Prize recognizes pioneering work in statistical methodology, and aims to raise awareness of the impact of statistics on society.Read More
Cost efficient ML inference with multi-framework models on Amazon SageMaker
Machine learning (ML) has proven to be one of the most successful and widespread applications of technology, affecting a wide range of industries and impacting billions of users every day. With this rapid adoption of ML into every industry, companies are facing challenges in supporting low-latency predictions and with high availability while maximizing resource utilization and reducing associated costs. Because each ML framework has its own dependencies, and deployment steps for each framework are different, deploying models built in different frameworks in production and managing each of the endpoints becomes more and more complex.
Amazon SageMaker multi-container endpoints (MCEs) enables us to group models on different frameworks and deploy them to the same host, creating a single endpoint. You can provide containers for the different frameworks that you’re using to build the models, and SageMaker takes all of these containers and puts them behind one endpoint. For instance, you could have a PyTorch and a TensorFlow model loaded up on two dedicated endpoints serving the same or entirely different use cases, and both of these models have intermittent incoming traffic not utilizing resources to its limit. In such a scenario, you could club them together using containers into one endpoint using an MCE, improving the resource utilization while reducing the costs incurred in having both the models serving from different endpoints.
Multi-container endpoints provide a scalable and cost-effective solution to deploy up to 15 models built on different ML frameworks, model servers, and algorithms serving the same or different use case, meaning that you can have models built on diverse ML frameworks or intermediary steps across all of these containers and models. All these models can be accessed individually via direct invocation or stitched into a pipeline using serial invocation, where the output of one model is the input for the next one.
In this post, we discuss how to perform cost-efficient ML inference with multi-framework models on SageMaker.
MCE invocation patterns
SageMaker MCE direct invocation is useful in cases where you have clubbed unrelated models into an MCE endpoint or you’re running an A/B test between the models behind an MCE endpoint to gauge their performance. You can call the specific container directly in the API call and get the prediction from that model.
With serial invocation, you can stitch together 2–15 containers, and the output of one becomes the input of the next container in sequence. This is an ideal use case if, for example, you have a multi-step prediction pipeline where a Scikit-learn model is used for an intermediate prediction and the result is fed to a TensorFlow model for final inference. Instead of having them deployed as different endpoints and another application or job orchestrating them and making multiple API calls, you can deploy them as a SageMaker MCE, abstracting the logic and setting them up for serial invocation, where SageMaker manages the data transfer between one container to another automatically and emits the output of the final container to the client making the API request.
SageMaker MCE serial invocation is fundamentally different from a SageMaker serial inference pipeline (more details in the sections below). A serial inference pipeline is targeted more to orchestrate complex ML workflows such as data preprocessing, building a model ensemble, implementing conditional checks to determine which model to invoke, or postprocessing the prediction, involving business logic before the prediction is sent out to the downstream applications. In contrast, MCE serial invocation is designed to stitch 2–14 models into a pipeline for inference, each model taking the prediction of the previous model as input.
All the containers in an MCE are always in service and in memory, so there is no cold start while invoking the endpoint. MCEs also improve endpoint utilization and improve costs because models are deployed behind one endpoint and share the underlying compute instance, instead of each model occupying individual compute resources.
Let’s look at a few use cases and see how you can use SageMaker MCEs to optimize ML inference.
Use cases for SageMaker MCEs
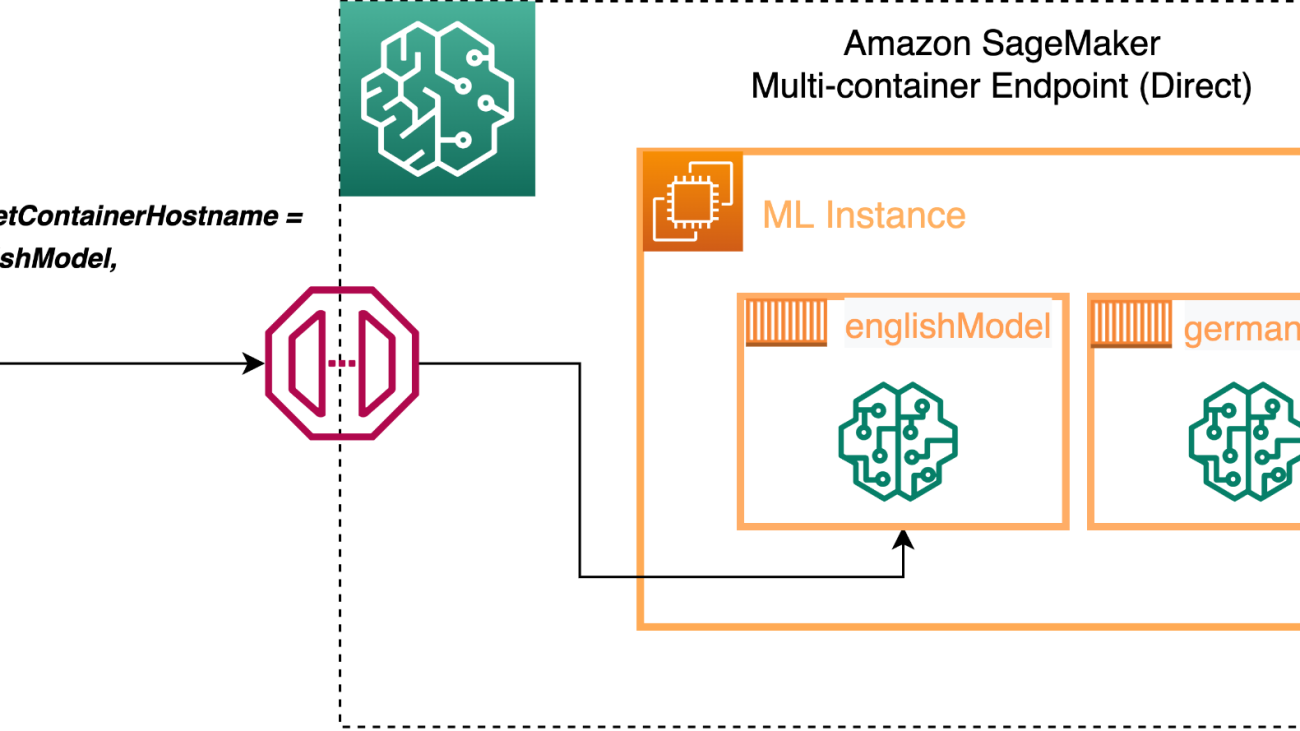
Suppose you have two models for sentiment classification, one for English language and other for German language, and these models are serving different geographies with traffic coming in at different times in a day. Instead of having two endpoints running 24/7, you can deploy both of them into one endpoint using an MCE and access them using direct invocation, thereby optimizing your resource utilization and costs. See the following code:
In this example, we have two models (englishModel and germanModel), and we define the containers in the SageMaker create_model construct and define the InferenceExecutionConfig as ‘Direct’. Now we can call the endpoint for inference and define the TargetContainerHostname as either englishModel or germanModel depending on the client making the API call:
You can also use direct invocation within the MCE to run A/B tests to compare the performance between the models.
The following diagram illustrates our architecture.

Similarly, in other ML use cases, when the trained model is used for processing a request, the model receives data in a format that needs to be preprocessed (for example, featurized) before it can be passed to the algorithm for inference. When ML algorithms are chained together, the output of one model serves as input for the next one before reaching the final result. In this case, you can build a SageMaker MCE serial pipeline, where the containers talk to each other in the sequence defined in the create_model construct instead of you deploying each of the models into different endpoints and writing an independent logic to facilitate the flow of data between all these models and API calls. The following diagram illustrates this architecture.

For this use case, we use the following code:
In this example, we have two processing containers (Processing-1 and Processing-2) for feature processing and data transformations, and two inference containers (Inference-1 and Inference-2) to run ML model predictions on the preprocessed data. The PipelineModel instance allows you to define the inference pipeline composed of a linear sequence of four containers that process requests for inference on data. The containers are co-located on the same instance, enabling you to run inference with low latency.
Scale multi-model endpoints for large numbers of models
The benefits of SageMaker multi-model endpoints increase based on the scale of model consolidation. You can see cost savings when hosting two models with one endpoint, and for use cases with hundreds or thousands of models, the savings are much greater.
Scaling the MCE endpoints is also straightforward using the SageMakerVariantInvocationsPerInstance predefined metric, which gives the average number of times per minute that each instance for a model endpoint is invoked to define a TargetScaling policy. SageMaker dynamically adjusts the number of instances provisioned for a model in response to changes in your workload. When the workload increases, autoscaling brings more instances online and loads with the target models and containers to keep up serving the requests. When the workload decreases, autoscaling removes unnecessary instances and offloads the model containers so that the containers don’t eat up the resources, and you don’t pay for instances that you aren’t using. The time to complete the first request against a given model experiences additional latency (called a cold start) to download the model from Amazon Simple Storage Service (Amazon S3) and load it into memory. Subsequent calls finish with no additional overhead because the model is already loaded. See the following code:
Following the preceding example policy configuration, we use the SageMakerVariantInvocationsPerInstance predefined metric to adjust the number of variant instances so that each instance has an InvocationsPerInstance metric of 70.
We can also scale SageMaker MCEs based on our own custom metric, such as CPUUtilization, MemoryUtilization, GPUUtilization, GPUMemoryUtilization, or DiskUtilization, to scale up or down the number of instances based on utilization of a specific resource. For more information, refer to Automatically Scale Amazon SageMaker Models.
It’s recommended that the model in each container exhibits similar compute and latency requirements on each inference request, because if traffic to the MCE shifts from a high CPU utilization model to a low CPU utilization model, but the overall call volume remains the same, the endpoint doesn’t scale out and there may not be enough instances to handle all the requests to the high CPU utilization model.
Secure MCEs
For MCEs with direct invocation, multiple containers are hosted in a single instance by sharing memory and a storage volume. It’s important to secure the containers, maintain the correct mapping of requests to target containers, and provide users with the correct access to target containers. You can restrict invoke_endpoint access to a limited set of containers inside an MCE using the sagemaker:TargetContainerHostname AWS Identity and Access Management (IAM) condition key. SageMaker uses IAM roles to provide IAM identity-based policies that you use to specify allowed or denied actions and resources and the conditions under which actions are allowed or denied. The following policies show how to limit calls to specific containers within an endpoint:
Monitor multi-model endpoints using Amazon CloudWatch metrics
To make price and performance trade-offs, you’ll want to test multi-model endpoints with models and representative traffic from your own application. SageMaker provides additional metrics in Amazon CloudWatch for multi-model endpoints so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. The metrics are as follows:
- ModelLoadingWaitTime – The interval of time that an invocation request waits for the target model to be downloaded or loaded to perform the inference.
- ModelUnloadingTime – The interval of time that it takes to unload the model through the container’s
UnloadModelAPI call. - ModelDownloadingTime – The interval of time that it takes to download the model from Amazon S3.
- ModelLoadingTime – The interval of time that it takes to load the model through the container’s
LoadModelAPI call. - ModelCacheHit – The number of
InvokeEndpointrequests sent to the endpoint where the model was already loaded. Taking theAveragestatistic shows the ratio of requests in which the model was already loaded. - LoadedModelCount – The number of models loaded in the containers in the endpoint. This metric is emitted per instance. The
Averagestatistic with a period of 1 minute tells you the average number of models loaded per instance, and theSumstatistic tells you the total number of models loaded across all instances in the endpoint. The models that this metric tracks aren’t necessarily unique because you can load a model in multiple containers in the endpoint.
There are also several other metrics that are used by each container running on an instance, such as Invocations indicating the number of InvokeEndpoint requests sent to a container inside an endpoint, ContainerLatency giving the time an endpoint took for the target container or all the containers in a serial invocation to respond as viewed from SageMaker, and CPUUtilization and MemoryUtilizaton indicating the CPU units and percentage of memory.
Conclusion
In the post, we discussed how SageMaker multi-container endpoints can be helpful in optimizing costs and resource utilization. Examples of when to utilize MCEs include, but are not limited to, the following:
- Hosting models across different frameworks (such as TensorFlow, PyTorch, and Scikit-learn) that don’t have sufficient traffic to saturate the full capacity of an instance
- Hosting models from the same framework with different ML algorithms (such as recommendations, forecasting, or classification) and handler functions
- Comparisons of similar architectures running on different framework versions (such as TensorFlow 1.x vs. TensorFlow 2.x) for scenarios like A/B testing
SageMaker MCEs support deploying up to 15 containers on real-time endpoints and invoking them independently for low-latency inference and cost savings. The models can be completely heterogenous, with their own independent serving stack. You can either invoke these containers sequentially or independently for each request. Securely hosting multiple models, from different frameworks, on a single instance could save you up to 90% in cost compared to hosting models in dedicated single-instance endpoints.
About the authors
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Vikram Elango is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps global financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps global financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Solve business problems end-to-end through machine learning in Amazon SageMaker JumpStart solutions
Amazon SageMaker JumpStart provides pre-trained, open-source models for a wide range of problem types to help you get started with machine learning (ML). JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker.
As a business user, you get to do the following with JumpStart solutions:
- Explore the solutions and evaluate which are a good match for your business needs.
- Launch solutions with a single click in Amazon SageMaker Studio. This launches an AWS CloudFormation template to create the required resources.
- Modify the solution to meet your needs with access to underlying notebook and model assets.
- Delete the acquired resources once done.
This post focuses on the five ML solutions that were recently added to address five different business challenges. As of this writing, JumpStart offers 23 business solutions varying from detecting fraud in financial transactions to recognizing handwriting. The number of solutions that are offered through JumpStart increase on a regular basis as more solutions are added to it.
Solution overview
The five new solutions are as follows:
- Price optimization – Offers customizable ML models to help you make optimal decisions for setting the price of your product or service in order to achieve your business objective, such as maximizing revenue, profit, or other custom metrics.
- Bird species prediction – Shows how you can train and fine-tune an object detection model. It demonstrates model tuning through training image augmentation, and charts the accuracy improvements that occur across the iterations (epochs) of the training job.
- Lung cancer survival prediction – Shows how you can feed 2D and 3D radiomic features and patient demographics to an ML algorithm to predict a patient’s lung cancer survival chances. The results from this prediction can help providers take appropriate proactive measures.
- Financial payment classification – Demonstrates how to train and deploy an ML model to classify financial transactions based on transaction information. You can also use this solution as an intermediate step in fraud detection, personalization, or anomaly detection.
- Churn prediction for mobile phone customers – Demonstrates how to quickly develop a churn prediction model using a mobile call transaction dataset. This is a simple example for users that are new to ML.
Prerequisites
To use these solutions, make sure that you have access to Studio with an execution role that allows you to run SageMaker functionality. For your user role within Studio, make sure that the SageMaker Projects and JumpStart option is turned on.
In the following sections, we go through each of the five new solutions and discuss how it works in detail, along with some recommendations on how you can use it for your own business needs.
Price optimization
Businesses like using various levers to fetch the best results. For example, the price of a product or a service is a lever that a business can control. The question is how to decide what price to set a product or service at, in order to maximize a business objective such as profit or revenue.
This solution provides customizable ML models to help you make optimal decisions for setting the price of your product or service in order to achieve your objective, such as maximizing revenue, profit, or other custom metrics. The solution uses ML and causal inference approaches to learn price-volume relations from historical data, and is able to make dynamic price recommendations in real time to optimize the custom objective metrics.
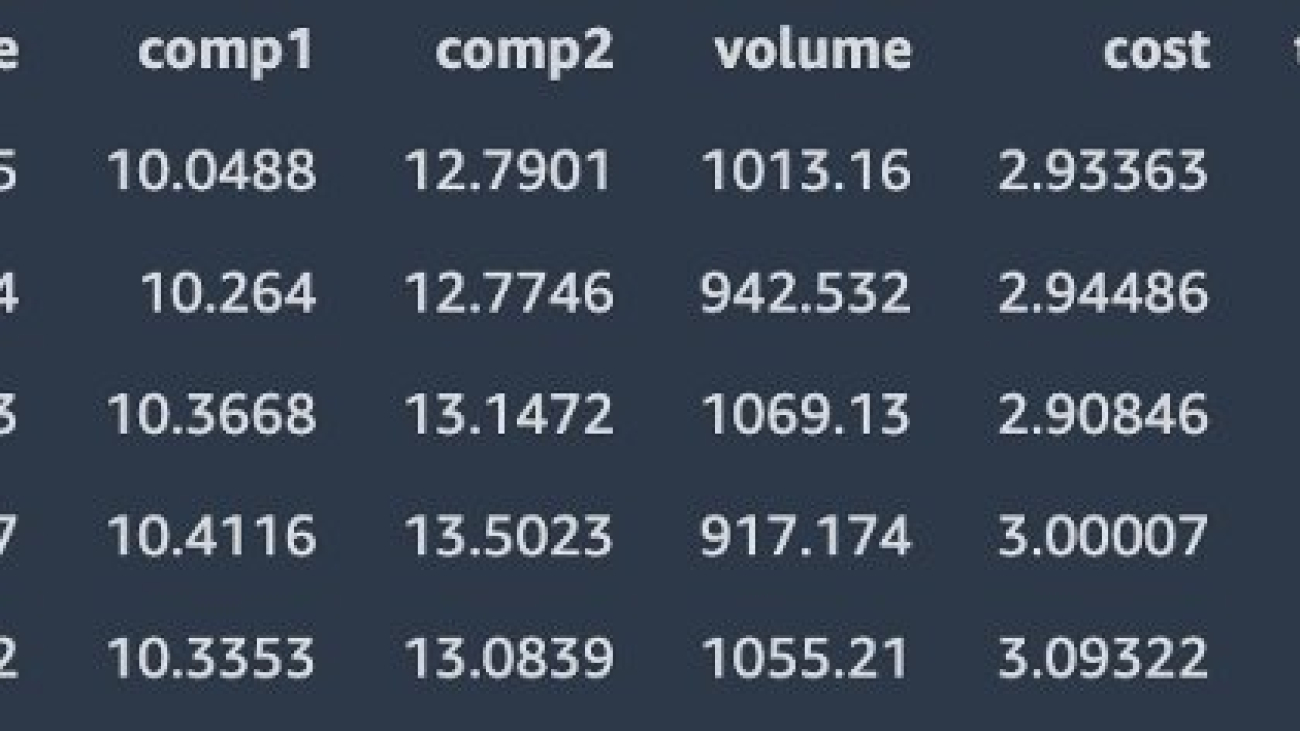
The following screenshot shows the sample input data.

The solution includes three parts:
- Price elasticity estimation – This is estimated by causal inference via a double ML algorithm
- Volume forecast – This is forecasted using the Prophet algorithm
- Price optimization – This is achieved by a what-if simulation through different price scenarios
The solution provides the recommended price for the next day for maximizing revenue. In addition, the outputs include the estimated price elasticity, which is a value indicating the effect of price on volume, and a forecast model, which is able to forecast the next day’s volume. The following chart shows how a causal model that incorporated the calculated price elasticity performs much better under a what-if analysis (with large deviations from behavior price) than a predictive model that uses Prophet for forecasting volume using time series data.

You could apply this solution to your business for the following use cases:
- Determine the optimal price of goods for a retail store
- Estimate the effect of discount coupons on customer purchases
- Predict the effect of various incentive methods in any business
Bird species prediction
There are several computer vision (CV) applications for businesses today. One of those applications is object detection, where an ML algorithm detects the location of an object in an image by drawing a bounding box around it, and identifies the type of object it is. Learning how to apply an object detection model and fine-tune it can be of great value to an organization that has CV needs.
This solution provides an example of how to translate bounding box specifications when providing images to the SageMaker algorithm. This solution also demonstrates how to improve an object detection model by adding training images that are flipped horizontally (mirror images).
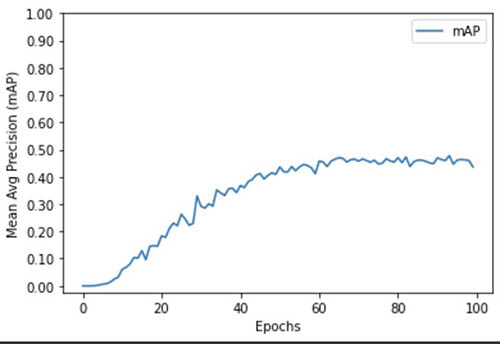
A notebook is provided for experimenting with object detection challenges when there are a large number of classes (200 bird species). The notebook also shows how to chart the accuracy improvements that occur across the epochs of the training job. The following image shows example images from the birds dataset.

This solution contains five steps:
- Prepare the data, including download and
RecordIOfile generation. - Create and train an object detection model.
- Deploy an endpoint and evaluate model performance.
- Create and train an object detection model again with the expanded dataset.
- Deploy an endpoint and evaluate the expanded model performance.
You get the following as output:
- Object detection results with bonding boxes against your test image
- A trained object detection model
- A trained object detection model with an additional expanded (flipped) dataset
- Two separate endpoints deployed with one of each model
The following chart shows model improvement against model iterations (epochs) during training.
The following examples are output from two test images.


You could apply this solution to your business for the following use cases:
- Detect objects on a conveyer belt in a packaging industry
- Detect toppings on a pizza
- Implement supply chain operational applications that involve object detection
Lung cancer survival prediction
COVID-19 brought a lot more attention to lung-related medical challenges. It has also put a lot of pressure on hospitals, doctors, nurses, and radiologists. Imagine a possibility where you can apply ML as a powerful tool to assist medical practitioners and help them speed up their work. In this solution, we show how 2D and 3D radiomic features and patient demographics can be fed to an ML algorithm to predict a patient’s lung cancer survival chances. Results from this prediction can help providers take appropriate proactive measures.
This solution demonstrates how to build a scalable ML pipeline for the Non-Small Cell Lung Cancer (NSCLC) Radiogenomics dataset, which consists of RNA sequencing data, clinical data (reflective of EHR data), and medical images. Using multiple types of data to create a machine model is referred to as multi-modal ML. This solution predicts survival outcome of patients diagnosed with non-small cell lung cancer.
The following image shows an example of the input data from the Non-Small Cell Lung Cancer (NSCLC) Radiogenomics dataset.

As part of the solution, total RNA was extracted from the tumor tissue and analyzed with RNA sequencing technology. Although the original data contains more than 22,000 genes, we keep 21 genes from 10 highly coexpressed gene clusters (metagenes) that were identified, validated in publicly available gene-expression cohorts, and correlated with prognosis.
The clinical records are stored in CSV format. Each row corresponds to a patient, and the columns contain information about the patients, including demographics, tumor stage, and survival status.
For genomic data, we keep 21 genes from 10 highly coexpressed gene clusters (metagenes) that were identified, validated in publicly available gene-expression cohorts, and correlated with prognosis.
For medical imaging data, we create patient-level 3D radiomic features that explain the size, shape, and visual attributes of the tumors observed in the CT scans. For each patient study, the following steps are performed:
- Read the 2D DICOM slice files for both the CT scan and tumor segmentation, combine them to 3D volumes, save the volumes in NIfTI format.
- Align CT volume and tumor segmentation so we can focus the computation inside the tumor.
- Compute radiomic features describing the tumor region using the pyradiomics library.
- Extract 120 radiomic features of eight classes, such as statistical representations of the distribution and co-occurrence of the intensity within tumorous region of interest, and shape-based measurements describing the tumor morphologically.
To create a multi-modal view of a patient for model training, we join the feature vectors from three modalities. We then process the data. First, we normalize the range of independent features using feature scaling. Then we perform principal component analysis (PCA) on the features to reduce the dimensionality and identify the most discriminative features that contribute 95% variance in the data.
This results in a dimensionality reduction from 215 features down to 45 principal components, which constitute features for the supervised learner.
The solution produces an ML model that predicts NSCLC patients’ survival status (dead or alive) in a form of probability. Besides the model and prediction, we also generate reports to explain the model. The medical imaging pipeline produces 3D lung CT volumes and tumor segmentation for visualization purposes.
You can apply this solution to healthcare and life sciences use cases.
Financial payment classification
Taking all financial transactions of a business or a consumer and organizing them into various categories can be quite helpful. It can help the user learn how much they have spent in which category, and it can also raise alerts when transactions or spending in a given category goes up or down unexpectedly.
This solution demonstrates how to train and deploy an ML model to classify financial transactions based on transaction information. Many banks provide this as a service to give their end-users an overview of their spending habits. You can also use this solution as an intermediate step in fraud detection, personalization, or anomaly detection. We use SageMaker to train and deploy an XGBoost model with the required underlying infrastructure.
The synthetic dataset that we to demonstrate this solution has the following features:
- transaction_category – The category of the transaction, out of the following 19 options:
Uncategorized,Entertainment,Education,Shopping,Personal Care,Health and Fitness,Food and Dining,Gifts and Donations,Investments,Bills and Utilities,Auto and Transport,Travel,Fees and Charges,Business Services,Personal Services,Taxes,Gambling,Home, andPension and insurances. - receiver_id – An identifier for the receiving party. The identifier consists of 16 numbers.
- sender_id – An identifier for the sending party. The identifier consists of 16 numbers.
- amount – The amount that is transferred.
- timestamp – The timestamp of the transaction in YYYY-MM-DD HH:MM:SS format.
The first five observations of the dataset are as follows:

For this solution, we use XGBoost, a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models. Its implementation is available in the SageMaker built-in algorithms.
The financial payment classification solution contains four steps:
- Prepare the data.
- Build a feature store.
- Create and train an XGBoost model.
- Deploy an endpoint and evaluate model performance.
We get the following output:
- A trained XGBoost model based on our example dataset
- A SageMaker endpoint that can predict the transaction category
After running this solution, you should see a classification report similar to the following.

Possible applications for your business include the following:
- Various financial applications in retail and investment banking
- When transactions need to be classified in any use case (not just financial)
Churn prediction for mobile phone customers
Predicting customer churn is a very common business need. Numerous studies show that the cost of retaining an existing customer is much less than acquiring a new customer. The challenge often comes from businesses having a tough time understanding why a customer is churning, or building a model that predicts churning.
In this example, users that are new to ML can experience how a churn prediction model can be quickly developed using a mobile call transaction dataset. This solution uses SageMaker to train and deploy an XGBoost model on a customer profile dataset to predict whether a customer is likely to leave a mobile phone operator.
The dataset this solution uses is publicly available and is mentioned in the book Discovering Knowledge in Data by Daniel T. Larose. It is attributed by the author to the University of California Irvine Repository of Machine Learning Datasets.
This dataset uses the following 21 attributes to describe the profile of a customer of an unknown US mobile operator.
- State: the US state in which the customer resides, indicated by a two-letter abbreviation; for example, OH or NJ
- Account Length: the number of days that this account has been active
- Area Code: the three-digit area code of the corresponding customer’s phone number
- Phone: the remaining seven-digit phone number
- Int’l Plan: whether the customer has an international calling plan: yes/no
- VMail Plan: whether the customer has a voice mail feature: yes/no
- VMail Message: the average number of voice mail messages per month
- Day Mins: the total number of calling minutes used during the day
- Day Calls: the total number of calls placed during the day
- Day Charge: the billed cost of daytime calls
- Eve Mins, Eve Calls, Eve Charge: the billed cost for calls placed during the evening
- Night Mins, Night Calls, Night Charge: the billed cost for calls placed during nighttime
- Intl Mins, Intl Calls, Intl Charge: the billed cost for international calls
- CustServ Calls: the number of calls placed to Customer Service
- Churn?: whether the customer left the service: true/false
This solution contains three stages:
- Prepare the data.
- Create and train an XGBoost model.
- Deploy an endpoint and evaluate model performance.
We get the following output:
- A trained XGBoost model based on our example dataset to predict user churn
- A SageMaker endpoint that can predict user churn
This model helps estimate how many of the 5,000 mobile phone customers are likely to stop using their current mobile phone operator.
The following chart shows a probability distribution of the churn as an output from the model.

You could apply this to your business for the following use cases:
- Predict customer churn in your own business
- Classify which customers may open your marketing email and who will not (binary classification)
- Predict which students are likely to drop out from a course
Clean up resources
After you’re done running a solution in JumpStart, make sure to choose Delete all resources so all the resources that you have created in the process are deleted and your billing is stopped.

Summary
This post showed you how to solve various business problems by applying ML, based on JumpStart solutions. Although this post focused on the five new solutions that were recently added to JumpStart, there are a total of 23 available solutions. We encourage you to log in to Studio and look at the JumpStart solutions yourselves and start deriving immediate value out of them. For more information, refer to Amazon SageMaker Studio and SageMaker JumpStart.
Note: If you don’t see all of the above five solutions in the JumpStart console of your AWS region, please wait for a week and check again. We are releasing them to various regions in a phased manner.
About the Authors
 Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He works on the low-code/no-code suite of services in SageMaker that help customers easily build and deploy machine learning models and solutions. When not helping customers, he likes traveling to new places.
Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He works on the low-code/no-code suite of services in SageMaker that help customers easily build and deploy machine learning models and solutions. When not helping customers, he likes traveling to new places.
 Manan Shah is a Software Development Manager at Amazon Web Services. He is an ML enthusiast and focuses on building no-code/low-code AI/ML products. He strives to empower other talented, technical people to build great software.
Manan Shah is a Software Development Manager at Amazon Web Services. He is an ML enthusiast and focuses on building no-code/low-code AI/ML products. He strives to empower other talented, technical people to build great software.

Train gigantic models with near-linear scaling using sharded data parallelism on Amazon SageMaker
In the pursuit of superior accuracy, deep learning models in areas such as natural language processing and computer vision have significantly grown in size in the past few years, frequently counted in tens to hundreds of billions of parameters. Training these gigantic models is challenging and requires complex distribution strategies. Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size.
This is why we recently launched sharded data parallelism on Amazon SageMaker, a new memory-saving distributed training technique in the SageMaker model parallel (SMP) library. Sharded data parallelism is purpose-built for extreme-scale models and uses Amazon in-house MiCS technology under the hood, a science effort to minimize the communication scale by bringing down expensive communication overhead rooted in parameter gathering and gradient synchronization. With a 30B parameter GPT-2 model with sequence length 2048, this new feature achieved 141 TFLOPs, a 39.7% speed up compared to DeepSpeed ZeRO-3. For a 10B GPT-2 model with sequence length 512, this new feature also achieved 564 samples per second, a 13.9% speed up compared to PyTorch’s Fully Sharded Data Parallel (FSDP). Remember that in gigantic model training, every percentage of speedup translates to dollars saved and productivity gained in your team.
In this blog post, we’ll first take a closer look at the key differentiators of sharded data parallelism and when to use it. Then, you’ll learn how to train a 30B parameter GPT-2 model on SageMaker with ease with this new feature. Finally we’ll compare the performance with other open source options, notably outperforming DeepSpeed ZeRO by up to 39.7% on 256 GPUs.
How sharded data parallelism works and when to use it
Before we introduce sharded data parallelism, let’s look at its broader technique family. Recent distributed training approaches for large models have moved to a paradigm where model parameters, gradients, and optimizer states are shared across data-parallel nodes. Unlike Pipeline Parallelism which has the innate complexity of choosing layers to partition across devices especially when your framework doesn’t support automated model splitting, this paradigm elegantly preserves the simplicity of data parallelism, while removing data parallelism’s constraint where a model must fit into a single GPU.
In existing frameworks that fall under this paradigm, notably DeepSpeed ZeRO-3 and PyTorch’s FSDP upstreamed from FairScale, model states are sharded across all GPUs, a strategy that lowers the memory consumption on each GPU at the cost of incurring large communication overhead which increases with cluster size and therefore causes the scalability to significantly drop at scale. In contrast, sharded data parallelism in the SMP library partitions model states in a scale-aware manner by partitioning each replica of model states only within a subset of GPUs.
Let’s look closer at the scale-aware model partitioning in MiCS, the core technology behind sharded data parallel. The intuition behind this design is that partitioning training states across the entire data-parallel group may not be required to train a model with tens of billions of parameters. For example, 8 V100 GPUs (32GB each) are sufficient to hold the model states replica of a 10B-parameter model which needs about 200GB of memory when training with Adam optimizer using mixed-precision. By limiting a complete replica of model states in the smallest subset of GPUs, we can effectively reduce the scale of communication overhead compared to DeepSpeed and PyTorch FSDP. Sharded data parallel also leverages other techniques in MiCS such as Hierarchical Communication and 2-hop Gradient Synchronization. For more information, check out Near-linear scaling of gigantic-model training on AWS or MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud.
Now, how do you know when to choose sharded data parallel over other distributed training techniques? The general rule is that if your model has less than 1 billion parameters and can fit into GPU memory, SageMaker data parallel library or SageMaker training compiler can be sufficient for you. If you have larger language or computer vision models, our suggestion is to train it with the sharded data parallelism technique combined with activation checkpointing and activation offloading in the SageMaker model parallel library first, before other techniques such as tensor parallelism or pipeline parallelism.
Using sharded data parallelism to train GPT-2 on Amazon SageMaker
Let’s now learn how to train a GPT-2 model with sharded data parallel, with SMP encapsulating the complexity for you. This complete tutorial notebook walks you through the entire process, from data processing, defining and submitting training jobs, to monitoring training logs. What follows is a brief overview highlighting key steps for using this feature.
1. Get started
Sharded data parallelism is available in PyTorch v1.12.0+ and works with both FP16 and BF16. The easiest way to use the SMP library is through a prebuilt AWS Deep Learning Container for PyTorch. However, if you want to bring your own Docker container, you can refer to Create Your Own Docker Container with the SageMaker Distributed Model Parallel Library. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. In this section, we only call out a few main steps with code snippets from the ready-to-use training script train_gpt_simple.py. You can follow the comments in the script and API document to learn more about where SMP APIs are used.
First, import and initialize the library by calling smdistributed.modelparallel.torch.init() at the beginning of the training script:
Second, wrap the model to be partitioned with smdistributed.modelparallel.torch.DistributedModel and use the returned DistributedModel object going forward:
Wrap the optimizer with smdistributed.modelparallel.torch.DistributedOptimizer for saving and loading optimizer states.
Put the forward and backward logic in a step function and decorate it with smdistributed.modelparallel.torch.step. Any computation defined inside the smp.step-decorated function is executed in a distributed manner.
2. Prepare the dataset
We use the openwebtext is the dataset we use in this example. The notebook uses the script data_prep_512.py to download and preprocess the dataset. You can also train with other datasets by modifying data_pipeline.py. When dealing with large dataset and model, you can speed up the training job by using data stored in Amazon FSx for Lustre, which provides a high-performance file system natively integrated with Amazon Simple Storage Service (S3). Please see the instructions from Configure Data Input Channel to Use Amazon FSx for Lustre for guidance on setting an FSx Lustre file system as data input channel.
3. Start the training jobs
This step assumes you have already modified your training script and prepared the dataset as mentioned in the preceding sections. To enable sharded data parallelism, simply set the sharded_data_parallel_degree in the PyTorch Estimator. In this tutorial, we set sharded_data_parallel_degree=128 and instace_count=32 for p4d.24xlarge nodes, which indicates that the model states will be sharded across 128 GPUs among the total 256 GPUs. Based on this selected value, SMP will then automatically sets the data parallel degree to 2 (because 256/128=2), meaning we’ll have two replicas for data parallelism. A general rule for picking an ideal value for sharded_data_parallel_degree is to add one more node to the sharing group per every 3B of model parameters. In this tutorial, our model size is 30B, so we should use at least 10 nodes for sharding. And because 16 nodes (128 GPUs) is the smallest power-of-2 above the threshold, we set sharded_data_parallel_degree=128.
For checkpointing, we also provide a set of checkpointing utilities in sharded_data_parallel_checkpoint.py , including a utility to reconstruct the full state_dict for advanced use cases. Finally, we can launch a distributed training job by calling fit() on the Estimator.
4. Monitor the training jobs
You can access the training logs and track GPU and memory utilization on Amazon CloudWatch. Make sure to look at the logs of “algo-1” because that is the main node whose output stream has the training job logs from all instances.
Benchmarking performance
We benchmarked sharded data parallelism in the SMP library on both 16 and 32 p4d.24xlarge nodes for sequence length 512 and 2048, respectively. The 30B-parameter GPT2 model is configured to use a hidden width of 7168, 48 layers, and 64 heads. You can adopt the exact same configuration where sequence length is 2048 by setting model_config = "gpt2-30b" in the tutorial notebook. With this setting, SMP achieved 73.52 samples per second, a 39.7% speed up compared to DeepSpeed ZeRO-3. If your token size is 500 billion, this speed up means nearly 367 hours of savings on p4d.24xlarge nodes, an equivalent of more than $12,000 budget saved per training! The following table summarizes our benchmark results.
| Configuration | Performance | Time to train with SMP (days) | |||||||
| Model/Training | Cluster | DeepSpeed | SMP | Speed (samples/sec) DeepSpeed v0.7.2 |
Speed (samples/sec) SMP v1.11 |
% Speedup of SMP | TFLOPS achieved by SMP | 100 billion tokens | 500 billion tokens |
| 30B GPT-2 Seq length:512 Global batch size:3072 FP16 |
16 p4d.24xlarge nodes | Activation checkpointing gradient_accumulation_steps:2 |
Activation checkpointing sharded_data_parallel_degree:64 gradient_accumulation:1 |
142 | 181.05 | 27.5 | 173.6 | 12.49 | 62.43 |
| 30B GPT-2 Seq length:2048 Global batch size 1536 FP16 |
32 p4d.24xlarge nodes | Activation checkpointing gradient_accumulation_steps:2 |
Activation checkpointing sharded_data_parallel_degree:128 gradient_accumulation:1 |
52.6 | 73.52 | 39.77 | 141 | 7.69 | 38.43 |
1/ For each model configuration, we tested different features, stages, and configurations in DeepSpeed ZeRO and chose the one that provides the best throughput as the DeepSpeed baseline. The benchmark was run on Amazon Elastic Compute Cloud (Amazon EC2). 2/ These results rely on improved communication collectives optimized for AWS which will be made available soon. 3/ Time to train is projected from speed based on number of tokens processed.
In summary, we observed consistently higher throughput with sharded data parallelism in SMP when compared to DeepSpeed across a range of models and configurations. This new feature also demonstrated a better memory efficiency compared to DeepSpeed, enabling SMP to fit a larger batch size and reduce the level of gradient accumulation required to fit a particular global batch size.
Conclusion
In this post, we introduced a new distributed training technique — sharded data parallelism — and how it speeds up gigantic model training with near linear-scaling on Amazon SageMaker. We also walked through how to train a GPT-2 model with the new technique following this complete example. You can follow the Amazon SageMaker Examples GitHub repo to track all SageMaker model parallel examples or attend our next distributed training workshops. To learn more about sharded data parallelism, please see the documentation.
About the authors
 Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
 Can Karakus is a Senior Applied Scientist at AWS, optimizing large-scale distributed deep learning on AWS. His research interests cover deep learning, distributed optimization, distributed systems, and information theory. Outside of work, he enjoys cycling, traveling, reading and learning.
Can Karakus is a Senior Applied Scientist at AWS, optimizing large-scale distributed deep learning on AWS. His research interests cover deep learning, distributed optimization, distributed systems, and information theory. Outside of work, he enjoys cycling, traveling, reading and learning.
 Rahul Huilgol is a Senior Software Engineer at AWS. He works on distributed deep learning systems, towards making it easy and performant to train large deep learning models in the cloud. In his spare time, he enjoys photography, biking and gardening.
Rahul Huilgol is a Senior Software Engineer at AWS. He works on distributed deep learning systems, towards making it easy and performant to train large deep learning models in the cloud. In his spare time, he enjoys photography, biking and gardening.
 Suhit Kodgule is a Software Development Engineer with AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling and cooking.
Suhit Kodgule is a Software Development Engineer with AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling and cooking.
 Erin Ho is a Product Manager for AWS Deep Learning. She works on products that make it easier for customers to train deep learning models on AWS. For fun outside work, she enjoys hiking and skiing.
Erin Ho is a Product Manager for AWS Deep Learning. She works on products that make it easier for customers to train deep learning models on AWS. For fun outside work, she enjoys hiking and skiing.
David Schuster’s quest to make practical quantum computers a reality
With quantum computers poised to take a big step forward, we speak to an Amazon Scholar who has spent two decades driving the technology to realize its enormous potential.Read More
Amazon SCOT announces 2022 INFORMS Scholars
Program was established to help expand the pipeline of operations research, management science, and analytics talent from underrepresented backgrounds.Read More
reMARS revisited: Autonomous mobile robots and safety design
Examining the opportunities for creating a functional safety certification for autonomous mobile robots.Read More
Improve price performance of your model training using Amazon SageMaker heterogeneous clusters
This post is co-written with Chaim Rand from Mobileye.
Certain machine learning (ML) workloads, such as training computer vision models or reinforcement learning, often involve combining the GPU- or accelerator-intensive task of neural network model training with the CPU-intensive task of data preprocessing, like image augmentation. When both types of tasks run on the same instance type, the data preprocessing gets bottlenecked on CPU, leading to lower GPU utilization. This issue becomes worse with time as the throughput of newer generations of GPUs grows at a steeper pace than that of CPUs.
To address this issue, in July 2022, we launched heterogeneous clusters for Amazon SageMaker model training, which enables you to launch training jobs that use different instance types in a single job. This allows offloading parts of the data preprocessing pipeline to compute-optimized instance types, whereas the deep neural network (DNN) task continues to run on GPU or accelerated computing instance types. Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training.
For a similar use case, Mobileye, an autonomous vehicle technologies development company, had this to share:
“By moving CPU-bound deep learning computer vision model training to run over multiple instance types (CPU and GPU/ML accelerators), using a tf.data.service based solution we’ve built, we managed to reduce time to train by 40% while reducing the cost to train by 30%. We’re excited about heterogeneous clusters allowing us to run this solution on Amazon SageMaker.”
— AI Engineering, Mobileye
In this post, we discuss the following topics:
- How heterogeneous clusters help remove CPU bottlenecks
- When to use heterogeneous clusters, and other alternatives
- Reference implementations in PyTorch and TensorFlow
- Performance benchmark results
- Heterogeneous clusters at Mobileye
AWS’s accelerated computing instance family includes accelerators from AWS custom chips (AWS Inferentia, AWS Trainium), NVIDIA (GPUs), and Gaudi accelerators from Habana Labs (an Intel company). Note that in this post, we use the terms GPU and accelerator interchangeably.
How heterogeneous clusters remove data processing bottlenecks
Data scientists who train deep learning models aim to maximize training cost-efficiency and minimize training time. To achieve this, one basic optimization goal is to have high GPU utilization, the most expensive and scarce resource within the Amazon Elastic Compute Cloud (Amazon EC2) instance. This can be more challenging with ML workloads that combine the classic GPU-intensive neural network model’s forward and backward propagation with CPU-intensive tasks, such as data processing and augmentation in computer vision or running an environment simulation in reinforcement learning. These workloads can end up being CPU bound, where having more CPU would result in higher throughput and faster and cheaper training as existing accelerators are partially idle. In some cases, CPU bottlenecks can be solved by switching to another instance type with a higher CPU:GPU ratio. However, there are situations where switching to another instance type may not be possible due to the instance family’s architecture, storage, or networking dependencies.
In such situations, you have to increase the amount of CPU power by mixing instance types: instances with GPUs together with CPU. Summed together, this results in an overall higher CPU:GPU ratio. Until recently, SageMaker training jobs were limited to having instances of a single chosen instance type. With SageMaker heterogeneous clusters, data scientists can easily run a training job with multiple instance types, which enables offloading some of the existing CPU tasks from the GPU instances to dedicated compute-optimized CPU instances, resulting in higher GPU utilization and faster and more cost-efficient training. Moreover, with the extra CPU power, you can have preprocessing tasks that were traditionally done offline as a preliminary step to training become part of your training job. This makes it faster to iterate and experiment over both data preprocessing and DNN training assumptions and hyperparameters.
For example, consider a powerful GPU instance type, ml.p4d.24xlarge (96 vCPU, 8 x NVIDIA A100 GPUs), with a CPU:GPU ratio of 12:1. Let’s assume your training job needs 20 vCPUs to preprocess enough data to keep one GPU 100% utilized. Therefore, to keep all 8 GPUs 100% utilized, you need a 160 vCPUs instance type. However, ml.p4d.24xlarge is short of 64 vCPUs, or 40%, limiting GPU utilization to 60%, as depicted on the left of the following diagram. Would adding another ml.p4d.24xlarge instance help? No, because the job’s CPU:GPU ratio would remain the same.
With heterogeneous clusters, we can add two ml.c5.18xlarge (72 vCPU), as shown on the right of the diagram. The net total vCPU in this cluster is 210 (96+2*72), leading to a CPU:GPU ratio to 30:1. Each of these compute-optimized instances will be offloaded with a data preprocessing CPU-intensive task, and will allow efficient GPU utilization. Despite the extra cost of the ml.c5.18xlarge, the higher GPU utilization allows faster processing, and therefore higher price performance benefits.

When to use heterogeneous clusters, and other alternatives
In this section, we explain how to identify a CPU bottleneck, and discuss solving it using instance type scale up vs. heterogeneous clusters.
The quick way to identify a CPU bottleneck is to monitor CPU and GPU utilization metrics for SageMaker training jobs in Amazon CloudWatch. You can access these views from the AWS Management Console within the training job page’s instance metrics hyperlink. Pick the relevant metrics and switch from 5-minute to 1-minute resolution. Note that the scale is 100% per vCPU or GPU, so the utilization rate for an instance with 4 vCPUs/GPUs could be as high as 400%. The following figure is one such example from CloudWatch metrics, where CPU is approximately 100% utilized, indicating a CPU bottleneck, whereas GPU is underutilized.

For detailed diagnosis, run the training jobs with Amazon SageMaker Debugger to profile resource utilization status, statistics, and framework operations, by adding a profiler configuration when you construct a SageMaker estimator using the SageMaker Python SDK. After you submit the training job, review the resulting profiler report for CPU bottlenecks.
If you conclude that your job could benefit from a higher CPU:GPU compute ratio, first consider scaling up to another instance type in the same instance family, if one is available. For example, if you’re training your model on ml.g5.8xlarge (32 vCPUs, 1 GPU), consider scaling up to ml.g5.16xlarge (64 vCPUs, 1 GPU). Or, if you’re training your model using multi-GPU instance ml.g5.12xlarge (48 vCPUs, 4 GPUs), consider scaling up to ml.g5.24xlarge (96 vCPUs, 4 GPUs). Refer to the G5 instance family specification for more details.
Sometimes, scaling up isn’t an option, because there is no instance type with a higher vCPU:GPU ratio in the same instance family. For example, if you’re training the model on ml.trn1.32xlarge, ml.p4d.24xlarge, or ml.g5.48xlarge, you should consider heterogeneous clusters for SageMaker model training.
Besides scaling up, we’d like to note that there are additional alternatives to a heterogeneous cluster, like NVIDIA DALI, which offloads image preprocessing to the GPU. For more information, refer to Overcoming Data Preprocessing Bottlenecks with TensorFlow Data Service, NVIDIA DALI, and Other Methods.
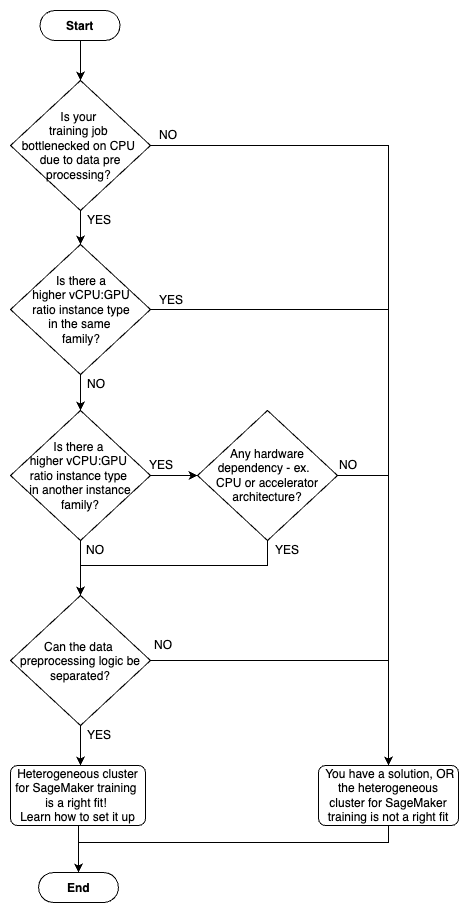
To simplify decision-making, refer to the following flowchart.
How to use SageMaker heterogeneous clusters
To get started quickly, you can directly jump to the TensorFlow or PyTorch examples provided as part of this post.
In this section, we walk you through how to use a SageMaker heterogeneous cluster with a simple example. We assume that you already know how to train a model with the SageMaker Python SDK and the Estimator class. If not, refer to Using the SageMaker Python SDK before continuing.
Prior to this feature, you initialized the training job’s Estimator class with the InstanceCount and InstanceType parameters, which implicitly assumes you only have a single instance type (a homogeneous cluster). With the release of heterogeneous clusters, we introduced the new sagemaker.instance_group.InstanceGroup class. This represents a group of one or more instances of a specific instance type, designed to carry a logical role (like data processing or neural network optimization. You can have two or more groups, and specify a custom name for each instance group, the instance type, and the number of instances for each instance group. For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs.
After you have defined the instance groups, you need to modify your training script to read the SageMaker training environment information that includes heterogeneous cluster configuration. The configuration contains information such as the current instance groups, the current hosts in each group, and in which group the current host resides with their ranking. You can build logic in your training script to assign the instance groups to certain training and data processing tasks. In addition, your training script needs to take care of inter-instance group communication or distributed data loading mechanisms (for example, tf.data.service in TensorFlow or generic gRPC client-server) or any other framework (for example, Apache Spark).
Let’s go through a simple example of launching a heterogeneous training job and reading the environment configuration at runtime.
- When defining and launching the training job, we configure two instance groups used as arguments to the SageMaker estimator:
from sagemaker.instance_group import InstanceGroup data_group = InstanceGroup("data_group", "ml.c5.18xlarge", 2) dnn_group = InstanceGroup("dnn_group", "ml.p4d.24xlarge", 1) from sagemaker.pytorch import PyTorch estimator = PyTorch(..., entry_point='launcher.py', instance_groups=[data_group, dnn_group] ) - On the entry point training script (named
launcher.py), we read the heterogeneous cluster configuration to whether the instance will run the preprocessing or DNN code:
With this, let’s summarize the tasks SageMaker does on your behalf, and the tasks that you are responsible for.
SageMaker performs the following tasks:
- Provision different instance types according to instance group definition.
- Provision input channels on all or specific instance groups.
- Distribute training scripts and dependencies to instances.
- Set up an MPI cluster on a specific instance group, if defined.
You are responsible for the following tasks:
- Modify your start training job script to specify instance groups.
- Implement a distributed data pipeline (for example,
tf.data.service). - Modify your entry point script (see
launcher.pyin the example notebook) to be a single entry point that will run on all the instances, detect which instance group it’s running in, and trigger the relevant behavior (such as data processing or DNN optimization). - When the training loop is over, you must make sure that your entry point process exits on all instances across all instance groups. This is important because SageMaker waits for all the instances to finish processing before it marks the job as complete and stops billing. The
launcher.pyscript in the TensorFlow and PyTorch example notebooks provides a reference implementation of signaling data group instances to exit when DNN group instances finish their work.
Example notebooks for SageMaker heterogeneous clusters
In this section, we provide a summary of the example notebooks for both TensorFlow and PyTorch ML frameworks. In the notebooks, you can find the implementation details, walkthroughs on how the code works, code snippets that you could reuse in your training scripts, flow diagrams, and cost-comparison analysis.
Note that in both examples, you shouldn’t expect the model to converge in a meaningful way. Our intent is only to measure the data pipeline and neural network optimization throughput expressed in epoch/step time. You must benchmark with your own model and dataset to produce price performance benefits that match your workload.
Heterogeneous cluster using a tf.data.service based distributed data loader (TensorFlow)
This notebook demonstrates how to implement a heterogeneous cluster for SageMaker training using TensorFlow’s tf.data.service based distributed data pipeline. We train a deep learning computer vision model Resnet50 that requires CPU-intensive data augmentation. It uses Horvod for multi-GPU distributed data parallelism.
We run the workload in two configurations: first as a homogeneous cluster, single ml.p4d.24xlarge instance, using a standard tf.data pipeline that showcases CPU bottlenecks leading to lower GPU utilization. In the second run, we switch from a single instance type to two instance groups using a SageMaker heterogeneous cluster. This run offloads some of the data processing to additional CPU instances (using tf.data.service).
We then compare the homogeneous and heterogeneous configurations and find key price performance benefits. As shown in the following table, the heterogeneous job (86ms/step) is 2.2 times faster to train than the homogeneous job (192ms/step), making it 46% cheaper to train a model.
| Example 1 (TF) | ml.p4d.24xl | ml.c5.18xl | Price per Hour* | Average Step Time | Cost per Step | Price Performance Improvement |
| Homogeneous | 1 | 0 | $37.688 | 192 ms | $0.201 | . |
| Heterogeneous | 1 | 2 | $45.032 | 86 ms | $0.108 | 46% |
* Price per hour is based on us-east-1 SageMaker on-demand pricing
This speedup is made possible by utilizing the extra vCPU, provided by the data group, and faster preprocessing. See the notebook for more details and graphs.
Heterogeneous cluster using a gRPC client-server based distributed data loader (PyTorch)
This notebook demonstrates a sample workload using a heterogeneous cluster for SageMaker training using a gRPC client-server based distributed data loader. This example uses a single GPU. We use the PyTorch model based on the following official MNIST example. The training code has been modified to be heavy on data preprocessing. We train this model in both homogeneous and heterogeneous cluster modes, and compare price performance.
In this example, we assumed the workload can’t benefit from multiple GPUs, and has dependency on a specific GPU architecture (NVIDIA V100). We ran both homogeneous and heterogeneous training jobs, and found key price performance benefits, as shown in the following table. The heterogeneous job (1.19s/step) is 6.5 times faster to train than the homogeneous job (0.18s/step), making it 77% cheaper to train a model.
| Example 2 (PT) | ml.p3.2xl | ml.c5.9xl | Price per Hour* | Average Step Time | Cost per Step | Price Performance Improvement |
| Homogeneous | 1 | 0 | $3.825 | 1193 ms | $0.127 | . |
| Heterogeneous | 1 | 1 | $5.661 | 184 ms | $0.029 | 77% |
* Price per hour is based on us-east-1 SageMaker on-demand pricing
This is possible because with a higher CPU count, we could use 32 data loader workers (compared to 8 with ml.p3.2xlarge) to preprocess the data and kept GPU close to 100% utilized at frequent intervals. See the notebook for more details and graphs.
Heterogeneous clusters at Mobileye
Mobileye, an Intel company, develops Advanced Driver Assistance Systems (ADAS) and autonomous vehicle technologies with the goal of revolutionizing the transportation industry, making roads safer, and saving lives. These technologies are enabled using sophisticated computer vision (CV) models that are trained using SageMaker on large amounts of data stored in Amazon Simple Storage Service (Amazon S3). These models use state-of-the-art deep learning neural network techniques.
We noticed that for one of our CV models, the CPU bottleneck was primarily caused by heavy data preprocessing leading to underutilized GPUs. For this specific workload, we started looking at alternative solutions, evaluated distributed data pipeline technologies with heterogeneous clusters based on EC2 instances, and came up with reference implementations for both TensorFlow and PyTorch. The release of the SageMaker heterogeneous cluster allows us to run this and similar workloads on SageMaker to achieve improved price performance benefits.
Considerations
With the launch of the heterogeneous cluster feature, SageMaker offers a lot more flexibility in mixing and matching instance types within your training job. However, consider the following when using this feature:
- The heterogeneous cluster feature is available through SageMaker PyTorch and TensorFlow framework estimator classes. Supported frameworks are PyTorch v1.10 or later and TensorFlow v2.6 or later.
- All instance groups share the same Docker image.
- All instance groups share the same training script. Therefore, your training script should be modified to detect which instance group it belongs to and fork runs accordingly.
- The training instances hostnames (for example, alog-1, algo-2, and so on) are randomly assigned, and don’t indicate which instance group they belong to. To get the instance’s role, we recommend getting its instance group membership during runtime. This is also relevant when reviewing logs in CloudWatch, because the log stream name
[training-job-name]/algo-[instance-number-in-cluster]-[epoch_timestamp]has the hostname. - A distributed training strategy (usually an MPI cluster) can be applied only to one instance group.
- SageMaker Managed Warm Pools and SageMaker Local Mode cannot currently be used with heterogeneous cluster training.
Conclusion
In this post, we discussed when and how to use the heterogeneous cluster feature of SageMaker training. We demonstrated a 46% price performance improvement on a real-world use case and helped you get started quickly with distributed data loader (tf.data.service and gRPC client-server) implementations. You can use these implementations with minimal code changes in your existing training scripts.
To get started, try out our example notebooks. To learn more about this feature, refer to Train Using a Heterogeneous Cluster.
About the authors
 Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
 Hrushikesh Gangur is a principal solutions architect for AI/ML startups with expertise in both ML Training and AWS Networking. He helps startups in Autonomous Vehicle, Robotics, CV, NLP, MLOps, ML Platform, and Robotics Process Automation technologies to run their business efficiently and effectively on AWS. Prior to joining AWS, Hrushikesh acquired 20+ years of industry experience primarily around Cloud and Data platforms.
Hrushikesh Gangur is a principal solutions architect for AI/ML startups with expertise in both ML Training and AWS Networking. He helps startups in Autonomous Vehicle, Robotics, CV, NLP, MLOps, ML Platform, and Robotics Process Automation technologies to run their business efficiently and effectively on AWS. Prior to joining AWS, Hrushikesh acquired 20+ years of industry experience primarily around Cloud and Data platforms.
 Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
 Chaim Rand is a machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye, an Intel Company. Check out his blogs.
Chaim Rand is a machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye, an Intel Company. Check out his blogs.
Reduce food waste to improve sustainability and financial results in retail with Amazon Forecast
With environmental, social, and governance (ESG) initiatives becoming more important for companies, our customer, one of Greater China region’s top convenience store chains, has been seeking a solution to reduce food waste (currently over $3.5 million USD per year). Doing so will allow them to not only realize substantial operating savings, but also support corporate sustainability goals.
In this post, we focus on forecasting demand of freshly prepared food by retail convenience stores. Our customer sells ready-to-eat food items with a short shelf life—typically 2–3 days. They faced two challenges: how to reduce food waste, and how to manage forecast models for over 10,000 SKUs and thousands of stores efficiently and at scale.
With Amazon Forecast, and support from the AWS ProServe team and AWS Machine Learning Solutions Lab, our customer—with limited internal data scientists—now has state-of-the-art forecasting capabilities. Within a few months, this forecasting solution has helped them reduce product waste by 37%, resulting in cost savings of 22% across 168 stores and three merchandise categories.
To achieve these operational benefits, they implemented a number of best practice processes, including a fast data iteration and testing cycle, and parallel testing to find optimal data combinations. They also established data processing and forecasting pipelines, which can scale to thousands of stores and product categories, and developed a scalable reference architecture to be used for future extensions.
The fresh foods ESG challenge
In addition to selling environmentally sustainable products, it’s also important for the retail industry to strive for environmentally friendly processes that minimize waste. Advanced inventory forecasting using machine learning (ML) allows retail stores to maximize sales and minimize waste through more effective inventory management and turnover. Inventory that can’t be sold is a problem for convenience store chains—it drives financial losses and furthers negative environmental effects through excess usage of energy inputs and inefficient production processes. And due to large volumes, short-dated fresh food items can play a big role in both financial and sustainability results.
Besides having a short shelf life, additional demand forecasting challenges for fresh food include rapid turnover, frequent new product launches, and high SKU volumes. Specifically:
- Compared to other categories, short-dated perishables must be sold within a short time window, otherwise they will expire and be discarded. Therefore, accurate forecasting is more important than for items that can be stored and sold over a longer time period.
- New product launches are frequent, making forecasting more challenging at the SKU-level (the cold start problem).
- A large number of items can cause model management issues for traditional algorithms such as ARIMA, which are configured for each item. Many models will need to be maintained, which is both costly and hard to scale.
Inventory forecasting
Amazon Forecast is a fully managed AI/ML service from AWS, and includes both statistical and deep learning algorithms that are based on over 20 years of forecasting experience. With item-level ensemble modeling and automatic model hyperparameter optimization, it provides forecasts that are up to 40% more accurate that using traditional methods alone. In addition, features such as predictor retraining can reduce training time and cost by up to 50%.
To optimize inventory forecasting, we looked at the main drivers of demand. Even within the fresh food category, there are items that are more popular—with higher inventory turnover—and items that sell slower. By separating popular from unpopular items and training predictors, we found that predictors can fit the dataset better and enhance model accuracy with different statistical distributions. In addition, because Forecast provides probabilistic forecasts based on customer-selected quantiles, we set up prediction quantiles based on item expiration dates and item profitability.
To implement demand forecasting that enhances sustainability, we also considered industry-specific properties:
- Short lead times
- High order frequencies
- Product alternatives and substitutes
- Consumer psychology (often, consumers are more likely to make a purchase if they have a diverse set of products to select from)
To balance shelf diversity against inventory wastage, we not only produced daily demand forecasts, but also performed what-if analyses to optimize promotion of unsold items before they expire.
We were able to incorporate these considerations and address our customer’s requirements with Forecast. In the next section, we walk through how the customer solution has been created in more detail.
Solution overview
To train a predictor, training data is ingested into data storage from a data source, using one of the formats supported by Forecast. Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. In the ingestion phase, we transform data from our source to the Forecast dataset format. Forecast uses three types of data: target time series (TTS), which is required, and related time series (RTS) and item metadata (IM), both of which are optional.
We started with the most-wasted SKUs at the stores that had the most waste. To forecast each store’s daily demand, we first started with time series (revenues, inventories, promotions) and then fine-tuned our approach based on store properties such as whether it’s a franchise or company-owned store, store type, restroom availability, store size (small or large), and store age. We also used industry knowledge, such as local holidays, promotions, weather, and daily traffic. Our TTS dataset consisted of timestamp, item ID, and demand; RTS consisted of timestamp, item ID, discount, inventory, and weather; and the IM dataset consisted of item ID, category, and store infrastructures. To quantify the importance of these features on our forecasts, we used explainability—a Forecast built-in feature that measures the relative impact of different attributes on forecast values.
A dataset must be created and associated with a dataset group to train the predictor. When creating a predictor, Forecast automatically selects the right algorithms, tunes hyperparameters, and performs ensemble modeling. In an interesting finding from this case, we used cross-COVID-19 data (from 2018–2021) to train the model and found that we didn’t need to add other COVID-19 features such as number of daily confirmed cases. The deep neural network models can learn directly from daily revenue.
The following diagram illustrates the solution architecture.

Our customer maintains their transactional records in Amazon Relational Database Service (Amazon RDS). We also use AWS Glue to conduct ETL (extract, transform, and load), read data covering the target SKUs across a meaningful time range, and load data to Amazon S3 with an indicated prefix. After data is loaded to Amazon S3, an S3 event triggers AWS Lambda and invokes AWS Step Functions as an orchestration tool.
In Step Functions, we prepare datasets that include target time series, related time series, and item metadata. We use an AWS Glue job to process the data into an S3 bucket. We can then call a Forecast API to create a dataset group and import data from the processed S3 bucket. When those datasets are ready, we can start to train the predictor.
To train a predictor, Forecast ensemble models six different algorithms and applies the optimal combination of algorithms to each time series in your dataset. We use the AutoPredictor API, which is also accessible through the Forecast console.
After the predictors have been created, we evaluated their quality metrics in the predictors dashboard. You can choose the predictor name to examine detailed results such as Weighted Quantile Loss (wQL), Weighted Absolute Percentage Error (WAPE), Mean Absolute Scaled Error (MASE), Root Mean Squared Error (RMSE), and Mean Absolute Percentage Error (MAPE). For customized evaluation and analysis, you can also export the forecasted values to evaluate predictor quality metrics. In this case, we used the customer’s original metric—MAPE—to produce a side-by-side comparison with the customer’s legacy model (ARIMA), and ensure that the Forecast model produced better results (a lower MAPE). For future model quality analyses, we recommended that the customer use RMSE, which better accounts for the fact that different items have different sales volumes.
After our predictor was ready, we generated forecast results for every item (item_id) and dimension (store_id) indicated in our target time series dataset. Forecast places results in an S3 bucket with the S3 prefix as the destination.
Forecast results are generated in the S3 bucket, triggering a Lambda function and writing the forecast result to Amazon Aurora for the end-user to query. To provide the forecasting result to the client side, we use Amazon API Gateway as the entry point and query Aurora through the Lambda function.
To automate this process, we used Step Functions, and we also maintain an Amazon SageMaker notebook for data scientists to featurize and test different data variations in the training dataset to find optimal data combinations.
Summary and next steps
In this post, we showed how to use Forecast to minimize waste through more effective inventory forecasting of food products with a short shelf life. The application of ML-based forecasting helped our retail customer reduce product waste by 37% and costs by 22% across 168 stores and three merchandise categories. Moreover, the reference architecture is able to support scaling to thousands of stores and product categories. These efforts not only improved financial outcomes, but also demonstrated their commitment to more sustainable, enviornmental friendly food practices. Together, these achievements helped our customer progress toward their ESG initiatives.
Next up for the team is using the what-if analysis capabilities of Forecast to further test the impact on demand, add subcategories for daily demand forecasting, and scale to more stores. In addition, the team will keep iterating the model to continue reducing food waste, and optimize processes to deliver more sustainable and environmentally friendly results.
To use Forecast to improve retail demand forecasting and support better environmental outcomes, you can access the service through the AWS Management Console, or through our AWS CloudFormation-based solution guidance on GitHub. To learn more about how to use Forecast, check out Amazon Forecast resources.
About the Authors
 Josie Cheng is a HKT AI/ML Go-To-Market at AWS. Her current focus is on business transformation in retail and CPG through data and ML to fuel tremendous enterprise growth. Before joining AWS, Josie worked for Amazon Retail and other China and US internet companies as a Growth Product Manager.
Josie Cheng is a HKT AI/ML Go-To-Market at AWS. Her current focus is on business transformation in retail and CPG through data and ML to fuel tremendous enterprise growth. Before joining AWS, Josie worked for Amazon Retail and other China and US internet companies as a Growth Product Manager.
 Ray Wang is a Solutions Architect at AWS. With 8 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in NoSQL, big data, and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
Ray Wang is a Solutions Architect at AWS. With 8 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in NoSQL, big data, and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
 Shanger Lin is Data Scientist and Consultant at AWS, leveraging machine learning, cloud computing, and data strategy to enable customers with digital transformation and to extract impact from data.
Shanger Lin is Data Scientist and Consultant at AWS, leveraging machine learning, cloud computing, and data strategy to enable customers with digital transformation and to extract impact from data.
 Dan Sinnreich is a Sr. Product Manager for Amazon Forecast. His focus is helping companies drive better business decisions with ML-based forecasting. Outside of work, he can be found playing hockey, reading science fiction, and scuba diving.
Dan Sinnreich is a Sr. Product Manager for Amazon Forecast. His focus is helping companies drive better business decisions with ML-based forecasting. Outside of work, he can be found playing hockey, reading science fiction, and scuba diving.
Transferring depth estimation knowledge between cameras
A model that estimates depth from 2-D images learns to adjust to differences between images produced by different cameras, reducing error by about 20%.Read More