0.847685 |
| Cohen’s Kappa | 0.003917 | 0.743801 |
| F1 | 0.007082 | 0.744186 |
| ROC AUC | – | 0.983515 |
We can see that a supervised learning method XGBoost with the weighting schema (using the hyperparameter scale_pos_weight) achieves significantly better performance than the unsupervised learning method RCF. There is still room to improve the performance, however. In particular, raising the Cohen’s Kappa score above 0.8 would be generally very favorable.
Apart from single-value metrics, it’s also useful to look at metrics that indicate performance per class. For example, the confusion matrix, per-class precision, recall, and F1-score can provide more information about our model’s performance.
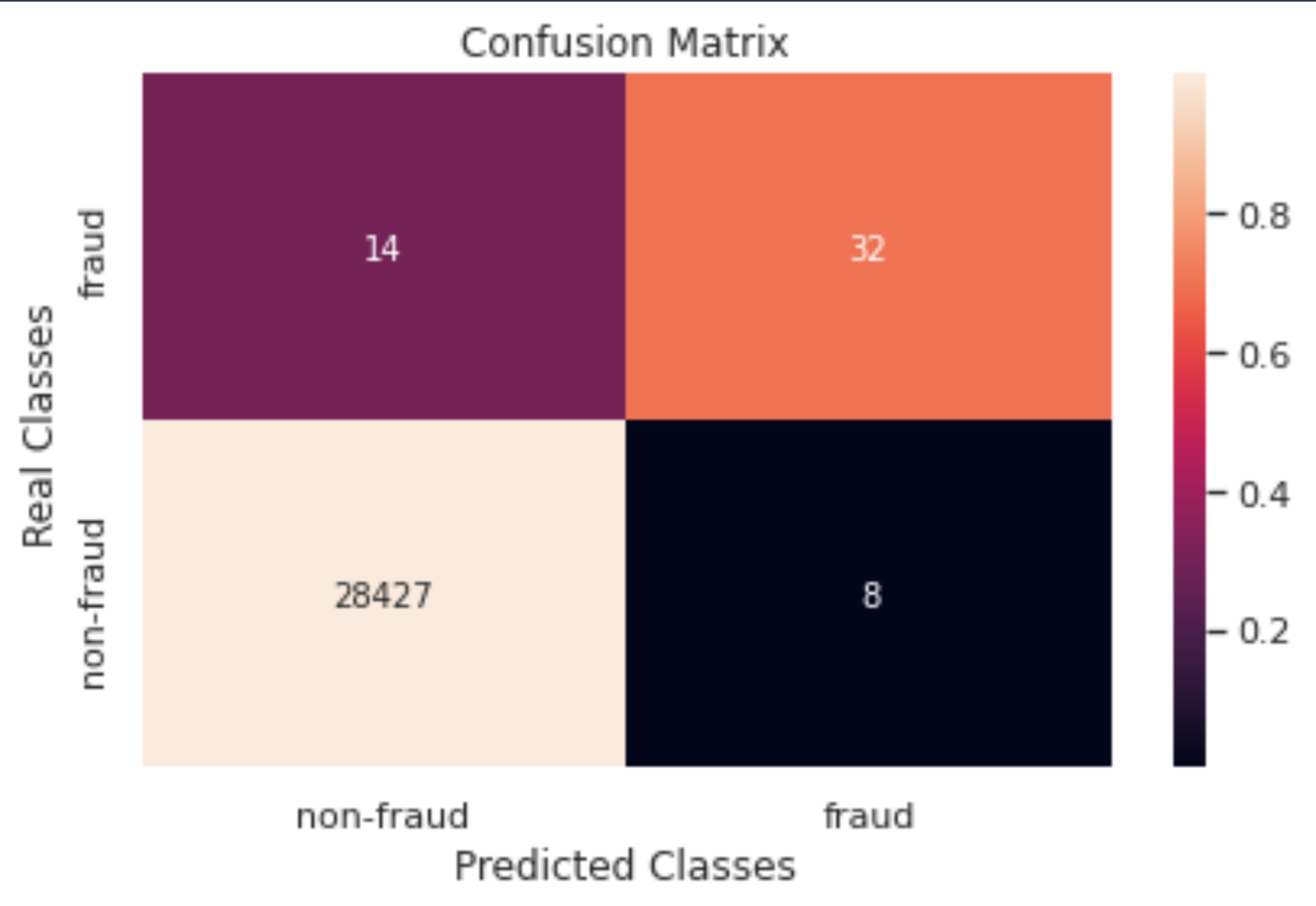
| . | precision | recall | f1-score | support |
| non-fraud | 1.00 | 1.00 | 1.00 | 28435 |
| fraud | 0.80 | 0.70 | 0.74 | 46 |
Keep sending test traffic to the endpoint via Lambda
To demonstrate how to use our models in a production system, we built a REST API with Amazon API Gateway and a Lambda function. When client applications send HTTP inference requests to the REST API, which triggers the Lambda function, which in turn invokes the RCF and XGBoost model endpoints and returns the predictions from the models. You can read the Lambda function code and monitor the invocations on the Lambda console.
We also created a Python script that makes HTTP inference requests to the REST API, with our test data as input data. To see how this was done, check the generate_endpoint_traffic.py file in the solution’s source code. The prediction outputs are logged to an S3 bucket through an Amazon Kinesis Data Firehose delivery stream. You can find the destination S3 bucket name on the Kinesis Data Firehose console, and check the prediction results in the S3 bucket.
Train an XGBoost model with the over-sampling technique SMOTE
Now that we have a baseline model using XGBoost, we can see if sampling techniques that are designed specifically for imbalanced problems can improve the performance of the model. We use Sythetic Minority Over-sampling (SMOTE), which oversamples the minority class by interpolating new data points between existing ones.
The steps are as follows:
- Use SMOTE to oversample the minority class (the fraudulent class) of our train dataset. SMOTE oversamples the minority class from about 0.17–50%. Note that this is a case of extreme oversampling of the minority class. An alternative would be to use a smaller resampling ratio, such as having one minority class sample for every
sqrt(non_fraud/fraud)majority sample, or using more advanced resampling techniques. For more over-sampling options, refer to Compare over-sampling samplers. - Define the hyperparameters for training the second XGBoost so that scale_pos_weight is removed and the other hyperparameters remain the same as when training the baseline XGBoost model. We don’t need to handle data imbalance with this hyperparameter anymore, because we’ve already done that with SMOTE.
- Train the second XGBoost model with the new hyperparameters on the SMOTE processed train dataset.
- Deploy the new XGBoost model to a SageMaker managed endpoint.
- Evaluate the new model with the test dataset.
When evaluating the new model, we can see that with SMOTE, XGBoost achieves a better performance on balanced accuracy, but not on Cohen’s Kappa and F1 scores. The reason for this is that SMOTE has oversampled the fraud class so much that it’s increased its overlap in feature space with the non-fraud cases. Because Cohen’s Kappa gives more weight to false positives than balanced accuracy does, the metric drops significantly, as does the precision and F1 score for fraud cases.
| . | RCF | XGBoost | XGBoost SMOTE |
| Balanced accuracy | 0.560023 | 0.847685 | 0.912657 |
| Cohen’s Kappa | 0.003917 | 0.743801 | 0.716463 |
| F1 | 0.007082 | 0.744186 | 0.716981 |
| ROC AUC | – | 0.983515 | 0.967497 |
However, we can bring back the balance between metrics by adjusting the classification threshold. So far, we’ve been using 0.5 as the threshold to label whether or not a data point is fraudulent. After experimenting different thresholds from 0.1–0.9, we can see that Cohen’s Kappa keeps increasing along with the threshold, without a significant loss in balanced accuracy.
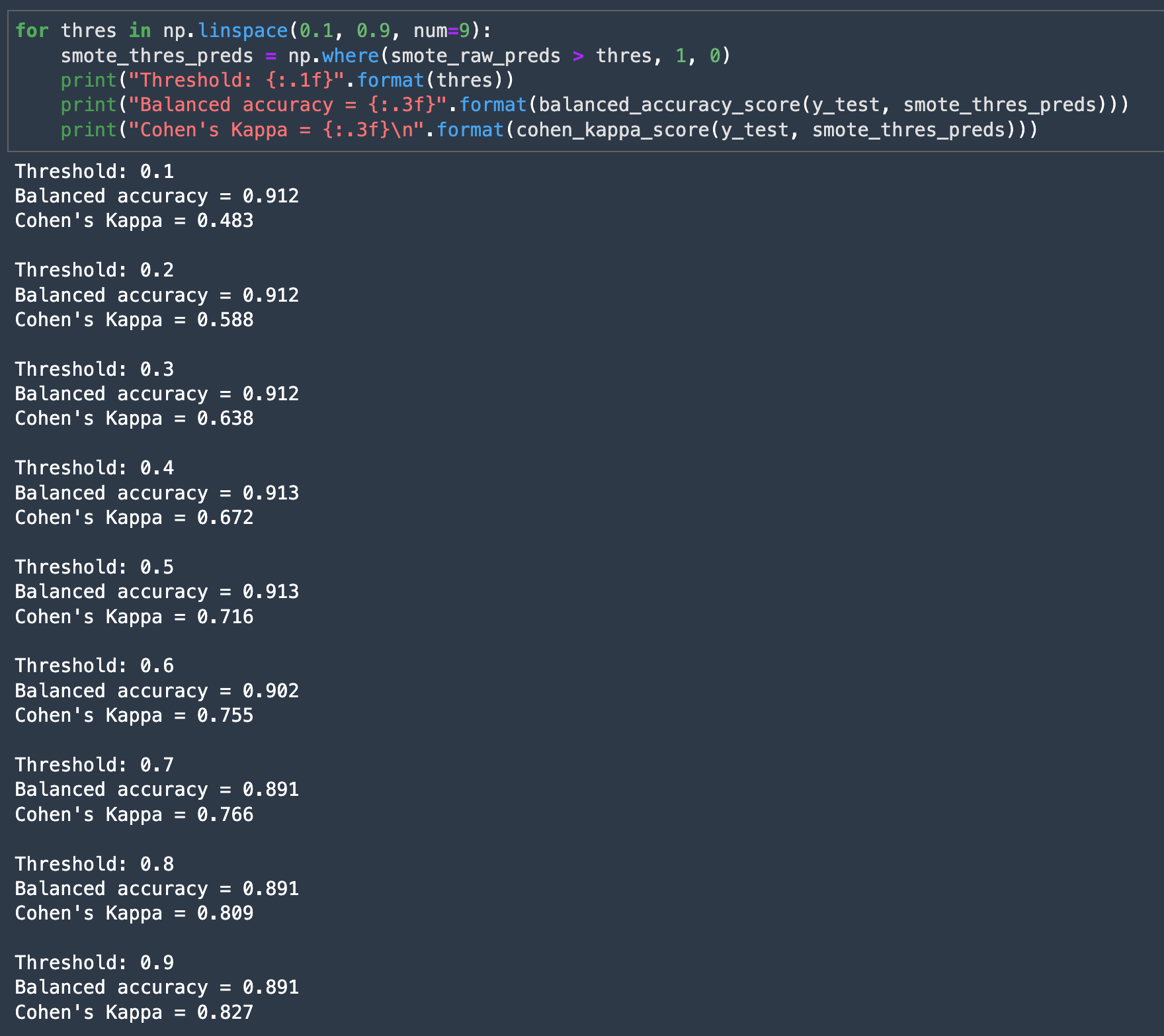
This adds a useful calibration to our model. We can use a low threshold if not missing any fraudulent cases (false negatives) is our priority, or we can increase the threshold to minimize the number of false positives.
Train an optimal XGBoost model with HPO
In this step, we demonstrate how to improve model performance by training our third XGBoost model with hyperparameter optimization. When building complex ML systems, manually exploring all possible combinations of hyperparameter values is impractical. The HPO feature in SageMaker can accelerate your productivity by trying many variations of a model on your behalf. It automatically looks for the best model by focusing on the most promising combinations of hyperparameter values within the ranges that you specify.
The HPO process needs a validation dataset, so we first further split our training data into training and validation datasets using stratified sampling. To tackle the data imbalance problem, we use XGBoost’s weighting schema again, setting the scale_pos_weight hyperparameter to sqrt(num_nonfraud/num_fraud).
We create an XGBoost estimator using the SageMaker built-in XGBoost algorithm container, and specify the objective evaluation metric and the hyperparameter ranges within which we’d like to experiment. With these we then create a HyperparameterTuner and kick off the HPO tuning job, which trains multiple models in parallel, looking for optimal hyperparameter combinations.
When the tuning job is complete, we can see its analytics report and inspect each model’s hyperparameters, training job information, and its performance against the objective evaluation metric.
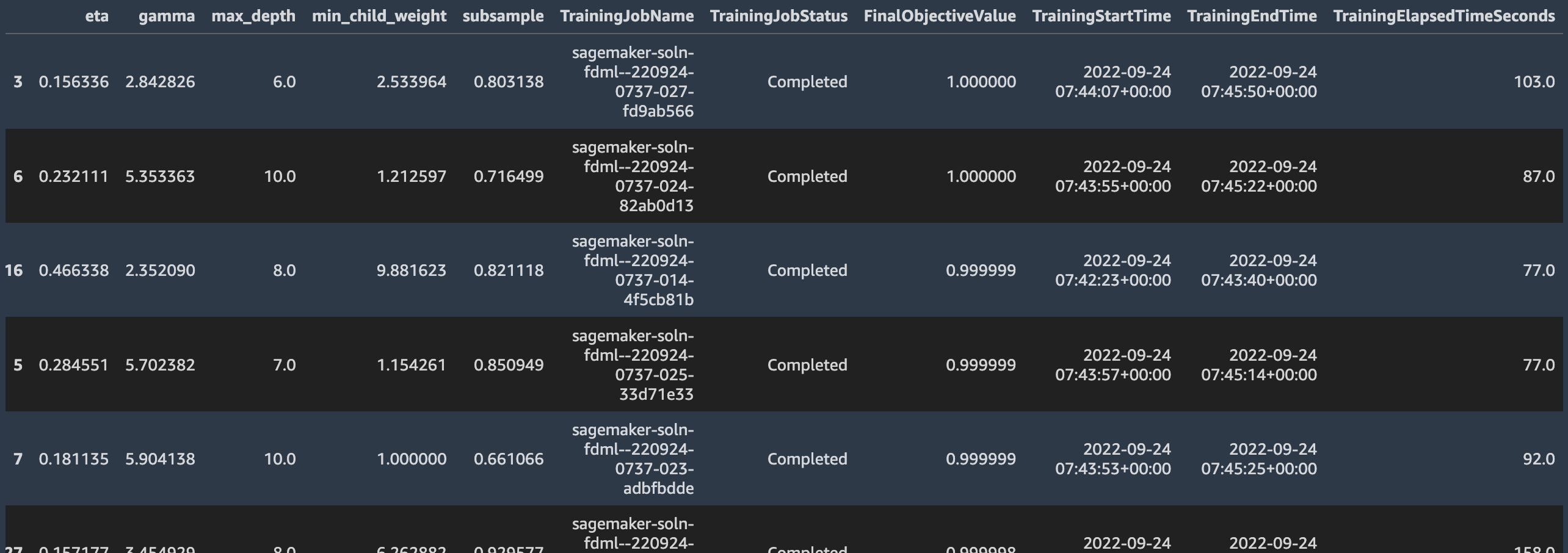
Then we deploy the best model and evaluate it with our test dataset.
Evaluate and compare all model performance on the same test data
Now we have the evaluation results from all four models: RCF, XGBoost baseline, XGBoost with SMOTE, and XGBoost with HPO. Let’s compare their performance.
| . | RCF | XGBoost | XGBoost with SMOTE | XGBoost with HPO |
| Balanced accuracy | 0.560023 | 0.847685 | 0.912657 | 0.902156 |
| Cohen’s Kappa | 0.003917 | 0.743801 | 0.716463 | 0.880778 |
| F1 | 0.007082 | 0.744186 | 0.716981 | 0.880952 |
| ROC AUC | – | 0.983515 | 0.967497 | 0.981564 |
We can see that XGBoost with HPO achieves even better performance than that with the SMOTE method. In particular, Cohen’s Kappa scores and F1 are over 0.8, indicating an optimal model performance.
Clean up
When you’re finished with this solution, make sure that you delete all unwanted AWS resources to avoid incurring unintended charges. In the Delete solution section on your solution tab, choose Delete all resources to delete resources automatically created when launching this solution.

Alternatively, you can use AWS CloudFormation to delete all standard resources automatically created by the solution and notebook. To use this approach, on the AWS CloudFormation console, find the CloudFormation stack whose description contains fraud-detection-using-machine-learning, and delete it. This is a parent stack, and choosing to delete this stack will automatically delete the nested stacks.
With either approach, you still need to manually delete any extra resources that you may have created in this notebook. Some examples include extra S3 buckets (in addition to the solution’s default bucket), extra SageMaker endpoints (using a custom name), and extra Amazon Elastic Container Registry (Amazon ECR) repositories.
Conclusion
In this post, we showed you how to build the core of a dynamic, self-improving, and maintainable credit card fraud detection system using ML with SageMaker. We built, trained, and deployed an unsupervised RCF anomaly detection model, a supervised XGBoost model as the baseline, another supervised XGBoost model with SMOTE to tackle the data imbalance problem, and a final XGBoost model optimized with HPO. We discussed how to handle data imbalance and use your own data in the solution. We also included an example REST API implementation with API Gateway and Lambda to demonstrate how to use the system in your existing business infrastructure.
To try it out yourself, open SageMaker Studio and launch the JumpStart solution. To learn more about the solution, check out its GitHub repository.
About the Authors
 Xiaoli Shen is a Solutions Architect and Machine Learning Technical Field Community (TFC) member at Amazon Web Services. She’s focused on helping customers architecting on the cloud and leveraging AWS services to derive business value. Prior to joining AWS, she was a tech lead and senior full-stack engineer building data-intensive distributed systems on the cloud.
Xiaoli Shen is a Solutions Architect and Machine Learning Technical Field Community (TFC) member at Amazon Web Services. She’s focused on helping customers architecting on the cloud and leveraging AWS services to derive business value. Prior to joining AWS, she was a tech lead and senior full-stack engineer building data-intensive distributed systems on the cloud.
 Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
 Vedant Jain is a Sr. AI/ML Specialist Solutions Architect, helping customers derive value out of the Machine Learning ecosystem at AWS. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, using Science to lead a meaningful life & exploring delicious vegetarian cuisine from around the world.
Vedant Jain is a Sr. AI/ML Specialist Solutions Architect, helping customers derive value out of the Machine Learning ecosystem at AWS. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, using Science to lead a meaningful life & exploring delicious vegetarian cuisine from around the world.
Implement RStudio on your AWS environment and access your data lake using AWS Lake Formation permissions
R is a popular analytic programming language used by data scientists and analysts to perform data processing, conduct statistical analyses, create data visualizations, and build machine learning (ML) models. RStudio, the integrated development environment for R, provides open-source tools and enterprise-ready professional software for teams to develop and share their work across their organization Building, securing, scaling and maintaining RStudio yourself is, however, tedious and cumbersome.
Implementing the RStudio environment in AWS provides elasticity and scalability that you don’t have when deploying on-prem, eliminating the need of managing that infrastructure. You can select the desired compute and memory based on processing requirements and can also scale up or down to work with analytical and ML workloads of different sizes without an upfront investment. This lets you quickly experiment with new data sources and code, and roll out new analytics processes and ML models to the rest of the organization. You can also seamlessly integrate your Data Lake resources to make them available to developers and Data Scientists and secure the data by using row-level and column-level access controls from AWS Lake Formation.
This post presents two ways to easily deploy and run RStudio on AWS to access data stored in data lake:
- Fully managed on Amazon SageMaker
- RStudio on amazon SageMaker is a managed service option which allows you to avoid having to manage the underlying infrastructure for your RStudio environment. You can easily bring your own RStudio Workbench license using AWS License Manager
- You can also use RStudio on Amazon SageMaker’s integration with AWS Identity and Access Management or AWS IAM Identity Center (successor of AWS Single Sign On) to implement user-level security access controls. As we will see later in this post, you can secure your data lake by using row-level and column-level access controls from AWS Lake Formation.
- RStudio on Amazon SageMaker enables you to dynamically choose an instance with desired compute and memory from a wide array of ML instances available on SageMaker.
- Self-hosted on Amazon Elastic Compute Cloud (Amazon EC2)
- You can choose to deploy the open-source version of RStudio using an EC2 hosted approach that we will also describe in this post. The self-hosted option requires the administrator to create an EC2 instance and install RStudio manually or using a AWS CloudFormation There is also less flexibility for implementing user-access controls in this option since all users have the same access level in this type of implementation.
RStudio on Amazon SageMaker
You can launch RStudio Workbench with a simple click from SageMaker. With SageMaker customers don’t have to bear the operational overhead of building, installing, securing, scaling and maintaining RStudio, they don’t have to pay for the continuously running RStudio Server (if they are using t3.medium) and they only pay for RSession compute when they use it. RStudio users will have flexibility to dynamically scale compute by switching instances on-the-fly. Running RStudio on SageMaker requires an administrator to establish a SageMaker domain and associated user profiles. You also need an appropriate RStudio license
Within SageMaker, you can grant access at the RStudio administrator and RStudio user level, with differing permissions. Only user profiles granted one of these two roles can access RStudio in SageMaker. For more information about administrator tasks for setting up RStudio on SageMaker, refer to Get started with RStudio on Amazon SageMaker. That post also shows the process of selecting EC2 instances for each session, and how the administrator can restrict EC2 instance options for RStudio users.

Fig1: Architecture Diagram showing the interaction of various AWS Services
Use Lake Formation row-level and column-level security access
In addition to allowing your team to launch RStudio sessions on SageMaker, you can also secure the data lake by using row-level and column-level access controls from Lake Formation. For more information, refer to Effective data lakes using AWS Lake Formation, Part 4: Implementing cell-level and row-level security.
Through Lake Formation security controls, you can make sure that each person has the right access to the data in the data lake. Consider the following two user profiles in the SageMaker domain, each with a different execution role:
| User Profile | Execution Role |
rstudiouser-fullaccess |
AmazonSageMaker-ExecutionRole-FullAccess |
rstudiouser-limitedaccess |
AmazonSageMaker-ExecutionRole-LimitedAccess |
The following screenshot shows the rstudiouser-limitedaccess profile details.
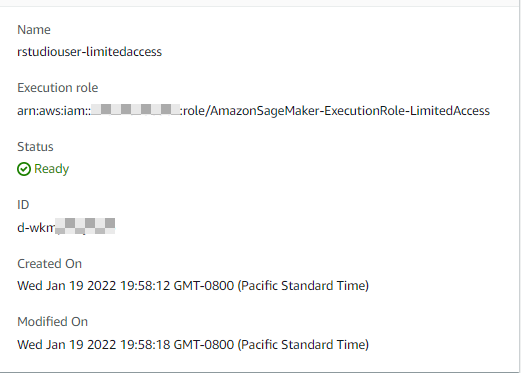
Fig 2: Profile details of rstudiouser-limitedaccess role
The following screenshot shows the rstudiouser-fullaccess profile details.

Fig 3: Profile details of rstudiouser-fullaccess role
The dataset used for this post is a COVID-19 public dataset. The following screenshot shows an example of the data:

Fig4: COVID-19 Public dataset
After you create the user profile and assign it to the appropriate role, you can access Lake Formation to crawl the data with AWS Glue, create the metadata and table, and grant access to the table data. For the AmazonSageMaker-ExecutionRole-FullAccess role, you grant access to all of the columns in the table, and for AmazonSageMaker-ExecutionRole-LimitedAccess, you grant access using the data filter USA_Filter. We use this filter to provide row-level and cell-level column permissions (see the Resource column in the following screenshot).

Fig5: AWS Lake Formation Permissions for AmazonSageMaker-ExecutionRole -Full/Limited Access roles
As shown in the following screenshot, the second role has limited access. Users associated with this role can only access the continent, date, total_cases, total_deaths, new_cases, new_deaths, and iso_codecolumns.
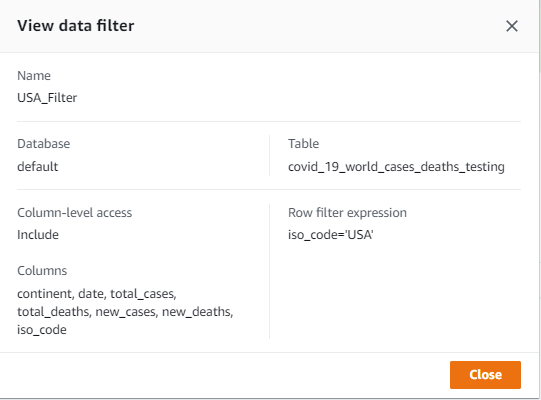
Fig6: AWS Lake Formation Column-level permissions for AmazonSageMaker-ExecutionRole-Limited Access role
With role permissions attached to each user profile, we can see how Lake Formation enforces the appropriate row-level and column-level permissions. You can open the RStudio Workbench from the Launch app drop-down menu in the created user list, and choose RStudio.
In the following screenshot, we launch the app as the rstudiouser-limitedaccess user.

Fig7: Launching RStudio session for rstudiouser-limitedaccess user from Amazon SageMaker Console
You can see the RStudio Workbench home page and a list of sessions, projects, and published content.

Fig8: R Studio Workbench session for rstudiouser-limitedaccess user
Choose a session name to start the session in SageMaker. Install Paws (see guidance earlier in this post) so that you can access the appropriate AWS services. Now you can run a query to pull all of the fields from the dataset via Amazon Athena, using the command “SELECT * FROM "databasename.tablename", and store the query output in an Amazon Simple Storage Service (Amazon S3) bucket.

Fig9: Athena Query execution in R Studio session
The following screenshot shows the output files in the S3 bucket.

Fig10: Athena Query execution results in Amazon S3 Bucket
The following screenshot shows the data in these output files using Amazon S3 Select.
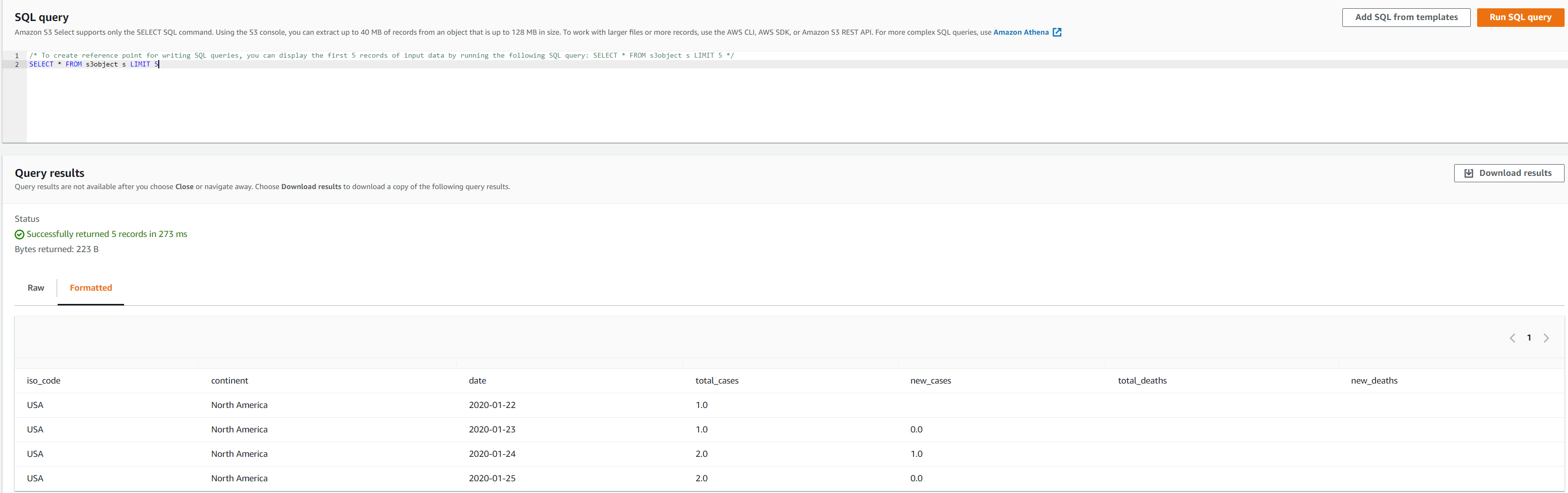
Fig11: Reviewing the output data using Amazon S3 Select
Only USA data and columns continent, date, total_cases, total_deaths, new_cases, new_deaths, and iso_code are shown in the result for the rstudiouser-limitedaccess user.
Let’s repeat the same steps for the rstudiouser-fullaccess user.

Fig12: Launching RStudio session for rstudiouser-fullaccess user from Amazon SageMaker Console
You can see the RStudio Workbench home page and a list of sessions, projects, and published content.
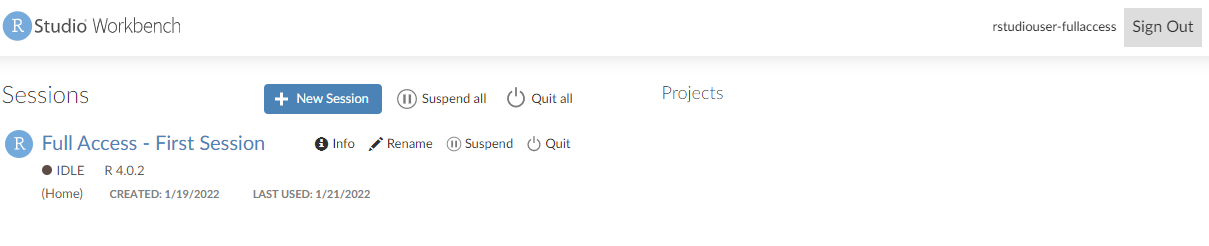
Fig13: R Studio Workbench session for rstudiouser-fullaccess user
Let’s run the same query “SELECT * FROM "databasename.tablename" using Athena.

Fig14: Athena Query execution in R Studio session
The following screenshot shows the output files in the S3 bucket.

Fig15: Athena Query execution results in Amazon S3 Bucket
The following screenshot shows the data in these output files using Amazon S3 Select.

Fig16: Reviewing the output data using Amazon S3 Select
As shown in this example, the rstudiouser-fullaccess user has access to all the columns and rows in the dataset.
Self-Hosted on Amazon EC2
If you want to start experimenting with RStudio’s open-source version on AWS, you can install Rstudio on an EC2 instance. This CloudFormation template provided in this post provisions the EC2 instance and installs RStudio using the user data script. You can run the template multiple times to provision multiple RStudio instances as needed, and you can use it in any AWS Region. After you deploy the CloudFormation template, it provides you with a URL to access RStudio from a web browser. Amazon EC2 enables you to scale up or down to handle changes in data size and the necessary compute capacity to run your analytics.
Create a key-value pair for secure access
AWS uses public-key cryptography to secure the login information for your EC2 instance. You specify the name of the key pair in the KeyPair parameter when you launch the CloudFormation template. Then you can use the same key to log in to the provisioned EC2 instance later if needed.
Before you run the CloudFormation template, make sure that you have the Amazon EC2 key pair in the AWS account that you’re planning to use. If not, then refer to Create a key pair using Amazon EC2 for instructions to create one.
Launch the CloudFormation templateSign in to the CloudFormation console in the us-east-1 Region and choose Launch Stack.
![]()
You must enter several parameters into the CloudFormation template:
-
InitialUser and InitialPassword – The user name and password that you use to log in to the RStudio session. The default values are
rstudioandRstudio@123, respectively. - InstanceType – The EC2 instance type on which to deploy the RStudio server. The template currently accepts all instances in the t2, m4, c4, r4, g2, p2, and g3 instance families, and can incorporate other instance families easily. The default value is t2.micro.
- KeyPair – The key pair you use to log in to the EC2 instance.
- VpcId and SubnetId – The Amazon Virtual Private Cloud (Amazon VPC) and subnet in which to launch the instance.
After you enter these parameters, deploy the CloudFormation template. When it’s complete, the following resources are available:
- An EC2 instance with RStudio installed on it.
- An IAM role with necessary permissions to connect to other AWS services.
- A security group with rules to open up port 8787 for the RStudio Server.
Log in to RStudio
Now you’re ready to use RStudio! Go to the Outputs tab for the CloudFormation stack and copy the RStudio URL value (it’s in the format http://ec2-XX-XX-XXX-XX.compute-1.amazonaws.com:8787/). Enter that URL in a web browser. This opens your RStudio session, which you can log into using the same user name and password that you provided while running the CloudFormation template.
Access AWS services from RStudio
After you access the RStudio session, you should install the R Package for AWS (Paws). This lets you connect to many AWS services, including the services and resources in your data lake. To install Paws, enter and run the following R code:
To use an AWS service, create a client and access the service’s operations from that client. When accessing AWS APIs, you must provide your credentials and Region. Paws searches for the credentials and Region using the AWS authentication chain:
- Explicitly provided access key, secret key, session token, profile, or Region
- R environment variables
- Operating system environment variables
- AWS shared credentials and configuration files in
.aws/credentialsand.aws/config - Container IAM role
- Instance IAM role
Because you’re running on an EC2 instance with an attached IAM role, Paws automatically uses your IAM role credentials to authenticate AWS API requests.
For production environment, we recommend using the scalable Rstudio solution outlined in this blog.
Conclusion
You learned how to deploy your RStudio environment in AWS. We demonstrated the advantages of using RStudio on Amazon SageMaker and how you can get started. You also learned how to quickly begin experimenting with the open-source version of RStudio using a self-hosted installation using Amazon EC2. We also demonstrated how to integrate RStudio into your data lake architectures and implement fine-grained access control on a data lake table using the row-level and cell-level security feature of Lake Formation.
In our next post, we will demonstrate how to containerize R scripts and run them using AWS Lambda.
About the authors
 Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
 Dr. Dawn Heisey-Grove is the public health analytics leader for Amazon Web Services’ state and local government team. In this role, she’s responsible for helping state and local public health agencies think creatively about how to achieve their analytics challenges and long-term goals. She’s spent her career finding new ways to use existing or new data to support public health surveillance and research.
Dr. Dawn Heisey-Grove is the public health analytics leader for Amazon Web Services’ state and local government team. In this role, she’s responsible for helping state and local public health agencies think creatively about how to achieve their analytics challenges and long-term goals. She’s spent her career finding new ways to use existing or new data to support public health surveillance and research.
Design patterns for serial inference on Amazon SageMaker
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models. These models can be sequentially combined to perform various tasks, such as preprocessing, data transformation, model selection, inference generation, inference consolidation, and post-processing. Organizations need flexible options to orchestrate these complex ML workflows. Serial inference pipelines are one such design pattern to arrange these workflows into a series of steps, with each step enriching or further processing the output generated by the previous steps and passing the output to the next step in the pipeline.
Additionally, these serial inference pipelines should provide the following:
- Flexible and customized implementation (dependencies, algorithms, business logic, and so on)
- Repeatable and consistent for production implementation
- Undifferentiated heavy lifting by minimizing infrastructure management
In this post, we look at some common use cases for serial inference pipelines and walk through some implementation options for each of these use cases using Amazon SageMaker. We also discuss considerations for each of these implementation options.
The following table summarizes the different use cases for serial inference, implementation considerations and options. These are discussed in this post.
| Use Case | Use Case Description | Primary Considerations | Overall Implementation Complexity | Recommended Implementation options | Sample Code Artifacts and Notebooks |
| Serial inference pipeline (with preprocessing and postprocessing steps included) | Inference pipeline needs to preprocess incoming data before invoking a trained model for generating inferences, and then postprocess generated inferences, so that they can be easily consumed by downstream applications | Ease of implementation | Low | Inference container using the SageMaker Inference Toolkit | Deploy a Trained PyTorch Model |
| Serial inference pipeline (with preprocessing and postprocessing steps included) | Inference pipeline needs to preprocess incoming data before invoking a trained model for generating inferences, and then postprocess generated inferences, so that they can be easily consumed by downstream applications | Decoupling, simplified deployment, and upgrades | Medium | SageMaker inference pipeline | Inference Pipeline with Custom Containers and xgBoost |
| Serial model ensemble | Inference pipeline needs to host and arrange multiple models sequentially, so that each model enhances the inference generated by the previous one, before generating the final inference | Decoupling, simplified deployment and upgrades, flexibility in model framework selection | Medium | SageMaker inference pipeline | Inference Pipeline with Scikit-learn and Linear Learner |
| Serial inference pipeline (with targeted model invocation from a group) | Inference pipeline needs to invoke a specific customized model from a group of deployed models, based on request characteristics or for cost-optimization, in addition to preprocessing and postprocessing tasks | Cost-optimization and customization | High | SageMaker inference pipeline with multi-model endpoints (MMEs) | Amazon SageMaker Multi-Model Endpoints using Linear Learner |
In the following sections, we discuss each use case in more detail.
Serial inference pipeline using inference containers
Serial inference pipeline use cases have requirements to preprocess incoming data before invoking a pre-trained ML model for generating inferences. Additionally, in some cases, the generated inferences may need to be processed further, so that they can be easily consumed by downstream applications. This is a common scenario for use cases where a streaming data source needs to be processed in real time before a model can be fitted on it. However, this use case can manifest for batch inference as well.
SageMaker provides an option to customize inference containers and use them to build a serial inference pipeline. Inference containers use the SageMaker Inference Toolkit and are built on SageMaker Multi Model Server (MMS), which provides a flexible mechanism to serve ML models. The following diagram illustrates a reference pattern of how to implement a serial inference pipeline using inference containers.

SageMaker MMS expects a Python script that implements the following functions to load the model, preprocess input data, get predictions from the model, and postprocess the output data:
- input_fn() – Responsible for deserializing and preprocessing the input data
- model_fn() – Responsible for loading the trained model from artifacts in Amazon Simple Storage Service (Amazon S3)
- predict_fn() – Responsible for generating inferences from the model
- output_fn() – Responsible for serializing and postprocessing the output data (inferences)
For detailed steps to customize an inference container, refer to Adapting Your Own Inference Container.
Inference containers are an ideal design pattern for serial inference pipeline use cases with the following primary considerations:
- High cohesion – The processing logic and corresponding model drive single business functionality and need to be co-located
- Low overall latency – The elapsed time between when an inference request is made and response is received
In a serial inference pipeline, the processing logic and model are encapsulated within the same single container, so much of the invocation calls remain within the container. This helps reduce the overall number of hops, resulting in better overall latency and responsiveness of the pipeline.
Also, for use cases where ease of implementation is an important criterion, inference containers can help, with various processing steps of the pipeline be co-located within the same container.
Serial inference pipeline using a SageMaker inference pipeline
Another variation of the serial inference pipeline use case requires clearer decoupling between the various steps in the pipeline (such as data preprocessing, inference generation, data postprocessing, and formatting and serialization). This could be due to a variety of reasons:
- Decoupling – Various steps of the pipeline have a clearly defined purpose and need to be run on separate containers due to the underlying dependencies involved. This also helps keep the pipeline well structured.
- Frameworks – Various steps of the pipeline use specific fit-for-purpose frameworks (such as scikit or Spark ML) and therefore need to be run on separate containers.
- Resource Isolation – Various steps of the pipeline have varying resource consumption requirements and therefore need to be run on separate containers for more flexibility and control.
Furthermore, for slightly more complex serial inference pipelines, multiple steps may be involved to process a request and generate an inference. Therefore, from an operational standpoint, it may be beneficial to host these steps on separate containers for better functional isolation, and facilitate easier upgrades and enhancements (change one step without impacting other models or processing steps).
If your use case aligns with some of these considerations, a SageMaker inference pipeline provides an easy and flexible option to build a serial inference pipeline. The following diagram illustrates a reference pattern of how to implement a serial inference pipeline using multiple steps hosted on dedicated containers using a SageMaker inference pipeline.

A SageMaker inference pipeline consists of a linear sequence of 2–15 containers that process requests for inferences on data. The inference pipeline provides the option to use pre-trained SageMaker built-in algorithms or custom algorithms packaged in Docker containers. The containers are hosted on the same underlying instance, which helps reduce the overall latency and minimize cost.
The following code snippet shows how multiple processing steps and models can be combined to create a serial inference pipeline.
We start by building and specifying Spark ML and XGBoost-based models that we intend to use as part of the pipeline:
The models are then arranged sequentially within the pipeline model definition:
The inference pipeline is then deployed behind an endpoint for real-time inference by specifying the type and number of host ML instances:
The entire assembled inference pipeline can be considered a SageMaker model that you can use to make either real-time predictions or process batch transforms directly, without any external preprocessing. Within an inference pipeline model, SageMaker handles invocations as a sequence of HTTP requests originating from an external application. The first container in the pipeline handles the initial request, performs some processing, and then dispatches the intermediate response as a request to the second container in the pipeline. This happens for each container in the pipeline, and finally returns the final response to the calling client application.
SageMaker inference pipelines are fully managed. When the pipeline is deployed, SageMaker installs and runs all the defined containers on each of the Amazon Elastic Compute Cloud (Amazon EC2) instances provisioned as part of the endpoint or batch transform job. Furthermore, because the containers are co-located and hosted on the same EC2 instance, the overall pipeline latency is reduced.
Serial model ensemble using a SageMaker inference pipeline
An ensemble model is an approach in ML where multiple ML models are combined and used as part of the inference process to generate final inferences. The motivations for ensemble models could include improving accuracy, reducing model sensitivity to specific input features, and reducing single model bias, among others. In this post, we focus on the use cases related to a serial model ensemble, where multiple ML models are sequentially combined as part of a serial inference pipeline.
Let’s consider a specific example related to a serial model ensemble where we need to group a user’s uploaded images based on certain themes or topics. This pipeline could consist of three ML models:
- Model 1 – Accepts an image as input and evaluates image quality based on image resolution, orientation, and more. This model then attempts to upscale the image quality and sends the processed images that meet a certain quality threshold to the next model (Model 2).
- Model 2 – Accepts images validated through Model 1 and performs image recognition to identify objects, places, people, text, and other custom actions and concepts in images. The output from Model 2 that contains identified objects is sent to Model 3.
- Model 3 – Accepts the output from Model 2 and performs natural language processing (NLP) tasks such as topic modeling for grouping images together based on themes. For example, images could be grouped based on location or people identified. The output (groupings) is sent back to the client application.
The following diagram illustrates a reference pattern of how to implement multiple ML models hosted on a serial model ensemble using a SageMaker inference pipeline.

As discussed earlier, the SageMaker inference pipeline is managed, which enables you to focus on the ML model selection and development, while reducing the undifferentiated heavy lifting associated with building the serial ensemble pipeline.
Additionally, some of the considerations discussed earlier around decoupling, algorithm and framework choice for model development, and deployment are relevant here as well. For instance, because each model is hosted on a separate container, you have flexibility in selecting the ML framework that best fits each model and your overall use case. Furthermore, from a decoupling and operational standpoint, you can continue to upgrade or modify individual steps much more easily, without affecting other models.
The SageMaker inference pipeline is also integrated with the SageMaker model registry for model cataloging, versioning, metadata management, and governed deployment to production environments to support consistent operational best practices. The SageMaker inference pipeline is also integrated with Amazon CloudWatch to enable monitoring the multi-container models in inference pipelines. You can also get visibility into real-time metrics to better understand invocations and latency for each container in the pipeline, which helps with troubleshooting and resource optimization.
Serial inference pipeline (with targeted model invocation from a group) using a SageMaker inference pipeline
SageMaker multi-model endpoints (MMEs) provide a cost-effective solution to deploy a large number of ML models behind a single endpoint. The motivations for using multi-model endpoints could include invocating a specific customized model based on request characteristics (such as origin, geographic location, user personalization, and so on) or simply hosting multiple models behind the same endpoint to achieve cost-optimization.
When you deploy multiple models on a single multi-model enabled endpoint, all models share the compute resources and the model serving container. The SageMaker inference pipeline can be deployed on an MME, where one of the containers in the pipeline can dynamically serve requests based on the specific model being invoked. From a pipeline perspective, the models have identical preprocessing requirements and expect the same feature set, but are trained to align to a specific behavior. The following diagram illustrates a reference pattern of how this integrated pipeline would work.

With MMEs, the inference request that originates from the client application should specify the target model that needs to be invoked. The first container in the pipeline handles the initial request, performs some processing, and then dispatches the intermediate response as a request to the second container in the pipeline, which hosts multiple models. Based on the target model specified in the inference request, the model is invoked to generate an inference. The generated inference is sent to the next container in the pipeline for further processing. This happens for each subsequent container in the pipeline, and finally SageMaker returns the final response to the calling client application.
Multiple model artifacts are persisted in an S3 bucket. When a specific model is invoked, SageMaker dynamically loads it onto the container hosting the endpoint. If the model is already loaded in the container’s memory, invocation is faster because SageMaker doesn’t need to download the model from Amazon S3. If instance memory utilization is high and a new model is invoked and therefore needs to be loaded, unused models are unloaded from memory. The unloaded models remain in the instance’s storage volume, however, and can be loaded into the container’s memory later again, without being downloaded from the S3 bucket again.
One of the key considerations while using MMEs is to understand model invocation latency behavior. As discussed earlier, models are dynamically loaded into the container’s memory of the instance hosting the endpoint when invoked. Therefore, the model invocation may take longer when it’s invoked for the first time. When the model is already in the instance container’s memory, the subsequent invocations are faster. If an instance memory utilization is high and a new model needs to be loaded, unused models are unloaded. If the instance’s storage volume is full, unused models are deleted from the storage volume. SageMaker fully manages the loading and unloading of the models, without you having to take any specific actions. However, it’s important to understand this behavior because it has implications on the model invocation latency and therefore overall end-to-end latency.
Pipeline hosting options
SageMaker provides multiple instance type options to select from for deploying ML models and building out inference pipelines, based on your use case, throughput, and cost requirements. For example, you can choose CPU or GPU optimized instances to build serial inference pipelines, on a single container or across multiple containers. However, there are sometimes requirements where it is desired to have flexibility and support to run models on CPU or GPU based instances within the same pipeline for additional flexibility.
You can now use NVIDIA Triton Inference Server to serve models for inference on SageMaker for heterogeneous compute requirements. Check out Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker for additional details.
Conclusion
As organizations discover and build new solutions powered by ML, the tools required for orchestrating these pipelines should be flexible enough to support based on a given use case, while simplifying and reducing the ongoing operational overheads. SageMaker provides multiple options to design and build these serial inference workflows, based on your requirements.
We look forward to hearing from you about what use cases you’re building using serial inference pipelines. If you have questions or feedback, please share them in the comments.
About the authors
 Rahul Sharma is a Senior Solutions Architect at AWS Data Lab, helping AWS customers design and build AI/ML solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance sector, helping customers build data and analytical platforms.
Rahul Sharma is a Senior Solutions Architect at AWS Data Lab, helping AWS customers design and build AI/ML solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance sector, helping customers build data and analytical platforms.
 Anand Prakash is a Senior Solutions Architect at AWS Data Lab. Anand focuses on helping customers design and build AI/ML, data analytics, and database solutions to accelerate their path to production.
Anand Prakash is a Senior Solutions Architect at AWS Data Lab. Anand focuses on helping customers design and build AI/ML, data analytics, and database solutions to accelerate their path to production.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and making machine learning more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and making machine learning more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.