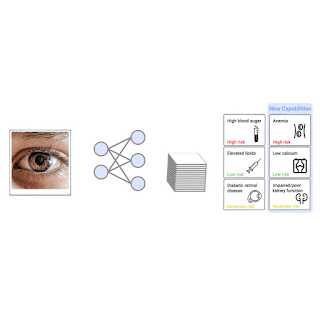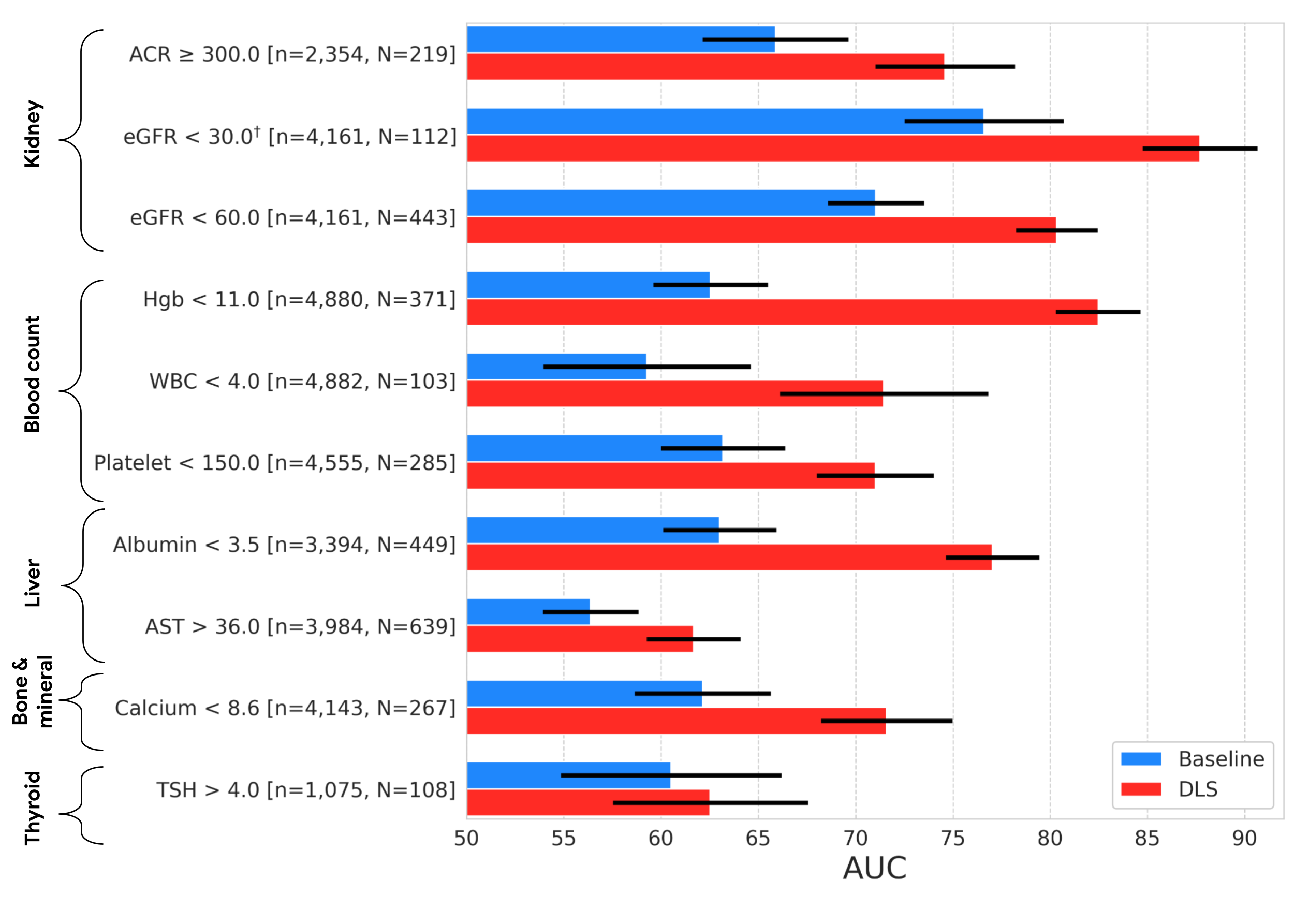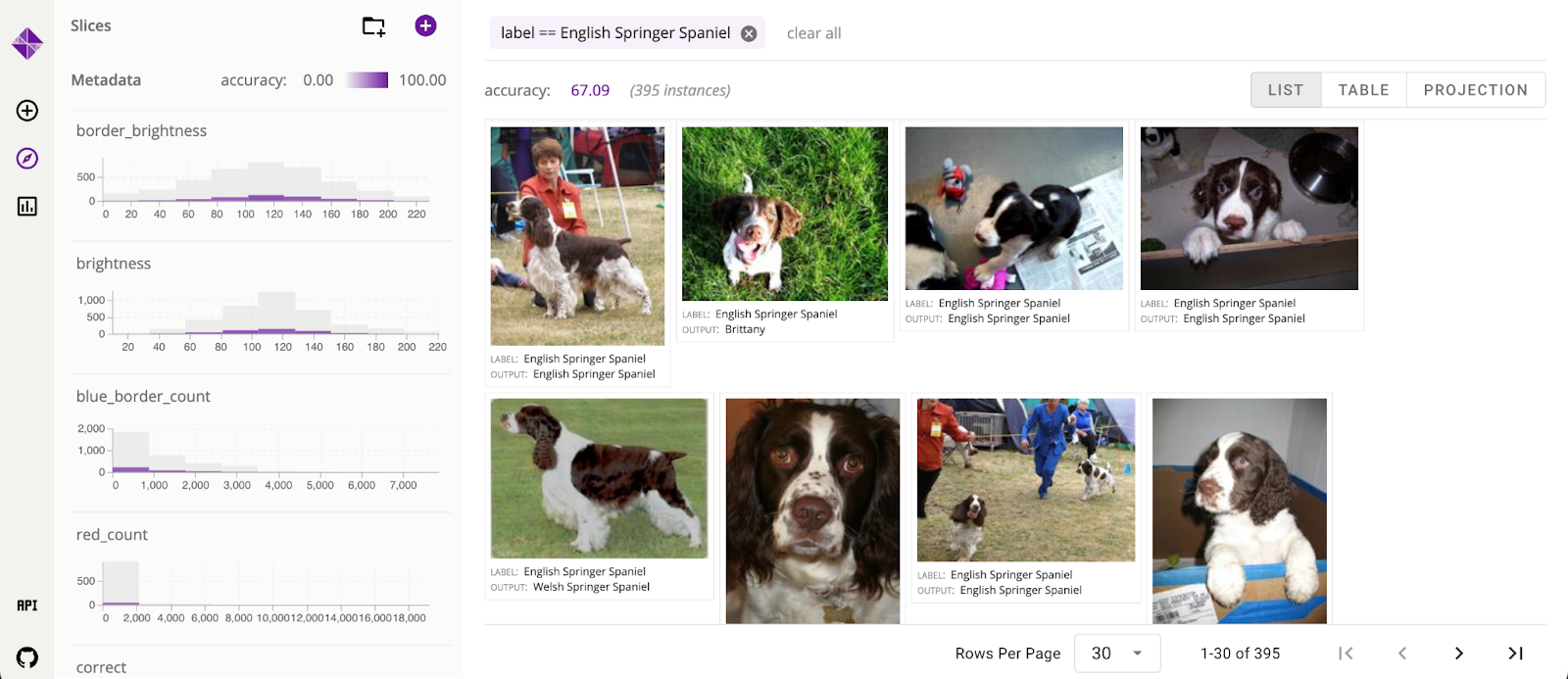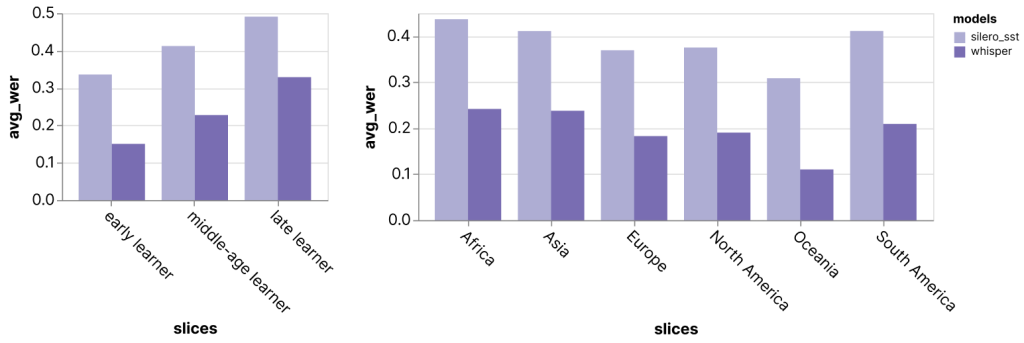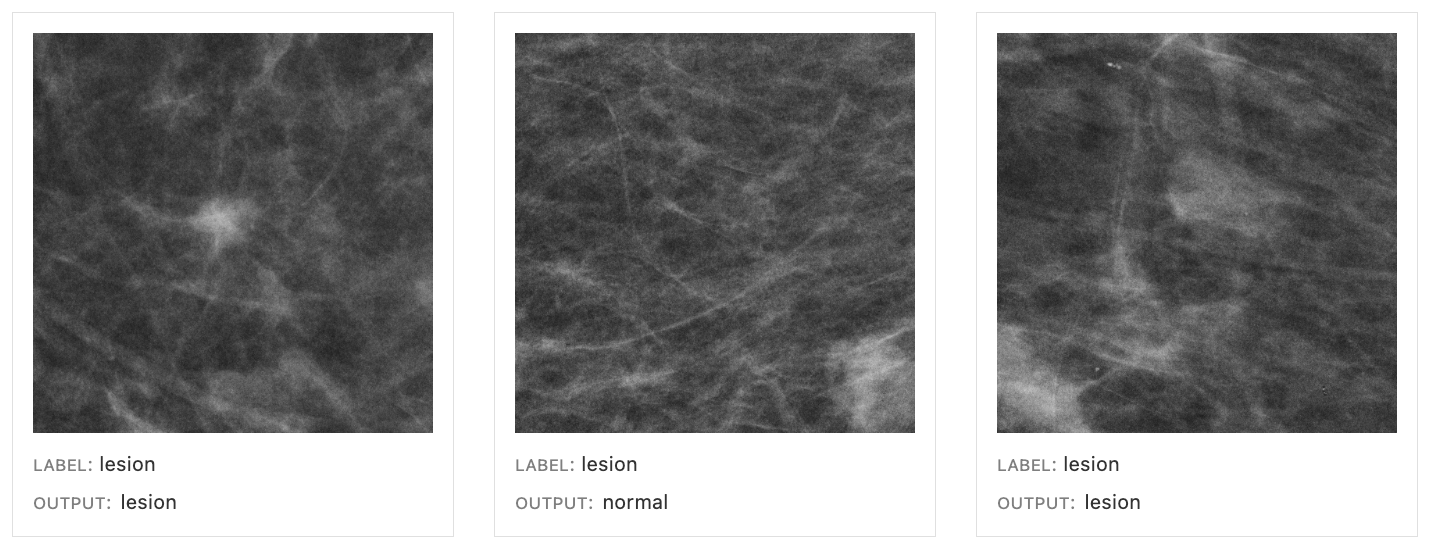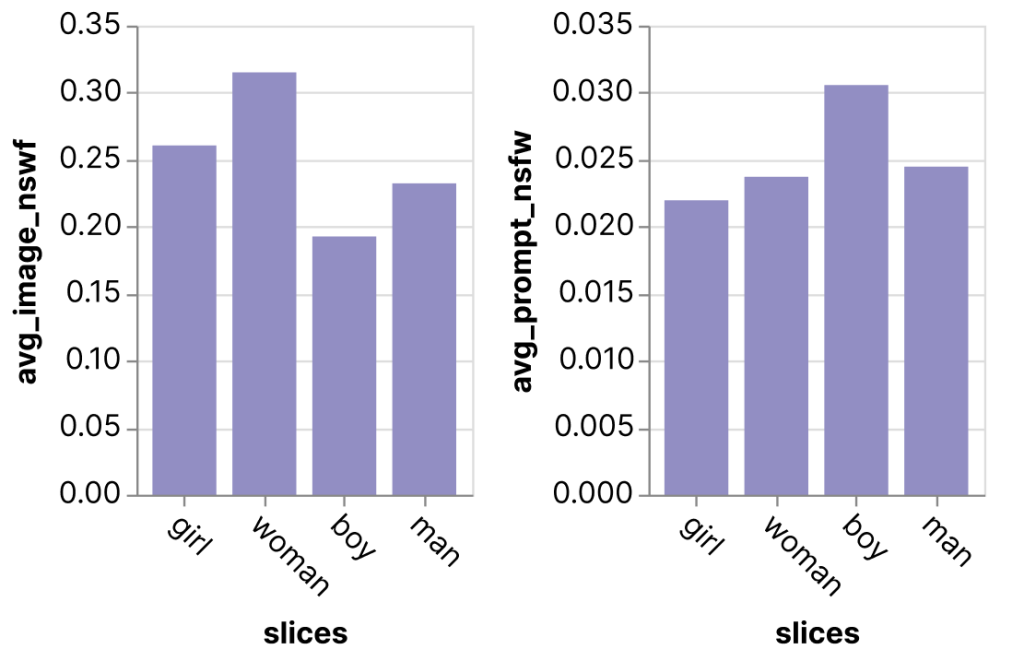
Predictive maintenance is a data-driven maintenance strategy for monitoring industrial assets in order to detect anomalies in equipment operations and health that could lead to equipment failures. Through proactive monitoring of an asset’s condition, maintenance personnel can be alerted before issues occur, thereby avoiding costly unplanned downtime, which in turn leads to an increase in Overall Equipment Effectiveness (OEE).
However, building the necessary machine learning (ML) models for predictive maintenance is complex and time consuming. It requires several steps, including preprocessing of the data, building, training, evaluating, and then fine-tuning multiple ML models that can reliably predict anomalies in your asset’s data. The finished ML models then need to be deployed and provided with live data for online predictions (inferencing). Scaling this process to multiple assets of various types and operating profiles is often too resource intensive to make broader adoption of predictive maintenance viable.
With Amazon Lookout for Equipment, you can seamlessly analyze sensor data for your industrial equipment to detect abnormal machine behavior—with no ML experience required.
When customers implement predictive maintenance use cases with Lookout for Equipment, they typically choose between three options to deliver the project: build it themselves, work with an AWS Partner, or use AWS Professional Services. Before committing to such projects, decision-makers such as plant managers, reliability or maintenance managers, and line leaders want to see evidence of the potential value that predictive maintenance can uncover in their lines of business. Such an evaluation is usually performed as part of a proof of concept (POC) and is the basis for a business case.
This post is directed to both technical and non-technical users: it provides an effective approach for evaluating Lookout for Equipment with your own data, allowing you to gauge the business value it provides your predictive maintenance activities.
Solution overview
In this post, we guide you through the steps to ingest a dataset in Lookout for Equipment, review the quality of the sensor data, train a model, and evaluate the model. Completing these steps will help derive insights into the health of your equipment.
Prerequisites
All you need to get started is an AWS account and a history of sensor data for assets that can benefit from a predictive maintenance approach. The sensor data should be stored as CSV files in an Amazon Simple Storage Service (Amazon S3) bucket from your account. Your IT team should be able to meet these prerequisites by referring to Formatting your data. To keep things simple, it’s best to store all the sensor data in one CSV file where the rows are timestamps and the columns are individual sensors (up to 300).
Once you have your dataset available on Amazon S3, you can follow along with the rest of this post.
Add a dataset
Lookout for Equipment uses projects to organize the resources for evaluating pieces of industrial equipment. To create a new project, complete the following steps:
- On the Lookout for Equipment console, choose Create project.
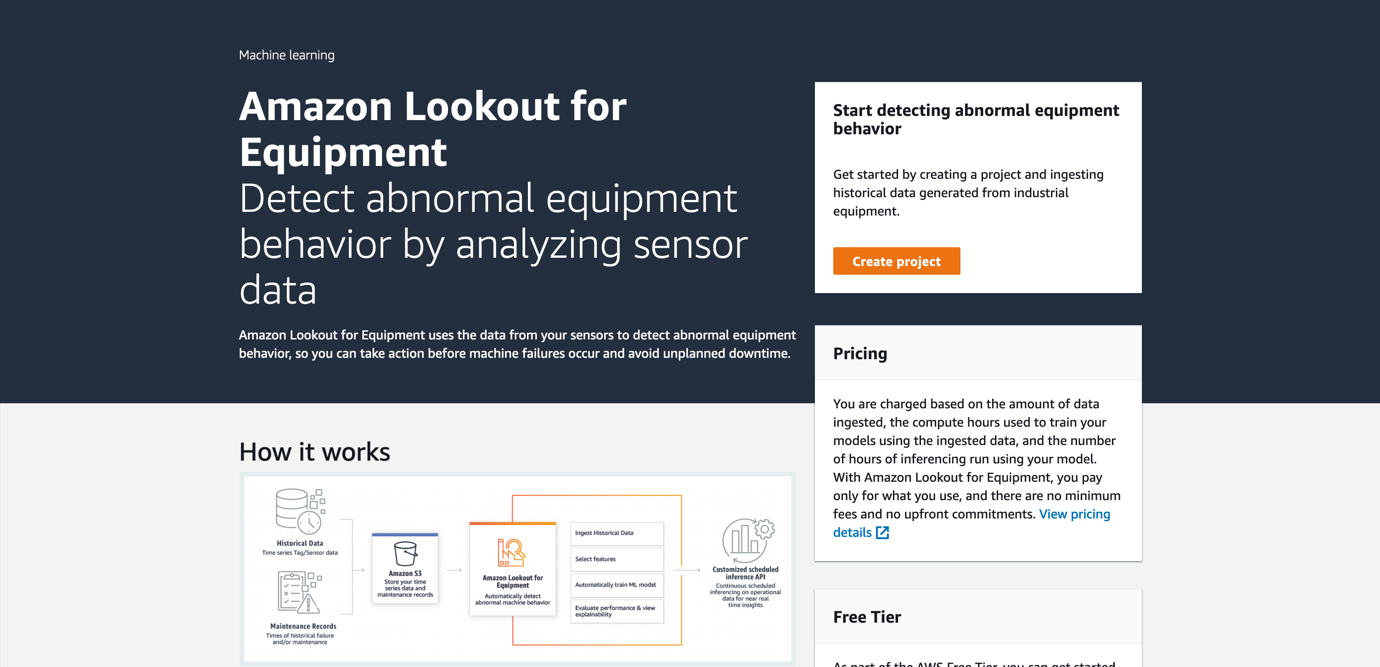
- Enter a project name and choose Create project.
After the project is created, you can ingest a dataset that will be used to train and evaluate a model for anomaly detection.
- On the project page, choose Add dataset.

- For S3 location, enter the S3 location (excluding the file name) of your data.
- For Schema detection method, select By filename, which assumes that all sensor data for an asset is contained in a single CSV file at the specified S3 location.
- Keep the other settings as default and choose Start ingestion to start the ingestion process.

Ingestion may take around 10–20 minutes to complete. In the background, Lookout for Equipment performs the following tasks:
- It detects the structure of the data, such as sensor names and data types.
- The timestamps between sensors are aligned and missing values are filled (using the latest known value).
- Duplicate timestamps are removed (only the last value for each timestamp is kept).
- Lookout for Equipment uses multiple types of algorithms for building the ML anomaly detection model. During the ingestion phase, it prepares the data so it can be used for training those different algorithms.
- It analyzes the measurement values and grades each sensor as high, medium, or low quality.
- When the dataset ingestion is complete, inspect it by choosing View dataset under Step 2 of the project page.
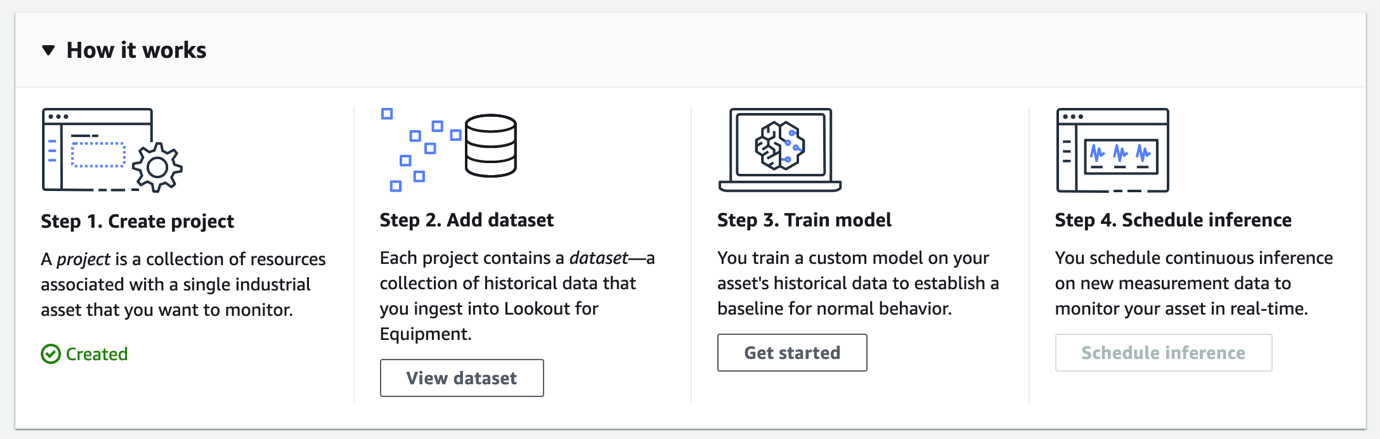
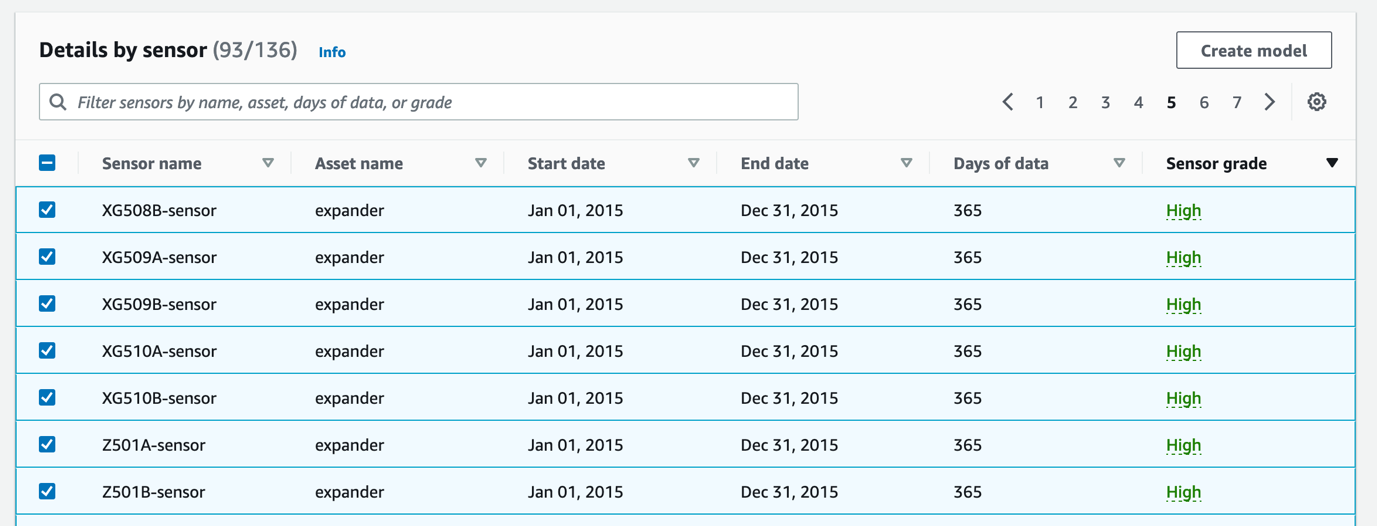
When creating an anomaly detection model, selecting the best sensors (the ones containing the highest data quality) is often critical to training models that deliver actionable insights. The Dataset details section shows the distribution of sensor gradings (between high, medium, and low), while the table displays information on each sensor separately (including the sensor name, date range, and grading for the sensor data). With this detailed report, you can make an informed decision about which sensors you will use to train your models. If a large proportion of sensors in your dataset are graded as medium or low, there might be a data issue needing investigation. If necessary, you can reupload the data file to Amazon S3 and ingest the data again by choosing Replace dataset.
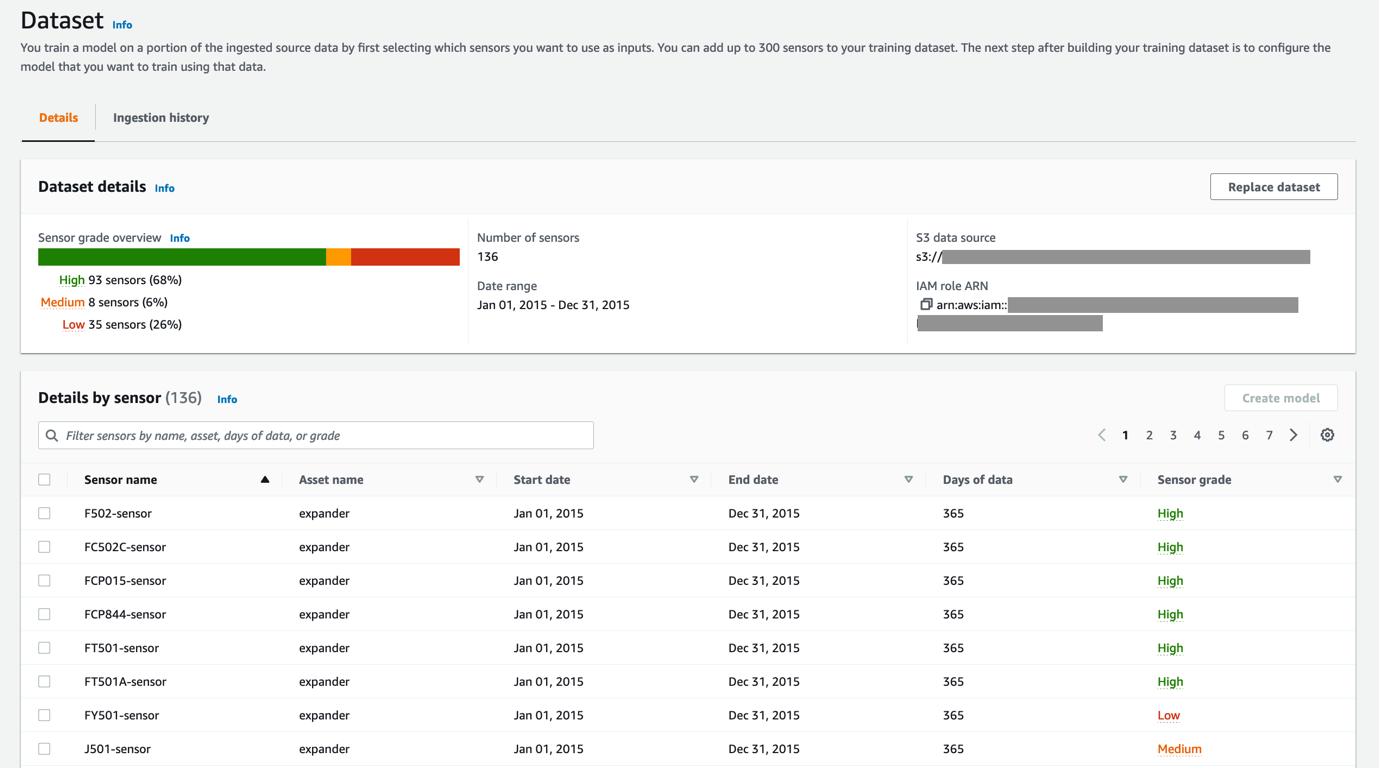
By choosing the sensor grade entry in the details table, you can review details on the validation errors resulting in a given grade. Displaying and addressing these details will help ensure information provided to the model is high quality. For example, you might see a signal has unexpected big chunks of missing values. Is this a data transfer issue, or was the sensor malfunctioning? Time to dive deeper in your data!

To learn more about the different type of sensor issues Lookout for Equipment addresses when grading your sensors, refer to Evaluating sensor grades. Developers can also extract these insights using the ListSensorStatistics API.
When you’re happy with your dataset, you can move to the next step of training a model for predicting anomalies.
Train a model
Lookout for Equipment allows the training of models for specific sensors. This gives you the flexibility to experiment with different sensor combinations or exclude sensors with a low grading. Complete the following steps:
- In the Details by sensor section on the dataset page, select the sensors to include in your model and choose Create model.
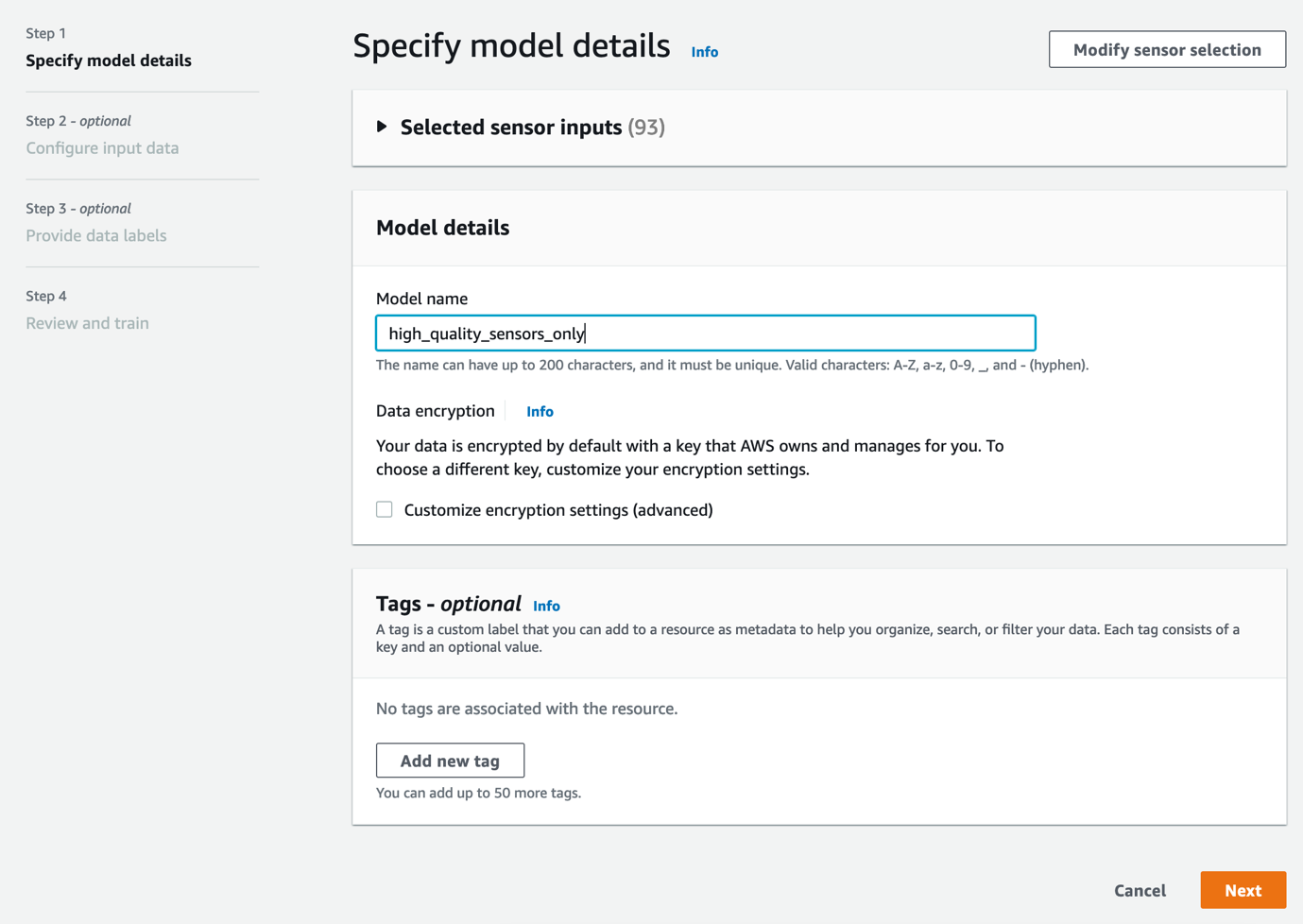
- For Model name, enter a model name, then choose Next.
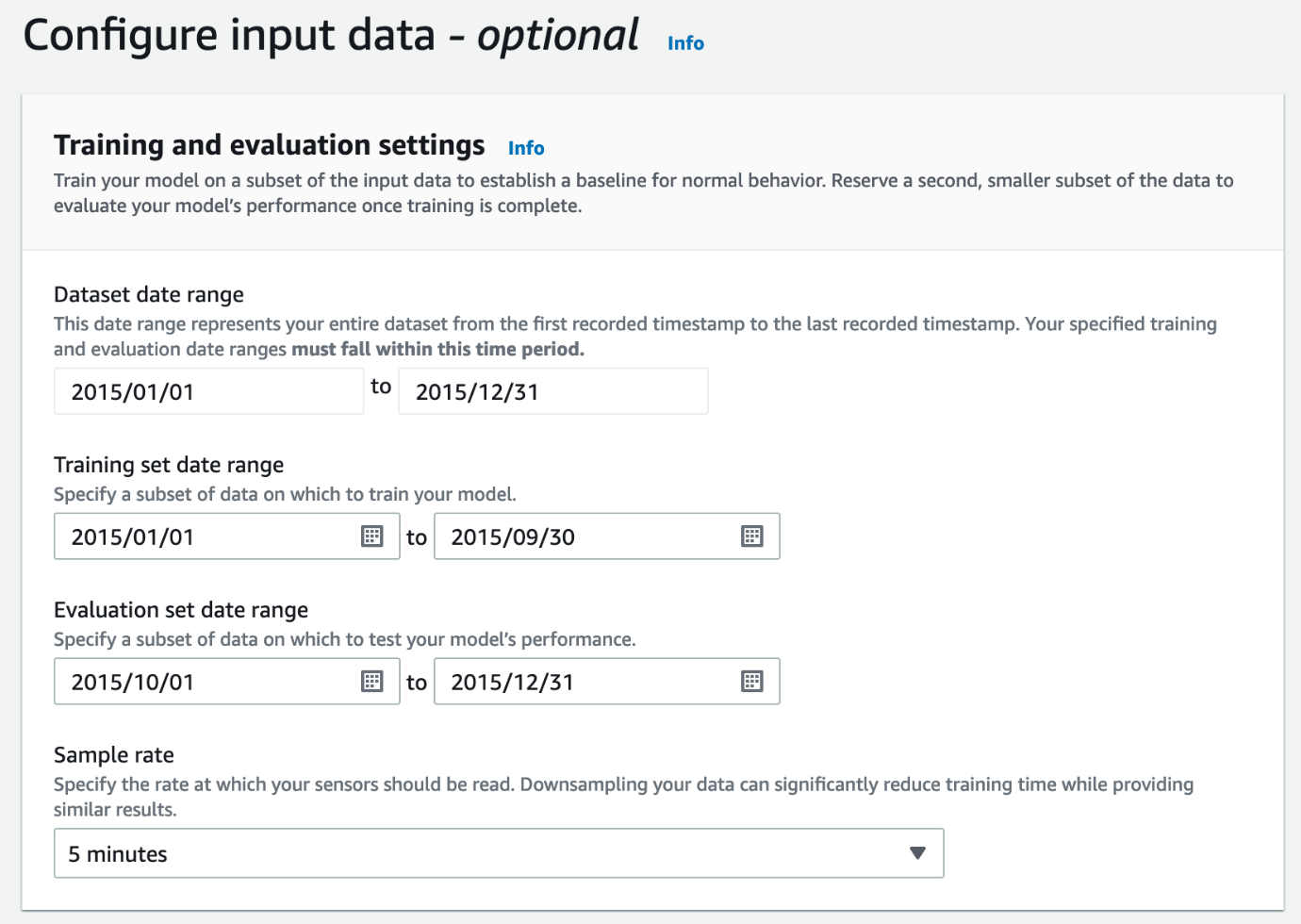
- In the Training and evaluation settings section, configure the model input data.
To effectively train models, the data needs to be split into separate training and evaluation sets. You can define date ranges for this split in this section, along with a sampling rate for the sensors. How do you choose this split? Consider the following:
- Lookout for Equipment expects at least 3 months of data in the training range, but the optimal amount of data is driven by your use case. More data may be necessary to account for any type of seasonality or operational cycles your production goes through.
- There are no constraints on the evaluation range. However, we recommend setting up an evaluation range that includes known anomalies. This way, you can test if Lookout for Equipment is able to capture any events of interest leading to these anomalies.
By specifying the sample rate, Lookout for Equipment effectively downsamples the sensor data, which can significantly reduce training time. The ideal sampling rate depends on the types of anomalies you suspect in your data: for slow-trending anomalies, selecting a sampling rate between 1–10 minutes is usually a good starting point. Choosing lower values (increasing the sampling rate) results in longer training times, whereas higher values (low sampling rate) shorten the training time at the risk of cutting out leading indicators from your data relevant to predicting the anomalies.
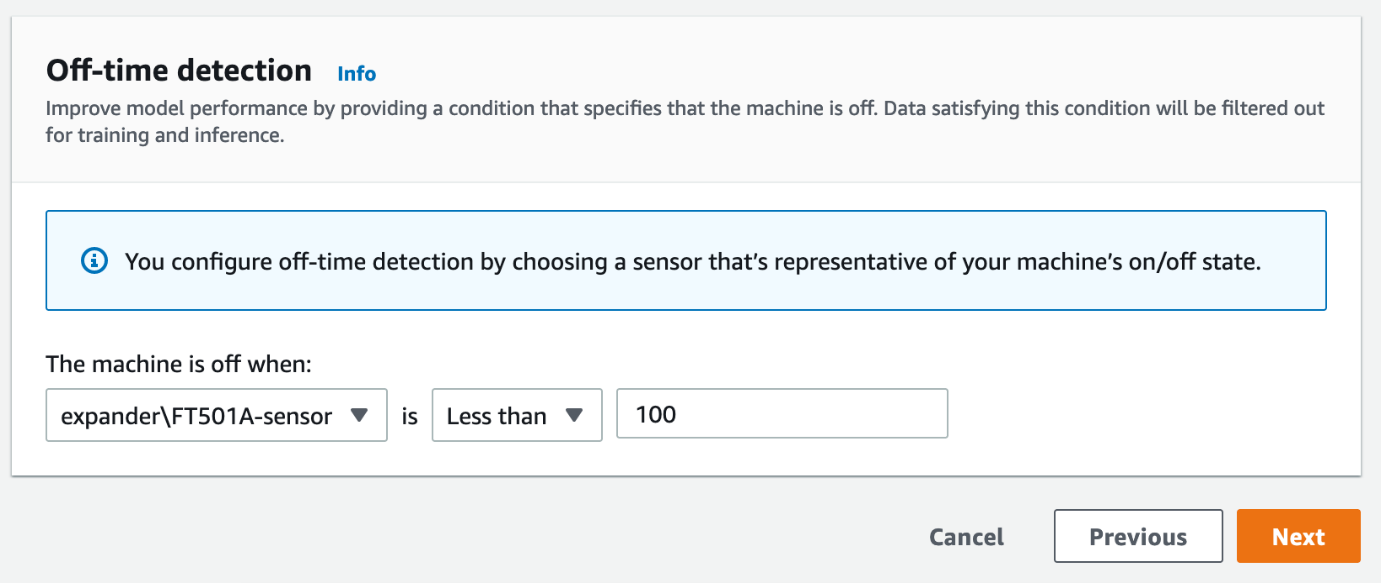
For training only on relevant portions of your data where the industrial equipment was in operation, you can perform off-time detection by selecting a sensor and defining a threshold indicating whether the equipment was in an on or off state. This is critical because it allows Lookout for Equipment to filter out time periods for training when the machine is off. This means the model learns only relevant operational states and not just when the machine is off.
- Specify your off-time detection, then choose Next.
Optionally, you can provide data labels, which indicate maintenance periods or known equipment failure times. If you have such data available, you can create a CSV file with the data in a documented format, upload it to Amazon S3, and use it for model training. Providing labels can improve the accuracy of the trained model by telling Lookout for Equipment where it should expect to find known anomalies.
- Specify any data labels, then choose Next.
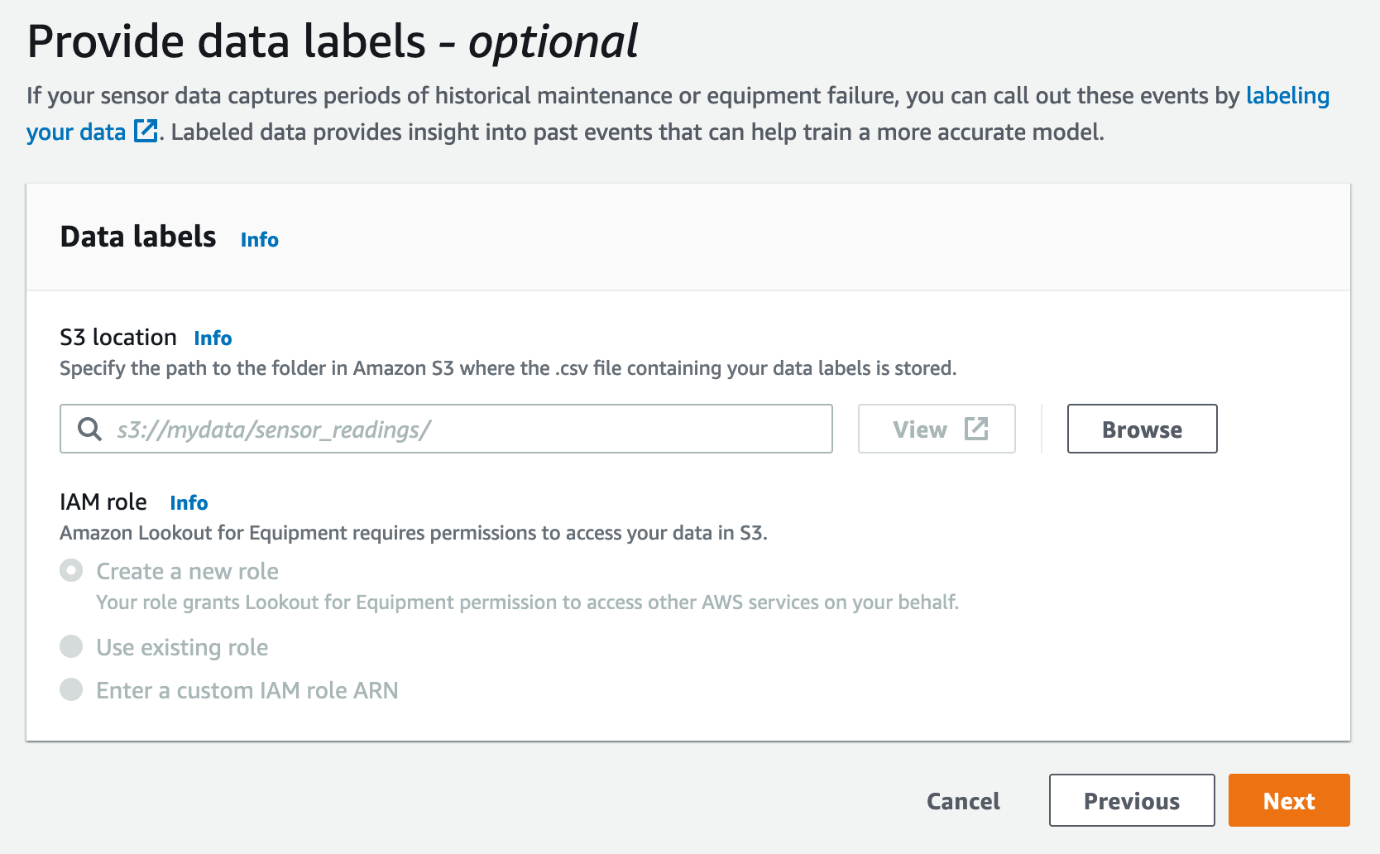
- Review your settings in the final step. If everything looks fine, you can start the training.
Depending on the size of your dataset, the number of sensors, and the sampling rate, training the model may take a few moments or up to a few hours. For example, if you use 1 year of data at a 5-minute sampling rate with 100 sensors and no labels, training a model will take less than 15 minutes. On the other hand, if your data contains a large number of labels, training time could increase significantly. In such a situation, you can decrease training time by merging adjacent label periods to decrease their number.
You have just trained your first anomaly detection model without any ML knowledge! Now let’s look at the insights you can get from a trained model.
Evaluate a trained model
When model training has finished, you can view the model’s details by choosing View models on the project page, and then choosing the model’s name.
In addition to general information like name, status, and training time, the model page summarizes model performance data like the number of labeled events detected (assuming you provided labels), the average forewarning time, and the number of anomalous equipment events detected outside of the label ranges. The following screenshot shows an example. For better visibility, the detected events are visualized (the red bars on the top of the ribbon) along with the labeled events (the blue bars at the bottom of the ribbon).
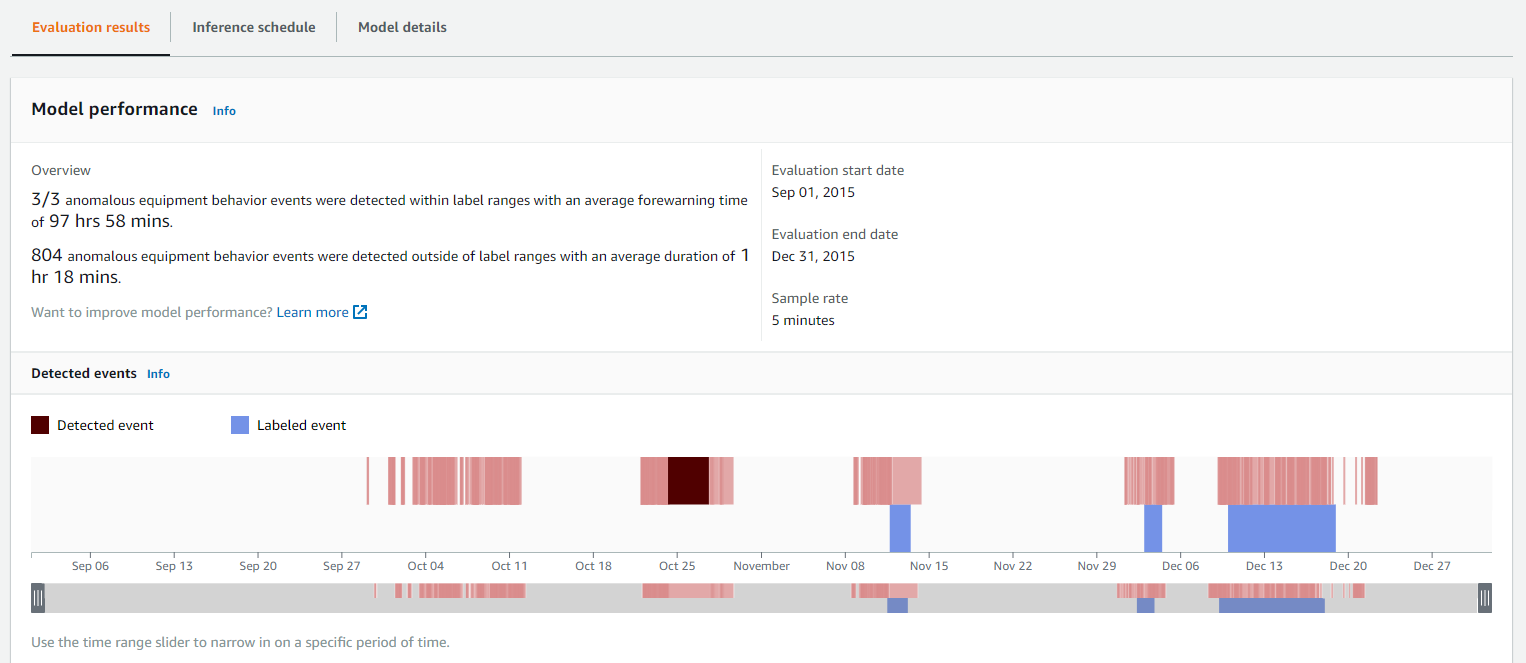
You can select detected events by choosing the red areas representing anomalies in the timeline view to get additional information. This includes:
- The event start and end times along with its duration.
- A bar chart with the sensors the model believes are most relevant to why an anomaly occurred. The percentage scores represent the calculated overall contribution.
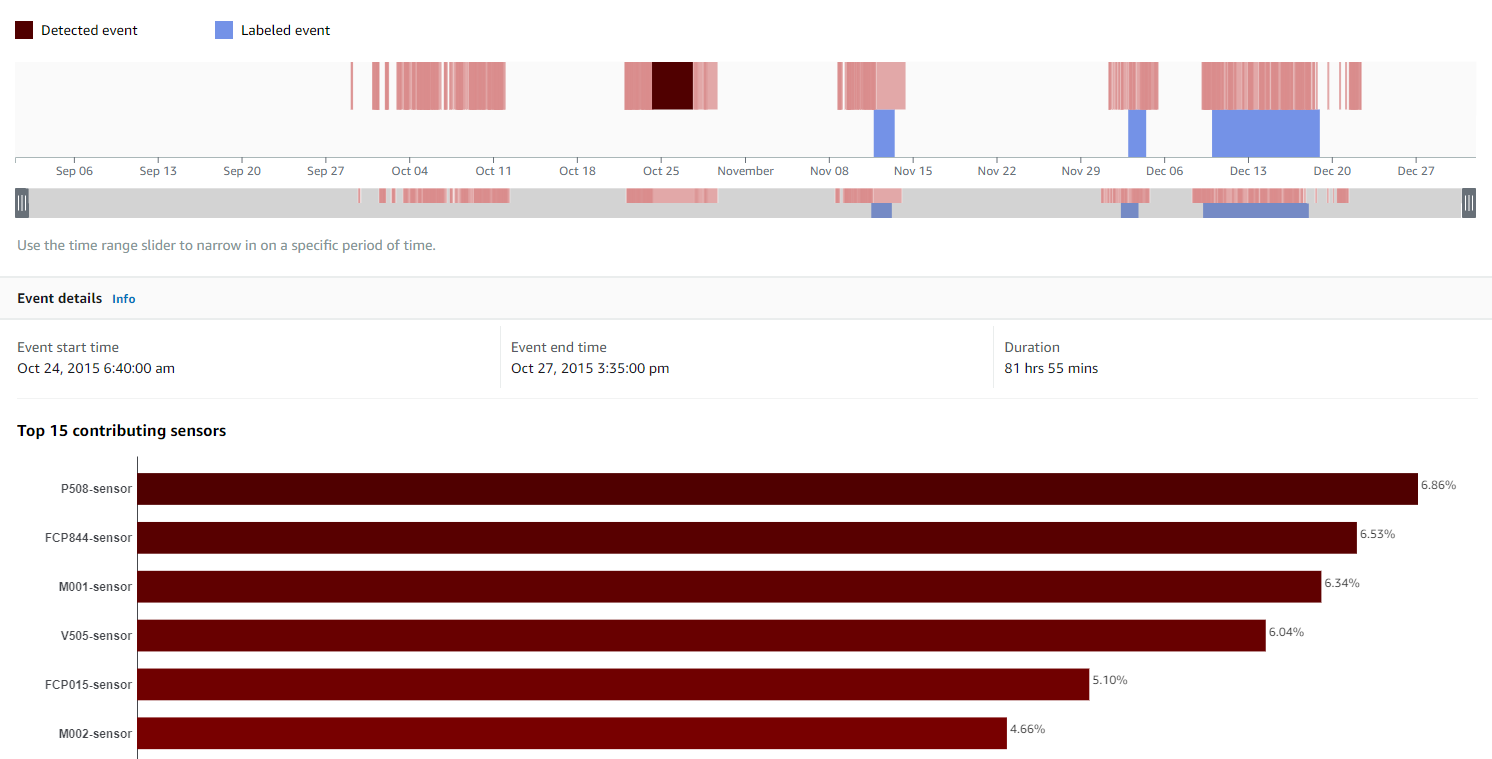
These insights allow you to work with your process or reliability engineers to do further root cause evaluation of events and ultimately optimize maintenance activities, reduce unplanned downtimes, and identify suboptimal operating conditions.
To support predictive maintenance with real-time insights (inference), Lookout for Equipment supports live evaluation of online data via inference schedules. This requires that sensor data is uploaded to Amazon S3 periodically, and then Lookout for Equipment performs inference on the data with the trained model, providing real-time anomaly scoring. The inference results, including a history of detected anomalous events, can be viewed on the Lookout for Equipment console.
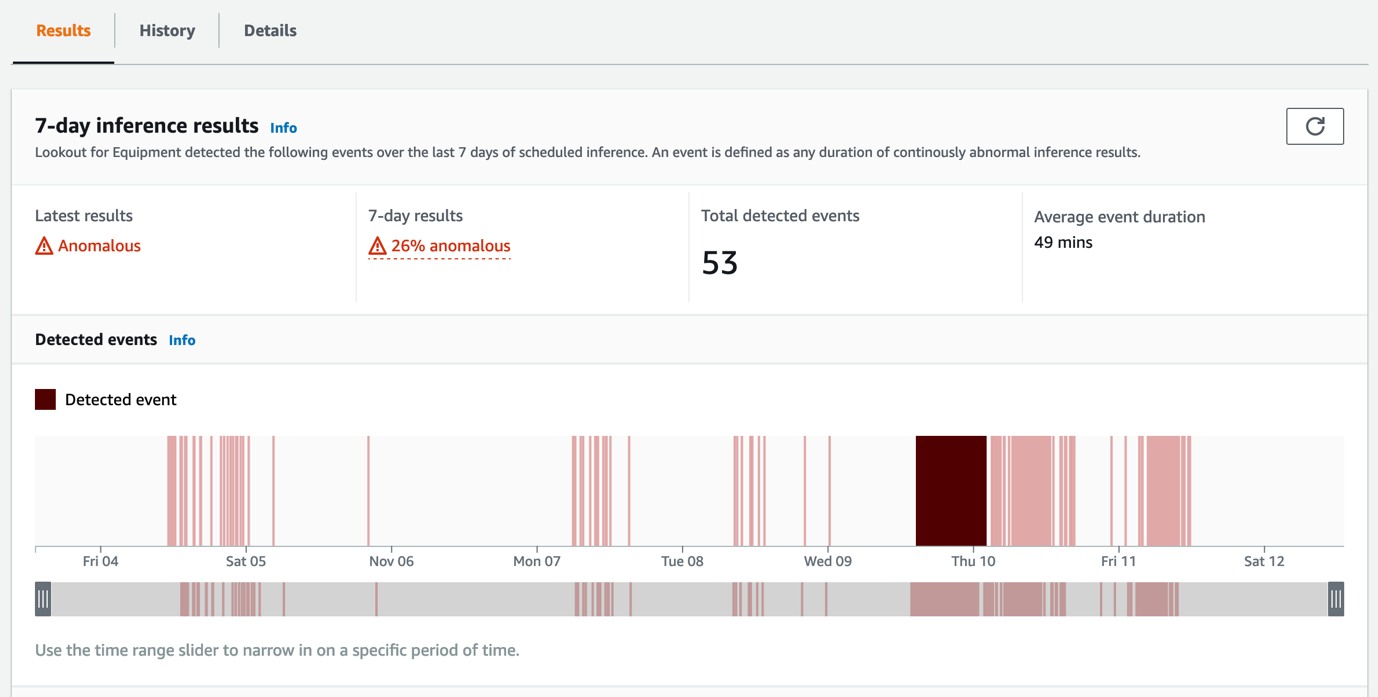
The results are also written to files in Amazon S3, allowing integration with other systems, for example a computerized maintenance management system (CMMS), or to notify operations and maintenance personnel in real time.
As you increase your Lookout for Equipment adoption, you’ll need to manage a larger number of models and inference schedules. To make this process easier, the Inference schedules page lists all schedulers currently configured for a project in a single view.
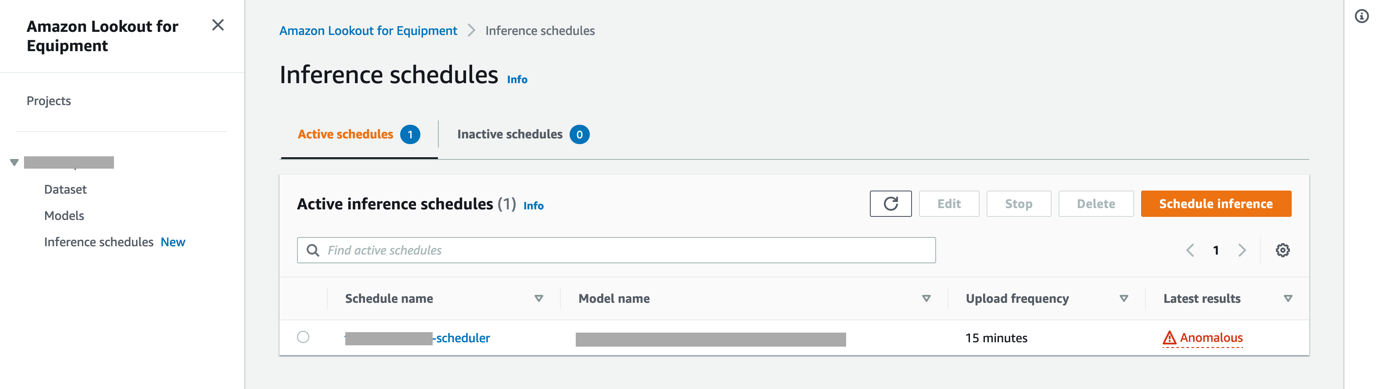
Clean up
When you’re finished evaluating Lookout for Equipment, we recommend cleaning up any resources. You can delete the Lookout for Equipment project along with the dataset and any models created by selecting the project, choosing Delete, and confirming the action.
Summary
In this post, we walked through the steps of ingesting a dataset in Lookout for Equipment, training a model on it, and evaluating its performance to understand the value it can uncover for individual assets. Specifically, we explored how Lookout for Equipment can inform predictive maintenance processes that result in reduced unplanned downtime and higher OEE.
If you followed along with your own data and are excited about the prospects of using Lookout for Equipment, the next step is to start a pilot project, with the support of your IT organization, your key partners, or our AWS Professional Services teams. This pilot should target a limited number of industrial equipment and then scale up to eventually include all assets in scope for predictive maintenance.
About the authors
 Johann Füchsl is a Solutions Architect with Amazon Web Services. He guides enterprise customers in the manufacturing industry in implementing AI/ML use cases, designing modern data architectures, and building cloud-native solutions that deliver tangible business value. Johann has a background in mathematics and quantitative modeling, which he combines with 10 years of experience in IT. Outside of work, he enjoys spending time with his family and being out in nature.
Johann Füchsl is a Solutions Architect with Amazon Web Services. He guides enterprise customers in the manufacturing industry in implementing AI/ML use cases, designing modern data architectures, and building cloud-native solutions that deliver tangible business value. Johann has a background in mathematics and quantitative modeling, which he combines with 10 years of experience in IT. Outside of work, he enjoys spending time with his family and being out in nature.
 Michaël Hoarau is an industrial AI/ML Specialist Solution Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the power of AI/ML to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.
Michaël Hoarau is an industrial AI/ML Specialist Solution Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the power of AI/ML to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.




 AI can be hugely beneficial to society if citizens, educators, academics, civil society and governments unite to shape it responsibly.
AI can be hugely beneficial to society if citizens, educators, academics, civil society and governments unite to shape it responsibly.
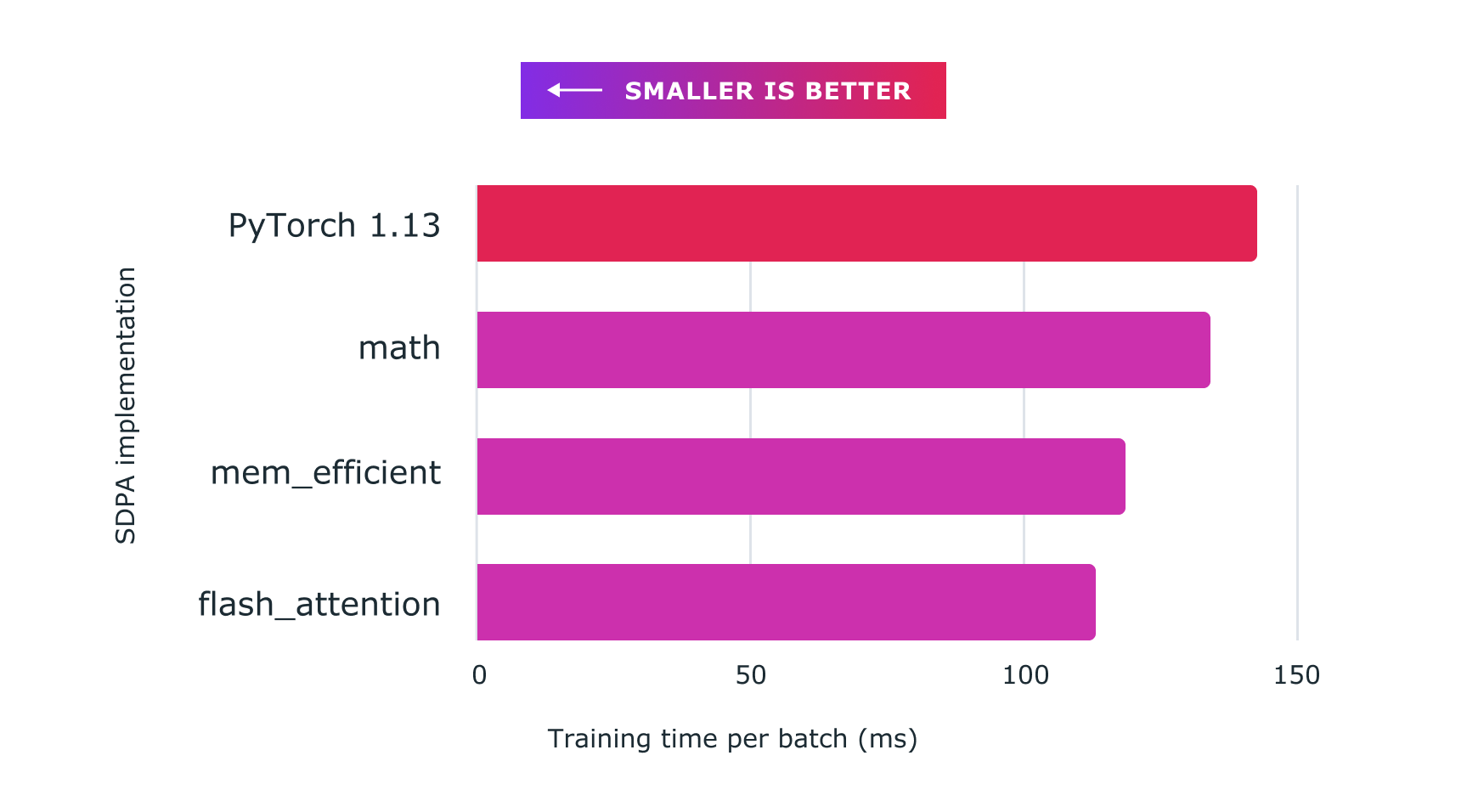 Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for
Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for