Posted by Miguel de Andrés-Clavera, Product Manager, Google PI
In this post, I’d like to share with you a demo we built for (and had planned to show at) Google I/O this year with TensorFlow Lite. I wish we had the opportunity to meet in person, but I hope you find this article interesting nonetheless!

Pixelopolis
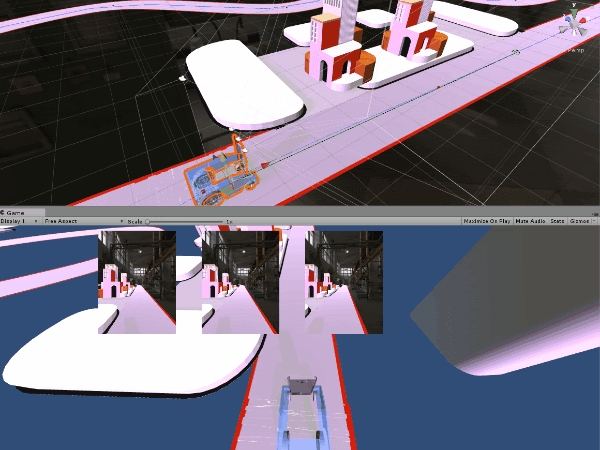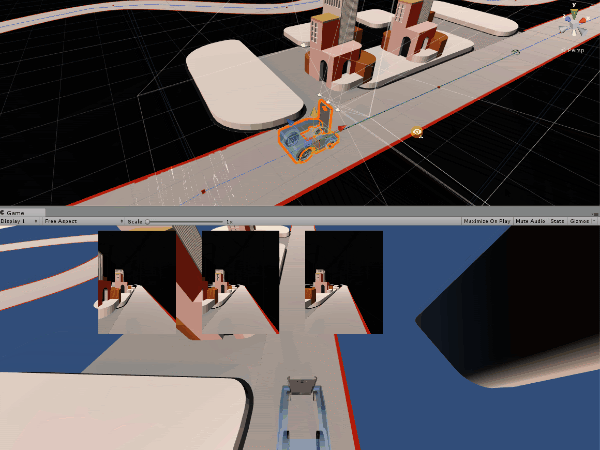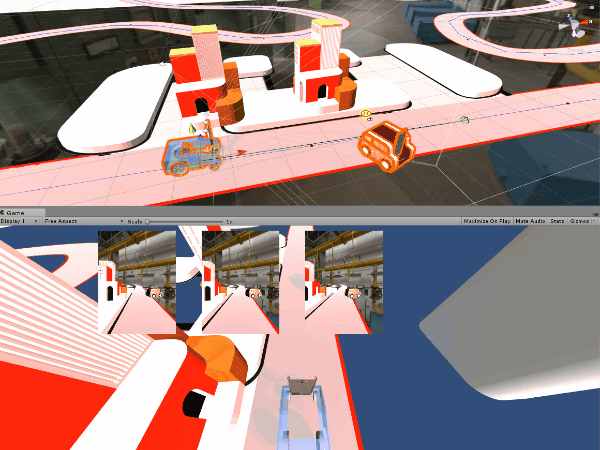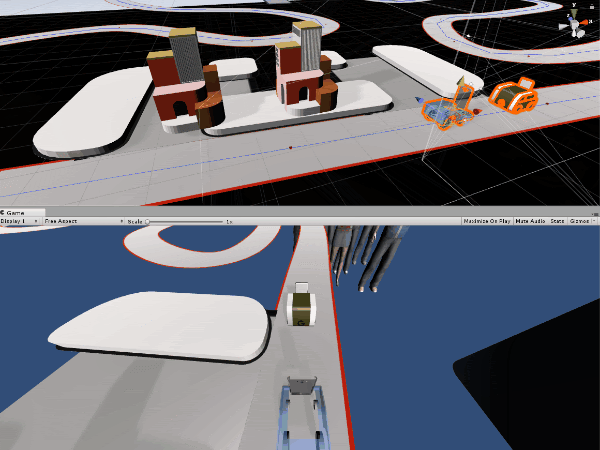
Pixelopolis is an interactive installation that showcases self-driving miniature cars powered by TensorFlow Lite. Each car is outfitted with its own Pixel phone, which used its camera to detect and understand signals from the world around it. In order to sense lanes, avoid collisions and read traffic signs, the phone uses machine learning running on the Pixel Neural Core, which contains a version of an Edge TPU.
An edge computing implementation is a good option to make projects like this possible. Processing video and detecting objects are much more difficult using Cloud-based methods – due to latency. If you can, doing it on-device is much faster.
Users can interact with Pixelopolis via a “station” (an app running on a phone), where they can select the destination the car will drive to. The car will navigate to the destination, and during the journey, the app shows real-time streaming video from the Car — this allows the user to see what the car sees and detects. As you may notice from the gifs below, Pixelopolis has multilingual support built-in as well.
 |
| Station App |
 |
| Car App |
How it works
Using the front camera on a mobile device, we perform lane-keeping, localization and object detection right on the device in real-time. Not only that, in our case, the Pixel 4 also controls the motors and other electronic components via USB-C, so the car can stop when it detects other cars or turn at a right interaction when it needs to.
If you’re interested in technical details, the remainder of this article describes the major components of the car, and our journey building it.
Lane-keeping
We explored a variety of models for Lane-keeping. As a baseline, we used a CNN to detect the traffic lines in each frame and adjust the steering wheel every frame, which works fine. We improved this by adding an LSTM and using multiple previous frames. After experimenting a bit more, we followed a similar model architecture to this paper.
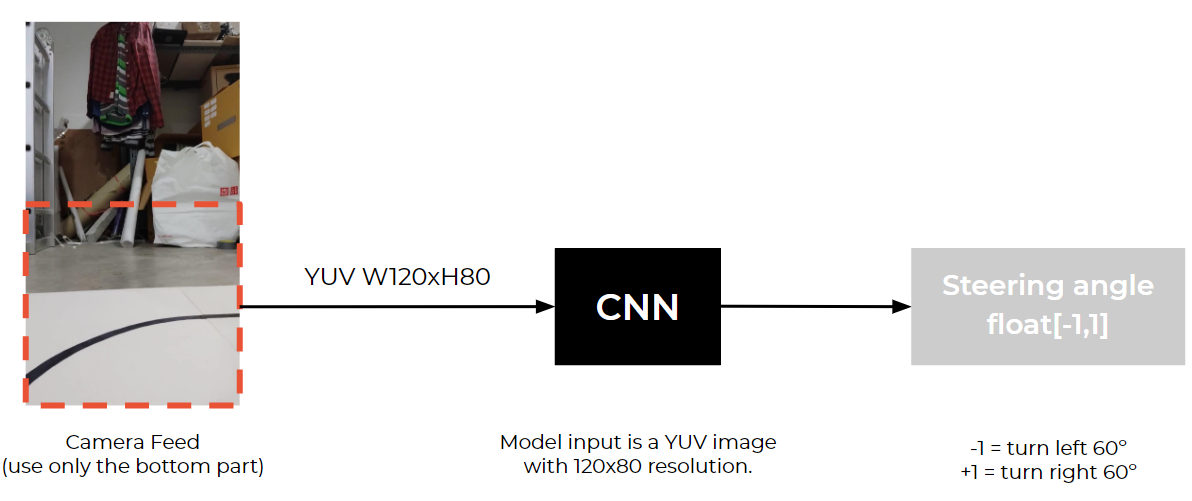 |
| CNN model input and output |
Model Architecture
net_in = Input(shape = (80, 120, 3))
x = Lambda(lambda x: x/127.5 - 1.0)(net_in)
x = Conv2D(24, (5, 5), strides=(2, 2),padding="same", activation='elu')(x)
x = Conv2D(36, (5, 5), strides=(2, 2),padding="same", activation='elu')(x)
x = Conv2D(48, (5, 5), strides=(2, 2),padding="same", activation='elu')(x)
x = Conv2D(64, (3, 3), padding="same",activation='elu')(x)
x = Conv2D(64, (3, 3), padding="same",activation='elu')(x)
x = Dropout(0.3)(x)
x = Flatten()(x)
x = Dense(100, activation='elu')(x)
x = Dense(50, activation='elu')(x)
x = Dense(10, activation='elu')(x)
net_out = Dense(1, name='net_out')(x)
model = Model(inputs=net_in, outputs=net_out)
Data Collection
Before we are able to use this model, we need to find a way to collect the image data from the car to train. The problem is we didn’t have a car or a track to use at the time. So, we decided to use a simulator. We chose Unity and this simulator project from Udacity for lane-keeping data collection.
 |
| Multiple waypoints on the track in the simulator |
By setting multiple waypoints on the track, the car bot is able to drive to different locations and also collects data for us. In this simulator, we collect image data and steering angle every 50ms.
Image Augmentation
 |
| Data Augmentation with various environments |
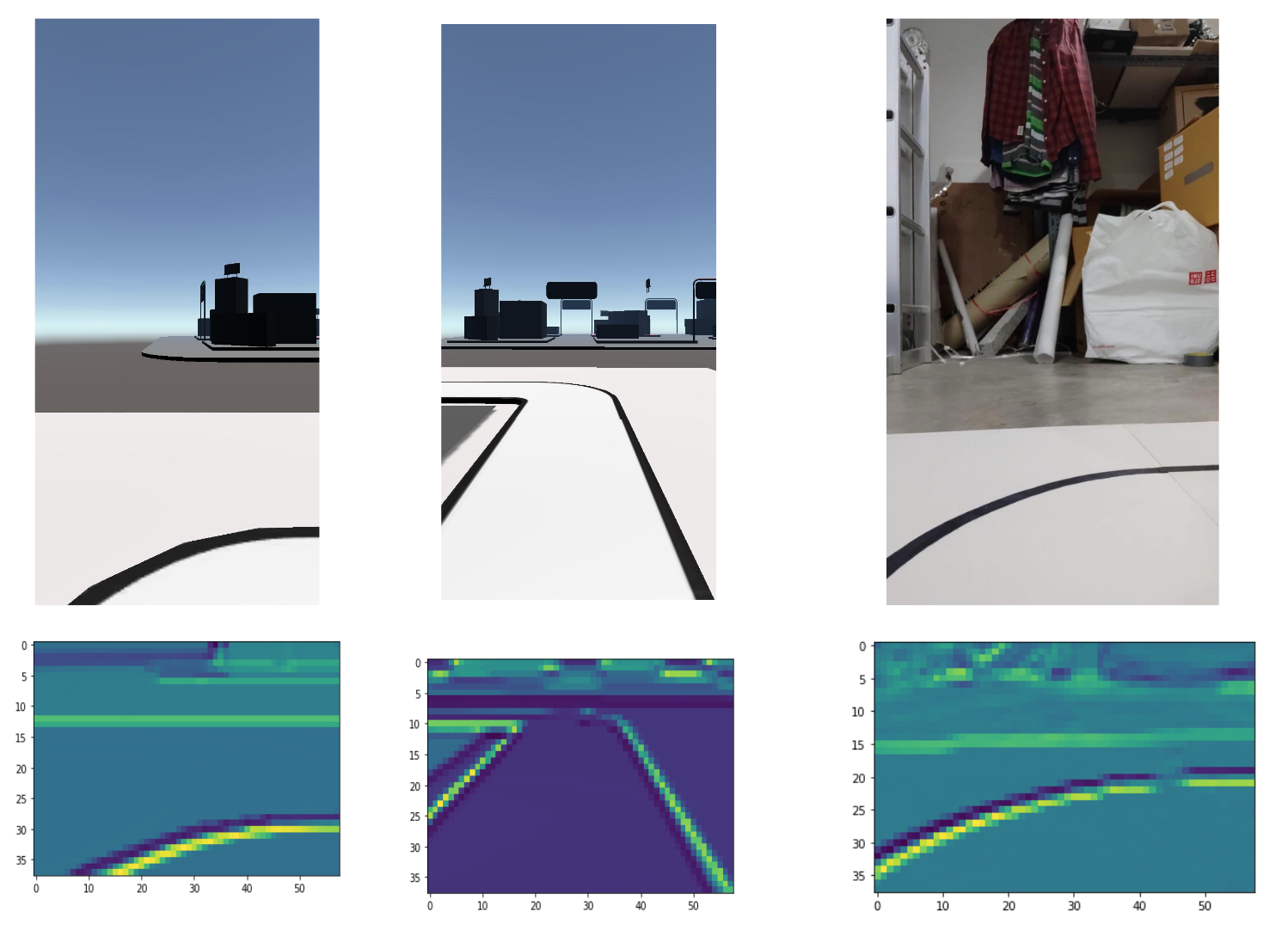
Since we do all data collection within the simulator, we need to create various environments in the scene because we want our model to be able to handle different lighting, background environment and other noises. We added these variables to the scene: random HDRI sphere ( with different rotation and exposure values), random brightness and color, and random cars.
Training
 |
| Output from the first Neural Network layer |
Training the ML model using only the simulator doesn’t mean it will actually work in the real-world situation, at least not the first try. The car ran on the tracks for a few seconds and then just went off the track for various reasons.
 |
| Early versions of the toy car running off the track/td> |
Later, we found out that we only trained the model using mostly straight tracks. To fix this imbalance data issue, we added various shapes of curves.
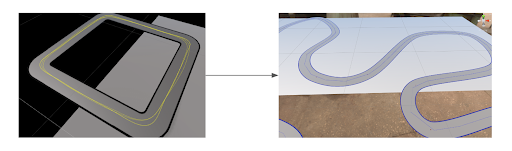 |
| (Left) square shape track, (Right) Curvy track |
After fixing the imbalanced dataset, the car began to correctly navigate corners.
 |
| Car successfully turn at the corners |
Training with the final track design
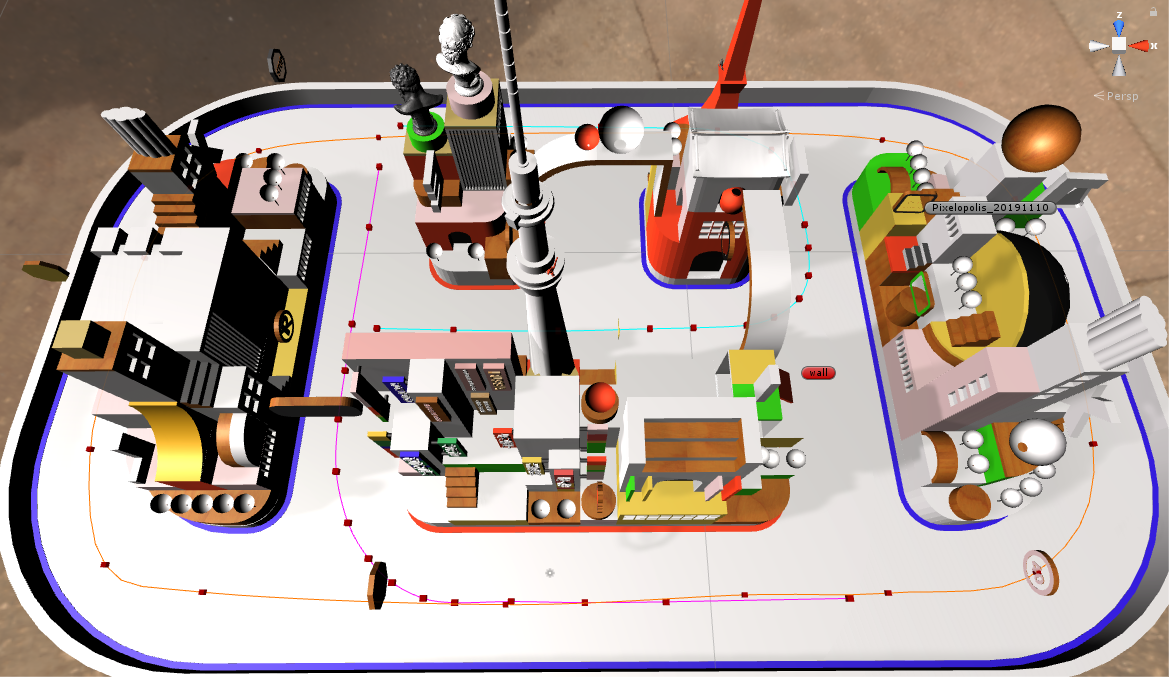 |
| Final track design |
We started creating more complex situations for the car, such as adding multiple intersections to the tracks. We also added more routing paths to make the car handle these new conditions. However, we ran into new problems right away which is the car turned and hit the side track when it tried to turn at the intersection because it saw some random objects outside the track.
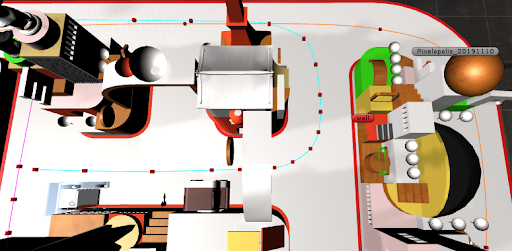 |
| Training the model with additional routing |
We tested out many solutions and went with the one that was most simple and effective. We cropped only the bottom ¼ of the image and fed it to the lane keeping model, then adjusted the model input size to 120×40 and it works like a charm.
 |
| Cropping bottom part of the image for lane-keeping |
Object Detection
We use object detection for two purposes. One is for localization. Each car needs to know where it is in the city by detecting objects in its environment (in this case, we detect the traffic signs in the city). The other purpose is to detect other cars, so they won’t bump into each other.
For choosing the object detector model there are many models already available in TensorFlow object detection model zoo. But, for the Pixel 4 edge TPU, we use the ssd_mobilenet_edgetpu model.
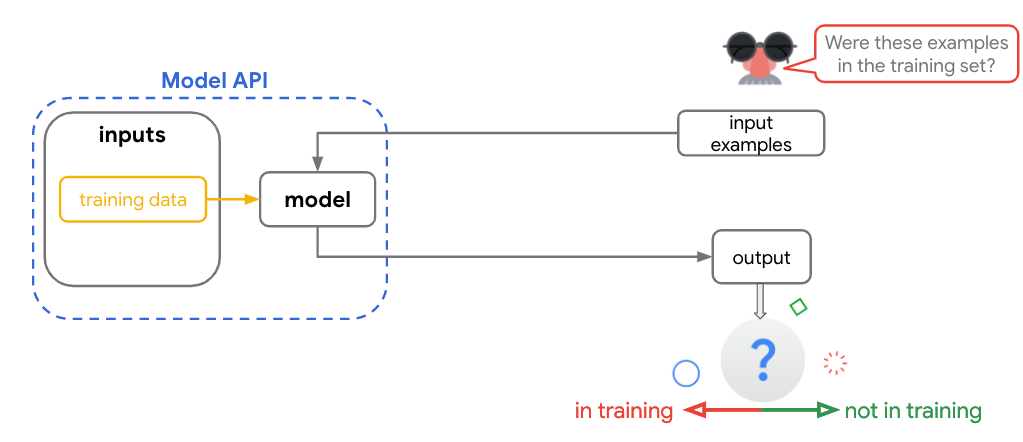
ssd_mobilenet_edgetpu model on Pixel 4’s “Neural Core” Edge TPU is currently the fastest mobilenet object detection. It takes only 6.6 ms per frame, which is more than enough for using with real-time applications.
 |
| Pixel 4 Edge TPU model performance |
Data labelling and Simulation
We use image data from both simulation and real scenes to train the model. Next, we developed our own simulator for this using Unreal Engine 4. The simulator generates random objects with random background and also an annotation file in a Pascal VOC format that is used in TensorFlow object detection API.
 |
| Object detection simulator using UE4 |
For images that were taken from the real scene We have to do manual labeling using the labelImg tool.
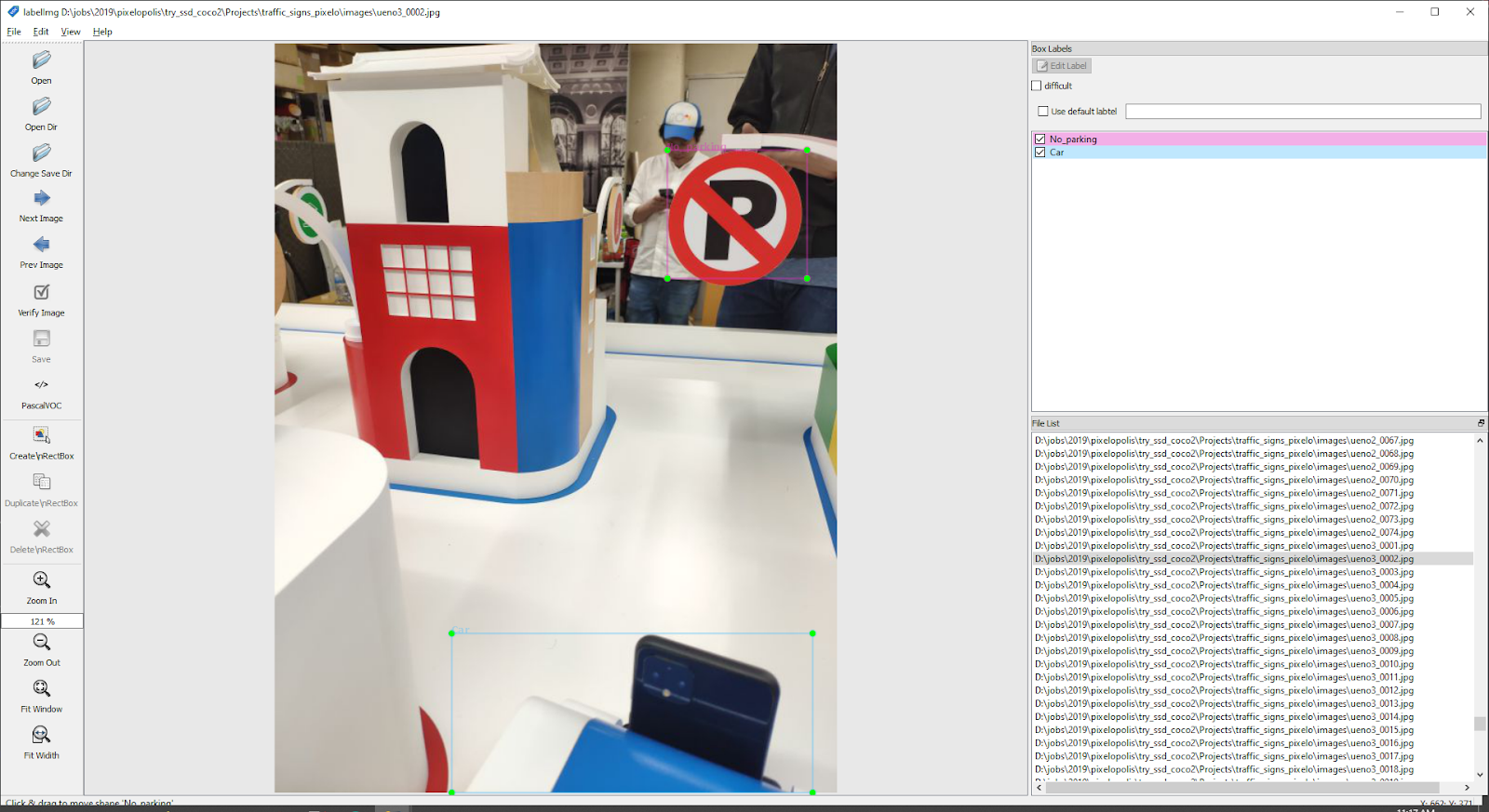 |
| Data labeling with labelImg |
Training
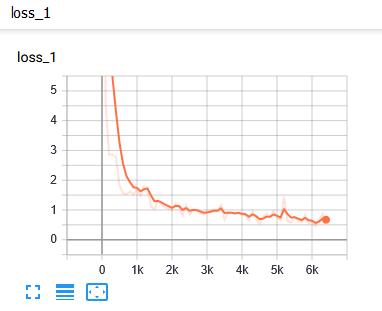 |
| Loss report |
We used TensorBoard to monitor training progress. We use it to evaluate mAP (mean Average Precision), which normally you have to do it manually.
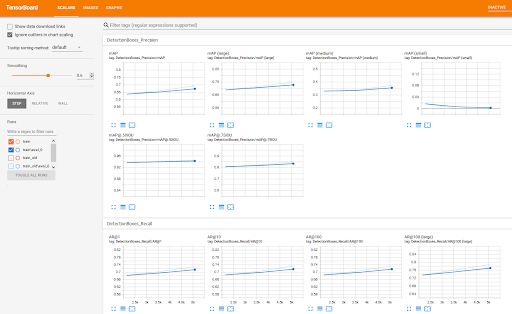 |
| TensorBoard |
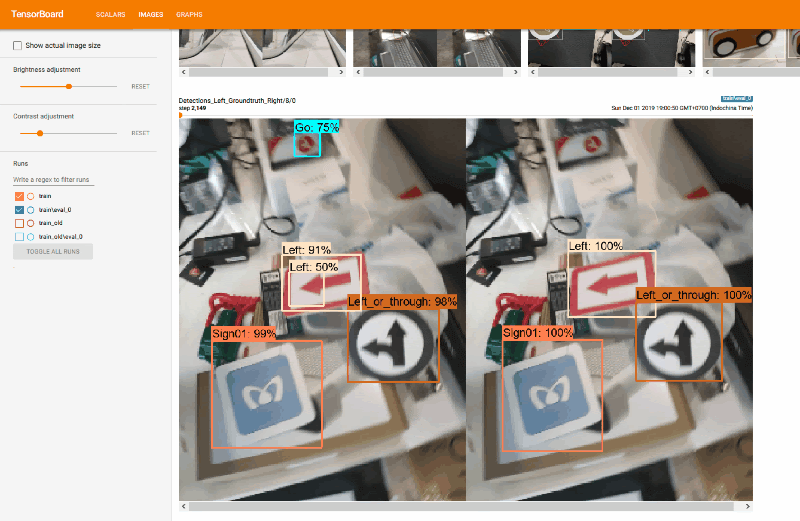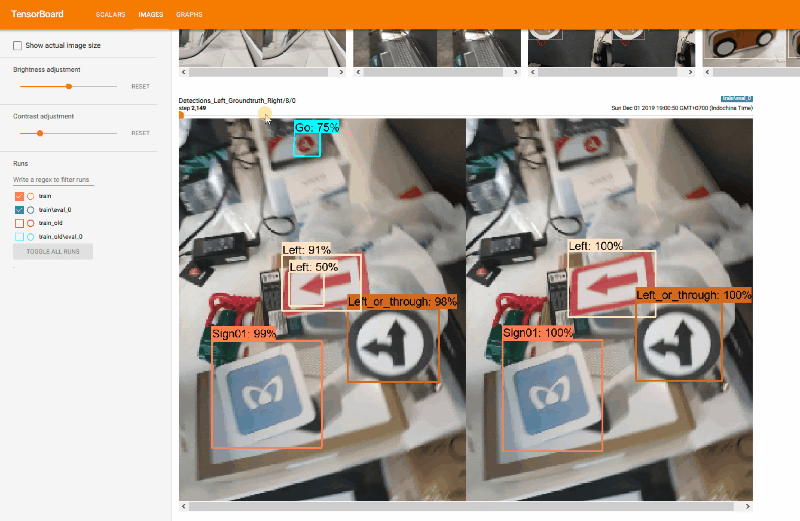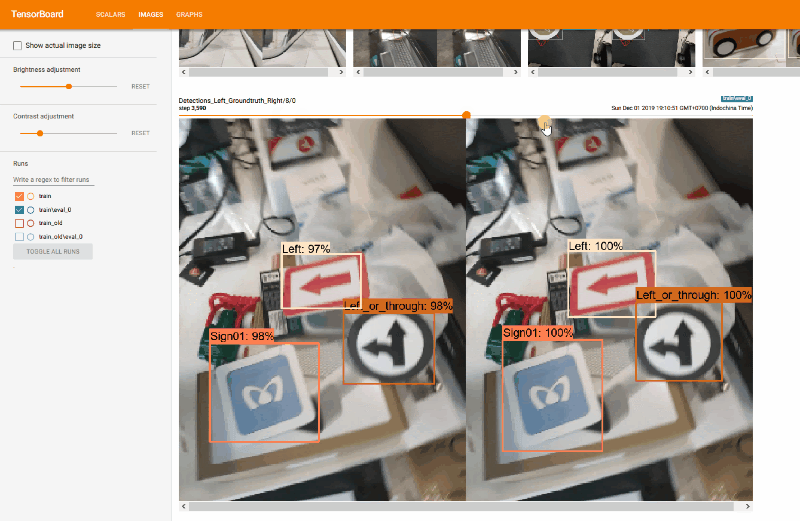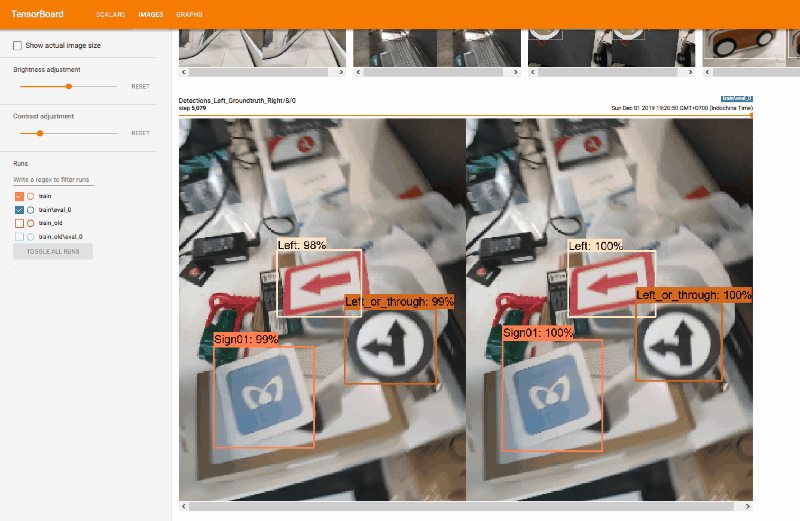 |
| Detection result and the groundtruth |
TensorFlow Lite
Since we want to run our ML model on the Pixel 4, which is running Android, we need to convert all the models to .tflite. Of course, you can use TensorFlow lite to target iOS and other devices as well (including microcontrollers). Here are the steps we did:
Lane keeping
First, we convert the lane keeping model from .h5 to .tflite by using
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model_file("lane_keeping.h5")
model = converter.convert()
file = open("lane_keeping.tflite",'wb')
file.write( model )
file.close()
Now, we have the model ready for the Android project. Next, we build a lane keeping class in our app. We began with an example android project from here.
Object detection
We have to convert the model checkpoint (.ckpt) to tensorflow lite format (.tflite)
- Using export_tflite_ssd_graph.py script to convert .ckpt to .pb file (the script already provided in Tensorflow object detector API)
- Using toco: TensorFlow Lite Converter to convert .pb to .tflite format
Using Neural Core
We use an Android sample project from here. Then we modified the delegate to use Pixel 4 Edge TPU with the following code.
Interpreter.Options tfliteOptions = new Interpreter.Options();
nnApiDelegate = new NnApiDelegate();
tfliteOptions.addDelegate(nnApiDelegate);
tfLite = new Interpreter(loadModelFile(assetManager, modelFilename),tfliteOptions);
Real-time Video Streaming
After a user selects a destination, the car will start driving itself. While it’s driving, the car will stream what it sees to the station phone as a video feed. When we started implementing this part, we knew right away that streaming a raw video feed wouldn’t be possible due to the amount of data that we need to transfer between several car phones and station phones. The solution that we use is, first, compress a raw image frame to a JPEG format to reduce the amount of that data, then stream the JPEG buffer via http protocol using multipart/x-mixed-replace as an HTTP Content-type. This way we can achieve several video streams at the same time with unnoticeable lag between the devices.
Server App
Server Stack
We use NodeJS for the server app and MongoDB for the database.
Hail a Car
Since we have multiple stations and cars, we need to find a way to connect these two together. We built a booking system similar to popular car apps. Our booking system has 3 steps. First, the car connects to the server and tells the server that it’s ready to be booked. Second, the station connects to the server and asks the server for a car. Third, the server looks for the car that’s ready and connects these two together and also stores the device_id from both station and car apps.
Navigation
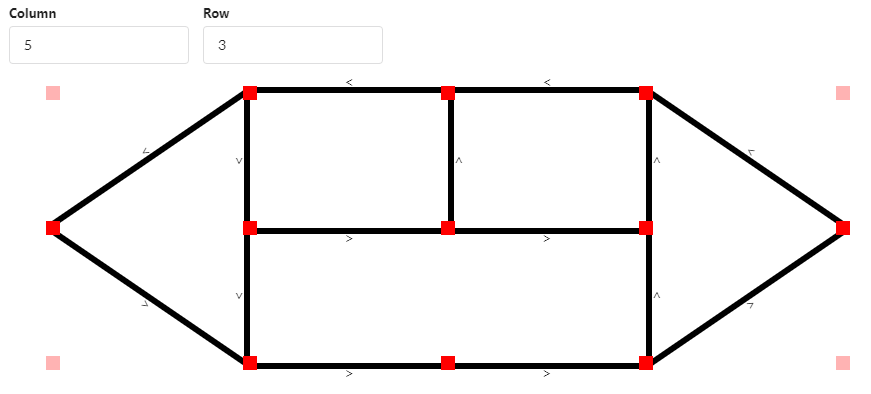 |
| Node/Edge |
Since we will have a fleet of cars running around in the city, we need to find a way to navigate them. We use the Node/Edge concept. Node is a place on the map and Edge is the path between two Nodes. We then map each node to the actual signs in the city.
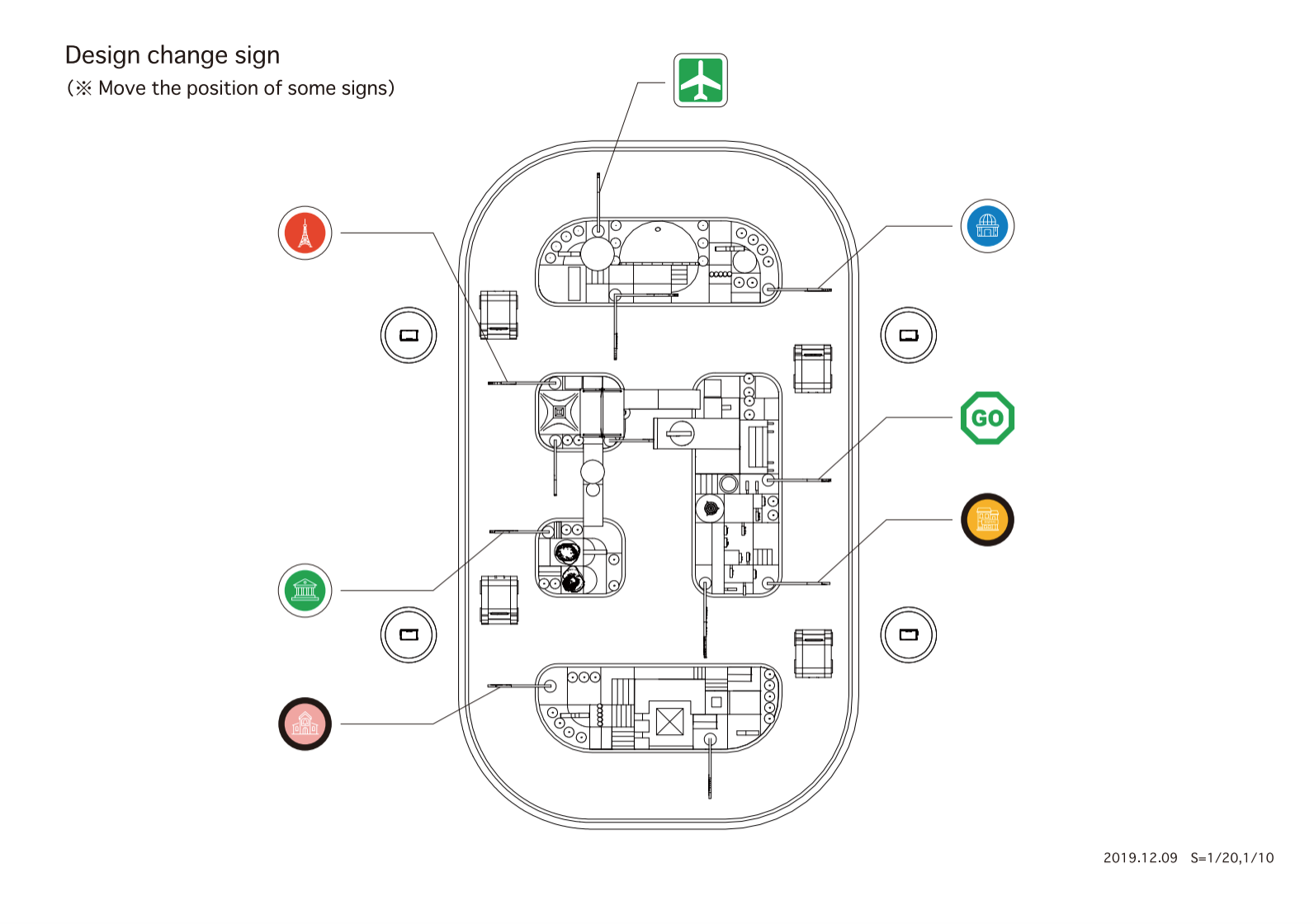 |
| Top view of the tracks and sign locations |
When the destination is selected on the station app, the station will send node_id to the server and the server will return an object which indicates a list of nodes and their properties so the car knows where to drive to and the expected sign it will see.
Electronics
Parts
We started off with NUCLEO-F411RE as our development board. We chose Dynamixel for the motors.
 |
| NUCLEO-F411RE |
We designed and developed a shield for additional components such as motors to reduce the number of wires inside the car chassis.There are three parts in the shield: 1) Battery measurement in voltage, 2) On/off switch with MOSFET, 3) Buttons.
 |
| (Left) Shield and Motors, (Right) Power socket, power switch, Enable motor button, Reset Motor button, Board status LED, Motor status LED |
In the later phase, we would like to make the car a lot smaller, so we moved from NUCLEO-F411RE to NUCLEO-L432KC because it has a lot smaller footprint.
 |
| NUCLEO-L432KC |
Car Chassis & Exterior
Mark I
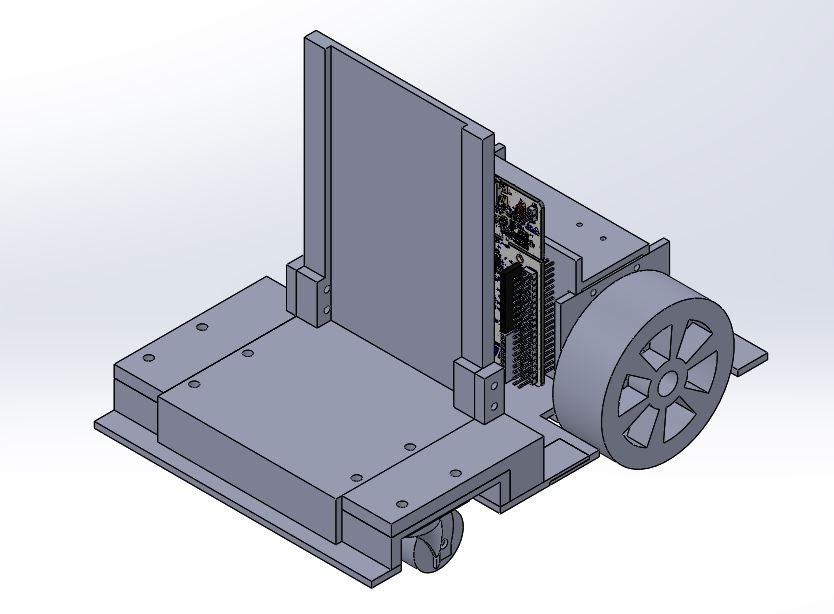 |
| Mark I Design |
We designed and 3D printed the car chassis with PLA material. The front wheels are castor wheels.
Mark II
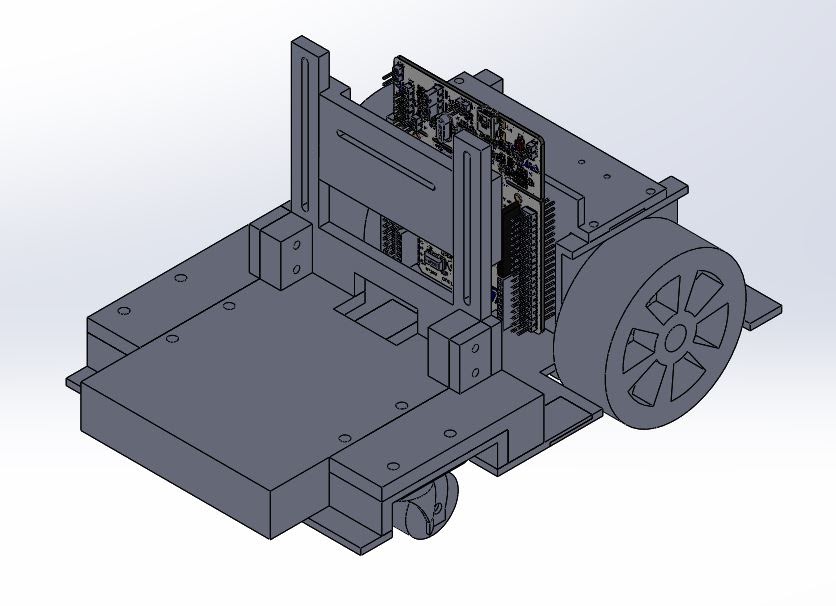 |
| Mark II Design |
We added a battery measurement circuit to the board and cut off the power when the phone detached from the board.
Mark III
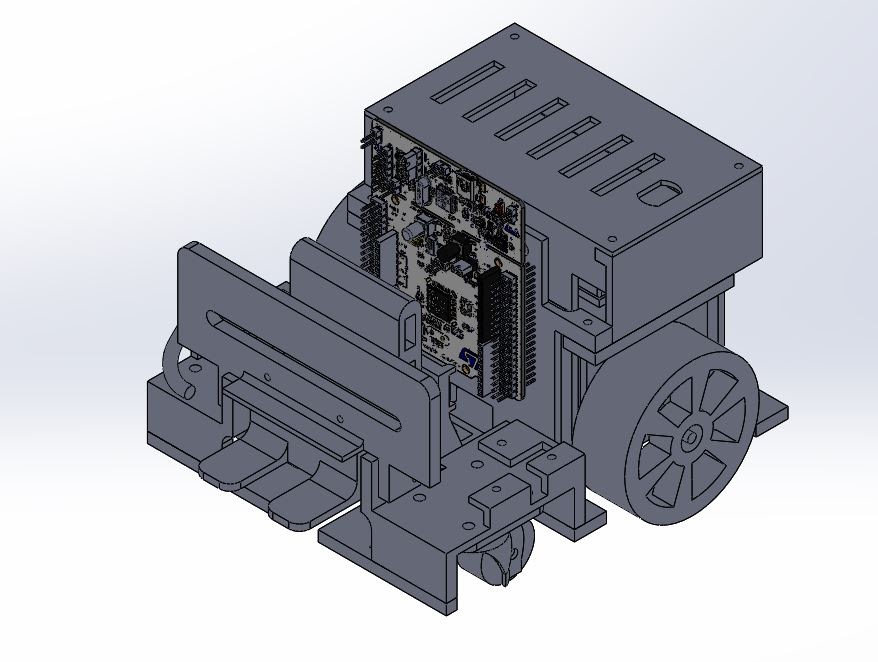 |
| Mark III Design |
We added status LEDs so we can easily debug the state of the board. From the previous version, we encountered a motor overheating issue, so in this version we improved the ventilation by adding a fan to the motor. We also added a USB Type-C power delivery to the board so the phone can use the car battery.
Mark IV
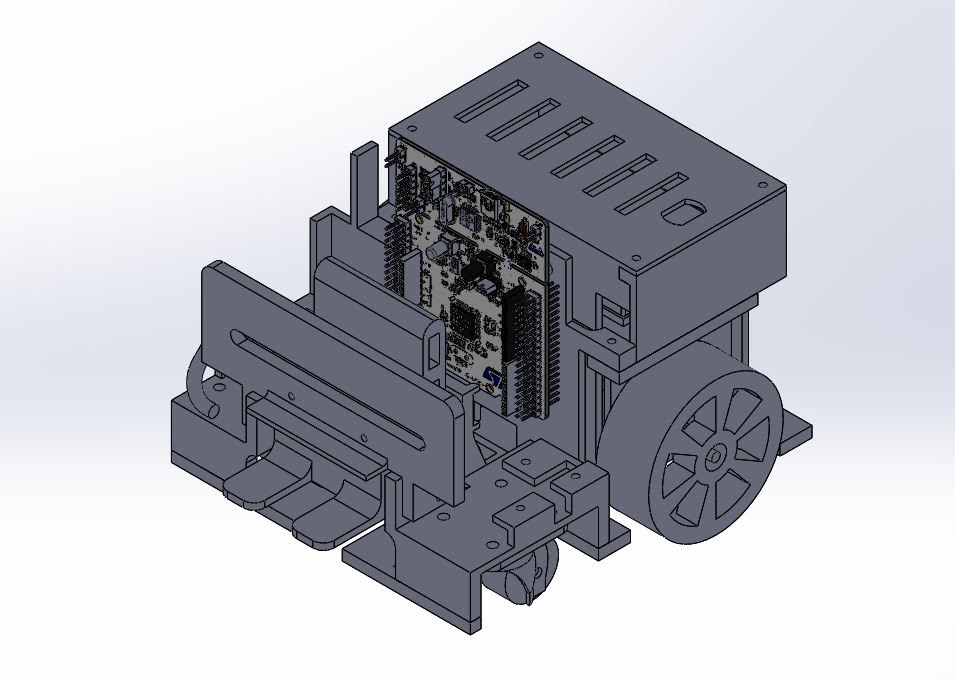 |
| Mark IV Design |
We moved all the control buttons and status LEDs to the back of the car for an easy access.
Mark V
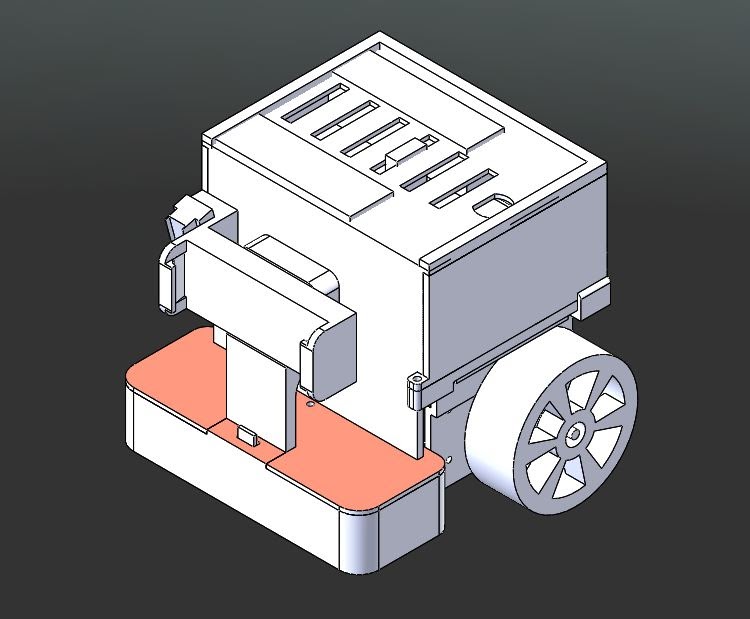 |
| Mark V Design |
This is the final version and we need to reduce the car footprint as much as possible. First, we changed the board from NUCLEO-F411RE to NUCLEO-L432KC to achieve a smaller footprint. Second, the front wheel has been changed to ball caster wheels. Third, we rearranged the board location to the top of the car and stacked the battery underneath the board. Lastly, we removed the USB Type-C power delivery because we want to prolong the driving time by giving all battery power to the board and motors instead of the phone.
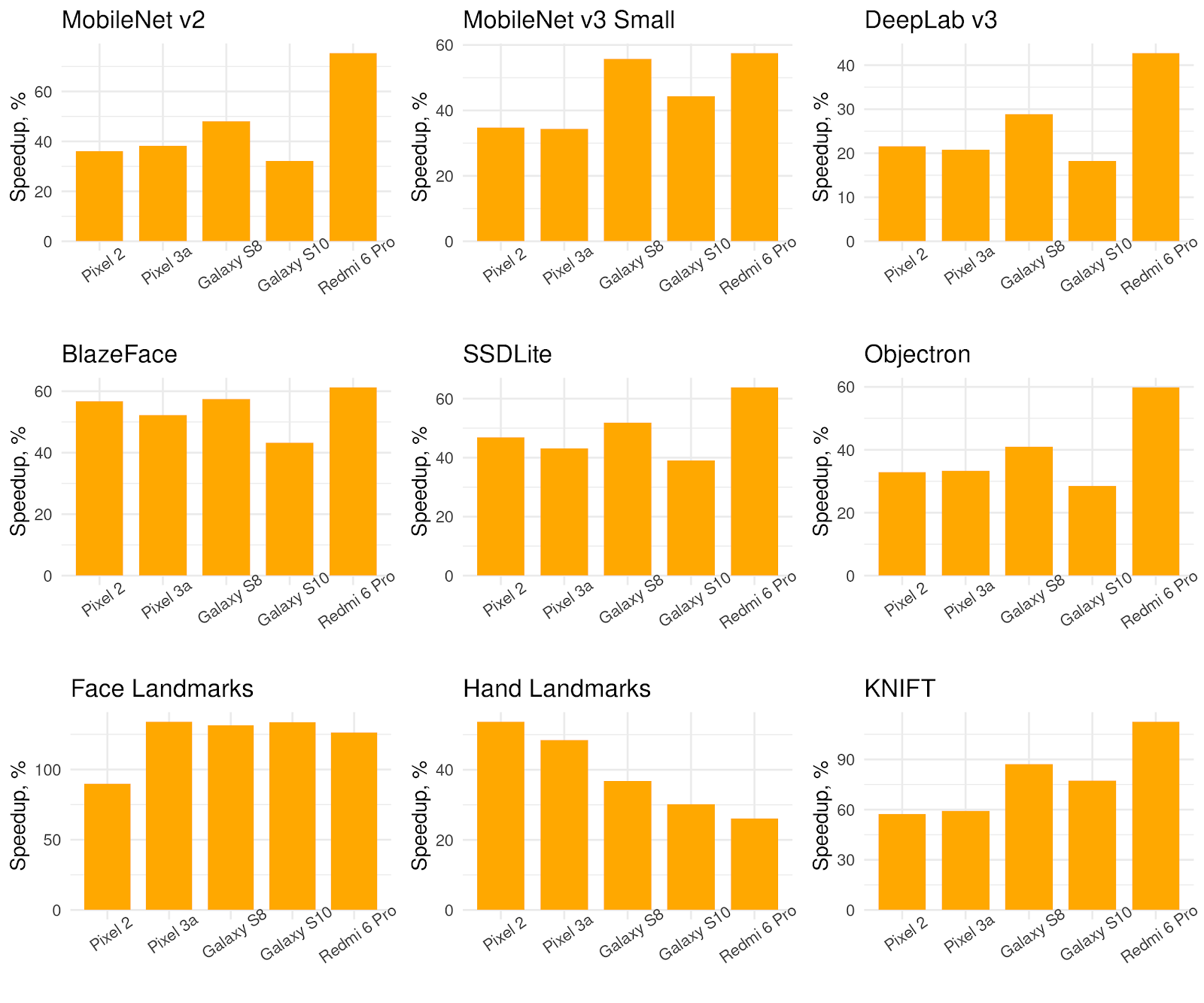
Performance metrics

Roadmap
There are many areas that we plan to improve this experience.
Battery
Currently, the motor and the controller board are powered by three packs of 3000mAh lithium-ion batteries and we have a charging circuit to handle the charging process. When we want to charge the battery, we would need to move the car to the charging station and plug the power adapter to the back of the car to charge. This has a lot of downsides because the car won’t be able to run on the track if it’s charging and the charging time is a few hours which is quite long.
 |
| 3000mAh Li-ion Battery (left), 18650 Li-ion Battery (right) |
We would like to reduce this process by changing the battery to an 18650 battery cell instead. This type of battery is used in electronics such as laptops, tools, and e-bikes, due to the high capacity in a small form factor. This way we can swap the battery easily by popping in the new ones and let the empty ones charge in the battery charger without leaving the car at the charging station.
Localization
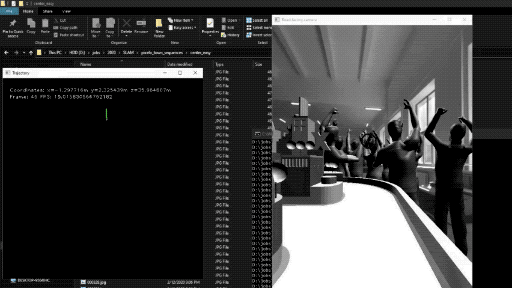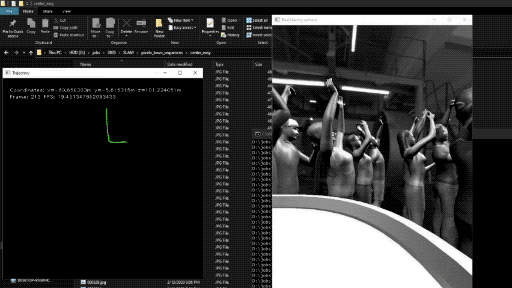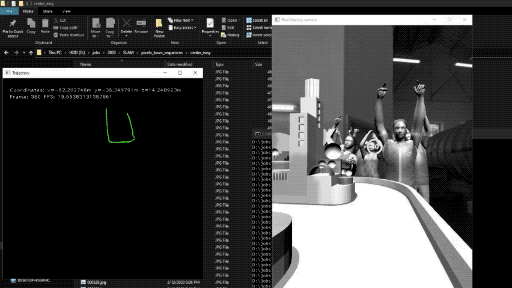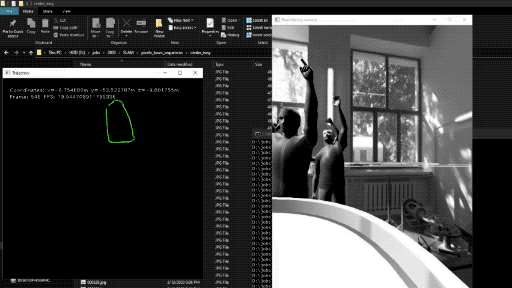 |
| Localization with SLAM |
Localization is a very important process for this installation and we would like to make it more robust by adding SLAM to our app. We believe that this would improve the turning mechanism significantly.
Learning more
Thanks so much for reading! It’s incredible what you can do with a phone camera, TensorFlow and a bit of imagination. Hopefully, this post gave you ideas for your own projects – we learned a lot working on this one, and hope you will in yours as well. The article provides links to resources for you to delve deeper into all the different areas and you can find plenty of ML models and tutorials by the developer community to learn from on TensorFlow hub.
If you’re really passionate about building self-driving cars and want to learn more about how machine learning and deep learning are powering the autonomous vehicle industry check out Udemy’s Self Driving Cars Nanodegree Program. It’s perfect for engineers & students looking for complete training in all aspects of self-driving cars, including computer vision, sensor fusion & localization.
Acknowledgements
This project would not have been possible without the following awesome and talented group of people: Sina Hassani, Ashok Halambi, Pohung Chen, Eddie Azadi, Shigeki Hanawa, Clara Tan Su Yi, Daniel Bactol, Kiattiyot Panichprecha Praiya Chinagarn, Pittayathorn Nomrak, Nonthakorn Seelapun, Jirat Nakarit, Phatchara Pongsakorntorn, Tarit Nakavajara, Witsarut Buadit, Nithi Aiempongpaiboon, Witaya Junma, Taksapon Jaionnom and Watthanasuk Shuaytong.Read More